MIT 6.S191 Lecture 6: Language Models and New Frontiers
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Alexander Amini 授课内容整理 |
| 来源 | Alexander Amini (MIT) |
| 日期 | 2025年春季 |

引言:课程回顾与本讲主旨
本讲是 MIT 6.S191 Introduction to Deep Learning 系列六节基础讲座的最后一讲。在之前的五讲中,课程系统地介绍了深度学习的核心方法论——从基础的全连接神经网络、序列建模(RNN / Transformer)、卷积神经网络(CNN),到生成模型(VAE / GAN)和深度强化学习。本讲将在回顾这些基础之上,聚焦两个核心议题:
- 深度学习的局限性(Limitations)——泛化困境、对抗攻击、不确定性表征等;
- 新前沿(New Frontiers)——Diffusion Models 和 Large Language Models (LLMs) 为代表的最新进展。

来源:Slides 第1页。
正如 Amini 在课上所说,深度学习已经在自动驾驶、医学影像、强化学习、生成建模、自然语言处理、金融、安全等众多领域带来了革命性进展。但作为技术从业者,我们不仅要理解这些算法的威力,更要清醒地认识其局限性,这样才能负责任地将 AI 部署到真实世界中。

来源:Slides 第10页。
本章小结
本讲作为基础讲座的收官之作,承上启下:回顾深度学习的核心作为函数逼近器的本质,指出其局限性,并展望以 Diffusion Models 和 LLM 为代表的新前沿方向。
神经网络的本质:函数逼近器
Universal Approximation Theorem
要理解深度学习的威力与局限,一个非常重要的出发点是 1989 年 Hornik 等人提出的 Universal Approximation Theorem(万能逼近定理):
Universal Approximation Theorem
一个具有单隐层的前馈神经网络,在隐藏单元数量足够多的情况下,能够以任意精度逼近任何连续函数。
其中:
- \(f(x)\):目标连续函数
- \(\hat{f}(x; W, b)\):单隐层神经网络的输出
- \(\sigma\):非线性激活函数
- \(W_1, W_2, b_1, b_2\):可学习的权重和偏置参数

