CS336 2026 Lecture 11:Scaling Case Study and Details
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方幻灯片重新整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |

本讲主线:scaling laws 在真实模型里的落地
读图:Slide 1 如何接续 Lecture 9
Lecture 9 讲 scaling laws 的基本形式和 Kaplan/Chinchilla/IsoFLOPS 等方法;Lecture 11 则进入“真实公开模型如何做 scaling”。重点不再是公式本身,而是公开论文里的 recipes:如何调 batch/LR,如何用 WSD 降低 sweep 成本,muP 是否真的稳定,optimizer scaling 如何验证。

读图:Slide 2 的三个现实问题
第一,Chinchilla 的 compute-optimal 方法在真实模型论文中是否还能工作。第二,完整从头训练网格非常贵,是否能用 WSD、早停或复用曲线节省计算。第三,架构、optimizer、learning rate、batch size 这些 hyperparameters 是否随 scale 改变,能否通过小模型可靠外推。

读图:Slide 3 的历史意义
Lecture 9 主要围绕 Kaplan、Chinchilla 等早期 scaling 研究;这页提醒我们,2024-2026 的公开模型开始公布更多 scaling 细节。Scaling law 已经从研究论文变成训练报告里的工程流程:MiniCPM、DeepSeek、Qwen、Kimi、Hunyuan、LLaMA 3、MiniMax 都在展示不同风格的 scaling recipe。
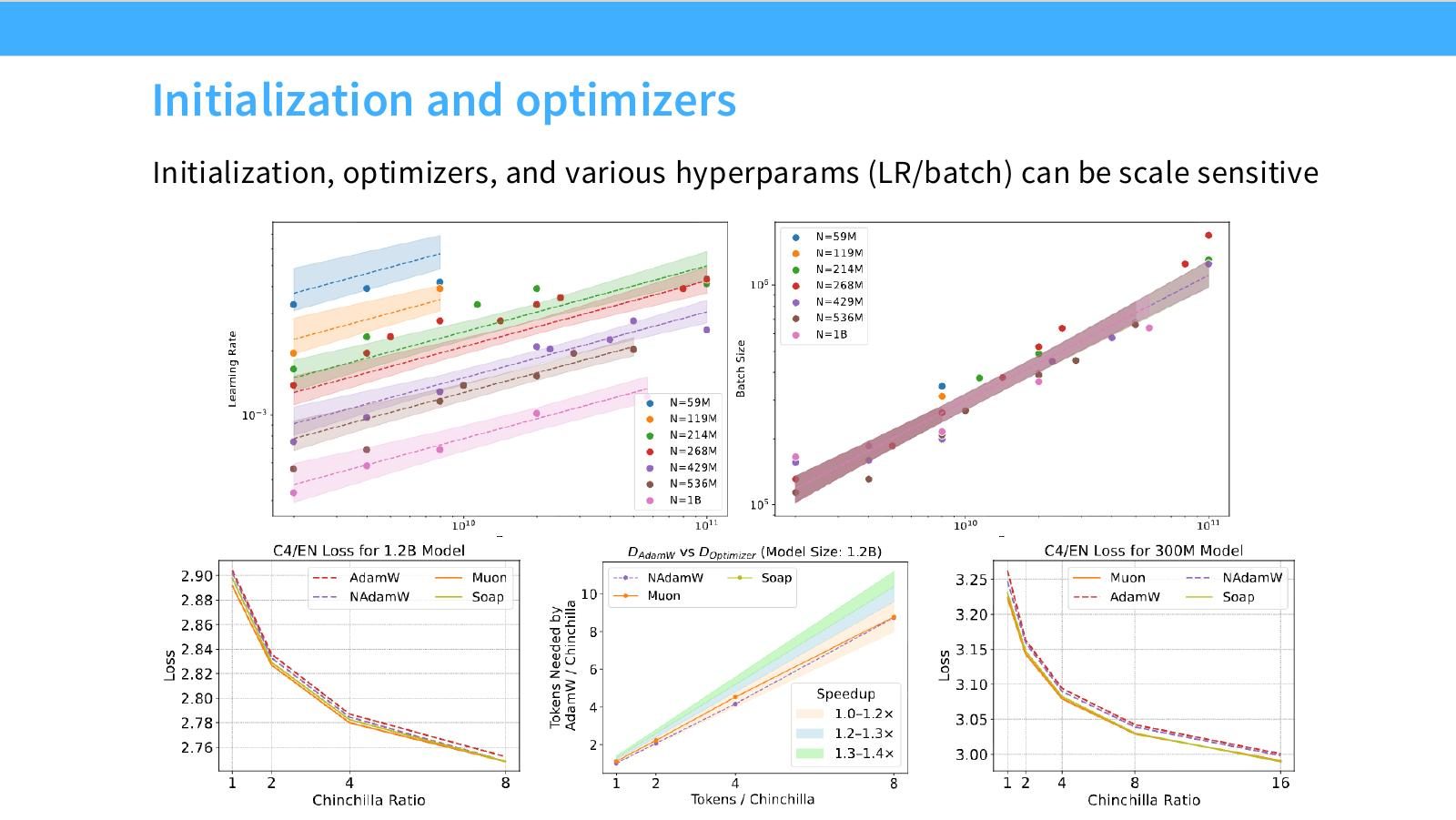
术语消化:scale-sensitive hyperparameters
| 对象 | 为什么 scale-sensitive | 课程中的检验方式 |
|---|---|---|
| Initialization | 宽度、深度改变会改变 activation 和 update magnitude。 | muP/SP 对比、activation/update 条件。 |
| Learning rate | 最优 LR 可能随参数量、batch、数据量变化。 | 小模型 grid search 或 muP 外推。 |
| Batch size | critical batch 随 loss 和数据规模变化。 | batch-loss 曲线、StepFun/DeepSeek/Qwen fits。 |
| Optimizer | 不同 optimizer 需要不同超参和 scaling rule。 | Muon、AdamC、exotic optimizers 的 scale study。 |

读图:Slide 5 的案例选择
MiniCPM 是小模型高性能路线,公开了细致的 scaling computation 和 muP 使用;DeepSeek 是更大规模高性能开源模型,展示了不使用 muP 时如何直接估计 batch/LR 和做 IsoFLOP 分析。二者形成对照:一个强调稳定参数化,一个强调直接经验拟合。
MiniCPM:小模型高性能与 muP 稳定 scaling

读图:Slide 6 为什么选 MiniCPM
MiniCPM 不是因为最大或最 SOTA 而重要,而是因为它公开展示了小模型如何通过 careful scaling、muP、batch/LR/token-to-size ratio tuning 得到强性能。它给课程提供了“scaling recipes 如何写进真实模型训练”的案例。
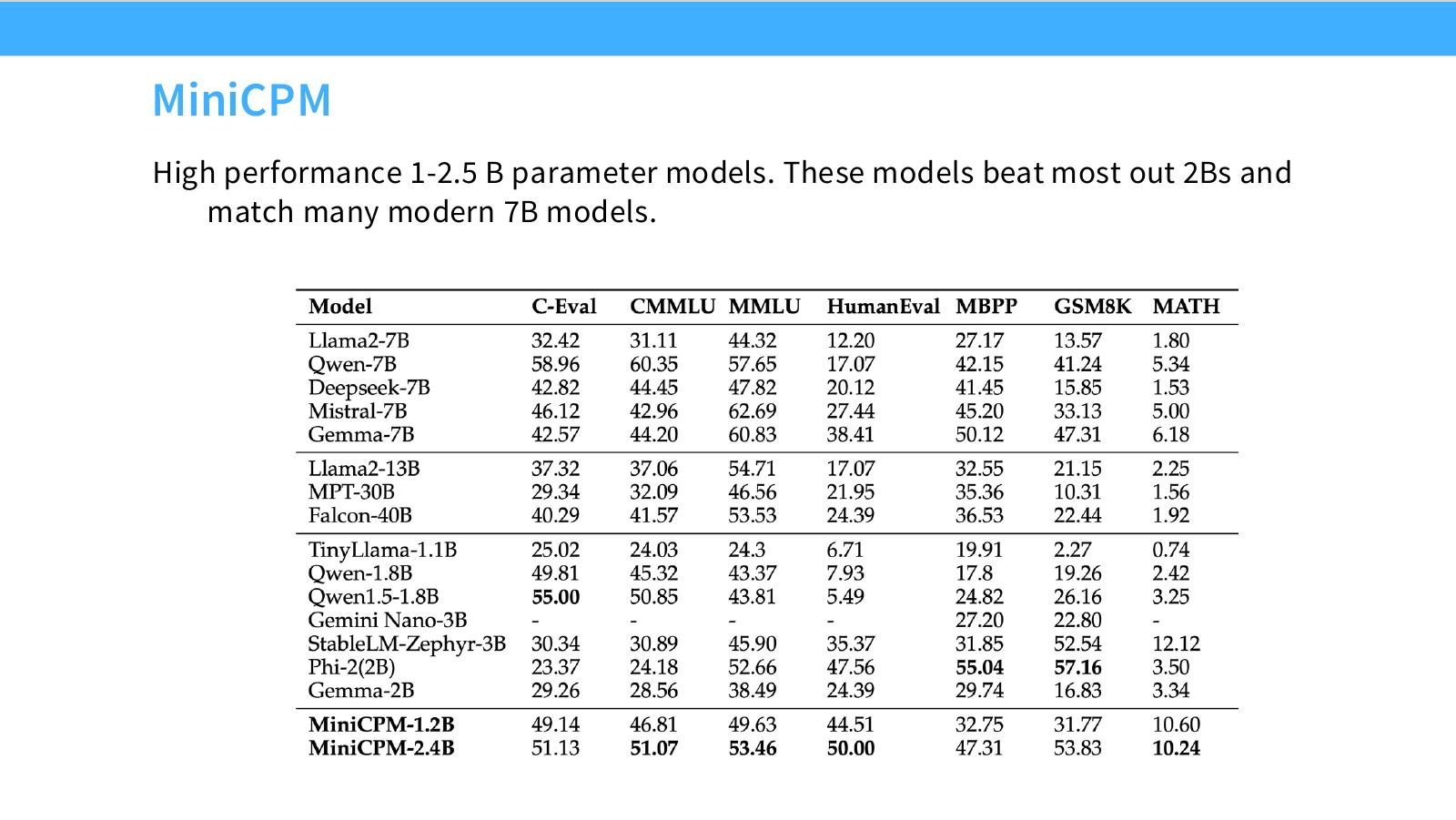
读图:Slide 7 不能只看模型大小
这页展示小模型通过训练策略和数据/超参优化达到强性能。它提醒我们:参数量不是性能唯一解释变量。若 scaling recipe 更好、数据更有效、训练 token 更多,小模型可能超过粗糙训练的大模型。

