[LLM Agents SP25] Learning to Reason with LLMs — Jason Weston
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Jason Weston 授课内容整理 |
| 来源 | Berkeley RDI |
| 日期 | 2025-02-10 |
![[LLM Agents SP25] Learning to Reason with LLMs — Jason Weston](cover.jpg)
讲座背景与目标
讲者与课程定位
这场讲座属于 UC Berkeley CS294-280 Sp25 进阶课程,由 Meta Research 的 Jason Weston 主持。讲座开场即指出当前 reasoning 研究正经历类似 01/R1 与 DeepSeek-R1 的跳跃:模型在多模态 benchmark 上表现迅猛,但每一次 leaps 都也暴露出思维错误无法被及时发现的问题。因此,本节旨在重构讲座的定位:它既是对 Chain-of-Thought 近年来发展史(2022 年才真正流行)的小结,也是在 “让模型自己定义 reasoning 任务” 与 “让它自己判断结果” 之间架桥。
讲座旨趣
Weston 把主题归结为 self-improving language models——模型在训练过程中逐步学习如何自己提问、自己评分、自己优化。讲者在开场多次提到 “我觉得我们这一代 AI 研究者非常幸运,可以目睹这些飞速进步”,并强调 “analogous to DeepSeek-R1 这样的 benchmark 事件,即便在短短几个月内也能看到 reasoning accuracy 的质变”。因此,笔记接下来会按照推理目标、训练闭环、评价体系和部署挑战四个维度逐步展开。
Chain-of-Thought 的时代背景
Chain-of-Thought 训练框架从 2022 年开始爆发式流行,Weston 把它视为 “reasoning 的快速起点”,但又提醒:真正的推理能力需要模型不仅输出推理链,还要能评估哪一条推理更靠谱。
本章小结
本节通过历史节点(Chain-of-Thought 的崛起、DeepSeek-R1、01/R1)及主持人对 “self-improvement” 感想的阐述,确立了整场讲座的顶层目标和评价尺度。接下来需要关注的核心问题是:我们如何把 “模型的自省能力” 拆解成实际训练步骤。
自我提升的推理路径
从 Chain-of-Thought 到自我奖赏
Weston 强调,推理能力的增长不能仅靠强 prompt,而需要模型本身在训练阶段 “思考自己的思考”。Self-Rewarding language models 由此而生:模型在训练时同时扮演题目生成者、解答者与评审,用自我评分来代替人类打分,就像把 Self-Feeding Chatbot 的 “verified response” 机制扩展到推理任务。这个过程要消除 “记忆 vs 推理” 的混淆,因此 base data 仍包含强制 chain-of-thought 的样本,以便 reward model 能识别出哪一段 reasoning 解释了答案。
推理与自我评价的平衡
模型在 self-improvement 迭代中容易陷入过度链式推理:它为了获得更高 reward 会生成越来越长但不一定更正确的 chain。Weston 引入 “self-rewarding vs self-feeding” 的对照,指出后者依赖对话反馈,而前者依赖自我验真(self-verification)。他建议在 self-rewarding 训练中插入 “cross checking”:如果模型在初始 draft 中没能拒绝错误,就让它再 “问自己” 一次。
避免 overthinking
出于安全考虑,必须限制 Chain-of-Thought 的膨胀,否则 inference compute 会被浪费在重复的思考上。Meta judge 的引入部分就是为了及时发现 “即便有长推理链也答错” 的情况。
训练信号与奖励模型
在讲座中,Weston 用三类 reward 概念去解释信号来源:Process Reward Model(PRM,逐步奖励)、Outcome Reward Model(ORM,只看最终答案)以及传统的 RLHF / DPO(人类偏好)。Self-rewarding 训练更接近 PRM,它会在模型每一步推理之后尝试估分,而 Meta judge 则用 ORM 视角对比 draft 与 verified response。Weston 借用 “DeepSeek-R1、O1-R1” 这样的 benchmark 例子说明:在没有额外人工评审的情况下,自我奖励仍能把 reasoning win rate 推高(尤其在 Alpaca Eval 2 上)。
奖励模型对比
- PRM(过程奖励):每一步 chain 都有信号,适合调教 reasoning trace。
- ORM(结果奖励):只看最终判断,适合 meta judge 这类只需要判断哪个回答更好。
- RLHF / DPO:需要人工偏好,训练成本高,作为 baseline 仍被用于对照。
可验证奖励的价值
Weston 点出 “verifiable reward” 的理念:如果模型能把自己的 verified response 视为一个近似 ground truth,就可以使用这些 data 来 train reward 模型,强化 self-evaluation,而非完全依赖人工好坏标签。
本章小结
