Deep Generative Modeling
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Alexander Amini 授课内容整理 |
| 来源 | Alexander Amini (MIT) |
| 日期 | 2025年春季 |

引言:生成式建模的时代
我们正处于生成式 AI(Generative AI)的巨大变革时代。生成式建模的核心目标不仅仅是从数据中识别模式并据此做出决策,更重要的是能够基于所学习到的模式生成全新的数据实例。这个看似简单的想法在近年来已经在图像生成、音频生成、自然语言处理等众多领域引发了革命性的变化。

来源:Slides 第2页。来源:thispersondoesnotexist.com
课程以一个引人深思的例子开始:展示了三张人脸照片,让观众判断哪张是真实的。答案揭示后,三张都是由生成模型合成的假脸。这生动地说明了现代生成模型的强大能力,也引出了本节课的核心议题——理解和掌握深度生成建模的基础理论。
生成式建模的核心目标
给定来自某个分布的训练样本,学习一个能够表示该分布的模型 \(P_{\text{model}}(x)\),使其尽可能接近真实数据分布 \(P_{\text{data}}(x)\)。生成模型可用于两大任务:
- 密度估计(Density Estimation):学习数据的底层概率分布
- 样本生成(Sample Generation):从学到的分布中采样以生成新数据
监督学习 vs. 无监督学习
在课程之前的内容中,我们主要关注监督学习(Supervised Learning)问题:给定带标签的数据 \((x, y)\),目标是学习从输入 \(x\) 到标签 \(y\) 的映射函数。而生成式建模属于无监督学习(Unsupervised Learning)的范畴:我们只有数据 \(x\),没有标签,目标是发现数据中隐藏的底层结构。
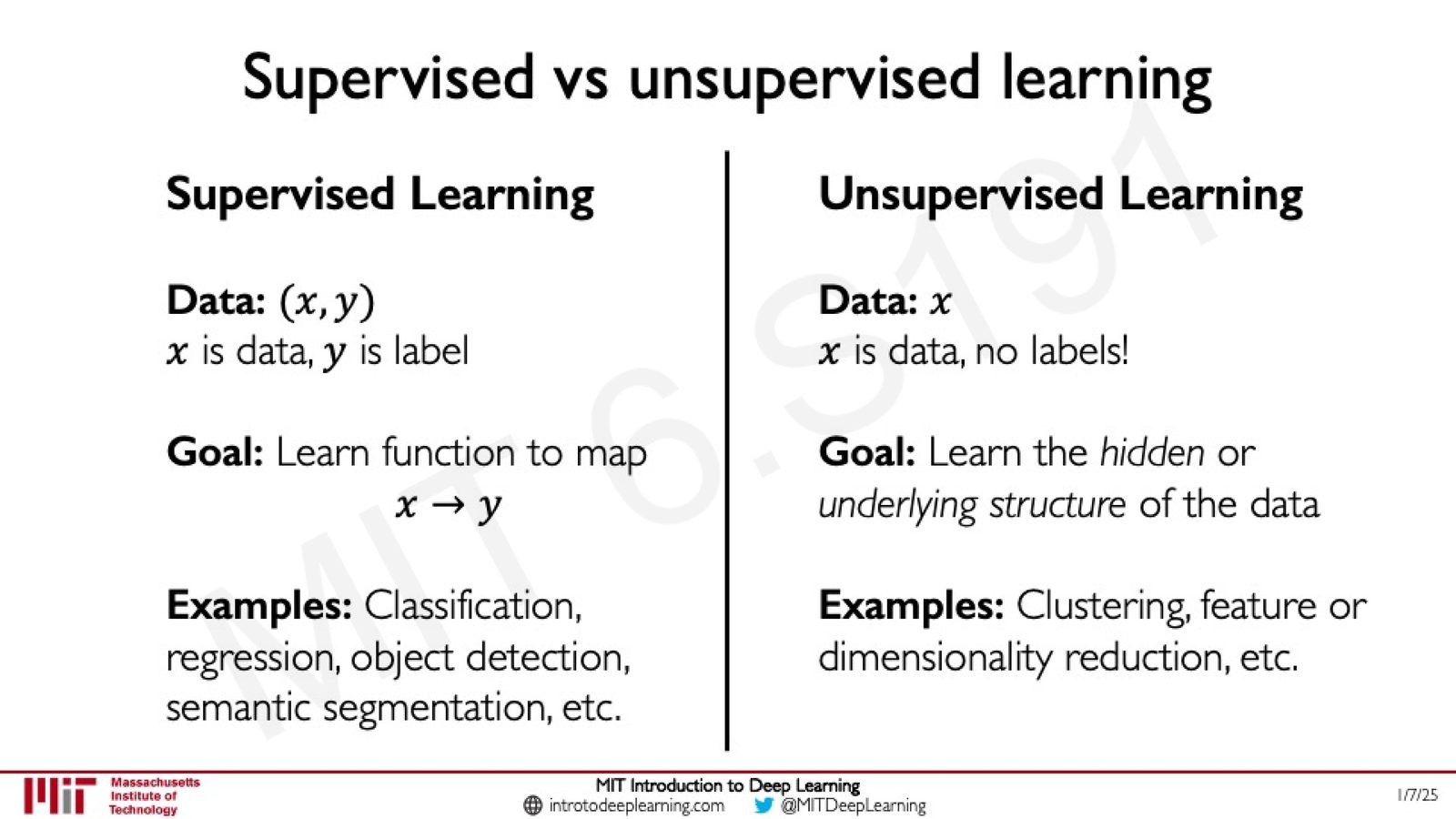
来源:Slides 第4页。
| 维度 | 监督学习 | 无监督学习 |
|---|---|---|
| 数据 | \((x, y)\),\(x\) 为数据,\(y\) 为标签 | 仅有 \(x\),无标签 |
| 目标 | 学习 \(x → y\) 的映射函数 | 发现数据的隐藏/底层结构 |
| 典型任务 | 分类、回归、目标检测 | 聚类、特征提取、降维 |
生成式建模的核心原理

来源:Slides 第5页。
生成式建模的根本问题可以表述为:如何学习一个概率分布 \(P_{\text{model}}(x)\),使其尽可能接近真实数据分布 \(P_{\text{data}}(x)\)?
一旦我们成功学到了这样的概率分布模型,就可以通过从中采样来生成全新的、从未见过的数据实例。生成的样本将反映训练数据的分布特征。
为什么关心生成模型?
生成模型在现实世界中有三大核心应用场景:
1. 去偏差(Debiasing):生成模型能够自动发现数据集中的底层特征分布。例如,面对一个人脸数据集,模型可以发现肤色、姿态、光照等特征是否存在过度或不足的代表,从而帮助创建更公平、更具代表性的数据集。

来源:Slides 第6页。来源:Amini/Soleymani+ AAAI/AIES 2019。
2. 异常检测(Outlier Detection):在自动驾驶等安全关键场景中,生成模型可以通过学习数据的概率分布来识别位于分布尾部的罕见事件(如极端天气、行人),从而检测这些异常情况并调整系统行为。
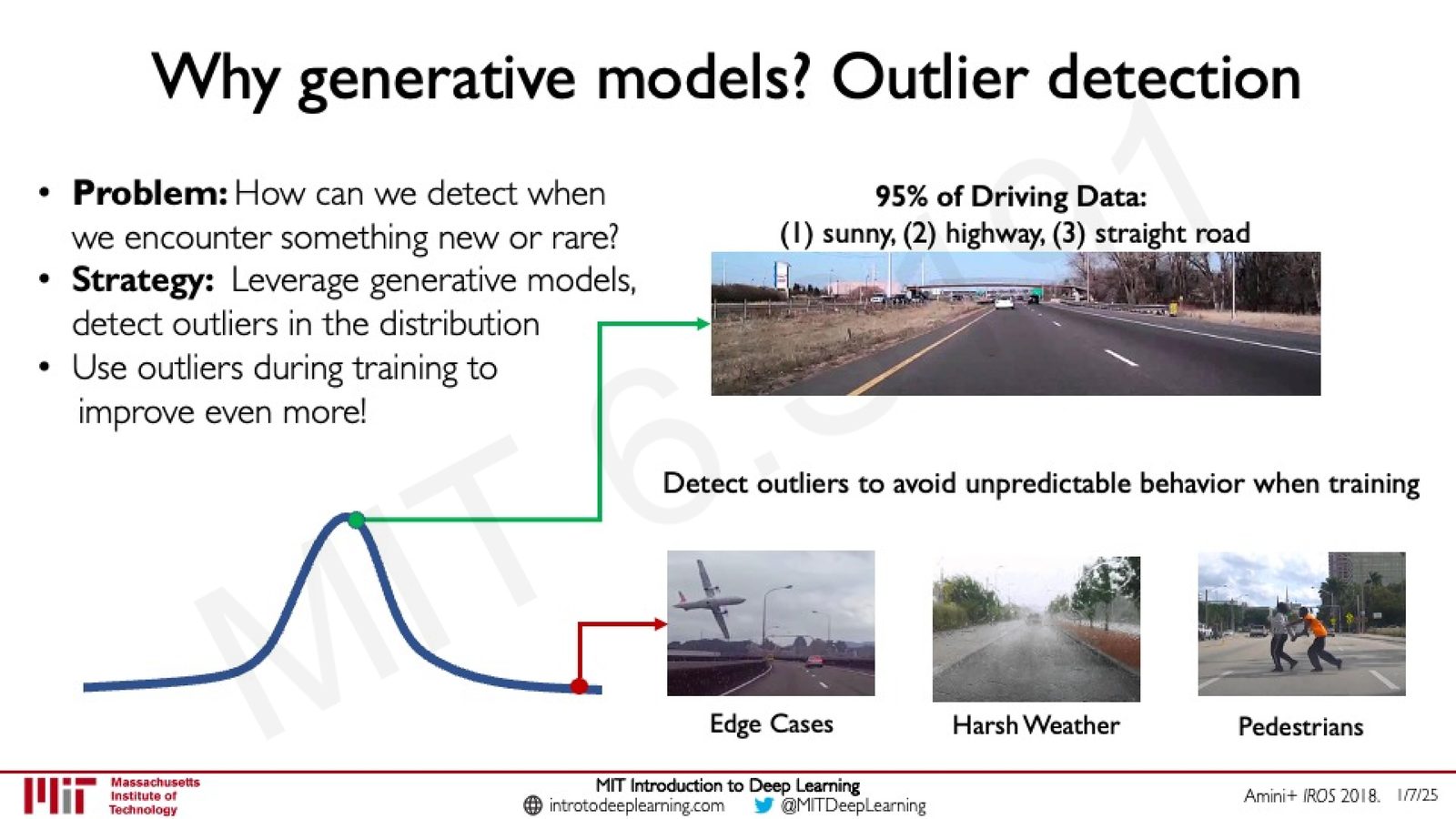
来源:Slides 第7页。来源:Amini+ IROS 2018。
3. 样本生成(Sample Generation):这是最广为人知的应用——利用生成模型创建全新的数据实例。这是 ChatGPT、图像生成、视频生成等 Generative AI 应用的基础。
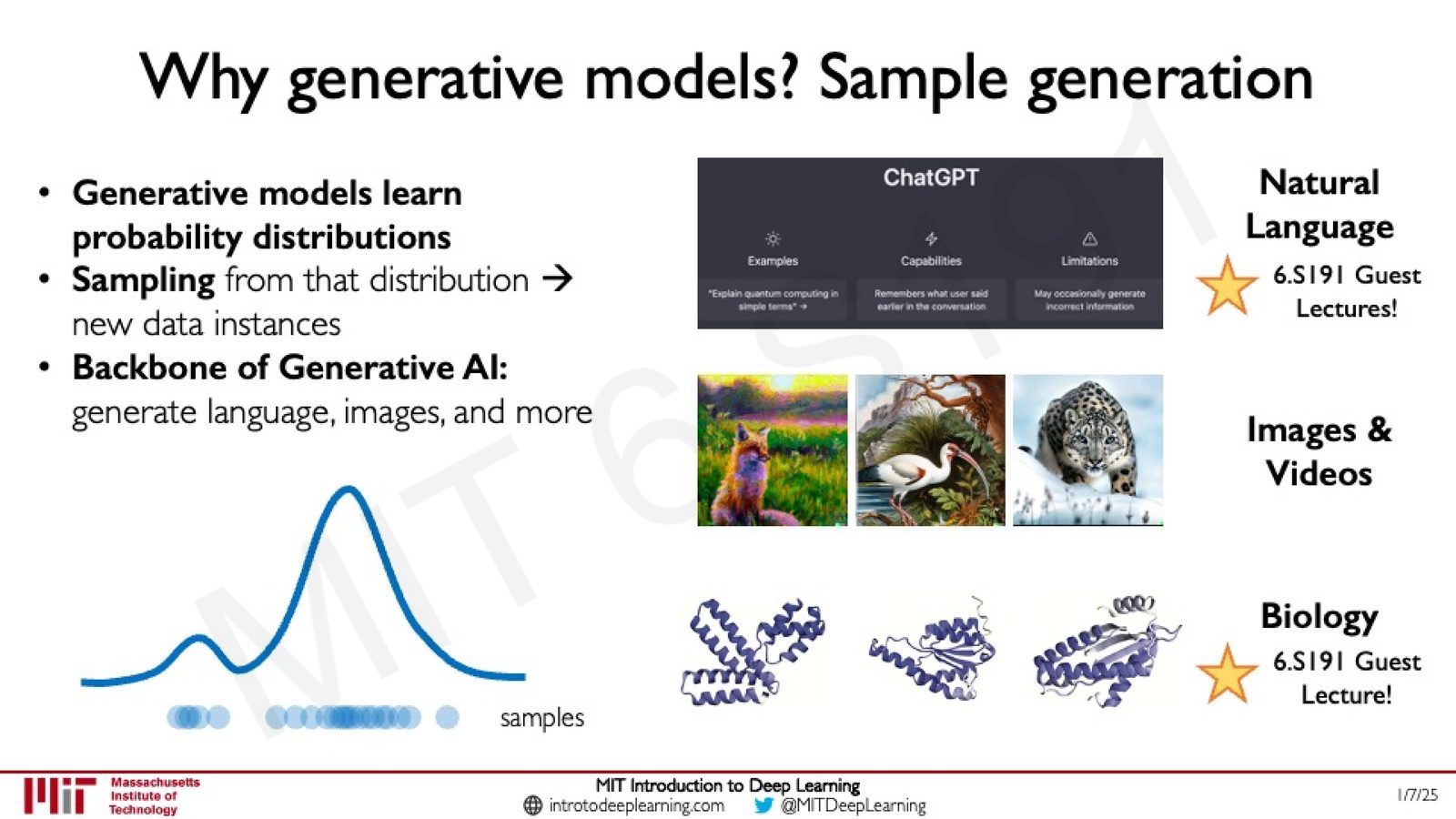
来源:Slides 第8页。
本章小结
本节引入了生成式建模的基本概念,阐明了从监督学习到无监督学习的转变。生成模型的核心目标是学习数据的概率分布,并可用于密度估计、异常检测和样本生成等场景。本讲将重点介绍两大基础架构:Variational Autoencoder (VAE) 和 Generative Adversarial Network (GAN),它们都属于 Latent Variable Model(隐变量模型)。
隐变量与 Autoencoder
什么是隐变量(Latent Variable)?
