CS231N Lecture 9: Object Detection and Image Segmentation
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Ehsan Adeli 授课内容整理 |
| 来源 | Stanford University |
| 日期 | 2025 |

引言与 Vision Transformer 回顾
本节课覆盖计算机视觉中若干核心任务——语义分割、目标检测、实例分割,以及神经网络的可视化与理解方法。在正式进入这些主题之前,讲者首先简要回顾了上节课介绍的 Vision Transformer(ViT)架构。
来源:Slides 第2页。
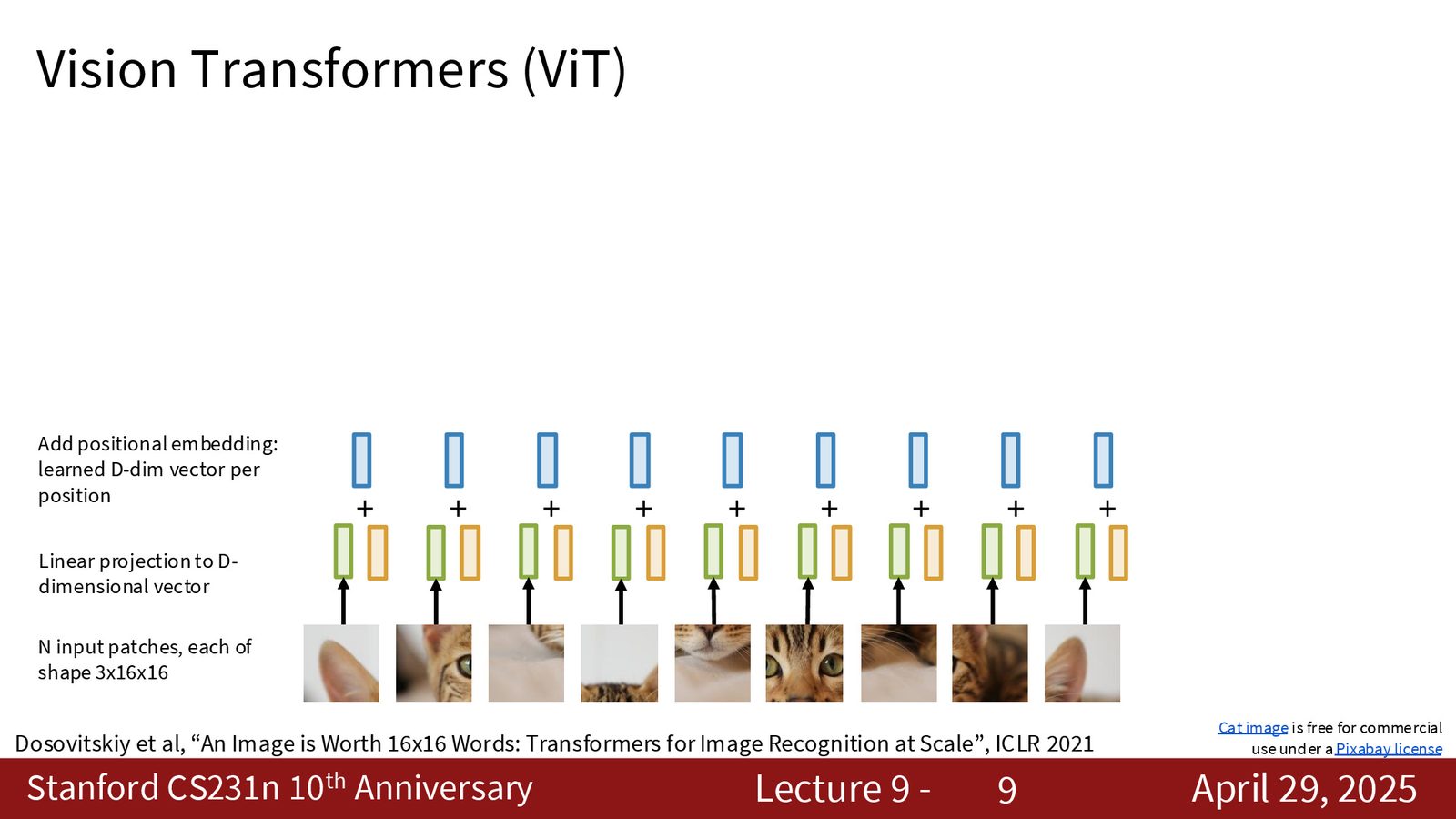
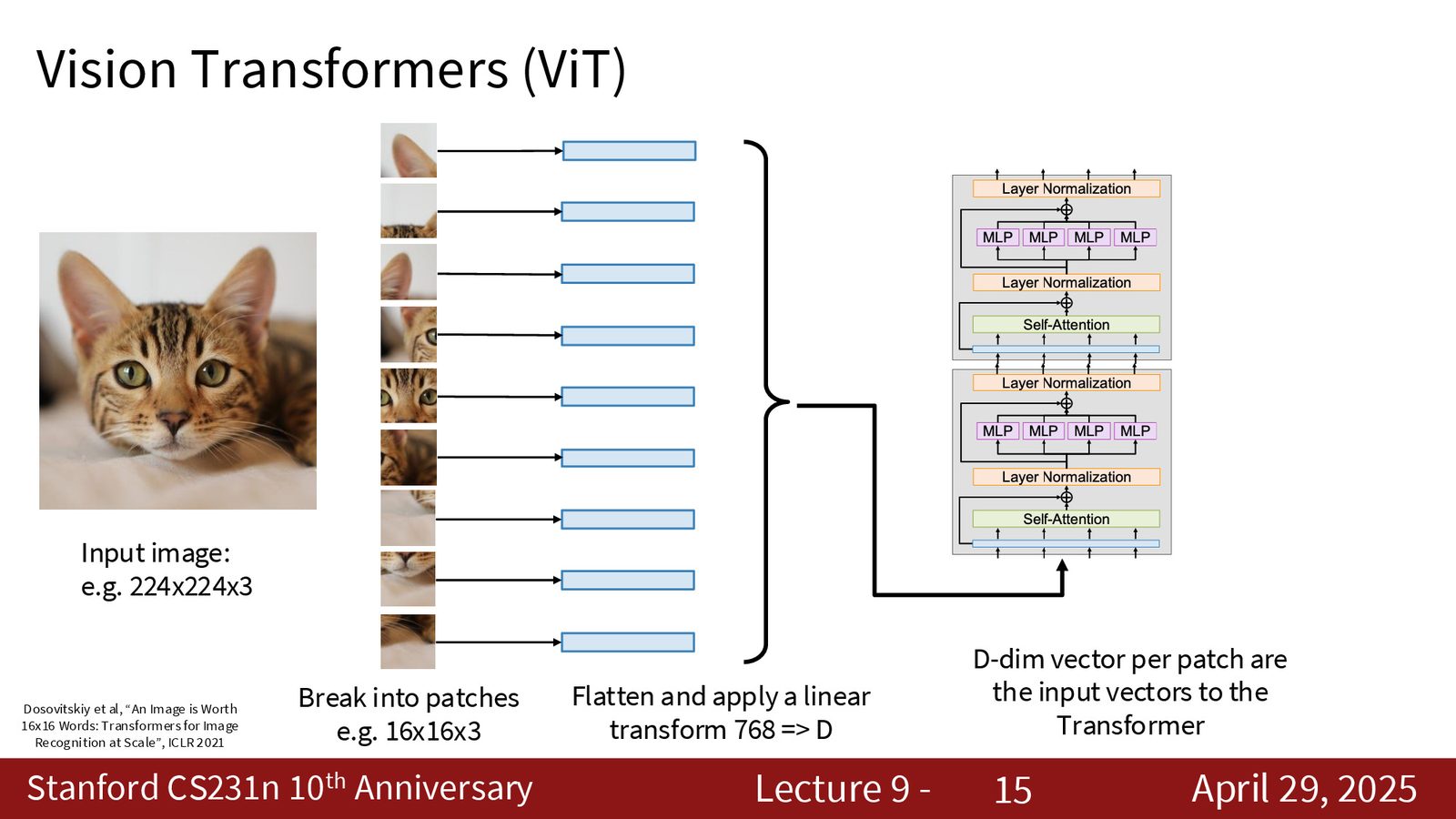
ViT 架构核心
Vision Transformer 的核心思想是将图像分割为若干 patch(例如 \(S \times S\) 的网格),将每个 patch 通过线性投影映射为 \(D\) 维的 token,加上位置编码(positional embedding)后送入标准 Transformer encoder。
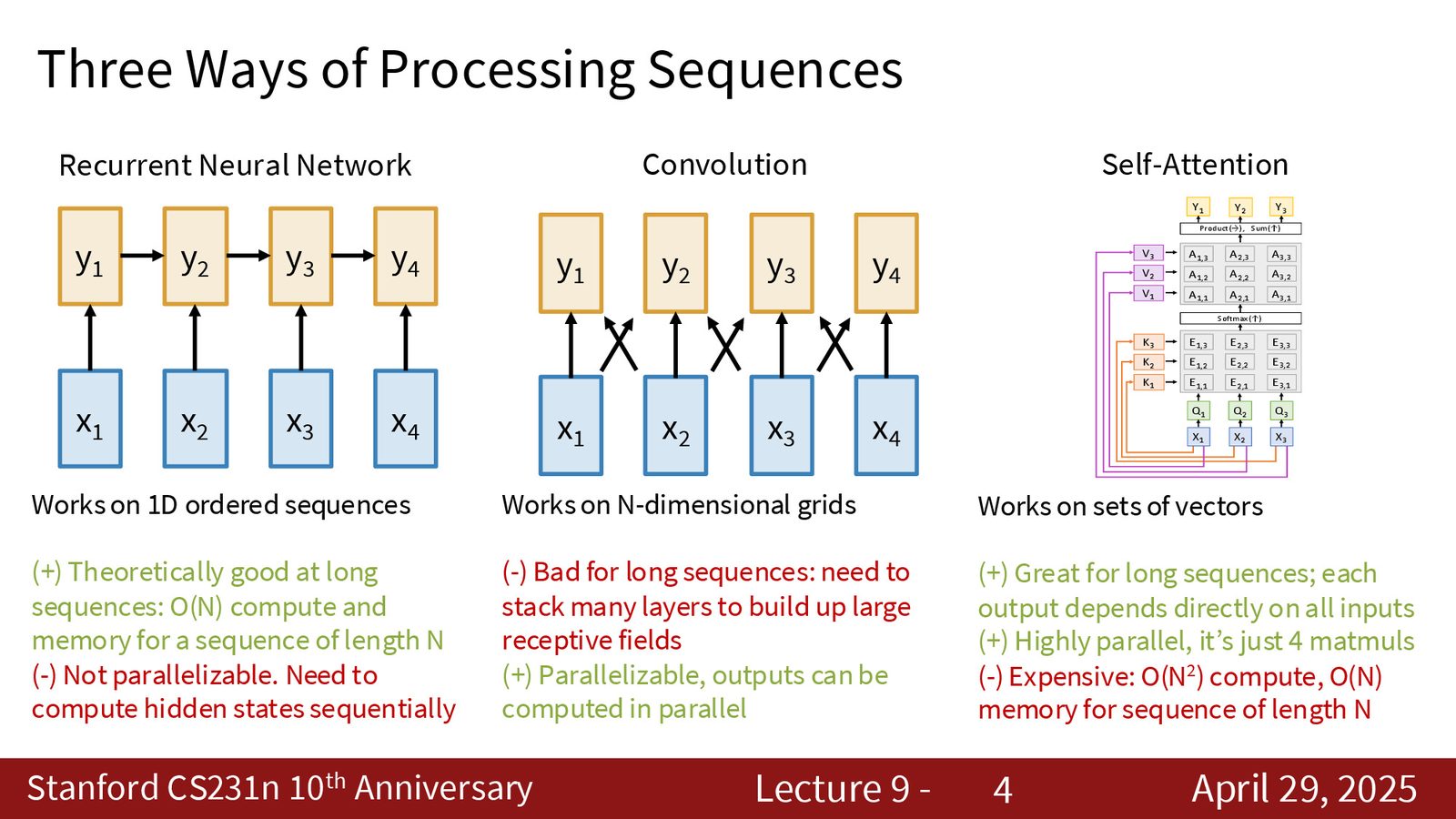
来源:Slides 第4页。
以一张 \(224 \times 224 \times 3\) 的输入图像为例,ViT 的具体数据流如下:
- 将图像切分为 \(14 \times 14 = 196\) 个大小为 \(16 \times 16 \times 3\) 的 patch
- 每个 patch 展平后为 \(768\) 维向量,通过线性变换映射为 \(D\) 维 token
- 加上可学习的位置编码(\(D\) 维向量),告知 Transformer 每个 patch 的二维空间位置
- 将 196 个 token 送入标准 Transformer encoder(自注意力 + MLP)
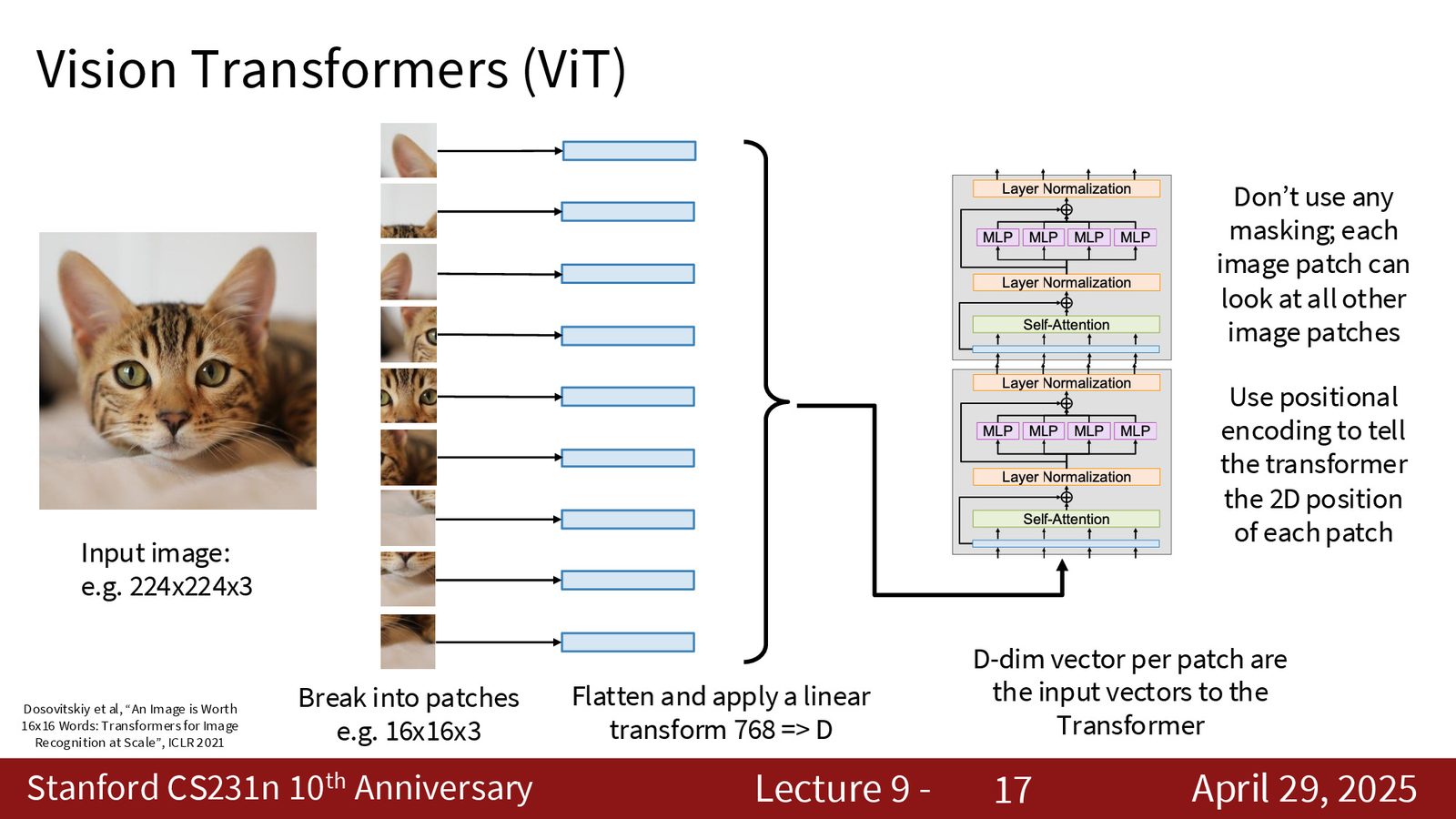
来源:Slides 第17页。
ViT 分类的两种方式
- Class Token:添加一个可学习的特殊 token 作为输入(\(D\) 维),其对应的输出经过线性层映射为类别概率向量
- 全局池化:对所有输出 token 做 pooling,再映射为类别概率
两种方式均使用 softmax 交叉熵损失进行监督训练。关键点在于:ViT 不使用任何 masking——每个 patch 可以关注所有其他 patch,这与 NLP 中的 causal attention 不同。
ViT 与 CNN 的关键差异
- 感受野:CNN 的感受野从局部逐步扩大;ViT 从第一层就具有全局感受野
- 归纳偏置:CNN 具有平移不变性和局部连接假设;ViT 几乎没有这些先验
- 数据需求:正因缺少归纳偏置,ViT 通常需要更大规模的数据集才能充分训练
- 可扩展性:ViT 的自注意力复杂度为 \(O(N^2)\)(\(N\) 为 token 数),而 CNN 为 \(O(N)\)
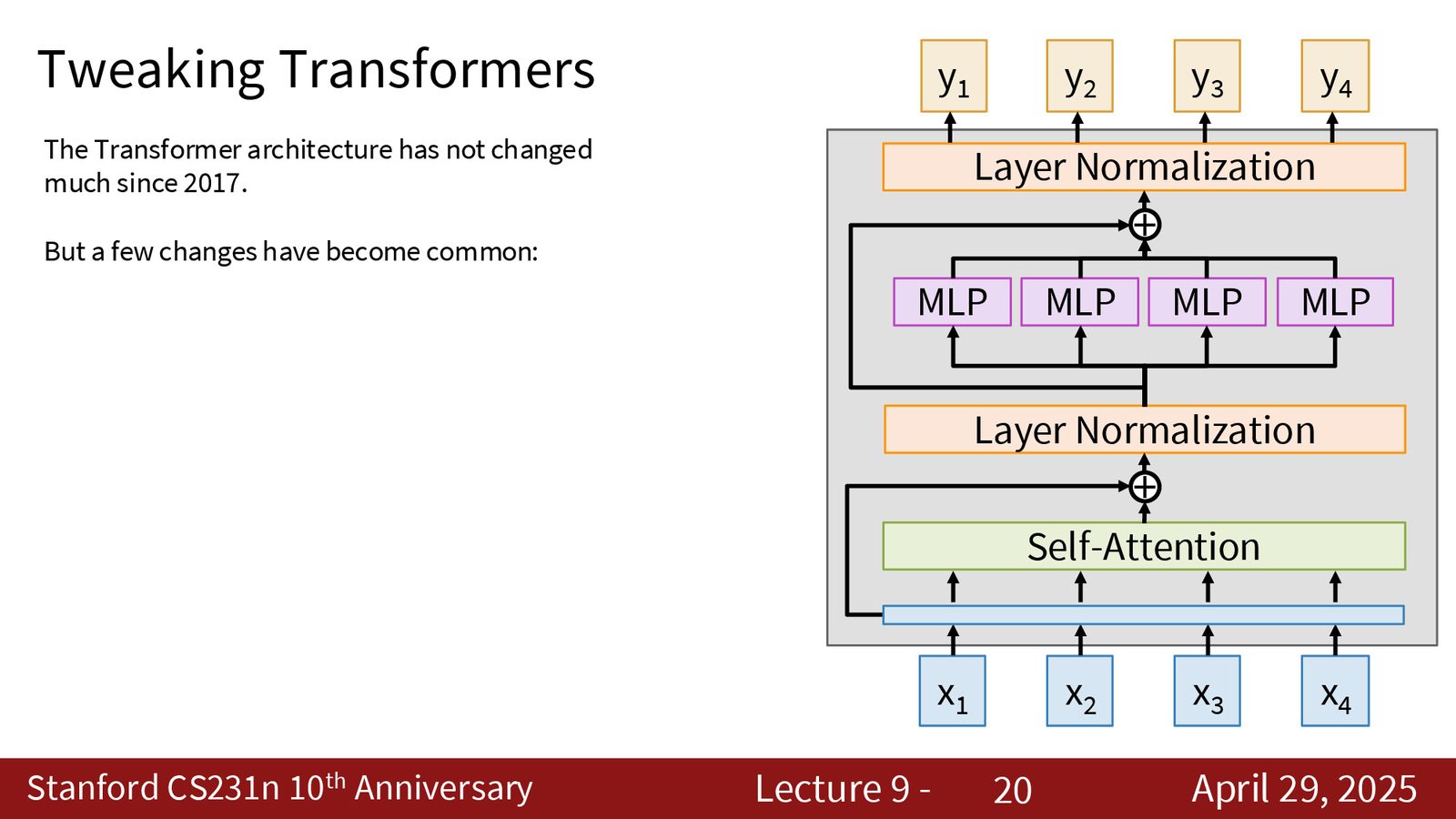
现代 Transformer 的优化技巧
讲者介绍了几种在现代 Transformer 架构中广泛使用的优化手段:
来源:Slides 第9页。
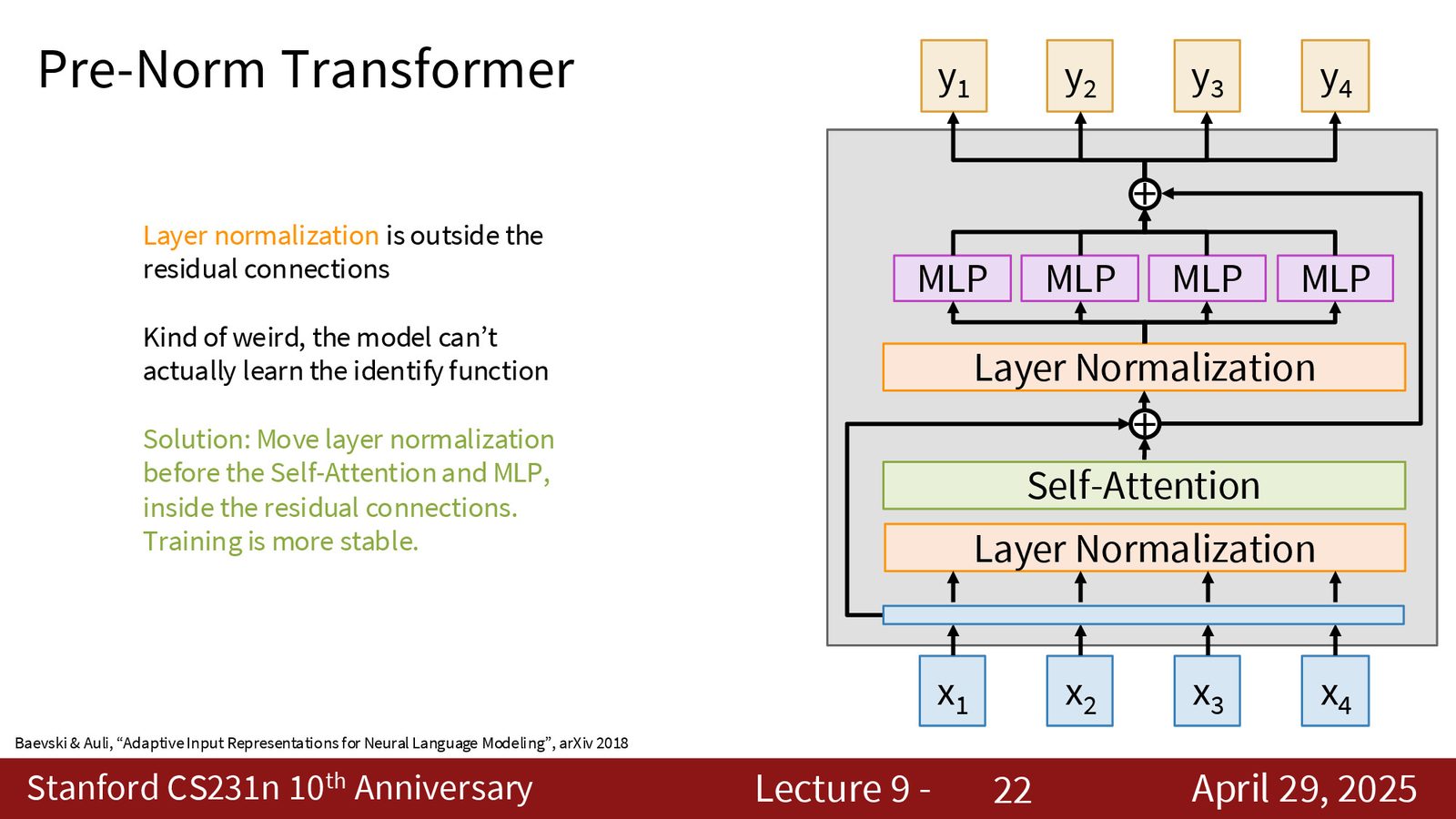
1. Pre-Norm(前置归一化):将 Layer Norm 放在自注意力和 MLP 之前(而非之后),以保留残差连接的恒等映射能力,使训练更加稳定。原始 Transformer 使用 Post-Norm(先计算再归一化),现代模型几乎全部改用 Pre-Norm。
2. RMS Norm:使用均方根归一化代替标准 Layer Norm,省去均值中心化步骤:
- \(x\):输入向量(shape \(D\))
- \(\gamma\):可学习的缩放参数(shape \(D\))
- \(\varepsilon\):防止除零的小常数
