CS336 Lecture 16: Reinforcement Learning from Verifiable Rewards
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于课堂字幕与 slides 整理 |
| 来源 | Stanford Online |
| 日期 | 2025年春季 |

开场:从 RLHF 走向 RLVR
这节课是 post-training 系列的第二讲。主线很明确:先补完上一讲的 RLHF 讨论,再把视角切到 reinforcement learning from verifiable rewards,也就是在那些“答案能被快速、准确地验证”的任务上,怎么把 RL 真正做成一个可扩展的训练工具。
这一讲的核心目标
- 搞清楚 RLHF 为什么会遇到过优化、校准性变差、实现复杂等问题。
- 搞清楚 PPO 为什么能工作,但工程上很笨重。
- 搞清楚 GRPO 为什么会成为更轻量的替代方案。
- 看三个真实系统案例:DeepSeek R1、Kimi K1.5、Qwen 3。

先回顾上一讲:DPO 为什么流行
上一讲已经把 RLHF 的基础目标讲清楚了:对成对偏好数据做优化,让模型更倾向于输出“好样本”。在这个框架里,DPO 之所以爆火,是因为它把原本复杂的 RL 问题,压缩成了一个很像监督学习的目标。
可以把它理解成两步:
- 在非参数化假设下,把奖励和策略写成某种闭式关系。
- 用偏好对比损失去更新策略,让“好回答”的概率上升,“坏回答”的概率下降。



DPO 的变体和经验性结论
课堂里特别强调了一个经验事实:RL 论文里的结论非常依赖具体设置。同样是 DPO、PO 或者它们的变体,不同的 base model、不同的数据、不同的 SFT 配方,最后可能给出完全不同的结果。
这也是为什么后来出现了大量 DPO 变体。课堂里点名了两个最近特别常见的方向:
- SimPO:不再依赖 reference policy,更像是把优化目标重新写成一个更直接的打分问题。
- Length-normalized DPO:保留 DPO 的结构,但把长度偏差显式处理掉。

RLHF 里的一个重要提醒
不要把单篇论文里的实验结果当成普适真理。RLHF 的曲线、胜率、稳定性,都高度依赖任务、模型、数据和训练细节。
两个必须记住的问题
课上后半段把两个问题提得很重。
第一个是 overoptimization。reward model 是从人类偏好或偏好代理上学来的,模型继续朝这个代理目标优化时,容易把 reward model 本身“学坏”,但真实的人类偏好并没有同步改善。
第二个是 calibration。RLHF 以后,模型已经不再是一个干净的概率模型;它更像一个 policy。于是很多原本从生成建模视角默认存在的“校准性”,在这里都不能再想当然。
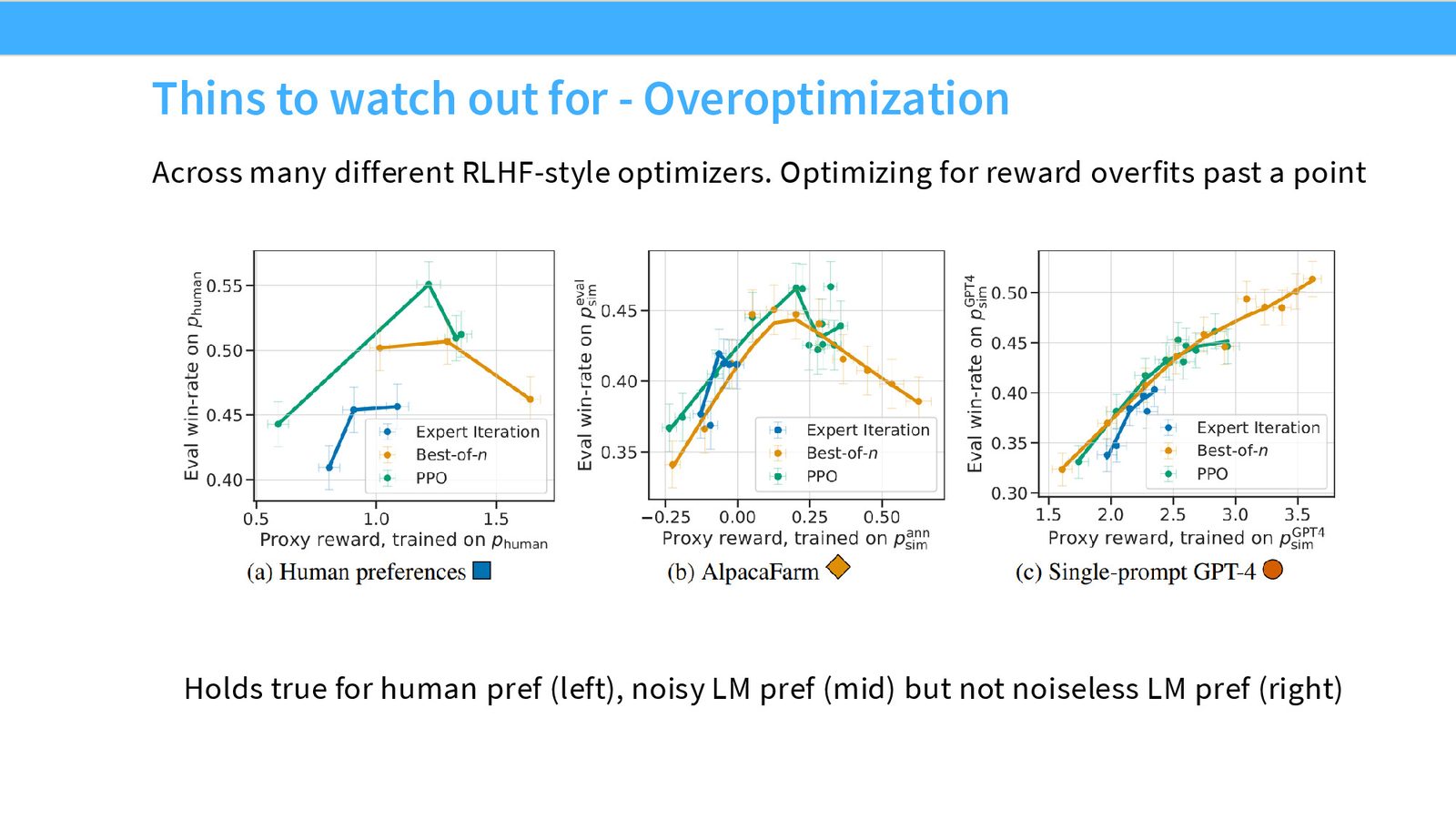
为什么要从 RLHF 转到 RLVR
从工程和研究两个角度看,人类反馈都很难规模化。它贵、慢、噪声大,而且容易被 hack。于是课堂自然把问题转到另一个方向:有没有一种奖励,我们能直接验证它对不对?
这就是 verifiable rewards 的出发点。数学、代码、某些形式化推理题,都是典型例子。只要任务有可验证的终局 reward,我们就可以把 RL 真正跑起来,而不是只盯着人类主观偏好。
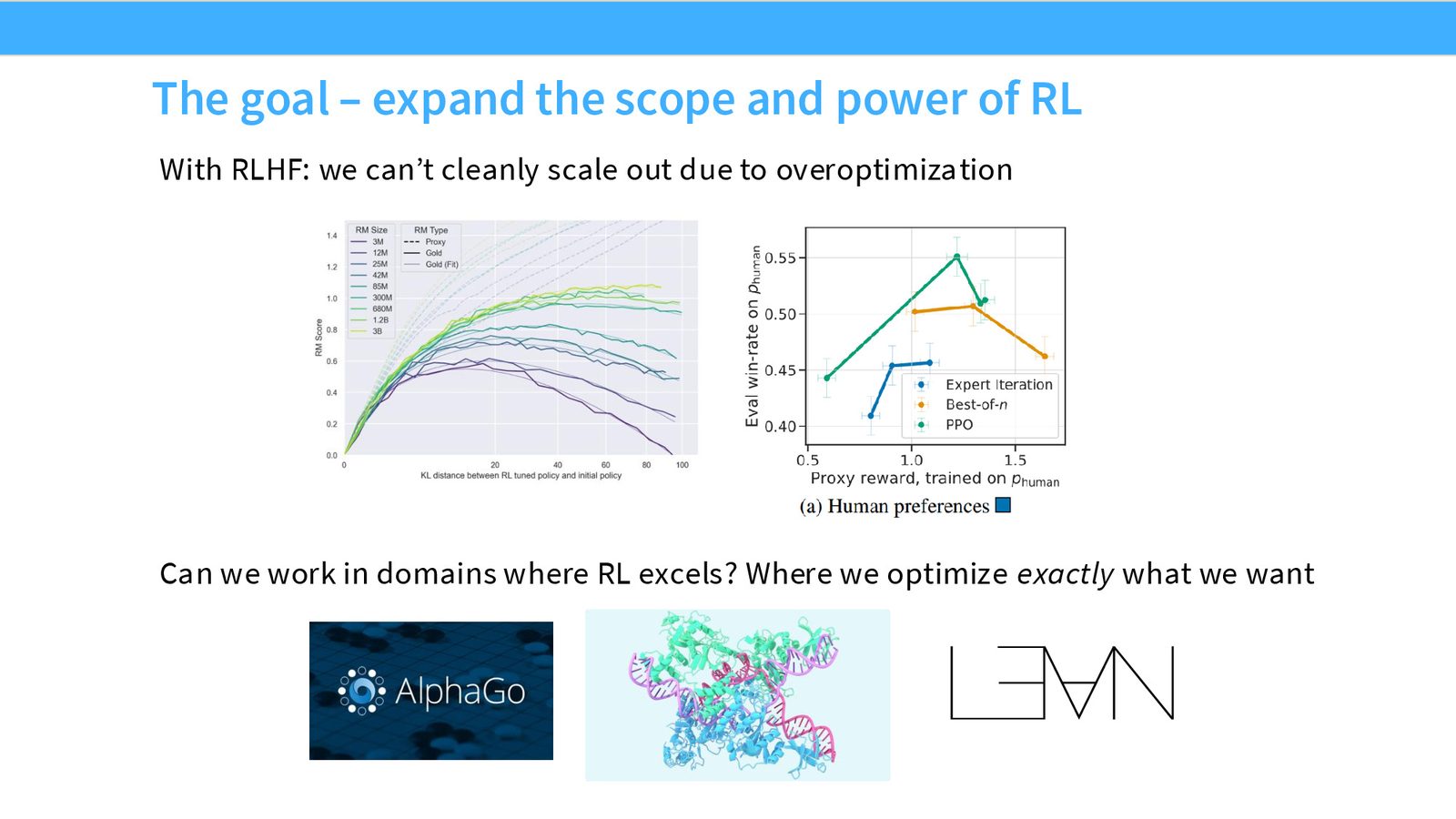

