CS336 Lecture 7: Parallelism 1
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Tatsu Hashimoto 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年5月 |

引言:从单 GPU 到数据中心
上一节课(Lecture 5/6)我们深入探讨了单 GPU 的工作原理和性能优化。然而,当代大语言模型的规模已经远远超出了单 GPU 的能力边界——无论是计算量还是内存容量。本节课的核心问题是:如何将训练工作高效地分配到成百上千个 GPU 上?
本课三大核心目标
- 理解多机并行训练的必要性——计算和内存两方面的驱动力
- 掌握四种主要并行策略——数据并行、流水线并行、张量并行、序列并行
- 学会组合使用——3D/4D 并行的设计经验法则

来源:Slides 第2页。
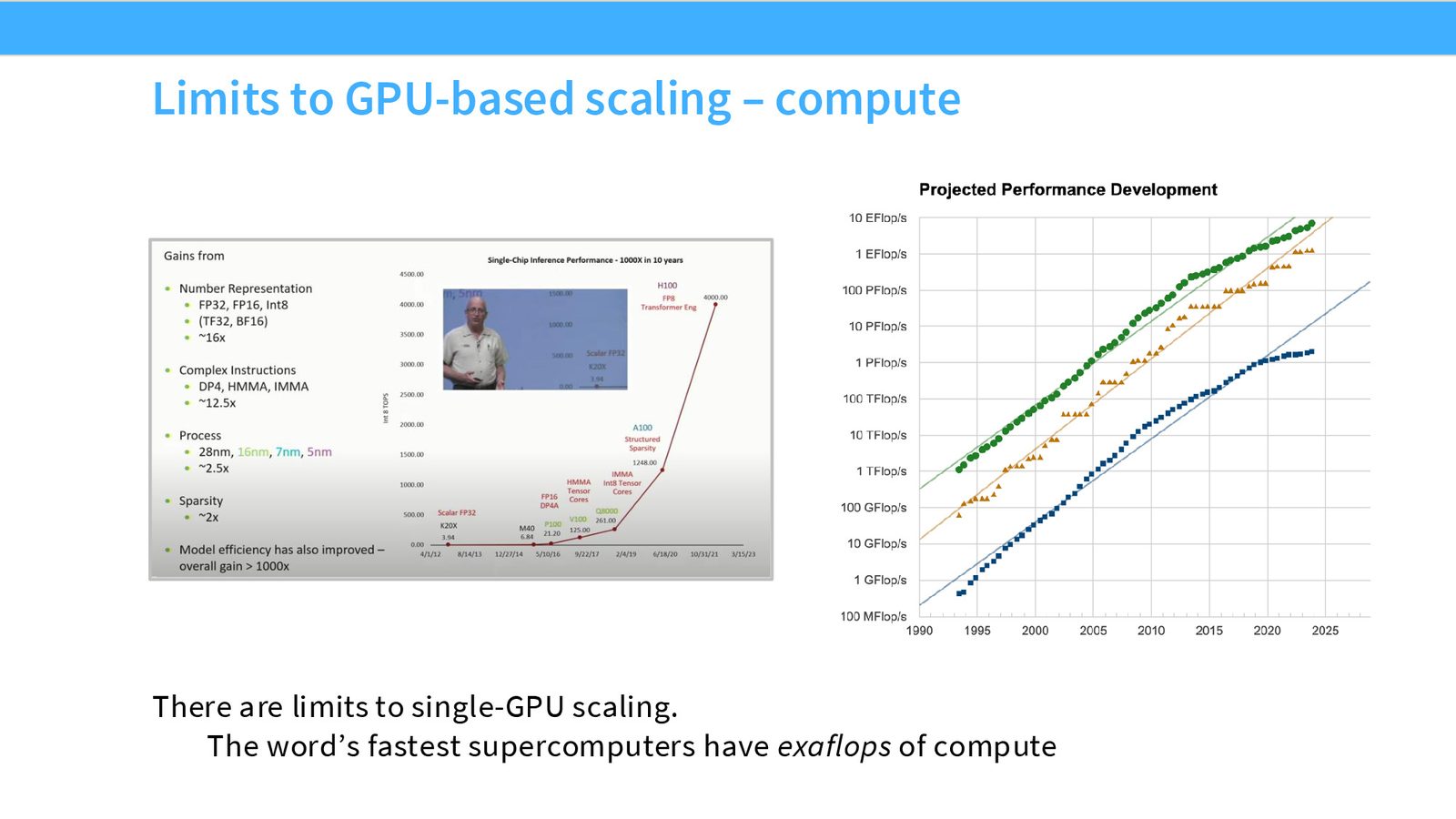
计算驱动:超级计算机的规模
单 GPU 的算力虽然在飞速增长(超指数增长曲线),但如果我们希望此时此刻训练最强大的语言模型,就必须依赖多机并行。当今世界最快的超级计算机拥有 exaFLOPS 级别的总算力,这正是训练最大模型所需要的资源规模。

来源:Slides 第3页。
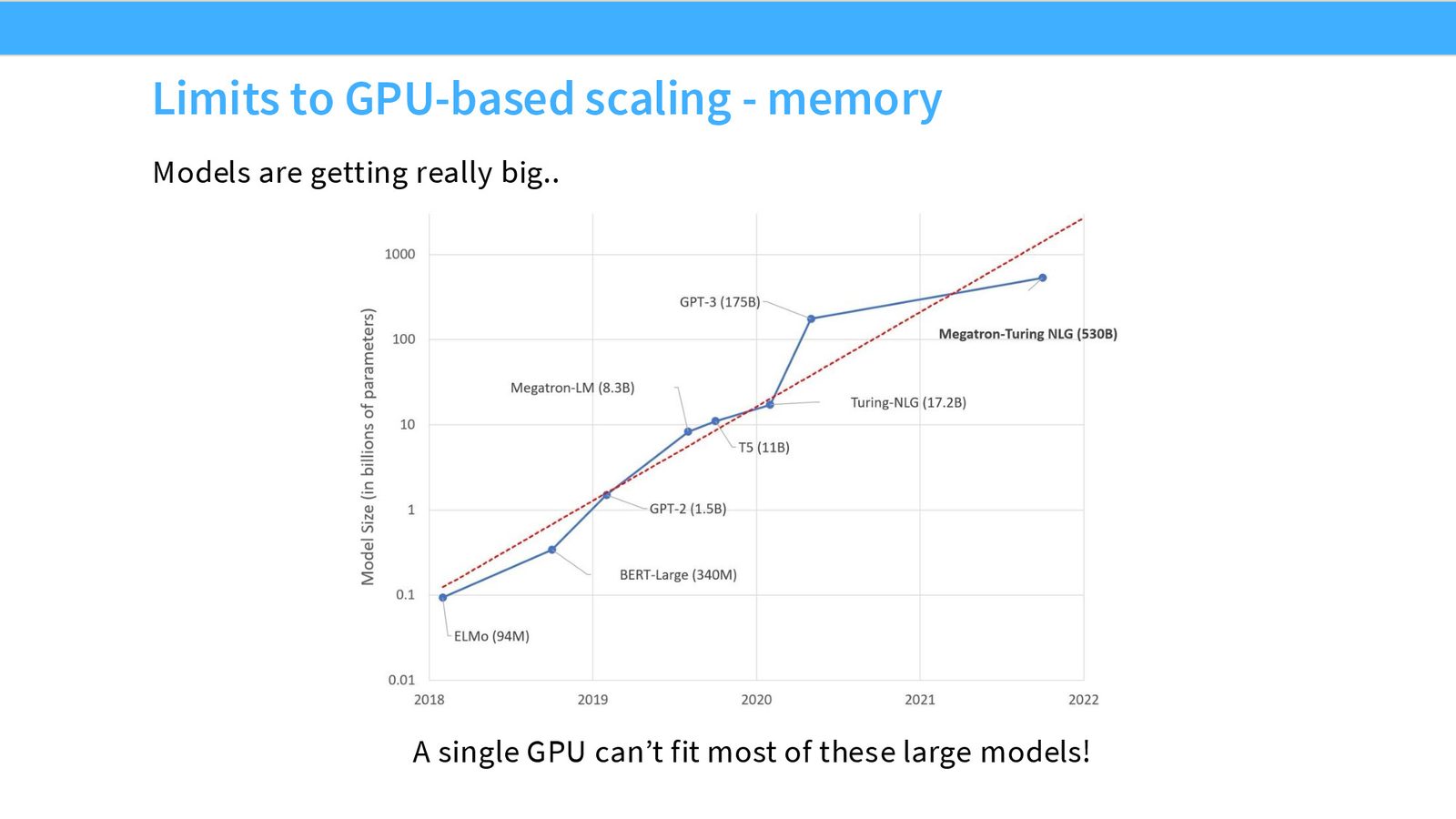
内存驱动:模型已超出单卡容量
除了计算之外,内存也是核心瓶颈。大模型拥有数十亿甚至数千亿参数,加上优化器状态、梯度和激活值,所需内存远超单 GPU 的 HBM 容量。
来源:Slides 第4页。
新的计算单元:数据中心
从这节课开始,我们的基本计算单元不再是单个 GPU,而是整个数据中心。我们需要设计算法和分片策略来实现两个目标:
- 线性内存扩展:GPU 数量翻倍,可训练的最大模型规模也翻倍
- 线性计算扩展:GPU 数量翻倍,有效计算吞吐量也翻倍
本章小结
多 GPU 并行训练的必要性来自两个方面:(1)计算需求——单 GPU 算力不足以在合理时间内完成训练;(2)内存需求——模型参数、优化器状态等无法放入单卡。本课将介绍如何通过不同的并行策略,在数据中心规模上同时解决这两个问题。
网络层次与集合通信
在讨论并行算法之前,我们需要理解 GPU 之间的通信拓扑。这一节课聚焦于硬件互连层次以及构建并行算法的基本通信原语。
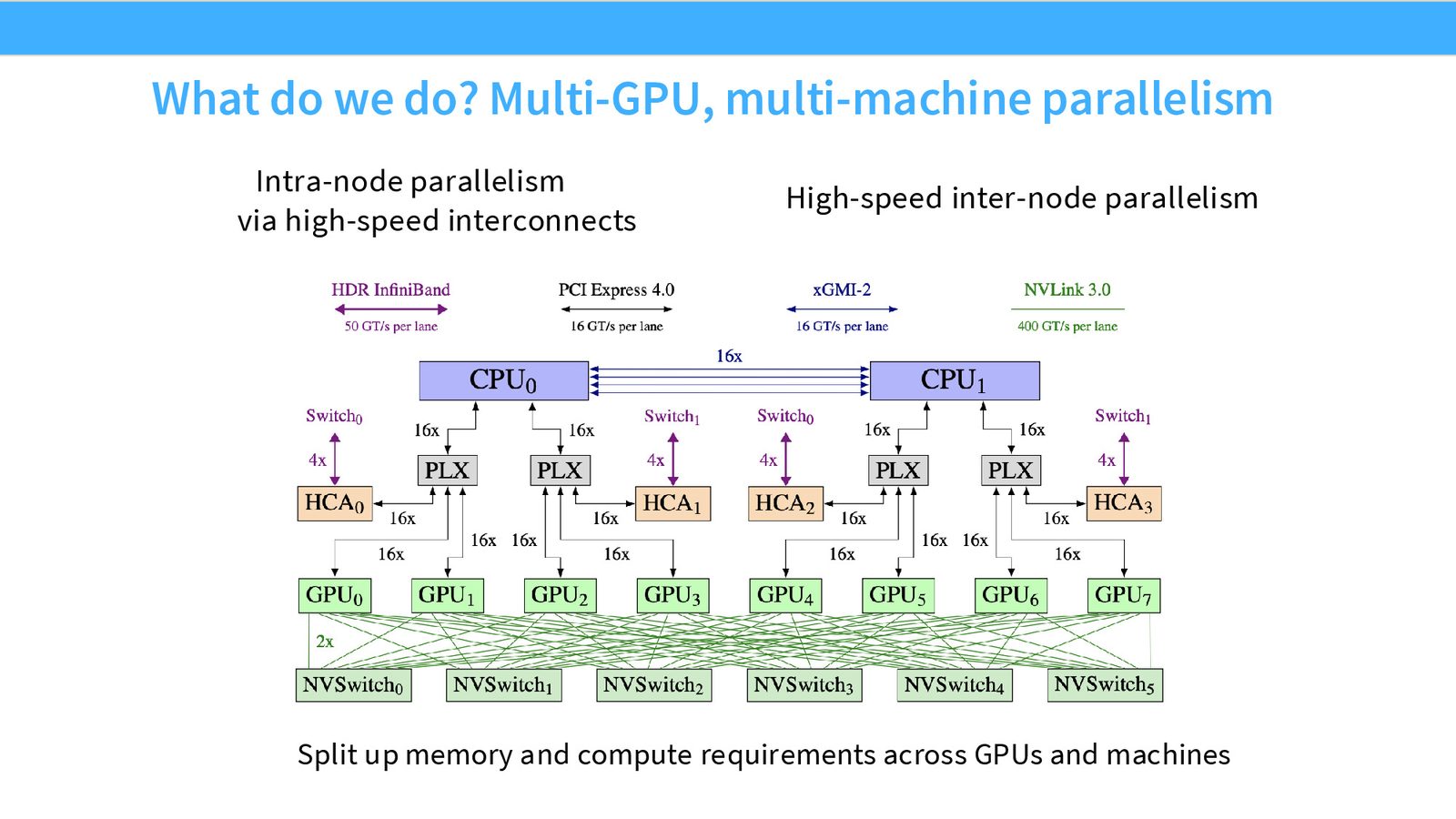
GPU 互连层次结构
GPU 不是孤立存在的。在 NVIDIA 的典型配置中,一台节点(node)包含 8 个 GPU,通过 NVSwitch/NVLink 实现超高速互连。不同节点之间则通过 InfiniBand 等网络互连,速度明显更低。
来源:Slides 第5页。来自 GPT-NeoX 论文,同样的层次结构适用于 H100 机器。
三级带宽层次
- 节点内(Intra-node):NVLink/NVSwitch,8 GPU 全互连,带宽极高(约 900 GB/s per GPU on H100)
- 机架内(Intra-rack):InfiniBand/RoCE,约 256 GPU 全互连,带宽约为节点内的 \(1/8\)
- 跨机架(Inter-rack):通过叶脊网络(leaf-spine),带宽进一步下降
这种异构的带宽层次将直接决定我们在不同层级上使用哪种并行策略。
集合通信原语
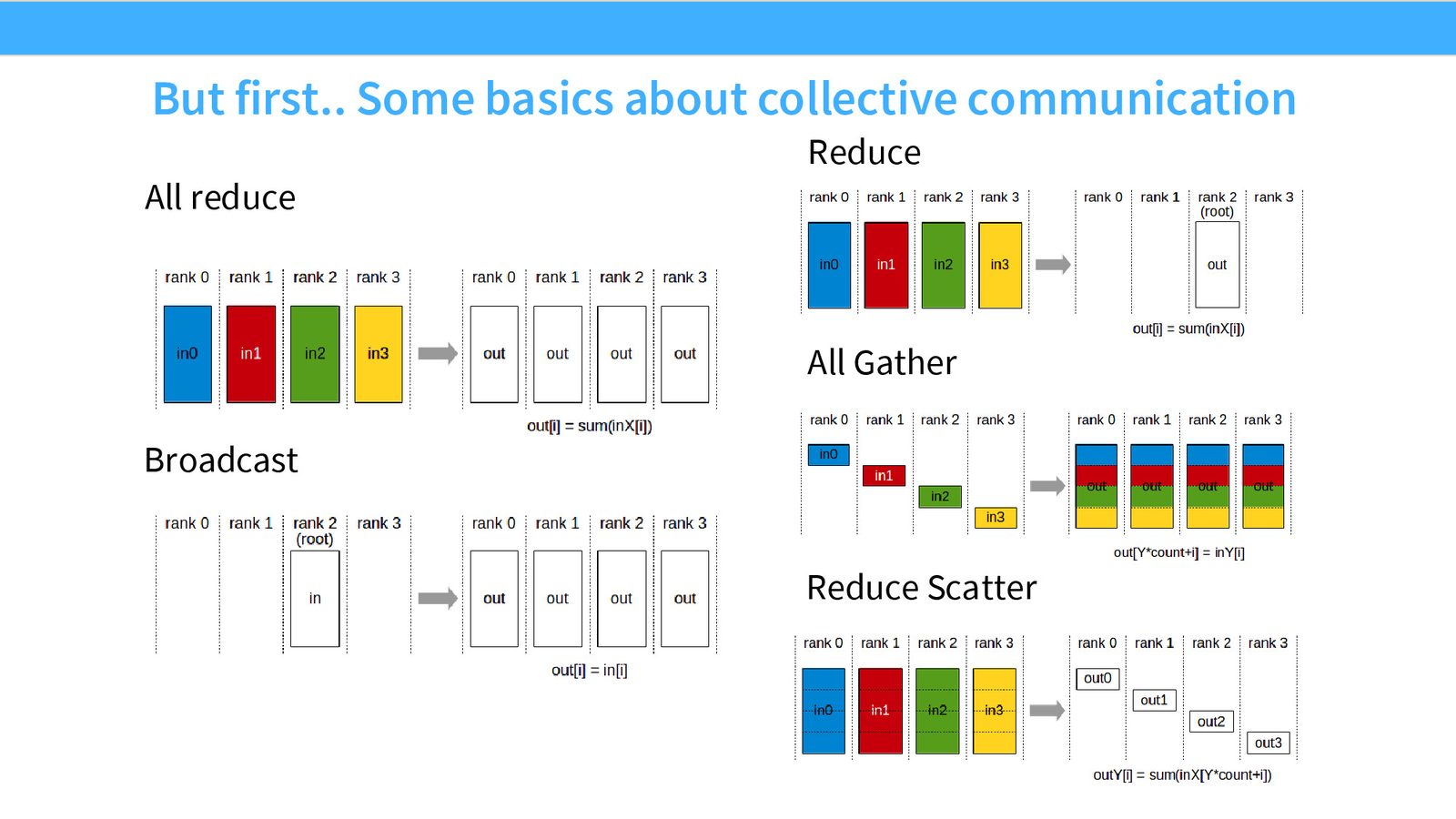
并行算法的核心构建块是一组集合通信(collective communication)操作。掌握它们是理解所有并行策略的基础。
来源:Slides 第6页。
五种基本集合通信操作
- All-Reduce:每个 rank 拥有一份数据,对所有数据执行归约(如求和),结果复制到所有 rank。通信量约 \(2 \times |data|\)
- Broadcast:一个 rank 的数据复制到所有 rank。通信量约 \(1 \times |data|\)
- Reduce:所有 rank 的数据归约到一个 rank。通信量约 \(1 \times |data|\)
- All-Gather:每个 rank 拥有数据的一个分片,收集后所有 rank 拥有完整数据。通信量约 \(1 \times |data|\)
- Reduce-Scatter:每个 rank 拥有完整数据,归约后将结果的不同分片分发到对应 rank。通信量约 \(1 \times |data|\)
核心恒等式:All-Reduce = Reduce-Scatter + All-Gather
来源:Slides 第7页。
关键恒等式
在带宽受限的情况下,这两种实现方式的通信开销完全等价。这一恒等式是理解 ZeRO 优化器和 FSDP 为何"零额外通信开销"的关键。
GPU 与 TPU 网络拓扑对比
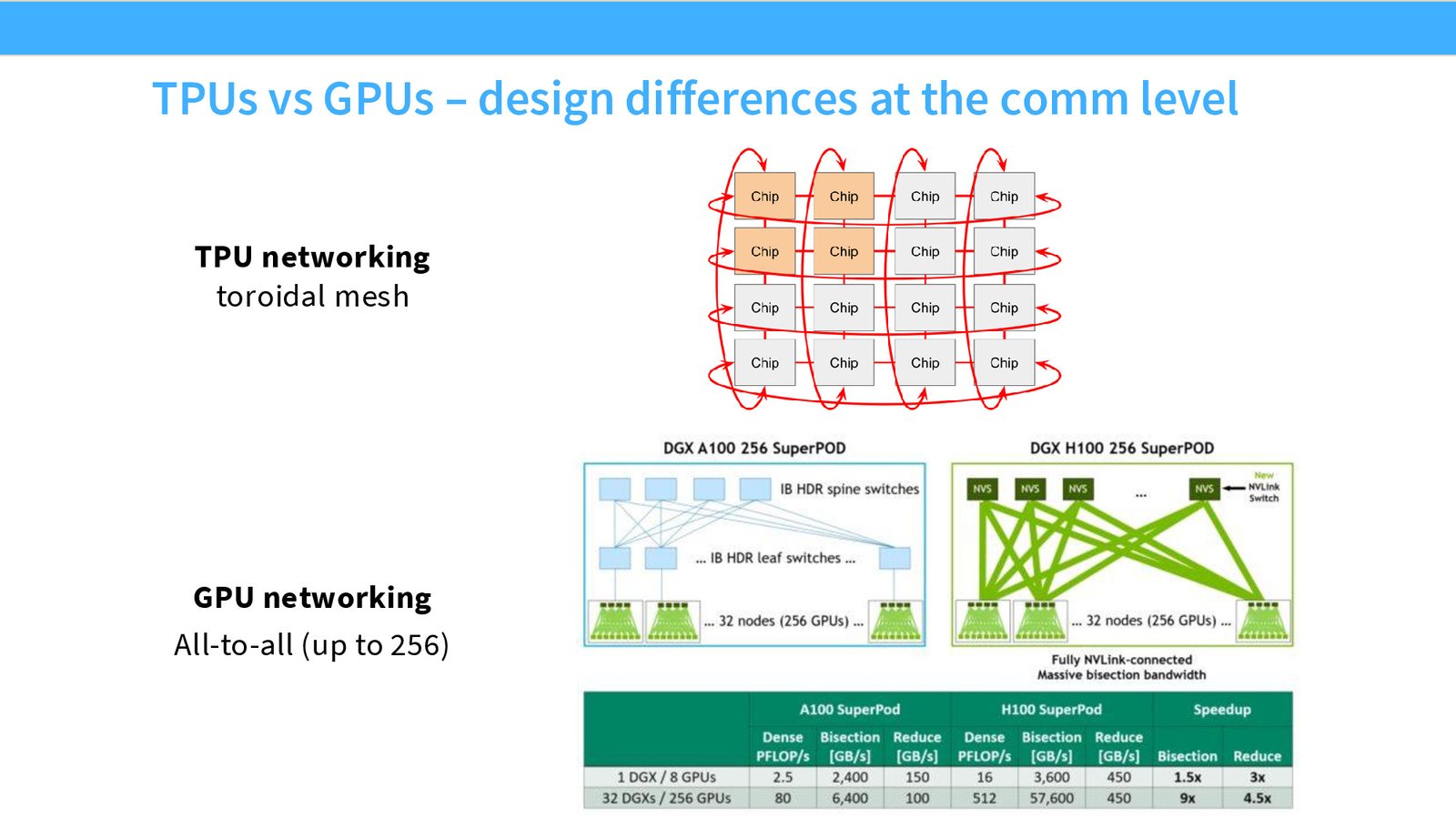
来源:Slides 第9页。
GPU vs. TPU 网络设计哲学
- GPU(NVIDIA):节点内 8 GPU 全互连 \(\rightarrow\) 约 256 GPU 通过交换机全互连 \(\rightarrow\) 更大规模需叶脊网络。全互连(all-to-all) 通信快速,但扩展到数千 GPU 时出现瓶颈。
- TPU(Google):采用环面网格拓扑,每个 TPU 只与邻居通信。扩展性极佳(无 256 GPU 阈值),且集合通信效率不逊于全互连。Google 因此可以减少对流水线并行的依赖。
本章小结
硬件层次结构决定了并行策略的选择。节点内的高速 NVLink 适合通信密集的张量并行;节点间较慢的 InfiniBand 适合通信量较小的数据并行和流水线并行。所有并行算法都可以用集合通信原语来描述和分析,其中 All-Reduce = Reduce-Scatter + All-Gather 是最重要的恒等式。
数据并行(Data Parallelism)
数据并行是最直观、最常用的并行策略。核心思想很简单:每个 GPU 拥有模型的完整副本,但处理不同的数据子集。