为了理解隐变量的概念,课程借用了柏拉图《理想国》中著名的洞穴寓言(Allegory of the Cave):一群囚犯被束缚在洞穴中面对墙壁,他们唯一能看到的只是火光映射在墙上的物体影子。对囚犯而言,影子就是他们的现实,但真正的物体结构——他们永远无法直接观察到的部分——才是产生这些影子的根本原因。

来源:Slides 第10页。来源:柏拉图《理想国》。
隐变量的哲学类比
在机器学习中,我们观察到的数据就像墙上的影子——它们是某些底层因素(隐变量)的表现形式。隐变量(Latent Variables)就像洞穴中投射影子的真实物体,虽然无法直接测量,却决定了我们观测到的数据的分布。生成式建模的一个核心目标就是从观测数据中提取这些隐变量。
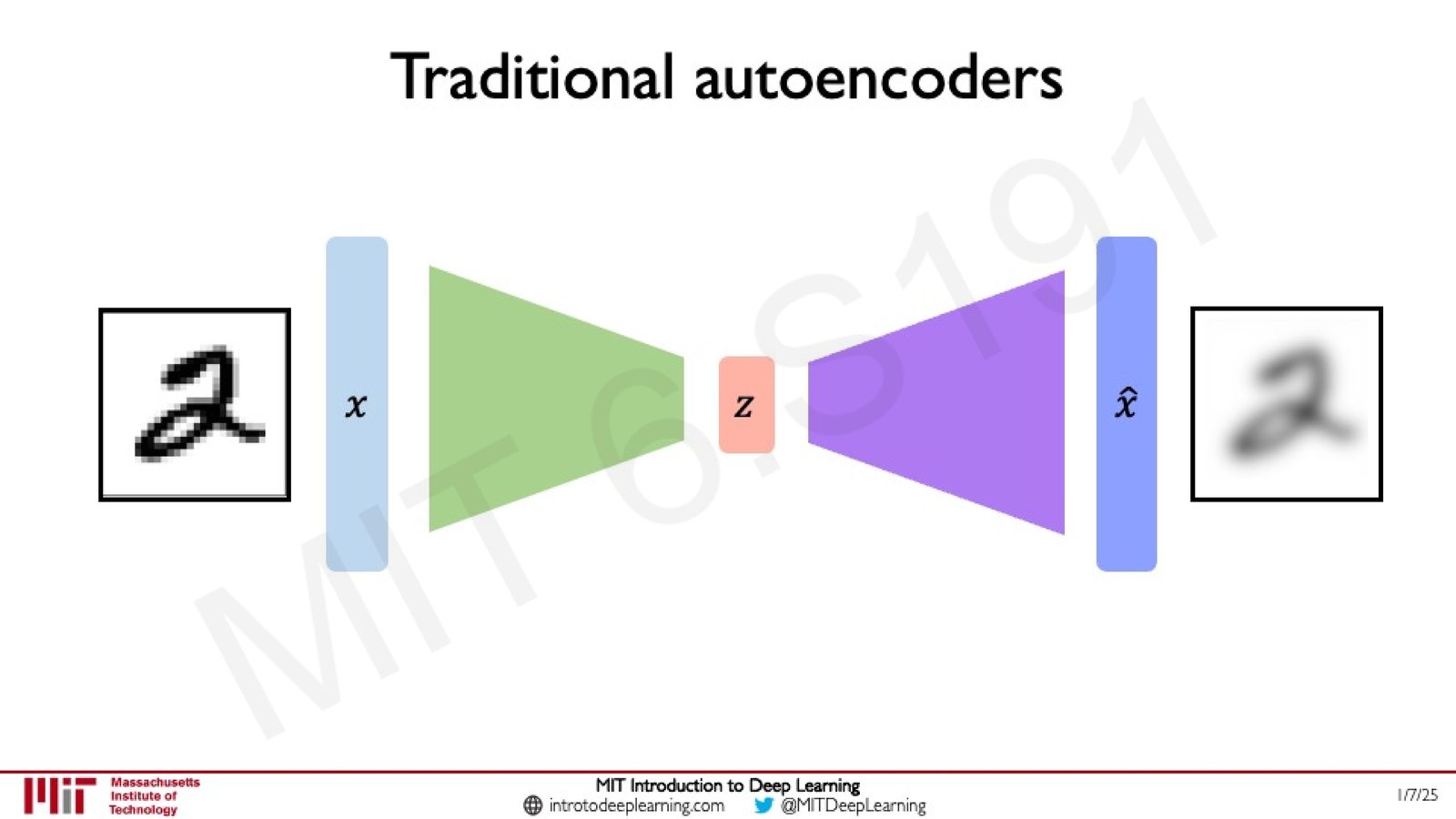
Autoencoder 的基本原理
Autoencoder(自编码器)是一种无监督学习方法,用于从无标签的训练数据中学习低维特征表示。其核心思想是:通过一个编码器(Encoder)将高维输入数据压缩到低维隐空间(Latent Space),然后通过一个解码器(Decoder)尝试从隐空间重建原始输入。
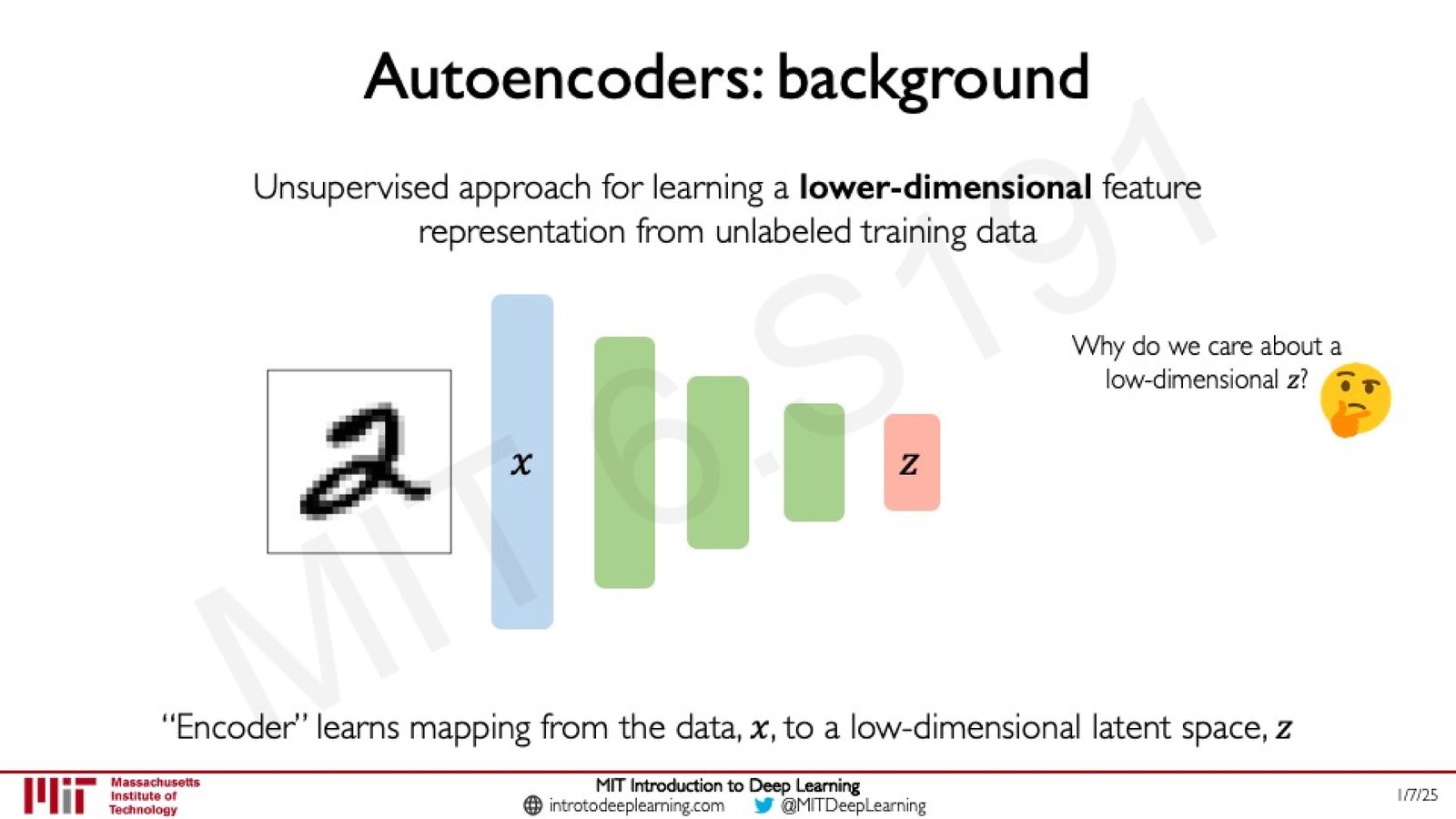
来源:Slides 第13页。
编码器学习的映射:
其中 \(x\) 是输入数据(如一张图片),\(z\) 是隐变量向量。之所以要保持 \(z\) 的维度远低于 \(x\),是因为我们希望网络能压缩数据,提炼出最本质的特征表示。
通过重建学习隐空间
关键问题:如何在没有标签的情况下训练编码器学习好的隐变量 \(z\)?
