CS231N Lecture 10: Video Understanding
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Ruohan Gao 授课内容整理 |
| 来源 | Stanford CS231n 10th Anniversary |
| 日期 | 2025年5月1日 |

导言:视频理解不是图像理解的简单加一维
Ruohan Gao 这一讲的目标很清楚:把我们已经熟悉的 2D 视觉问题扩展到真正的视频世界。视频看起来只是“图像序列”,但只要加入时间维,任务性质就会改变。动作、节奏、持续时间、上下文变化、声音和交互,都会进入模型视野。因此,视频理解不是把 CNN 原样复制到时间轴,而是重新思考什么信息值得保留、如何建模、以及怎样控制计算成本。
本讲主线
- 视频是什么,以及为什么它比图像更难。
- 短 clip、3D CNN、two-stream 是怎样建模时序的。
- 长视频为什么需要 RNN、attention 和更高效的结构。
- 视频理解如何走向多模态、具身和 foundation model。

来源:Slides 第1页。

来源:Slides 第3页。
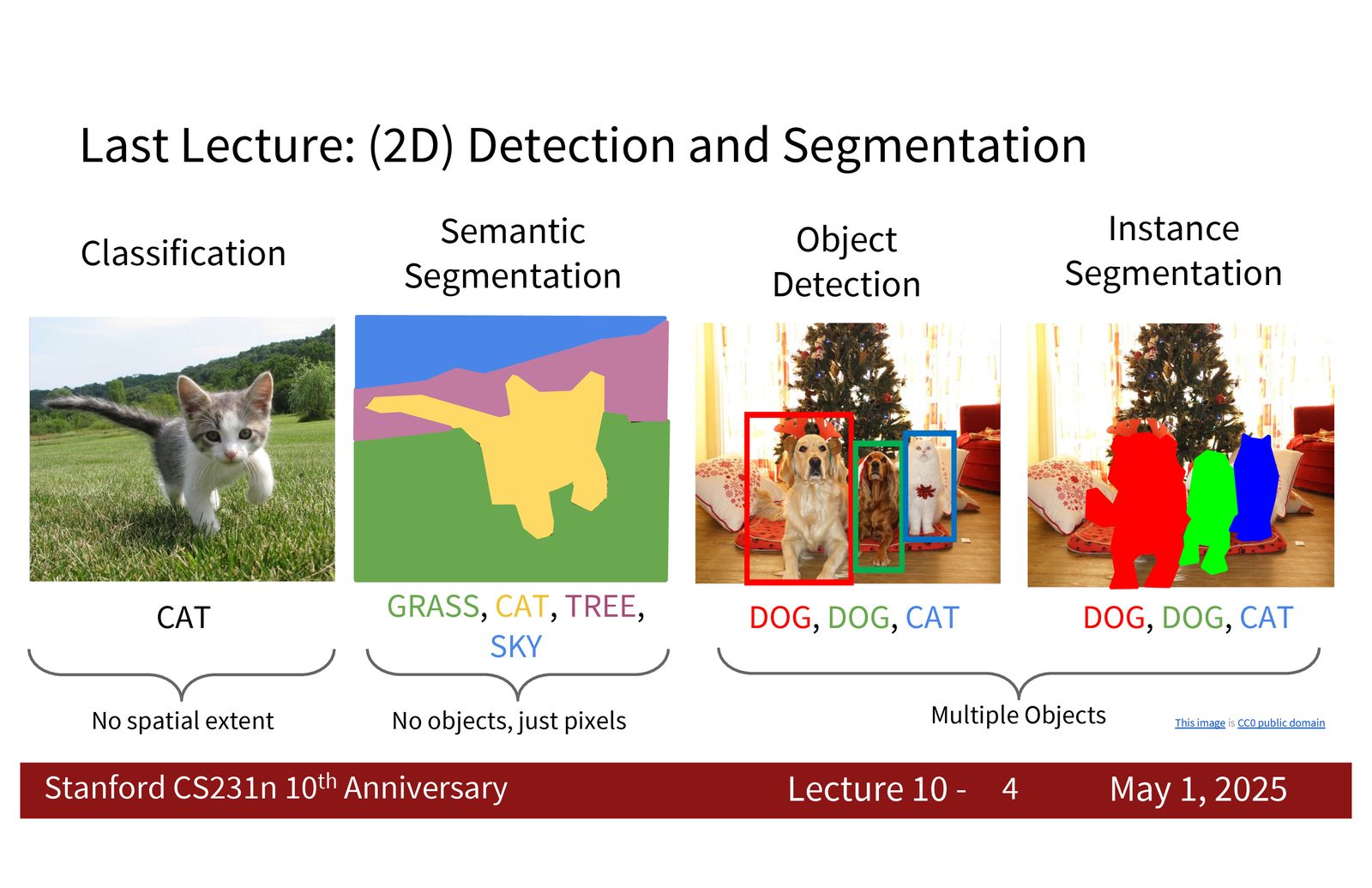
来源:Slides 第4页。
视频到底是什么
最基本的定义是:视频就是带时间维度的图像序列。对单张图像而言,输入通常是 \(3 \times H \times W\);对视频而言,输入可以写成
这里的 \(T\) 不是装饰性的维度,而是承载“动作如何展开”的核心变量。视频中的信息可以粗略分为两类:
- 外观:场景里有什么,人的姿态是什么,物体长什么样。
- 运动:东西怎么动,动作如何持续,事件如何演化。
为什么视频会改变问题本质
- 图像问题回答的是“这是什么”。
- 视频问题往往回答的是“这在做什么、何时发生、接下来会怎样”。
- 也就是说,视频不只是增加了帧数,而是增加了事件和时间结构。

来源:Slides 第7页。

来源:Slides 第8页。
视频理解的典型任务
视频任务的语义重心偏向动作、时间和事件边界。常见任务包括:
- Video classification:判断整个 clip 在做什么。
- Temporal action localization:找出动作在时间轴上的起止位置。
- Spatio-temporal detection:同时找时间和空间中的人、物与动作。
- Audio-visual understanding:把声音和画面一起用于理解或分离。
视频任务为什么更难
- 数据更大:存储、解码和训练都更贵。
- 信息更稀疏:关键动作可能只出现在少量帧里。
- 依赖更长:很多标签对应的是时序上下文,而不是某一帧。
- 噪声更多:镜头切换、运动模糊、遮挡和背景变化都更常见。

来源:Slides 第9页。

来源:Slides 第10页。
视频太大了
视频理解的第一道工程门槛不是模型,而是数据体积。课程里给出的粗略估算很直接:视频通常以 30 fps 左右采样,未压缩视频会迅速增长到 GB 级别。按课上给出的量级,标准清晰度视频每分钟约 1.5 GB,高清甚至可到 10 GB 级别。

来源:Slides 第11页。
这意味着一个现实结论:长视频不能整段直接喂给模型。 最常见的应对方式,是把长视频切成短 clip,降低空间分辨率与帧率,让训练和推理都落到可控区间。

来源:Slides 第12页。
短 clip 训练的直觉
很多动作不需要完整看完才能判断。对“跑步”“游泳”“举重”这类动作来说,几秒钟内的局部运动模式通常就已经足够,因此训练时可以随机采样多个短片段,再把它们的预测聚合起来。

来源:Slides 第14页。

来源:Slides 第15页。
视频数据工程不是附属问题
视频任务里的很多失败,不是模型不够强,而是采样、解码、压缩、链接失效和帧率设置出了问题。视频理解比图像理解更像一个完整系统工程。
短时序建模:单帧、早融合、晚融合和 3D CNN
单帧 baseline 为什么常常不差
最朴素的做法,是把视频当成一堆图像来处理:抽取单帧、丢给图像分类器、最后在时间上平均或投票。这个 baseline 常常 surprisingly strong,因为很多动作本身就带着明显的静态线索,比如场景、道具、人体姿态和运动装备。
单帧 baseline 的意义
- 它是最便宜的对照组。
- 它能告诉你“外观信息到底有多强”。
- 如果单帧已经很强,说明任务可能被静态背景严重污染。
Early fusion, late fusion, 3D CNN
短时序建模阶段最重要的不是某一个单独网络,而是“什么时候开始把时间维度纳入计算”。课程把它分成三类:
| 方法 | 核心做法 | 主要特点 |
|---|---|---|
| Late fusion | 每帧先用 2D CNN 编特征,最后再聚合时间 | 先学空间,再合并时间,最朴素也最稳妥 |
| Early fusion | 一开始就把多帧堆成更厚的 channel | 早早混合时间信息,但很粗暴 |
| 3D CNN | 用 3D 卷积和 3D pooling 逐步融合时空信息 | 更自然,但算力更贵 |