为什么 RLVR 适合当作 post-training 的试验田
这类任务最吸引人的地方,不只是 reward 更干净,而是它让研究者可以把主要精力放在算法、采样、搜索与 credit assignment 上,而不用先解决“人类是否喜欢这个回答”的测量难题。也正因为如此,数学、代码、可执行工具调用常被用来观察 RL 是否真的把模型推向了更强的推理行为,而不是仅仅学会迎合评测器。
PPO:能用,但不轻
从 policy gradient 到 PPO
课上先快速回顾了 PPO 的理论谱系:
- 直接 policy gradient:概念最简单,但方差很高。
- TRPO:用重要性采样和 trust region 控制 policy 漂移。
- PPO:把更新约束成 clip 形式,既稳定又容易实现。
核心目标可以写成标准的 clipped objective:


工程上为什么麻烦
课堂里强调,PPO 的“理论版本”和“代码版本”差距很大。真正麻烦的地方主要有三类:
- rollouts 很贵。每次更新都要跑模型采样,生成样本是最慢的那部分。
- value function 让系统更重。它要额外占显存,还引入了训练调参压力。
- reward shaping 和 GAE 让实现细节变多。虽然都不是神秘概念,但凑在一起就很容易把训练管线搞复杂。



reward shaping 和 GAE
在语言模型里,PPO 往往被当成一个 contextual bandit:输入一个 prompt,输出一个整段回答,最后再看 reward。为了让学习更稳定,实践里经常把 reward 分解成两类:
- per-token 的 KL 惩罚,用来约束新 policy 不要离 reference 太远。
- 末端的任务成功 reward,用来表示真正的目标是否完成。
而 GAE 的作用,是把高方差的原始回报,变成一个更平滑的 advantage 估计。课堂里的关键点不是公式本身,而是它的工程意义:如果没有这些技巧,PPO 很容易训练得又慢又不稳。

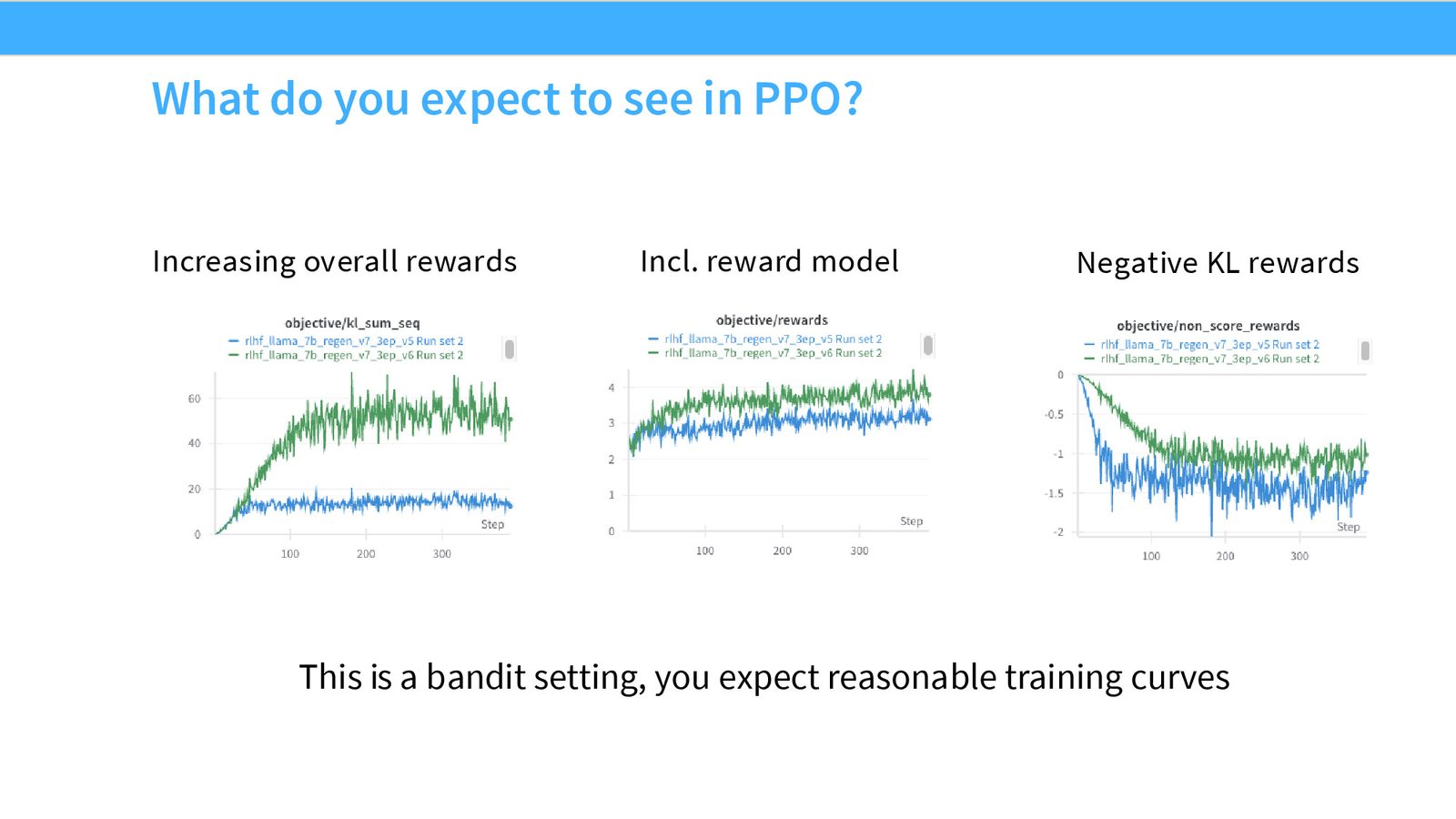
GRPO:把 PPO 再简化一层
为什么需要 GRPO
课堂给出的动机很直接:
- PPO 太复杂,value model 很占资源。
- DPO 虽然简单,但它假设数据本身就是 pairwise preference。
- 现实里的 RLVR 场景往往不是纯 pairwise 数据,而是更一般的 rollout + verifiable reward。
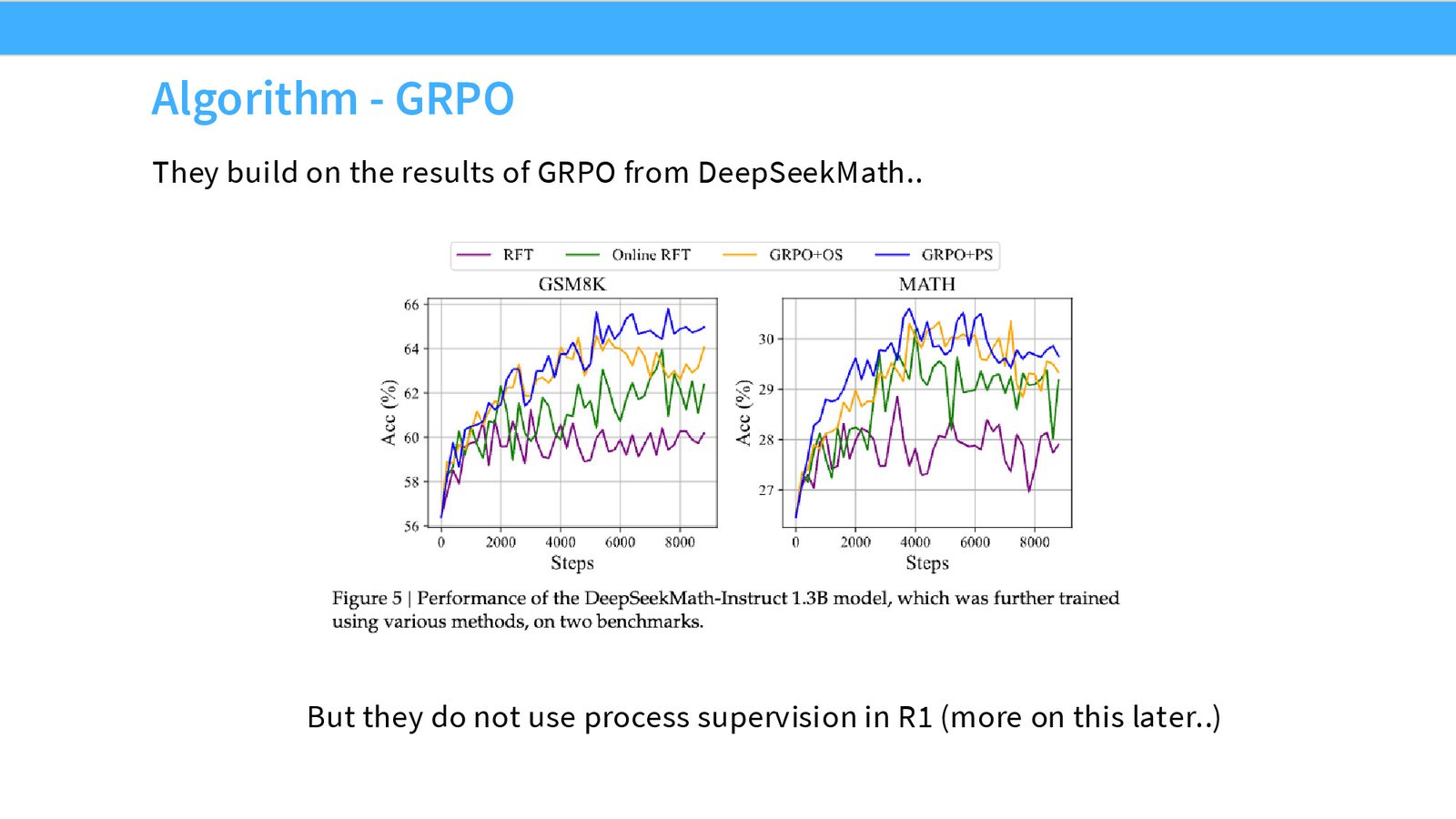
于是就有了 GRPO。它的思路可以概括成一句话:保留 PPO 的外壳,去掉 value function,把 advantage 变成 group 内标准化的分数。