来源:Slides 第12页。引用 Hornik+ Neural Networks 1989。
定理的局限
虽然该定理在理论上非常强大,但存在两个关键的 caveat:
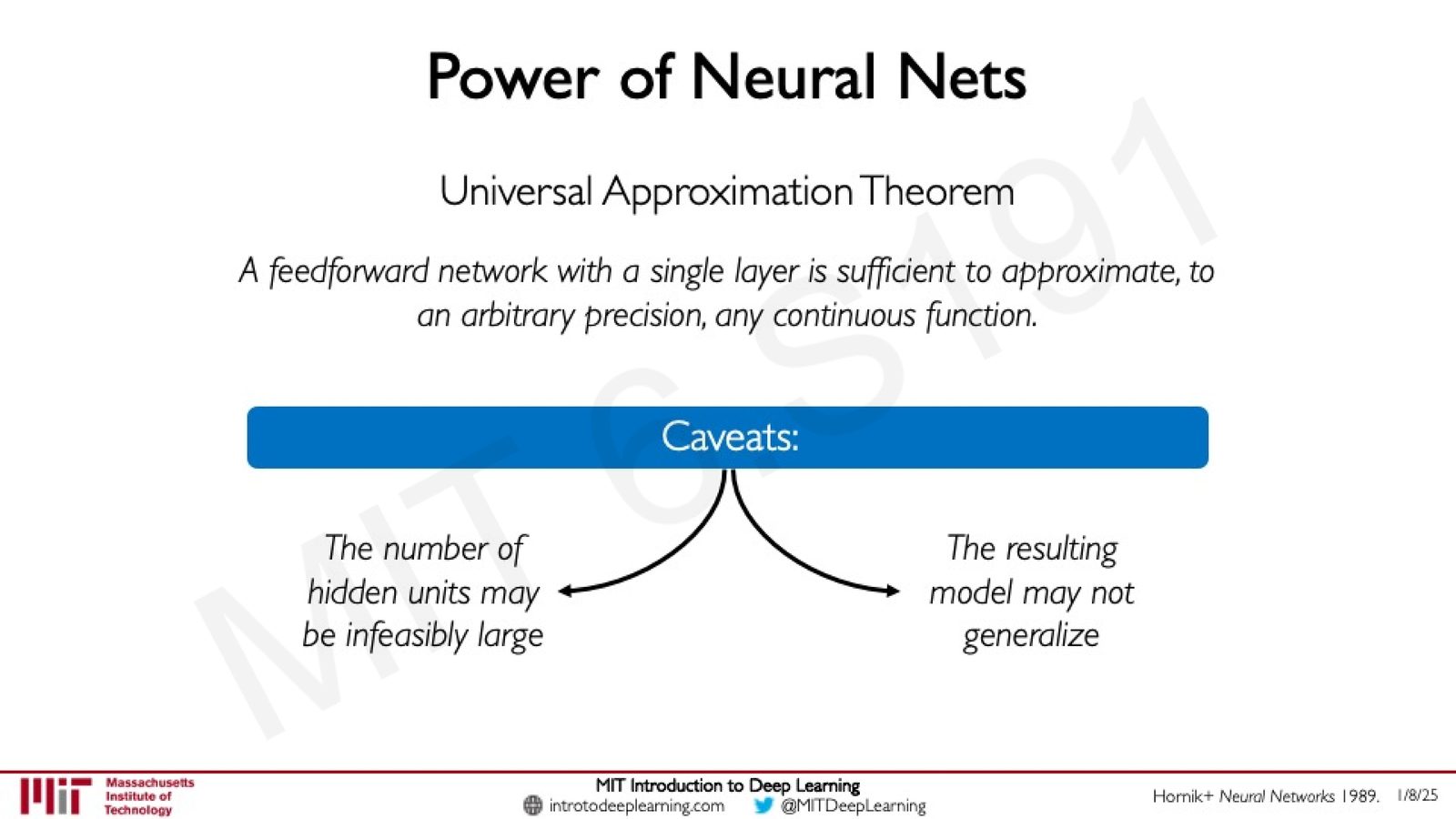
来源:Slides 第13页。
万能逼近定理的两大注意事项
- 隐藏单元数量可能不可行地大:定理保证存在这样一个网络,但没有给出所需神经元数量的上界——对于复杂函数,可能需要天文数字级别的参数。
- 不保证泛化能力:定理只保证逼近能力,不保证学到的模型能在未见数据上表现良好。拟合训练数据不等于理解数据的底层规律。
此外,定理并未提供如何找到最优权重的方法论。梯度下降虽然是一种有效的优化策略,但在高维非凸损失曲面上,优化本身就是一个高度非平凡的问题。
AI 发展的历史视角
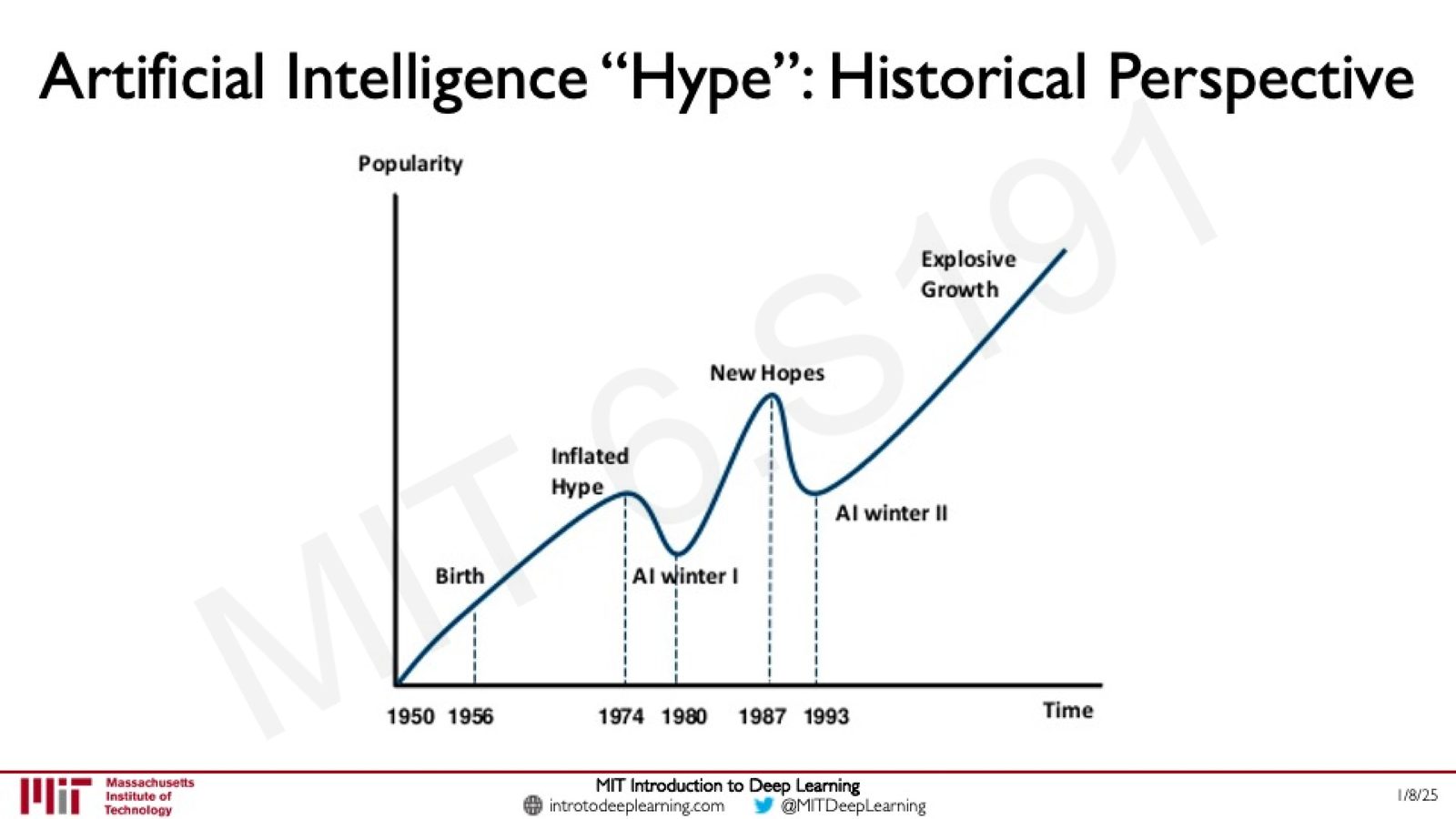
来源:Slides 第14页。
AI 的发展史经历了典型的 hype cycle:从 1956 年达特茅斯会议的诞生,到 1974--1980 年的第一次 AI 寒冬,再到 1987--1993 年的第二次寒冬,最终在深度学习时代迎来爆发式增长。理解这段历史有助于我们对当前的 AI 热潮保持清醒的判断——既要拥抱技术进步,也要警惕过度炒作。
本章小结
神经网络从本质上说是函数逼近器。万能逼近定理保证了理论上的表达能力,但在实际应用中,隐藏层大小、优化难度和泛化能力都是必须面对的现实挑战。这一认识框架为下一节讨论深度学习的具体局限性奠定了基础。
深度学习的局限性
重新审视泛化:随机标签实验
Amini 介绍了一个经典的实验——来自 Zhang 等人 2017 年发表在 ICLR 的论文 Understanding Deep Neural Networks Requires Rethinking Generalization。
实验设计
研究者取 ImageNet 数据集中的图片及其标签,然后对每张图片独立地掷一个 \(k\) 面骰子(\(k\) 为类别总数),将原有标签替换为随机结果。这样做的后果是:同一类别的两张图可能被分配到完全不同的标签,标签与图像内容之间失去了所有语义关联。
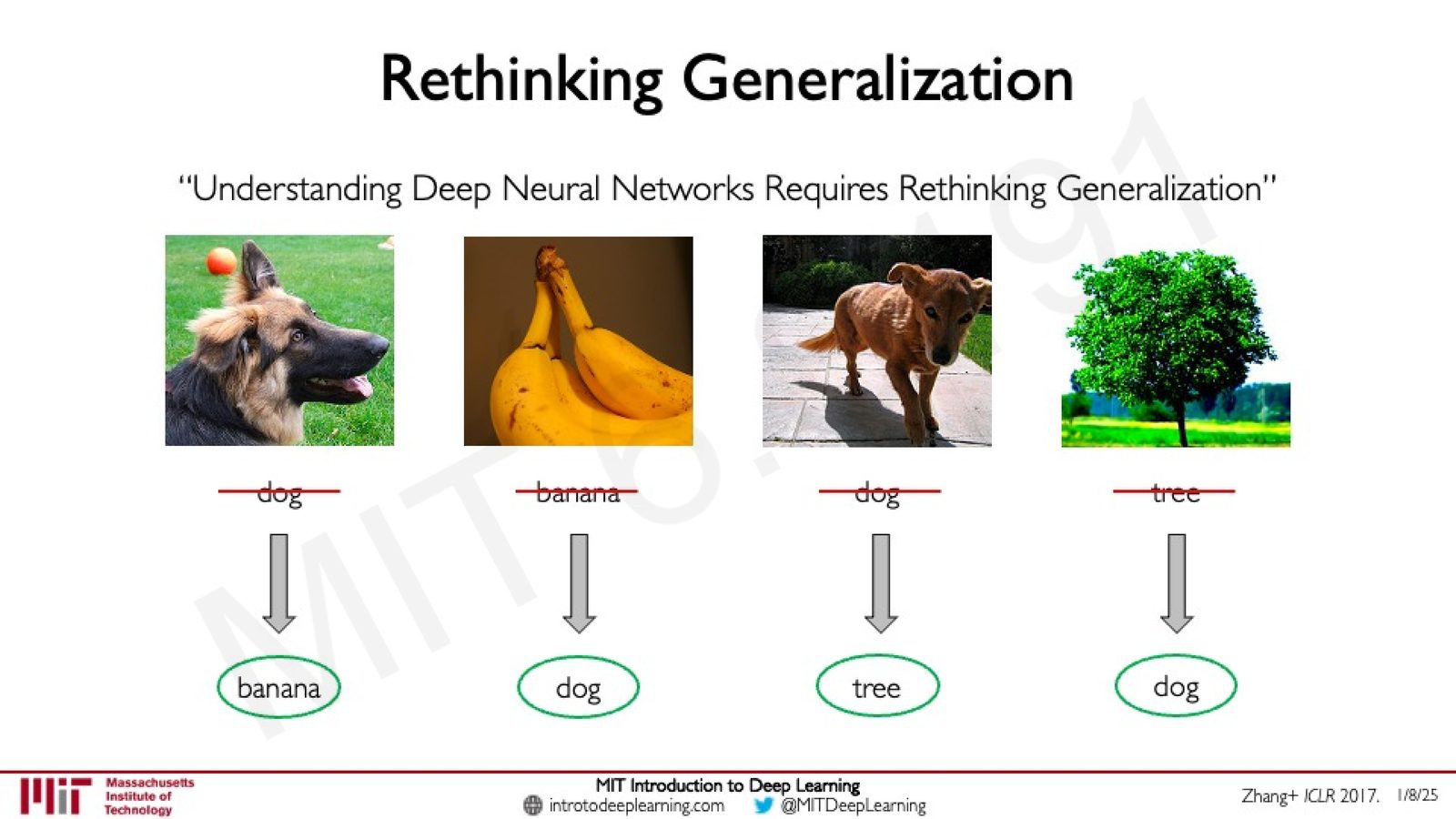
来源:Slides 第19页。引用 Zhang+ ICLR 2017。
实验结果
研究者在不同程度的标签随机化下训练深度神经网络,观察训练集和测试集的表现:
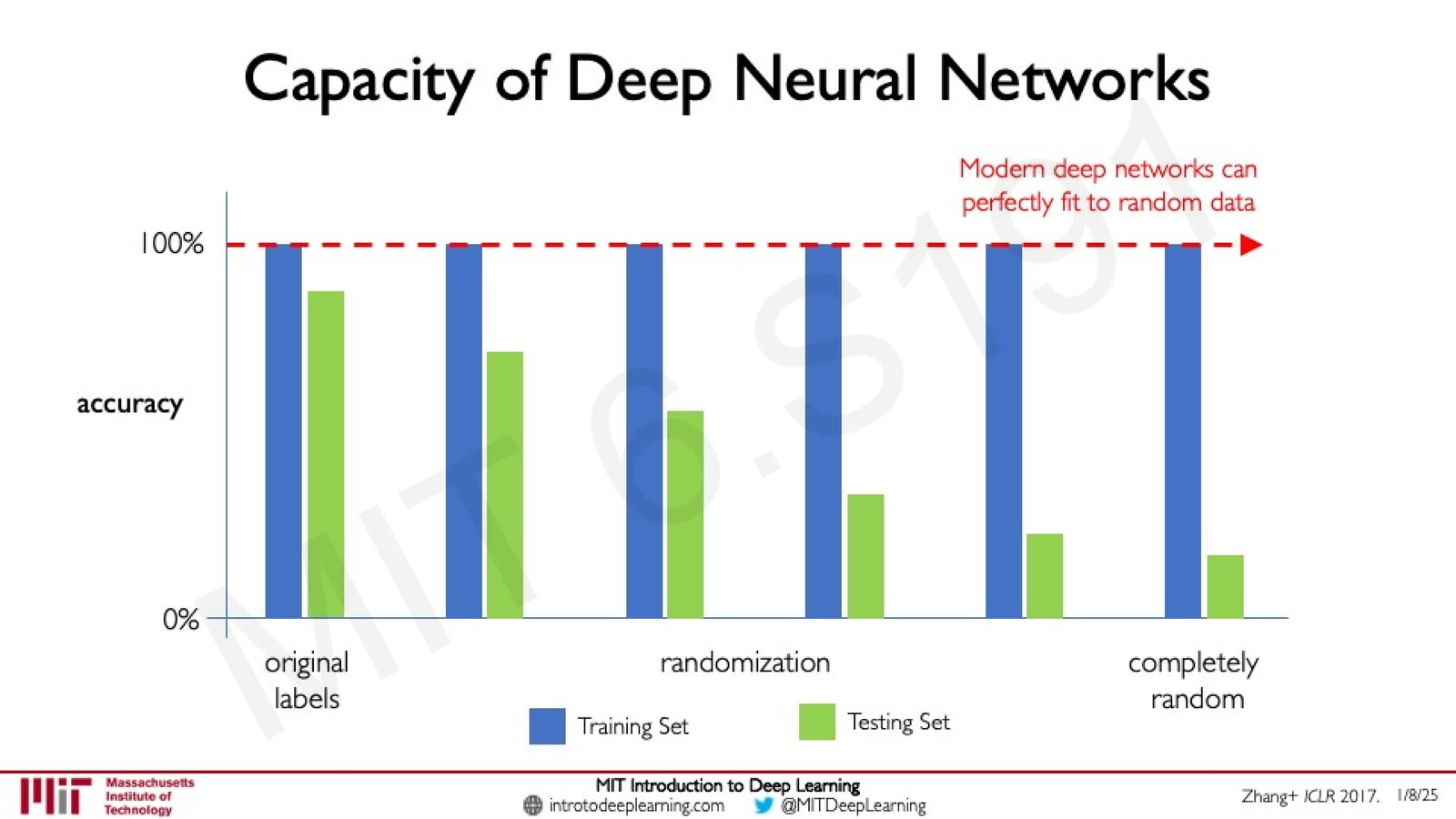
来源:Slides 第22页。红色虚线标注训练精度始终接近 100%。
核心发现:深度网络的惊人拟合能力
- 测试精度:随着标签随机化程度增加,测试集精度持续下降(符合直觉)。
- 训练精度:无论标签多随机,深度网络始终可以在训练集上达到接近 100% 的准确率。
这意味着现代深度网络拥有足够的容量(capacity)来“记住”整个训练集,即使数据中完全不存在可学习的模式。
函数逼近器的双刃剑
基于上述实验,Amini 进一步用函数拟合的视角来阐释这一现象:
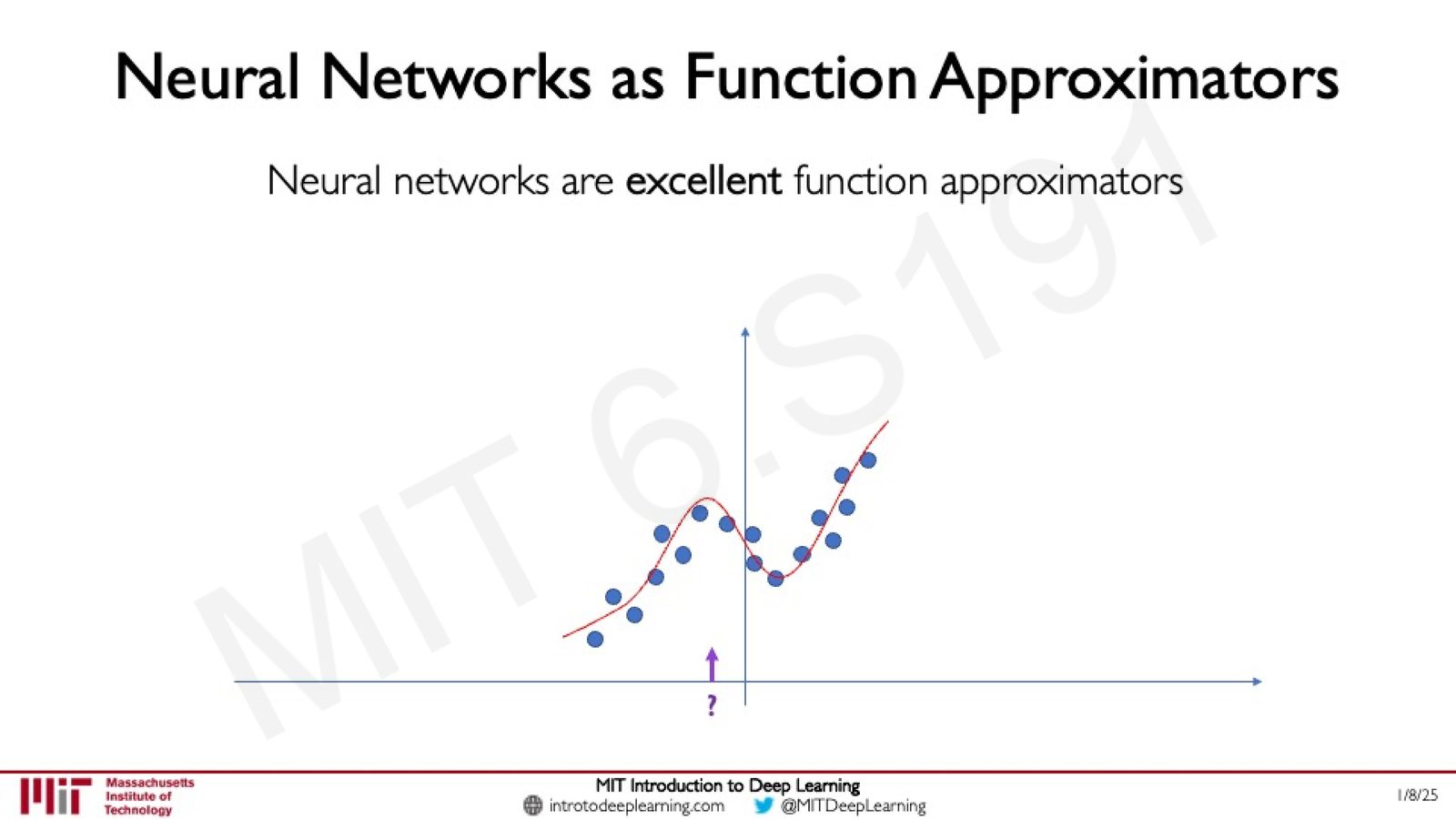
来源:Slides 第25页。
神经网络可以非常好地拟合训练数据点附近的函数值。给定一个新的数据点(紫色),如果它落在训练数据的分布范围内,网络可以给出合理的预测。但关键问题是:
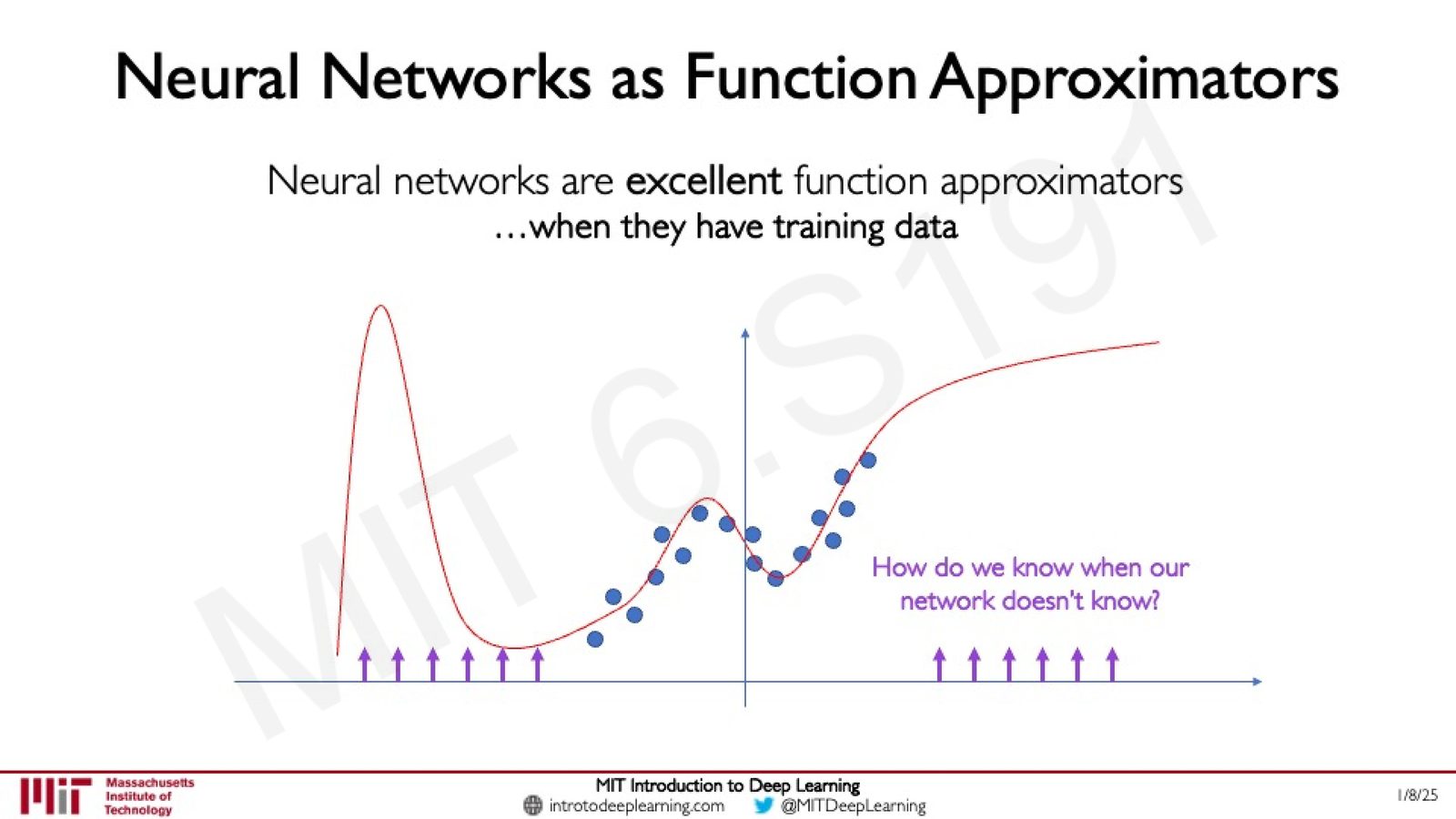
来源:Slides 第28页。
Out-of-Distribution 问题
当输入数据超出训练分布(out-of-distribution, OOD)时,神经网络的行为是不可预测的。在没有训练数据的区域,拟合函数可能产生任意的输出值——而网络不会“告诉你”它不确定。这就引出了一个核心问题:我们如何知道模型不知道什么?
深度学习不是炼金术