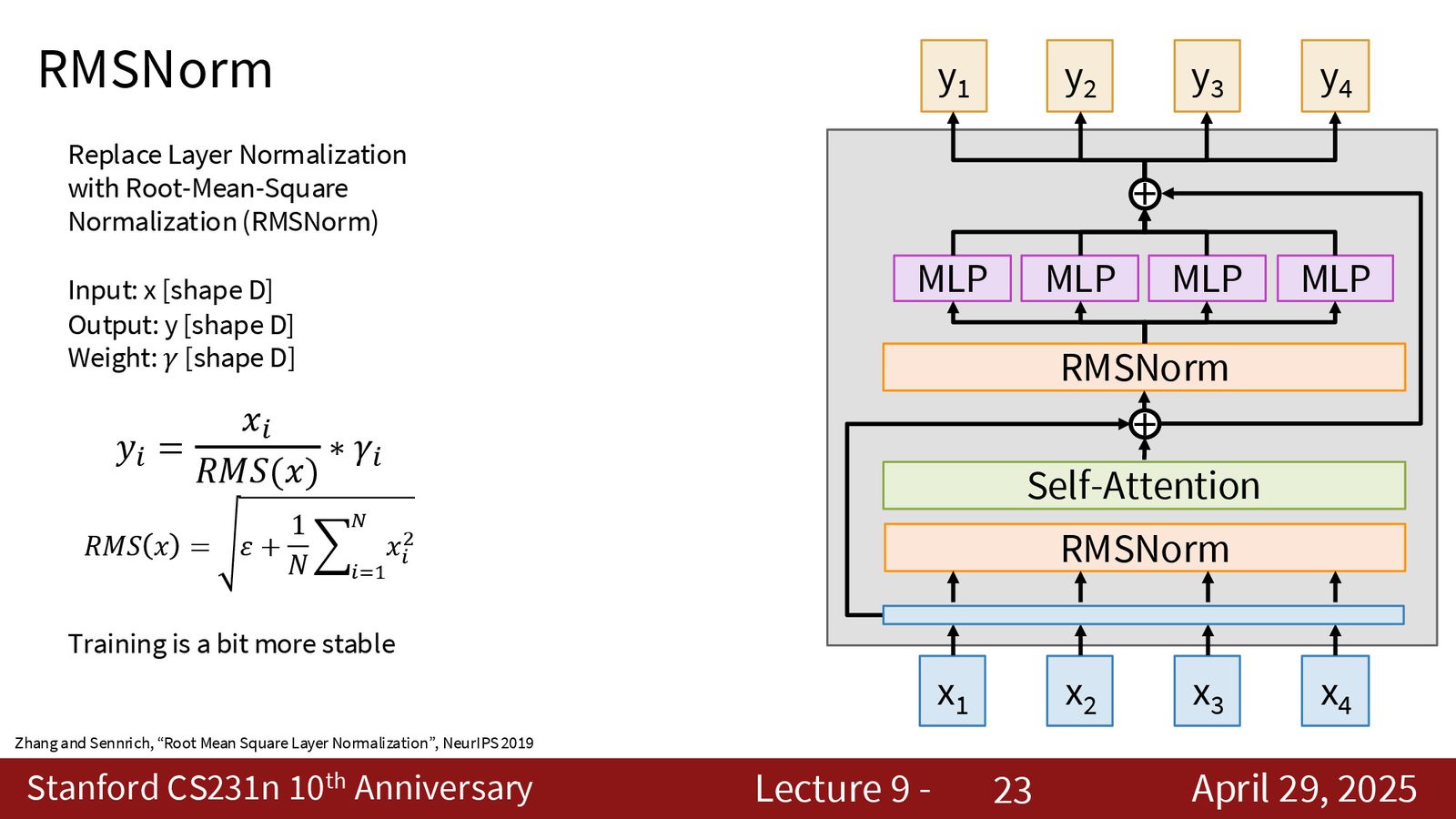
来源:Slides 第23页。
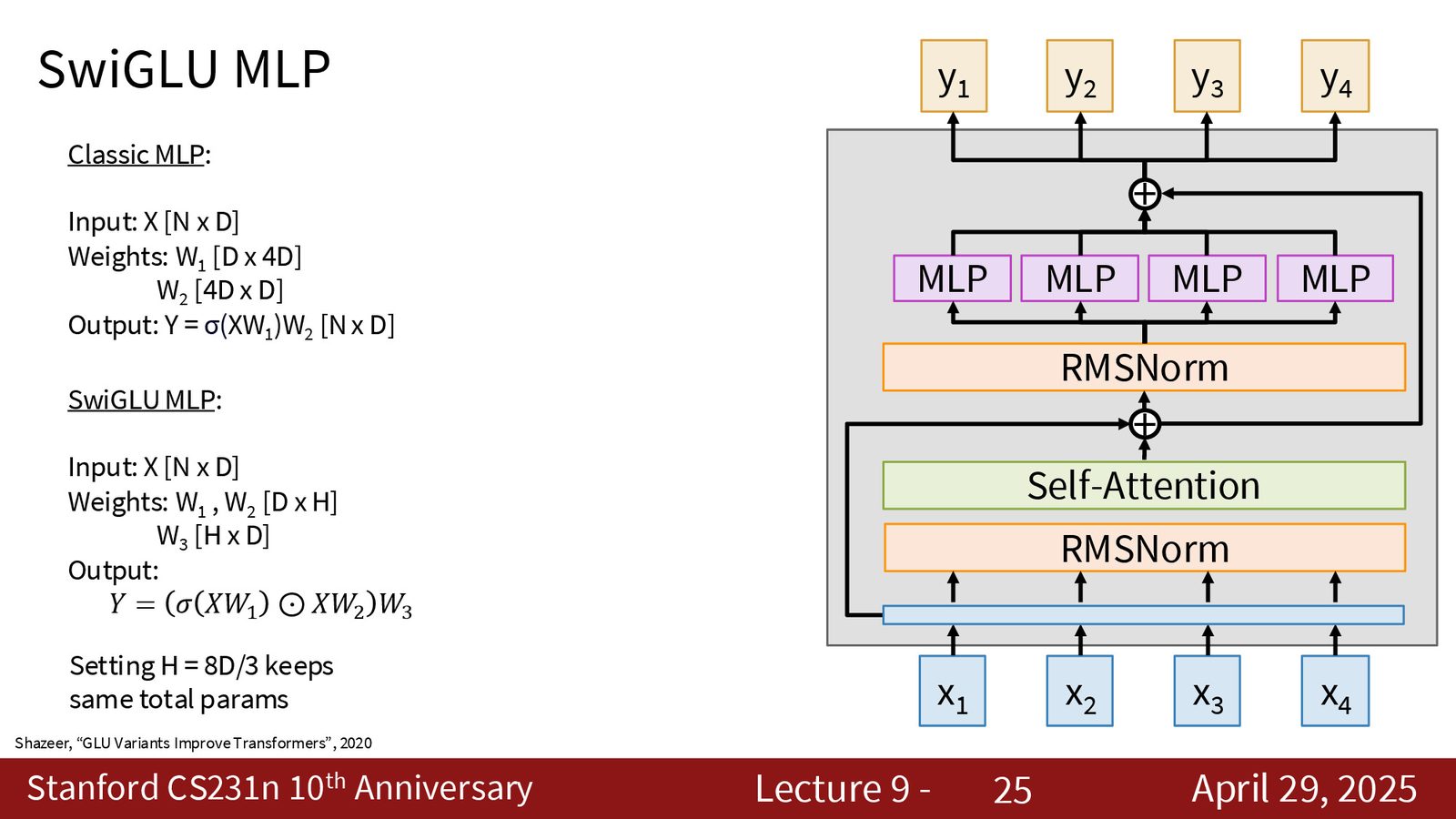
3. SwiGLU MLP:使用门控非线性(gated nonlinearity),引入第三个权重矩阵 \(W_3\),在保持参数量不变的情况下(隐藏层维度设为 \(8d/3\))学习更高维的非线性表示。
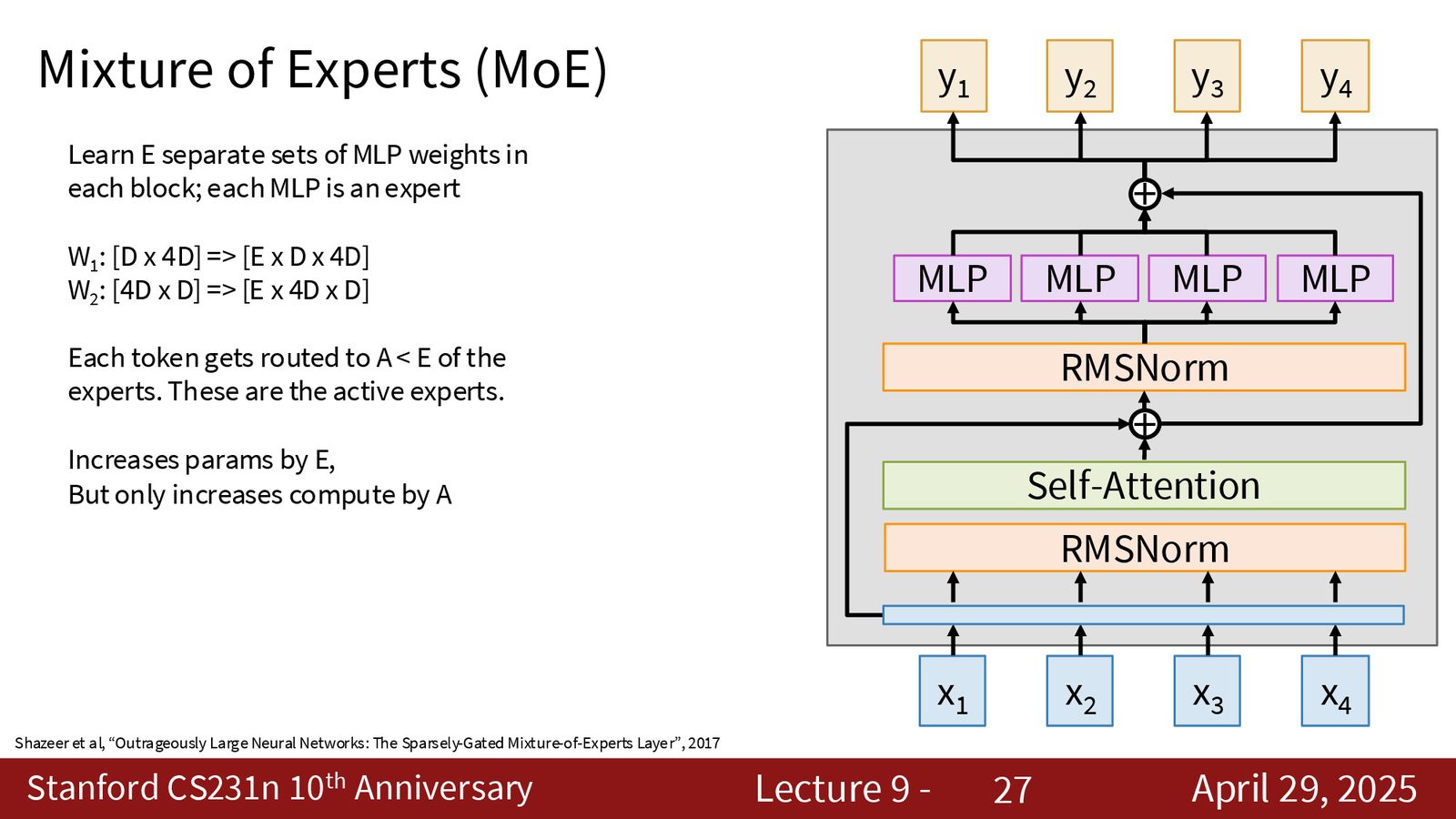
4. Mixture of Experts (MoE):将 MLP 层替换为多组并行的 MLP “专家”,通过 router 将不同 token 路由到不同专家。这增加了参数量但不成比例地增加计算量(每次只有部分专家被激活),被现代大型语言模型广泛采用。
| 技巧 | 核心改进 | 典型效果 |
|---|---|---|
| Pre-Norm | 归一化前置于残差分支 | 训练更稳定,不需要 warm-up |
| RMS Norm | 去掉均值归一化步骤 | 计算更快,精度不降 |
| SwiGLU MLP | 门控非线性,三矩阵设计 | 同参数量下表达力更强 |
| MoE | 多专家并行,稀疏激活 | 参数量大增但计算量可控 |
MoE 并非免费午餐
MoE 虽然在理论上可以用固定计算量支撑更大的参数空间,但实际部署中面临几个挑战:(1) 专家负载不均衡可能导致部分专家过载;(2) 模型的总参数量更大,推理时需要加载所有专家权重到内存;(3) 路由策略本身需要精心调优。
本章小结
Vision Transformer 将图像视为 patch 序列,通过自注意力机制全局建模像素间关系。以 \(224 \times 224\) 的图像为例,ViT 会生成 196 个 token,每个 token 从第一层起就具有全局感受野。现代 Transformer 通过 Pre-Norm、RMS Norm、SwiGLU 和 MoE 等技巧进一步提升了训练稳定性和模型容量,这些改进构成了当前视觉和语言模型的标准组件。
语义分割
任务定义
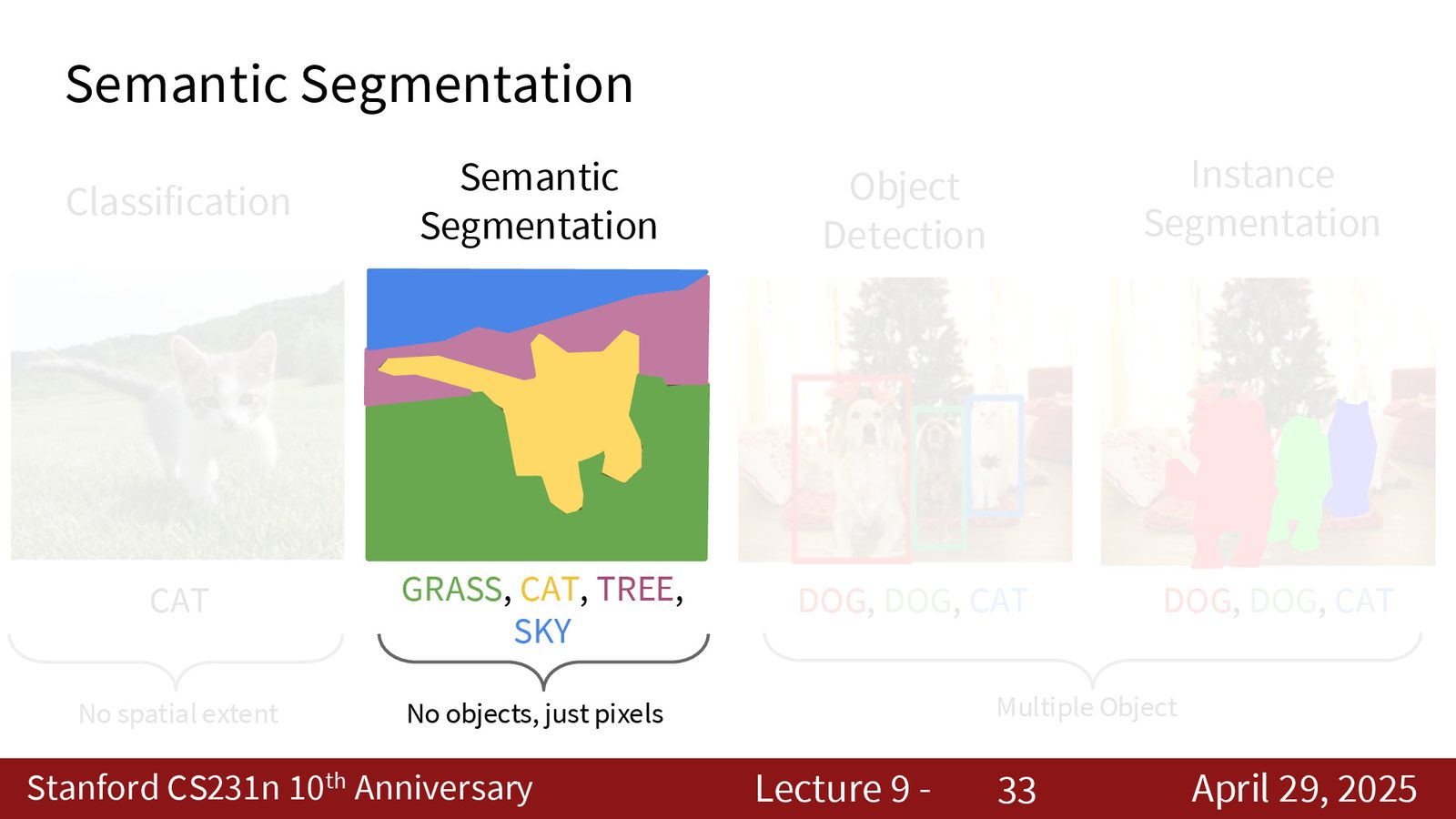
语义分割(Semantic Segmentation)的目标是为图像中的每个像素分配一个类别标签。与图像分类(为整张图输出一个标签)不同,语义分割输出与输入图像等尺寸的标签图。
来源:Slides 第15页。
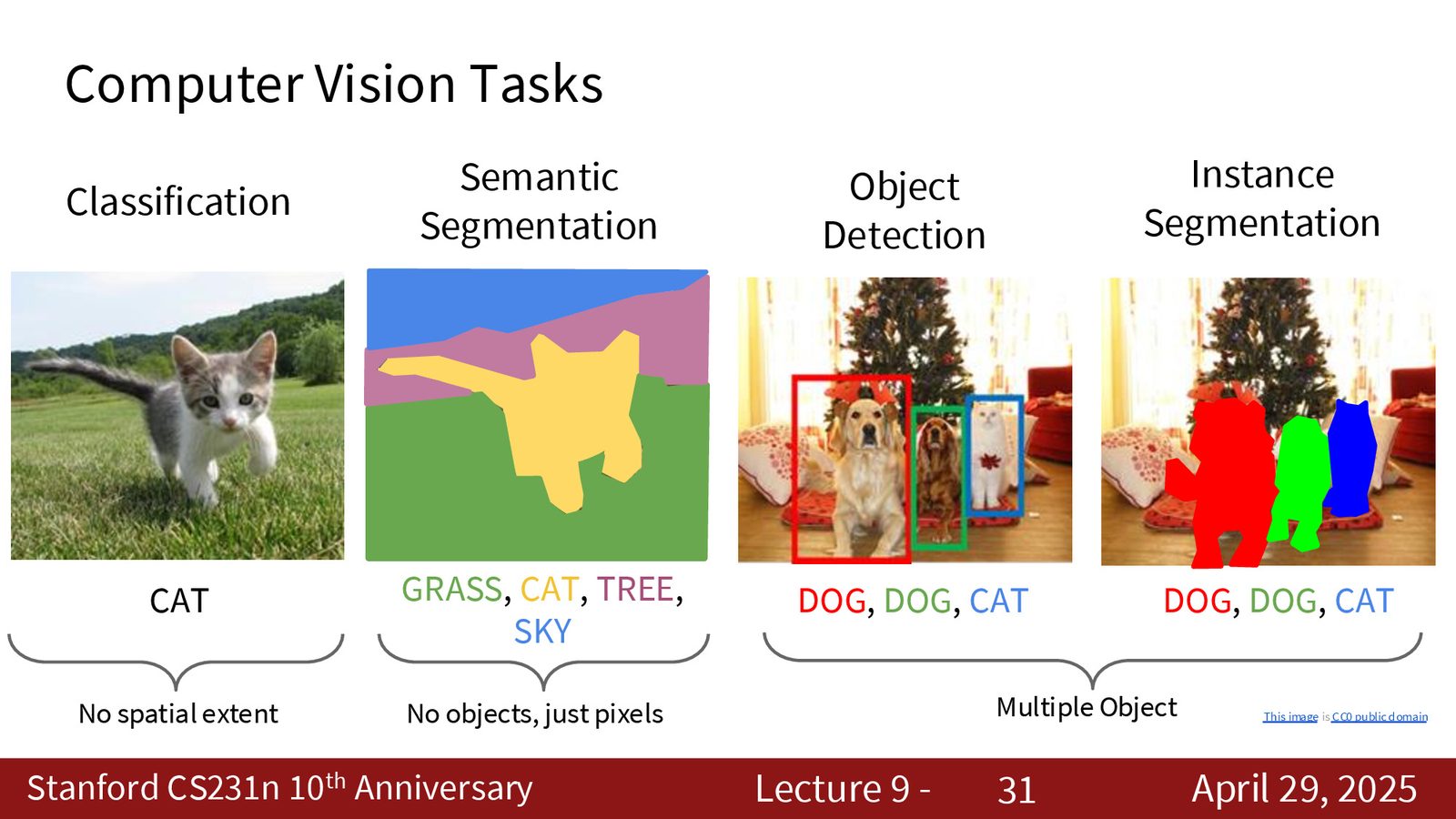
四种核心视觉任务的输出对比
- 图像分类:输入一张图,输出一个类别标签(如“猫”)
- 语义分割:输入一张图,输出每个像素的类别标签(\(H \times W\) 的标签图)
- 目标检测:输入一张图,输出若干边界框 + 类别(\((x,y,w,h,c)\) 列表)
- 实例分割:目标检测 + 每个实例的像素级掩码
语义分割不区分实例
语义分割只关心每个像素属于哪个类别(如“狗”、“草地”),不区分同类的不同个体。如果图像中有两只狗,语义分割会把所有“狗像素”标为同一类别,无法区分“狗1”和“狗2”。要区分个体,需要实例分割。
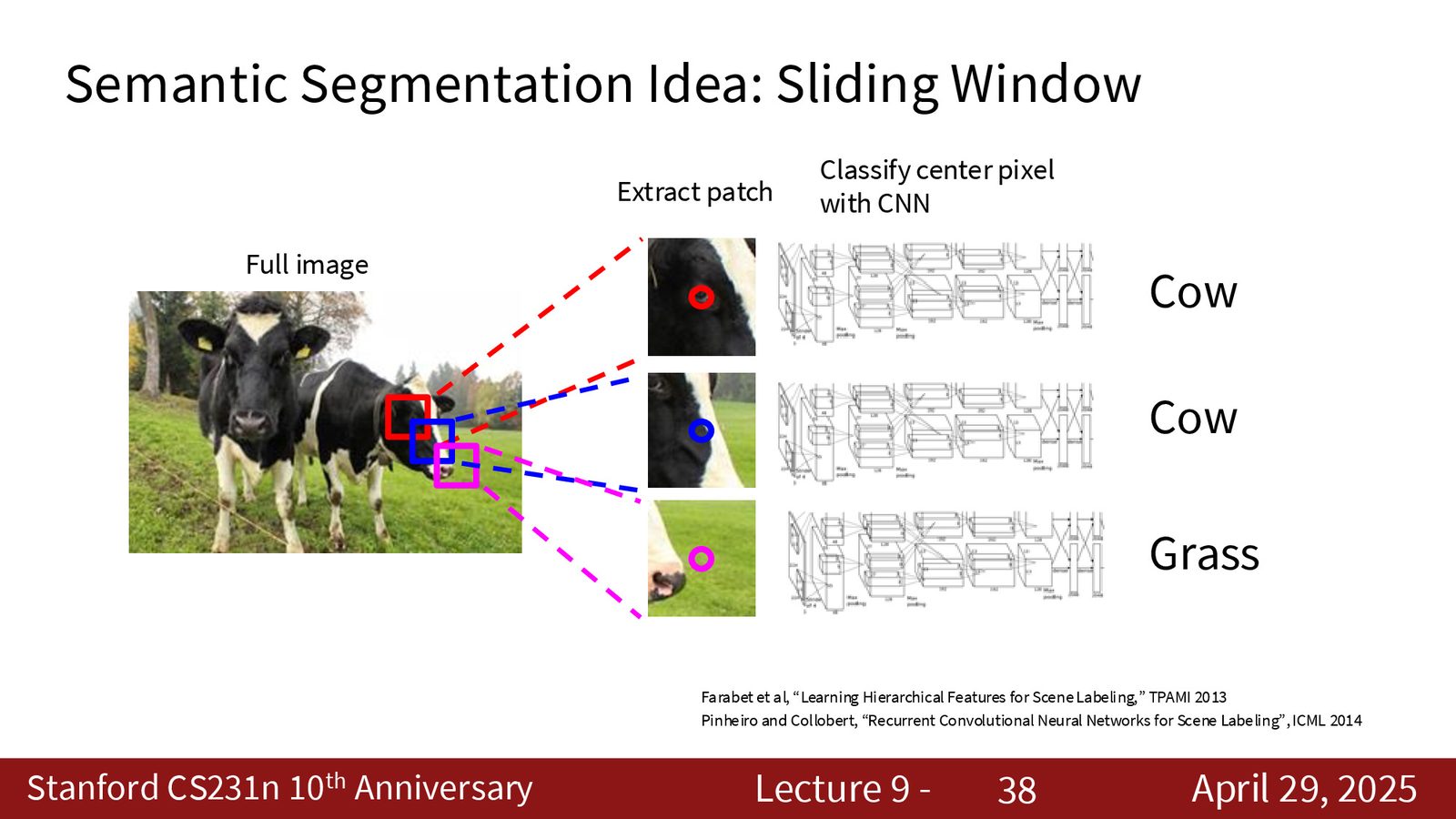
朴素方法:滑动窗口
最朴素的做法是对每个像素取一个局部 patch,用分类网络判断中心像素的类别。

来源:Slides 第35页。
这种方法的问题非常明显:假设图像大小为 \(640 \times 480\),共有 \(307{,}200\) 个像素,每个像素都要跑一遍完整网络——计算代价极高,且相邻像素的 patch 高度重叠,存在大量冗余计算。
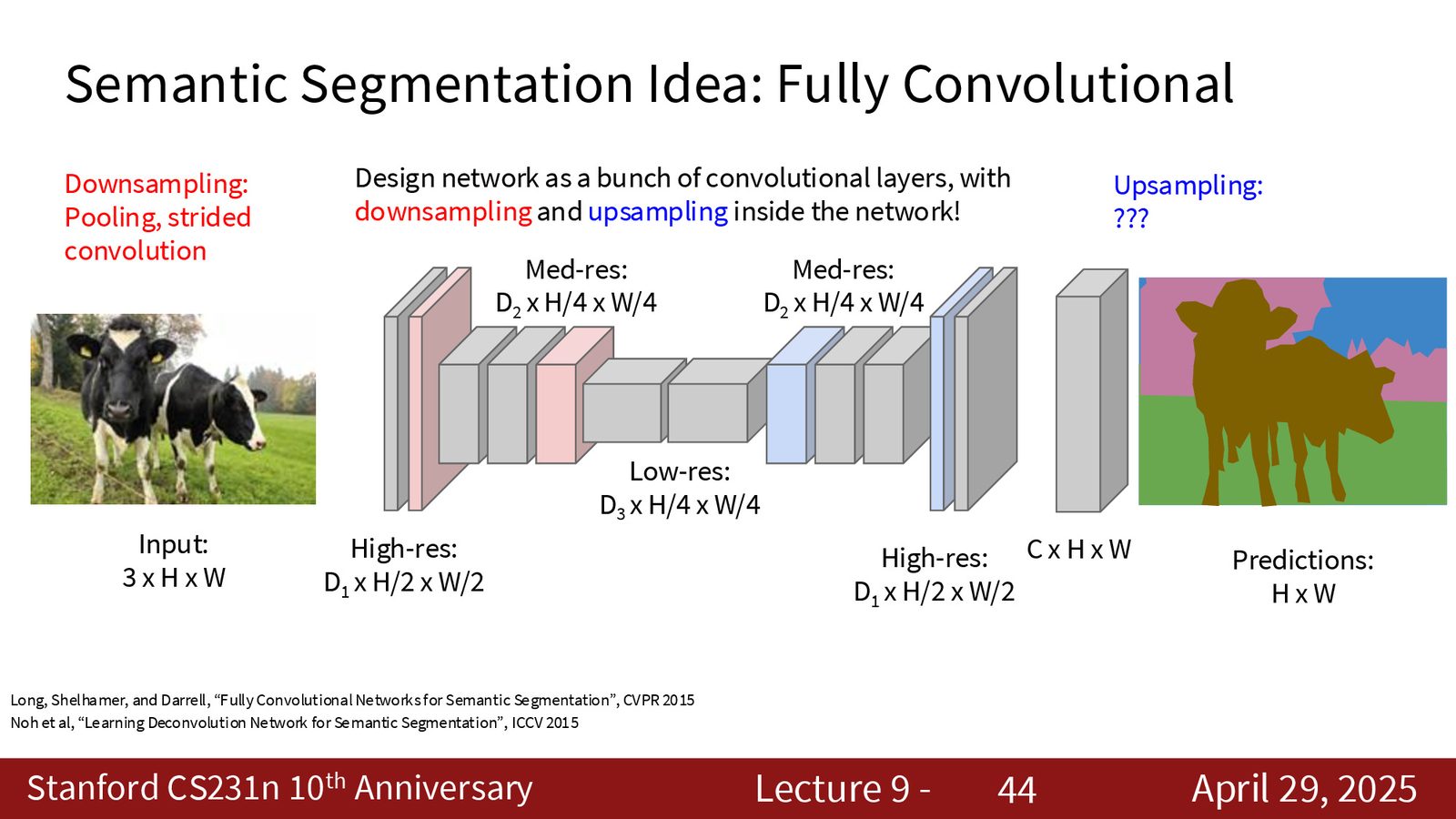
全卷积网络(FCN)
更高效的方案是使用全卷积网络(Fully Convolutional Network, FCN):训练一个端到端的网络,输入完整图像,直接输出像素级标签图。
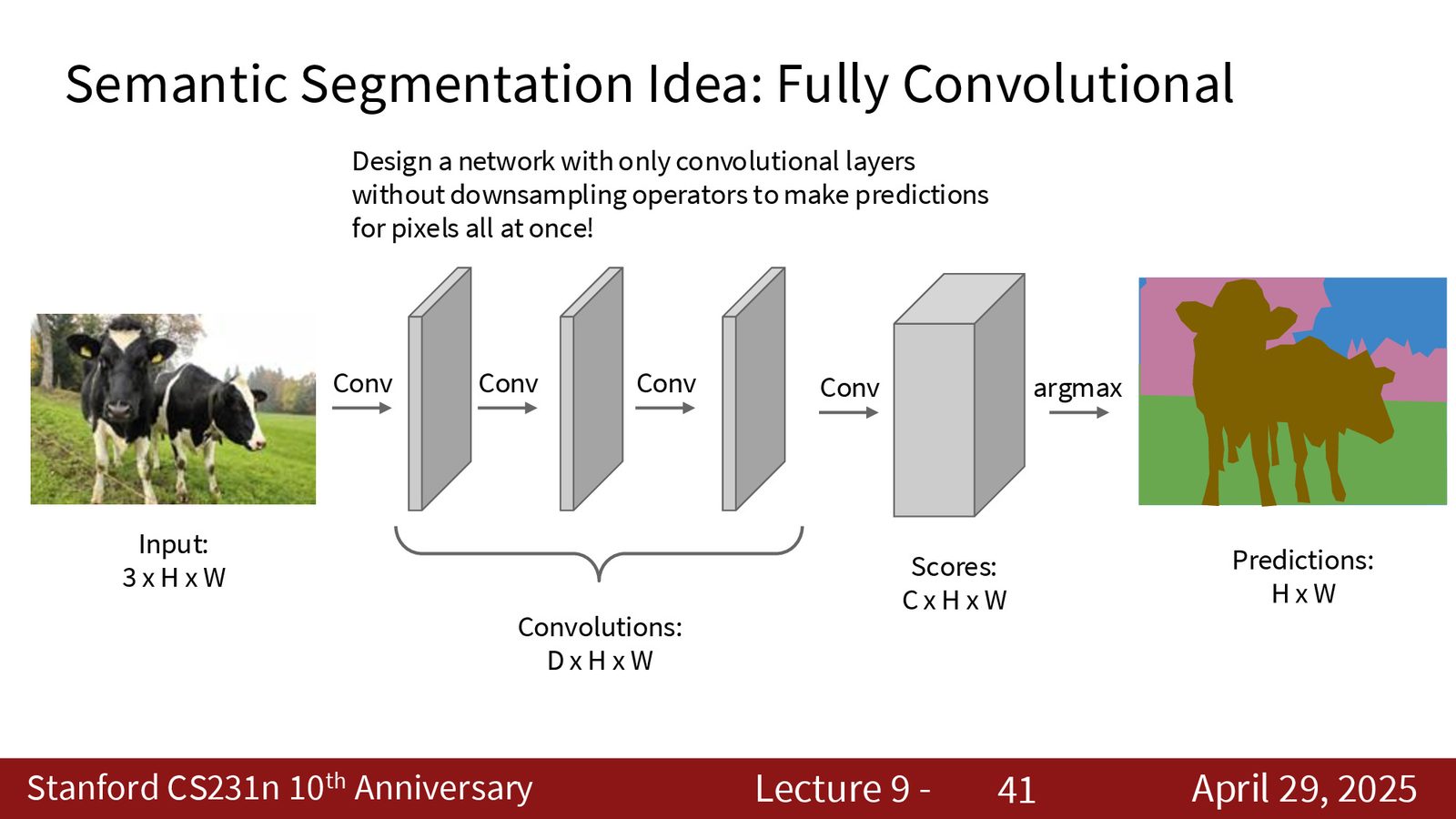
来源:Slides 第41页。
为什么不能在原分辨率上做所有卷积