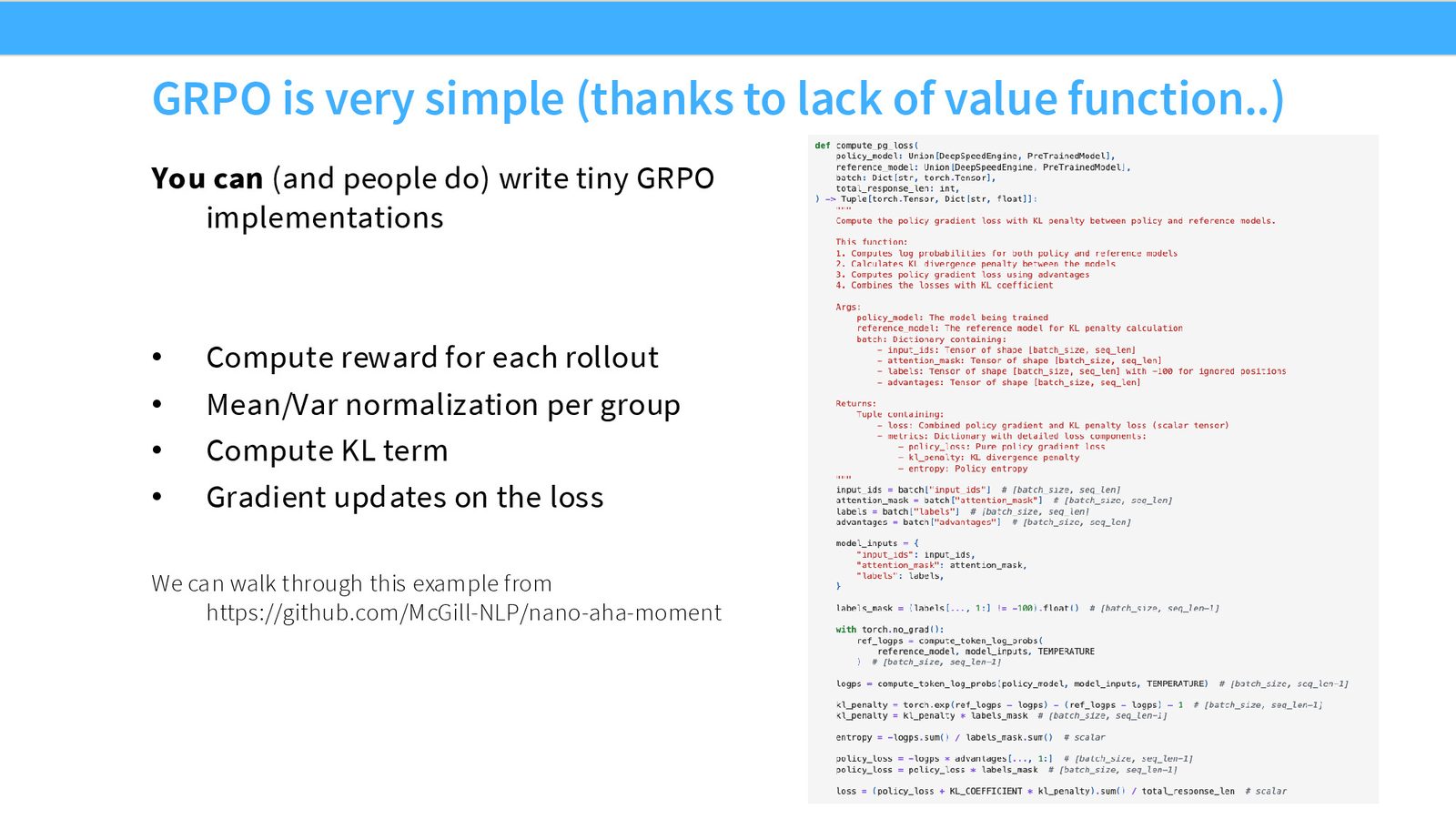
GRPO 的简单实现
GRPO 在代码里非常短。最核心的流程就是:
- 对同一个 prompt 采样一组 rollouts。
- 给每个 rollout 计算可验证 reward。
- 在 group 内做均值和方差归一化,得到 advantage。
- 加上 KL 约束,直接对 policy 做梯度更新。
这也是为什么课堂里说它“看起来像是 policy gradient,但已经被整理得更像工程实现”。
如果把这个式子和 PPO 相比,你会发现它少了一个 value network,但代价是:这个“标准化”并不一定是严格无偏的 baseline。
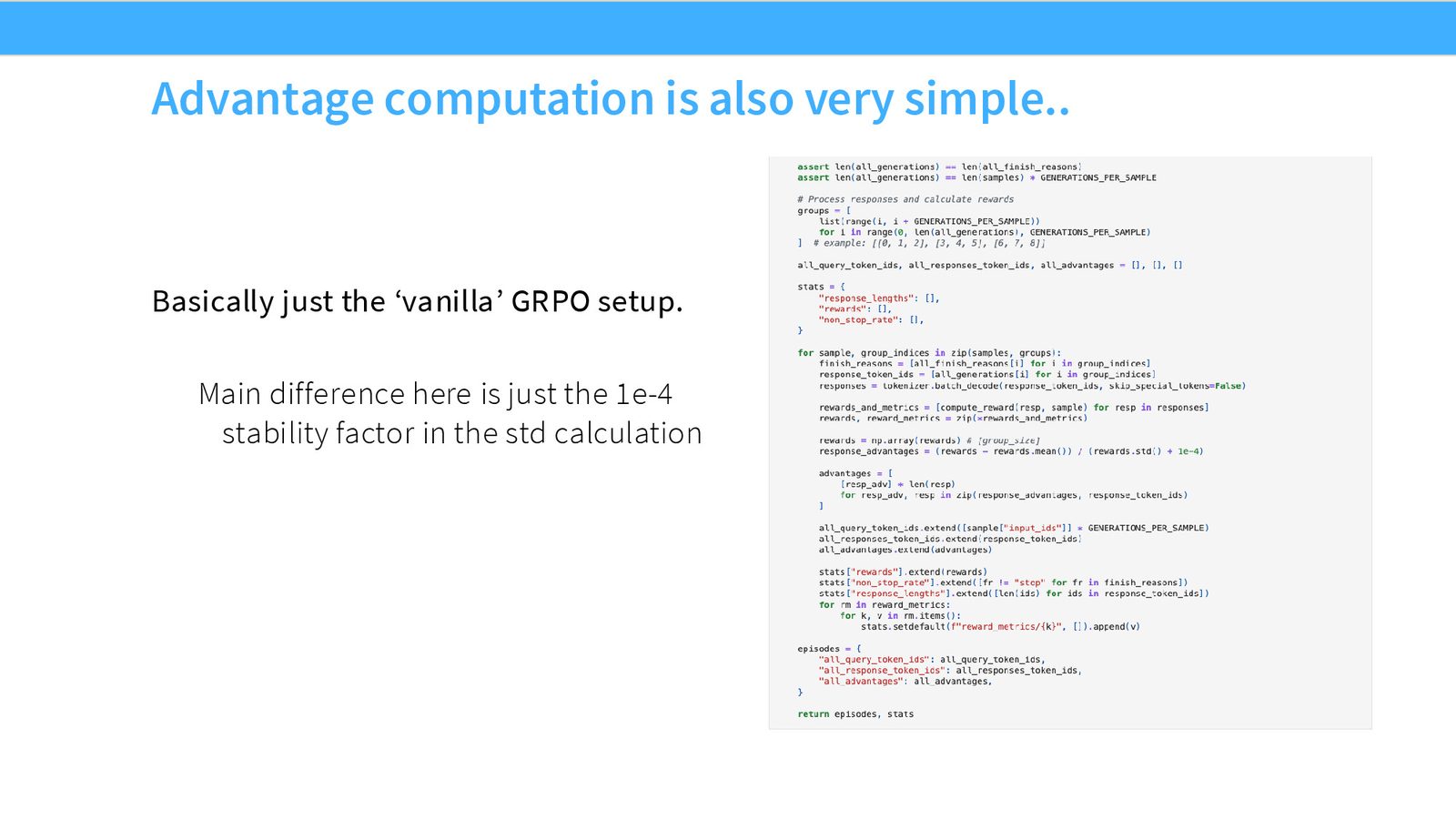