读图:Slide 8 中 muP 的作用
muP 的目标是让不同宽度模型的训练动力学更可比,使小模型上找到的 learning rate 和初始化规则更稳定迁移到大模型。这里的具体数值不是通用处方,而是 MiniCPM architecture 和训练 recipe 下的标定结果。
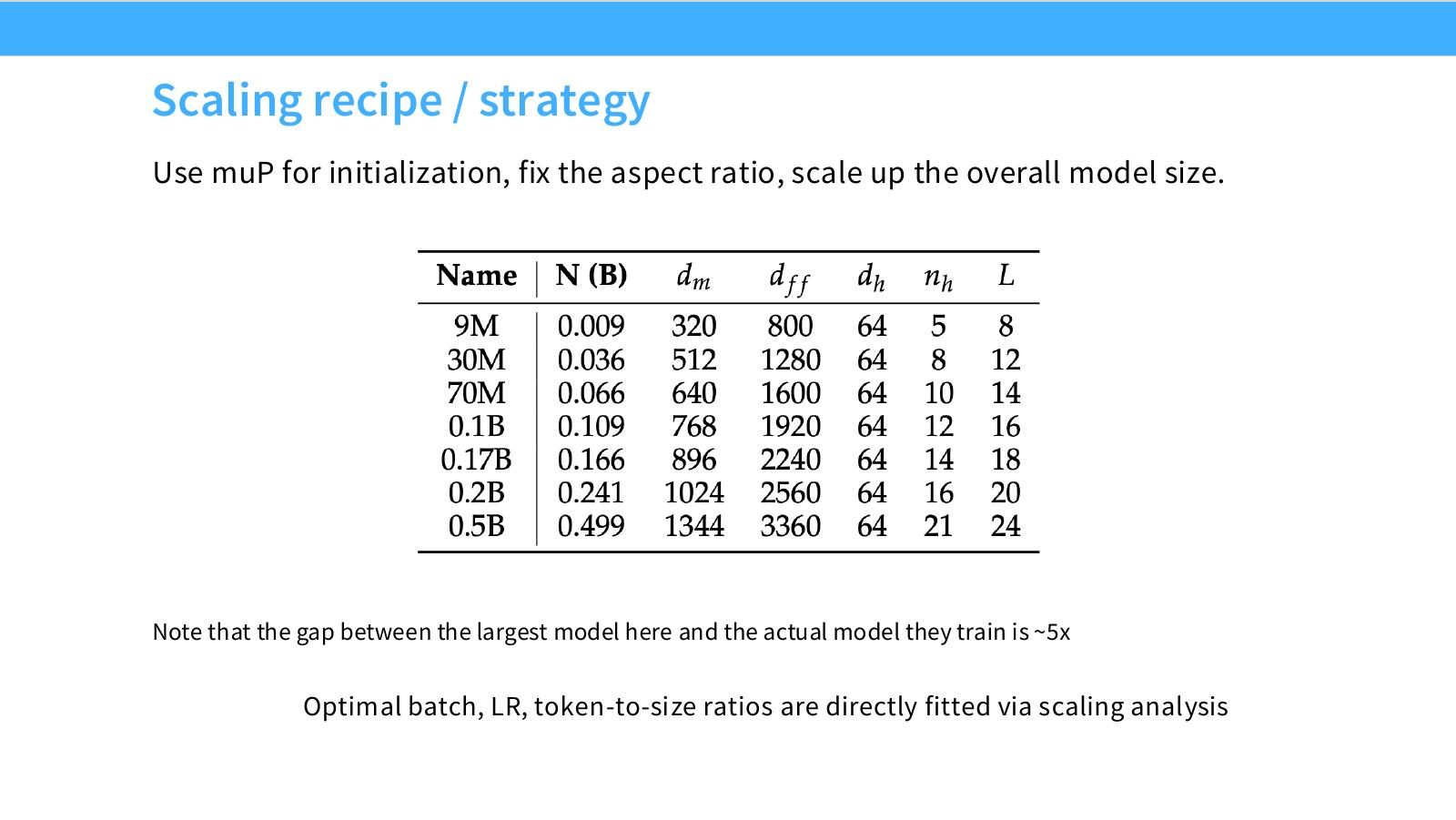
读图:Slide 9 的 strategy 为什么省事
固定 aspect ratio 意味着不在每个规模都重新搜索 depth/width/head 等比例;muP 则希望 LR 和初始化跨宽度稳定。这样 scaling sweep 的变量更少,外推更容易。但图中也提醒:最大小模型和最终模型之间仍有约 5 倍 gap,外推并非无风险。
MiniCPM 的 LR、batch 和 WSD
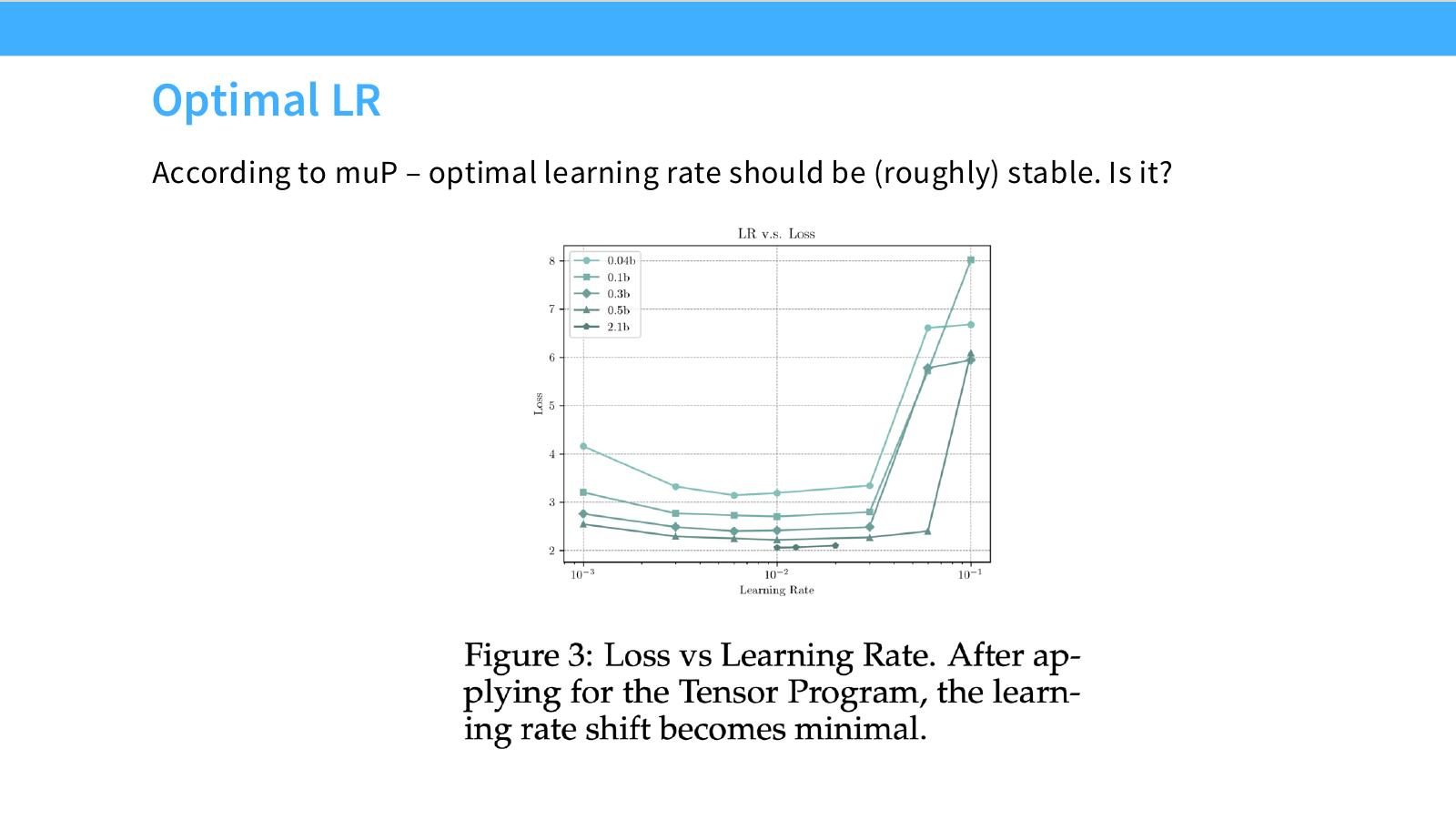
读图:Slide 10 应看“最优点是否横向稳定”
若不同模型规模的 loss-vs-LR 曲线最小点接近同一个 LR,说明 muP 达到了 scale-invariant tuning 的目标。若最优点随规模漂移,说明小模型 LR 外推到大模型仍不可靠。
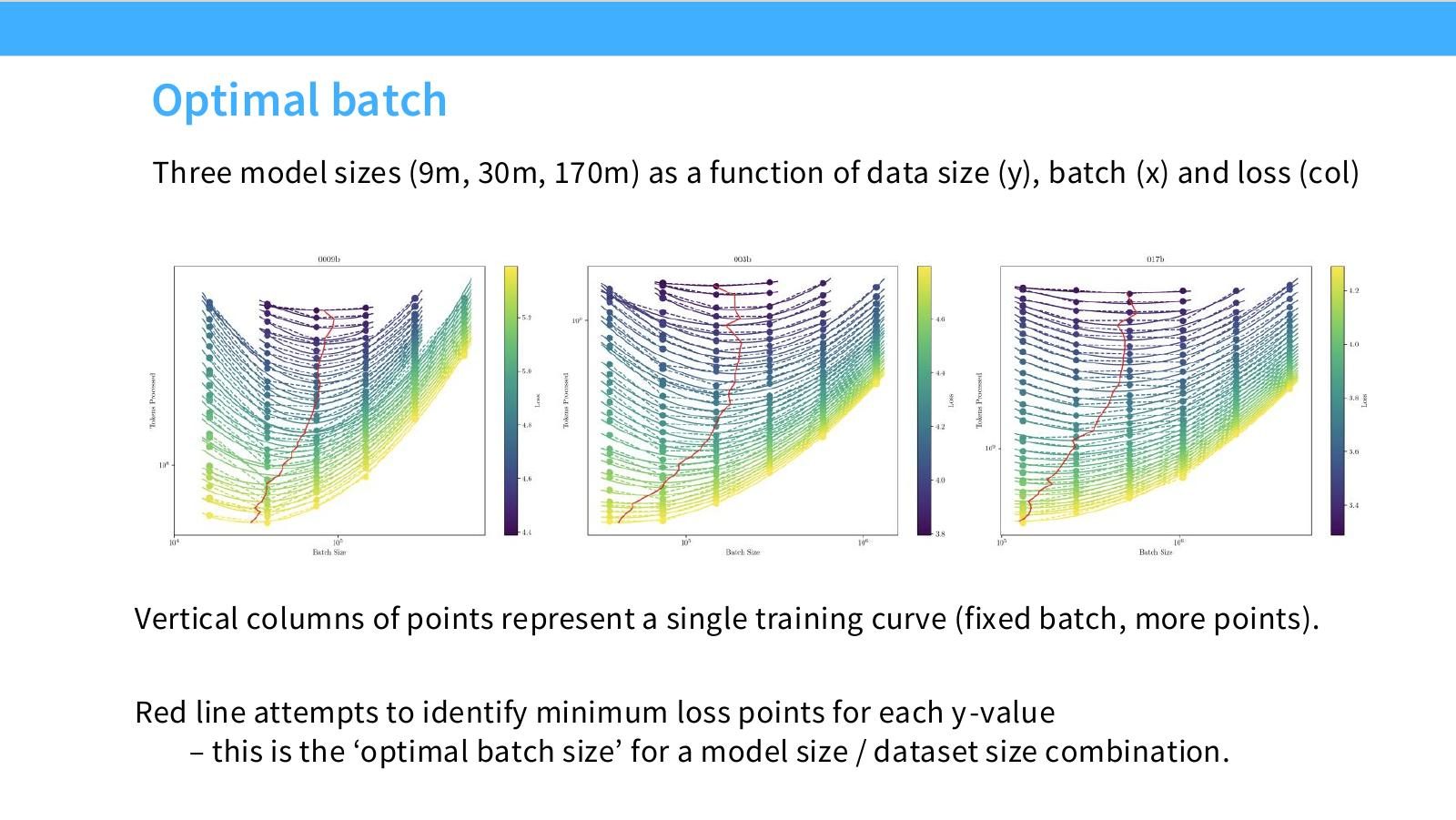
读图:Slide 11 的三维 batch 曲面
横轴是 batch,纵轴或多条曲线代表数据/训练进度,颜色表示 loss。垂直列是一条固定 batch 的训练曲线。红线追踪不同数据量下的最优 batch。读这页时要看最优 batch 如何随 loss 下降而增大,而不是只找某个全局最小点。
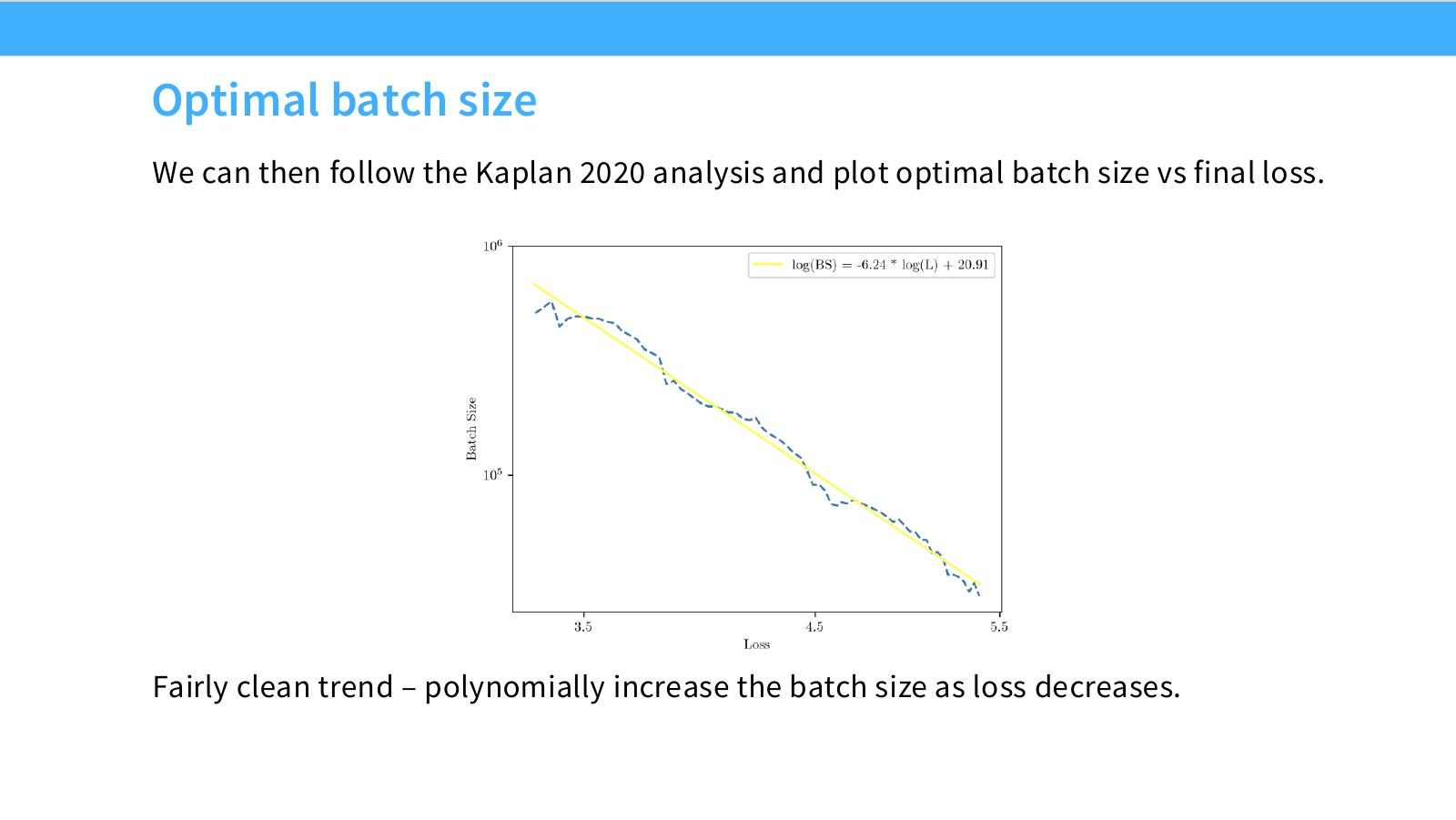
读图:Slide 12 与 critical batch 的关系
最终 loss 越低,训练越接近后期,critical batch 通常越大。图中的多项式趋势说明 batch size 也可被 scaling law 拟合。它不是说 batch 越大越好,而是说目标 loss 变化时,最优 batch 也应随之 schedule。
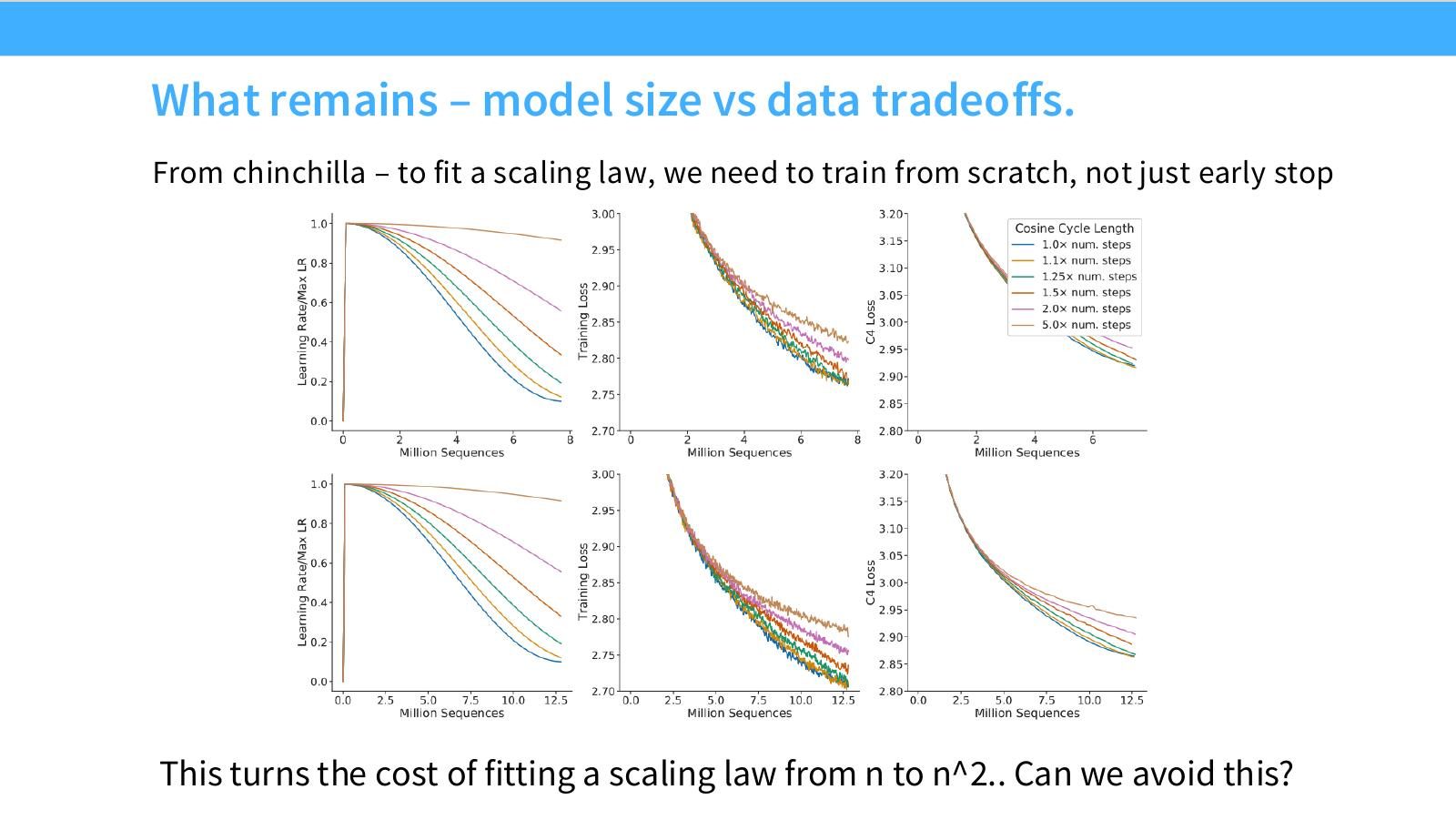
读图:Slide 13 的成本爆炸
若每个模型大小都要从头训练多个数据量点,网格成本会快速变成 \(n_{\text{models}}\times n_{\text{data}}\)。这正是 scaling in practice 的核心痛点:拟合 scaling law 本身也要花 compute,必须寻找复用曲线或降低 sweep 成本的方法。
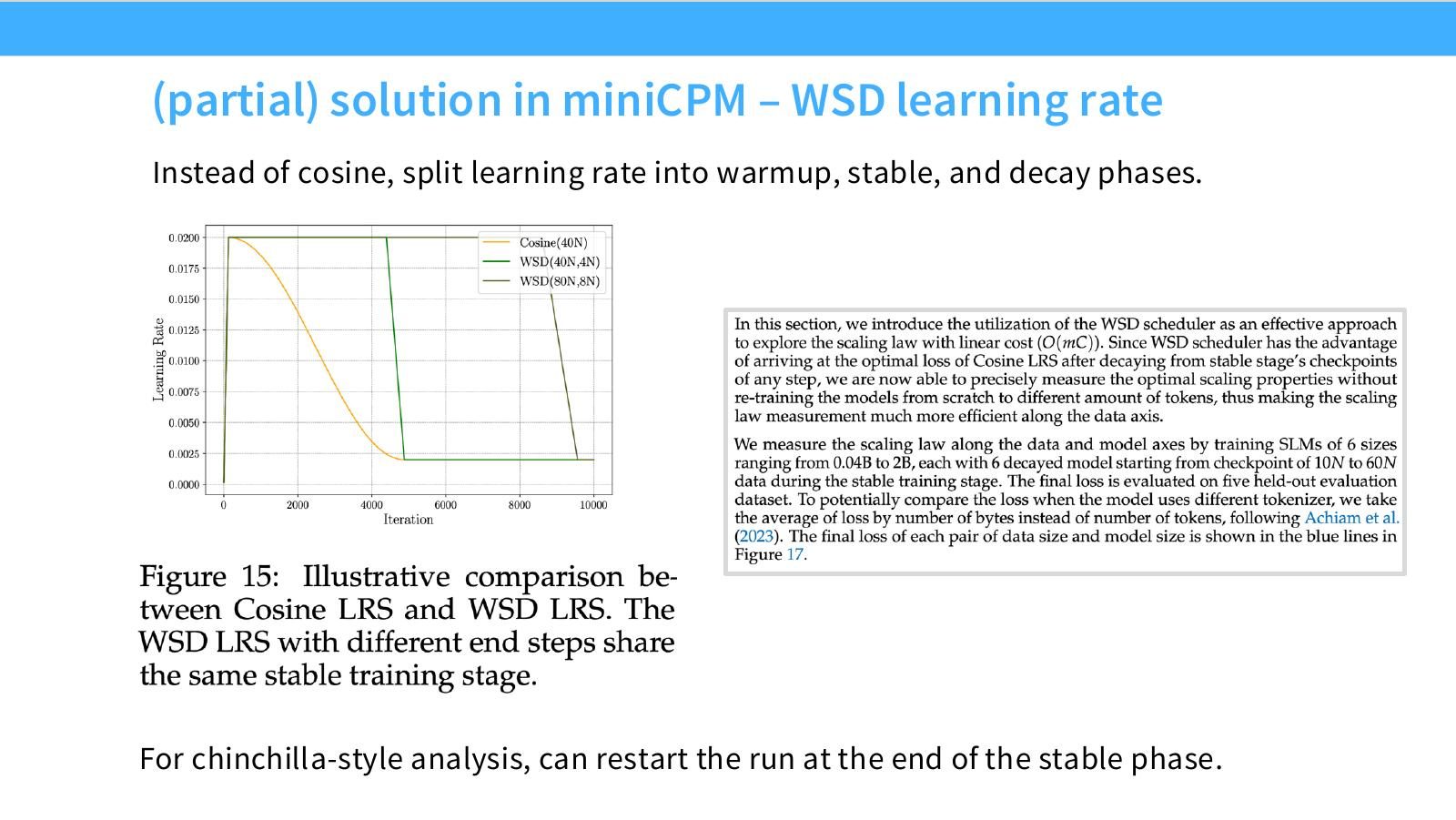
术语消化:什么是 WSD learning rate
WSD 是 warmup-stable-decay。先 warmup 到学习率平台,在 stable phase 长时间训练;需要 Chinchilla-style 不同 token budget 时,可以从 stable 末尾 restart decay,而不是每个数据量都从头训练。它用训练曲线复用降低 scaling sweep 成本。
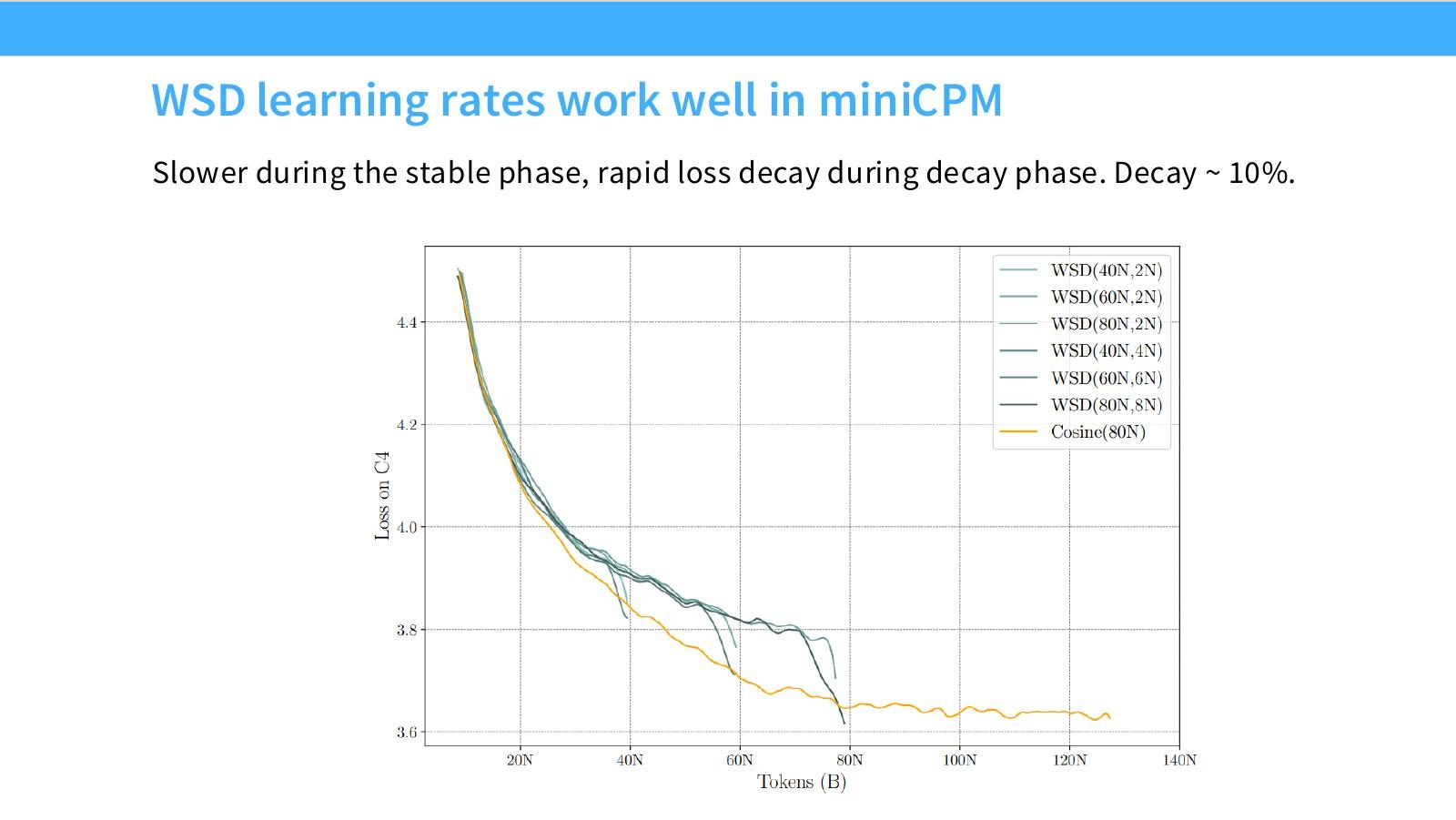
读图:Slide 15 的曲线说明什么
WSD 的好处不是让 stable 阶段最快,而是让同一条训练轨迹在多个候选 token budget 上可复用。Decayed tail 给出类似“如果在这里结束训练”的 loss 点,从而支持 lower-envelope 或 joint fit。
MiniCPM 的 Chinchilla 分析