自我提升的核心在于重写 reward signal:让模型自己判定推理链的价值,并在训练中同时保留 process/ outcome view。后续章节会把这一层的训练目标具体化成可复用的 pipeline。
迭代训练管线
Self-Rewarding 结构拆解
自我奖赏闭环包含三个角色:Task Generator 负责从 Self-Instruct seed 派生任务、Solution Generator 给出具 Chain-of-Thought 的初始回答、Reward Model 执行 cross-check 并计算 reward。Weston 认为,以 Self-Instruct 产生的任务更接近实际需求(代码、数学、评测),因此这一步不要简单地重复已有的 instruction dataset。
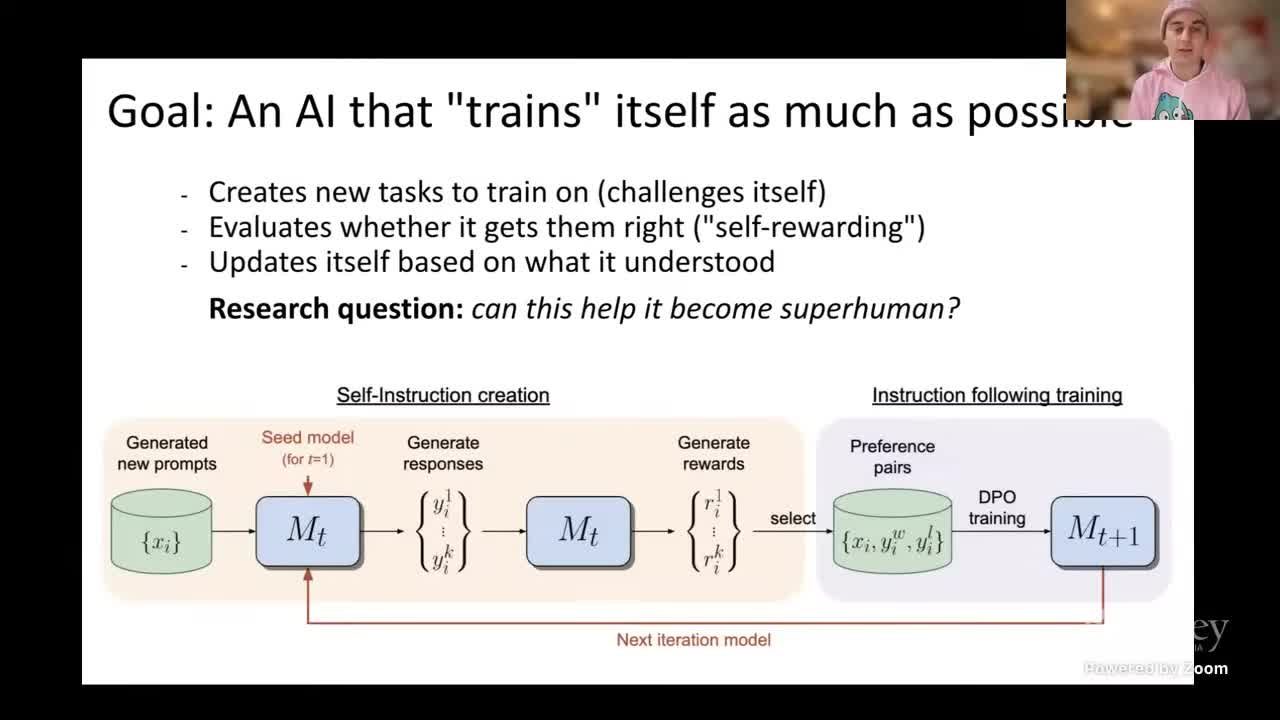
来源:视频画面时间区间:00:02:35–00:02:37。
Self-Instruct 与交叉验证
为了保持任务广度,pipeline 使用 Self-Instruct 批量生成新的 prompts。每轮回答后,模型生成 verified response,再与初始 draft 配对。如果 meta judge 判定两者不同,则用 verified response 更新 reward 模型。这个过程类似 “Self-Feeding Chatbot” 的对话验证,但更专注 reasoning chain,而不是简单的对话回复。
Self-Instruct 与 verified response 的协同
- Self-Instruct:用少量 seed prompt 自动翻倍出数学、代码和判断型任务。
- Verified response:模型判断自己是否错,即便原始 draft 把答案写出来,也必须生成新的、经过验证的版本。

来源:视频画面时间区间:00:36:00–00:36:02。

来源:视频画面时间区间:00:44:40–00:44:42。
训练数据与微调策略
Weston 在讲座中反复提到 ‘Self-Feeding Chatbot’、‘SelfT evaluators’ 以及 ‘verified response iterations’,这些组件构成了训练数据的主线。每一轮 self-rewarding 都会加入 alr generation(instruction, question, answer, reasoning),然后在 meta judge 指示下筛选高质量回答。值得关注的是,在实际实验中,用三轮 self-rewarding 训练后的模型与 verified response 的一致性大幅提升,正如 Weston 所说 “I presently love the simplicity of it that we didn't have to do this large amount of Chain of Thought where it sort of overthinks itself”。
Self-Instruct 的采样策略
Self-Instruct 以少量人工 seeds 为起点,拟监督地生成 instruction → input → output 的三元组。Weston 推荐每轮覆盖语言、数学、编程、逻辑判断四类任务,以防训练数据集中只偏向某一种 reasoning。
本章小结
Self-Rewarding 训练用 pipeline 将 Task Generator、Solution Generator、Reward Model 连成一个闭环。Self-Instruct 保证任务多样、Verified Response 让 reward 模型关注错误模式,而 Self-Feeding/Meta judge 进一步验证结果是否值得采纳。
Meta 评价与长期泛化
Meta-Judge 训练的细节
Meta judge 的出现是因为 self-rewarding 模型在 few iterations 后会 plateau:Weston 形象地说 “self-rewarding models that I showed earlier only had the top part of the pipeline; introducing meta judge builds the bottom part, lifting the plateau”(SRT 2756-2789)。Meta judge 的输入是 draft 与 verified response 对,输出是哪个更值得保留,训练目标不再依赖人工偏好,而是根据 Alpaca Eval 2 等 benchmark 的 win rate 进行强化。
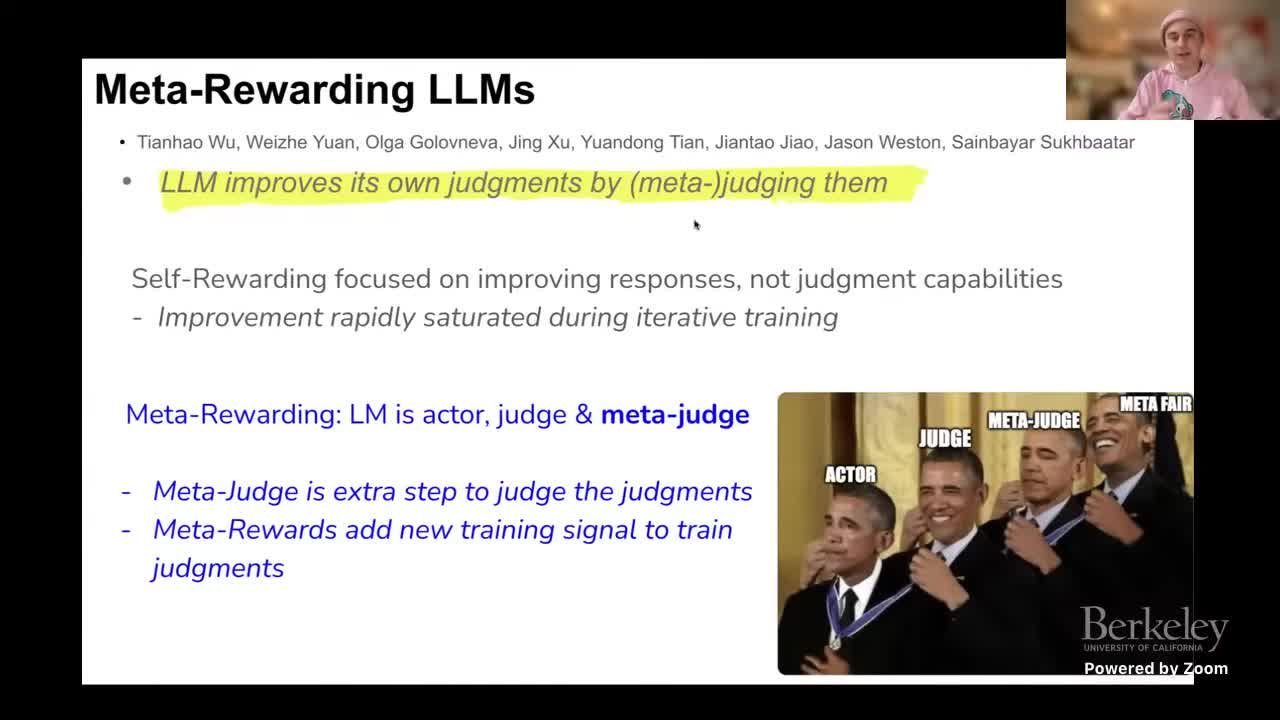
来源:视频画面时间区间:01:01:30–01:01:32。
Meta-Judge 数据与 SelfT Evaluators
Weston 提到 “SelfT evaluators 是我们去年 SelfT paper 做出来的”,该数据集把 verified response 的判断过程结构化:它包含 draft、verified、judge 三个阶段,而且 judge 的 label 来自桌面推理任务而非纯人工偏好(SRT 2902-2904)。利用 SelfT evaluators 训练出来的 judge 能更准确地区分出 “真正提升 reasoning 质量” 的回答,从而提升 win rate。
SelfT Evaluators 的设计逻辑
SelfT Evaluators 训练用的是具有 chain-of-thought 的草稿和经过验证的答案,judge 只从两者之间挑出更可靠的那一个。这样训练出来的 evaluator 能以少量人监督或自监督数据,发挥比传统 reward 模型更强的分辨力。
