CS224N Lecture 18: NLP, Linguistics, and Philosophy
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Christopher Manning 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025-03-04 |

引言:最后一讲想回答什么
这是 CS224N 的最后一讲。Manning 教授没有再去讲一条新的模型管线,而是把课程里最重要的线索重新串起来:NLP 的主线是什么、语言学在今天还重要吗、神经模型和符号系统到底是什么关系、以及我们应该如何看待 LLM 带来的机会与风险。
本讲的四个中心问题
- CS224N 里那些最重要的想法,最后到底收束成了什么?
- NLP 和语言学的关系,是被 Transformer 时代削弱了,还是重新变得重要了?
- 语言的“意义”应该怎样理解,神经模型真的在做语义吗?
- 当模型变得更强之后,我们应该担心什么,应该继续研究什么?

来源:Slides 第1页。
整门课可以粗略地归纳成一条连续的演进路线:
- 从词向量和分布式语义开始;
- 到神经网络、序列模型、RNN/LSTM;
- 再到 Transformer、预训练和大模型;
- 然后进一步进入基准评测、推理、可解释性、多语言能力和安全问题。
课程里最稳固的几条经验
- dense representation 和上下文语义是现代 NLP 的基础。
- residual connection 让训练深层模型变得可靠。
- language modeling 看似简单,但确实是极强的通用预训练目标。
- benchmark 不是终点,generalization、reasoning、meaning 和 safety 仍然没有解决。
本章小结
最后一讲不是“补一门新课”,而是把前面的技术路线提升成三个更大的问题:语言如何表示、语言如何理解、以及语言技术如何进入真实世界。
CS224N 的主线:我们到底学到了什么
