CS224N Lecture 8: Transformers
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Anna Goldie 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年春季 |

引言:为什么 Transformers 重要
本讲的主题是 Transformers。这类模型建立在 self-attention 之上,已经成为现代 NLP 的默认架构,也逐渐扩展到图像、蛋白质、系统优化等领域。
本讲核心内容
- Transformers 为什么在 NLP 中迅速取代 RNN
- self-attention 的直觉、公式与向量化实现
- Transformer encoder-decoder 的完整结构
- positional encoding、multi-head attention、masked attention 的作用
- Transformer 的局限,以及后续的高效变体

来源:Slides 第1页。
Transformers 改变了什么
过去几年里,Transformer 不只是提升了机器翻译的质量,更改变了整个 NLP 研究范式。其核心优势不是某一个小技巧,而是把序列建模的主干从 recurrence 改成了 attention。
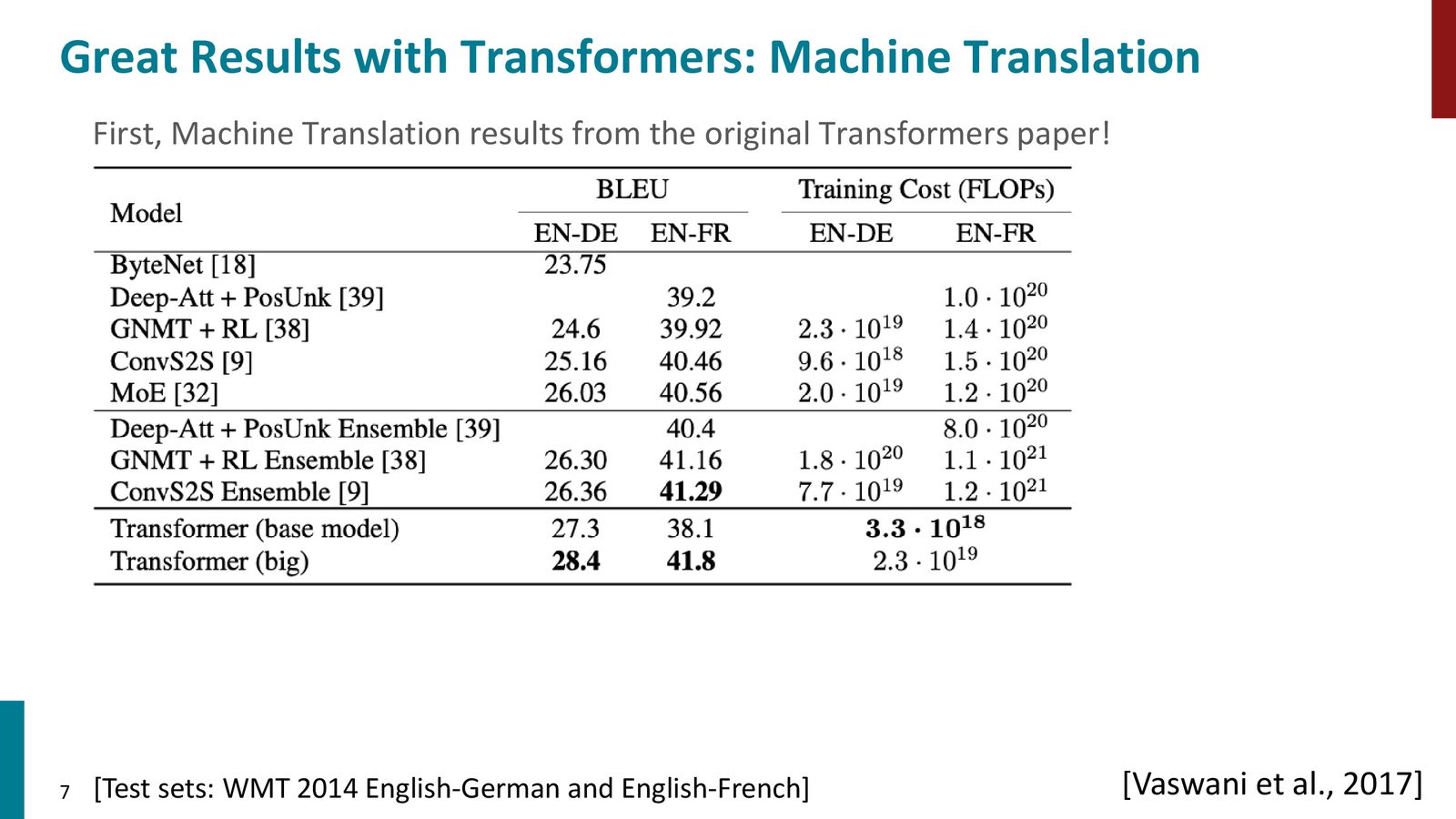
来源:Slides 第7页。
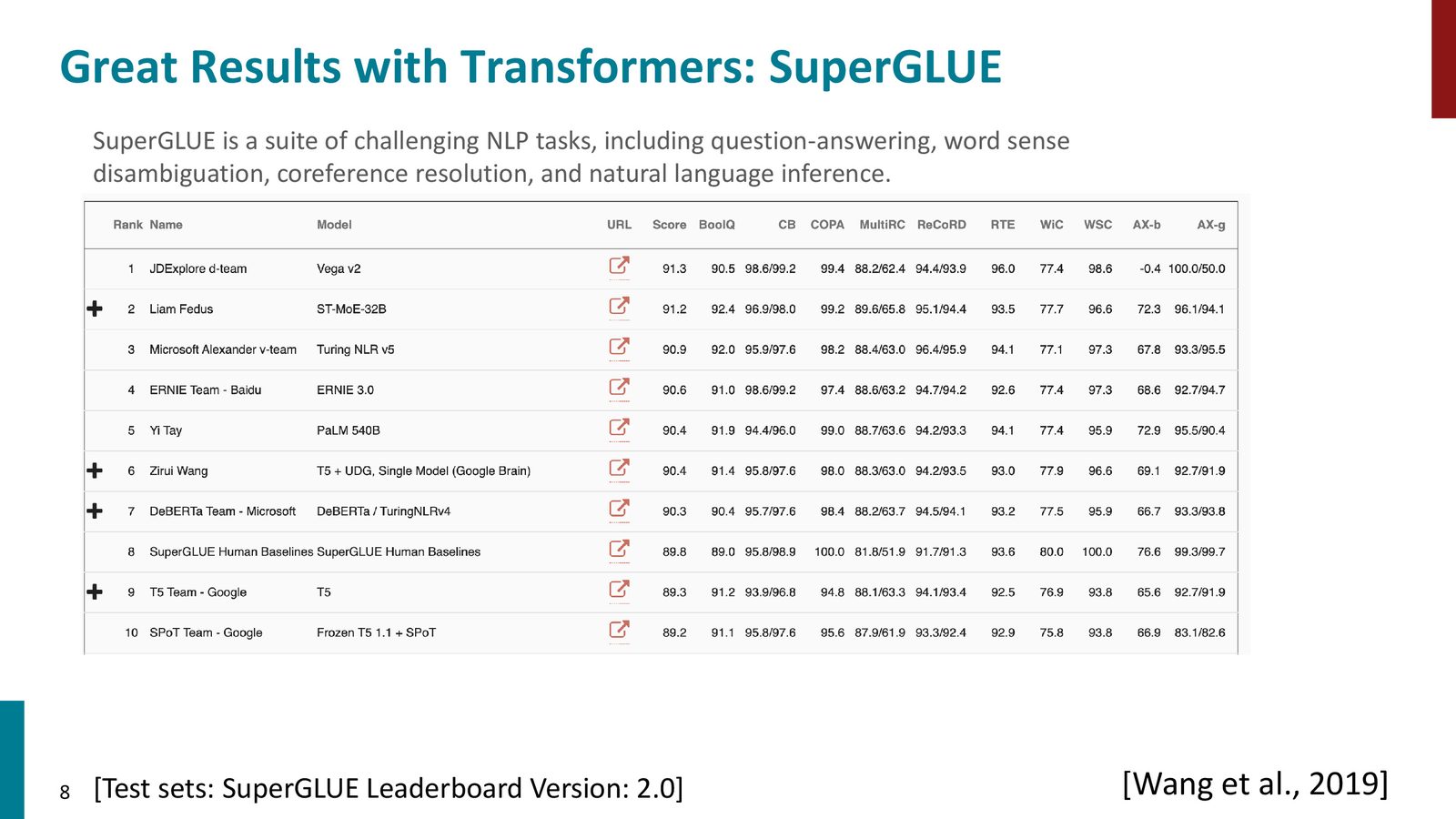
来源:Slides 第8页。

来源:Slides 第9页。

来源:Slides 第10页。
Transformer 不只属于 NLP
本讲也强调了一个趋势:Transformer 不是只在文本任务里有效,而是已经扩散到更广泛的领域。幻灯片中给出了蛋白质折叠、图像分类和系统优化的例子。

来源:Slides 第11页。

来源:Slides 第12页。

来源:Slides 第13页。

来源:Slides 第14页。
缩放律的启示
幻灯片用 scaling laws 提出一个更大的问题:如果 Transformer 的性能会随着模型、数据和计算规模平滑上升,那么我们是否只需要继续扩大同样的架构?

来源:Slides 第15页。
本讲的判断
标题里问的是 “Is Attention All We Need?”,但本讲给出的答案更接近 “Attention 很重要,但还不够”。Transformer 的成功来自 attention + 位置编码 + 多头机制 + 残差 + layer norm + feedforward 的组合。
本章小结
Transformer 之所以重要,是因为它在训练效率、长距离依赖建模和大规模扩展性上都比经典 RNN 更适合现代深度学习工作负载。接下来要理解的是:它到底是怎么工作的。
从递归到 Attention
RNN 时代的主流做法
在 Transformer 之前,NLP 的主流方案是用双向 LSTM 编码输入,再用解码器逐步生成输出。这个范式虽然有效,但它有两个明显问题:难以并行,且长距离依赖的梯度传播路径太长。