答案是:在编码器后面接一个解码器(Decoder),训练整个网络重建原始输入。
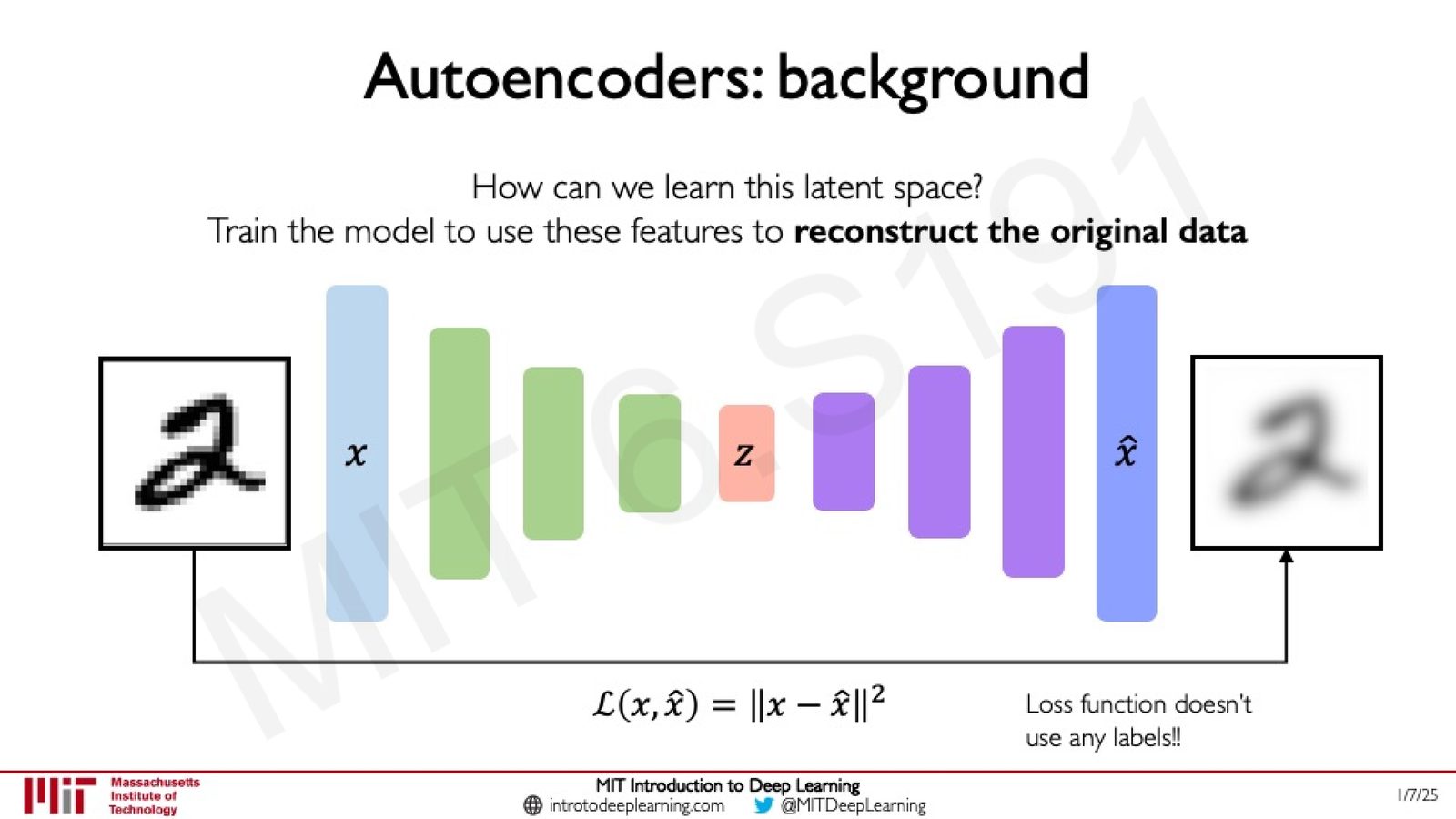
来源:Slides 第15页。
训练目标是最小化输入 \(x\) 与重建输出 \(\hat{x}\) 之间的距离:
- \(x\):原始输入数据
- \(\hat{x}\):经过编码-解码后的重建数据
- \(\|\cdot\|^2\):均方误差(Mean Squared Error)
Autoencoder 的自监督本质
Autoencoder 的损失函数不需要任何外部标签!它使用输入本身作为学习信号,通过最小化重建误差来迫使网络学习有意义的压缩表示。这使得 Autoencoder 成为一种自监督的无标签学习方法。
隐空间维度与重建质量
隐空间的维度直接影响重建质量。Autoencoding 本质上是一种压缩操作:隐空间越小,信息瓶颈越大,网络被迫学习更紧凑的表示。

来源:Slides 第17页。
如图所示,当隐空间为 2D 时,重建结果明显模糊;当增加到 5D 时,重建质量显著提升。这体现了表示能力与压缩程度之间的权衡。
本章小结
Autoencoder 通过编码器-解码器架构实现了无标签的特征学习。它将数据压缩到低维隐空间,再从隐空间重建原始输入。但传统 Autoencoder 存在一个关键问题:编码过程是确定性的(deterministic),给定相同输入总是产生相同的隐变量。这意味着隐空间可能不够平滑连续,无法有效用于生成新样本。这引出了下一节的 Variational Autoencoder。
Variational Autoencoder (VAE)
从确定性到概率性编码
传统 Autoencoder 的编码是确定性的:给定输入 \(x\),编码器输出固定的隐向量 \(z\)。这使得隐空间可能存在"空洞"和不连续区域,从这些区域采样将产生无意义的输出。
来源:Slides 第20页。
Variational Autoencoder (VAE) 引入了概率性的改进:编码器不再输出固定的隐向量,而是输出一个概率分布的参数——均值向量 \(\mu\) 和标准差向量 \(\sigma\)。然后从该分布中采样得到隐向量 \(z\)。
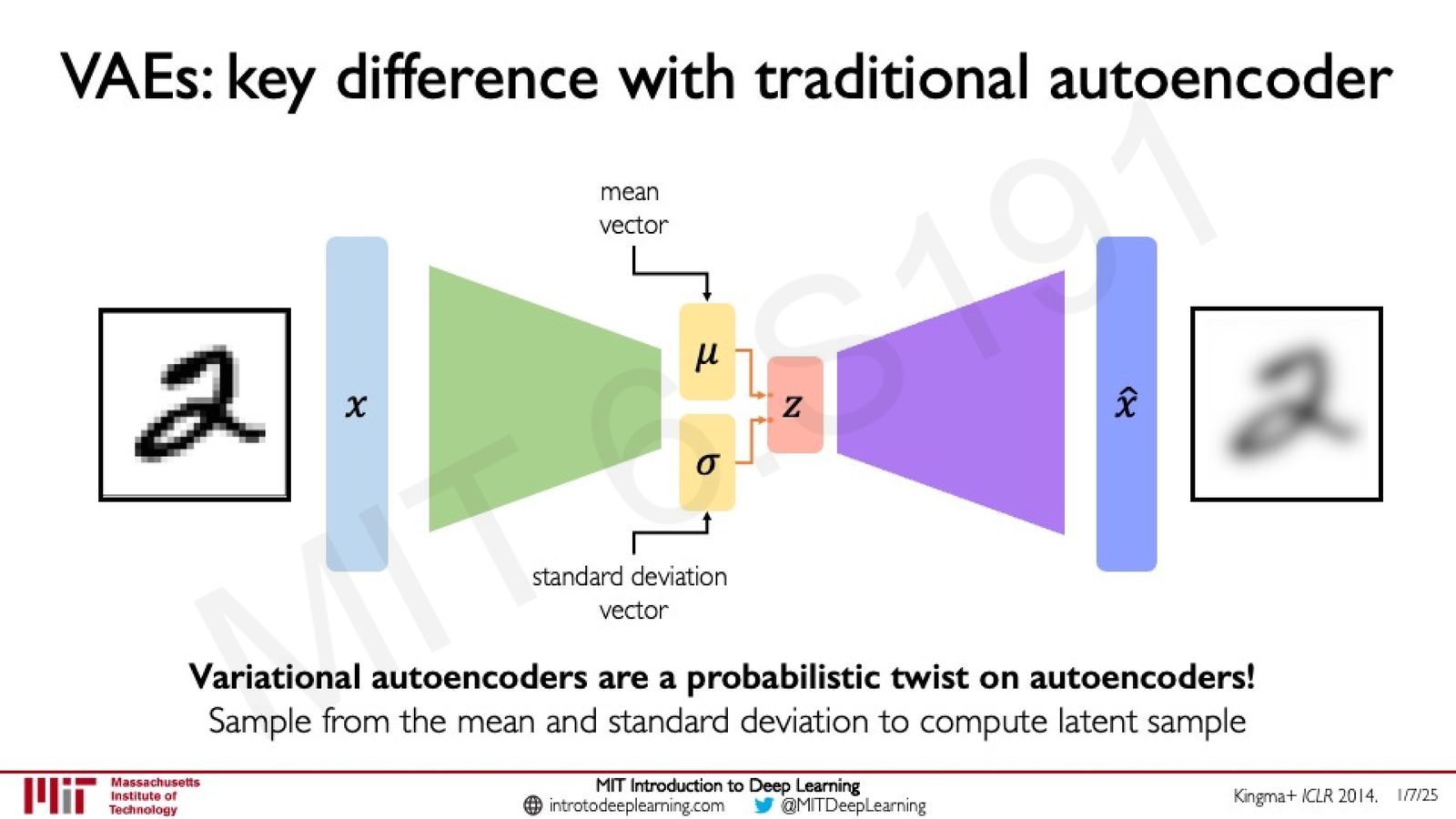
来源:Slides 第22页。来源:Kingma+ ICLR 2014。
VAE 的核心思想
VAE 是 Autoencoder 的概率性改进。编码器输出均值 \(\mu\) 和标准差 \(\sigma\),定义一个关于隐变量的概率分布 \(q_\phi(z|x)\)。通过从该分布中采样,VAE 可以生成不同的隐向量,从而实现多样化的生成。
VAE 的损失函数
VAE 的优化目标由两部分组成:
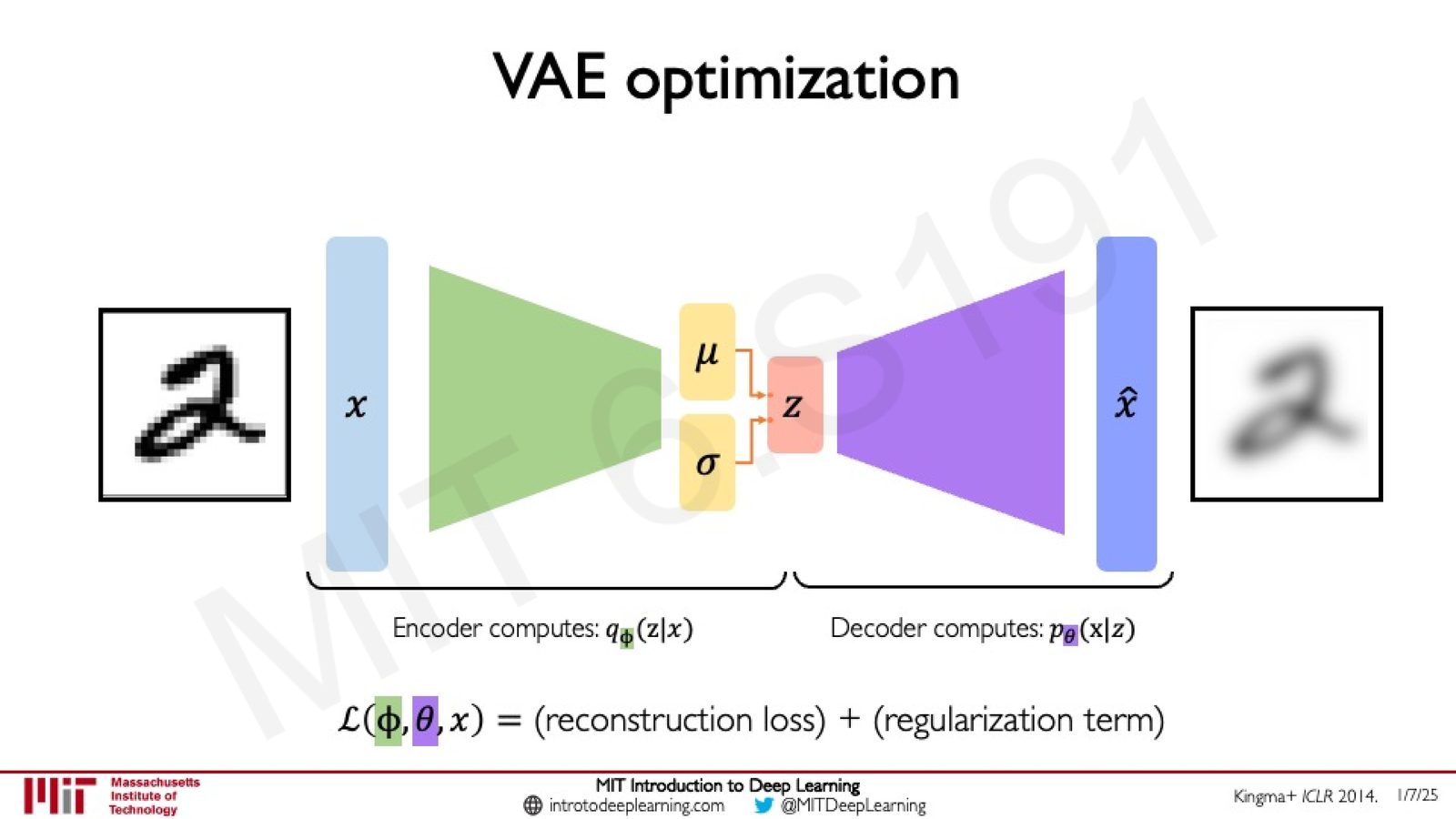
来源:Slides 第25页。来源:Kingma+ ICLR 2014。
- 重建损失:衡量解码器从隐变量 \(z\) 重建数据 \(\hat{x}\) 的质量,鼓励 \(\hat{x}\) 尽可能接近 \(x\)
- 正则化项(KL Divergence):衡量编码器输出的隐变量分布 \(q_\phi(z|x)\) 与先验分布 \(p(z)\) 之间的距离,鼓励隐空间具有良好的结构
- \(\phi\):编码器的参数
- \(\theta\):解码器的参数
先验分布与 KL Divergence
VAE 需要对隐变量设定一个先验分布(Prior)\(p(z)\)。最常见的选择是标准正态分布:

来源:Slides 第28页。来源:Kingma+ ICLR 2014。
为什么选择正态先验?