如果所有卷积都在原分辨率(如 \(640 \times 480\))上操作,计算量和内存占用会非常大。一个 \(3 \times 3\) 的卷积核在 \(D\) 个通道上的 FLOPs 为 \(O(9 \cdot D^2 \cdot H \cdot W)\)——当 \(H, W\) 很大时,这是不可接受的。因此实际中需要先下采样减少空间分辨率,再上采样恢复。
来源:Slides 第20页。
FCN 的损失函数
语义分割的训练目标非常直观:对图像中每个像素独立计算 softmax 交叉熵损失,然后对所有像素取平均:
其中 \(y_{ij}\) 是像素 \((i,j)\) 的真实标签,\(\hat{y}_{ij}\) 是预测的类别概率分布。注意:类别不平衡(如大面积背景 vs 小面积物体)会影响训练效果,实际中常使用加权交叉熵或 focal loss。
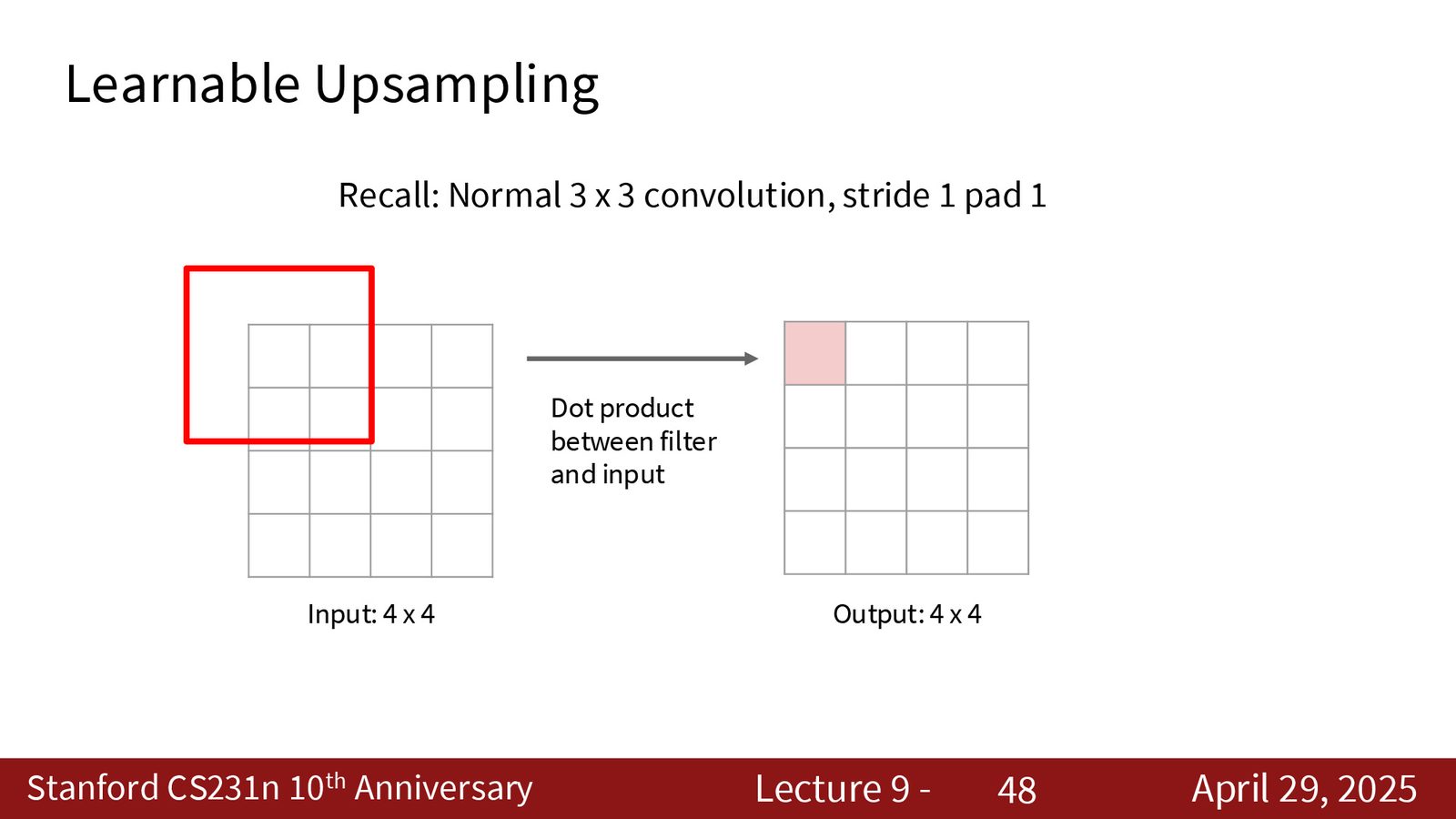
上采样方法
FCN 的编码部分(下采样)可以使用标准的池化和步长卷积,但解码部分(上采样)需要专门设计。讲者详细介绍了四种上采样方法:
来源:Slides 第22页。
1. 最近邻插值:将低分辨率的值复制到对应的高分辨率区域。简单但产生块状伪影。
2. Bed of Nails:将值放在角落位置,其余填零。
3. Max Unpooling:在编码阶段记录 max pooling 的位置索引,解码时将值放回对应位置。
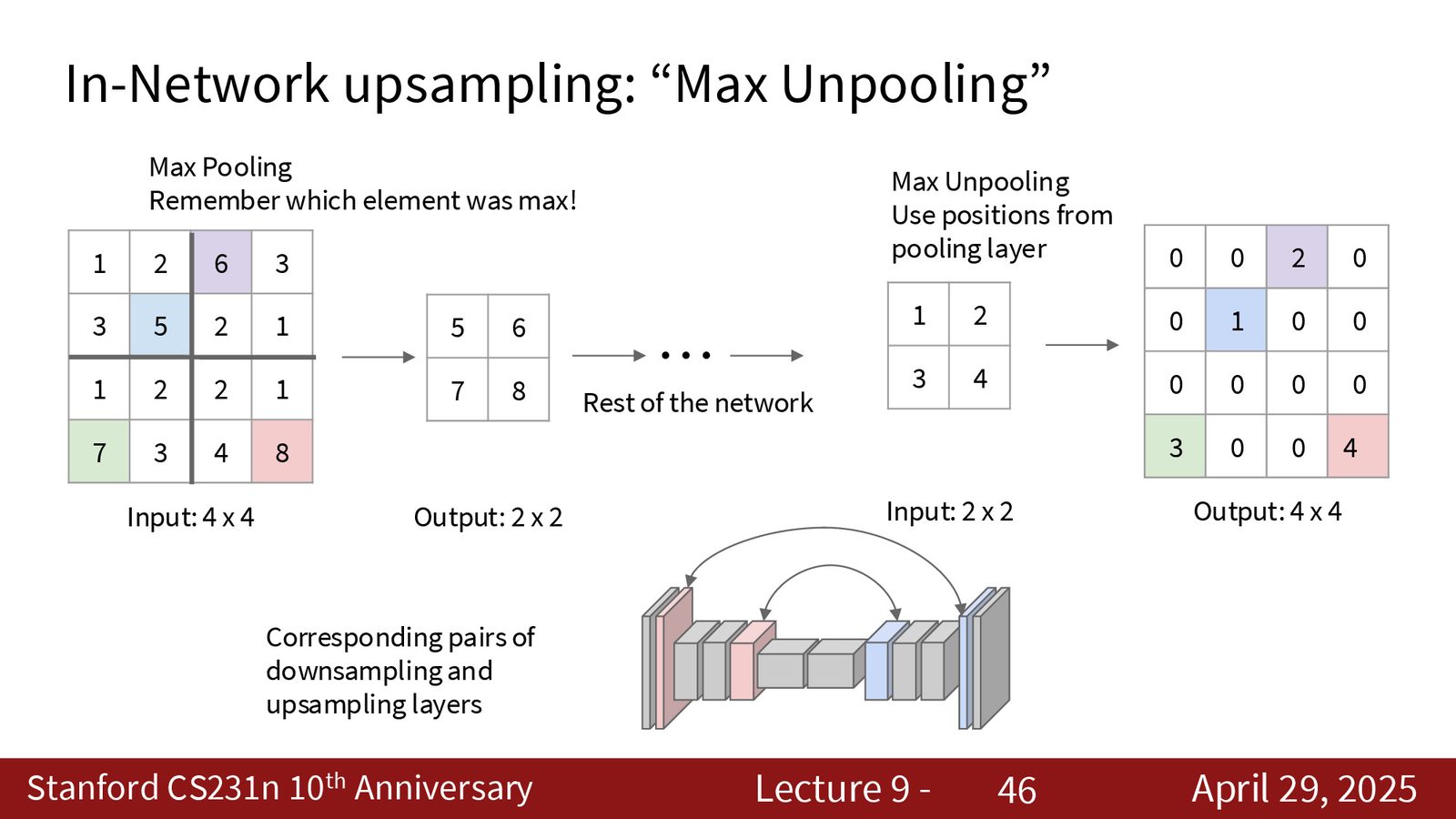
来源:Slides 第46页。
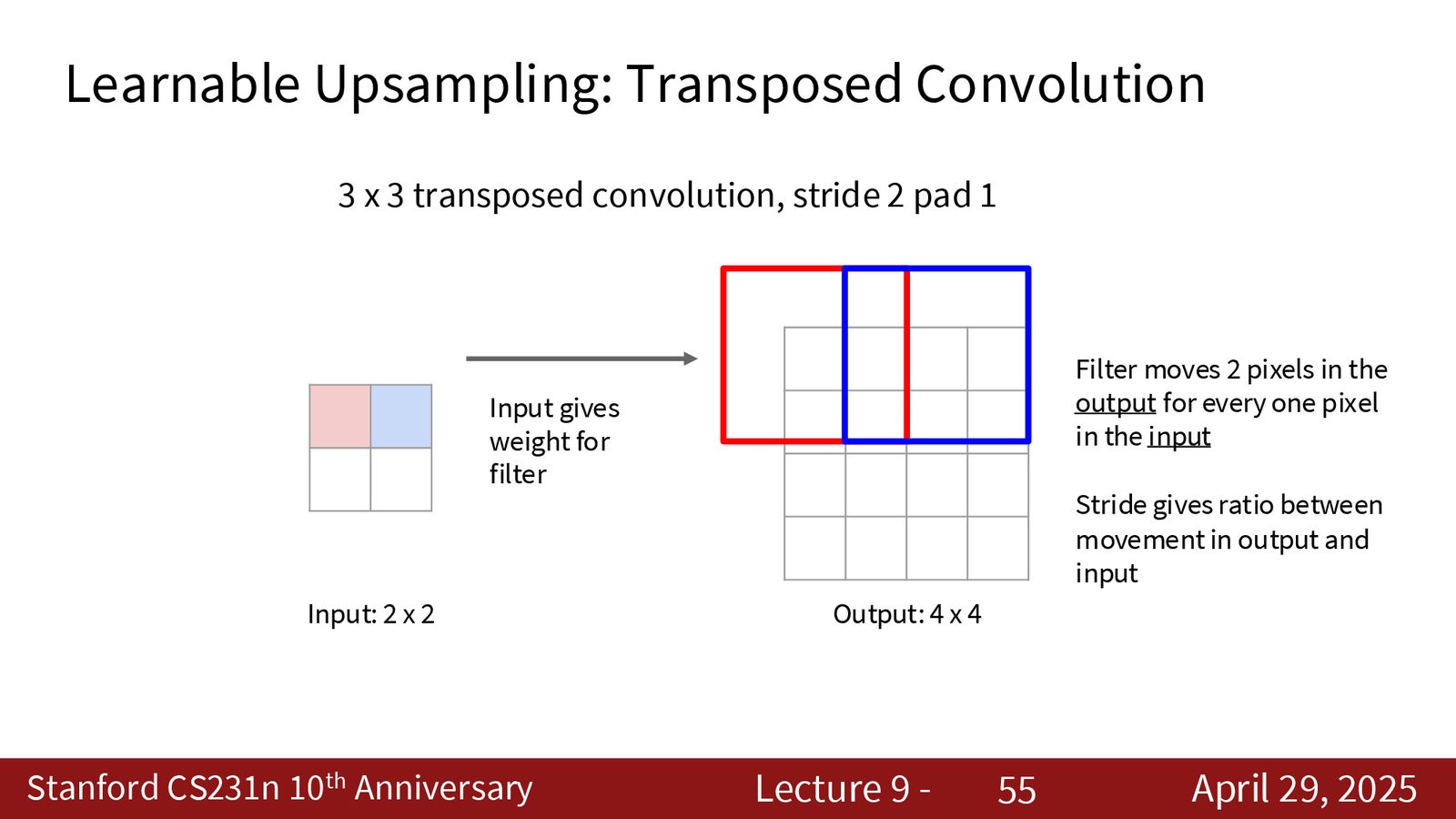
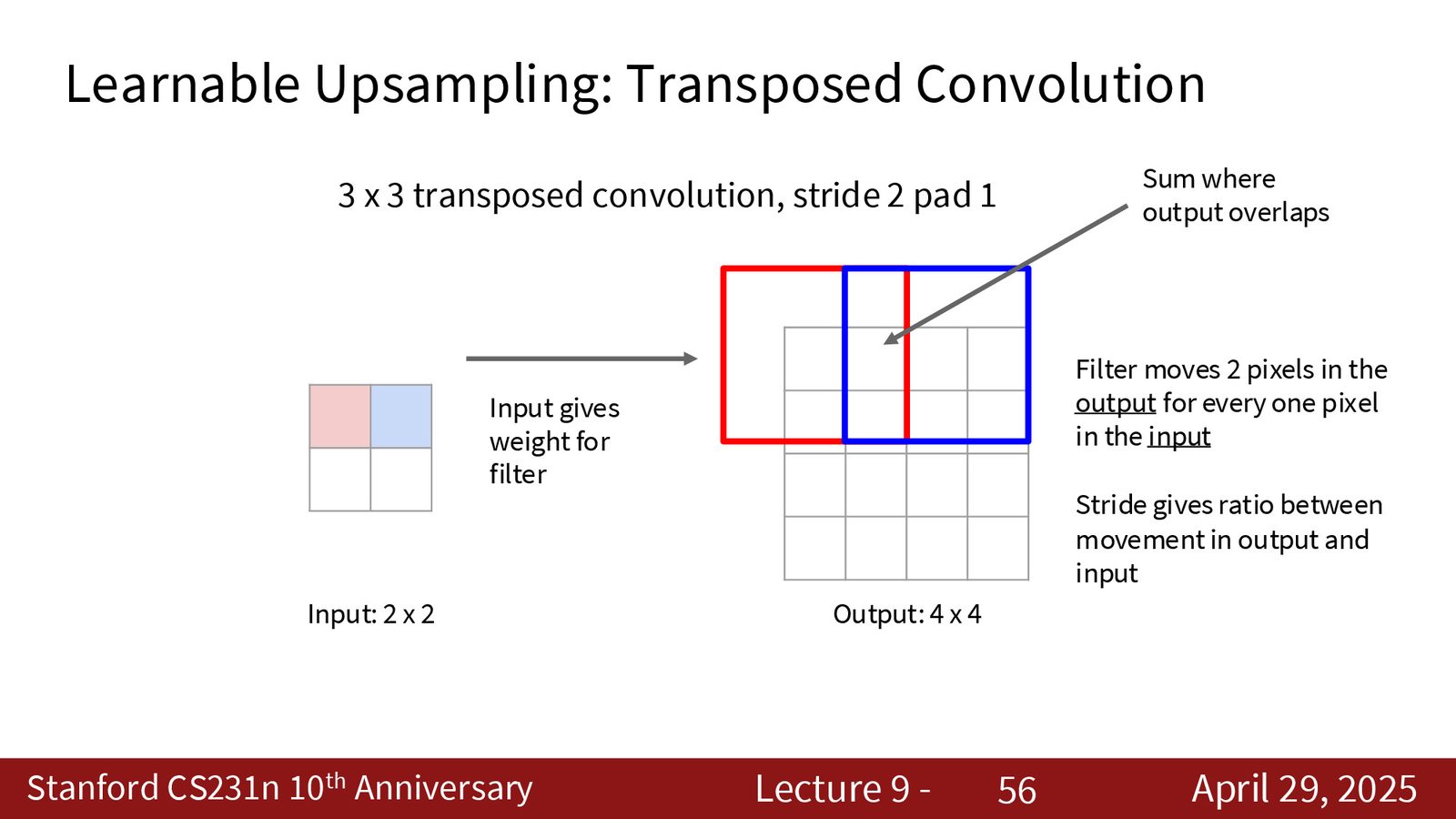
4. 转置卷积(Transpose Convolution):可学习的上采样方法。
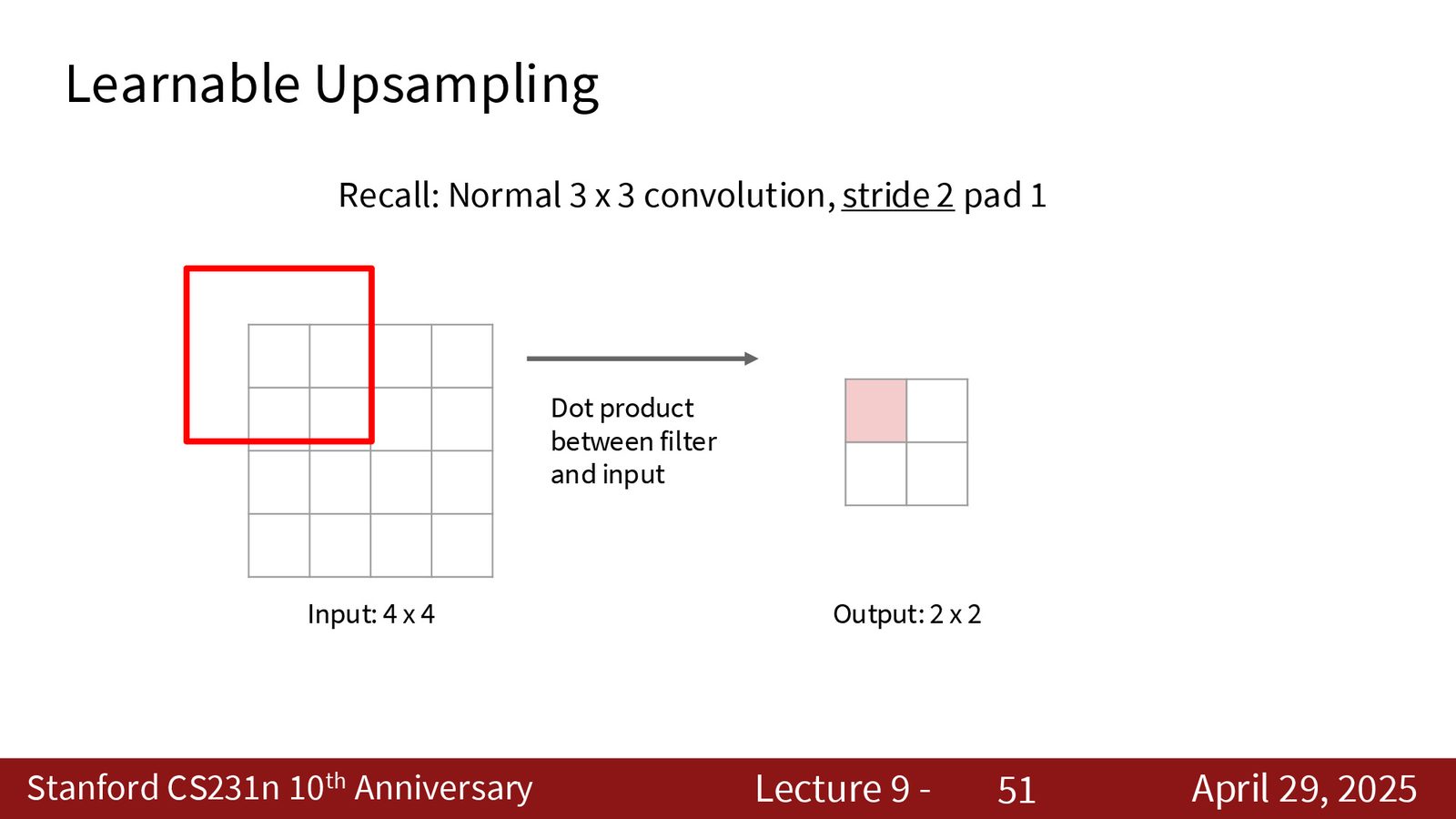
来源:Slides 第51页。
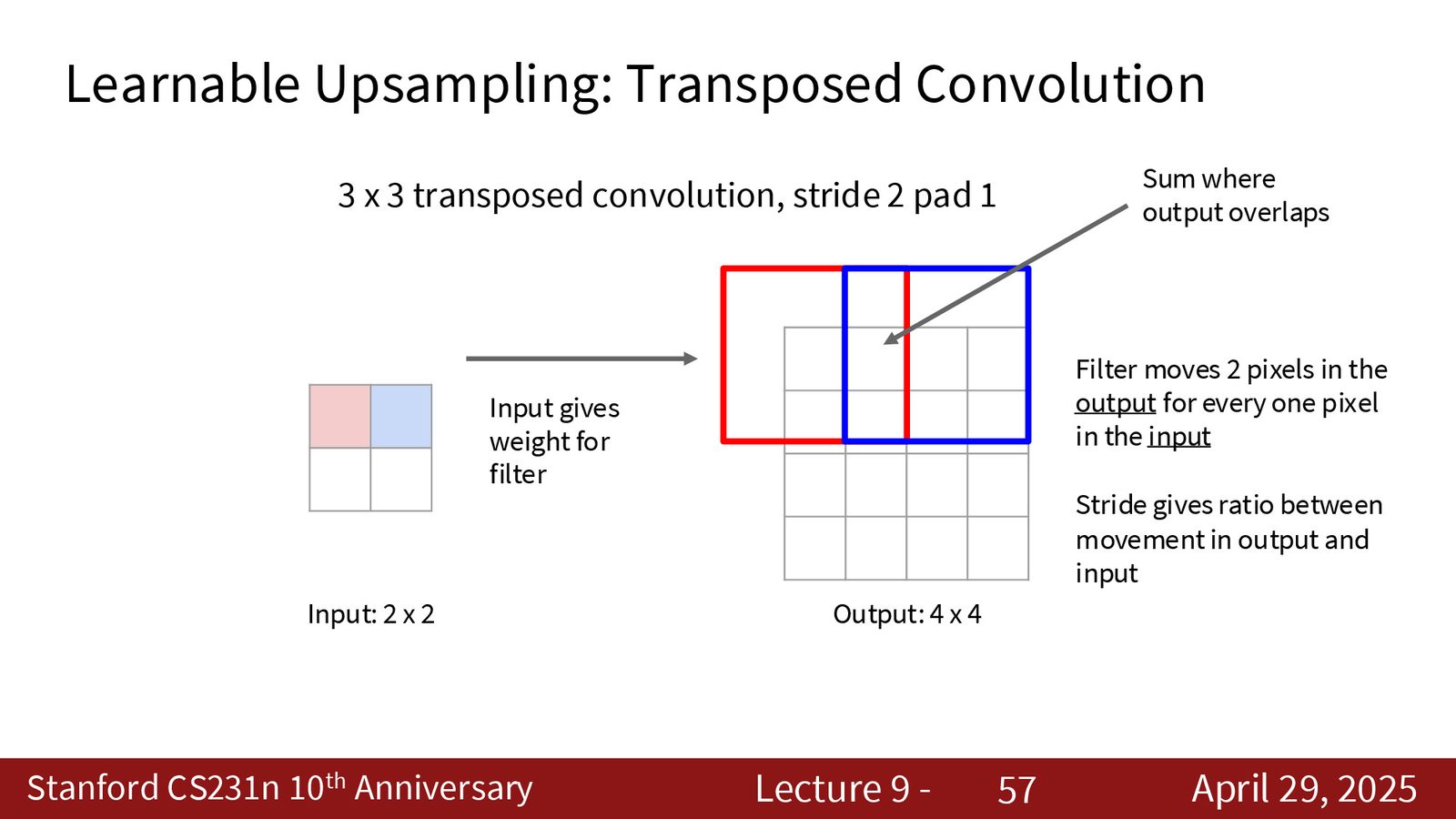
来源:Slides 第57页。
来源:Slides 第25页。
转置卷积 \(≠\) 反卷积
转置卷积(Transpose Convolution)有时被误称为“反卷积”(Deconvolution),但它并不是卷积的数学逆运算。它只是在矩阵运算层面使用了卷积矩阵的转置。滤波器权重是通过训练学习的,而非由下采样过程决定。此外,如果 stride 和 kernel size 选择不当,转置卷积会产生棋盘格伪影(checkerboard artifacts),这在生成模型中是常见问题。
| 方法 | 可学习 | 计算开销 | 特点 |
|---|---|---|---|
| 最近邻插值 | 否 | 极低 | 简单但有块状伪影 |
| Bed of Nails | 否 | 极低 | 大量零值,信息利用率低 |
| Max Unpooling | 否 | 低 | 保留空间位置信息 |
| 转置卷积 | 是 | 中等 | 权重可学习,表达力最强 |
| 双线性插值 | 否 | 低 | 平滑,可与卷积配合使用 |
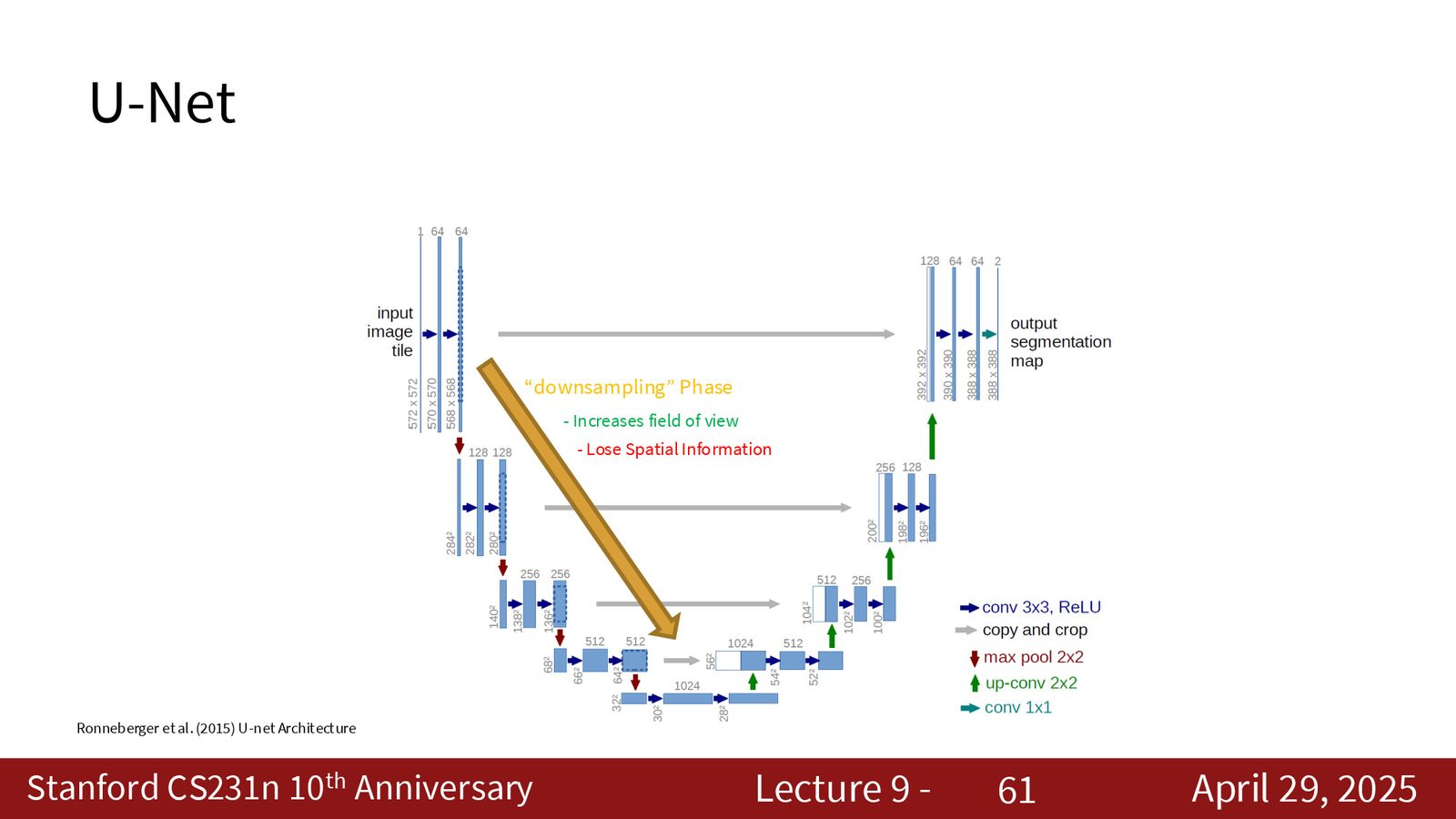
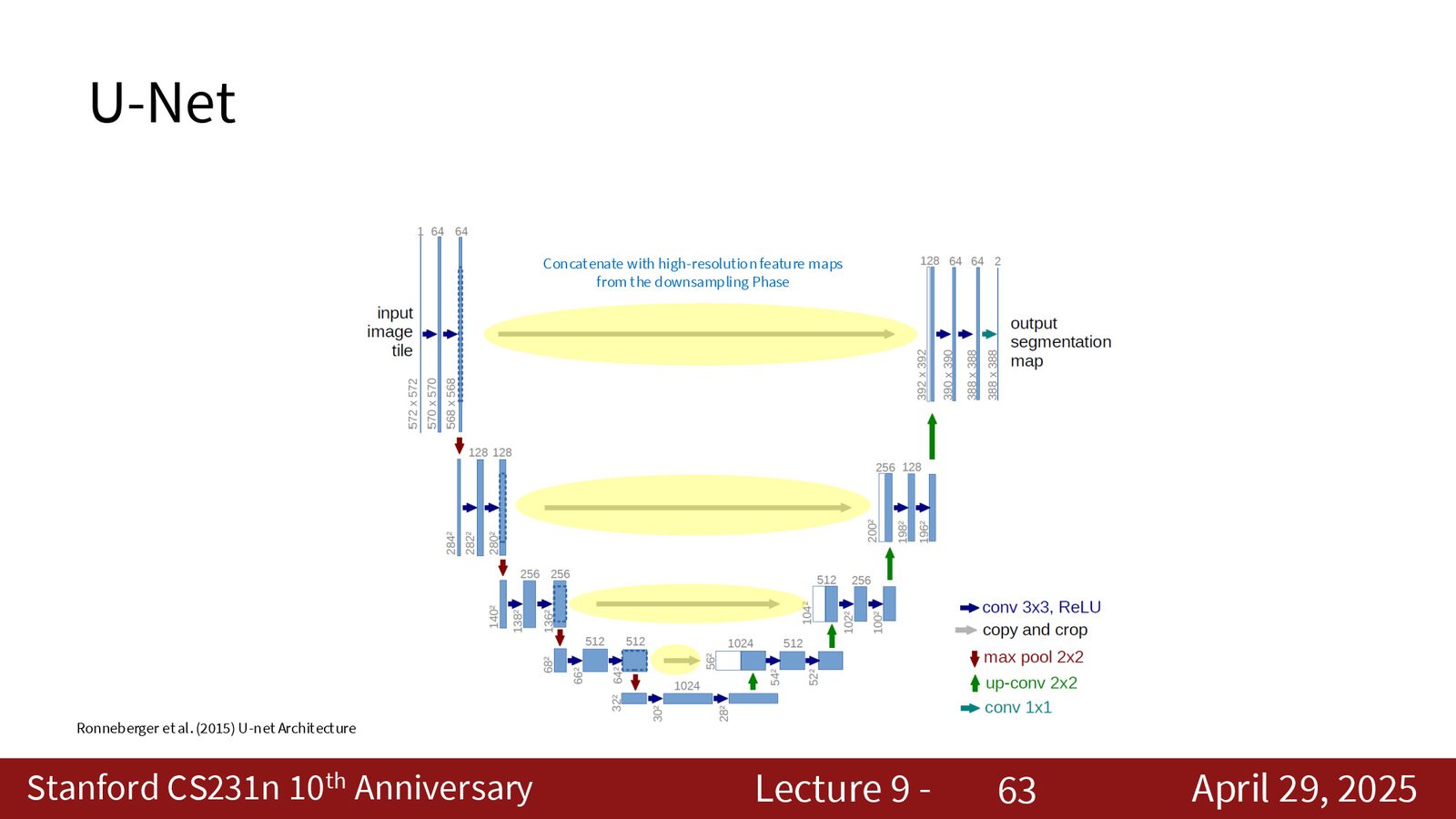
U-Net 架构
U-Net 是语义分割领域最具影响力的架构之一。其结构呈 U 形:左侧为编码器(下采样),右侧为解码器(上采样),关键创新在于跳跃连接(skip connections)——将编码器各层的特征图直接复制并拼接到解码器对应层。
来源:Slides 第27页。
U-Net 跳跃连接的作用
下采样过程中空间信息不可避免地丢失。跳跃连接将编码器的高分辨率特征图直接传递给解码器,使得上采样过程能够恢复精细的边界信息。具体来说:
- 编码器浅层特征:包含丰富的空间/边缘信息,但语义信息较弱
- 编码器深层特征:包含强语义信息,但空间分辨率低
- 跳跃连接让解码器同时获得两者,实现“语义 + 空间”的融合
U-Net 至今仍是医学图像分割的主流架构,也是 Stable Diffusion 等扩散模型的核心组件。
U-Net 的历史影响
