CS336 2026 Lecture 9:Scaling Laws Basics
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方幻灯片重新整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |

本讲问题:把 scaling laws 当成工程预测工具
读图:Slide 1 标记课程转向
前面几讲已经讨论数据、GPU、kernel 和并行训练。Lecture 9 关注一个更上层的问题:当你真的有大规模算力时,如何决定模型大小、数据量、训练步数、架构、优化器和超参数。Scaling laws 的角色是把这些决定从经验崇拜变成可预测的工程决策。

读图:Slide 2 的场景为什么尖锐
这页把 scaling laws 放到真实资源决策里。算力巨大时,随机试错非常昂贵;照抄已有模型配置也不可靠,因为硬件、数据、目标和预算不同。你需要先设计小规模实验,再预测大规模训练结果,最后决定把训练 compute 放在哪里。
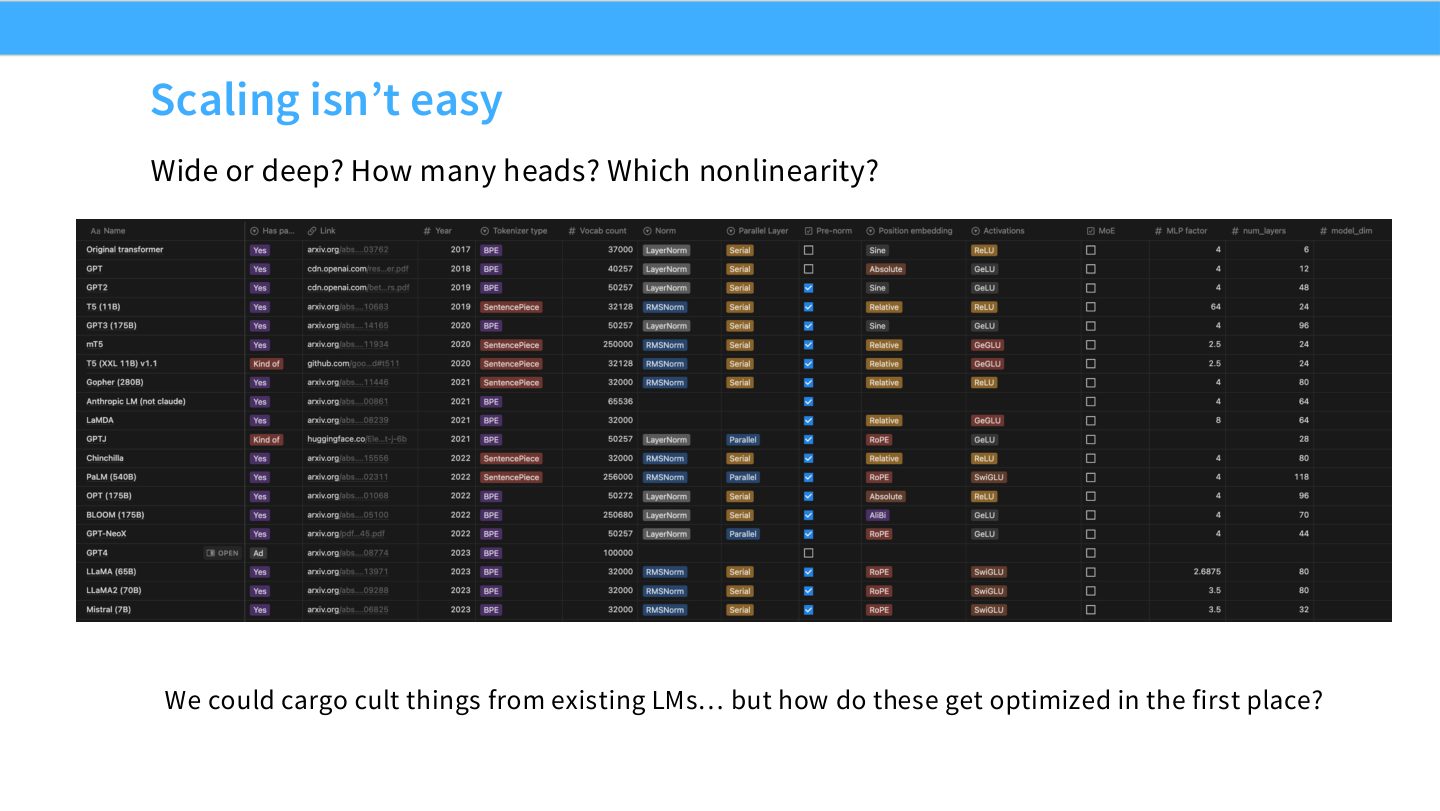
读图:Slide 3 反对的是盲目照抄
公开模型给了很多配置,但它们是特定资源、数据、训练目标和组织能力下的结果。Scaling law 实验要回答的是:哪些选择能在小规模上拟合出稳定趋势,并且外推到目标规模时仍可信。它不是魔法,也不是替代所有大规模验证。
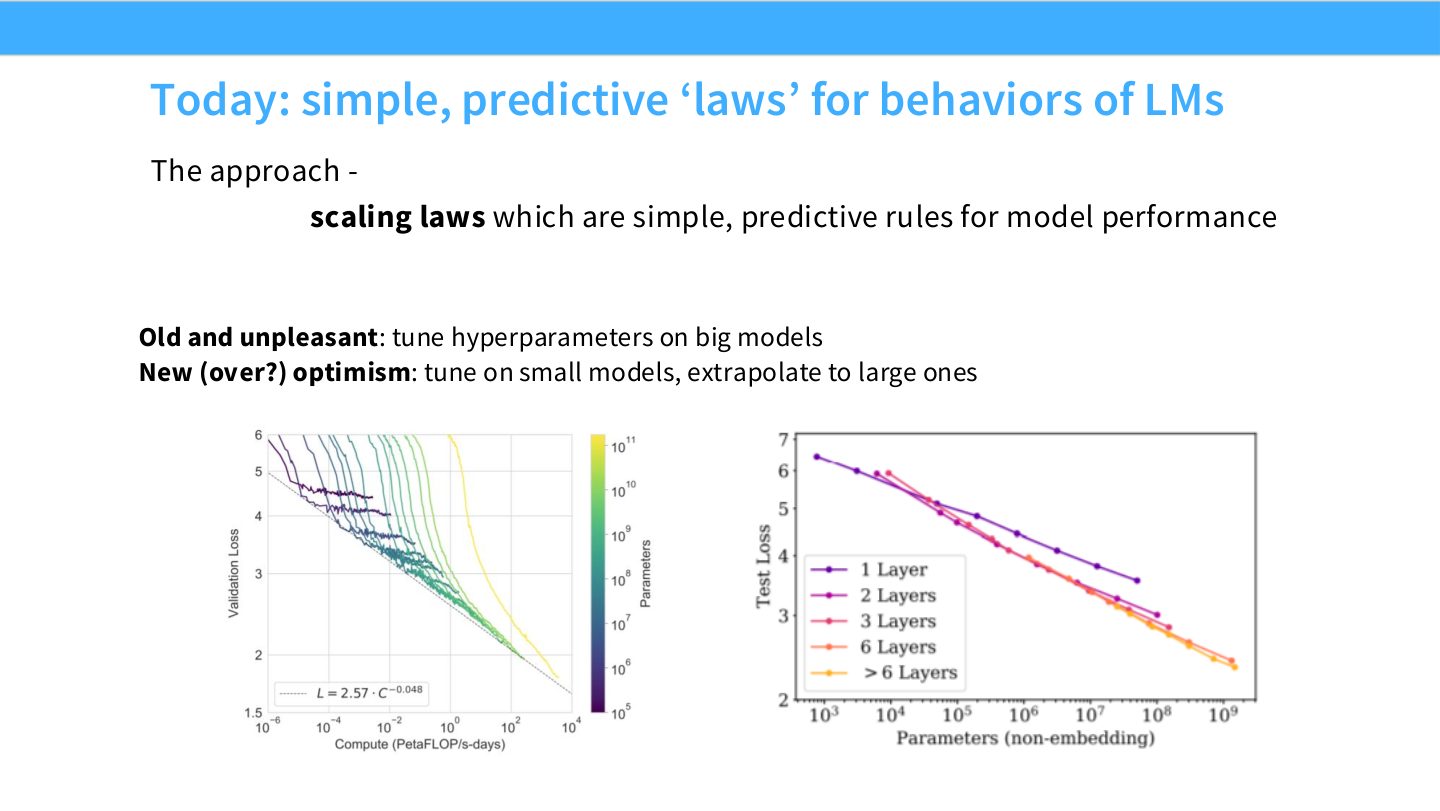
术语消化:什么是 scaling law
Scaling law 是把某个规模变量映射到 loss、error 或 performance 的经验公式。常见形式是 power law,例如
其中 \(x\) 可以是数据量、模型参数量或计算量,\(A\) 是尺度系数,\(\alpha\) 是 scaling exponent,\(C\) 是不可约误差或 offset。它的工程价值在于:用小规模点估计曲线,再预测大规模资源分配。
Part 1:Scaling laws 的历史和数据 scaling

读图:Slide 5 的 Part 1 不是只讲历史
这一部分先把 scaling laws 放进学习理论和经验 NLP 的背景:理论上早就有 sample complexity 和 rate 的概念,但它们往往是上界;现代 scaling laws 更关注实际模型、实际数据和实际 loss 曲线是否可预测。

读图:Slide 6 的理论上界与实际 loss
理论 sample complexity 常告诉我们达到某个 error 需要多少样本,或者 error 上界如何随 \(n\) 衰减。但 frontier LMs 关心的是实际验证 loss 在真实训练分布上的可实现值。Scaling laws 更像工程经验曲线,不等同于严格泛化上界。
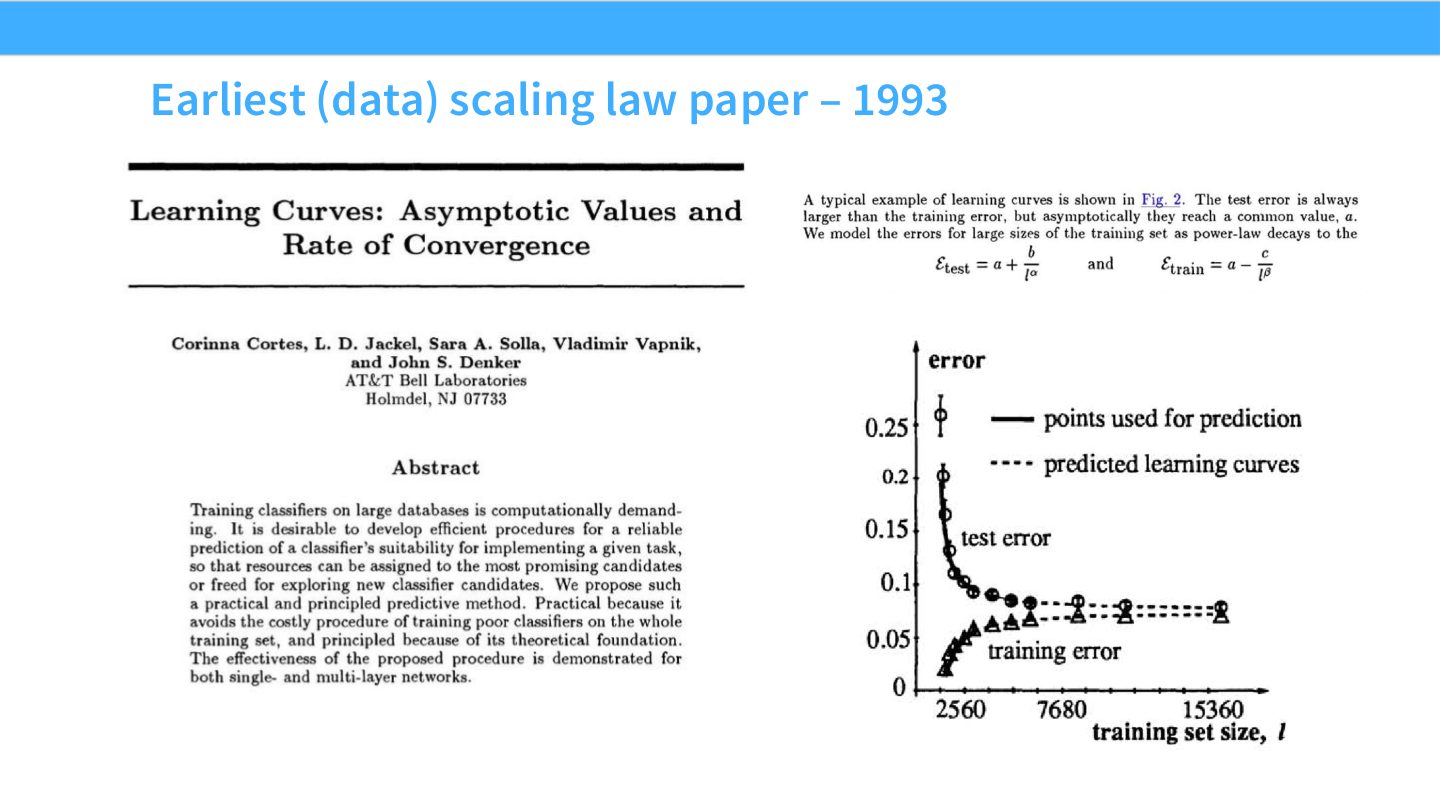
读图:Slide 7 的历史意义
这页说明 scaling 的想法并非 LLM 时代突然出现。早期研究已经观察到更多数据与性能之间的规律关系。LLM 时代的新东西是规模更大、曲线更平滑、投资更昂贵,因此这些规律变成了核心工程工具。
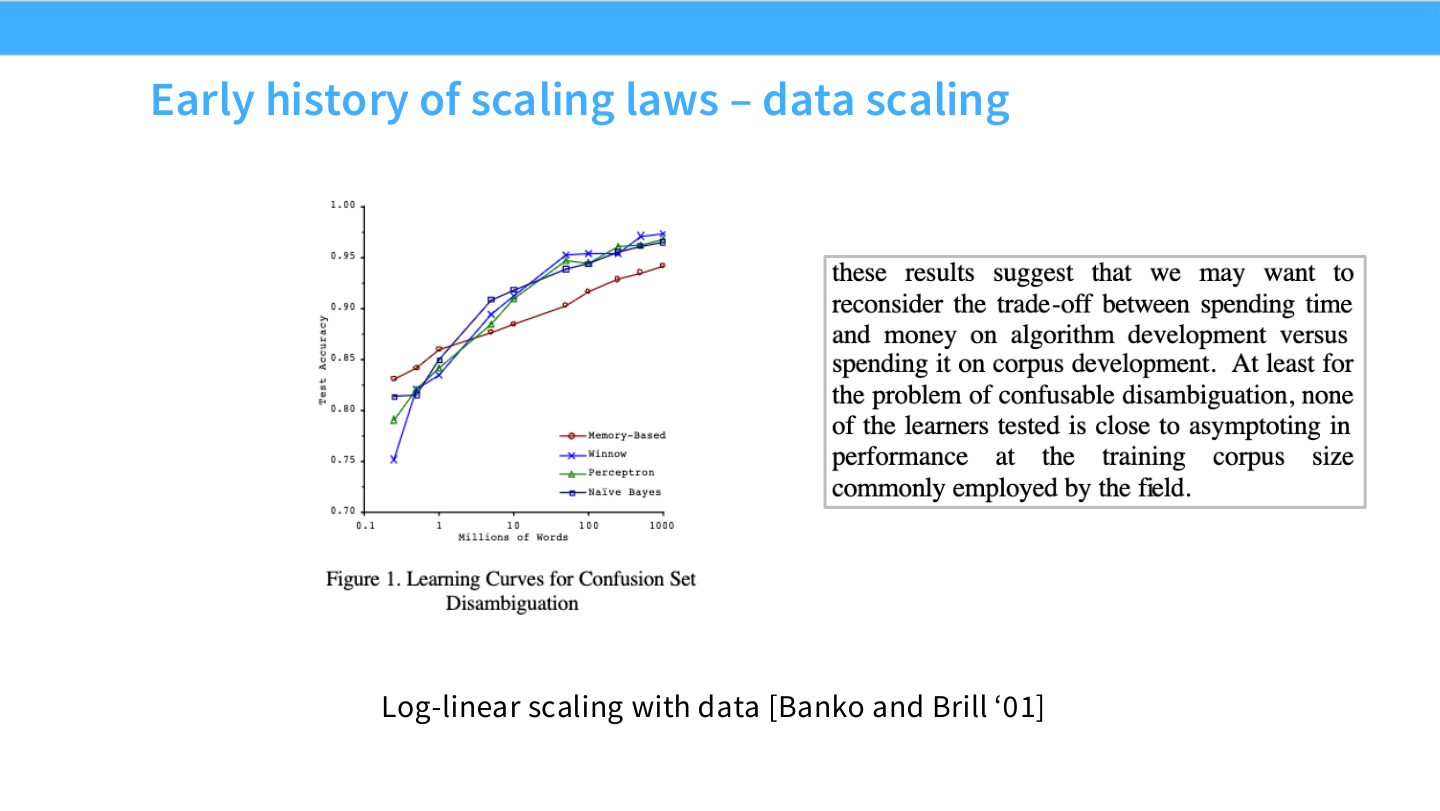
读图:Slide 8 的横纵轴直觉
这类图通常横轴是数据量,纵轴是错误率或性能指标。重点不是某个点,而是随着数据增加,性能按简单函数改善。早期 NLP 的经验已经提示:更多数据在相当长范围内有可预测收益。
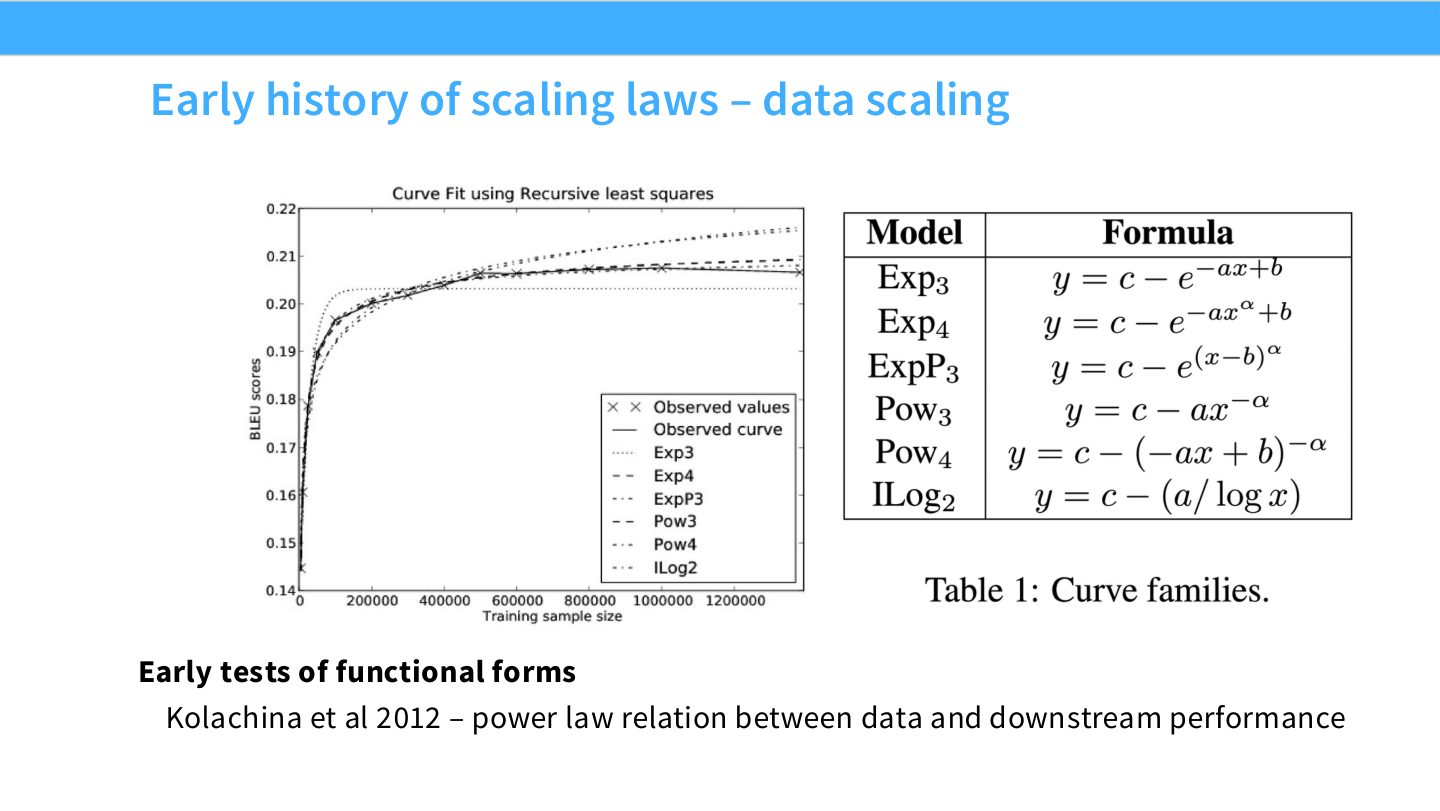
读图:Slide 9 应该比较函数形式
这页的教学点是:scaling law 不是先验假设某条线,而是比较不同函数形式对实验点的拟合和外推能力。Power law 之所以重要,是因为在 log-log 坐标中会变成近似直线,便于拟合和解释。
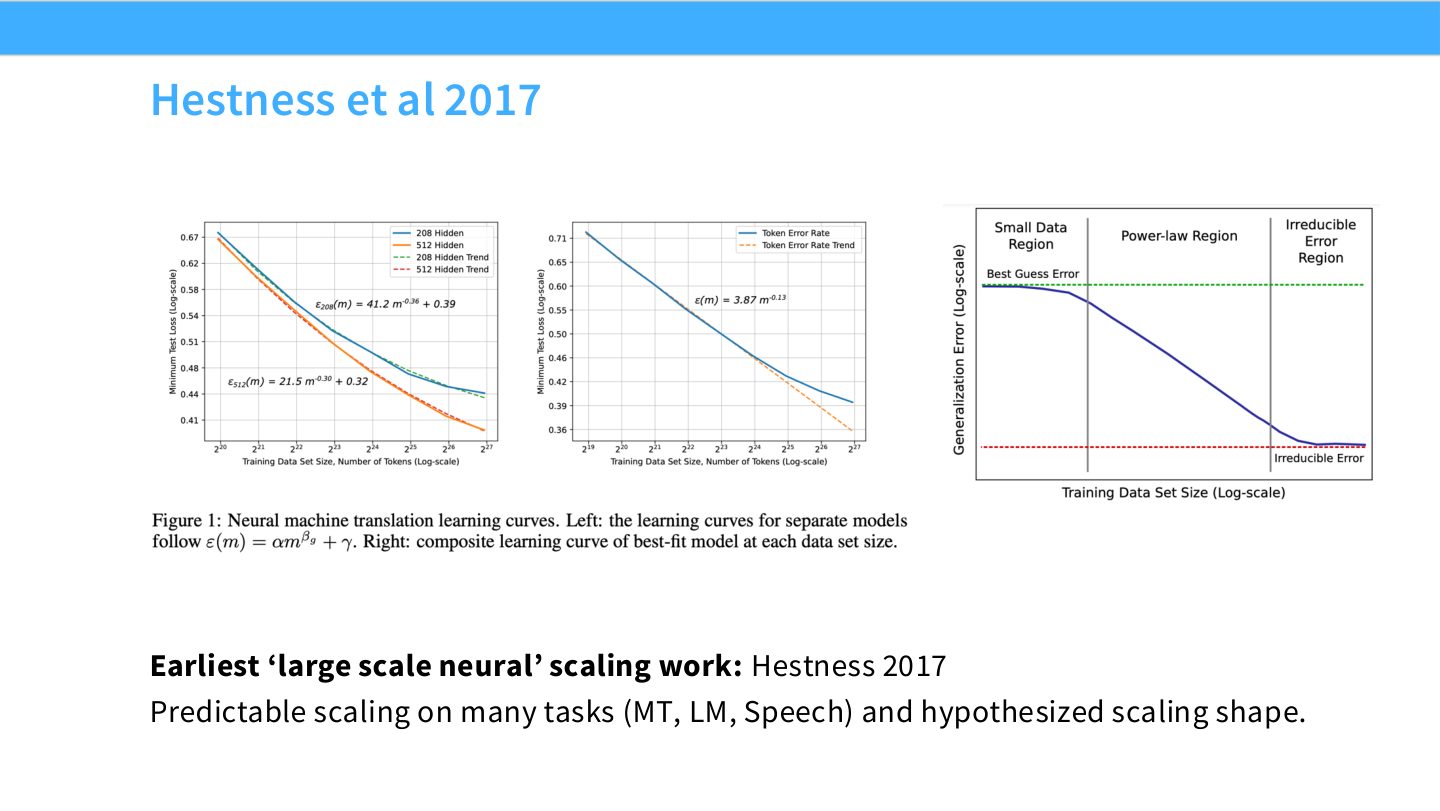
读图:Slide 10 的跨任务稳定性
Hestness 的重要性在于跨任务:MT、LM、Speech 都呈现规律 scaling。若 scaling 只在单个 benchmark 上出现,它只能算偶然经验;跨任务出现说明某些统计或优化机制具有普遍性。