来源:Slides 第11页。
朴素数据并行
给定总批次大小 \(B\) 和 \(M\) 个 GPU,每个 GPU 处理 \(B/M\) 个样本。各 GPU 独立计算梯度,然后通过 All-Reduce 同步梯度,最后各自更新参数。

来源:Slides 第12页。
其中求和 \(\sum_{i=1}^{B}\) 可以分配到 \(M\) 个 GPU 上,每个 GPU 计算 \(B/M\) 个样本的梯度,然后通过 All-Reduce 汇总。
朴素数据并行的特性
- 计算扩展:每个 GPU 处理 \(B/M\) 个样本——只要 \(B\) 足够大,每个 GPU 都能充分利用算力
- 通信开销:每个批次需要一次 All-Reduce,通信量为 \(2 \times |\theta|\)(参数数量)
- 内存扩展:\textcolor{red}{无}——每个 GPU 必须存储完整的参数、梯度和优化器状态
训练内存的详细分析
来源:Slides 第13页。
以使用 AdamW 优化器的混合精度训练为例,每个参数需要存储:
| 组件 | 精度 | 字节数/参数 |
|---|---|---|
| 模型参数(BF16) | FP16 | 2 |
| 梯度(BF16) | FP16 | 2 |
| 主权重副本(FP32) | FP32 | 4 |
| Adam 一阶矩 | FP32 | 4 |
| Adam 二阶矩 | FP32 | 4 |
| 合计 | 16 |
优化器状态是内存的主要消耗者
在混合精度训练中,优化器状态(主权重 + Adam 一阶矩 + Adam 二阶矩)占据了每参数 12 字节,是参数本身(2 字节)的 6 倍。这意味着即使参数量看起来"不大",实际训练内存可能远超预期。

来源:Slides 第14页。
以 7.5B 参数模型在 64 个加速器上的朴素数据并行为例,每个 GPU 需要约 120 GB 内存——远超 80 GB 的 A100。这引出了 ZeRO 优化的核心动机。
ZeRO 优化器:分级内存分片
ZeRO(Zero Redundancy Optimizer)通过三个阶段逐步减少数据并行中的内存冗余。

来源:Slides 第15页。
ZeRO Stage 1:优化器状态分片
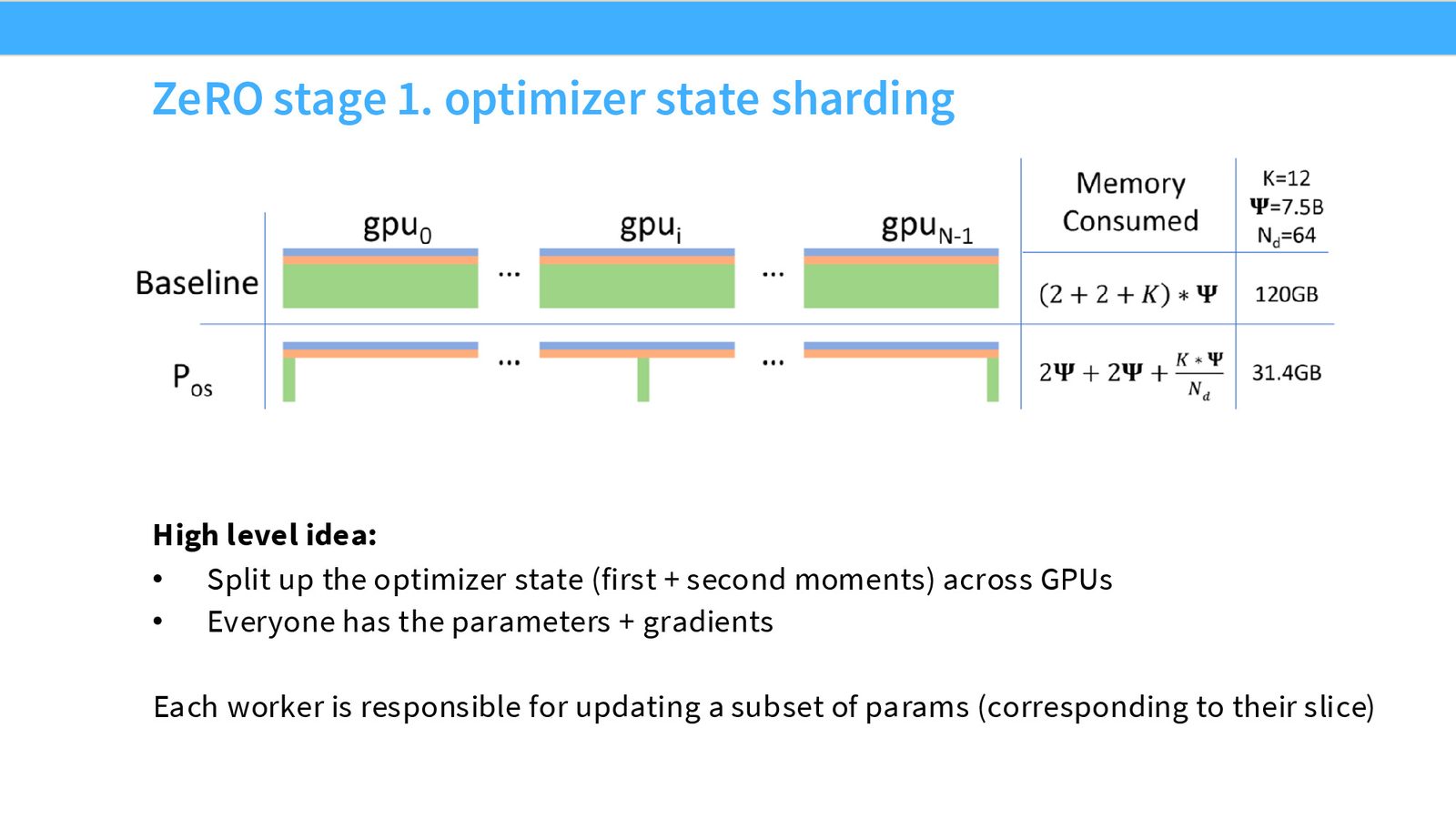
来源:Slides 第16页。
核心思想:每个 GPU 仍然拥有完整的参数和梯度,但只负责一部分优化器状态。

来源:Slides 第17页。
具体步骤:
- 每个 GPU 在自己的数据上计算完整梯度
- Reduce-Scatter:将梯度按参数分片归约——GPU \(i\) 收到第 \(i\) 分片的汇总梯度
- 每个 GPU 用自己持有的优化器状态更新第 \(i\) 分片的参数
- All-Gather:将更新后的参数分片广播给所有 GPU
ZeRO Stage 1 的"零额外开销"性质
朴素数据并行需要一次 All-Reduce(通信量 \(2|\theta|\)),而 ZeRO Stage 1 需要一次 Reduce-Scatter + 一次 All-Gather(通信量也是 \(2|\theta|\))。根据 All-Reduce = Reduce-Scatter + All-Gather 恒等式,Stage 1 的通信量与朴素数据并行完全相同,但优化器状态内存减少为 \(1/M\)。
ZeRO Stage 2:梯度分片