来源:Slides 第17页。
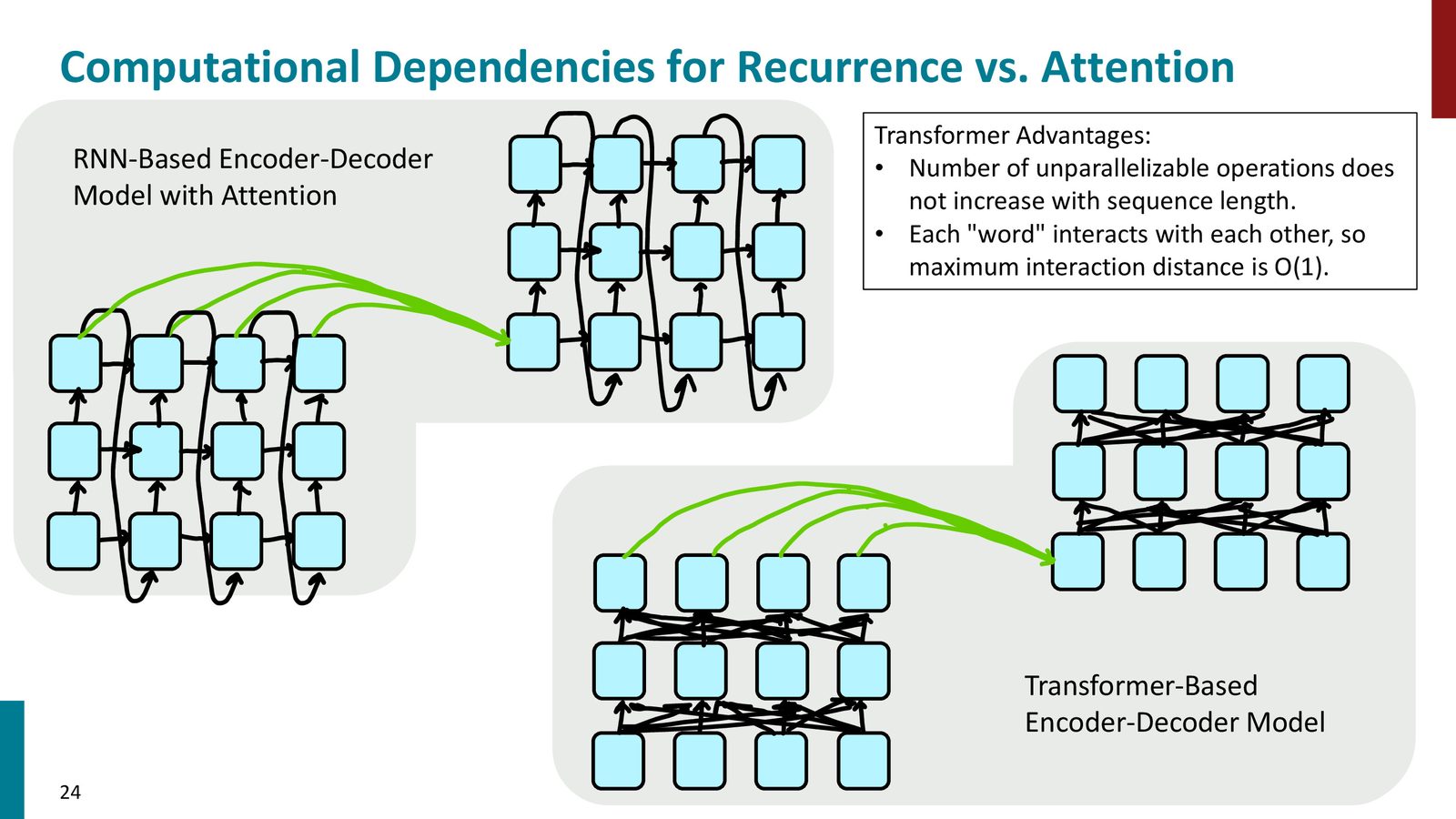
来源:Slides 第24页。
RNN 的两个结构性瓶颈
- 并行性差:下一个状态必须依赖上一个状态,训练时很难充分利用硬件
- 交互距离长:两个相距很远的词要通过许多时间步才能彼此影响,信息和梯度都更难传播
Attention 作为过渡
上一讲已经看到,attention 可以让 decoder 直接访问 encoder 中任意位置的信息。Transformer 进一步把这个思想推广到编码器和解码器内部,变成 self-attention。
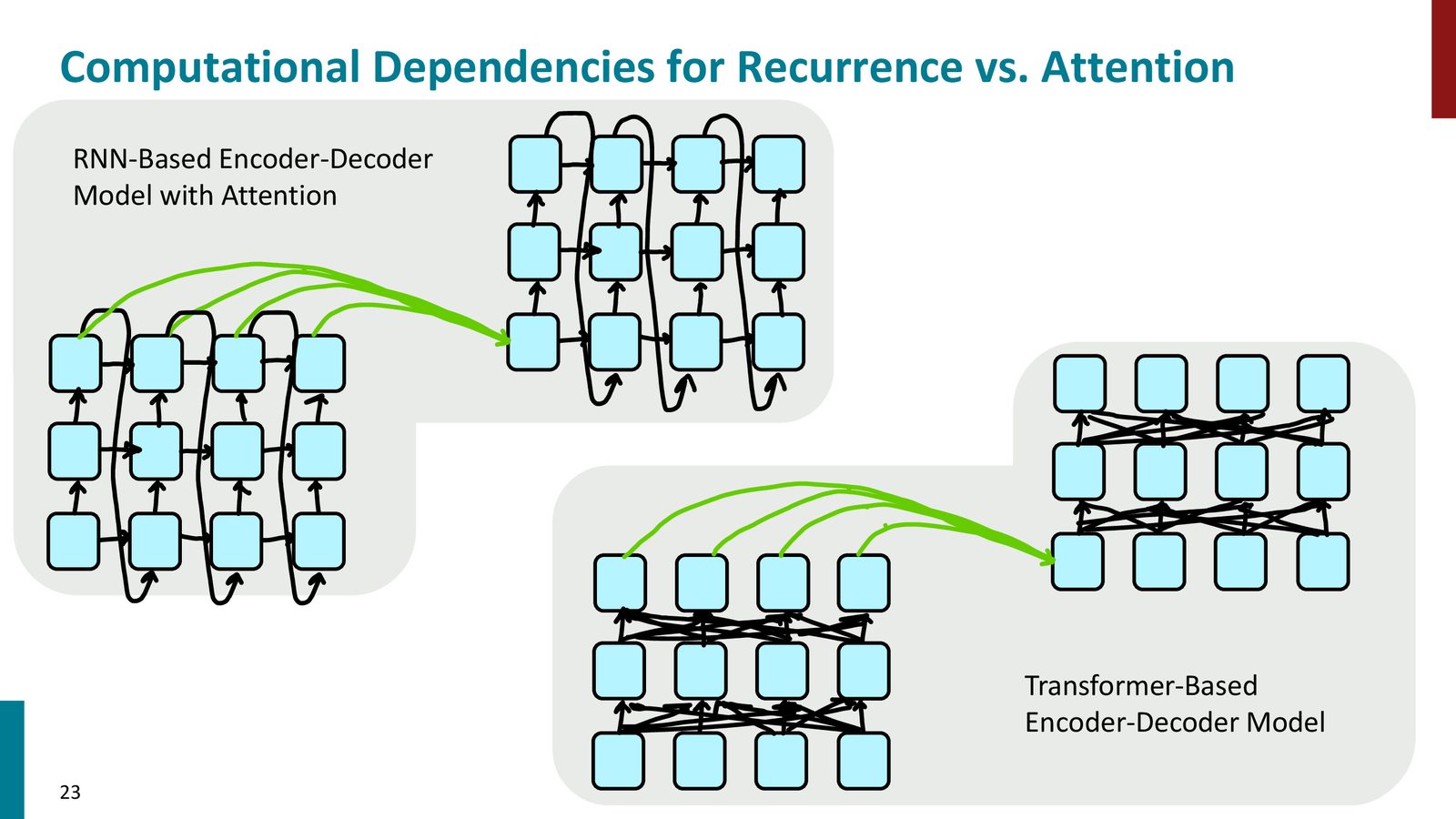
来源:Slides 第23页。

来源:Slides 第25页。
本章小结
从 RNN 到 attention 的关键转变是:不再让信息只能沿着时间轴一步一步流动,而是允许每个位置直接检索整个序列。Transformer 把这个思想推到极致,于是计算图也变得更适合并行硬件。
理解 Transformer
完整架构
Transformer 由 encoder 和 decoder 两部分组成。encoder 反复堆叠 self-attention 与 feedforward,decoder 则在 self-attention 之外,再增加一层 cross-attention 去读取 encoder 输出。
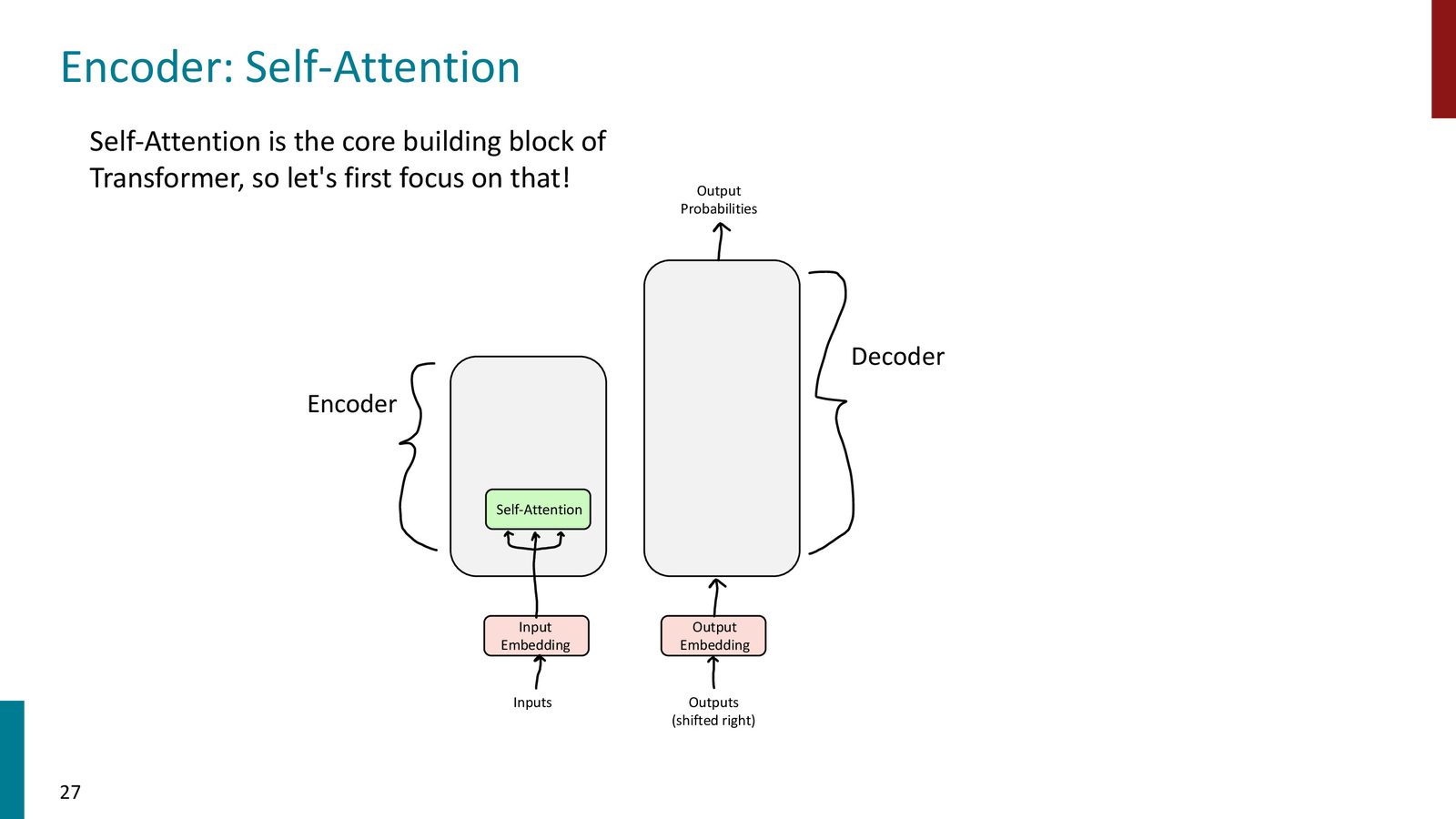
来源:Slides 第27页。
Self-Attention 的直觉
Attention 可以被理解成一个 “fuzzy hashtable”:不是精确查找一个 key,而是根据 query 与所有 key 的匹配程度,返回一个加权和。
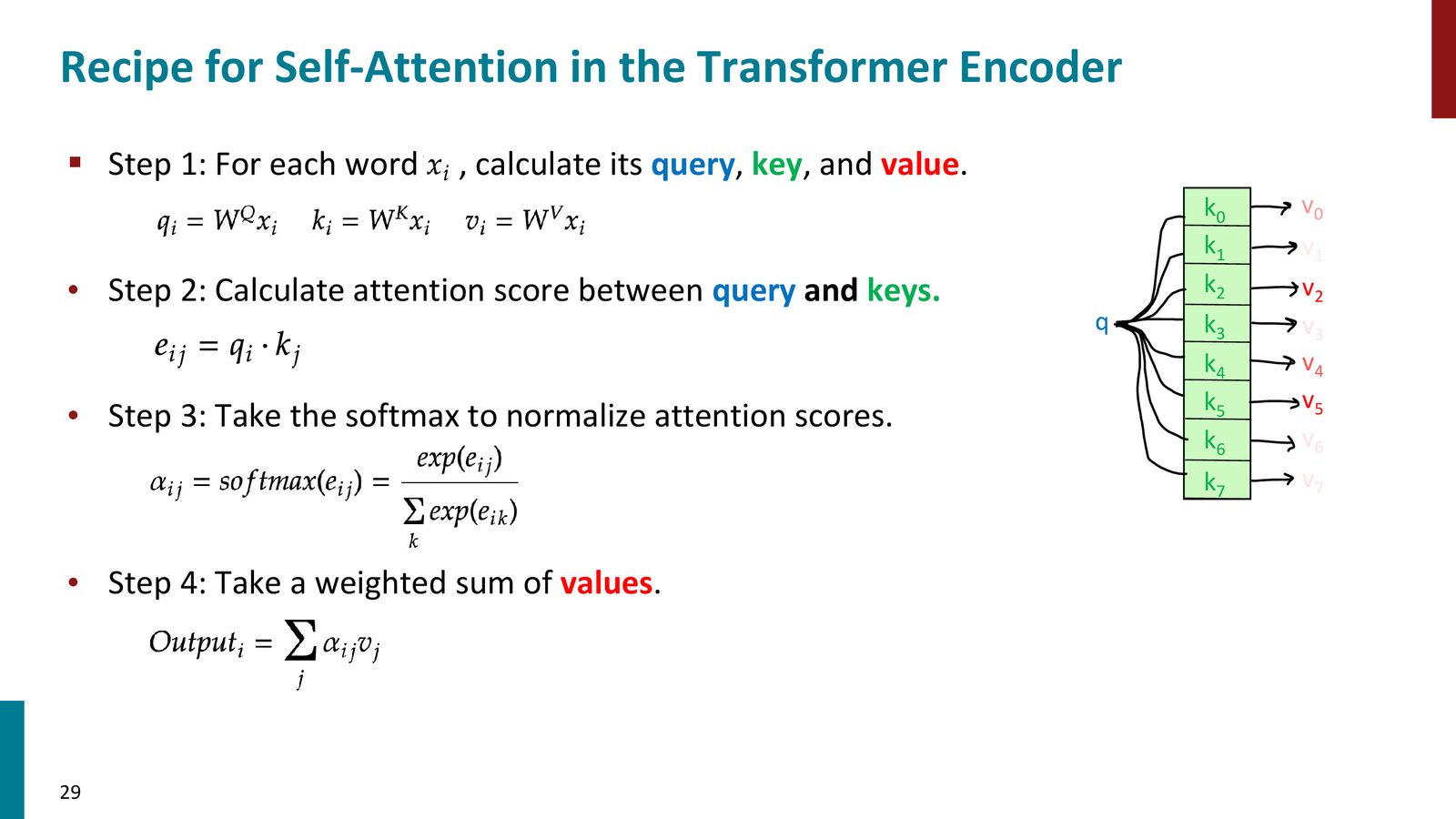
来源:Slides 第29页。
self-attention 的计算步骤
- 对每个词计算 query、key、value
- 用 query 和所有 key 计算 attention score
- 对 score 做 softmax 归一化
- 对 value 做加权求和,得到该词的新表示
从公式到向量化
对第 \(i\) 个位置,令
则 attention 权重为
输出为
把整个序列堆起来后,向量化实现更简单:

来源:Slides 第30页。
来源:Slides 第31页。
为什么 attention 还不够
如果只有 self-attention,模型本质上只是把 value 向量重新加权平均。这样虽然强大,但表达力仍然不够,所以 Transformer 在每个 attention block 后面还加了 feedforward 层。
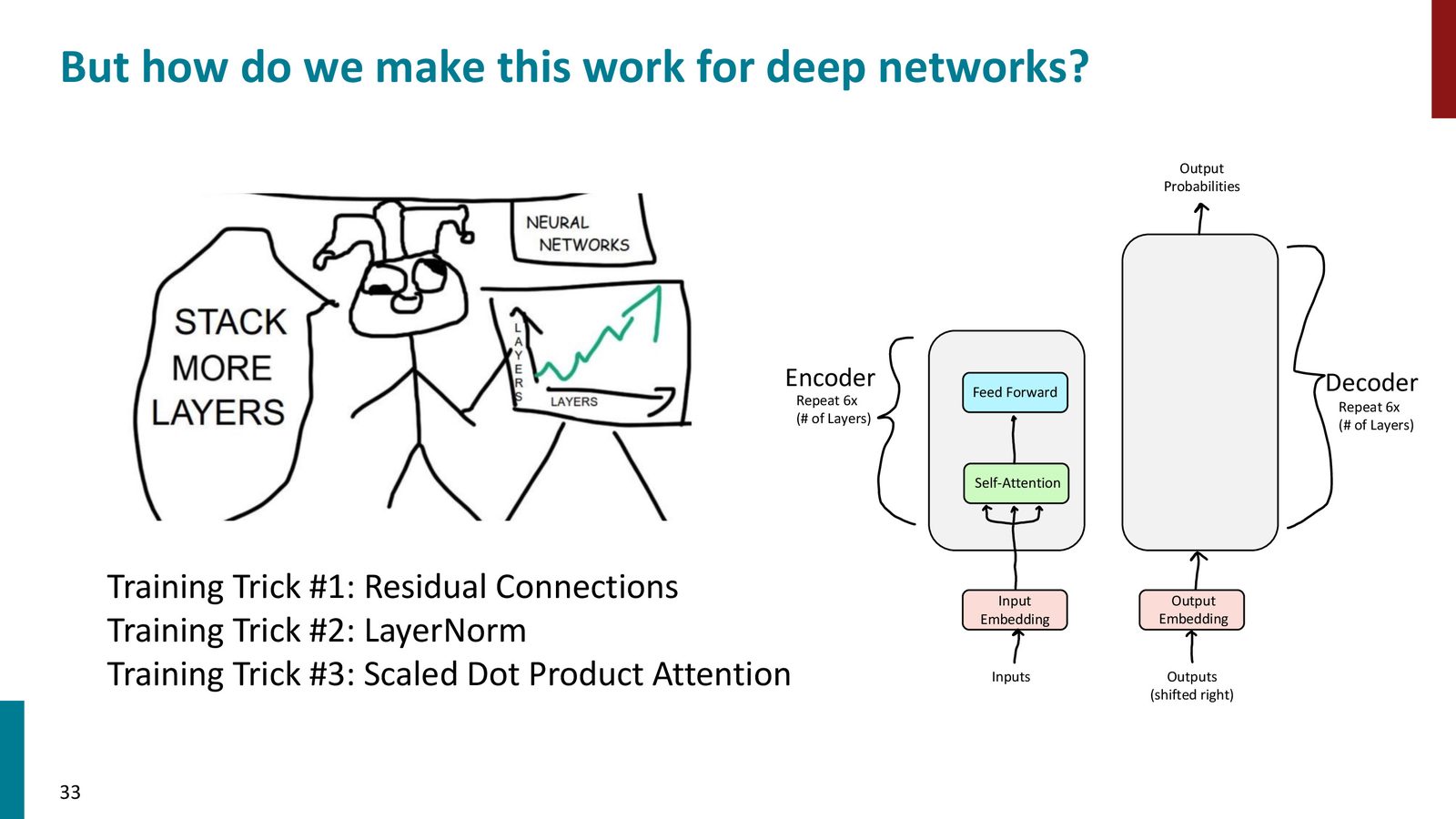
来源:Slides 第33页。
Residual、LayerNorm 和 Scaled Dot-Product
为了让深层 Transformer 可训练,原论文引入了三类训练技巧。
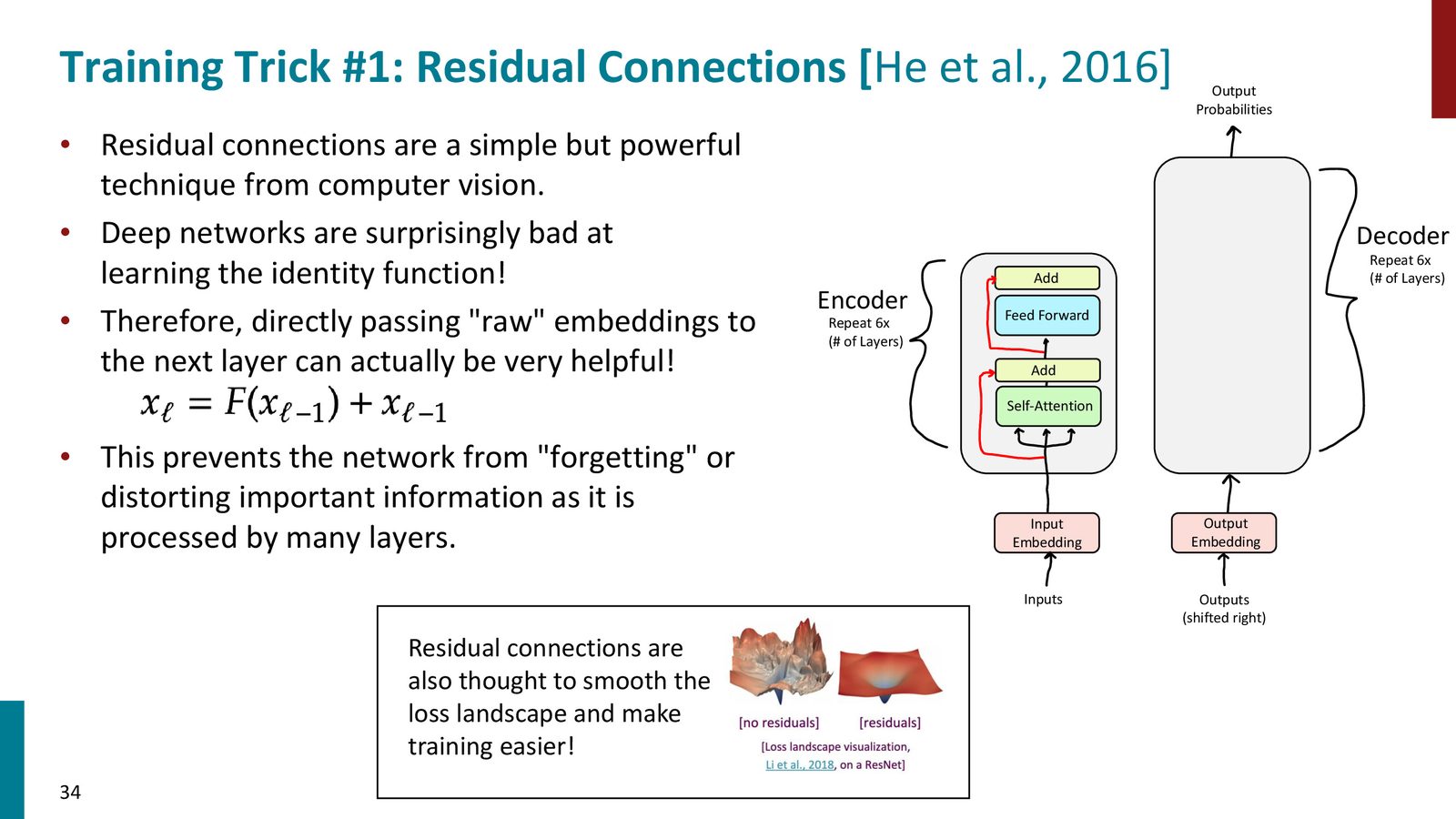
来源:Slides 第34页。
Residual Connection
残差连接把输入直接加到子层输出上:
它的作用是保留原始信息、帮助梯度传播,并让深层网络更容易学习到接近恒等映射的行为。
Layer Normalization
LayerNorm 在每个 token 的特征维度上做归一化,减少 layer 输入分布的漂移:
它比 batch norm 更适合 NLP,因为句子长度变化大,batch 的统计量也不稳定。
Scaled Dot-Product Attention
当 \(d_k\) 很大时,\(q^\top k\) 的方差会变大,softmax 容易饱和。于是要除以 \(\sqrt{d_k}\),把数值尺度控制在更稳定的范围内。
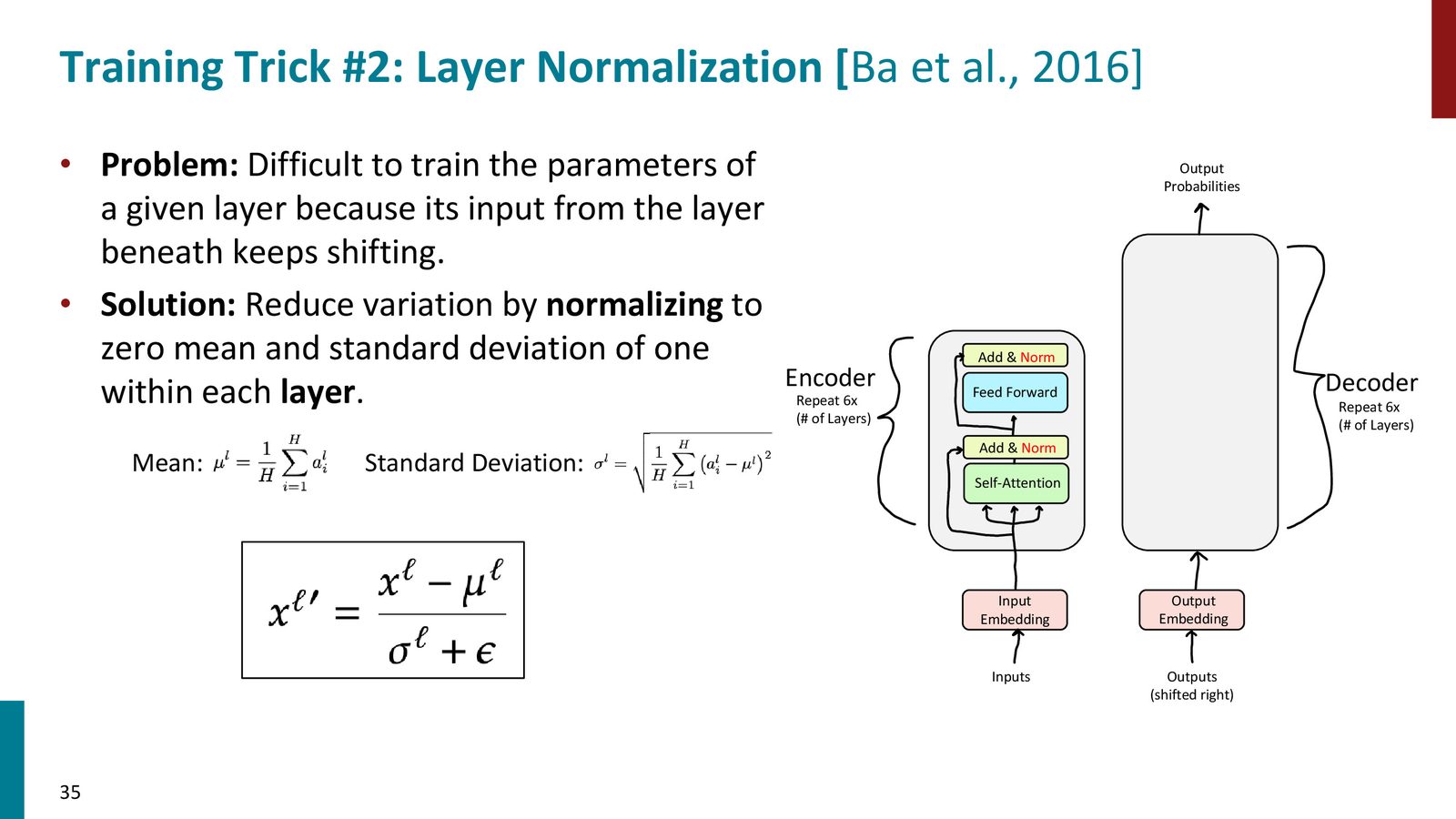
来源:Slides 第35页。
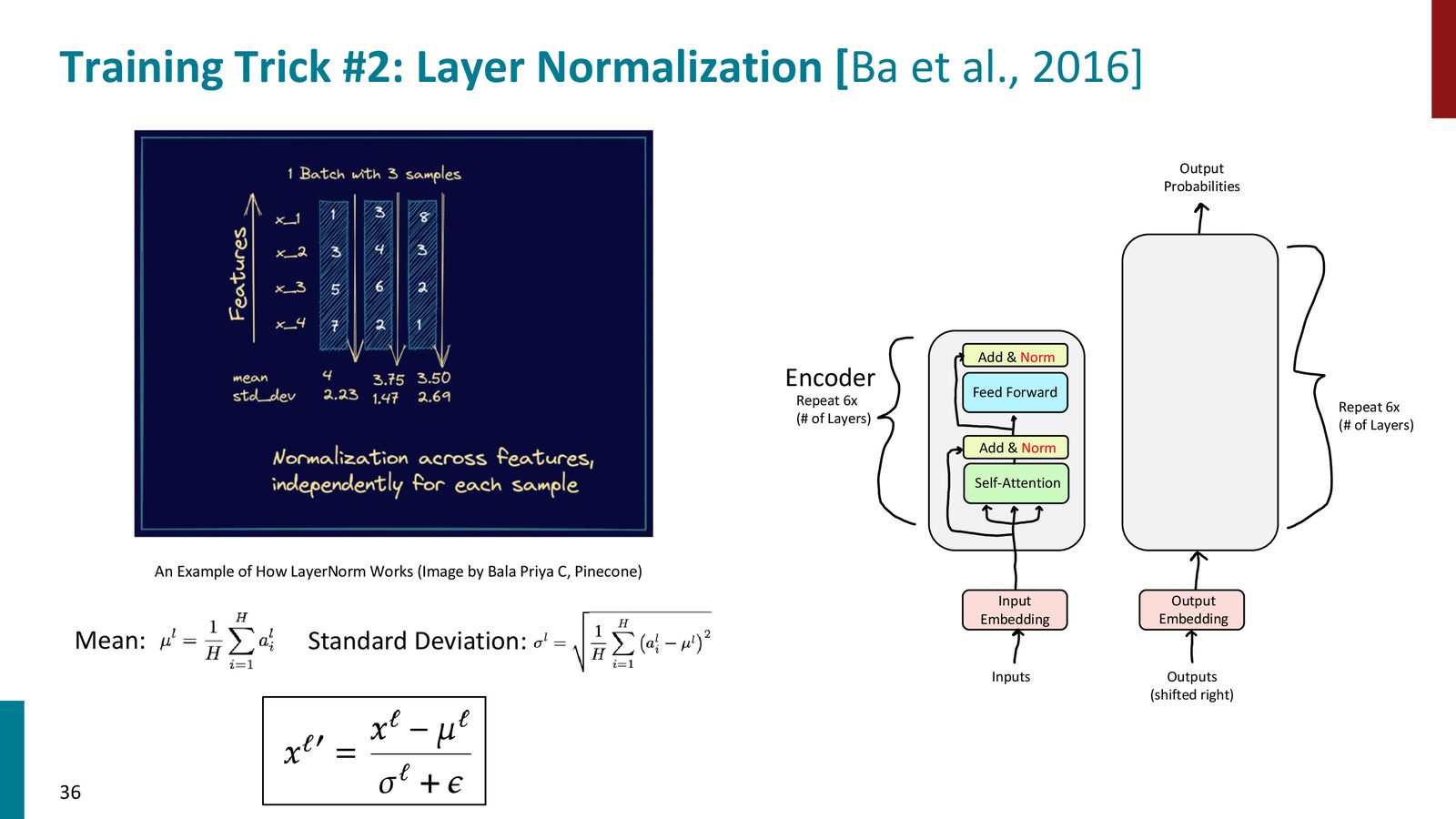
来源:Slides 第36页。
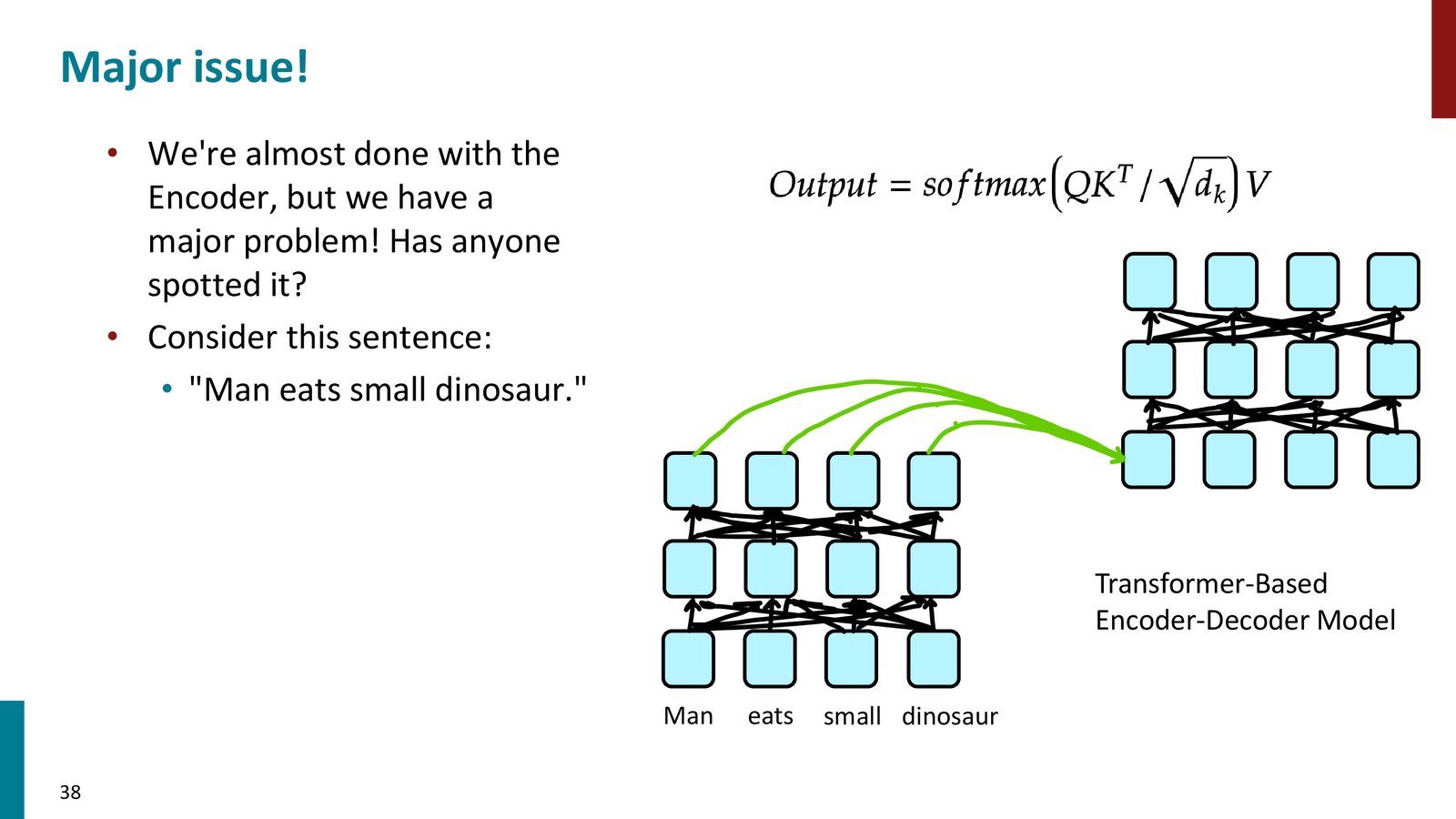
来源:Slides 第38页。
位置编码:解决顺序信息缺失
self-attention 本身不关心词序。若直接把词向量送进去,“Man eats small dinosaur” 和 “Dinosaur eats small man” 的表示几乎没有顺序差别,这显然不对。因此需要把位置编码注入模型。