读图:Slide 11 连接到今天的 emergence 讨论
这页提示,许多今天看似新的问题,如能力涌现、计算速度和准确率 trade-off,早期 scaling 工作已经触及。Scaling laws 不只预测 loss,也帮助我们判断某类能力是否可能通过 brute force scale 获得。
本章小结
Part 1 的历史线索说明:scaling laws 不是 LLM 独有魔法,而是数据、模型和计算规模增加时经常出现的经验规律。LLM 的特殊性在于这些规律足够平滑、成本足够高,因而成为训练决策的基础设施。
Part 2:Neural 和 LLM scaling behaviors

读图:Slide 12 的三个问题
第一,数据量如何影响 loss;第二,给定 compute 时应该增加数据还是模型参数;第三,架构、优化器、batch size、learning rate 等超参数如何随规模变化。这三类问题对应 LLM 训练前最昂贵的决策。
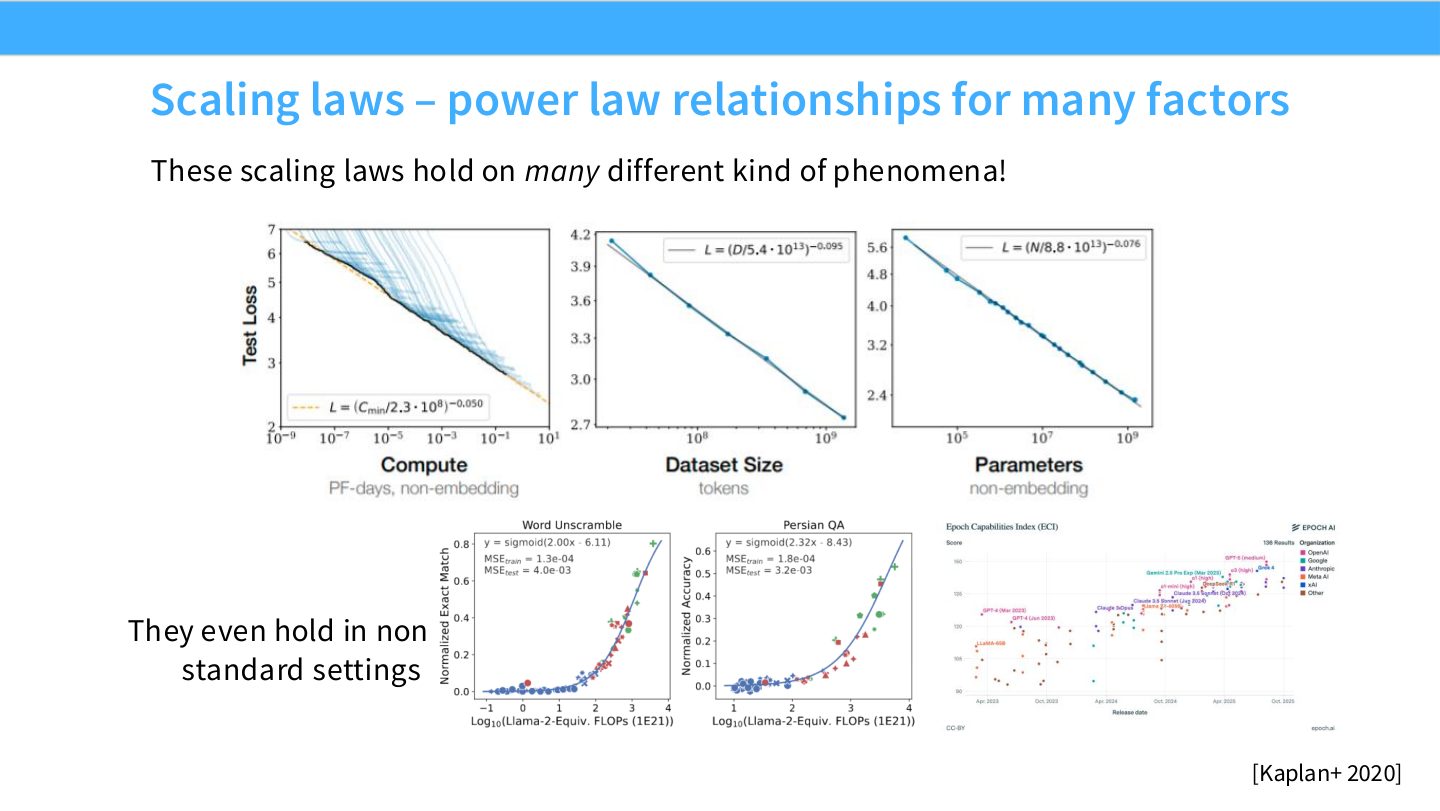
读图:Slide 13 强调“many factors”
Power law 不只出现在数据量上,也出现在模型参数、计算量、某些架构选择和任务指标上。它的工程吸引力来自同一种拟合工具可以服务多个设计问题。但这也带来风险:不是所有指标、所有下游任务都同样平滑。
data vs performance
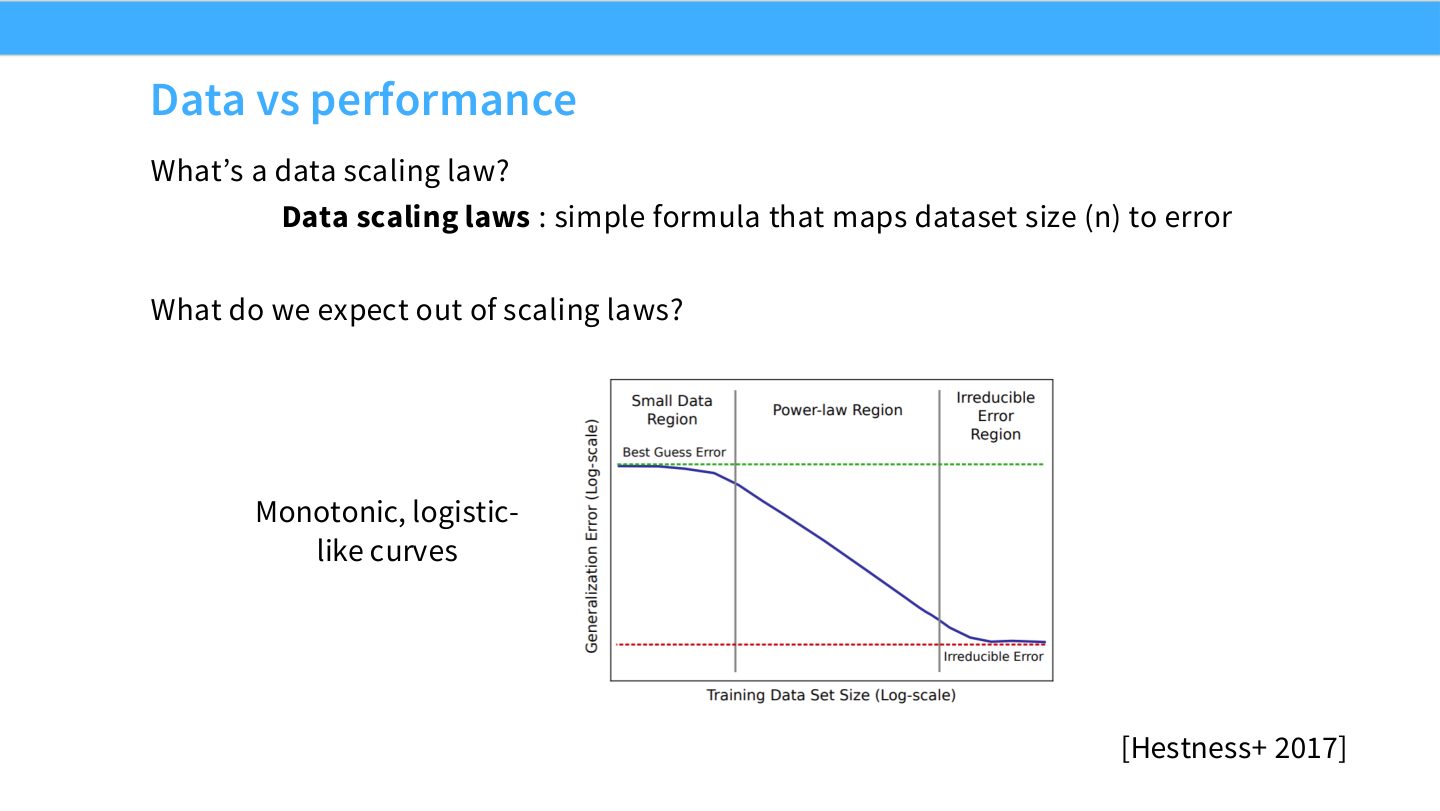
读图:Slide 14 的数据 scaling law
横轴是数据集大小 \(n\),纵轴是 error 或 loss。合理曲线应该单调下降,但不可能无限下降到负数;在有限区间内,power law 常能很好拟合。曲线的 slope 告诉我们继续加数据的边际收益。

读图:Slide 15 的 log-log 直线
如果
两边取对数得到
其中 \(L(n)\) 是数据量为 \(n\) 时的 loss,\(L_\infty\) 是不可约或远端 offset,\(\alpha\) 是数据 scaling exponent。log-log 图上的斜率就是 \(-\alpha\)。
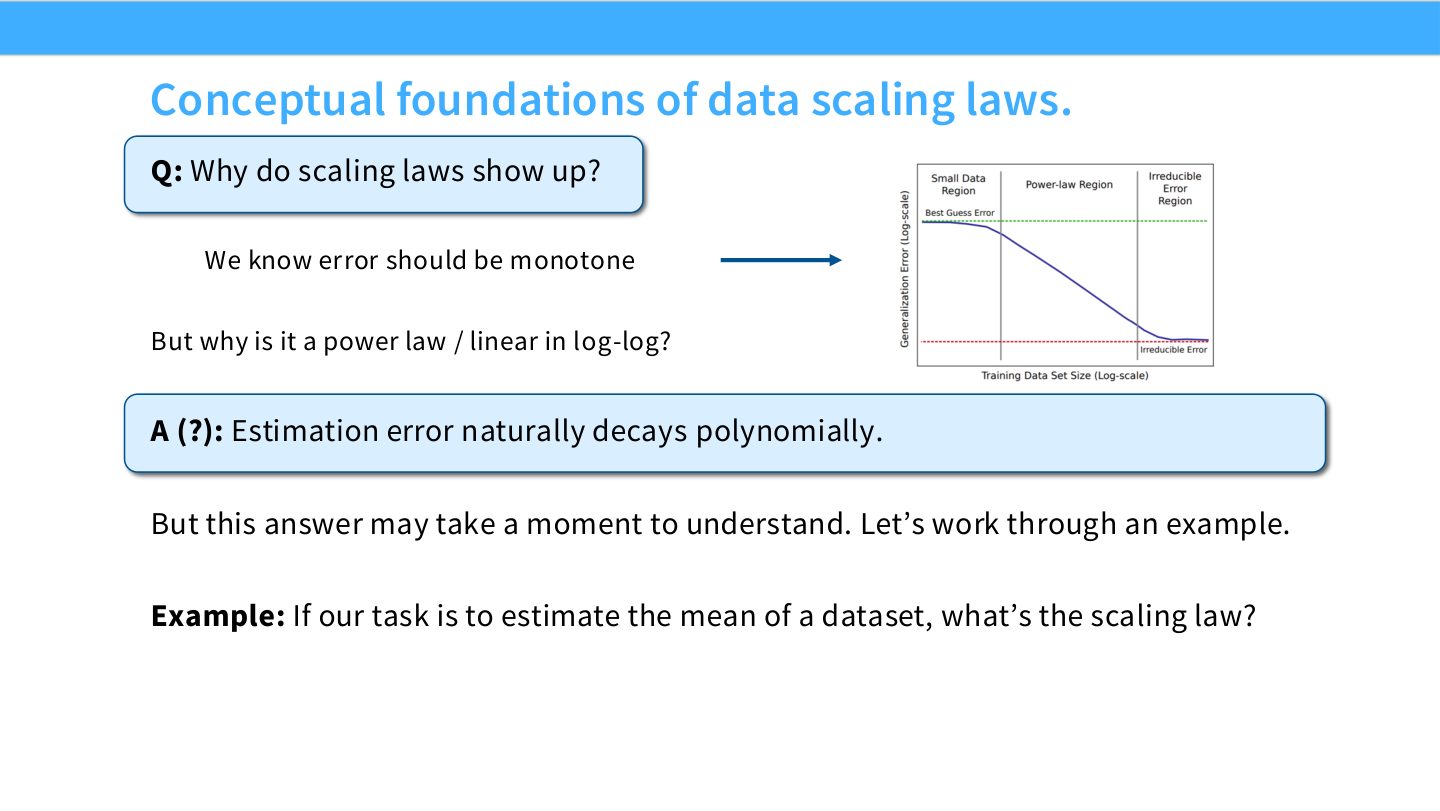
读图:Slide 16 的解释不是完整理论
“估计误差多项式衰减”能解释为什么 power law 合理,但不能完全解释神经网络 exponent 的数值、不同数据分布的 offset、下游任务的不平滑性。Scaling laws 在工程上有用,不代表我们已完全理解其机制。
![Slide 17:mean estimation toy example,误差 \([(-)^2]=σ^2/n\) 是最简单 scaling law。](slides-images/slide-017.jpg)
读公式:Slide 17 的 mean estimation
输入 \(x_1,\dots,x_n\sim\mathcal{N}(\mu,\sigma^2)\),估计量 \(\hat{\mu}=\frac{1}{n}\sum_i x_i\)。均方误差为
取对数后是 \(\log \text{Error}=-\log n + 2\log\sigma\),斜率为 \(-1\)。这说明 power law 可以从很基础的统计估计中出现。

读图:Slide 18 的 mystery
若所有任务都像均值估计,log-log 斜率应接近 \(-1\)。但机器翻译、语音、语言模型等神经 scaling 的 slope 通常更平缓。这说明模型、数据分布、任务复杂度和有效维度共同决定 exponent,而不是单纯样本平均。

