CS231N Lecture 5: Image Classification with CNNs
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Justin Johnson 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025 |

深度学习基础回顾
本节课由 Justin Johnson 主讲,他是 CS231N 的创始人之一,曾在 Stanford 攻读博士学位(2012--2018),之后在 Facebook AI Research 和 University of Michigan 从事深度学习与计算机视觉研究。本节课是课程前半段(深度学习基础)与后半段(视觉世界感知)的分水岭,我们首先回顾前几节课的核心内容,然后深入介绍卷积神经网络。
图像分类与线性分类器

来源:Slides 第3页。
图像分类是计算机视觉最核心的任务之一:给定一张输入图像(三维张量,\(H \times W \times 3\)),模型需要输出一组分数,表示该图像属于每个预定义类别的可能性。
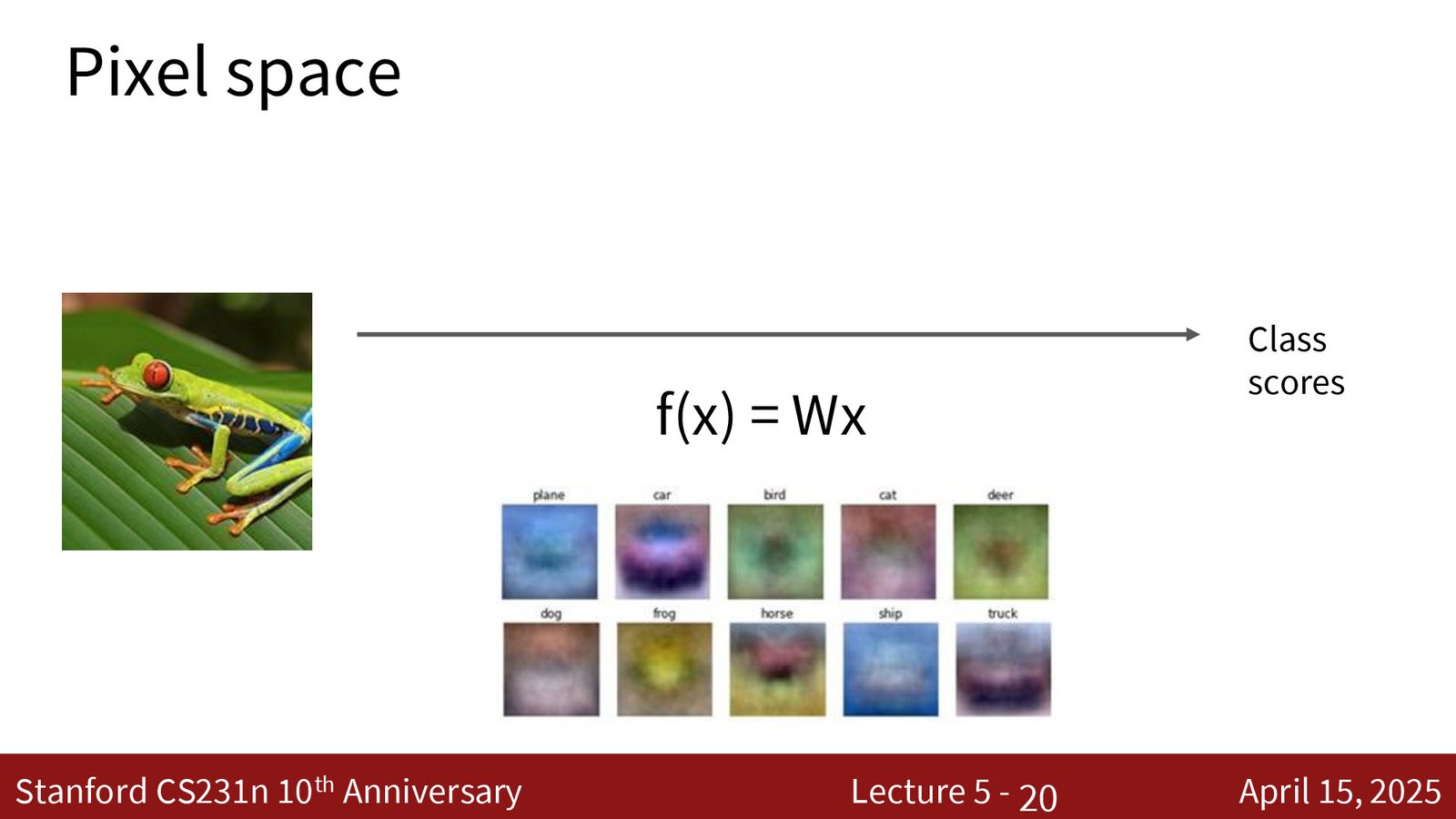
线性分类器是最简单的模型形式:
其中 \(x\) 是展平后的像素向量(如 \(32 \times 32 \times 3 = 3072\) 维),\(W\) 是权重矩阵,\(b\) 是偏置。每一行 \(W_i\) 可以被视为一个类别模板——模型通过计算输入图像与每个模板的内积来得到分类分数。
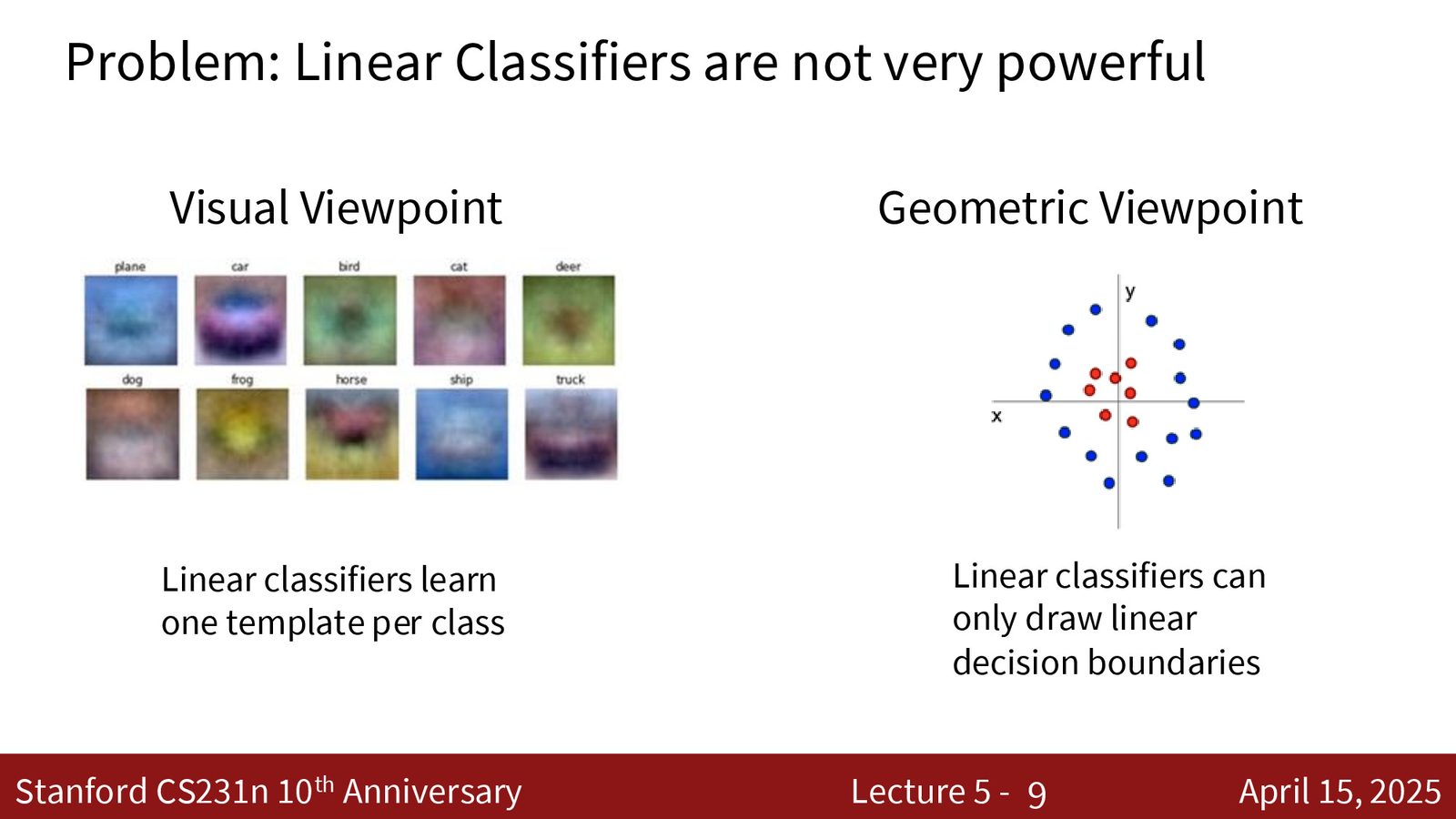
线性分类器的两种视角
- 模板视角:权重矩阵的每一行是一个与整张图像大小相同的模板。分类分数就是输入与模板的相似度。缺陷:每个类别只能有一个模板,无法处理同一类物体的多种外观(如红色汽车 vs 蓝色汽车)。
- 几何视角:线性分类器在高维空间中用超平面划分不同类别的区域。缺陷:如果数据不是线性可分的,线性分类器无能为力。
损失函数与优化
有了模型之后,我们需要损失函数来衡量当前参数的好坏。常用的分类损失包括 Softmax 交叉熵损失和 SVM Hinge 损失。

来源:Slides 第5页。