来源:Slides 第29页。引用 U. Muller, 6.S191 2018。
Amini 强调:深度学习不是一个可以把任何东西丢进去就能得到完美输出的“魔法黑箱”。经典的 “garbage in, garbage out”(垃圾进,垃圾出)原则完全适用。部署 AI 解决方案之前需要考虑两个核心问题:
- 这个任务是否真的适合用深度学习来解决?
- 你能为这个任务收集和整理出高质量的数据吗?
失败模式一:数据偏差

来源:Slides 第30–31页。引用 P. Isola 6.869。
课程举了一个生动的例子:训练一个 CNN 将黑白照片转换为彩色照片。当输出的狗照片下巴区域出现了粉色斑块时,原因是训练集中大量狗的照片都是伸着粉色舌头的姿态,模型学到了“狗的下巴附近应该是粉色的”这一统计关联——而非真正理解了颜色的含义。
失败模式二:安全关键场景的不确定性

来源:Slides 第32页。引用 ABC News。
Amini 提到了一起真实的自动驾驶致命事故:一辆 Tesla 在同一路段多次出现向隔离带偏转的现象,最终导致了碰撞。调查发现,该路段的隔离带是在训练数据采集之后才建造的——自动驾驶系统遇到了一个训练分布之外的场景。

来源:Slides 第33页。
深度学习中的不确定性
在以下场景中,可靠地检测和量化不确定性尤为重要:
- 安全关键应用:自动驾驶、医疗诊断、人脸识别
- 数据质量问题:类别不平衡(imbalance)、数据噪声(data noise)
- 分布外检测:当输入数据与训练分布显著不同时,模型应当“知道自己不知道”
失败模式三:对抗攻击
对抗攻击(Adversarial Attacks)是深度学习中一个非常经典且重要的安全问题。
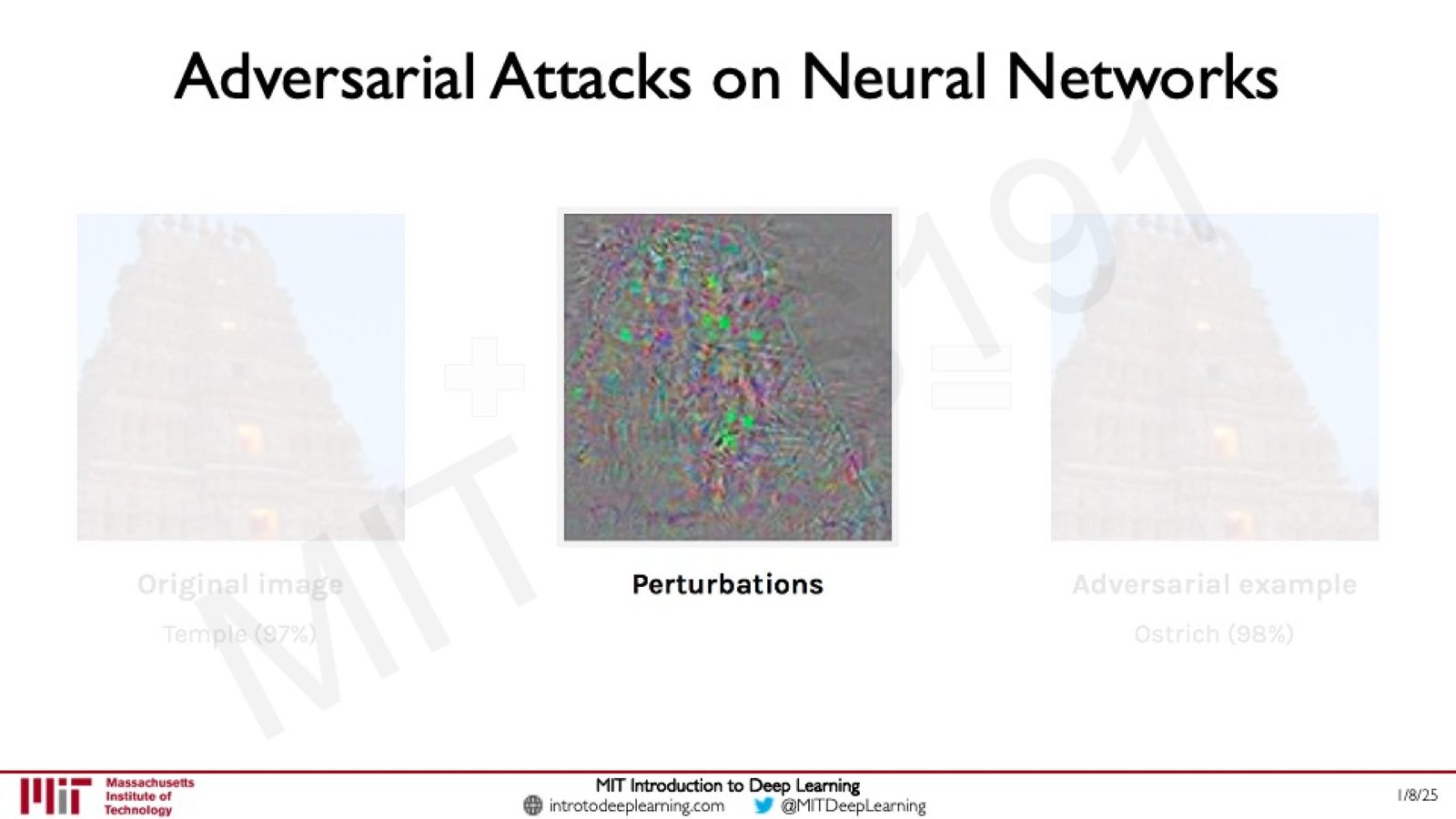
来源:Slides 第35页。
对抗攻击的数学原理
回顾梯度下降的核心公式:
其中 \(W\) 是权重,\(\eta\) 是学习率,\(J\) 是损失函数,\((x, y)\) 是固定的输入和标签。训练时,我们固定输入 \(x\) 和标签 \(y\),优化权重 \(W\) 来最小化损失。