从 word vectors 到 foundation models
如果把整门课压缩成一句话,那就是:我们从“如何给词建一个几何空间”出发,最后走到了“如何让模型成为一个可以做事的通用语言系统”。
- Word vectors:词的意义可以由其上下文来定义。
- Neural NLP:用可学习的表示替代手工特征。
- Sequence models:RNN、LSTM 处理序列依赖。
- Transformers:通过 attention 和并行化把大模型训练变成现实。
- Pretraining + post-training:大规模预训练再做任务对齐,形成 foundation model。
- Evaluation and reasoning:模型越来越强,但评测、推理和可靠性仍然是难点。
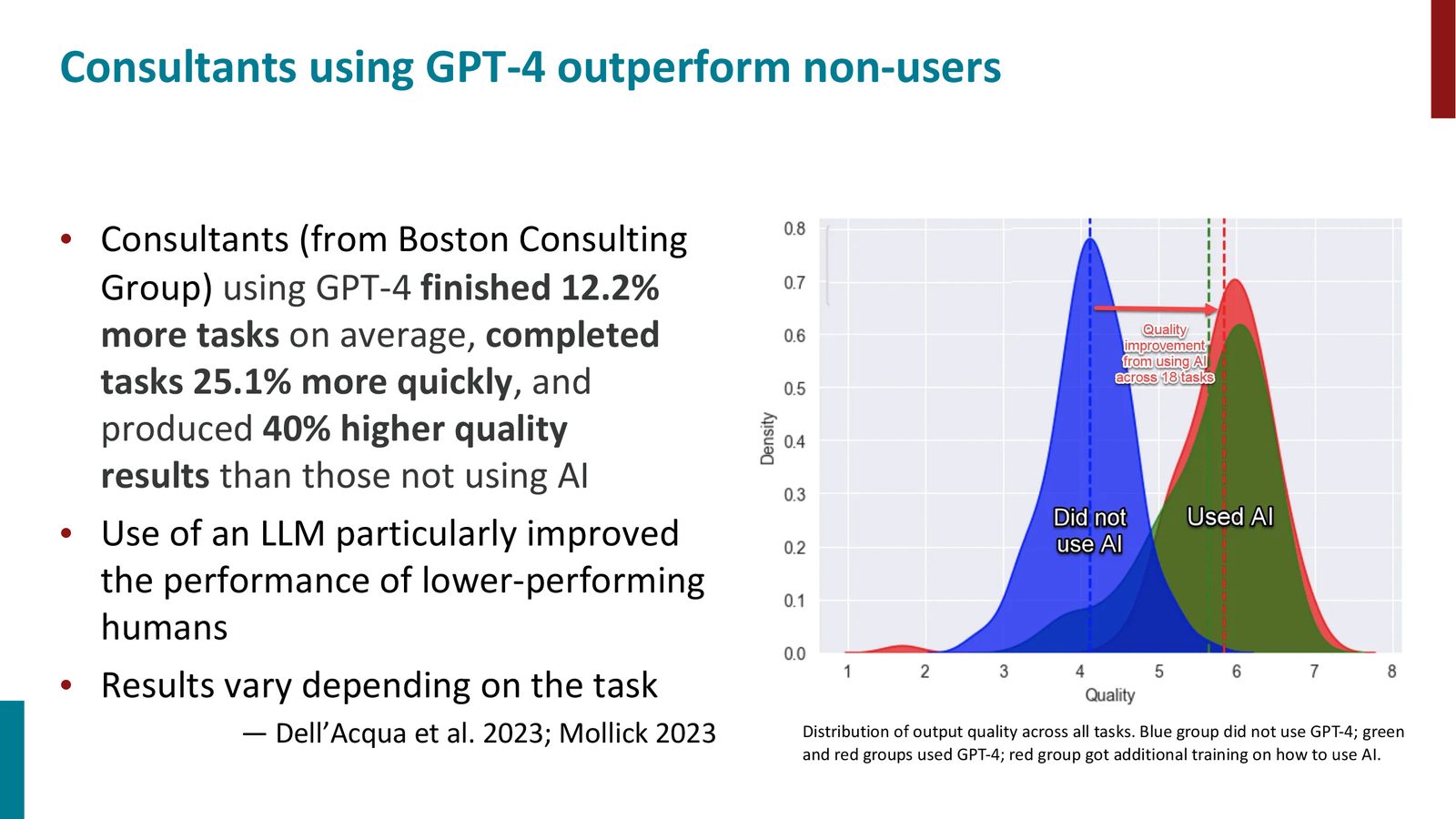
来源:Slides 中展示了咨询任务里的结果分布。
“看起来很强”不等于“已经理解”
LLM 在很多任务上确实很有用,但这不自动说明它们已经具备和人类相同的泛化能力。更现实的说法是:模型已经变得非常会“利用经验”,但是否真正“理解”语言,仍然是开放问题。
本章小结
课程前半段解决的是“怎么建模”,后半段逐步转向“这些模型到底在学什么、能做什么、还缺什么”。最后一讲把这两类问题放到一起:技术进步是真实的,但它并没有关闭更深层的科学问题。
开放问题:泛化、黑箱与数据效率
泛化和记忆之间的张力
Manning 在这一讲里反复强调一个直觉:大模型的成功并不意味着它们已经像人类一样理解世界。很多收益来自于海量训练数据和强大的统计模式记忆。

来源:Slides 讨论了符号系统与认知科学、工程系统之间的关系。
一个重要的对比是数据效率:
- 人类往往可以从极少量示例中学会一个新技能;
- Transformer 在很多设置下仍然更依赖大量数据;
- 在某些低数据场景里,LSTM 甚至表现出更好的归纳偏置。
这里真正值得追问的不是“能不能拟合”
更关键的问题是:
- 模型是否学到了可复用的结构?
- 它们是在泛化,还是在检索相似模式?
- 这些能力在什么条件下会失效?