优化算法负责在参数空间中搜索低损失的区域。常用算法包括随机梯度下降(SGD)、带动量的 SGD、RMSProp 和 Adam 等。
Adam 获得 ICLR 2025 时间检验奖
就在本节课授课前一天,ICLR 2025 将“时间检验奖”(Test of Time Award)颁给了 Adam 优化器的论文。Adam 最初于 2015 年在 ICLR 发表,至今仍是深度学习中使用最广泛的优化器之一。
从线性到非线性:神经网络
线性分类器的表达能力严重不足。解决方案:堆叠多个线性变换并在它们之间插入非线性激活函数。
这就是最简单的两层神经网络。虽然代数变化很小(多了一个矩阵和一个非线性函数),但分类能力得到了质的飞跃。
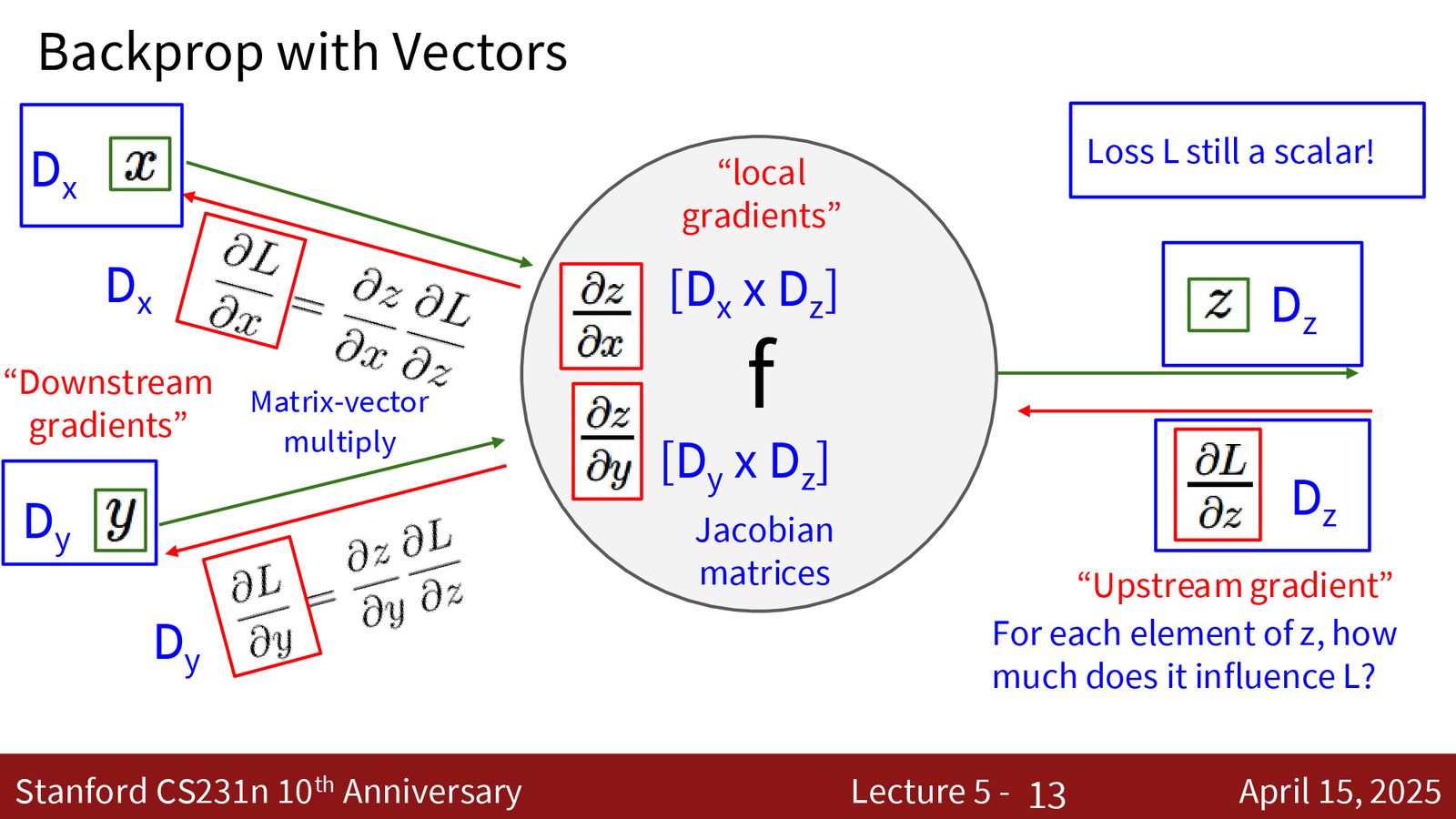
计算图与反向传播
来源:Slides 第9页。
反向传播的核心思想
反向传播将全局问题(计算损失对所有参数的梯度)转化为局部问题——每个计算节点只需要:
- 前向:根据输入计算输出
- 反向:接收上游梯度,计算对自身输入的梯度(链式法则)
节点不需要知道自己处于什么样的网络中、要解决什么问题。这种局部 API 设计使得我们可以像搭积木一样构建任意复杂的神经网络。
梯度形状法则
对于标量损失 \(L\):
- 上游梯度 \(\frac{\partial L}{\partial \text{output}}\) 的形状 = output 的形状
- 下游梯度 \(\frac{\partial L}{\partial \text{input}}\) 的形状 = input 的形状
这是因为 \(L\) 是标量,梯度本质上是“如果微扰张量中某个元素,损失会怎么变化”。
深度学习通用配方
这几节课建立了解决几乎所有深度学习问题的通用配方:
- 将问题编码为张量输入/输出
- 设计计算图(神经网络架构)
- 选择损失函数
- 用梯度下降 + 反向传播优化
无论是图像分类、图像生成还是大语言模型,底层都遵循这个配方。
本章小结
前四节课覆盖了深度学习的所有基础组件:线性分类器定义了问题形式,损失函数衡量了解的质量,优化算法搜索参数空间,神经网络提供了强大的函数族,计算图和反向传播让梯度计算自动化。接下来我们将进入课程第二阶段,学习如何针对图像设计更好的网络架构。