读图:Slide 19 的非参数直觉
如果目标函数在二维空间上变化,把空间切成更细网格需要更多样本才能估计每个区域。维度越高,样本需求越大,error 下降越慢。这给 scaling exponent 和 intrinsic dimensionality 的联系提供直觉。
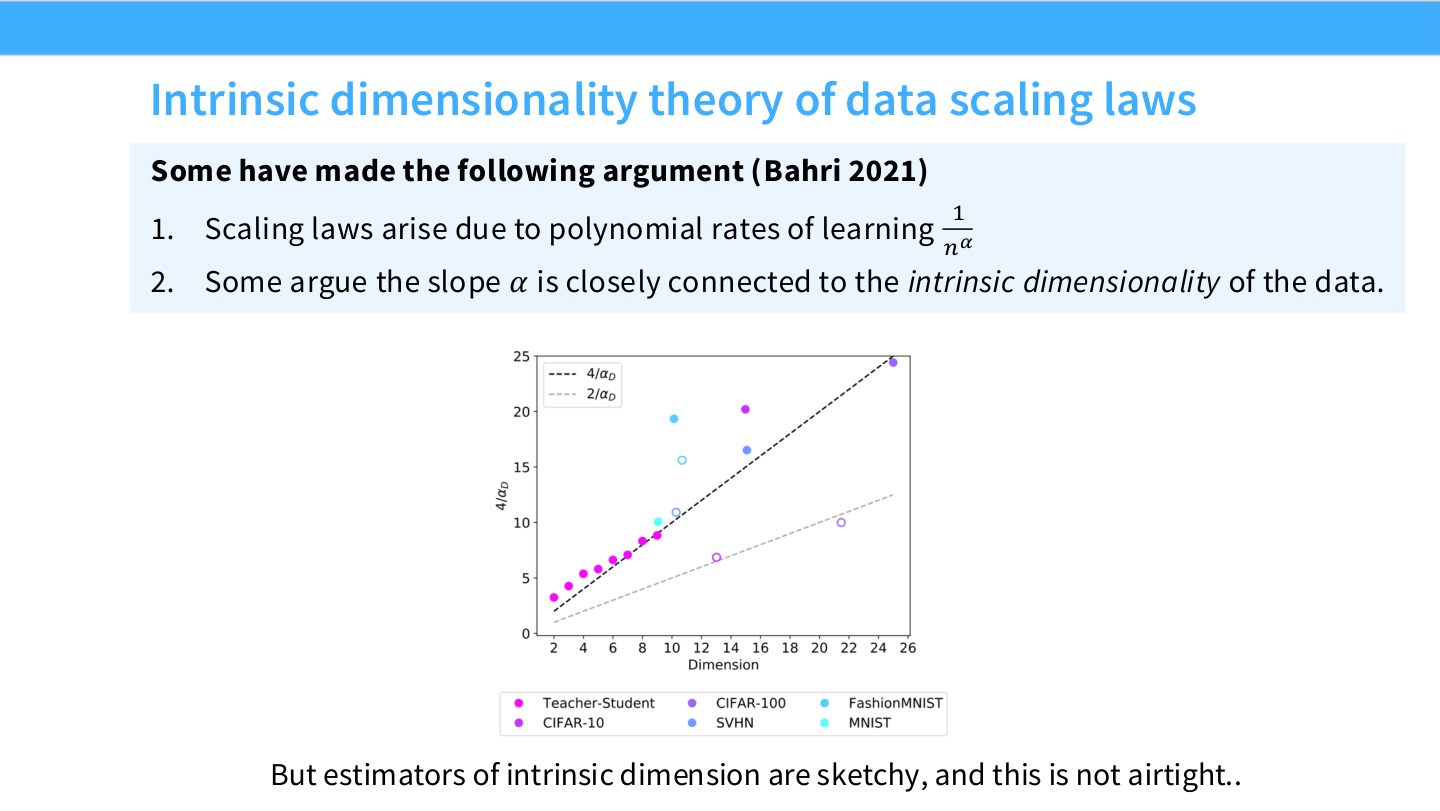
读图:Slide 20 的理论路线
这页给出一种解释:学习速率 \(n^{-\alpha}\) 中的 \(\alpha\) 受数据或函数的 intrinsic dimension 影响。维度越高,可学习结构越复杂,error 随数据下降越慢。该理论有启发性,但对现代 LLM 的完整解释仍不充分。
data composition、shift 和 repetition

读图:Slide 21 把数据问题从“多少”扩展到“什么”
数据量相同,不同 mixture 可能导致不同 loss offset 和下游能力。Scaling law 不只用来决定 token 数,也可以比较 data mixture、domain mix、是否重复有限数据等问题。
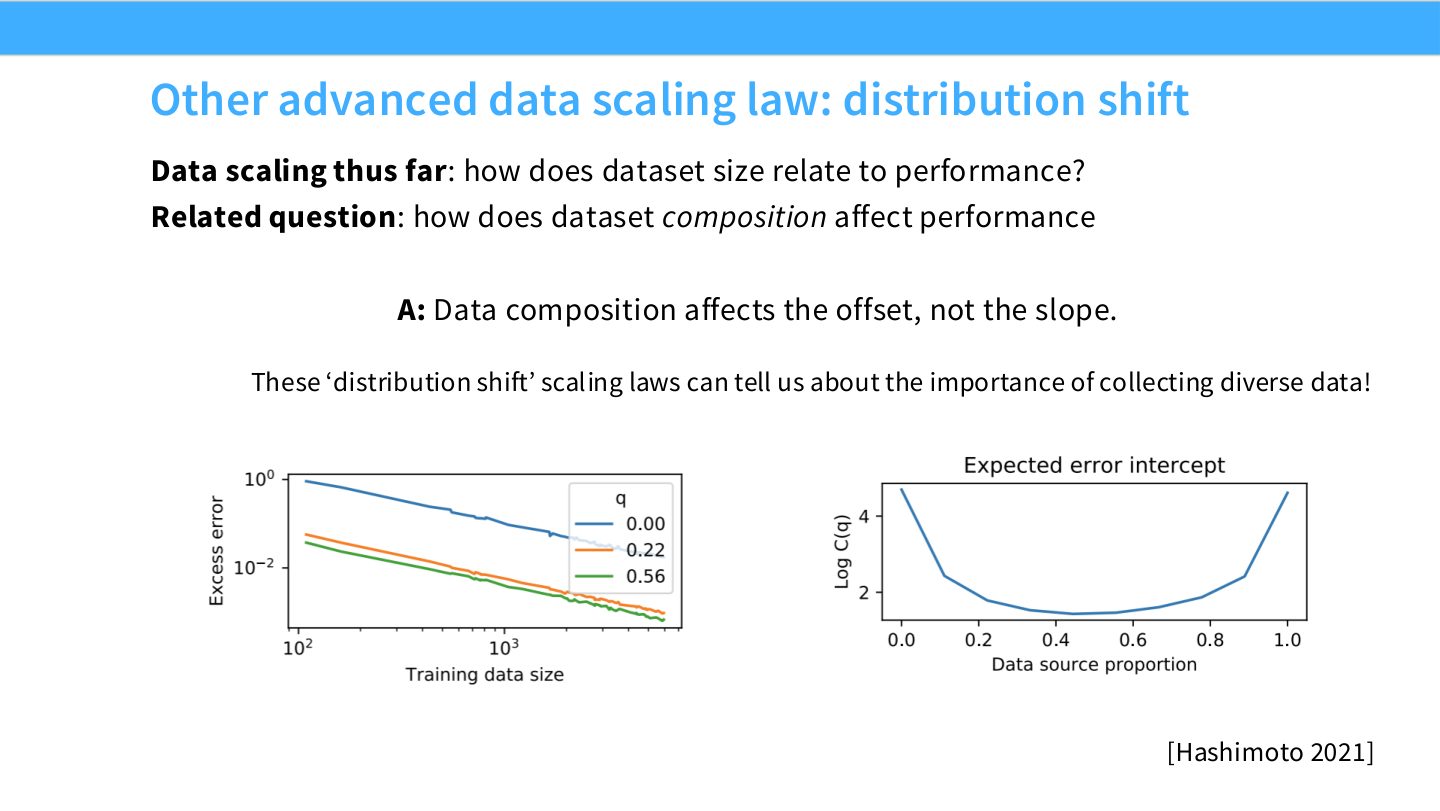
读图:Slide 22 的 offset 工程含义
如果不同数据 mixture 主要改变 offset,那么小规模实验可以帮助选择“整条曲线更低”的数据组合。Slope 相近意味着继续 scale 时排序可能保持;但如果下游任务或分布改变,offset 和 slope 都可能变化。
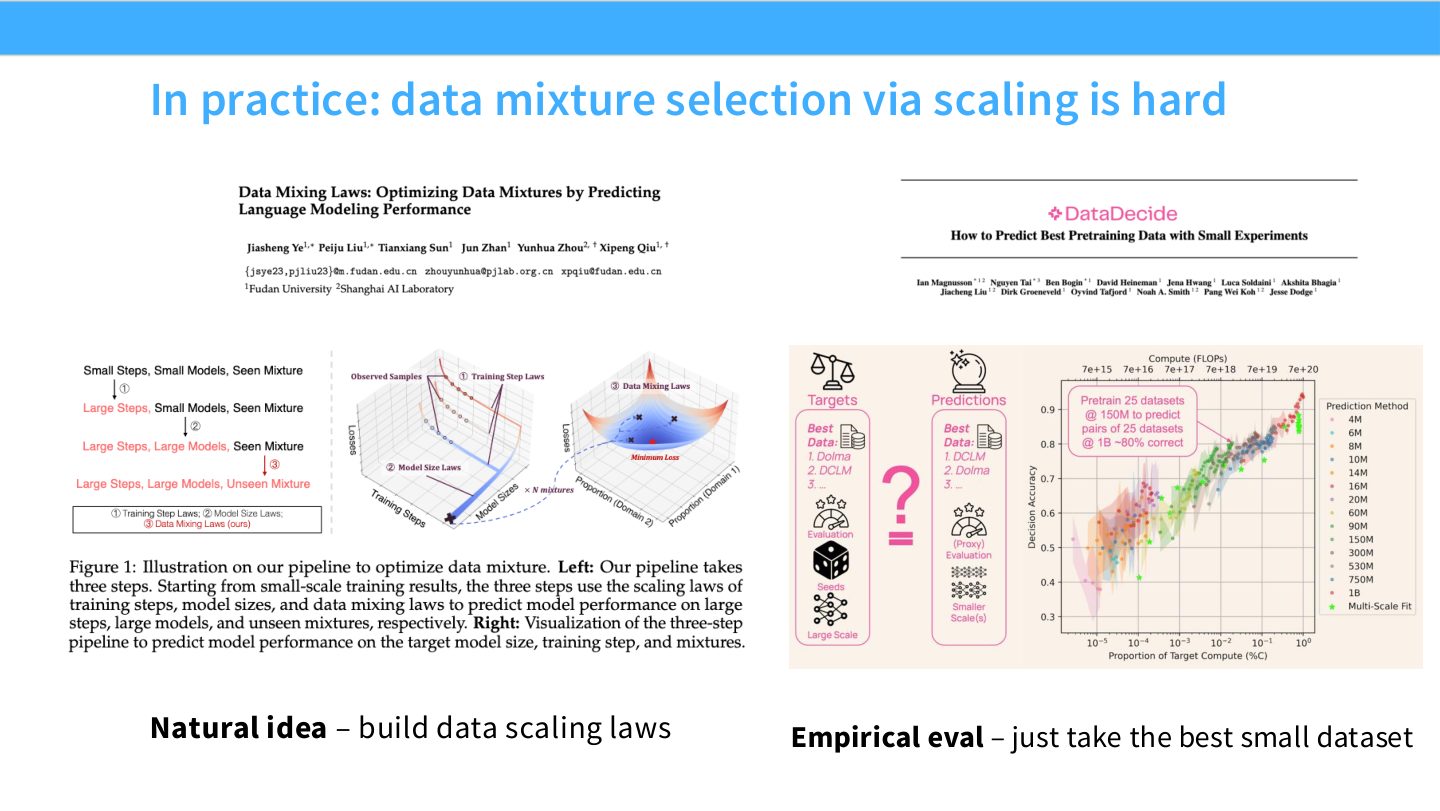
读图:Slide 23 的警告
自然想法是用小模型拟合每种数据 mixture 的 scaling law,再选最优。但数据质量、任务覆盖、去重、污染、下游迁移、模型大小都可能改变排序。因此 mixture selection 的 scaling 需要多尺度验证,不能只拿最小模型的赢家。
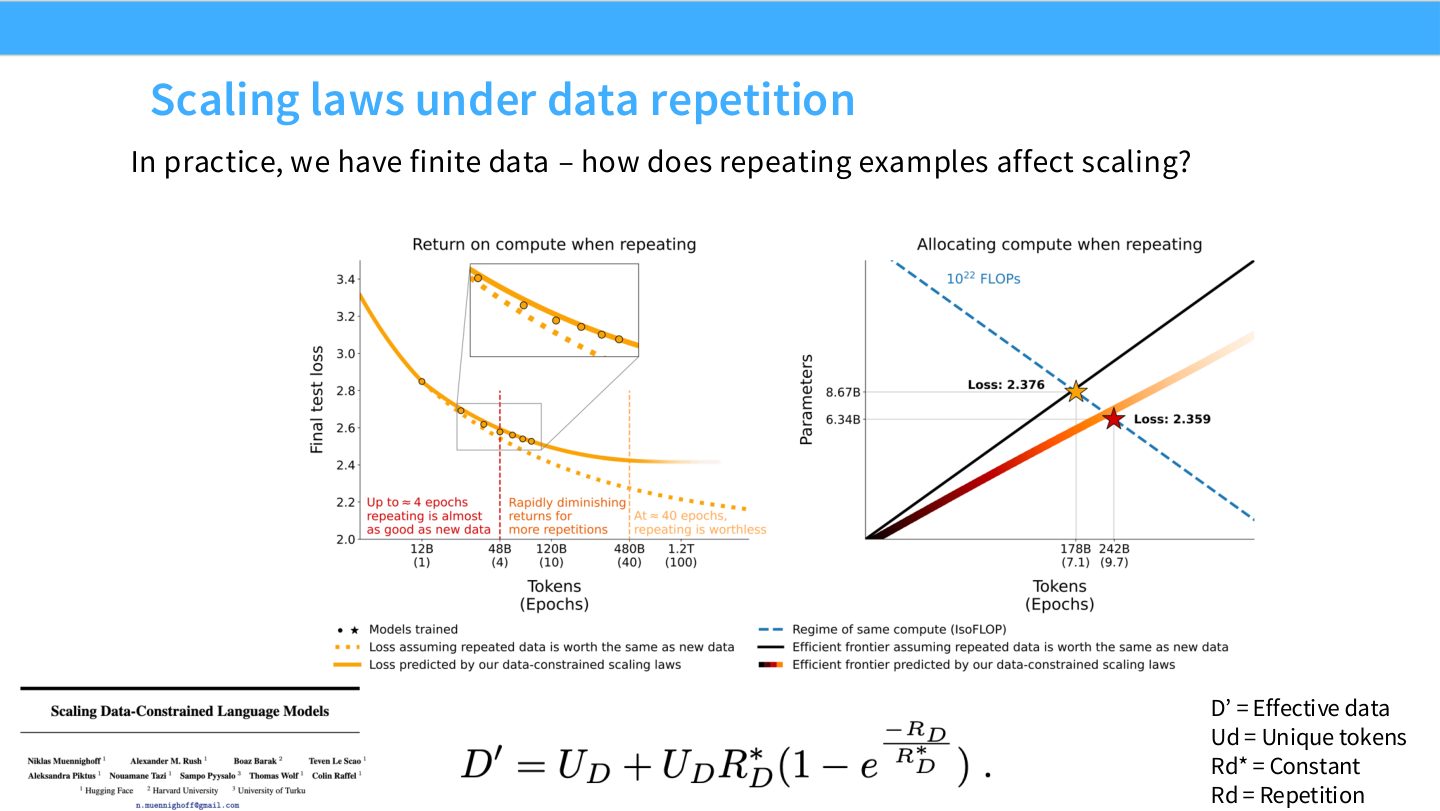
读公式:Slide 24 的重复数据账本
\(U_d\) 表示 unique tokens,\(R_d\) 表示重复次数,\(D'\) 表示有效数据量。重复数据不是完全没用,但边际价值低于新数据。随着重复率上升,有效数据增长会折损,scaling curve 可能偏离只看 token count 的预测。
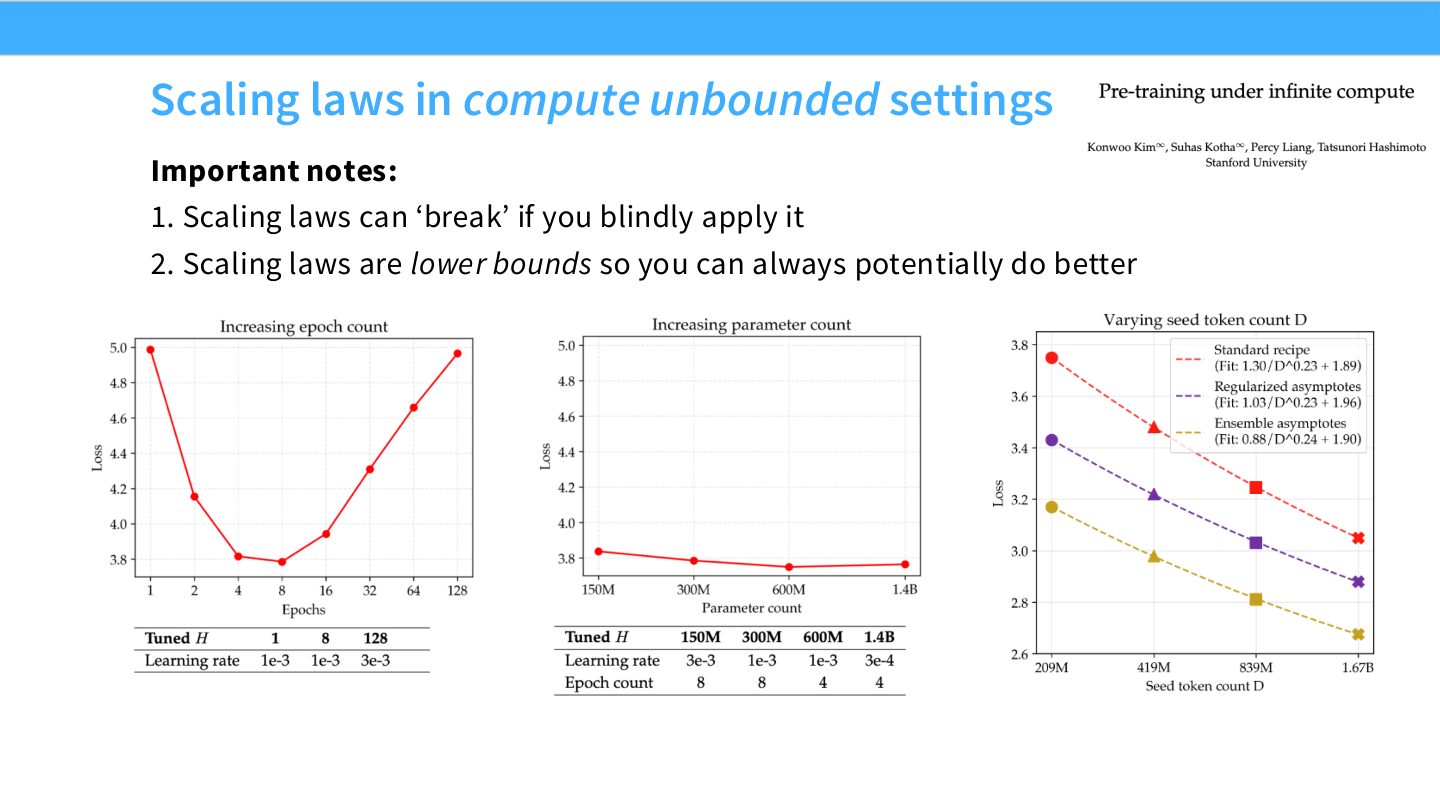
读图:Slide 25 不要盲目外推
Scaling laws 是已观察训练 recipe 下的经验下界或趋势。若算法、数据清洗、架构、优化器或训练过程改变,你可能做得比旧曲线更好;若超出拟合区间太远,也可能更差。它们是决策工具,不是自然定律。
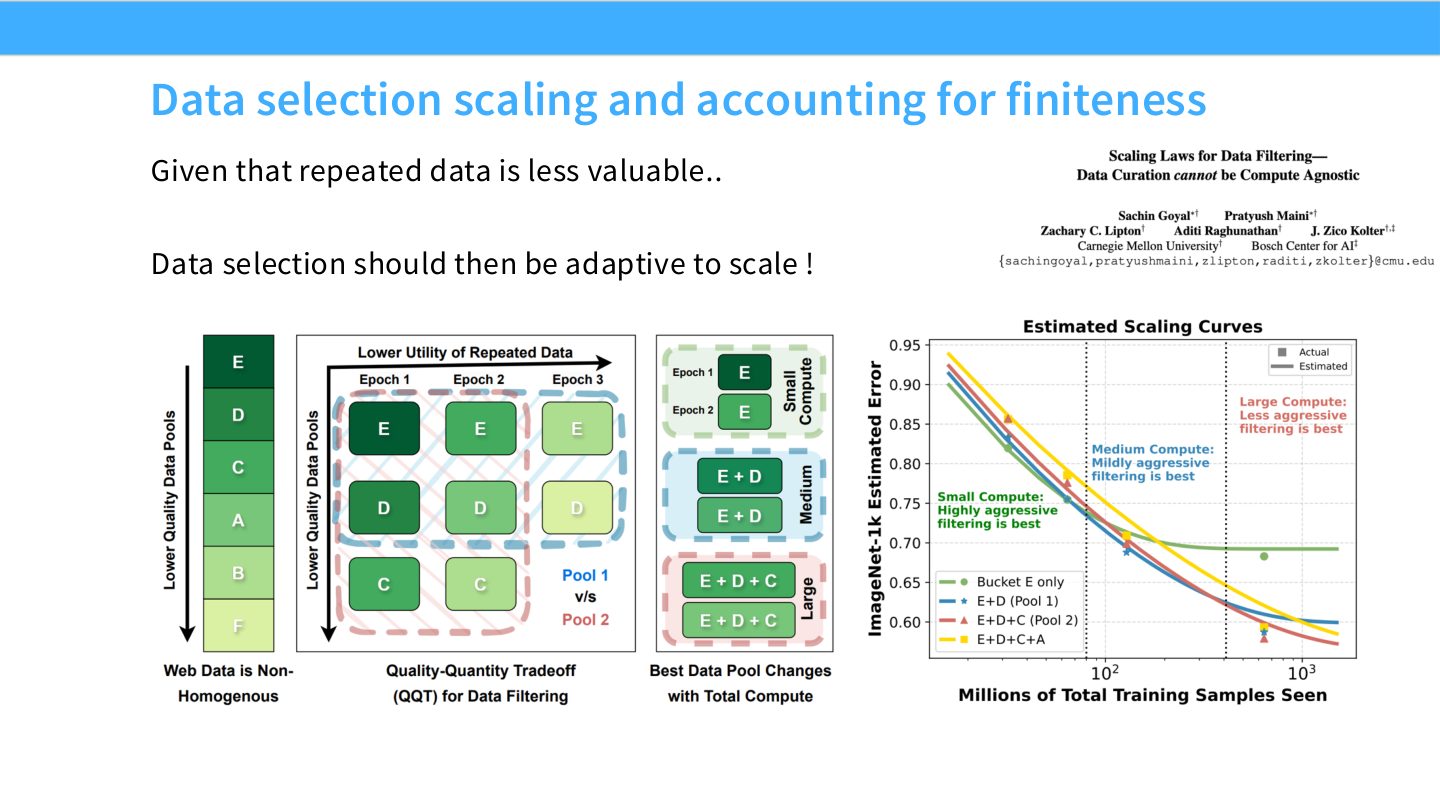
读图:Slide 26 的 adaptive data selection
如果重复数据价值下降,那么不同规模下最优数据选择可能不同:小模型需要高质量/高密度信号,大模型可能需要更多覆盖和多样性。数据 pipeline 不应是一次性静态配方,而应随目标 compute 和模型规模变化。