黑箱与可解释性
神经网络仍然常常表现为黑箱。我们通常知道最终分数,却不知道模型内部到底学了什么。于是,解释性研究变得重要:
- Mechanistic interpretability:从内部电路角度解释模型行为;
- Causal abstraction:寻找更高层次的可解释机制;
- Neuron / feature analysis:观察某些神经元或特征是否对应特定语言现象。
这类研究不是纯理论兴趣,而是因为我们真的需要知道模型是怎样成功、怎样失败的。
本章小结
大模型带来了能力跃迁,但也暴露出三个长期问题:数据效率不够、人类式泛化仍未实现、内部机制仍不透明。
语言学为什么仍然重要
语言学组织 NLP 的未来
这节课有一个很明确的立场:语言学不是过时的背景知识,而是理解和评估 NLP 的关键工具。即使具体的语法理论流派未必是今天最需要纠结的点,语言学提供的那些宽泛区分依然很有用。

来源:Slides 强调:结构、篇章、推理、语用等语言学概念在 2020s NLP 中仍然有用。
语言学在今天的重要性,主要体现在三个层面:
- 定义任务:我们到底要让系统理解什么;
- 分析行为:模型为什么会在某些现象上失败;
- 设计评测:不能只看一个总分,必须细分语言现象。
具体来说,现代 NLP 仍然会遇到大量语言学现象:句法结构、篇章结构、NLI、夸张、变体语言、语体、隐喻、指代、预设、语气、风格、语音协同发音等。它们不是“边角料”,而是自然语言本身的一部分。
语言学不是只有句法
如果只盯着“句子树”或“依存边”,就会误以为语言学只关心形式结构。实际上,语言学还关心语义、语用、篇章、话语角色、说话方式、社会语境和语音细节。很多模型看似能做 translation 或 summarization,但在这些层次上仍然脆弱。
本章小结
语言学并没有被神经模型取代,而是在新的 NLP 时代变成了分析框架和问题分类器。它帮助我们把“模型错了”这件事说得更具体。
符号 AI、赛博系统与神经网络
两种 AI 观
课程中一个非常重要的讨论,是“符号系统”和“神经系统”两种 AI 路线的差别。前者强调由符号、规则和结构组成的显式系统;后者强调通过数据和参数学习隐式表示。

来源:Slides 并列展示了符号 AI 与 cybernetics 的历史脉络。

来源:Slides 展示了早期感知机和生物启发式连接主义。
符号系统与神经系统各自擅长什么
- 符号系统擅长显式结构、可组合性和可控推理。
- 神经系统擅长从数据中学习、鲁棒泛化和容纳复杂模式。
- 今天的关键问题不是简单二选一,而是如何让两种能力互补。
传统语义学的启发
在传统逻辑语义学里,意义常常被表示为“由词义和结构合成出来”的结果。一个经典例子是:

来源:Slides 用 “The red apple is on the table” 说明从句法到语义的组合过程。
这种观点的核心是假设:先知道词的意义,再通过组合规则得到整句意义。它是形式语义学和很多逻辑化 NLP 系统的基础。

来源:Slides 直接提出了“Do neural models provide suitable meaning composition functions?”
本章小结
符号系统和神经系统不是互相消灭的关系,而是两套不同的表达和推理范式。最终更实际的问题是:我们能否用神经模型承载足够多的结构,同时又保留足够强的统计学习能力。
