CS231N Lecture 4: Neural Networks and Backpropagation
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Ehsan Adeli 授课内容整理 |
| 来源 | Stanford CS231N |
| 日期 | 2025年4月10日 |

回顾:从线性分类器到优化
讲者 Ehsan Adeli 首先回顾了前三节课的核心内容,为本节课的神经网络和反向传播奠定基础。

来源:Slides 第2页。
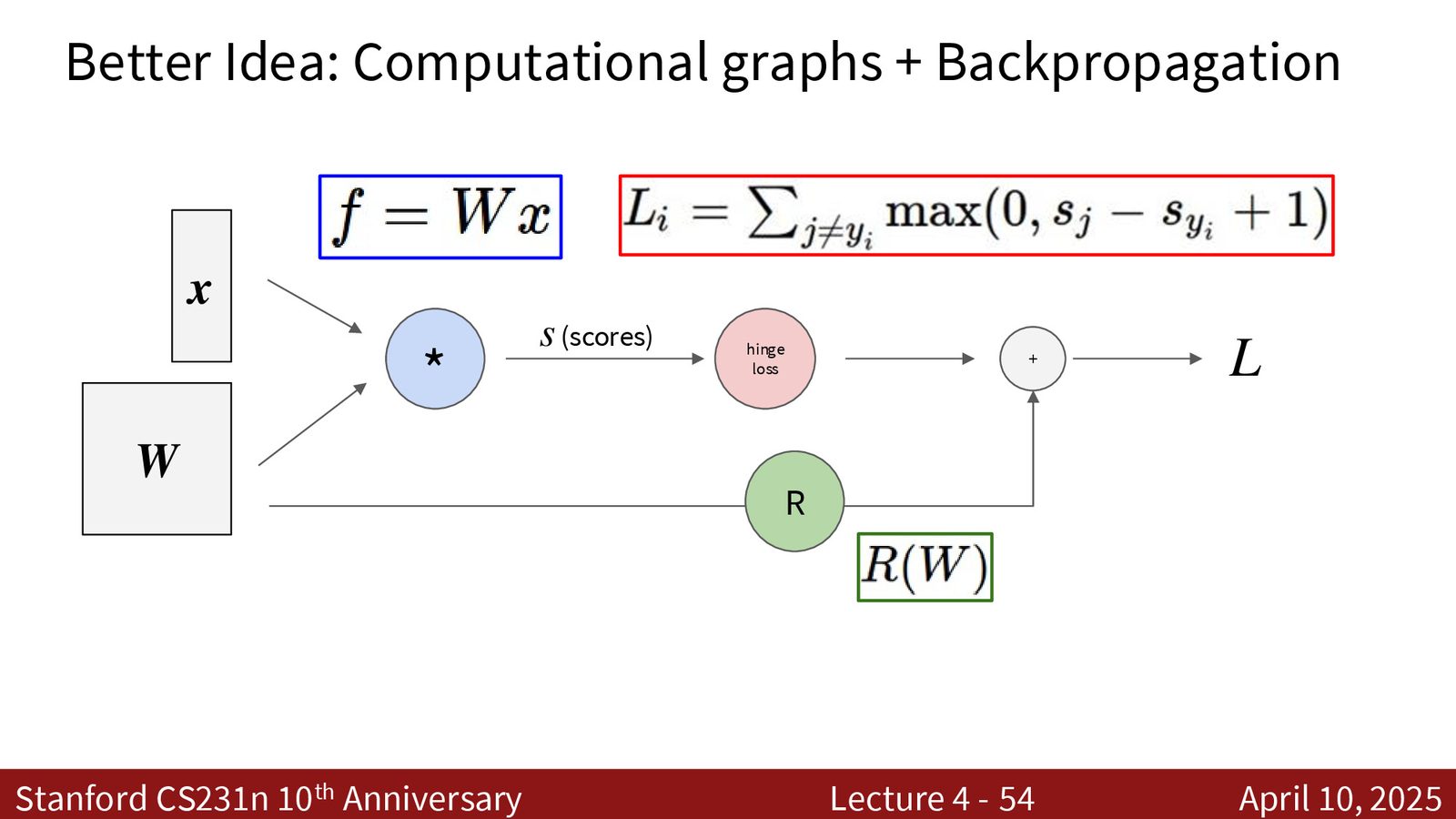
评分函数与损失函数
我们已经建立了完整的学习框架:
- 评分函数:线性模型 \(f(\mathbf{x}, W) = W\mathbf{x}\),将输入映射到类别分数
- 损失函数:衡量预测的好坏,包括数据损失和正则化项
- 优化:通过梯度下降找到最优权重 \(W\)

来源:Slides 第4页。
Hinge Loss vs Softmax Loss
除了上一节课详细讨论的 Softmax(交叉熵)损失外,另一种常见的分类损失是 Hinge Loss(SVM 损失):
它鼓励正确类别的分数比所有错误类别的分数至少高出一个 margin(此处为 1)。与 Softmax 不同,Hinge Loss 不将分数转换为概率。
优化回顾

来源:Slides 第8页。
梯度下降的更新规则为 \(W \leftarrow W - \alpha \nabla_W L\)。为了降低计算成本,我们使用 SGD(随机梯度下降),每次只用一个 mini-batch(如 32、64、128 或 256 个样本)来估计梯度。我们还讨论了 SGD+Momentum、RMSProp 和 Adam 等高级优化器。