来源:Slides 第41页。
一种经典做法是把位置向量 \(p_i\) 加到 token 表示上:
原始 Transformer 使用正弦/余弦位置编码:
这种设计的优点是可外推到更长的序列,而且不同频率的正弦信号能编码相对位置信息。

来源:Slides 第42页。
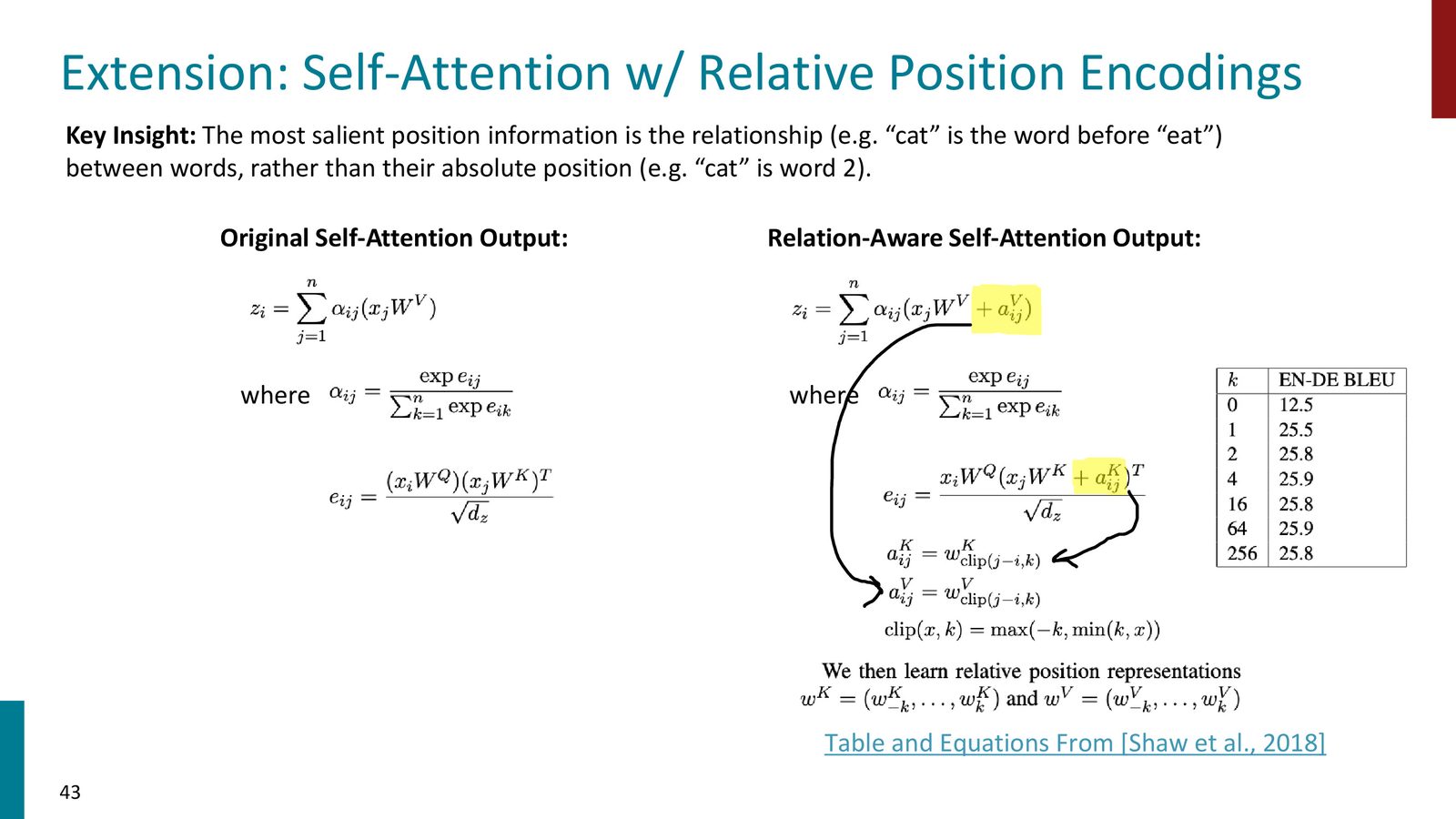
来源:Slides 第43页。
多头注意力
单个 attention head 往往只能学到一种局部模式。多头注意力让模型并行地学习多个投影空间里的匹配关系。