意义是什么:从词到句子
意义并不是二元开关
最后一讲最有哲学味道的部分,是对“meaning”的讨论。Manning 明确表达了一个立场:意义不是非黑即白,而是渐变的;它既来自真实世界的指称,也来自词语在各种使用场景中的关联方式。

来源:Slides 展示了经典的组合语义树。
“意义是梯度的”
一个词或短语的意义不是“有”或者“没有”。更合理的理解是:我们对一个表达的理解程度是渐变的。你对一个词知道得越多、接触的语境越广,你对它的意义理解就越丰富。
use theory of meaning
Manning 在这一段里提到了一个接近 Wittgenstein 的想法:词的意义来自它在语言和生活中的使用,而不仅仅是对应某个静态对象。
- 有些词的意义主要通过指称对象来理解;
- 但很多词更多是通过语境、惯用法、社会实践和话语功能来理解;
- 因此,单纯“查字典式”的语义观并不够。
这也解释了为什么语言模型在某些意义上确实可以学到很多“用法知识”。它们看到的大量文本本身就是一个巨大的使用语料库。
神经模型和语义的关系
一个争论很集中的问题是:神经语言模型到底有没有语义?不同观点并不完全一致,但 Manning 的态度比较清楚:
- 神经模型不只是“符号索引器”,它们确实学到了有关世界和语言使用的结构;
- 但这不等于它们已经具有和人类完全相同的理解方式;
- 意义很可能不只存在于词表定义里,也不只存在于纯粹的外部世界指称里。

来源:Slides 在讨论 AI 的同时也提醒了现实世界的代价。
本章小结
“意义”不是一个单点,而是一组相关但不相同的问题:词义、句义、使用、指称、语境、社会实践和可操作的任务行为。CS224N 的最后一讲并没有给出终极定义,但给出了一个更成熟的态度:不要把语义简化成任何一个单一视角。
未来风险:能力增长之外的代价
从生产力到社会成本
模型越来越强,并不意味着所有结果都朝正方向走。课程最后把视角推向了更现实的层面:AI 系统的收益和成本是同时扩张的。
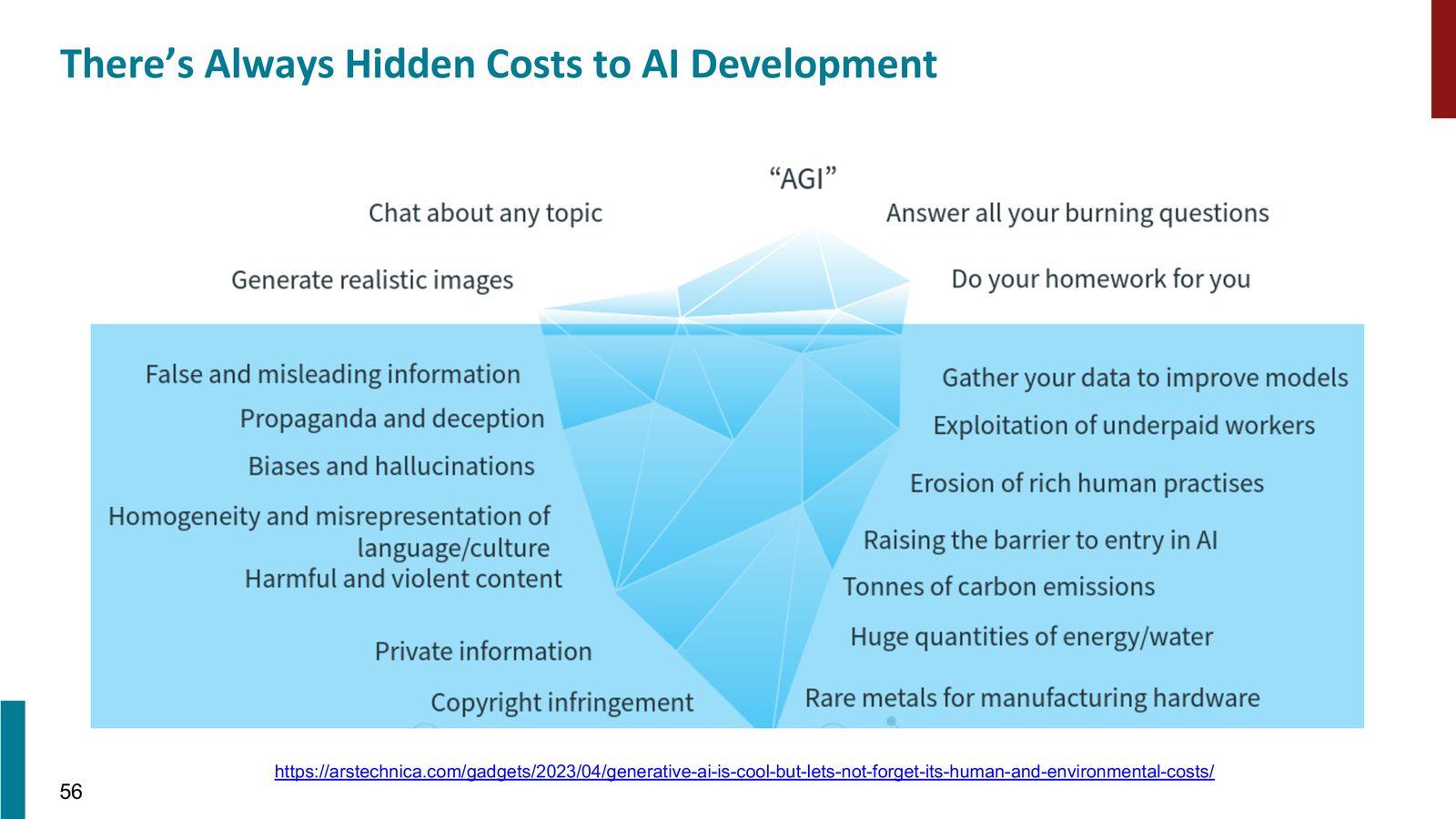
来源:Slides 直接列出了多种 human and environmental costs。
这些成本并不是“未来可能出现”的抽象概念,而是已经存在的现实问题:
- 虚假信息和误导内容;
- 偏见、幻觉和歧视性输出;
- 隐私泄露和版权争议;
- 数据采集、标注和算力背后的劳动与环境成本。
“更强”不等于“更安全”
能力上升会同时放大正效应和负效应。系统越强,越需要在评测、部署、治理和责任边界上保持谨慎。
关于存在风险的讨论
课尾还触及了 existential risk / extinctions risk 这类更激烈的话题。Manning 的处理方式并不是耸动,而是承认它是一个需要讨论的真实议题,同时也指出这不应遮蔽当下更具体、更可验证的风险。
- 有些讨论强调极端远期风险;
- 另一些讨论则提醒我们不要忽视当前已经发生的系统性伤害;
- 对研究者来说,最重要的是把抽象担忧落到可观测的机制和政策上。
本章小结
AI 风险不是附录,而是模型能力增长的一部分。最后一讲把这件事说得很明确:如果只看 benchmark 上升,就会错过技术扩张带来的社会后果。
下一阶段的研究议程:从更强模型到更好语言系统
Benchmark 之后,我们还需要什么