来源:Slides 第21页。
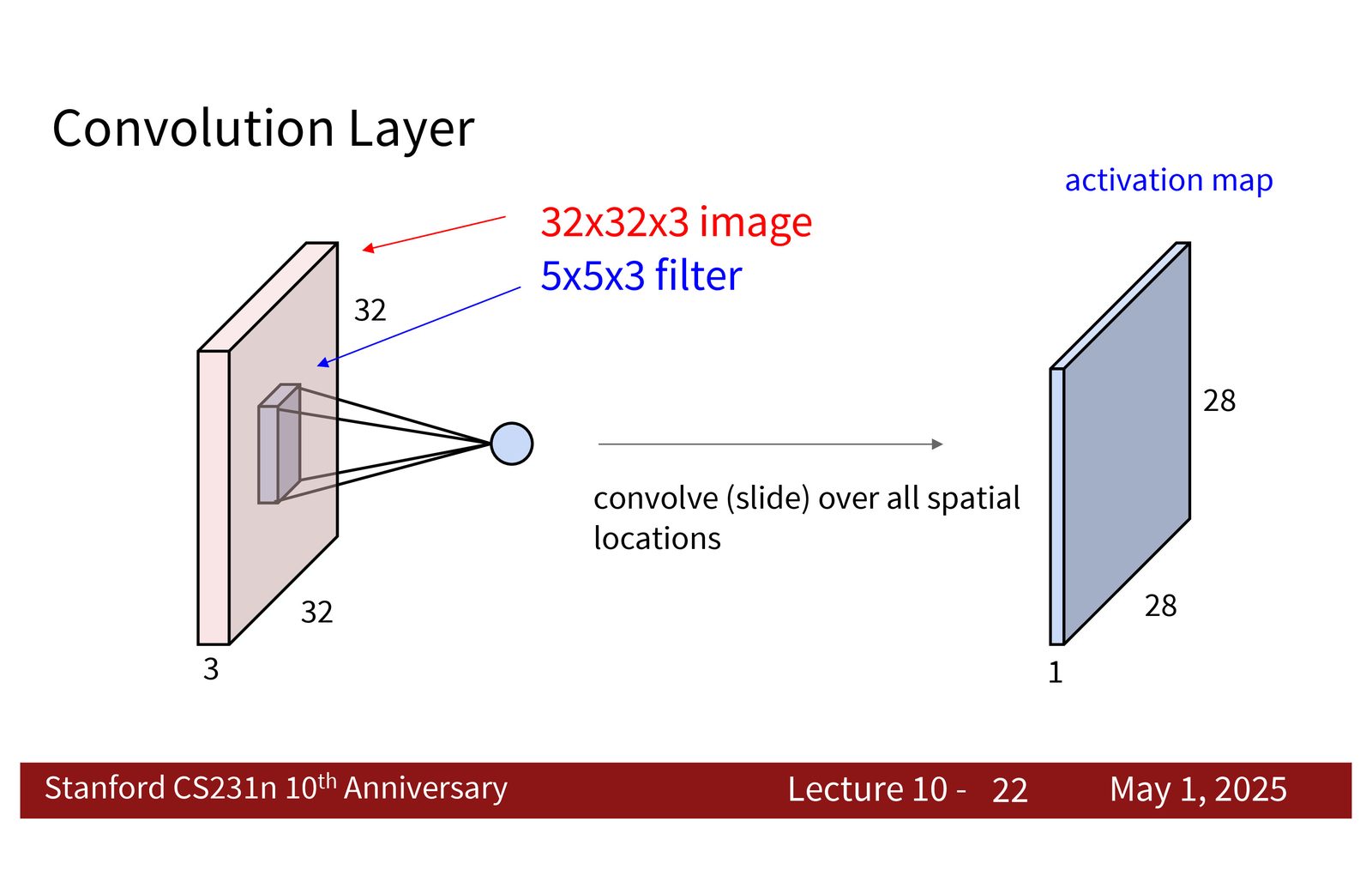
来源:Slides 第22页。
为什么 3D CNN 是“慢融合”
3D CNN 的直觉很好理解:如果视频里的模式本来就会在时间上移动,那卷积也应该在时间上滑动。于是,输入从 \(C \times H \times W\) 变成 \(C \times T \times H \times W\),卷积核也从 \(k_H \times k_W\) 变成 \(k_T \times k_H \times k_W\)。
3D 卷积的基本形式
如果输入特征是 \(X \in \mathbb{R}^{C \times T \times H \times W}\),那么一个 3D 卷积核会在 \((T, H, W)\) 三个维度上滑动,输出仍然保留时间维。这样做的效果是:模型在每一层都能逐渐扩大时空感受野,而不是把时间只留到最后一层处理。
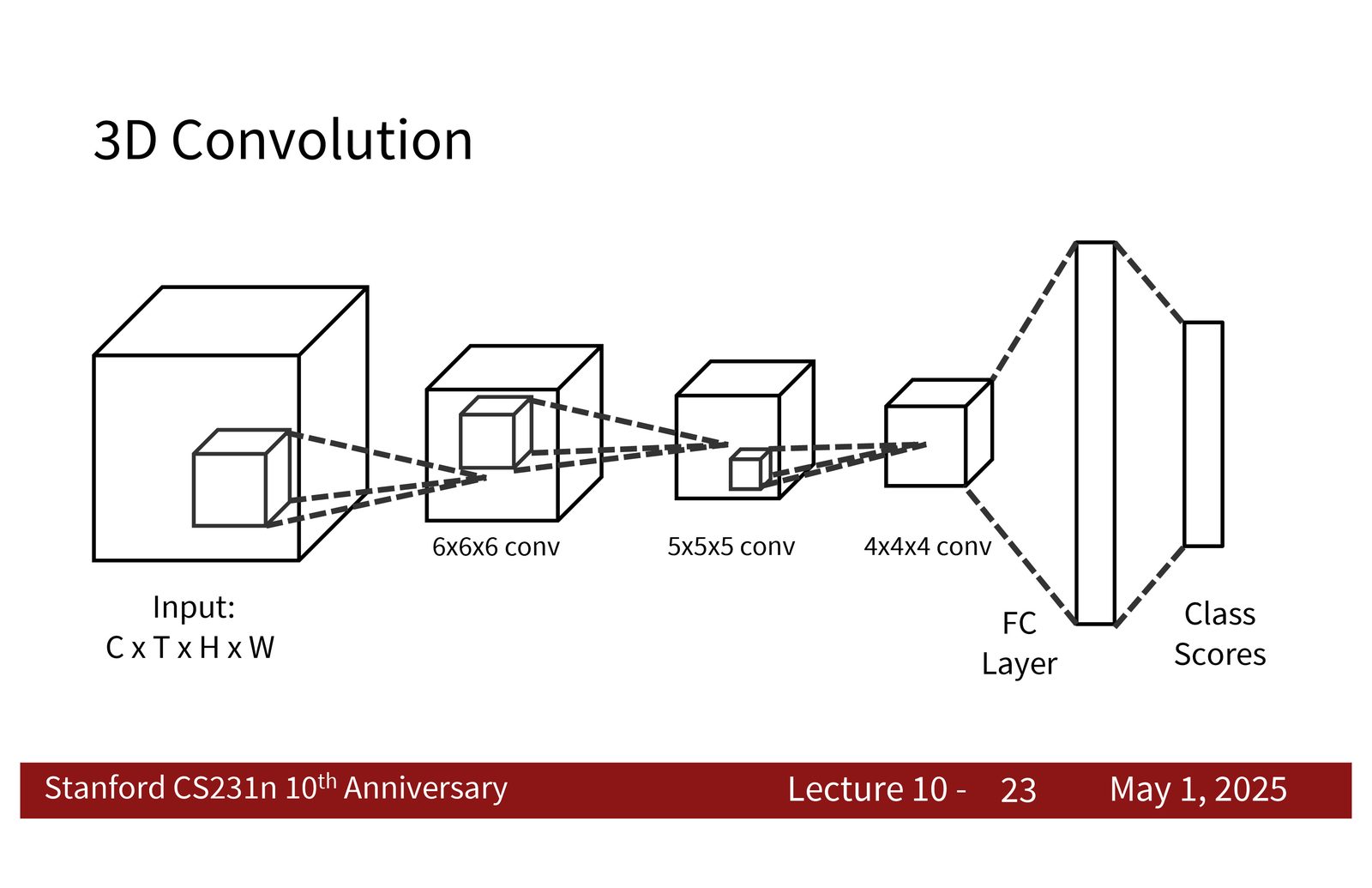
来源:Slides 第23页。