来源:Slides 第40页。
对抗攻击则完全翻转了这个过程:
对抗攻击 vs. 正常训练
- 正常训练:固定输入 \((x, y)\),优化权重 \(W\) 来最小化损失
- 对抗攻击:固定权重 \(W\) 和标签 \(y\),修改输入 \(x\) 来最大化损失
关键区别:梯度的计算对象从 \(\partial W\) 变成了 \(\partial x\),优化方向从减号变成了加号。
物理世界中的对抗样本
对抗攻击不仅存在于数字空间,还可以在物理世界中实现。Amini 介绍了 MIT 学生利用 3D 打印技术制造的物理对抗样本——一只经过精心设计纹理的 3D 打印乌龟,在各种角度和光照条件下,都被分类器识别为“步枪”而非“乌龟”。
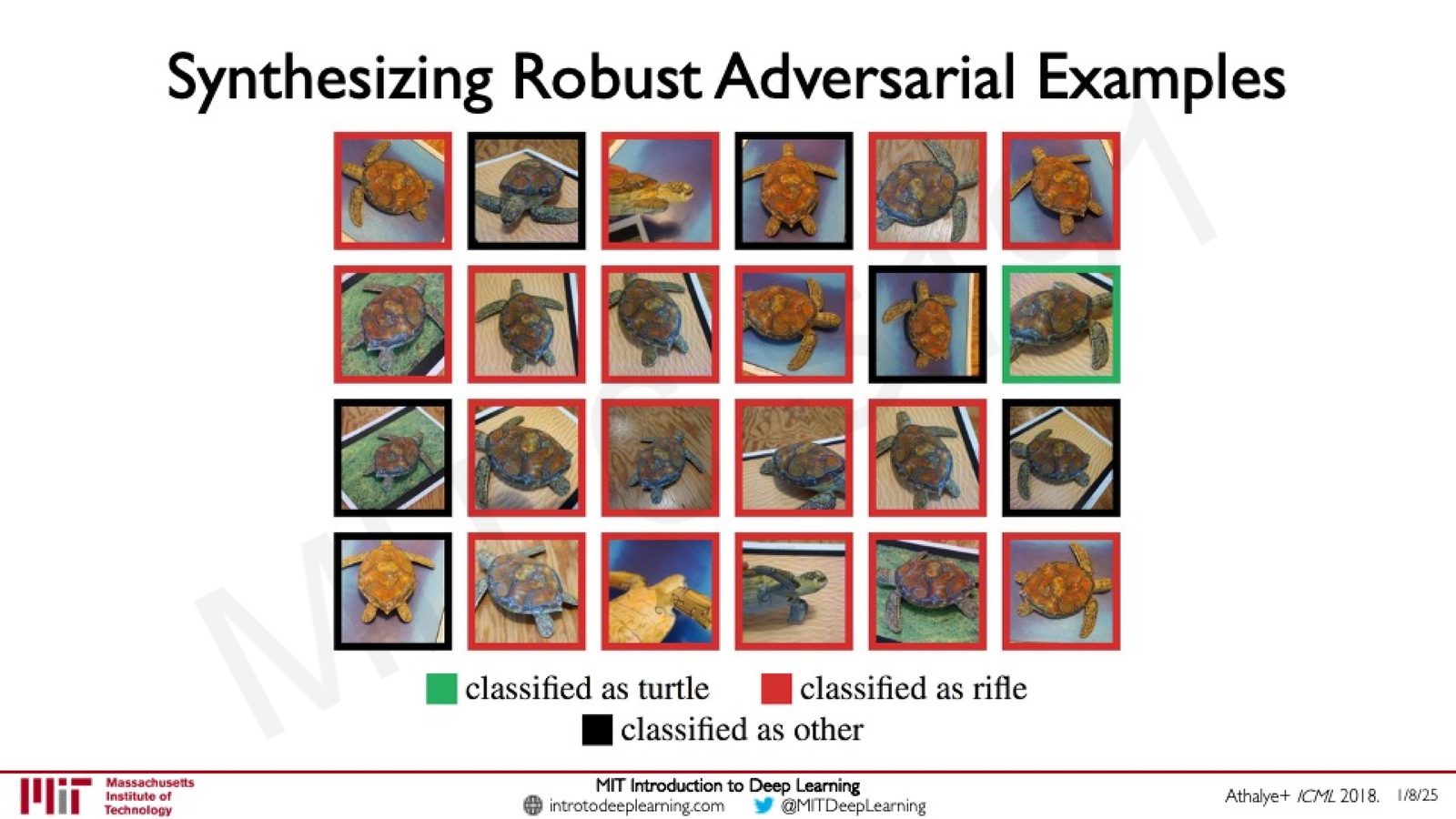
来源:Slides 第42页。引用 Athalye+ ICML 2018。
对抗攻击的现实威胁
对抗样本的存在意味着:在安全关键场景(如自动驾驶的交通标志识别、安防系统的人脸识别),精心设计的微小扰动就可能导致系统做出完全错误的判断。这不仅是学术问题,更是实际部署 AI 系统时必须考虑的安全风险。
局限性总结

