CS231N Lecture 8: Attention and Transformers
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Justin Johnson 授课内容整理 |
| 来源 | Stanford University |
| 日期 | 2025 |

引言:从 RNN 到 Transformer
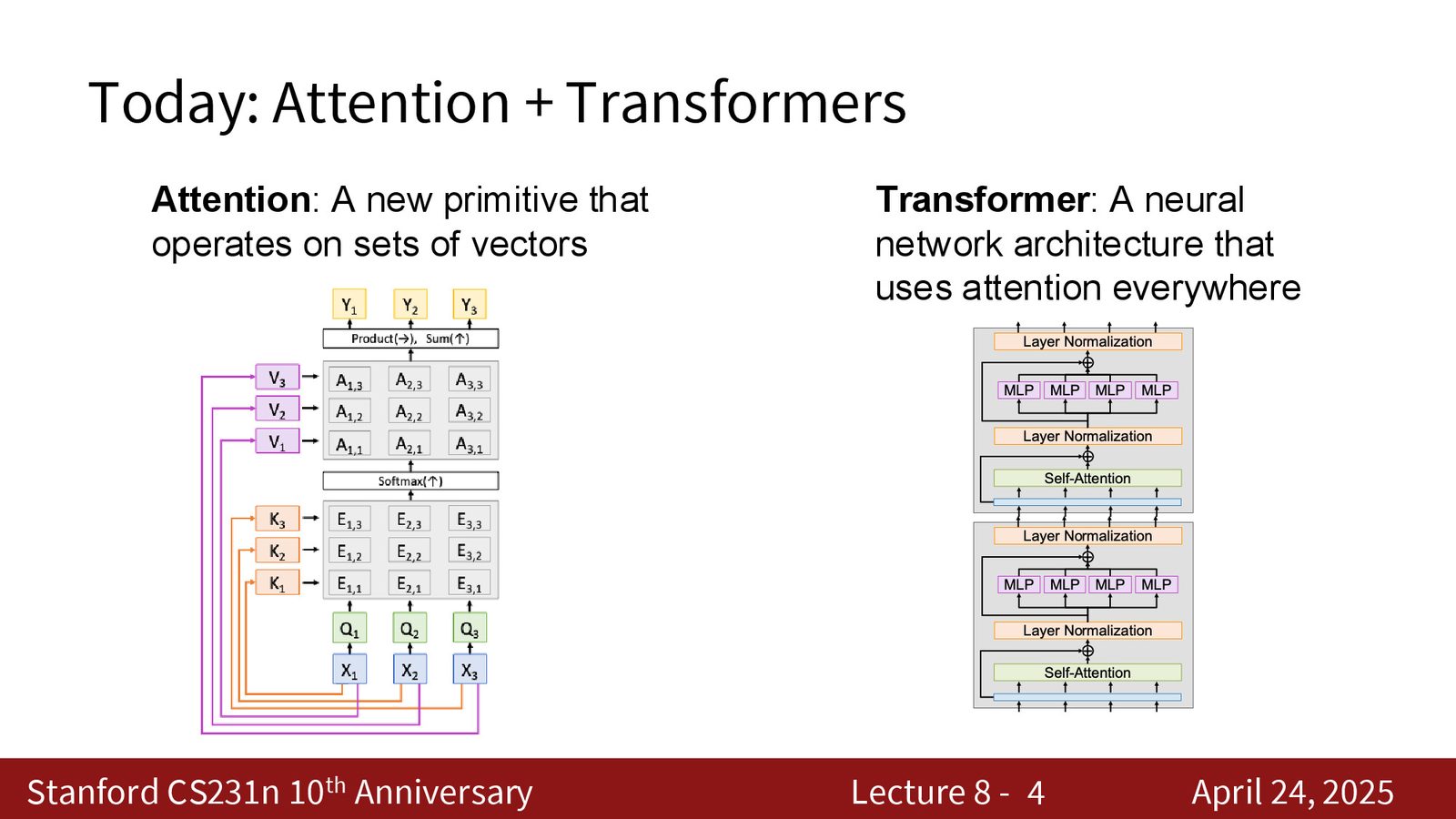
本讲将介绍深度学习中最重要的两个概念:注意力机制(Attention)和Transformer 架构。Attention 是一种全新的神经网络计算原语,本质上操作于向量集合之上;Transformer 则是以 self-attention 为核心的神经网络架构。
Transformer 的统治地位
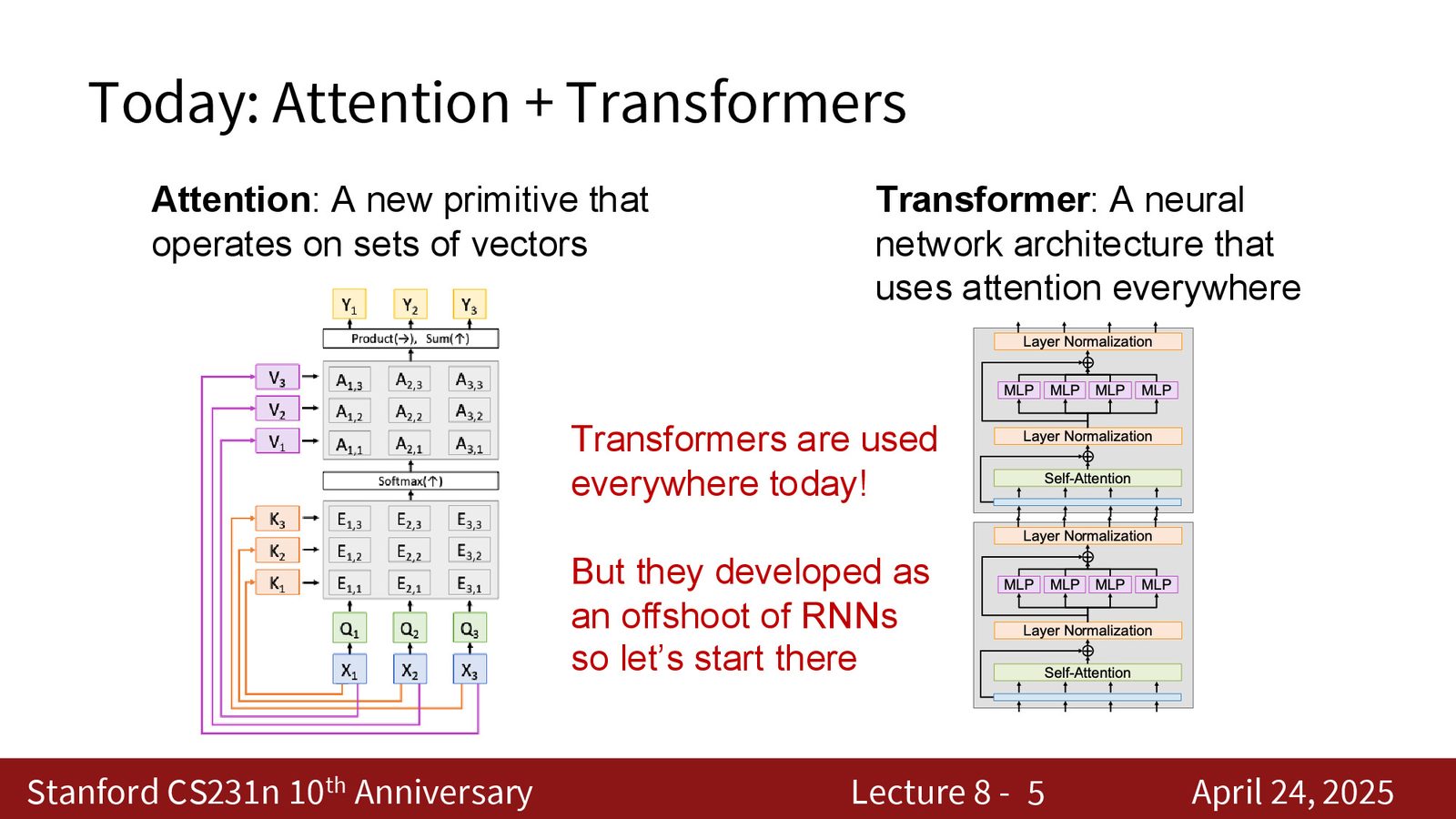
今天几乎所有大规模的深度学习应用——图像分类、图像生成、文本生成、文本分类、音频处理——都在使用 Transformer 架构。它自 2017 年提出以来,已经跨越了多个数量级的规模增长(从 2 亿参数到数万亿参数),且架构本身变化甚微。
尽管 Transformer 是现代深度学习的基石,但注意力机制的思想源于 RNN。我们将沿着历史脉络,从 RNN 的瓶颈问题出发,逐步推导出注意力机制和 Transformer 架构。

来源:Slides 第2页。
本章小结
注意力机制和 Transformer 是当代深度学习的核心。理解它们不仅需要掌握数学公式,更要理解其设计动机——如何克服 RNN 的固有局限。
序列到序列模型与瓶颈问题
Encoder-Decoder RNN 回顾
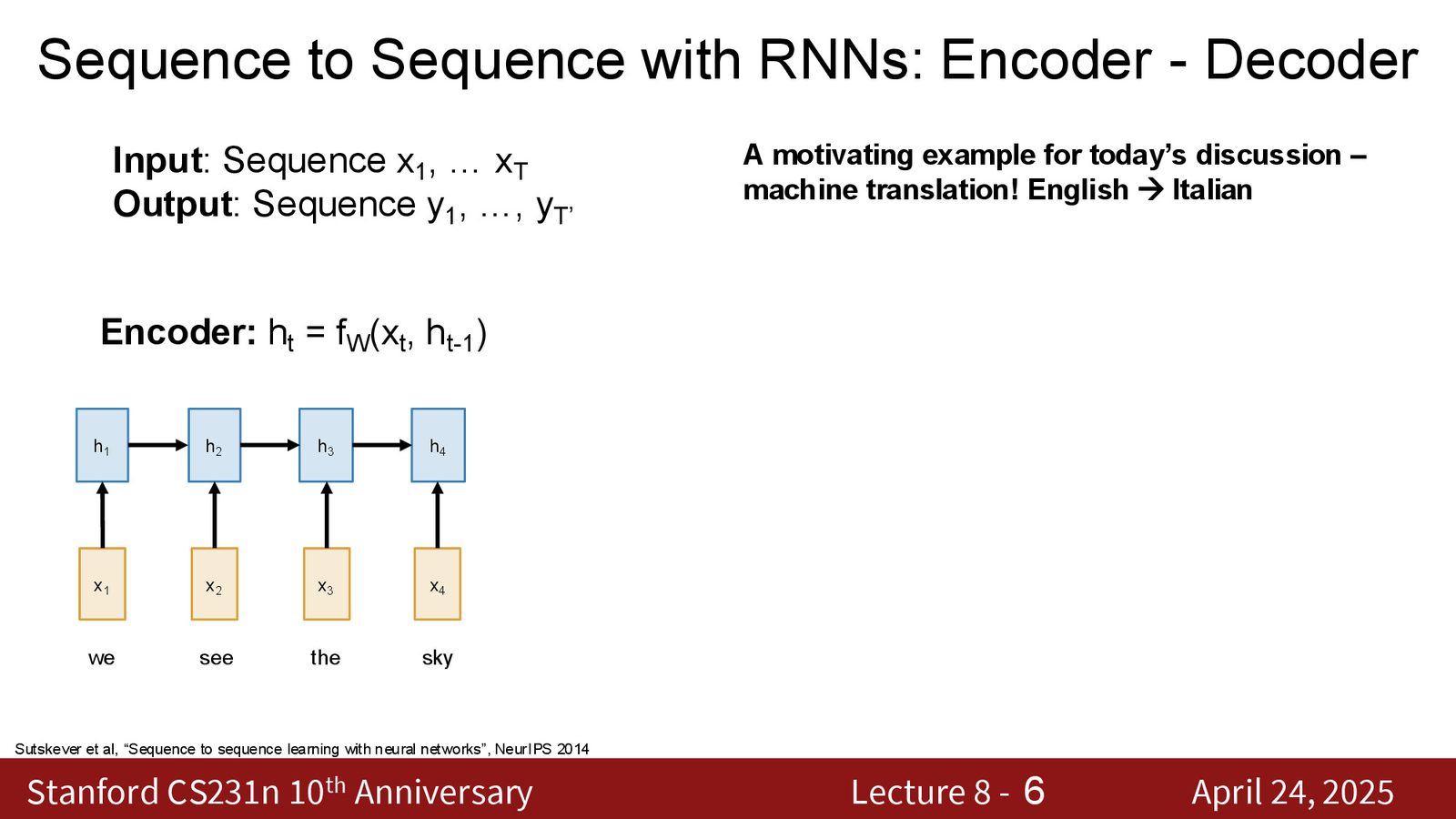