读图:Slide 27 的 recap
数据 scaling 的核心事实是 log-log 线性;理论直觉来自 generalization/sample-complexity;实践用途包括数据收集、数据重复、data mixture 和分布迁移。它最大的限制是:loss 曲线平滑不代表所有下游能力都同样可预测。
本章小结
数据 scaling laws 告诉我们,更多数据通常按 power law 改善 loss,但数据质量、composition、重复和分布迁移会改变 offset 甚至 slope。用于训练决策时,要同时记录 unique tokens、重复率、mixture、评估分布和模型规模。
Scaling laws for model engineering
读图:Slide 28 的工程问题
大模型设计不是只问“多大最好”,还包括 LSTM vs Transformer、Adam vs SGD、深度/宽度、batch size、learning rate 等选择。Scaling law 实验的目标是用小模型筛掉明显差的方向,再把预算集中到最有希望的设计。

读图:Slide 29 是超参数实验 checklist
这页列出的不是独立小问题,而是训练 recipe 的关键轴。每个轴都可以通过小规模 sweep 建立性能曲线,然后判断哪个选择在大规模下仍有优势。关键是比较曲线,而不是比较某个小模型点。
for config in candidate_configs:
runs = train_small_models(config, budgets=[1e18, 3e18, 1e19])
curve = fit_scaling_law(runs)
predicted_loss = curve.predict(target_budget)
select_config_with_lowest_predicted_loss()
Architecture、optimizer、depth/width
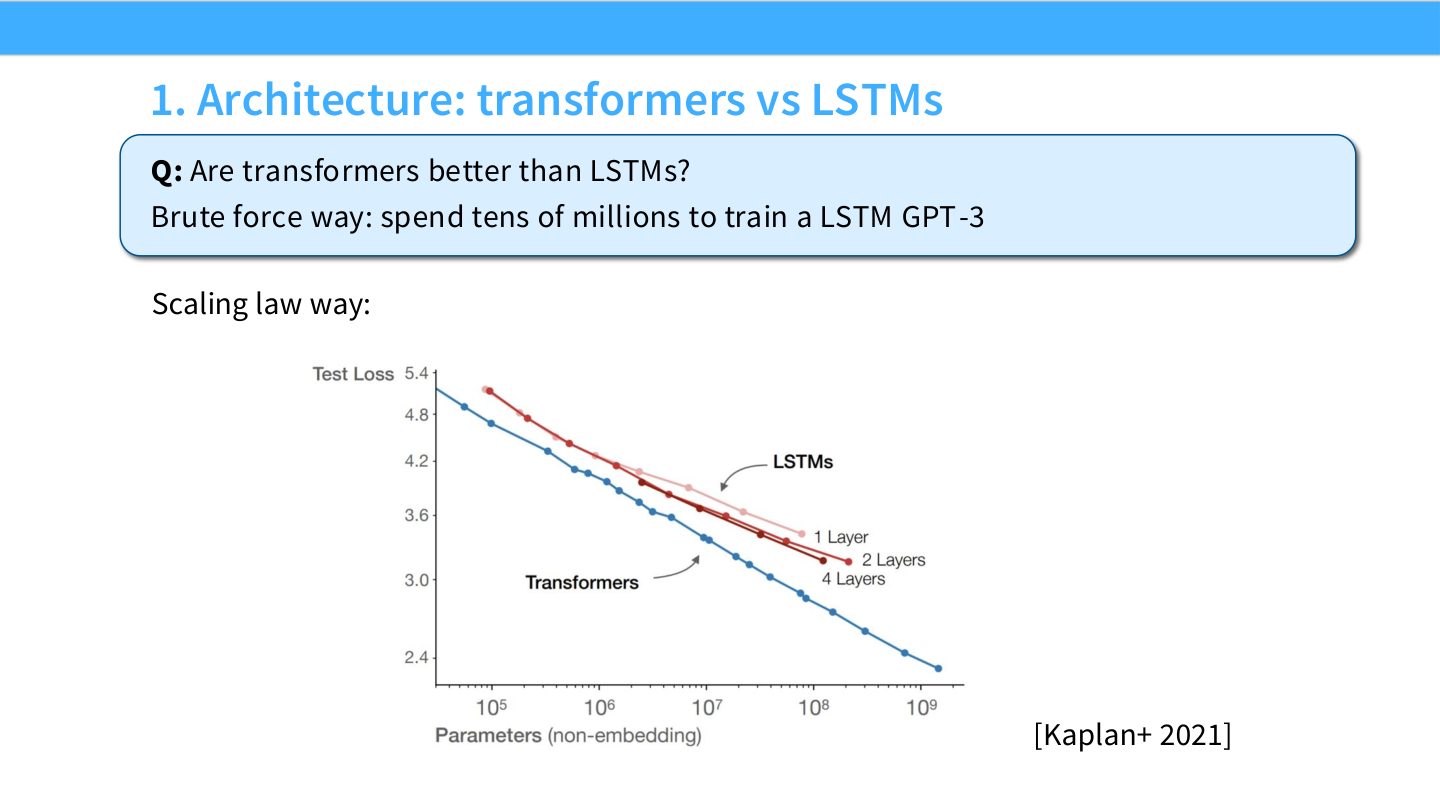
读图:Slide 30 的架构比较方法
比较架构要比较同等 compute 或同等参数预算下的 scaling curve。如果 Transformer 曲线整体低于 LSTM,且外推稳定,那么不需要在最大规模上训练 LSTM 才能判断方向。Scaling law 是降低架构搜索成本的工具。
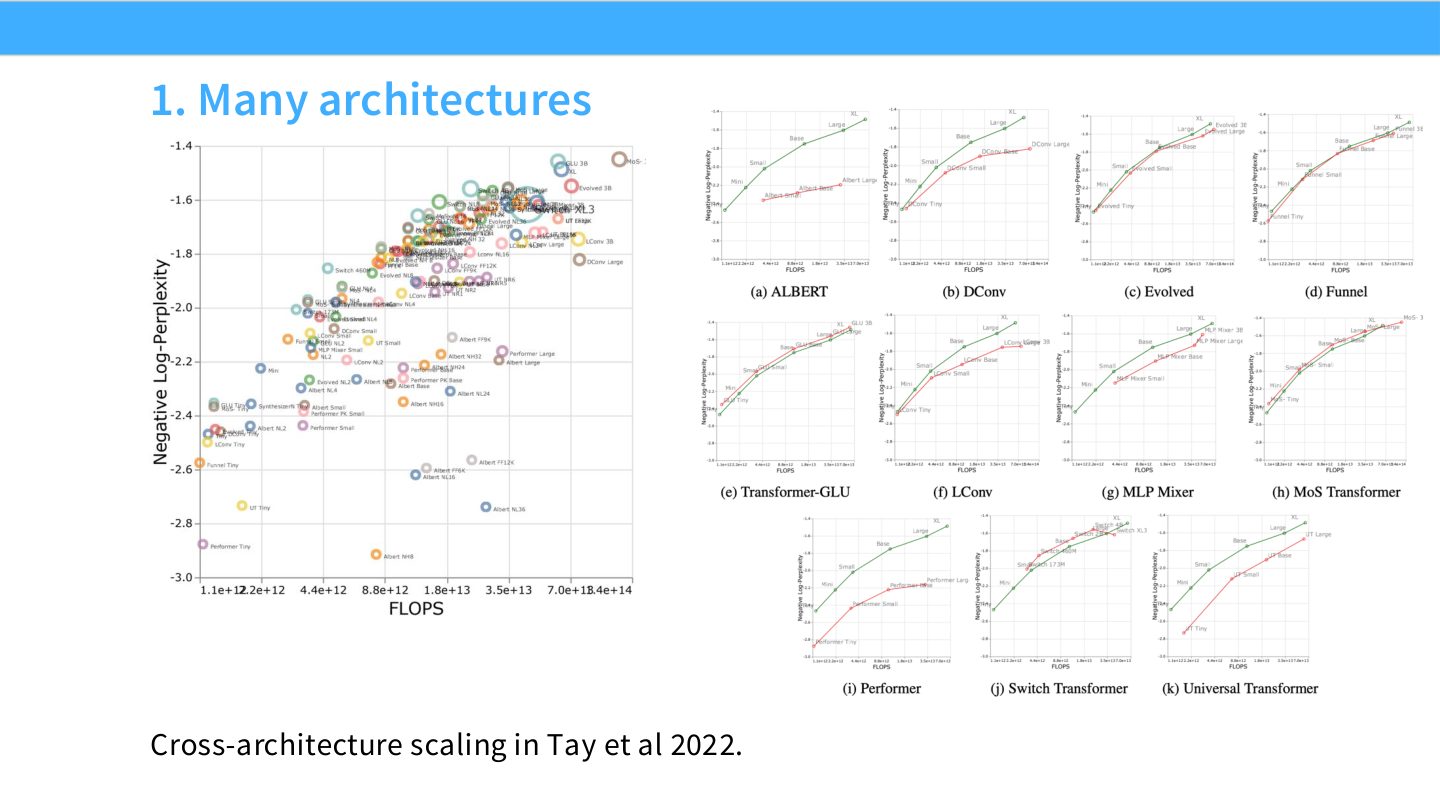
读图:Slide 31 应看曲线族而非单点排名
不同架构可能在小规模交叉,在大规模排序改变。图中多条曲线的相对 slope 和 offset 都重要:offset 低代表当前规模好,slope 更陡代表继续 scale 更有潜力。工程上要选择目标预算附近预测最优的架构。
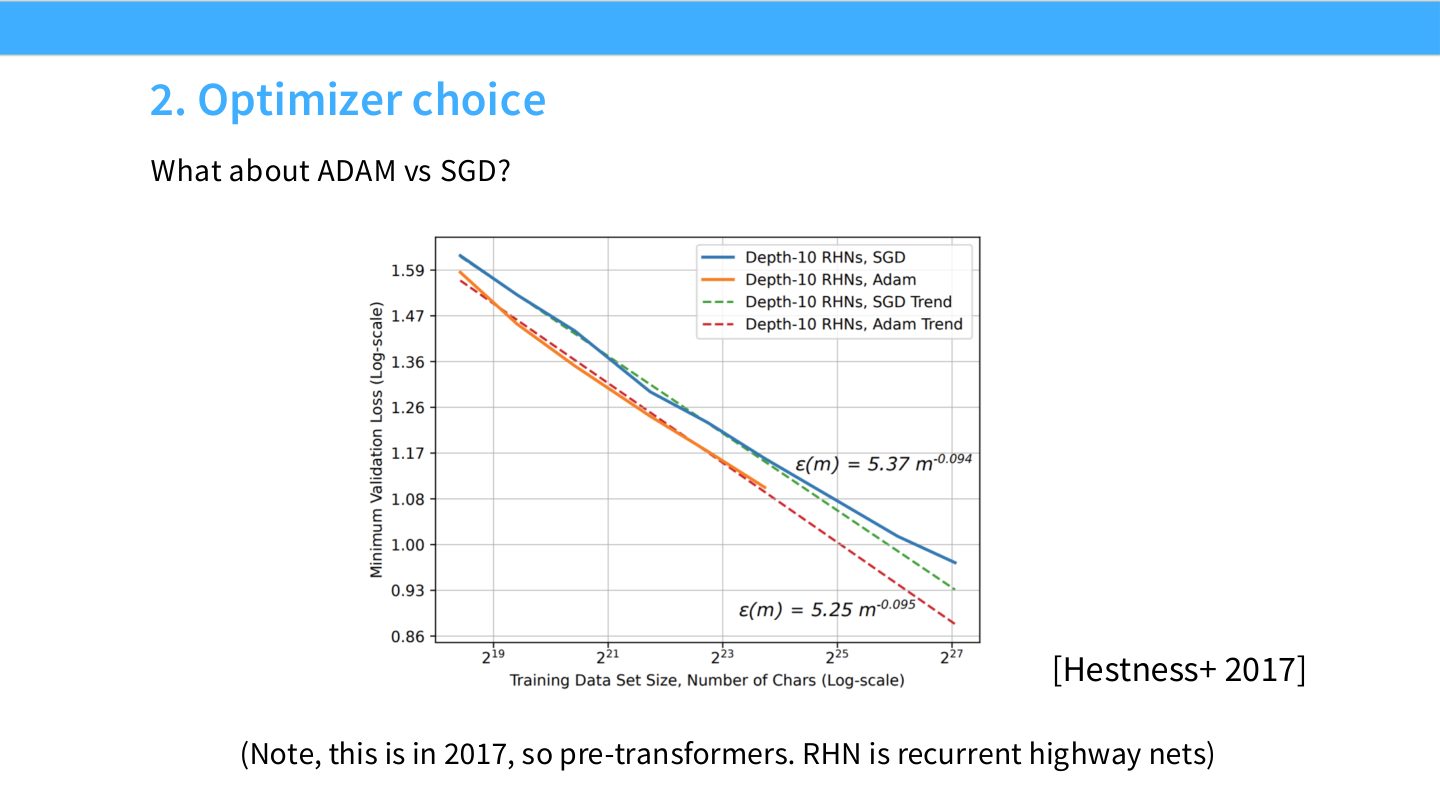