读图:Slide 16 的方法选择
Method 1 是 lower envelope:看所有训练曲线在不同 compute 下的最小点。Method 3 是 joint fit:拟合参数量和数据量到 loss 的曲面。MiniCPM 同时使用两者,是为了在降低成本的同时增强外推可信度。
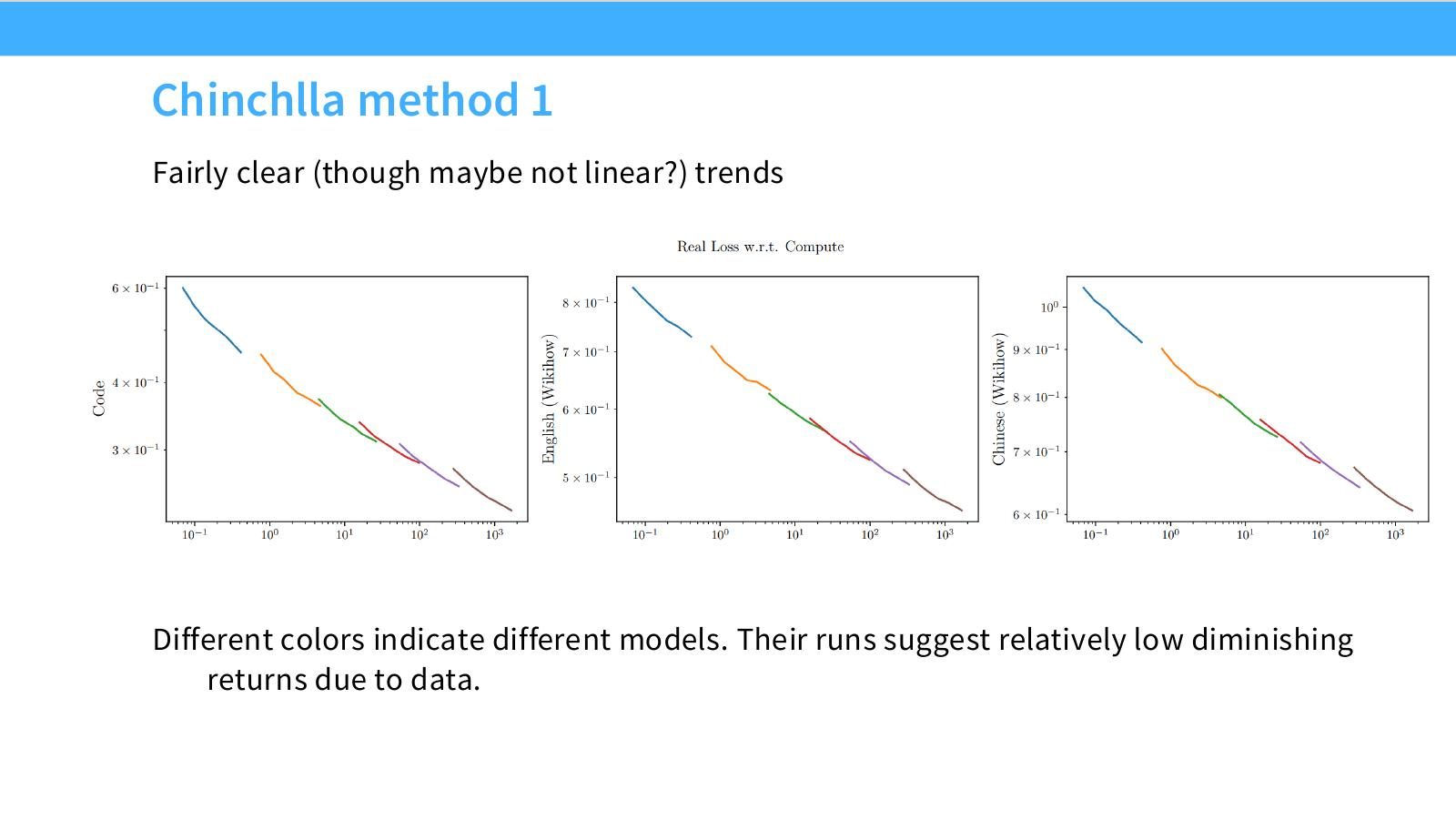
读图:Slide 17 的颜色和趋势
不同颜色代表不同模型规模。若 lower envelope 呈直线或平滑曲线,就可以外推 compute-optimal 关系。图中趋势清晰但不完美,说明公开 scaling recipe 在真实数据中会有噪声,不能只看拟合线的漂亮程度。
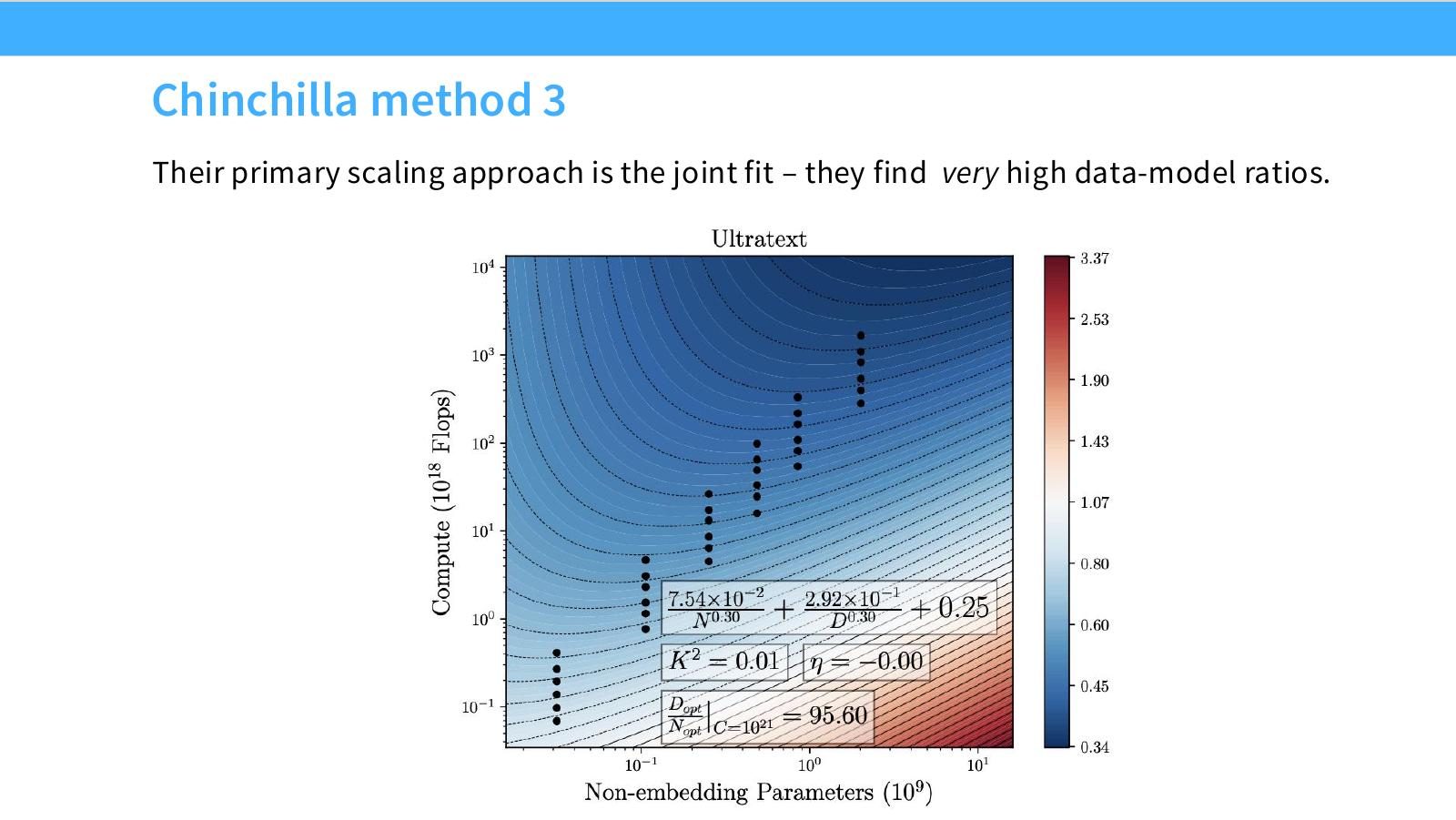
读图:Slide 18 的高 data-model ratio 意味着什么
如果 joint fit 推荐很高 token-to-parameter ratio,训练策略会偏向“小一些模型 + 多训练数据”。这与 Chinchilla 以来的过训趋势一致,也解释为什么小模型通过更多 token 和精细 tuning 能表现很强。
DeepSeek 与近期 scaling recipes

读图:Slide 19 的 DeepSeek 对照
DeepSeek 与 MiniCPM 的区别在于它不依赖 muP,而是直接估计 batch/LR scaling,并使用 WSD-style learning rate 和 IsoFLOP 分析。它代表另一条路线:用足够多小规模实验证明超参趋势,而不是依赖参数化理论稳定性。
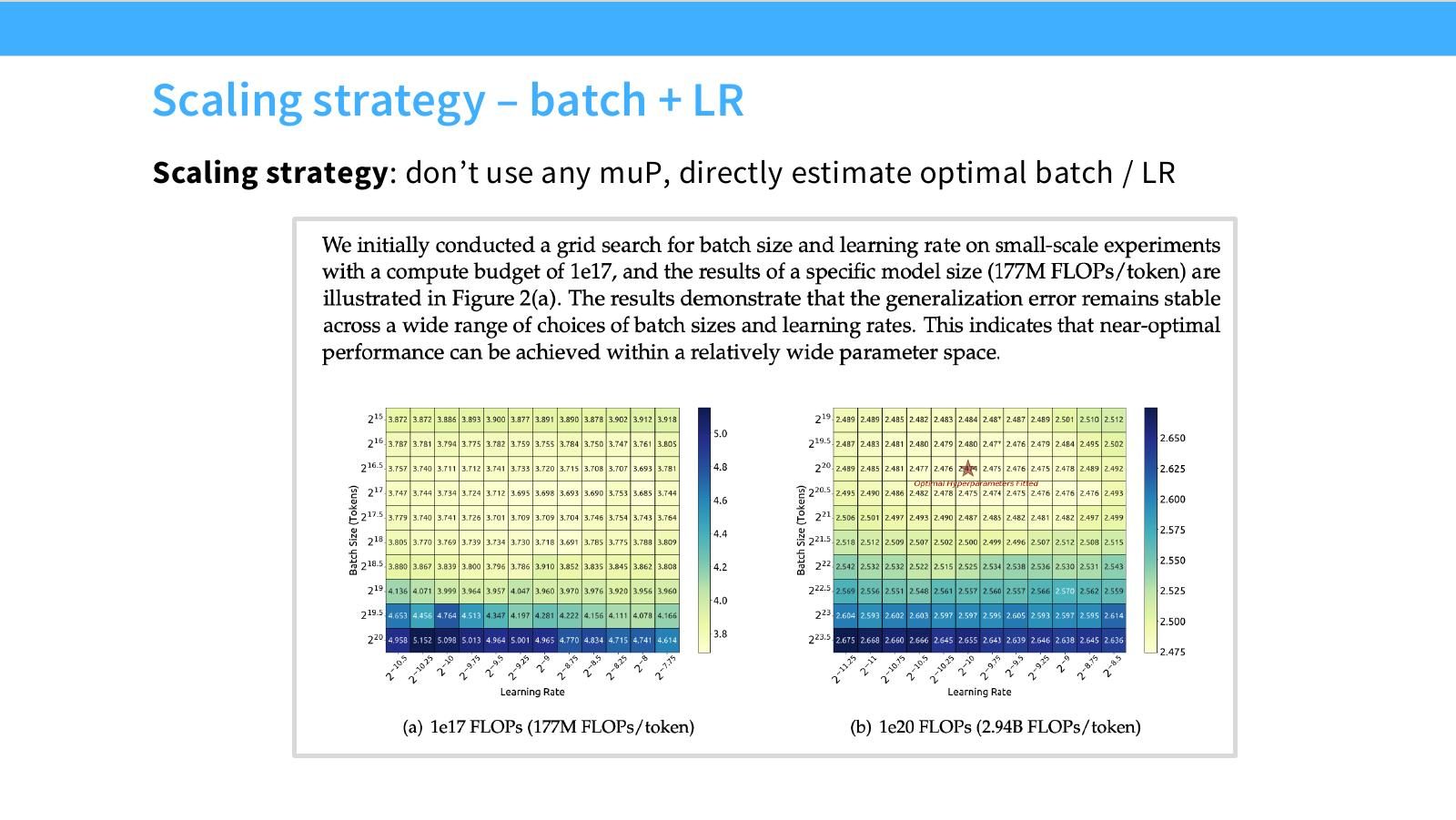
读图:Slide 20 的风险
不用 muP 意味着最优 LR 可能随 scale 漂移,因此必须更认真地做 LR/batch sweep。直接经验拟合很实用,但外推风险也更依赖实验覆盖和函数形式选择。
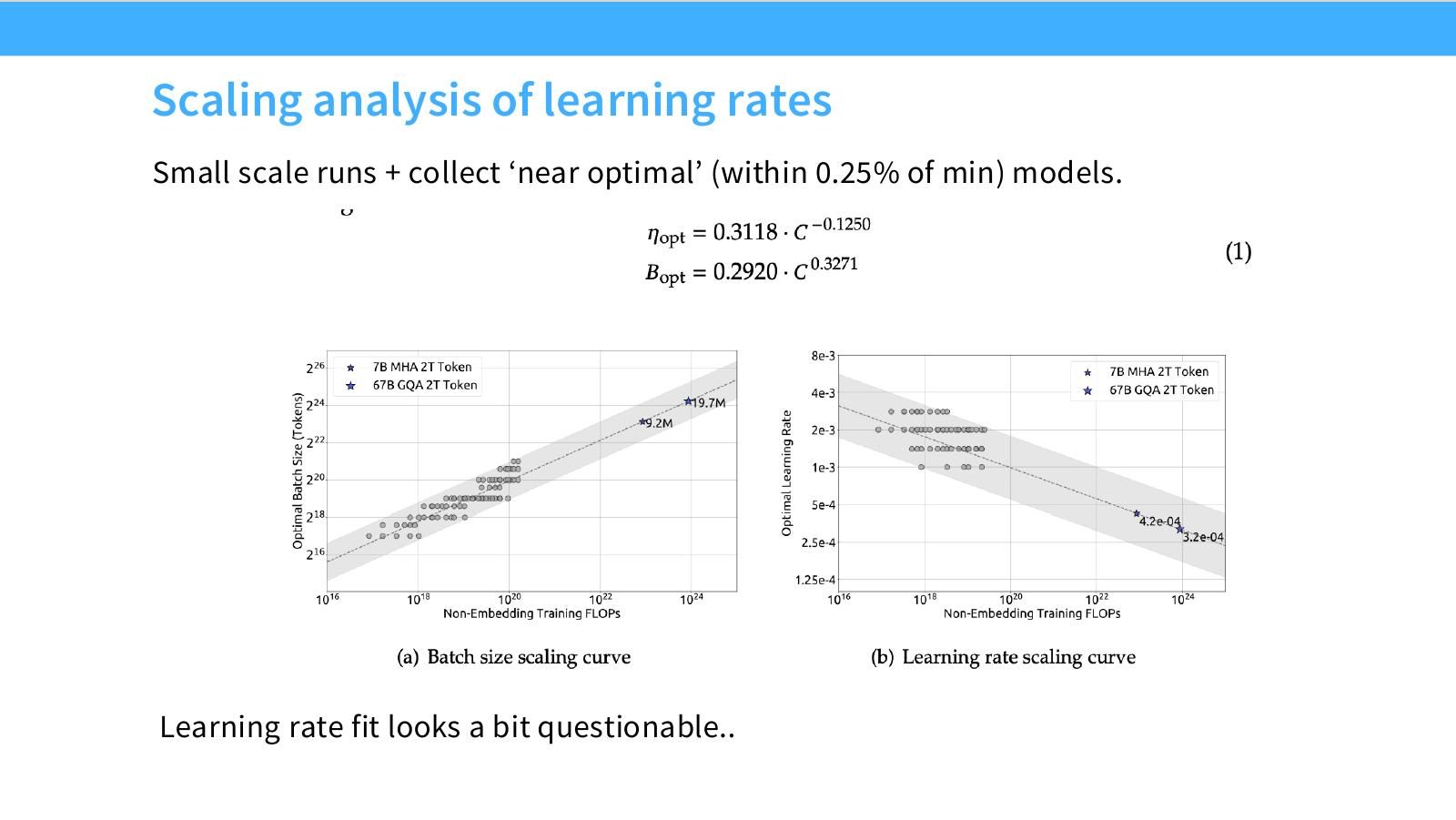
读图:Slide 21 的“questionable fit”怎么看
Near-optimal 定义为距离最小 loss 0.25% 以内,这能缓解噪声,但 LR 的最优区间可能很平。若点分布宽、拟合斜率不稳,就不能过度相信外推公式。公开论文里的 scaling fit 也需要质疑。
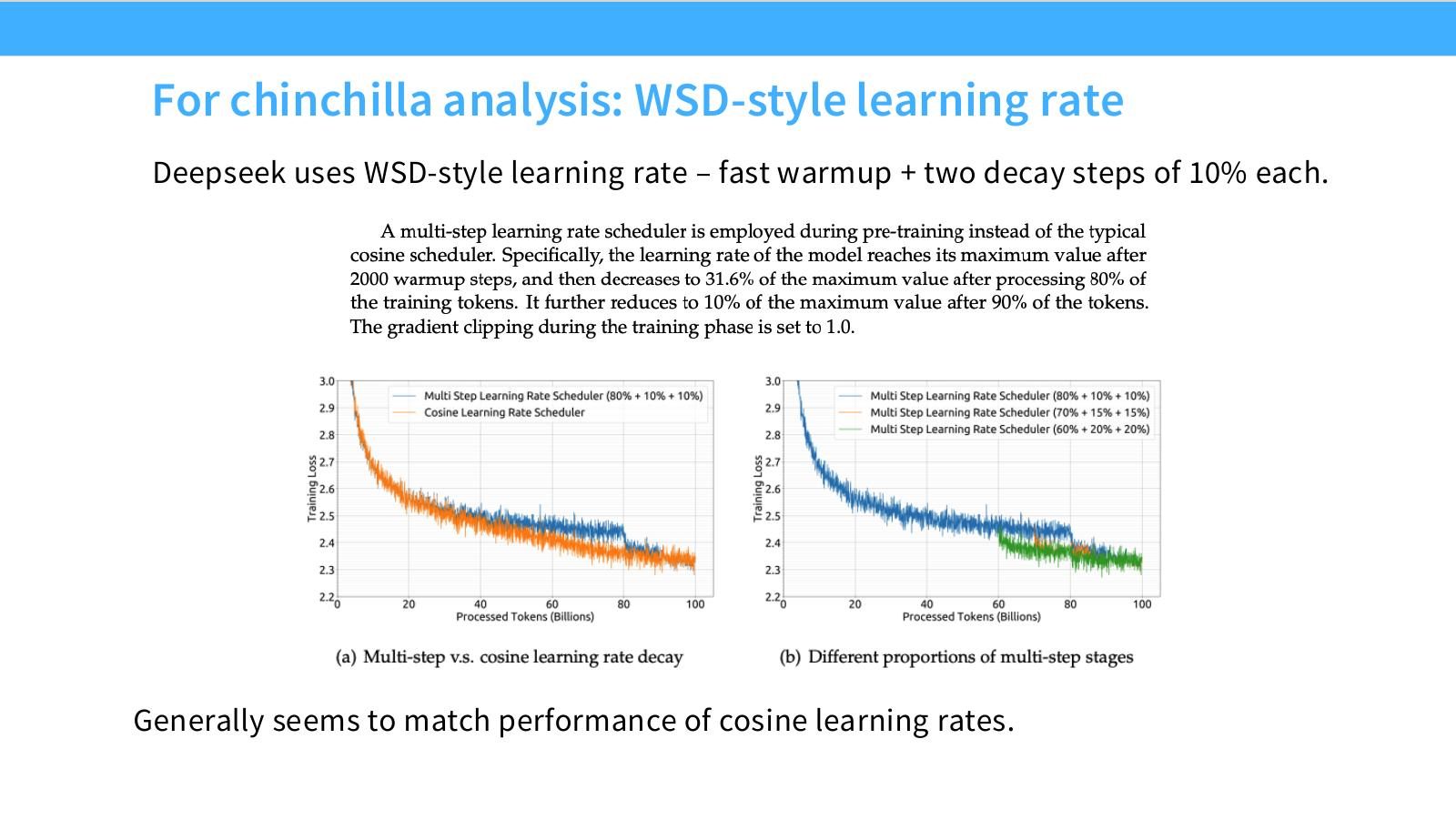
读图:Slide 22 的 WSD 共性
MiniCPM 和 DeepSeek 都使用 WSD 类思想,说明 WSD 的价值不仅是曲线形状,而是可复用训练轨迹、支持 scaling 分析。它让同一段 stable training 可以接多个 decay endings,减少重复从头训练。
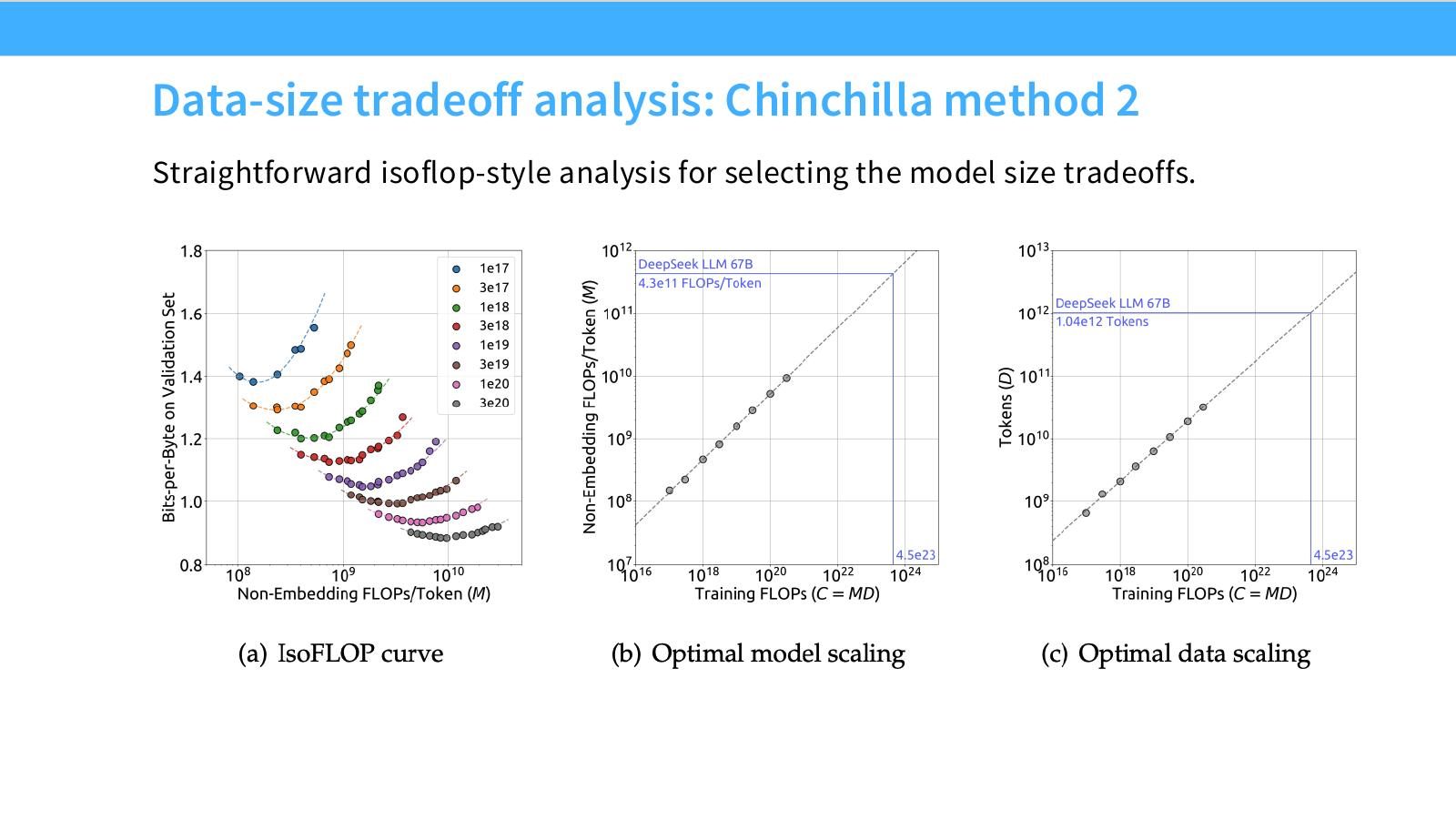
读图:Slide 23 的 IsoFLOP 逻辑
固定 FLOP budget,扫 model size 和 data size,取 loss 最小点。这样得到每个 compute 下的 optimal model size。它比直接 joint fit 更直观,也更容易发现某些点是否异常。
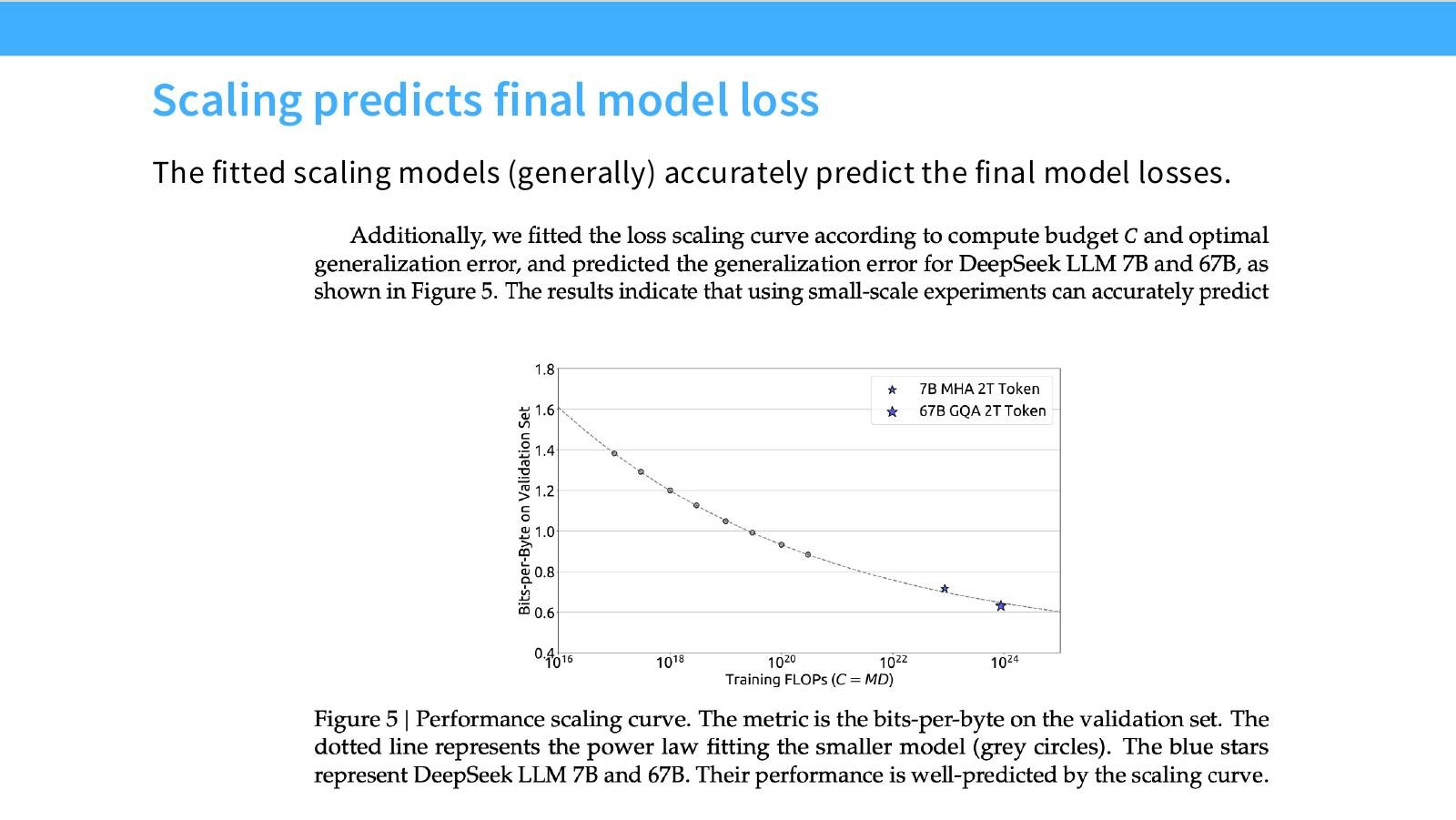
读图:Slide 24 是 scaling recipe 的验收
Scaling law 最终要看外推预测是否命中大模型 final loss。若小规模 fitted curve 能预测 7B/67B 等最终 loss,说明超参、数据、训练 recipe 在外推区间内足够稳定。反之,漂亮的小规模曲线也可能没有工程价值。
更多公开模型 scaling 片段