来源:Slides 第19页。
Stage 2 在 Stage 1 的基础上进一步分片梯度。关键约束:不能在内存中实例化完整的梯度向量。
具体做法:在反向传播过程中,每计算完一层的梯度,就立即通过 Reduce 操作将该层的梯度发送到负责它的 GPU,然后释放本地梯度内存。这样,峰值内存使用被限制在"完整参数 + 分片梯度 + 分片优化器状态"。
逐层梯度传输
Stage 2 的关键技巧是在反向传播过程中逐层执行 Reduce 操作,而非等所有梯度计算完毕后一次性通信。这避免了在任何时刻实例化完整梯度向量,总通信量仍为 \(2|\theta|\),但引入了轻微的同步开销。
ZeRO Stage 3 / FSDP:完全分片
ZeRO Stage 3 是最激进的版本——参数、梯度和优化器状态全部分片。PyTorch 中的 FSDP(Fully Sharded Data Parallel)正是 Stage 3 的实现。

来源:Slides 第21页。
由于没有任何 GPU 拥有完整参数,前向和反向传播都需要按需请求参数:
- 前向传播:处理第 \(l\) 层时,All-Gather 该层的参数 \(\rightarrow\) 计算 \(\rightarrow\) 释放参数
- 反向传播:All-Gather 参数 \(\rightarrow\) 计算梯度 \(\rightarrow\) Reduce-Scatter 梯度 \(\rightarrow\) 释放参数和非本地梯度
- 参数更新:每个 GPU 用本地的分片梯度和分片优化器状态更新分片参数
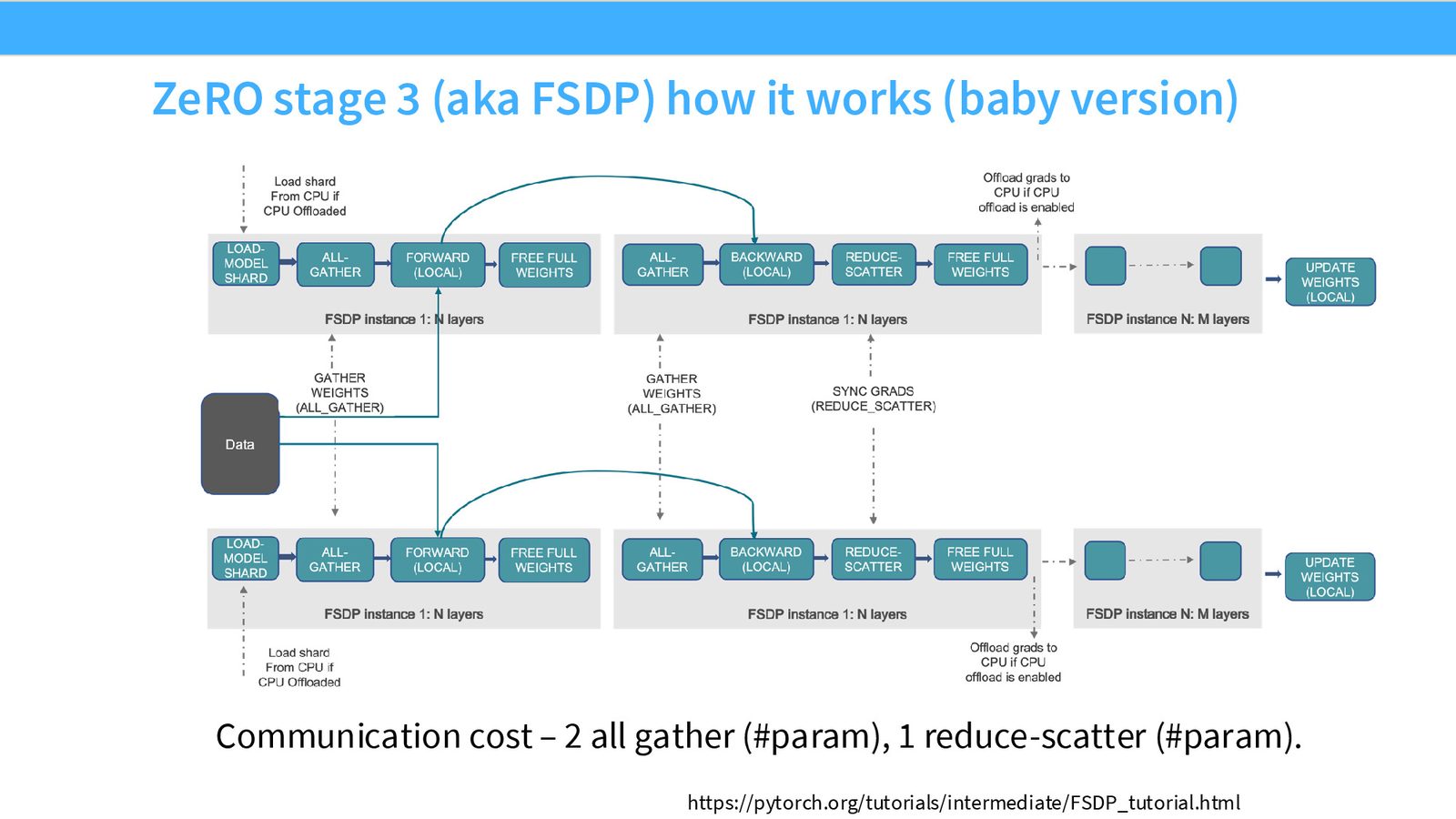
来源:Slides 第22页。
FSDP 的通信开销与效率
FSDP 总通信量为 \(3|\theta|\):前向 All-Gather + 反向 All-Gather + 反向 Reduce-Scatter。相比朴素数据并行的 \(2|\theta|\),仅增加 50%。通过预取(prefetching)——在计算当前层时预加载下一层参数——可以有效隐藏通信延迟,使 GPU 大部分时间保持在计算状态。

来源:Slides 第24页。
ZeRO 三阶段对比总结
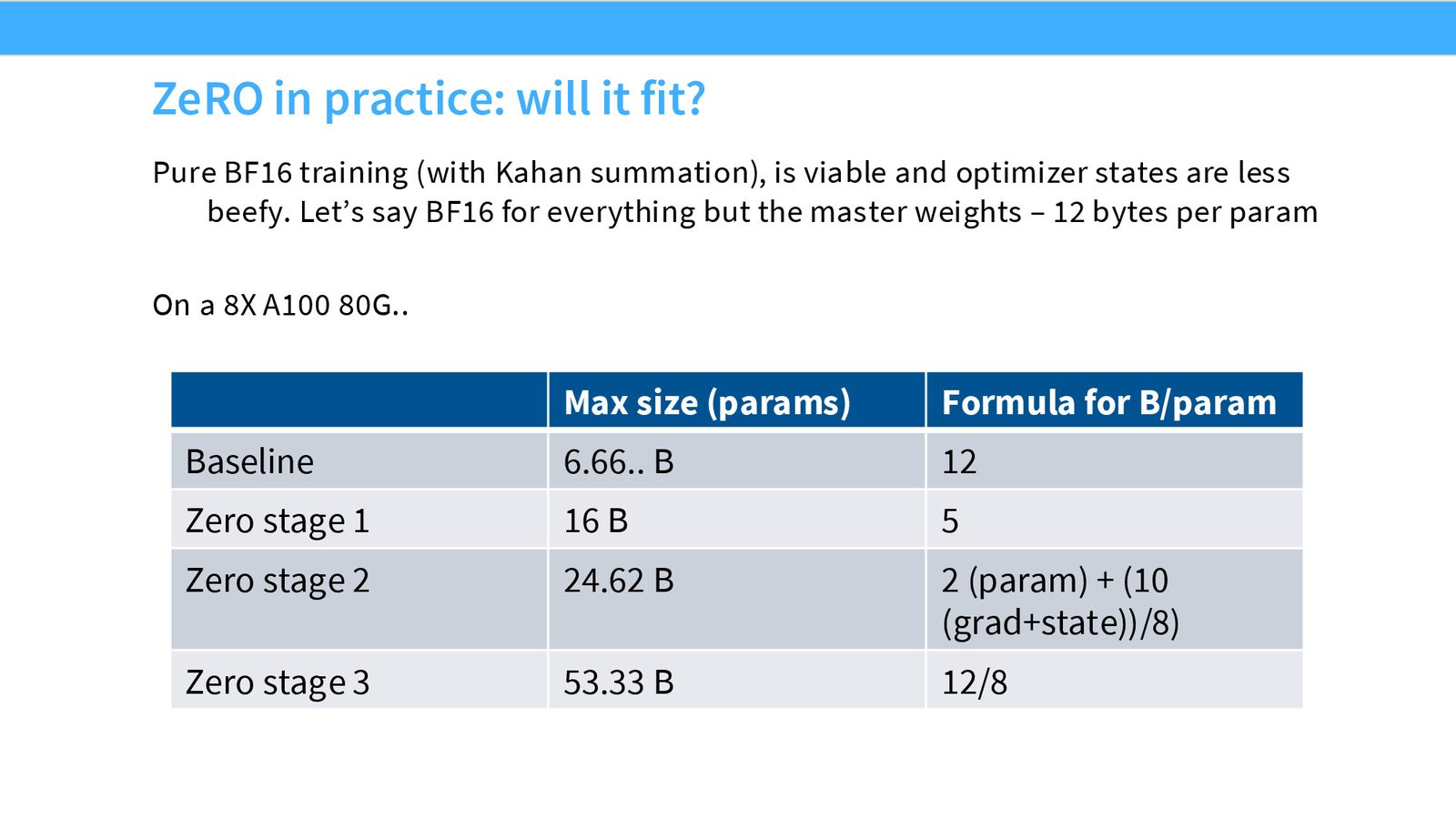
来源:Slides 第25页。
| 策略 | 通信量 | 内存/GPU | 实现复杂度 |
|---|---|---|---|
| 朴素 DP | $2 | θ | $ |
| ZeRO Stage 1 | $2 | θ | $ |
| ZeRO Stage 2 | $2 | θ | $ |
| ZeRO Stage 3 (FSDP) | $3 | θ | $ |
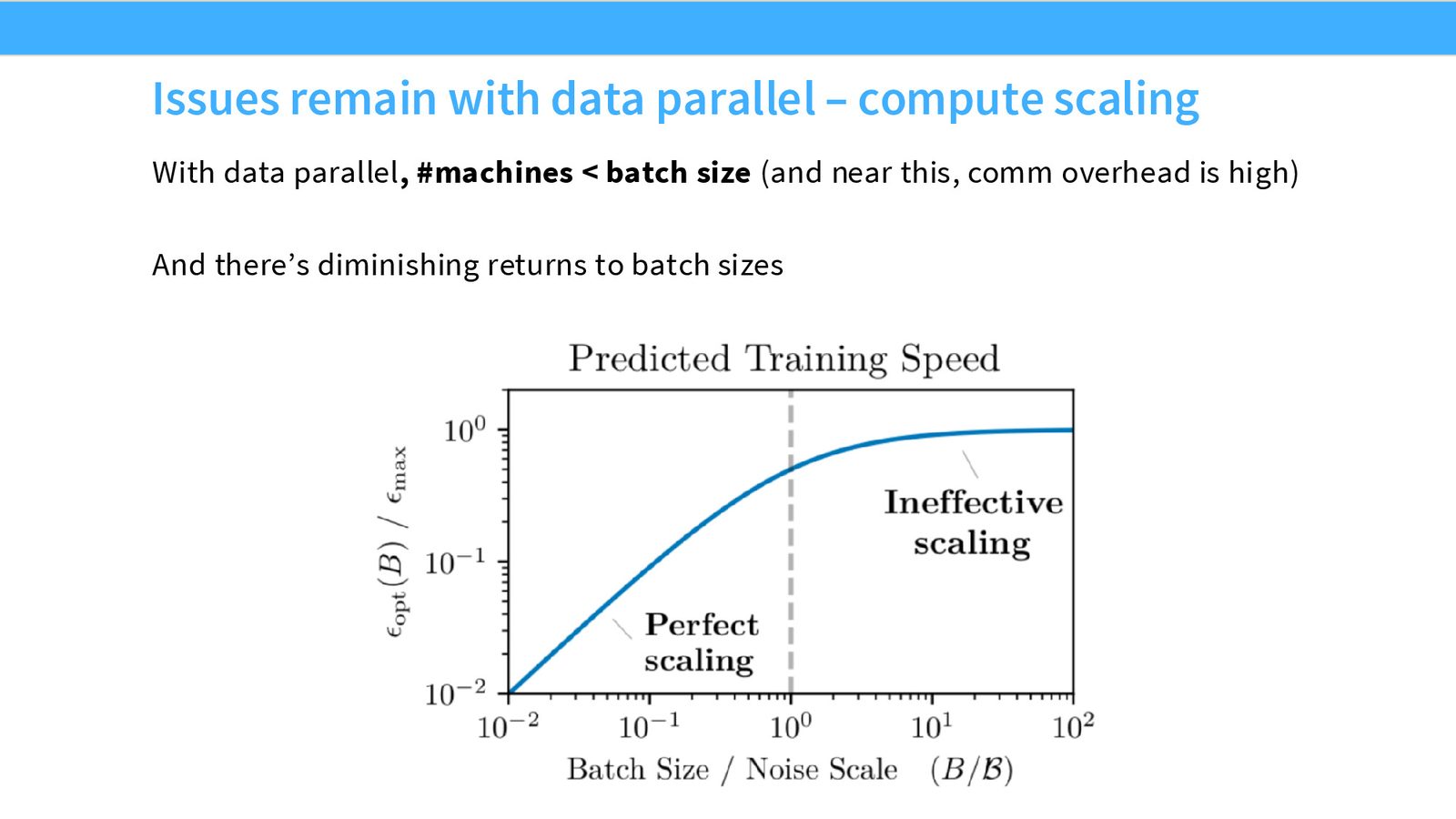
来源:Slides 第26页。
批次大小是一种有限资源