U-Net 最初由 Ronneberger 等人于 2015 年发表在 MICCAI,目标是解决医学图像分割中标注稀缺的问题。它的成功不仅限于医学领域:在卫星图像分割、材料缺陷检测、扩散生成模型(如 DDPM、Stable Diffusion)中都作为核心架构出现。截至 2025 年,原论文引用量超过 80,000 次。
本章小结
语义分割是像素级分类任务。滑动窗口方法虽然概念直观但计算不可行。全卷积网络(FCN)通过编码器-解码器结构实现端到端训练。上采样方法从简单的插值到可学习的转置卷积,逐步提升了重建质量。U-Net 的跳跃连接设计有效解决了下采样导致的空间信息丢失问题,至今仍被广泛使用。
目标检测
从语义分割到目标检测
语义分割的局限在于:它只能为每个像素分配类别标签,但无法区分同类的不同实例。如果图像中有两只狗,语义分割只会标记所有“狗像素”为同一类,无法区分哪些像素属于哪只狗。要解决这个问题,我们首先需要目标检测——找到每个物体的位置(边界框)和类别。
来源:Slides 第31页。
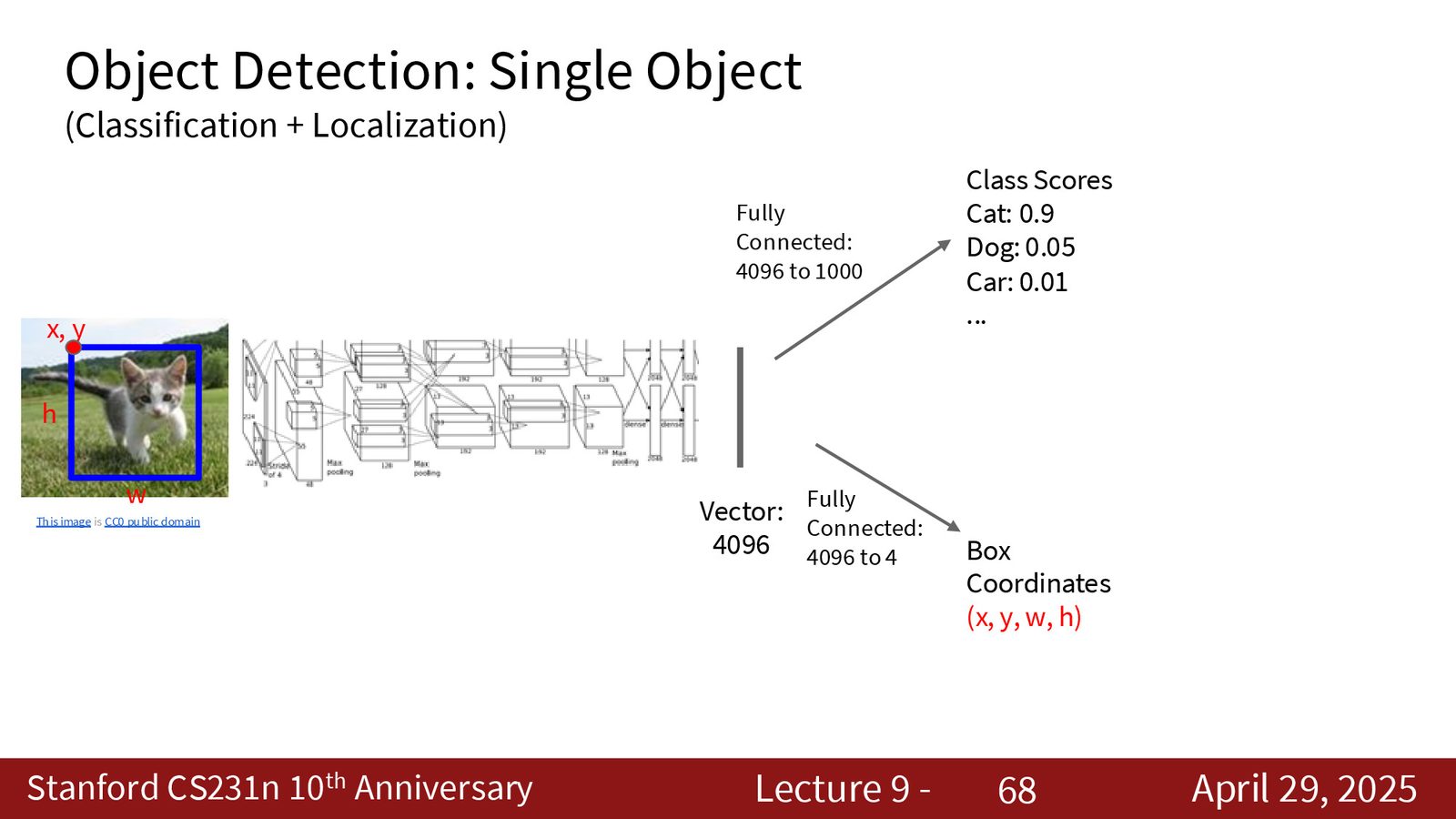
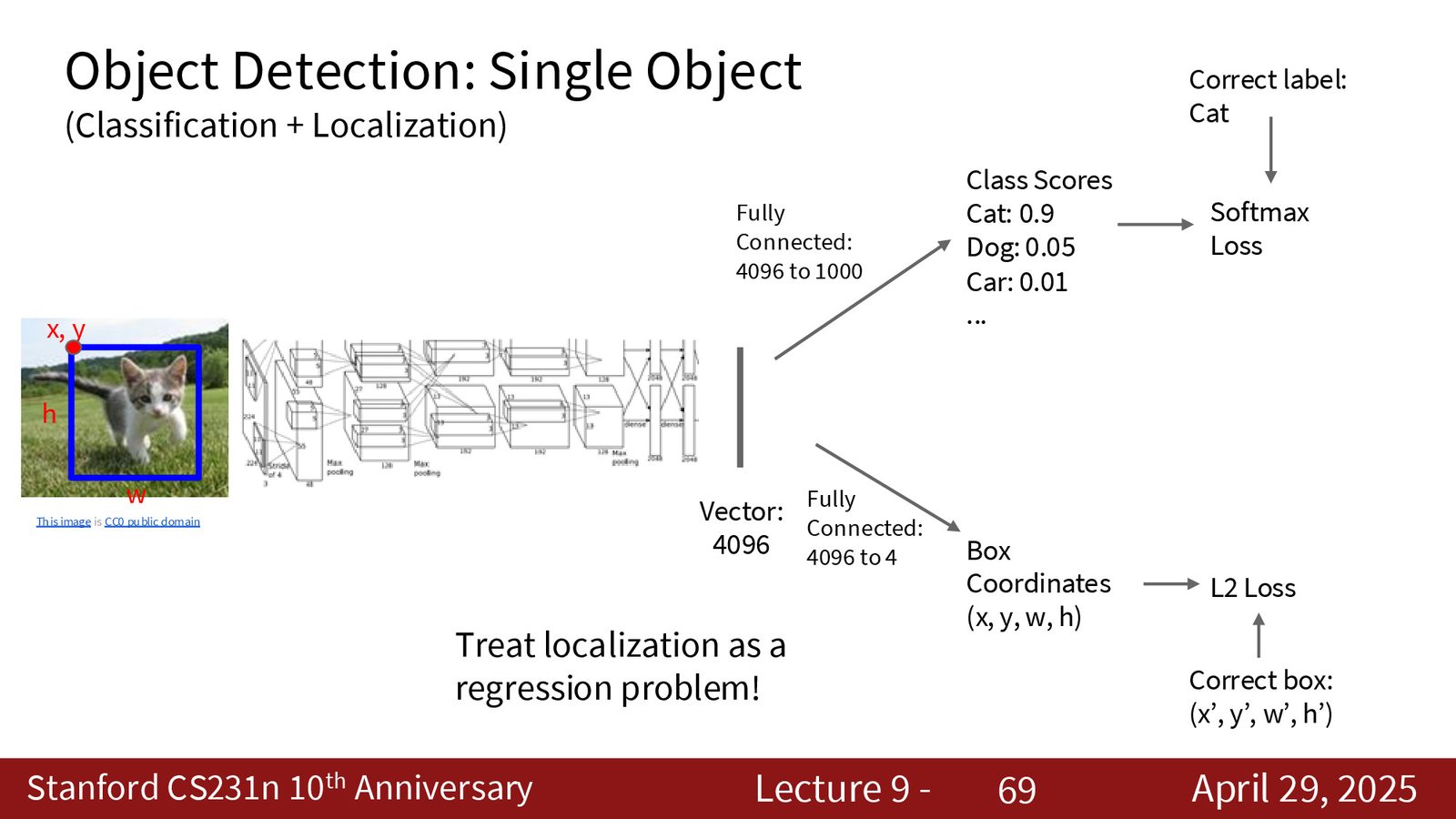
单物体检测:多任务学习
对于只含单个物体的图像,目标检测可以简化为一个多任务学习问题:
来源:Slides 第33页。
- \(L_{\text{cls}}\):softmax 交叉熵损失,用于分类
- \(L_{\text{box}}\):L2 回归损失,用于预测边界框坐标 \((x, y, h, w)\)
- \(\lambda\):平衡两个损失的权重超参数
多任务学习中的损失平衡
分类损失和回归损失的量纲完全不同(交叉熵 vs L2),因此需要通过 \(\lambda\) 来平衡。实践中 \(\lambda\) 通常通过验证集调优。另一个常见问题是两个损失的梯度量级差异过大,现代方法会使用 uncertainty weighting 或 gradient normalization 来自动平衡。
多物体检测的挑战

来源:Slides 第71页。
直接回归法不可扩展
当图像中有多个物体时,网络需要同时输出所有物体的边界框和类别。对于 \(N\) 个物体,需要输出 \(N \times (4 + C)\) 个数值(4 个坐标 + \(C\) 类概率)。但 \(N\) 事先未知,且可以很大——这使得直接回归方法不可扩展。解决此问题有两条主要路线:(1) 先提议候选区域,再逐个分类(两阶段方法);(2) 将图像网格化,每个网格独立预测(单阶段方法)。
R-CNN:开创区域提议方法
面对多物体场景,经典方法是先生成候选区域(Region Proposals),再对每个区域进行分类。
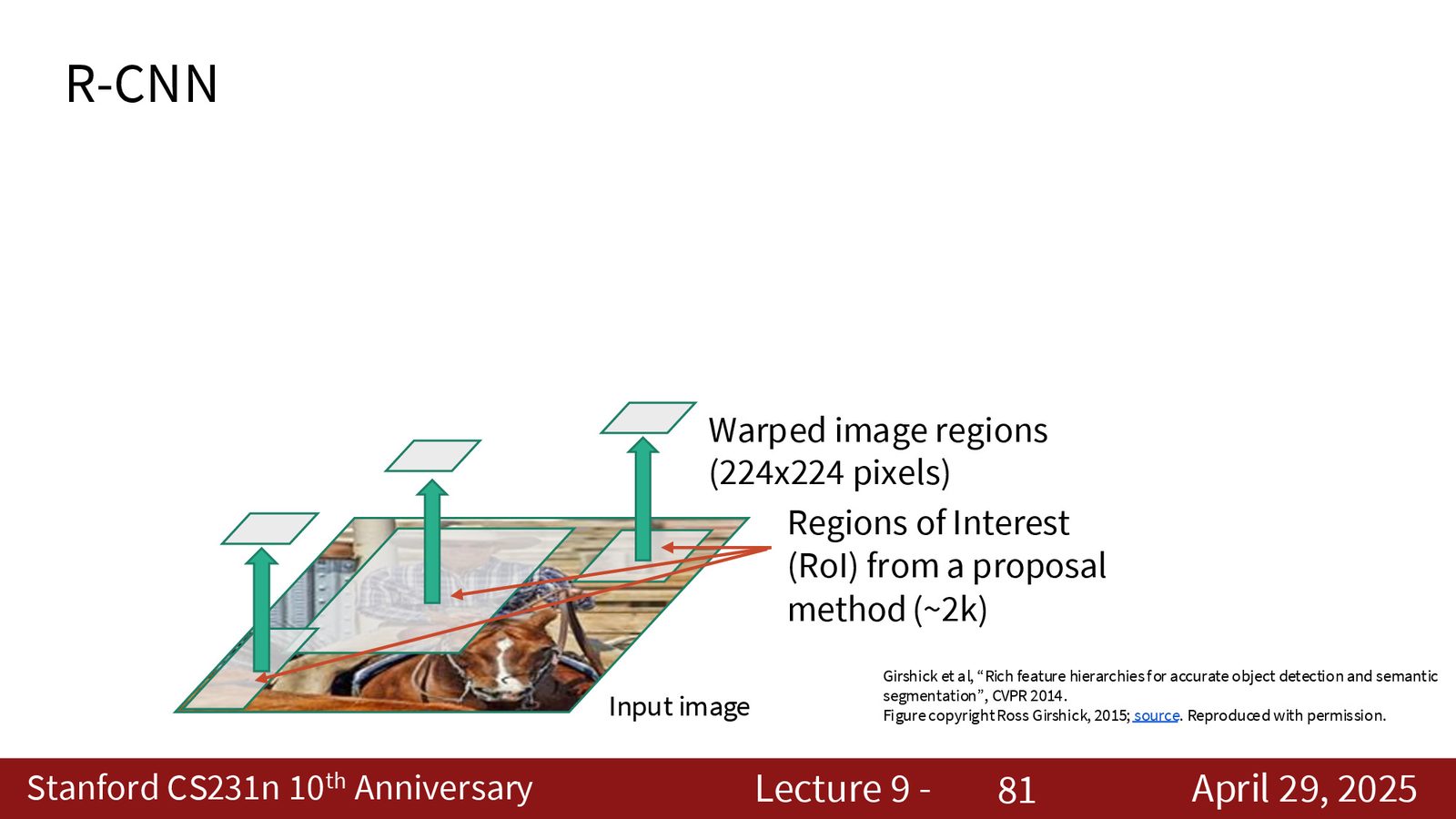
来源:Slides 第81页。
R-CNN(Regions with CNN, CVPR 2014)的流程:
- 使用选择性搜索(Selective Search)等算法生成约 2000 个候选区域
- 将每个区域裁剪并缩放到 \(224 \times 224\) 的固定大小
- 用 CNN(如 AlexNet)提取特征向量
- 用 SVM 分类器判断类别 + 线性回归器精调边界框

来源:Slides 第36页。
R-CNN 的严重效率问题
R-CNN 对每个候选区域独立运行完整 CNN——2000 个区域就要跑 2000 次前向传播。在 VGG-16 上处理一张图像需要约 47 秒,完全无法满足实时需求。更严重的是,相邻区域之间存在大量重叠,对应的 CNN 计算也完全重复,极其浪费。
Fast R-CNN:共享特征图
Fast R-CNN 的核心改进:不再对每个区域独立运行 CNN,而是先对整张图像运行一次 CNN 得到特征图,然后在特征图上裁剪对应区域(RoI Pooling),大幅减少重复计算。
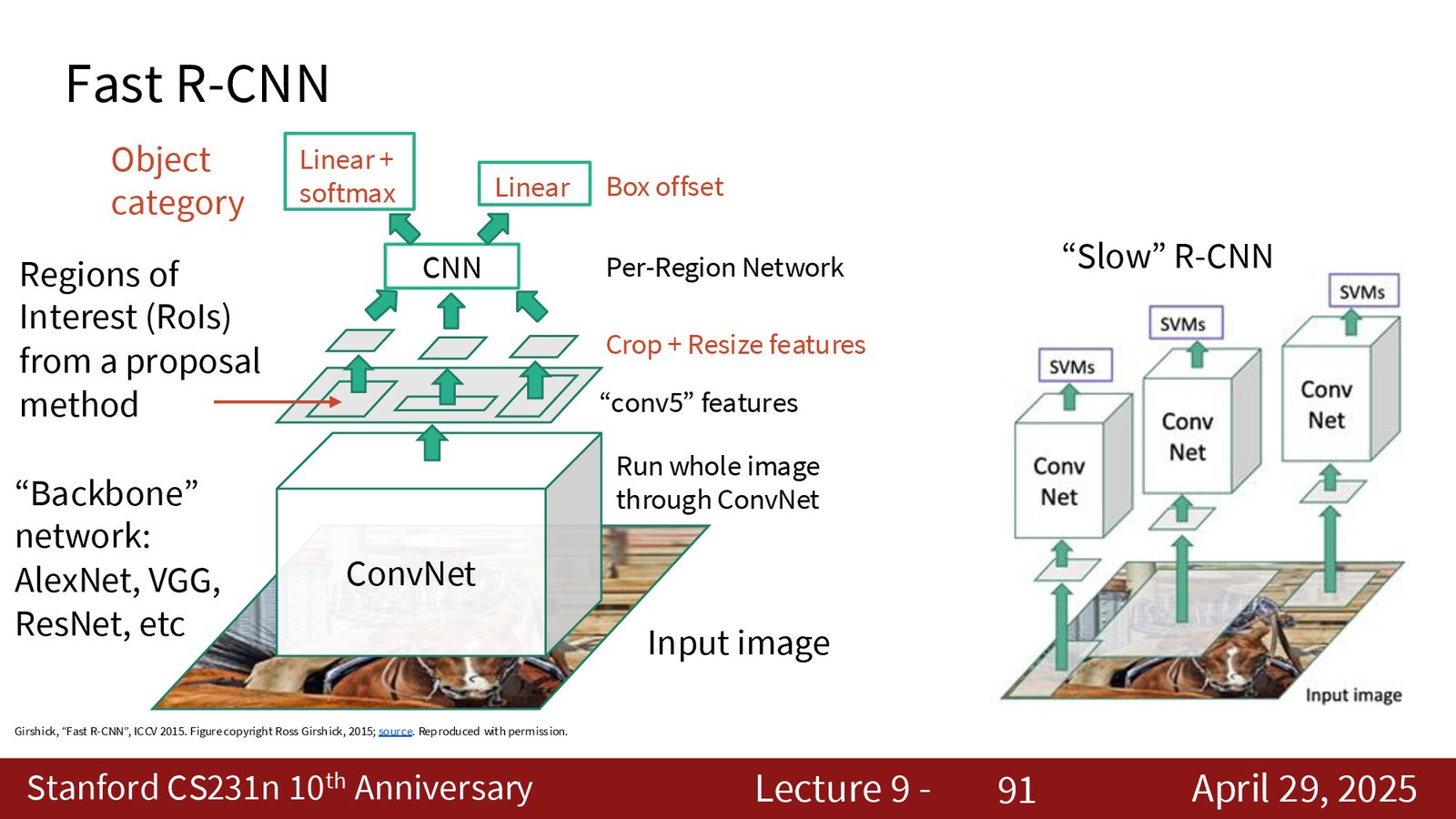
来源:Slides 第91页。
来源:Slides 第38页。
RoI Pooling 的工作原理
RoI Pooling 将特征图上不同大小的区域映射到固定大小的输出(如 \(7 \times 7\)):
- 将区域均匀划分为 \(7 \times 7\) 的子网格
- 每个子网格内做 max pooling