来源:Slides 第46页。
课程总结了神经网络的主要局限性:
| 局限性 | 说明 |
|---|---|
| 数据饥渴 (Data hungry) | 通常需要百万级训练样本 |
| 计算密集 (Computationally intensive) | 训练和部署都需要 GPU |
| 对抗脆弱 (Adversarial examples) | 容易被精心设计的扰动欺骗 |
| 算法偏见 (Algorithmic bias) | 可能放大数据中的社会偏见 |
| 不确定性表征差 (Uncertainty) | 难以知道模型何时“不知道” |
| 黑箱不可解释 (Black boxes) | 难以理解和信任 |
| 需要专家知识 (Expert knowledge) | 架构设计和调参依赖经验 |
| 难以编码结构 (Encode structure) | 难以在学习中融入先验知识 |
| 外推困难 (Extrapolation) | 难以超越训练数据的分布范围 |
局限性孕育新前沿
Amini 指出:作为技术人员和科学家,局限性恰恰代表着发展机遇。课程后半部分介绍的 Diffusion Models 和 LLMs 正是对“外推困难”和“编码结构困难”这两个核心挑战的回应——通过建模数据分布本身,基础模型(Foundation Models)有望实现更强大的泛化能力。
本章小结
深度学习的局限性涵盖多个层面:泛化能力不足(随机标签实验揭示了惊人的过拟合能力)、数据偏差导致的系统性错误、安全关键场景中的不确定性挑战,以及对抗攻击对模型鲁棒性的威胁。理解这些局限性是负责任地使用 AI 技术的前提,也是推动下一代算法发展的动力。
新前沿 I:生成式 AI 与 Diffusion Models
生成建模的发展脉络
在 Lecture 4 中,课程介绍了两种经典的生成模型——VAE(Variational Autoencoder)和 GAN(Generative Adversarial Network)。这两类模型虽然开创性地实现了从数据中学习生成新样本的能力,但它们面临着几个关键的局限:
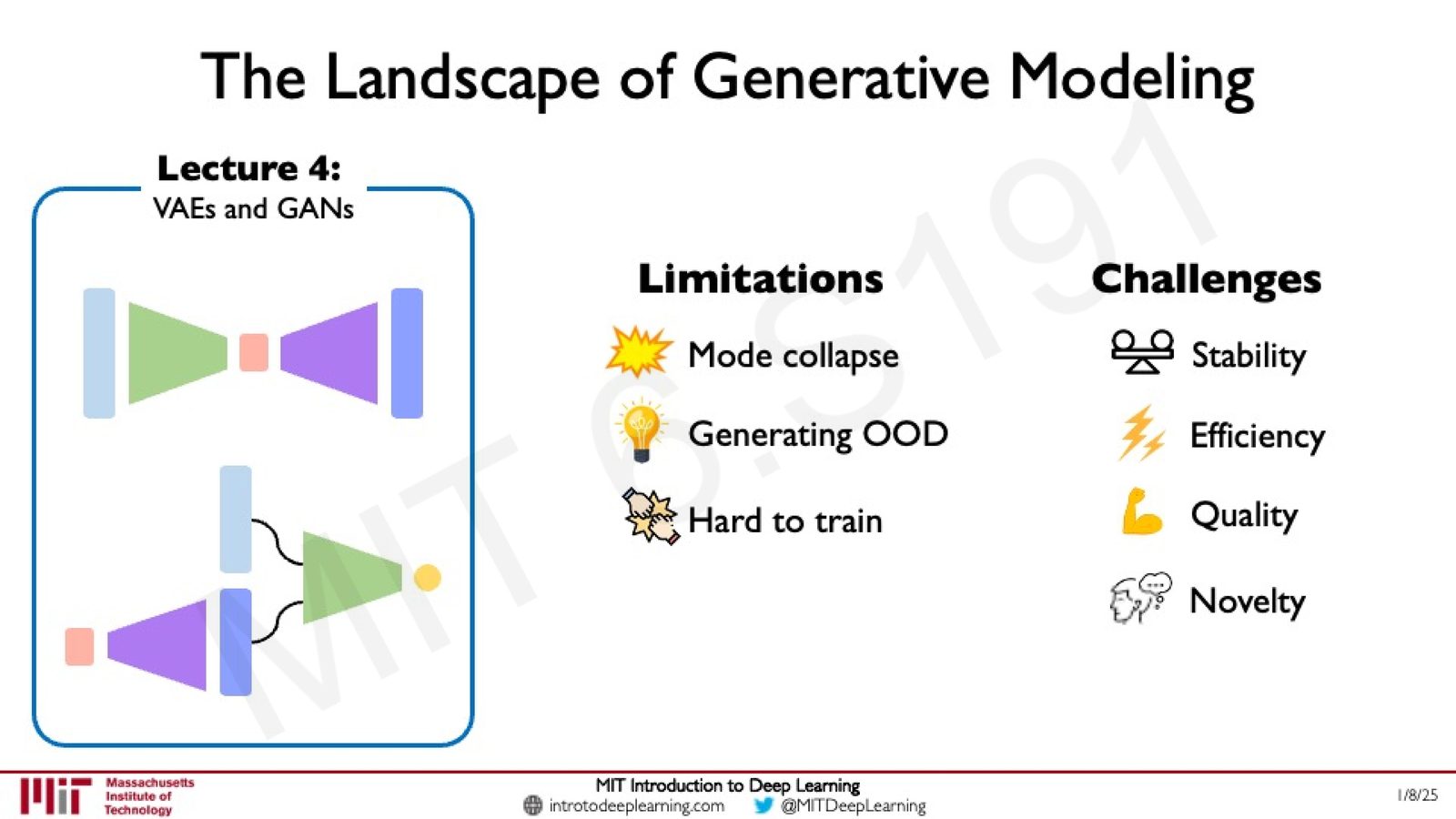
来源:Slides 第48页。
VAE 和 GAN 的主要问题
局限性(Limitations):
- Mode collapse:模型倾向于只生成“平均”样本,丧失多样性
- 分布外生成困难:难以生成训练分布之外的新颖样本
- 训练困难:特别是 GAN 的对抗训练过程极不稳定
挑战(Challenges):稳定性、效率、生成质量、新颖性
Diffusion Models 的核心思想
Diffusion Models 提出了一种与 VAE/GAN 截然不同的生成范式:
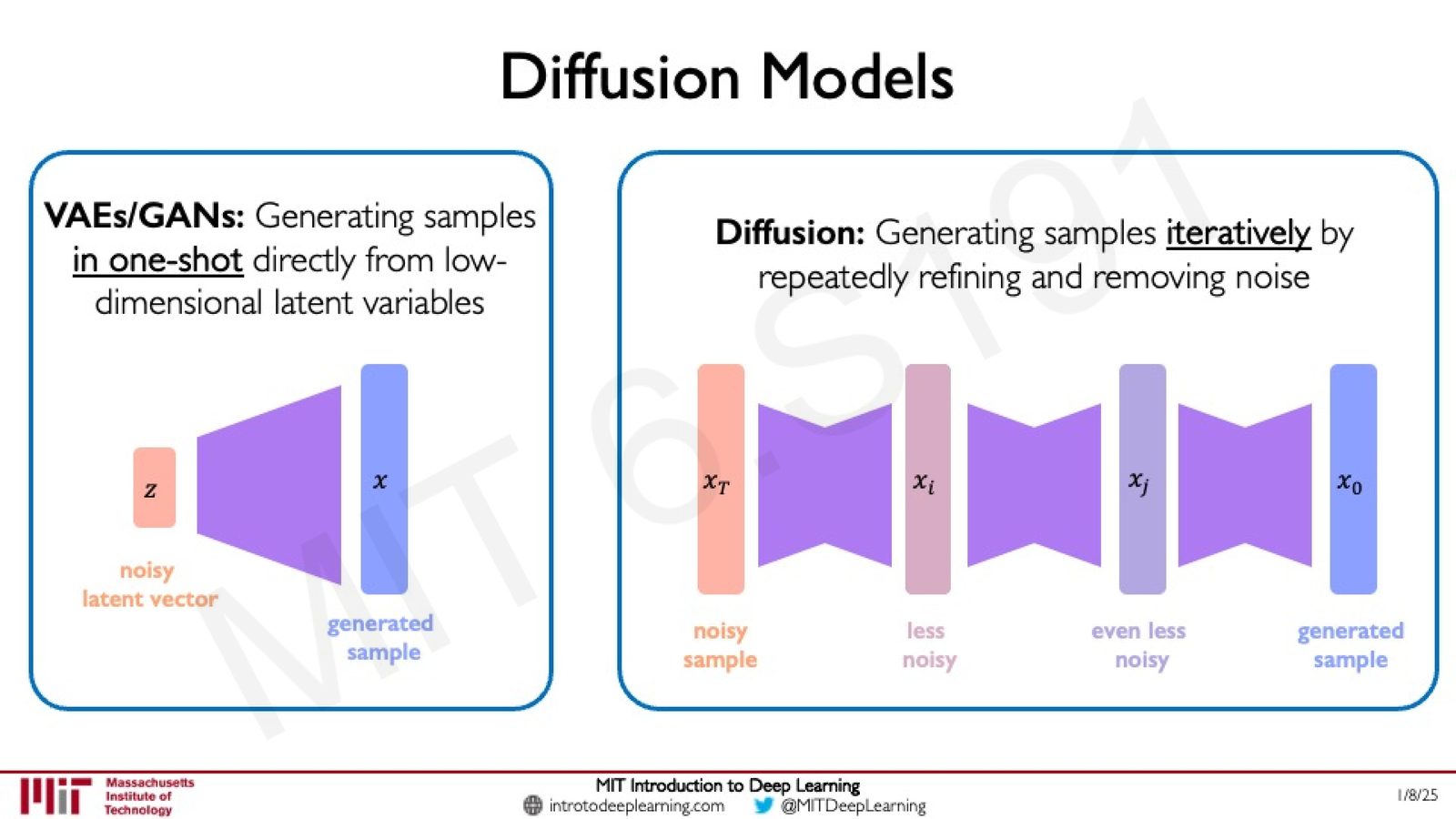
来源:Slides 第50页。
Diffusion Models 的关键创新
- VAE/GAN:从低维隐变量一步到位(one-shot)地生成完整样本
- Diffusion Models:通过迭代地(iteratively)逐步去噪来生成样本
这种迭代策略将困难的生成任务分解为一系列简单的去噪步骤,从而显著提升了生成质量。
前向加噪过程 (Forward Noising)
Diffusion 模型的第一步是构建训练数据——通过一个前向加噪过程(Forward Noising Process)。

来源:Slides 第51页。引用 Sohl-Dickstein+ ICML 2015; Ho+ NeurIPS 2020。

来源:Slides 第53页。
前向过程的关键步骤:
- 给定一张训练图像 \(x_0\)
- 采样一个随机噪声模式
-
按预定的时间表(schedule)逐步增加噪声比例:
-
\(T=0\):100% 图像,0% 噪声
- \(T=1\):75% 图像,25% 噪声
- \(T=2\):50% 图像,50% 噪声
- \(T=3\):25% 图像,75% 噪声
- \(T=4\):0% 图像,100% 噪声(纯随机噪声)
前向过程不需要训练
前向加噪过程完全是确定性的(给定噪声 schedule),不涉及任何可学习参数。它的唯一目的是为反向去噪过程生成训练对——每一对 \((x_t, x_{t-1})\) 就是一个训练样本。
反向去噪过程 (Reverse Denoising)
训练的核心任务是让神经网络学会反向过程——给定时刻 \(T\) 的带噪图像,估计时刻 \(T-1\) 的更干净的图像。

来源:Slides 第54页。引用 Ho+ NeurIPS 2020。
Diffusion 训练目标
给定时刻 \(T\) 的带噪图像 \(x_T\),训练一个神经网络 \(f_\theta\) 来预测时刻 \(T-1\) 的图像 \(x_{T-1}\): $$ \hat{x}{T-1} = f\theta(x_T, T) $$ 训练损失为预测图像与真实图像之间的差异(通常是 MSE 或预测噪声的 MSE)。这个网络在所有时间步上共享参数,时间步 \(T\) 作为条件输入。
采样生成新图像
训练完成后,生成新图像的过程就是从纯噪声开始,反复应用去噪网络:
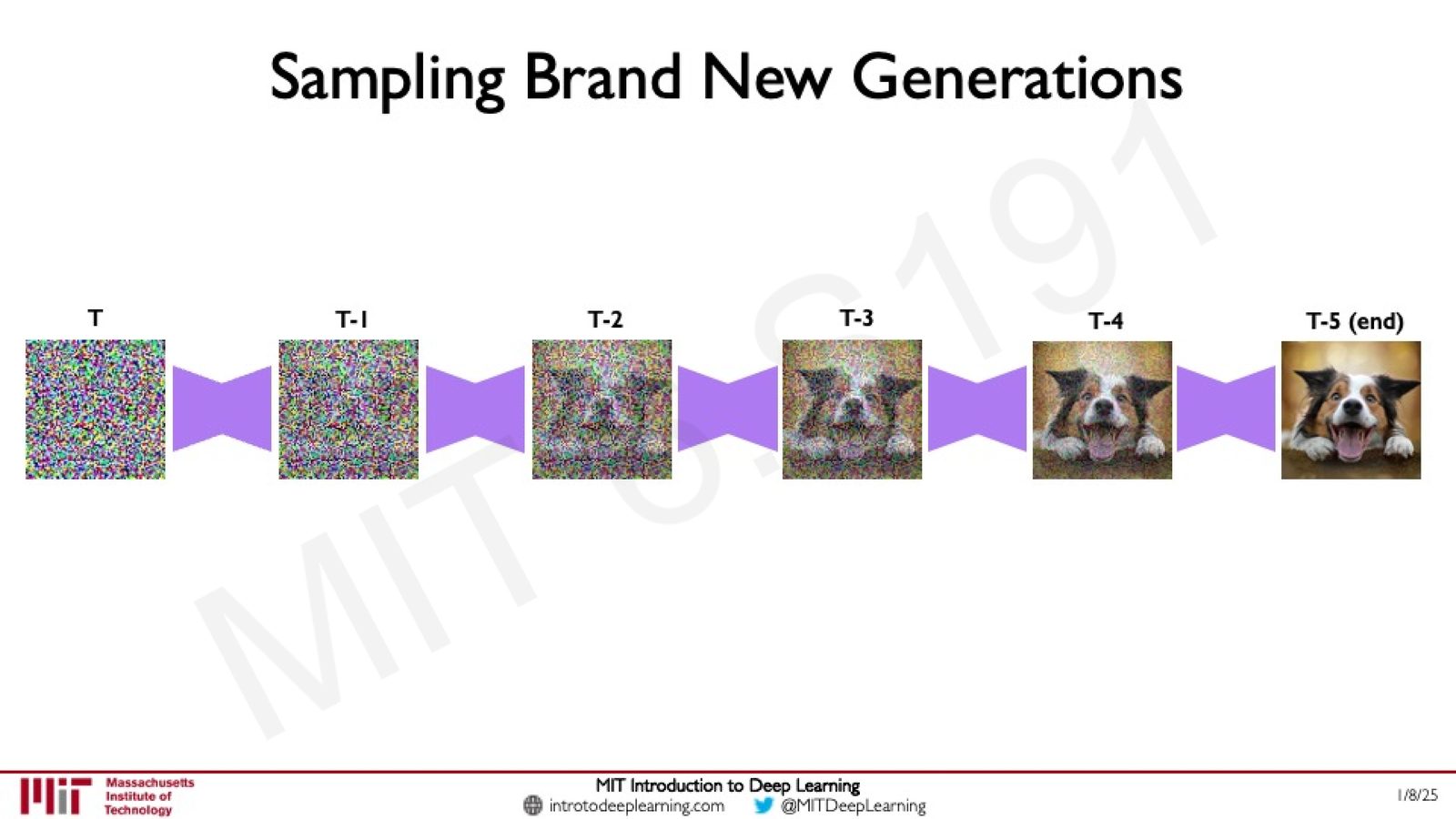
来源:Slides 第61页。
采样过程:\(x_T \xrightarrow{f_\theta} x_{T-1} \xrightarrow{f_\theta} x_{T-2} \xrightarrow{f_\theta} \cdots \xrightarrow{f_\theta} x_0\)
每一步去噪都只需要移除“一小部分”噪声,这比一步到位生成完整图像要简单得多——这正是 Diffusion Models 生成质量优越的根本原因。
从图像到自然语言:Text-to-Image
Diffusion Models 的一个重要应用是与自然语言处理的结合——文本生成图像(Text-to-Image Generation)。

