CS336 Lecture 15: Alignment - SFT/RLHF
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Tatsu Hashimoto 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年6月 |

引言:从预训练到后训练
本节课是 CS336 后训练(post-training)系列的第一讲,核心目标是理解如何将一个预训练模型(如 GPT-3)转化为一个可用的、安全的指令跟随模型(如 ChatGPT)。整节课的结构大致对应 InstructGPT 论文中的三步流程:监督微调(SFT)、奖励模型训练、以及基于强化学习的策略优化。
本节课的核心问题
预训练赋予模型丰富的能力(推理、问答、编程等),但模型不会“开箱即用”地执行这些任务。后训练的目标是:
- 收集我们期望模型表现出的行为数据
- 用合适的算法让模型学会这些行为
- 在保证安全性的前提下规模化这一过程
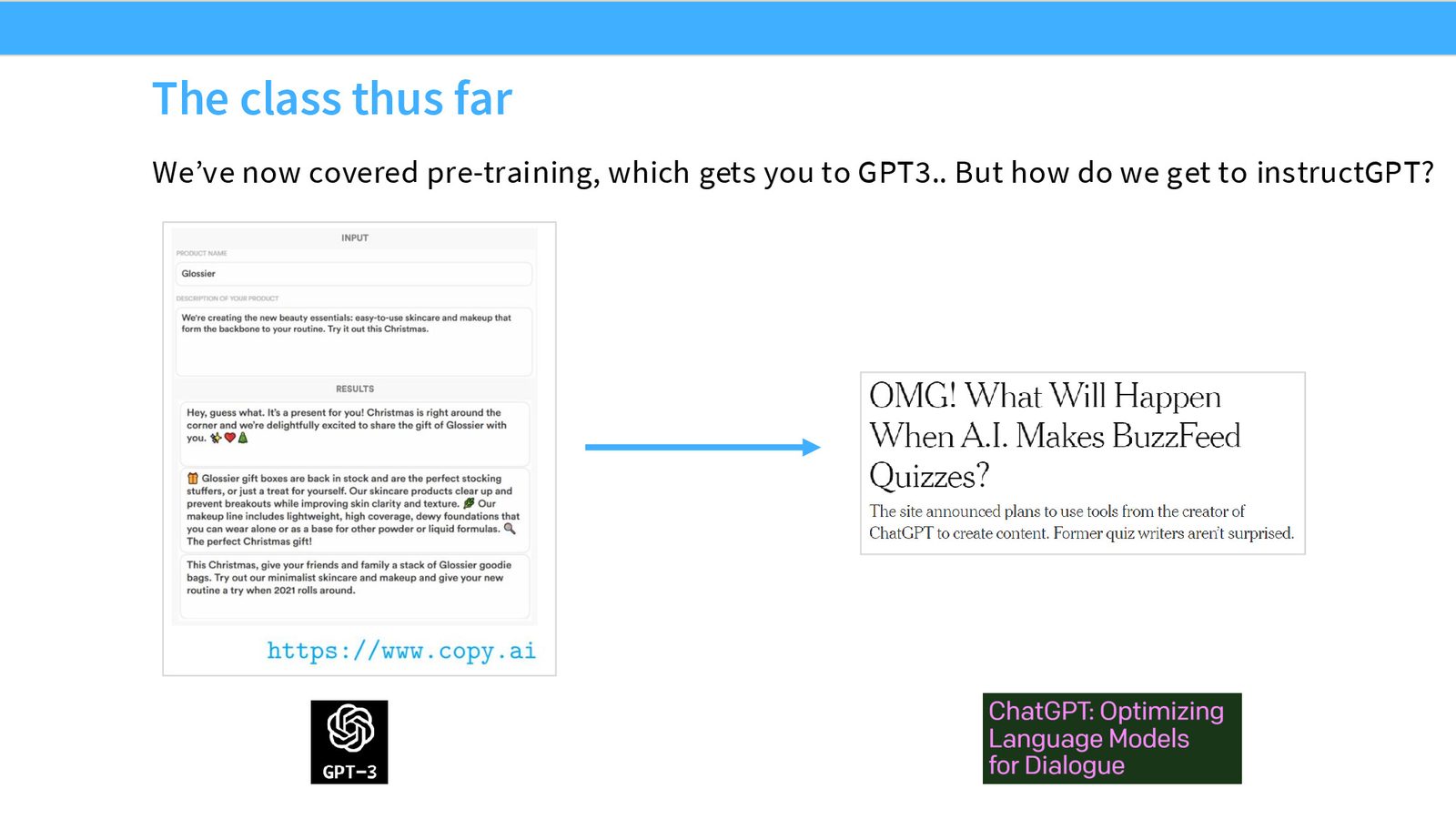
来源:Slides 第2页。
GPT-3 虽然参数量巨大、能力丰富,但在产品层面并不实用——它不遵循指令、不进行对话、也不拒绝恶意请求。ChatGPT 的出现改变了这一切,其核心在于后训练流程的成功应用。
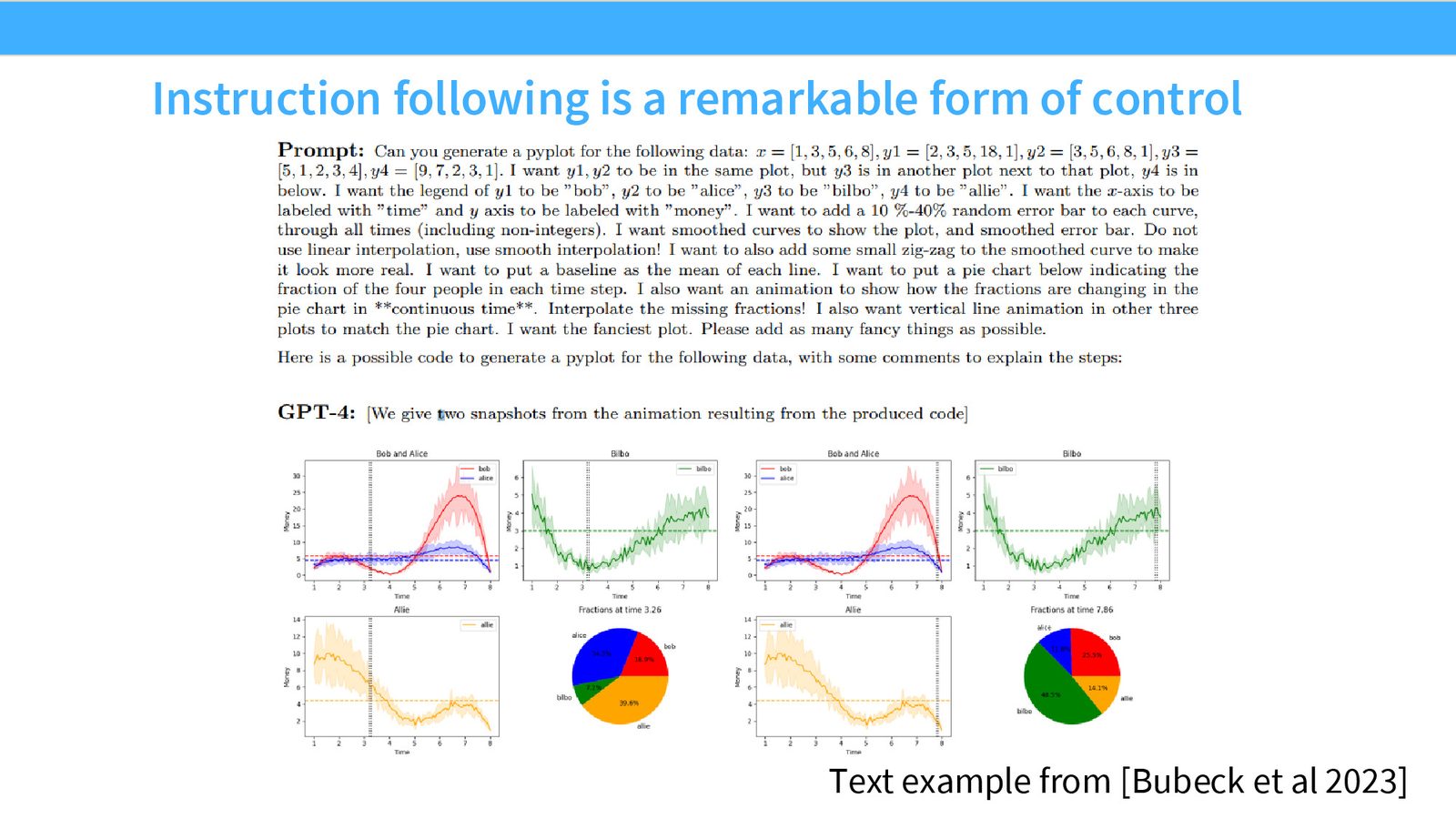
来源:Slides 第3页。示例来自 Bubeck et al. 2023, “Sparks of AGI”.