选择 \(\mathcal{N}(0, 1)\) 作为先验有两个重要目的:
- 集中编码:鼓励编码器将隐变量分布在隐空间的中心区域
- 防止"作弊":防止网络将不同类别的数据点聚集到隐空间的特定孤立区域(即记忆数据),而是迫使它学习有意义的、连续的表示
KL Divergence(KL 散度)是衡量两个概率分布之间"距离"的指标。对于正态分布先验,KL 散度有解析表达式:
其中 \(J\) 是隐变量的维度,\(\mu_j\) 和 \(\sigma_j\) 分别是第 \(j\) 个隐变量的均值和标准差。
正则化的直觉:连续性与完整性
正则化的作用是确保隐空间具有两个关键性质:
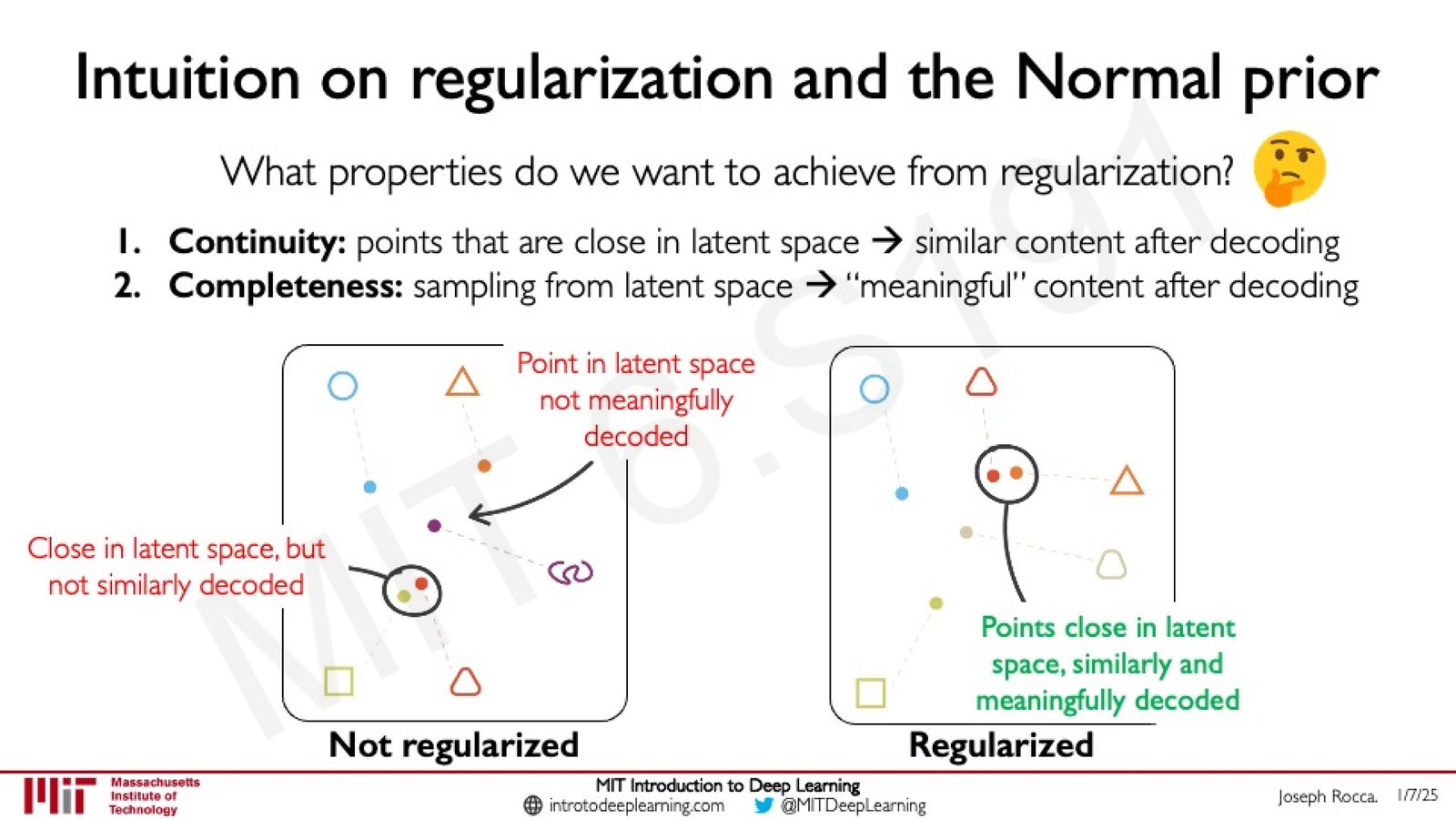
来源:Slides 第30页。来源:Joseph Rocca。
- 连续性(Continuity):在隐空间中相邻的点,解码后应产生语义相似的内容
- 完整性(Completeness):从隐空间的任意位置采样,都应解码出有意义的内容

来源:Slides 第32页。来源:Joseph Rocca。
无正则化的隐空间问题
如果没有正则化(仅使用重建损失),网络可能学到的隐空间存在大量"空洞"——这些区域没有被训练数据覆盖。从空洞区域采样将产生无意义的噪声输出。正则化通过迫使隐变量分布接近标准正态分布,填充了这些空洞。
Reparameterization Trick
VAE 训练面临一个技术难题:隐变量 \(z\) 是通过采样操作得到的,而采样是不可微的——无法通过采样层进行反向传播。
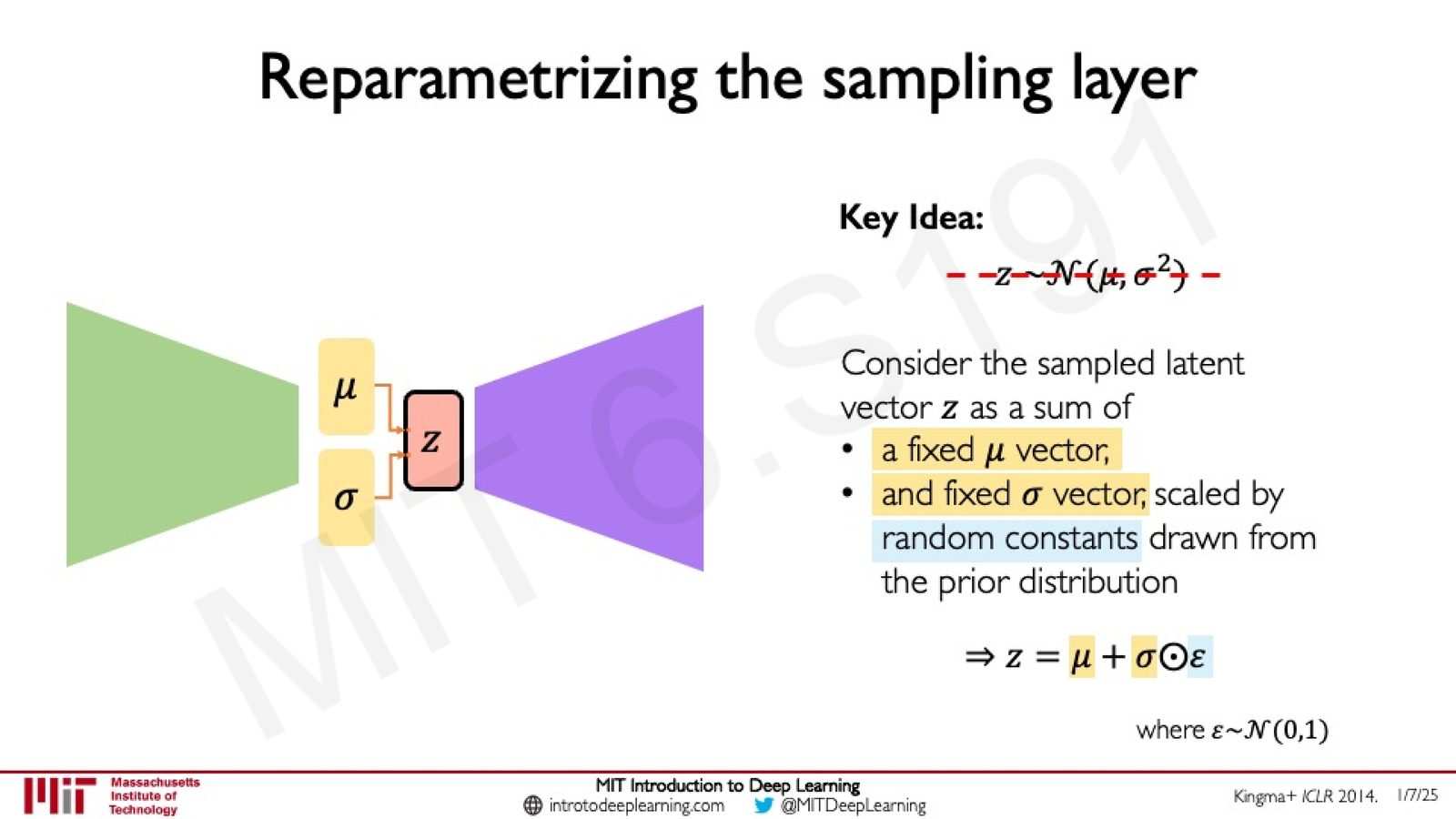
来源:Slides 第35页。来源:Kingma+ ICLR 2014。
解决方案是Reparameterization Trick(重参数化技巧)。核心思想是将随机性从隐变量 \(z\) 中分离出来:
- \(\mu\):编码器输出的均值向量(可微的确定性节点)
- \(\sigma\):编码器输出的标准差向量(可微的确定性节点)
- \(\epsilon\):从标准正态分布采样的随机噪声(固定的随机常数)
- \(\odot\):逐元素乘法
Reparameterization Trick 的精髓
通过将 \(z\) 重写为 \(\mu\)、\(\sigma\) 的确定性函数加上一个外部随机噪声 \(\epsilon\),梯度可以通过 \(\mu\) 和 \(\sigma\) 正常反向传播。随机性被"外部化"为从固定分布采样的常数,不阻断梯度流。这使得整个 VAE 可以端到端地用反向传播训练。