来源:Slides 第64页。引用 Ramesh+ arXiv 2022。

来源:Slides 第65页。引用 OpenAI, Ramesh+ arXiv 2022。
当今主流的 Text-to-Image 系统(如 DALL-E、Stable Diffusion、Midjourney)的图像生成骨干网络大多采用 Diffusion Model。用户输入的文本通过语言编码器转化为条件向量,引导去噪过程朝着符合文本描述的方向生成图像。
超越图像:分子设计
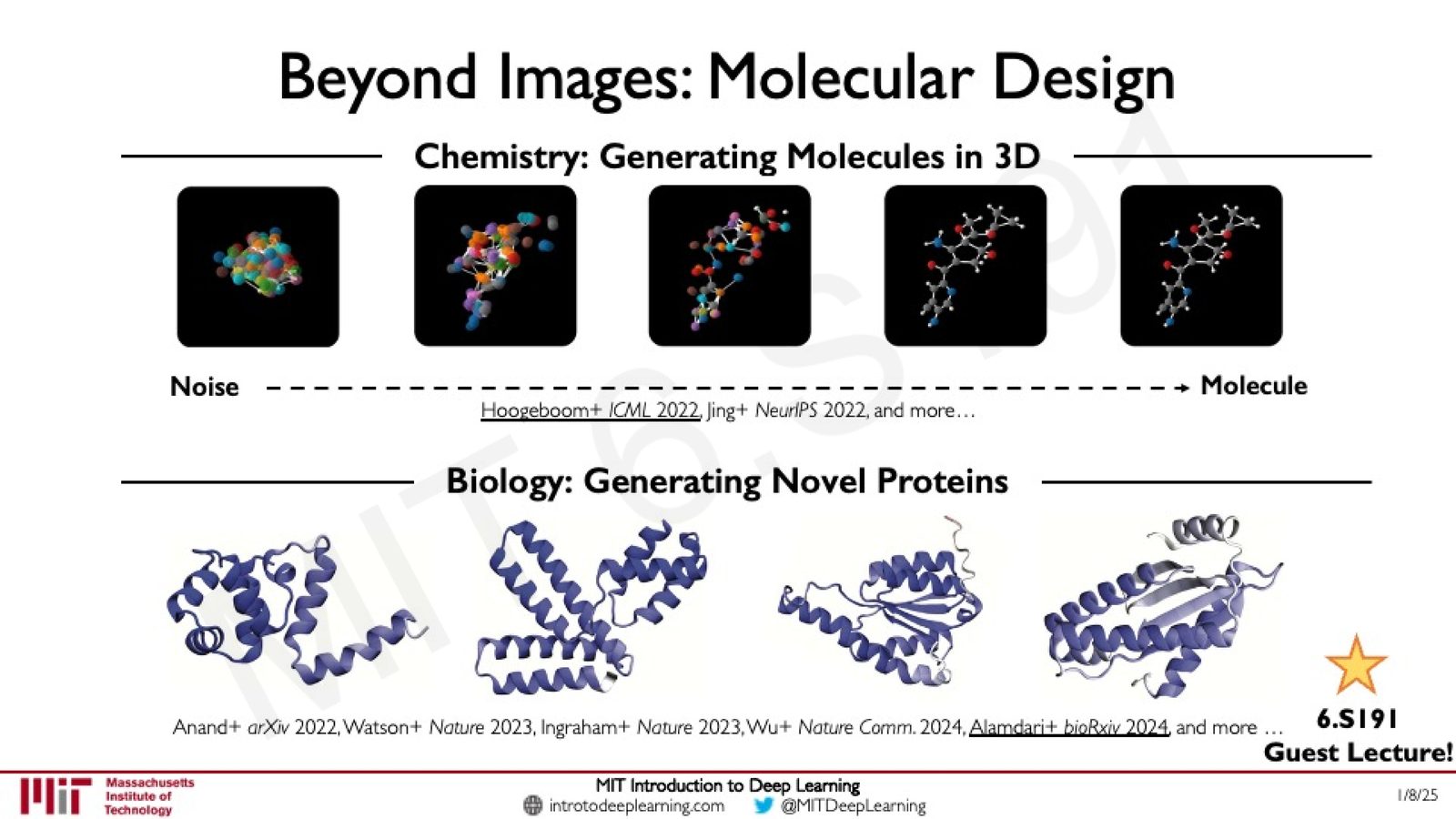
来源:Slides 第66页。
Diffusion Models 的应用远不止于图像生成。在化学和生物学领域,同样的“从噪声到结构”的范式被用于:
- 分子生成:从 3D 噪声中逐步生成药物分子结构
- 蛋白质设计:生成具有特定功能的新型蛋白质结构
Diffusion 的通用性
Diffusion Models 的“加噪 \(\rightarrow\) 去噪”框架具有高度通用性:只要数据可以被逐步“破坏”并“恢复”,这个框架就可以适用。这使得它成为当前最活跃的生成建模范式之一,跨越图像、视频、音频、3D 结构、分子等多个领域。
本章小结
Diffusion Models 通过将生成任务分解为多步迭代去噪,克服了 VAE/GAN 在生成质量、稳定性和多样性方面的局限。其核心思想包括:前向加噪构建训练数据,反向去噪学习生成过程,最终从纯噪声采样出高质量样本。该范式已广泛应用于 Text-to-Image、视频生成、分子设计等领域。
新前沿 II:大语言模型 (LLMs)
LLM 的定义与定位
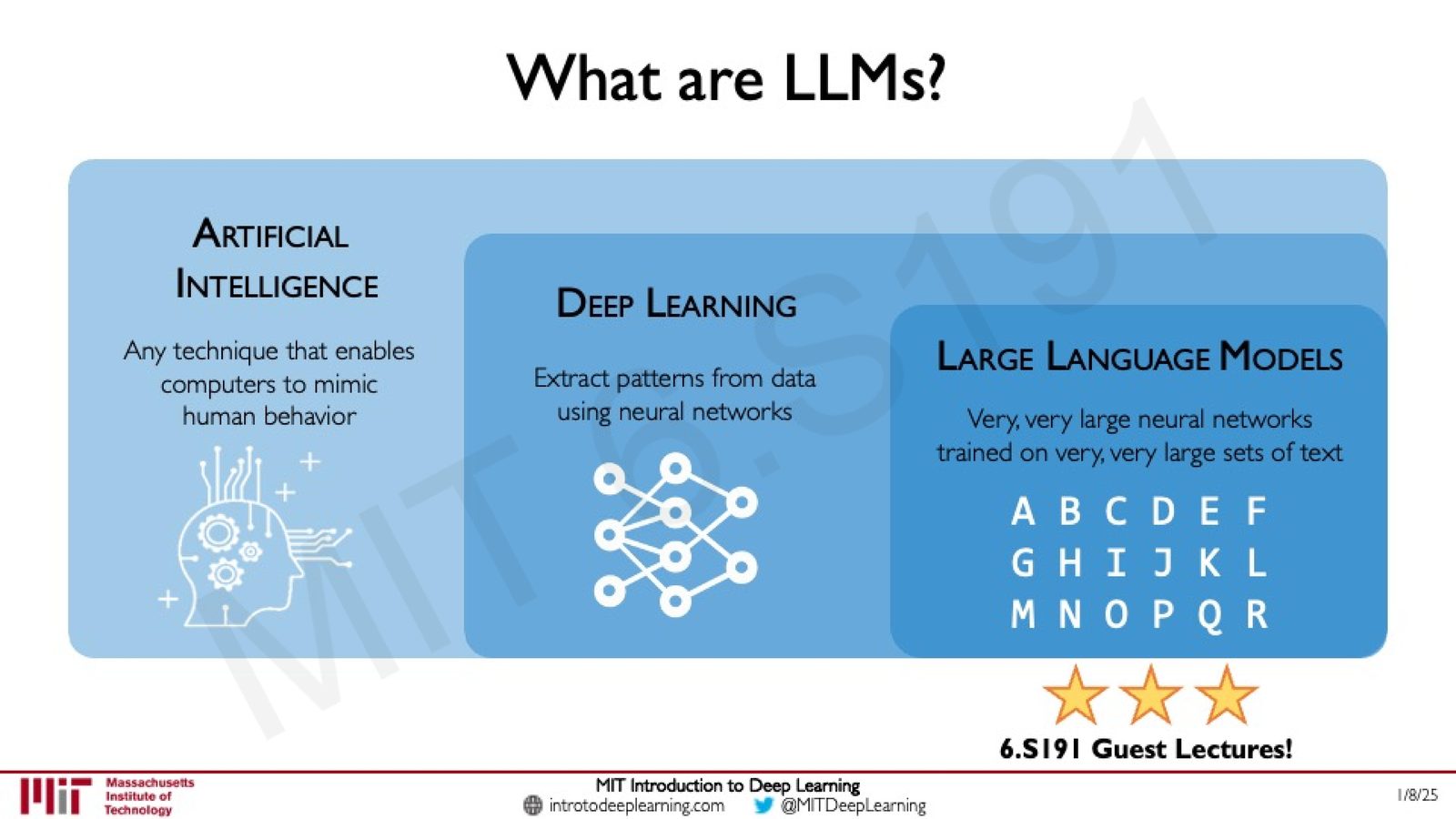
来源:Slides 第69页。
什么是大语言模型 (LLM)?
LLM 是 AI 领域中的一个层级概念:
- Artificial Intelligence:使计算机模拟人类行为的所有技术
- Deep Learning:利用神经网络从数据中提取模式
- Large Language Models:在超大规模文本数据上训练的超大规模神经网络
关键词:“very, very large neural networks trained on very, very large sets of text”。
LLM 的工作原理:Next Token Prediction
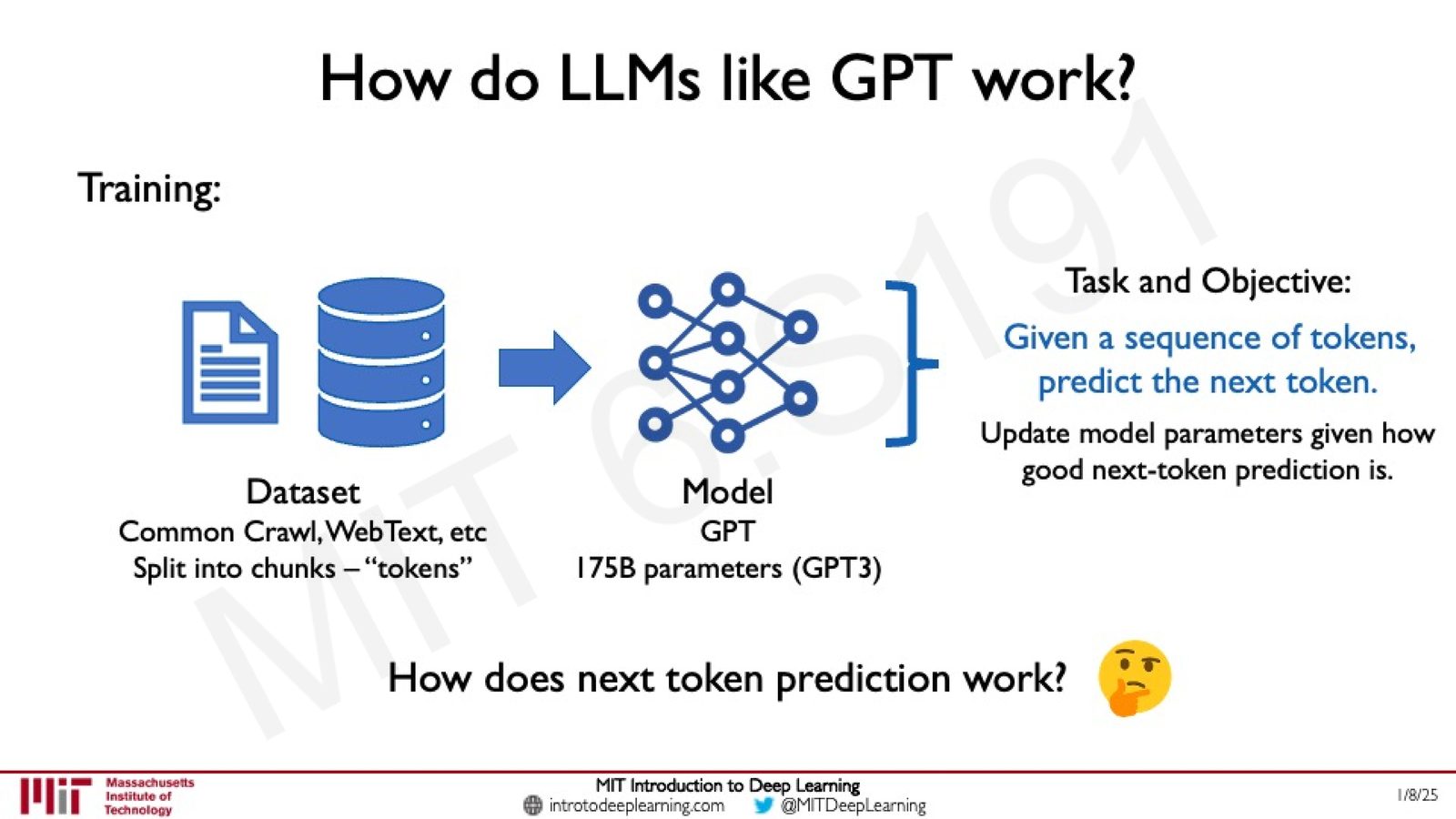
来源:Slides 第70页。
LLM 的训练可以概括为一个极其简洁的目标:
具体流程:
- 数据集:Common Crawl、WebText 等大规模文本语料,被切分为 tokens
- 模型:如 GPT-3 拥有 1750 亿参数
- 训练目标:给定一个 token 序列,预测下一个 token 的概率分布
- 损失函数:Cross-Entropy Loss,衡量预测分布与真实下一个 token 之间的差距
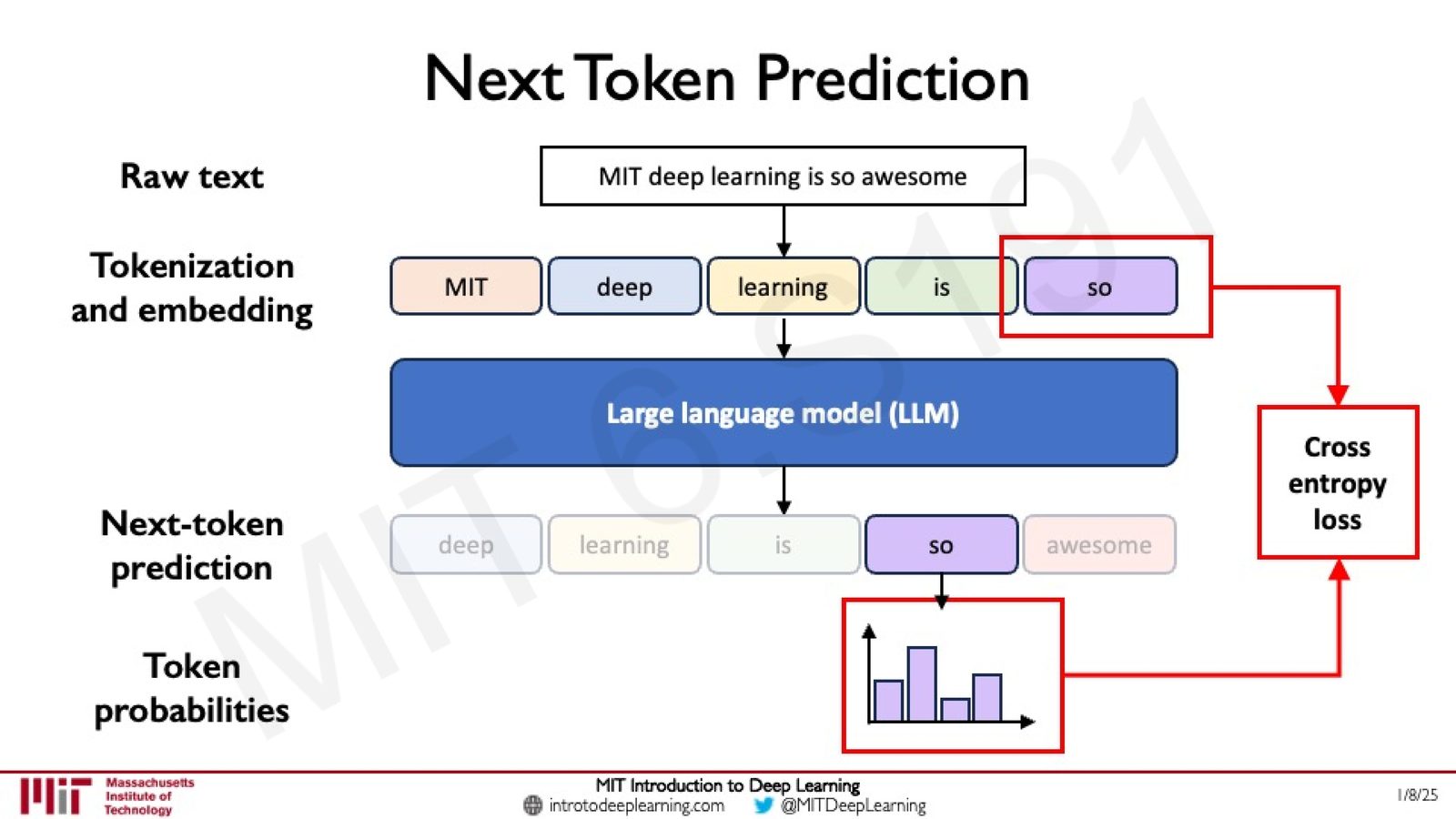
来源:Slides 第71页。
从 Next Token Prediction 到文本生成
训练完成后,LLM 的使用方式是自回归生成(autoregressive generation):
- 用户输入一段 prompt(如“I'm giving a talk on AI at MIT. Can you outline it?”)
- 模型预测下一个 token 的概率分布,采样得到一个 token
- 将新 token 追加到序列末尾,重复上述过程
- 直到生成结束符或达到最大长度
整个“智能”的涌现,本质上都建立在这个看似简单的 next token prediction 任务之上。
LLM 的能力