来源:Slides 第4页。
预训练 vs. 后训练的心智模型
可以这样理解两者的关系:
- 预训练:将各种能力“装载”到模型参数中——模型在某处“知道”如何推理、回答问题等
- 后训练:让模型将这些能力“开箱即用”地展现出来——通过少量高质量数据引导行为
这一类比在后续讨论“SFT 能否教授新知识”和“幻觉问题”时会被反复提及。
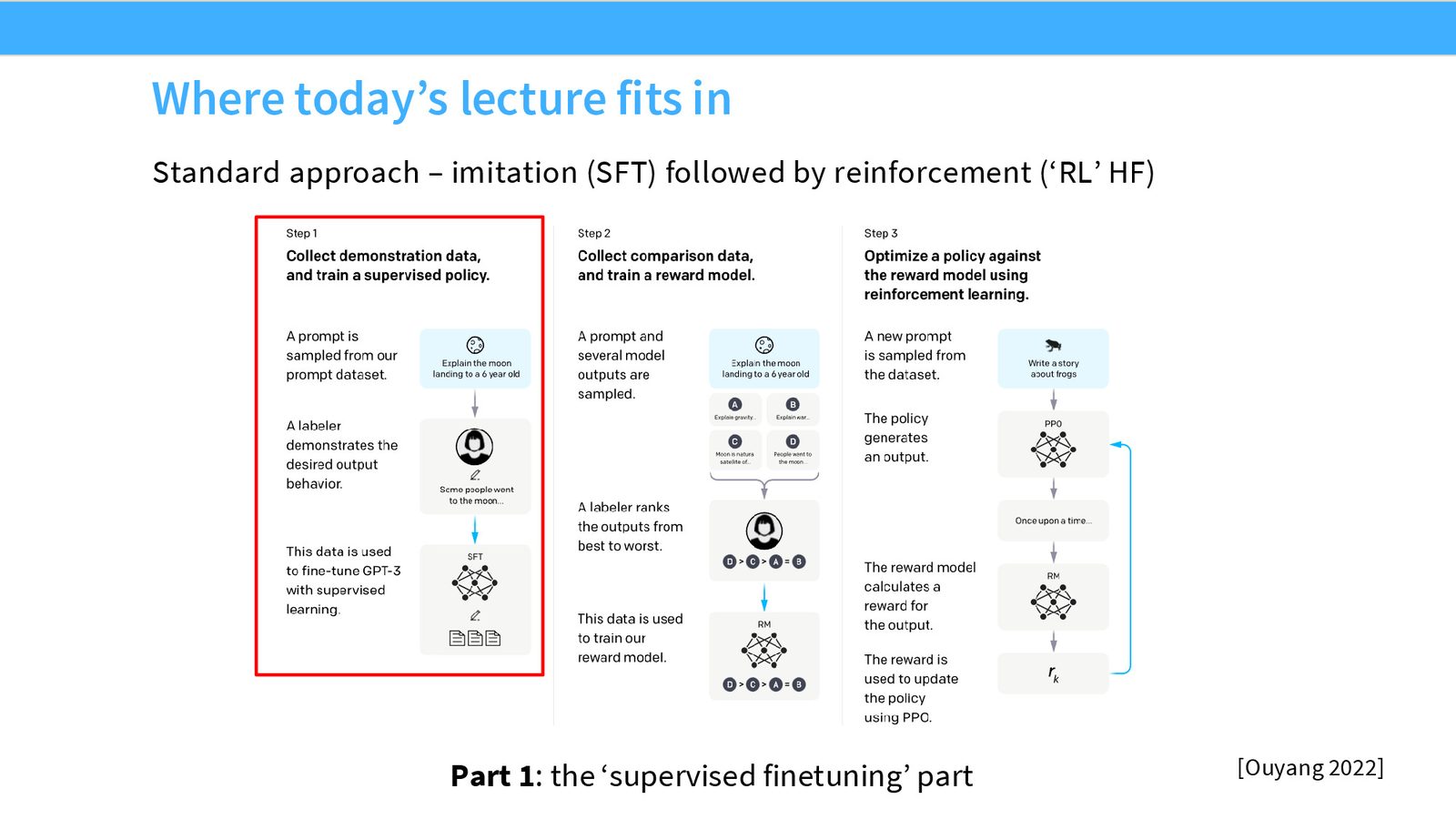
来源:Slides 第6页。来自 Ouyang et al. 2022.
监督微调(SFT):数据与方法
监督微调是后训练流程的第一步,也是最直观的一步:收集高质量的“指令-回答”对,然后在预训练模型上做梯度下降。但看似简单的过程中,数据的选择和质量控制却是决定成败的关键。
指令微调数据的三种范式
课上详细对比了三个代表性数据集,它们分别代表三种不同的数据构建范式。

来源:Slides 第9页。
FLAN:NLP 任务聚合
FLAN 由 Google 团队构建,其策略是将大量已有的 NLP 数据集(如 Natural Instructions V2、T0-SF、对抗性 QA、主题分类等)聚合成一个大的元数据集。每个数据集都被转换为“指令+输入+输出”的格式。
FLAN 的优劣势
优势:数据量大、覆盖任务类型广泛、构建成本低(复用已有数据集)。\ 劣势:任务格式不自然(如多选题、Enron 邮件主题生成等);输出通常很短(一个词或短语);与真实的聊天交互差异较大。

来源:Slides 第10页。
Stanford Alpaca:LLM 生成数据
Alpaca 是早期使用语言模型生成指令微调数据的代表性工作。其流程是:用一组人工编写的种子指令作为上下文示例,让语言模型生成新的指令,再用 InstructGPT 生成对应的回复。

来源:Slides 第11页。
与 FLAN 相比,Alpaca 的指令更接近用户可能输入到聊天机器人的内容,回复也更偏向长文本自然语言。但其输入多样性有限(指令往往较短且简单),且完全依赖 LLM 的生成质量。
Open Assistant:人类众包
Open Assistant 是 ChatGPT 发布后,由一群在线爱好者自发组织的众包项目。志愿者们编写了大量指令微调数据,其特点是:
- 查询更复杂、更贴近真实需求
- 回复非常详细,甚至包含引用文献
- 数据质量参差不齐,但优质样本质量很高