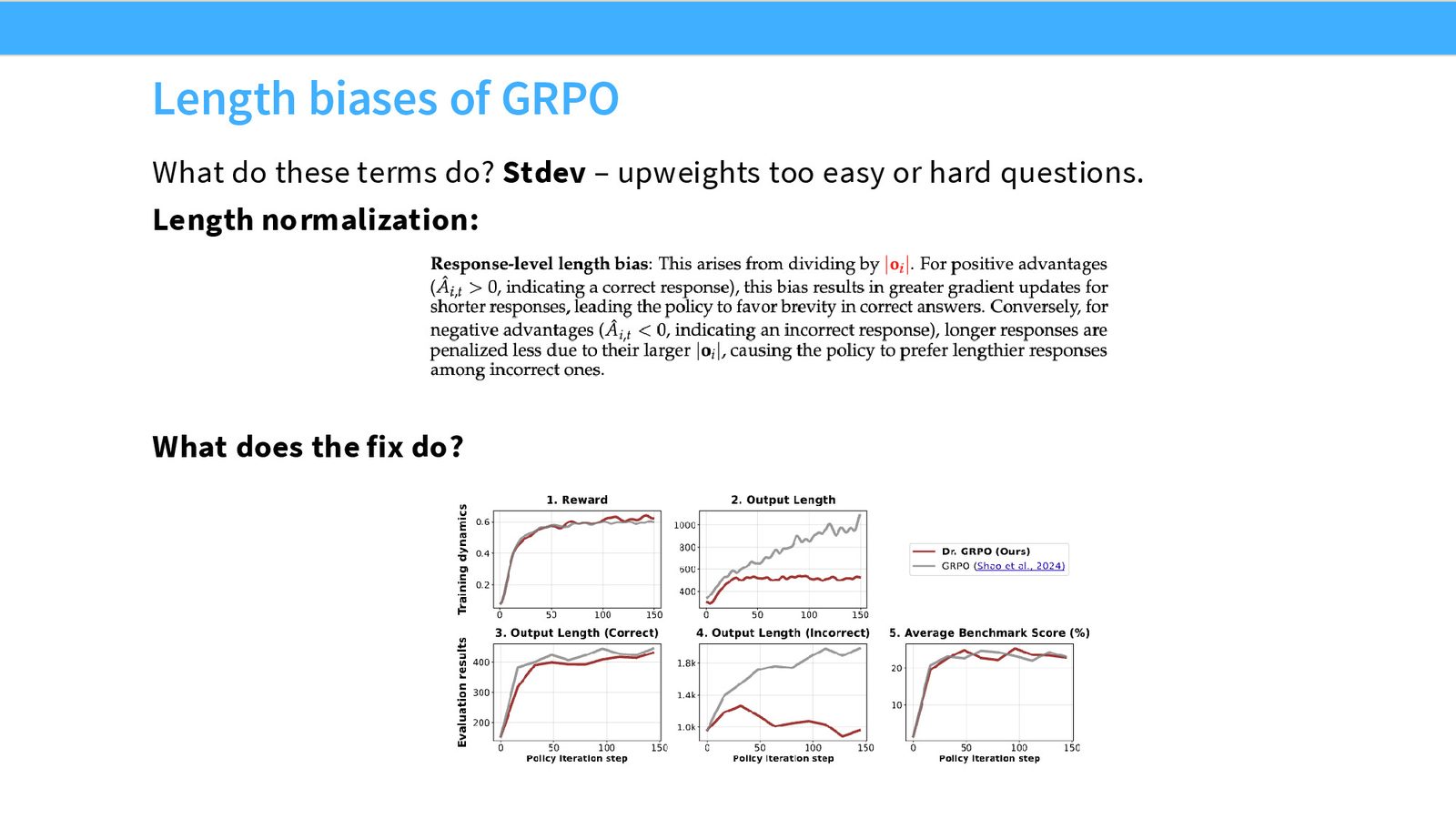
length bias 和 unbiased 版本
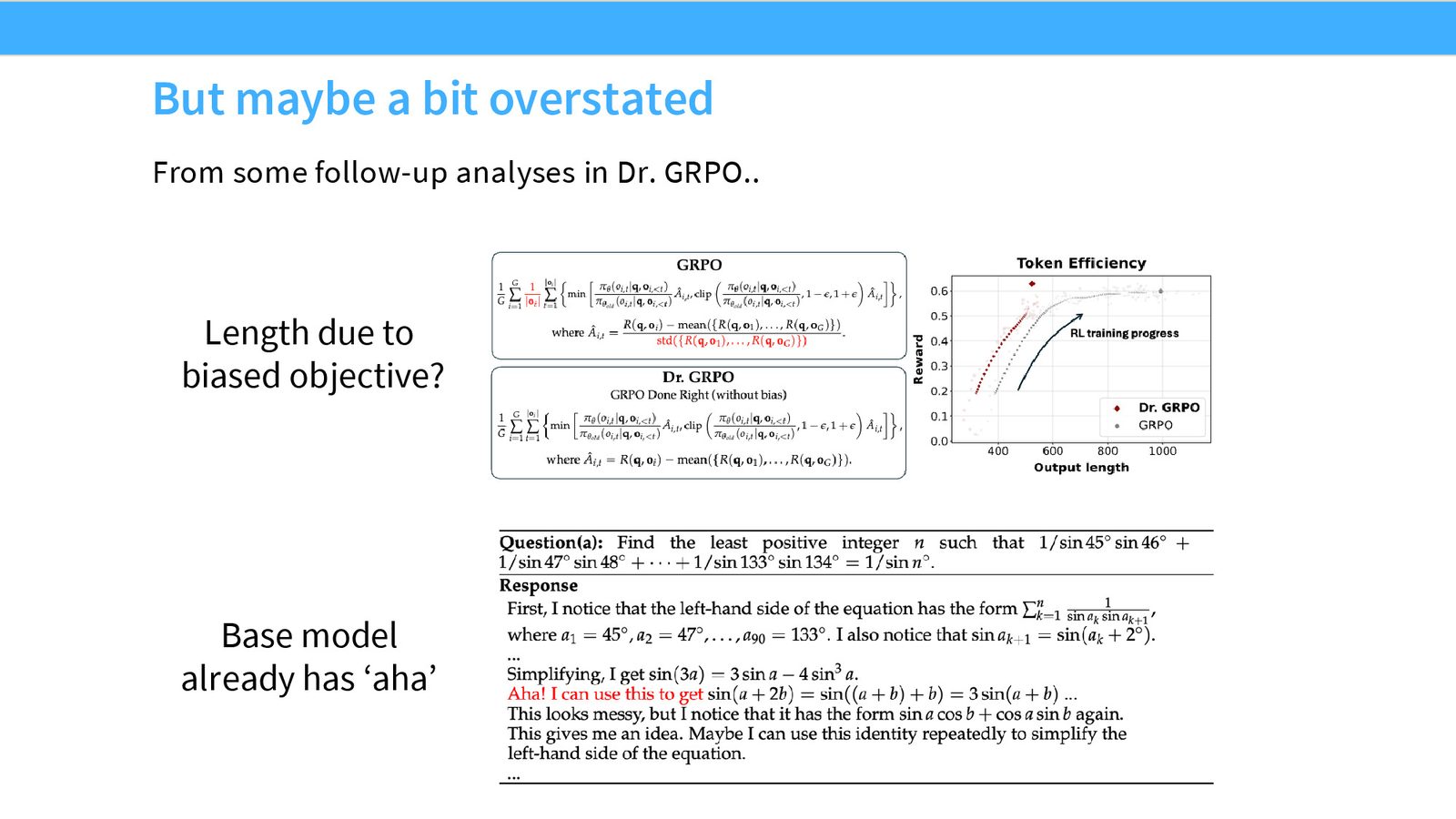
GRPO 的一个副作用是 长度偏差。因为它对 group 内的分数做归一化,模型可能会学到偏向更长或更短的回答。课堂里还提到了后续工作对这点的修正:如果希望更严格地保持梯度无偏,标准化项和长度归一化项都要重新审视。