读图:Slide 25 的 Qwen 证据
Qwen 的公开信息说明 batch 和 LR scaling 已经成为主流模型训练报告的重要组成。不同团队可能用不同函数形式,但共同目标都是减少大模型调参风险。
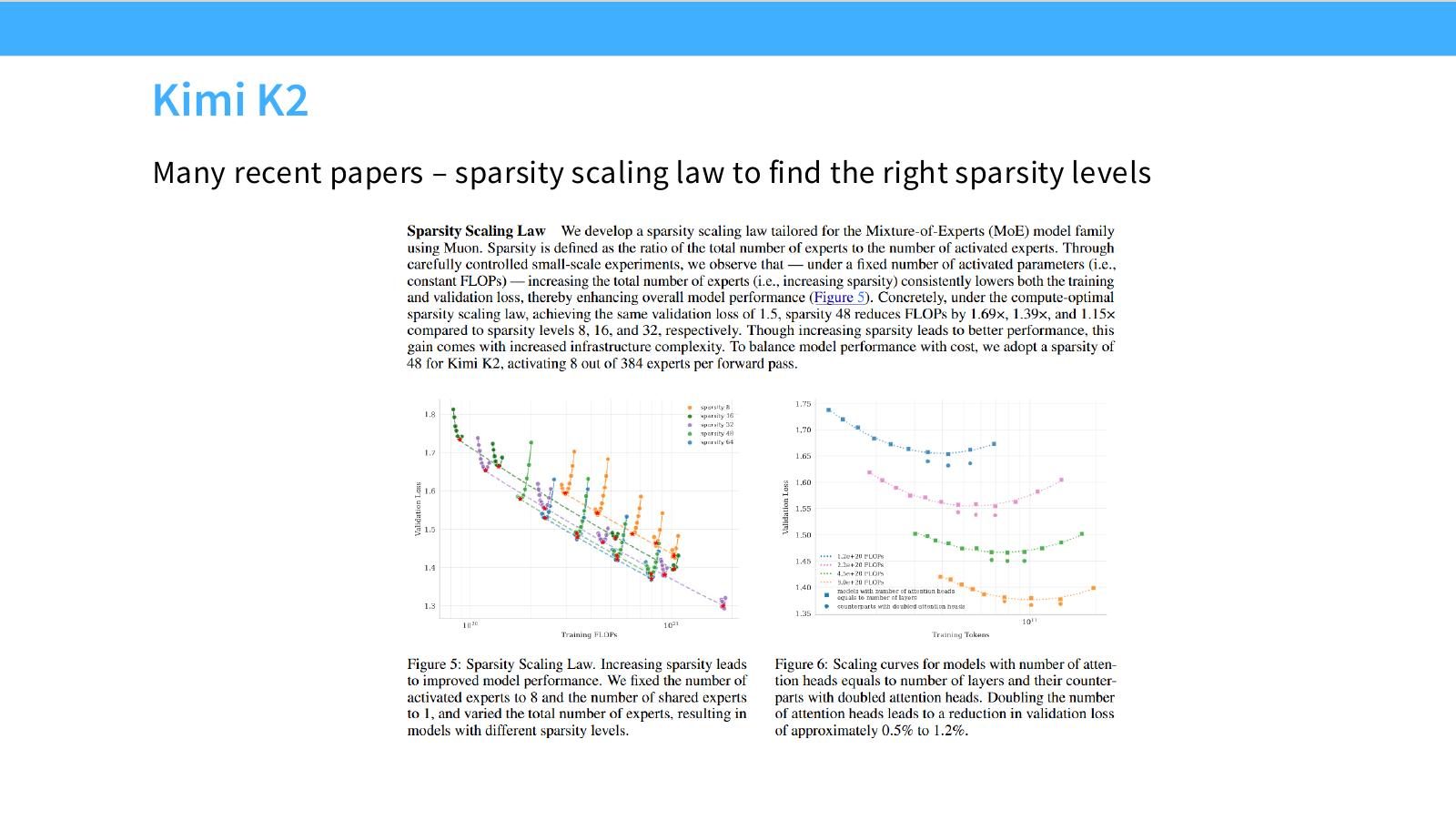
读图:Slide 26 把 scaling 扩展到 sparsity
Scaling 不只决定模型大小和 token 数,也可以决定 sparse/MoE 模型里 active parameters、expert 数、稀疏比例。Kimi K2 这类模型说明“参数价值”在稀疏模型里更复杂,必须把 active compute 和 total parameters 分开。
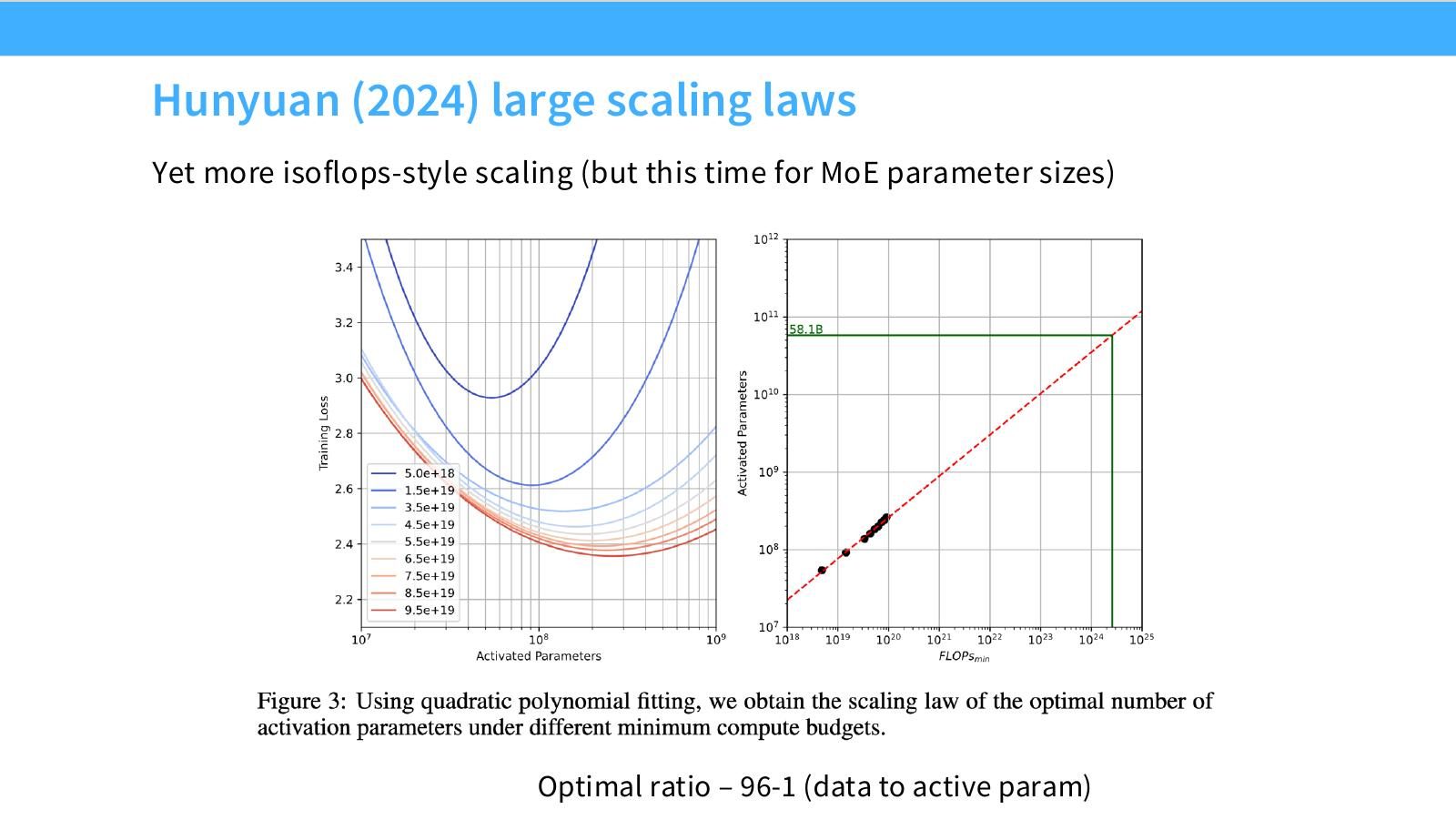
读图:Slide 27 的 active param ratio
MoE 的 total parameters 远大于每 token active parameters,因此 compute-optimal ratio 应以 active param 或 activated FLOPs 理解。96:1 这样的比例提醒我们,Chinchilla dense 模型口径不能直接套到 MoE。
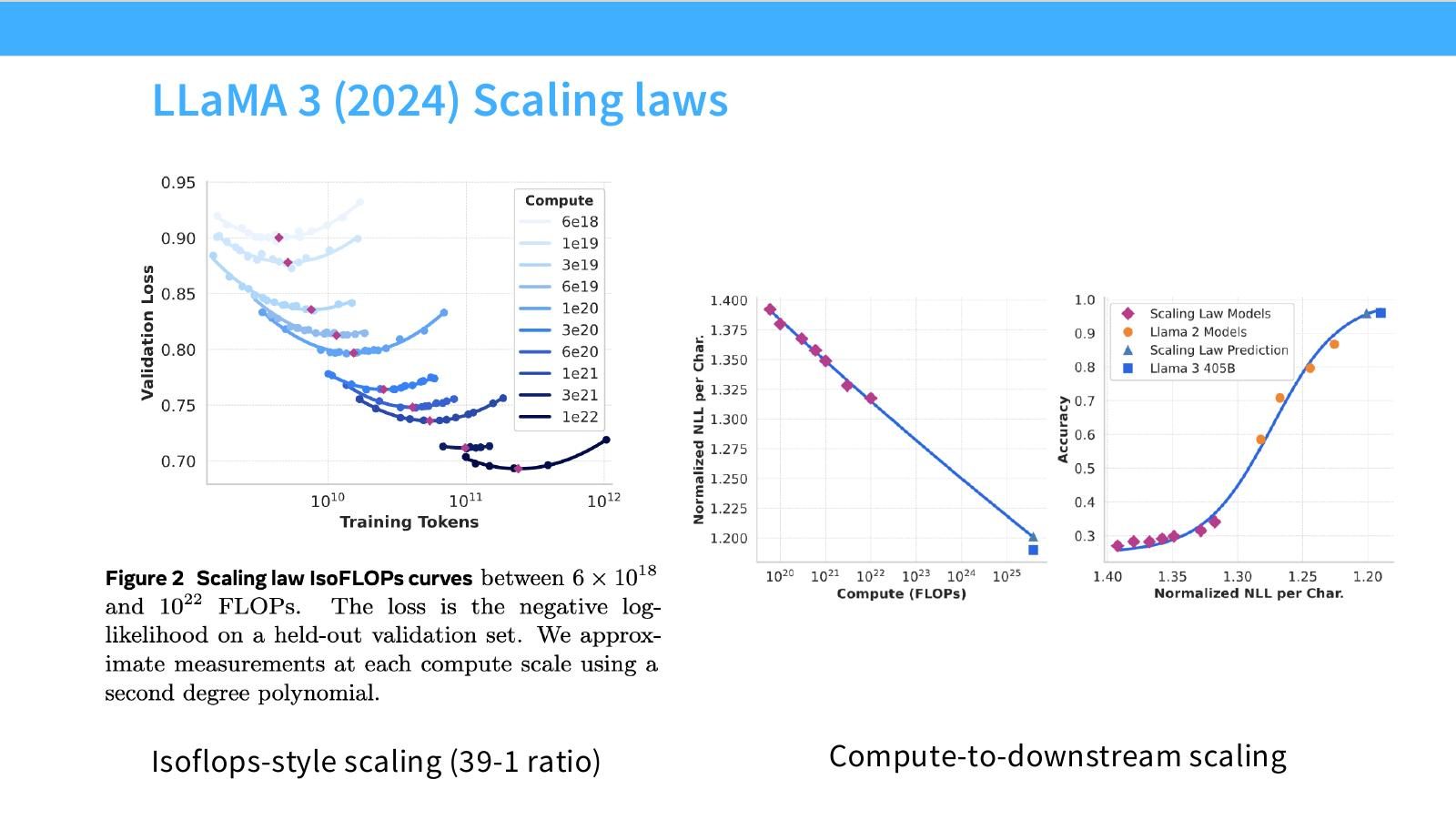
读图:Slide 28 的两个层次
预训练 loss 的 IsoFLOPS 只是第一层;compute-to-downstream scaling 关注下游任务如何随 compute 改善。大模型训练真正关心的是产品能力和 benchmark,而不仅是 cross entropy。因此 downstream scaling 是更难也更有价值的外推。
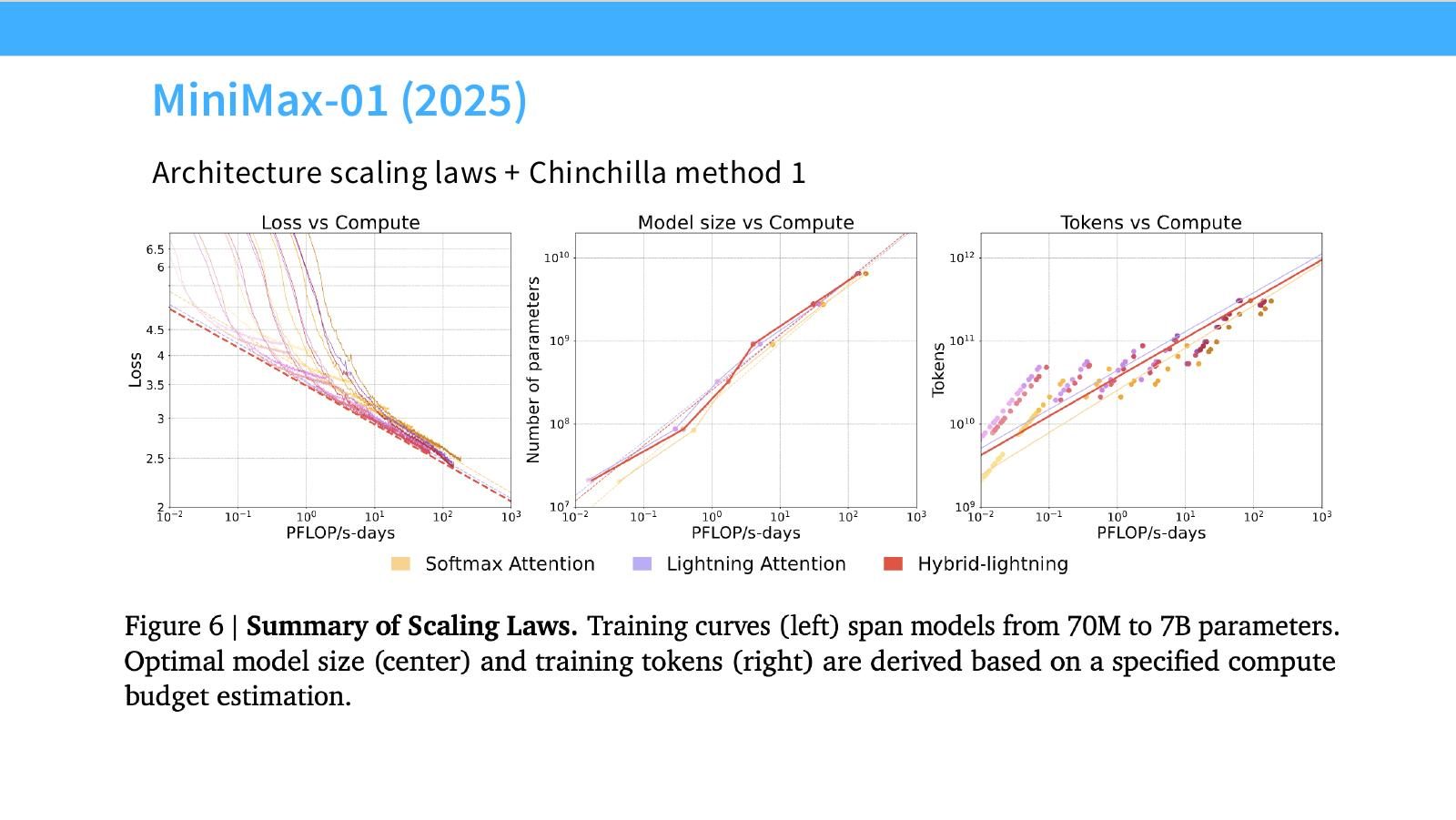
读图:Slide 29 的 architecture scaling
Architecture scaling laws 用来比较不同结构随规模变化的 loss 或能力曲线。MiniMax-01 的例子说明,架构选择也可以进入 scaling law pipeline,而不只是凭最大模型结果判断。