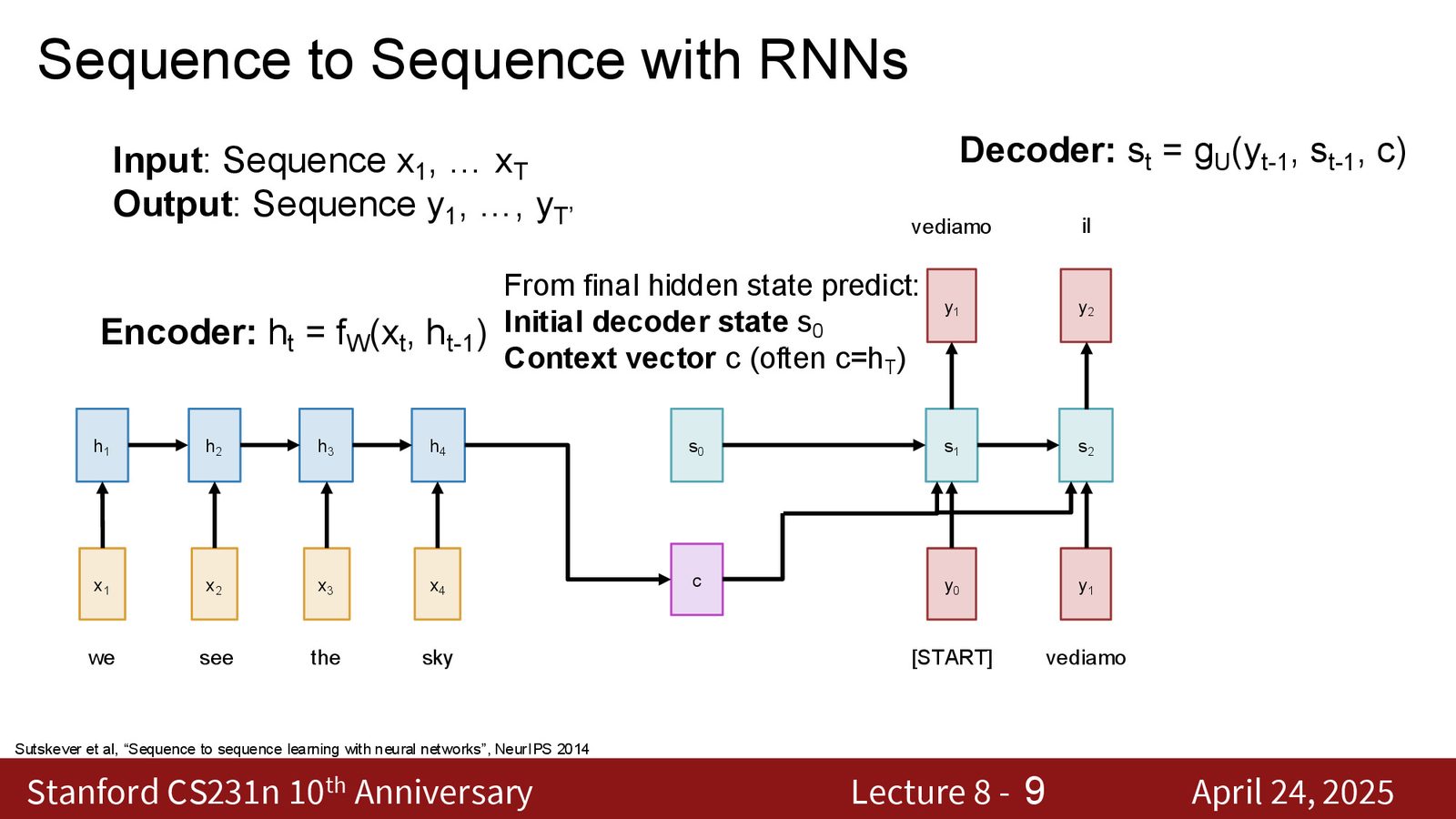
序列到序列(Seq2Seq)问题的经典架构是 Encoder-Decoder RNN:
来源:Slides 第4页。
- 编码器(Encoder):一个 RNN,逐词处理输入序列(如英文句子“we see the sky”),将整个输入压缩为最终隐藏状态
- 上下文向量(Context Vector)\(c\):编码器的最终隐藏状态,被视为整个输入序列的“摘要”
- 解码器(Decoder):另一个 RNN,以上下文向量 \(c\) 为初始输入,逐词生成输出序列(如意大利语翻译)
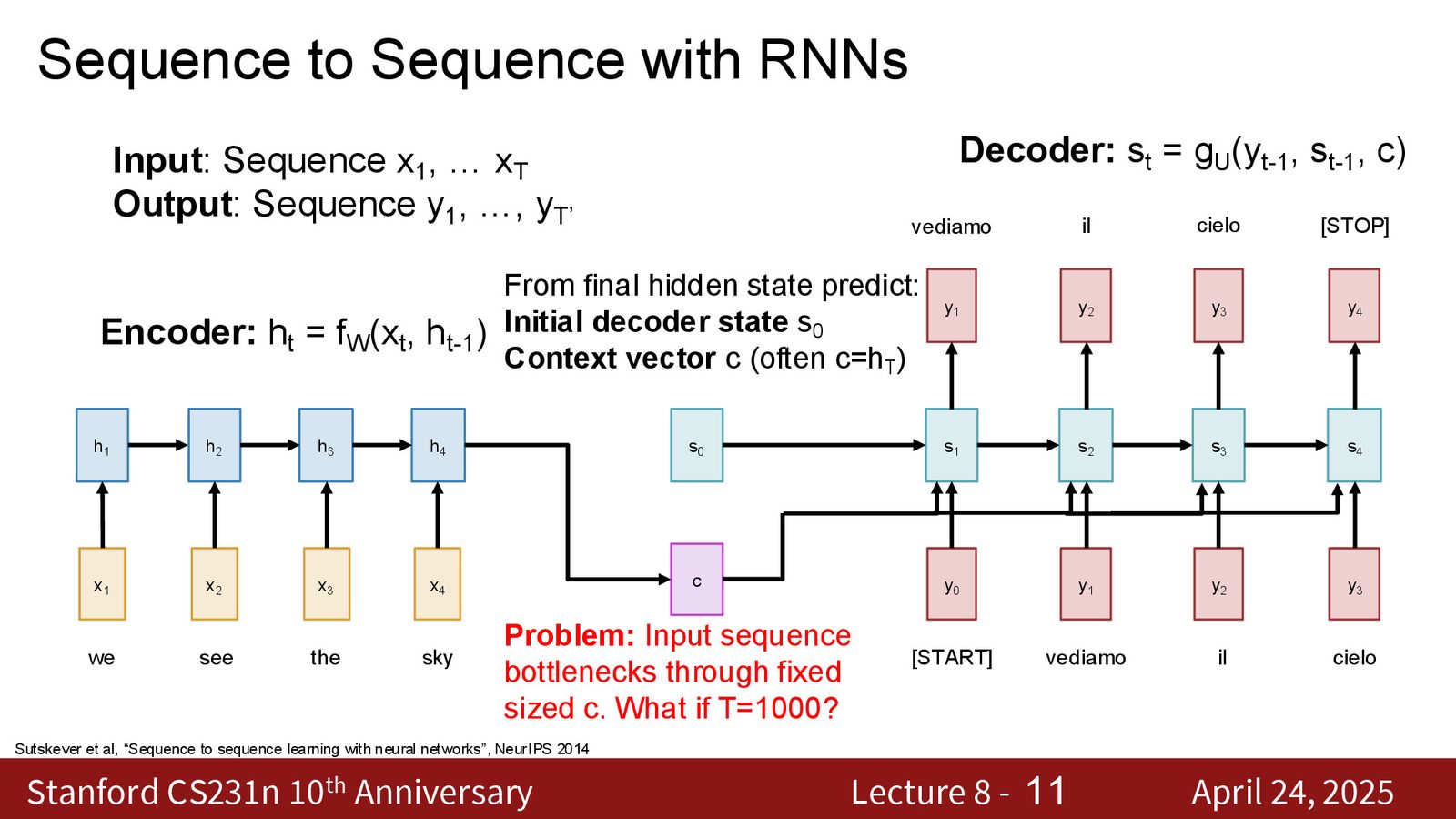
固定长度瓶颈
来源:Slides 第5页。
固定长度向量的信息瓶颈
问题的核心在于:输入序列和输出序列之间的唯一通信通道是上下文向量 \(c\)——一个固定维度的向量(如 128 或 1024 个浮点数)。
- 对于短句子(“we see the sky”),1024 维可能足够
- 对于长段落、整本书或海量语料,将所有信息压缩到 1024 个浮点数中显然不切实际
- 随着输入长度增加,信息损失会越来越严重
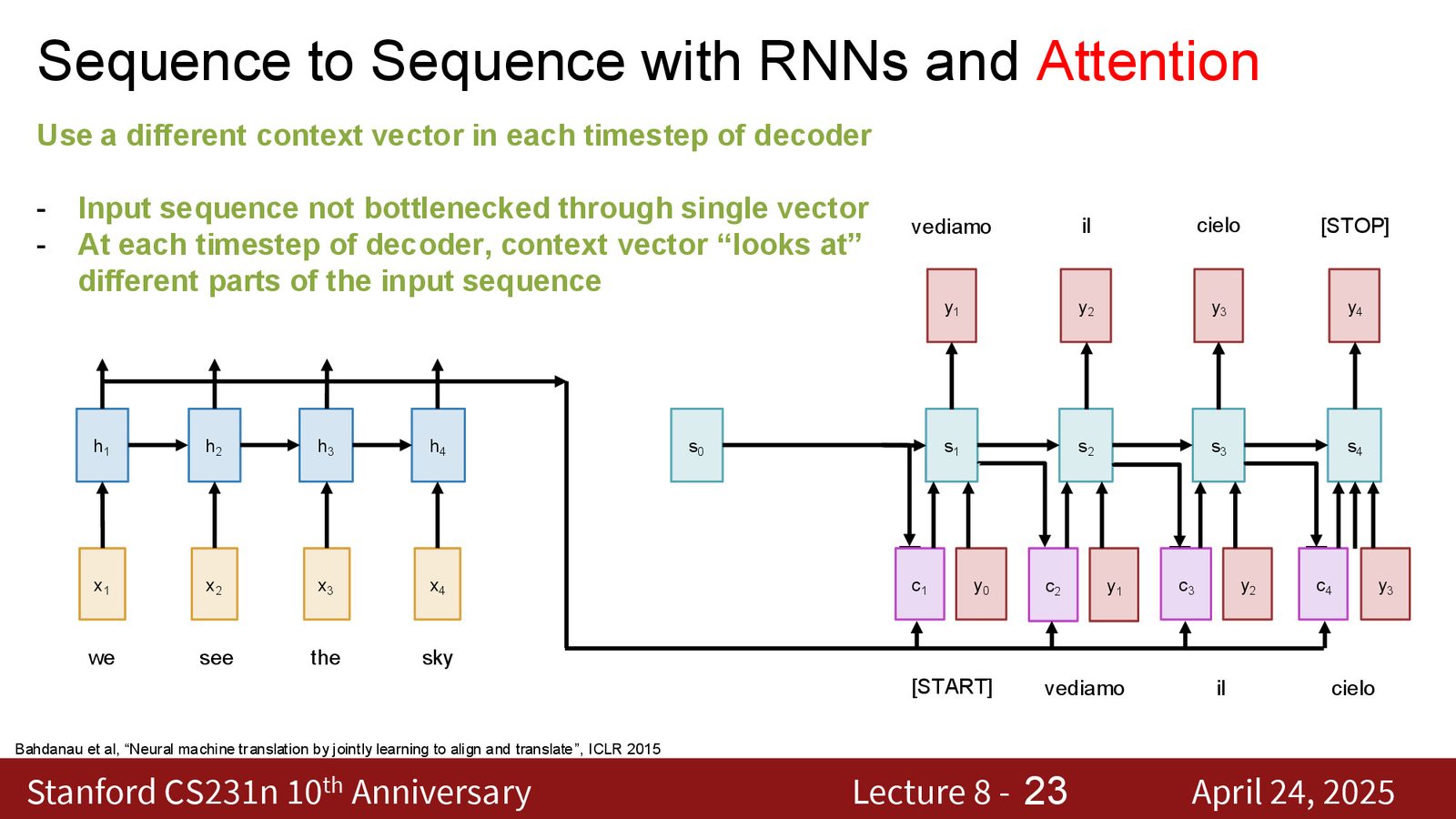
解决方案的直觉:不再强制网络将整个输入序列压缩为一个向量。取而代之,让解码器在生成每个输出 token 时,都有机会回头查看整个输入序列的不同部分——这就是注意力机制的核心思想。
本章小结
Encoder-Decoder RNN 中的固定长度上下文向量是一个严重的信息瓶颈。注意力机制的诞生正是为了消除这个瓶颈,让解码器能够在每个时间步动态地访问编码器的所有隐藏状态。
注意力机制:从 RNN 瓶颈到通用操作
注意力机制的基本流程
注意力机制对 Encoder-Decoder 架构的改进如下:
来源:Slides 第6页。
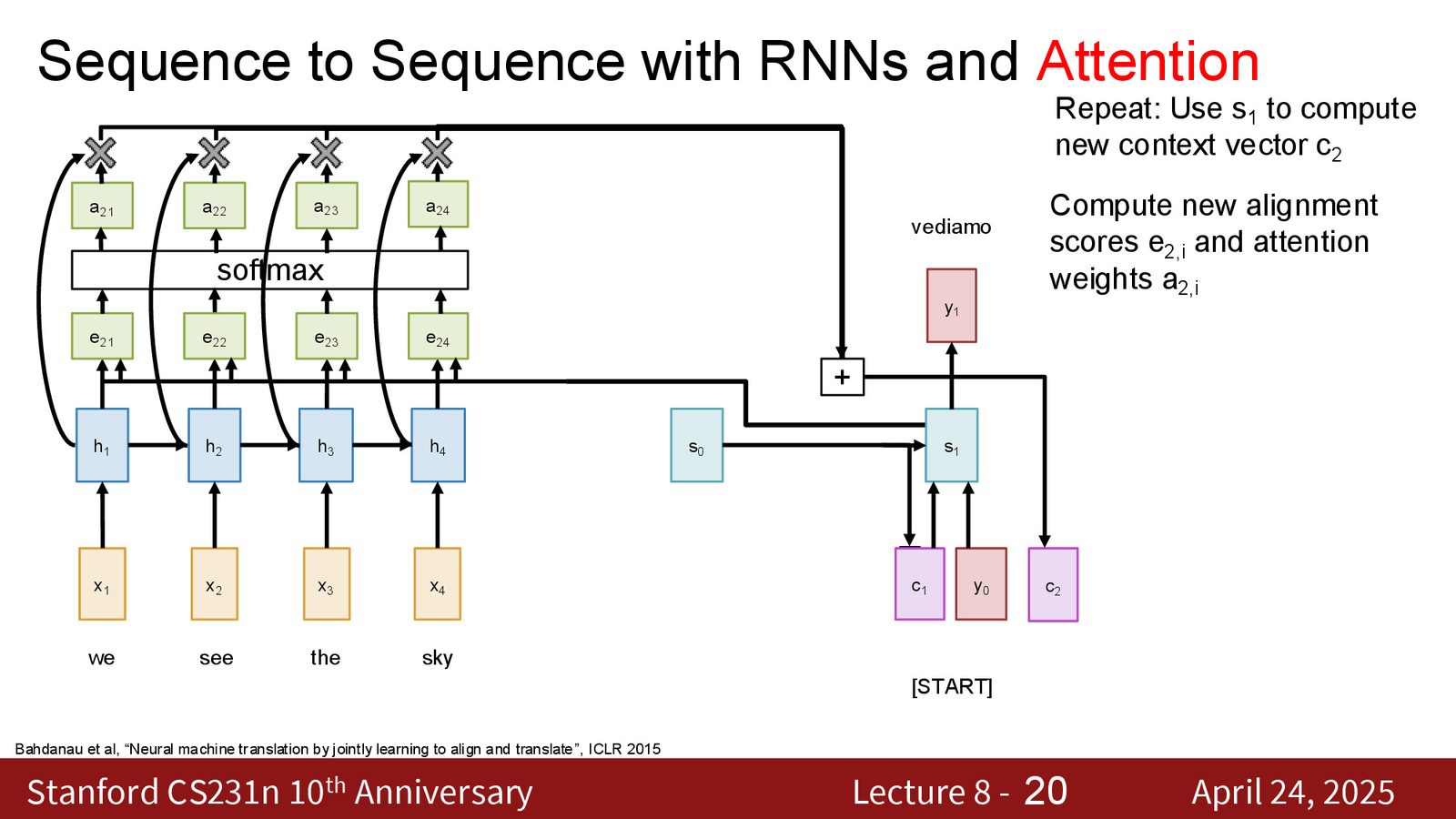
以解码器生成第一个输出词为例,完整流程:
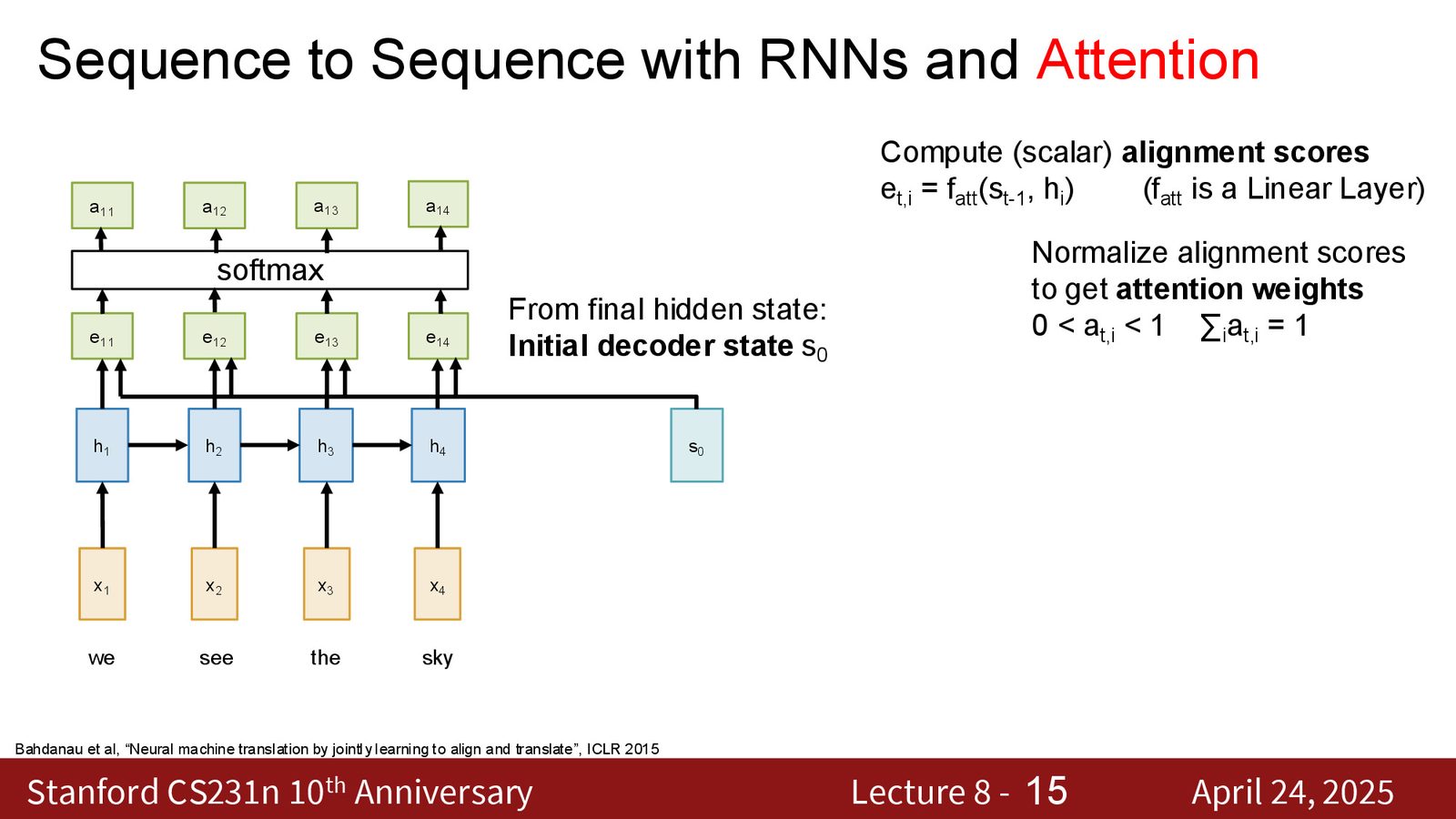
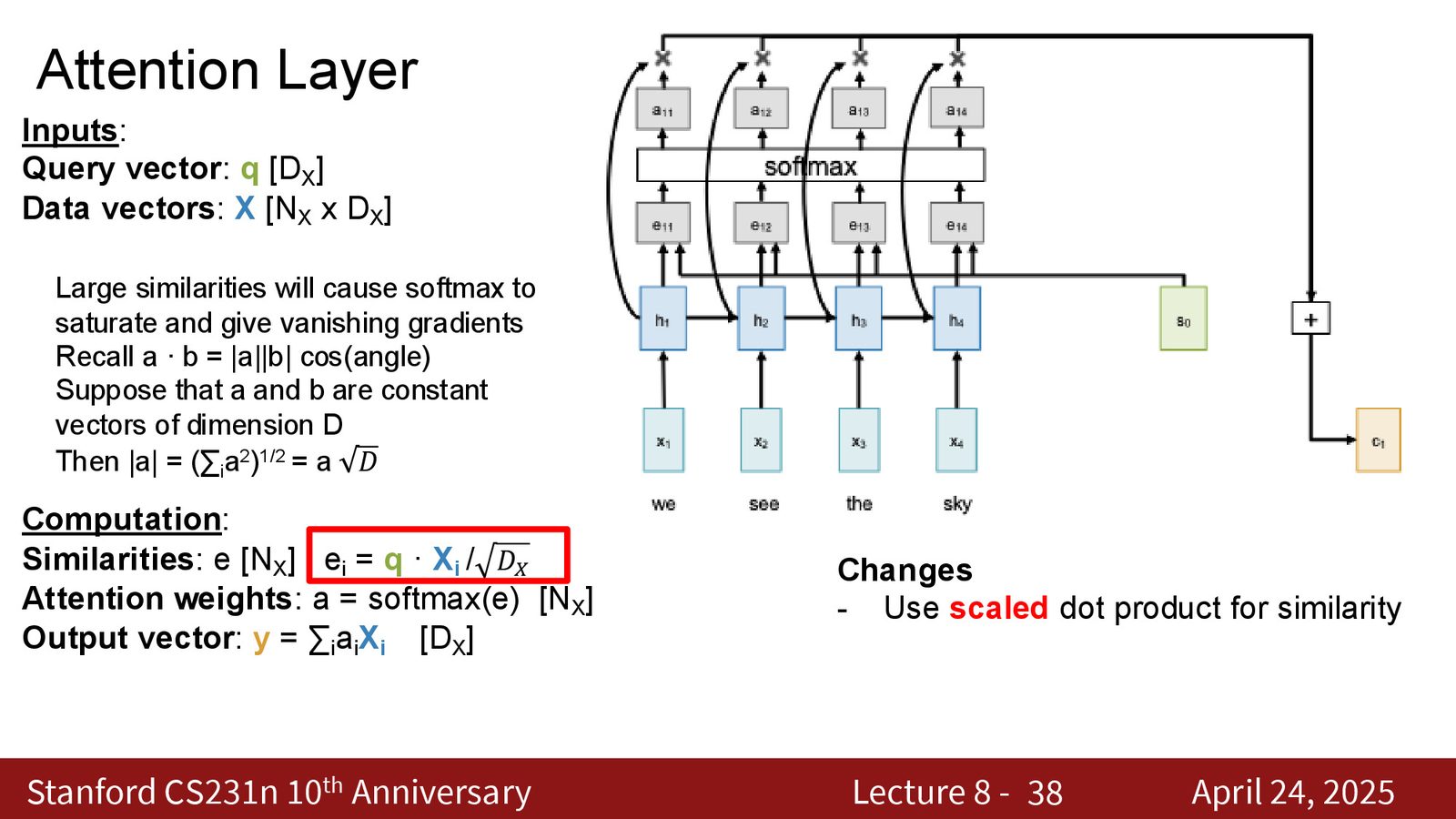
Step 1:计算对齐分数(Alignment Scores)
对于解码器的隐藏状态 \(s_0\) 和编码器的每个隐藏状态 \(h_i\),计算它们的“匹配程度”:
其中 \(f_{\text{att}}\) 是一个可学习的函数(最初使用的是一个线性层:将 \([s_0; h_i]\) 拼接后通过线性变换映射为标量)。
Step 2:Softmax 归一化
得到一个在所有输入 token 上的概率分布——这就是注意力权重。
来源:Slides 第9页。
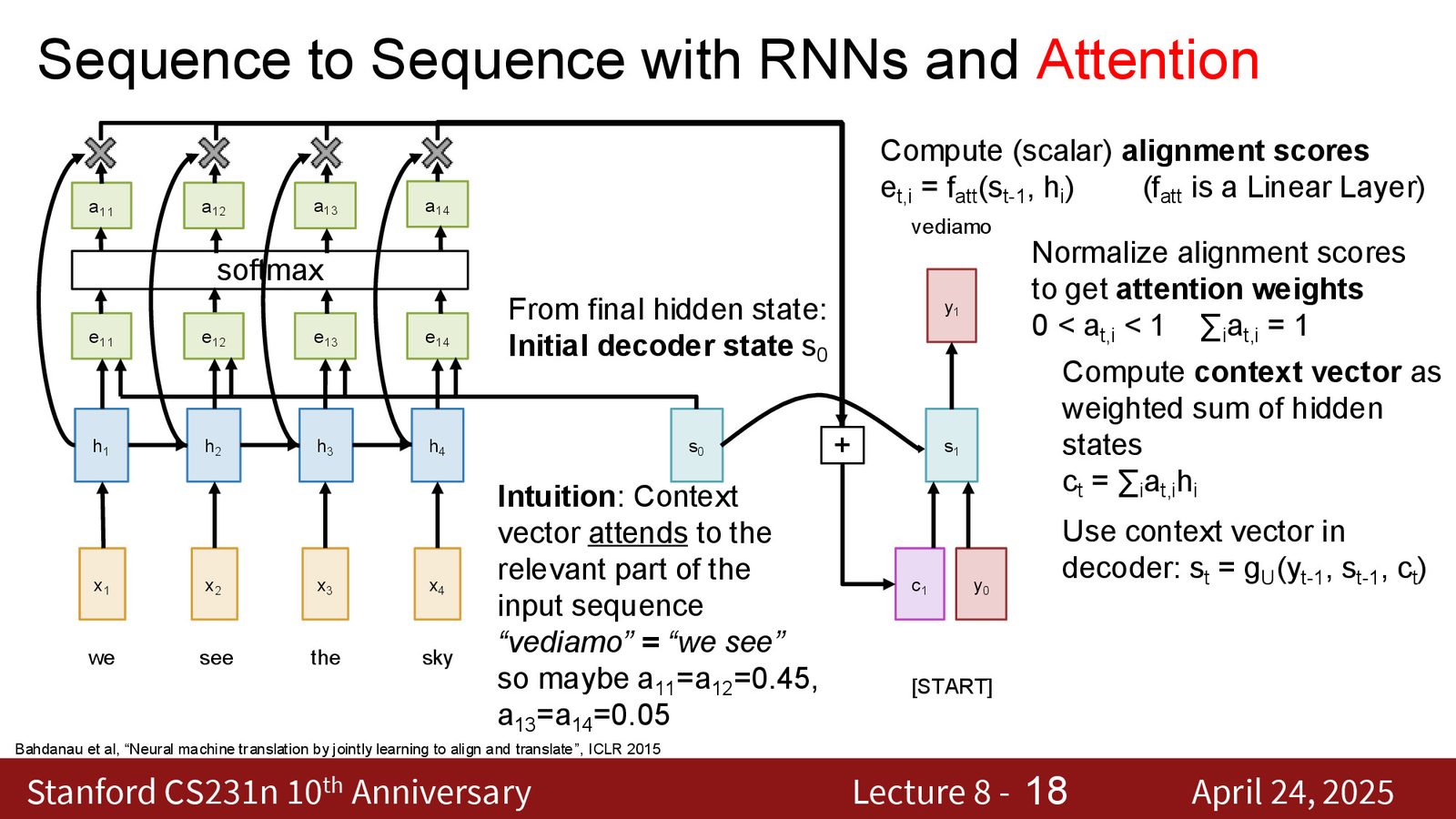
Step 3:加权求和
注意力权重加权的编码器隐藏状态的线性组合,产生上下文向量 \(c_1\)。
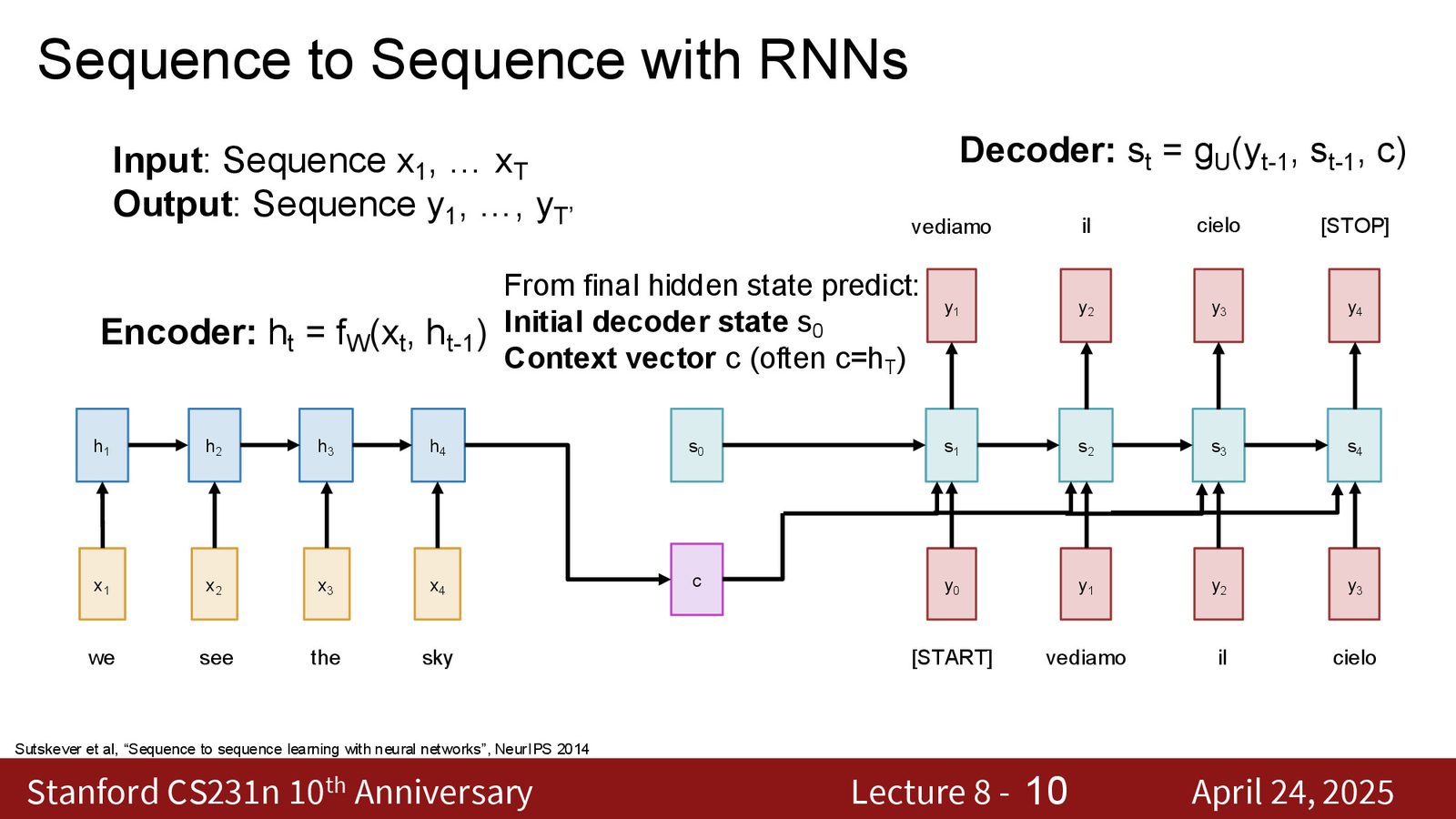
来源:Slides 第10页。
Step 4:生成输出
将上下文向量 \(c_1\) 与解码器的其他输入一起送入解码器 RNN,生成下一个隐藏状态和输出 token。
来源:Slides 第11页。
注意力机制的核心思想
- 不再通过单一向量传递所有信息
- 解码器在每个时间步都重新“审视”整个输入序列
- 每次生成不同的上下文向量——动态聚焦于输入中与当前输出最相关的部分
- 整个过程完全可微,注意力权重通过梯度下降端到端学习
注意力权重的可视化
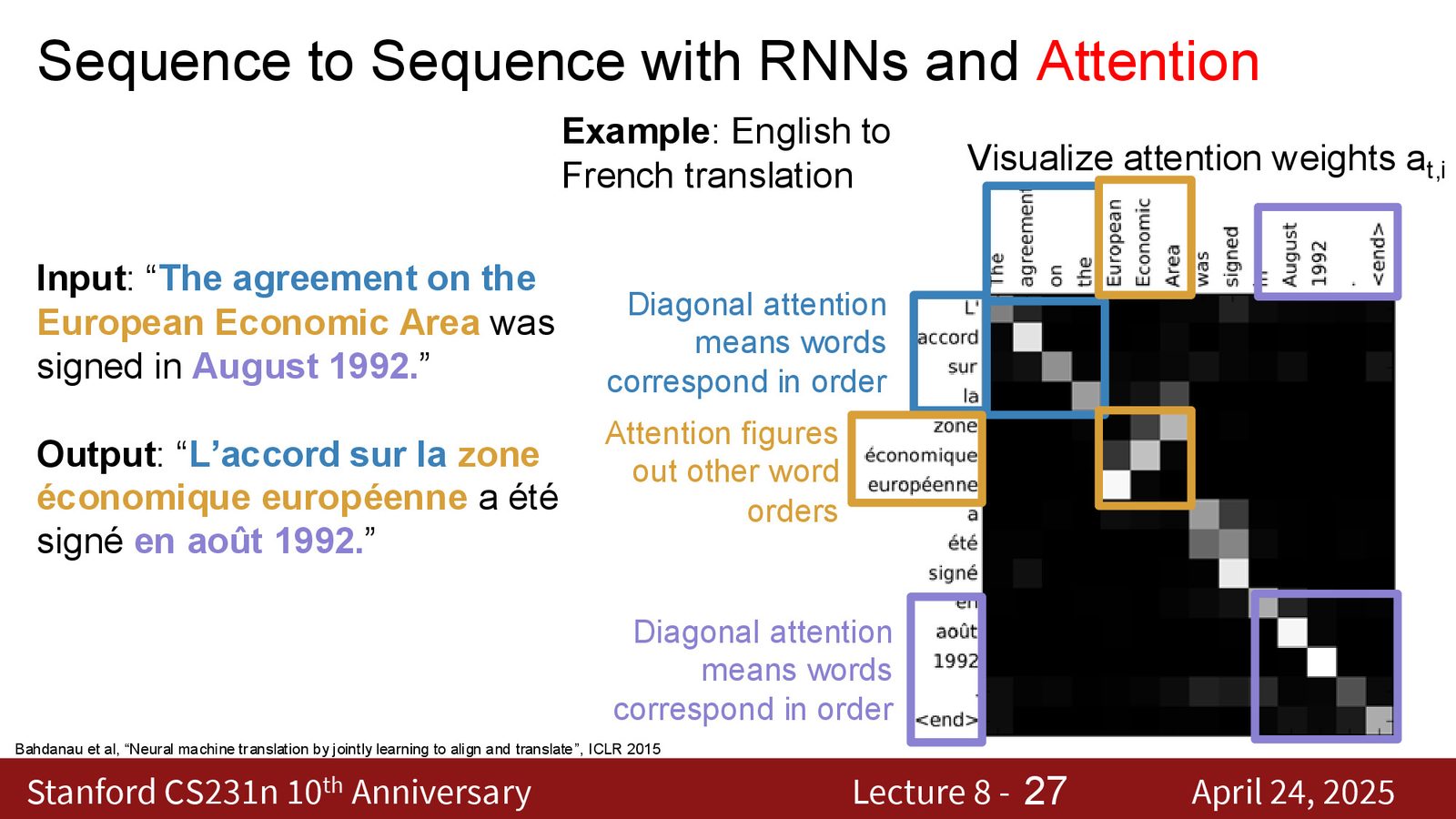