来源:Slides 第12页。
本章小结
前几节课建立了“评分函数 \(\rightarrow\) 损失函数 \(\rightarrow\) 梯度下降”的完整框架,但仅限于线性分类器。本节课将扩展到非线性的神经网络,并介绍如何高效计算复杂网络中的梯度——这就是反向传播算法。
从线性分类器到神经网络
线性分类器的局限性
线性分类器 \(f = W\mathbf{x}\) 只能学习一条直线(或超平面)作为决策边界。对于线性不可分的数据(如环形分布),线性分类器完全无法处理。
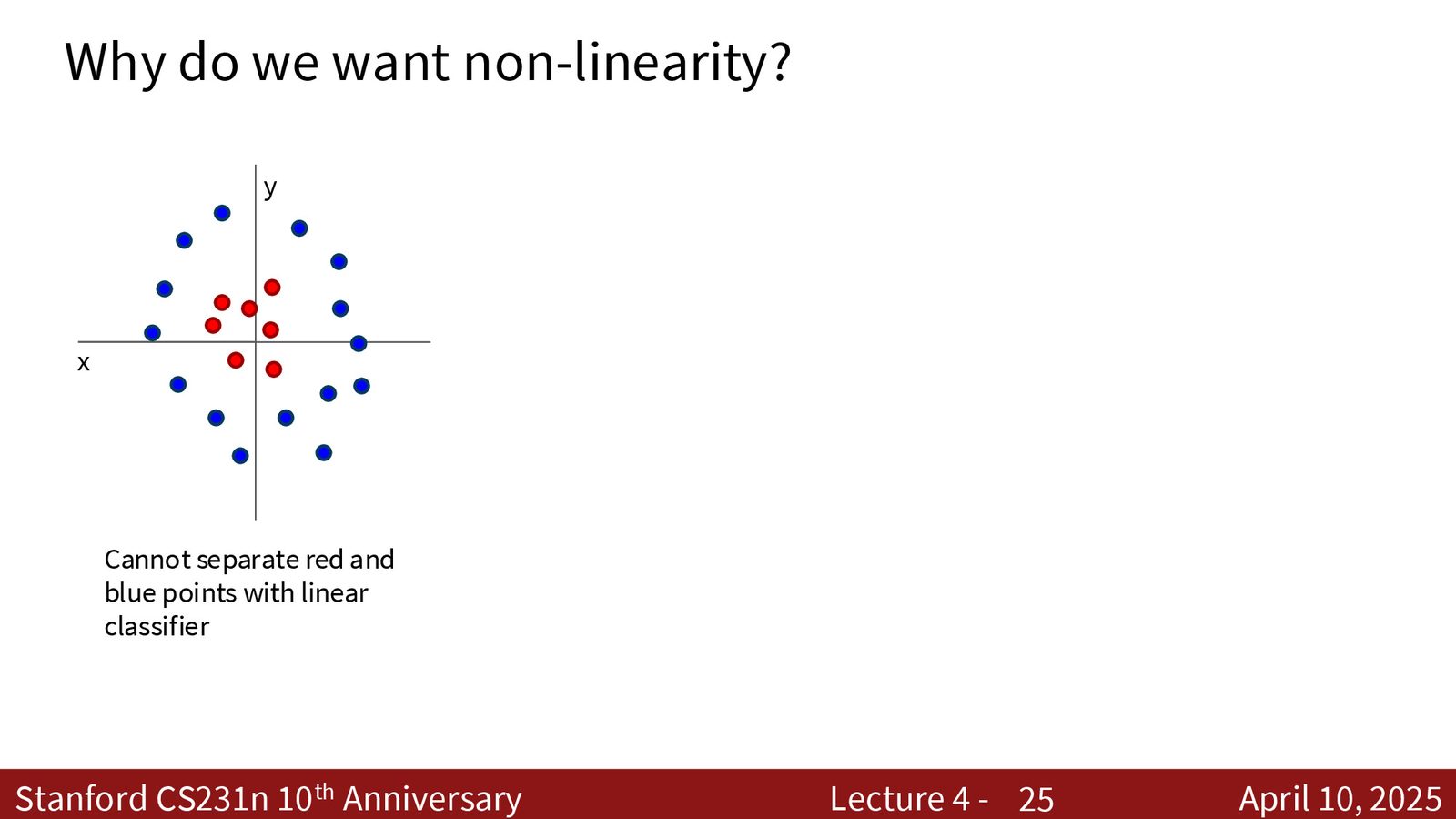
来源:Slides 第24页。
非线性变换的力量
解决方案是将数据从原始空间非线性变换到新空间。例如,将笛卡尔坐标 \((x, y)\) 转换为极坐标 \((r, \theta)\) 后,原本线性不可分的环形数据变得线性可分。神经网络的核心能力就是自动学习这种非线性变换。
构建两层神经网络
最简单的神经网络——两层全连接网络的公式为:

来源:Slides 第22页。
关键维度分析:
- \(\mathbf{x} \in \mathbb{R}^D\):输入向量(\(D\) 个特征)
- \(W_1 \in \mathbb{R}^{H \times D}\):第一层权重(\(H\) 个隐藏神经元)
- \(W_2 \in \mathbb{R}^{C \times H}\):第二层权重(\(C\) 个输出类别)
- \(\max(0, \cdot)\):ReLU 激活函数(非线性)
没有非线性等于没有多层
如果去掉 \(\max(0, \cdot)\),两层网络变成 \(f = W_2 \cdot W_1 \mathbf{x}\),而 \(W_2 W_1\) 可以合并为一个矩阵 \(W_3\),回到单层线性分类器!非线性激活函数是神经网络能够解决非线性问题的根本原因。
更深的网络
可以继续堆叠更多层来构建更深的网络:

来源:Slides 第23页。
这些只使用全连接层(矩阵乘法)和激活函数的网络被称为全连接网络(Fully Connected Network)或多层感知机(MLP, Multi-Layer Perceptron)。
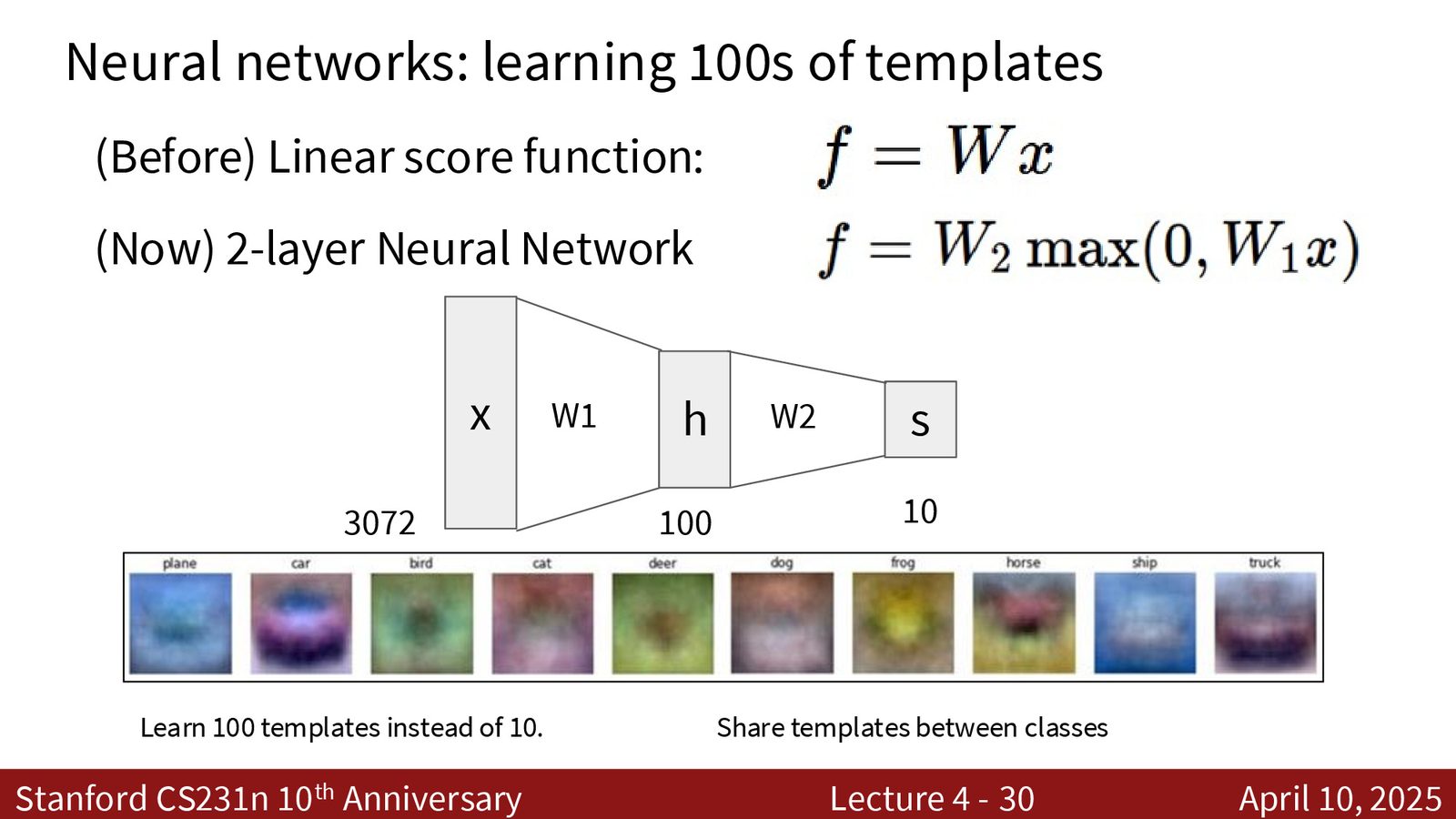
模板学习的视角

来源:Slides 第26页。
从模板的角度理解网络能力的提升:
- 线性分类器:每个类别只有 1 个模板(即 \(W\) 的对应行),很受限
- 神经网络:隐藏层有 \(H\) 个神经元,可以学到 \(H\) 个“部分模板”。例如,鸟、猫、鹿、狗都有眼睛,某个隐藏神经元可能专门检测“眼睛”特征,被多个类别共享
神经网络的表示能力
增加隐藏层神经元的数量相当于增加网络的“模板库”。更多神经元 = 更多部分模板 = 更强的函数逼近能力 = 更复杂的决策边界。但过多的容量也会导致过拟合——这时需要正则化来控制。
本章小结
神经网络通过交替使用线性变换(矩阵乘法)和非线性激活函数来突破线性分类器的局限。两层网络 \(f = W_2 \cdot \sigma(W_1 \mathbf{x})\) 已经可以理论上逼近任意连续函数。隐藏层的宽度决定了网络的表示能力。
激活函数
ReLU 及其变体
ReLU(Rectified Linear Unit)是最广泛使用的激活函数:
来源:Slides 第29页。
ReLU 的问题:当输入为负时,输出恒为 0,梯度也为 0,导致所谓的“死神经元”——一旦某个神经元的输入持续为负,它将永远无法恢复。
为此,出现了多种改进变体:

来源:Slides 第30页。
- Leaky ReLU:\(f(x) = \max(0.01x, x)\),负半轴给一个小斜率,避免死神经元
- ELU(Exponential Linear Unit):负半轴使用指数函数,具有更好的零中心性
- GELU(Gaussian Error Linear Unit):在 Transformer 架构中广泛使用
- SiLU/Swish:\(f(x) = x \cdot \sigma(x)\),Google 在 EfficientNet 等模型中采用
Sigmoid 和 Tanh

来源:Slides 第31页。
Sigmoid:\(\sigma(x) = \frac{1}{1 + e^{-x}}\),输出范围 \((0, 1)\)
Tanh:\(\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}\),输出范围 \((-1, 1)\)
Sigmoid 和 Tanh 的梯度消失问题
这两个函数将值压缩到很窄的范围内。当输入值的绝对值很大时,函数曲线几乎是平的,导数接近零。在深层网络中,这些接近零的梯度经过链式法则逐层相乘,最终变得极其微小——这就是梯度消失(Vanishing Gradient)问题。因此,Sigmoid 和 Tanh 通常不用在网络的中间层,而只用在输出层(如二分类的 Sigmoid 输出)。
激活函数的选择
激活函数选择指南
- 默认选择:ReLU,简单高效,在大多数场景下表现良好
- CNN 架构:ReLU 或 SiLU/Swish
- Transformer 架构:GELU 是标准选择
- 输出层:Sigmoid(二分类)、Softmax(多分类)、无激活(回归)
- 所有激活函数的共同要求:非线性且可微
选择激活函数更多是经验性的——通常沿用同类型架构已验证有效的选择。
本章小结
激活函数是神经网络的核心组件,为网络提供非线性能力。ReLU 是最常用的默认选择,但存在死神经元问题。GELU 和 SiLU 是更现代的替代方案。Sigmoid 和 Tanh 因梯度消失问题通常不用于中间层。
神经网络的实现
用 Python 实现两层网络
一个完整的两层神经网络可以用不到 20 行 Python 代码实现:
来源:Slides 第34页。
# 定义网络维度
N, D_in, H, D_out = 64, 1000, 100, 10
X = np.random.randn(N, D_in)
Y = np.random.randn(N, D_out)
W1 = np.random.randn(D_in, H)
W2 = np.random.randn(H, D_out)
for t in range(2000):
# 前向传播
h = X.dot(W1) # 第一层线性变换
h_relu = np.maximum(h, 0) # ReLU 激活
y_pred = h_relu.dot(W2) # 第二层线性变换
# 计算损失
loss = np.square(y_pred - Y).sum()
# 反向传播(手动计算梯度)
grad_y_pred = 2.0 * (y_pred - Y)
grad_W2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(W2.T)
grad_h = grad_h_relu.copy()
grad_h[h < 0] = 0
grad_W1 = X.T.dot(grad_h)
# 参数更新
W1 -= learning_rate * grad_W1
W2 -= learning_rate * grad_W2
代码中最关键的部分是反向传播:计算损失对 \(W_1\) 和 \(W_2\) 的解析梯度。这正是本节课的重点。
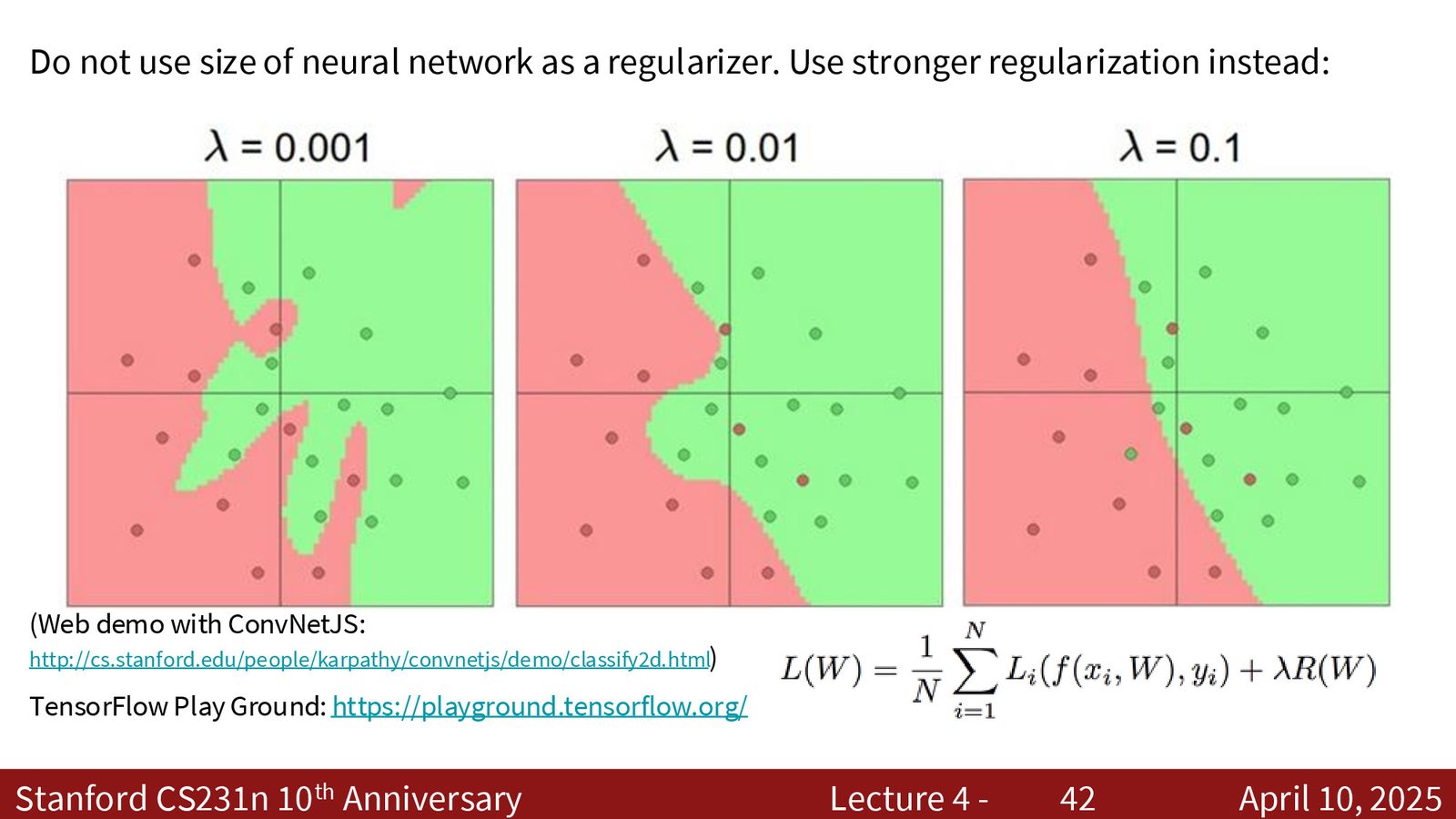
网络容量与正则化