来源:Slides 第28页。
批次大小的限制
数据并行的并行度不能超过批次大小——每个 GPU 至少需要处理一个样本。此外,批次大小存在临界批次大小(critical batch size):超过该值后,增加批次大小的优化收益急剧递减。这意味着数据并行无法无限扩展。
OpenAI 的研究表明,训练效率与批次大小之间存在一个"甜蜜点":低于临界批次大小时,更大批次可以显著降低梯度噪声;超过后则受限于梯度步数不足。批次大小在数据并行、流水线并行等策略之间需要合理分配。
数据并行的剩余问题
来源:Slides 第29页。
即使使用 FSDP(ZeRO Stage 3),数据并行仍有两个重要局限:
- FSDP 可能较慢,因为需要频繁的参数请求和释放
- 不减少激活内存——每个 GPU 仍然需要存储完整的前向传播激活值
这些局限引出了模型并行的需求。
本章小结
数据并行是最基础的并行策略。ZeRO 优化器通过三个阶段逐步消除内存冗余,其中 Stage 1 是"免费午餐"(通信量不变但内存减少),Stage 3(FSDP)实现完全分片但有 50% 的通信量增加。关键限制是批次大小的有限性和激活内存无法分片。
模型并行(Model Parallelism)
当数据并行无法满足内存需求或批次大小限制时,我们需要将模型本身切分到不同 GPU 上。模型并行有两种主要形式:流水线并行(Pipeline Parallelism)和张量并行(Tensor Parallelism)。
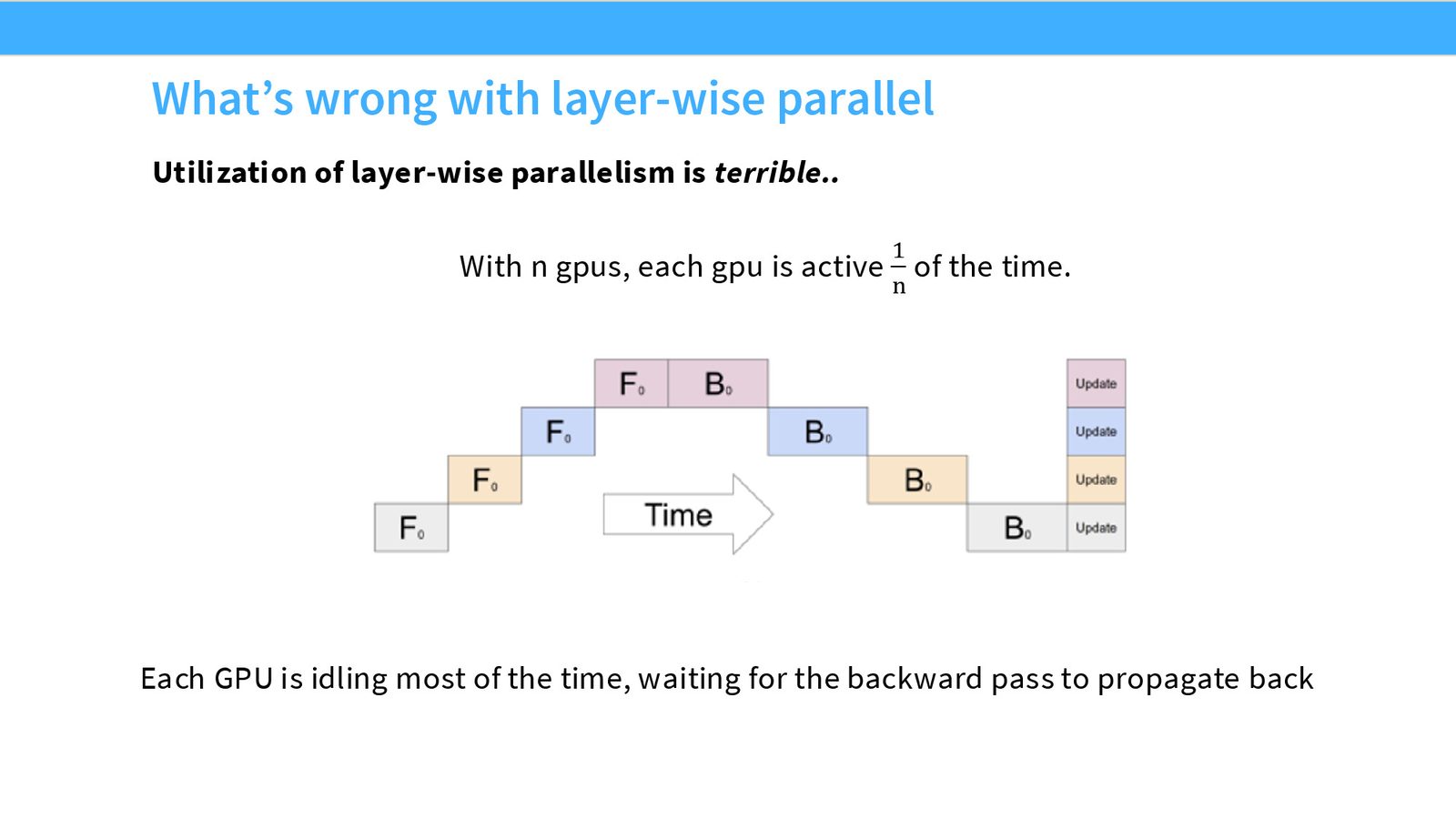
来源:Slides 第30页。
与数据并行不同,模型并行中 GPU 之间传递的是激活值而非参数。当激活值远小于参数时,这是非常有利的。
流水线并行
基本思想
流水线并行是最直观的模型切分方式:按层切分。每个 GPU 负责模型的若干连续层,前一个 GPU 的输出激活传递给下一个 GPU。
来源:Slides 第31页。
气泡问题
朴素的流水线并行存在严重的气泡(bubble)问题:大部分时间里,大部分 GPU 处于空闲状态。