来源:Slides 第15页。来自 Bahdanau et al., 2015。
注意力矩阵的可视化揭示了网络学到的输入-输出对齐关系:
- 对角线结构:输入和输出中词序一致的部分(如“the agreement” \(\leftrightarrow\) “L'accord”)
- 反对角线:词序发生变化的部分(如“European economic area” 在法语中的不同语序)
- \(2 \times 2\) 块:一个输入词对应多个输出词或反之
注意力机制的历史地位
注意力机制首次出现在 Bahdanau et al. 2015 年的论文“Neural Machine Translation by Jointly Learning to Align and Translate”中。该论文获得了 ICLR 2025 的 runner-up Test of Time Award。这一工作虽然是在 RNN 框架内提出的,但其核心思想远超 RNN 本身——它开创了一种全新的计算范式。
本章小结
注意力机制通过让解码器在每个时间步动态地关注输入序列的不同部分,消除了固定长度上下文向量的瓶颈。这一机制完全可微,通过端到端训练自动学习输入-输出之间的对齐关系。
从 RNN 注意力到通用注意力算子
抽象出注意力的本质
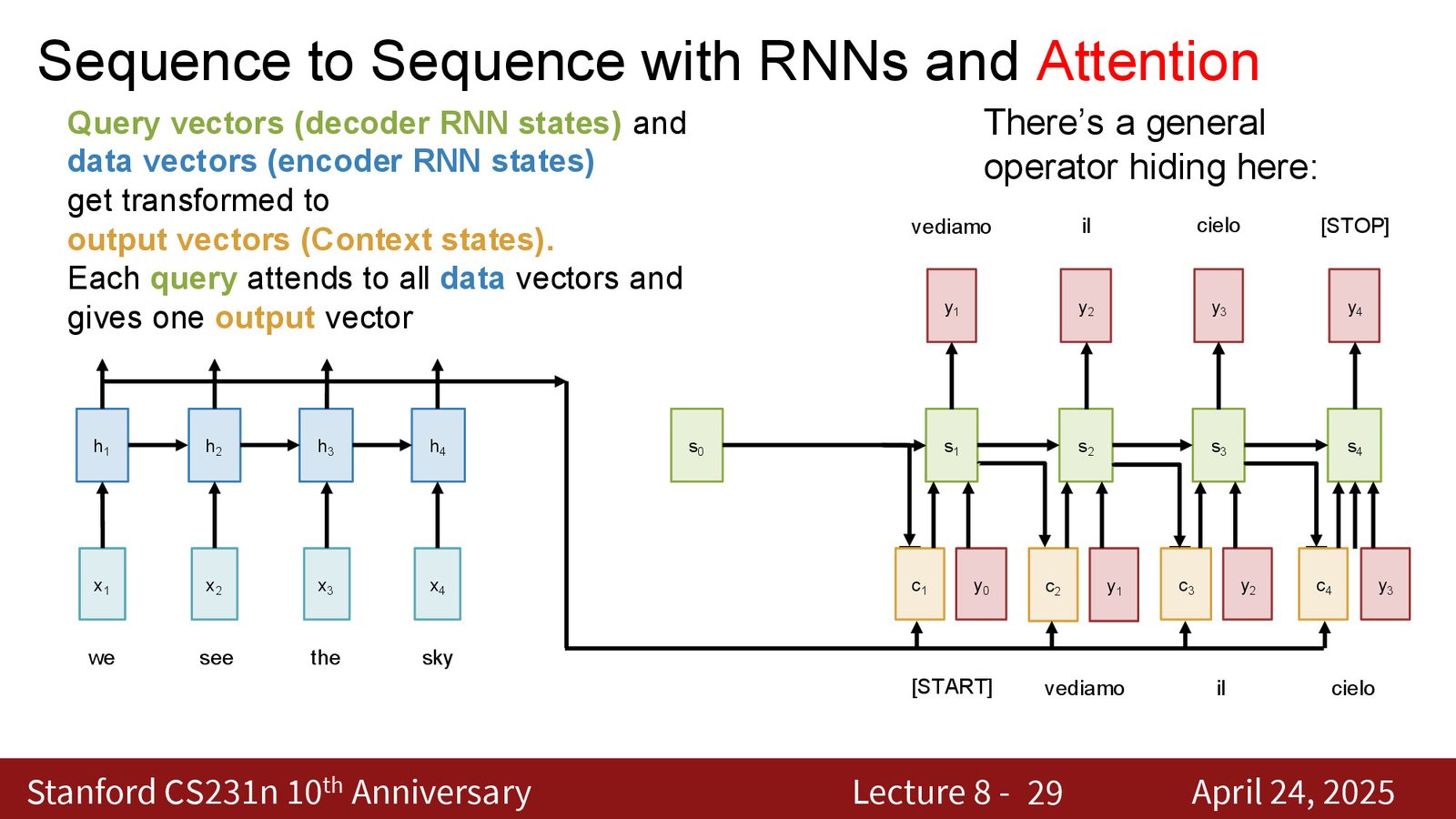
注意力机制的核心操作可以从 RNN 中剥离出来,形成一个独立的计算原语。从抽象角度看,注意力机制做了以下事情:
- 存在一组数据向量(data vectors)——编码器的隐藏状态
- 存在查询向量(query vectors)——解码器的隐藏状态
- 对每个查询向量,计算它与所有数据向量的相似度
- 使用相似度权重对数据向量进行加权求和,产生输出向量
来源:Slides 第18页。
第一步泛化:缩放点积相似度