读图:Slide 32 的 optimizer 结论要带上下文
这页数据来自 pre-transformer 时代和特定模型族。它说明 optimizer choice 可以通过 scaling 实验比较,但不能直接把旧结论搬到现代 Transformer。读图时要区分“方法论可迁移”和“具体最优选择可迁移”。
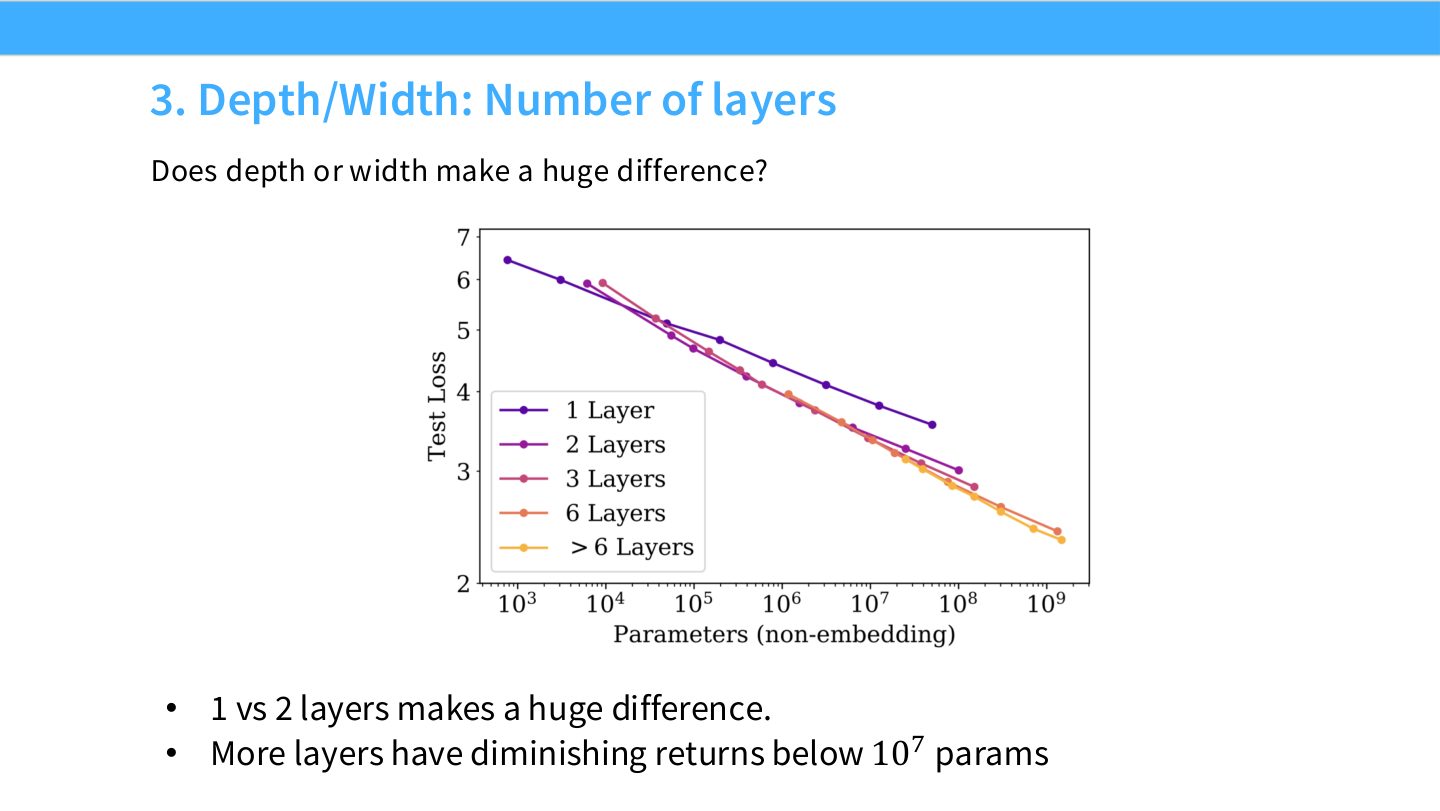
读图:Slide 33 的 depth/width 信息
浅层到两层可能带来结构性收益,但继续加深会遇到边际收益递减。对 Transformer 来说,depth/width 还影响并行切分、激活显存和推理延迟,因此 scaling law 的架构选择要同时考虑系统成本。
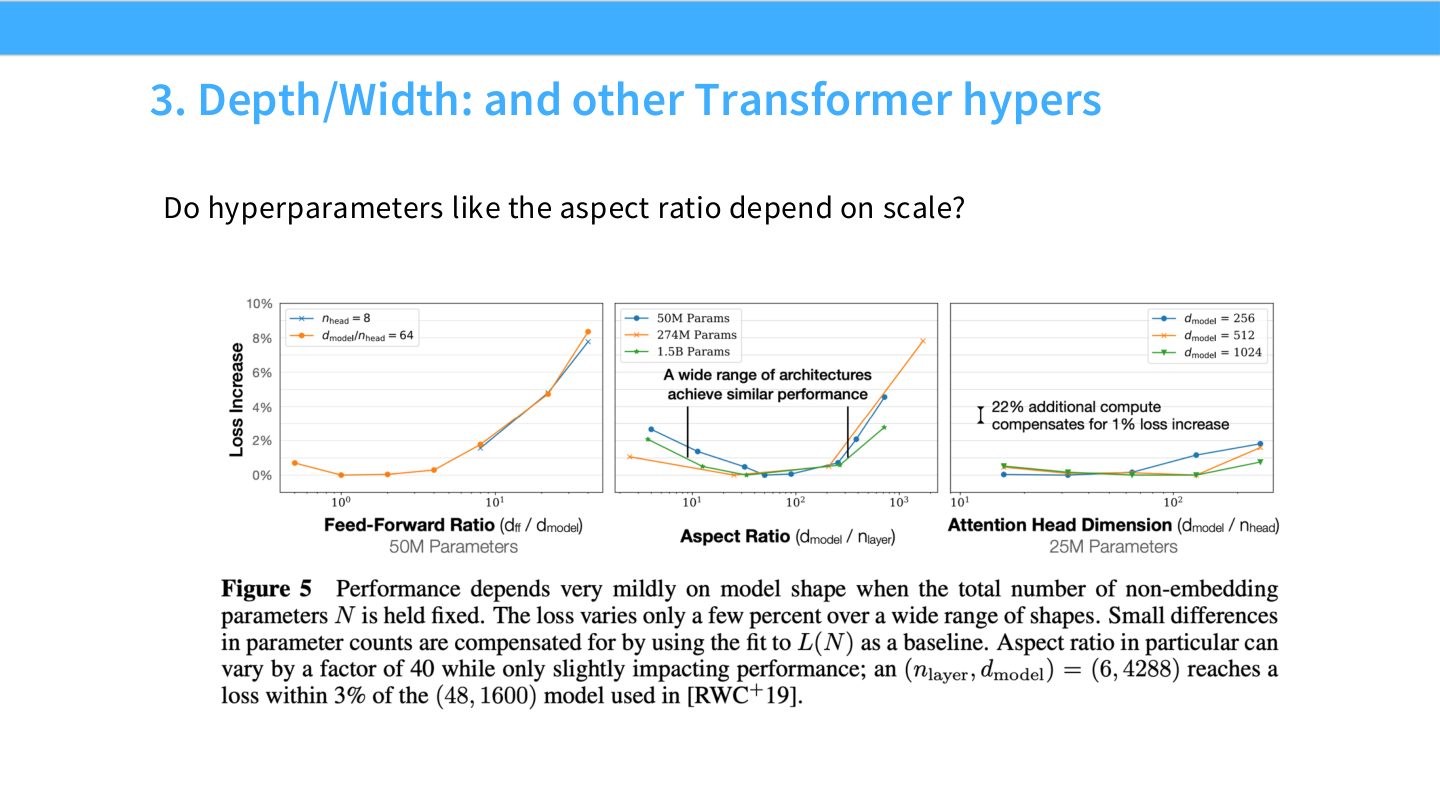
读图:Slide 34 的 aspect ratio 问题
Aspect ratio 指 depth、width、heads、MLP expansion 等比例关系。若最优比例随 scale 变化,小模型 tuning 就不能直接复制到大模型。Scaling experiment 要检查这些超参数的最优区间是否稳定。
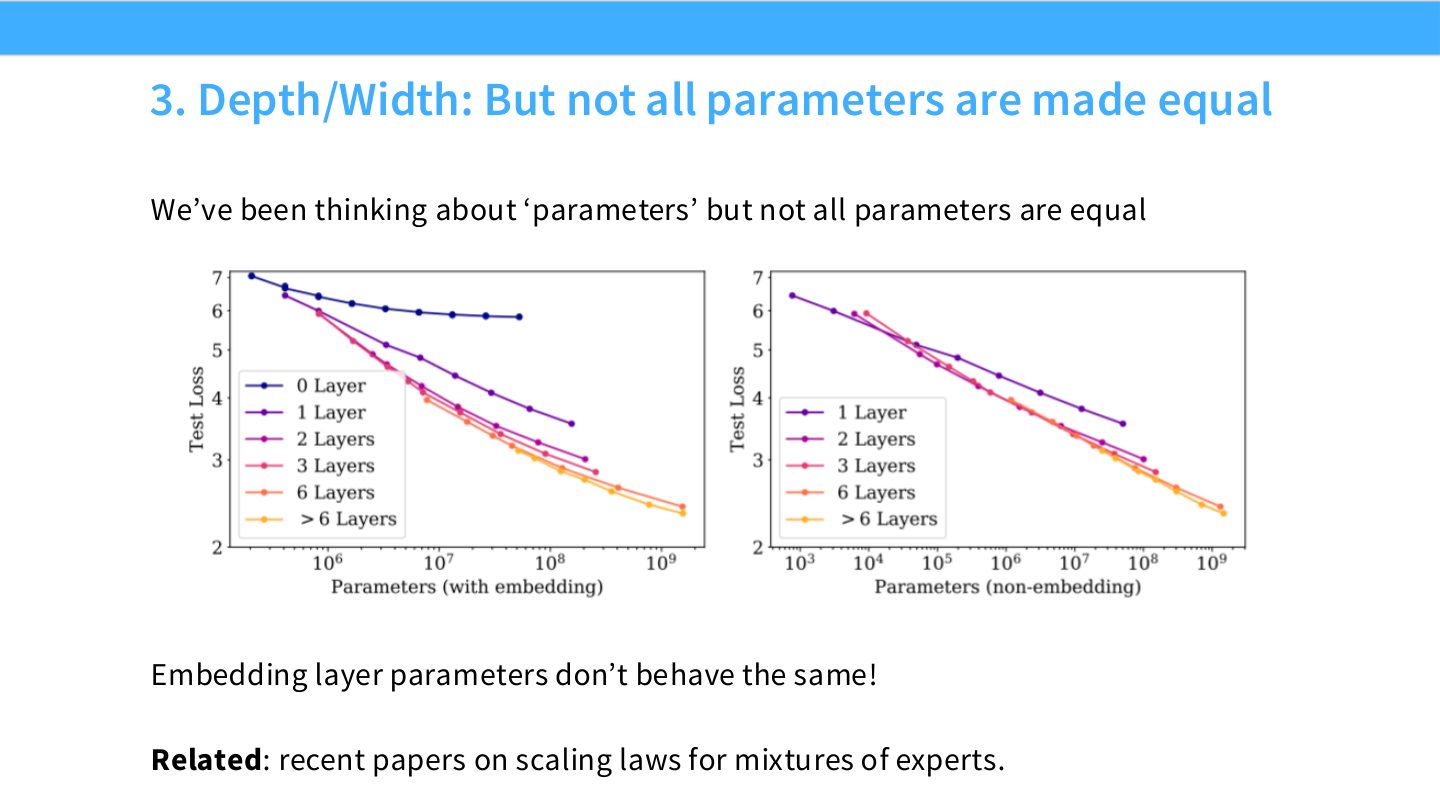
读图:Slide 35 的参数计数陷阱
Scaling law 常用 parameter count \(N\),但 embedding、attention、MLP、MoE inactive parameters 的“价值”不同。若把所有参数粗暴相加,可能错误估计模型能力和 compute-optimal 配置。MoE 模型尤其需要区分 total parameters 和 active parameters。
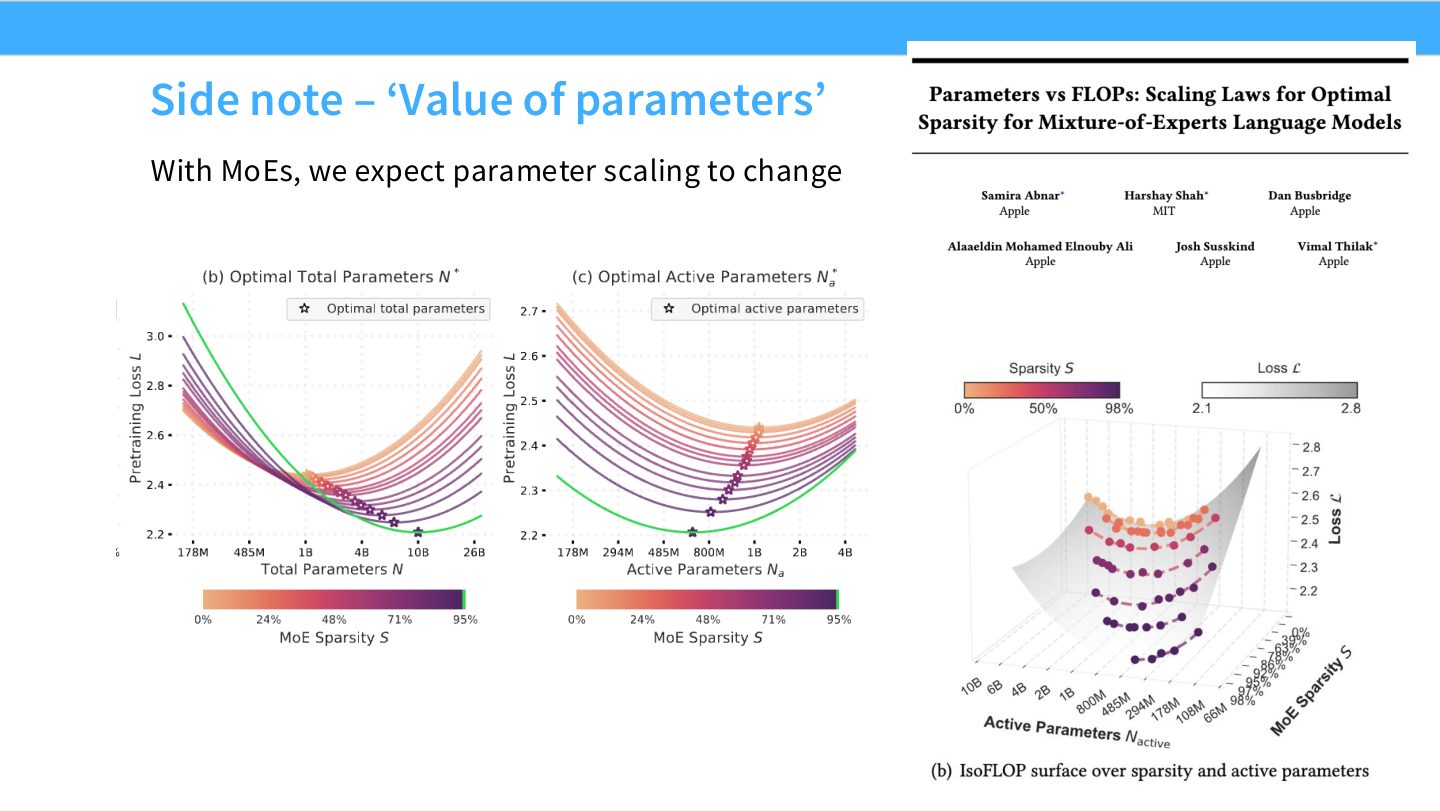
读图:Slide 36 的 MoE 参数价值
MoE 增加 total parameters,但每个 token 只激活部分 experts。其 scaling 可能更接近 active compute 和 routing quality,而不是 total parameter count。评估 MoE scaling 时必须记录 active parameters、expert count、routing、负载均衡和通信成本。
Batch size、critical batch size 与 muP
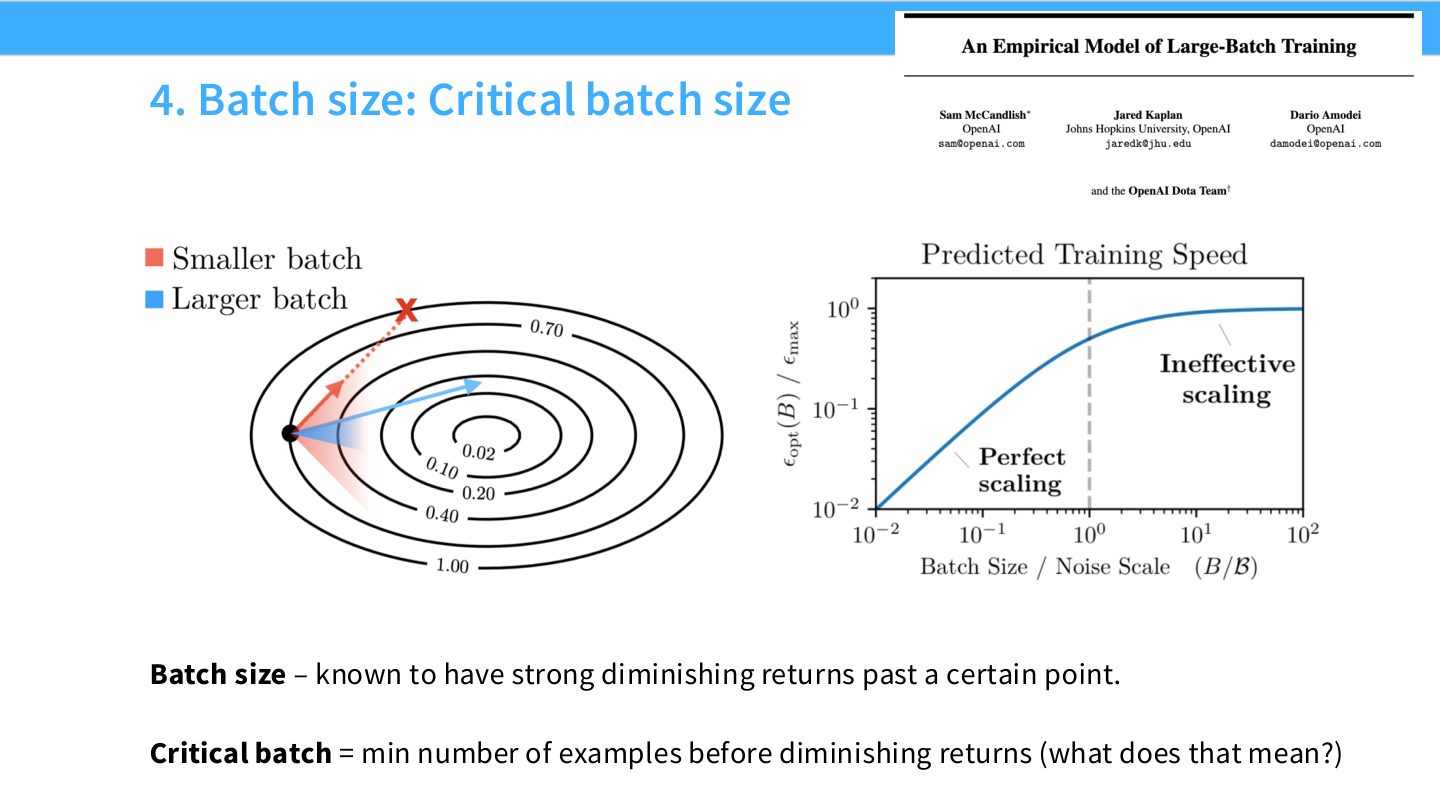
读图:Slide 37 的 critical batch 定义直觉
Critical batch 是在达到某个目标 loss 时,继续增大 batch 开始明显降低样本效率的区域。小 batch 需要更多 wall-clock step,但样本效率高;大 batch 并行度高,但可能浪费样本或需要学习率调整。