读图:Slide 30 的 recipe 可执行版本
实践中常先固定大多数 architecture hypers,只做 batch/LR scaling,再用 IsoFLOP 选择模型大小和 token 数。这样把指数级超参搜索压缩成少数关键轴。代价是:如果固定的 architecture hypers 实际随 scale 变化,recipe 会漏掉更优方案。
本章小结
MiniCPM 和 DeepSeek 展示了两种 scaling 实践:一类用 muP 稳定迁移,另一类用直接 empirical sweep 拟合 batch/LR 和 IsoFLOP。近期模型则说明 scaling law 的对象正在扩展到 MoE sparsity、architecture、downstream 能力和 active parameters。
Optimizer scaling:StepFun、Muon 与 scale dependence
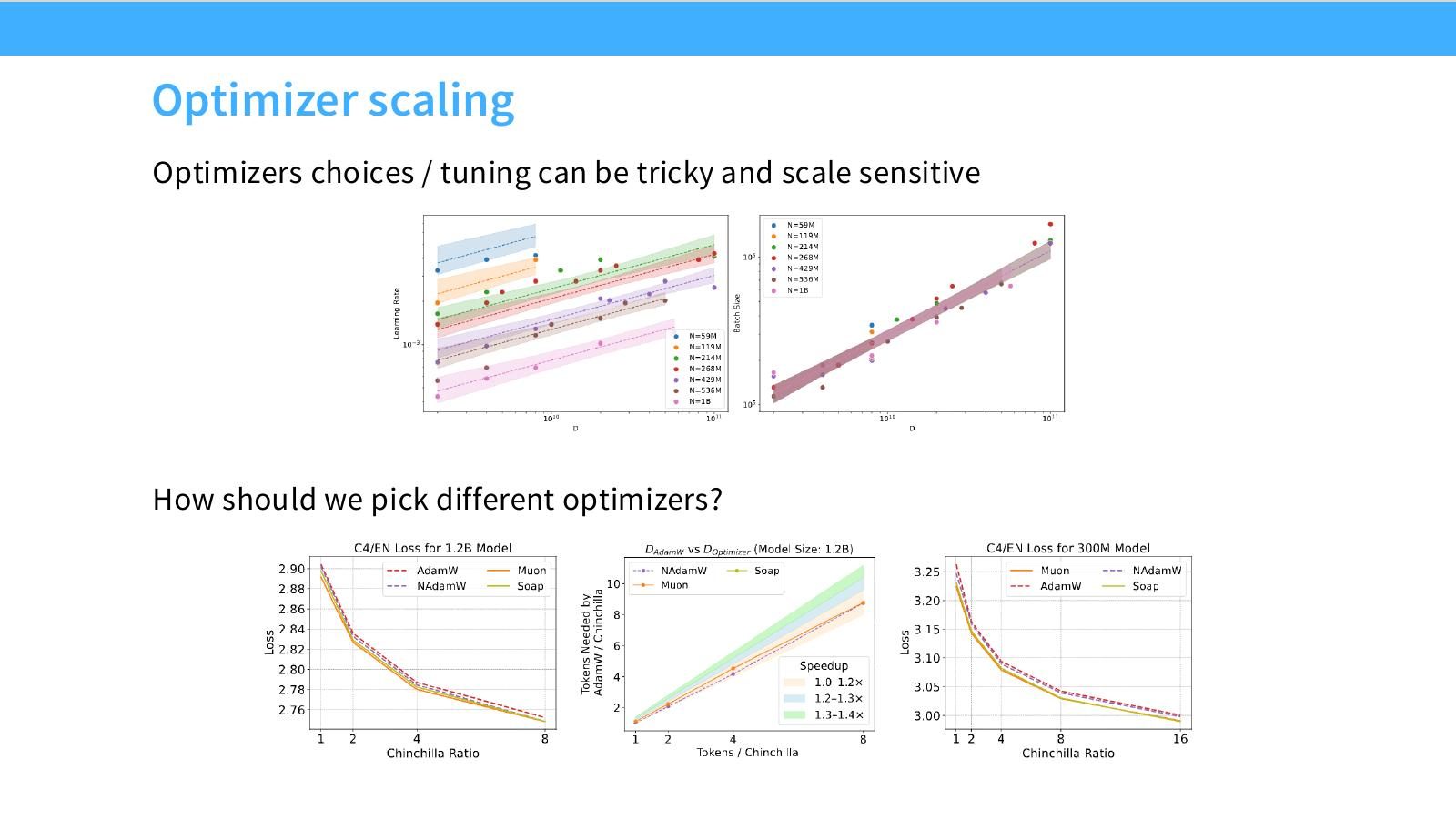
读图:Slide 31 的问题
Optimizer 不是“选 AdamW 就结束”。不同 optimizer 的最优 LR、batch、weight decay、momentum 可能随 scale 变化;如果只在小模型上比较,可能因为没调好超参而误判算法。

读图:Slide 32 的 StepFun 角色
StepFun 类研究把 optimizer hyperparameter scaling 当成主要对象,而不只是模型大小。它类似 DeepSeek/Qwen 路线:训练大量小模型,在 LR/batch 空间中找规律。