来源:Slides 第32页。
朴素流水线 = 用 4 个 GPU 获得 1 个 GPU 的吞吐
如果只有一个样本流经流水线,那么 \(N\) 个 GPU 的利用率只有 \(1/N\)。这是因为前向和反向传播的层间依赖导致 GPU 必须等待前一阶段完成。
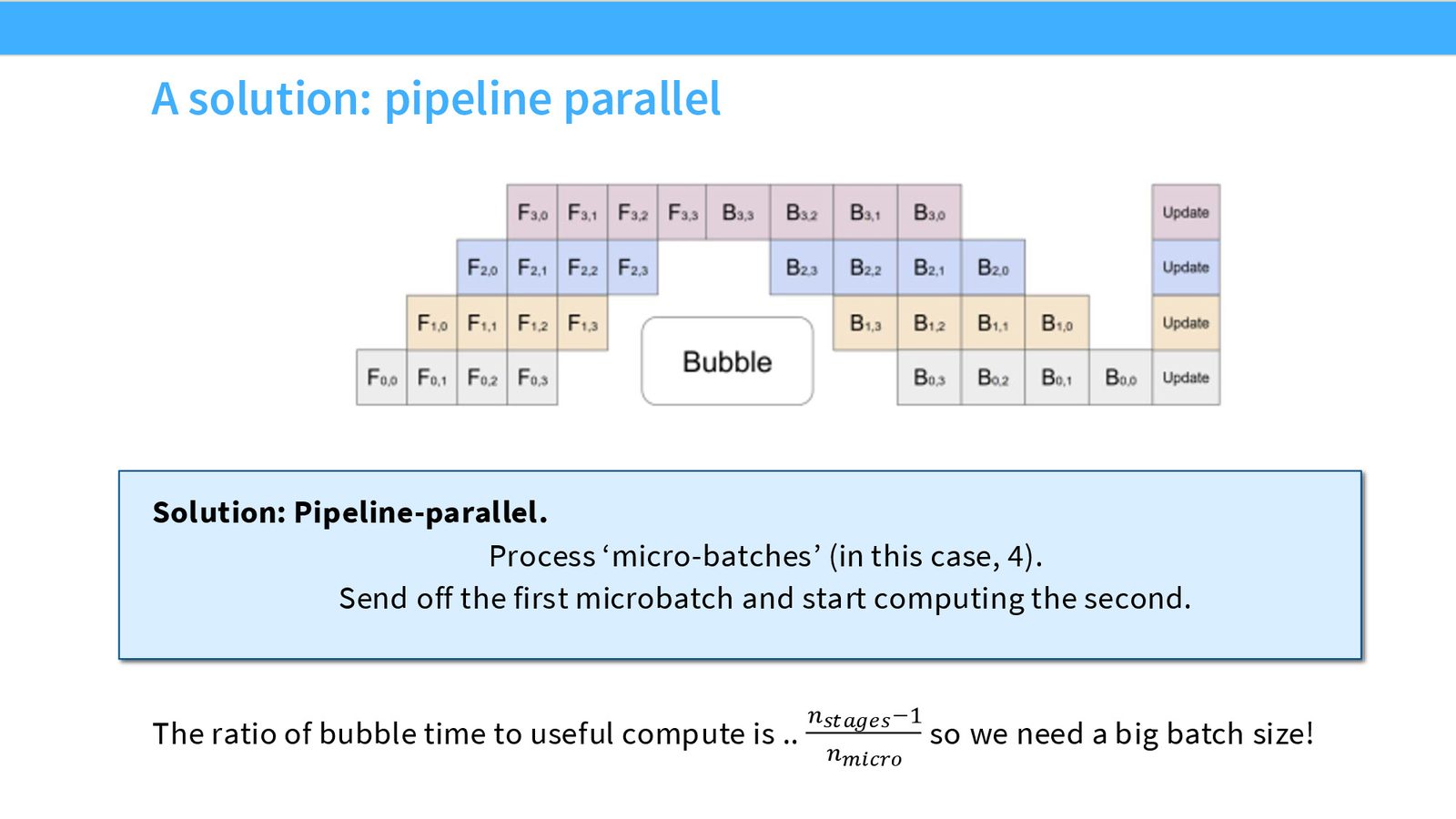
微批次流水线
通过将批次拆分为多个微批次(micro-batch),可以显著减少气泡大小。当一个微批次在 GPU 2 上处理时,GPU 1 可以开始处理下一个微批次。
来源:Slides 第33页。
气泡比例公式:
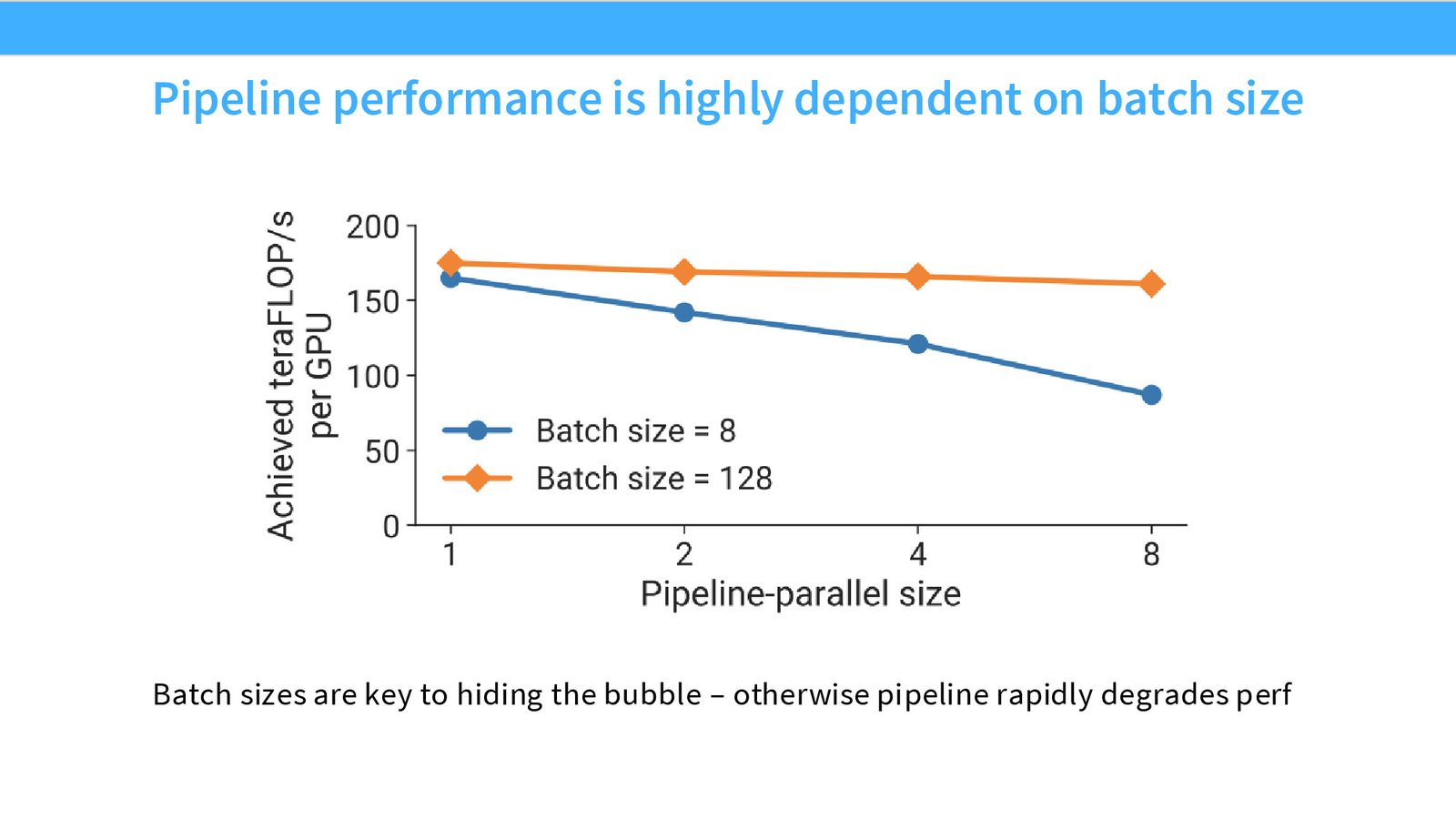
其中 \(P\) 是流水线阶段数(GPU 数),\(M\) 是微批次数。增大微批次数可以降低气泡比例,但这需要更大的批次大小。
来源:Slides 第34页。来自 NVIDIA Megatron-LM 论文。
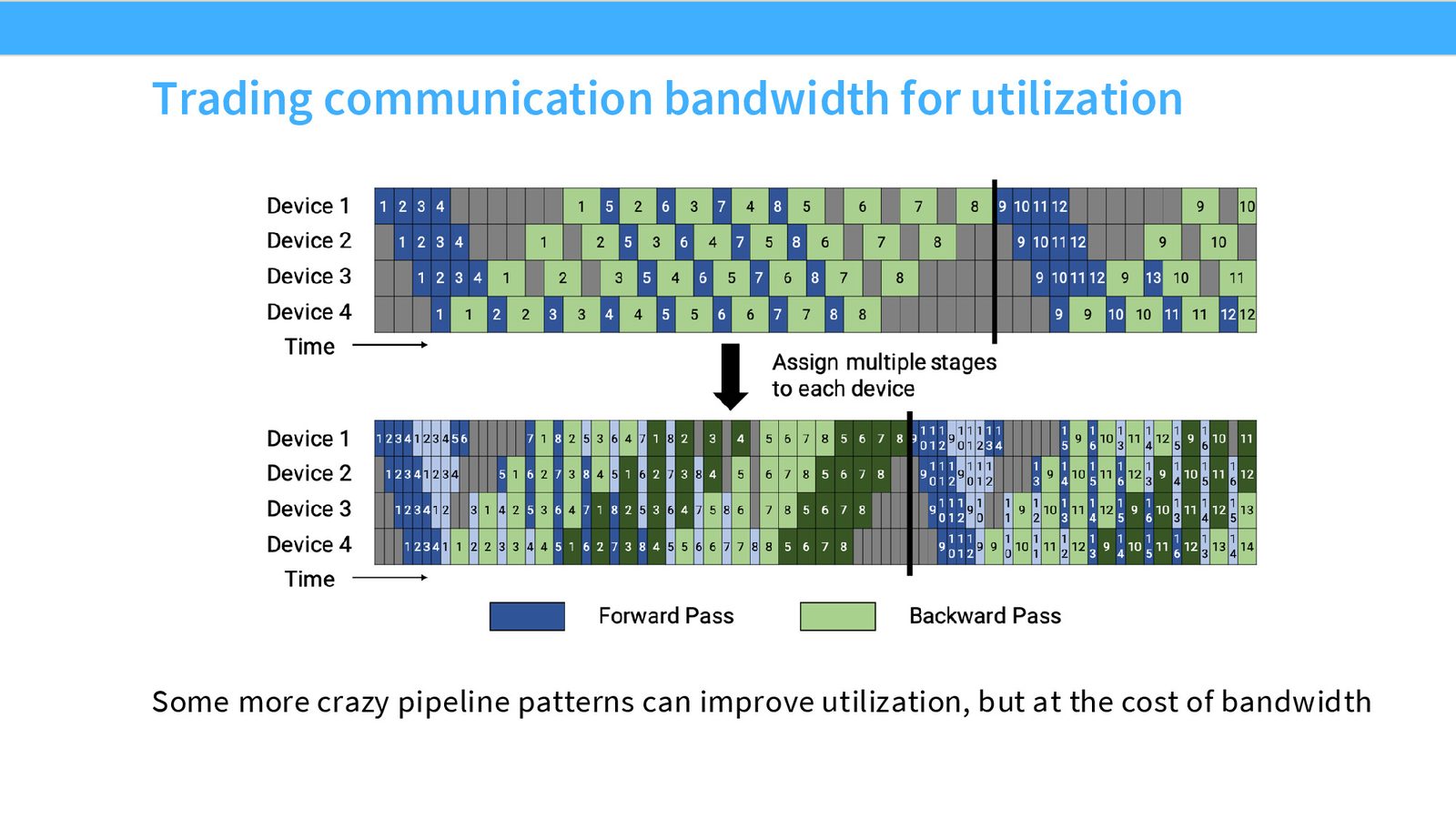
零气泡流水线(Zero Bubble Pipeline / DualPipe)
来源:Slides 第36页。
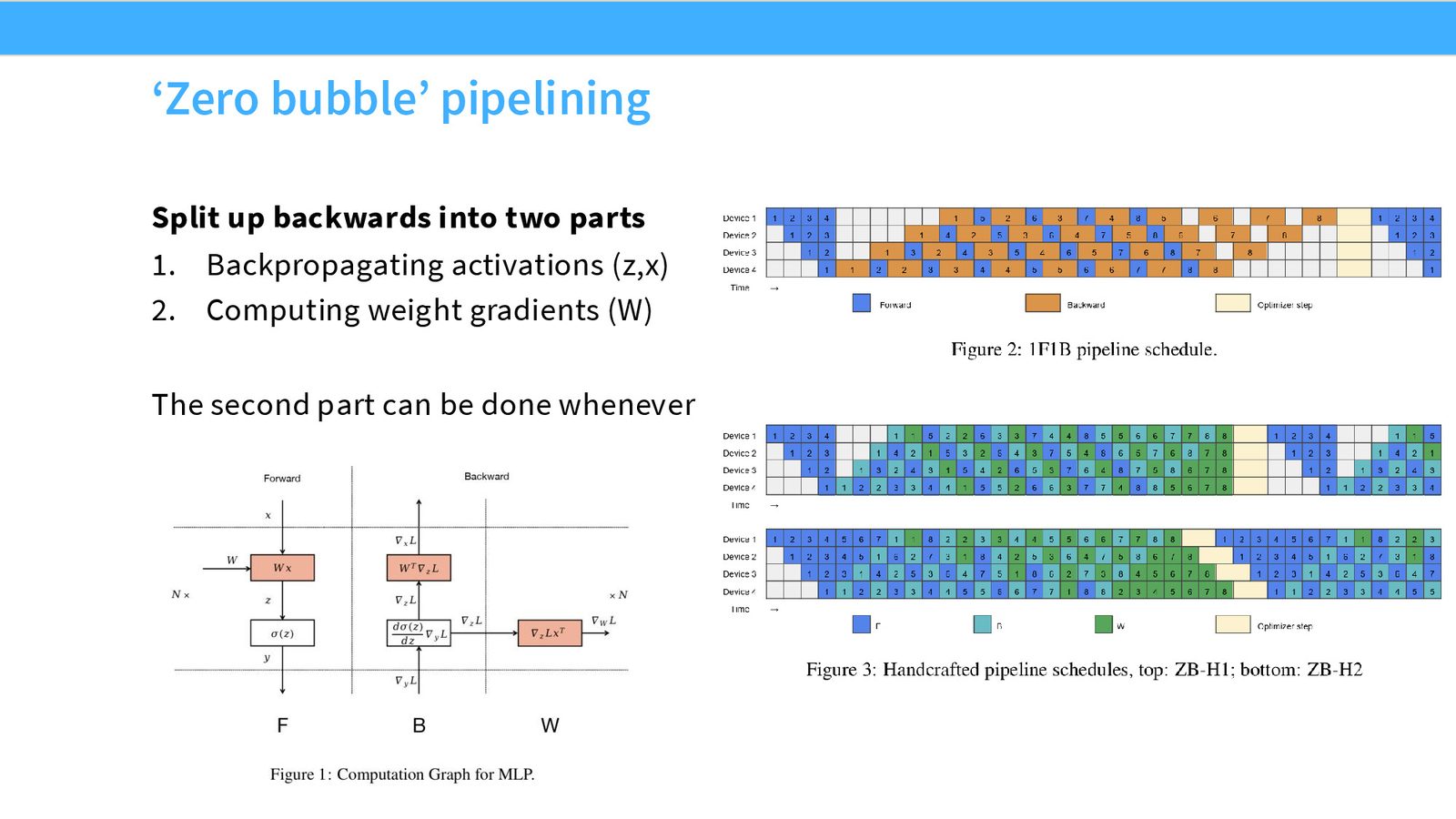
这是一个非常巧妙的优化。观察到反向传播可以分解为两个子操作:
- B(Backward activation):计算关于输入激活的梯度——这部分有串行依赖,必须按层顺序执行
- W(Weight gradient):计算关于权重的梯度——这部分没有依赖,可以在任意时刻执行
来源:Slides 第37页。
零气泡的关键洞察
反向传播中,激活梯度(\(\frac{\partial \mathcal{L}}{\partial x}\))需要立即传递给前一层(串行依赖),但权重梯度(\(\frac{\partial \mathcal{L}}{\partial W}\))可以延后计算。将 W 调度到流水线气泡位置,即可接近 100% 利用率。DeepSeek 的 DualPipe 正是基于此思想。
流水线并行的工程复杂度
实现高效的流水线并行需要干预自动微分系统、维护复杂的调度队列。Tatsu 引用了一个轶事:某前沿实验室中只有两人理解流水线并行的实现,其中一人已离职,导致只剩一个"承重人"维护整个训练基础设施。
流水线并行的优劣势
来源:Slides 第35页。
优势:
- 通信量小:仅传递激活值,且为点对点通信(非集合通信)
- 内存扩展:参数和激活都被分到不同 GPU
- 适合慢速链路:跨节点、跨机架时的首选
劣势:
- 气泡浪费:即使优化后仍有一定开销
- 消耗批次大小:需要足够多的微批次来填充流水线
- 实现极其复杂
Google TPU 团队的观点
Google 工程师表示,TPU 的环面网格网络使他们不需要大量使用流水线并行——因为没有 GPU 世界中 256 GPU 之后带宽骤降的问题。这使得 TPU 训练框架更加简洁。
本章小结
流水线并行通过按层切分模型来减少内存需求,适用于慢速跨节点链路。气泡是核心挑战,可通过增大微批次和零气泡调度来缓解。但其实现复杂度很高,在实践中应尽可能用其他方式替代。
张量并行(Tensor Parallelism)
与流水线并行"纵向"切分不同,张量并行是"横向"切分:将每一层的矩阵乘法分解为子矩阵,分配到不同 GPU 上并行计算。
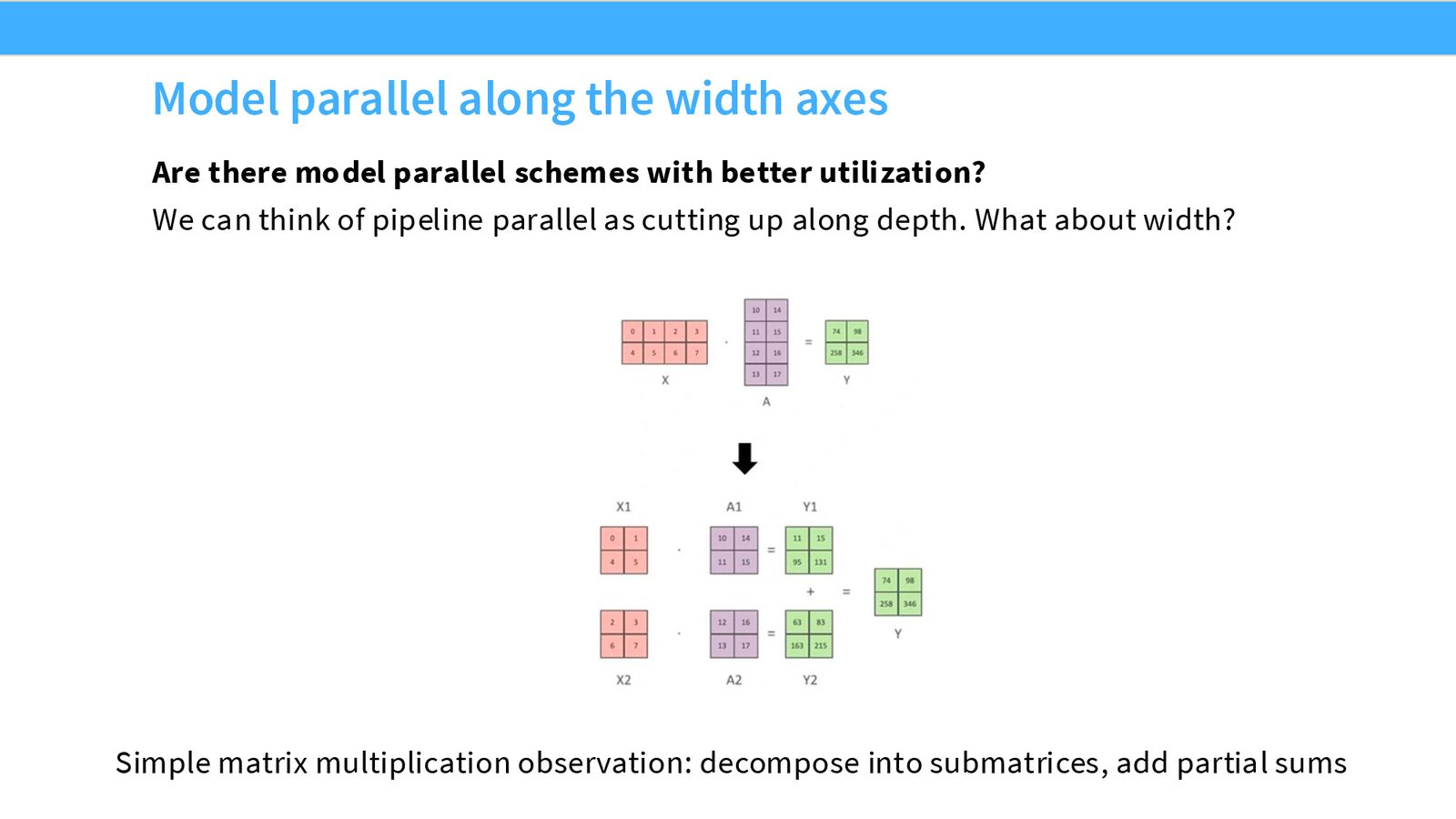
基本原理:矩阵乘法分块