- 输出固定为 \(D \times 7 \times 7\)(\(D\) 为特征通道数)
这样无论原始区域大小如何,后续的全连接层都能正常工作。改进版本 RoI Align 使用双线性插值替代硬量化,避免坐标对齐误差。
Faster R-CNN:端到端训练
Faster R-CNN 进一步引入区域提议网络(Region Proposal Network, RPN),用神经网络替代手工区域提议算法,实现全流程端到端训练:
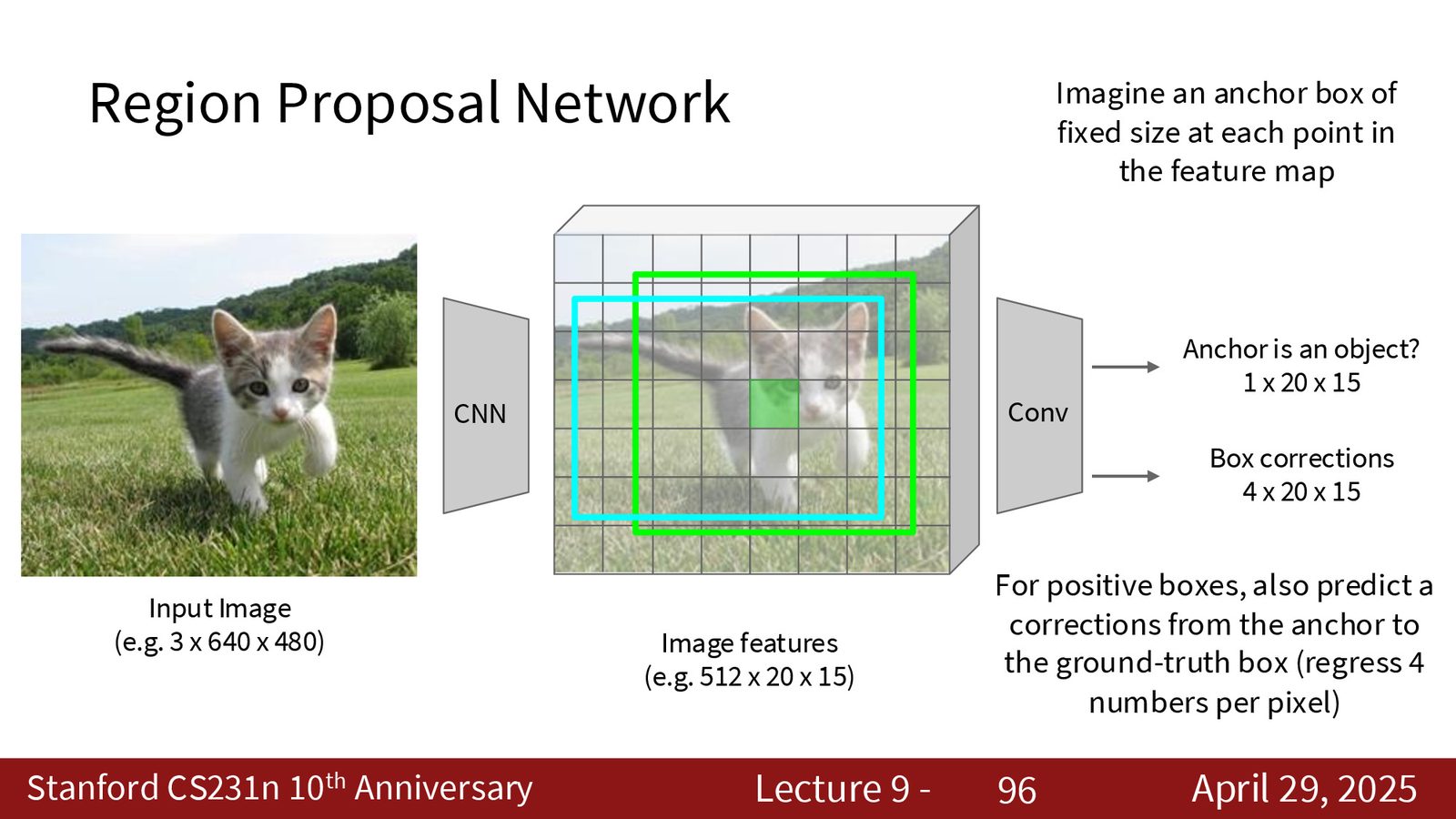
来源:Slides 第96页。

来源:Slides 第40页。
锚框(Anchor Boxes)的设计
RPN 在特征图的每个空间位置预设 \(K\) 种锚框(不同尺度和长宽比的组合)。例如使用 3 种尺度 \(\times\) 3 种长宽比 = 9 种锚框。对于 \(20 \times 15\) 的特征图,总共有 \(20 \times 15 \times 9 = 2{,}700\) 个候选锚框。RPN 为每个锚框预测:
- 物体/背景概率:该锚框是否包含物体
- 边界框修正量:\((dx, dy, dw, dh)\) 四个偏移值
| 方法 | 区域提议 | 特征提取 | 训练方式 | 速度 |
|---|---|---|---|---|
| R-CNN | Selective Search | 每区域独立CNN | 多阶段 | \(≈\)47s/图 |
| Fast R-CNN | Selective Search | 共享特征图 | 端到端 | \(≈\)2s/图 |
| Faster R-CNN | RPN (学习) | 共享特征图 | 端到端 | \(≈\)0.2s/图 |
YOLO:单阶段目标检测
YOLO(You Only Look Once)是最具代表性的单阶段检测器,通过一次前向传播同时完成候选框生成和分类。

来源:Slides 第101页。
来源:Slides 第44页。
YOLO 的核心设计:
- 将图像划分为 \(S \times S\) 的网格(如 \(7 \times 7\))
- 每个网格单元预测 \(B\) 个边界框(含位置、大小、置信度)和 \(C\) 个类别概率
- 输出张量大小为 \(S \times S \times (5B + C)\)
- 通过阈值化和非极大值抑制(Non-Maximum Suppression, NMS)去除冗余框
NMS(非极大值抑制)的具体步骤
当多个网格/锚框都预测到同一物体时,需要 NMS 去重:
- 按置信度排序所有候选框
- 选择置信度最高的框,加入最终结果
- 删除所有与该框 IoU \(>\) 阈值(如 0.5)的其他框
- 重复步骤 2--3 直到没有剩余候选框
IoU(Intersection over Union)= 两个框交集面积 / 两个框并集面积。
YOLO 的实际影响与版本演进
YOLO 至今仍是工业界最常用的目标检测框架。版本演进:
- YOLOv1 (2016):提出基本框架,\(7 \times 7\) 网格
- YOLOv2/v3:引入锚框、多尺度预测、Darknet backbone
- YOLOv4/v5:大量工程优化(CSPNet、Mosaic 增强等)
- YOLOv8+ (Ultralytics):现代化设计,anchor-free,高精度实时检测
从 v1 到 v8,检测精度(mAP)提升了 30+ 个百分点,但核心的单阶段设计理念始终不变。
| 特性 | Faster R-CNN | YOLO | DETR |
|---|---|---|---|
| 阶段数 | 两阶段 | 单阶段 | 单阶段 |
| 区域提议 | RPN | 网格化 | Object Queries |
| 锚框 | 需要 | 需要(v1-v5) | 不需要 |
| NMS 后处理 | 需要 | 需要 | 不需要 |
| 速度 | 中等 | 快 | 中等 |
| 小物体检测 | 强 | 弱(v1-v3) | 弱 |
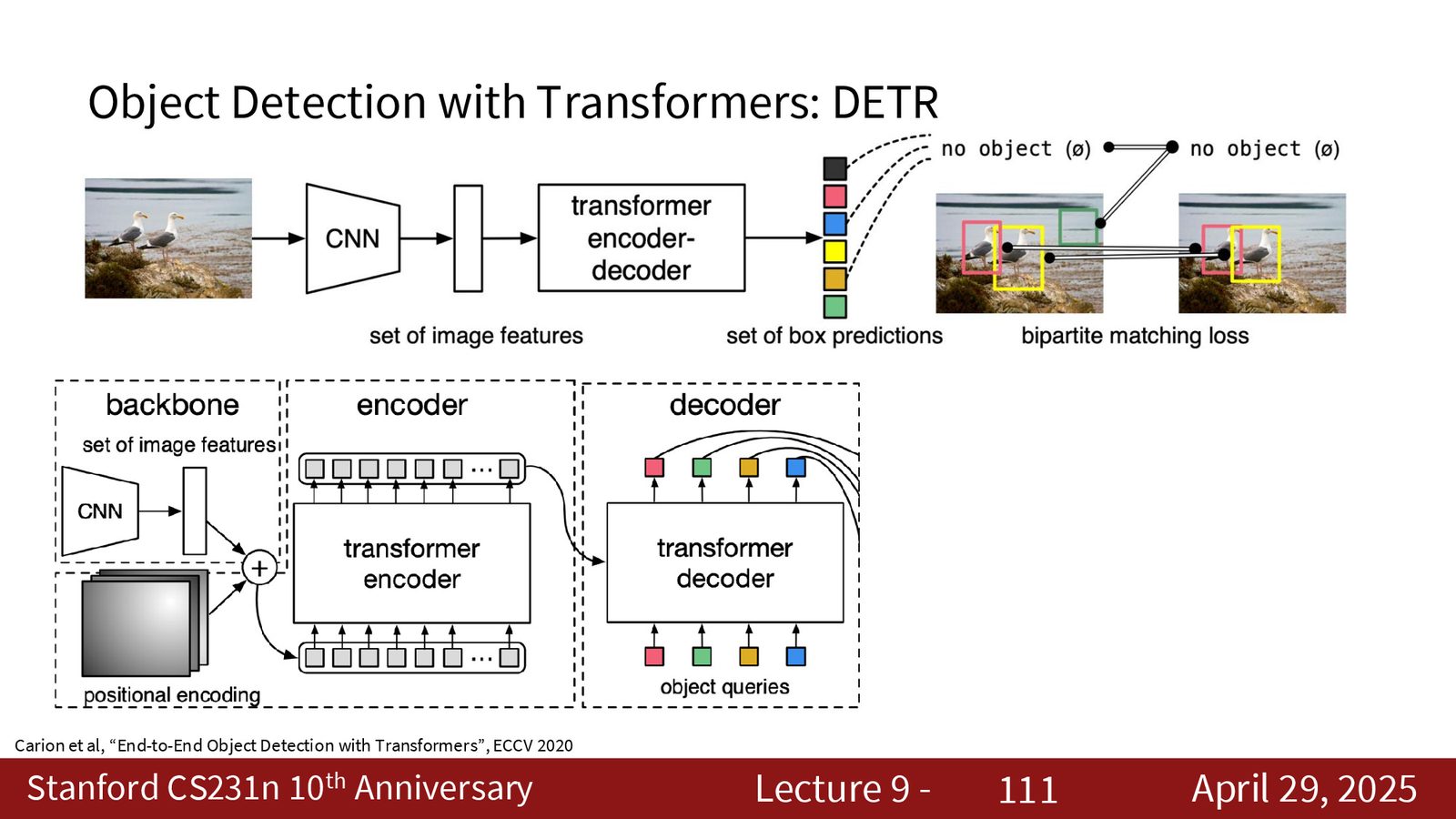
DETR:基于 Transformer 的目标检测