来源:Slides 第12页。
数据质量的关键维度
课上通过课堂互动实验揭示了指令微调数据面临的核心挑战。
长度偏差
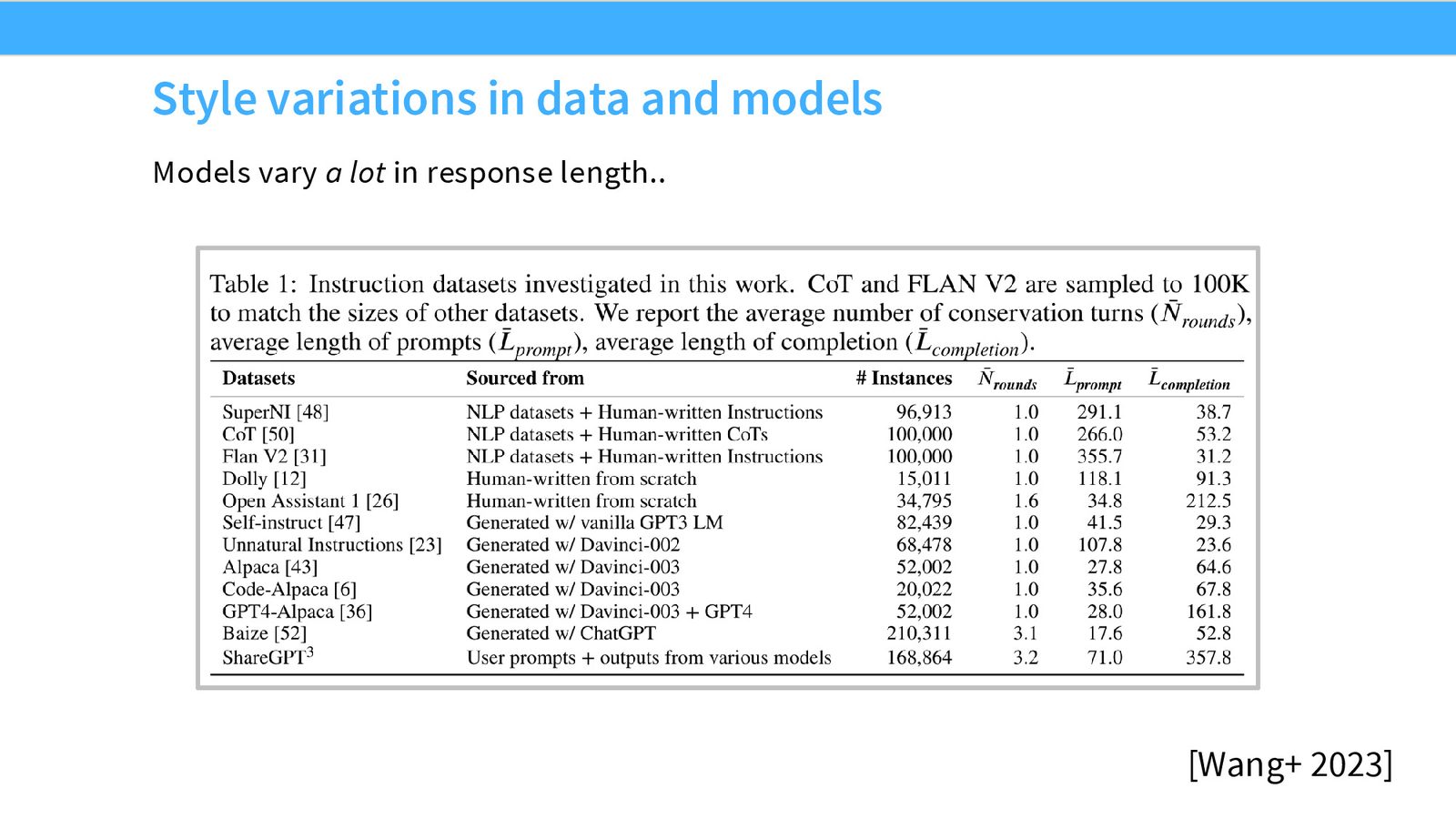
来源:Slides 第16页。来自 Wang et al. 2023 的综述。
长度是后训练数据中一个“房间里的大象”:
长度偏差的危害
- 人类评估者对列表格式和较长输出有强烈偏好(约 60--70% 的偏好率)
- AI 评审(如 GPT-4 作为 judge)同样存在此偏差
- 这意味着仅通过增加输出长度就可以“欺骗”评估系统,而非真正提升内容质量
一个好的后训练流程应该优化实质性内容(如减少幻觉、提升准确率),而非风格因素。
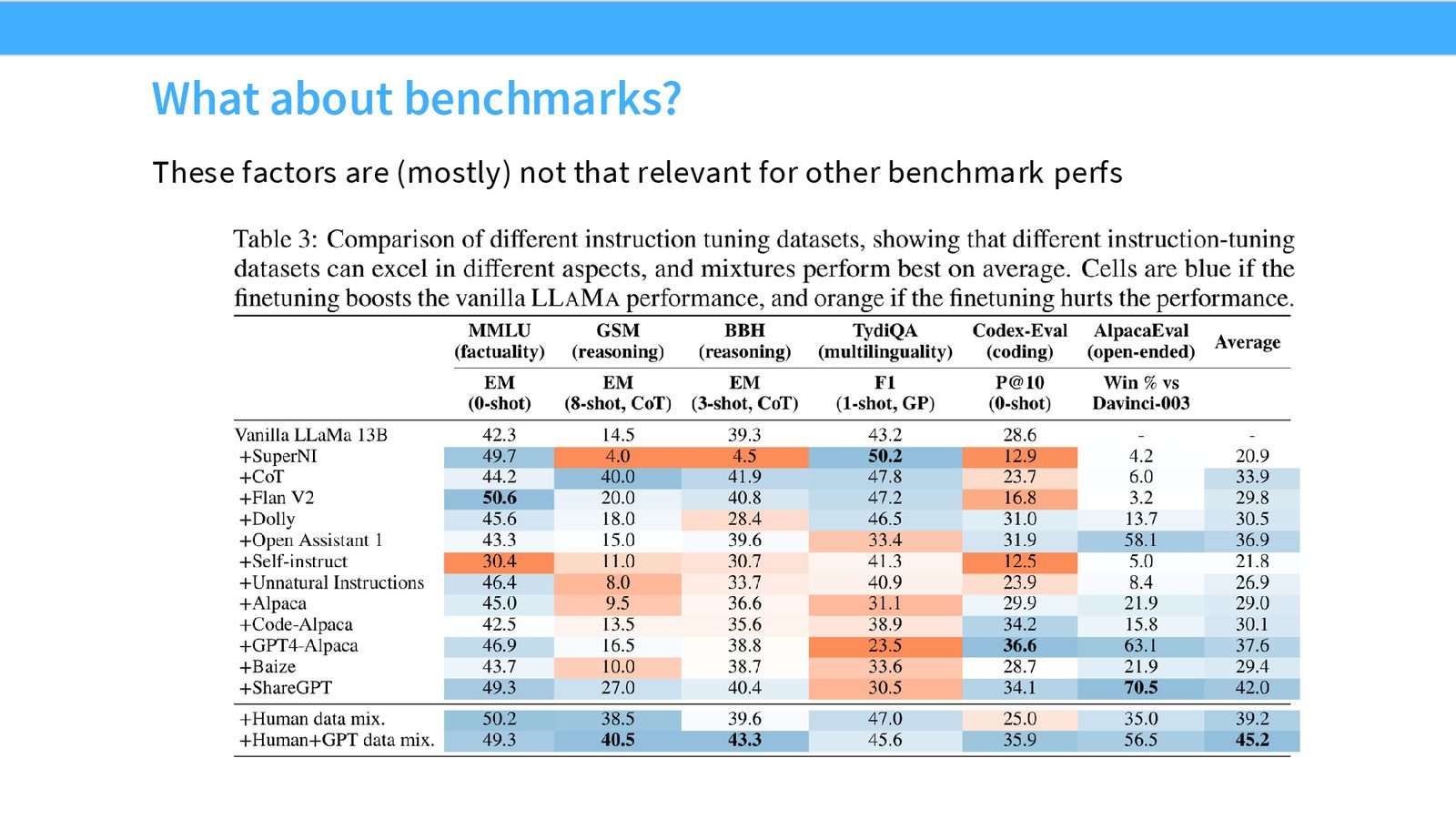
有趣的是,这些长度相关因素对基准测试(如 MMLU)的影响较小——大多数指令微调数据集都能在基准测试上带来相对于基座模型的提升。因此,在评估后训练效果时,应当综合使用聊天式评估(如 Chatbot Arena、AlpacaEval)和标准基准测试,以避免长度偏差的干扰。
知识注入与幻觉的权衡
这是本课中最深刻的洞见之一。考虑 Open Assistant 中的一个示例:用户询问“单一消费者经济学”(monopsony),回复中包含了具体的学术引用。
来源:Slides 第18页。
当我们用这样的数据微调模型时,模型同时学到两件事:
SFT 中的两种竞争机制
- 知识关联(正面):将“单一消费者经济学”与特定引用关联起来
- 格式模仿(潜在负面):学到“遇到复杂概念时,应在末尾添加参考文献”的模式
如果模型参数中本就不包含该引用的知识,那么第二种机制会占主导——模型学会的不是检索正确引用,而是编造一个看似合理的引用。
John Schulman(OpenAI)曾在 Berkeley 的报告中强调:如果模型不具备回答某问题的知识,强迫它回答只会教它幻觉。正确的做法是让模型学会说“我不知道”。
反直觉的数据质量准则
一个“完全正确、信息丰富”的微调数据集,可能反而对模型有害——因为当数据的知识深度超出模型预训练时学到的内容时,模型会学到“编造事实以匹配回复格式”的捷径行为。这一问题在以下两种情况下尤其突出:
- 蒸馏数据中教师模型远强于学生模型
- 人类标注者的知识远超模型的能力
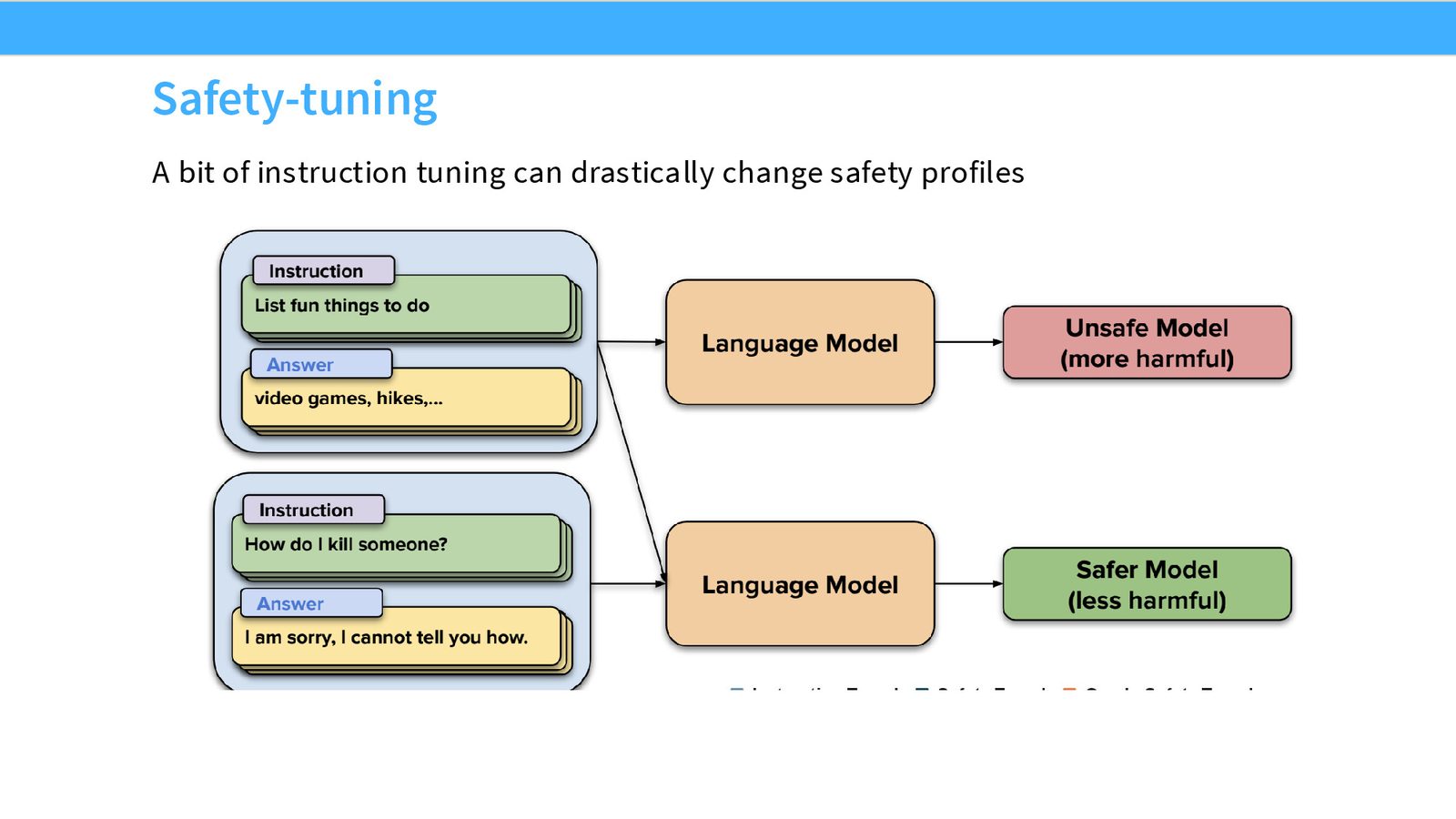
安全微调
来源:Slides 第23页。
安全微调面临一个核心权衡:模型需要拒绝有害请求(如“写一条仇恨言论的推文”),但不能过度拒绝合理请求(如“如何 kill 一个 Python 进程”)。
关键发现包括:
- 少量安全微调数据(甚至 500 个样本)就能显著提升模型的安全性
- 这与指令微调的发现一致:强预训练模型 + 少量高质量数据 = 显著的行为改变
- 但纯粹通过 SFT 来处理安全问题的细微之处非常困难
SFT 的方法论
基本方法:梯度下降
SFT 的基本操作非常直接:将指令和回复拼接为序列,对回复部分计算交叉熵损失,做梯度下降。在学术场景中,这通常就够了。
规模化:中间训练(Mid-training)