隐变量扰动与可解释性
训练好的 VAE 具有一个重要特性:隐空间中的不同维度往往对应不同的可解释特征。
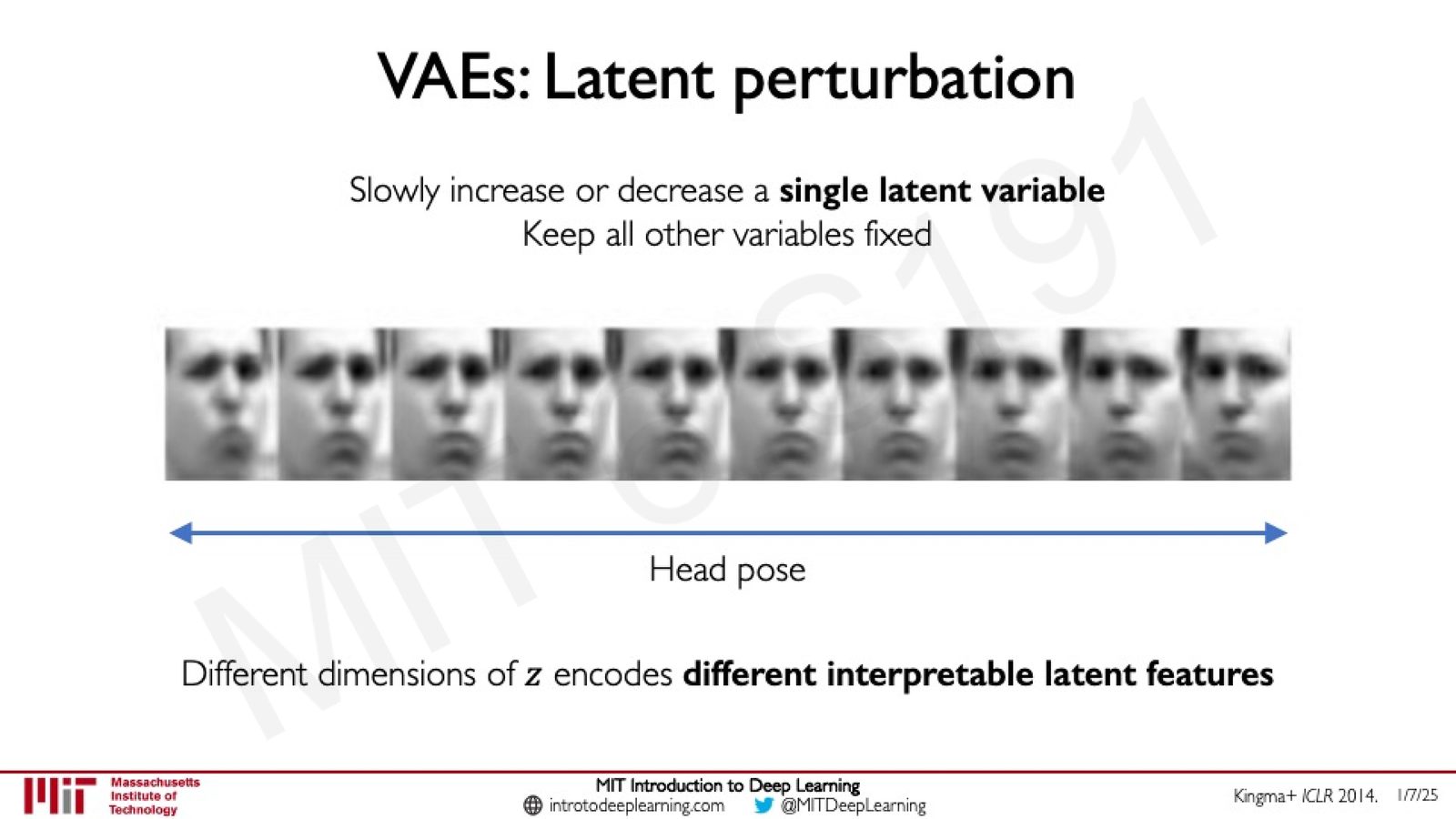
来源:Slides 第38页。来源:Kingma+ ICLR 2014。
例如,在人脸数据集上训练的 VAE 中,固定所有隐变量但缓慢改变其中一个维度的值,可以观察到生成的人脸在某个特定属性(如头部姿态、表情等)上的平滑变化。这说明 VAE 成功地学习到了数据中隐含的语义特征。
\(β\)-VAE 与隐空间解耦
标准 VAE 的隐空间中,不同维度可能编码了纠缠在一起的特征。\(\beta\)-VAE 通过在正则化项前添加一个超参数 \(\beta > 1\) 来加强解耦:

来源:Slides 第40页。来源:Higgins+ ICLR 2017。
当 \(\beta = 1\) 时退化为标准 VAE;\(\beta > 1\) 时更强地约束隐空间瓶颈,鼓励每个隐变量独立编码不同的语义特征(disentanglement),从而改变一个属性时不会影响其他属性。
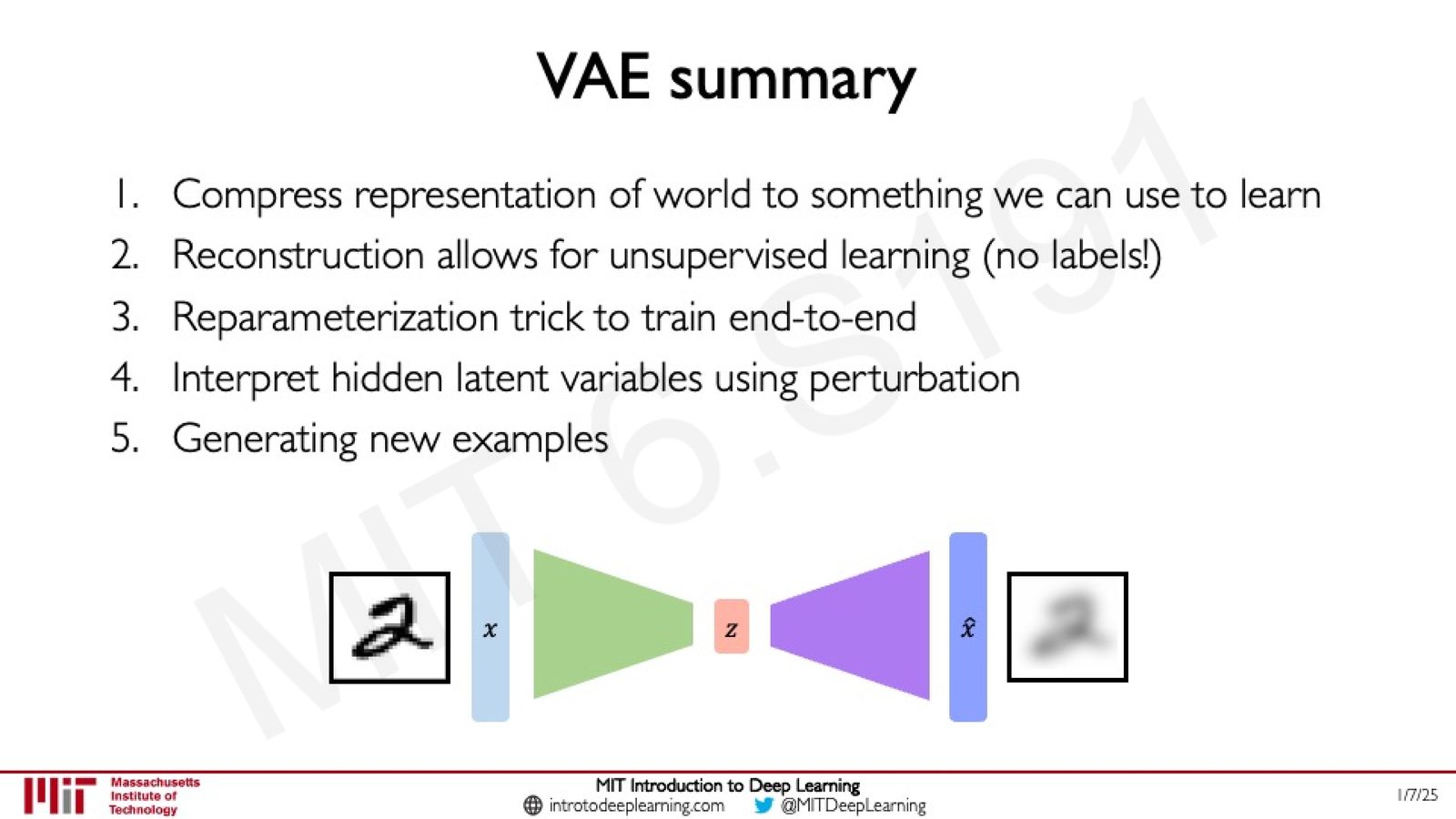
VAE 总结
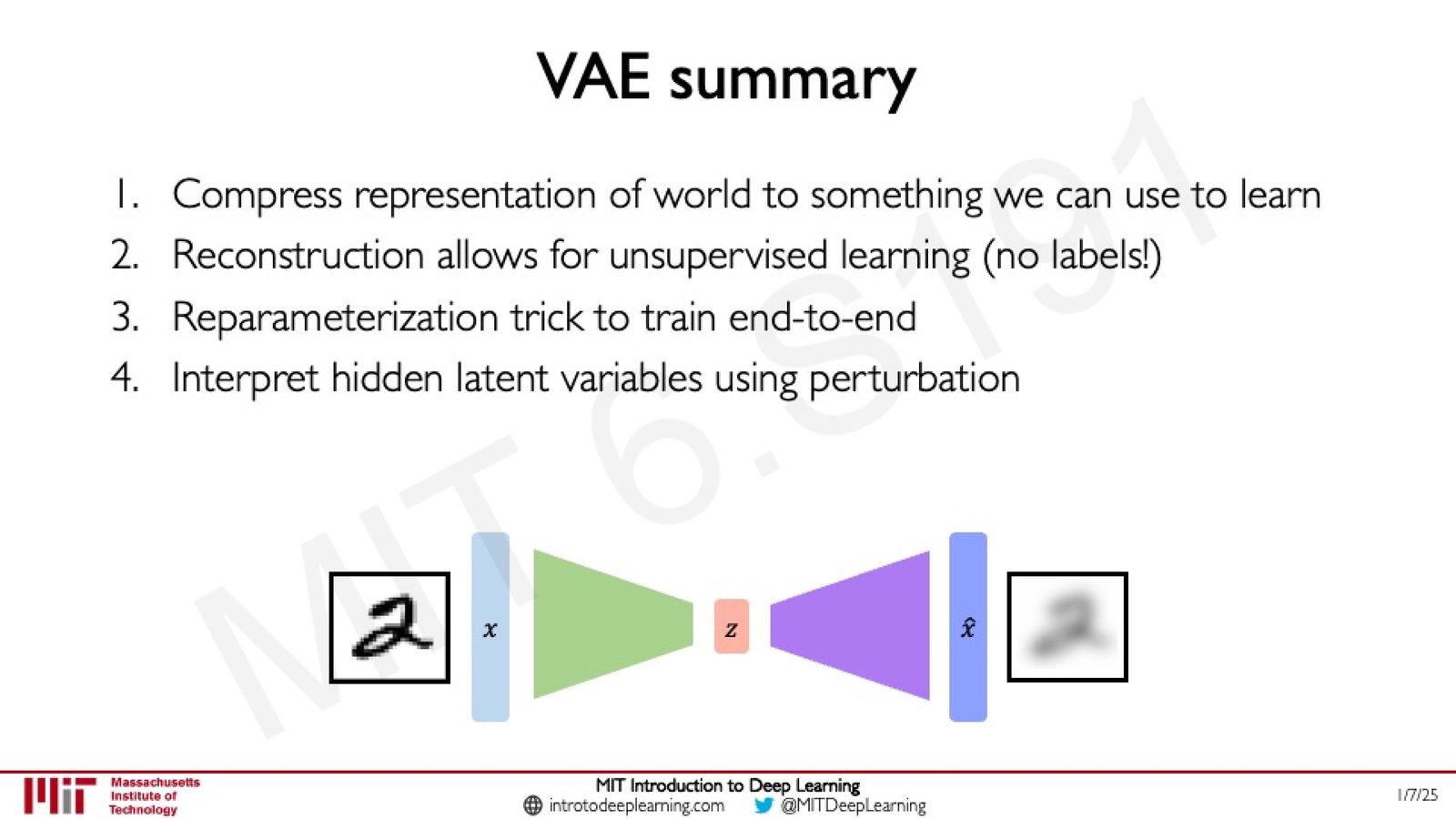
来源:Slides 第45页。
VAE 的五个核心要点:
- 压缩表示:将世界的高维表示压缩为可学习的低维隐空间
- 无监督学习:通过重建损失实现无标签学习
- Reparameterization Trick:使含采样层的网络可端到端训练
- 可解释隐变量:通过扰动分析理解各隐变量对应的语义特征
- 生成新样本:从隐空间采样并解码即可生成新数据
本章小结
VAE 是 Autoencoder 的概率性扩展,通过引入概率隐空间和 KL Divergence 正则化,解决了传统 Autoencoder 隐空间不连续、不完整的问题。Reparameterization Trick 巧妙地解决了通过采样层反向传播的难题。VAE 是第一个被介绍的深度生成模型,它属于 Latent Variable Model 家族。
Generative Adversarial Networks (GANs)
从显式建模到隐式采样
VAE 试图显式地建模数据的概率密度 \(p(x)\)。但如果我们的目标只是生成新样本,是否一定需要显式建模密度?