DETR(DEtection TRansformer)(ECCV 2020)是将 Transformer 应用于目标检测的里程碑工作,完全去除了锚框和 NMS 后处理。
来源:Slides 第111页。
来源:Slides 第48页。
DETR 的关键创新在于引入Object Queries和二部图匹配(Bipartite Matching):
- 用 CNN 将图像转换为 patch token,加上位置编码
- Transformer Encoder 对 token 进行自注意力编码
- Transformer Decoder 接收一组可学习的 Object Queries(如 100 个)
- 每个 Query 通过自注意力和交叉注意力生成输出
- 每个输出经 FFN 映射为(类别, 边界框)或“无物体”(\(\varnothing\))
- 训练时用匈牙利算法在预测和真实框之间做一对一最优匹配
二部图匹配为什么能替代 NMS
传统方法中,多个锚框可能预测到同一物体,需要 NMS 去重。DETR 用匈牙利算法强制每个真实物体只匹配一个预测——这从损失函数层面就保证了一对一关系,训练完成后自然不会产生重复预测,因此完全不需要 NMS。这也是 DETR “End-to-End” 的核心含义。
DETR 的已知局限
- 收敛慢:原始 DETR 需要 500 个 epoch 才能收敛,是 Faster R-CNN 的 10 倍以上
- 小物体检测弱:Transformer 对低分辨率特征的处理能力有限
- Query 数量限制:如果 Query 数量少于实际物体数量,只会检测出置信度最高的物体
- 后续改进(Deformable DETR, DINO-DETR 等)已大幅缓解这些问题
本章小结
目标检测经历了从两阶段(R-CNN 系列)到单阶段(YOLO)再到基于 Transformer(DETR)的演进。核心挑战在于:如何在保持高精度的同时高效处理数量未知的多个物体。R-CNN 通过区域提议解决了多物体问题但速度较慢(47s \(\rightarrow\) 0.2s);YOLO 通过网格化预测实现了实时检测;DETR 用 Object Queries 和二部图匹配优雅地回避了锚框设计和 NMS 后处理。
实例分割
Mask R-CNN
实例分割在目标检测的基础上,进一步为每个检测到的物体生成像素级掩码。Mask R-CNN(ICCV 2017)在 Faster R-CNN 的基础上增加了一个掩码预测分支:
来源:Slides 第55页。
- 对整张图运行 CNN + RPN 获得区域提议
- 对每个区域提取特征(RoI Align,使用双线性插值避免量化误差)
-
三个并行输出头:
-
分类头:输出类别概率
- 回归头:精调边界框坐标
- 掩码头:使用 FCN 输出 \(C \times M \times M\) 的二值掩码(\(C\) 个类别,\(M \times M\) 分辨率)
来源:Slides 第56页。
Mask R-CNN 的掩码预测机制
掩码头为每个类别独立预测一个 \(M \times M\) 的二值掩码(通常 \(M=28\)),最终根据分类头的预测选取对应类别的掩码作为输出。这种“分类与掩码解耦”的设计比“直接预测多类掩码”效果更好,因为它避免了类别间的竞争。掩码损失使用逐像素的二值交叉熵(Binary Cross-Entropy)。
从 RoI Pooling 到 RoI Align 的关键改进
原始 RoI Pooling 需要将浮点坐标量化为整数格点,这引入了最多半个格点的对齐误差。对于分类任务,这种误差可以容忍;但对于掩码预测,哪怕一两个像素的偏差都会导致边界不准。RoI Align 使用双线性插值替代硬量化,在非整数坐标处精确采样,使掩码精度显著提升。这一改进是 Mask R-CNN 成功的关键因素之一。
Panoptic Segmentation
讲者还简要提到了全景分割(Panoptic Segmentation)——它统一了语义分割和实例分割:对“可数物体”(人、车、狗)做实例分割,对“不可数区域”(天空、草地、道路)做语义分割,最终输出一张完整的场景理解图。
| 任务 | 输出 | 区分实例 | 代表方法 |
|---|---|---|---|
| 语义分割 | 每像素类别 | 否 | FCN, U-Net |