来源:Slides 第45页。
若有 \(h\) 个头,第 \(\ell\) 个头使用自己的参数:
每个头独立计算 attention,再把输出拼接:
直观上,不同的 head 可以分别关注词法邻近、句法依赖、长程共指等不同模式。
Decoder 的两类 attention
Transformer decoder 需要先做 masked self-attention,再做 encoder-decoder attention。前者防止“偷看未来”,后者从 encoder 的 memory 中读取源句信息。
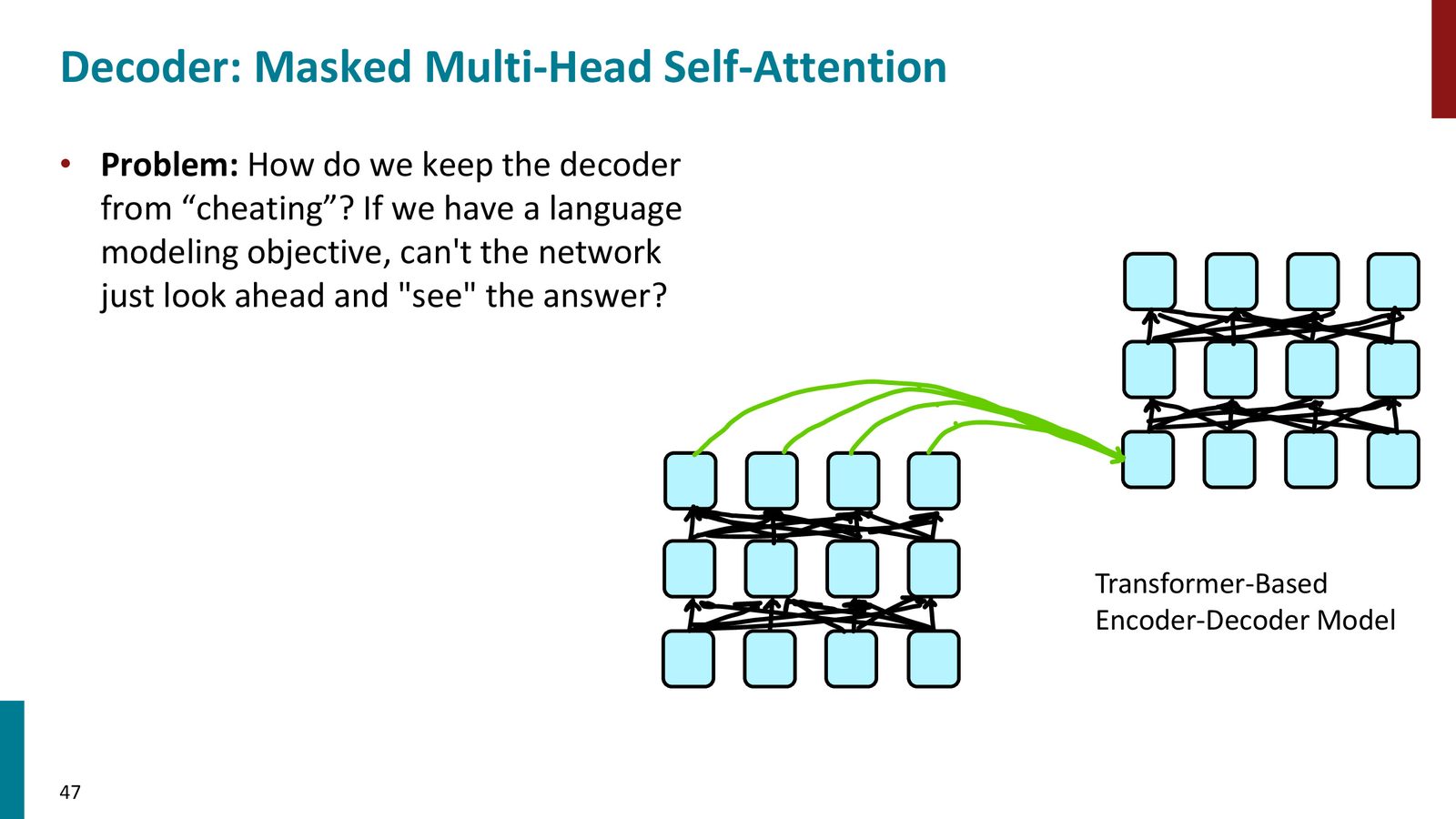
来源:Slides 第47页。
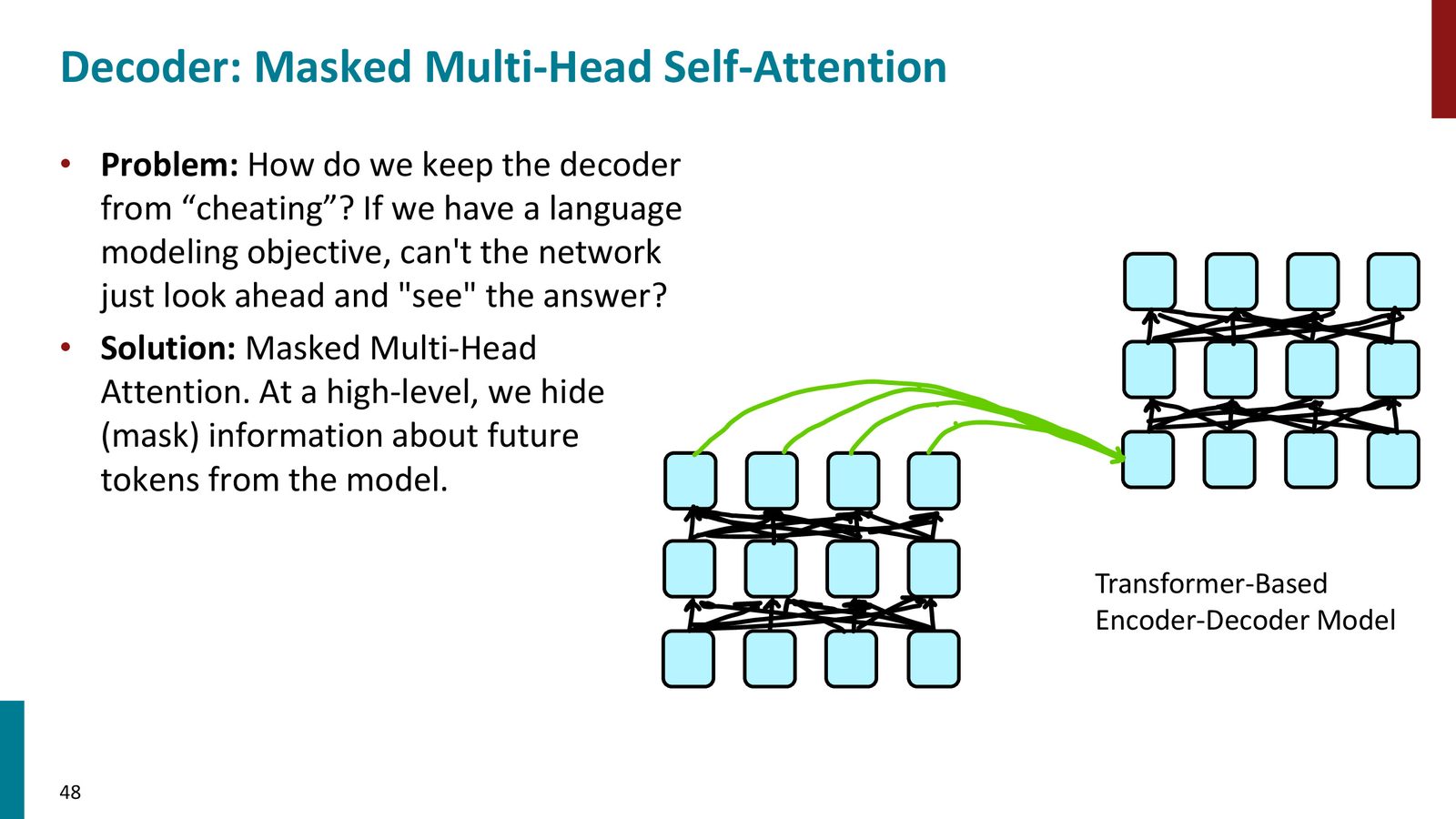
来源:Slides 第48页。
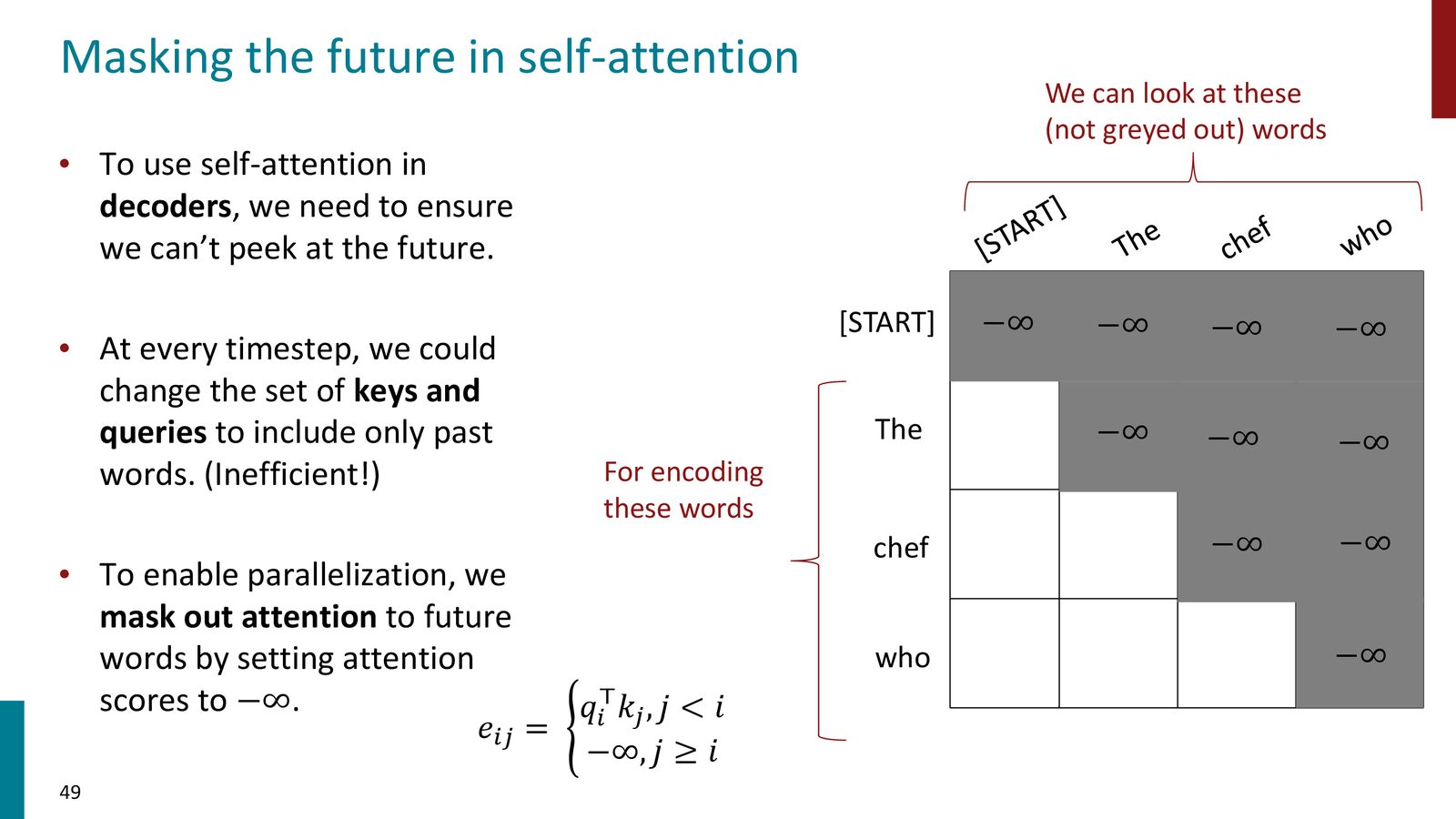
来源:Slides 第49页。
这保证了训练时可以并行计算所有位置,但每个位置仍然只能依赖左侧上下文。
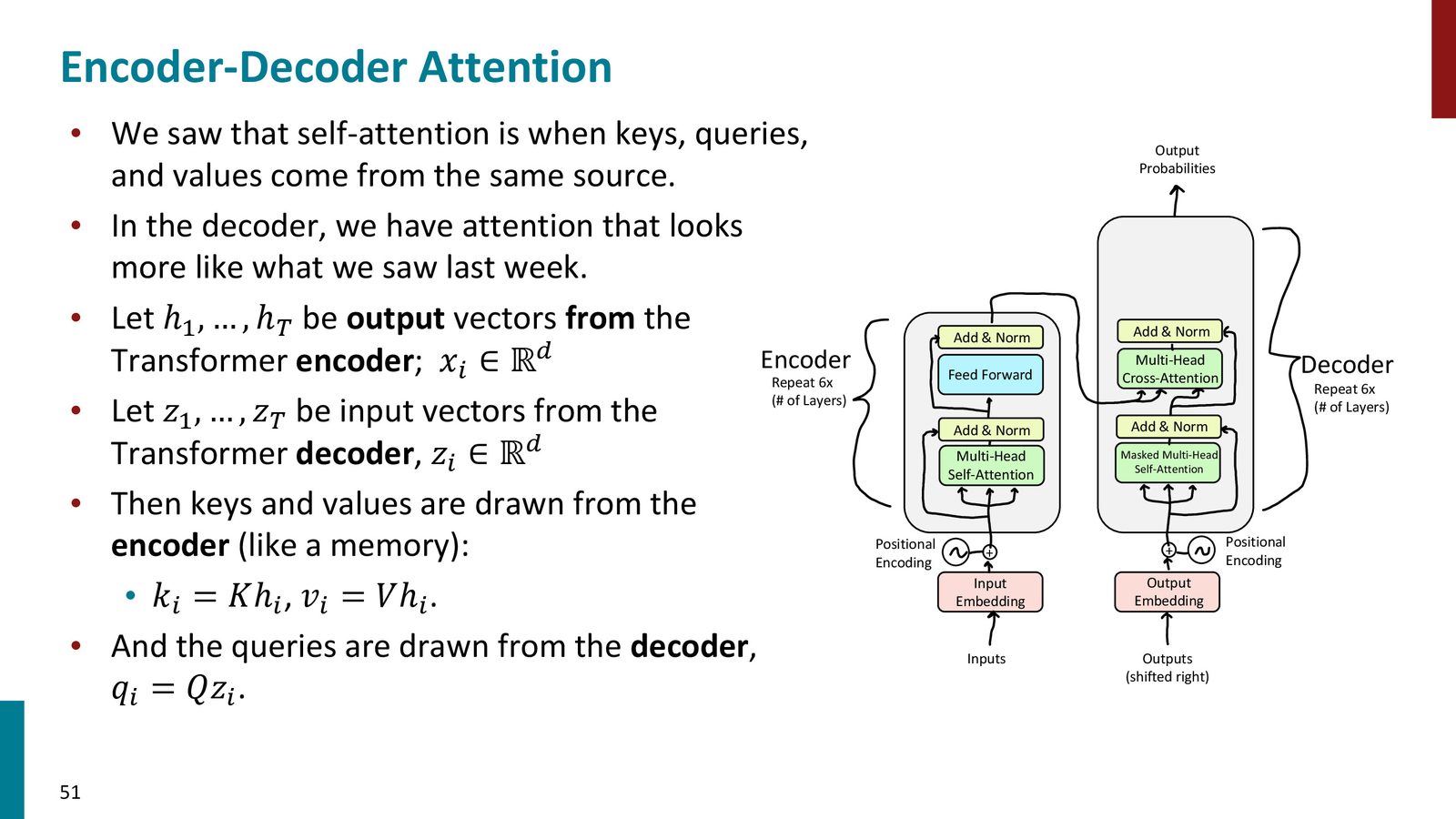
来源:Slides 第51页。
来源:Slides 第52页。
Self-attention 与 cross-attention 的区别
- Self-attention:\(Q,K,V\) 都来自同一序列