来源:Slides 第39页。
对于矩阵乘法 \(Y = XA\),可以沿不同维度切分矩阵 \(A\):
每个 GPU 负责一个子矩阵的乘法,然后通过 All-Reduce 或拼接来聚合结果。
MLP 中的张量并行
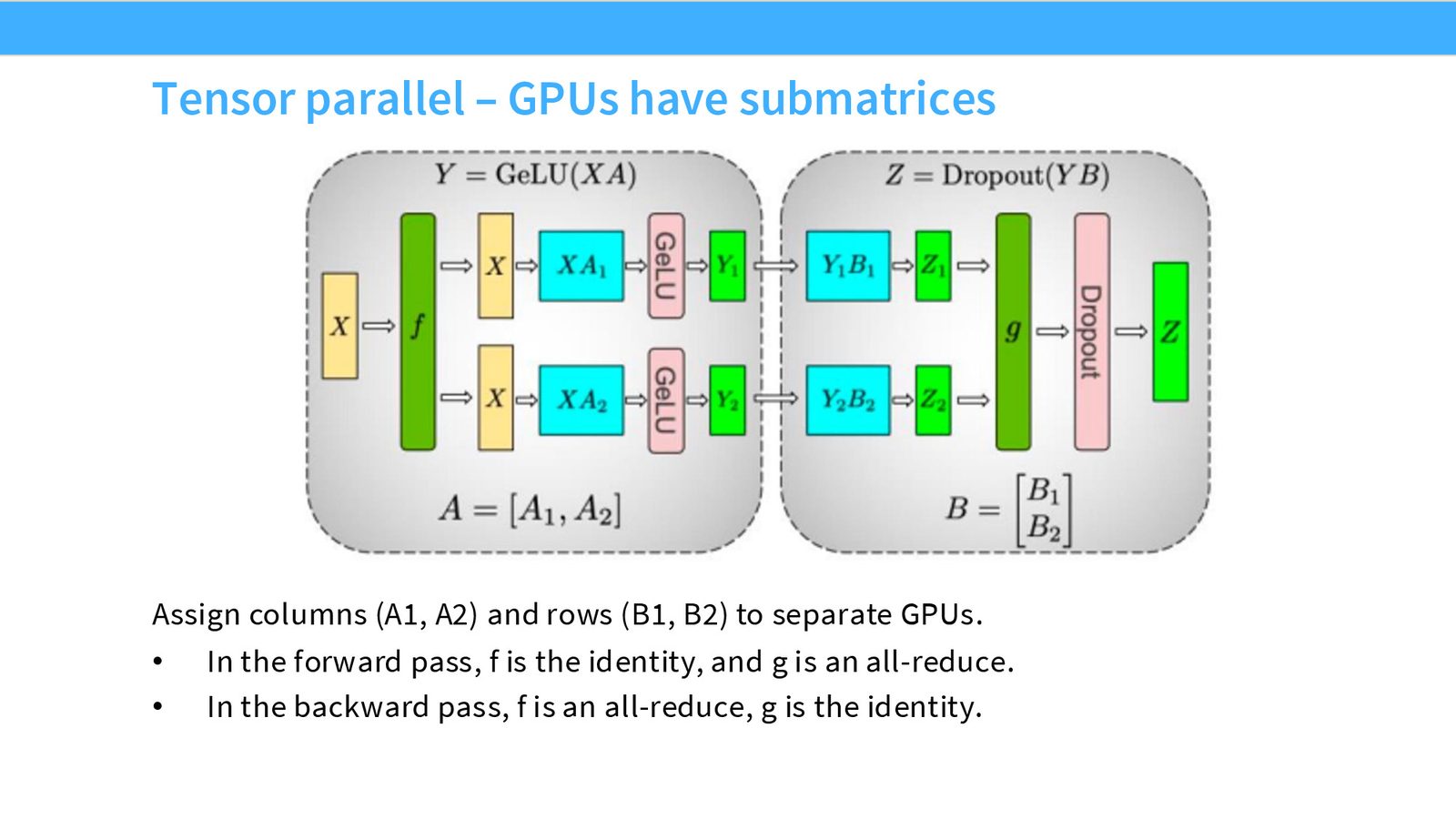
来源:Slides 第40页。
以两层 MLP(\(Z = \text{dropout}(\text{GeLU}(XA) \cdot B)\))为例:
-
前向传播:
-
在 \(f\) 处复制输入 \(X\) 到所有 GPU
- 每个 GPU 计算 \(Y_i = \text{GeLU}(X \cdot A_i)\),然后 \(Z_i = Y_i \cdot B_i\)
- 在 \(g\) 处 All-Reduce 求和:\(Z = \sum_i Z_i\)
-
反向传播:
-
在 \(g\) 处复制梯度到所有 GPU
- 各 GPU 独立计算反向
- 在 \(f\) 处 All-Reduce 梯度
张量并行的同步模式
每一层需要一次前向 All-Reduce 和一次反向 All-Reduce。对于 \(L\) 层 Transformer,每个训练步需要 \(2L\) 次 All-Reduce,每次通信量为 \(B \times S \times H\)(批次 \(\times\) 序列长度 \(\times\) 隐藏维度)。这是一种通信密集型策略。
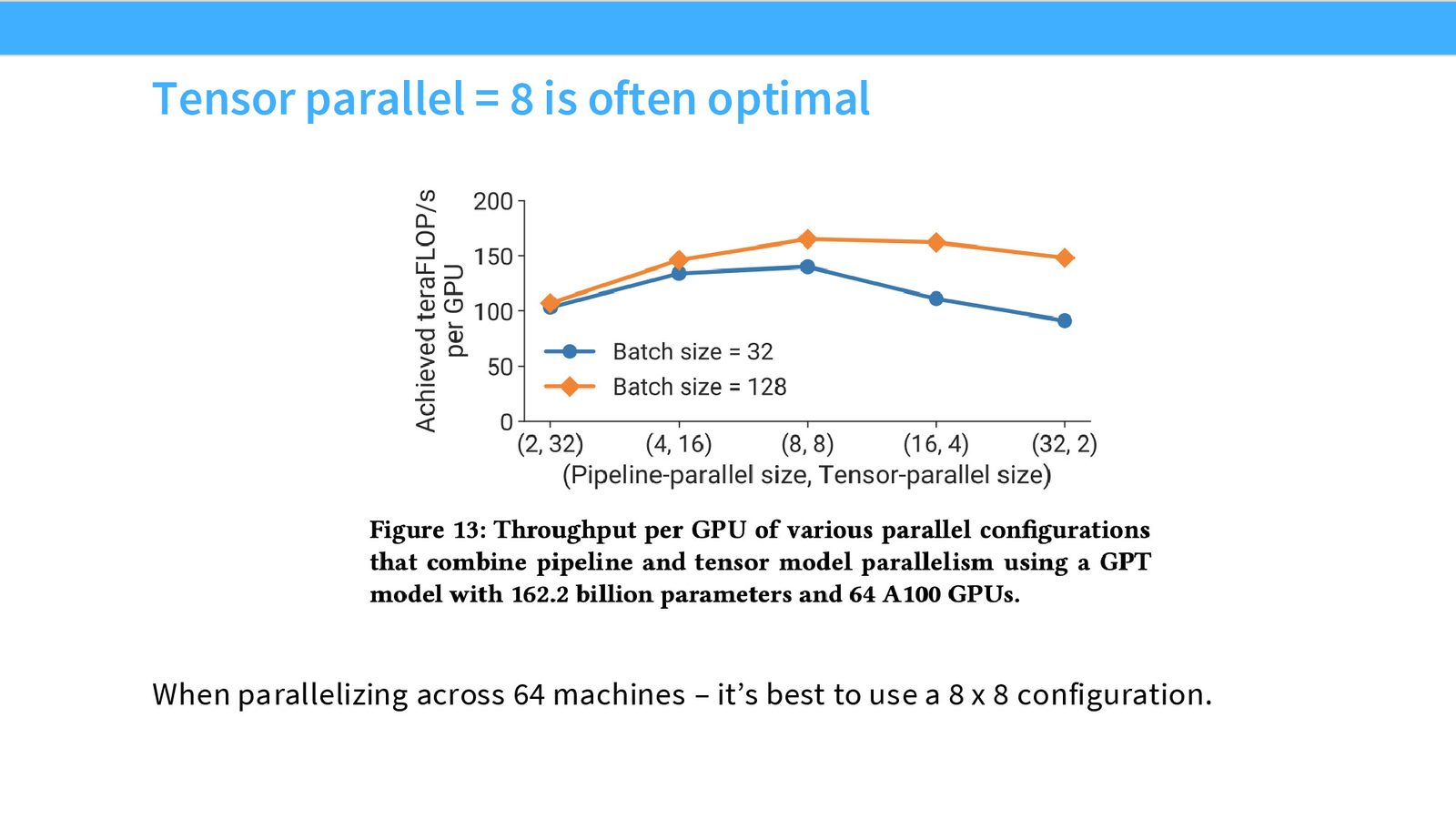
张量并行的经验法则
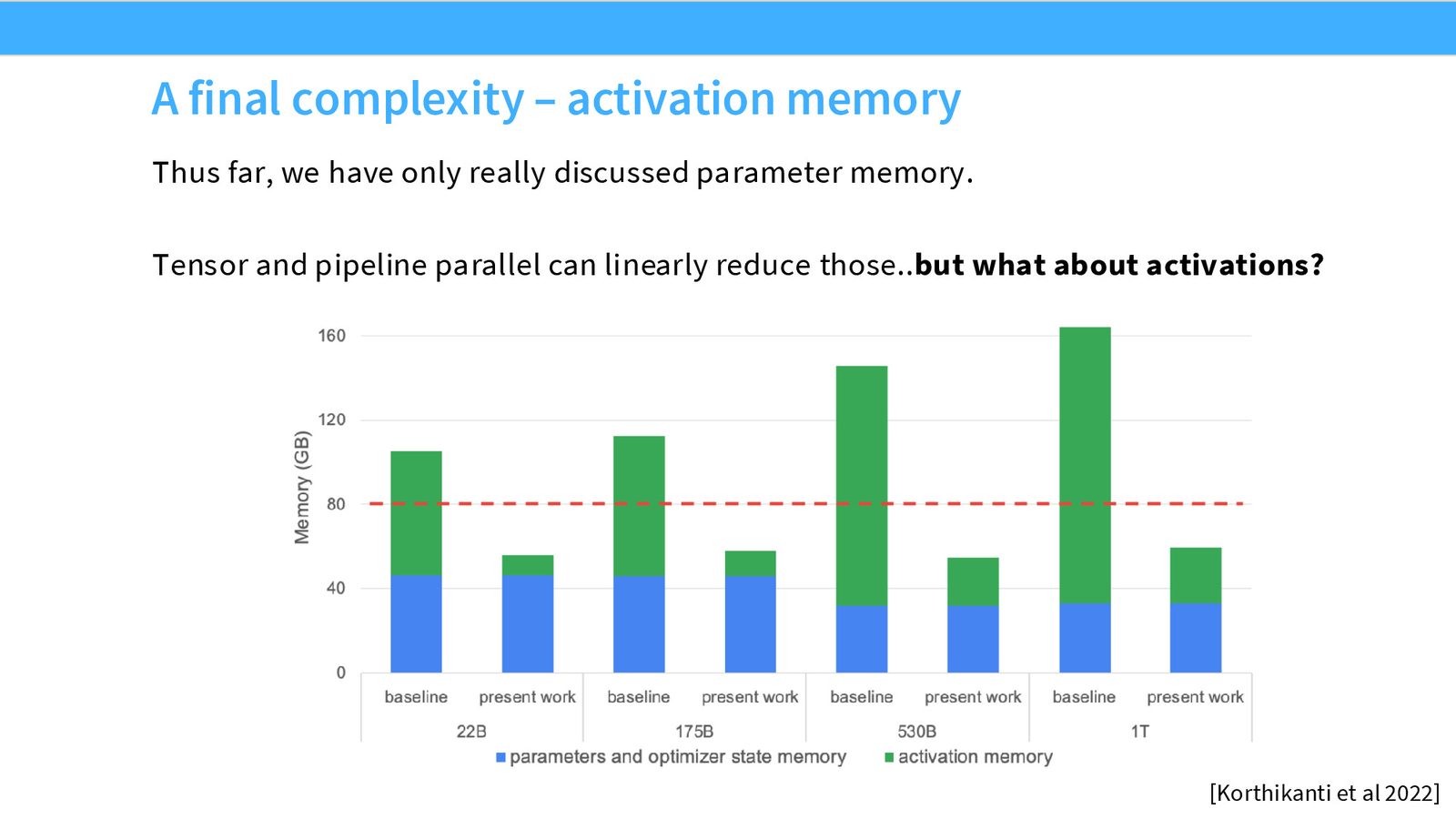
来源:Slides 第41页。来自 HuggingFace 并行化教程。
张量并行度 \(≤\) 8(节点内 GPU 数)
实验数据显示:
- TP=2: 吞吐下降约 10%
- TP=4: 吞吐下降约 10%
- TP=8: 吞吐下降约 12%(仍在节点内)
- TP=16: 吞吐下降约 42%(跨节点!)
- TP=32: 吞吐下降约 65%
一旦超出节点内的 NVLink 带宽,性能急剧恶化。因此,张量并行应始终限制在单节点内。
张量并行 vs. 流水线并行

来源:Slides 第43页。
| 特性 | 流水线并行 | 张量并行 |
|---|---|---|
| 切分方式 | 按层(深度) | 按矩阵(宽度) |
| 通信类型 | 点对点 | All-Reduce |
| 通信量/层 | \(B × S × H\) | \(8 × B × S × H\) |
| 气泡 | 有(需微批次缓解) | 无 |
| 批次消耗 | 是 | 否 |
| 实现复杂度 | 非常高 | 中等 |
| 最佳使用场景 | 跨节点慢速链路 | 节点内高速互连 |
本章小结
张量并行通过矩阵分块将单层计算分布到多个 GPU 上,无气泡开销但通信密集。实践中应限制在单节点内(\(\leq 8\) GPU),利用 NVLink 高带宽。与流水线并行互补:张量并行用于节点内,流水线并行用于跨节点。
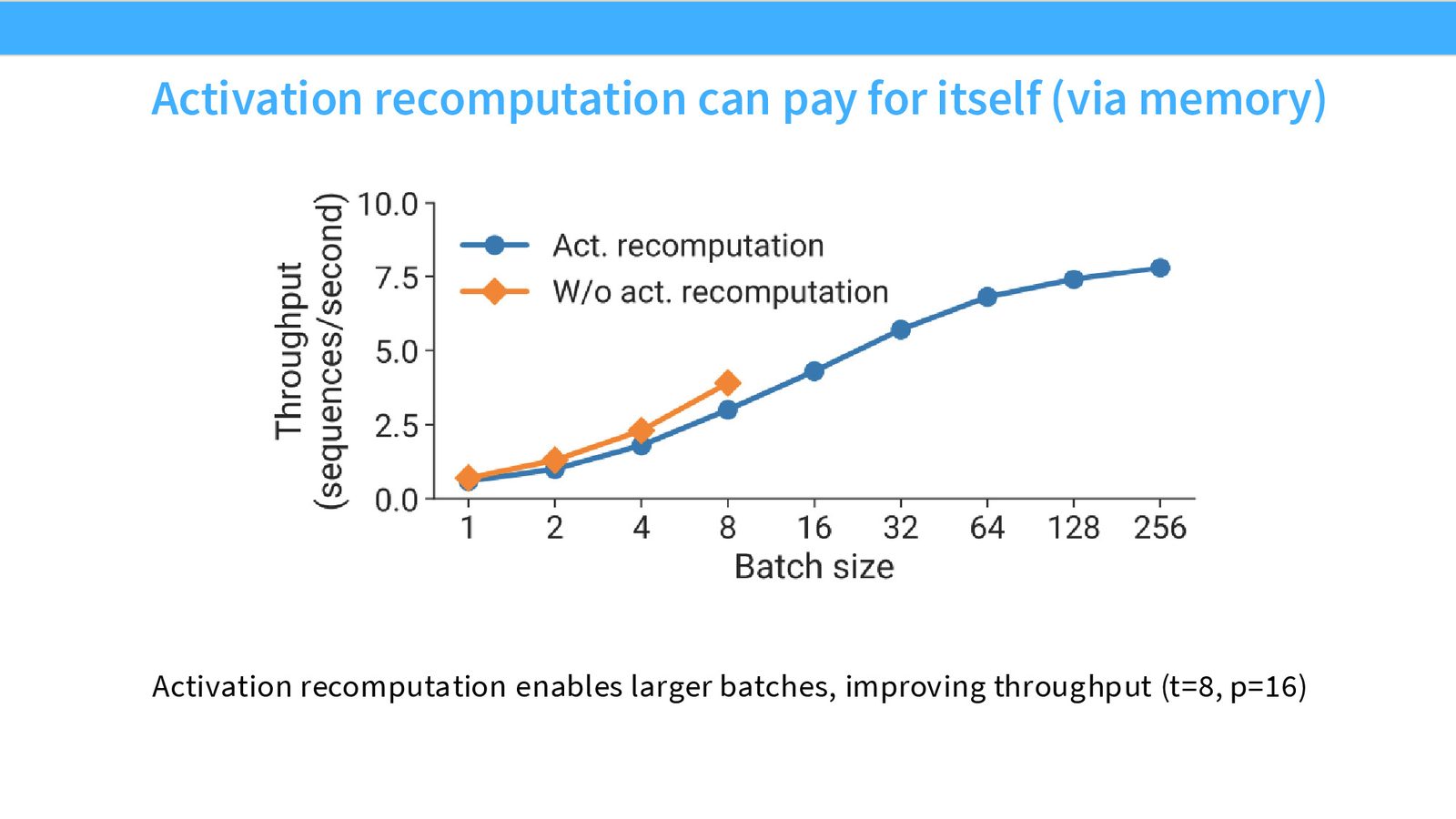
序列并行与激活内存
数据并行和模型并行可以有效地分片参数和优化器状态,但激活内存是另一个必须解决的瓶颈。
激活内存的分析
来源:Slides 第45页。
在前向传播过程中,每一层的激活值需要保存以供反向传播使用。对于 Transformer,每层的激活内存为:
其中 \(S\) = 序列长度,\(B\) = 批次大小,\(H\) = 隐藏维度,\(A\) = 注意力头数。
激活内存公式解读
- 左项 \(34 \cdot SBH\):来自 MLP 和逐元素操作(LayerNorm、Dropout、残差连接等),与 \(H\) 成正比
- 右项 \(5AS^2B\):来自注意力矩阵(\(QK^\top\) 和 Softmax),与 \(S^2\) 成正比——使用 FlashAttention 可通过重计算大幅减少此项
张量并行对激活内存的影响