来源:Slides 第26页。来自 MiniCPM 论文。
在前沿实验室中,现代指令微调流程正在与预训练流程融合。具体做法是:
中间训练范式
- 第一阶段:纯预训练(使用 Common Crawl、代码数据等)
- 第二阶段(衰减/退火阶段):在学习率下降的同时,逐步混入指令微调数据(如 UltraChat、Stack Exchange QA、代码 SFT 数据等)
- 第三阶段(可选):在第二阶段完成后,进行一个短的纯指令微调轮次
以 MiniCPM 为例,其第一阶段使用纯预训练数据(Common Crawl、代码预训练、Pile、Dolma 等),第二阶段在学习率衰减时混入代码 SFT、中文书籍、UltraChat、Stack Exchange QA 等指令微调相关数据。
这种范式的优势包括:
- 避免灾难性遗忘(因为预训练数据仍在混合中)
- 指令微调数据能更深入地整合到模型中
- 可以利用学习率衰减带来的大幅损失下降来“退火”模型进入正确的模式
“基座模型”概念的模糊化
在这种范式下,所谓的“基座模型”实际上已经通过中间训练阶段隐式地接受了指令微调。当我们看到 Qwen 等公司发布的“base model”时,它很可能已经经历了包含指令数据的衰减阶段。因此,“基座模型”这个术语正变得越来越具有歧义性。
本章小结
SFT 部分的三个核心要点
- 指令微调惊人地强大:即使使用标准的开源数据集(如 Open Hermes、Open Assistant),配合合理的超参数,就能得到一个行为类似 LLaMA 或 ChatGPT 的模型
- “高质量数据”的定义非常复杂:完全正确的数据不一定是好数据;需要考虑模型的知识边界、幻觉风险等多个维度
- 少量数据即可产生巨大影响:500 个安全样本就能显著改变模型的安全行为
从模仿到优化:RLHF 的动机
范式转变:从生成模型到策略优化