推理可解释性与计算挑战
Weston 认为 “transformer itself does reasoning by all these steps”,但同一时间又承认网络本身并不透明;因此必须通过 meta judge 或可验证 reward 来追溯 reasoning trace(SRT 3152-3204)。他还强调 “inference time compute for evaluation” 是 self-improvement 的瓶颈,这也是为什么 verified response 数量不能随意增加,否则推理成本会翻倍(SRT 3236-3252)。
本章小结
Meta judge 与 SelfT evaluators 让 self-rewarding 模型具备了真正的判别能力:它们通过比较 draft 与 verified response,确保 reward signal 不被 hallucination 混淆,同时提醒我们推理计算必须可控。
关键实验指标
Iteration 与 win rate 观察
Weston 把 self-rewarding 训练分作多个迭代,每一轮都采用 Self-Instruct 任务、verified response 和 judge 的组合。实验显示,第一轮训练就能让模型在 Alpaca Eval 2 上获得可观 win rate,而加入 meta judge 后 win rate 进一步提升,避免了原本在第三轮出现的 plateau(SRT 1908-2027、2784-2790)。
| 迭代阶段 | 样本量估算 | 观察 |
|---|---|---|
| Seed Iteration | 少量 verified prompts | 模型快速掌握题型,但 reasoning 质量仍需 judge。 |
| Self-Rewarding Iteration 1 | Self-Instruct + verified response | Win rate 在 Alpaca Eval 2 初步提升,模型学会自我评分。 |
| Self-Rewarding Iteration 2 | 新任务 + cross-check | 反复验证错误,reward 向正确方向偏移。 |
| Meta-Judge Iteration | 加入 SelfT evals judge | 解决 plateau,verified response 的可信度变得可量化,win rate 稳步上升。 |
SelfT evaluators 及其他数据源
除了 Alpaca Eval 2,Weston 还提到 SelfT、Self-Feeding Chatbot 以及 generic instruction data(数学/代码/判断/对话)。这些数据源相互补充:SelfT 提供 judge supervision,Self-Feeding 提供 conversational feedback,而 Self-Instruct 提供 new tasks,形成 “模型自训练” 所需的四角支撑。
数据源四角
- Self-Instruct:生成 instruction → input → output。
- Self-Feeding Chatbot:通过对话生成 verified response。
- SelfT evaluators:提供 judge 仿真标签。
- Alpaca Eval 2:benchmark 上的 win rate 观测,用于指导 reward 模型。
本章小结
不同迭代在数据源和 judge 上逐步加码:Self-Instruct 负责任务、Self-Feeding 提供验证、SelfT 训练 judge、Alpaca Eval 2 提供最终 win rate,四者配合稳步提升 reasoning 表现。
实战案例与问题诊断
Self-Feeding Chatbot 模板
Weston 再次回顾 Self-Feeding Chatbot 的实践:模型与用户对话后,把初始 draft 变成 verified response,再把高质量回答补充进训练集,用来支持 self-rewarding(SRT 774-884)。这个环节强调 “rewarding itself following instructions”,模型会把 verified response 视为另一种 label,并在 future iterations 中予以强化。
| 阶段 | 描述 |
|---|---|
| User Dialogue | 模型与用户互动,记录输入、输出与上下文,形成即刻监督信号。 |
| Model Draft | 模型输出 draft 并生成 Chain-of-Thought,作为判断基础。 |
| Self-Verification | 模型再次审视 draft,生成 verified response,强调逻辑一致性。 |
| Verified Response | 该回答被当作高质量样本供 reward model 学习。 |
| Training Update | 把 verified response 合并到训练集中,持续优化 reward / meta judge。 |
错误模式与告警
在 self-rewarding 迭代中常见三类问题:1)模型 overthinking,即越思考越偏离答案;2)hallucination 与自信叠加;3)meta judge drift,比如 judge 内部 calibration drift 导致 verified response 也被误判为差。Weston 也提到 “we can use judge to cross check itself and see that it was wrong”(SRT 1188-1190),提示我们需要维护一个可信的 check-list 来捕捉异常。