- Cross-attention:\(Q\) 来自 decoder,\(K,V\) 来自 encoder
前者负责建模句内依赖,后者负责在生成时读取输入句子的记忆。
Decoder 的收尾
decoder 最后还会经过 feedforward、线性层和 softmax,变成下一个 token 的概率分布。
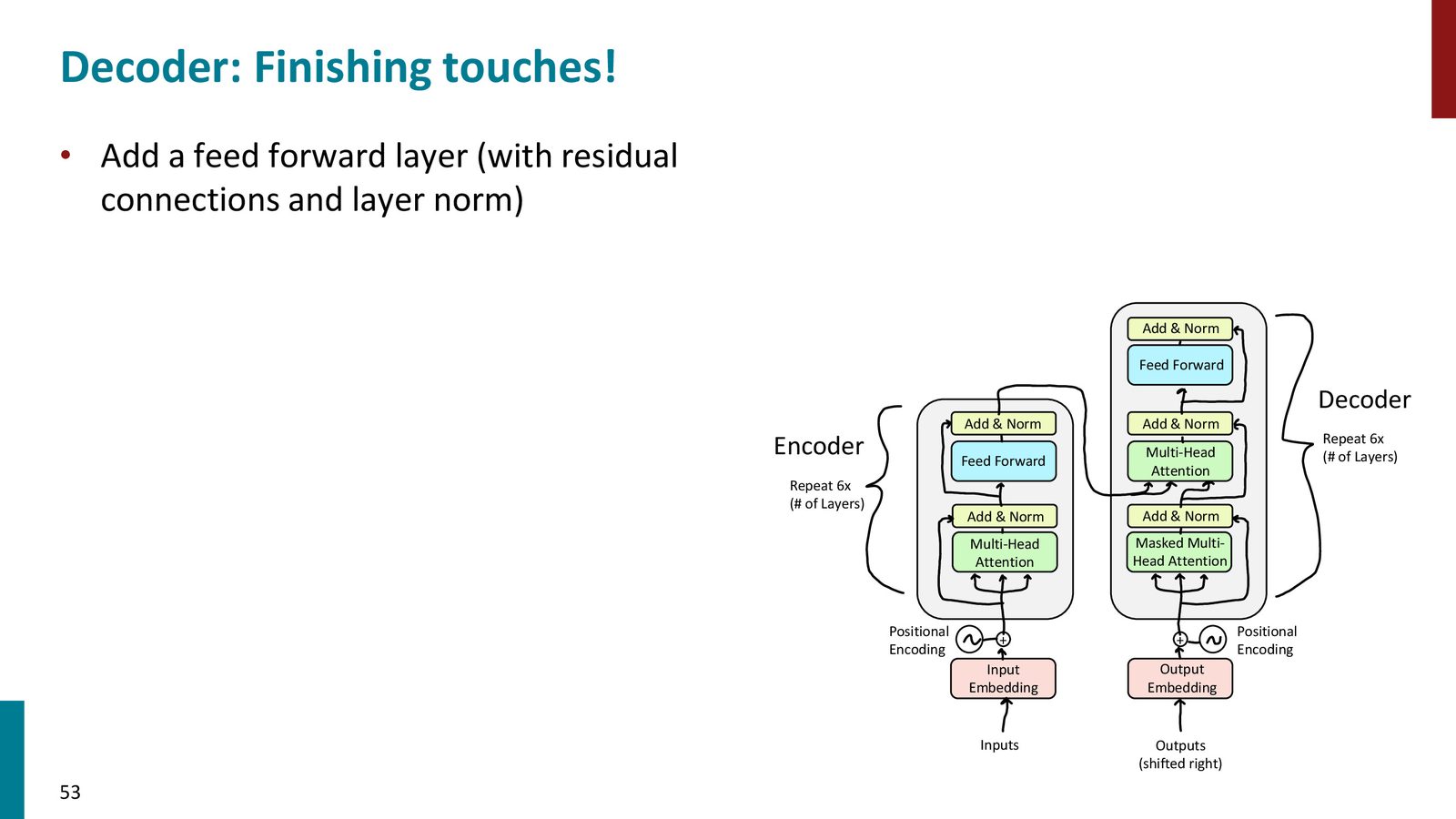
来源:Slides 第53页。
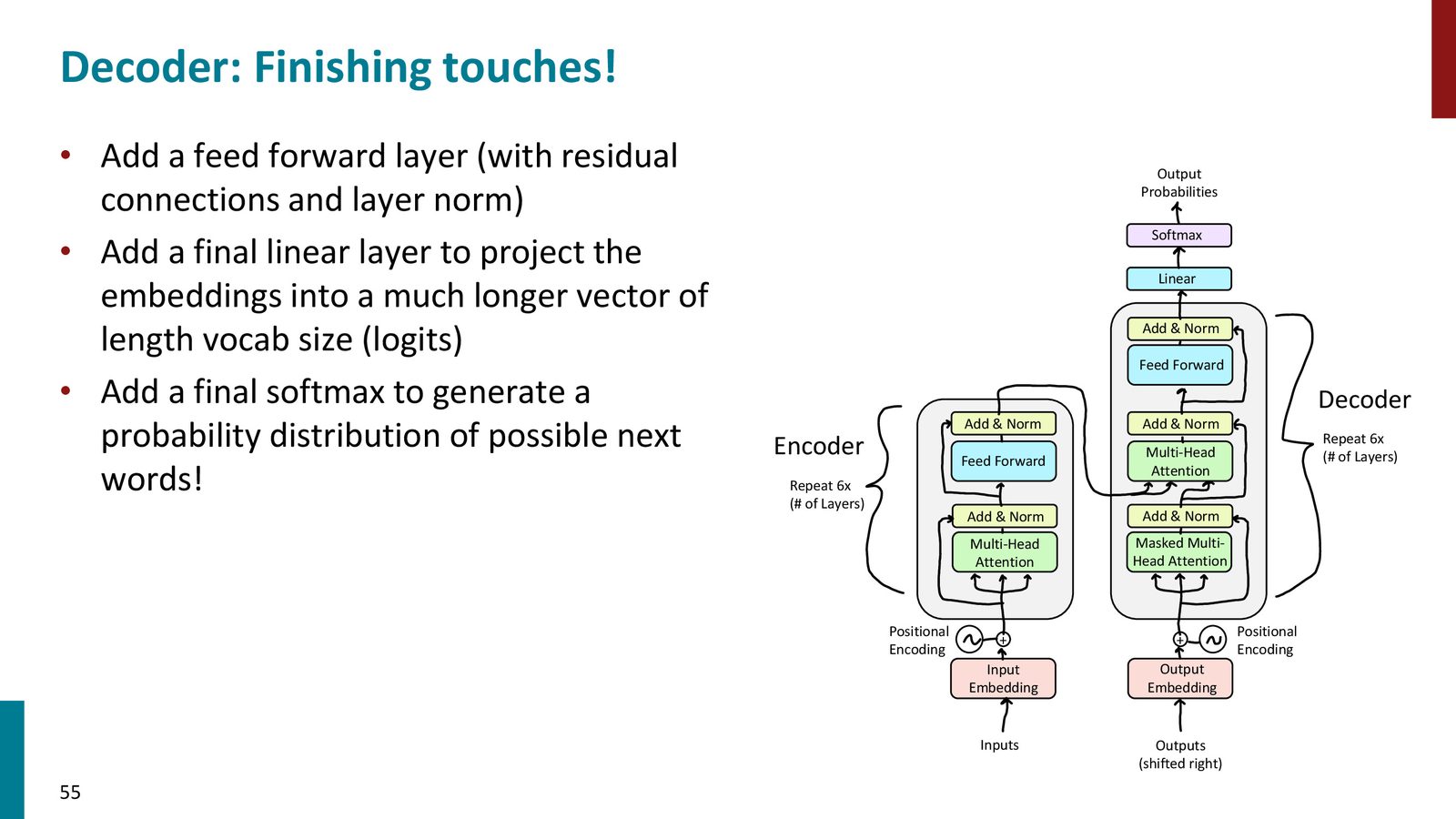
来源:Slides 第55页。
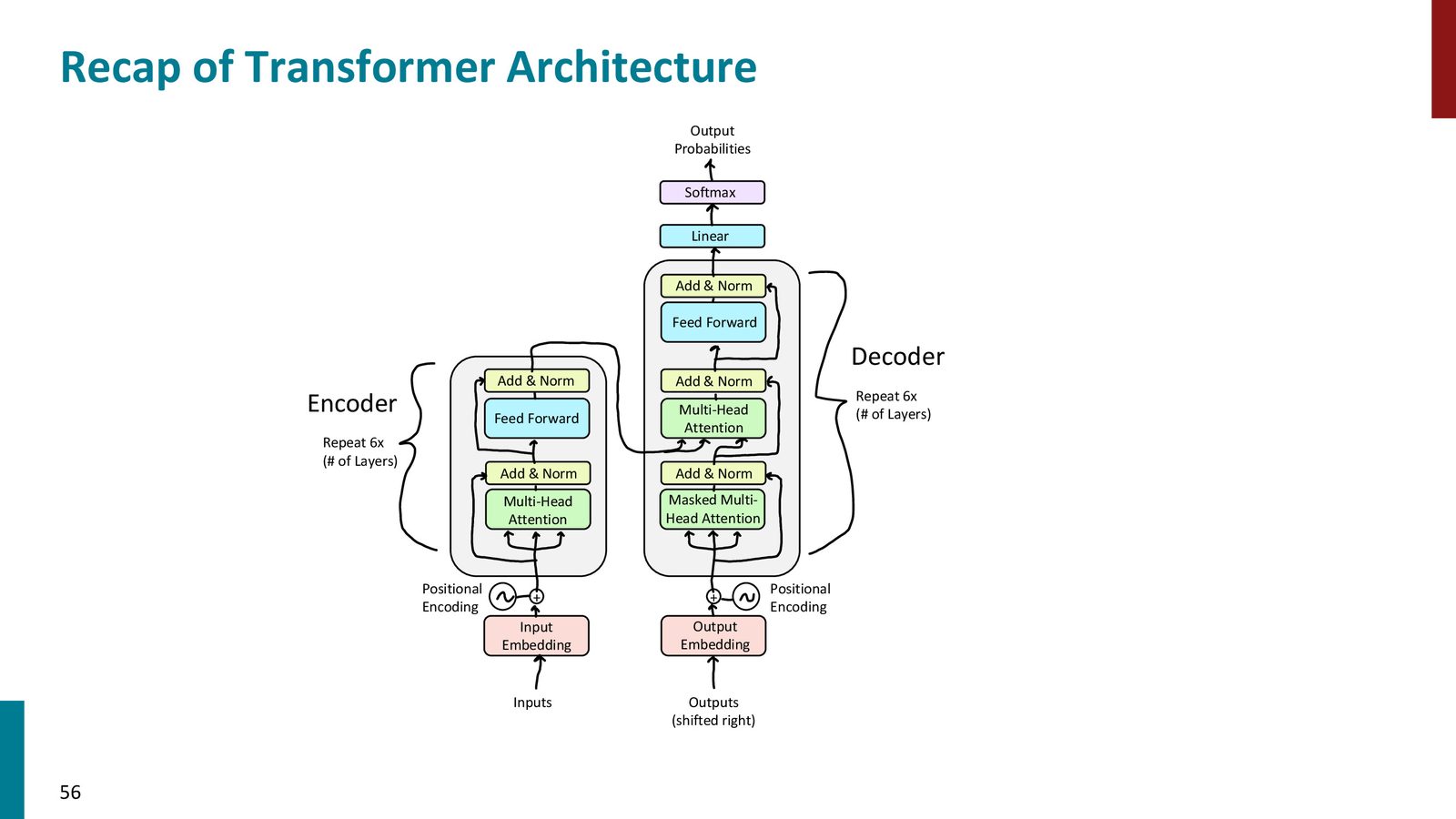
来源:Slides 第56页。
本章小结
Transformer 的主体可以概括为:位置编码 + 多头 self-attention + 残差连接 + layer norm + feedforward。encoder 和 decoder 的差异主要在于 decoder 多了 mask 和 cross-attention。
缺点与变体
Transformer 的主要缺点
即使 Transformer 很强,它仍然有两个广为人知的短板:第一,self-attention 的计算和显存开销对序列长度是二次的;第二,绝对位置编码未必是最好的顺序表示。