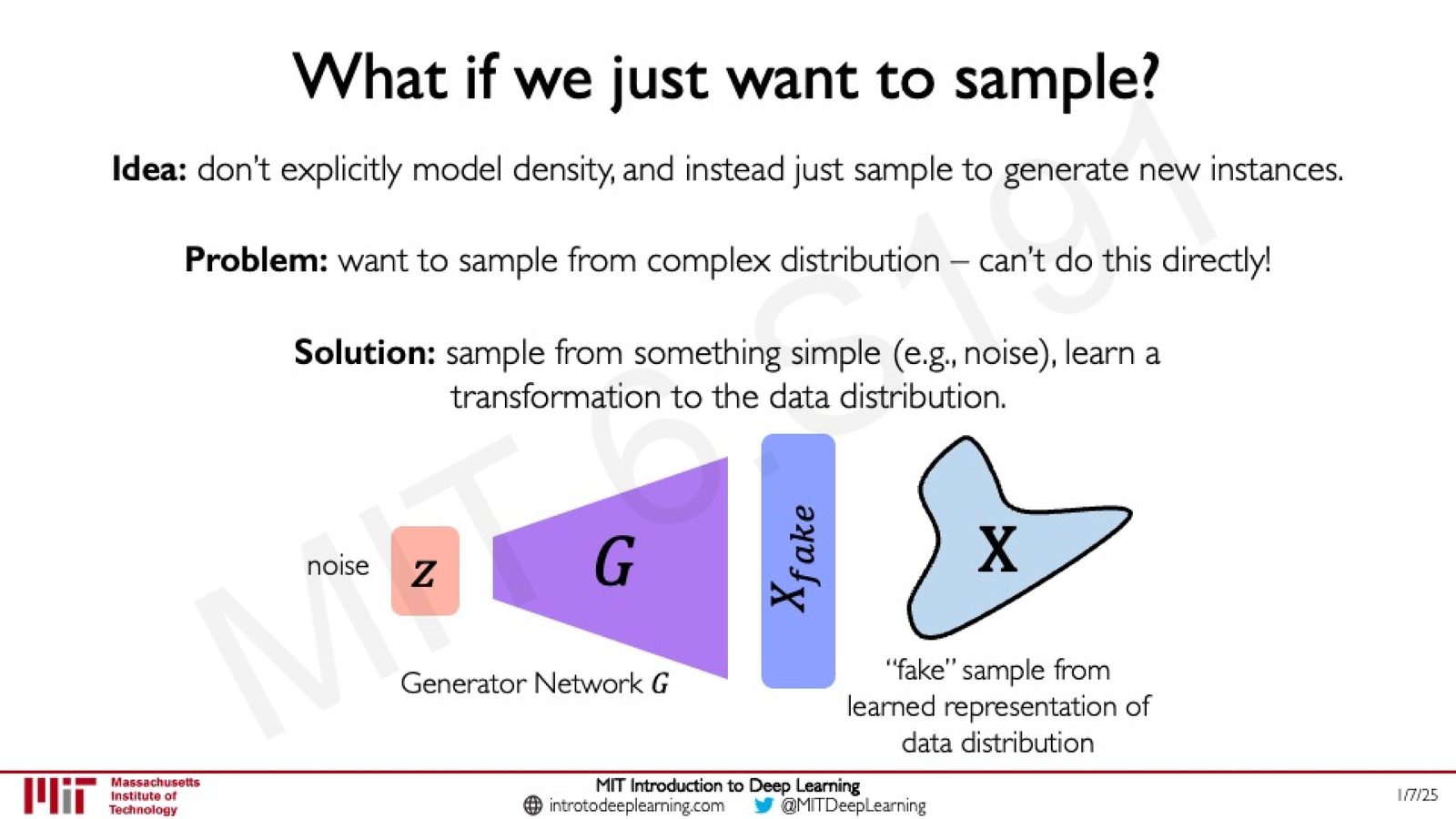
来源:Slides 第48页。
GAN 的设计哲学
GAN 的核心思路是:不去显式建模 \(p(x)\),而是直接学习一个从简单分布(如高斯噪声)到复杂数据分布的变换。具体做法是从简单的噪声分布中采样,然后训练一个生成器网络将噪声变换为逼真的数据样本。关键问题变成了:如何训练这个生成器?
GAN 的对抗训练思想
GAN 提出了一个优雅的解决方案:引入两个互相竞争的网络——生成器(Generator, \(G\))和判别器(Discriminator, \(D\))。
- 生成器 \(G\):接收随机噪声 \(z\),尝试生成尽可能逼真的假数据 \(x_{\text{fake}} = G(z)\)
- 判别器 \(D\):接收数据样本(可能是真实的或生成的),输出该样本为真实数据的概率 \(D(x) \in {[}0, 1{]}\)
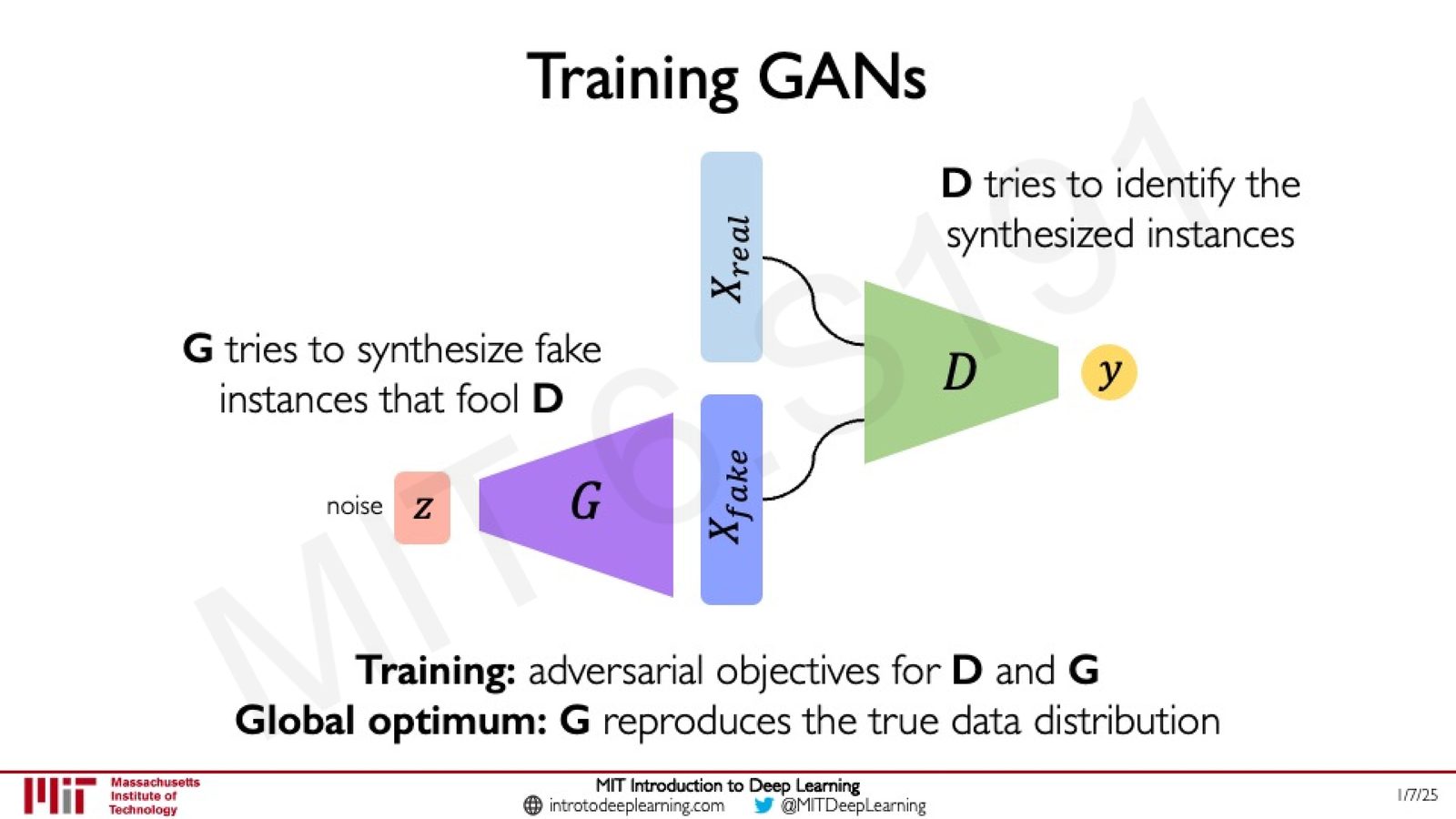
来源:Slides 第68页。
两个网络形成对抗博弈:
- \(G\) 试图生成足以欺骗 \(D\) 的假数据
- \(D\) 试图正确区分真实数据和 \(G\) 生成的假数据
- 在训练达到全局最优时,\(G\) 能够生成与真实数据分布一致的样本
GAN 训练的直觉
课程用一维数据线上的动画生动展示了 GAN 的训练过程:
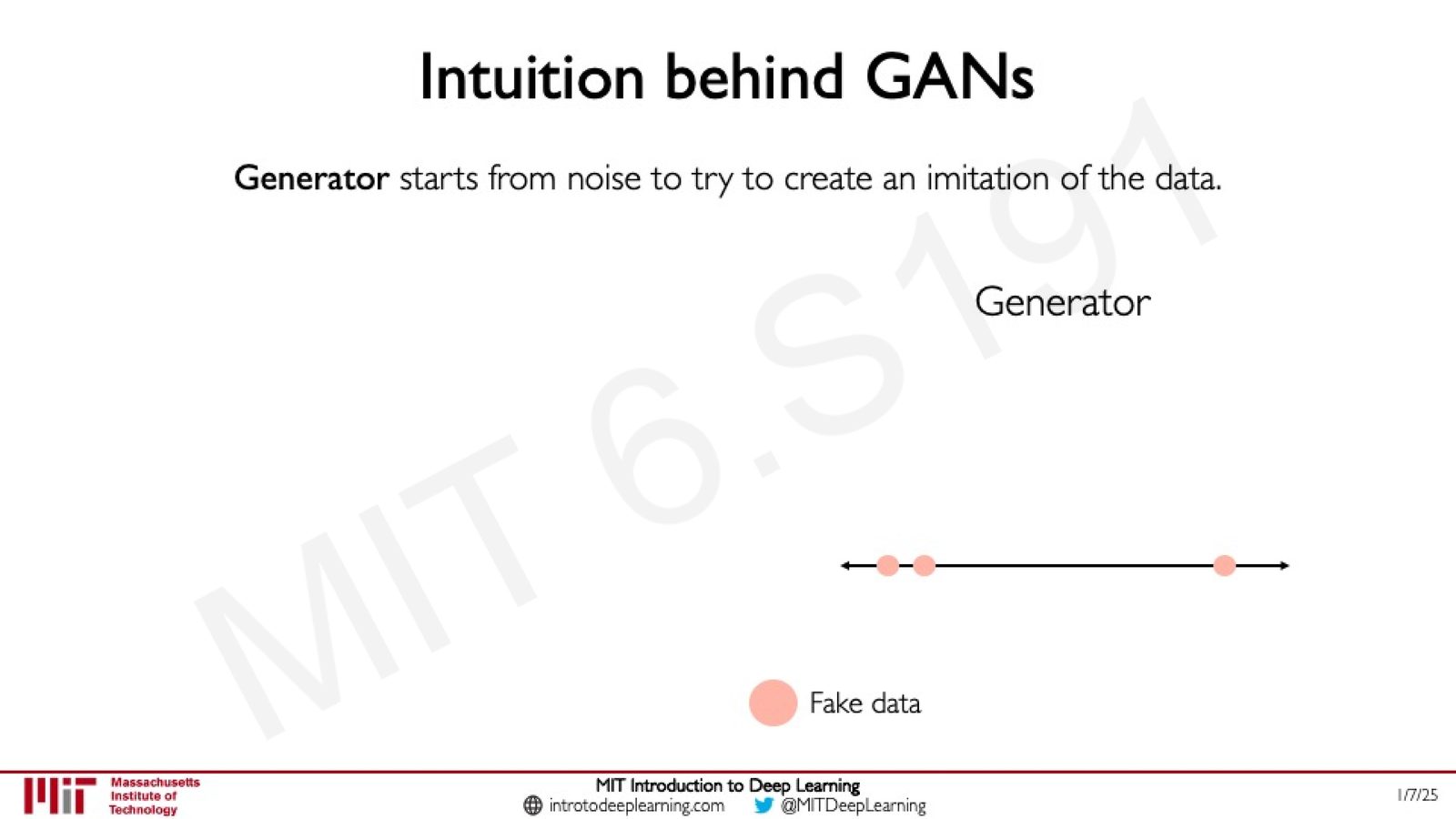
来源:Slides 第50页。
训练过程的迭代:
- 生成器初始时从随机噪声生成质量很差的假数据
- 判别器学习区分真实数据(绿色点)和假数据(粉色点),为真实数据赋予高概率
- 生成器根据判别器的反馈,调整生成的数据分布,使假数据更接近真实数据
- 判别器再次更新以适应更好的假数据
- 反复迭代,直到假数据与真实数据无法区分
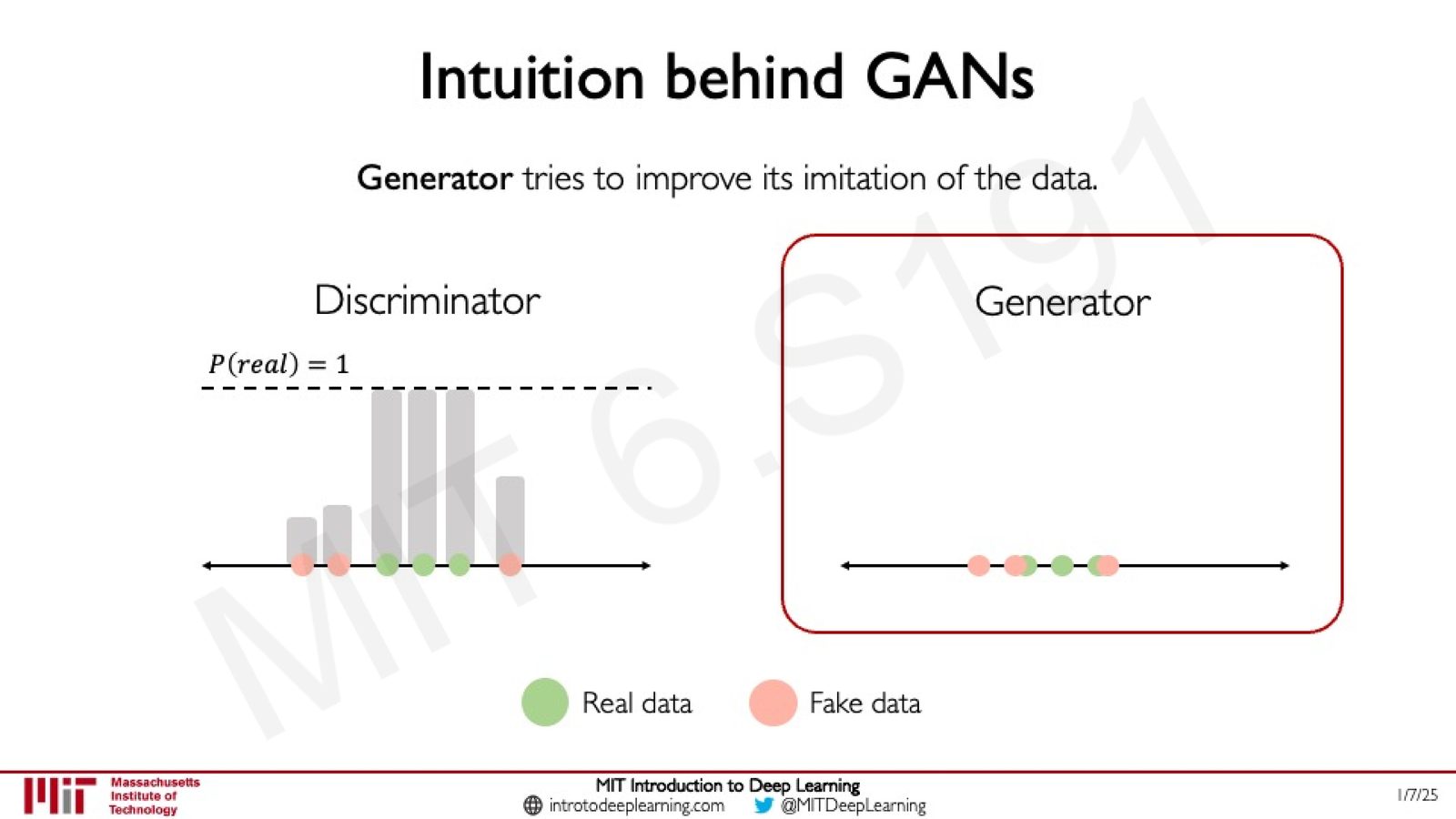
来源:Slides 第65页。
GAN 的损失函数
GAN 的训练目标可以用一个 minimax 博弈形式表达:

来源:Slides 第70页。
GAN 损失函数解读
判别器的目标(最大化):
- \(\log D(x)\):对真实数据 \(x\),希望 \(D(x) \to 1\)(正确识别为真)
- \(\log(1 - D(G(z)))\):对生成数据 \(G(z)\),希望 \(D(G(z)) \to 0\)(正确识别为假)
生成器的目标(最小化):
- 希望 \(D(G(z)) \to 1\),即让判别器将假数据误判为真
- 等价于最小化 \(\log(1 - D(G(z)))\)
GAN 训练的不稳定性
GAN 的对抗训练在实践中可能非常不稳定。两个网络需要保持相对平衡的训练进度——如果判别器太强,生成器得不到有用的梯度信号;如果生成器太强,判别器无法提供有效的反馈。常见问题包括模式崩塌(Mode Collapse)和训练振荡。后续工作如 Wasserstein GAN (WGAN) 提出了更稳定的替代损失函数。
GAN 作为分布变换器
训练完成后,我们丢弃判别器,只使用生成器来生成新数据:

来源:Slides 第72页。
从根本上讲,GAN 的生成器学习了一个分布变换:从高斯噪声分布 \(z \sim \mathcal{N}(0, 1)\) 到目标数据分布的映射。
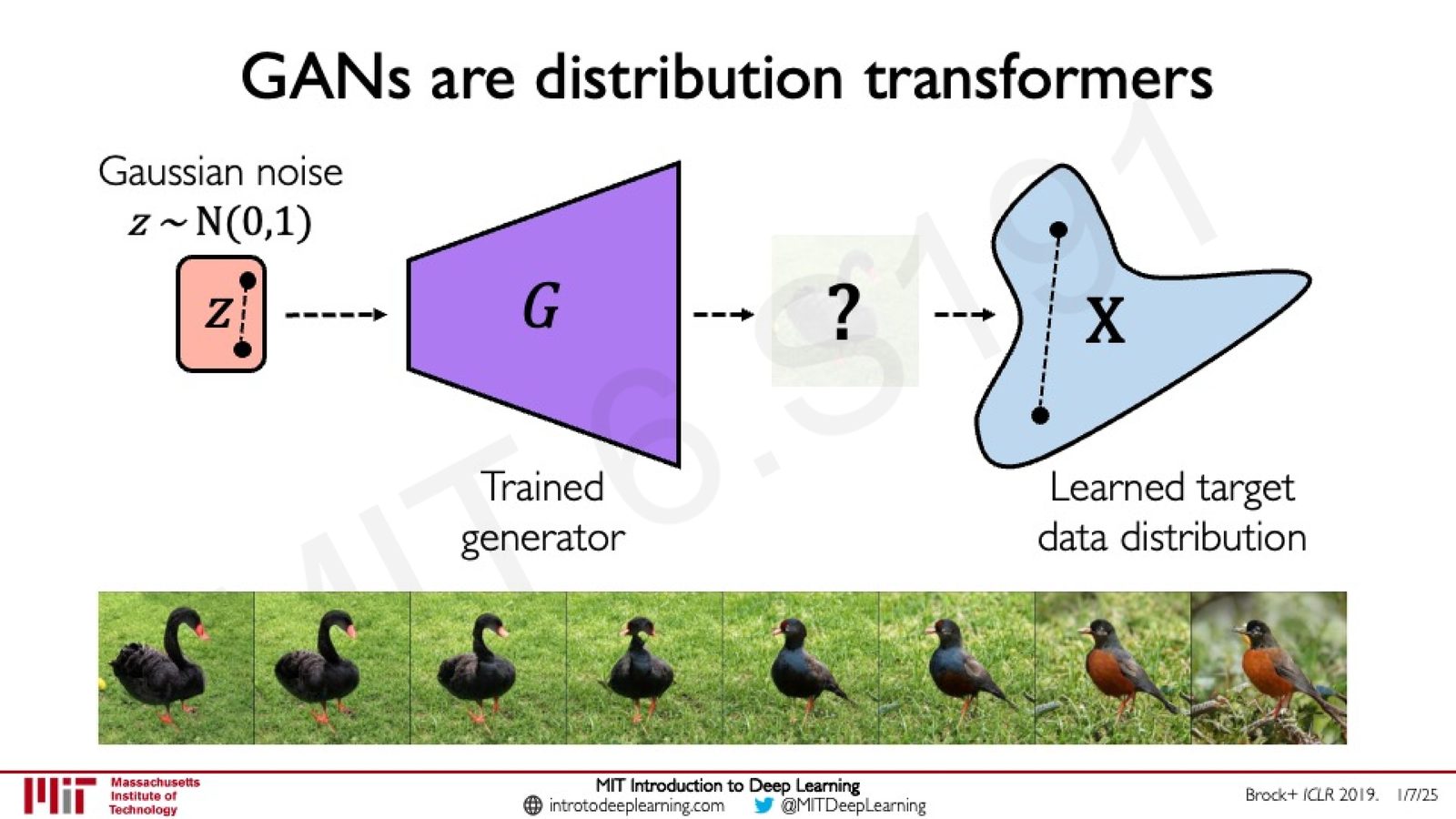
来源:Slides 第75页。来源:Brock+ ICLR 2019。
在噪声空间中进行平滑插值时,生成的样本也会在数据流形上平滑过渡,说明生成器学到了数据的连续结构。
GAN 的发展与应用
Progressive Growing of GANs:通过逐步增加网络层数和分辨率,可以生成极为逼真的高分辨率人脸图像。

来源:Slides 第78页。来源:Karras+ ICLR 2018。