最初的注意力使用一个可学习的线性层来计算相似度。但最简单的相似度度量是点积。然而,纯点积存在一个与维度相关的问题:
点积与 softmax 的不良交互
假设查询向量和数据向量的维度为 \(d\),且各分量独立同分布(均值 0,方差 1)。那么点积的期望方差为 \(d\)。当 \(d\) 很大时:
- 点积值的绝对值会很大
- softmax 会变得非常“尖锐”——几乎所有权重集中在一个位置
- 导致梯度消失,阻碍学习
解决方案:使用缩放点积(Scaled Dot Product)作为相似度函数:
除以 \(\sqrt{d_q}\) 使得无论维度如何变化,点积值的方差始终为 1,从而保证 softmax 的梯度行为稳定。
来源:Slides 第20页。
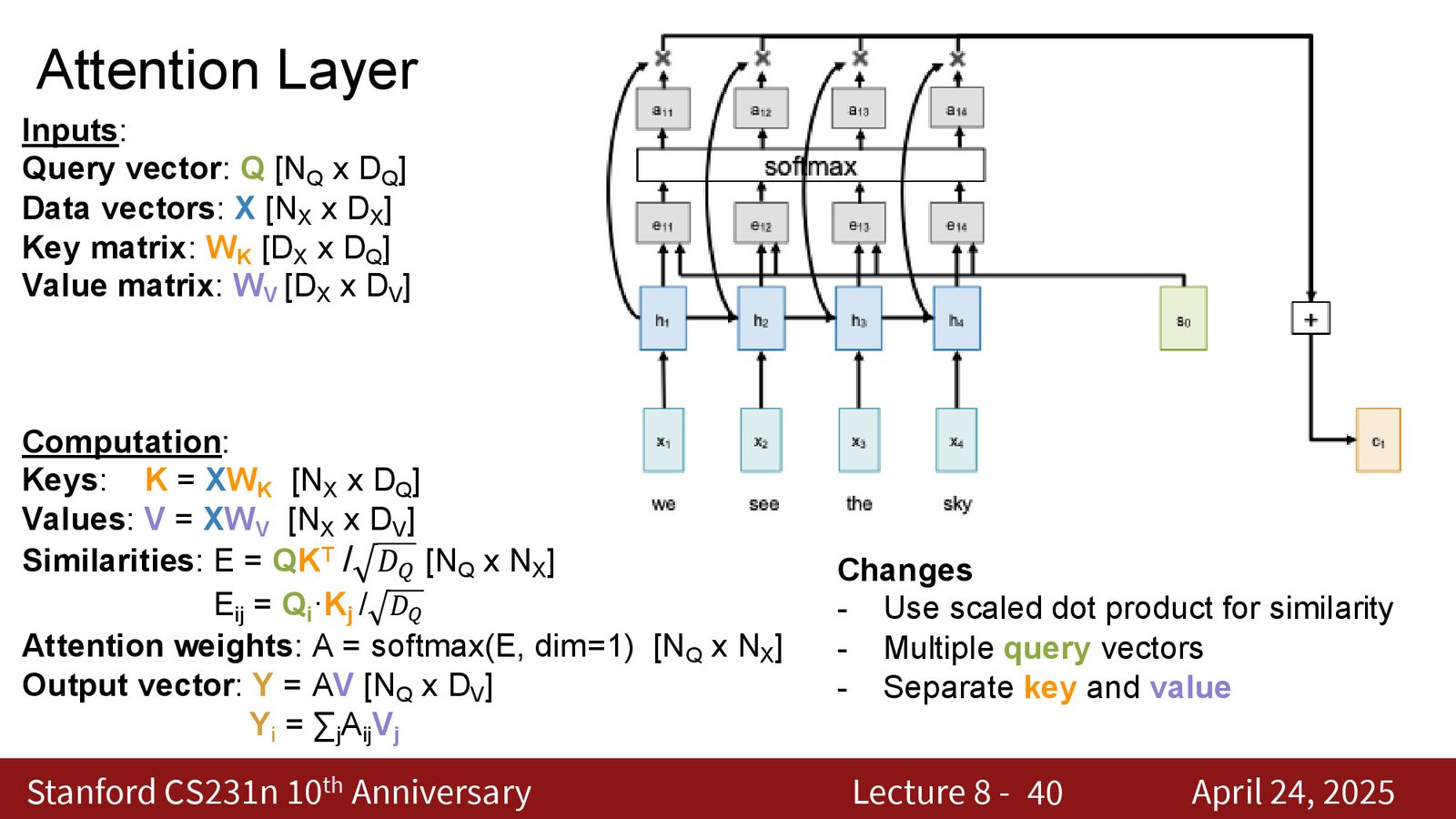
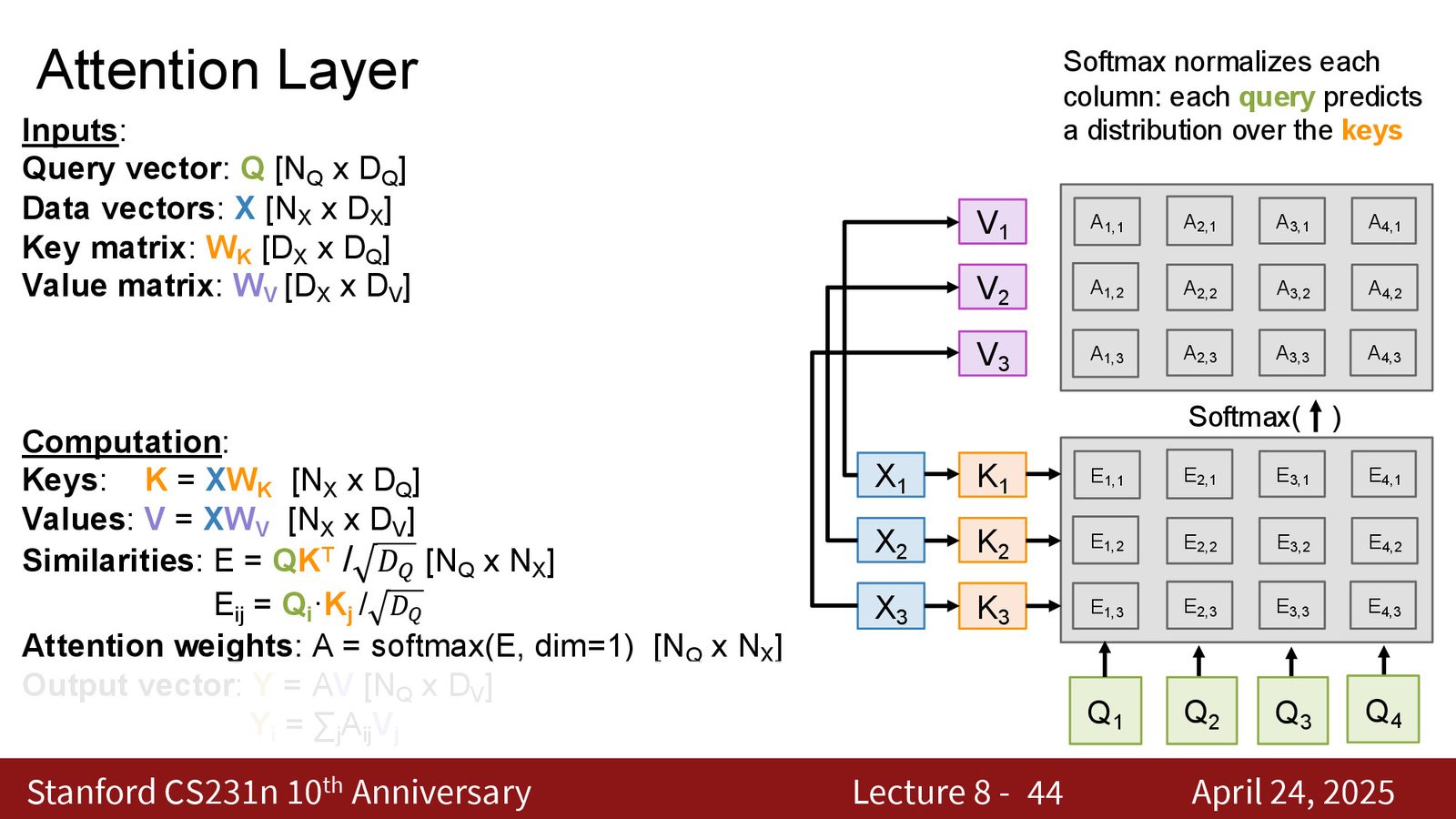
第二步泛化:多查询并行
不再逐个处理查询向量,而是一次处理所有查询向量。将查询向量堆叠为矩阵 \(Q\)(\(n_q \times d_q\)),数据向量堆叠为矩阵 \(X\)(\(n_x \times d_q\))。
所有查询与所有数据向量的相似度可以通过一个矩阵乘法高效计算:
来源:Slides 第23页。
注意力权重矩阵:\(A = \text{softmax}(E, \text{dim}=\text{columns})\)
输出:\(Y = A \cdot X\)
注意力 = 矩阵乘法
整个注意力操作可以表示为:
核心计算只有两次矩阵乘法(相似度计算 + 加权求和)加一次 softmax。矩阵乘法是 GPU 上最高效的操作——这正是注意力机制能够大规模扩展的关键。
第三步泛化:Key-Value 分离
在上述公式中,数据向量 \(X\) 被使用了两次:
- 与查询向量计算相似度(“你与我有多匹配?”)