来源:Slides 第58页。
两个主要方向
- 降低 \(O(T^2)\) self-attention 的成本
- 改进位置表示,让模型更好地利用顺序与结构信息
位置表示的后续工作
讲义里提到的几个方向包括 relative linear position attention、dependency syntax-based position 和 rotary embeddings。它们都试图让位置不只是一个静态的绝对 index,而是更贴近词与词之间的关系。
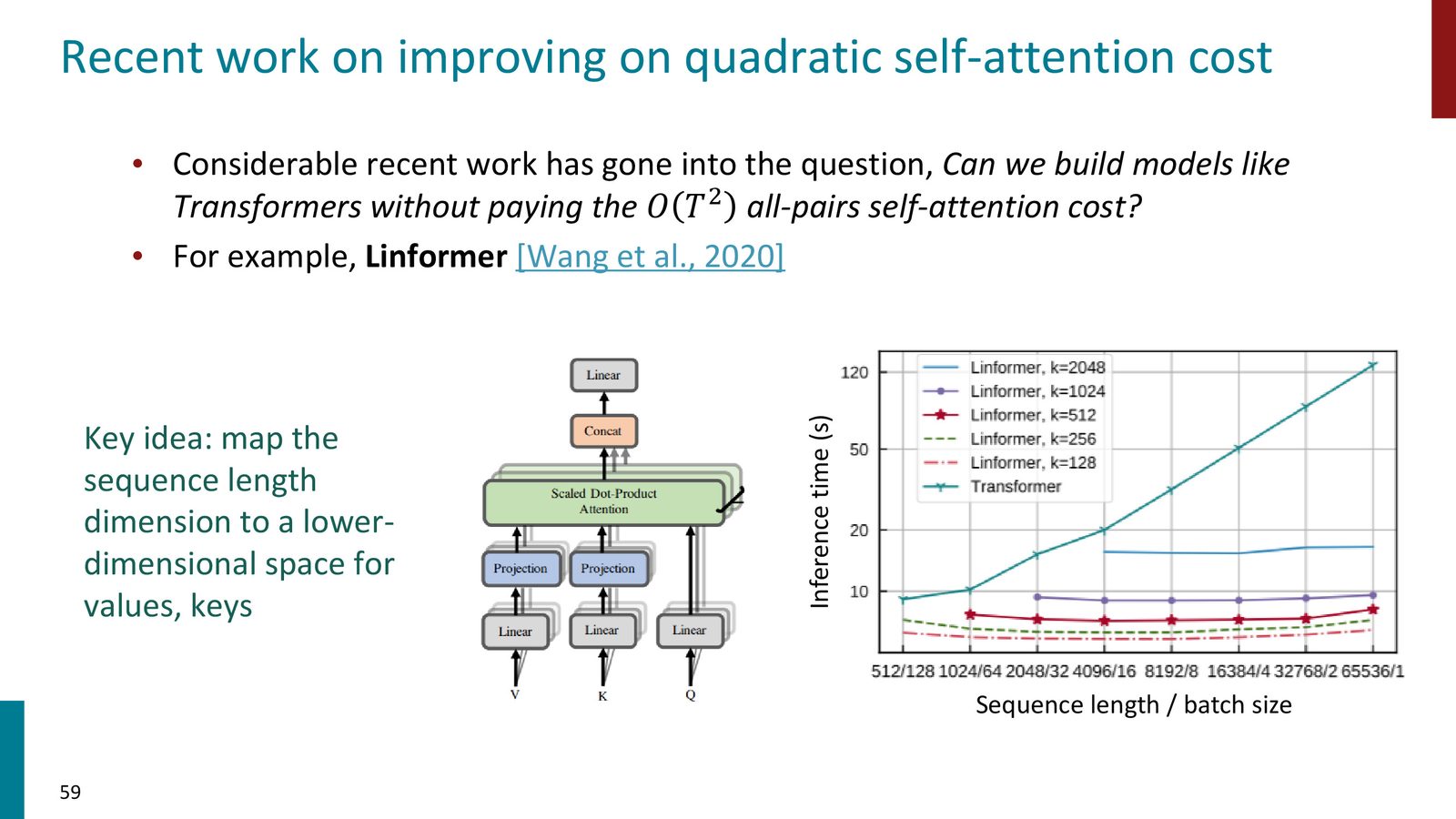
来源:Slides 第59页。
高效 attention 变体
为了摆脱 \(O(T^2)\),研究者提出了许多高效 Transformer 变体。例如 Linformer 通过把序列长度维度投影到低维空间减少成本,BigBird 则用局部窗口、全局 token 和随机连接替代全连接注意力。
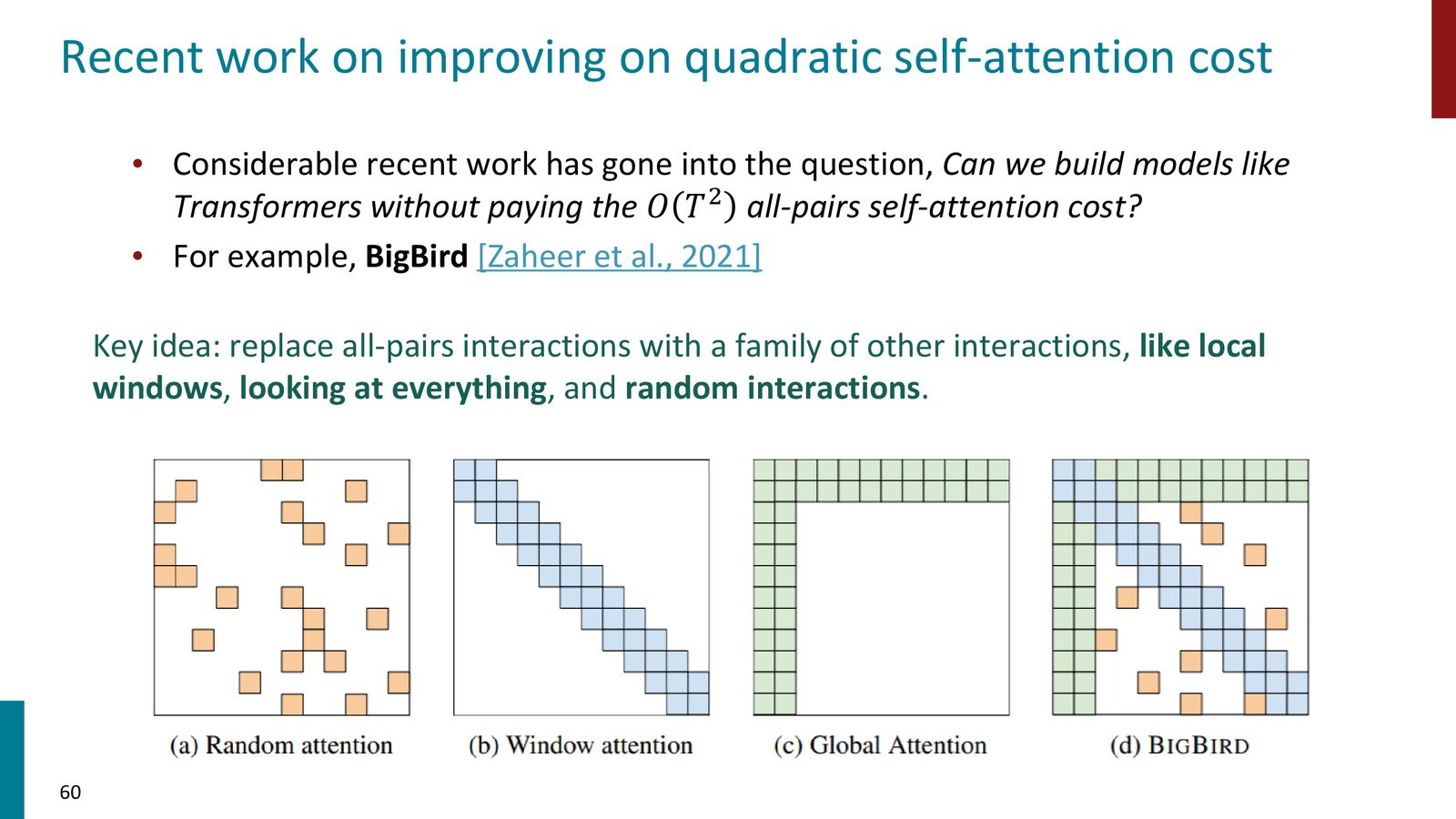
来源:Slides 第60页。