| 实例分割 | 每实例掩码+类别 | 是(仅物体) | Mask R-CNN |
| 全景分割 | 统一场景理解 | 是+语义背景 | Panoptic FPN |
本章小结
实例分割通过在目标检测基础上添加掩码预测,实现了像素级的实例区分。Mask R-CNN 凭借三头并行设计(分类 + 回归 + 掩码)和 RoI Align 的精确采样成为标杆方法。全景分割进一步统一了“物体”和“背景区域”的理解。
可视化与理解
理解神经网络的内部工作机制对于模型调试、安全评估和科学发现至关重要。讲者介绍了几种核心的可视化方法,从低层(滤波器权重)到高层(类激活图)逐步深入。
滤波器可视化
最直接的方法是可视化卷积层的滤波器权重。对于第一层(输入为 3 通道 RGB),可以直接将滤波器显示为小图片:
来源:Slides 第61页。
第一层滤波器的学习结果具有高度一致性——无论在 ImageNet、COCO 还是其他数据集上训练,第一层滤波器几乎总是学到类似的边缘检测器和颜色检测器。这暗示了视觉系统底层特征的“普遍性”。
深层滤波器难以直接可视化
只有第一层滤波器(输入通道为 3,可映射为 RGB)能被直观可视化。深层滤波器通常有 64、128 甚至 512 个输入通道,无法直接显示为人眼可理解的图像。对于深层特征的理解,需要借助下面介绍的间接方法。常见的替代策略是可视化每个通道的最大激活 patch——找到训练集中使某个神经元激活值最大的图像区域。
显著性图(Saliency Maps)
显著性图回答一个核心问题:哪些像素对分类决策影响最大?

来源:Slides 第131页。
具体方法:计算目标类别得分 \(S_c\) 对输入像素 \(x_{ij}\) 的梯度:
对于 RGB 图像,取三个通道梯度绝对值的最大值(max over RGB channels)。梯度绝对值大的像素意味着:微小改变该像素的值就会显著影响分类得分。
来源:Slides 第63页。
显著性图的医学应用
在医学影像分析中,显著性图尤其重要。例如,当网络判断一张 CT 图像“有肿瘤”时,医生需要知道网络关注的是图像的哪个区域。如果网络关注的不是肿瘤区域而是图像伪影或标注信息,就意味着模型学到了虚假相关(spurious correlation)。这种检查在模型部署到临床之前是必须的。
显著性图 vs 梯度方法的改进
原始显著性图使用原始梯度,容易产生噪声。后续改进包括:
- SmoothGrad:多次加噪采样后取梯度平均,降低噪声
- Integrated Gradients:沿从基线到输入的路径积分梯度,满足公理性质
- Guided Backpropagation:只回传正梯度,得到更清晰的可视化
类激活图(CAM)与 Grad-CAM
CAM(Class Activation Mapping)利用全局平均池化层的结构特性,将分类得分追溯到最后一个卷积层的空间位置:

来源:Slides 第65页。

来源:Slides 第66页。
CAM 的局限在于只能应用于最后一个卷积层之后紧接全局平均池化的架构。Grad-CAM 通过使用梯度来计算权重,突破了这一限制,可以应用于任意卷积层:
- \(A^k\):第 \(k\) 个特征图(\(H' \times W'\) 的空间分辨率)
- \(\alpha_k^c\):类别 \(c\) 对特征图 \(k\) 的重要性权重(梯度的全局平均池化)
- \(Z = H' \times W'\):空间维度的像素总数
- ReLU 确保只保留正向激活(对分类有正贡献的区域)
来源:Slides 第68页。
Grad-CAM 的解读陷阱
Grad-CAM 显示的是“哪些区域对分类有贡献”,但不等于“模型理解了这个物体”。模型可能只依赖背景上下文(如看到草地就预测“牛”)而非物体本身的特征。此外,Grad-CAM 的分辨率受限于特征图大小(通常是 \(7 \times 7\) 或 \(14 \times 14\)),无法提供像素级精确的解释。
Transformer 的注意力可视化
对于 Vision Transformer,可视化注意力权重矩阵本身就是天然的“激活图”。自注意力机制计算每对 token 之间的注意力分数,这些分数可以直接映射回图像空间。
来源:Slides 第69页。
CNN vs Transformer 可解释性对比