读图:Slide 33 的变量选择
Critical batch 把 batch 写成 loss 的函数;DeepSeek 风格可能把超参写成 compute 的幂函数;也可能与数据量、模型大小分别相关。函数形式不是数学细节,而是决定外推是否可信的建模选择。
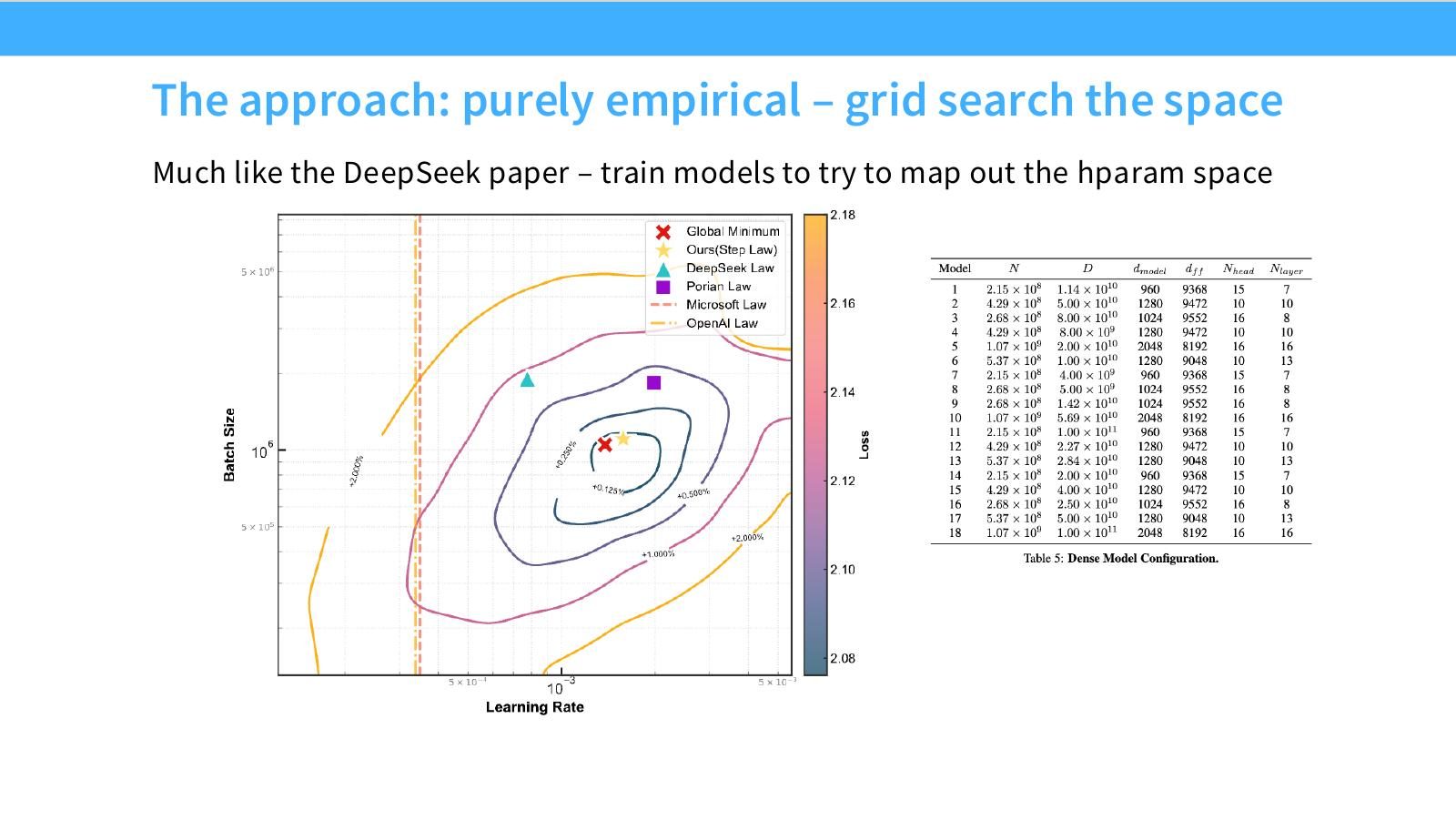
读图:Slide 34 的 grid search 代价
纯经验方法的优势是不依赖强理论假设;劣势是成本高,且容易受数据范围影响。它要求每个模型规模和数据量上都有足够覆盖,否则拟合出的 scaling rule 只是局部规律。
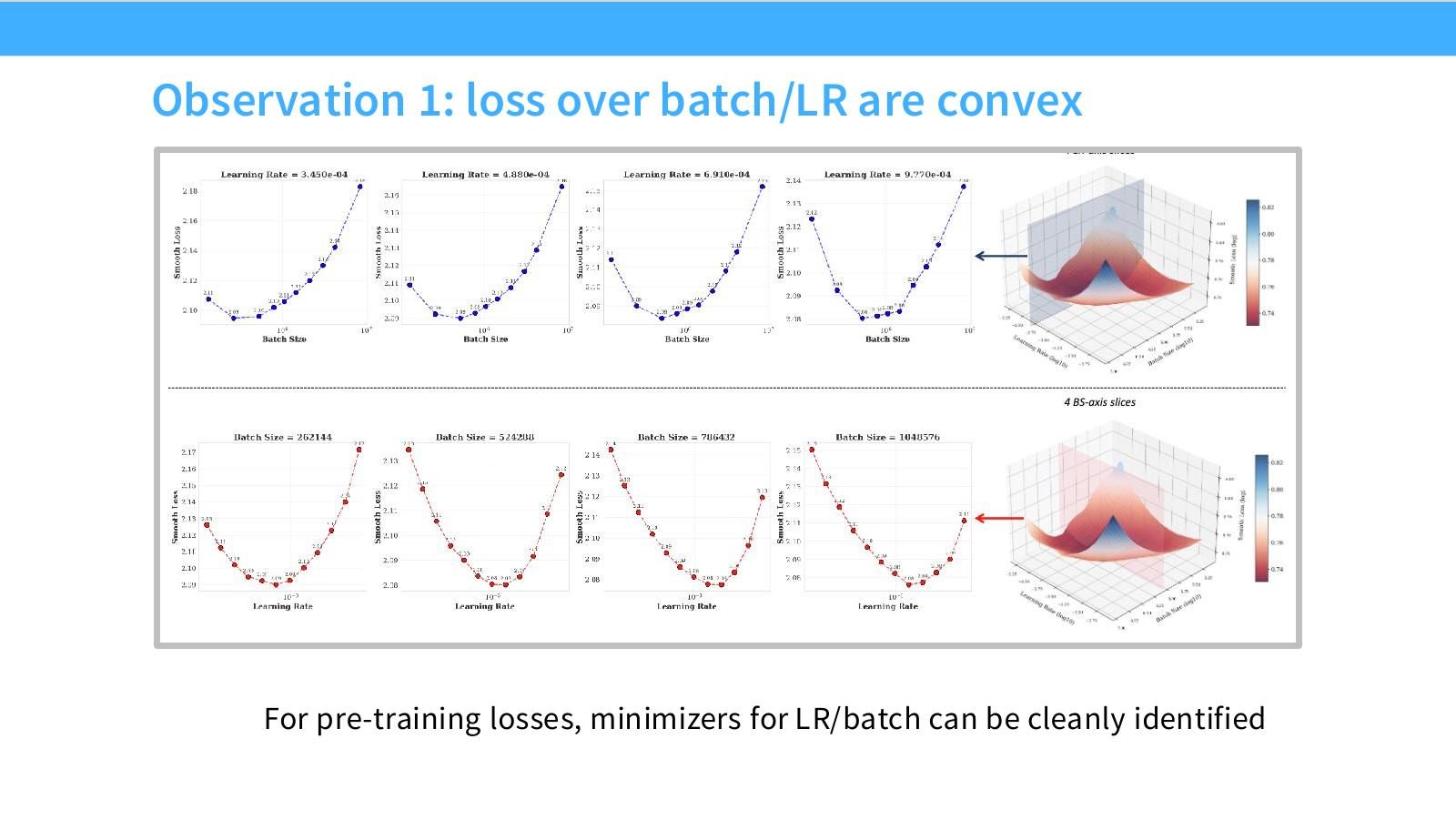
读图:Slide 35 为什么重要
若 loss surface 对 LR/batch 近似凸,hyperparameter tuning 就可被系统化:每个 scale 找最小点,再拟合最小点随 scale 的轨迹。若曲面多峰或噪声大,外推就危险得多。
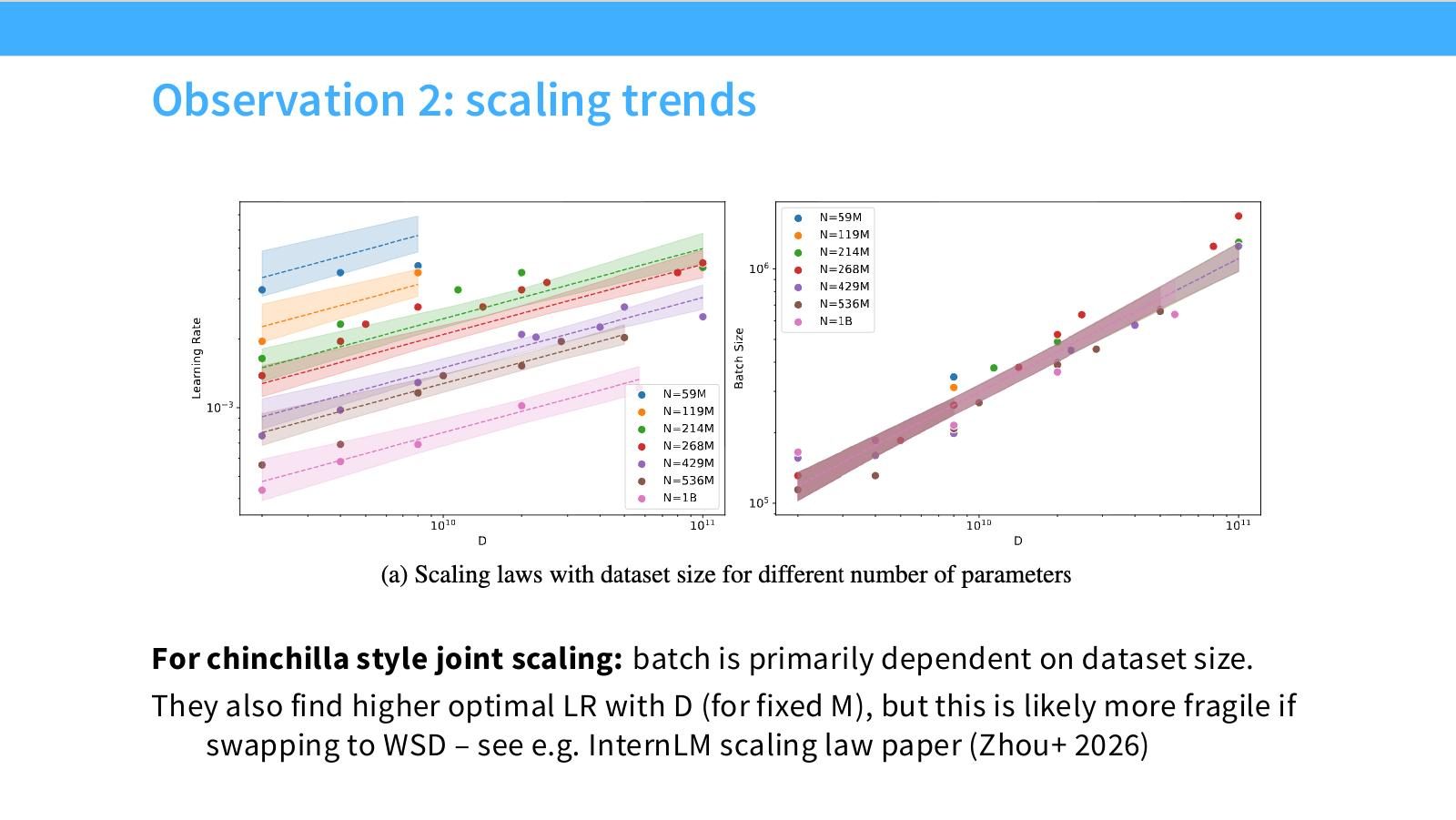
读图:Slide 36 的 fragile LR 结论
如果换成 WSD schedule、不同 warmup、不同 decay 或不同 optimizer,LR scaling 结论可能改变。Batch scaling 可能更稳定,LR scaling 更依赖训练 recipe。因此公开 LR 幂律要带着 recipe 一起读。
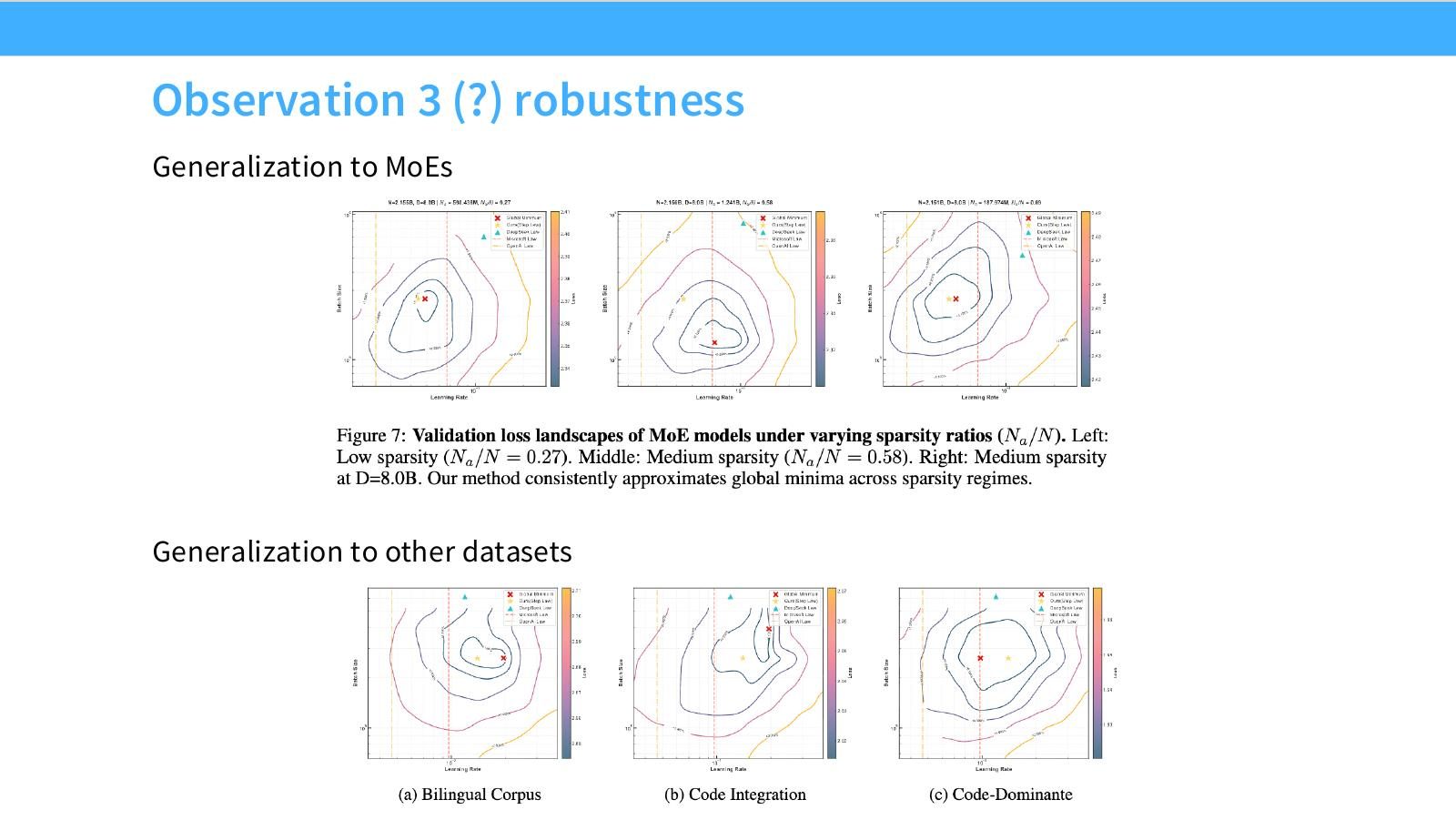
读图:Slide 37 的 robustness 问题
Scaling rule 是否跨模型族、数据集、dense/MoE 架构泛化,是 optimizer scaling 的核心。若泛化好,小模型 tuning 价值很大;若不泛化,每个新数据集/架构都要重新 sweep。
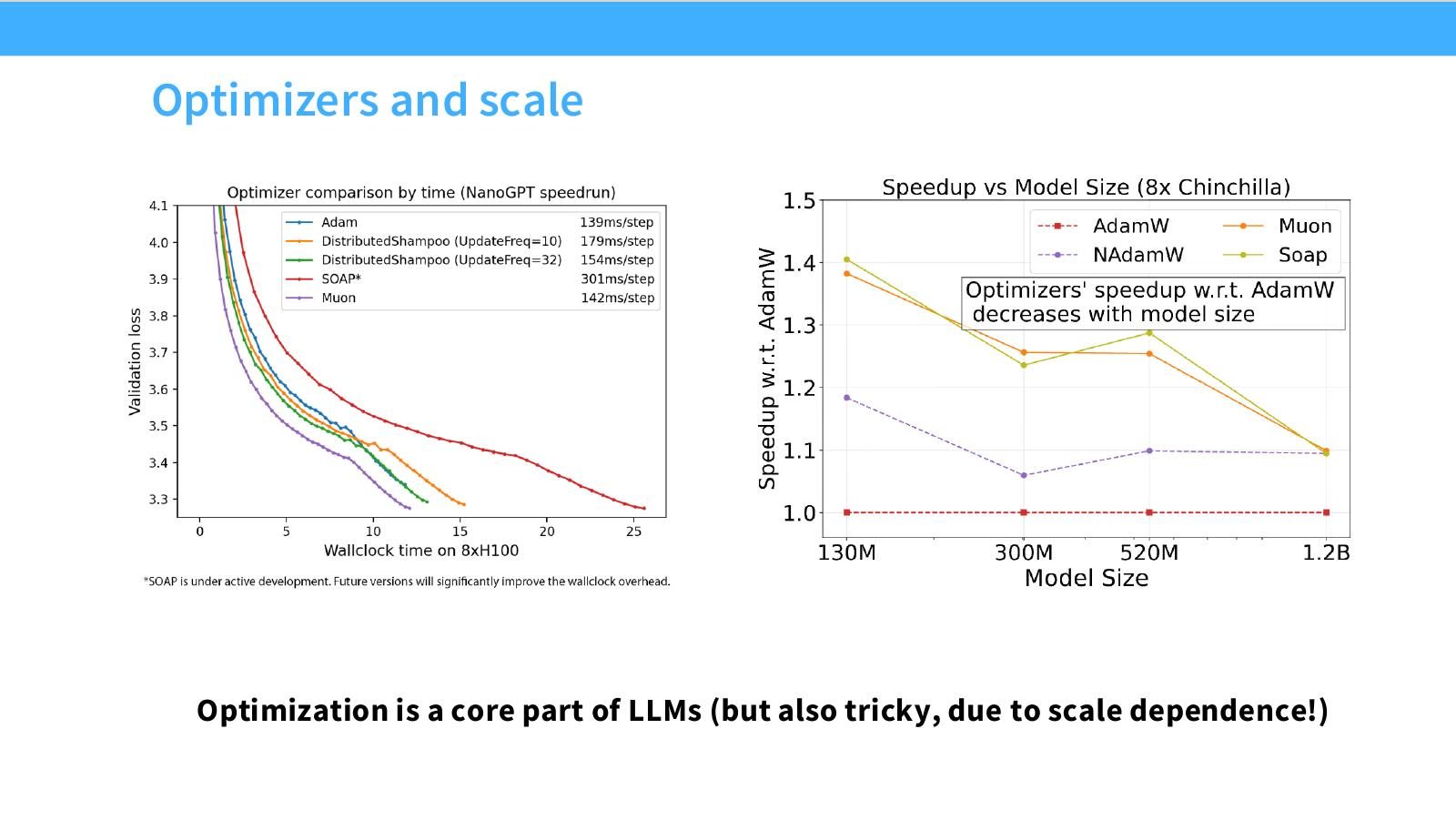
本节核心观点
评估 optimizer 时,必须同时控制 compute、Chinchilla ratio、batch/LR scaling 和模型规模。否则一个 optimizer 看似更好,可能只是因为它在某个 scale 上超参调得更合适。
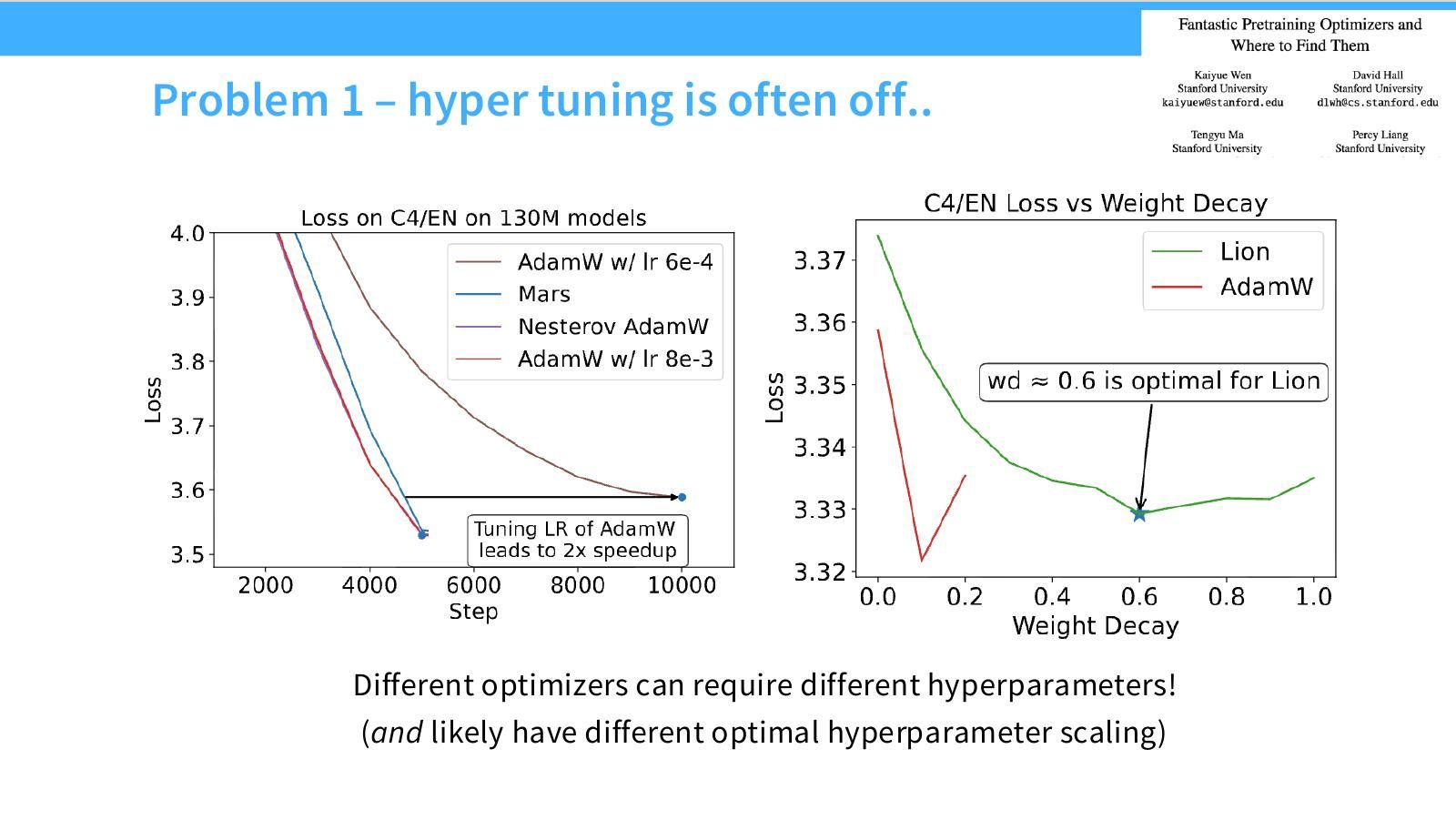
读图:Slide 39 的 optimizer 比较陷阱
若 AdamW 调得很好、Muon 或 SGD 没调好,比较没有意义。每个 optimizer 都需要自己的 learning-rate/batch/weight-decay scaling rule。公平比较不是同一套超参,而是各自最优超参。
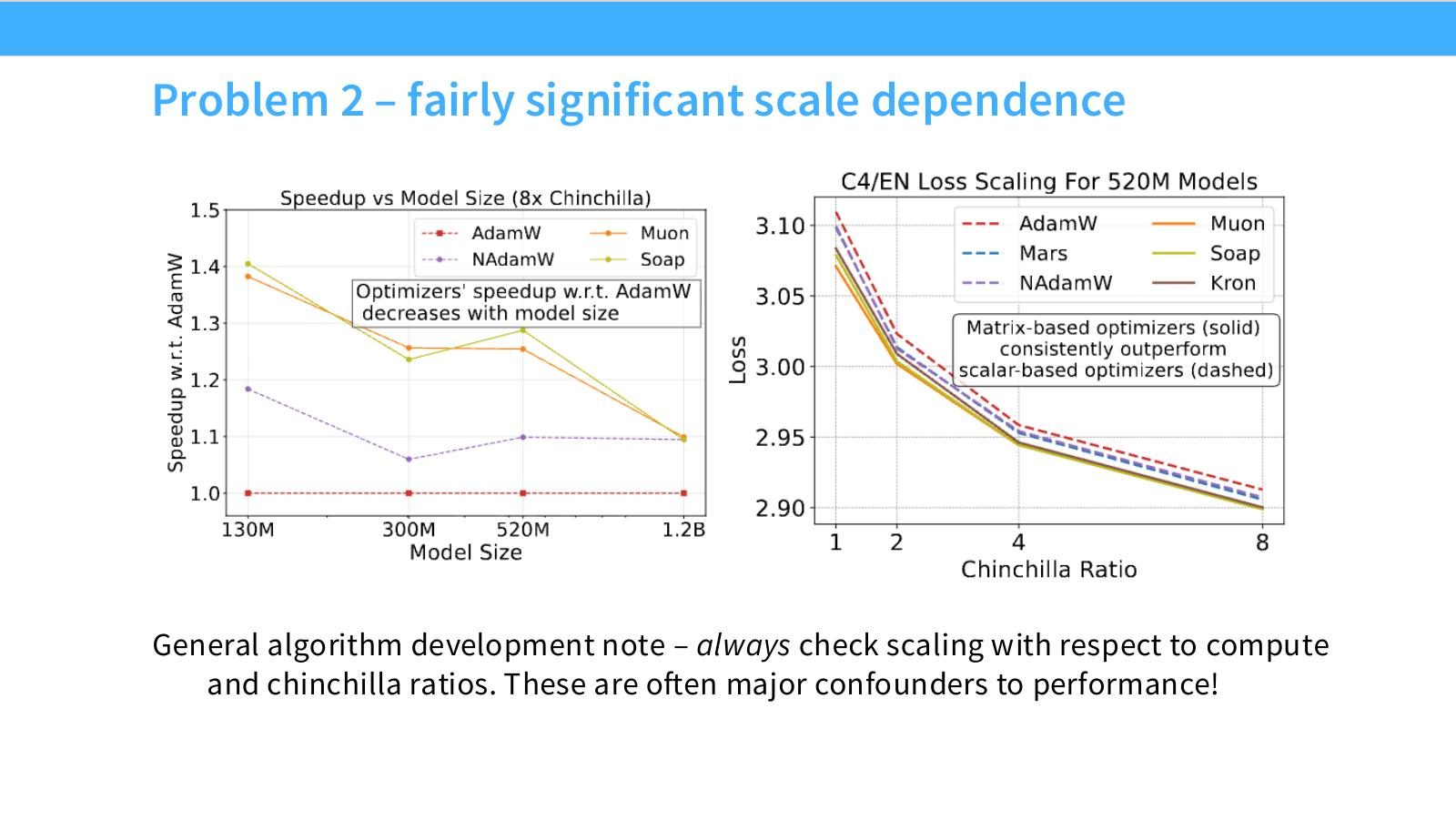
读图:Slide 40 对算法论文的提醒