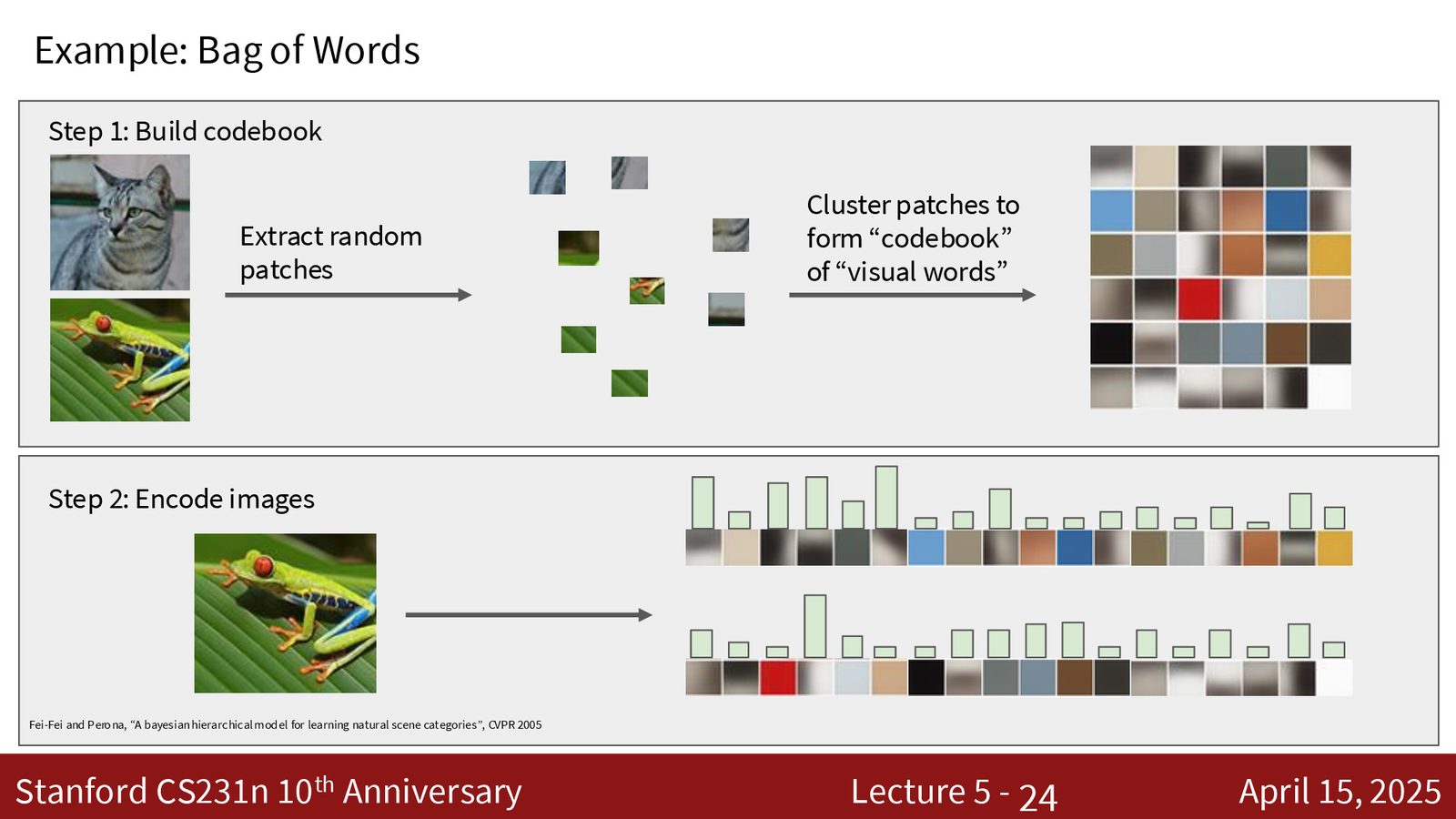
从特征工程到端到端学习
传统特征表示
在深度学习时代之前(约 2000--2012 年),计算机视觉的标准范式是手工特征提取 + 线性分类器。研究者会设计各种特征表示来捕获图像中的关键信息:
来源:Slides 第13页。
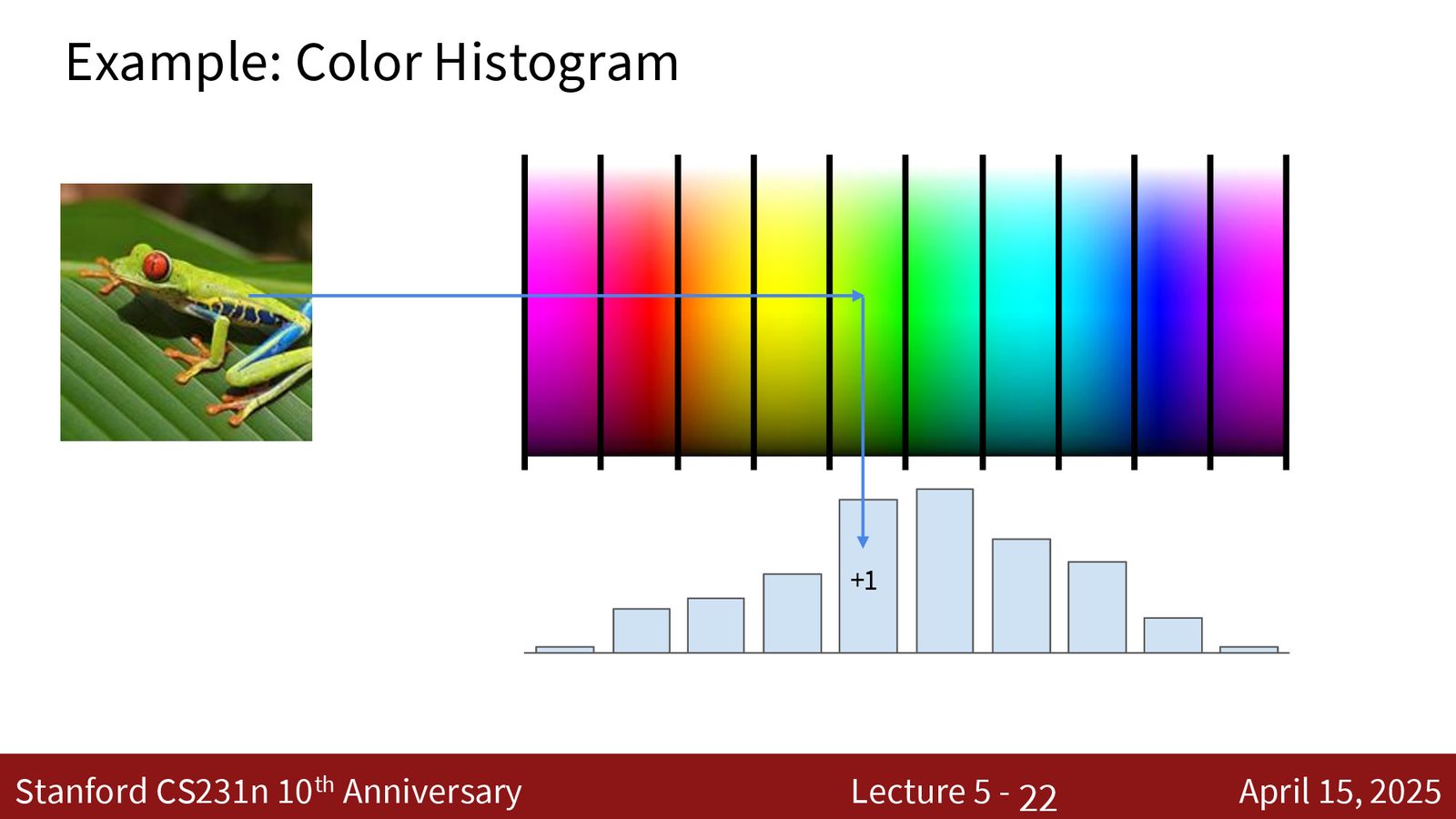
- 颜色直方图(Color Histogram):将色彩空间离散化为若干桶,统计每个桶中像素数量。捕获颜色分布,但完全丢弃空间结构。
- 方向梯度直方图(HoG, Histogram of Oriented Gradients):在图像的每个局部区域计算边缘方向的分布。捕获空间结构,但丢弃颜色信息。
- 拼接特征:实践中通常将多种特征向量拼接起来,形成一个大的特征表示。
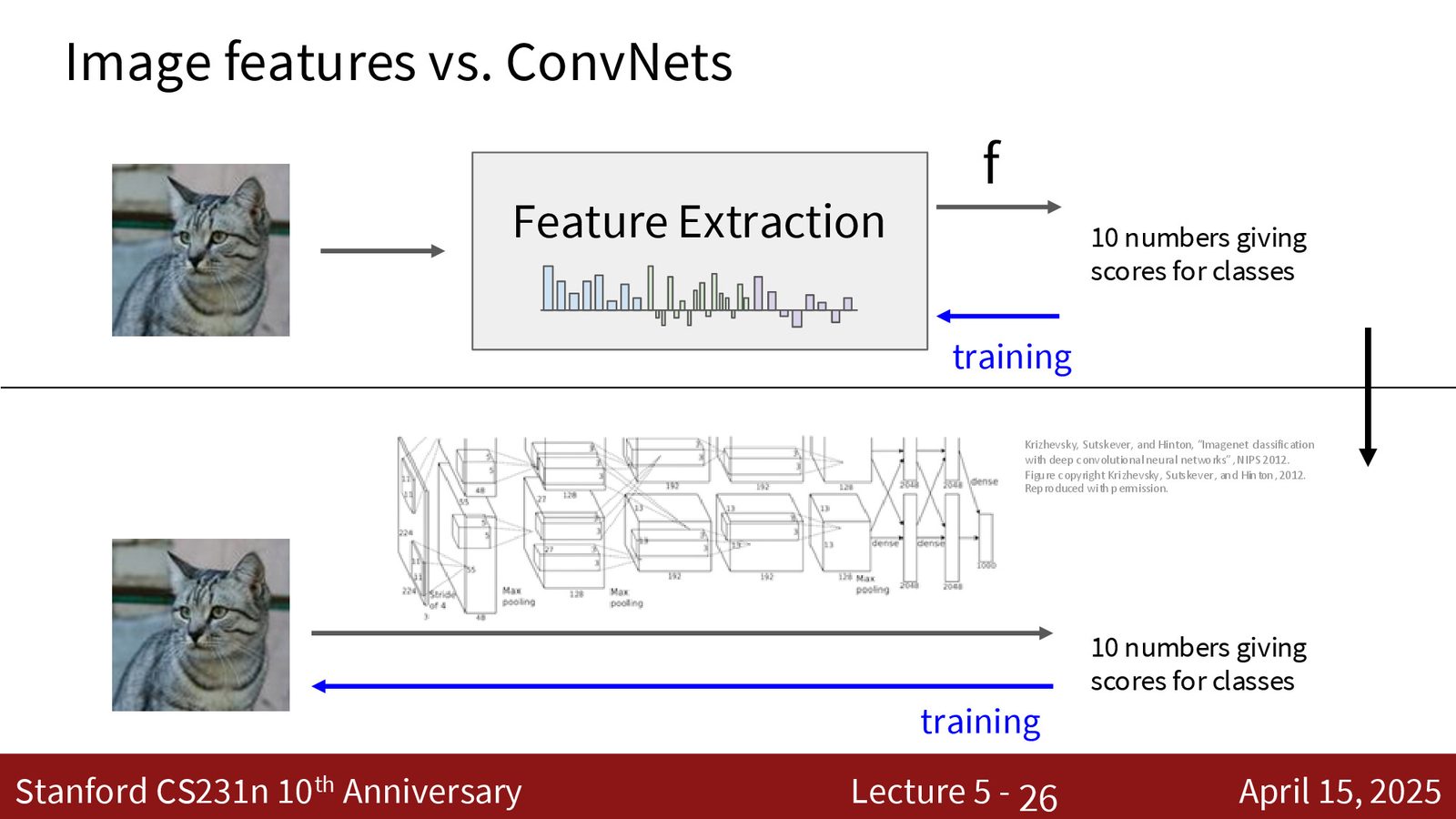
特征提取 vs 端到端学习

来源:Slides 第16页。
端到端学习的核心理念
梯度下降可能比你更擅长编程,海量数据可能比你更了解问题。
传统方法中,特征提取部分由人类设计(可能包含错误直觉或遗漏),只有分类器部分从数据中学习。而端到端神经网络让整个系统——从原始像素到最终预测——都通过梯度下降从数据中学习。
过去十余年的实践反复证明:端到端学习在几乎所有问题上都优于手工特征工程。
人类设计者的角色变化
在端到端学习时代,人类的角色从“设计特征提取器”变为“设计网络架构”。两者的区别是:
- 设计特征提取器 = 定义一个具体函数
- 设计网络架构 = 定义一个函数族(由计算图结构决定),具体参数留给梯度下降从数据中学习
本章小结
从手工特征提取到端到端学习是计算机视觉发展的关键转折。端到端学习的成功建立在三个基础之上:(1)足够强大的函数族(深度神经网络),(2)足够多的数据(ImageNet 等大规模数据集),(3)足够快的计算(GPU)。接下来我们将学习专门为图像设计的计算图元件——卷积层和池化层。
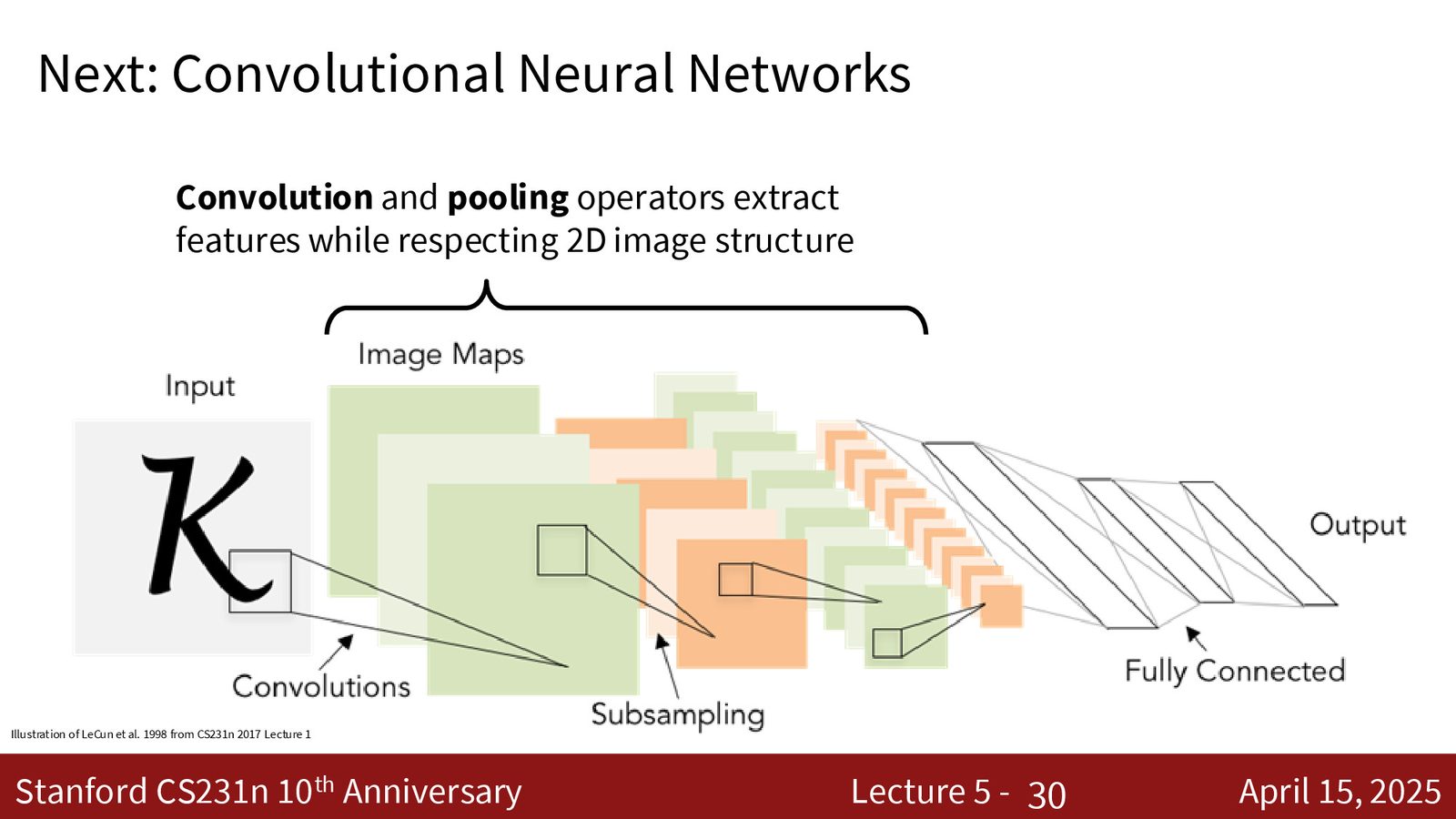
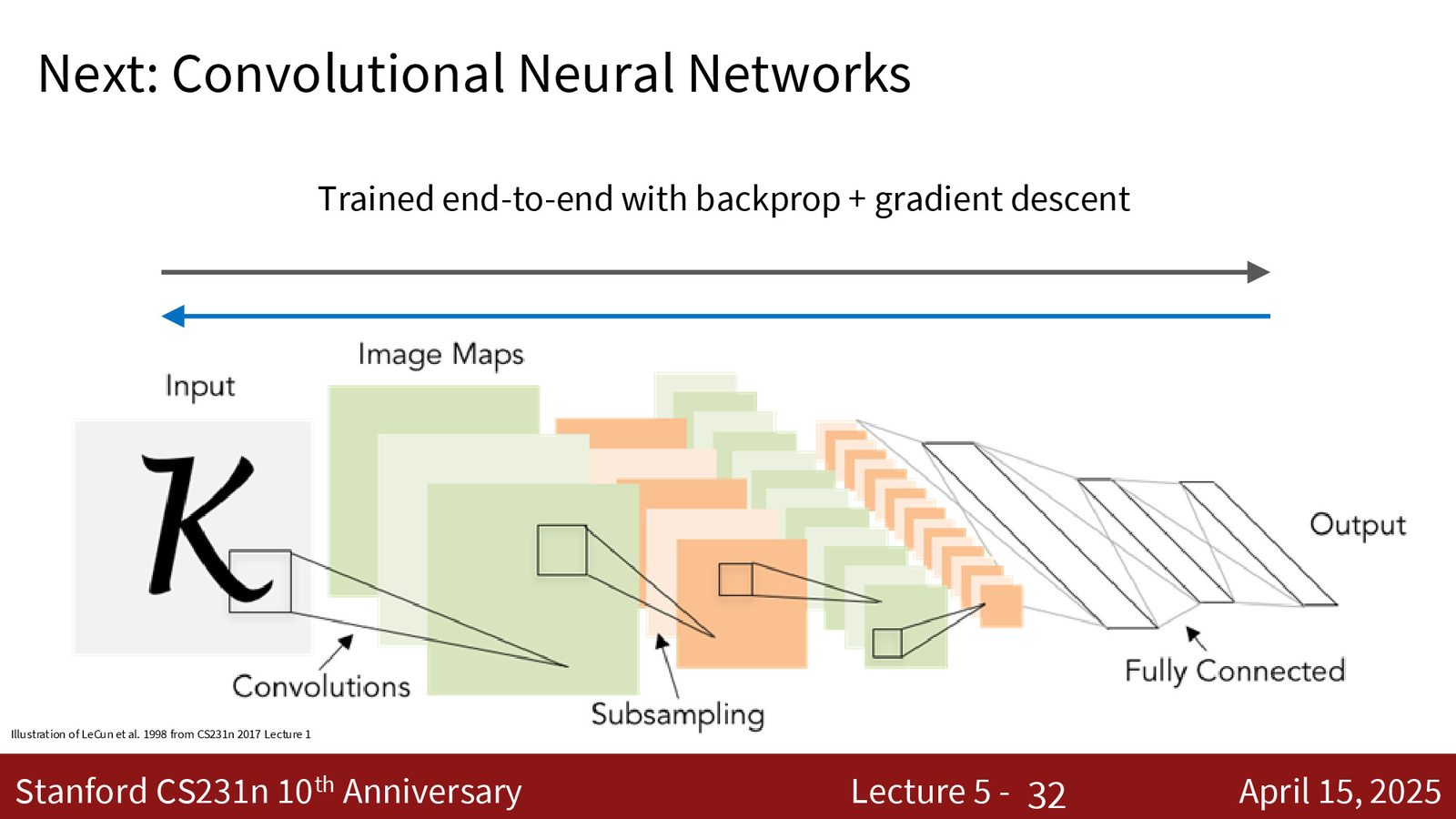
卷积神经网络概述
为什么需要卷积?