来源:Slides 第36页。
增加隐藏层神经元的数量可以学到更复杂的决策边界。但过大的网络容量会导致过拟合。
不要用网络大小作为正则化手段
正确的做法是:选择一个略大于需要的网络,然后通过调节正则化强度 \(\lambda\) 来控制过拟合。原因:
- 训练大型网络成本高,如果发现网络太小还要重新训练
- 正则化参数 \(\lambda\) 可以快速调整
- 先让网络有足够容量“记住”数据,再用正则化让它“忘记”不重要的细节

来源:Slides 第38页。
本章小结
实现一个两层神经网络只需要矩阵乘法、ReLU 和损失计算。关键挑战是梯度的计算。网络大小应略大于需要,通过正则化控制过拟合而非限制网络容量。
神经网络的生物学启发
生物神经元 vs 人工神经元
来源:Slides 第41页。
人工神经网络与生物神经元有松散的类比关系:
- 树突(dendrites)\(\leftrightarrow\) 输入连接:接收来自其他神经元的信号
- 细胞体(cell body)\(\leftrightarrow\) 激活函数:汇聚输入信号并进行非线性变换
- 轴突(axon)\(\leftrightarrow\) 输出连接:将处理后的信号传递给下一层神经元
来源:Slides 第42页。
脑科学类比需谨慎
人工神经网络与生物神经系统的相似性非常松散。生物神经元远比人工神经元复杂:它们有不同类型的突触、时间动态、化学信号、稀疏连接等。人工神经网络为了计算效率使用规则的层状结构,而大脑的连接模式复杂得多。不应过度解读这种类比。
本章小结
人工神经网络受到生物神经系统的启发,但已经发展出独立的理论和实践体系。现代深度学习的成功更多依赖于数学和工程优化,而非神经科学。
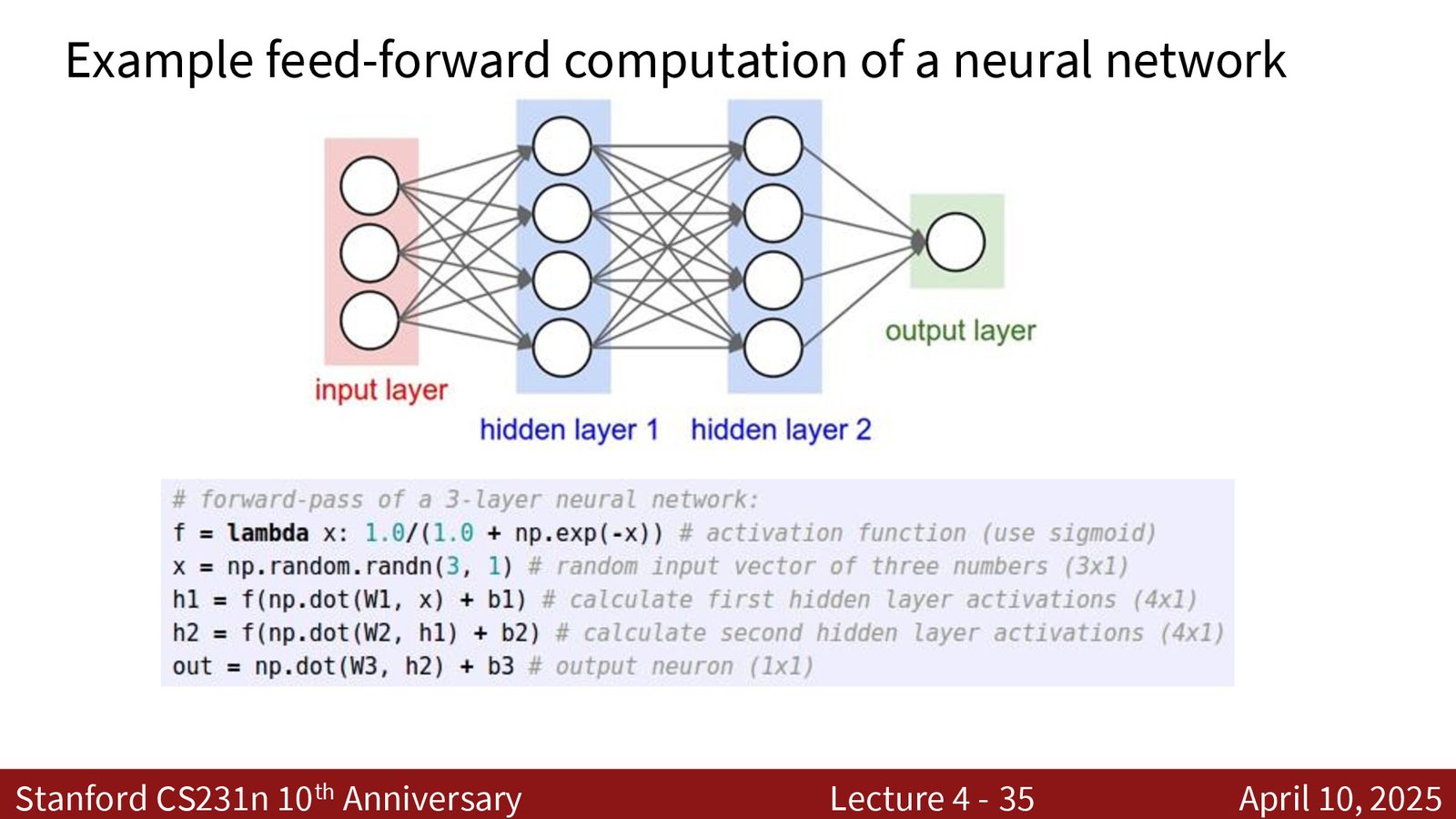
计算图与反向传播
这是本节课最核心的内容。反向传播是现代深度学习的基石——所有神经网络的训练都依赖于它。
为什么需要反向传播
要训练神经网络,我们需要计算损失函数 \(L\) 对所有权重 \(W_1, W_2, \ldots\) 的偏导数。直接对整个网络写出解析导数公式面临三个问题:
- 繁琐:涉及大量矩阵运算的链式求导
- 不灵活:改变损失函数或网络结构后需要重新推导
- 不可行:对于上百层的网络,手动推导不现实