Case Study 1: DeepSeek R1
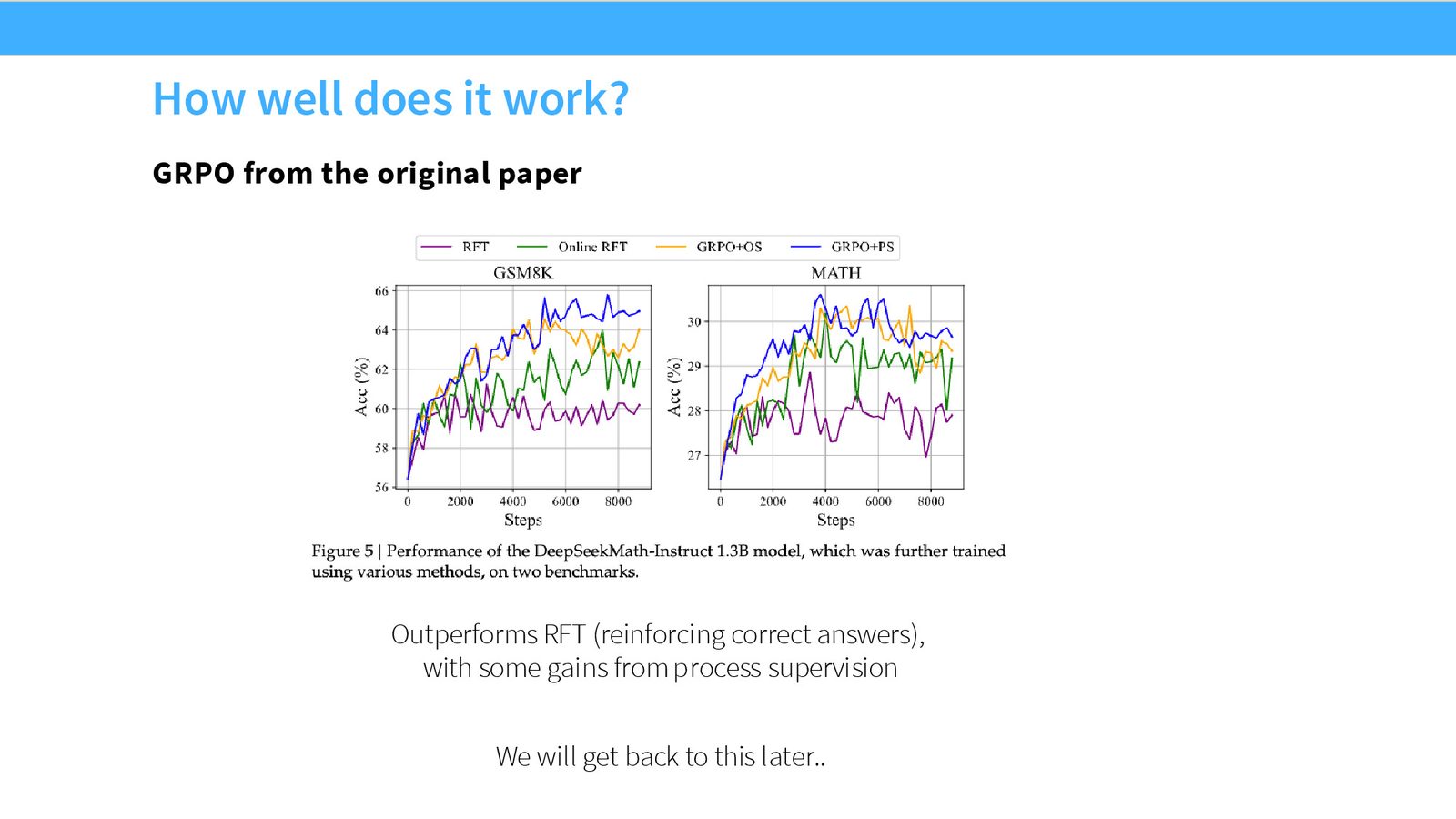
DeepSeek R1 是课堂里第一个重点案例。它之所以重要,不只是因为性能强,还因为它把一条相对简洁的 RLVR recipe 推到了大众视野:强 verification reward + GRPO + 合理的 SFT 初始化 + 后续蒸馏。