来源:Slides 第47页。
应用张量并行后,每层激活内存变为:
其中 \(T\) 为张量并行度。注意 \(10 \cdot SBH\) 项无法被张量并行减少——这些对应 LayerNorm、Dropout 等逐元素操作,它们在张量并行中仍然是全量复制的。
序列并行:解决逐元素操作的激活冗余
来源:Slides 第48页。
序列并行的核心思想
LayerNorm 和 Dropout 等操作在不同序列位置之间完全独立(不存在跨位置的依赖)。因此可以将序列维度平均分配到 \(T\) 个 GPU 上:
- 每个 GPU 只处理 \(S/T\) 个位置的 LayerNorm 和 Dropout
- 进入 MatMul 前需要 All-Gather 恢复完整序列
- 退出 MatMul 后需要 Reduce-Scatter 重新分片
前向传播中的同步点变为 All-Gather + Reduce-Scatter(代替原来的复制 + All-Reduce),总通信量不变。
激活内存的最终优化
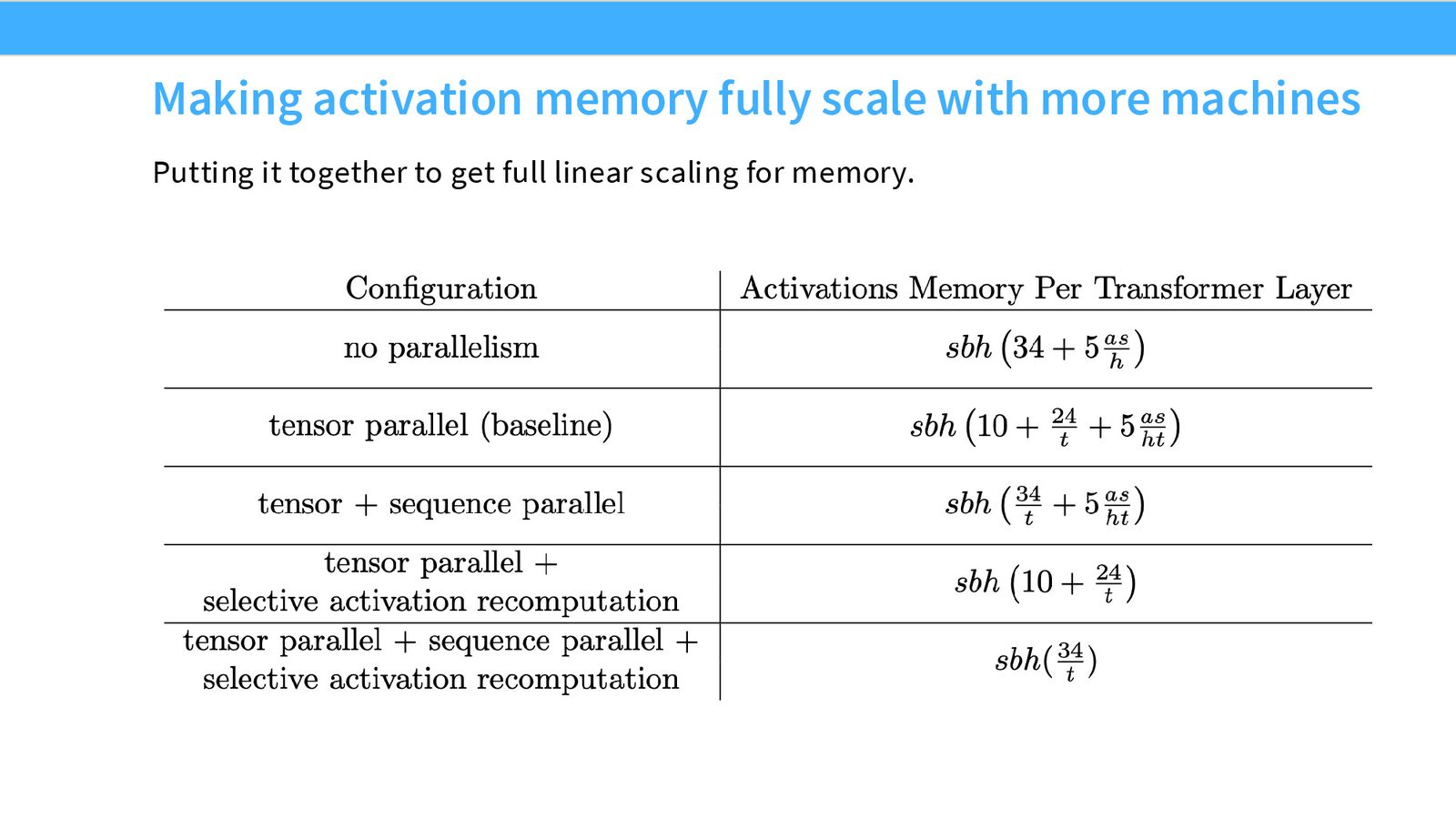
来源:Slides 第49页。
逐步优化路径:
- 无并行:\(SBH \cdot (34 + 5AS/H)\)
- 张量并行:MatMul 相关项除以 \(T\),但逐元素项 \(10 \cdot SBH\) 不变
- + 序列并行:逐元素项也除以 \(T\)
- + 激活重计算(FlashAttention):消除 \(5AS^2B/T\) 项
最终每层激活内存的实用下界为:
这也是社区中广泛使用的"\(34SBH/T\)"公式的来源。
本章小结
激活内存是大模型训练的重要瓶颈。张量并行可以减少 MatMul 相关的激活,序列并行通过沿序列维度分片来减少逐元素操作的激活。配合 FlashAttention 的激活重计算,可以将每层激活内存降至 \(34SBH/T\)。
其他并行策略简介
上下文并行 / Ring Attention
来源:Slides 第51页。
上下文并行(Context Parallelism)专门用于超长序列的注意力计算。核心思想:
- 每个 GPU 负责不同位置的 Query
- Key 和 Value 以环形方式在 GPU 之间传递
- 利用 FlashAttention 的在线分块计算能力,边传递边计算
这与 FlashAttention 的 Tiling 思想一脉相承——你已经在作业中实现过注意力的分块计算,Ring Attention 只是将"块"分布到不同 GPU 上。
专家并行(Expert Parallelism)
来源:Slides 第52页。
专家并行用于混合专家(Mixture-of-Experts, MoE)模型。概念上类似张量并行——将一个大 MLP 拆分为多个小"专家"MLP,分布到不同 GPU。关键区别在于专家是稀疏激活的(只有部分专家处理每个 token),因此路由(routing)的负载均衡成为额外挑战。
本章小结
上下文并行解决长序列注意力的内存和计算问题,专家并行用于 MoE 架构。这些策略与前述的数据/张量/流水线并行组合使用,形成完整的 4D/5D 并行方案。
组合并行:3D/4D 并行实践
并行策略全景对比
来源:Slides 第53页。
| 策略 | 通信开销 | 内存扩展 | 消耗批次 | 适用链路 |
|---|---|---|---|---|
| DDP + ZeRO-1 | 每批 $2 | θ | $ | 无 |
| FSDP (ZeRO-3) | 每层同步 | 线性 | 是 | 中速 |
| 流水线并行 | 小(点对点) | 线性 | 是 | 慢速 |
| 张量并行 | 大(每层 All-Reduce) | 线性 | 否 | 高速必需 |
三种核心有限资源
大规模训练需要平衡三种有限资源:
- 内存:参数 + 优化器状态 + 激活
- 带宽/计算:通信开销 vs. 有效计算
- 批次大小:一种非传统但极其重要的资源——数据并行和流水线并行都"消耗"它
批次大小与并行策略的关系

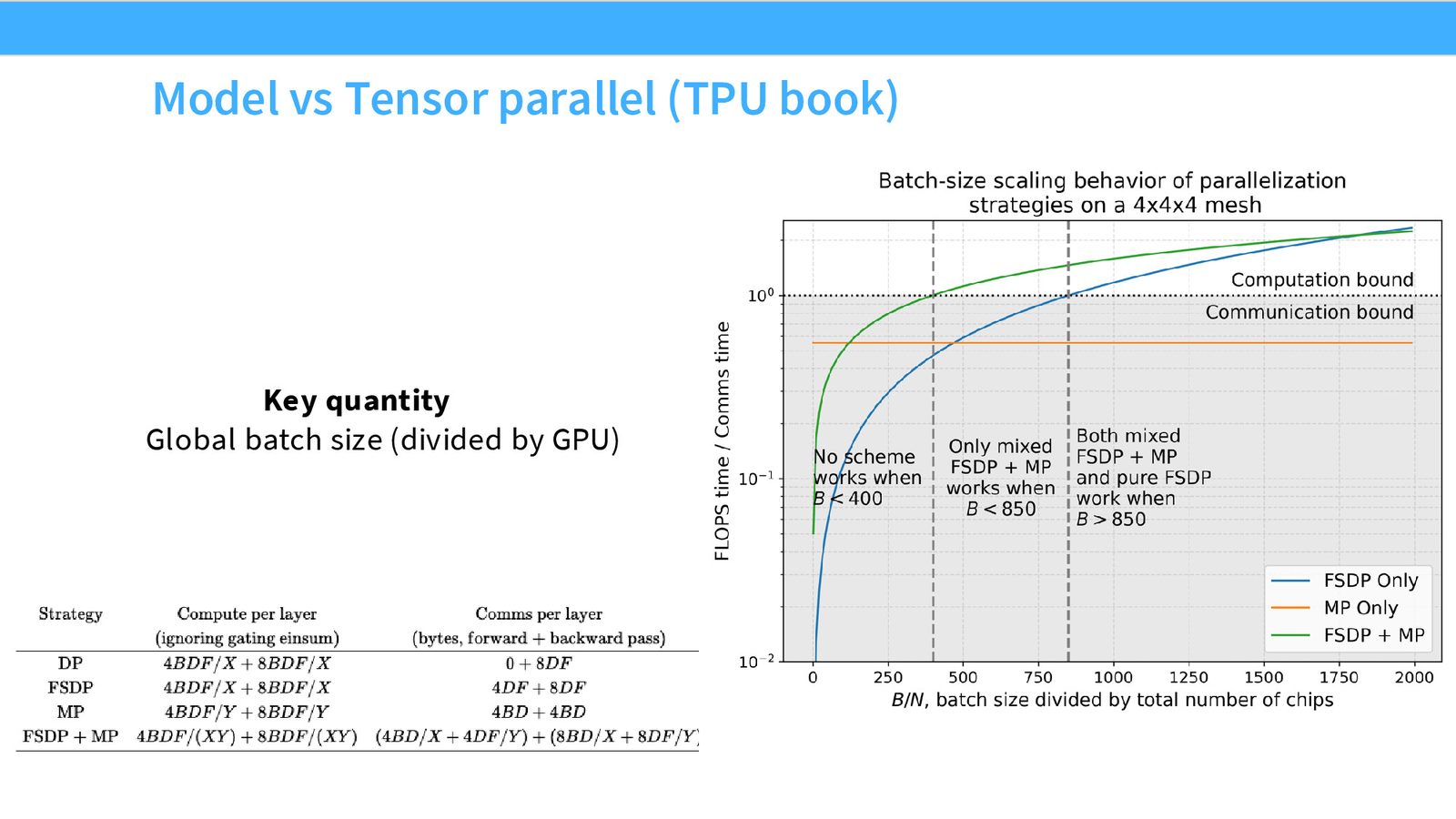
来源:Slides 第54页。来自 Google TPU 并行化指南。
批次大小决定最优策略
- 批次太小:通信受限,无论用哪种策略都效率低下
- 中等批次:需要 FSDP + 张量并行的组合才能达到计算受限(compute-bound)
- 大批次:纯 FSDP(数据并行)就足以实现高效率
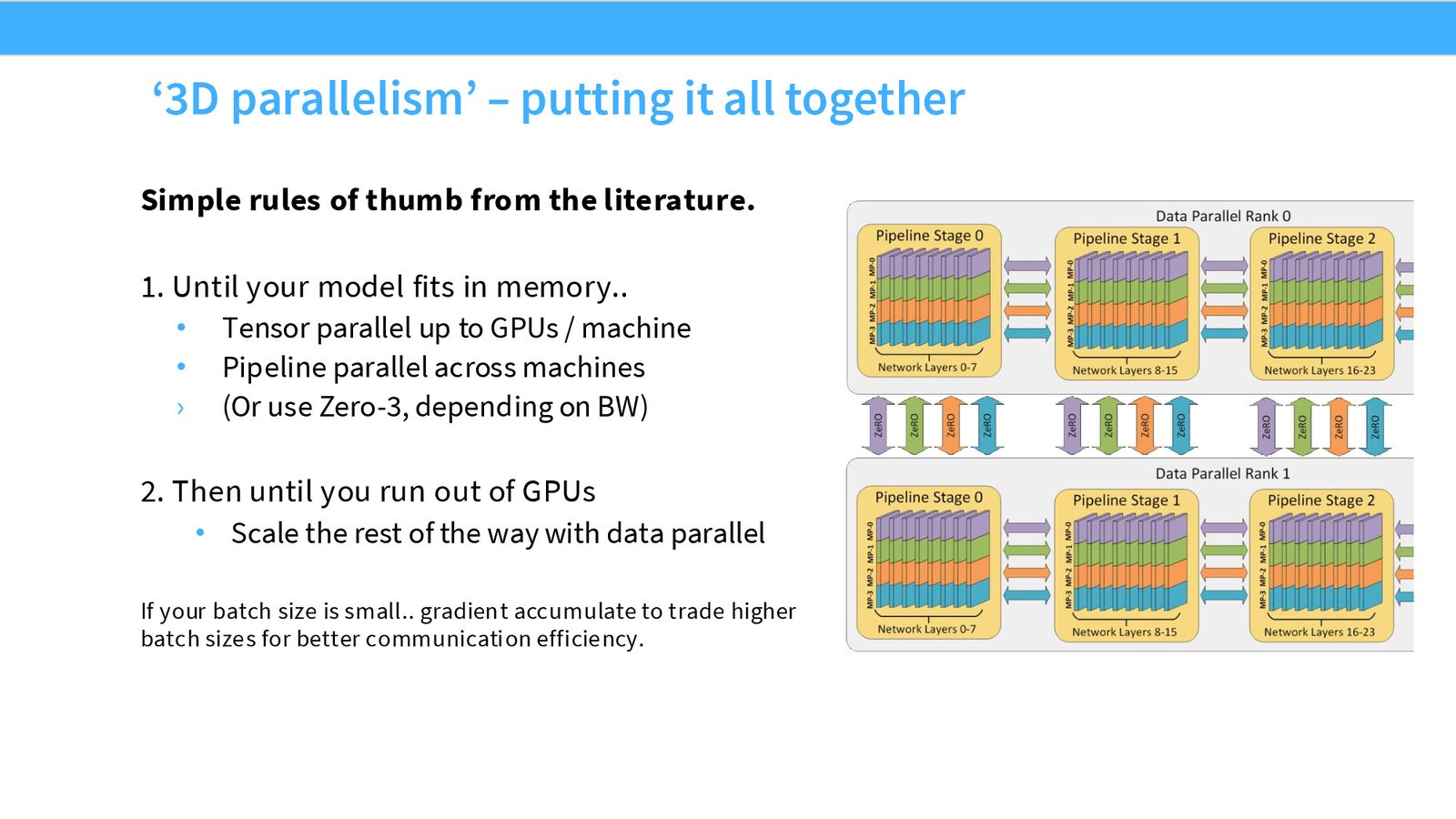
3D 并行的经验法则