来源:Slides 第49页。
计算图
解决方案是将复杂函数分解为一系列简单操作(加法、乘法、指数等)的组合,用计算图表示。

来源:Slides 第50页。
对于任意神经网络,计算图从输入数据和参数出发,经过一系列操作节点,最终得到损失值 \(L\)。
计算图的通用性
计算图可以表示任意可微函数。无论网络多复杂——从简单的两层 MLP 到 Neural Turing Machine——都可以画成计算图。这使得反向传播成为一种完全通用的梯度计算方法。
反向传播的核心思想
前向传播:从输入到输出,逐步计算每个节点的值。
反向传播:从输出到输入,逐步计算损失对每个节点的梯度。核心工具是链式法则。
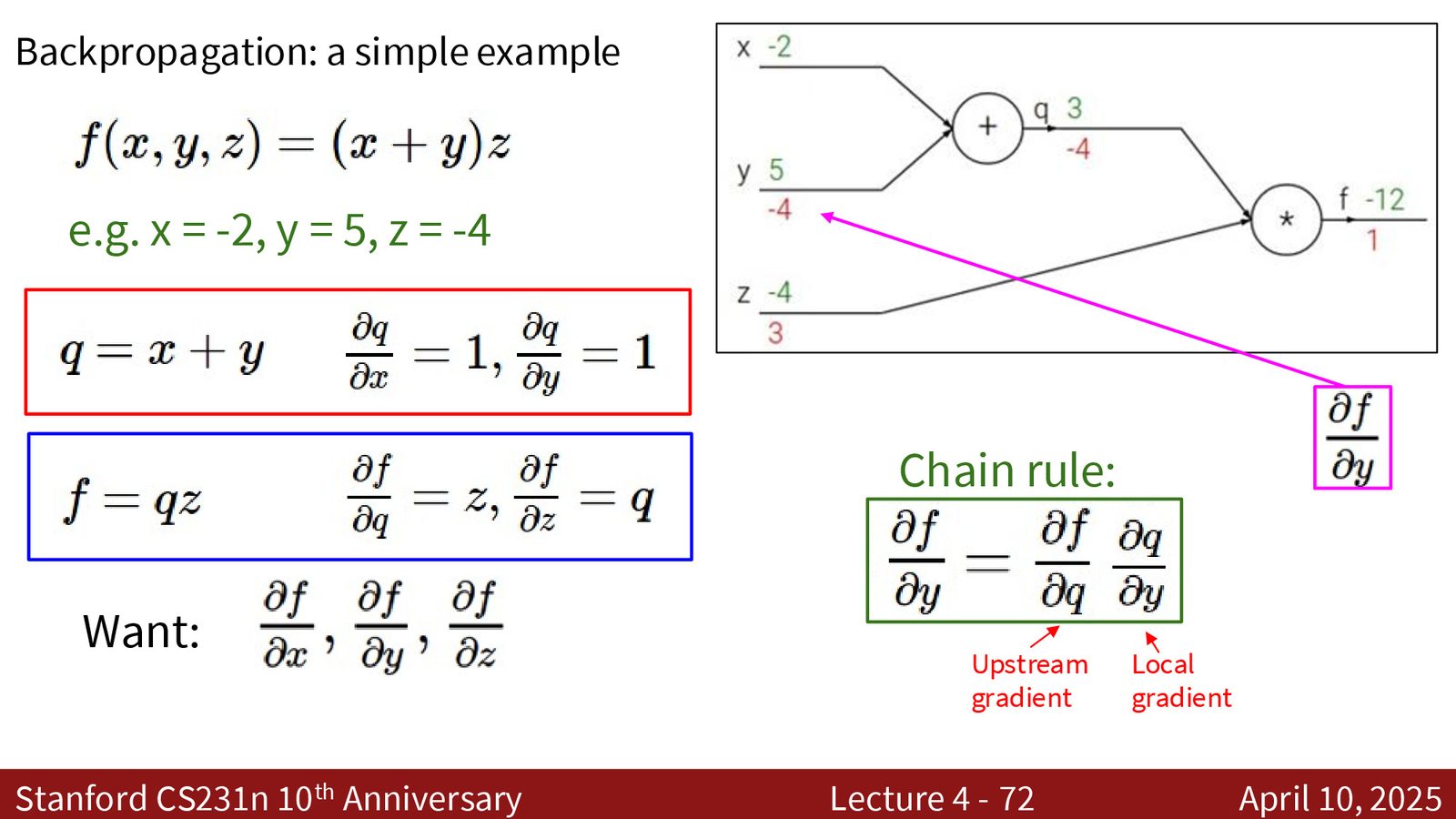
简单示例:\(f(x, y, z) = (x + y) · z\)
来源:Slides 第52页。
设 \(x = -2, y = 5, z = -4\)。
前向传播:
- \(q = x + y = -2 + 5 = 3\)
- \(f = q \cdot z = 3 \times (-4) = -12\)
反向传播(从后向前):
- \(\frac{\partial f}{\partial f} = 1\)(起始点)
- \(\frac{\partial f}{\partial z} = q = 3\)(乘法节点:对 \(z\) 的局部梯度是 \(q\))
- \(\frac{\partial f}{\partial q} = z = -4\)(乘法节点:对 \(q\) 的局部梯度是 \(z\))
- \(\frac{\partial f}{\partial y} = \frac{\partial f}{\partial q} \cdot \frac{\partial q}{\partial y} = (-4) \times 1 = -4\)(链式法则)
- \(\frac{\partial f}{\partial x} = \frac{\partial f}{\partial q} \cdot \frac{\partial q}{\partial x} = (-4) \times 1 = -4\)(链式法则)
反向传播的两个关键概念
- 上游梯度(Upstream Gradient):从网络末端传回到当前节点的梯度,即 \(\frac{\partial L}{\partial \text{output}}\)
- 局部梯度(Local Gradient):当前节点输出对输入的导数,即 \(\frac{\partial \text{output}}{\partial \text{input}}\)