到目前为止,我们唯一会用的网络架构是“全连接网络”——将图像展平为一维向量,然后做矩阵乘法。这有一个致命问题:它破坏了图像的空间结构。
来源:Slides 第20页。
图像是二维对象——像素之间的空间关系(邻近、对称、层次结构)对于理解图像内容至关重要。全连接层将图像视为无结构的数字序列,无法利用这些先验知识。
全连接网络处理图像的根本缺陷
- 展平操作破坏了二维空间结构
- 参数数量巨大(如 \(224 \times 224 \times 3 = 150528\) 维输入,即使只有 1000 个隐藏单元也需要 1.5 亿参数)
- 无法利用图像的局部性和平移不变性
卷积网络的整体结构
卷积神经网络(CNN / ConvNet)是由卷积层、池化层、全连接层和非线性激活函数构成的计算图,其一般结构为:

- 前缀(body):交替的卷积层 + 激活函数 + 池化层,负责从原始像素中提取越来越抽象的特征表示
- 后缀(head):一个或多个全连接层,将特征映射到最终的预测分数
- 整个系统通过梯度下降端到端训练
来源:Slides 第22页。
卷积网络的历史
卷积神经网络的历史可以追溯到 1998 年 Yann LeCun 等人的 LeNet-5。尽管当时没有 GPU,计算资源极其有限,但网络架构的基本形式与 2010 年代的现代 CNN 几乎一致。2012 年 AlexNet 在 ImageNet 竞赛中的巨大成功开启了深度学习革命,从那时到约 2020 年,CNN 在计算机视觉的几乎每个任务上都占据统治地位。
CNN 的应用领域
来源:Slides 第24页。
从 2012 到 2020 年,CNN 几乎垄断了所有图像相关任务:
- 目标检测:在图像中画出每个物体的边界框并标注类别
- 语义分割:为每个像素分配一个类别标签
- 图像描述生成:从图像生成自然语言描述