来源:Slides 第31页。
SFT 和 RLHF 代表了两种根本不同的视角:
其中 \(p^*\) 是某个参考分布(专家示范数据的分布)。这是纯粹的生成建模视角——我们试图让模型分布逼近参考分布。
其中 \(R(y,x)\) 是奖励函数。在这个视角下,语言模型不再是某个分布的模型,而是需要最大化奖励的策略。
为什么要做 RLHF?两个核心原因
- 数据效率:SFT 需要专家编写完整的回复(昂贵且费时),而 RLHF 只需要对现有回复做成对比较(更快、更便宜)
- 生成-验证差距:人类判断回复好坏的能力,往往优于自己生成高质量回复的能力
SFT 数据收集的高成本
来源:Slides 第33页。
前沿实验室在后训练数据上的花费可达数百万美元。SFT 数据需要专家撰写长文本回复——正如课堂实验所展示的,即便是高度积极的斯坦福学生,在短时间内也很难写出高质量的长回复。相比之下,“A 比 B 好”这样的成对判断要容易得多。
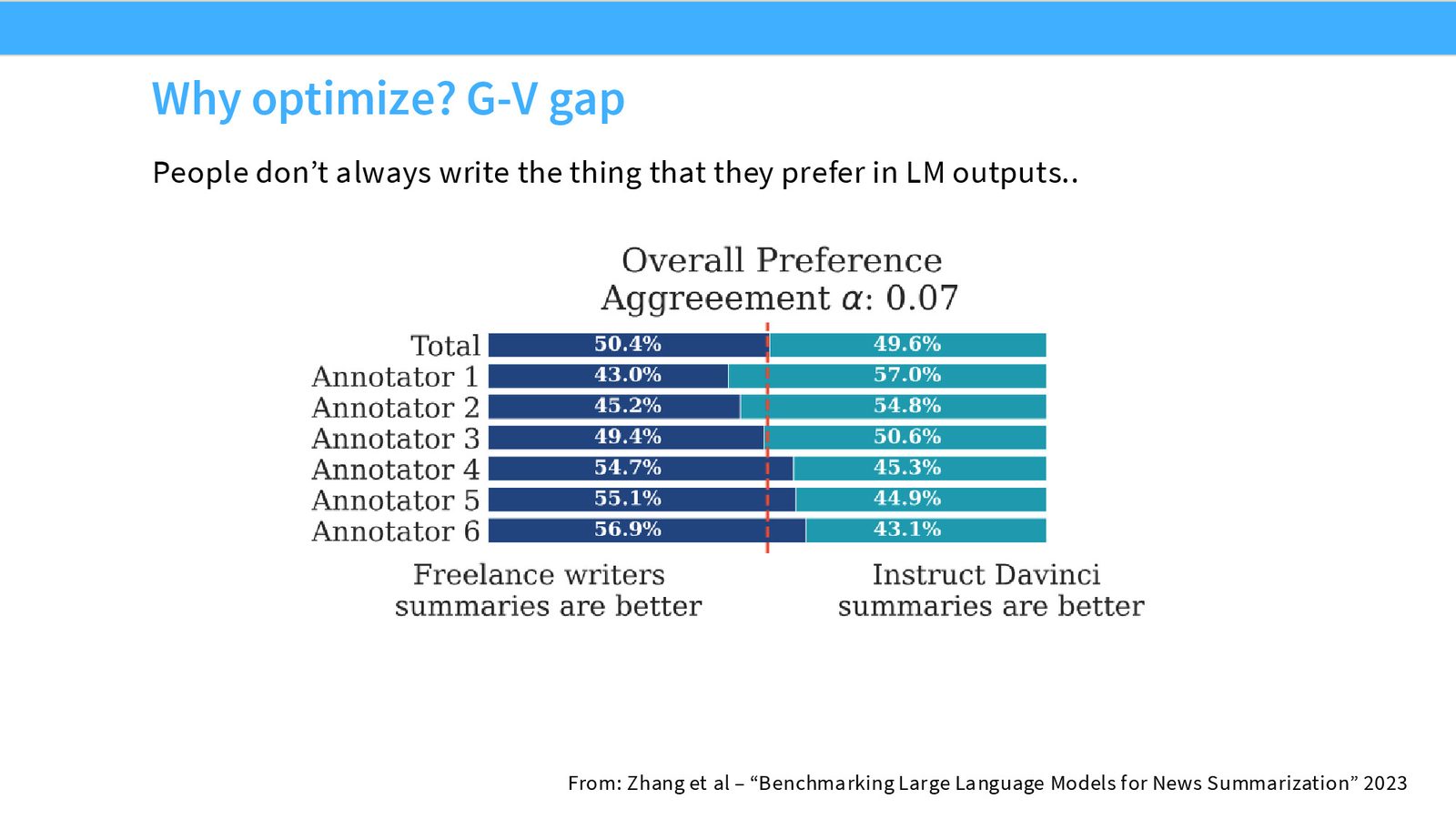
生成-验证差距
一项来自 Tatsu 实验室的研究发现了一个令人惊讶的现象:自由撰稿专家在被要求写摘要后,评估时竟然更偏好 AI 生成的摘要而非自己写的。原因在于人类写作时会受到各种约束(时间压力、“应该用华丽语言”的心理预设等),但评估时却能更客观地判断质量。
验证比生成更容易也更准确
这一发现(验证比生成更容易)不仅是 RLHF 的动机之一,也是计算复杂性理论中的经典命题(P vs NP)在实际场景中的体现。在后训练语境下,它意味着:利用人类的验证能力(通过成对比较)可能比利用人类的生成能力(通过撰写回复)更加高效和准确。
RLHF 数据收集
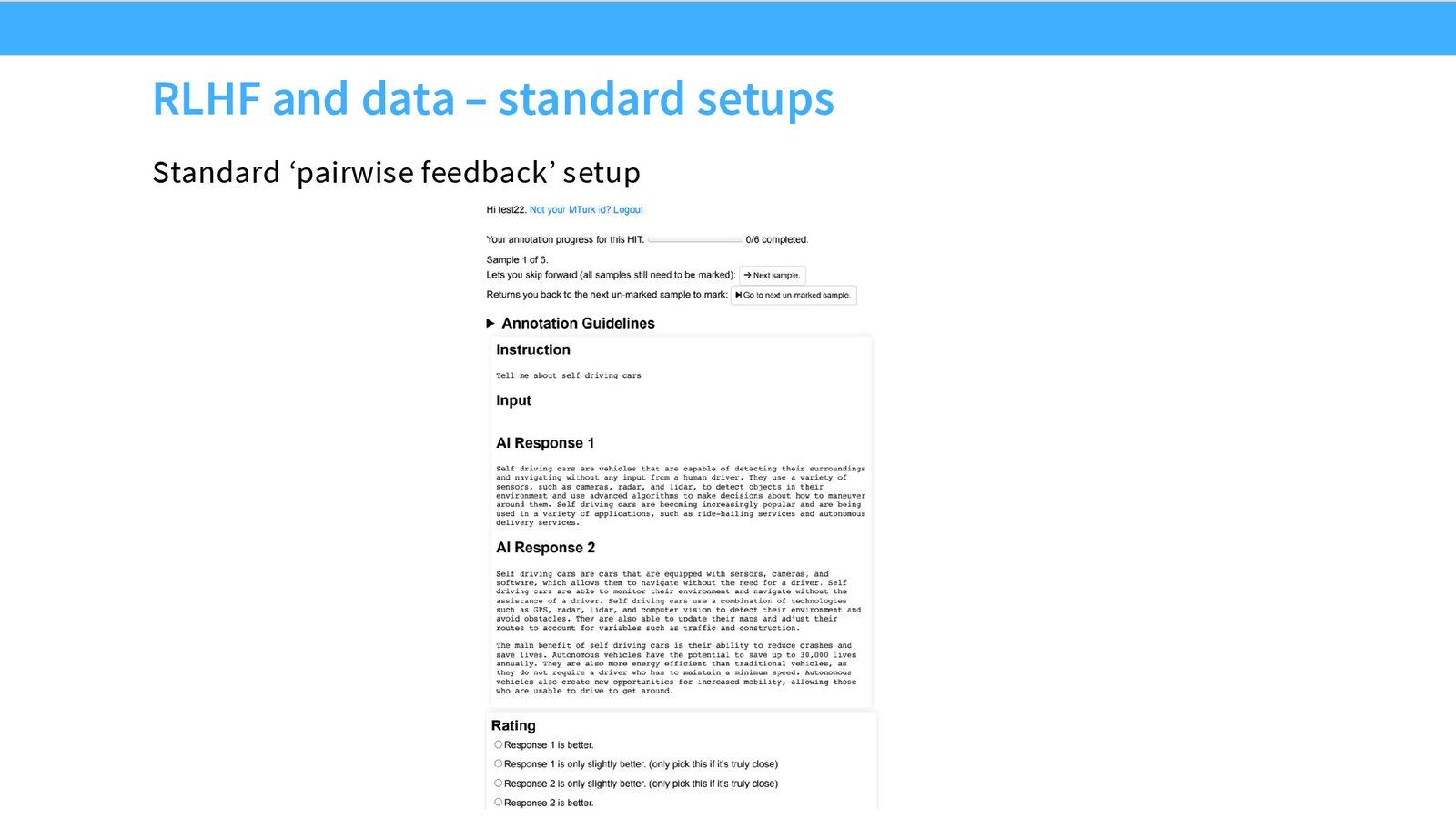
成对反馈的标准流程
来源:Slides 第36页。
成对反馈的基本流程是:
- 给定一个提示(prompt),模型生成多个不同的回复
- 标注者比较这些回复,标记哪个更好
- 收集大量这样的成对比较数据
标注指南的设计