读图:Slide 38 的两个量
固定目标 loss,训练多个 batch size。记录达到目标 loss 所需 steps \(S\) 和 examples \(E\)。小 batch 区域 \(E\) 接近最优但 \(S\) 大;大 batch 区域 \(S\) 接近最小但 \(E\) 增大。critical batch 大致是两种成本开始折中的点。
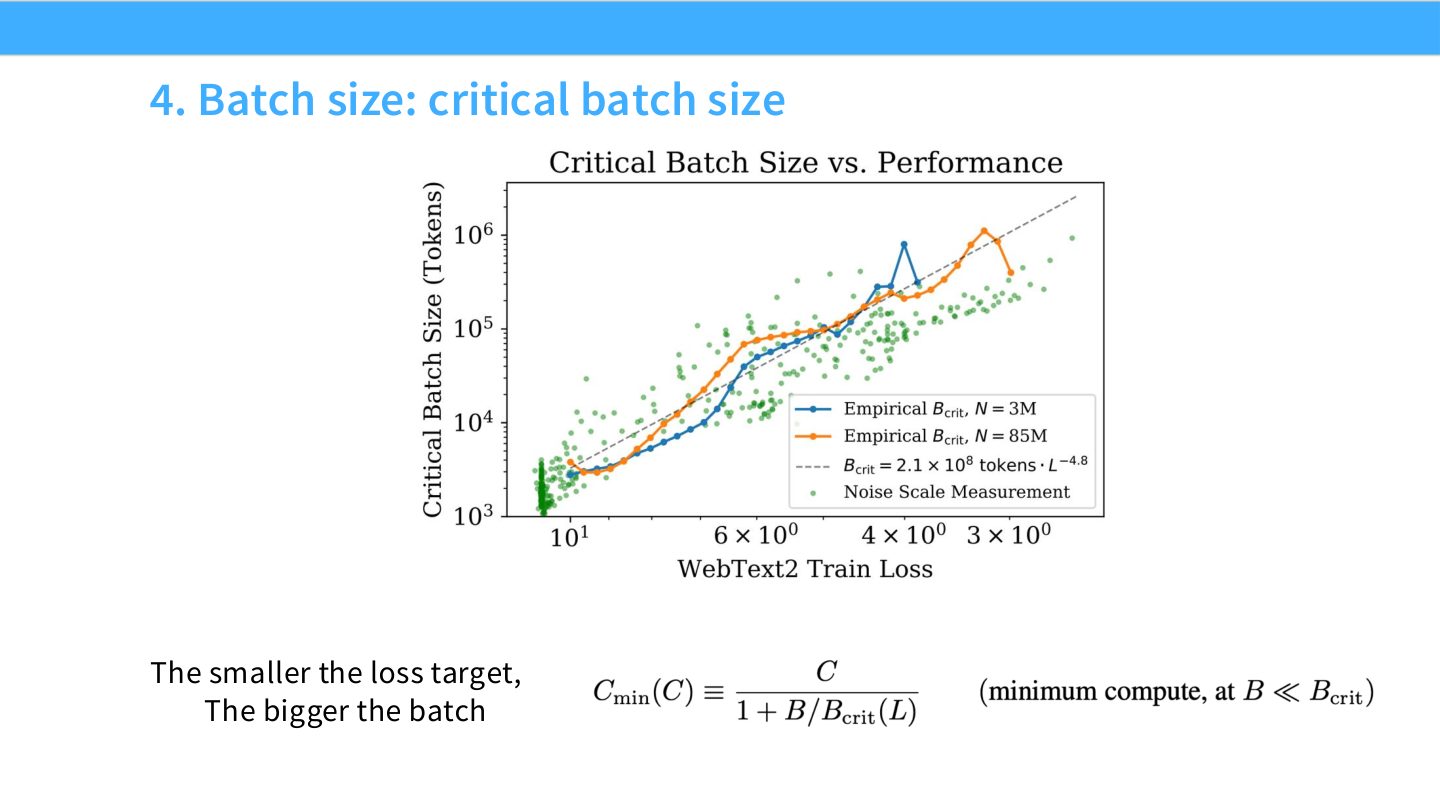
读图:Slide 39 的训练阶段含义
训练早期 loss 高,critical batch 较小;训练后期目标 loss 更低,可以使用更大 batch 而不那么浪费样本。这也是 batch size schedule、gradient accumulation 和并行规模选择会随训练阶段变化的原因。
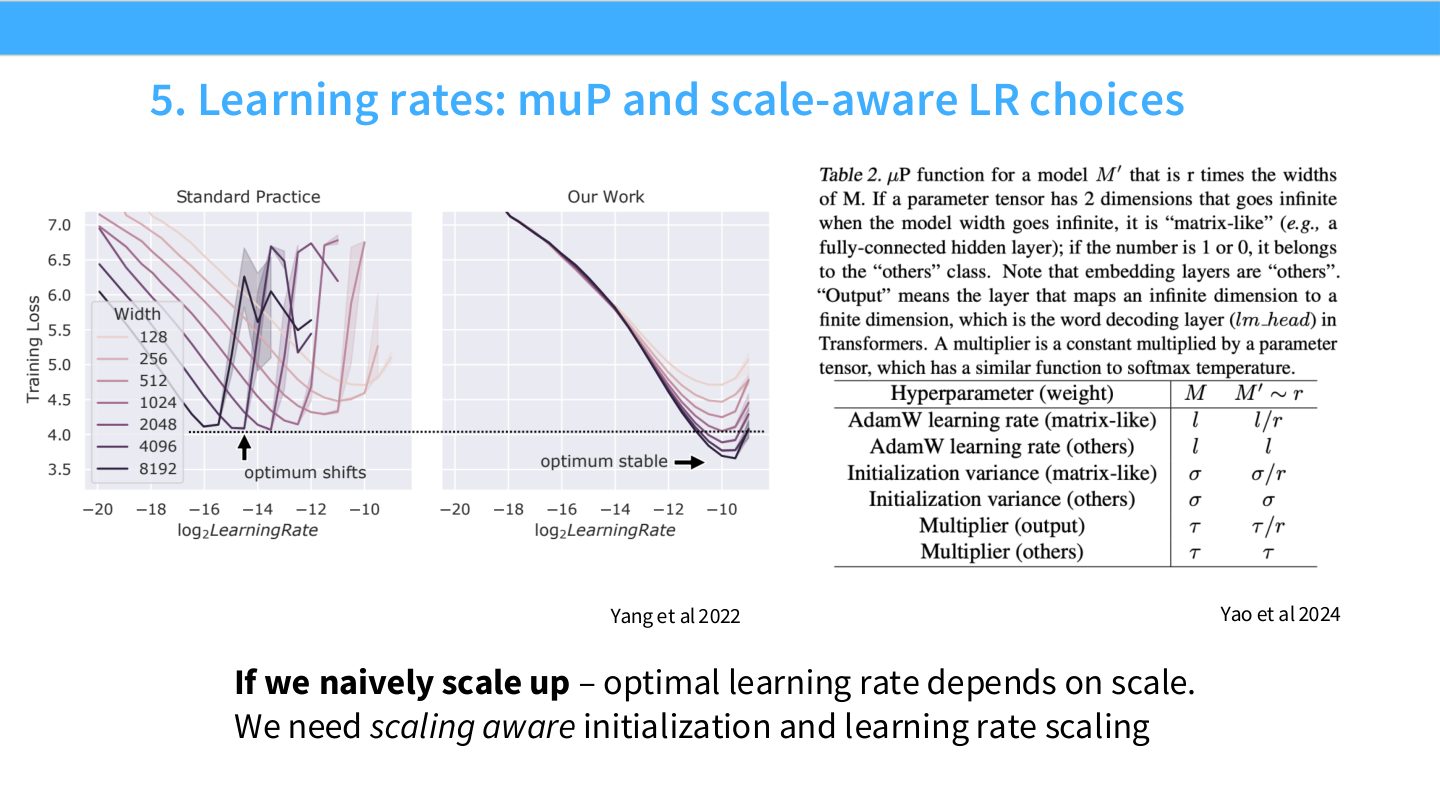
术语消化:muP 的工程价值
muP(maximal update parameterization)是一套让不同宽度模型在训练动力学上更可比的参数化和学习率规则。目标是让小模型上调出的 learning rate、初始化和超参数更可靠地迁移到大模型。它解决的不是 loss curve 拟合,而是让“用小模型预测大模型”这件事的实验条件更一致。
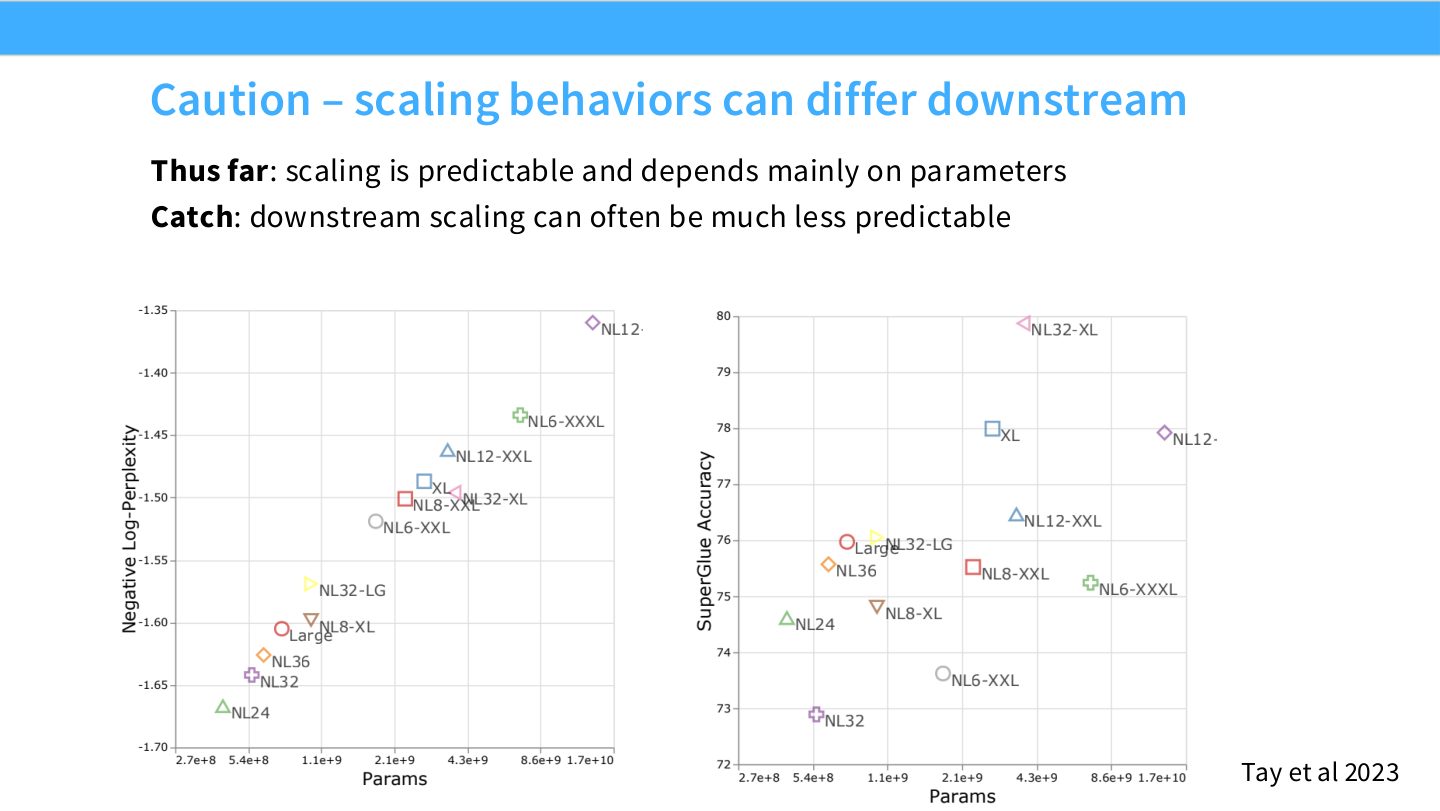
读图:Slide 41 的 downstream caveat
预训练 loss 往往平滑,但下游任务、能力阈值、prompting、评测噪声和数据污染会让曲线更乱。Scaling law 可以预测平均 loss,不保证所有能力指标单调、平滑或按相同 exponent 改善。
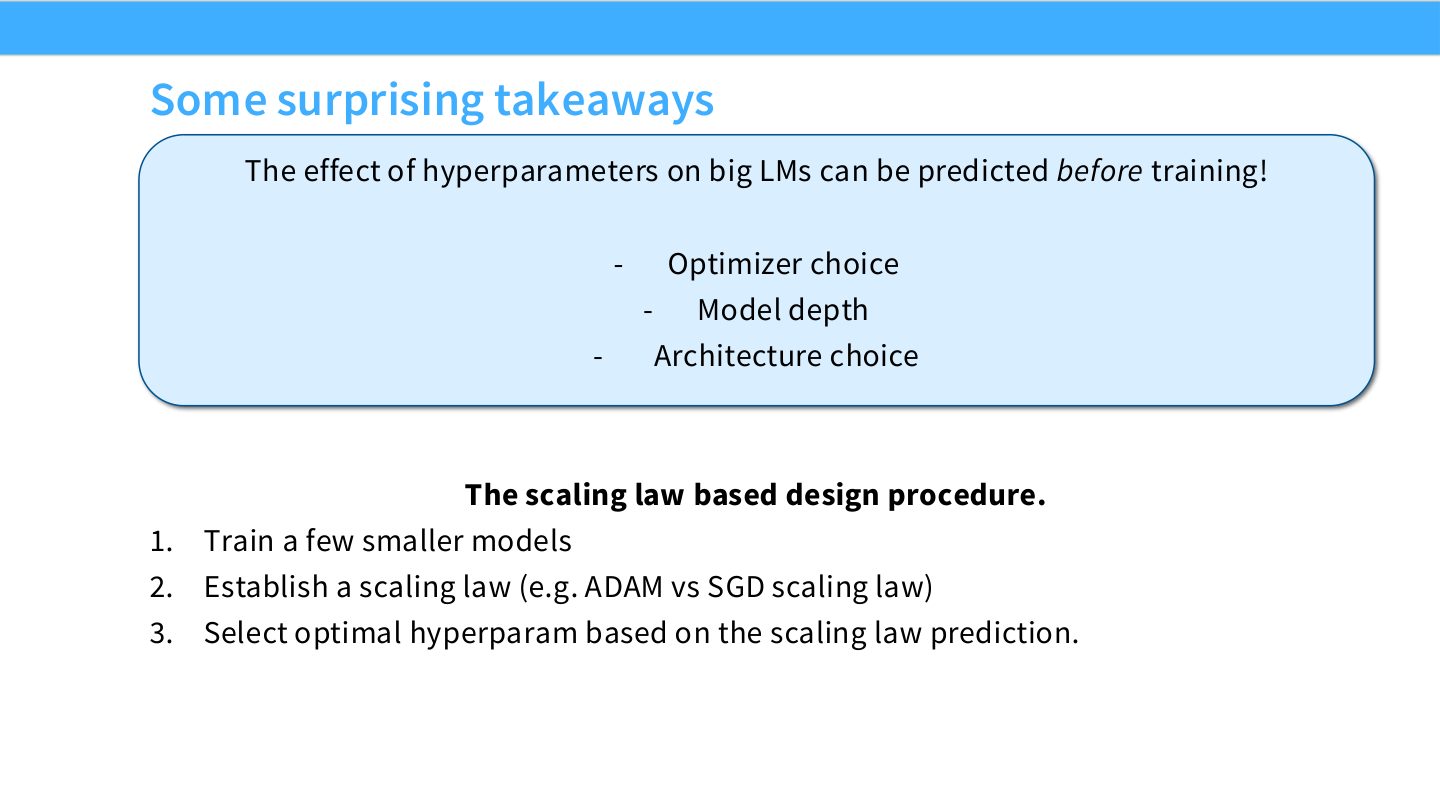
读图:Slide 42 的 scaling-law design procedure
流程是:训练若干小模型,建立 scaling law,外推后选择大模型配置。关键不是“少训几个模型就够了”,而是要覆盖足够尺度、控制变量、评估拟合残差,并在目标规模前做 sanity check。
本章小结
模型工程 scaling 把架构、优化器、depth/width、batch size、learning rate 等选择变成曲线比较问题。它能大幅降低设计成本,但依赖实验设计质量和外推范围,不能替代最终大规模验证。
Joint data-model scaling 与 compute-optimal training
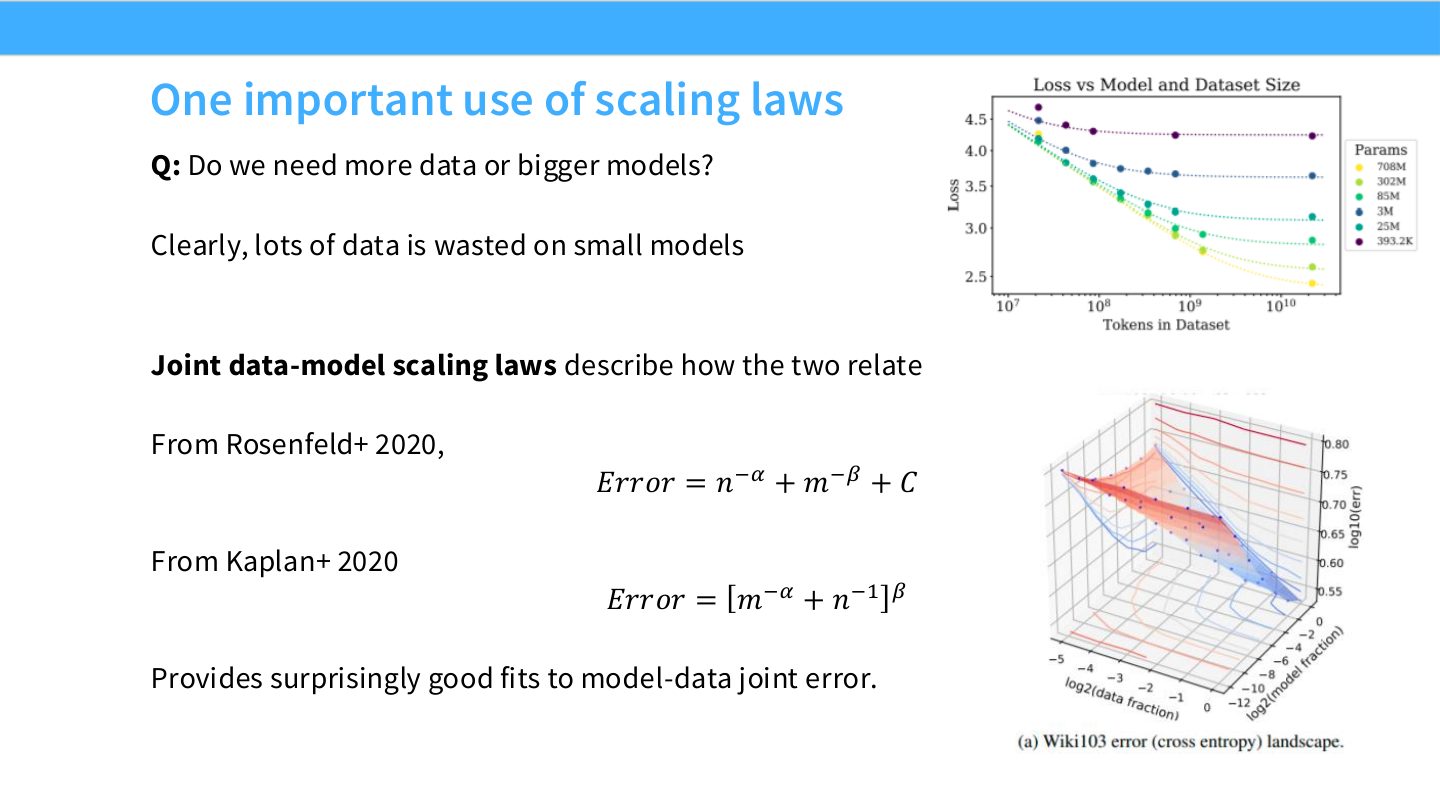
读公式:Slide 43 的联合 scaling
一种简化形式是
其中 \(n\) 是数据量,\(m\) 是模型大小,\(\alpha,\beta\) 分别表示数据和模型 scaling exponent,\(C\) 是 offset。工程问题是在 compute budget 下选择 \(n,m\),而不是单独最大化某一个。
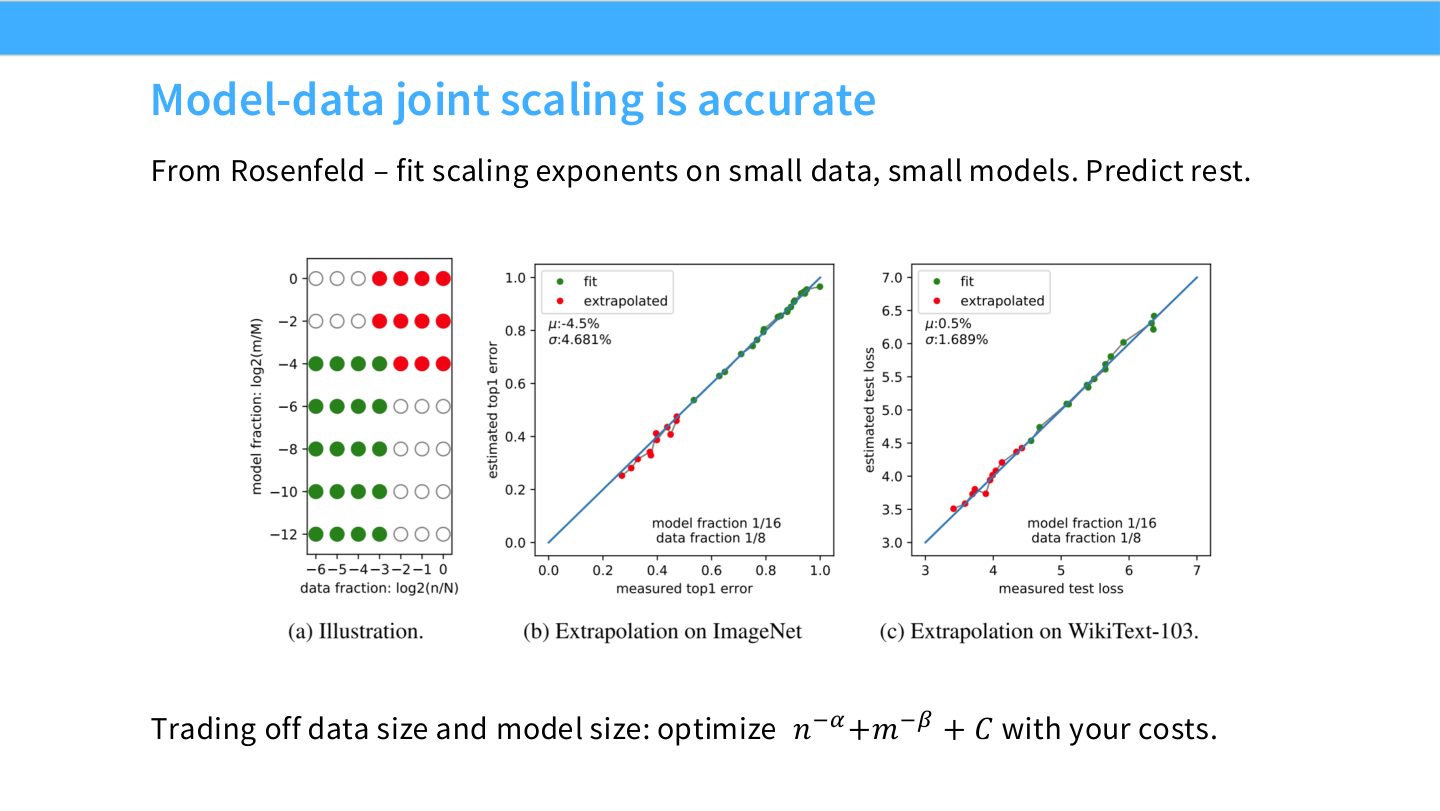
读图:Slide 44 的 trade-off 曲面
把 data size 和 model size 放到同一张图上,就能看到等 loss 或等 compute 的 trade-off。若模型太小,大量数据会被浪费;若数据太少,大模型会过拟合或欠训练。联合 scaling 的价值是找到预算下的平衡点。
def predict_loss(N, D, params):
A, alpha, B, beta, C = params
return A * N ** (-alpha) + B * D ** (-beta) + C
params = fit_least_squares(observed_runs)
best = argmin_over_budget(lambda N, D: predict_loss(N, D, params))
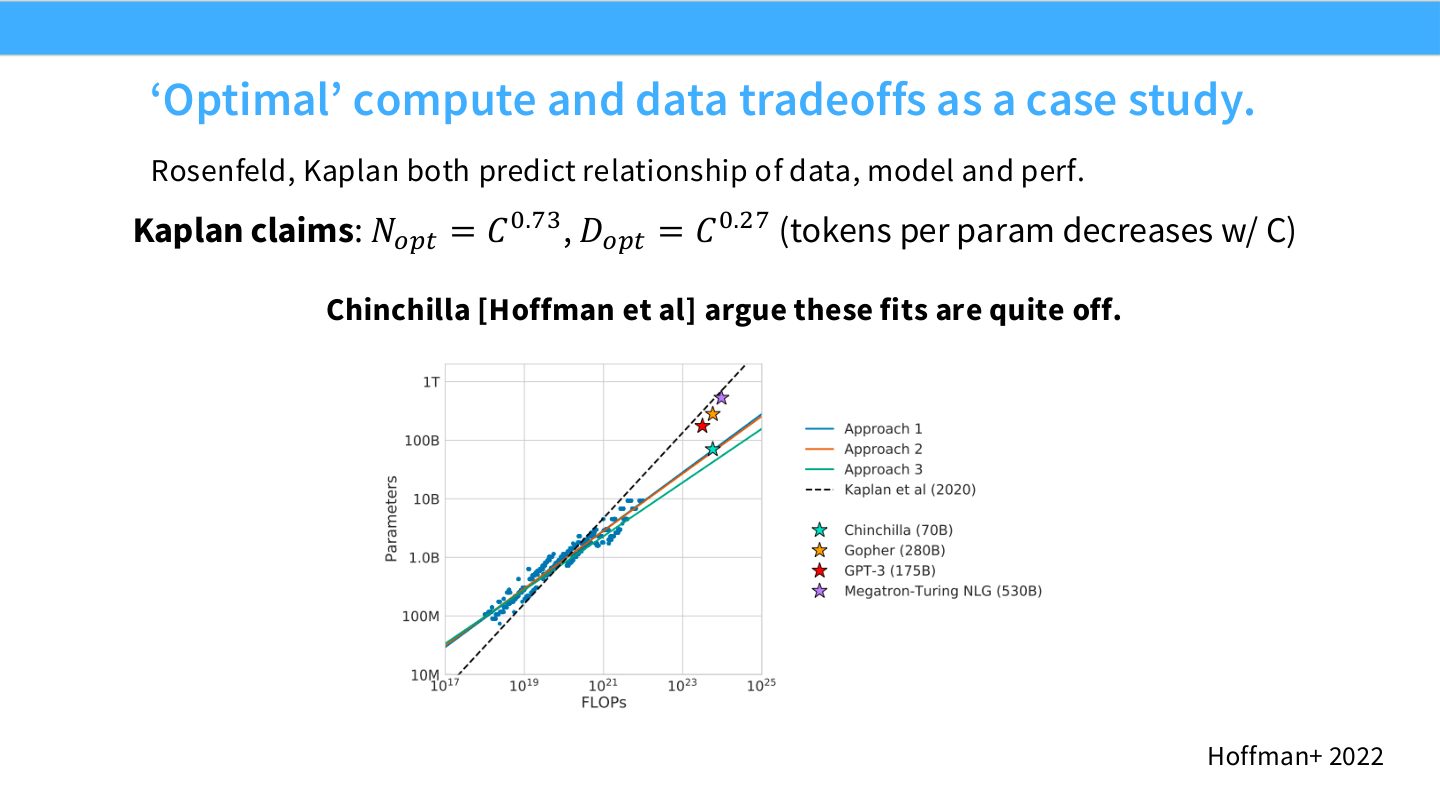
读图:Slide 45 的 Kaplan vs Chinchilla
Kaplan 结论中 \(N_{\text{opt}}\) 随 compute \(C\) 增长更快,\(D_{\text{opt}}\) 增长较慢,tokens per parameter 随 \(C\) 下降。Chinchilla 则认为大模型通常训练 token 不够,compute-optimal 应该用更小模型、更多数据。这个差异直接改变大模型训练预算分配。