- 图像生成:Stable Diffusion 的第一个版本也基于卷积网络
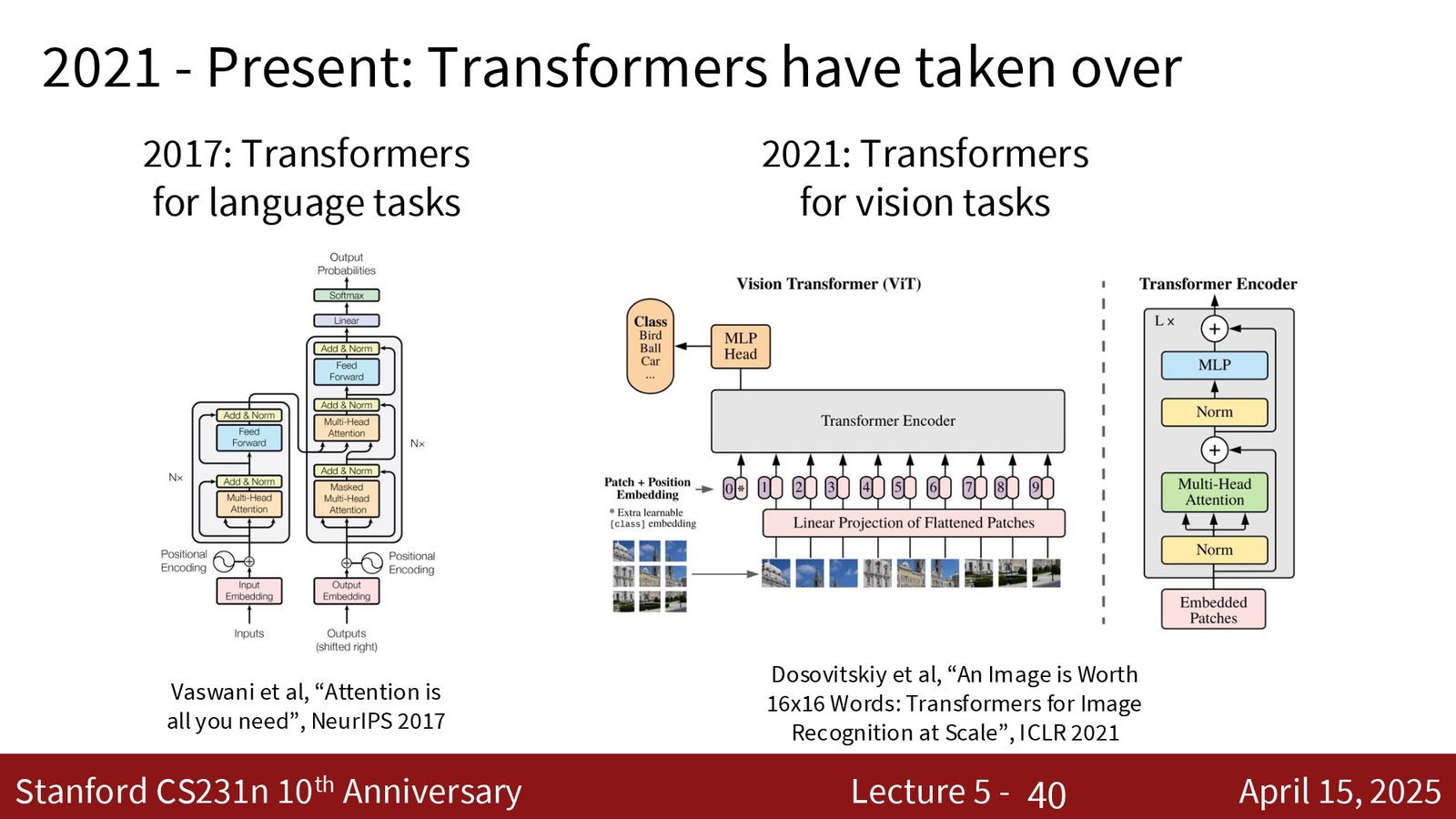
CNN vs Transformer
来源:Slides 第26页。
2017 年 Transformer 架构出现在 NLP 领域,2021 年 ViT(Vision Transformer)将几乎相同的架构应用于图像处理,并在许多任务上超越了 CNN。现在的趋势是 Transformer 逐渐取代 CNN 成为视觉任务的主流架构。
为什么还要学习 CNN?
尽管 Transformer 在很多任务上超越了 CNN,学习 CNN 仍然非常重要:
- 巨大的历史意义——CNN 开启了深度学习时代
- CNN 在实践中仍被广泛使用
- 帮助建立图像处理的直觉
- CNN 并未完全“死亡”——很多现代系统是 CNN + Transformer 的混合架构
本章小结
卷积神经网络是专门为处理图像(以及其他具有空间结构的数据)设计的网络架构。它通过卷积层保留空间结构,通过池化层逐步缩小空间尺寸、扩大感受野,最终通过全连接层输出预测。尽管 Transformer 正在逐步取代 CNN,后者仍是理解现代视觉系统的重要基础。
卷积层详解
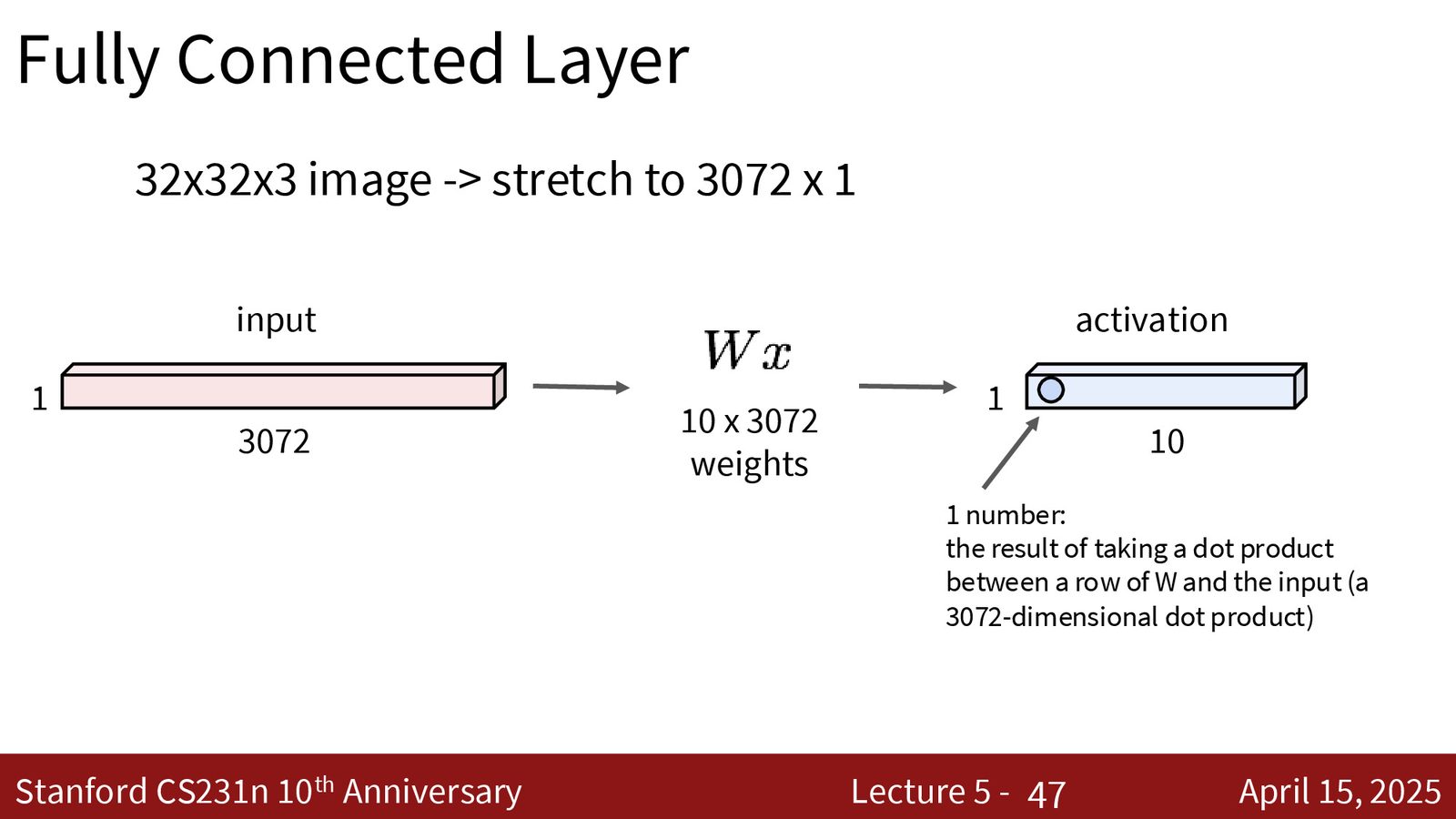
从全连接到卷积

来源:Slides 第28页。
全连接层中,输出向量的每个元素是权重矩阵的一行与整个输入向量的内积。这意味着:
- 每个输出数值“看到”了图像中的所有像素
- 空间结构被完全丢弃
卷积层的核心改变:每个输出数值只依赖于输入图像的一个局部区域。
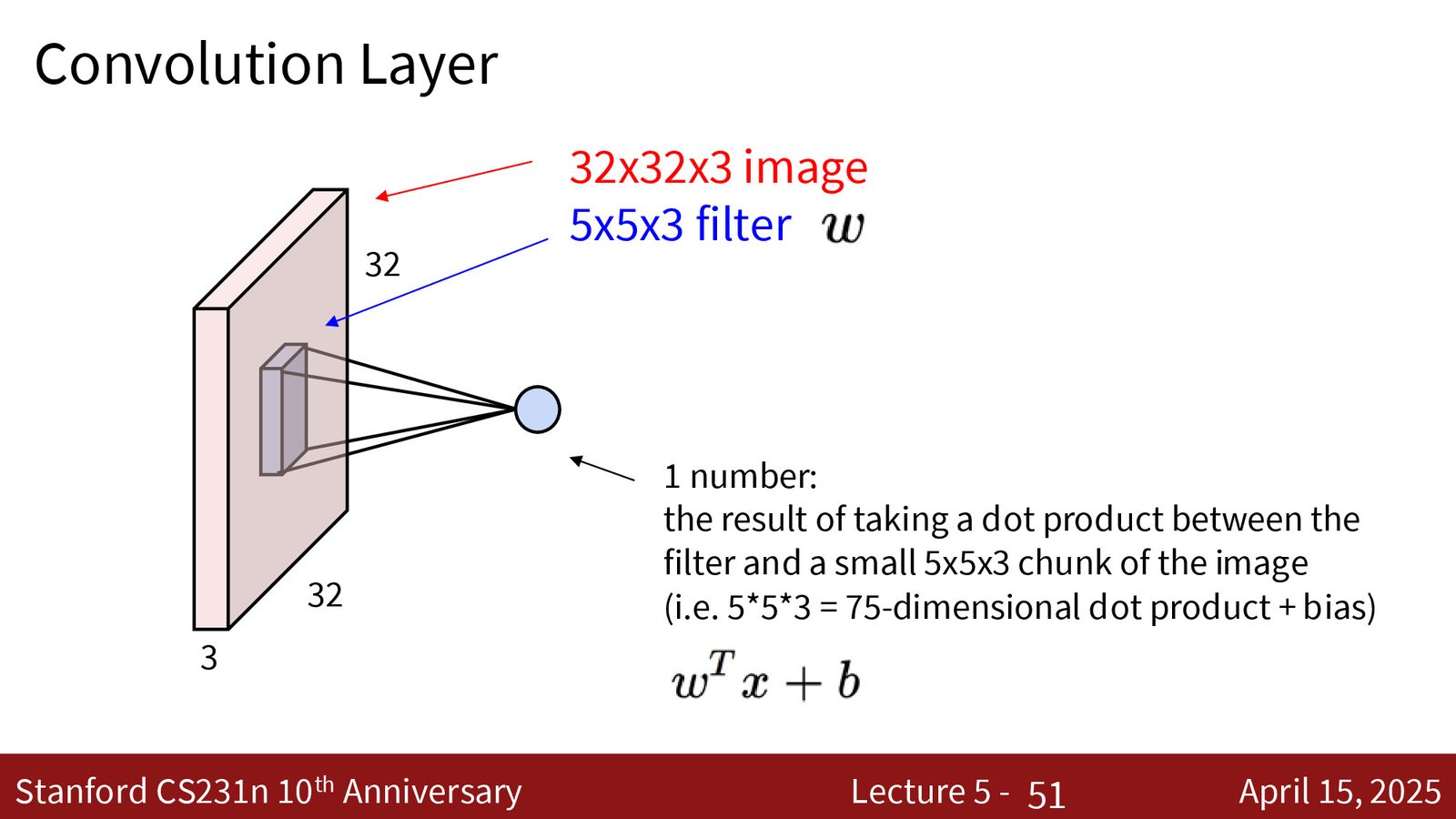
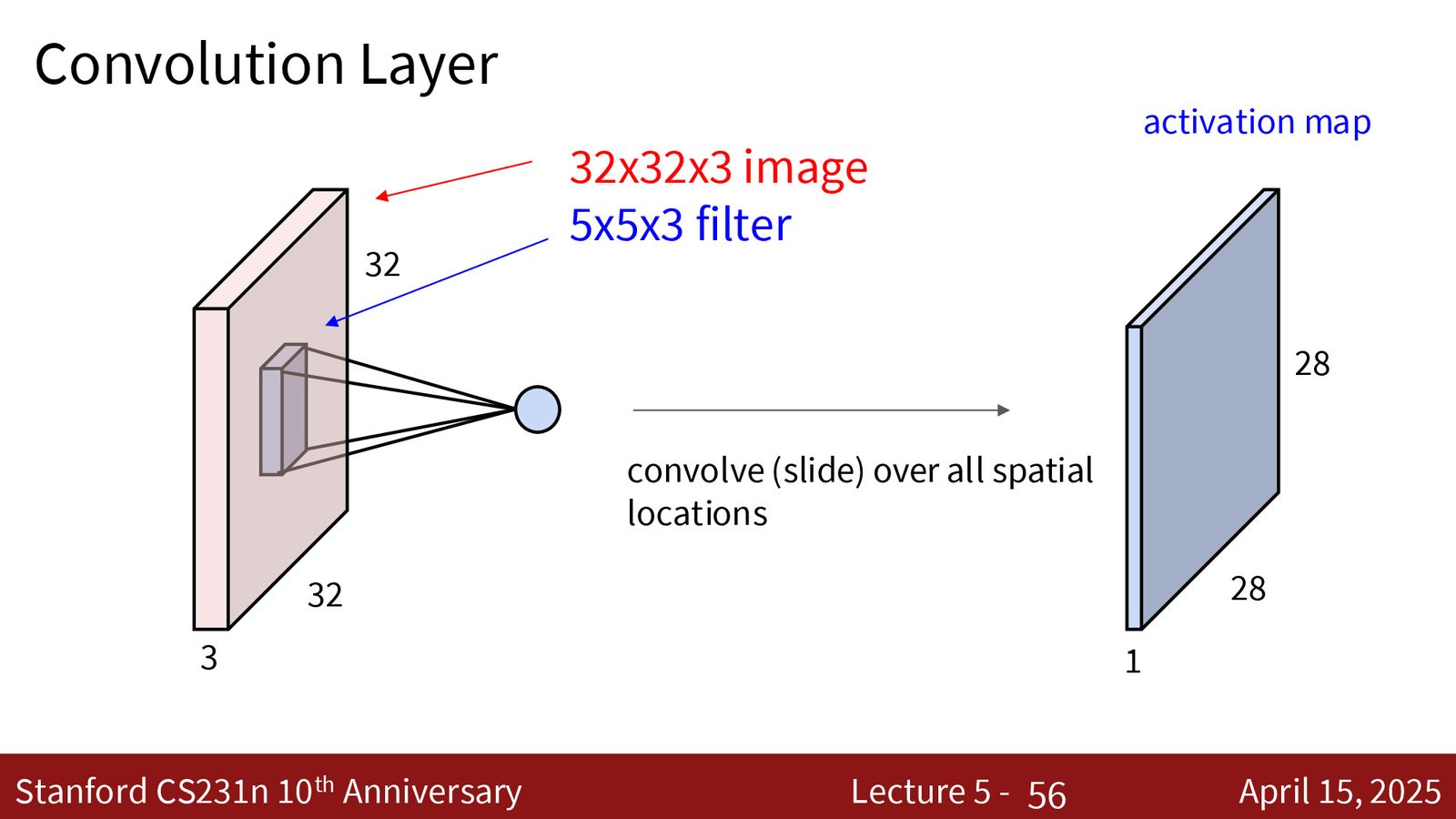
卷积运算
