CS224N Lecture 15: Life After DPO
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Nathan Lambert 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年5月21日 |

引言:对齐研究的时代背景
本次讲座由 Nathan Lambert 主讲,他曾在 UC Berkeley 完成博士学位,先后在 Hugging Face 和 Allen Institute for AI(AI2)工作,是后训练(post-training)和对齐(alignment)领域的核心研究者之一。讲座标题"Life after DPO"试图回答一个关键问题:在 DPO 之后,对齐研究的下一步方向是什么?

来源:Slides 第1页。
讲座的核心结构分为三部分:
- 历史回顾:从语言模型发展到 RLHF 和 DPO 的演进
- 评估工具:RewardBench——如何评估奖励模型
- 前沿探索:DPO vs PPO 的实证比较,以及在线(online)方法的兴起
讲者背景
Nathan Lambert 的研究背景是强化学习(RL)。他从机器人 RL 转向语言模型 RL,在 Hugging Face 期间参与了 Zephyr 等开源对齐模型的开发,后加入 AI2 主导 T\"ulu 系列模型和 RewardBench 项目。他既有学术研究视角,也有工业界一线经验,对开放对齐生态有深刻理解。
语言模型的简要历史
Lambert 快速回顾了语言模型的发展脉络:
- 2017:Transformer 论文发表
- 2018:GPT-1、ELMo、BERT——奠定现代 NLP 基础
- 2019--2020:GPT-2 与 Scaling Laws——人们开始意识到大规模语言模型的潜力
- 2021:Stochastic Parrots 论文——在 ChatGPT 之前就对语言模型提出警告
- 2022年末:ChatGPT 发布——本应是 OpenAI 的一个低调 demo,却引爆了全球关注

来源:Slides 第2页。
ChatGPT 能否脱离 RLHF 而存在?
Lambert 提出了一个核心问题:ChatGPT 能否在没有 RLHF 的情况下存在?答案是:RLHF 似乎是必要但不充分的(necessary but not sufficient)。预训练提供了基础能力,但 RLHF 和后训练技术是让模型真正"可用"的关键一步。

来源:Slides 第6页。
Lambert 特别引用了 Meta 在 Llama 2 技术报告中的一段话:"强化学习以其不稳定性著称,对 NLP 研究社区来说像是某种神秘领域;然而,强化学习被证明非常有效,尤其考虑到其成本和时间效率。"这段话生动地反映了 2023 年年中时业界对 RLHF 从怀疑到认可的态度转变。

来源:Slides 第7页。
本章小结
语言模型的发展经历了从自回归损失函数到 Transformer 再到大规模预训练的漫长积累。ChatGPT 的成功不仅依赖于强大的预训练基础,更需要 RLHF 等后训练技术的加持。理解这一历史背景,是理解当前对齐研究方向的前提。
对齐的核心概念与定义
术语辨析
在后训练领域,有大量容易混淆的术语。Lambert 对此做了清晰的区分:

来源:Slides 第11页。
五个关键定义
- 指令微调(Instruction Fine-Tuning, IFT):训练模型遵循用户指令,通常使用自回归 LM 损失
- 监督微调(Supervised Fine-Tuning, SFT):训练模型学习特定任务能力,同样使用自回归损失
- 对齐(Alignment):训练模型使其行为与用户意图一致的通用概念,不限于特定损失函数
- 基于人类反馈的强化学习(RLHF):使用人类反馈数据训练模型的特定技术工具
- 偏好微调(Preference Fine-Tuning):使用标注的偏好数据微调语言模型(可用 RL 或 DPO 等损失函数)
指令微调 \(≠\) 监督微调
这两个概念经常被混用,但有重要区别。指令微调侧重于让模型学会"遵循指令"的通用能力,数据形式通常是 instruction-response 对;监督微调则更侧重于特定领域的能力提升。两者都使用自回归损失函数,但目标和数据分布不同。
指令微调中的一个重要概念是系统提示词(System Prompt)。OpenAI 在其 Model Spec 文档中甚至引入了"第二级系统提示词"的概念,为模型接收数据提供结构化方式,使得开发者可以传递用户看不到的信息。
指令微调的数据来源
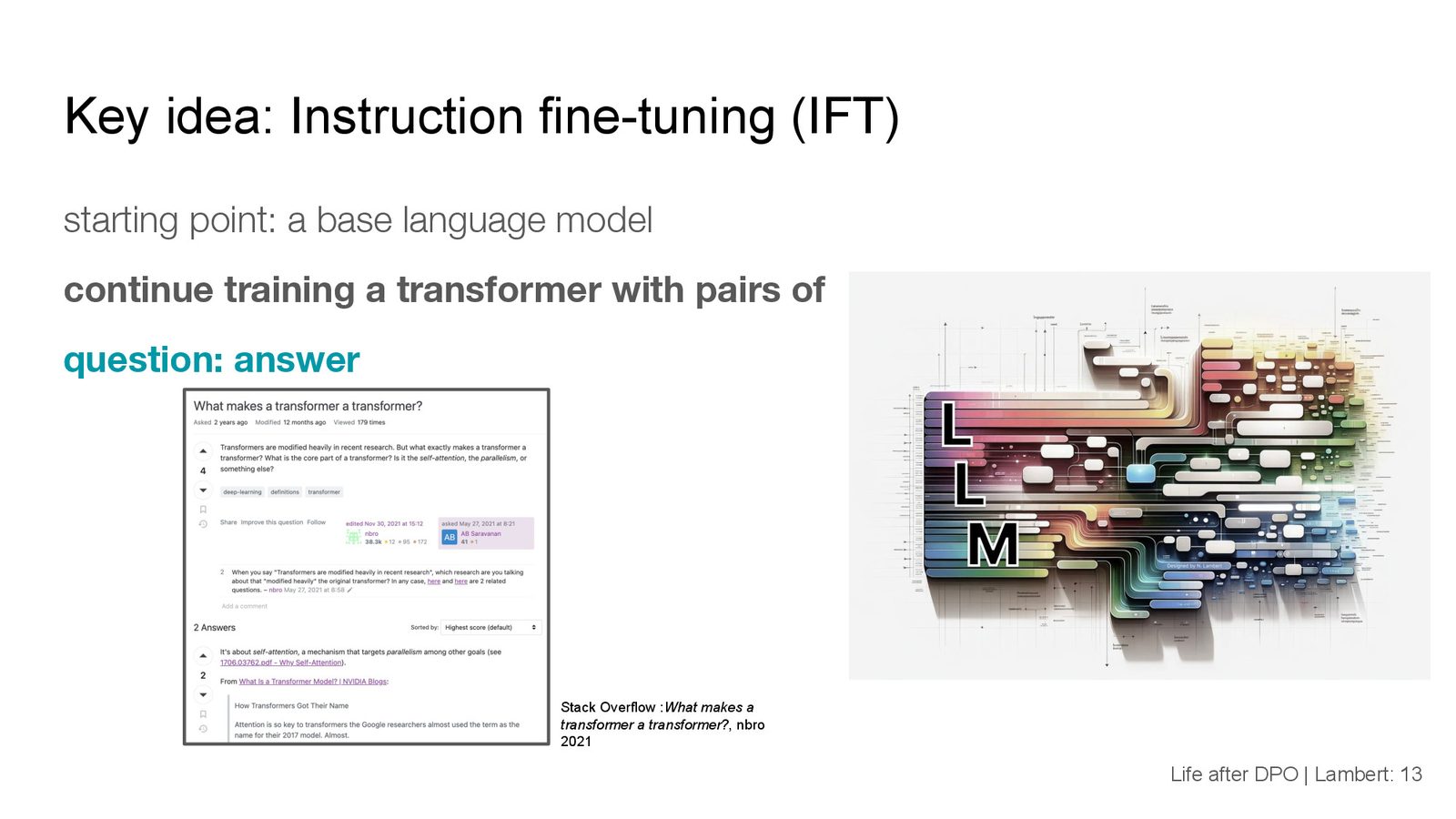
指令微调的数据通常来源于:
- Stack Overflow、Reddit 等问答数据
- 合成数据(如使用 GPT-4 生成)
- 专门收集的 instruction-response 对
Lambert 强调,大量学术研究表明"仅靠指令微调就够了",但他认为这个结论过于简化。指令微调是正确的起点,但要达到 ChatGPT 级别的效果,还需要偏好微调和 RLHF。
来源:Slides 第13页。
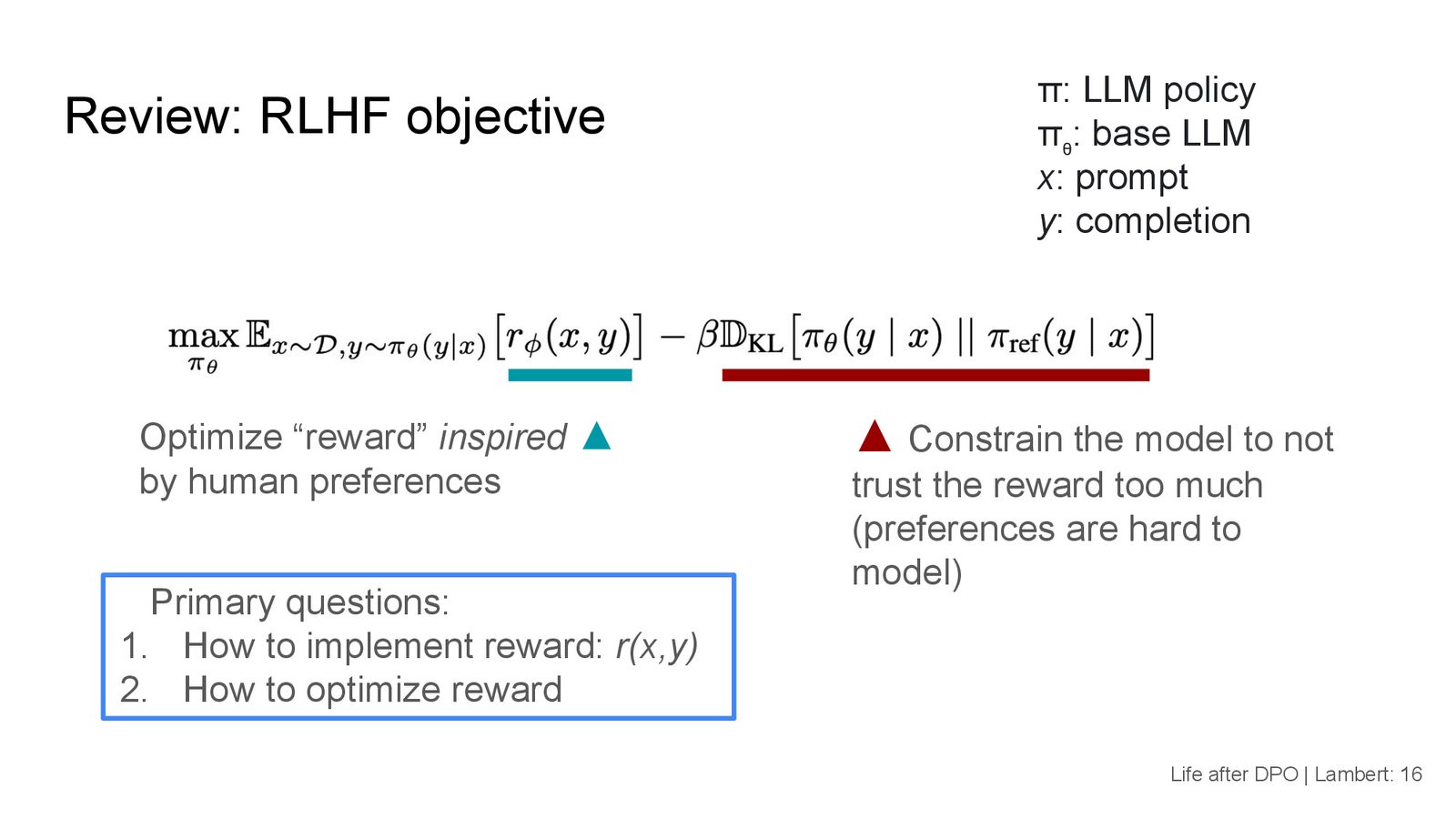
RLHF 目标函数
RLHF 的核心目标函数可以写为:
其中:
- \(\pi_\theta\):当前策略(即正在训练的语言模型)
- \(\pi_{\mathrm{ref}}\):参考策略(训练起点的基础模型)
- \(r_\phi(x, y)\):奖励函数,来自人类偏好
- \(\beta\):KL 散度惩罚系数
- \(x\):提示(prompt),\(y\):补全(completion)
来源:Slides 第16页。
KL 散度约束的作用
目标函数右侧的 KL 散度项起到正则化作用:它约束训练后的策略 \(\pi_\theta\) 不要偏离参考策略 \(\pi_{\mathrm{ref}}\) 太远。这是为了防止过度优化(over-optimization)——如果不加约束地最大化奖励,模型可能会找到奖励模型的漏洞(reward hacking),产生高分但低质量的输出。
RLHF 的两个核心问题是:
- 如何实现奖励函数\(r(x,y)\)?——需要训练一个专门的奖励模型
- 如何优化奖励?——需要选择合适的策略优化算法(PPO、REINFORCE 等)
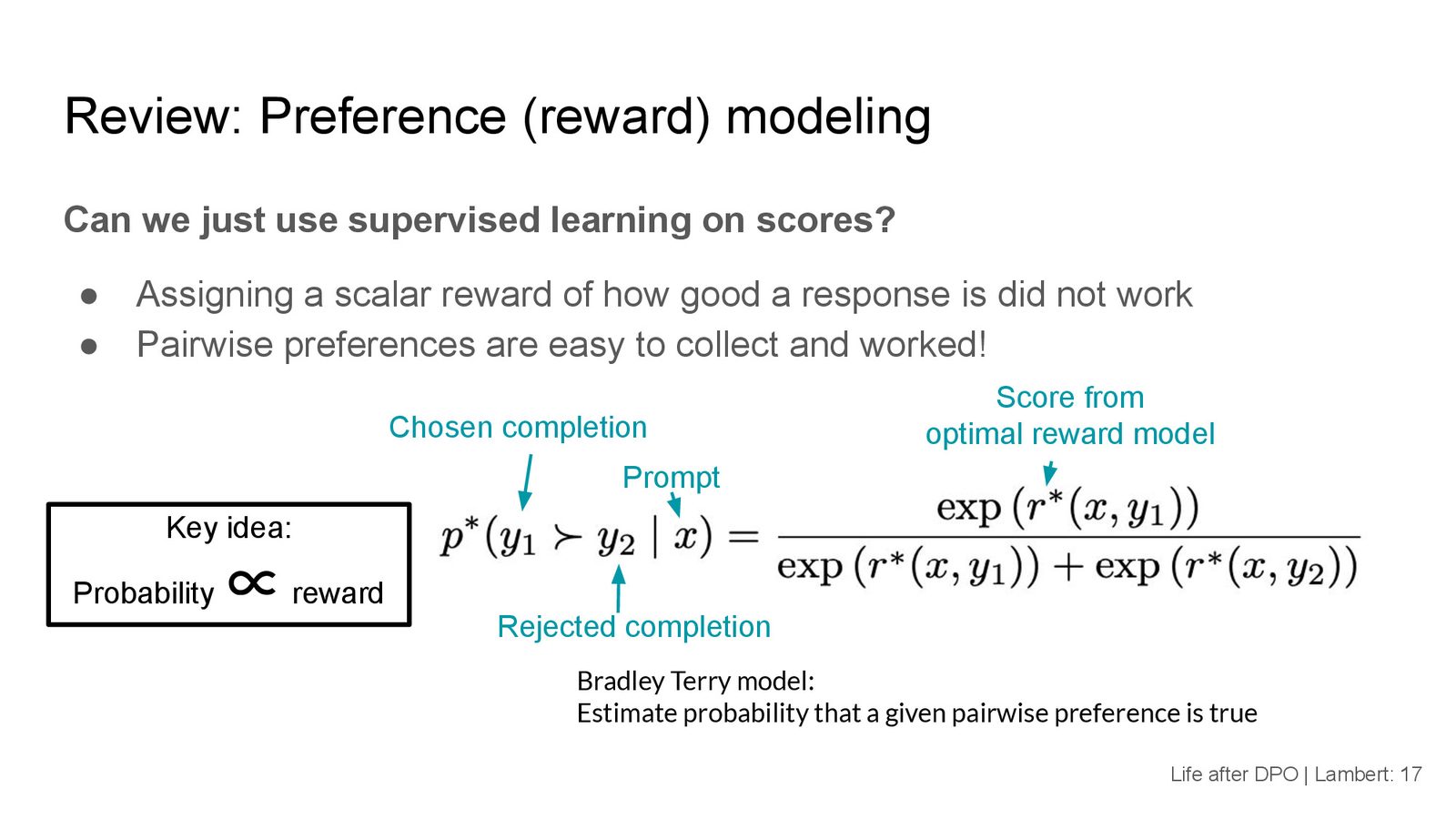
Bradley-Terry 偏好模型
奖励模型的训练基于 Bradley-Terry 模型——一个源自 1950 年代经济学的成对比较概率模型。该模型定义了在给定两个选项时,其中一个被选中的概率:
其中 \(\sigma\) 是 sigmoid 函数。这个模型的一个关键假设是:成对偏好概率可以由个体的标量分数之差来决定。
来源:Slides 第17页。
从偏好概率到奖励分数的跳跃
Lambert 特别指出,从成对偏好概率到将其输出直接用作奖励分数,存在一个"mental crazy step":我们原本训练的是一个判断"A 比 B 好"的概率模型,但在实际使用时却把它当作单个输入的评分器——传入一段文本,得到的是"该文本被选中而非任意其他文本"的概率。这个假设虽然在实践中有效,但从理论上说是一个不小的飞跃。
DPO:直接偏好优化
DPO(Direct Preference Optimization)的核心思想是:为什么不能直接对 RLHF 目标函数做梯度上升,而非经过训练单独奖励模型再做 RL?