最后一讲隐含的研究判断是:NLP 不应停在“再追一个更高分数”。当 foundation model 已经把许多通用 benchmark 做到很高以后,研究重点必须继续上移。
- 更细粒度的语言现象评测:不是只看平均分,而是看模型在指代、蕴含、歧义、语用和风格变化上的表现。
- 更真实的人机任务:从单轮问答转向长上下文阅读、写作、检索、工具使用与协作任务。
- 更可信的失败分析:不只展示成功案例,而是系统记录模型在何种语言现象、何种社会语境下容易失败。
NLP 已经从 task solving 进入 system building
早年的 NLP 论文经常围绕某个清晰任务展开,例如 parsing、NER、sentiment。今天更关键的问题变成了:如何把语言模型做成一个能在真实世界稳定工作的系统。这要求评测、交互、鲁棒性和治理一起前进。
grounding 会把很多旧问题重新带回来
如果语言只在文本内部流转,统计模式就足以带来惊人的效果;但一旦语言要稳定地指向对象、行动和真实环境,问题就会变难。
- 指称稳定性:同一句话在不同环境中到底指向什么
- 世界更新:外部事实变化后,模型如何及时纠正旧知识
- 行动后果:当模型驱动搜索、代码或 agent 行动时,语言错误会转化为真实代价
为什么 grounded NLP 让语言学重新变得锋利
一旦语言需要连接视觉、动作、工具和社会情境,语义、语用、篇章与指代这些传统语言学问题就会重新变成系统瓶颈。也正因此,Manning 才强调语言学不是旧时代遗产,而是未来系统设计的分析工具。
多语言与社会语言学将重新进入主线
真正全球可用的 NLP 系统,不能只在标准英语上工作。未来研究至少要同时面对三类差异:
- 语言之间的资源差异:高资源语种和低资源语种的训练条件截然不同
- 同一语言内部的变体差异:方言、口语、社媒语言和专业语体都可能偏离标准书面语
- 社会偏见与表示不均:谁的数据更多、谁的话语方式更被模型偏好,都会影响最终系统行为
只在主流英语基准上进步,会制造能力错觉
一个系统在英文 benchmark 上持续上升,并不意味着它对语言本身理解得更好了。一旦切到低资源语言、口语、方言或强语境文本,很多能力会迅速崩塌。这不是边缘问题,而是 NLP 是否具有普适性的核心检验。
本章小结
后 LLM 时代的 NLP 研究,不应只问模型还能多大、多强,而应更具体地问:它是否真正更可解释、更可泛化、更可治理,也是否更能处理真实世界里复杂、多语言、强语境的语言任务。
对今天 LLM 与 Agent 实践的启示
别把语言模型当成 “万能语义机”
这节课对今天工程实践者最重要的提醒之一,是不要因为模型输出流畅,就误以为语义问题已经被彻底解决。对实际系统来说,至少还要分清三件事:
- 表面流畅性:模型能否说出自然、连贯、貌似合理的话
- 任务正确性:模型是否真的完成了用户意图,而不是只生成一段好看的文本
- 语境适配性:模型是否知道在这个组织、这个工具链、这个文化语境下该如何表达
很多产品失败,不是因为模型太弱,而是因为把流畅性当成了正确性
当系统从聊天扩展到搜索、代码、工作流或 agent 执行时,这种混淆会迅速放大。一个会写漂亮自然语言的模型,不等于一个会稳定完成任务的系统。
语言学视角为什么对 Agent 依然重要
今天很多 agent 系统看起来已经走出传统 NLP 的边界,但它们仍然深受语言现象约束:
- 用户指令常带有省略、歧义、语气和隐含前提