- 作为加权求和的对象(“匹配后我能获得什么信息?”)
这两种用途本质上不同。因此,我们引入两个可学习的线性投影,将数据向量分别投影为:
来源:Slides 第27页。
- Key 向量 \(K = X W_K\):用于与 Query 计算相似度
- Value 向量 \(V = X W_V\):用于在加权求和中提供信息
Key-Query-Value 的搜索引擎类比
Justin Johnson 用搜索引擎来类比 KQV:
- Query(查询):你在搜索框中输入的问题——“世界上最好的学校是哪个?”
- Key(键):后端数据库中每条记录的索引标签——用于匹配查询
- Value(值):匹配成功后返回的实际内容——“Stanford”
Query 需要与 Key 匹配来找到相关数据,但返回的信息(Value)与 Key 不同。这种分离让网络能够灵活地学习“如何查找”和“返回什么”。
最终的注意力公式:
来源:Slides 第29页。
本章小结
通过三步泛化——缩放点积、多查询并行、Key-Value 分离——我们将 RNN 中的注意力机制提升为一个独立的、通用的神经网络算子。整个操作本质上就是几次矩阵乘法加一次 softmax,高度适合 GPU 并行计算。
Cross Attention 与 Self Attention
Cross Attention
当 Query 向量和 Data 向量来自两个不同的来源时,这种注意力称为 Cross Attention(交叉注意力)。
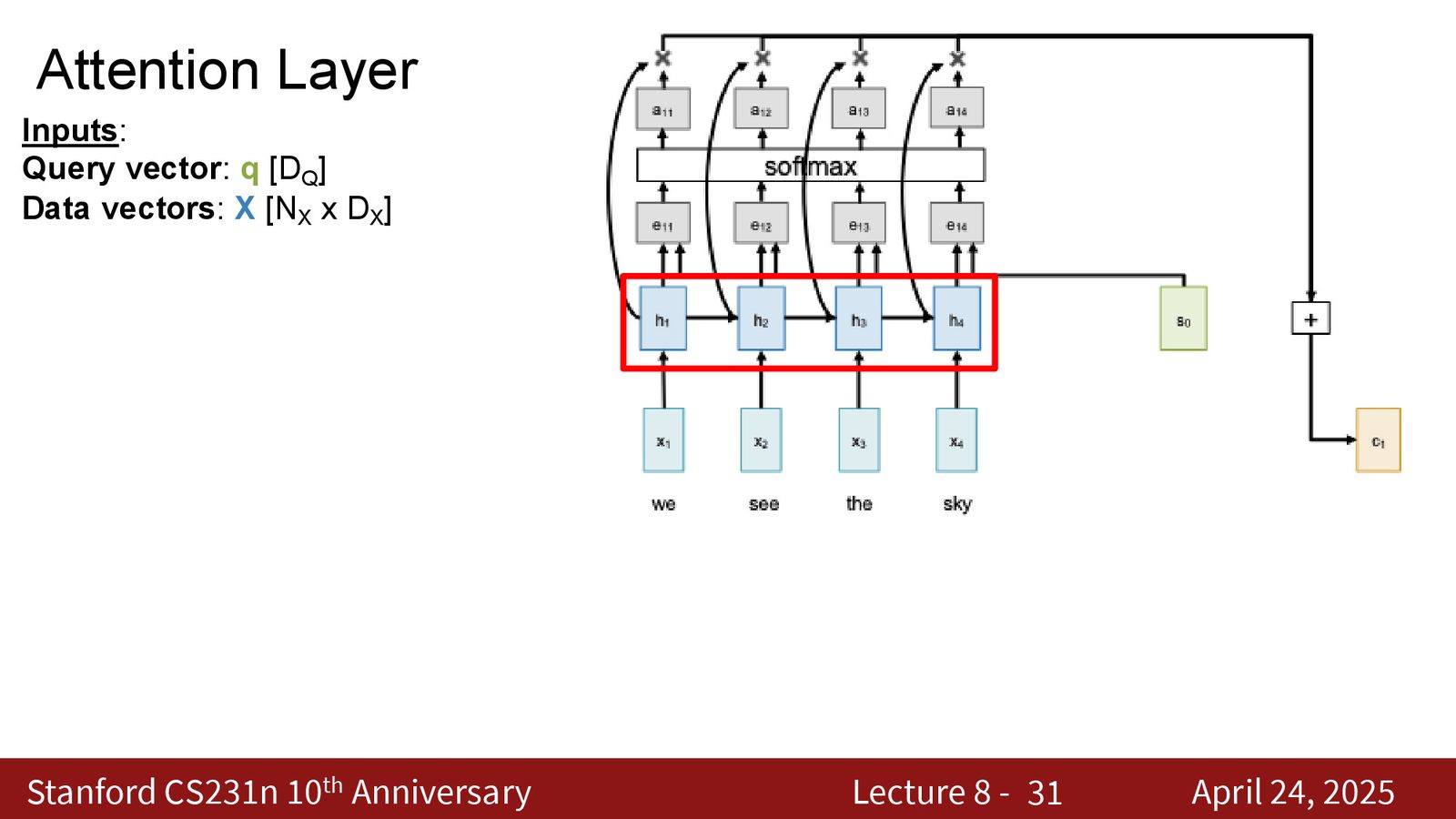
来源:Slides 第31页。
Cross Attention 的典型应用场景:
- 机器翻译:解码器的状态(Query)关注编码器的隐藏状态(Key/Value)
- 图像描述:生成的文本 token(Query)关注图像的 patch 特征(Key/Value)
- 多模态融合:一种模态的表示(Query)从另一种模态中检索信息
Self Attention
当 Query、Key、Value 全部来自同一组输入向量时,这种注意力称为 Self Attention(自注意力)。
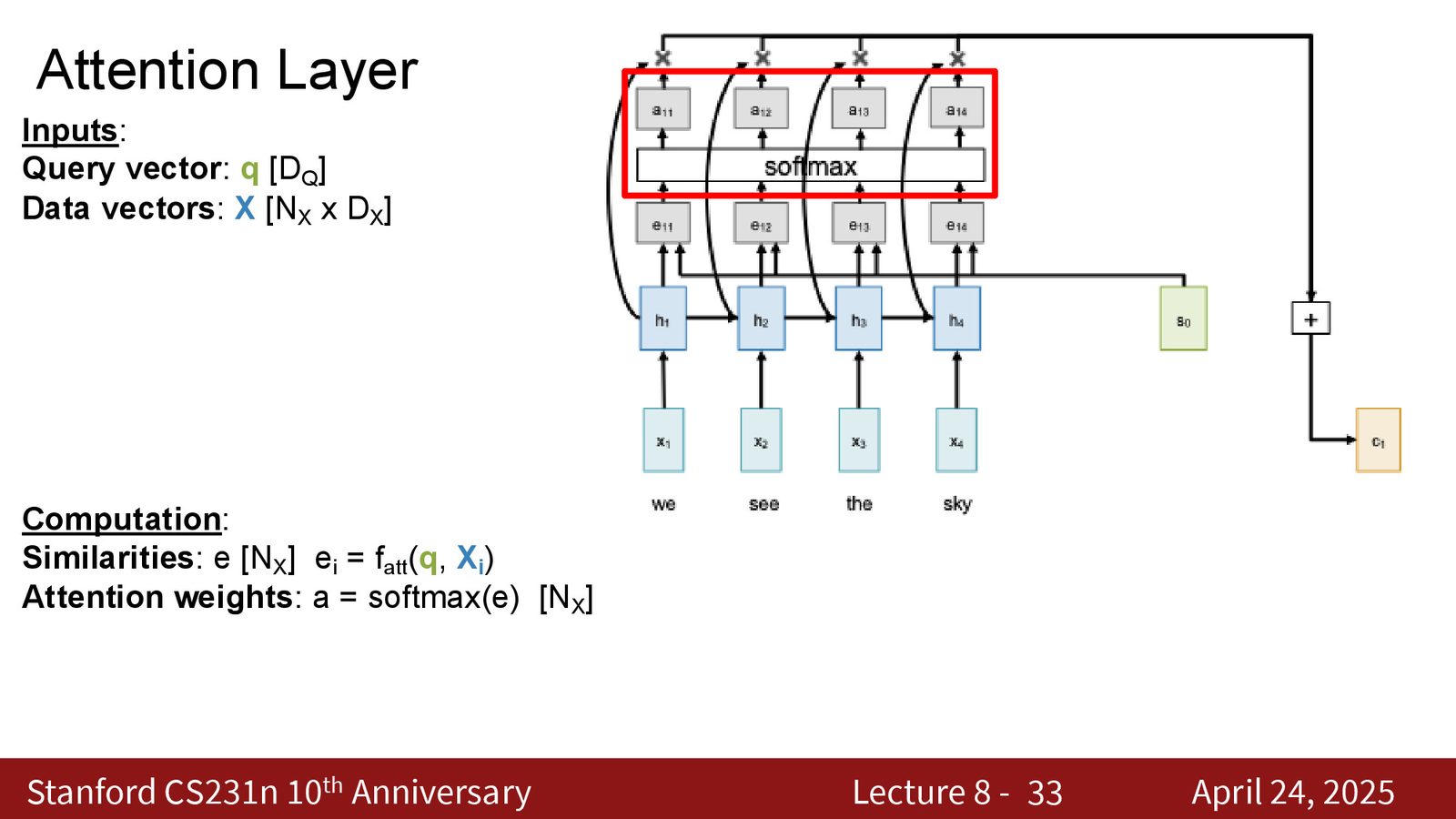
来源:Slides 第33页。
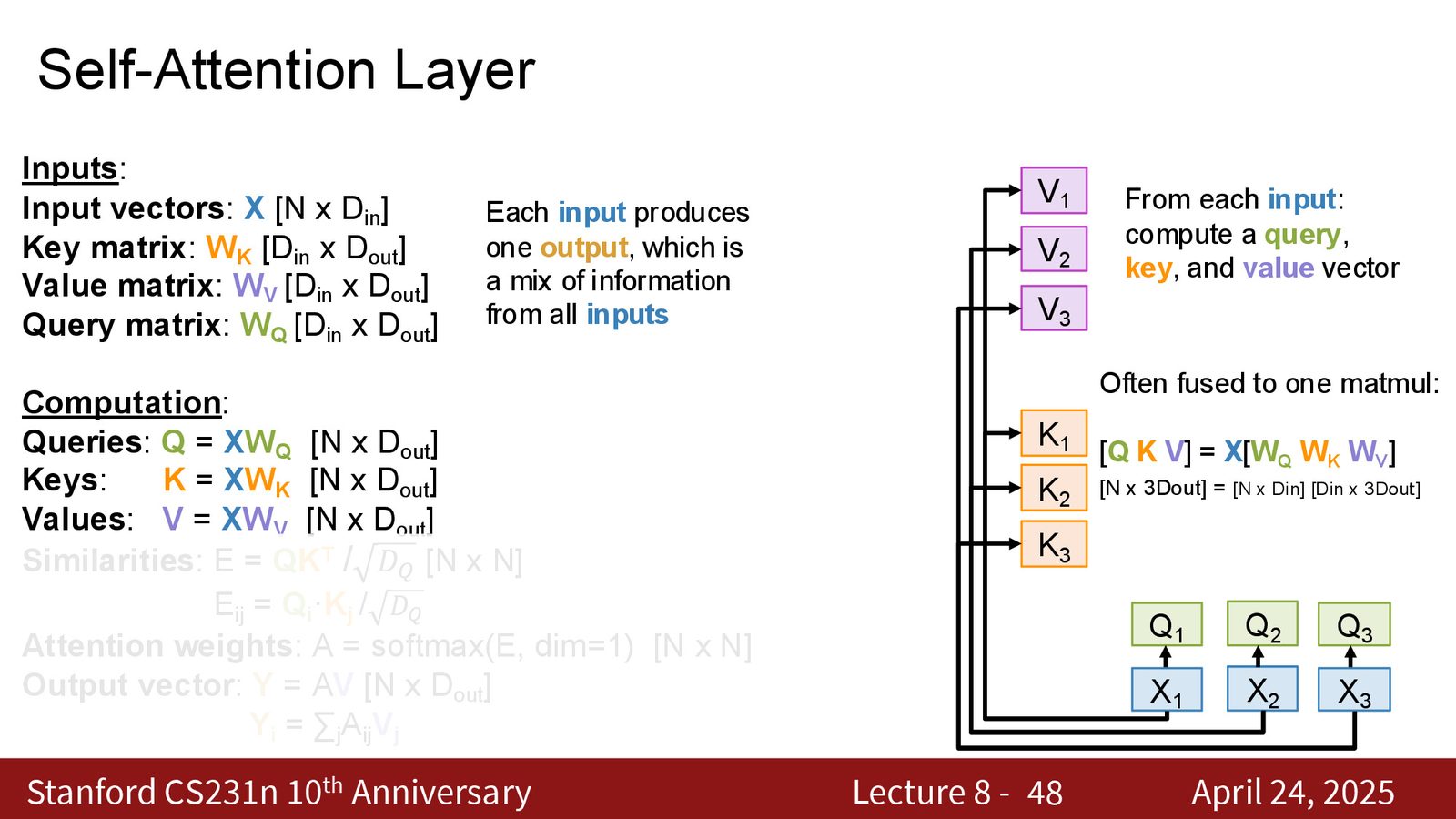
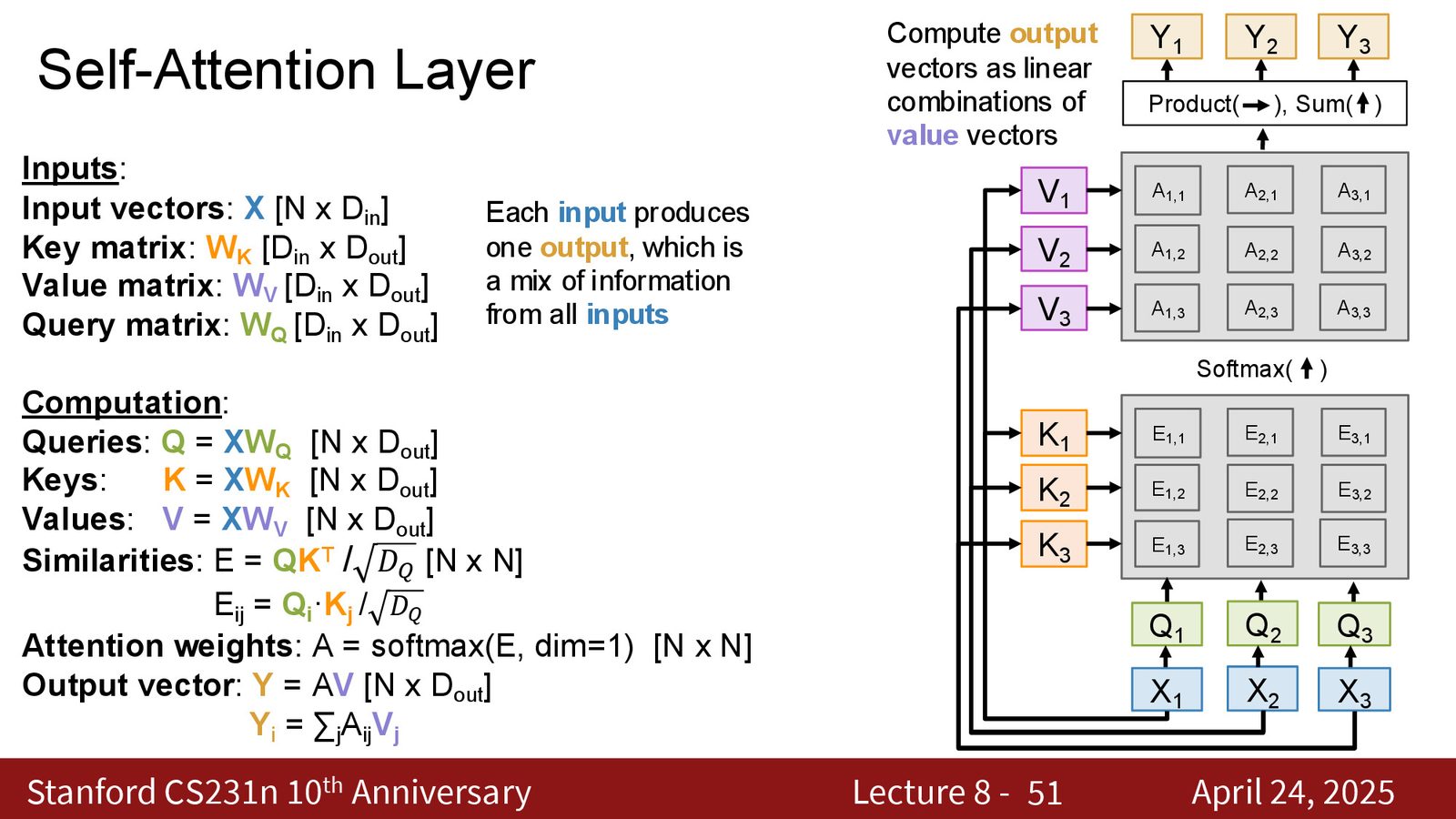
Self Attention 的计算
给定 \(n\) 个输入向量 \(X \in \mathbb{R}^{n \times d_{\text{in}}}\),self attention 通过三个可学习的权重矩阵将每个输入投影为 Query、Key 和 Value:
然后执行标准的注意力计算:
输出 \(Y \in \mathbb{R}^{n \times d_v}\),与输入具有相同数量的向量。
本章小结
Cross Attention 处理两个不同源的交互(如翻译中的源语言和目标语言),Self Attention 处理同一组向量内部的交互(如一个句子中词与词之间的关系)。Self Attention 是 Transformer 的核心构件。
Self Attention 的重要性质
置换等变性
Self Attention 有一个重要的数学性质:置换等变性(Permutation Equivariance)。
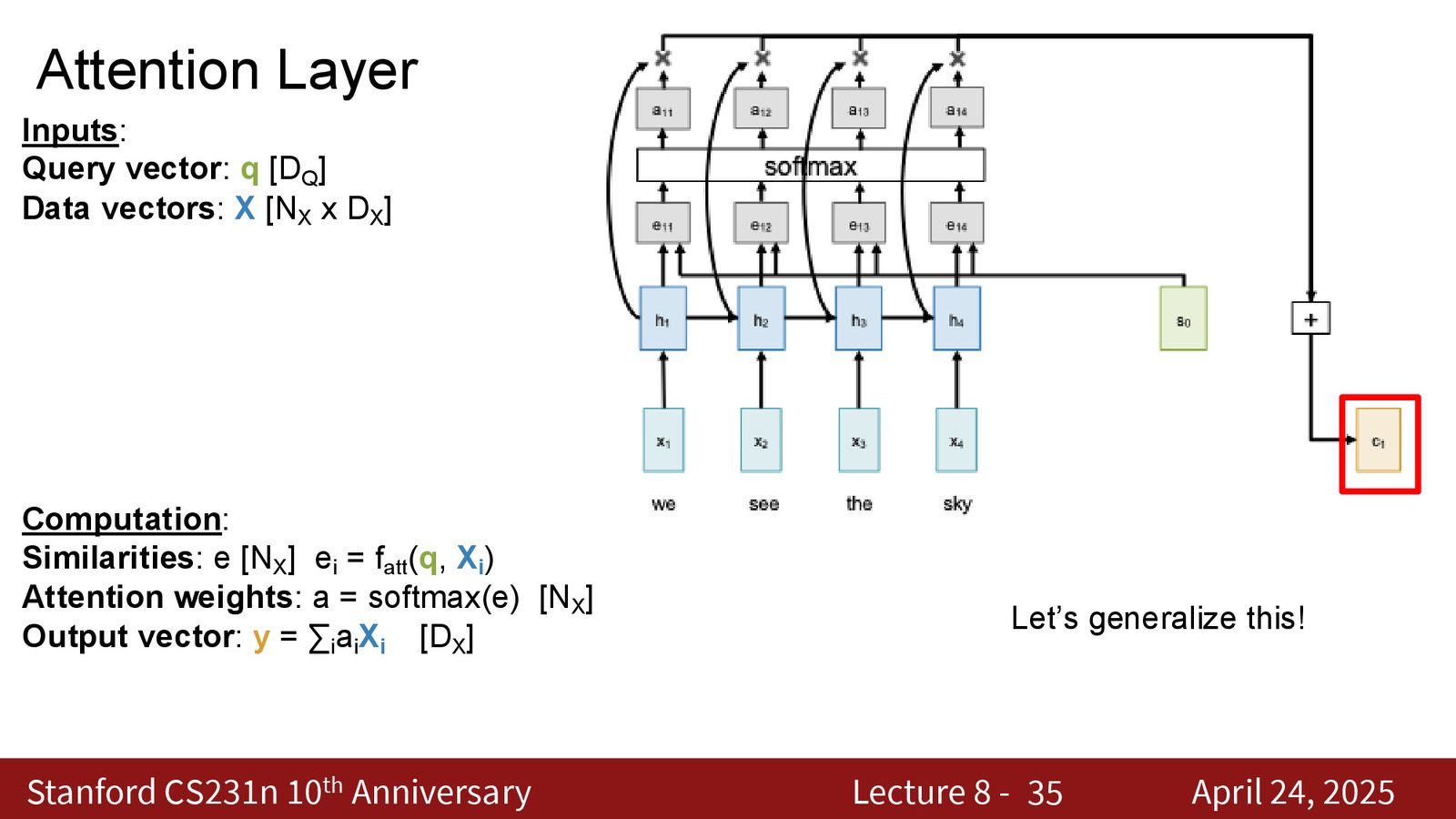
来源:Slides 第35页。
Self Attention 操作于集合而非序列
因为 Self Attention 具有置换等变性,它实际上不关心输入向量的顺序——它将输入视为一个无序集合(set),而非有序序列(sequence)。
这既是优势也是挑战:
- 优势:天然适合处理无序数据(如点云、图的节点集合)
- 挑战:对于语言等有序数据,需要额外机制来注入位置信息
位置编码(Positional Encoding)
为了让 Self Attention 感知输入的顺序,我们在每个输入向量上拼接(或相加)一个位置编码(Positional Embedding),告诉模型每个向量在序列中的位置。
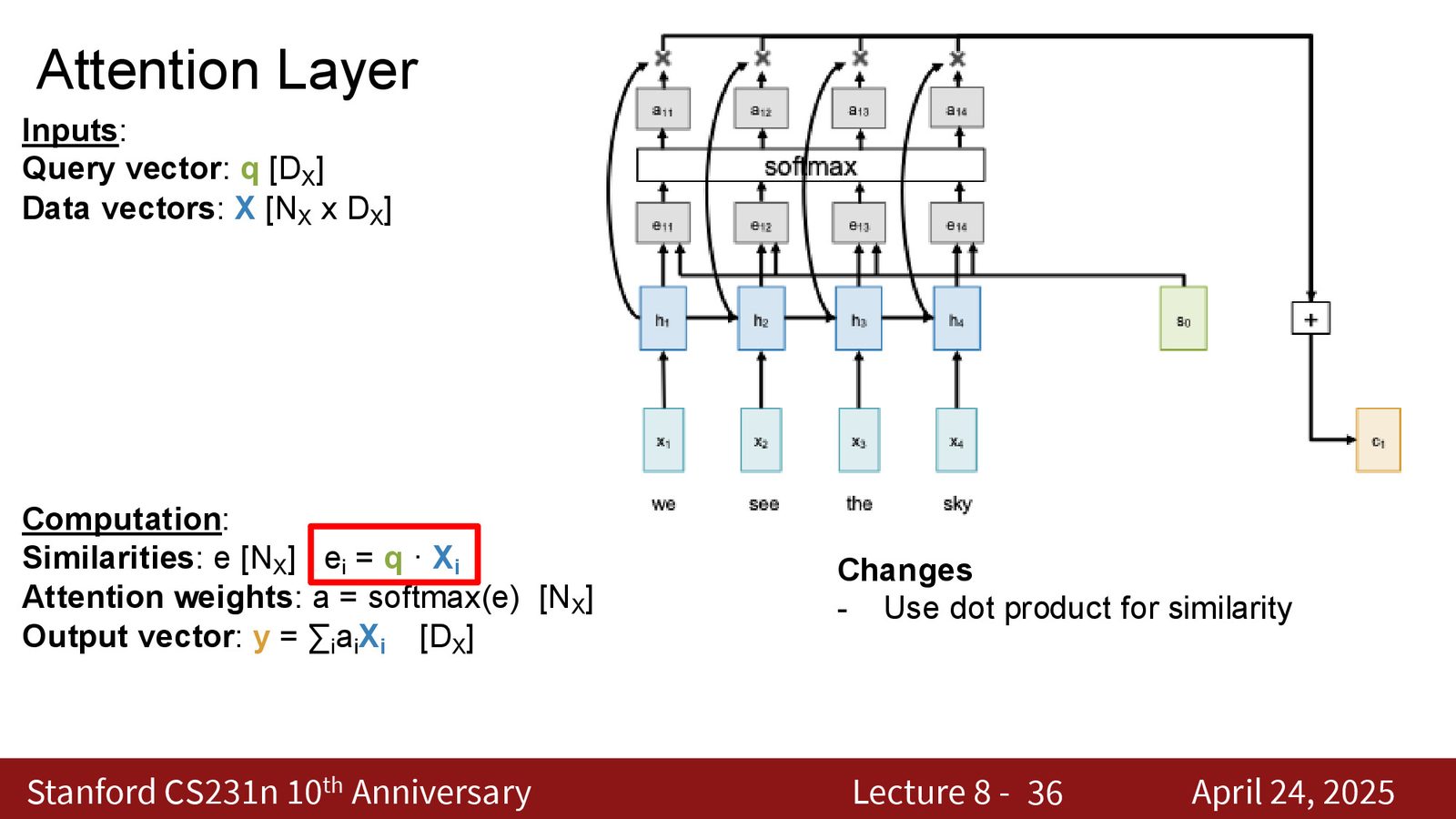
来源:Slides 第36页。
位置编码的常见方法
- 正弦/余弦编码(原始 Transformer):使用不同频率的正弦函数,无需训练
- 可学习位置编码:每个位置对应一个可训练的向量
- 旋转位置编码(RoPE):通过旋转矩阵将位置信息编码到 Query/Key 中,支持外推到更长序列
- 相对位置编码:编码向量之间的相对距离而非绝对位置
本章小结
Self Attention 天然具有置换等变性,本质上处理的是无序集合。位置编码是让注意力机制处理有序序列数据的关键补丁。
Masked Self Attention
为什么需要 Masking
在语言建模等自回归任务中,生成第 \(t\) 个 token 时不应该看到位置 \(t+1, t+2, \ldots\) 的信息——否则就是“作弊”。但标准的 Self Attention 允许每个位置看到所有其他位置。
来源:Slides 第38页。
实现方式
在计算完对齐分数 \(E = \frac{QK^T}{\sqrt{d_q}}\) 之后:
-
构造一个因果掩码(causal mask)矩阵 \(M\),其中位置 \((i,j)\):
-
若 \(j \leq i\)(允许看到),\(M_{ij} = 0\)
- 若 \(j > i\)(不允许看到),\(M_{ij} = -\infty\)