R1-zero 和 R1
课堂区分了两个版本:
- R1-zero:更“纯”的 RLVR 设置,用 accuracy reward 和 format reward 推动训练。
- R1:在 R1-zero 的基础上,再加 SFT 初始化、语言一致性 reward、以及更实用的后处理阶段。
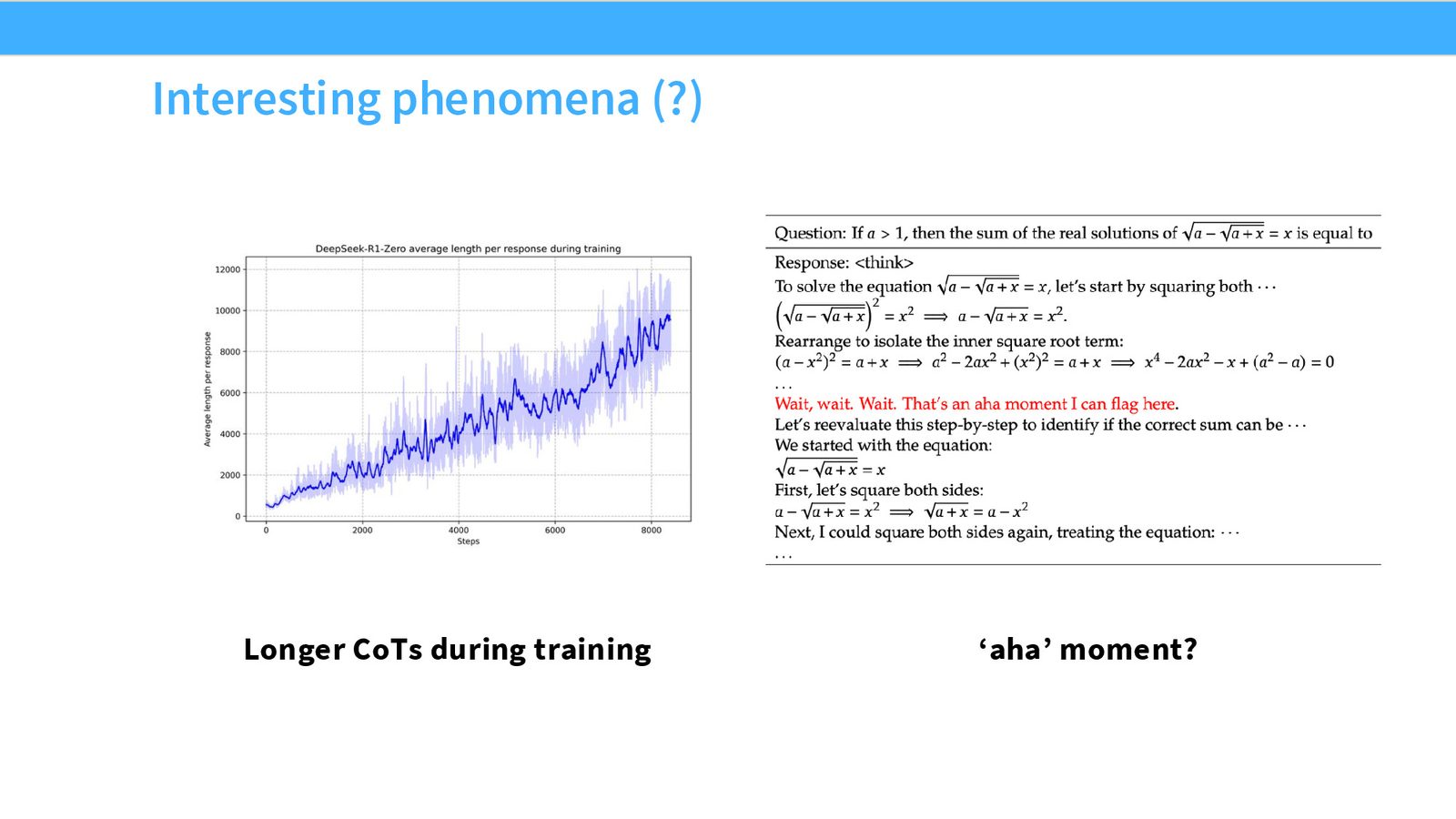
R1-zero 的有趣现象是:训练中会出现更长的 CoT,有时还会冒出所谓的 aha moment。但课上也提醒,不能把这些现象讲得太神秘,因为它们也可能部分来自目标函数偏置和基座模型本身的能力。

蒸馏和失败路线
DeepSeek R1 还有一个很重要的结论:reasoning 能蒸馏。也就是说,让大模型先用 RLVR 形成 reasoning traces,再把这些长 CoT 蒸馏给较小模型,是一条非常实用的路线。
同时,课堂也提醒了另一个事实:很多大家曾经寄予厚望的路线,未必是最后赢家,例如 PRM、MCTS 等。这个领域里真正起作用的,往往不是“理论上最花哨的东西”,而是能稳定跑通的 recipe。