来源:Slides 第25页。

来源:Slides 第28页。
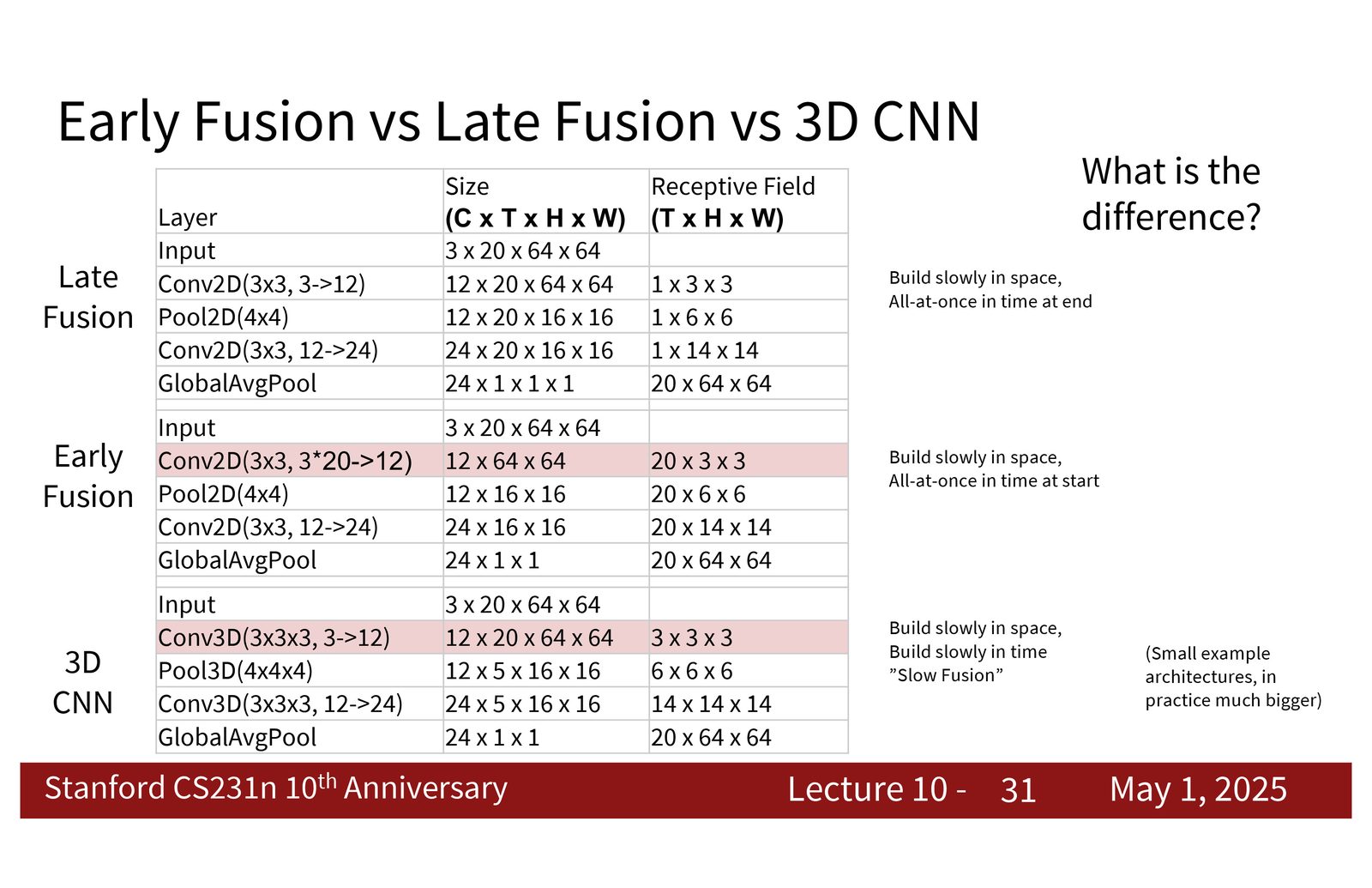
来源:Slides 第31页。
三种融合方式的核心差别
- Late fusion 是“先空间、后时间”。
- Early fusion 是“先时间、后空间”。
- 3D CNN 是“时间和空间一起慢慢融合”。
为什么 early fusion 还不够
讲者在 toy example 里给出的对比很清楚:early fusion 的第一层 2D 卷积虽然看到了多帧,但它本质上还是把时间当作额外 channel,一次性压缩。问题在于,一层卷积通常不足以编码复杂动作的全部时间结构。很多动作不是“某一帧像什么”,而是“变化过程如何发生”。
early fusion 的局限
它把时间信息“早早压扁”,因此对需要逐层抽象运动模式的任务不够灵活。这个设计在工程上简单,但表达能力有限。
C3D:3D CNN 的 VGG 风格版本
3D CNN 真正成为成熟方案,C3D 是里程碑之一。它像 VGG 一样堆很多简单的 3x3x3 卷积和 2x2x2 pooling,把视频看成一个真正的 3D 体。其结构简洁,便于迁移,也容易作为 feature extractor 直接下游使用。