Conditional GAN 与 Pix2Pix:通过在生成器和判别器中加入条件信息,可以实现配对的图像翻译任务——如从语义分割图生成真实街景照片。
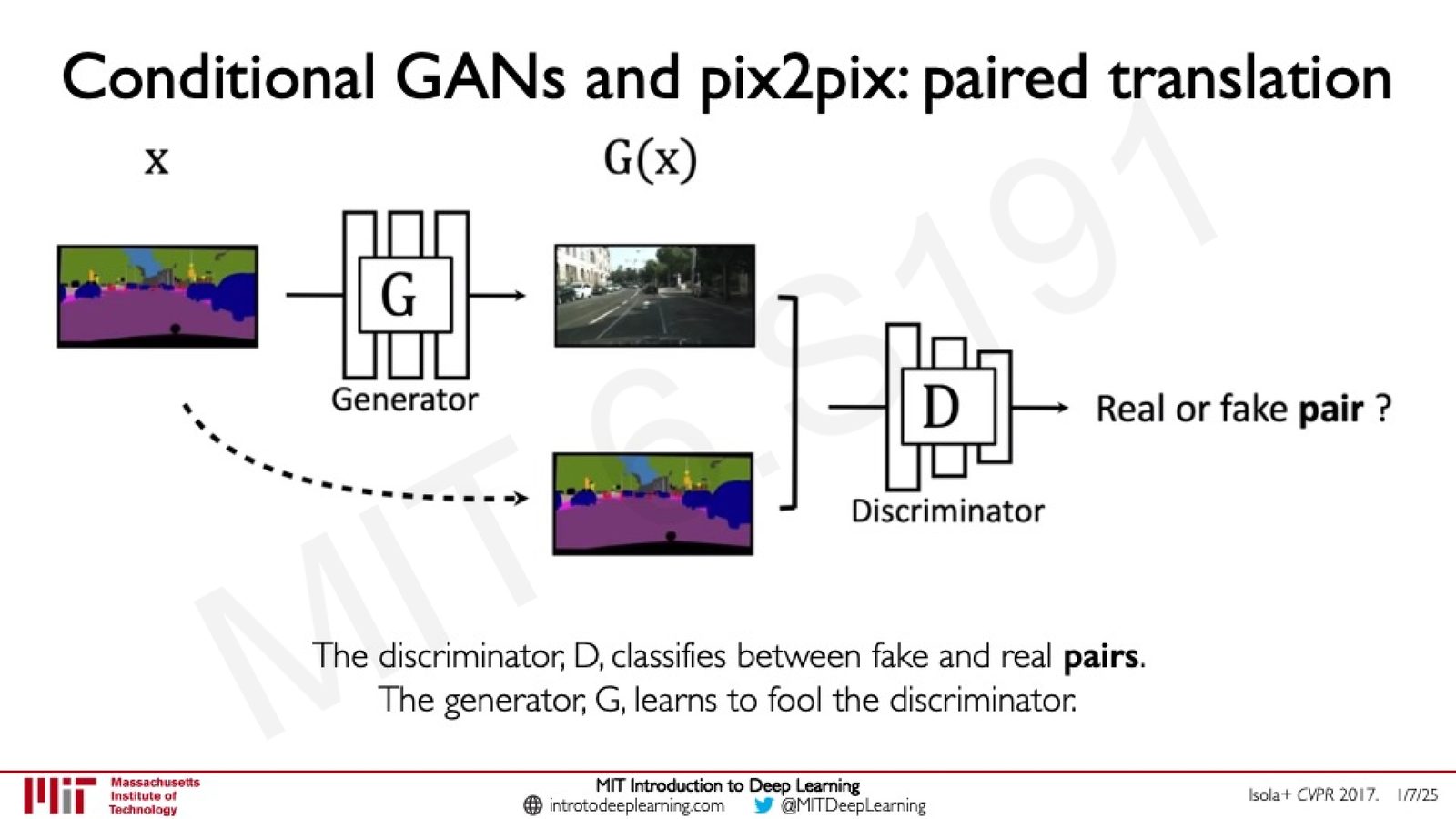
来源:Slides 第80页。来源:Isola+ CVPR 2017。
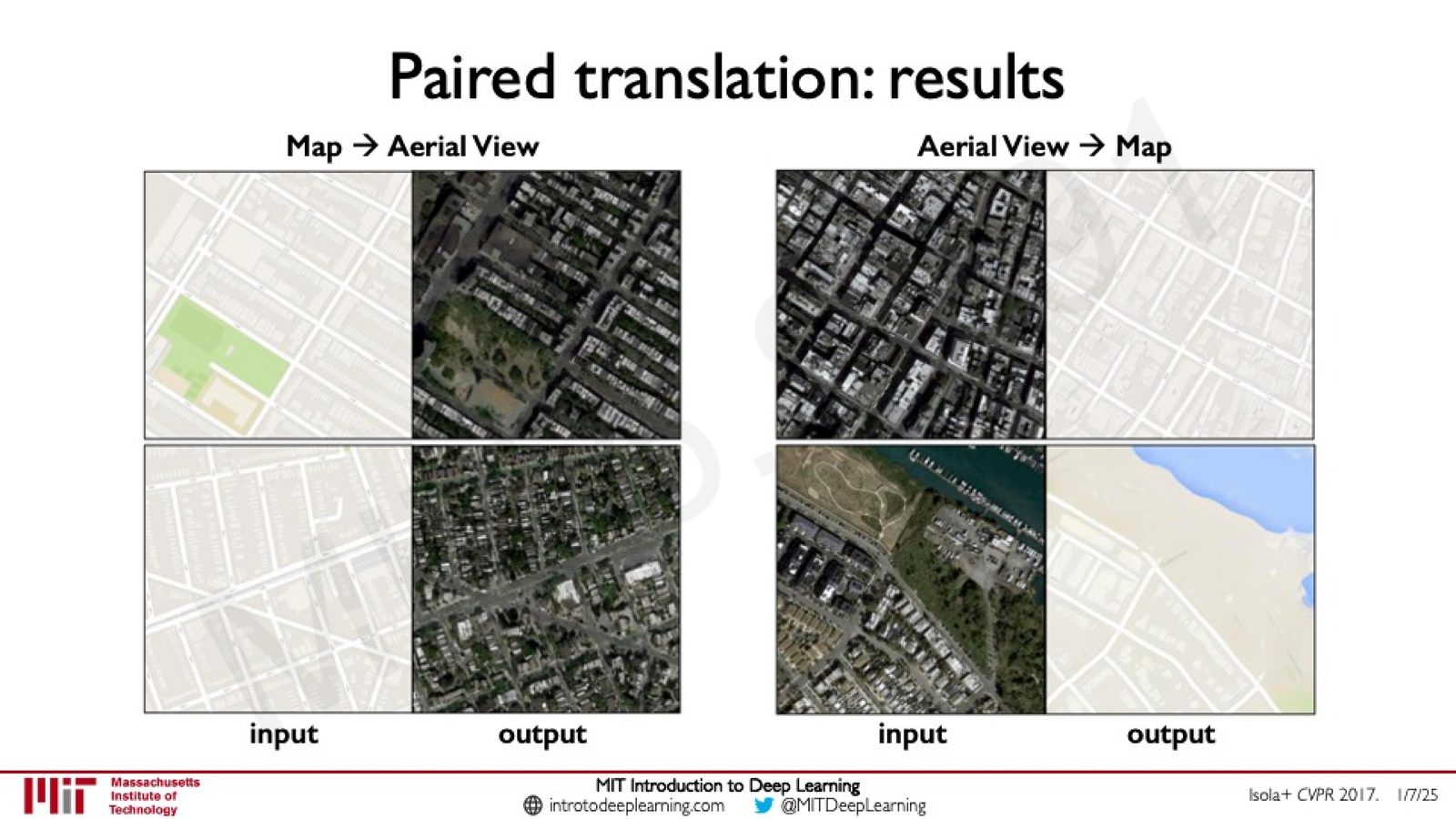
来源:Slides 第82页。来源:Isola+ CVPR 2017。
CycleGAN:不需要配对数据即可实现跨域转换。不仅限于图像,还可以应用于语音变换等领域。
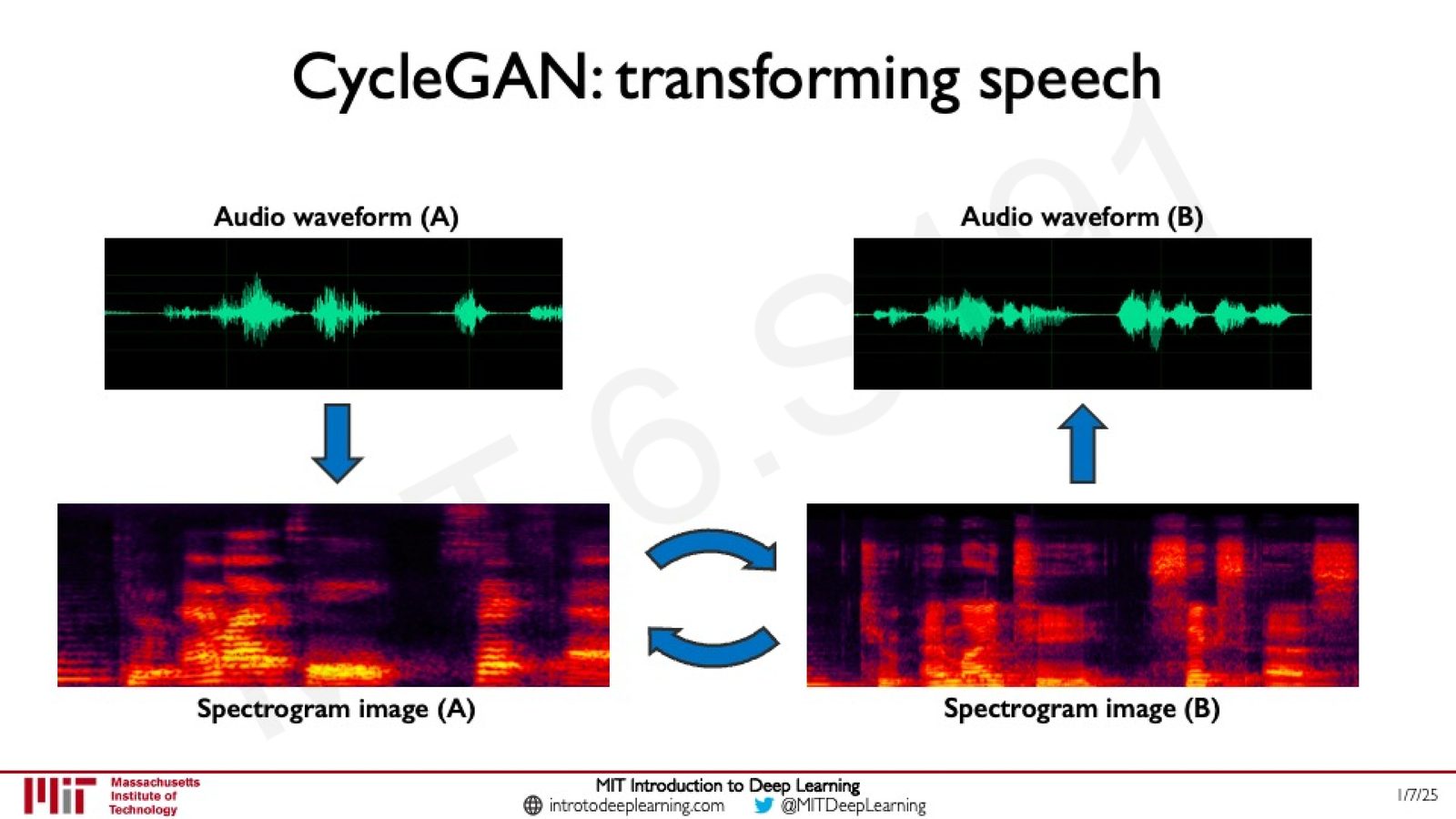
来源:Slides 第85页。
CycleGAN 的创新
传统 GAN 从噪声分布生成目标分布。CycleGAN 扩展了这个思想:它不从噪声出发,而是从一个数据分布出发,学习到另一个数据分布的映射。关键创新是使用循环一致性损失(Cycle Consistency Loss),确保从 A 域转到 B 域再转回 A 域时,能恢复原始输入。这使得无需配对数据即可训练。
本章小结
GAN 通过生成器-判别器的对抗训练,实现了不需要显式建模密度即可生成高质量样本的目标。GAN 本质上是一个分布变换器,将简单的噪声分布映射到复杂的数据分布。虽然 GAN 训练存在不稳定的挑战,但其生成质量(尤其是图像)通常优于 VAE,并且衍生出了 Conditional GAN、CycleGAN 等强大的变体。
两大模型的对比与联系
VAE vs. GAN:架构对比
来源:Slides 第46页。
| 维度 | VAE | GAN |
|---|---|---|
| 建模方式 | 显式建模密度 \(p(x)\) | 隐式学习采样过程 |
| 网络结构 | 编码器 + 解码器 | 生成器 + 判别器 |
| 训练方式 | 最大化 ELBO | Minimax 对抗博弈 |
| 隐空间 | 编码器产生,结构化 | 噪声空间,无编码器 |
| 生成质量 | 通常较模糊 | 通常更清晰锐利 |
| 训练稳定性 | 相对稳定 | 不稳定,易模式崩塌 |
| 可解释性 | 隐空间可解释 | 隐空间解释性较弱 |
VAE 生成模糊的原因
VAE 使用像素级重建损失(如 MSE),这导致模型倾向于输出多种可能结果的"平均",产生模糊的输出。GAN 则通过判别器提供的对抗信号来优化生成质量,不受这个限制,因此通常能生成更清晰的图像。但 GAN 缺少 VAE 那样的显式编码器,难以进行推断和隐空间操控。
本章小结
VAE 和 GAN 是两种互补的生成模型范式。VAE 提供了结构化的隐空间和稳定的训练,但生成质量有限;GAN 提供了卓越的生成质量,但训练不稳定且缺乏显式的隐空间。在实际应用中,可以根据需求选择合适的模型,或使用结合两者优点的混合架构。
实践:Lab 2 — 面部检测系统
课程配套了一个动手实验(Lab 2),使用 VAE 对人脸数据集进行训练,自动发现隐变量(如肤色、姿态、光照等),并利用这些隐变量检测数据集中的偏差和不足代表的特征。
来源:Slides 第89页。
Lab 2 的教学意义
这个实验将理论与实践相结合:
- 构建 VAE 模型处理人脸图像
- 通过隐变量扰动发现数据中的潜在特征
- 检测训练数据中的偏差(如某些肤色或姿态是否被低估)
- 利用生成模型创建更公平、更平衡的数据集
本章小结
配套实验帮助学生在动手实践中深化对 VAE 的理解,特别是如何利用生成模型发现和缓解数据集中的偏差问题——这是 AI 公平性研究的重要课题。
总结与延伸
核心知识回顾
本讲系统介绍了深度生成建模的两大基础架构:
1. Variational Autoencoder (VAE):
- 通过编码器-解码器架构将数据压缩到概率性隐空间
- 损失函数 = 重建损失 + KL Divergence 正则化