来源:Slides 第19页。
DPO 的损失函数极其简洁:
其中 \(y_w\) 是被选中的(chosen)回复,\(y_l\) 是被拒绝的(rejected)回复。

来源:Slides 第20页。
DPO 的三大优势
- 实现简单:只需修改损失函数,不需要构建完整的 RL 基础设施
- 计算扩展更容易:不需要同时维护多个模型(策略、奖励、价值函数)
- 调试容易:相比 PPO 的众多超参数,DPO 更容易排查问题
DPO vs PPO:不同但可以共存

来源:Slides 第21页。
Lambert 强调:DPO 和 PPO 是根本不同的损失函数,做着不同的事情,但可以得到类似的结果。DPO 直接从偏好数据中学习,而 PPO 使用 RL 更新规则。DPO 也不是严格意义上的 online vs offline RL 之分,但这两者经常在讨论中被混淆。
核心结论是:如果两种方法都能得到相似结果,而其中一种简单得多,那就应该从简单的开始。这就是为什么 DPO 成为了大多数人的起点。
DPO 仍然隐含了一个奖励模型
一个重要但容易被忽略的数学事实是:DPO 的推导中仍然隐含了一个奖励模型。DPO 使用语言模型本身作为一种"不同类型的奖励模型"——奖励通过策略与参考模型的对数概率比来定义。这对后续的模型评估和使用方式有重要影响。
本章小结
对齐研究涉及多个层次的概念:从指令微调到 RLHF 再到 DPO,每一层都有其特定的数据需求和技术特点。RLHF 通过 Bradley-Terry 模型将人类偏好转化为可优化的奖励信号;DPO 则绕过了显式奖励模型的训练,直接在偏好数据上做梯度优化。两者各有优势,在实践中可以互补使用。
开源对齐的演进之路
指令微调模型的崛起(2023年春)
2023年4月,第一批开源指令微调模型集中涌现:

来源:Slides 第23页。
- Alpaca:基于 LLaMA + 合成数据(Self-Instruct 方法)
- Vicuna:使用了 ShareGPT 数据——第一次让开放研究者获得了来自真实人类的对话数据
- Koala、Dolly:类似方法的变体
ShareGPT 数据的历史意义
ShareGPT 是一个 Chrome 扩展,让用户可以分享 ChatGPT 对话。虽然存在法律灰色地带(用户数据被未经充分同意地记录),但这些数据对开源对齐研究至关重要——它是学术界首次大规模获取真实人类提示(prompt)的渠道。至今仍有模型将 ShareGPT 数据作为训练数据的子集。后来出现了更合规的替代品,如 LMSYS Chat 和 WildChat。
Open Assistant 与人类数据的稀缺

来源:Slides 第25页。
Open Assistant 是一个 Discord 社区项目,由志愿者手动生成提示、回复和偏好对。Lambert 指出,虽然这个项目展示了人类数据的价值,但也暴露了其困难——参与者的反馈普遍是"再也不想做了"。遗憾的是,类似规模和质量控制水平的开源数据收集项目此后再未出现。
第一个开源 RLHF 模型

来源:Slides 第26页。
2023年4月,Carper AI 发布了 StableVicuna——第一个使用标准 PPO 训练的开源 RLHF 模型。虽然它的性能优于 Vicuna,但几乎没有人在此基础上继续构建。Lambert 认为这揭示了一个重要教训:即使方法是开源的,如果没有易用的代码库和充足的数据,社区也不会跟进。
Llama 2 安全过滤的反噬
Llama 2 发布后出现了一个著名事件:当用户让模型"kill a Linux process"时,模型拒绝了——因为它将"kill"理解为暴力行为。这催生了一系列"uncensored"模型的开发潮流。
过度安全(Over-safety)的代价
Llama 2 的过度安全问题并非有意的"审查",而是 RLHF 训练数据的副作用。模型学到了过于保守的拒绝策略。这个案例说明:对齐不仅仅是"让模型更安全",还需要在安全性和实用性之间找到平衡。过度拒绝同样是一种对齐失败。
Zephyr:DPO 的第一次大放异彩

来源:Slides 第30页。
DPO 论文于 2023年5月发表,但直到2023年9月 Zephyr 模型的发布,社区才真正认可了 DPO 的实用性。Lambert 参与了 Zephyr 的开发,他回忆了两个关键成功因素:
- 新数据集:UltraFeedback——由 OpenBMB 制作的合成偏好数据集,使用 GPT-4 进行标注
- 极低学习率:\(5 \times 10^{-7}\),比通常的 \(3 \times 10^{-4}\) 低几个数量级
DPO 需要极低的学习率
Zephyr 的成功很大程度上依赖于一个反直觉的超参数选择:极低的学习率(\(5 \times 10^{-7}\))。如果团队更早进行超参数搜索,DPO 可能提前几个月就被广泛采用。这提醒我们:即使算法本身是正确的,找到正确的超参数设置也至关重要——而这往往是通过大量试错才能实现的。
T\"ulu 2:DPO 规模化的验证

来源:Slides 第31页。
Lambert 转到 AI2 后,参与了 T\"ulu 2 项目。这个项目的核心贡献是:
- 首次将 DPO 成功扩展到 70B 参数规模
- 使用相同的 UltraFeedback 数据 + 低学习率方案
- 在 MT-Bench 上达到 7.89 分(70B 版本)
- 正式引发了 DPO vs PPO 的学术讨论
从 Zephyr 到 T\"ulu 2 不到两个月。此后,DPO 模型如潮水般涌出——几乎每个发布开源模型的公司或团队都会推出一个"instruct"版本,通常基于 DPO 训练。
本章小结
从 2023年4月的第一批指令微调模型到 2023年底 DPO 的大规模应用,开源对齐经历了快速而曲折的发展。关键里程碑包括:ShareGPT 数据的出现、第一个 RLHF 模型、UltraFeedback 数据集的创建,以及 Zephyr 和 T\"ulu 2 对 DPO 的验证。整个过程中,数据始终是最稀缺也最关键的资源。
RewardBench:奖励模型的评估
为什么需要评估奖励模型?
Lambert 反复强调一个观点:工业界声称奖励模型是 RLHF 成功的关键,但我们却缺乏系统评估奖励模型的工具。

来源:Slides 第36页。
在标准的 RLHF 反馈循环中:策略模型生成回复 \(\rightarrow\) 奖励模型评分 \(\rightarrow\) 策略更新。但现有的评估工具(如 AlpacaEval、MT-Bench、Chatbot Arena)都是评估最终策略的——没有工具直接评估奖励模型本身。

来源:Slides 第38页。
为什么评估奖励模型如此重要?
训练模型时,你不可能等 Chatbot Arena 一个月后返回结果来判断训练是否有效。你需要本地评估工具——能在训练过程中快速给出信号,告诉你技术改进是否真正有效。评估奖励模型是理解和改进整个 RLHF 流程的关键环节。
奖励模型的训练方式
奖励模型的训练有几个独特的特点:

来源:Slides 第41页。
训练奖励模型需要成对偏好数据:一个 prompt 配两个 completion(chosen 和 rejected)。模型同时处理两个输入,输出两个标量值,通过损失函数拉大它们之间的距离:
奖励模型训练的特殊性
- 通常只训练 1 个 epoch——多训会过拟合
- 评估时与标注者的一致性只有 65--75%
- 可以添加 margin loss、使用模型集成等技巧,但效果提升有限
- 低一致性可能不完全是 bug——人的偏好本身就存在分歧,模型不应该过于"狭隘"
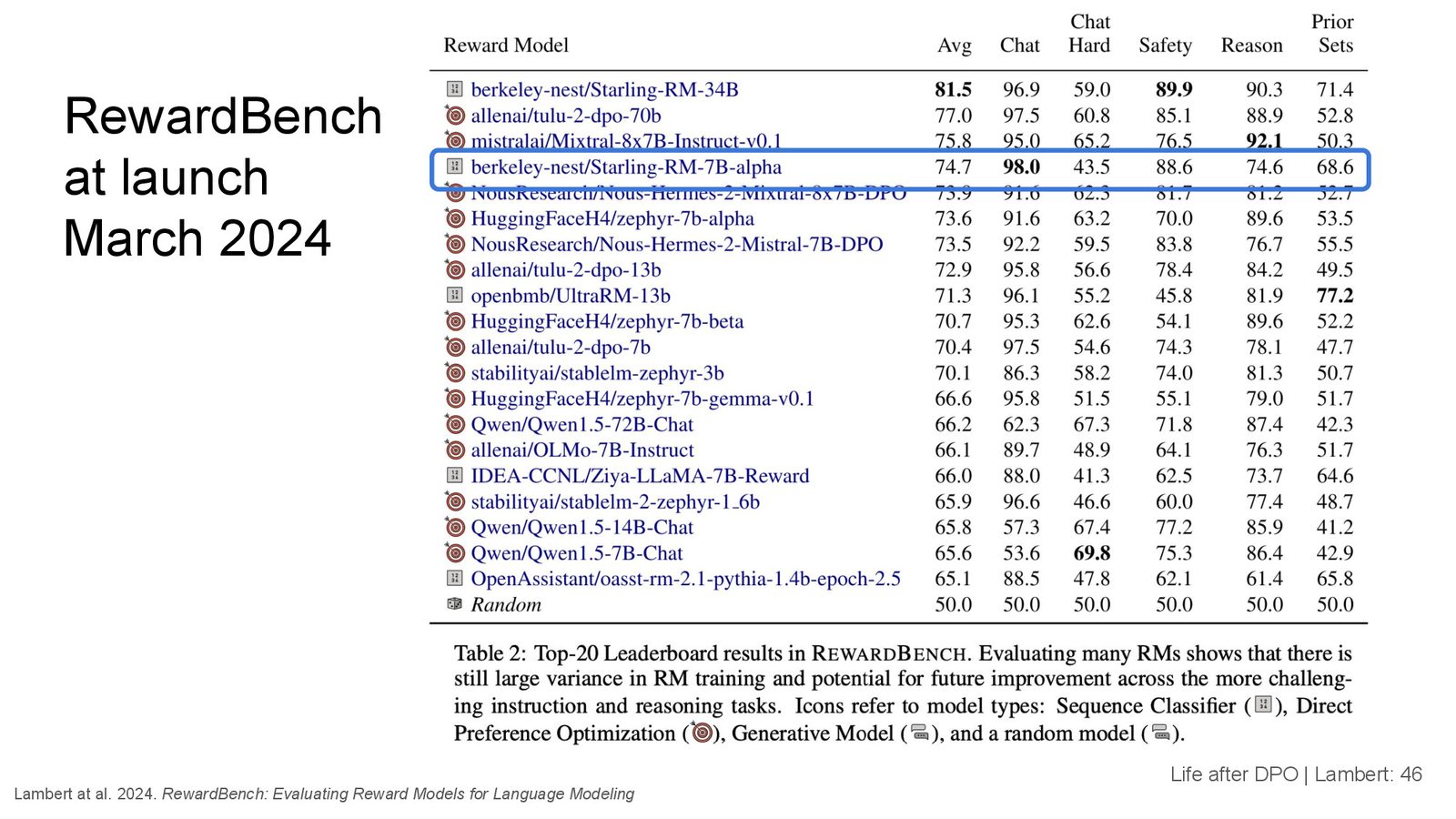
RewardBench 的设计与结果
RewardBench 的设计很直接:收集一组 prompt,每个 prompt 手动创建 chosen 和 rejected 回复,然后测试奖励模型是否能正确识别。
来源:Slides 第46页。
排行榜中包含多种类型的模型:
- 序列分类器(Sequence Classifier):传统的奖励模型训练方式
- DPO 模型:可以利用隐含的奖励函数进行评估
- 生成模型(Generative Model / LLM-as-a-judge):直接用语言模型判断哪个回答更好
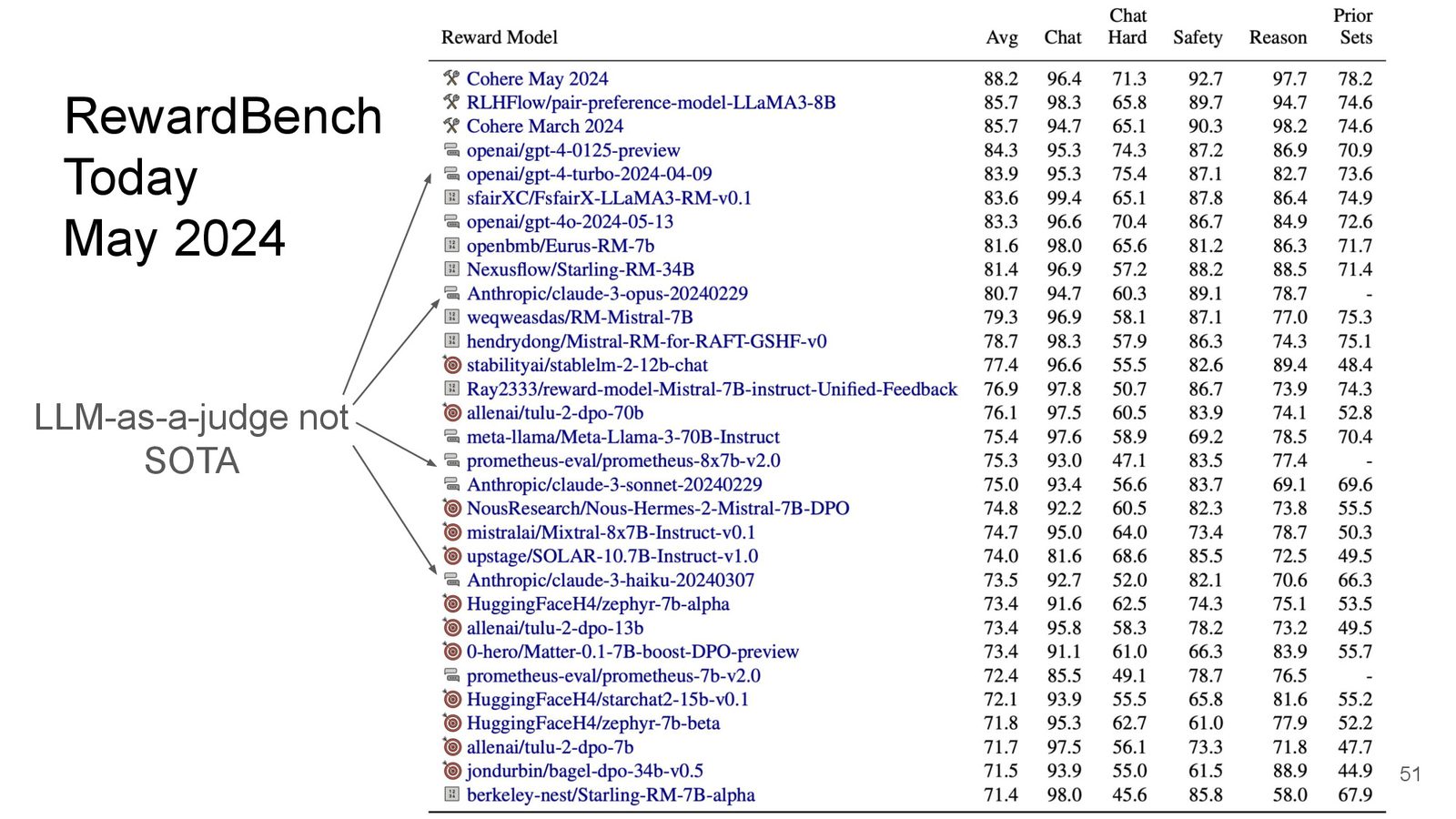
来源:Slides 第51页。
一个关键发现是:GPT-4 和 GPT-4o 在作为 LLM-as-a-judge 时,表现并不如 Cohere 专门训练的奖励模型。这说明通用能力强的模型不一定是好的奖励模型——专门训练的小模型在这个任务上可能更有效。
Chat Hard 子集:真正的难题
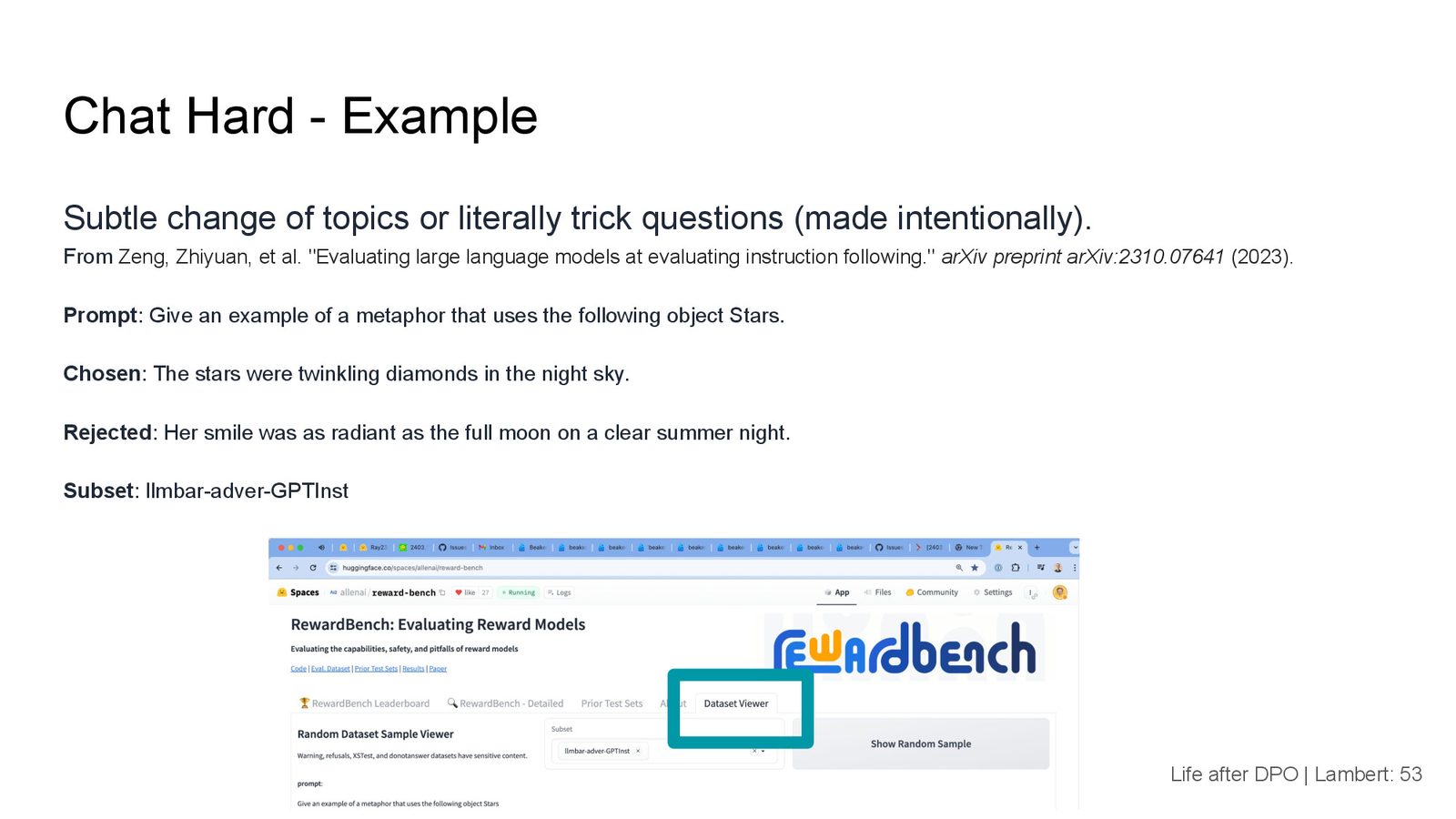
来源:Slides 第53页。
RewardBench 中最有价值的子集是 Chat Hard——专门设计的"陷阱题"。例如:给定提示"用星星写一个比喻",chosen 回复是关于星星的比喻,rejected 回复则是关于月亮的比喻。由于星星和月亮在语义空间中高度关联,这对语言模型来说是一个非常困难的判断任务。这个子集是 RewardBench 中唯一尚未被"饱和"的部分。
安全性评估的洞察