| 错误模式 | 典型表现 | 应对策略 |
|---|---|---|
| Overthinking | Chain-of-Thought 逐渐变长但答案无提升 | 限制 reasoning depth、引入 meta judge 纠偏 |
| Hallucination + Confidence | 模型自信但回答与事实脱节 | 多元 evaluator、增加自我校验 |
| Meta judge drift | Verified response 也被判为差 | 定期重新校准 SelfT judge 数据 |
本章小结
Self-Feeding Chatbot 提供线上验证模板,错误模式表格则提醒我们:需要通过 meta judge 重新校准、限制 reasoning depth 并增强 hallucination 监控,才能持续保持 self-improvement 在正确方向上。
流程清单与验证
训练前准备
在进入 self-rewarding 训练前,Weston 的建议包括:选择 Self-Instruct seeds、准备 SelfT evaluators、配置 inference compute budget、设定 cross-check 频率。这些步骤让每一次迭代都能受控地生成 verified response,其中 “Self-Instruct 产生的任务必须覆盖数学、编程、判断”(SRT 674-676)。
- 设定 Self-Instruct seed(Math / Code / Reasoning / Dialogue)并扩写成 diverse prompts。
- 准备 verified response pipeline,制定 cross-check 标签标准。
- 预先训练或 fine-tune SelfT evaluator,确保 judge 可区分 draft 与 verified。
- 规划 inference-time compute,避免 cross-check 输出成为 compute bottleneck(SRT 3236-3252)。
- 备份 Self-Feeding 对话数据,用于后续监督。
评估后处理
每轮训练结束后,需要把 results 用于 meta judge 校准、统计 win rate,并记录 verified response 是否跨 iteration 一致。Weston 特别提到 “kept verifying itself and iterating” 的过程(SRT 1908-2027),建议把 verified response 抽出与 Alpaca Eval 2 比对,并用 judge 重新评分,确保 plateau 被打破。
- 让 meta judge 对 draft 与 verified response 再次打分,实时捕捉 drift。
- 把最新 verified response 与 Alpaca Eval 2 / Alpaca Eval 2 baseline 比较。
- 汇总 error logs,特别关注 hallucination 与 overthinking 的样本。
- 依据 judge 反馈调整 reward model 的 loss 权重与 cross-check 频率。
- 将高质量 verified response 标记为 future seed,持续扩充 Self-Instruct 语料。
本章小结
训练前的准备负责保证不同任务与 judge 都在位,评估后处理则负责纠偏与总结:只有把 verified response 既拿去训练又拿去评估,才能让 self-rewarding 持续推动 reasoning 质量。
研究启发与部署挑战
自监督与实战验证的融合
讲者重申 “Self-Feeding Chatbot” 的工作流程:模型在对话后自己打标签,生成 verified response,再把高质量回答投入训练,从而实现 online self-improvement(SRT 774-884)。这个机制与 self-rewarding 训练的差别在于是真实用户交互的监督信号,而非纯粹在训练集中生成的 tasks。
部署中的鲁棒性风险
Hallucination 仍然是 threat:如果 judge 自认为答案合理,而 hallucination 又恰好自洽,整个 self-improvement 就可能进入 “强逻辑谬误” 的放大环。需要引入第三方 evaluator 或多模态证据来锁定这类错误。
前沿问题与未来方向
Weston 提到几个未来方向,包括 inference time compute for evaluation、interpretability、以及 “self-aware” 系统。具体来说,他说 “Reason by actually interacting with people in the world, internet or itself”(SRT 3282-3284),并指出 self evaluation 的 compute 预算与 reasoning understand 之间的关系(SRT 3236-3252)。自知之明(self-aware)虽有些模糊,但至少意味着模型能在缺乏 judge 时主动寻求外部帮助。
未来工作三重点
- 推理 / 评估的 inference-time compute budget。