来源:Slides 第40页。
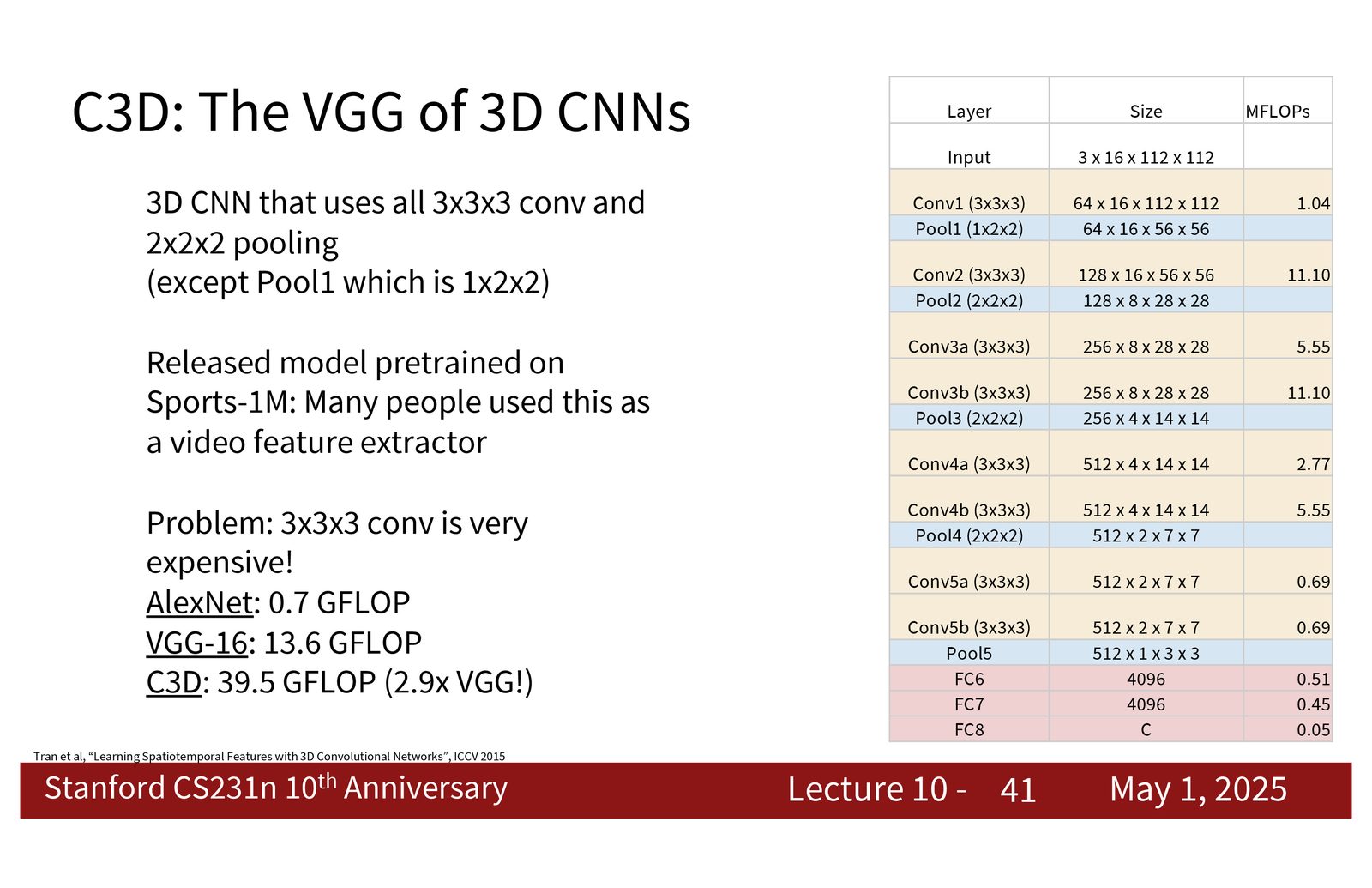
来源:Slides 第41页。
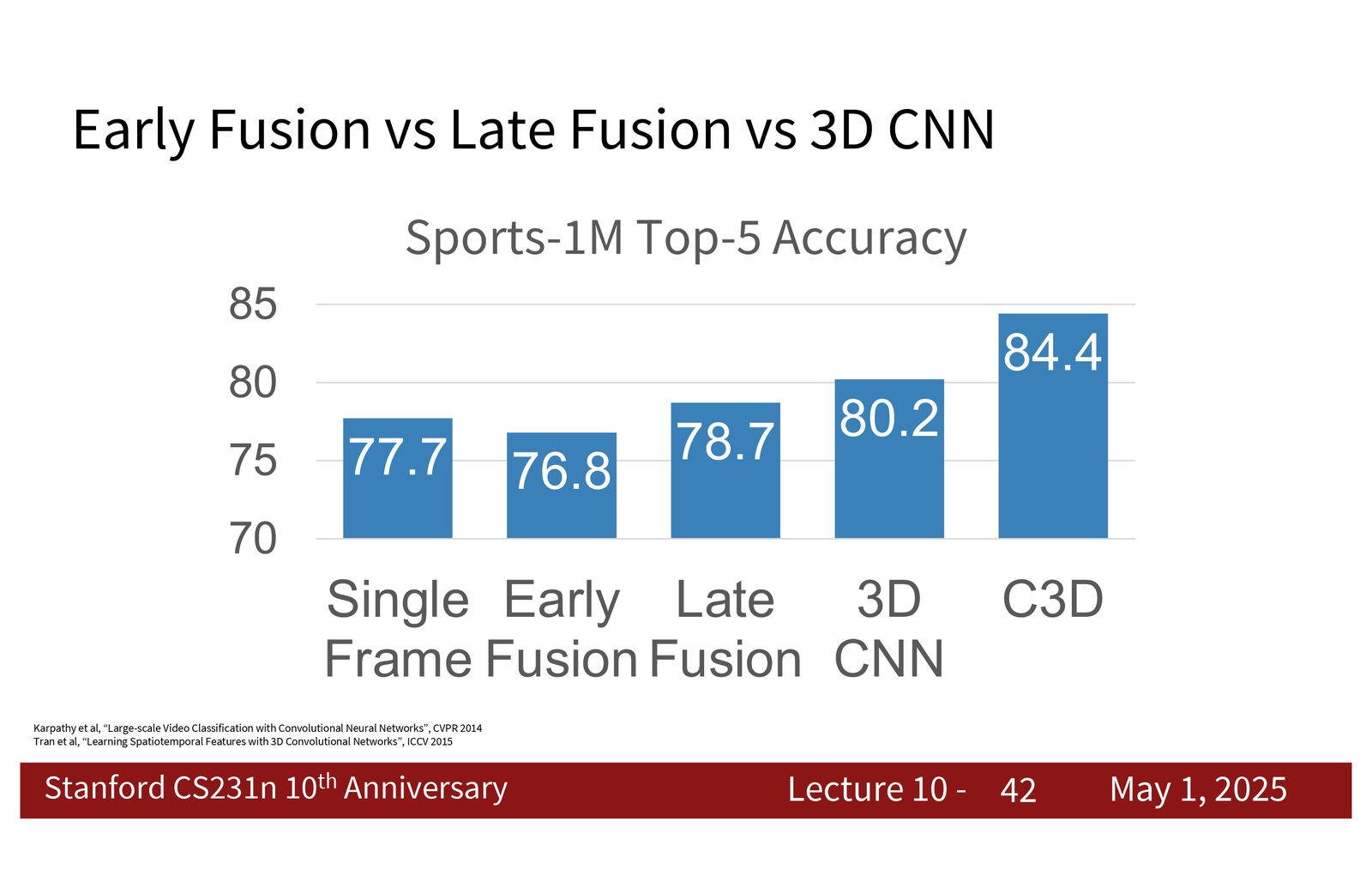
来源:Slides 第42页。
C3D 的重要性
C3D 的价值不在于它是最终答案,而在于它把“视频也可以像图像一样用标准卷积堆起来”这件事讲清楚了。它把视频理解从概念问题推进到可工程化实现的问题。

来源:Slides 第43页。
短时序阶段的结论
- 单帧 baseline 是必须先看的参照。
- Early fusion 简单,但时间压缩太早。
- 3D CNN 更自然地融合时空信息。
- 但 3D 卷积计算代价高,后续方法必须继续追求效率。
运动与外观分离:Two-Stream 网络和光流
为什么要把 motion 和 appearance 拆开
视频里的信息并不总是适合混在一起处理。很多动作识别任务里,外观和运动各自携带不同类型的线索:
- 外观分支更像图像分类器,负责识别人、物体和背景。
- 运动分支更像动作分类器,负责识别帧与帧之间的变化。
把这两种信号拆开,往往比强行一锅炖更有效。这就是 two-stream 的核心直觉。

来源:Slides 第44页。
光流到底在测什么
Two-stream 最经典的运动表示是 optical flow。它不是直接输入 RGB,而是输入相邻帧之间每个像素的位移估计。更形式化地说,光流是一个位移场
其中 \(d_x\) 和 \(d_y\) 分别表示水平和垂直方向的位移。直觉上,光流告诉我们“这个像素在下一帧会往哪里动”。在经典亮度恒常假设下,可以写成
为什么光流有用
- 它把“运动”显式化了。
- 它让模型少做一层“自己猜运动”的工作。
- 它对动作识别特别有效,因为很多动作的核心就是动态变化,而不是静态外观。