来源:Slides 第30页。
卷积层的核心操作:
- 定义一组滤波器(filters / kernels),每个滤波器是一个小的三维张量,空间尺寸为 \(K \times K\),深度等于输入通道数 \(C_{in}\)
- 将滤波器在输入图像上滑动,在每个位置计算滤波器与对应局部区域的内积(点积 + 偏置)
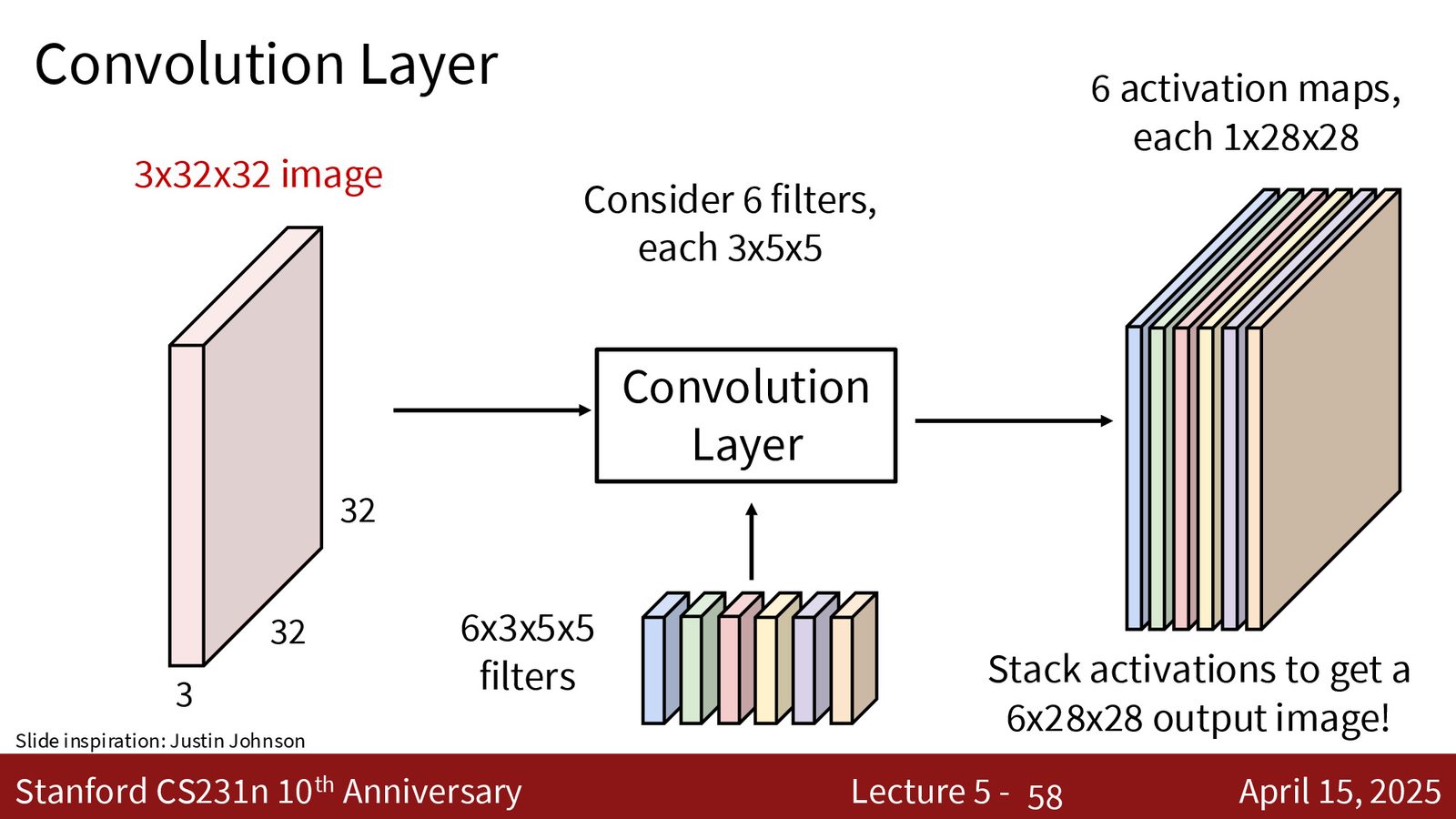
- 每个滤波器产生一个二维激活图(activation map)
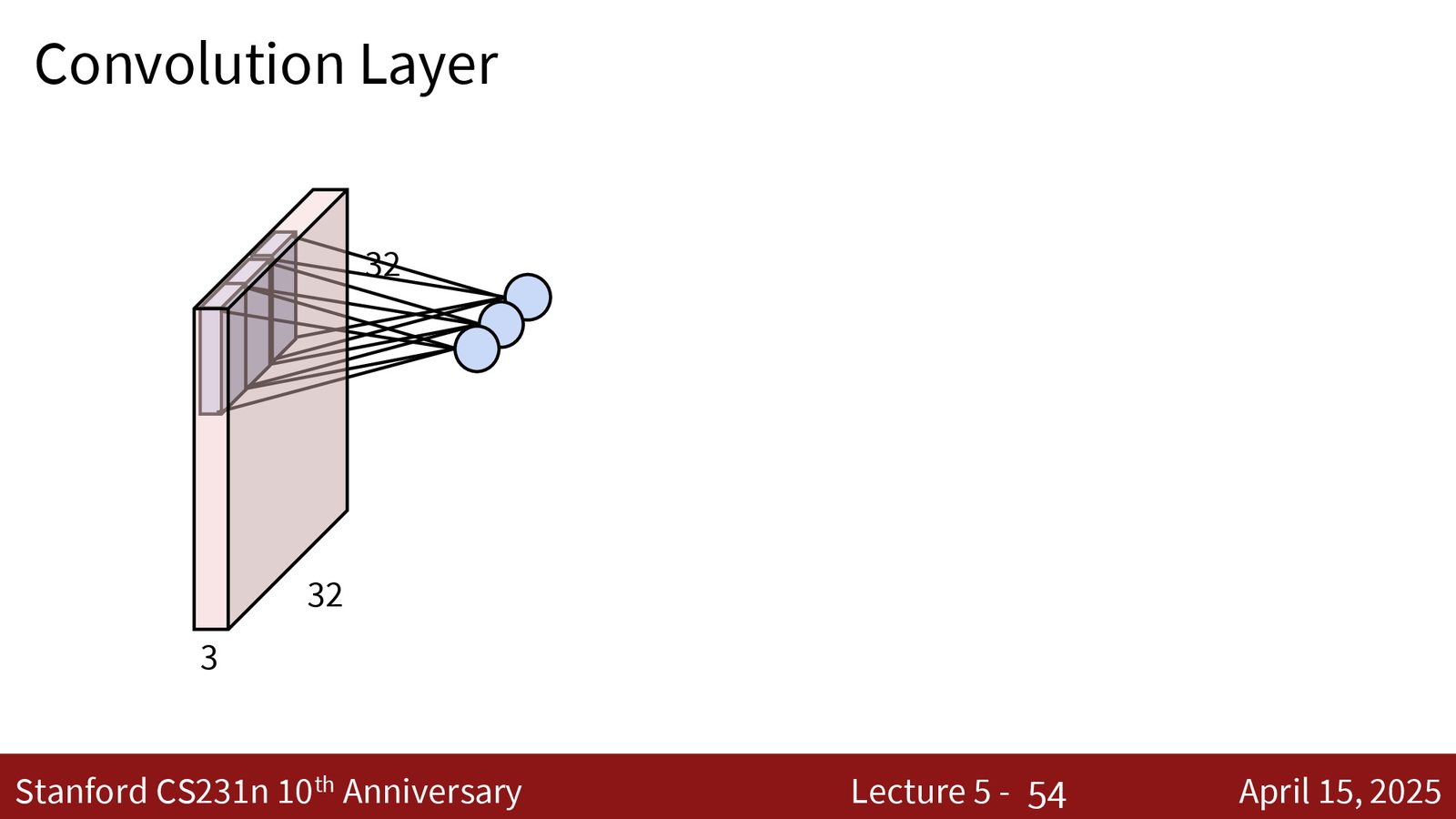
- \(C_{out}\) 个滤波器产生 \(C_{out}\) 个激活图,堆叠后形成输出张量
卷积层的参数与输出形状
输入:\(C_{in} \times H \times W\)
滤波器:\(C_{out}\) 个,每个大小为 \(C_{in} \times K \times K\)
输出:\(C_{out} \times H' \times W'\)
其中 \(H' = \lfloor(H - K + 2P) / S\rfloor + 1\),\(W'\) 类似。
总参数量:\(C_{out} \times (C_{in} \times K \times K + 1)\)(含偏置)
来源:Slides 第32页。
参数 vs 超参数
区分参数与超参数
- 超参数(训练前设定,不可学习):滤波器数量 \(C_{out}\)、滤波器大小 \(K\)、步幅 \(S\)、填充 \(P\)
- 参数(通过梯度下降学习):滤波器中每个元素的数值、偏置值
超参数决定了张量的形状,参数决定了张量的数值。滤波器在训练开始时随机初始化,然后通过反向传播不断优化。
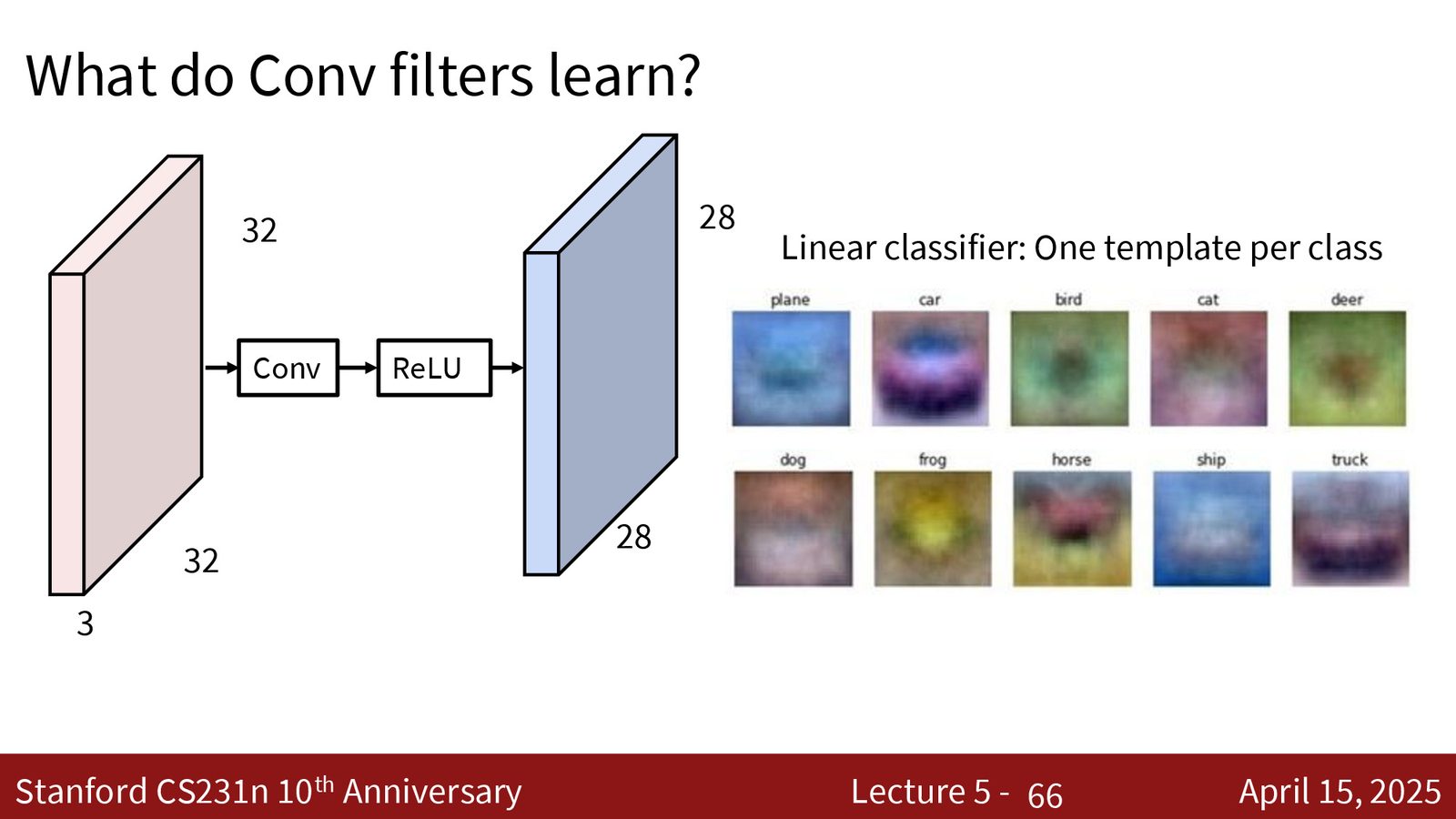
卷积滤波器学到了什么?