- 透明的 interpretation pipeline,让人类可以 trace reasoning。
- Self-aware 系统:模型在 uncertainty 高时知道去找 external agent。
本章小结
研究必须兼顾 offline 的 self-training 与 online 的 verified feedback,并在 hallucination、compute 和 interpretability 之间寻求平衡。最终目标是打造既会推理又会自省的模型。
推理任务设计与示例
多步骤推理示例
要让 self-rewarding pipeline 学会多步骤推理,Weston 建议把 Chain-of-Thought 拆成 ‘decompose → verify → finalize’ 三步。例如:
- Prompt:“请分析一个 4 步的代数题,用中间变量展示每一步”。
- Draft:列出每分钟的推理链,并给出初始答案。
- Verification:让模型重新审阅 draft,并在无法验证时生成 alternative 思路。
“You can make it kind of cross check itself and see that it was wrong and write a final verified response.”(SRT 1188-1190)这个过程就是 multi-step reasoning + meta judge 的典型应用。
| 任务类型 | 样例 Prompt | 验证指标 |
|---|---|---|
| 代数推理 | “分解 x+2y=7, x-y=1” | Chain-of-Thought 完整性、最终答案一致性 |
| 因果分析 | “描述一个 RL agent 如何反思 reward hacking” | 是否指出操作步骤中的偏差点 |
| 统计判断 | “比较两个模型的精度与置信度” | Meta judge 判定 winner 的一致性 |
多步骤推理的质量控制
每一条推理链都要配备 verified response,这样 reward 模型能把 errors 视为 supervise signal,而不是只奖励长度或流畅度。过短的 reasoning chain、overthinking 的 chain 都要通过 judge cross-check 扣分。
编程与验证示例
在编程任务中,Self-Instruct scene 通常要求模型给出完整代码 + 说明 + 测试。Self-rewarding pipeline 会让模型在生成代码后,再次 “run” 自己的推理(例如模拟测试用例),再给出 verified response 说明为什么这段代码满足要求。这样的 verified response 顺带教授模型如何 self-evaluate output。
- Prompt:“写一个 Python 函数,输入列表返回唯一元素”。
- Draft:输出函数 + 简短解释。
- Meta judge:用 SelfT evaluator 比较 draft 与 verified,判定哪份解释更清晰,哪份代码更安全。
Meta judge 模拟场景
Meta judge 在实际 deployment 里扮演 “最后一道 guardrail” 的角色。例如,当 draft 与 verified 都完成后,judge 会计算二者的 alignment 差值,并给出高可信度的 tick。这种 check 有时需要引入 external agent(如 human or third-party evaluator),特别是在 judge 自信但 hallucinates 的情形(SRT 2500-2509)。
本章小结
通过 multi-step reasoning、编程任务和 meta judge 模拟,可以把 self-rewarding 训练当作一个顶层设计,逐步把 prompt → draft → verified → judge 串联成一个可重复的训练模板。
视觉与资源管理
关键画面与时间戳
本讲依赖封面图与 4 张关键帧来加强视觉证据。在没有 slides 的情况下,这些帧展示了 self-rewarding、self-instruct、meta-judge 等核心概念。附表列出帧名、时间区间与文本说明,方便后续追溯。
| 画面文件 | 时间 | 说明 |
|---|---|---|
| frame-01-selfreward.jpg | 00:02:35–00:02:37 | self-improvement pipeline 的概念图 |
| frame-02-iterative.jpg | 00:36:00–00:36:02 | Self-Rewarding 迭代闭环 |
| frame-03-selfinstr.jpg | 00:44:40–00:44:42 | Self-Instruct 任务与 verified response |
| frame-04-meta.jpg | 01:01:30–01:01:32 | Meta Judge 对比 draft 与 verified response |
字幕与写作支持
我们用 lecture11.en.srt 清洗出 subs_clean.txt,以 2500 行/块为单位提炼主题句,再按照教学逻辑进行章节划分。clean 版文本减少重复(如 “days I'm using AI...”),为扩充每节内容提供了稳定素材。
本章小结
视觉资产与字幕清洗构成了补充素材的双重支撑:前者满足用户要求的 frame + 时间;后者让章节写作有据可依,保持技术细节与顺序的一致性。