反向传播规则:下游梯度 = 上游梯度 \(\times\) 局部梯度。每个节点只需要知道自己的局部梯度和收到的上游梯度,就可以计算出传给前一层的下游梯度。
Sigmoid 函数的反向传播
考虑一个更复杂的例子:Sigmoid 函数 \(\sigma(x) = \frac{1}{1 + e^{-x}}\)。
来源:Slides 第55页。
将 \(\sigma(x)\) 分解为基本操作的链:
每一步的局部梯度都很简单:
- \(1/x\) 的导数:\(-1/x^2\)
- \(+c\) 的导数:\(1\)
- \(e^x\) 的导数:\(e^x\)
- \(-x\) 的导数:\(-1\)
- \(cx\) 的导数:\(c\)
反向传播从末端的 \(\frac{\partial L}{\partial L} = 1\) 开始,逐节点乘以局部梯度,最终得到 \(\frac{\partial L}{\partial w_0}, \frac{\partial L}{\partial w_1}, \frac{\partial L}{\partial x_0}, \frac{\partial L}{\partial x_1}\)。

来源:Slides 第56页。
Sigmoid 导数的优雅形式
Sigmoid 函数有一个美妙的性质:\(\sigma'(x) = \sigma(x)(1 - \sigma(x))\)。这意味着在实现中,如果前向传播已经计算了 \(\sigma(x)\) 的值,反向传播时不需要重新计算,直接用前向值即可。这也是为什么在很多实现中会将 Sigmoid 作为一个整体节点而非拆分为基本操作。
常见操作的梯度模式

来源:Slides 第57页。
三种基本操作的梯度行为
- 加法门(Add Gate):分发器——上游梯度原样传递给两个输入。\(\frac{\partial(x+y)}{\partial x} = 1\),\(\frac{\partial(x+y)}{\partial y} = 1\)
- 乘法门(Multiply Gate):交换器——每个输入收到的梯度是上游梯度乘以另一个输入的值。\(\frac{\partial(xy)}{\partial x} = y\),\(\frac{\partial(xy)}{\partial y} = x\)
- Max 门(Max Gate):路由器——梯度全部传给值较大的输入,另一个输入的梯度为零
多分支节点的梯度
当计算图中一个变量被多个后续节点使用时(即一个节点有多条出边),反向传播时需要将各分支的梯度相加。