来源:Slides 第40页。
对第一层卷积滤波器的可视化揭示了两类模式:
- 颜色检测器:检测对比色(如红-绿对比、色块等)
- 边缘检测器:检测水平、垂直、对角线方向的边缘
这个结果具有惊人的普遍性——几乎所有 CNN、所有数据集、所有任务中,第一层滤波器都学到类似的模式。
来源:Slides 第41页。
CNN 的层级特征学习
CNN 自动学习了一个从低级到高级的特征层次结构:
- 第 1 层:边缘和颜色
- 中间层:纹理和简单形状
- 高层:物体部件和语义概念
这与人类视觉系统中初级视皮层到高级视觉区域的层级处理有着惊人的相似性。
非线性激活函数不可或缺

来源:Slides 第38页。
卷积运算本质上是内积——一种线性运算。两个线性运算的复合仍然是线性运算。因此,如果直接堆叠多个卷积层而不加非线性激活函数,整个网络的表达能力等价于单个卷积层。
线性层堆叠 = 单层
\(f_2 \circ f_1(x) = W_2(W_1 x) = (W_2 W_1)x = W'x\)
无论堆叠多少个线性层,等价于一个线性变换。必须在卷积层之间插入非线性激活函数(如 ReLU)才能增加网络的表达能力。
本章小结
卷积层是 CNN 的核心组件。它通过局部连接和权值共享实现了两个关键优势:(1)保留图像的空间结构,(2)大幅减少参数量。滤波器通过梯度下降自动学习,无需人工设计。不同层的滤波器自然形成从边缘到物体的层级特征表示。非线性激活函数是多层卷积网络表达能力的关键保障。
卷积运算的数学细节
输出尺寸计算
给定输入空间尺寸 \(W\)、滤波器大小 \(K\)、填充 \(P\) 和步幅 \(S\),输出尺寸为:
来源:Slides 第45页。
填充(Padding)
来源:Slides 第47页。
不使用填充时,每次卷积都会使空间尺寸缩小 \(K-1\) 个像素。这在深层网络中会导致特征图迅速缩小到 0。
保持空间尺寸的常用设置
当 \(K\) 为奇数时,设置 \(P = \frac{K-1}{2}\)、\(S = 1\) 可以保持卷积前后的空间尺寸不变。这是最常见的卷积配置。例如:
- \(K = 3, P = 1, S = 1\)
- \(K = 5, P = 2, S = 1\)
- \(K = 7, P = 3, S = 1\)
步幅(Stride)与下采样

来源:Slides 第49页。
步幅大于 1 的卷积会缩小空间尺寸——这是在网络内部实现下采样的一种方式。下采样非常重要,因为它允许网络的感受野以指数速度增长。
感受野(Receptive Field)
来源:Slides 第51页。
感受野(receptive field)指的是:网络某一层的一个激活值,能“看到”原始输入图像中多大的区域。
感受野的增长规律
- 无下采样(\(S = 1\)):感受野线性增长。\(L\) 层 \(K \times K\) 卷积的感受野为 \(L(K-1) + 1\)。这意味着需要很多层才能覆盖大图像的全部区域。
- 有下采样(\(S = 2\)):感受野指数增长。较少的层即可覆盖整张图像。
最终分类决策需要聚合整张图像的信息,因此下采样对于构建实用的 CNN 至关重要。
1x1 卷积
来源:Slides 第54页。
\(1 \times 1\) 卷积是一种特殊的卷积:空间上不做任何邻域操作,只在通道维度上做线性组合。它可以看作在每个空间位置独立应用的全连接层。主要用途:
- 改变通道数(降维或升维)
- 增加非线性(配合激活函数)
- 减少计算量(先降维再做大卷积)
卷积层的计算量分析
来源:Slides 第56页。
对于一个卷积层(\(C_{in}\) 输入通道,\(C_{out}\) 输出通道,\(K \times K\) 滤波器,输出空间大小 \(H' \times W'\)):
| 指标 | 数值 |
|---|---|
| 参数量 | \(C_out × C_in × K × K\) |
| FLOPs | \(C_out × C_in × K × K × H' × W'\) |
| 输出内存 | \(C_out × H' × W'\) |
CNN 中计算量和参数量的分布
在典型的 CNN 中:
- 前面的卷积层:空间尺寸大、通道数少,计算量大但参数少
- 后面的卷积层:空间尺寸小、通道数多,计算量相对小但参数多
- 全连接层:参数量最多但计算量相对少
这种分布特性对网络设计和硬件优化都非常重要。
本章小结
卷积运算的数学细节虽然看起来复杂,但核心思想简单:在局部区域做内积,然后滑动。填充保持空间尺寸,步幅实现下采样,感受野随深度增长。理解这些细节对于设计和调试 CNN 架构至关重要。
池化层
池化的基本概念
来源:Slides 第58页。
池化层是 CNN 中另一种实现空间下采样的方式。与带步幅的卷积不同,池化层:
- 没有可学习的参数
- 对每个通道独立操作
- 保持通道数不变,只缩小空间尺寸
最大池化(Max Pooling)
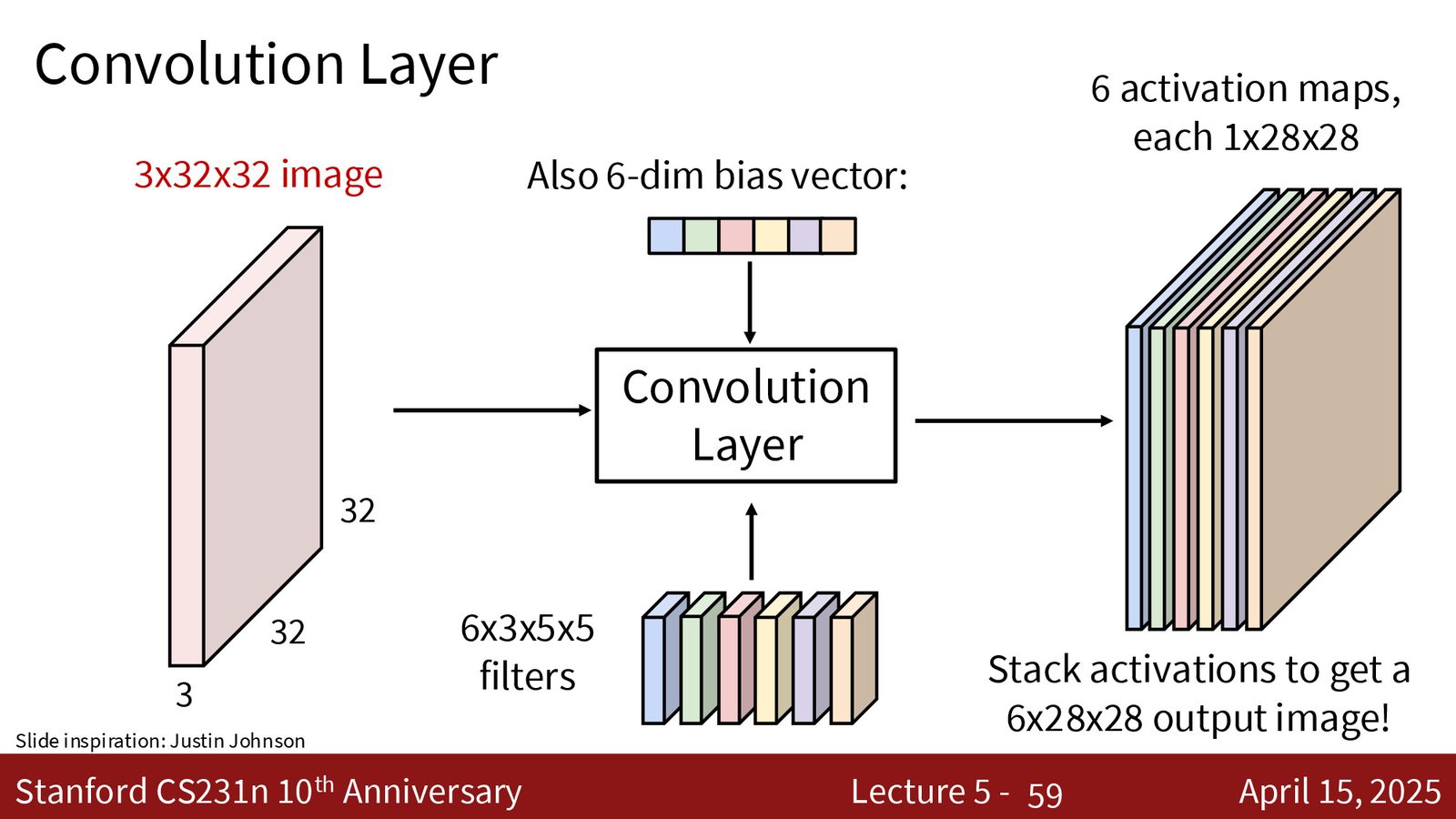
来源:Slides 第59页。
最常见的池化操作是 \(2 \times 2\) 最大池化,步幅为 2:
- 将每个通道的特征图划分为不重叠的 \(2 \times 2\) 小块
- 在每个小块内取最大值
- 空间尺寸缩小为原来的一半
其他选择包括平均池化(Average Pooling)和抗锯齿下采样(Anti-alias Downsampling)。
池化层的实践建议
- 最常用的配置:\(2 \times 2\) kernel,stride 2(“我想把空间尺寸减半”)