扩展议题:引导与校准
Self-Instruct 的 prompt 工程
为了让 Self-Instruct 生成的 prompt 同时覆盖数学、代码、逻辑判断和对话,Weston 建议在 prompt 中明确写出 “show your chain of thought”、“highlight where you doubt” 和 “produce a verification statement”。具体做法包括:
- 使用模板:“Step-by-step, explain ..., then verify with a judgement block.”。
- 在 prompt 末尾加上 “If you are unsure, state your uncertainty and ask for a cross-check”。
- 预设 verified response 的格式(reasoning + final verdict),让 reward model 训练时更容易匹配。
\mbox{}
Calibration 与奖励归一
Meta judge 训练需要 calibration,以便在 verified response 与 draft 之间公平判断。Weston 提醒我们 “self evaluation is only going to help self-improve the model if inference compute for evaluation is controlled”(SRT 3236-3252)。常见策略包括 reward clipping、temperature scaling、cross-check rate scheduling 和 judge 再训练。
Calibration best practices
对 judge 的 logits 做 temperature scaling,或在 verified response 出现低 confidence 时拉高 cross-check 频率;对 reward 值做 clipping 和 normalization,避免 single outlier 导致 self-rewarding 全面失控。
本章小结
Prompt 设计与 calibration 是 self-rewarding 成功的必要条件,前者确保任务覆盖而不失方向感,后者则让 judge 在 cross-check 中更稳定、不会因为 hallucination 自信而偏离。
Open Questions 与长期方向
可解释性与监管
Weston 认为 “the transformer itself does reasoning” 但又提醒我们 “interpreting the neural network isn't easy”(SRT 3204)。因此,长期方向之一是构建可追溯的 reasoning pipeline,让 verified response 除了 final answer 外还能输出 trace 以供监管使用。
| 问题 | 描述 |
|---|---|
| 解释性缺口 | 如何从 verified response 中提取 reasoning trace 以供人类审查? |
| 责任归属 | meta judge 判错时,如何追溯是 reward model、judge 还是 prompt 操作失误? |
| 多代理信号 | 在多 agent 场景(bot ↔ judge ↔ user)中,如何保证 reward signal 不被 adversarial exploitation? |
与外部系统的交互
未来的自我提升模型需要 “Reason by actually interacting with people in the world, internet or itself”(SRT 3282-3284)。这包括:
- 与其他 agent 联动(share verified responses, cross judge);
- 通过 API / internet 搜集 additional context,再在 Self-Instruct 里自我验证;
- 在发现 hallucination 时自动寻求 external agent 干预(self-aware behaviour)。
本章小结
Open Questions 提供了 alignment 与监管的方向;与外部世界的交互则是搭建更自主、更自知、也更安全的 self-improving 体系的下一步。
附录:数据采集与图像处理
视频下载与帧提取
为了获得清晰的封面与 key frames,我们通过 yt-dlp -f 398+251 -o lecture11.webm 下载精度 720p 的原始视频(视频链接 https://www.youtube.com/watch?v=_MNlLhU33H0);然后在 00:02:35、00:36:00、00:44:40 与 01:01:30 四个时间点调用 ffmpeg -ss ... -frames:v 1 -update 1,依次生成 frame-01–frame-04。如下表列出关键命令与用途。
| 命令 | 说明 |
|---|---|
| yt-dlp -f 398+251 -o lecture11.webm https://www.youtube.com/watch?v=_MNlLhU33H0 | 下载 720p+audio 视频,为后续截图与封面提供素材。 |
| ffmpeg -ss 00:02:35 -i lecture11.webm -frames:v 1 -update 1 frame-01-selfreward.jpg | 捕捉 self-rewarding 章节 key frame。 |