- CNN:需要 Grad-CAM 等后处理方法来“反向追踪”模型的关注区域;可视化结果受限于特征图分辨率
- Transformer:注意力权重本身就是可解释的——直接反映了哪些 token 对当前决策最重要;不同层、不同注意力头可以分别可视化
但要注意:注意力权重高并不严格等于“模型依赖这个区域做决策”。有研究表明,梯度加权的注意力(attention \(\times\) gradient)比原始注意力更能反映真实的特征重要性。
卷积作为矩阵乘法:理解转置卷积
讲者还从矩阵运算的角度深入解释了为什么“转置卷积”叫这个名字:

来源:Slides 第151页。
以 1D 为例,kernel size=3, stride=2, padding=1 的卷积可以表示为:
转置卷积就是使用这个矩阵的转置 \(X^T\),将 2 维输出映射回 6 维输入空间。
本章小结
神经网络可视化方法从低层(滤波器可视化)到高层(显著性图、CAM/Grad-CAM、注意力图),层层深入地揭示了模型的决策依据。显著性图通过梯度直接反映像素对分类的影响;Grad-CAM 将类别得分追溯到卷积特征图的空间位置;Transformer 的注意力机制天然具备可解释性。这些工具在模型调试、安全验证和医学应用中至关重要。
总结与延伸
关键 Takeaways
核心要点
- 语义分割是像素级分类:编码器-解码器 + 跳跃连接(U-Net)是经典范式
- 上采样方法的选择很重要:从不可学习的插值到可学习的转置卷积,表达力逐步增强
- 目标检测的三代方法:两阶段(R-CNN 系列)\(\rightarrow\) 单阶段(YOLO)\(\rightarrow\) Transformer(DETR)
- 实例分割 = 检测 + 分割:Mask R-CNN 中 RoI Align 的精确对齐是关键
- YOLO 仍是工业首选:简单、快速、不断迭代,适合实时应用
- DETR 消除了手工组件:不需要锚框、不需要 NMS,但训练成本高
- 可视化是信任的基础:显著性图和 Grad-CAM 不仅是研究工具,更是模型部署前的必要验证手段
- Transformer 天然可解释:注意力权重直接反映模型关注区域,但也不能过度解读
拓展阅读
- Dosovitskiy et al., An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021
- Long et al., Fully Convolutional Networks for Semantic Segmentation, CVPR 2015
- Ronneberger et al., U-Net: Convolutional Networks for Biomedical Image Segmentation, MICCAI 2015
- Girshick et al., Rich Feature Hierarchies for Accurate Object Detection, CVPR 2014
- Girshick, Fast R-CNN, ICCV 2015
- Ren et al., Faster R-CNN: Towards Real-Time Object Detection, NeurIPS 2015
- Redmon et al., You Only Look Once: Unified, Real-Time Object Detection, CVPR 2016
- Carion et al., End-to-End Object Detection with Transformers (DETR), ECCV 2020
- He et al., Mask R-CNN, ICCV 2017
- Selvaraju et al., Grad-CAM: Visual Explanations from Deep Networks, ICCV 2017
- Ultralytics YOLO: https://github.com/ultralytics/ultralytics
- Detectron2: https://github.com/facebookresearch/detectron2