一个 optimizer 在小模型或非 Chinchilla ratio 下胜出,不代表在大模型 compute-optimal setting 中胜出。算法开发需要 scaling with compute,而不是只报告一个固定规模实验。
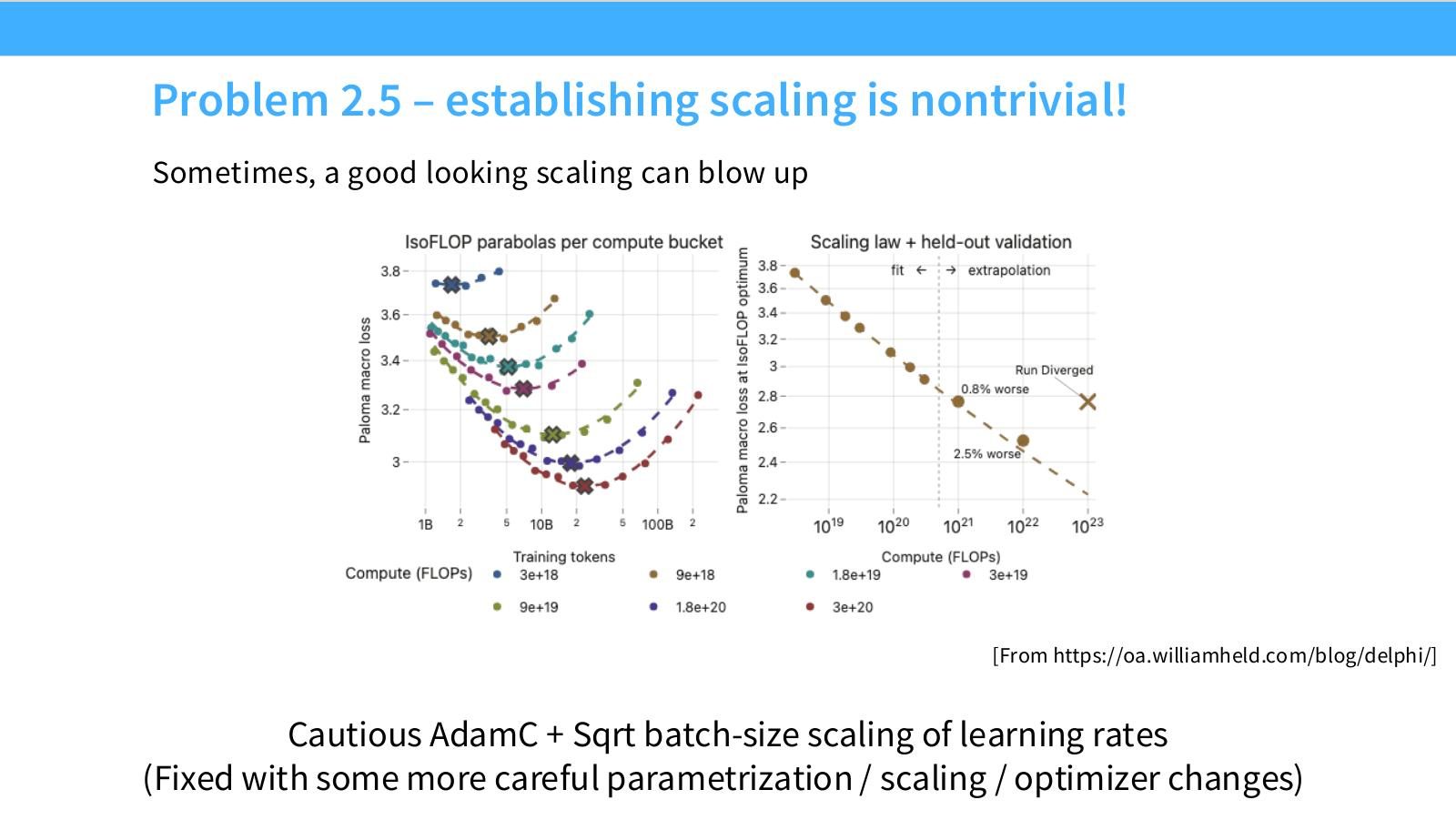
读图:Slide 41 的 blow-up 教训
Scaling curves 在小范围内平滑,不代表在更大 compute 上稳定。某些参数化、batch-size LR scaling 或 optimizer tweak 可能在大 scale 才暴露不稳定。外推前必须留出中间 scale 验证点。
Muon
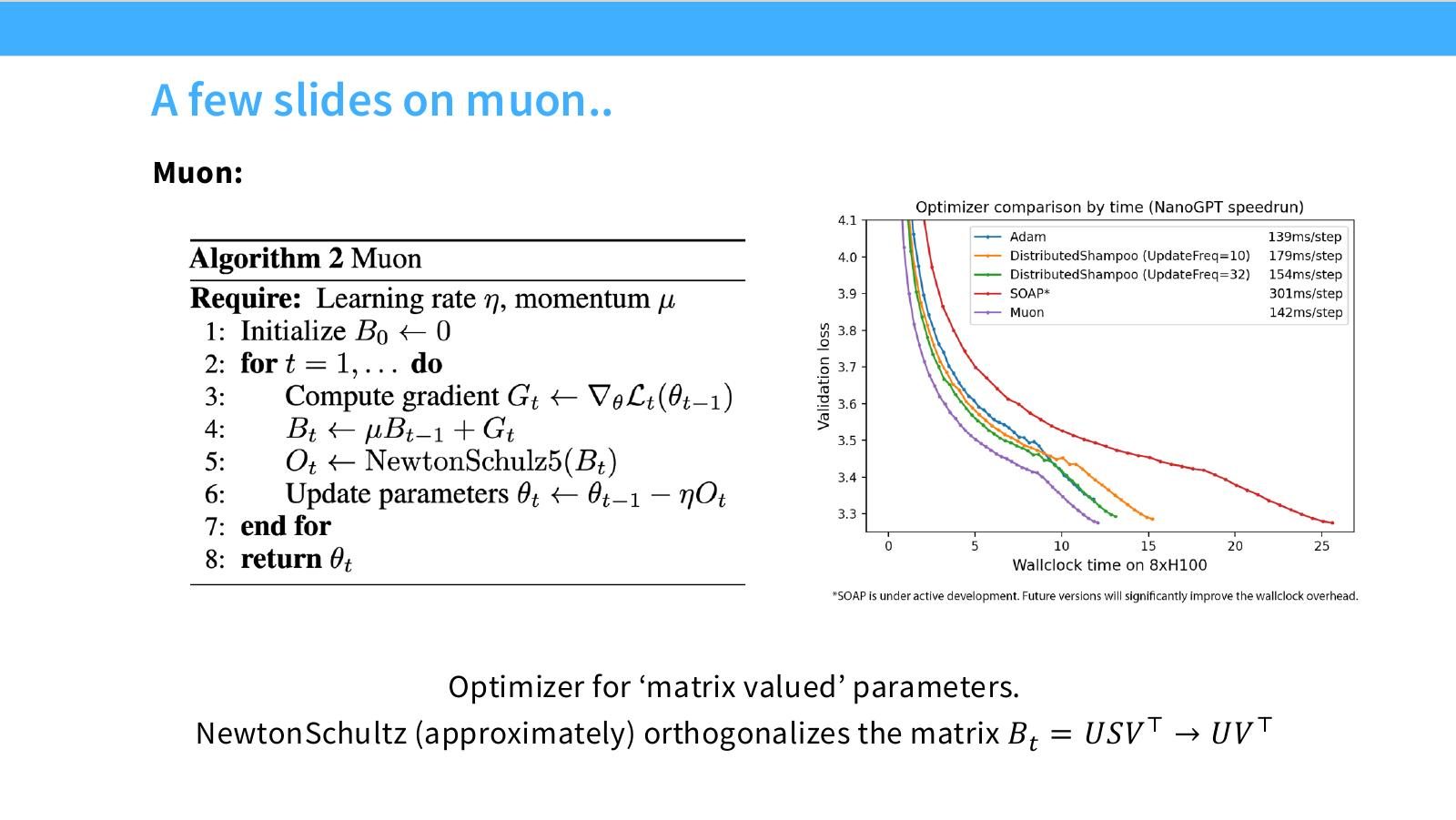
读公式:Slide 42 的 Muon 直觉
若更新矩阵 \(B_t=USV^\top\),Muon 近似把它转成 \(UV^\top\),也就是去掉奇异值尺度,只保留方向上的正交化结构。它试图让矩阵参数的更新更均衡,但实际收益必须看 scaling 和超参调优。
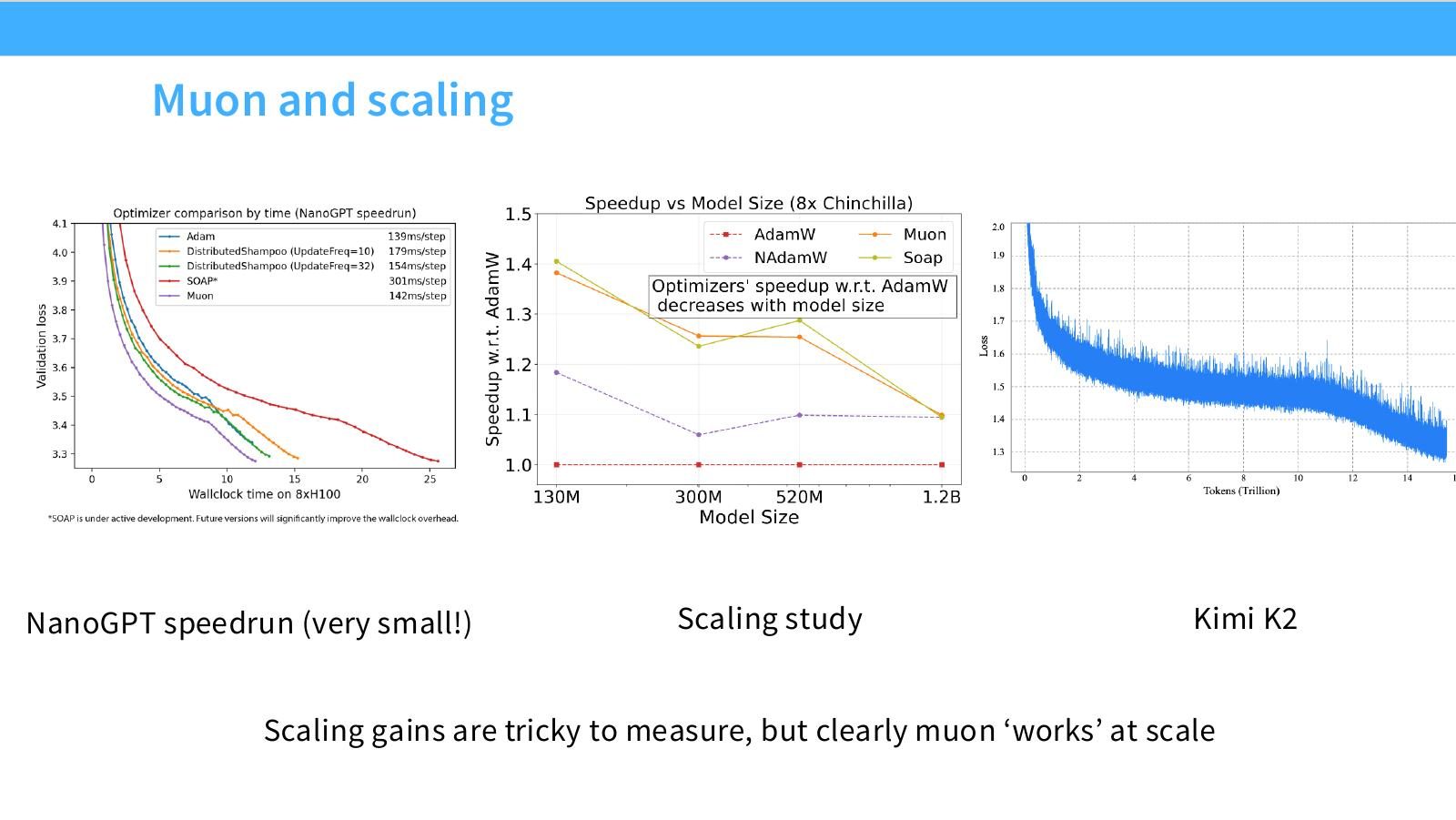
读图:Slide 43 的保守结论
Muon “works at scale” 不等于它在所有 scale、所有模型、所有 compute ratios 下都优于 AdamW。Scaling gains 很难测,因为要公平调参、控制 compute、控制数据和架构。课程更看重方法论:optimizer 改动必须做 scaling 验证。
本章小结
Optimizer scaling 的难点在于:不同 optimizer 有不同最优超参,而且这些超参随 scale、数据、compute 和训练 schedule 变化。任何 optimizer 结论都必须绑定 scaling study,而不是孤立单点。
muP in depth:为什么它想让超参跨宽度稳定
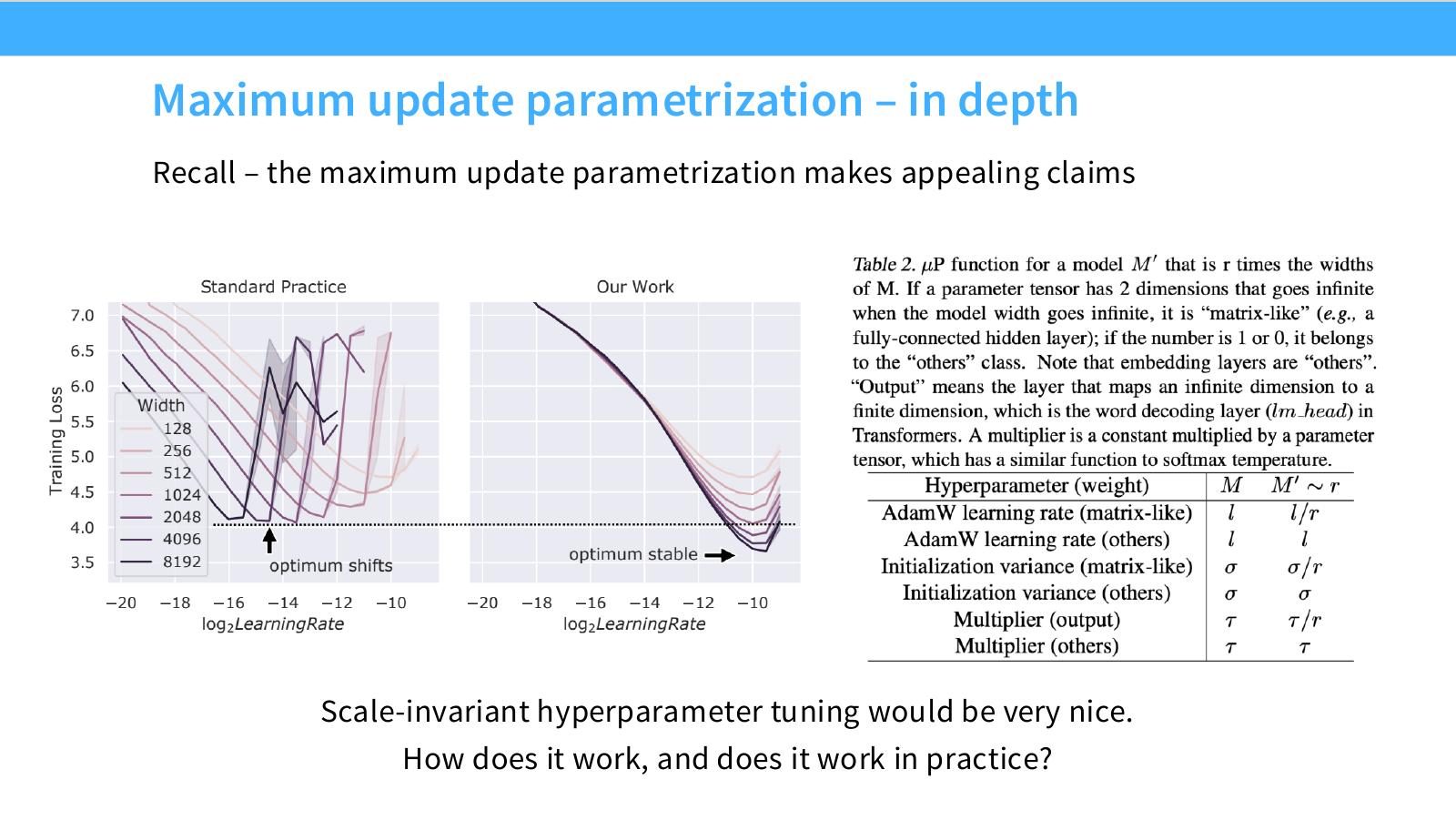
术语消化:muP 与 SP
muP 是 maximum update parametrization,希望在宽度变化时保持 activation 和 update 的量级稳定,从而让小模型最优 learning rate 更可迁移。SP 是 standard parametrization,常见但宽度放大时训练动力学可能变化。Lecture 11 后半段问:现代 LM 里 muP 的理论条件哪些仍成立,哪些会被 RMSNorm、SwiGLU、exotic optimizers、weight decay 破坏。
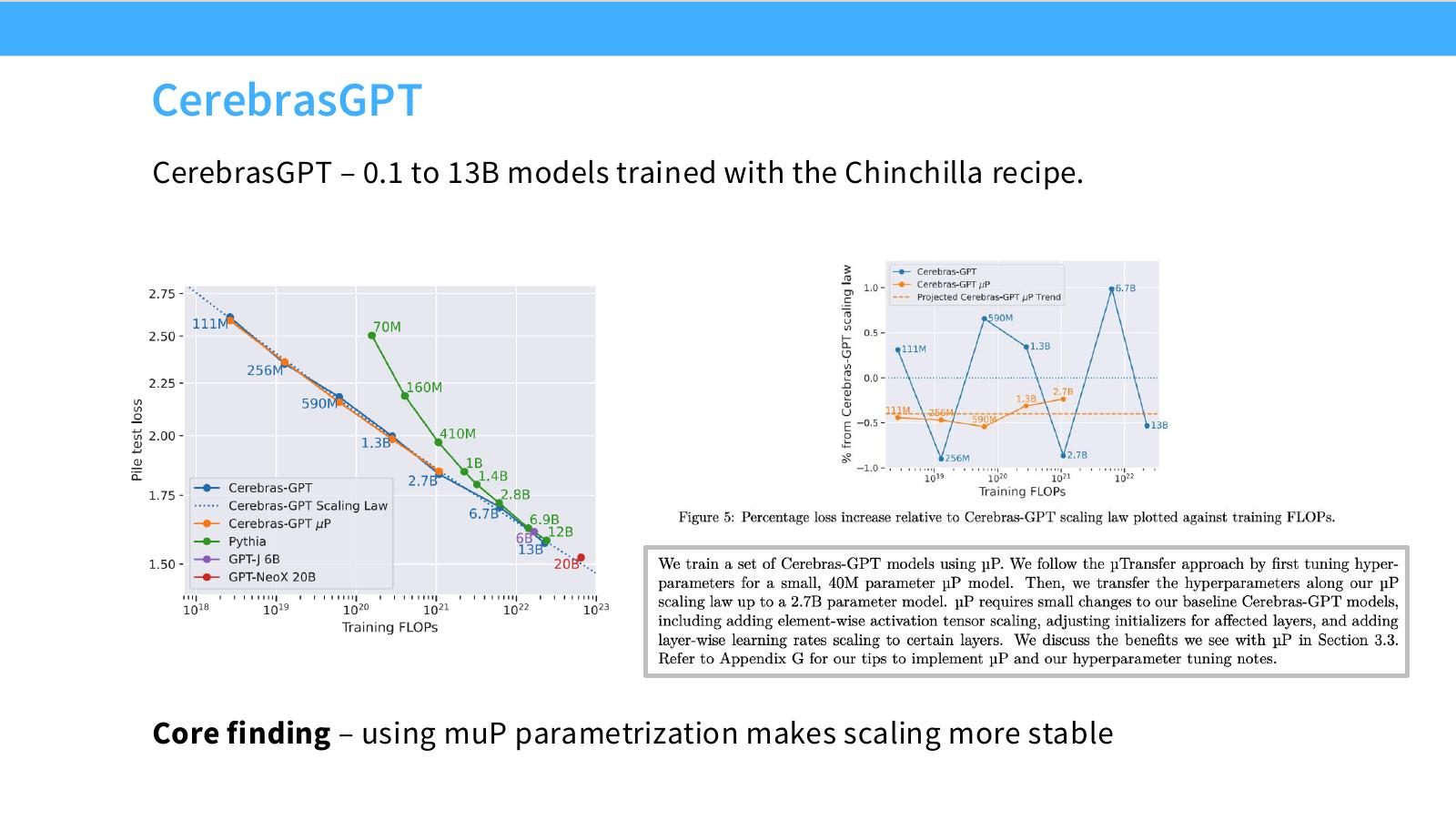
读图:Slide 45 的证据类型
CerebrasGPT 是 muP 实践证据之一:跨多个模型大小训练,比较稳定性和超参迁移。它说明 muP 不是纯理论玩具,但也不是所有现代架构自动适用的万能钥匙。