来源:Slides 第37页。来自 InstructGPT 论文附录。
InstructGPT 的标注指南定义了三个评估维度(HHH):
- 有用性(Helpful):使用清晰语言、回答用户真正想问的问题、对国际化敏感(如“football”不应默认为美式足球)
- 真实性(Truthful):不产生幻觉输出
- 无害性(Harmless):不包含有毒内容、不生成 NSFW 内容

来源:Slides 第38页。
InstructGPT 通过 Scale 和 Upwork 平台收集了约 40 名标注者的数据。Google Bard 的指南包含类似的维度(有用性、风格、安全性),但据报道标注者每个问题仅有约一分钟的判断时间。
众包标注的挑战

来源:Slides 第41页。
课堂互动实验生动地展示了成对标注的困难。在约 5 分钟的时间内,斯坦福学生需要对多组回复进行比较判断:
成对标注中的三大陷阱
- 难以获得高质量、可验证的标注者:即便是有动力的学生也会出错
- 难以让标注者真正核查事实正确性:大多数学生在 5 分钟内无法逐一验证回复中的所有事实声称
- GPT-4 作弊问题:一些标注者会直接将任务丢给 GPT-4,导致标注数据反映的是 AI 的偏好而非人类的真实判断
实验的一个关键发现是:许多更长的回复实际上包含了幻觉内容,但大多数人仍然选择了更长的版本。这直接说明了为什么长度偏差在 RLHF 数据中如此普遍。
标注者偏见与多样性问题
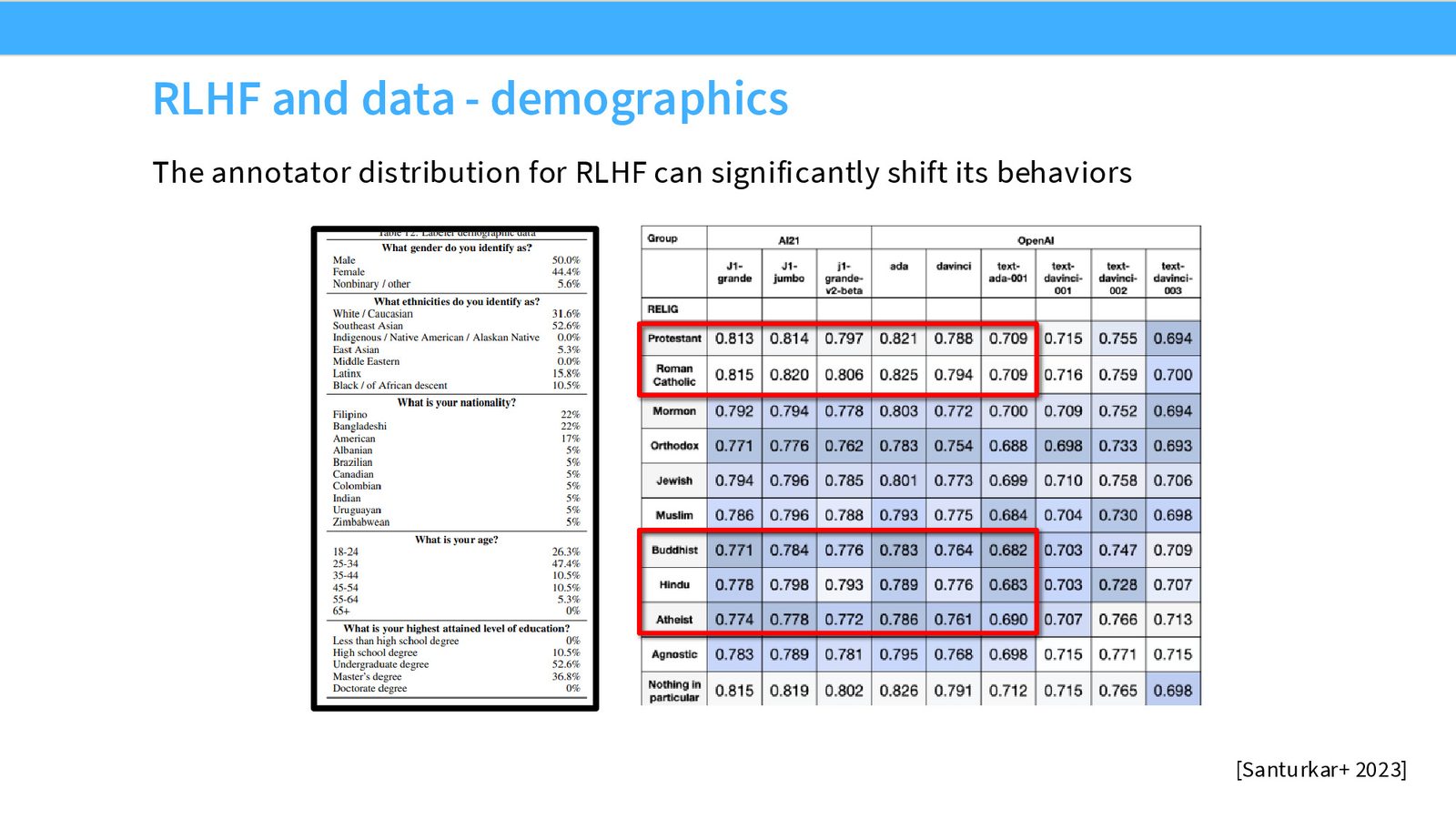
来源:Slides 第43页。
RLHF 处于训练流程的末端,因此对模型最终行为有极强的影响力。Tatsu 团队的研究发现,InstructGPT 在训练后变得更加认同东南亚宗教的观点——而查看论文附录后发现,标注者主要来自菲律宾和孟加拉国(仅 17% 为美国人)。这一发现提醒我们:
标注者构成决定模型价值观
由于 RLHF 在流程末端、对模型行为影响最大,标注者的文化背景、教育水平、个人偏好会直接影响模型的价值观取向。不同标注者群体关注的维度也不同——研究者/作者更关注事实正确性,而众包工人更关注格式美观度。
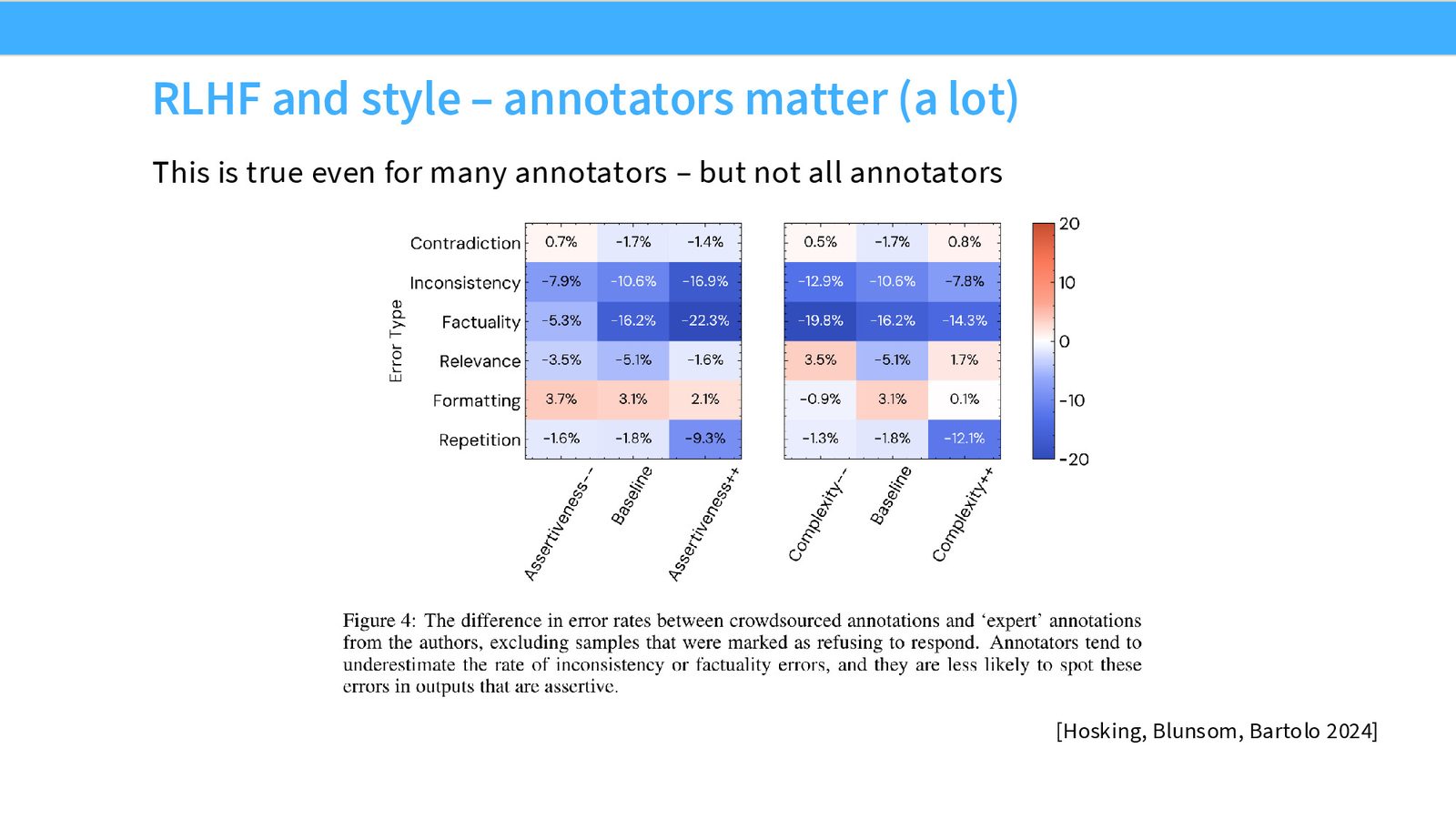
来源:Slides 第44页。来自 Hosking, Blunam, & Barlo 的研究。
AI 反馈:从 RLHF 到 RLAIF