来源:Slides 第45页。

来源:Slides 第46页。
Two-stream 的架构
Two-stream 的结构很直接:
- Spatial stream:输入单帧 RGB 图像,学外观。
- Temporal stream:输入多帧光流堆叠,学运动。
- Fusion:把两个分支的预测平均、加权或用分类器再融合。
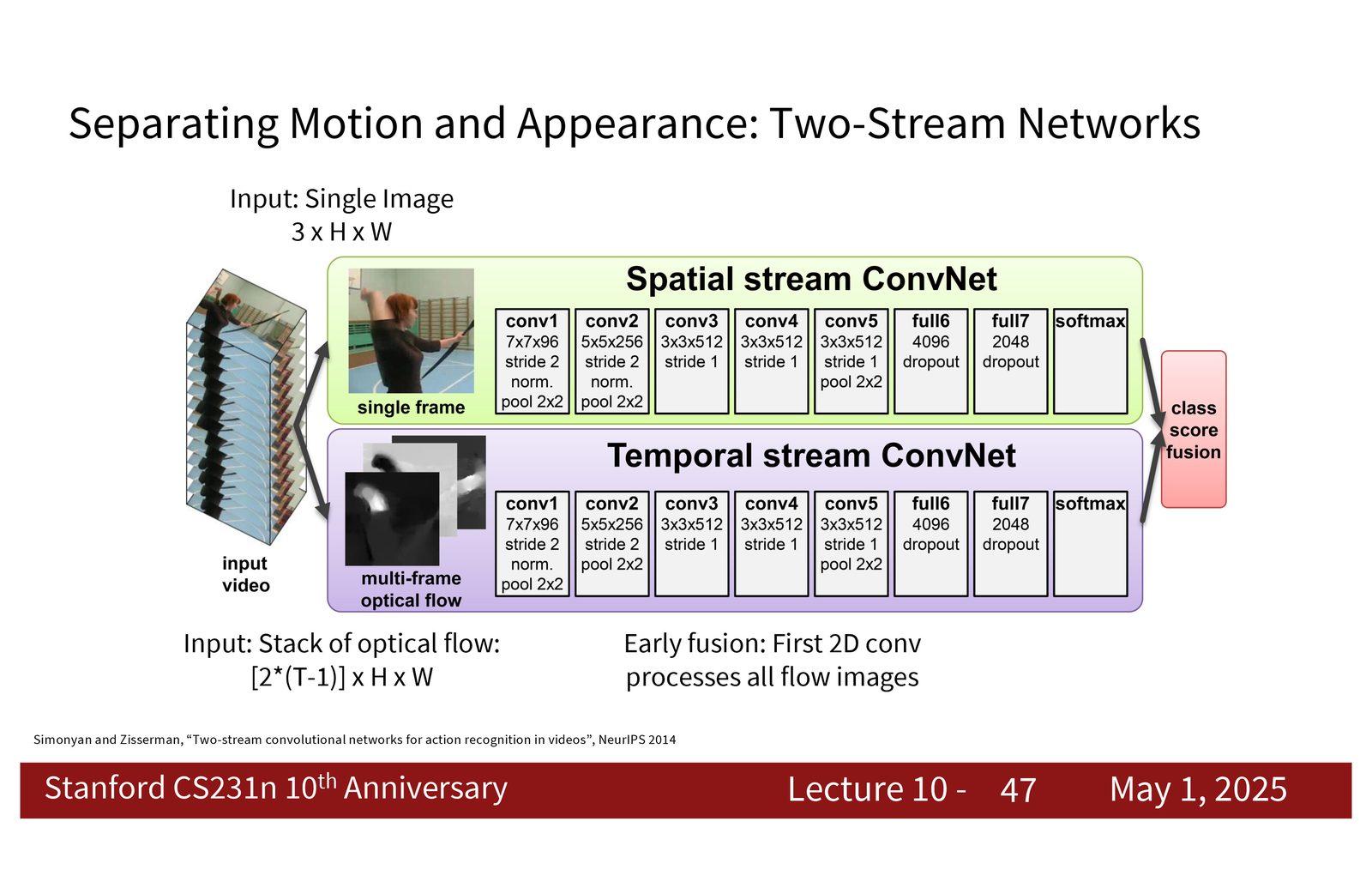
来源:Slides 第47页。
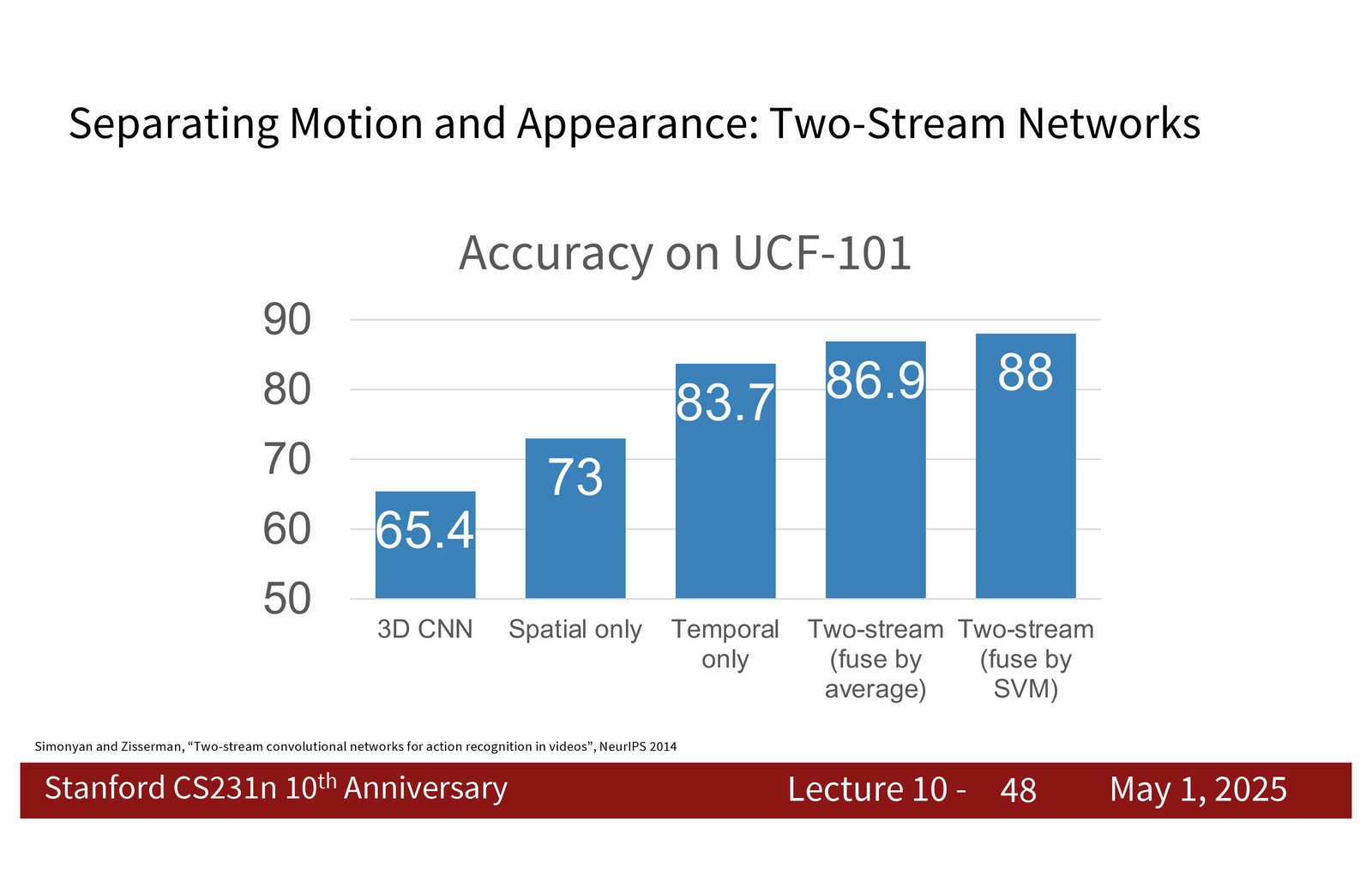
来源:Slides 第48页。
Two-stream 的经验现象
课程中强调了一个反直觉但重要的现象:只看 motion 的 temporal stream 往往已经很强,有时甚至比单纯的 spatial stream 更强。这说明动作任务里,运动信号可能比静态外观更关键。
Two-stream 的局限
Two-stream 解决了“外观和运动混在一起不容易学”的问题,但它也有明显代价:
- 光流本身要预计算,工程成本高;
- 模型是两个分支,整体更复杂;
- 两个分支的信息融合还比较粗。
这也是后续 3D CNN、I3D、Non-local block 和 Transformer 风格方法出现的背景。
Two-stream 的经验教训
显式运动表示很强,但它把前处理和模型切成了两部分。随着任务变大、视频变长、数据变多,大家越来越希望模型内部自己学会时空表征。
长时序建模:CNN + RNN 到 self-attention
为什么短 clip 不够
短 clip 能捕获局部动作,但很多任务需要更长时间跨度上的语义。例如,一个人先站、后跑、再停下,或者一个动作从准备、执行到完成,往往都需要跨越更长的时间窗口。此时只看几秒钟就不够了。
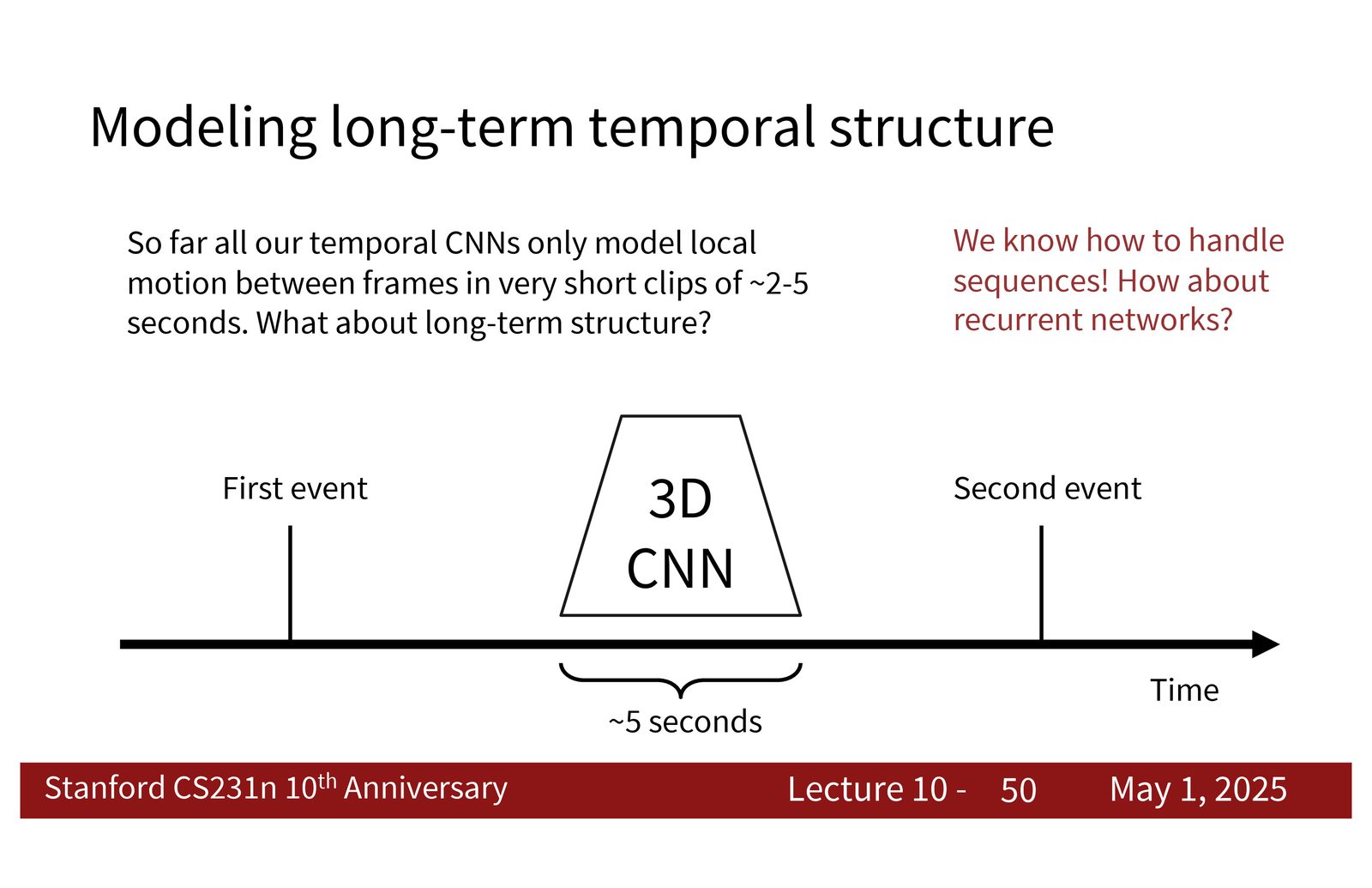
来源:Slides 第50页。
CNN + RNN / LSTM
一个自然的想法是:先用 CNN 对每个短片段或每一帧提取特征,再把这些特征送进 RNN 或 LSTM 聚合时间信息。这样做的好处是把问题拆成两个层次:
- CNN 负责局部空间或局部时空特征;
- RNN 负责更长范围的时间依赖。
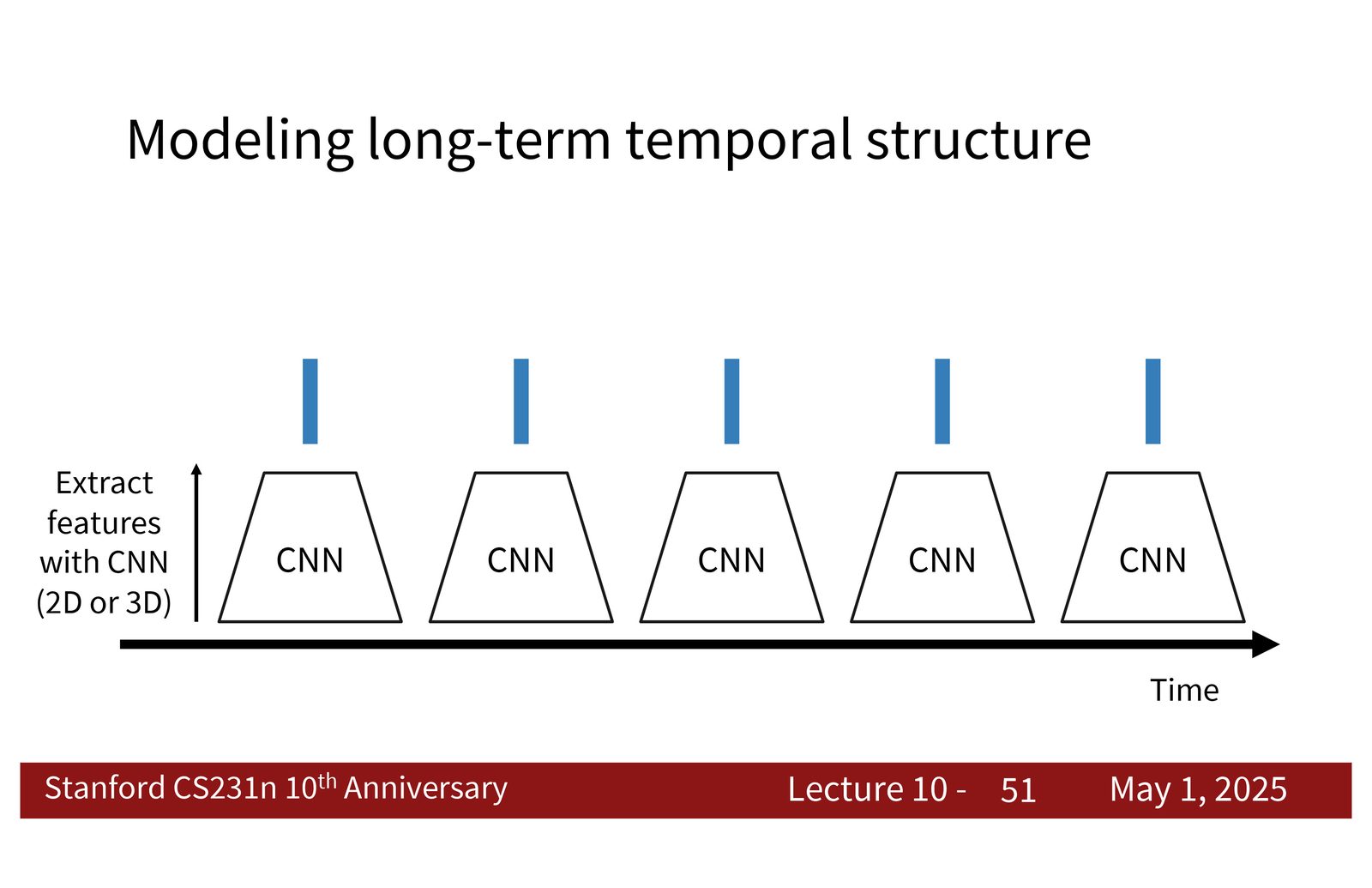
来源:Slides 第51页。
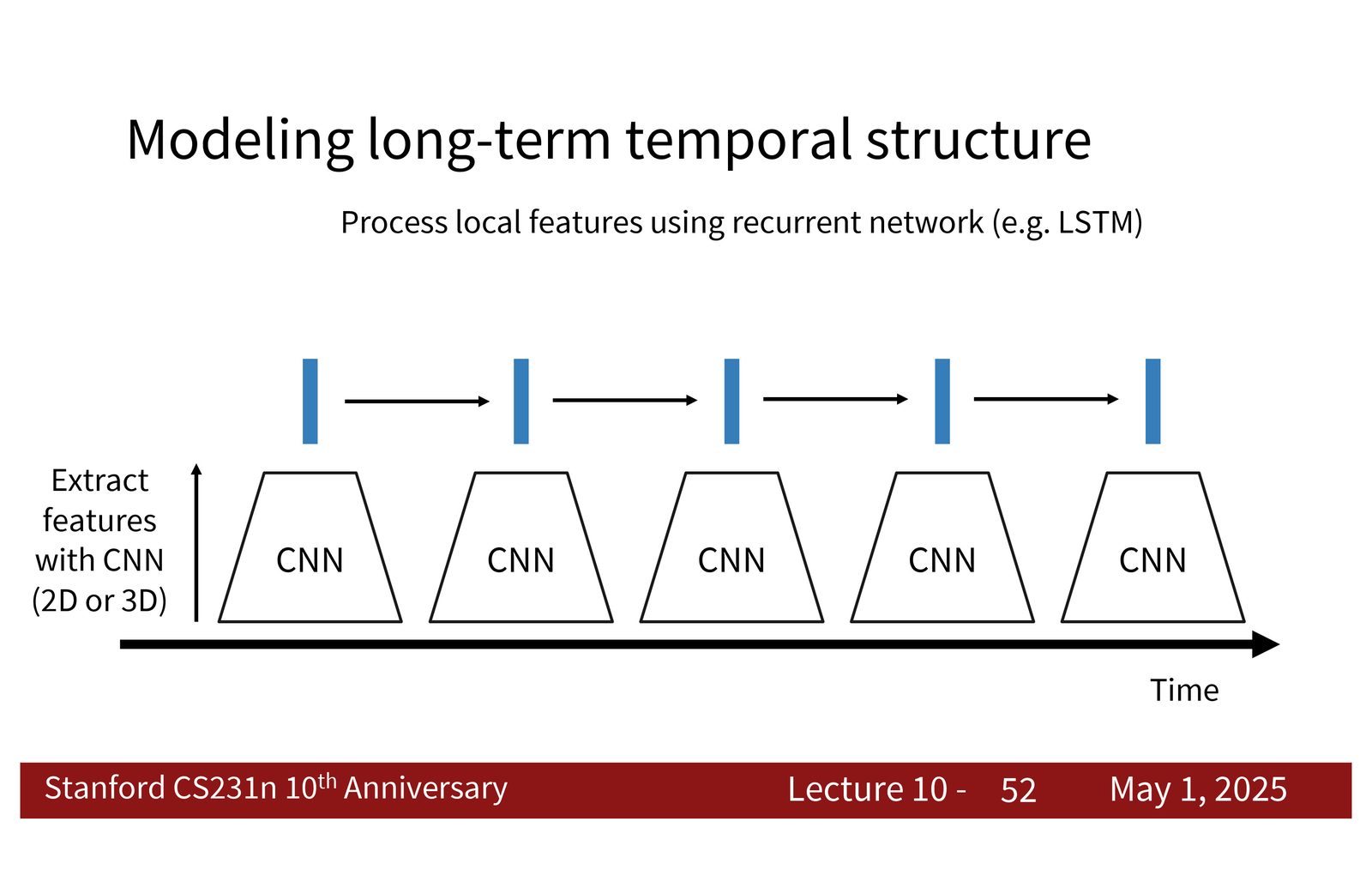
来源:Slides 第52页。
CNN + RNN 的核心思想
CNN 看到的是局部窗口,RNN 看到的是时间序列。把两者串起来,就能兼顾“局部动作模式”和“全局视频语义”。
Recurrent convolutional network
课程还提到一种更细粒度的组合方式:把 RNN 的矩阵乘法替换成卷积,得到 recurrent convolutional network。它的思想是:
- 在空间维度上保留卷积的局部归纳偏置;
- 在时间维度上递归地传递状态;
- 通过时空联合建模来处理视频序列。
这种设计在概念上很自然,但受限于 RNN 本身的顺序性,训练和推理都不算高效。
为什么长序列会逼出 attention
RNN 可以做长时序建模,但它难并行、难优化、长距离依赖也容易变弱。attention 的价值,就是把“远处帧之间可以直接连接”这件事做成显式计算。
self-attention 和 non-local block
当视频足够长时,局部卷积和循环结构仍然会受限。一个更直接的思路是引入 self-attention 或 non-local block:让任意两个时空位置都能交互,而不是只看邻近窗口。
如果输入向量为 \(x\),那经典 self-attention 可以写成:
- Query / Key / Value 的逻辑和 Transformer 类似;
- 它可以在 3D 特征图上做全局匹配;
- 这样能捕获更长范围的时空依赖。
self-attention 在视频里有什么用
- 它让远距离帧之间直接交互。
- 它适合捕获长程依赖和非局部关系。
- 它为后续 Transformer 化的视频模型铺路。
长时序建模的共同目标
不管是 RNN、Recurrent CNN、Non-local block 还是 Transformer,目标都一样:把“很远的帧之间可能有关联”这件事显式编码进模型。
从短 clip 到复杂动作任务
动作不一定靠外观猜
讲者给出了一些非常典型的动作识别例子:举重、涂眼影、快速挥动之类的动作,往往更依赖运动而不是静态外观。视觉模型如果只盯着某一帧,很容易忽略“动作过程”。
Temporal action localization
分类只回答“是什么动作”,但实际视频里还常常要问“动作什么时候开始、什么时候结束”。Temporal action localization 就是在时间轴上找动作边界。这个任务把片段级分类推进到“时间上的定位 + 分类”。
Spatio-temporal detection
如果还想知道动作发生在画面的哪个位置,那就变成空间和时间同时定位的问题。这比普通检测更难,因为每个预测不仅有 box,还要有时间维度。
长视频任务的核心难点
真正困难的不是“有没有模型”,而是“模型如何在有限算力下看完足够多的内容”。因此 clip 采样、关键片段选择和高效推理,都是视频理解里绕不开的问题。
多模态视频理解:声音、视觉和融合
为什么要把音频也算进来
视频并不只有视觉。很多场景中,音频同样提供重要线索:
- 人在说话时,声音能帮助识别是谁在说。
- 乐器演奏时,画面和声音可以互相约束。
- 某些动作在视觉上相似,但声音差异很大。
视觉引导的音频分离
一个很有代表性的任务是 visually guided audio source separation。直觉很简单:如果视频里能看到谁在动、谁在发声,那就可以借助视觉把混合音频拆开。