来源:Slides 第61页。
这源自多元链式法则:如果 \(z\) 通过 \(f\) 和 \(g\) 影响 \(L\),则:
梯度相加,不是取平均
当一个变量有多个使用者时,它对最终损失的影响是所有路径影响的总和。这是多元链式法则的直接结果。在实现自动微分系统时,一个常见 bug 是漏掉某条分支的梯度贡献。
向量化的反向传播
前面的例子都是标量运算。在实际神经网络中,操作的对象是向量和矩阵。

来源:Slides 第63页。
对于向量函数 \(\mathbf{y} = f(\mathbf{x})\),局部梯度变成 Jacobian 矩阵:
反向传播规则变为:\(\frac{\partial L}{\partial \mathbf{x}} = \frac{\partial L}{\partial \mathbf{y}} \cdot J\)(上游梯度乘以 Jacobian)。

来源:Slides 第65页。
逐元素操作的 Jacobian 是对角矩阵
对于逐元素操作(如 ReLU、Sigmoid),输出的第 \(i\) 个元素只依赖于输入的第 \(i\) 个元素。因此 Jacobian 矩阵是对角矩阵——大量元素为零。在实现中,不需要显式构造完整的 Jacobian,只需对上游梯度做逐元素操作即可。
矩阵运算的反向传播

来源:Slides 第68页。
对于全连接层的核心操作 \(Y = XW\)(\(X \in \mathbb{R}^{N \times D}\),\(W \in \mathbb{R}^{D \times M}\)),反向传播公式为:
矩阵反向传播的维度检查技巧
利用维度匹配来验证公式的正确性:
- \(\frac{\partial L}{\partial X}\) 的形状必须与 \(X\) 相同:\((N \times D)\)
- \(\frac{\partial L}{\partial Y}\) 的形状为 \((N \times M)\),\(W^T\) 的形状为 \((M \times D)\)
- \((N \times M) \cdot (M \times D) = (N \times D)\) \checkmark
同理可验证 \(\frac{\partial L}{\partial W}\) 的维度正确性。这个技巧在调试反向传播实现时非常有用。
本章小结
反向传播通过链式法则在计算图上从后向前逐节点传播梯度。每个节点只需知道自己的局部梯度和收到的上游梯度。关键模式:加法分发、乘法交换、max 路由、多分支相加。向量化时局部梯度变为 Jacobian 矩阵。
自动微分与深度学习框架
前向传播与反向传播的模块化
反向传播的美妙之处在于其模块化:每个操作只需要实现两个接口:
- forward:给定输入,计算输出(并保存中间值供反向使用)
- backward:给定上游梯度,计算对每个输入的下游梯度
来源:Slides 第70页。
前向传播保存的值在反向传播中使用
前向传播时,每个节点不仅需要计算输出,还需要缓存计算中间值。例如:
- 乘法 \(z = xy\):反向时需要 \(x\) 和 \(y\) 的值来计算 \(\frac{\partial z}{\partial x} = y\) 和 \(\frac{\partial z}{\partial y} = x\)
- ReLU \(y = \max(0, x)\):反向时需要知道 \(x\) 是否大于 0
- Sigmoid \(y = \sigma(x)\):反向时可以用 \(y\) 来计算 \(y(1-y)\)
这就是为什么训练神经网络比推理需要更多内存——需要保存所有中间激活值。
现代深度学习框架
PyTorch、TensorFlow 等框架的核心能力就是自动微分(Automatic Differentiation):用户只需定义前向计算,框架自动构建计算图并执行反向传播。
来源:Slides 第73页。
静态图 vs 动态图
- 静态图(如早期 TensorFlow):先定义整个计算图,然后执行。优点是可以做全局优化
- 动态图(如 PyTorch):逐行执行代码时动态构建计算图。优点是更灵活,更容易调试
现代框架(包括 TensorFlow 2.x)已经普遍支持动态图模式,PyTorch 是目前学术研究中最流行的框架。
本章小结
反向传播的模块化设计使得自动微分成为可能。现代深度学习框架让用户只需关注前向计算,梯度计算完全自动化。这极大降低了构建和实验新神经网络架构的门槛。
总结与延伸
全课知识图谱
本课建立了从神经网络到反向传播的完整认知链:

关键 Takeaways
六条核心原则
- 非线性是神经网络的灵魂:没有激活函数,多层网络等价于单层线性模型
- 反向传播 = 链式法则的系统化应用:将复杂函数分解为简单操作,逐个求导
- 每个节点只需关心局部:计算局部梯度,乘以上游梯度,传给下游
- 加法分发、乘法交换、max 路由:三种基本操作的梯度模式是所有复杂网络的构建块
- 维度匹配是最好的调试工具:梯度矩阵的形状必须与对应参数矩阵相同
- 自动微分解放了研究者:理解反向传播原理后,实践中由框架自动完成
拓展阅读
- Rumelhart, Hinton & Williams, Learning Representations by Back-propagating Errors (1986): https://www.nature.com/articles/323533a0 —— 反向传播的经典论文
- Goodfellow, Bengio & Courville, Deep Learning, Chapter 6: https://www.deeplearningbook.org/ —— 深度前馈网络详解
- Stanford CS231N 作业 1: http://cs231n.stanford.edu/ —— 手动实现反向传播的练习
- PyTorch Autograd 文档: https://pytorch.org/docs/stable/autograd.html —— 自动微分机制详解
- Andrej Karpathy, micrograd: https://github.com/karpathy/micrograd —— 一个极简自动微分引擎,适合理解反向传播