- 多轮协作要求系统理解篇章结构和对话状态,而不只是单轮句子
- 工具调用和最终回答之间,需要明确区分事实、假设、计划和执行结果
Agent 本质上把 NLP 的老问题转成了更高风险的问题
过去一个指代错误可能只会让 QA 模型答错一句话;今天同样的指代错误,可能让 agent 打开错误文件、调用错误工具或者误解组织规则。语言理解问题没有消失,只是进入了代价更高的系统层。
给工程团队的评估清单
如果把 Lecture 18 的思想转成实际系统评估,可以得到下面这张表:
| 评估维度 | 不该只看的指标 | 更应该补充看的内容 |
|---|---|---|
| 语言能力 | benchmark 总分、主观流畅度 | 指代、语用、长上下文一致性、风格迁移 |
| 泛化能力 | 单一公开数据集表现 | 领域迁移、任务改写、低资源语言与 OOD 测试 |
| 系统可靠性 | 单次 demo 成功率 | 多轮失败模式、恢复能力、工具误调用分析 |
| 社会影响 | 简单安全分类标签 | 偏见、版权、隐私、能耗与人工劳动成本 |
为什么这门课到今天仍然不过时
尽管 Lecture 18 讨论的是 NLP、语言学与哲学,看起来不像一门 “how to build agents” 的实战课,但它反而解释了为什么很多现代系统在强模型之上仍会失败:因为模型之外,还有表示、语境、目标、评测和社会后果这些更大的问题。
系统越强,越需要回到基本问题
当模型能力弱时,我们忙着追求更高分;当模型能力开始足够强时,真正拉开差距的是谁更清楚地理解语言任务本身。Lecture 18 的价值就在这里:它强迫我们重新思考,究竟什么叫理解,什么叫可靠,什么叫可用。
本章小结
对今天的 LLM 和 agent 实践而言,这节课最重要的价值不是提供一个新技巧,而是提供一套更高层的判断框架:把语言能力、任务成功、泛化边界和社会成本分开看,才能避免把强模型误当成完整系统。
总结与延伸
最后的主张
如果把整门 CS224N 的知识压成几条结论,大致是:
六条最后的 takeaway
- 分布式表示是现代 NLP 的基础:上下文和 dense vectors 改变了我们表示语言的方式。
- Transformer 和预训练极其强大:但强大不代表问题已经解决。
- 泛化、解释和多语言仍然开放:这些不是边角,而是核心科学问题。
- 语言学依旧重要:它帮助我们划分问题、分析失败和设计评测。
- 意义是渐变的、使用性的、组合性的混合体:不能用单一理论一把抓。
- 能力增长伴随真实代价:评测、对齐和治理必须和模型进步同步推进。
一个更温和但更准确的结论
人类语言不是单纯的符号,也不是单纯的统计模式。它既涉及世界中的对象,也涉及社会中的使用;既能被形式系统刻画,也会被大规模神经模型近似。CS224N 的最后一讲没有给出一个封闭答案,而是把问题推回到一个更诚实的位置:我们已经学会了做出很强的系统,但对语言、意义和智能本身,仍然需要更深的理论和更稳的实验。

来源:Slides 的结尾视觉上回到了 Stanford 的封印。
课程全局总结表
| 主线问题 | 课程给出的答案 | 仍未解决的部分 | 对今天 NLP 的启示 |
|---|---|---|---|
| 语言怎么表示 | 分布式表示与上下文化 embedding 极其成功 | 表示是否对应可解释结构仍不清楚 | 表示学习仍是系统能力的底座 |