来源:Slides 第55页。
3D 并行配置法则
按优先级从高到低:
- 首先用张量并行填满节点内 GPU(通常 \(T=8\)),确保模型参数能放进内存
- 如果还放不下,用 ZeRO Stage 3 或流水线并行跨节点扩展
- 剩余 GPU 用数据并行来扩展总吞吐量
- 如果批次大小仍有余量,用梯度累积增大有效批次,减少同步频率
带宽需求从高到低:张量并行 \(>\) 上下文并行 \(>\) 流水线并行 \(>\) 数据并行。
本章小结
实际训练中需要组合多种并行策略。核心原则是:高通信量的策略放在高带宽链路上(张量并行 \(\rightarrow\) 节点内),低通信量的策略放在慢速链路上(数据并行 \(\rightarrow\) 跨机架)。批次大小是连接所有策略的关键资源。
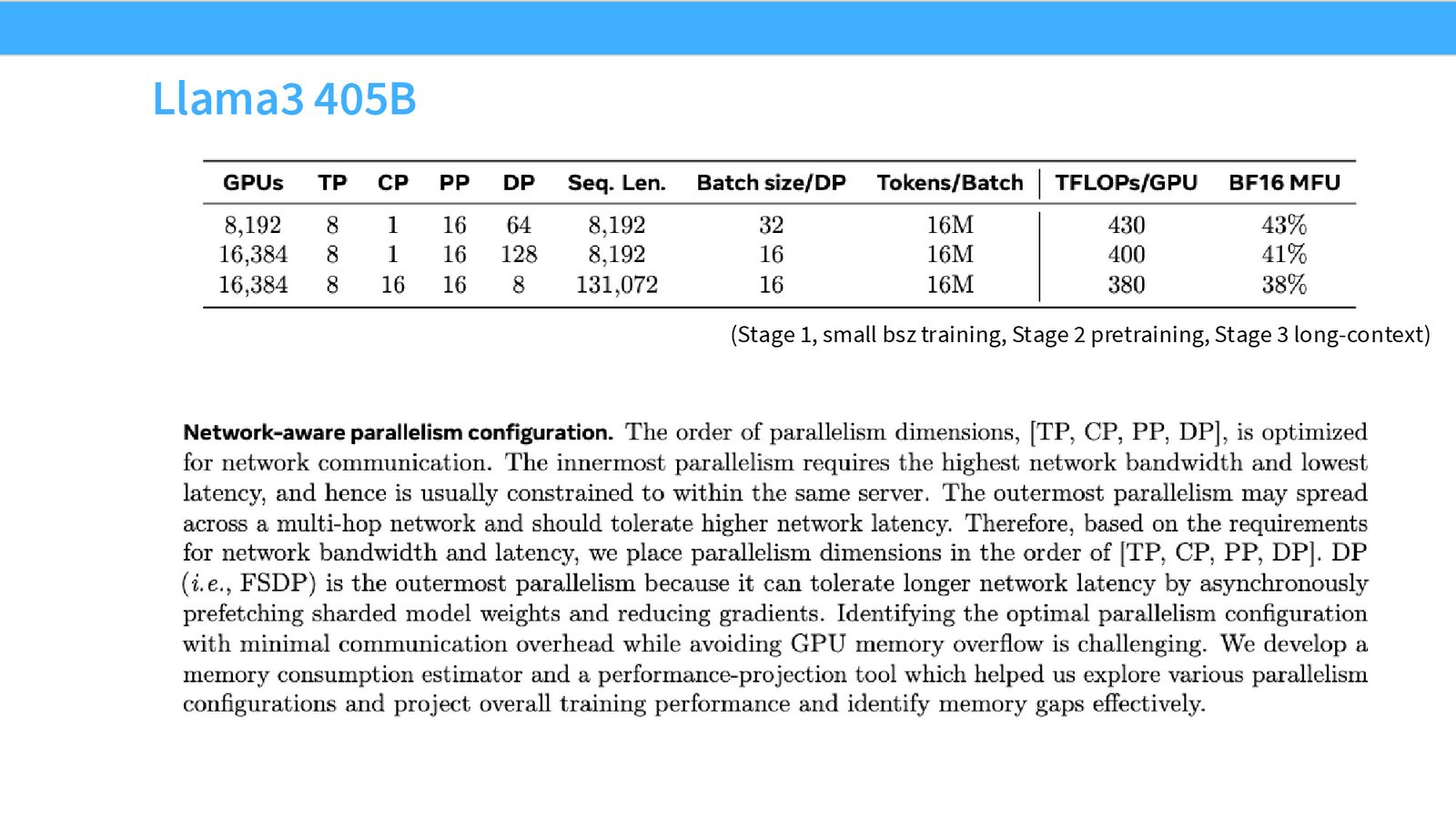
案例研究:真实大模型的并行策略
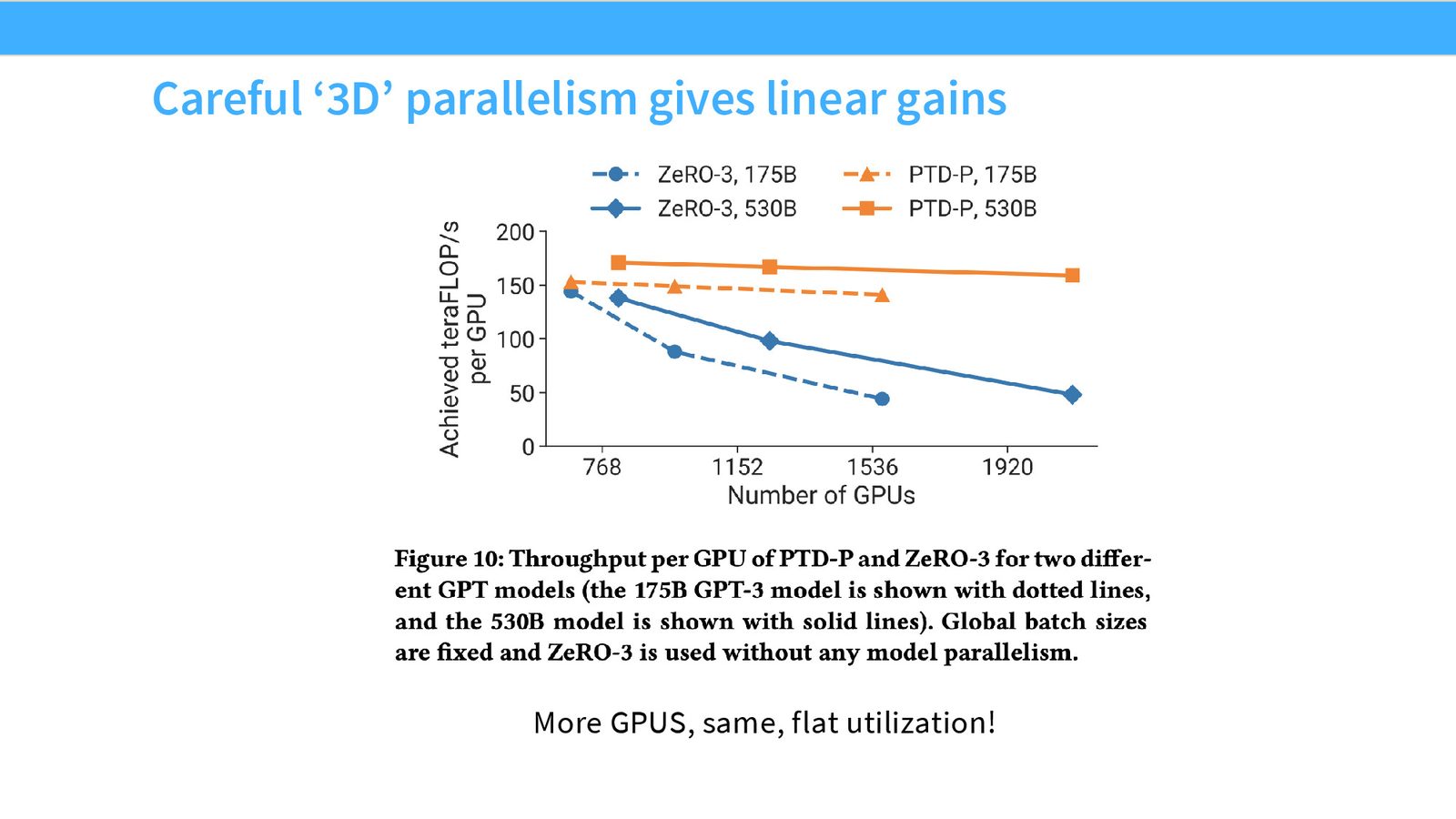
Megatron-LM:系统化的 3D 并行

来源:Slides 第56页。来自 Narayanan et al., 2021。
从 1.7B 到 1T 参数的模型,可以清晰地看到经验法则的应用:
- 张量并行从 1 增长到 8(封顶于节点内 GPU 数)
- 流水线并行在模型超出单节点内存后启用
- 数据并行从最大值开始逐步减小
- 所有配置都达到了理论峰值 40--52% 的 FLOPS 利用率
来源:Slides 第57页。
近期语言模型的并行策略
来源:Slides 第58页。
| 模型 | 数据并行 | 张量并行 | 流水线并行 |
|---|---|---|---|
| OLMo (7B) | FSDP | – | – |
| DeepSeek v1 | ZeRO-1 | 有 | 有 |
| DeepSeek v3 | ZeRO-1 | 64路专家并行 | 16路 |
| Qwen | ZeRO-1 | 有 | 有 |
| Qwen-MoE | ZeRO-1 | 专家并行 | 有 |
Llama 3:Meta 的大规模训练实践

来源:Slides 第59页。
Llama 3 的 405B 模型训练使用了标准的 4D 并行组合:
- 张量并行 = 8(节点内)
- 流水线并行用于跨节点(视阶段调整)
- 上下文并行(CP)仅在长上下文训练阶段启用
- 数据并行用于剩余 GPU
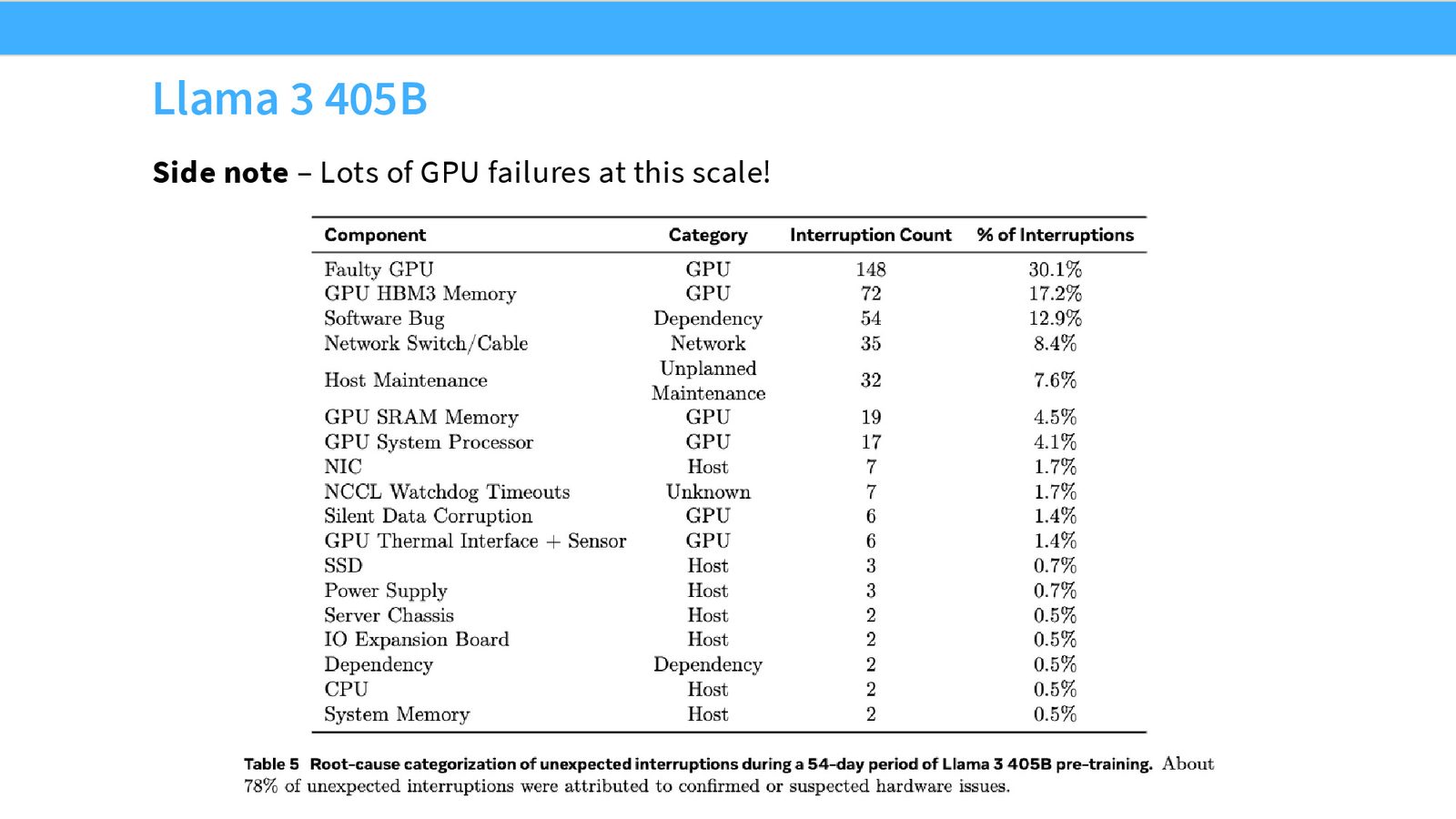
大规模训练中的硬件故障
Llama 3 训练报告显示:
- 148 次由 GPU 故障导致的训练中断(占总中断的 30%)
- 32 次计划外硬件维护
- 更隐蔽的威胁是静默数据损坏——GPU 不报错但输出错误数据,可能毁掉整个训练运行
大规模训练不仅需要高效的并行算法,还需要健壮的容错和检查点机制。
Gemma 2(TPU 案例)

来源:Slides 第60页。
Google 的 Gemma 2 基于 TPU 训练,使用 ZeRO Stage 3(类似 FSDP)+ 模型并行 + 数据并行。TPU 的环面网格使模型并行度可以超过 8,避免了流水线并行的复杂性。
本章小结
从 Megatron-LM 到 Llama 3 到 DeepSeek V3,所有大规模训练都遵循类似的经验法则:张量并行用于节点内、流水线或 FSDP 用于跨节点、数据并行扩展总吞吐。具体的并行度配置取决于模型规模、硬件拓扑和批次大小预算。
总结与延伸
讲者的核心总结
Tatsu Hashimoto 在课程结尾强调了以下要点:
- 没有银弹:单一并行策略无法解决所有问题,需要组合数据并行、张量并行和流水线并行
- 硬件拓扑决定策略:不同层级的带宽差异直接决定了应在哪个层级使用哪种并行
- 简洁的经验法则:先用张量并行填满节点、再跨节点扩展、最后数据并行填充剩余 GPU
- 批次大小是资源:有限的批次大小需要在数据并行度和流水线微批次数之间权衡
全课知识图谱

关键公式汇总
- All-Reduce 恒等式:\(\text{All-Reduce} \equiv \text{Reduce-Scatter} + \text{All-Gather}\)
- 每参数训练内存:\(16\) 字节(BF16 混合精度 + AdamW)
- 流水线气泡比例:\((P-1)/M\)(\(P\) = 阶段数,\(M\) = 微批次数)
- 每层激活内存:\(SBH \cdot (34 + 5AS/H)\)
- 优化后激活内存:\(34 \cdot SBH / T\)(张量+序列并行+重计算)
- FSDP 通信量:\(3|\theta|\)(vs 朴素 DP 的 \(2|\theta|\))
拓展阅读
- Rajbhandari et al., ZeRO: Memory Optimizations Toward Training Trillion Parameter Models: https://arxiv.org/abs/1910.02054
- Narayanan et al., Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM: https://arxiv.org/abs/2104.04473
- Llama 3 Technical Report: https://arxiv.org/abs/2407.21783
- DeepSeek-V3 Technical Report: https://arxiv.org/abs/2412.19437
- Google, Introduction to TPU Training (Parallelism Chapter): https://cloud.google.com/tpu/docs/introduction-to-tpu-training
- Zero Bubble Pipeline Parallelism: https://arxiv.org/abs/2401.10241
- OpenAI, An Empirical Model of Large-Batch Training (Critical Batch Size): https://arxiv.org/abs/1812.06162