来源:Slides 第55页。
安全性评估中观察到的模式完全符合预期:有些模型(过度安全型)会拒绝所有请求,有些模型("uncensored"型)会回答所有请求。理想的模型应该能够区分真正应该拒绝的请求和只是看起来敏感但实际上应该回答的请求。
DPO 隐含奖励模型的局限

来源:Slides 第56页。
DPO 论文中定义的隐含奖励为:
使用 DPO 模型作为奖励模型时,需要同时拥有训练后的策略和参考模型(训练前的检查点)。但实际上,大多数人发布 DPO 模型时不会发布参考模型。
没有参考模型的 DPO 无法作为好的奖励模型
如果去掉参考模型(即划掉公式中的 \(\pi_{\mathrm{ref}}\) 项),DPO 模型在 RewardBench 上的表现会大幅下降。这是因为参考模型在数学推导中起到关键的正则化作用。这意味着:要把 DPO 模型当作奖励模型使用,你必须同时拥有参考模型——但这在实践中很难要求所有模型发布者都做到。
本章小结
RewardBench 填补了对齐研究中奖励模型评估的空白。核心发现包括:(1)专门训练的奖励模型优于通用 LLM-as-a-judge;(2)Chat Hard 子集是衡量奖励模型能力的关键指标;(3)DPO 模型作为奖励模型有数学上的局限性——需要参考模型才能正常工作;(4)奖励模型的评估领域仍在快速发展,两个月内排行榜就会发生巨大变化。
DPO vs PPO:实证探索
实验设计
Lambert 的团队在 AI2 进行了一系列系统实验,试图回答:PPO 是否真的比 DPO 更好?如果是,好在哪里?
实验基于 Llama 2 13B 模型,逐步叠加不同的训练方案:

来源:Slides 第63页。
指令微调的提升幅度远大于偏好优化
在所有实验中,从 base 模型到 SFT 模型的指令微调阶段带来的提升最大——它将模型"放到了地图上"。之后的 DPO/PPO 阶段带来的提升通常在 0--2% 之间。这提醒我们:对齐优化的收益是边际的,但正是这些边际改进决定了模型在竞争中的位置。
数据集的影响
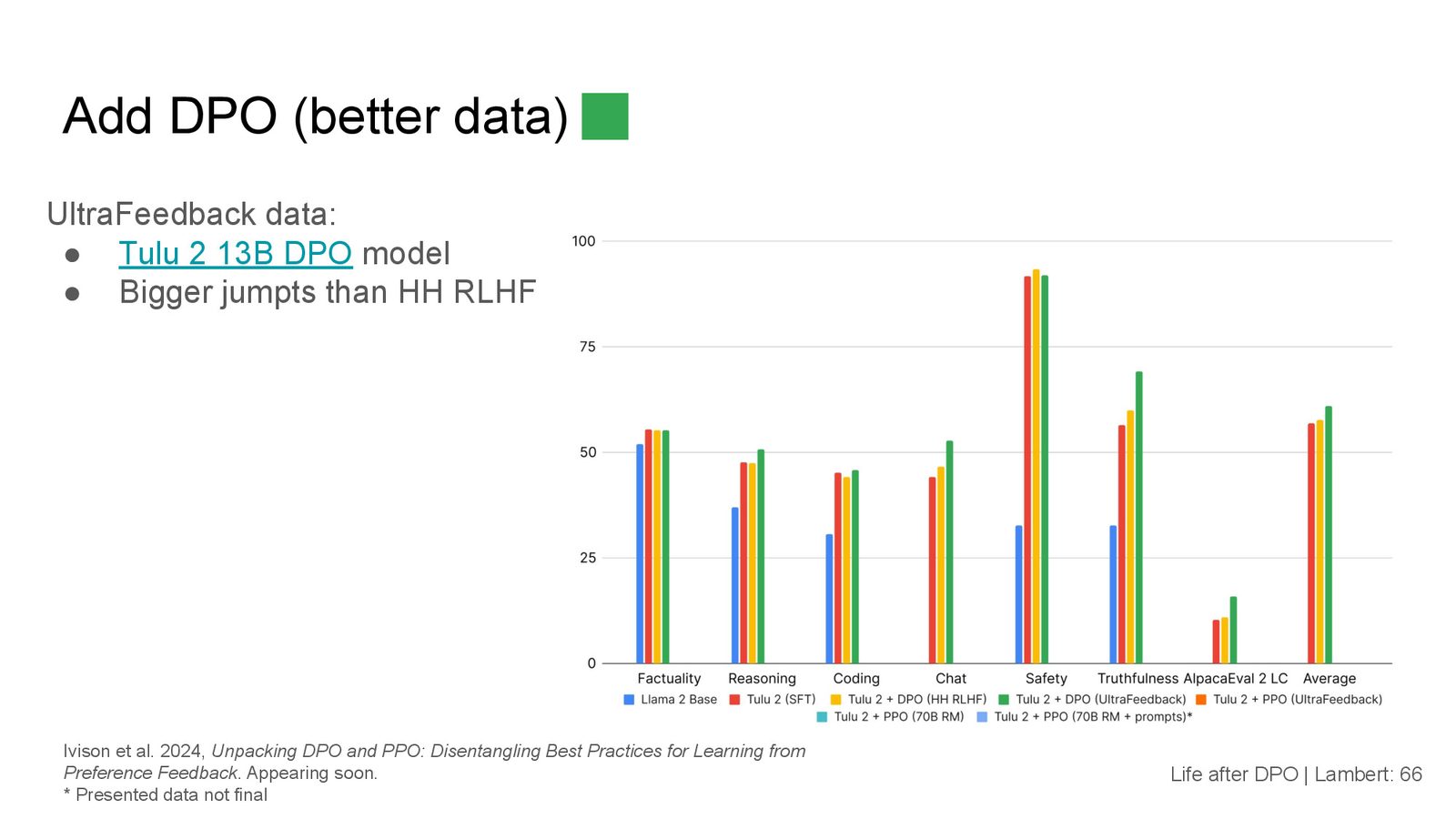
来源:Slides 第66页。
实验中测试了多个偏好数据集:
- Anthropic HH-RLHF:虽然噪声较大,但仍能提供小幅提升
- UltraFeedback:提供了更大的性能提升
- 其他多个开源数据集:效果参差不齐
一个令人意外的发现是:在事实性(factuality)维度上,几乎所有偏好数据集都不起作用。这说明当前的偏好优化方法在提升模型知识准确性方面存在根本限制。
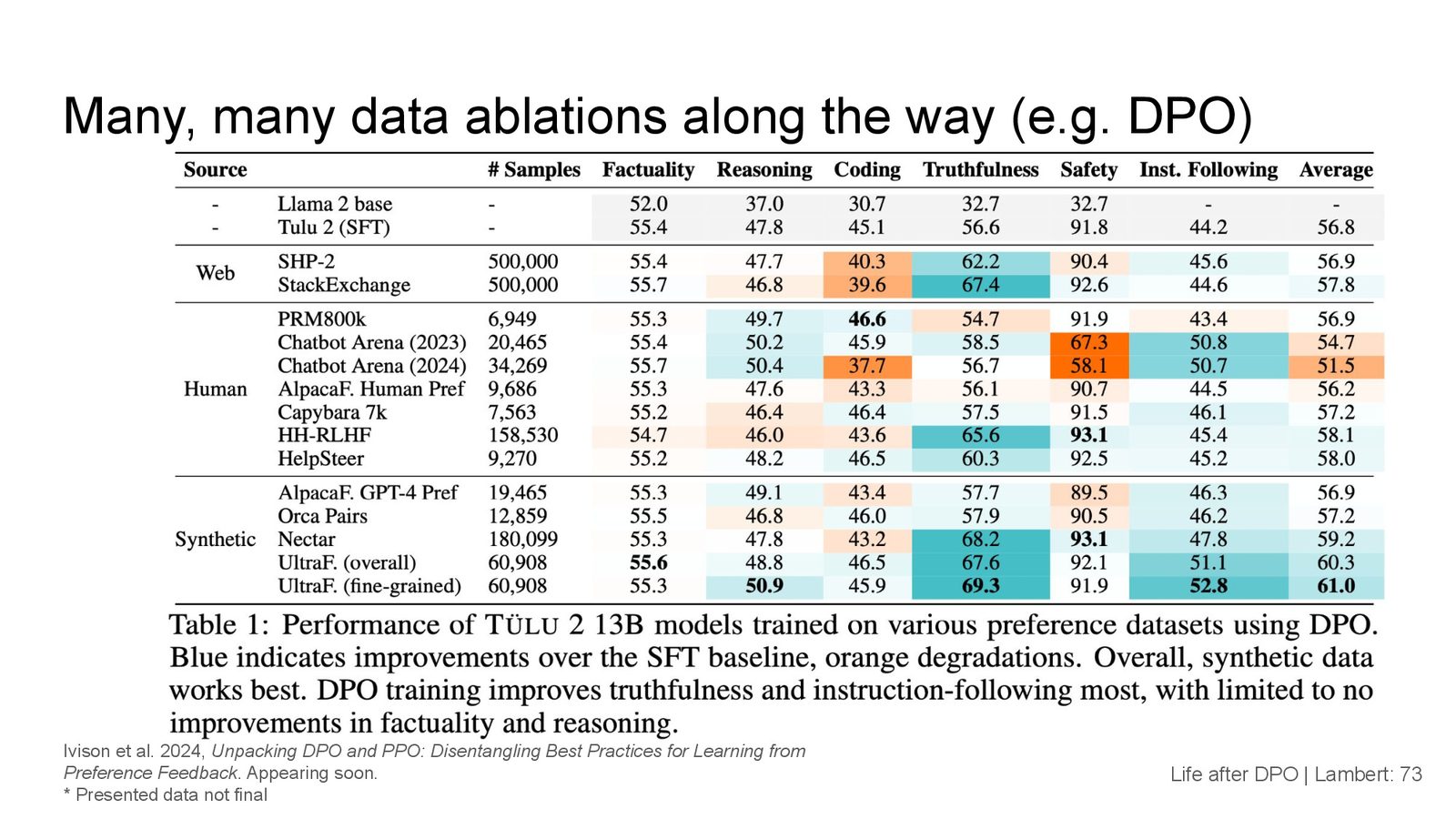
来源:Slides 第73页。
PPO 的实验结果
当团队实现并测试 PPO 后:
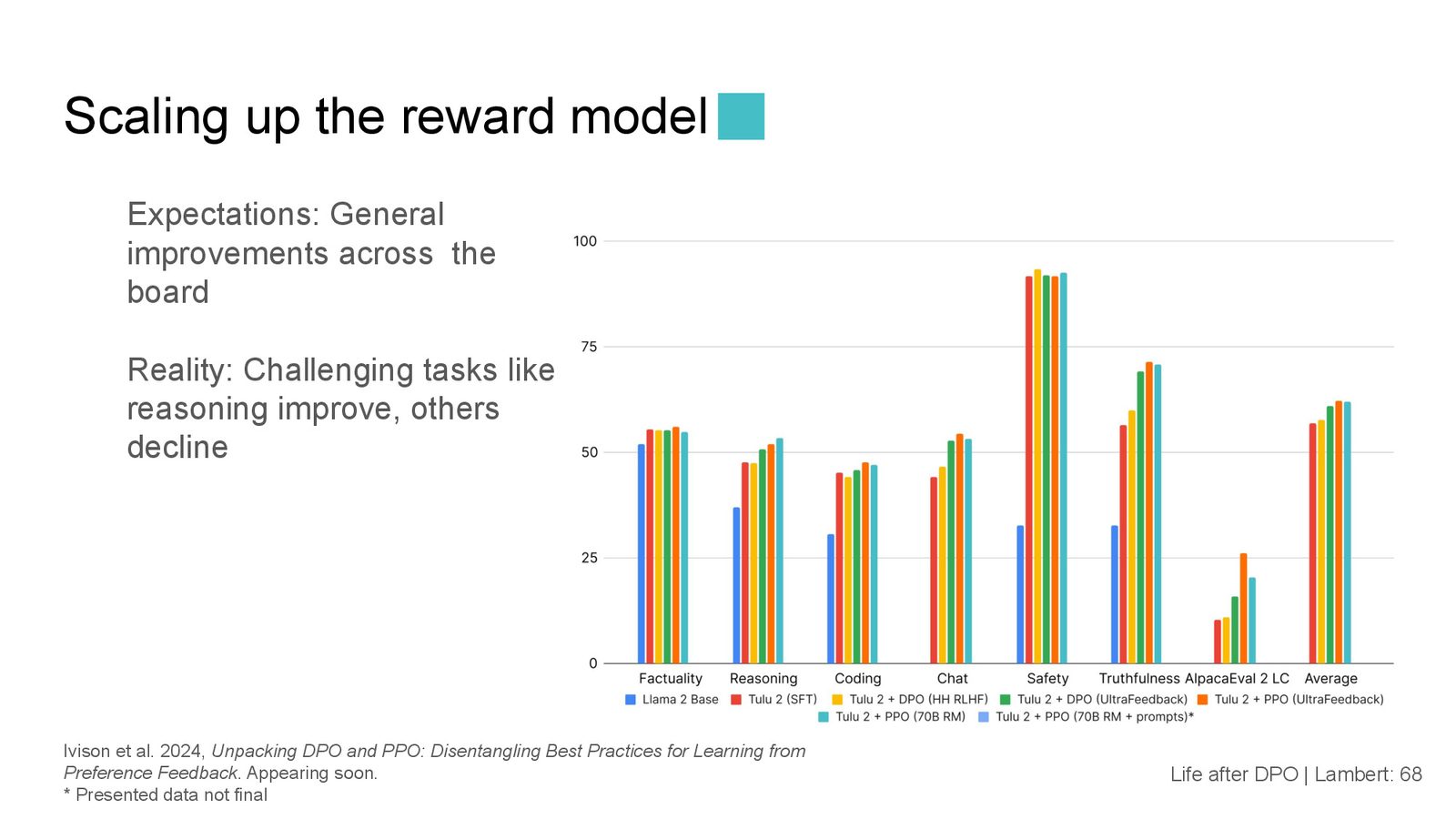
来源:Slides 第68页。
- PPO 在大多数情况下略优于 DPO,大约 1% 的提升
- 使用更大的奖励模型(70B)并没有带来预期的显著提升
- 添加更多类型的提示(代码、推理)对特定评估有帮助,但不改变整体平均分