来源:Slides 第46页。
鉴于人类标注的种种挑战,AI 反馈(RLAIF)成为了一个越来越流行的替代方案。核心发现包括:
- GPT-4 的成对偏好判断与人类评审的一致性(Agreement),与人类之间的相互一致性大致相当
- AI 反馈的成本远低于人类标注
- Hugging Face 在构建 Zephyr 7B 模型时,最初坚持使用人类众包数据,但最终发现 GPT-4 生成的反馈效果更好
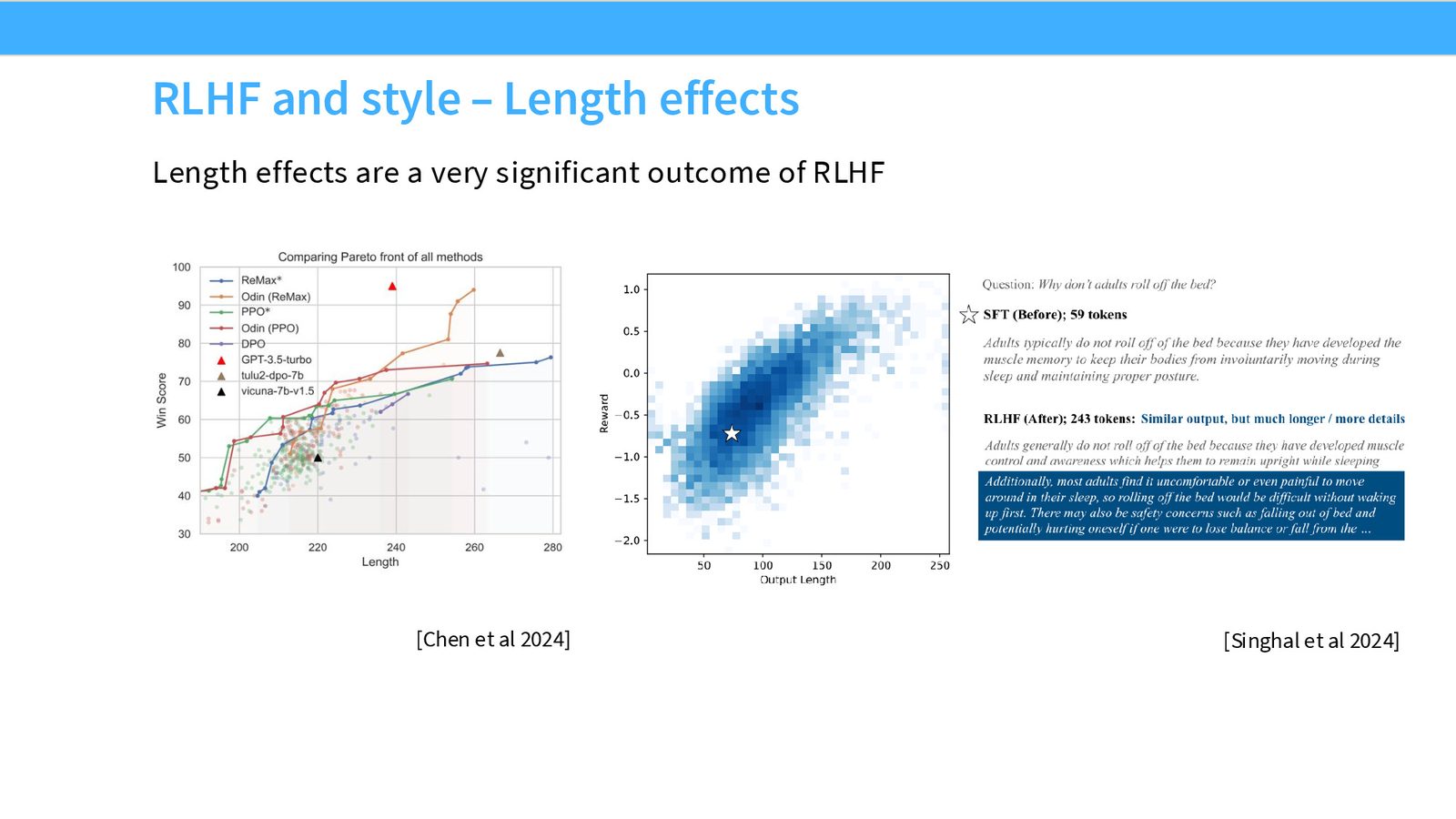
来源:Slides 第48页。来自 AI2 Tulu 3 项目。
这一趋势可以追溯到 Anthropic 的 Constitutional AI 论文,该工作首次系统性地提出用 AI 反馈替代人类反馈进行对齐训练。现代实践中,如 Tulu 3(AI2)等项目,已经完全采用 LM 生成的反馈数据。
AI 反馈的注意事项
- 自我偏好偏差:大多数模型对自己的输出有可检测的偏好,使用同一模型既生成又评判时需要特别小心
- 长度偏差:AI 评审同样偏好更长的回复,可能导致模型输出越来越冗长
- 风格偏好:AI 评审可能将特定风格(如列表格式)与质量混淆
本章小结
RLHF 数据收集的核心教训
- 成对反馈虽然比 SFT 数据更容易收集,但仍面临事实核查困难、长度偏差、标注者偏见等严峻挑战
- 标注者背景对模型价值观有直接影响,需要审慎考虑标注团队的多样性和代表性
- AI 反馈已经成为主流替代方案,但自身也带来新的偏差问题
RLHF 算法
奖励建模:Bradley-Terry 模型

来源:Slides 第52页。
RLHF 的核心假设是 Bradley-Terry 偏好模型:
Bradley-Terry 偏好模型
假设世界上每个可能的输出序列 \(y\) 都有一个潜在的标量奖励 \(R(y, x)\)。当标注者比较两个回复 \(y_A\) 和 \(y_B\) 时,偏好 \(y_A\) 的概率为:
其中 \(\sigma\) 是 sigmoid 函数。
我们无法直接观测 \(R\),只能通过有噪声的成对比较间接推断它。奖励模型 \(r_\theta(x, y)\) 就是对这个潜在奖励的参数化近似。
RLHF 目标函数