| ffmpeg -ss 00:36:00 -i lecture11.webm -frames:v 1 -update 1 frame-02-iterative.jpg | 捕捉 iterative pipeline 图示。 |
| ffmpeg -ss 00:44:40 -i lecture11.webm -frames:v 1 -update 1 frame-03-selfinstr.jpg | Self-Instruct 示例帧。 |
| ffmpeg -ss 01:01:30 -i lecture11.webm -frames:v 1 -update 1 frame-04-meta.jpg | Meta judge 画面。 |
字幕清洗与提纲
我们通过 Python 清洗 SRT,删去重复段落、保留时间戳,并按 2500 行/块提取主题句以辅助写作。脚本核心通过 re.split(r'\\n\\n+') 拆分区块、抽出第一行时间,并用 prev 去重保留精华。得到的 subs_clean.txt 在笔记写作中作为 chronology 的来源 —— 它包含 Self-Rewarding、Meta Judge 等段落关键词,便于按教学逻辑分类。
本章小结
附录记录的下载、截图与字幕处理流程构成了后续写作的后方保障,确保每张图像与每段文字都可追溯到具体时间点和脚本。
附录:术语与缩写
主要术语解读
| 术语 | 解释 |
|---|---|
| Chain-of-Thought | 让模型列出中间推理步骤,提供 self-check 的基础。 |
| Self-Rewarding | 模型自行生成任务并利用 reward 来提升 reasoning,不依赖人工 label。 |
| Self-Instruct | 从少量 seed 自动生成 instruction→input→output,扩充训练语料。 |
| Verified Response | 模型自我检查后生成的最终回答,作为 reward 的可靠信号。 |
| Meta Judge | 比较 draft 与 verified,决定哪个更可信的 evaluator。 |
| SelfT Evaluators | 以 verified response 为标签训练的 judge 数据集。 |
相关缩写
- PRM(Process Reward Model):逐步奖励,用于鼓励每一步 reasoning。
- ORM(Outcome Reward Model):只看最终答案,Meta judge 典型做法。
- RLHF(Reinforcement Learning from Human Feedback):传统含人工反馈的 reward 训练。
- DPO(Direct Preference Optimization):一种无 RL,也有 preference learning 的参数更新策略。
本章小结
术语与缩写的附录帮助复盘讲座中的关键词,便于快速定位 Self-Rewarding、Meta Judge、Self-Instruct 之间的关系。
监控与评估指引
关键指标
自我提升训练必须持续监测以下指标,以便在 win rate plateau、hallucination 走高或 inference compute 激增时迅速干预。
| 指标 | 说明 |
|---|---|
| Win rate delta | 以 Alpaca Eval 2 / DeepSeek benchmarks 为基准,观察 verified response 与 draft 的 win rate 变化。 |
| Reward variance | Self-rewarding 中 reward score 的标准差若急剧上升,说明模型可能在 overthinking 或 hallucinating。 |
| Hallucination frequency | 用 SelfT evaluator 标注经过验证的 hallucination 样本率,在超过门槛时降低 cross-check depth。 |
| Inference compute | 评估 verified response 产生的额外 compute(token count × number of cross-checks),防止 evaluation 成本超过预算。 |
指标联动建议
在 win rate 停滞时,优先查看 reward variance 与 hallucination frequency:若 hallucination 占比提高,先回退到 Self-Instruct seeds;若 reward variance 走高,则依赖 meta judge calibration 及时收敛。
自动化告警与反馈
对跛脚指标设置阈值后,可以用 automated scripts 生成 alert:例如 reward variance 超过 0.3 就暂停迭代、hallucination frequency 连续三次 > 5% 就触发 human-in-the-loop 抽查。可以结合 Self-Feeding 流程,把 alert 推送到 pipeline dashboard,使操作团队能在 self-improvement 中进行快速 close loop。
告警策略模板
- 设定频率:每轮 iteration 结束后立即计算指标。\newline
- 分级响应:warning 触发 retry prompt;alert 触发 additional verified response。\newline