来源:Slides 第73页。
GPT 等 LLM 已展现出对自然语言的“掌控力”(mastery over natural language),在以下方面表现可靠:
- 知识检索(Knowledge Retrieval):回答事实性问题
- 写作辅助(Writing Co-Pilot):文章撰写、润色、翻译
- 规划辅助(Planning Co-Pilot):制定计划、实验设计
LLM 的局限性
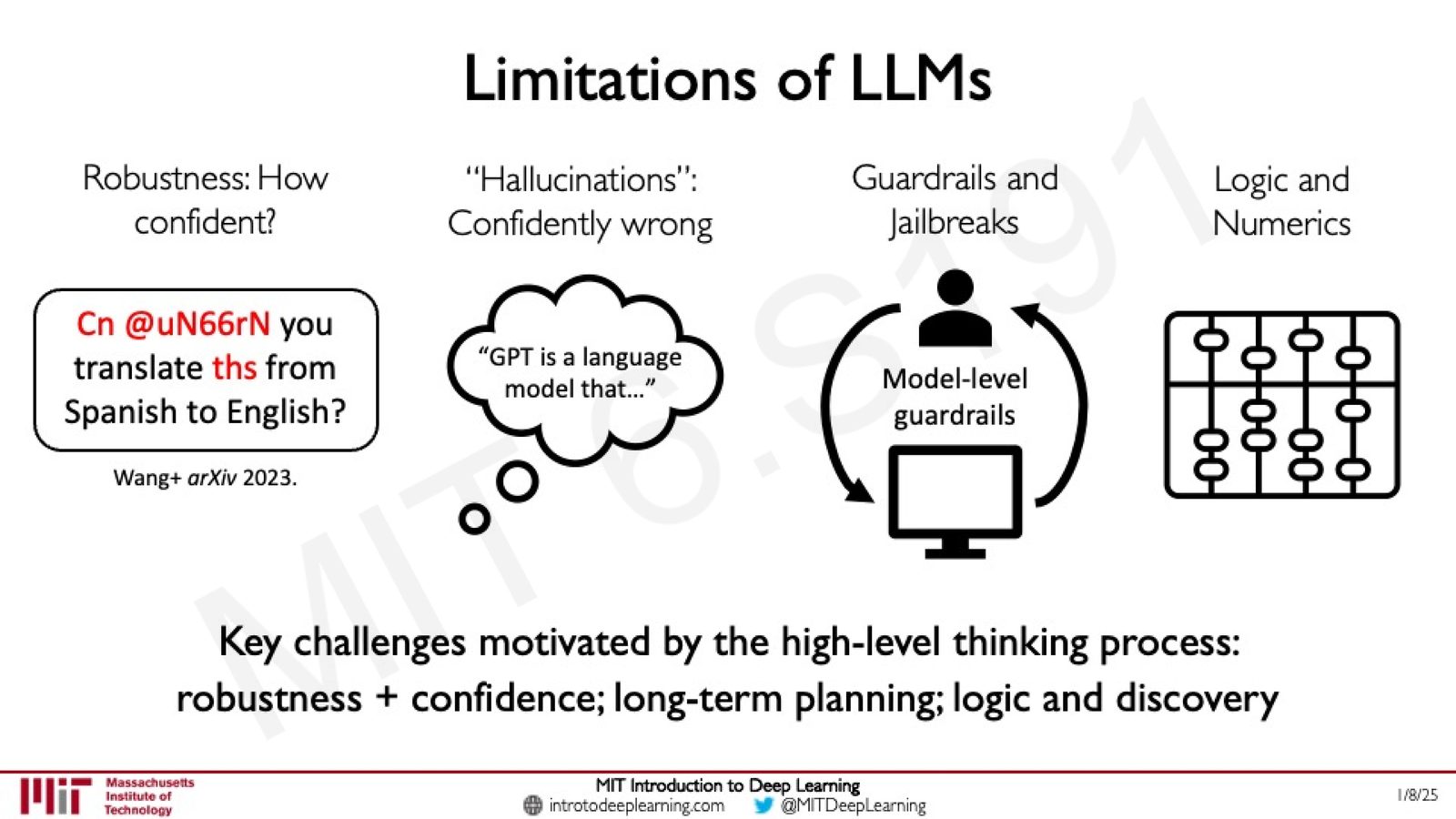
来源:Slides 第74页。
LLM 的四大关键挑战
- 鲁棒性(Robustness):对输入中的拼写错误、格式变化等极为敏感(如 “Cn @uN66rN you translate ths from Spanish to English?”)
- 幻觉(Hallucinations):自信地生成错误信息。“GPT is a language model that...” 可能看起来完全合理,但内容可能完全虚构
- 防护栏与越狱(Guardrails and Jailbreaks):模型层面的安全限制可能被巧妙绕过
- 逻辑与数值推理(Logic and Numerics):在需要严格逻辑推理和数学计算的任务上表现较弱
这些挑战的共同根源在于 LLM 的高层思维过程:鲁棒性与置信度校准、长期规划能力、逻辑推理与科学发现能力,都是当前研究的前沿方向。
涌现能力与 Scaling Laws
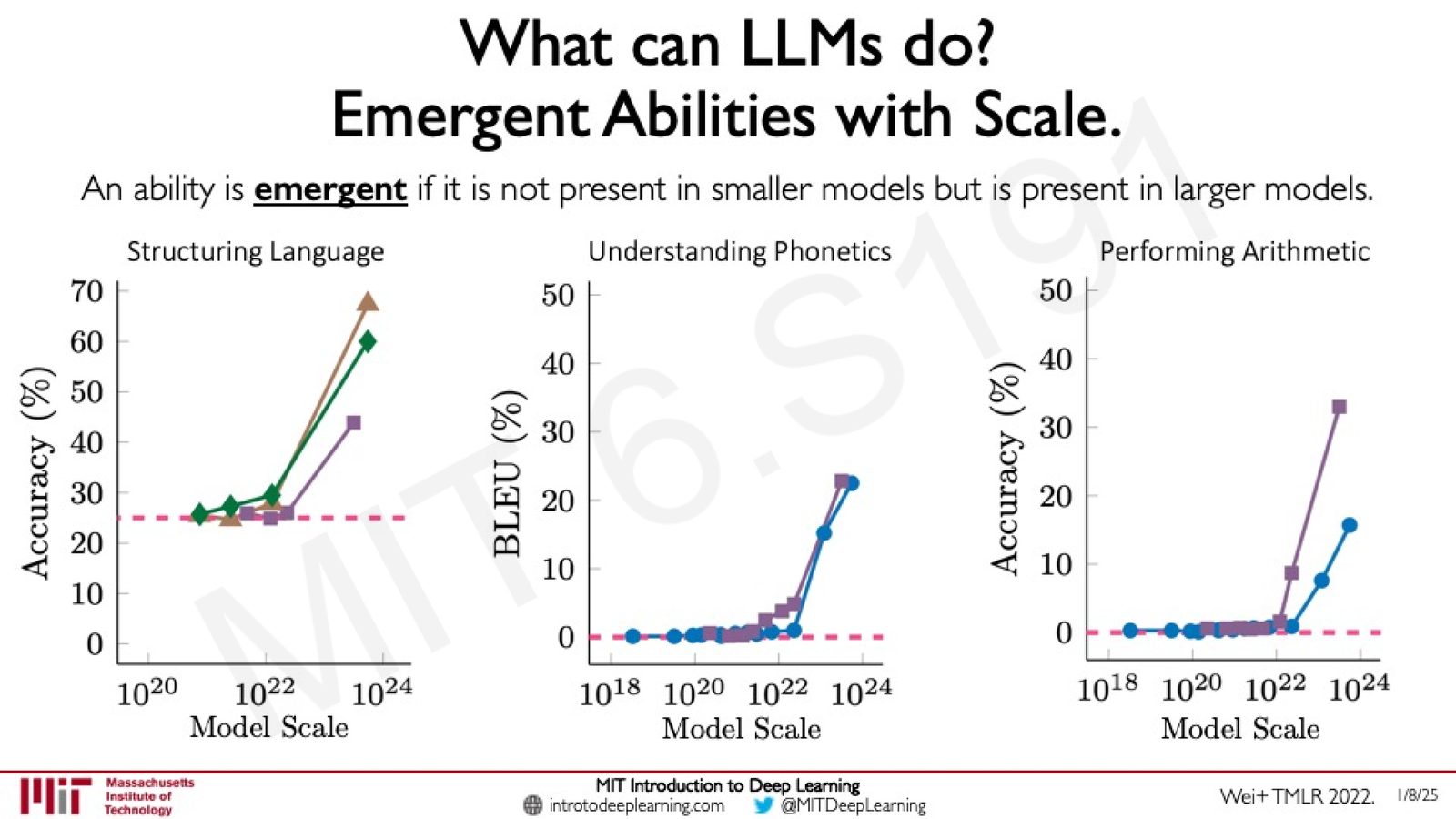
来源:Slides 第75页。引用 Wei+ TMLR 2022。
涌现能力 (Emergent Abilities)
一种能力被称为涌现的(emergent),如果它在小模型中不存在,但在大模型中出现。具体来说:
- 结构化语言(Structuring Language):在模型参数达到 \(\sim 10^{22}\) 量级时突然涌现
- 语音学理解(Understanding Phonetics):类似的突变式提升
- 算术运算(Performing Arithmetic):在更大规模时才出现
这些能力的涌现呈现出“相变”(phase transition)特征——不是渐进式提升,而是在某个规模阈值处突然出现。