读图:Slide 46 的方法地图
三种方法分别从训练曲线最小点、IsoFLOPS sweep、joint grid fit 估计 compute-optimal 关系。它们使用相同实验事实的不同投影,因此结果接近时更可信;结果分歧时要检查数据、参数计数和训练 recipe。
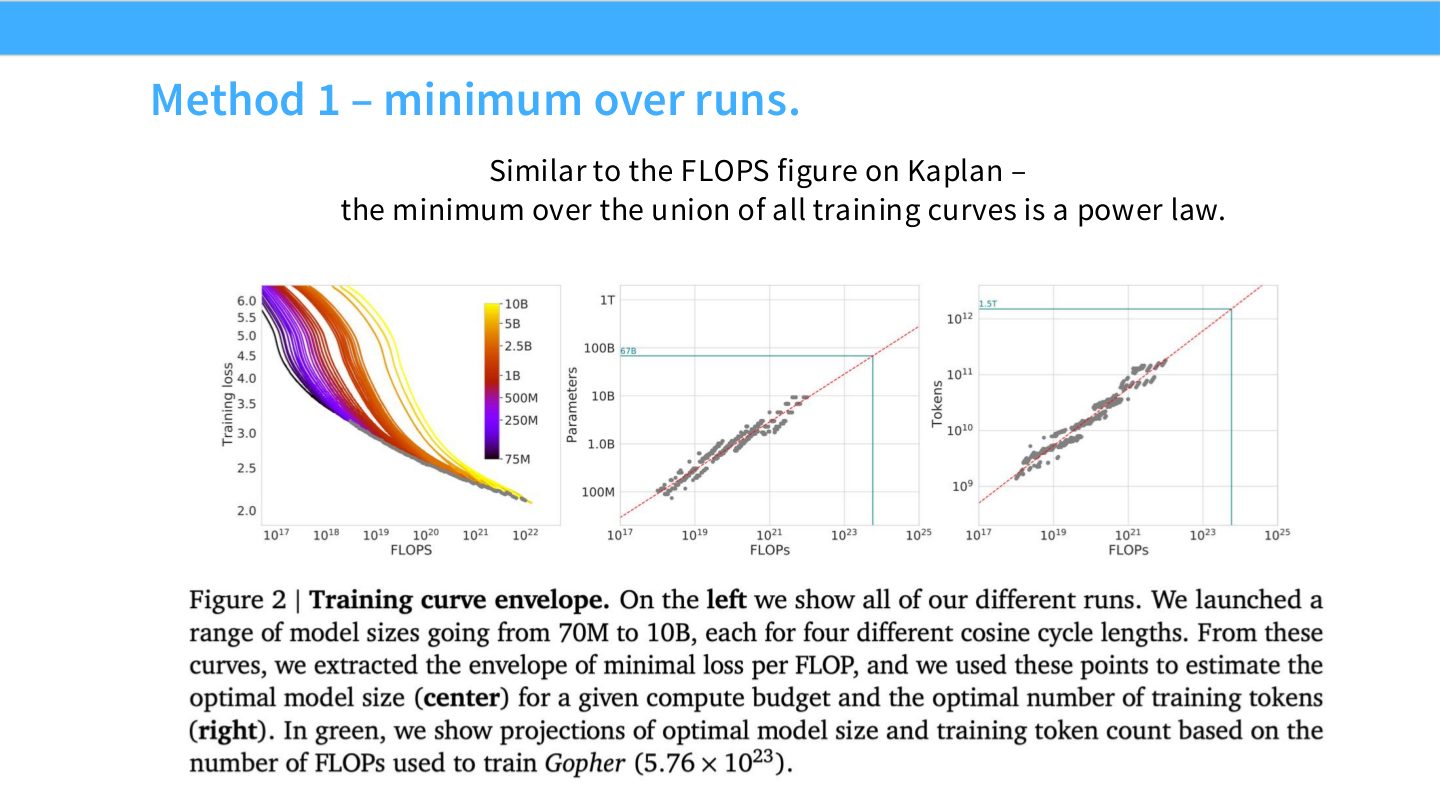
读图:Slide 47 的 minimum-over-runs
对每个 compute budget,看所有训练 run 中谁达到最低 loss。把这些 envelope minima 连起来,得到 compute vs loss 的 power law。优点是直观,缺点是依赖实验覆盖是否足够密集。
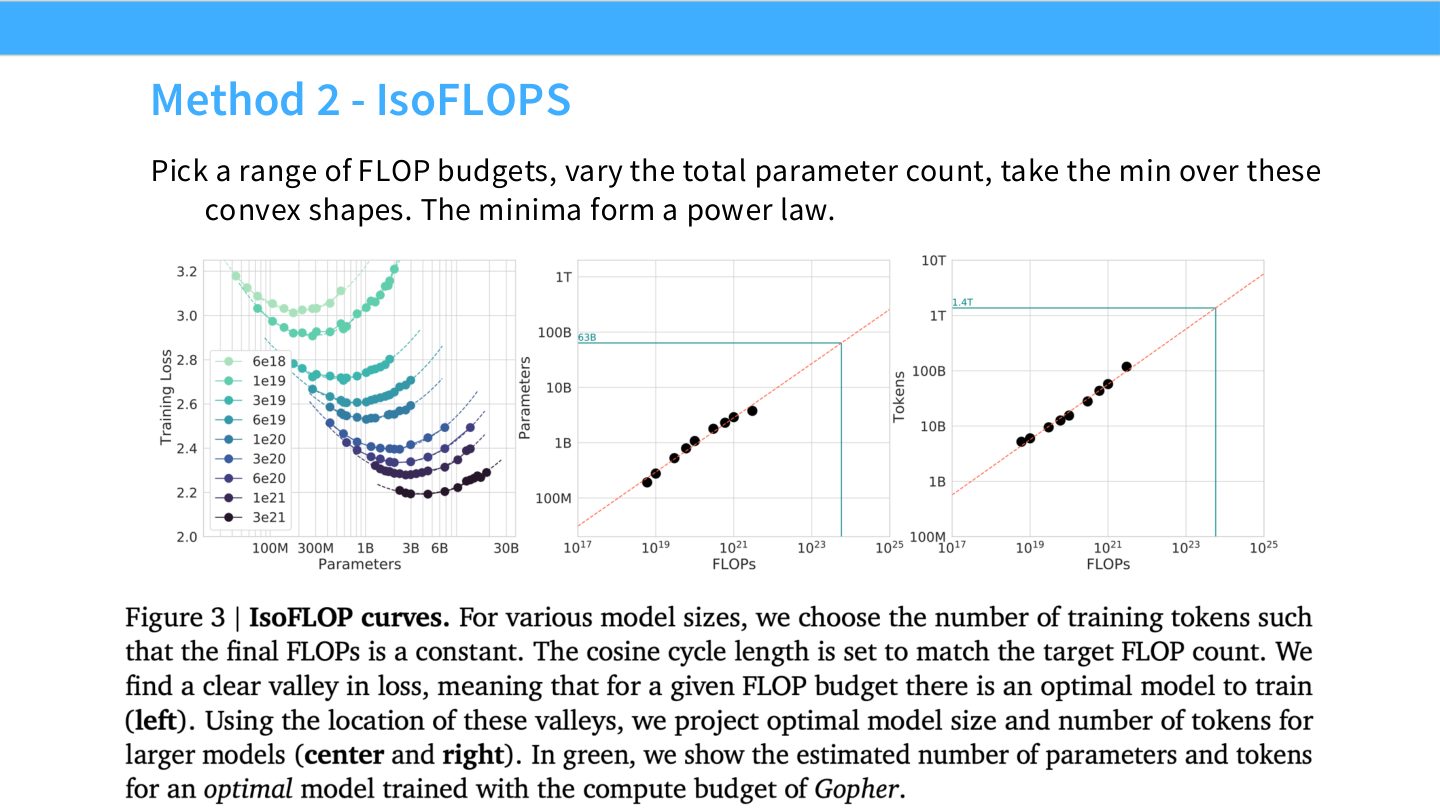
读图:Slide 48 的 IsoFLOPS
IsoFLOPS 固定训练计算量 \(C\),改变模型大小 \(N\) 和训练数据 \(D\)。每个 \(C\) 下 loss 对 \(N\) 往往呈 U 形或凸形:模型太小会欠容量,模型太大会欠训练。每条曲线的最小点给出该 compute 下的 \(N_{\text{opt}}\)。
for C in flops_budgets:
losses = []
for N in model_sizes:
D = C / (6 * N) # rough dense Transformer training FLOPs
losses.append(train_and_eval(N=N, tokens=D))
record_argmin(C, model_sizes, losses)
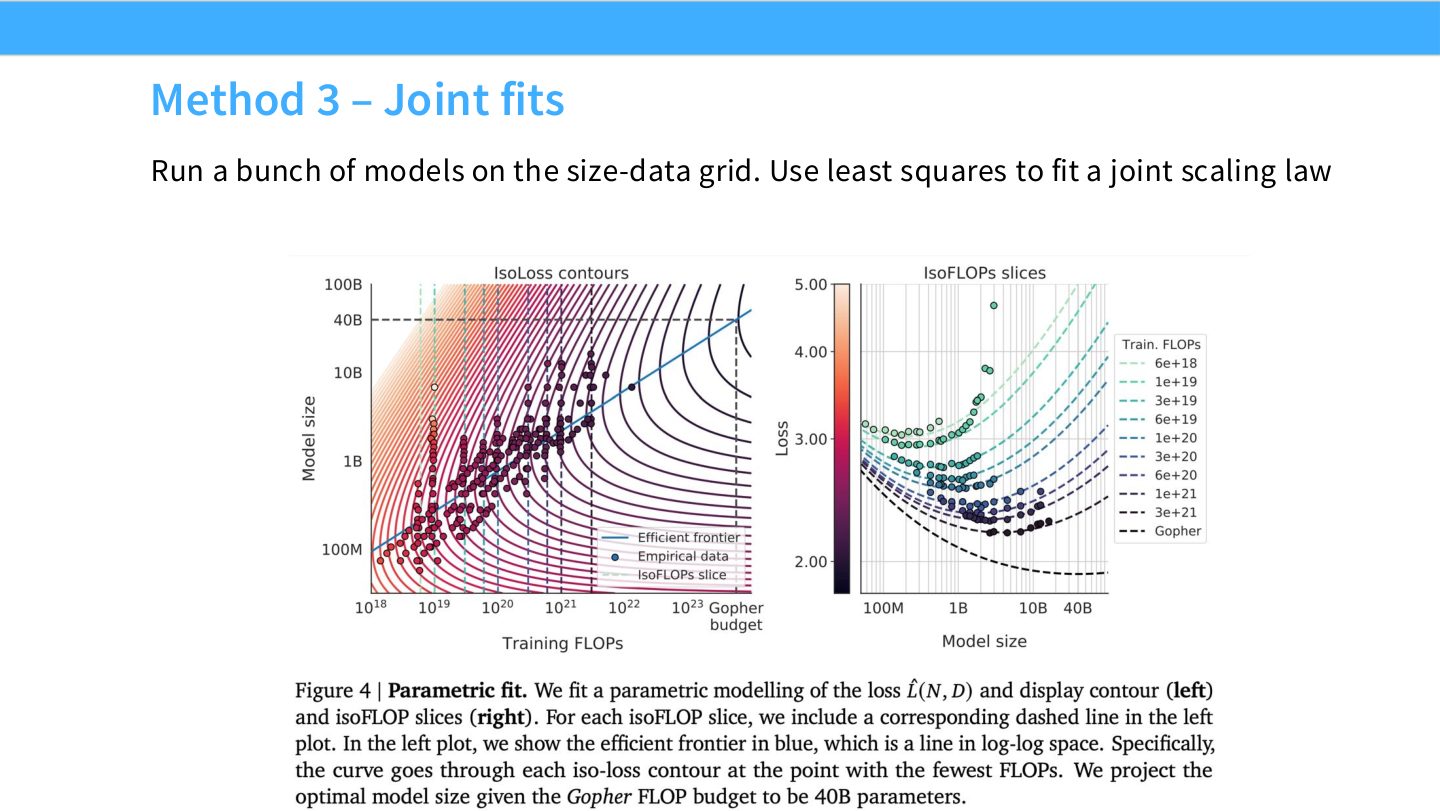
读图:Slide 49 的 joint fit
Joint fit 直接拟合 \(N,D\) 到 loss 的曲面。优点是利用所有点,能同时估计数据和模型 exponent;风险是函数形式、权重、异常点和数据覆盖会强烈影响结果。后面关于 Chinchilla method 3 的争议正与此有关。
Kaplan 与 Chinchilla 差异的解释
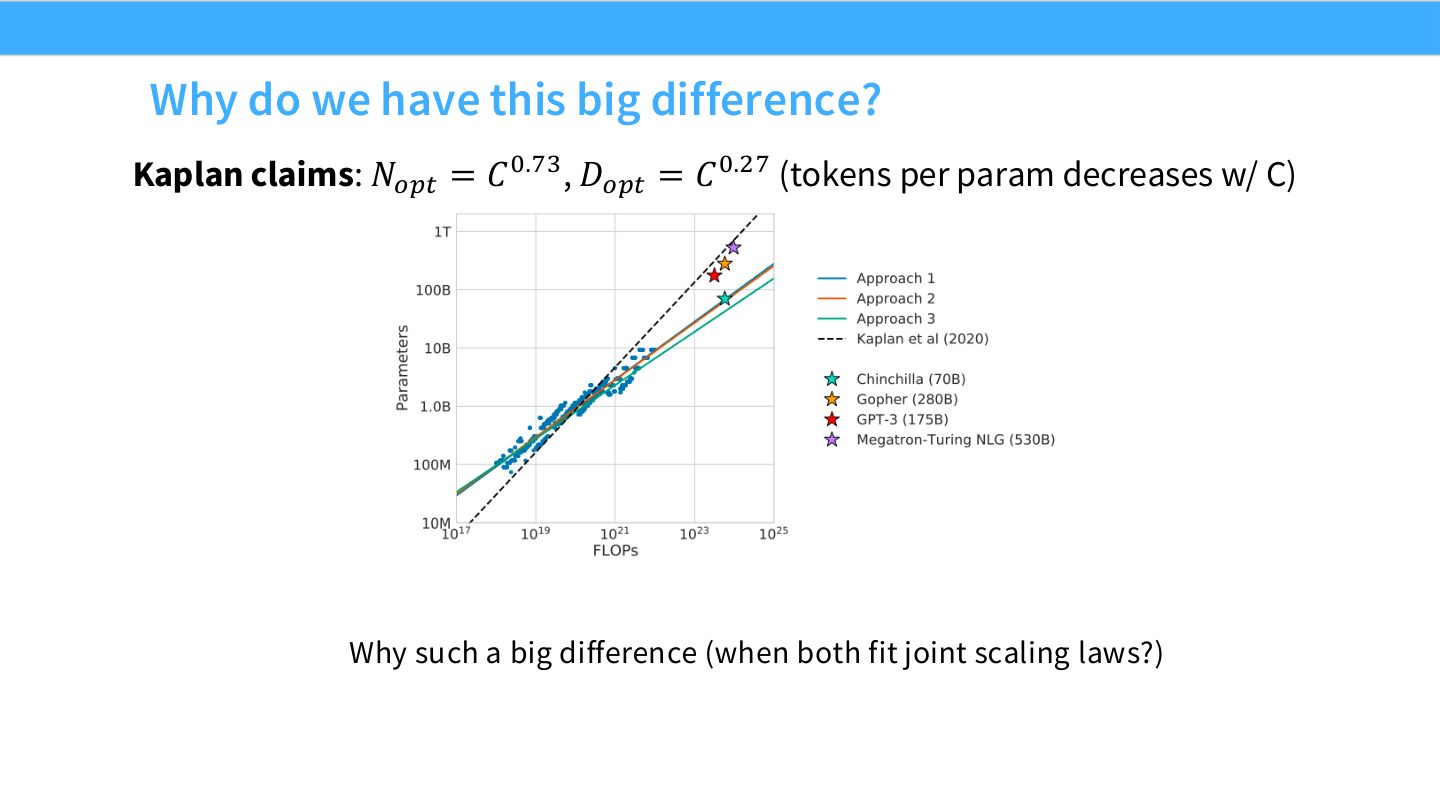
读图:Slide 50 的问题意识
当两个 scaling law 都看似拟合数据,却给出不同 compute-optimal recipe,真正要查的是实验设计:参数计数、学习率 schedule、warmup、数据范围、模型范围、拟合方法和训练稳定性。Scaling law 的可信度来自可解释的数据生成过程。
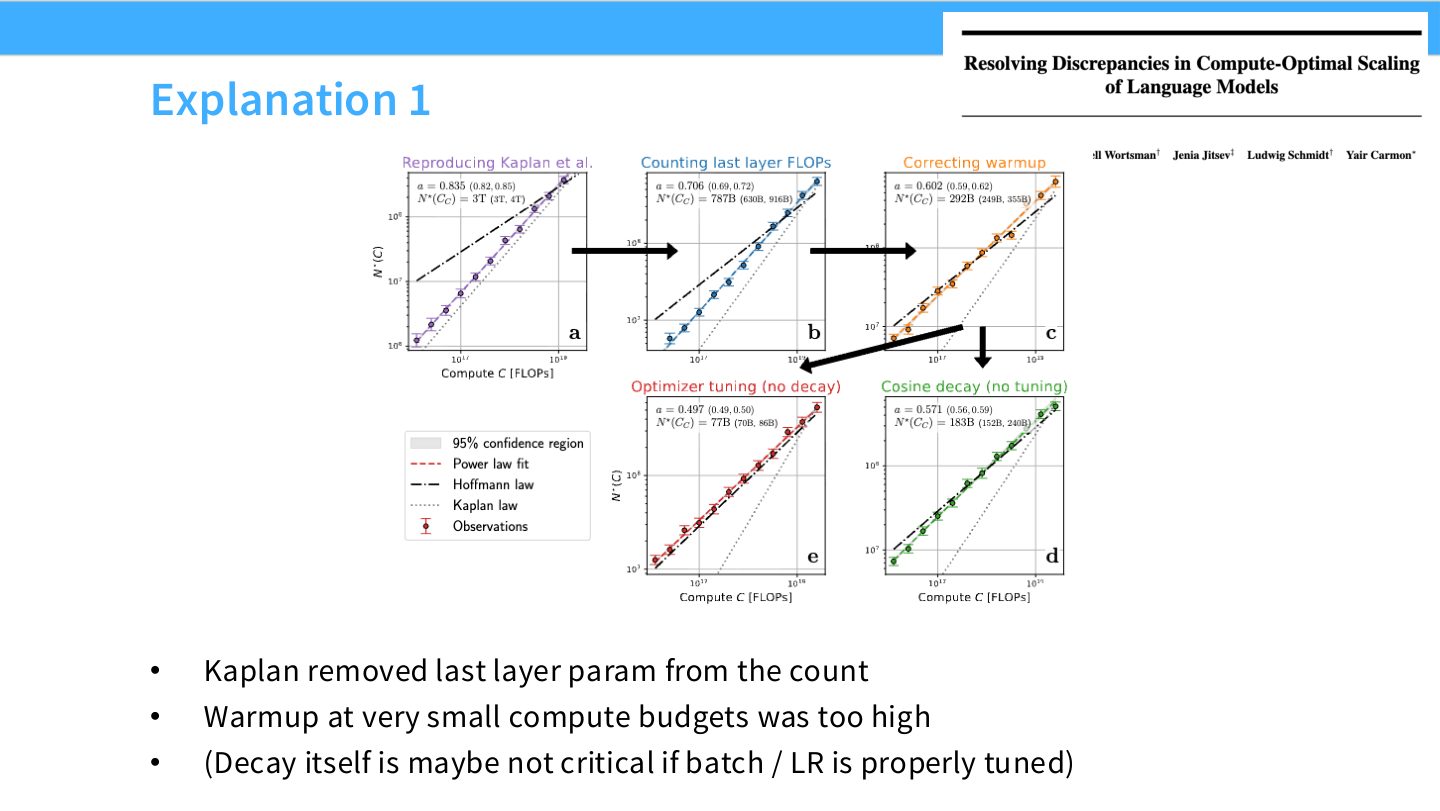
读图:Slide 51 的参数和 warmup 细节
参数计数是否包含 embedding/最后层会改变 \(N\);小 compute budget 下 warmup 比例过高会让训练效率失真。Scaling law 拟合对这些 seemingly boring 的工程细节很敏感,因为它们改变了曲线低规模区域。
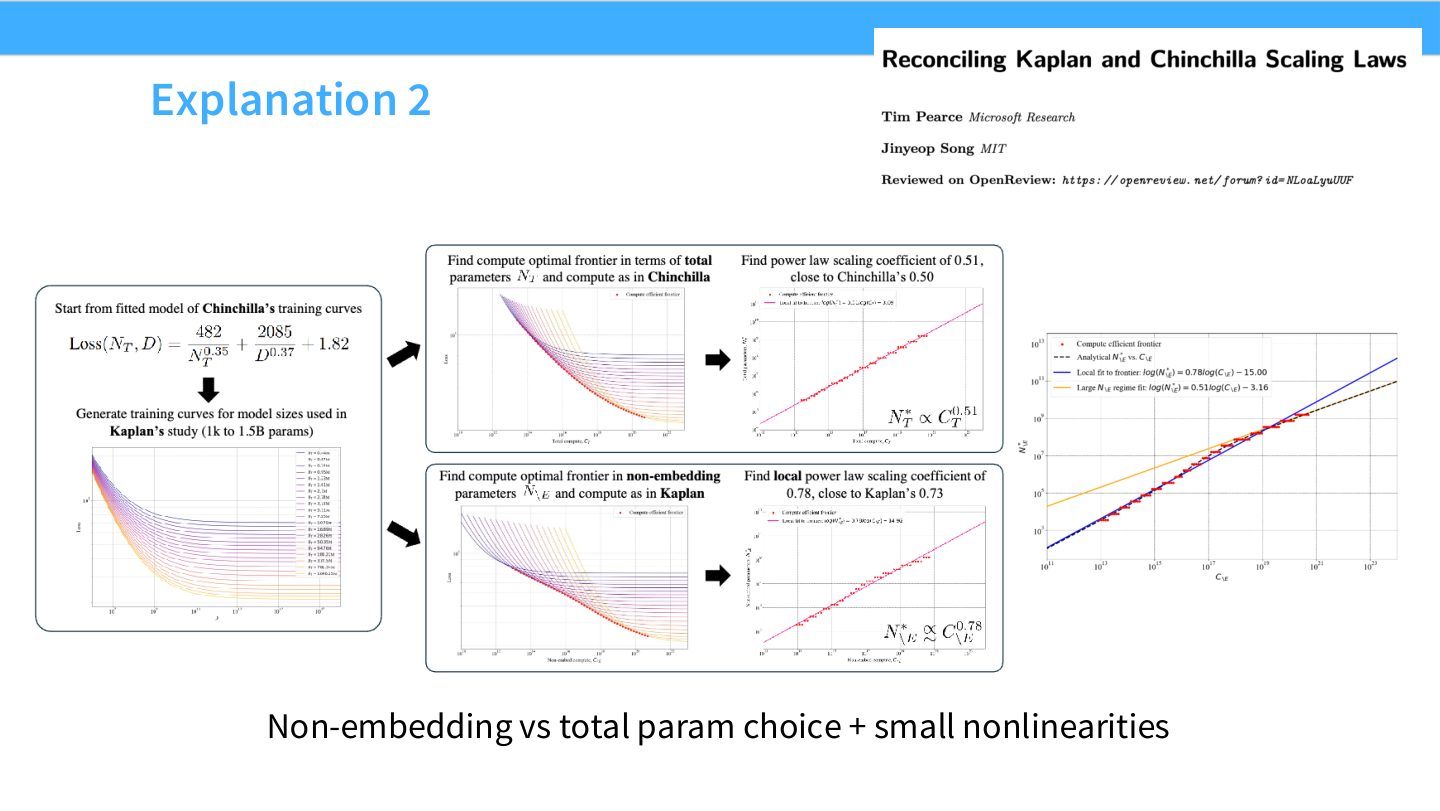
读图:Slide 52 的计数口径风险
同一个模型可以按 total params、non-embedding params、active params、训练 FLOPs 等多种口径记录。口径不一致会让 scaling exponent 不能比较。做实验时必须把参数计数、token 计数、FLOPs 估算和 loss 计算写清楚。
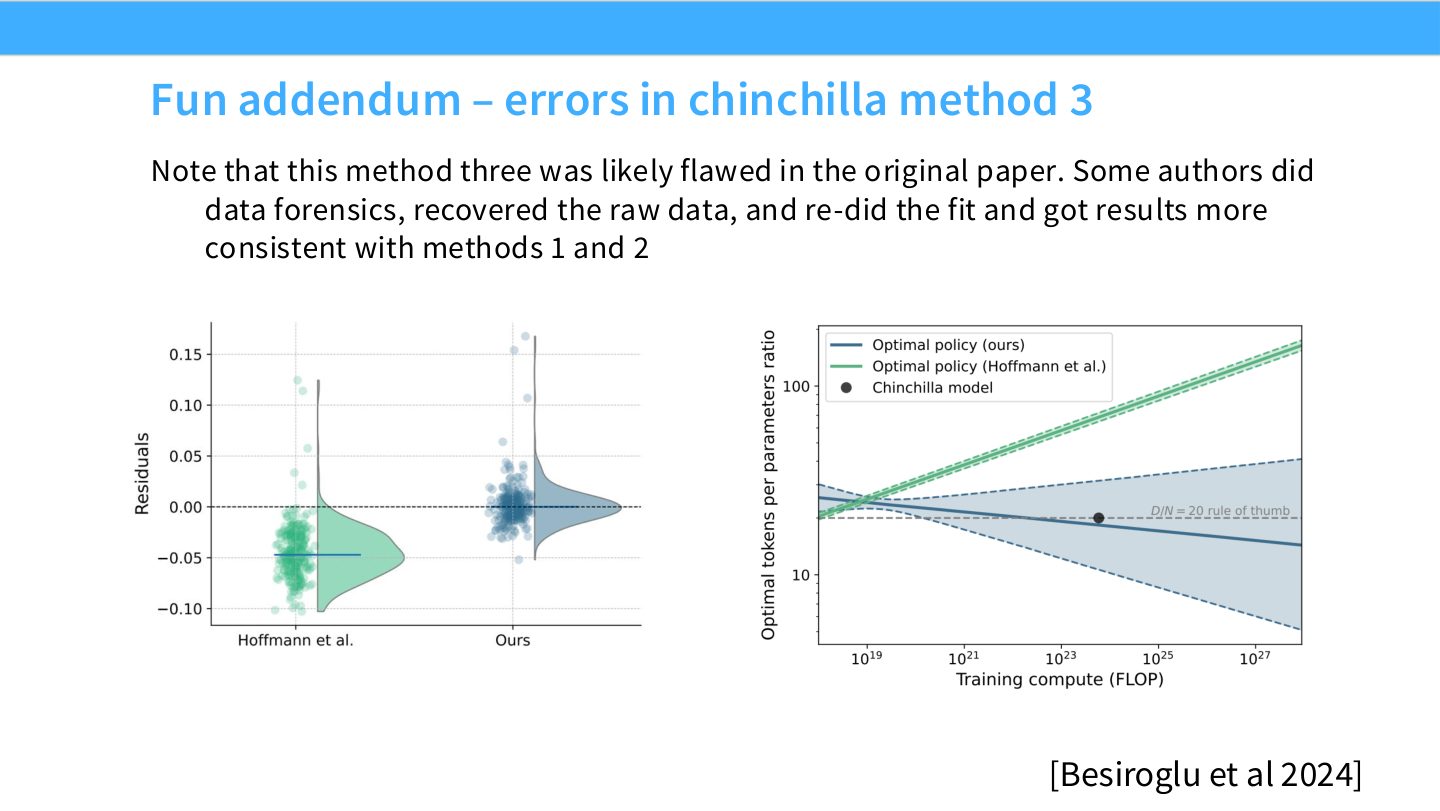
读图:Slide 53 的方法论教训
Scaling law 不是因为曲线漂亮就可靠。需要公开原始 run、拟合代码、过滤规则和参数口径。若一个方法的结论与其他方法冲突,要优先检查数据和拟合流程,而不是只引用最终 exponent。
train-optimal 与 deployment-optimal