- 将掩码加到对齐分数上:\(E' = E + M\)
- 执行 softmax:因为 \(e^{-\infty} = 0\),被掩码的位置注意力权重为 0
Masked Self Attention 用于语言建模
所有现代的自回归语言模型(GPT 系列、LLaMA、Claude 等)都使用 Masked Self Attention(也称为 Causal Attention)。它确保模型在训练时只能依赖已经生成的 token,与推理时的自回归生成过程保持一致。
这也是所谓“decoder-only transformer”(仅解码器 Transformer)的核心——不需要单独的编码器和解码器,只需一个带因果掩码的 Self Attention 层栈。
本章小结
Masked Self Attention 通过在注意力分数中注入 \(-\infty\) 来阻止信息的“前向泄露”,使得 Self Attention 可以用于自回归生成任务。这是现代语言模型的基础构件。
多头注意力(Multi-Head Attention)
动机与设计
单个 Self Attention 层使用一组 \(W_Q, W_K, W_V\) 矩阵。为了增加模型的容量和表达能力,我们可以运行 \(H\) 个独立的 Self Attention“头”(head)。
来源:Slides 第40页。
Multi-Head Attention 的计算
- 对输入 \(X\),每个头 \(h\) 独立计算 \(Q^h, K^h, V^h\)(使用各自的权重矩阵)
- 每个头独立执行注意力:\(Y^h = \text{Attention}(Q^h, K^h, V^h)\)
- 将所有头的输出拼接:\([Y^1; Y^2; \ldots; Y^H]\)
- 通过一个线性投影 \(W_O\) 融合所有头的信息
每个头可以学习关注输入的不同方面:
- 某个头可能学会关注语法结构
- 另一个头可能关注语义相似性
- 还有的头可能关注局部上下文
计算效率
尽管 Multi-Head Attention 看起来很复杂,但整个操作本质上只是四次(批量)矩阵乘法:
- QKV 投影:一次矩阵乘法,将输入投影为所有头的 Q、K、V
- Q-K 相似度:一次批量矩阵乘法,计算所有头的注意力分数
- V 加权:一次批量矩阵乘法,对 Value 进行加权求和
- 输出投影:一次矩阵乘法,融合所有头的输出
实际实现中的高效技巧
在实际代码中,\(H\) 个头的计算并不需要 for 循环,而是通过张量重塑(reshape)和批量矩阵乘法(batched matmul)来并行计算。三个投影矩阵 \(W_Q, W_K, W_V\) 也通常拼接为一个大矩阵,用一次矩阵乘法完成所有投影。这使得 Multi-Head Attention 在 GPU 上非常高效。
本章小结
Multi-Head Attention 通过运行多个独立的注意力头来增加模型容量。每个头学习不同的注意力模式,最终通过线性投影融合。整个操作高度适合 GPU 并行计算。
三大序列处理原语对比
在本课程中,我们已经学习了三种不同的神经网络原语来处理序列/结构化数据:
来源:Slides 第44页。
| RNN | CNN | Self Attention | |
|---|---|---|---|
| 操作对象 | 1D 有序序列 | 多维网格 | 无序向量集合 |
| 信息交互范围 | 理论无限 | 局部(核大小) | 全局(一层即可) |
| 序列方向并行性 | 不可 | 可以 | 可以 |
| 计算复杂度 | \(O(n)\) | \(O(n)\) | \(O(n^2)\) |
| 长距离依赖 | 困难(梯度消失) | 需要多层 | 一层直达 |
| 可扩展性 | 差 | 中 | 好 |
Self Attention 的 \(O(n^2)\) 代价
Self Attention 的计算和内存复杂度都是 \(O(n^2)\)(\(n\) 为序列长度):
- 需要计算所有 \(n \times n\) 对的相似度
- 需要存储 \(n \times n\) 的注意力矩阵
当 \(n = 100{,}000\) 甚至 \(n = 1{,}000{,}000\) 时,这会变得非常昂贵。但 Justin Johnson 指出,更多计算并不一定是坏事——更多的计算意味着网络有更强的“思考”能力。解决方案是:买更多 GPU。
Attention is All You Need
在三种原语中,Self Attention 凭借以下优势胜出:
- 全局信息交互:一层 Self Attention 就能让所有位置互相“看到”
- 高度并行:核心计算是矩阵乘法,完美适配 GPU
- 可扩展性:通过增加硬件即可处理更大的模型和更长的序列
这正是 2017 年那篇标志性论文的标题所传达的信息:“Attention is All You Need”。
本章小结
RNN 擅长序列但不可并行,CNN 擅长网格但感受野有限,Self Attention 擅长全局交互但代价是 \(O(n^2)\) 复杂度。在现代深度学习的规模下,Self Attention 的可扩展性使其成为首选。
Transformer 架构
Transformer Block
Transformer 的核心构件是Transformer Block,由以下组件按顺序组成:

来源:Slides 第47页。
Transformer Block 的四个核心组件
- Multi-Head Self Attention:让所有向量互相交互——“集体讨论”
- MLP / FFN:对每个向量独立进行非线性变换——“独立思考”