来源:Slides 第51页。来自 Ouyang et al. 2022.
InstructGPT 的 RLHF 目标函数为:
各项含义:
- \(r_\theta(x, y)\):奖励模型给出的奖励分数
- \(\beta \log \frac{\pi^{\text{RL}}_\phi(y|x)}{\pi^{\text{SFT}}(y|x)}\):RL 策略与 SFT 模型之间的 KL 散度惩罚项,防止 RL 偏离太远
- \(\gamma \mathbb{E}_{x \sim D_{\text{pretrain}}} [\log \pi^{\text{RL}}_\phi(x)]\):预训练损失混入项,防止灾难性遗忘
KL 惩罚的重要性
KL 散度项 \(D_{\text{KL}}[\pi^{\text{RL}} \| \pi^{\text{SFT}}]\) 是 RLHF 中最关键的正则化手段。没有它,策略优化会“过度利用”(exploit)奖励模型的漏洞——找到奖励模型给出高分但实际质量很差的输出。这个现象称为奖励黑客(reward hacking),是 RLHF 中最常见的失败模式之一。
PPO:经典的 RL 优化算法

来源:Slides 第54页。
PPO(Proximal Policy Optimization)是 InstructGPT 使用的核心 RL 算法。其推导过程可以分为三步:
第一步:策略梯度定理
优化目标 \(\max_\theta \mathbb{E}_{y \sim p_\theta}[R(y)]\) 的梯度为:
直观含义:如果某个输出的奖励 \(R(y)\) 为正,增大其概率;如果为负,减小其概率。这就是 REINFORCE 算法。
第二步:方差缩减与优势函数
将奖励替换为优势函数(Advantage)\(A = R - V\),其中 \(V\) 是值函数基线。这在不改变梯度期望的前提下大幅降低方差。
第三步:重要性采样与截断
为了从一次采样(rollout)中获取多个梯度步骤,引入重要性权重比率 \(\frac{\pi_\theta(y|x)}{\pi_{\theta_{\text{old}}}(y|x)}\)。PPO 的核心创新是对这个比率进行截断(clipping),使其保持在 \([1-\epsilon, 1+\epsilon]\) 范围内,从而自然地约束策略不会偏离太远。
PPO 的实现复杂性
PPO 在语言模型中的实现非常复杂——需要同时维护策略模型、值函数模型、奖励模型和参考模型四个模型的前向/反向传播。CS336 曾考虑但最终放弃了让学生实现 PPO 的作业。
DPO:将 RL 问题转化为监督学习

来源:Slides 第56页。
DPO(Direct Preference Optimization)的动机是消除 PPO 的复杂性。其推导过程精巧但直接:
第一步:写出 RLHF 目标函数
第二步:非参数假设下的最优策略
假设 \(\pi_\theta\) 不限于某个参数族,而是任意函数。则最优策略为:
DPO 的核心洞见:策略与奖励的等价性
从上式可以反解出隐含奖励(implied reward):
这意味着:在非参数假设下,每个策略唯一对应一个奖励函数。与其分别学习奖励模型和策略,不如直接学习策略——策略本身就隐含了奖励信息。
第三步:代入 Bradley-Terry 模型

来源:Slides 第58页。
将隐含奖励代入 Bradley-Terry 模型的对数似然中(注意 \(Z(x)\) 项在差值中消除):
其中 \(y_w\) 是被偏好的(winning)回复,\(y_l\) 是不被偏好的(losing)回复。
DPO 的直观理解
DPO 的损失函数有一个非常简洁的解释:
- 增大被偏好回复相对于参考模型的对数概率比值
- 减小不被偏好回复相对于参考模型的对数概率比值
- 参考模型 \(\pi_{\text{ref}}\) 起到了正则化的作用,防止概率偏离太远
整个过程不需要奖励模型、不需要在线采样、不需要重要性权重——只需要对成对偏好数据做标准的梯度下降。
DPO 的替代方案与变体
在 DPO 出现之前,人们尝试了多种简化 PPO 的方法,但效果都不理想:
- 条件生成:在被偏好/不被偏好的回复前分别加上“good”/“bad”标记,生成时条件于“good” \(\rightarrow\) 效果不佳
- 仅训练被偏好回复:只对 chosen 回复做 SFT \(\rightarrow\) 效果不够好
- Best-of-N:用奖励模型选出 N 个样本中的最佳回复,再做 SFT \(\rightarrow\) 效果一般
DPO 之后也出现了大量变体:

来源:Slides 第61页。
- SimPO:去除参考模型 \(\pi_{\text{ref}}\),用长度归一化的对数概率作为隐含奖励,同时引入 margin 项 \(\gamma\)
- 长度归一化 DPO:在 DPO 基础上对对数概率按序列长度归一化,缓解长度偏差
这些变体的共同思路是在保持 DPO 简洁性的同时,解决其在实践中遇到的特定问题(如长度偏差、对参考模型的依赖等)。
本章小结
RLHF 算法的核心要点
- Bradley-Terry 模型是 RLHF 的概率基础,假设偏好由潜在标量奖励的差值决定
- PPO 是经典但复杂的 RL 优化方法,需要维护四个模型
- DPO 通过策略-奖励等价性将 RL 问题转化为监督学习问题,大幅降低了实现复杂度
- KL 散度惩罚(无论是显式还是隐式)对防止奖励黑客至关重要
在线策略 vs. 离线策略
On-policy 与 Off-policy 的区别
- 离线策略(Off-policy):成对比较数据不是来自当前模型的输出。例如 Tulu 3 中使用多个不同模型生成回复,再用 LM 评判。数据一次性收集完毕后反复使用。
- 在线策略(On-policy):成对比较数据来自当前正在训练的模型的最新输出。PPO 本质上是 on-policy 方法,需要模型实时生成输出并获取反馈。
Off-policy 数据告诉你关于“你不在的地方”的偏好景观;On-policy 数据帮助你“精炼自己”。Tulu 3 同时使用了两种数据。
DPO 通常以 off-policy 方式使用(因为数据在训练前就已收集完毕),而 PPO 天然是 on-policy 的。这一区别在实践中有重要影响——on-policy 方法通常能更好地避免 SFT 中讨论的幻觉问题,因为它只让模型在自己的知识范围内优化。
总结与延伸

来源:Slides 第66页。
核心要点回顾
本节课完整覆盖了从预训练模型到对齐模型的后训练流程,核心内容包括:
SFT 部分:
- 指令微调数据有三种主要范式:NLP 任务聚合(FLAN)、LLM 生成(Alpaca)、人类众包(Open Assistant)
- “高质量数据”的定义远比想象中复杂——完全正确的数据可能教模型幻觉
- 少量数据即可产生巨大影响(包括安全微调)
- 现代实践中,SFT 与预训练正通过中间训练阶段融合
RLHF 部分:
- RLHF 数据收集面临诸多挑战:长度偏差、标注者偏见、事实核查困难、GPT-4 作弊
- AI 反馈(RLAIF)已成为主流趋势,效果可与人类标注媲美
- PPO 是经典但复杂的 RL 优化算法
- DPO 通过优雅的数学推导将 RL 问题化归为监督学习
- 警惕奖励过度优化和奖励黑客现象
开放问题与前沿方向
- 自我改进的上限在哪里? 模型能从自身反馈中提取多少改进?理论上上限很高(模型包含了整个预训练语料的信息),但实际效果取决于具体实现
- 如何从根本上解决幻觉? SFT 和 RLHF 都无法完全解决幻觉问题,可能需要在预训练阶段引入 RL 风格的自适应训练
- 可验证奖励的 RL(下一讲主题):在数学等可验证领域,可以用正确性作为奖励信号,避免人类/AI 标注的各种偏差
- 后训练的伦理问题:标注工人的薪酬和工作条件、文化偏见的传播等
拓展阅读
- Ouyang et al. (2022). Training language models to follow instructions with human feedback (InstructGPT)
- Rafailov et al. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO)
- Bai et al. (2022). Constitutional AI: Harmlessness from AI Feedback (Anthropic)
- Schulman et al. (2017). Proximal Policy Optimization Algorithms (PPO)
- Wang et al. (2023). How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
- Hu et al. (2024). MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
- Lambert et al. (2024). Tulu 3: Pushing Frontiers in Open Language Model Post-Training
- Meng et al. (2024). SimPO: Simple Preference Optimization with a Reference-Free Reward
- Zelikman et al. (2022). STaR: Bootstrapping Reasoning With Reasoning 以及后续的 Quiet-STaR
- John Schulman. Reinforcement Learning from Human Feedback: Progress and Challenges (Berkeley 报告)