Case Study 2: Kimi K1.5
Kimi K1.5 和 R1 几乎是同时代的另一个重要例子。课堂把它挑出来,是因为它和 R1 有相似的目标,但在细节上提供了不同的工程视角。
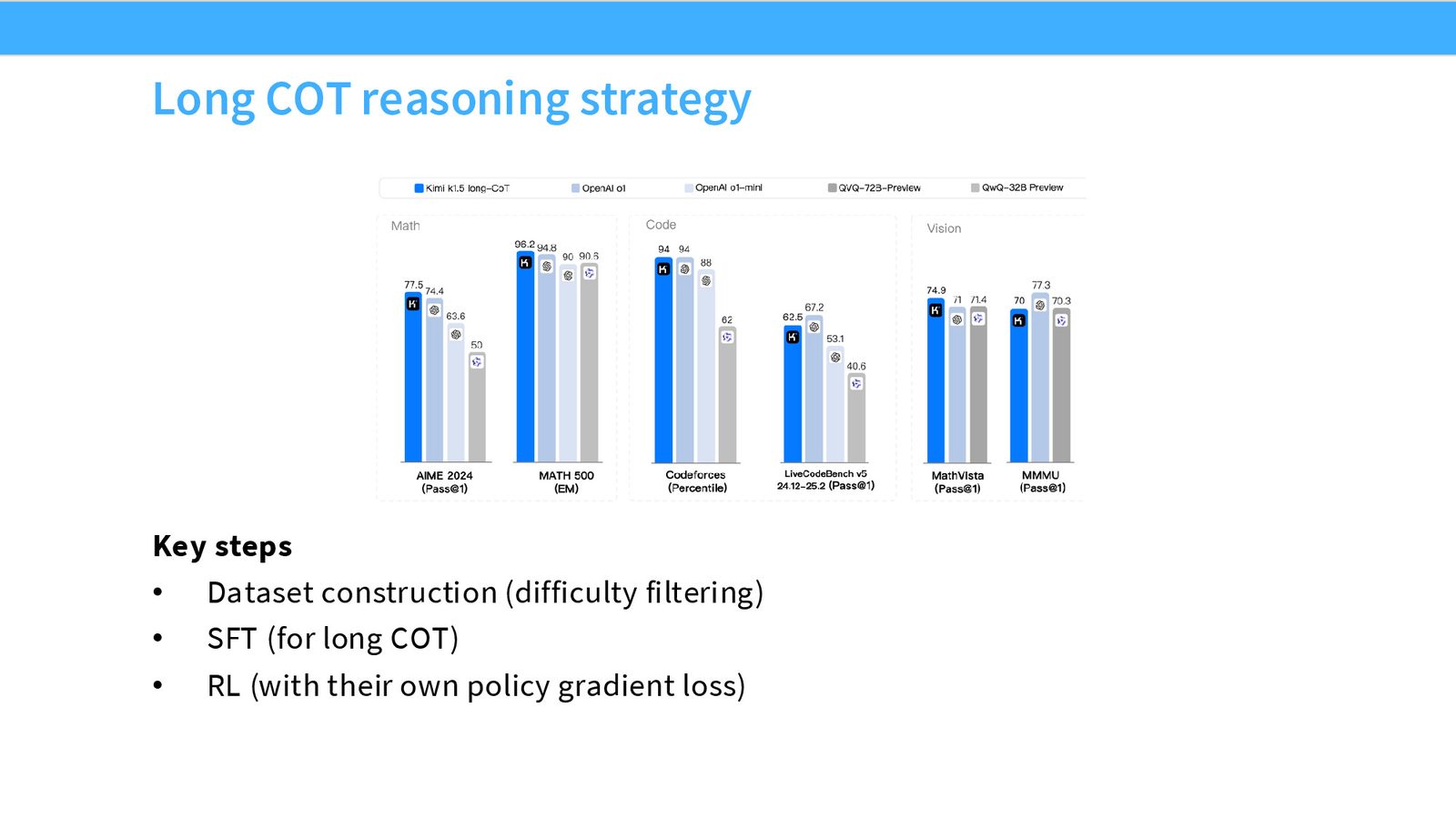
数据、长度控制和系统细节
Kimi 这条线的重点很实际:
- 先做难度过滤和数据课程安排。
- 先用长 CoT 的 SFT 打底。
- 再用自己的 policy gradient / RL 配方去做强化。
- 训练中还加入了长度控制,避免 CoT 无限制拉长。
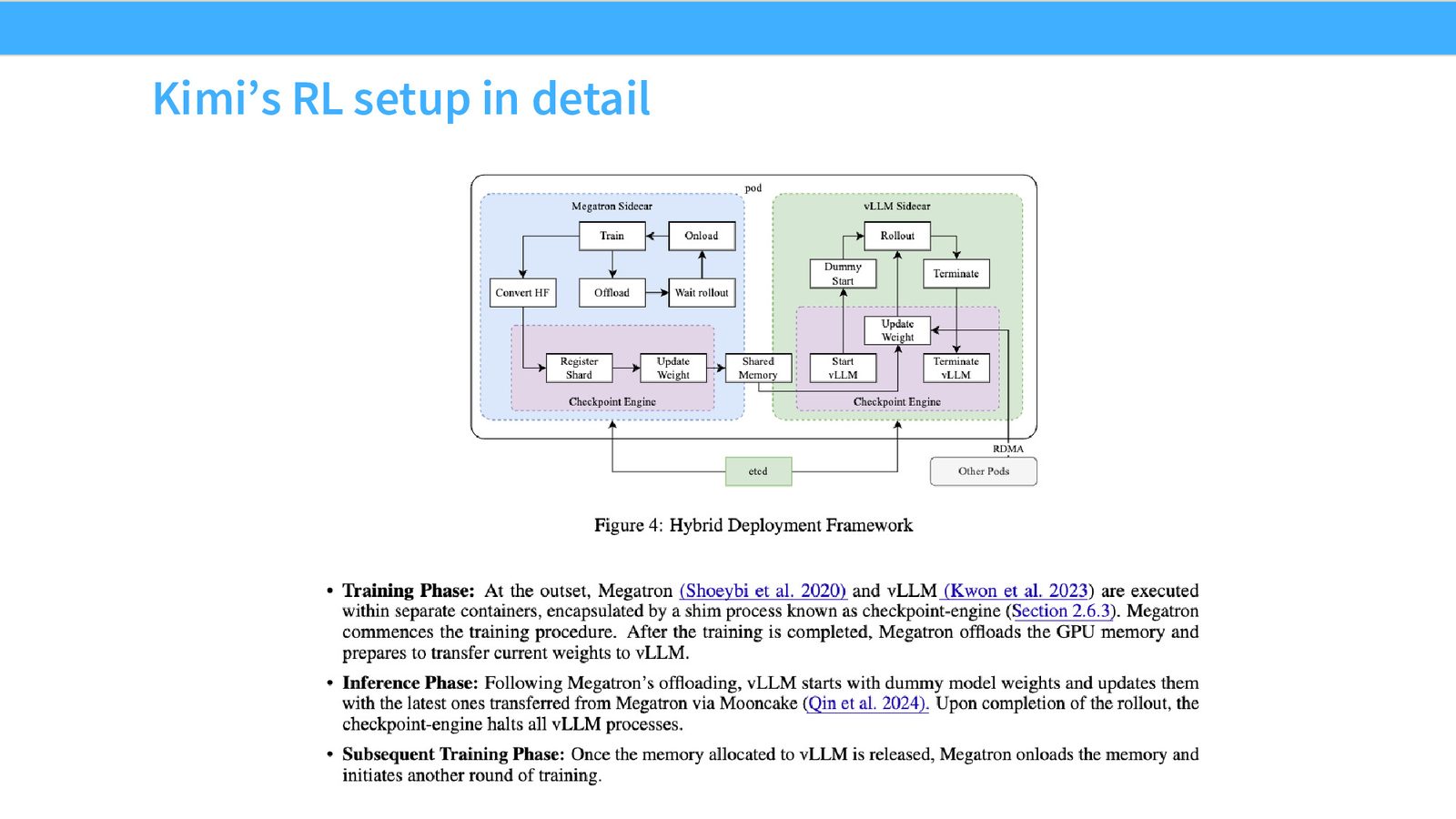
课堂特别强调,RL 系统本身很吃工程:on-policy rollouts 慢、训练框架切换麻烦、长 CoT 让 batch 更不均匀。这些都不是“算法论文里一个公式”能解决的。