读图:Slide 54 的 overtraining 经济学
Chinchilla 目标是固定训练 compute 下 loss 最优。但部署时,模型会被调用很多次,推理成本可能远超训练成本。更小模型训练更多 tokens(overtrain)可能训练上不是最优,但推理更便宜,总拥有成本更低。GPT-3、Llama 等例子都体现了这一点。
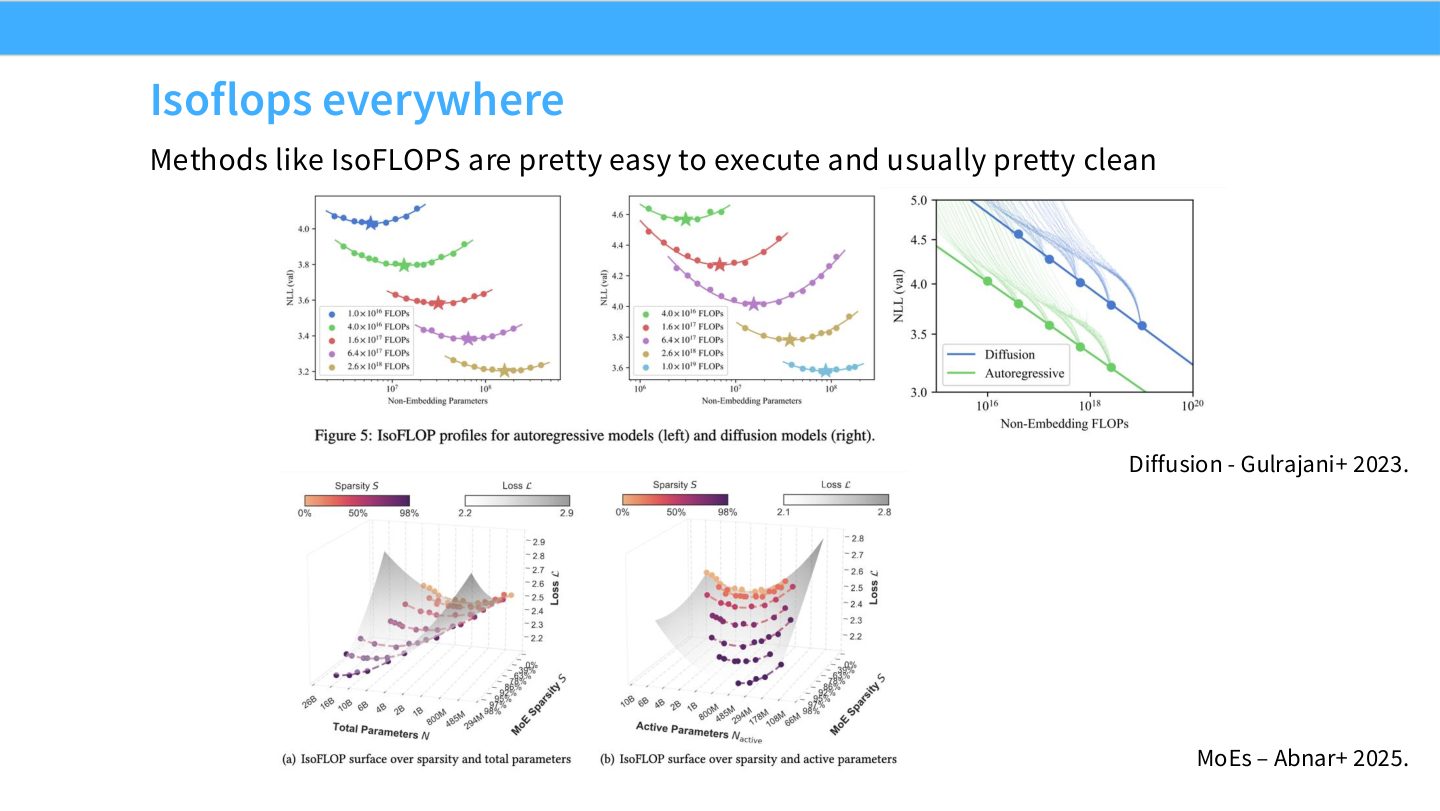
读图:Slide 55 的跨领域价值
IsoFLOPS 的核心是固定预算扫模型规模,找每个预算的最优点。这种实验设计不依赖语言模型特有结构,因此可扩展到 diffusion、MoE 等模型族。它是一种通用资源分配实验,而不只是 Chinchilla 论文技巧。
读图:Slide 56 的工程总结
Scaling laws 的最大价值是把昂贵训练决策前置:先在小规模比较 optimizer、architecture、model sizes,再用曲线做资源 trade-off。它不能保证万无一失,但能显著减少盲目训练巨型模型的风险。

读图:Slide 57 的最终信息
Scaling laws 帮我们理解数据如何影响模型,显著降低模型工程成本,并预测哪些问题可以靠 scale brute force。它们最适合用于资源分配、设计筛选和风险控制;最不适合被当成脱离数据质量、优化细节和部署成本的“万能定律”。
本章小结
Joint scaling 把模型大小、数据量和 compute 放进同一张账本。Kaplan、Chinchilla 和 IsoFLOPS 的核心差异不是谁更“有名”,而是拟合方法、参数口径和目标函数不同。工程上还要区分 train-optimal 与 deployment-optimal。
总结与延伸
Lecture 9 给出的不是一个公式,而是一套训练前预测方法。先从历史和数据 scaling 建立 power-law 直觉,再用模型工程 scaling 比较架构、优化器和超参数,最后用联合 data-model scaling 决定 compute、parameter、token 的分配。它把大模型训练从“大赌注”变成一组可审计的小实验和外推。
最终 takeaways
- Scaling law 常见形式是 \(L(x)=A x^{-\alpha}+C\),在 log-log 图上近似直线。
- 数据 scaling 的 slope 反映继续加数据的边际收益,offset 常受数据 mixture 和分布影响。
- 小模型 scaling 实验可以预测架构、optimizer、depth/width、batch size 和 learning rate 的大规模趋势,但必须控制变量。
- Critical batch size 随目标 loss 变化,batch 不是越大越好。
- muP 的价值是让小模型超参数更可靠迁移到大模型。
- Joint scaling law 决定更多数据还是更大模型;Chinchilla 改变了 compute-optimal 训练的直觉。
- Train-optimal 不等于 deployment-optimal,推理成本会推动 overtraining。
拓展阅读
- Kaplan et al. 2020, Scaling Laws for Neural Language Models.
- Hoffmann et al. 2022, Training Compute-Optimal Large Language Models.
- Hestness et al. 2017, Deep Learning Scaling is Predictable.
- Rosenfeld et al. 2020, A Constructive Prediction of the Generalization Error Across Scales.
- Yang et al. on muP / maximal update parameterization.