来源:Slides 第71页。
PPO 的关键发现
- "总有下一个要消融的东西":PPO 的超参数空间极大(正则化、value function、warmup、batch size 等),每次调好一个还有下一个
- "PPO 能得到最好的模型,但我们不知道为什么":PPO 可靠地给出了稍好的结果,但缺乏对其优势来源的清晰理解
- 生成是最大瓶颈:PPO 需要在训练过程中不断从策略模型生成新回复,这比 DPO 慢得多
PPO 的投入产出比令人质疑
Lambert 坦言:PPO 虽然可靠地产出了稍好的模型,但投入的工程和计算资源远超 DPO。对于一个只有几名研究生的学术团队来说,"不知道这是否值得"。他理解为什么 OpenAI 使用 PPO——因为在他们的规模上,1% 的改进意义重大——但对于大多数研究者来说,DPO 的投入产出比更好。
本章小结
通过系统的实证比较,Lambert 的团队得出了几个重要结论:(1)数据质量比算法选择更重要——UltraFeedback 在 DPO 和 PPO 上都显著优于其他数据集;(2)PPO 略优于 DPO,但代价是巨大的工程复杂性;(3)更大的奖励模型不一定带来更好的最终策略;(4)对齐优化的边际收益递减——从 base 到 SFT 的提升远大于从 SFT 到 DPO/PPO 的提升。
在线方法:DPO 之后的前沿
什么是"在线"数据?
来源:Slides 第76页。
"在线"在对齐语境中有两层含义:
- 数据文本的新鲜度:数据是由当前策略模型生成的(on-policy),还是来自其他模型的历史数据(off-policy)?
- 标签的新鲜度:偏好标签是训练前一次性标注的,还是在训练过程中由奖励模型动态重新标注的?
PPO 与 DPO 在"在线"维度上的根本差异
PPO 天然是在线的:它在训练过程中不断从当前策略生成新回复,然后用奖励模型评分。DPO 则使用固定的离线数据集——数据中的回复来自各种不同的模型(GPT-3.5、GPT-4、Alpaca、Vicuna 等),而非当前正在训练的模型。这种数据分布的差异可能是 PPO 略优于 DPO 的根本原因。
在线 DPO 方法的兴起
2024年4--5月,大量论文开始研究如何将"在线"特性引入 DPO:

来源:Slides 第79页。
主要方法包括:
- Self-Rewarding Language Models(Meta):让 DPO 模型自己作为 judge 来重新标注偏好数据,然后进行多轮迭代 DPO 训练
- 分批 DPO:不一次性用完所有数据,而是分批训练,每批之间更新数据标签
- Discriminator-Guided DPO(D2PO):Lambert 参与指导的项目,在 DPO 过程中动态重训奖励模型并重新标注数据
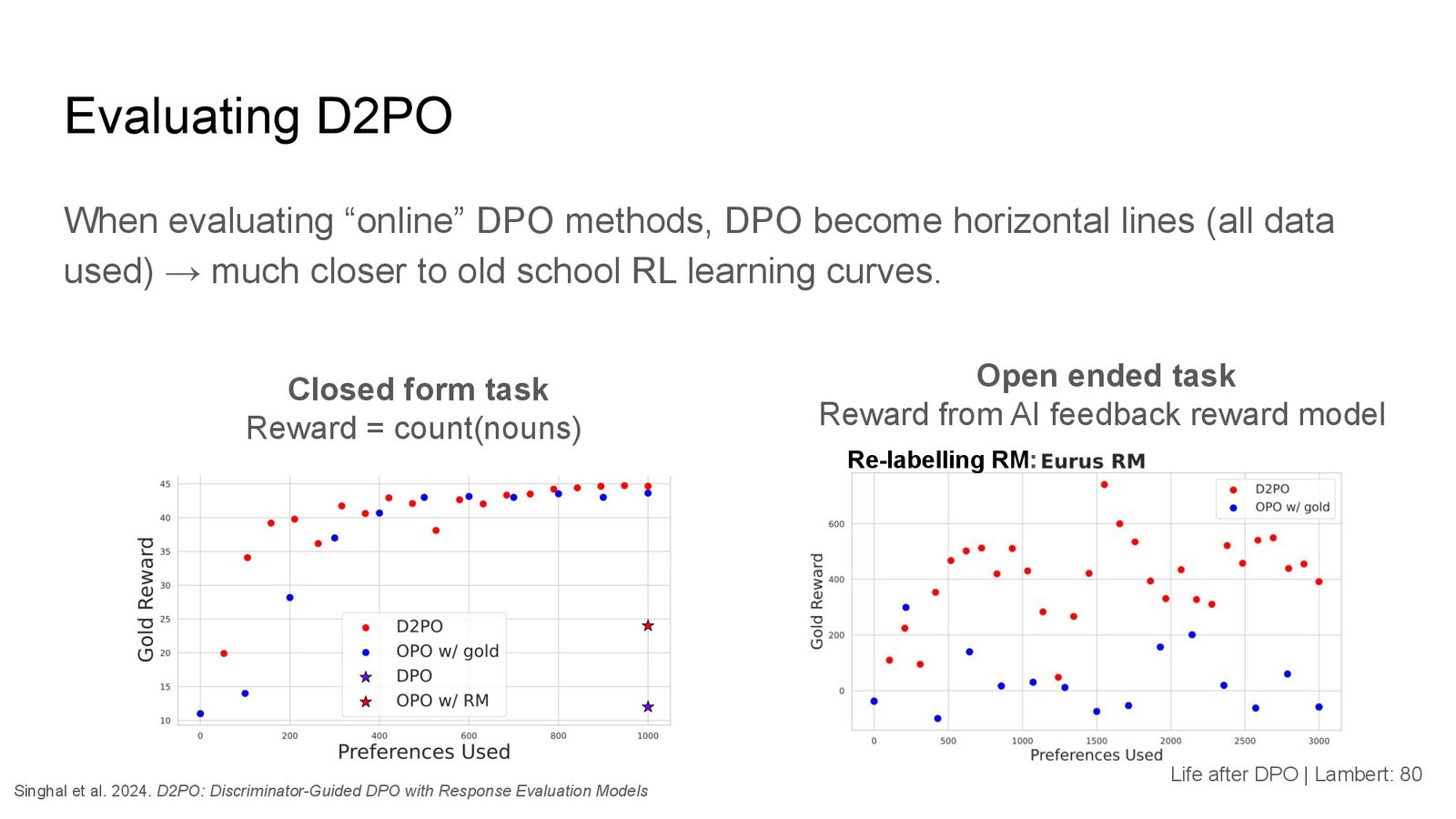
来源:Slides 第80页。
D2PO:判别器引导的 DPO
D2PO 比较了三种方案:
- 标准 DPO:固定数据集,一次性训练
- 在线偏好优化:使用奖励模型反复重新标注偏好数据
- D2PO:不仅重新标注数据,还在训练过程中重训奖励模型
实验使用了一个可度量的闭式任务(计算句子中名词数量作为奖励),结果表明 D2PO 比单纯重新标注偏好数据收敛更好。这说明保持奖励模型与策略模型同步更新是有价值的。
工业界的迭代 RLHF
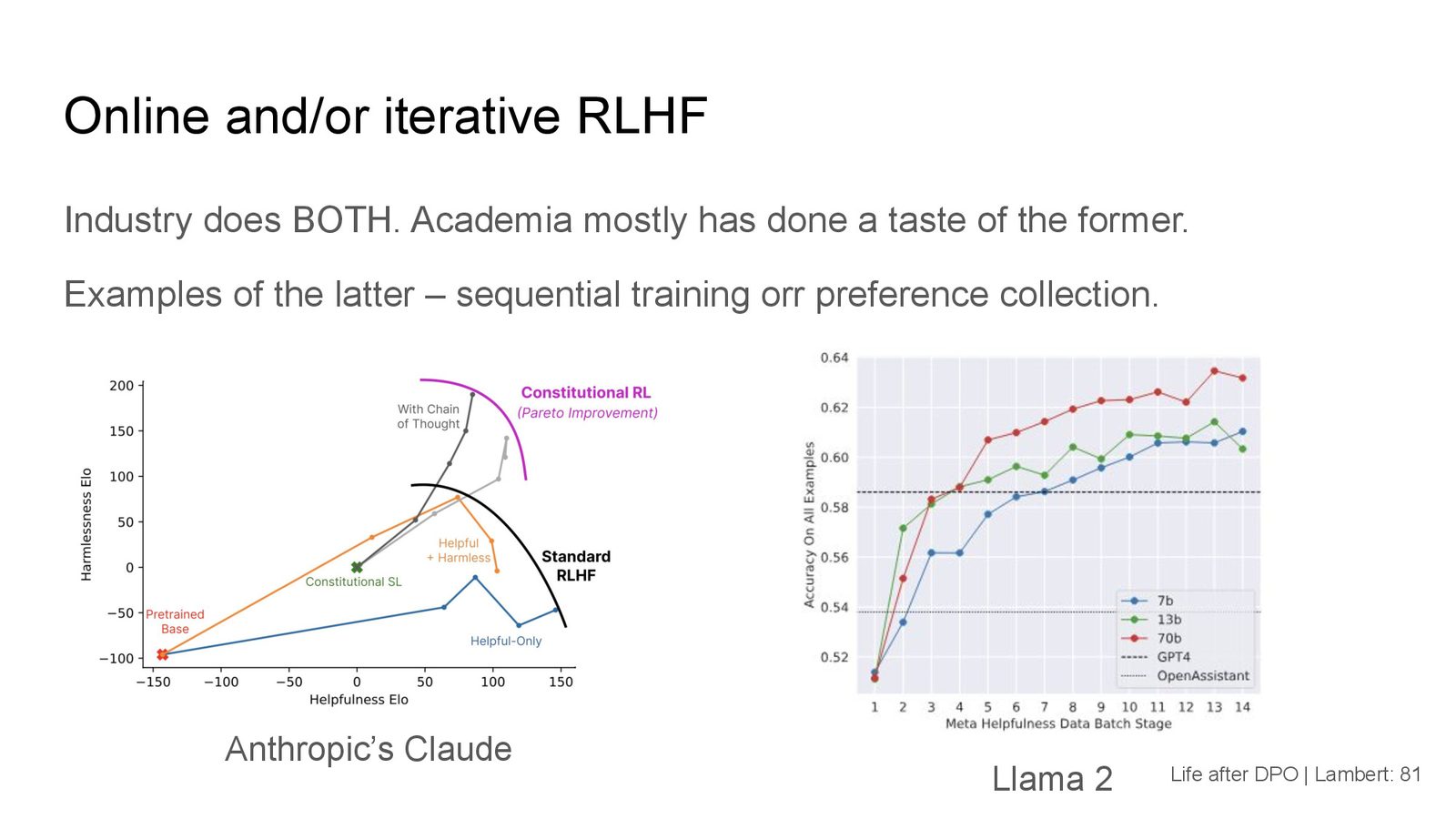
来源:Slides 第81页。
工业界的做法更加直接:
- Anthropic(Claude):多轮 Constitutional RL,每轮使用新的人类数据
- Meta(Llama 2):明确说明与标注公司合作,分批收集数据,每批使用上一轮模型的检查点进行生成
工业界与学术界的"在线"差异
工业界的"在线"意味着不断收集新的人类数据——每个数据点都是花钱买来的。学术界的"在线"更多是用奖励模型重新标注已有数据或从策略模型生成新数据。两者的规模和质量有本质差异:Meta 在 Llama 2 中购买了约 150 万条比较数据,远超 Chatbot Arena 收集的 80 万条。
Llama 3 的后训练策略
Llama 3 的博客文章透露了一句意味深长的话:"Our approach to post-training is a combination of supervised fine-tuning, rejection sampling, proximal policy optimization, and direct preference optimization."
Lambert 的解读是:Meta 在不同训练阶段使用了不同的方法——在每个检查点尝试多种方法,选择效果最好的。这是一种非常实用主义的策略:
- Rejection Sampling(最简单):用奖励模型对 SFT 输出排序,取最好的继续训练
- DPO(较简单):适合快速迭代
- PPO(最复杂但最强):在最终阶段精细调优