音视频分离为什么值得做
- 它把“看见谁在动”转化成“知道声音属于谁”。
- 它能改善会议、访谈、音乐和机器人交互中的感知质量。
- 它说明视频理解不仅是识别,还可以是信号分解和重建。
Audio-visual transformers 和多模态理解
进一步地,研究者开始把图像 patch、视频 clip 和音频谱图一起送进 Transformer 结构,做统一的多模态建模。课程里列出的方向包括 attention bottleneck、audio-adaptive recognition、audio-visual masked autoencoding 等。这里的重点已经不只是“加一条音频分支”,而是把多模态表示统一进一个可学习框架。
多模态的两个方向
- 判别式:做分类、检索、定位。
- 生成式:做重建、补全、mask prediction。
高效视频理解:采样、选择和轻量化
为什么效率问题会变成主问题
长视频很长,3D 卷积很贵,attention 更贵。如果模型每次都把所有帧完整跑一遍,成本会迅速失控。因此,视频理解越来越像一个“在预算内找信息”的问题,而不是纯粹的分类问题。
效率优化的思路
高效视频理解不是简单“把模型变小”,而是把计算集中在最有用的时间段、空间区域和模态上。它本质上是在做信息预算分配。
几类常见策略
效率提升通常有几种思路:
- 采样更少的 clip:只处理更有信息的片段。
- 选择更轻的骨干:例如更轻量的 3D 网络或更高效的 backbone。
- 做模态选择:有些任务不一定需要所有模态同时推理。
- 做预览机制:先用便宜模态估计哪里值得看,再做精细处理。
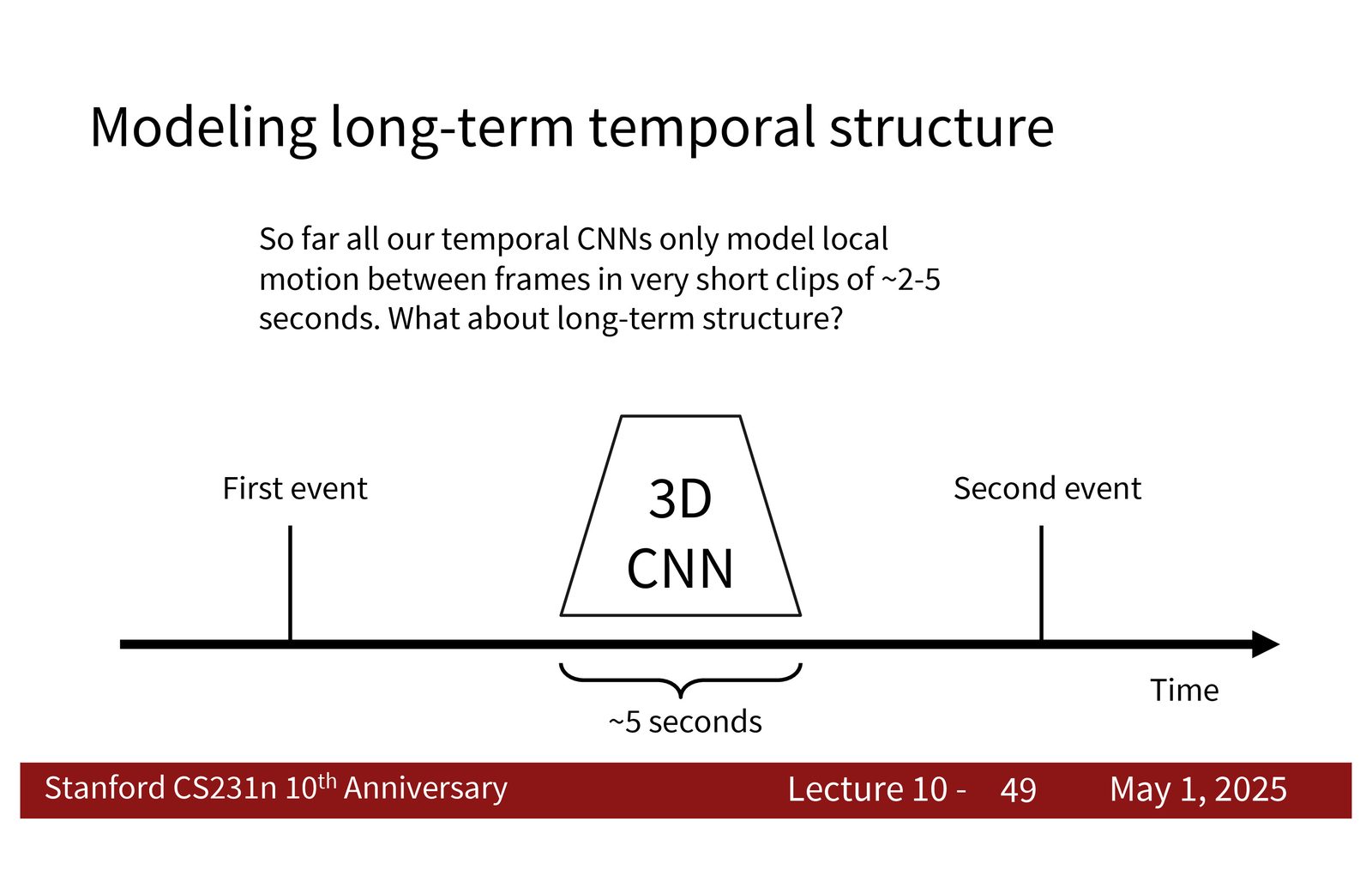
来源:Slides 第49页。
从长视频到 egocentric video
更进一步,课程把话题推进到 egocentric / exocentric 结合的场景。第一视角视频和外部视角视频可以互相补充,尤其在多人与多摄像头场景里,视频理解开始变成“谁在看什么、谁在和谁交互”的问题。
第一视角视频更难
第一视角视频更接近真实体验,但同时也更抖、更碎、更依赖上下文,还会把“操作者意图”引入任务。这让模型更接近人,也更难。
视频理解和大模型
为什么视频理解会走向 LLM
视频模型下一步不只是分类器,而是可以被 prompt 的系统:输入视频和问题,输出描述、解释或结构化答案。课程最后提到的 Video-LLaVA、Video-ChatGPT、VideoLLaMA 3,都说明视频理解正在进入统一的多模态对话框架。
视频 LLM 的意义
- 它把视频理解从分类器推进到交互式系统。
- 它把动作识别推进到语言解释和任务规划。
- 它也把视频理解和具身智能、助手系统更紧密地连起来。
这一讲真正想让你记住什么