| 语言怎么组合成意义 | Transformer 能学到大量可用组合规律 | 神经组合是否等价于人类式语义组合仍有争议 | 需要语言学和解释性研究补足 |
| 模型是否真的泛化 | 在大规模任务上表现很强 | 数据效率、OOD 泛化、人类式学习仍不足 | benchmark 之外的评测要成为主线 |
| 语言系统如何进入现实世界 | 预训练模型已能提升生产力 | 偏见、幻觉、能耗、版权与治理问题同步放大 | 系统设计必须把安全与社会成本前置 |
给后续学习者的延伸路线
- 从语言学和哲学角度继续追问 meaning、reference、use 和 compositionality
- 从 mechanistic interpretability 和 causal evaluation 角度研究模型内部到底学到了什么
- 从 multilingual NLP、speech、dialogue 和 grounded agents 的角度检验模型是否真的具备更强语言能力
如果重新学一遍 CS224N,建议这样重走
| 阶段 | 应重点抓住的概念 | 最容易忽略的问题 | 重学时的关注点 |
|---|---|---|---|
| 表示学习阶段 | word vectors、distributional semantics、context | 把 embedding 当成纯技巧,不问它表示了什么 | 重新理解分布式表示与语义之间的关系 |
| 序列建模阶段 | RNN/LSTM、attention、Transformer | 只记结构,不问 inductive bias 为何不同 | 对比不同架构的归纳偏置与数据效率 |
| 预训练阶段 | language modeling、scaling、instruction tuning | 只看能力提升,忽略评测边界 | 把 pretraining 当作系统起点而不是终点 |
| 系统与社会阶段 | reasoning、alignment、multilinguality、safety | 低估语言学和治理问题的重要性 | 把语言能力放进真实任务和社会环境里重新看 |
这张表背后的意思很简单:技术章节最好和问题章节一起重读。否则很容易把 CS224N 误解成一门 “神经网络模型年鉴”,而忽略它真正反复追问的那些核心问题。
拓展阅读
- Manning, Christopher D. et al. CS224N 课程主页:https://web.stanford.edu/class/cs224n/
- Bender & Koller, Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data:https://aclanthology.org/2020.acl-main.463/
- Ribeiro et al., "Why Should I Trust You?": Explaining the Predictions of Any Classifier:https://arxiv.org/abs/1602.04938
- Elhage et al., Transformer Circuits:https://transformer-circuits.pub/
- Manning et al., The Stanford NLP Group: https://nlp.stanford.edu/