来源:Slides 第83页。
本章小结
"在线"方法代表了对齐研究最活跃的前沿方向。核心洞察是:使用当前策略生成的数据(on-policy data)和及时更新的偏好标签,比使用固定的离线数据集能够带来更好的训练效果。在工业界,这意味着持续投入人类标注资源;在学术界,这意味着开发创新的自标注和迭代训练方法。
未来方向与开放问题
数据是核心瓶颈

来源:Slides 第84页。
Lambert 认为对齐研究最大的瓶颈不是算法,而是数据:
- 学术界几乎试遍了所有公开数据集——但选择仍然非常有限
- UltraFeedback 已经使用了半年多,按照行业标准已经"过时"
- 新数据集的创建需要大量人力和资源,但社区缺乏可持续的数据收集机制
五大研究方向
Lambert 列出了他最关注的五个方向:
- 数据创新:需要新的偏好数据集,特别是能够提升特定能力(如事实性、推理)的数据
- DPO 方法的变体:包括去除参考模型、修改损失函数、使用单侧偏好(如 KTO 方法)等
- 小模型对齐:在 7B 甚至更小的模型上进行对齐研究——这是学术界可以发力的方向,因为大公司都在竞争更大的模型
- 更好的评估工具:需要更具体、更有针对性的评估基准,而非通用排行榜
- 个性化对齐:训练适合个人需求的模型,而非一个通用模型服务所有人
超越二元偏好的可能性
Q&A 环节中讨论了是否存在比成对偏好更好的反馈形式。Lambert 列举了几个方向:
- KTO(Stanford):使用单侧偏好(yes/no)而非成对比较
- K-wise 偏好(Starling 模型):同时比较 5--9 个回复并排序
- 细粒度偏好:为每个回复标注多个维度(简洁性、有用性、诚实性等)
- 社会选择理论:整个社会选择(social choice)领域的知识还未被充分引入
Reward Hacking 是永恒的挑战
在 Q&A 环节中,关于 reward hacking 的讨论引发了深入思考:
Reward Hacking 不可完全避免
当你有一个强大的优化器(如 PPO)和一个不完美的奖励表示时,优化器总会找到奖励表示的漏洞。Lambert 举了一个有趣的例子:如果训练不加约束,模型可能会对所有问题都回答"JavaScript"——因为这恰好能在某些评估指标上获得高分。KL 散度约束就是用来缓解这个问题的"刹车",但不可能完全消除 reward hacking。
超越人类水平的对齐
另一个重要问题是:如果对齐依赖于人类反馈,如何让模型超越人类水平?Lambert 认为搜索(search)将是关键:
- 搜索本质上是 RL 中的探索(exploration)
- 语言模型可以通过搜索生成新的合成数据
- 人类的作用将从"提供所有答案"转变为"验证和纠正搜索结果"
- 这可能是 OpenAI 的 Q* 项目试图解决的问题
本章小结
对齐研究正处于快速发展但充满不确定性的阶段。数据是最大的瓶颈,算法创新空间仍然广阔,评估工具亟需完善。未来的方向可能包括:在线方法的成熟、超越二元偏好的反馈机制、小模型对齐、个性化对齐,以及利用搜索突破人类水平的限制。
总结与延伸
讲者的核心总结

来源:Slides 第86页。
Nathan Lambert 在讲座中传递了几个核心信息:
- DPO 是正确的起点:对于任何想进入对齐研究的人,DPO 简单、有效、易于调试
- 数据比算法更重要:UltraFeedback 数据集的影响力远超任何单一算法改进
- PPO 略优但代价高昂:如果你有资源,PPO 能给你额外 1% 的提升
- 在线方法是未来:无论是 PPO 的天然在线性,还是 DPO 的在线变体,数据新鲜度都至关重要
- 评估是基础设施:没有好的评估工具,我们就在黑暗中摸索
全课知识图谱

关键 Takeaways
六条核心原则
- RLHF 是必要但不充分的:预训练提供基础,后训练使模型"可用"
- 从 DPO 开始:简单、有效、可扩展,是任何对齐项目的正确起点
- 数据决定上限:算法只能在数据质量允许的范围内优化
- 评估驱动研发:没有好的评估工具,就无法判断改进是否有效
- 在线 > 离线:新鲜的、来自当前策略的数据比历史数据更有价值
- 对齐是多阶段过程:工业界在不同阶段组合使用 SFT、Rejection Sampling、DPO 和 PPO
拓展阅读
- Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model, 2023: https://arxiv.org/abs/2305.18290
- Lambert et al., RewardBench: Evaluating Reward Models for Language Modeling, 2024: https://arxiv.org/abs/2403.13787
- Ivison et al., Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback, 2024
- Tunstall et al., Zephyr: Direct Distillation of LM Alignment, 2023: https://arxiv.org/abs/2310.16944
- Ivison et al., Camels in a Changing Climate: Enhancing LM Adaptation with T\"ulu 2, 2023: https://arxiv.org/abs/2311.10702
- Yuan et al., Self-Rewarding Language Models, Meta, 2024: https://arxiv.org/abs/2401.10020
- Nathan Lambert's Blog: https://www.interconnects.ai
- Chatbot Arena: https://chat.lmsys.org/