- 池化层通常不使用填充——对于最大池化,填充零等价于 ReLU,是多余的
- 现代架构越来越倾向于用带步幅的卷积代替池化,因为前者有可学习参数
全局平均池化
在 CNN 的末尾,常用全局平均池化(Global Average Pooling)将每个通道的整个空间维度压缩为一个数值。如果最后的特征图大小为 \(C \times H \times W\),全局平均池化输出 \(C \times 1 \times 1\),直接用于分类。
本章小结
池化层通过无参数的空间下采样操作缩小特征图尺寸,从而增大后续层的感受野并减少计算量。最大池化是最经典的选择,但现代架构中带步幅的卷积越来越多地取代了池化层的角色。
构建完整的 CNN
经典 CNN 架构模式
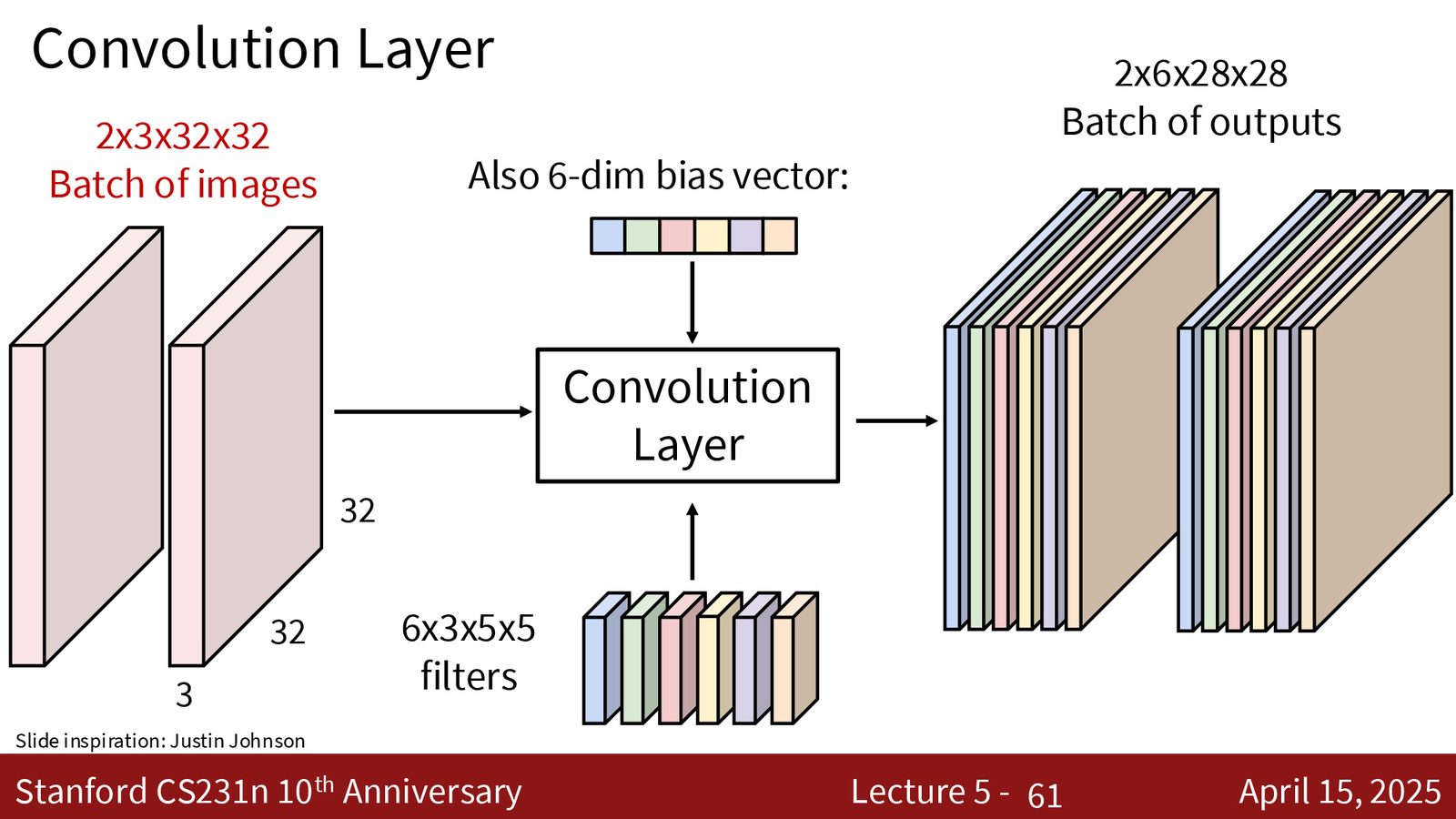
来源:Slides 第61页。
经典的 CNN 遵循以下模式:
- 随着网络深度增加,空间尺寸逐渐缩小(通过池化或带步幅的卷积)
- 通道数逐渐增加(每次池化后通常将通道数翻倍)
- 直觉:空间尺寸缩小但通道数增加,总信息量大致保持不变
详细示例:一个简单的 CNN
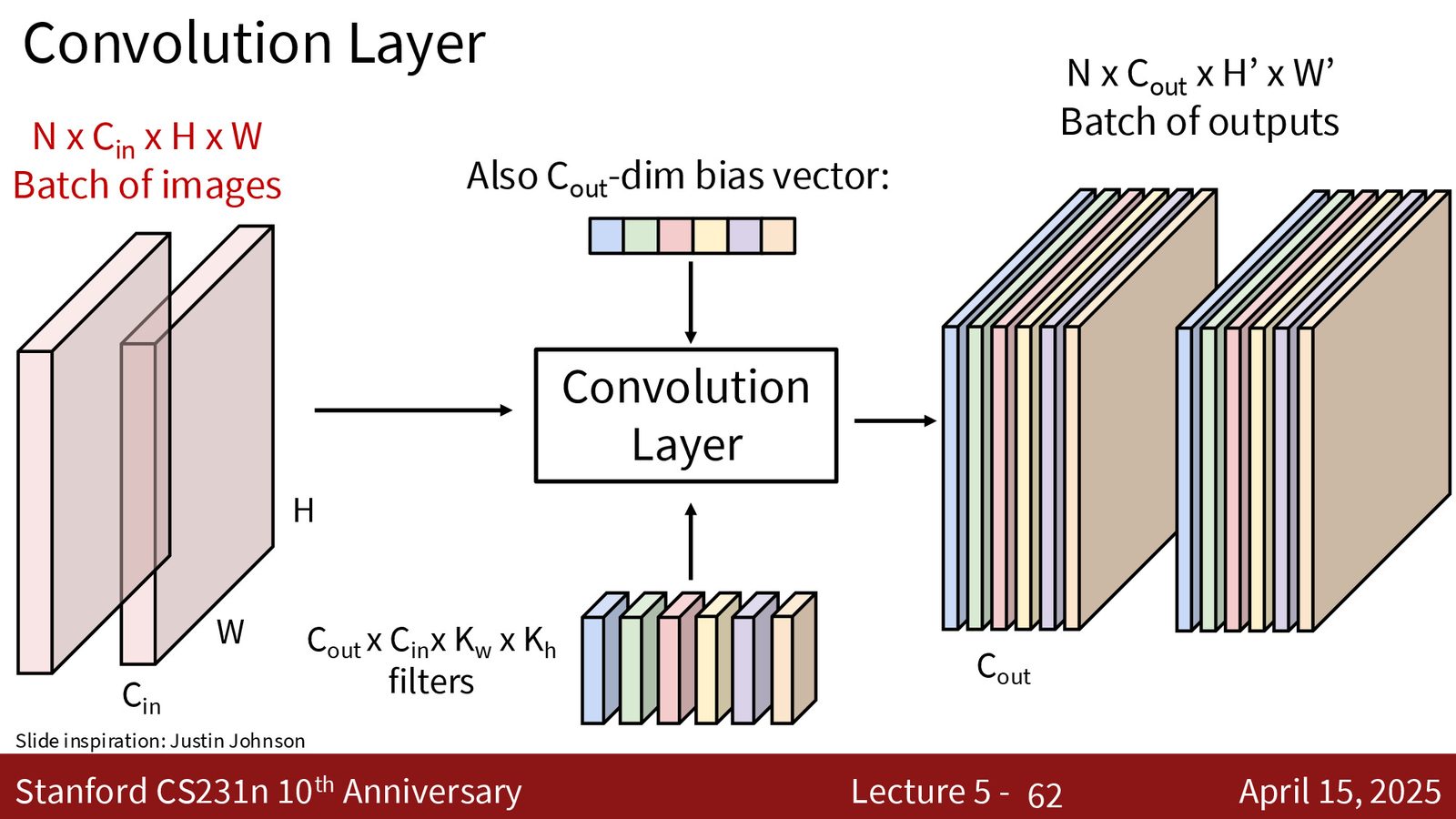
来源:Slides 第62页。
以输入尺寸 \(3 \times 224 \times 224\) 的 CNN 为例,追踪各层的张量形状变化:
| 层 | 输出形状 | 参数量 | 说明 |
|---|---|---|---|
| 输入 | \(3 × 224 × 224\) | – | RGB 图像 |
| Conv1 (\(7 × 7\), S=2) | \(64 × 112 × 112\) | 9,472 | 下采样 2x |
| Pool (\(2 × 2\), S=2) | \(64 × 56 × 56\) | 0 | 下采样 2x |
| Conv2 (\(3 × 3\)) | \(192 × 56 × 56\) | 110,784 | 增加通道 |
| Pool (\(2 × 2\), S=2) | \(192 × 28 × 28\) | 0 | 下采样 2x |
| Conv3 (\(3 × 3\)) | \(384 × 28 × 28\) | 663,936 | 增加通道 |
处理不同尺寸的输入
输入图像必须大小一致
在当前框架下,同一个 batch 中的所有图像必须具有相同的空间尺寸。常见的处理方法:
- 将所有图像 resize 到固定大小(最常见)
- 用零填充到统一大小
- 宽高比分桶(Aspect Ratio Bucketing)——同一 batch 内使用相同宽高比,不同 batch 可以不同
本章小结
构建一个完整的 CNN 就是在计算图中组合卷积层、激活函数、池化层和全连接层。核心设计原则是:空间尺寸逐层缩小,通道数逐层增加,形成从像素到语义的特征金字塔。输出端用全连接层(或全局平均池化 + 线性层)将特征映射到分类分数。
AlexNet:深度学习的引爆点
AlexNet 的历史意义
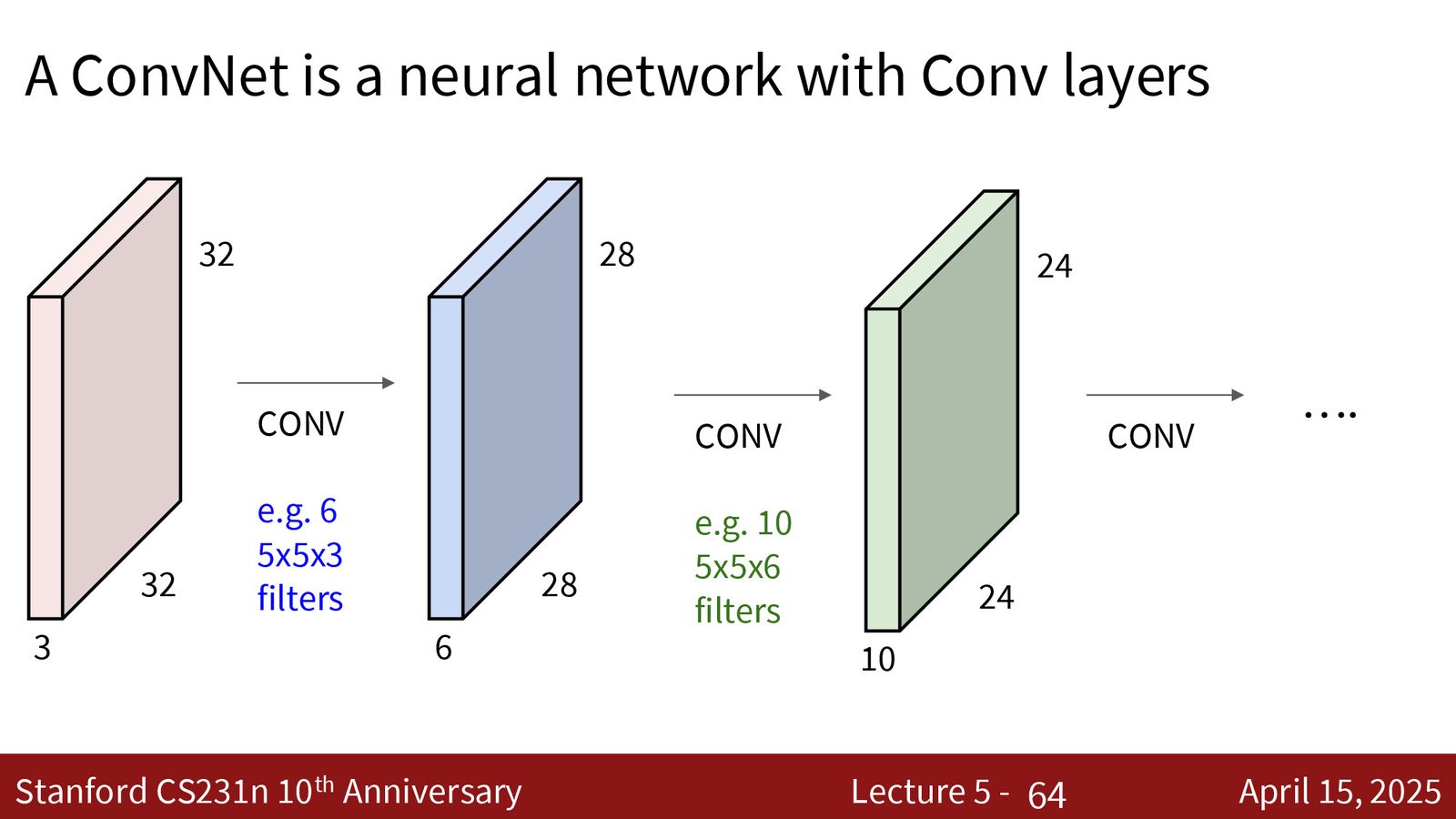
来源:Slides 第64页。
AlexNet(Krizhevsky, Sutskever, Hinton, 2012)是在 ImageNet 大规模视觉识别挑战赛(ILSVRC 2012)上取得突破性成绩的卷积神经网络。它在 Top-5 错误率上以 \(\sim\)10% 的优势击败了传统方法(从 \(\sim\)26% 降到 \(\sim\)16%),开启了深度学习在计算机视觉中的统治时代。
AlexNet 的成功因素:
- 使用GPU 训练(当时是两块 GTX 580)
- 大规模数据集 ImageNet(120 万张图片)
- ReLU 激活函数(取代 sigmoid/tanh)
- Dropout 正则化
来源:Slides 第66页。
本章小结
AlexNet 的架构本身并不复杂——它基本上就是 LeNet-5 的放大版本。它的革命性在于证明了三件事:(1)CNN 可以在大规模数据集上训练,(2)GPU 是深度学习的关键加速器,(3)端到端学习的特征远优于手工特征。
总结与延伸
全课知识图谱
本节课建立了从深度学习基础到卷积神经网络的完整知识链:

关键 Takeaways
五条核心原则
- 端到端学习优于手工特征:让梯度下降从数据中学习特征表示,而非依赖人类直觉
- 卷积利用了图像的先验知识:局部性(每个输出只看一小块区域)和平移不变性(同一滤波器在所有位置共享)
- 层级特征自动涌现:浅层学边缘和颜色,深层学纹理和物体部件,无需人工设计
- 非线性是深度网络的灵魂:没有激活函数,再深的网络也等价于一层线性变换
- 设计模式:空间尺寸逐步缩小 + 通道数逐步增加 = 从像素到语义的特征金字塔
拓展阅读
- LeCun et al., “Gradient-Based Learning Applied to Document Recognition” (1998) —— LeNet-5 原始论文
- Krizhevsky et al., “ImageNet Classification with Deep Convolutional Neural Networks” (2012) —— AlexNet
- Dosovitskiy et al., “An Image is Worth 16x16 Words” (2021) —— Vision Transformer (ViT)
- CS231N 课程主页:https://cs231n.stanford.edu/