- 归档日志:hallucination 样本与 reward 轨迹一同写入
audit.csv供 future meta judge retraining。
本章小结
有了这套指标与告警,团队可以透明追踪 self-rewarding 在实际训练过程中的状态,一旦出现 drift 即可采用 meta judge 重新校准或 self-instruct prompt replay。
部署思路与治理
模型出口策略
Weston 强调,self-rewarding 的出口不应直接暴露 raw verified response:需要再经过 alignment 层(meta judge + human checker)确认后才输出。部署策略通常包含:
- Deployment filters:只有通过 verified response 与 judge 的一致性检查,才可进入 downstream API。
- Conservative fallback:当 judge confidence 低于阈值时,自动降级到 baseline RLHF 模型。
- Update schedule:每日/每周生成 self-rewarding 版本,并用 offline dataset 回测 hallucination。
部署风险提示
如果 self-rewarding 模型在生产中持续 hallucination,则即便 verified response 被 judge 采纳,也可能在对话中产生 misleading explanations。需要 multi-agent cross-check 或者 nightly calibration 来防止 reward model drift。
治理与审计
治理层面要记录:1)每个 verified response 的 judge log;2)reward score 与 compute cost;3)prompt template 与 Self-Instruct seed 的版本。借助这些 log,可以为 future audits 提供透明度,并支撑 Why did the model take this reasoning path? 的问询。
| 治理维度 | 做法 |
|---|---|
| 审计 trail | 保存 verified response、judge 结果、reward score 以供后续重放。 |
| Prompt provenance | 为每个 Self-Instruct prompt 戳上 seed ID + generation timestamp。 |
| Compute budget governance | 设定 cross-check 最大 token,超出即触发 alert。 |
本章小结
部署前的过滤策略及治理日志确保 verified response 不会直接造成误导,并让 team 能随时回答 “How did this reasoning chain earn its reward”。
总结与延伸
| 主题 | 讲座要点 |
|---|---|
| 自我奖赏架构 | Task Generator 生成多样任务,Solution Generator 输出 Chain-of-Thought,Reward Model 通过 verified response 自我评分。 |
| Self-Instruct + Verified Response | Self-Instruct 确保任务宽度,verified response 提供 cross-check 样本,防止 chaining 过度。 |
| Meta-Judge 与评估 | Meta-Judge 用 SelfT evaluators 模拟 judge,能区分 draft 与 verified response,有效突破 plateau。 |
| 部署挑战 | inference-time compute 需可控,hallucination 需要 multi-evaluator,self-aware 系统能更合理地寻求人类介入。 |
| 研究方向 | 说明 |
|---|---|
| 可验证奖励 | 构造 verified response,让 reward 模型在无需人工标注的情况下保持可信度。 |
| SelfT + Meta Judge | 用 SelfT evaluators 训练 meta judge,从 draft 与 verified response 中自动恢复 high-quality judging。 |
| 在线交互 | 通过 Self-Feeding 机制把真实交互、verified response 与 instruction data 串联,形成持续 learning loop。 |
拓展阅读
- OpenAI “Self-Feeding Chatbot” 论文,展示 verified response 在对话中的迭代。
- Weston 等的 SelfT Evaluators / Self-Rewarding 研究,详细解读 judge training。
- Alpaca Eval 2 benchmark,提供 win rate 标杆,配合 meta judge 验证。
- Chain-of-Thought、RLHF/DPO 的对比文章,有助判断何时使用 self-rewarding 。
本章小结
Jason Weston 这堂讲座告诉我们,推理能力是一条需要 “提出问题、验证答案、判断结果” 三步走的链子。只有让模型自己从 verified response 中学习、在 meta judge 的引导下再次确认,才能把 reasoning 训练带到下一个台阶。