读图:Slide 46 的两个条件
A1:随着层宽 \(n_l\) 改变,初始化时的 activations 不应爆炸或消失,应为 \(\Theta(1)\)。A2:一次梯度更新造成的 activation change 也应为 \(\Theta(1)\)。muP 的学习率和初始化规则就是围绕这两个量级条件设计的。
Deriving muP:condition A1

读公式:Slide 47 的初始化尺度
若 \(W_l\sim \mathcal{N}(0,\sigma^2 I)\),矩阵谱范数会随输入/输出维度变化。要让 \(\|h_l\|\) 不随宽度爆炸,就要让 \(\sigma\) 随 \(n_{l-1},n_l\) 缩放。标准 Xavier/He 初始化和 muP 都在解决“宽度变大时 activation 尺度如何保持”的问题。
Deriving muP:condition A2

读公式:Slide 48 的 update 尺度
线性层更新可写为
这说明 update 尺度由学习率 \(\eta_l\)、上游 loss gradient 和前一层 activation 共同决定。宽度变化时,若 \(\eta_l\) 不随维度调整,\(\Delta W_l h_{l-1}\) 可能不再是 \(\Theta(1)\)。

读公式:Slide 49 的 learning-rate 缩放
这页的关键是把“update 后 activation change 保持常数”翻译成学习率缩放规则。不同层、不同参数类型可能需要不同 LR scaling;这也是 muP 比普通“所有参数同一 LR”更细的原因。

读图:Slide 50 的 baby muP 总结
muP 不是一条单独公式,而是一组随宽度缩放的初始化和学习率规则。其目标是让 activation scale 和 update scale 在不同宽度下可比。这样小模型调参才有希望迁移到大模型。
现代 LM 中 muP 的适用性

读图:Slide 51 的细节意义
现代 Transformer 参数类型很多:embedding、attention projection、MLP matrix multiply、softmax/output linear。不同参数在前向和反向中的维度角色不同,因此 muP 需要按参数类型分别指定初始化和 LR scaling。
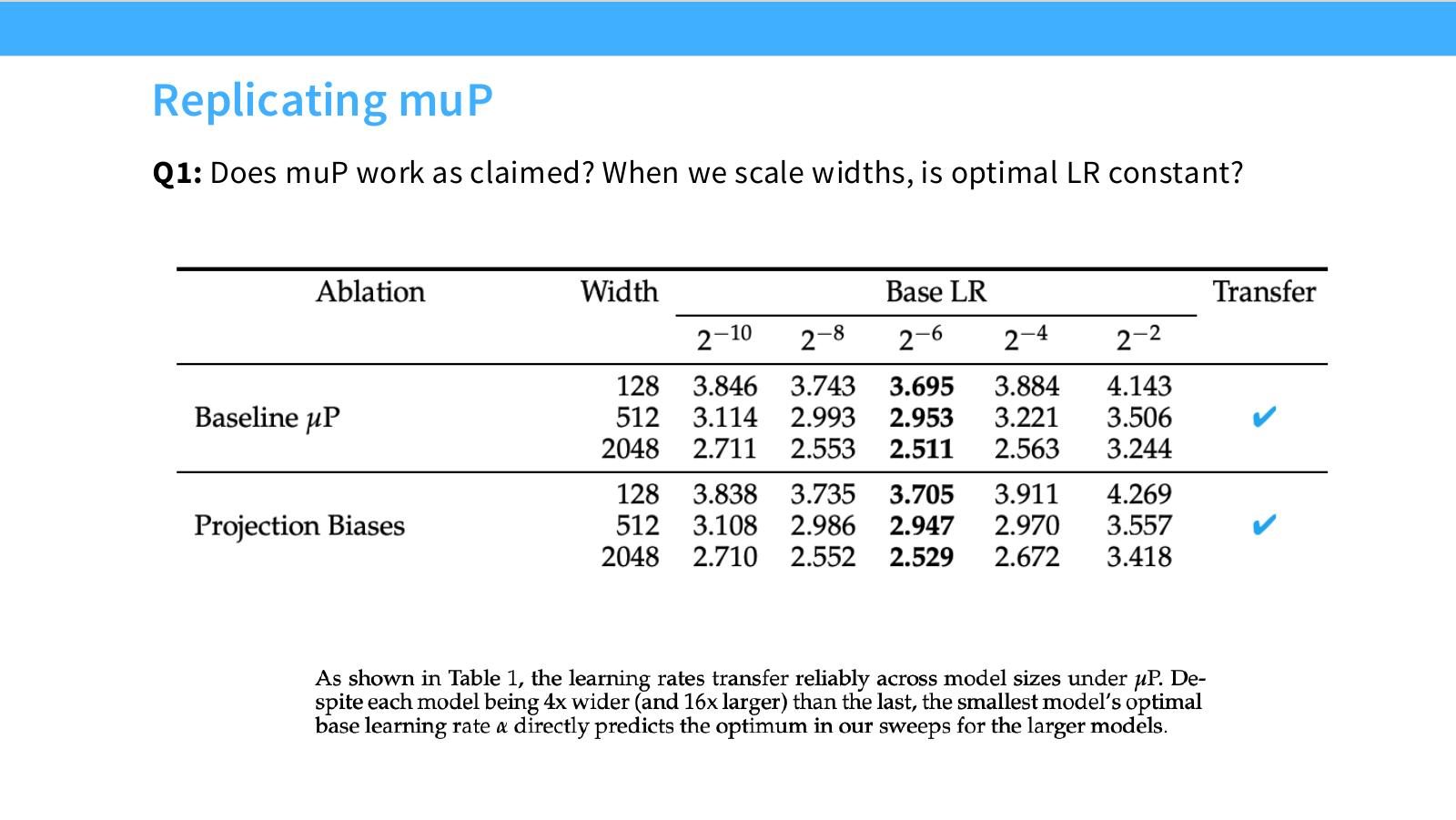
读图:Slide 52 的核心验证
muP 的实证检验不是看训练是否能跑,而是看不同宽度模型的 optimal LR 曲线是否对齐。如果最优 LR 随宽度稳定,muP 才实现了 scale-invariant tuning;如果漂移,说明理论假设或实现细节被破坏。

读图:Slide 53 是 muP 实践风险清单
muP 理论常在简化网络中推导,但现代 LM 包含 gating activations、normalization、attention details、复杂 optimizer 和大 batch。每个偏离都可能破坏 scale invariance。因此使用 muP 时要做 replication,而不是只引用理论。

读图:Slide 54 的工程修正
若 RMSNorm gain 是可学习参数,它可能引入随宽度变化的额外尺度自由度,使 muP 预期的 activation/update scaling 失效。一个务实修正是移除 learnable gains,并验证性能损失是否可接受。
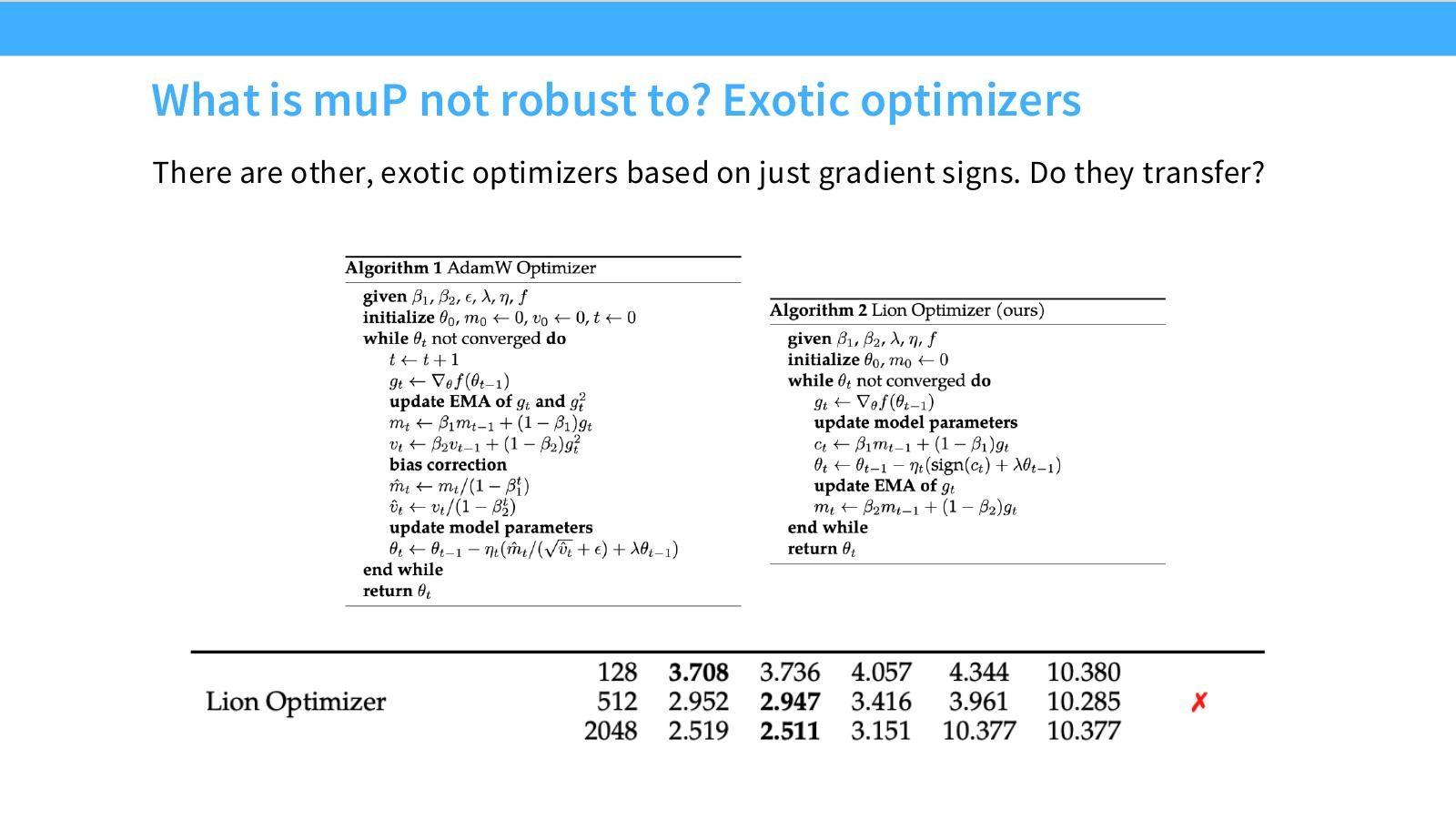
读图:Slide 55 的 optimizer 交互
muP 给的是参数化和 LR scaling 规则;optimizer 改变 update 方向和尺度。若 optimizer 使用 sign、orthogonalization 或其他非 AdamW 机制,muP 条件 A2 的 update 尺度可能重新变化,需要单独验证。

读图:Slide 56 的 weight decay 警告
Weight decay 直接改变权重尺度动态。强 decay 会和 muP 试图维持的尺度条件冲突,导致小模型 tuning 不再可迁移。做 muP 实验时,weight decay 不是次要超参,而是需要纳入 scaling check。
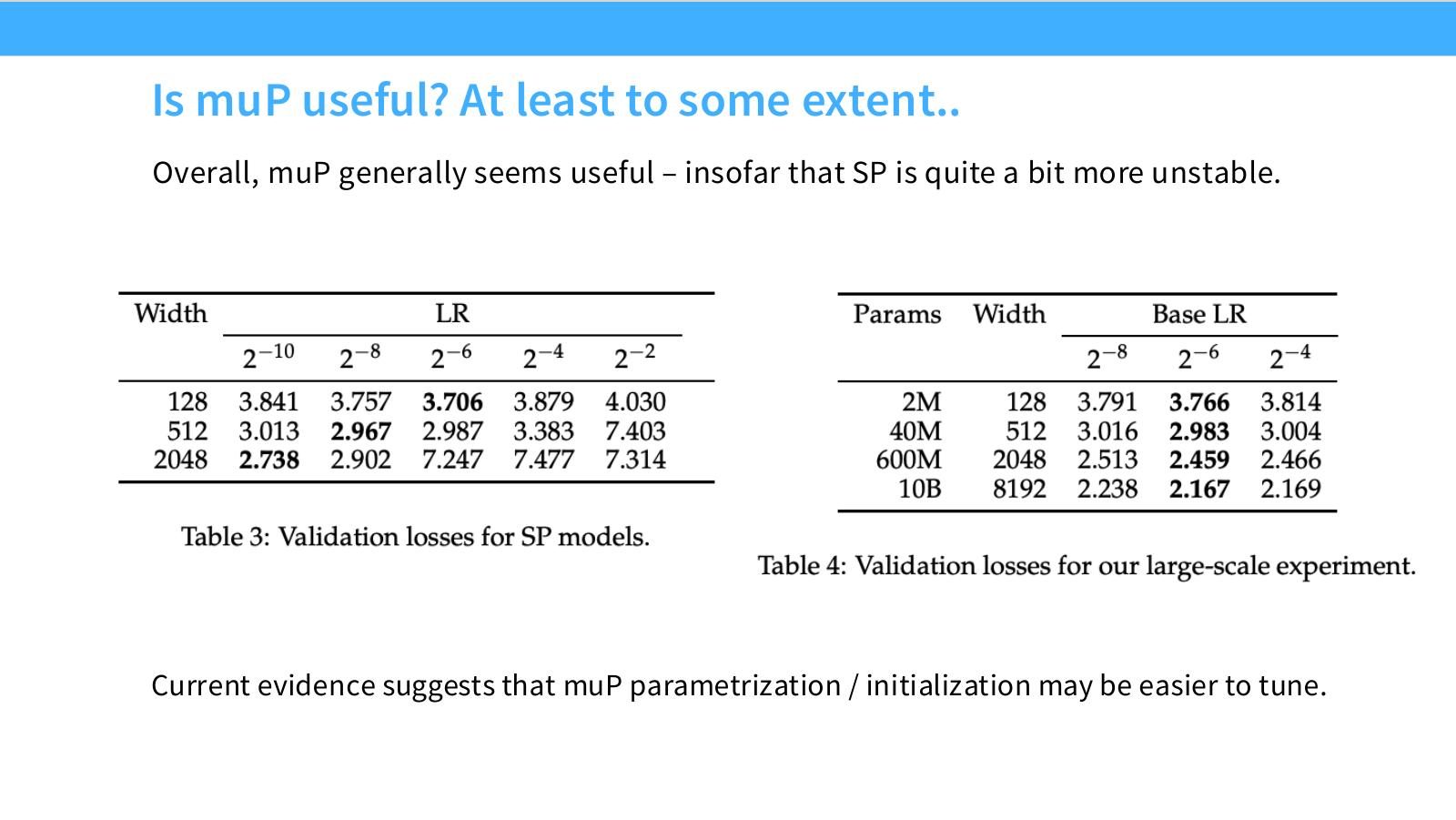
读图:Slide 57 的保守结论
muP 的价值是降低小模型到大模型超参迁移的不稳定性,而不是保证一次调参永远正确。当前证据支持“muP generally useful”,但现代 LM 组件会引入例外,需要针对架构做验证。
总结与延伸

读图:Slide 58 的最终框架
真实 scaling 的挑战有三类:模型架构超参如何设,optimizer/LR/batch 如何随 scale 变,拟合 compute-optimal sweep 本身如何不花掉太多 compute。解决方案对应三类:muP 或架构假设降低搜索空间,empirical LR/batch scaling 拟合超参,WSD/IsoFLOP/joint fit 降低 Chinchilla sweep 成本。
本章小结
Lecture 11 把 scaling laws 从干净公式带到真实模型训练报告中。MiniCPM 展示了 muP 和 WSD 如何降低 scaling 成本;DeepSeek 展示了直接 batch/LR 和 IsoFLOP 拟合;近期模型说明 scaling 的对象已经扩展到 sparsity、MoE active parameters、architecture 和 downstream 能力;optimizer scaling 和 muP 深入则提醒我们,初始化、LR、batch、optimizer 都可能随 scale 改变。
最终 takeaways
- Scaling in practice 的核心不是拟合一条线,而是降低大模型训练前的决策风险。
- MiniCPM 的路线是 muP 稳定超参迁移,WSD 降低从头训练网格成本。
- DeepSeek 的路线是不依赖 muP,直接做 batch/LR 和 IsoFLOP scaling。
- 近期模型把 scaling 扩展到 MoE sparsity、active parameters、architecture 和 downstream metrics。
- Optimizer 比较必须做 scale-aware tuning,否则很容易比较错。
- muP 有用但不万能;RMSNorm gains、exotic optimizers、strong weight decay 等都可能破坏其假设。
拓展阅读
- MiniCPM technical report and scaling computations.
- DeepSeek scaling analysis and WSD/IsoFLOP recipes.
- Qwen, Kimi K2, Hunyuan, LLaMA 3, MiniMax scaling reports.
- StepFun scaling law study on LR/batch.
- muP / maximal update parametrization papers and CerebrasGPT.
- Muon optimizer and scaling studies.