Case Study 3: Qwen 3
最后一个案例是 Qwen 3。课堂给它的定位是“更晚出现、但更系统地整合了前面这些经验”的一个开放模型尝试。
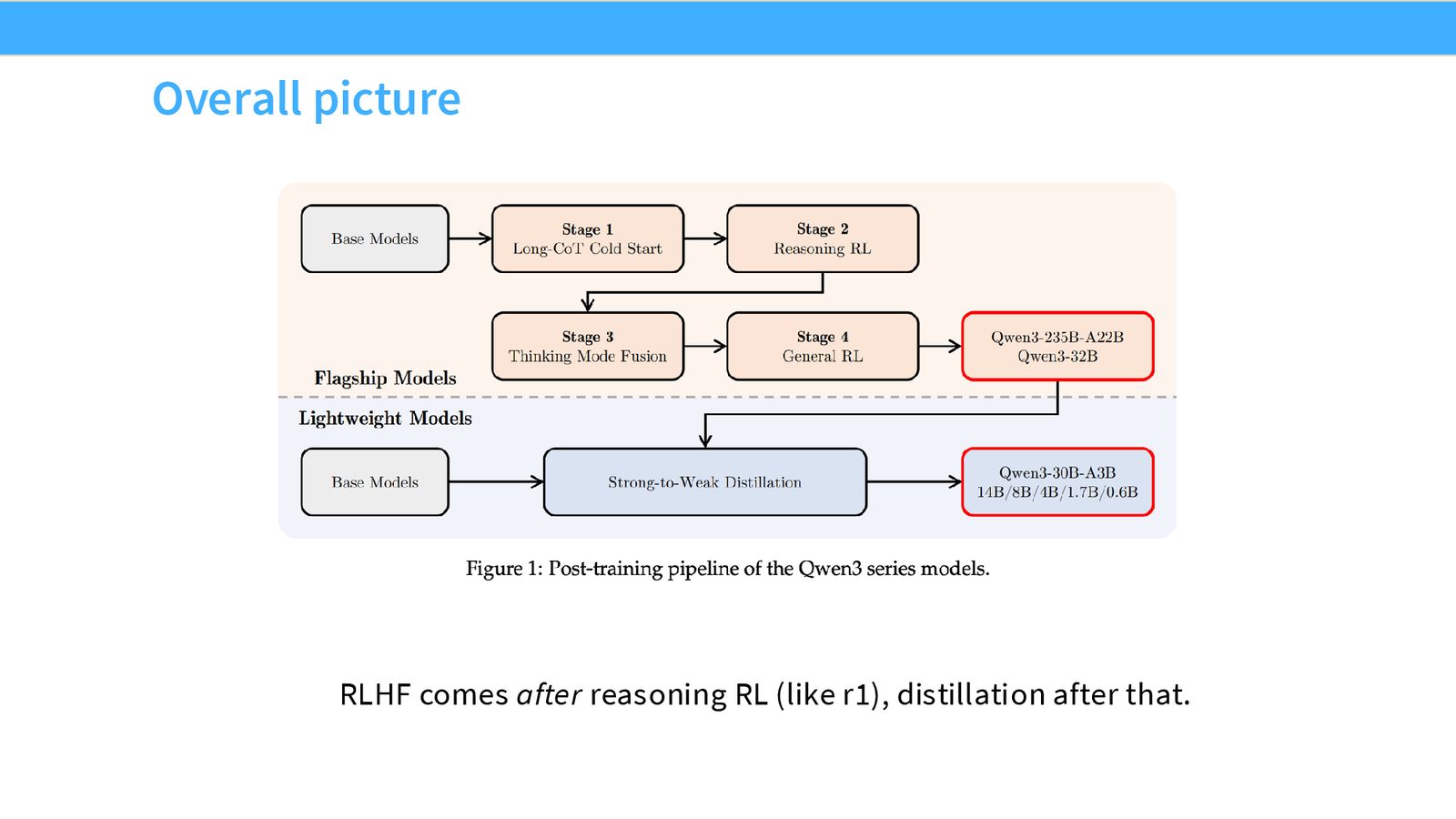
SFT + reasoning RL + 组合策略
Qwen 3 的 recipe 里有几个很清楚的点:
- 对训练数据做难度过滤,优先保留模型最开始做不好的题。
- 清理掉模型本来就能轻松做对的题,避免把算力浪费在简单样本上。
- 对 CoT 的质量做人工或半人工过滤,区分“猜对”和“真推对”。
- 用很小的一批样本也能启动 reasoning RL。
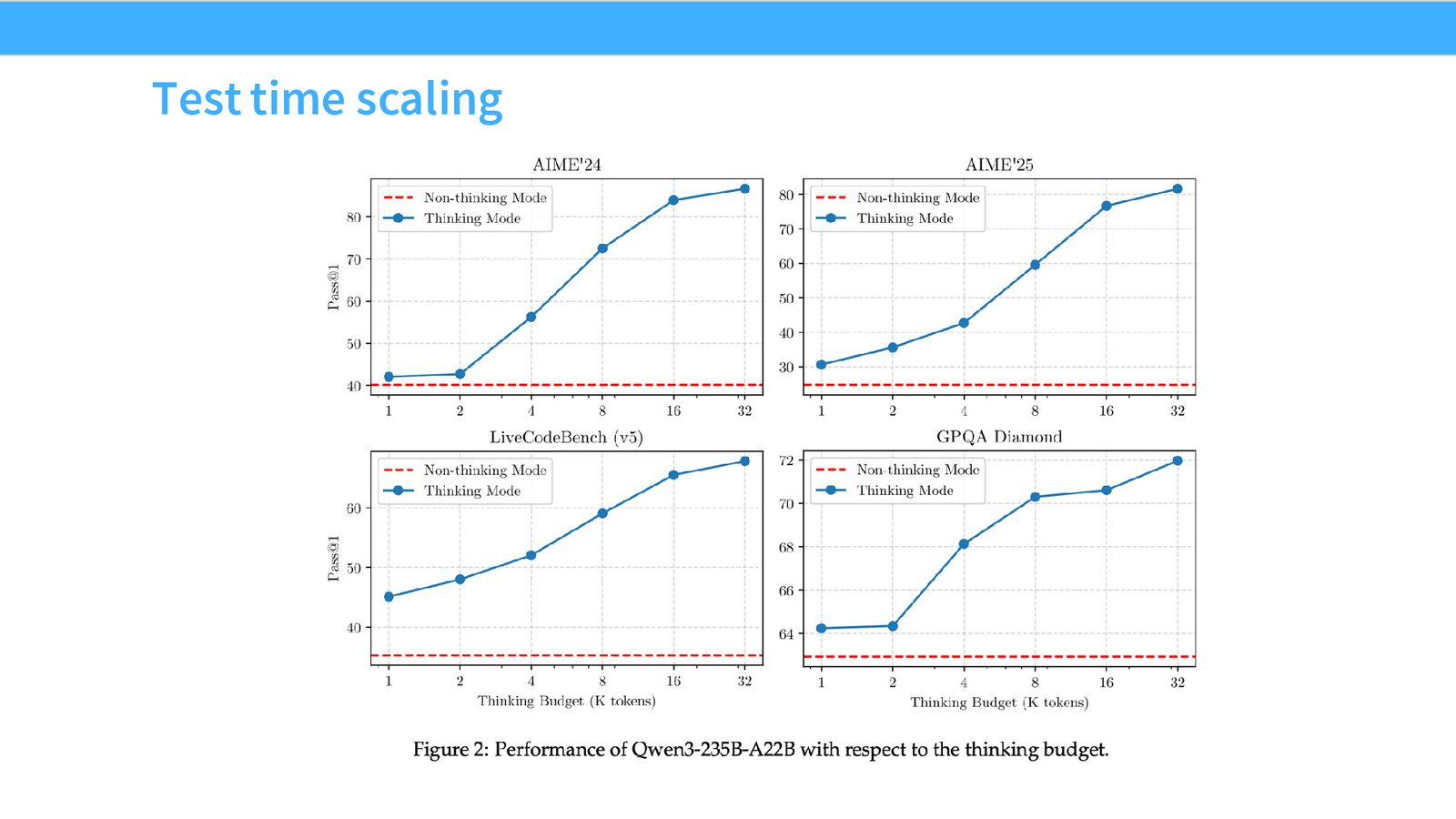
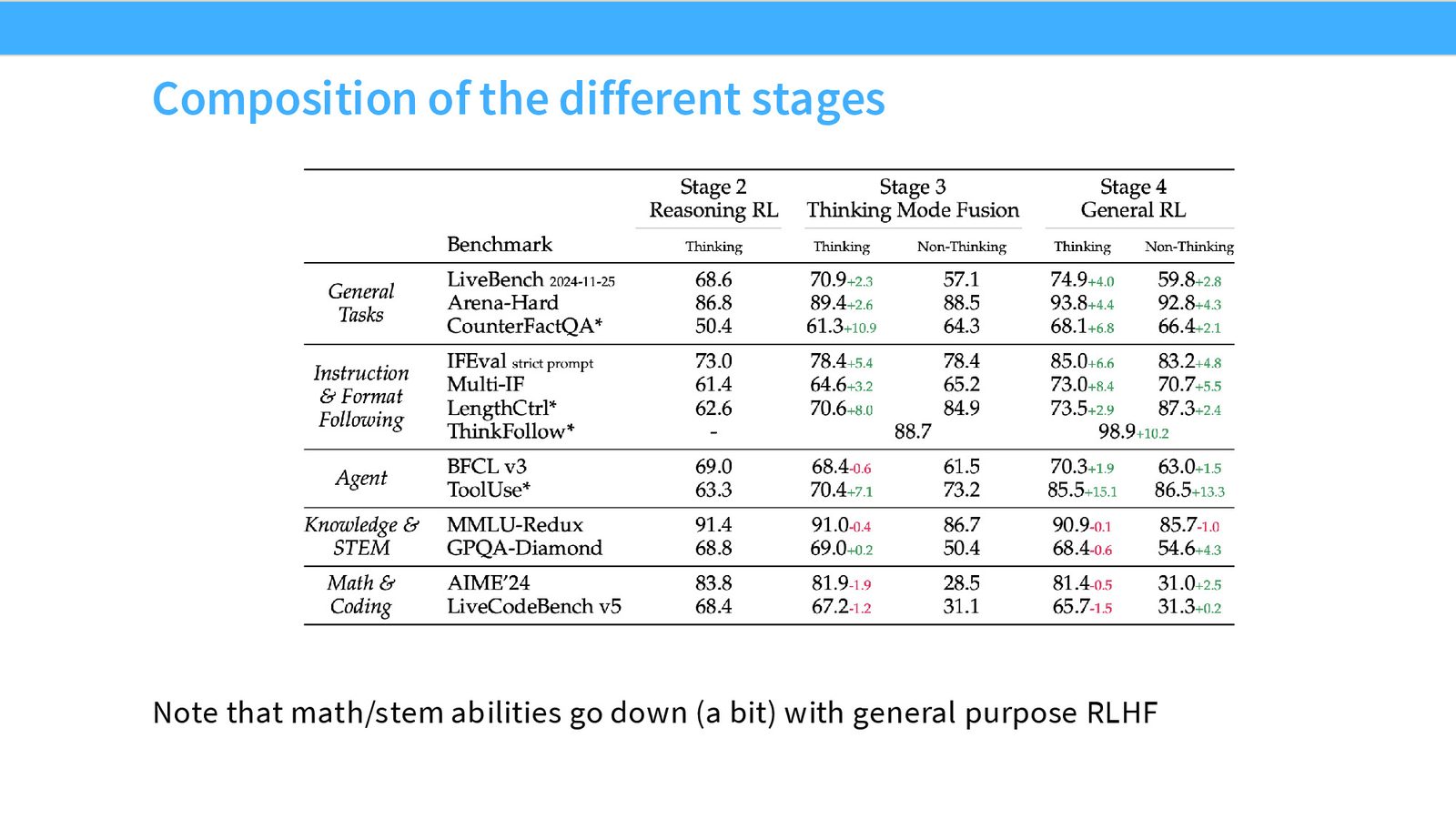
之后再进入更成熟的 post-training 流程:先 reasoning RL,再做常规 RLHF,最后配合蒸馏和 test-time scaling。


总结与延伸
本章小结
这一讲的主结论可以压缩成四句:
- RLHF 有用,但很难规模化,而且容易出现 overoptimization 和 calibration 退化。
- PPO 能工作,但工程上重,value function、rollout、reward shaping 都让系统复杂。
- GRPO 把 PPO 进一步简化,去掉 value 网络,用 group normalization 代替复杂的 advantage 估计。
- RLVR 是 reasoning 模型的重要路线,DeepSeek R1、Kimi K1.5、Qwen 3 都说明了这点。
今天最值得带走的一句话
当 reward 可验证时,RL 不再只是“更难调的偏好优化”,它会变成一个能真正推动 reasoning 模型扩展的训练工具。