来源:Slides 第76页。引用 Google AI Blog。
随着模型规模从 80 亿参数不断增长,LLM 依次获得了语言理解、算术运算和问答等能力——如同一棵不断生长、不断开花的能力之树。
本章小结
LLM 本质上是在海量文本数据上训练的超大规模神经网络,通过 next token prediction 这一简洁目标实现了惊人的语言能力。其能力随模型规模增长呈现涌现特征。但 LLM 在鲁棒性、幻觉、安全防护和逻辑推理方面仍面临重大挑战,这些也正是当前最活跃的研究方向。
基础模型与通用 AI 的愿景

来源:Slides 第77页。
在讲座的最后,Amini 将视野拓展到 Foundation Models 的更宏大愿景:
Foundation Models 的核心愿景
- 中央推理系统:生成式基础模型能否为通用 AI 提供一个统一的推理引擎?
- AI 设计 AI:能否用 AI 来改进和进化 AI 本身?
- 跨领域生成式 AI:从图像、生物学、语言到更多领域——既有巨大潜力,也需谨慎对待
- 人工智能与人类智能的关系:理解两者之间的联系与差异
这些问题不仅是技术挑战,更涉及深层的科学和哲学思考。正如 Amini 所强调的:力量与责任并存(power and caution),我们在推动 AI 前沿的同时,必须审慎地考虑其社会影响。
总结与延伸
本讲核心要点回顾
本讲作为 MIT 6.S191 基础讲座系列的总结篇,覆盖了三个核心主题:
-
深度学习的本质与局限
-
神经网络是函数逼近器,Universal Approximation Theorem 保证了理论能力但不保证泛化
- 随机标签实验揭示了深度网络惊人的过拟合(memorization)能力
- 三大失败模式:数据偏差、安全关键场景的不确定性、对抗攻击
- 九大局限性:数据饥渴、计算密集、对抗脆弱、算法偏见、不确定性差、黑箱、需要专家知识、难编码结构、外推困难
-
新前沿 I -- Diffusion Models
-
克服 VAE/GAN 的 mode collapse 和训练不稳定问题
- 前向加噪构建训练对,反向去噪实现生成
- 迭代生成策略是质量优势的核心
- 广泛应用:Text-to-Image、视频生成、分子/蛋白质设计
-
新前沿 II -- Large Language Models
-
本质:超大规模神经网络 + 超大规模文本数据
- 核心训练目标:Next Token Prediction
- 涌现能力随模型规模出现“相变”式增长
- 关键挑战:鲁棒性、幻觉、安全防护、逻辑推理
拓展阅读
- Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural Networks.
- Zhang, C., et al. (2017). Understanding deep learning requires rethinking generalization. ICLR 2017.
- Goodfellow, I., Shlens, J., & Szegedy, C. (2015). Explaining and harnessing adversarial examples. ICLR 2015.
- Athalye, A., et al. (2018). Synthesizing robust adversarial examples. ICML 2018.
- Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. NeurIPS 2020.
- Sohl-Dickstein, J., et al. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. ICML 2015.
- Ramesh, A., et al. (2022). Hierarchical text-conditional image generation with CLIP latents. arXiv 2022.
- Wei, J., et al. (2022). Emergent abilities of large language models. TMLR 2022.
- 课程官网: http://introtodeeplearning.com
- GitHub: https://github.com/MITDeepLearning/introtodeeplearning/