这节课表面上讲的是视频理解方法史,实际上讲的是一条更大的路径:从短 clip 到长视频,从外观到运动,从单模态到多模态,从分类到定位,从识别到问答,再从问答走向可操作的系统。
| 阶段 | 核心问题 | 主要方法 |
|---|---|---|
| 短 clip 分类 | 动作是什么 | 单帧、late fusion、early fusion、3D CNN |
| 运动分离 | 动作靠什么线索 | optical flow、two-stream |
| 长时序建模 | 动作如何跨越更长时间 | CNN + RNN、recurrent CNN、attention |
| 复杂任务 | 动作何时何地发生 | temporal localization、spatio-temporal detection |
| 多模态与未来 | 还能利用什么信息 | 音视频融合、efficiency、LLM |
这节课最值得记住的几句话
- 视频就是 2D + time,但时间维度会带来完全不同的建模挑战。
- 单帧 baseline 往往不差,但它忽略了真正的运动信息。
- 3D CNN 的本质是让卷积在时空体上滑动,而不是只在图像平面上滑动。
- Two-stream 说明了外观和运动可以分开建模,光流是经典运动表示。
- 长视频不能只靠短 clip;需要 RNN、attention 或更高效的时序聚合。
- 现实系统里,数据规模、采样策略和效率和模型结构同样重要。
总结与延伸
本章小结
这一讲把视频理解拆成三层问题:如何表示局部运动、如何跨更长时间建模时序,以及如何在真实系统里兼顾精度与效率。3D CNN、two-stream、attention 和多模态融合并不是互斥路线,而是围绕“如何把时间维度引入视觉表示”这个核心问题的不同答案。
拓展阅读
- Ji et al., 3D Convolutional Neural Networks for Human Action Recognition。
- Tran et al., Learning Spatiotemporal Features with 3D Convolutional Networks(C3D)。
- Simonyan and Zisserman, Two-Stream Convolutional Networks for Action Recognition in Videos。
- Donahue et al., Long-term Recurrent Convolutional Networks for Visual Recognition and Description。
- Wang et al., Non-local Neural Networks。
- Carreira and Zisserman, Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset(I3D)。