- 残差连接(Residual Connection):围绕 Self Attention 和 MLP 各加一个跳跃连接——改善梯度流动(与 ResNet 相同的原理)
- Layer Normalization:在残差连接之后进行归一化——稳定训练过程
Self Attention 和 MLP 协同工作:
- Self Attention 负责向量间的信息交流
- MLP 负责向量内的非线性处理
完整 Transformer 模型
一个完整的 Transformer 就是将多个 Transformer Block 堆叠在一起:
来源:Slides 第48页。
Transformer 的规模演变
- 2017(原始 Transformer):约 12 个 Block,\(\sim\)200M 参数
- 2020(GPT-3):96 个 Block,175B 参数
- 2023--2025(现代大模型):数百个 Block,数万亿参数
- 架构本身变化极小——核心的 Self Attention + MLP + 残差 + LayerNorm 结构始终未变
- 性能提升主要来自更大的规模和更多的训练数据
Transformer 用于语言建模
将 Transformer 用于自回归语言建模:
- 将文本序列分割为 token
- 每个 token 通过 Embedding 层映射为向量
- 添加位置编码
- 通过多层 Transformer Block(带因果掩码的 Self Attention)
- 最终层输出经过线性投影 + softmax,预测下一个 token 的概率分布
Vision Transformer (ViT)
来源:Slides 第51页。
Transformer 同样可以处理图像:
- 将图像划分为固定大小的patch(如 \(16 \times 16\) 像素)
- 每个 patch 通过线性投影映射为向量
- 添加位置编码
- 通过标准 Transformer Block 处理
- 对输出向量进行池化,通过线性层预测类别
一种架构,多种数据
Transformer 的强大之处在于其通用性:
- 语言:token \(\rightarrow\) embedding \(\rightarrow\) Transformer
- 图像:patch \(\rightarrow\) linear projection \(\rightarrow\) Transformer
- 音频:频谱帧 \(\rightarrow\) linear projection \(\rightarrow\) Transformer
- 视频:时空 patch \(\rightarrow\) linear projection \(\rightarrow\) Transformer
同一种架构,只需改变输入的“向量化”方式,就能应用于截然不同的数据模态。
本章小结
Transformer 架构由 Self Attention + MLP + 残差连接 + Layer Norm 四个组件构成。它的设计简洁、高度可扩展,自 2017 年以来几乎统治了深度学习的所有领域。通过不同的输入编码方式,同一个 Transformer 架构可以处理语言、图像、音频等多种数据类型。
拓展阅读
- Vaswani et al.: Attention Is All You Need, NeurIPS 2017 https://arxiv.org/abs/1706.03762
- Bahdanau et al.: Neural Machine Translation by Jointly Learning to Align and Translate, ICLR 2015 https://arxiv.org/abs/1409.0473
- Dosovitskiy et al.: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021 https://arxiv.org/abs/2010.11929
- Jay Alammar: The Illustrated Transformer https://jalammar.github.io/illustrated-transformer/
- Lilian Weng: Attention? Attention! https://lilianweng.github.io/posts/2018-06-24-attention/
总结与延伸
讲者的核心总结
Justin Johnson 在课程结尾强调了两个核心贡献:
- Attention:一种新的计算原语,本质上操作于向量集合之上。它高度可并行、可扩展,核心计算只有几次矩阵乘法。
- Transformer:以 Self Attention 为核心的神经网络架构。自 2017 年以来统治了深度学习的几乎所有领域,从语言到视觉到多模态。
全课知识图谱

关键 Takeaways
六条核心原则
- 注意力的本质是动态的信息检索:给定查询,从数据中按相关性加权提取信息
- KQV 分离是关键设计:让网络分别学习“如何匹配”(Key-Query)和“返回什么”(Value)
- Self Attention 操作于集合:天然不感知顺序,需要位置编码来注入序列信息
- 注意力本质上是矩阵乘法:四次 matmul 就是整个 Multi-Head Self Attention
- Transformer = Attention + MLP + 残差 + 归一化:简洁的组合,强大的效果
- 并行性决定可扩展性:Transformer 之所以胜出,是因为它能充分利用大规模并行硬件