来源:Slides 第61页。
变体不一定真的更好
讲义最后提醒:很多 Transformer 修改并不会带来显著收益。也就是说,改结构并不天然意味着更强,是否 transfer 到实际任务中仍然需要实证验证。

来源:Slides 第62页。
本章小结
Transformer 的成功并不意味着它已经没有缺陷。它仍然面对 quadratic cost 和位置表示设计的问题。后续研究主要围绕两条线展开:一条是让 attention 更省算力,另一条是让位置编码更符合语言结构。
总结与延伸
全讲回顾
这节课从 “attention 是否足够” 的问题出发,最终给出一整套 Transformer 的机制:
- 用 self-attention 代替 recurrence,让交互距离降到 \(O(1)\)
- 用 positional encoding 把顺序信息重新注入模型
- 用 multi-head attention 捕捉不同类型的依赖
- 用 masked self-attention 保证 decoder 不偷看未来
- 用 cross-attention 让 decoder 访问 encoder 记忆
- 用 residual、LayerNorm 和 feedforward 让深层模型可训练
本讲的 takeaways
- Transformers 不是只有 attention,而是 attention + 一整套配套设计
- self-attention 的最大优势是并行性和短路径依赖
- 位置编码是 Transformer 里不可或缺的一层
- 多头机制让模型可以同时学习多个关系视角
- 未来的改进主要集中在效率和位置建模上
课程结语
来源:Slides 第62页。
讲义最后的提醒也很直接:继续准备 assignment 4,并关注后续的 project proposal。理解 Transformer 之后,下一步就是理解为什么 pre-training 能把模型性能再推高一个量级。
- “Good luck on assignment 4!”
- “Remember to work on your project proposal!”
延伸阅读
- Vaswani et al., Attention Is All You Need (2017): Transformer 的原始论文
- Shaw et al., Self-Attention with Relative Position Representations (2018): 相对位置编码
- Wang et al., Linformer / BigBird 等高效 attention 工作:降低 quadratic cost
- Vaswani 相关后续 lecture 和 CS224N 作业 4:Transformer 的实践训练