- Reparameterization Trick 实现端到端可微训练
- 隐空间具有连续性和完整性,支持可解释的特征操控
2. Generative Adversarial Network (GAN):
- 生成器与判别器的 minimax 对抗博弈
- 不需要显式建模密度,直接学习分布变换
- 生成质量优异,但训练稳定性是核心挑战
- 衍生出 Progressive GAN、Conditional GAN、CycleGAN 等强大变体
生成模型的统一视角
无论是 VAE 还是 GAN,它们的共同目标都是学习数据的底层概率分布。VAE 通过显式的密度估计实现这一目标,而 GAN 通过对抗训练隐式地学习数据分布。两种方法各有优劣,代表了生成建模的两种基本哲学:显式建模 vs. 隐式采样。
从 VAE/GAN 到现代生成模型
本讲介绍的 VAE(2014)和 GAN(2014)是生成模型领域的两座里程碑。在它们之后,生成模型领域继续快速发展:
- Diffusion Models(扩散模型,2020--):通过逐步去噪过程生成数据,已成为图像生成的主流方法(如 Stable Diffusion、DALL-E 2/3)
- Flow-based Models(流模型):通过可逆变换显式建模密度,如 Glow、RealNVP
- Autoregressive Models(自回归模型):如 GPT 系列,逐 token 建模条件概率分布
- Score-based Models:通过估计数据分布的梯度场来生成样本
为什么 Diffusion Models 后来居上?
Diffusion Models 结合了 VAE 和 GAN 的优点:它们像 VAE 一样有稳定的训练过程(基于似然优化),同时像 GAN 一样能生成高质量的样本。通过逐步去噪的马尔可夫过程,Diffusion Models 避免了 GAN 的训练不稳定性和 VAE 的生成模糊问题。MIT 6.S191 的后续讲座会专门讲解 Diffusion Models。
拓展阅读
- Kingma & Welling, “Auto-Encoding Variational Bayes,” ICLR 2014 --- VAE 的开创性论文
- Goodfellow et al., “Generative Adversarial Nets,” NeurIPS 2014 --- GAN 的开创性论文
- Higgins et al., “\(\beta\)-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework,” ICLR 2017
- Isola et al., “Image-to-Image Translation with Conditional Adversarial Networks (Pix2Pix),” CVPR 2017
- Karras et al., “Progressive Growing of GANs,” ICLR 2018
- Zhu et al., “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks (CycleGAN),” ICCV 2017
- Brock et al., “Large Scale GAN Training for High Fidelity Natural Image Synthesis (BigGAN),” ICLR 2019
- Ho et al., “Denoising Diffusion Probabilistic Models,” NeurIPS 2020 --- Diffusion Models
- MIT 6.S191 课程主页:introtodeeplearning.com
- Lab 2 代码:github.com/MITDeepLearning/introtodeeplearning