CS231N Lecture 1: Introduction
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Fei-Fei Li, Ehsan Adeli 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年4月1日 |

引言:课程定位与视觉智能
CS231N 是斯坦福大学的经典课程,全称为“Deep Learning for Computer Vision”(计算机视觉中的深度学习)。2025年春季学期是该课程创立的十周年,由 Fei-Fei Li、Ehsan Adeli 和 Zane Durante 共同讲授。

来源:Slides 第1页(Part 1)。

来源:Slides 第4页(Part 1)。
AI、机器学习、深度学习与计算机视觉
Fei-Fei Li 在开场时明确了本课程在 AI 学科图谱中的位置。AI 是一个宏大的研究领域,计算机视觉和机器学习是其中两个重要的子领域,而深度学习是机器学习的一个分支。本课程聚焦的正是计算机视觉与深度学习的交叉地带。
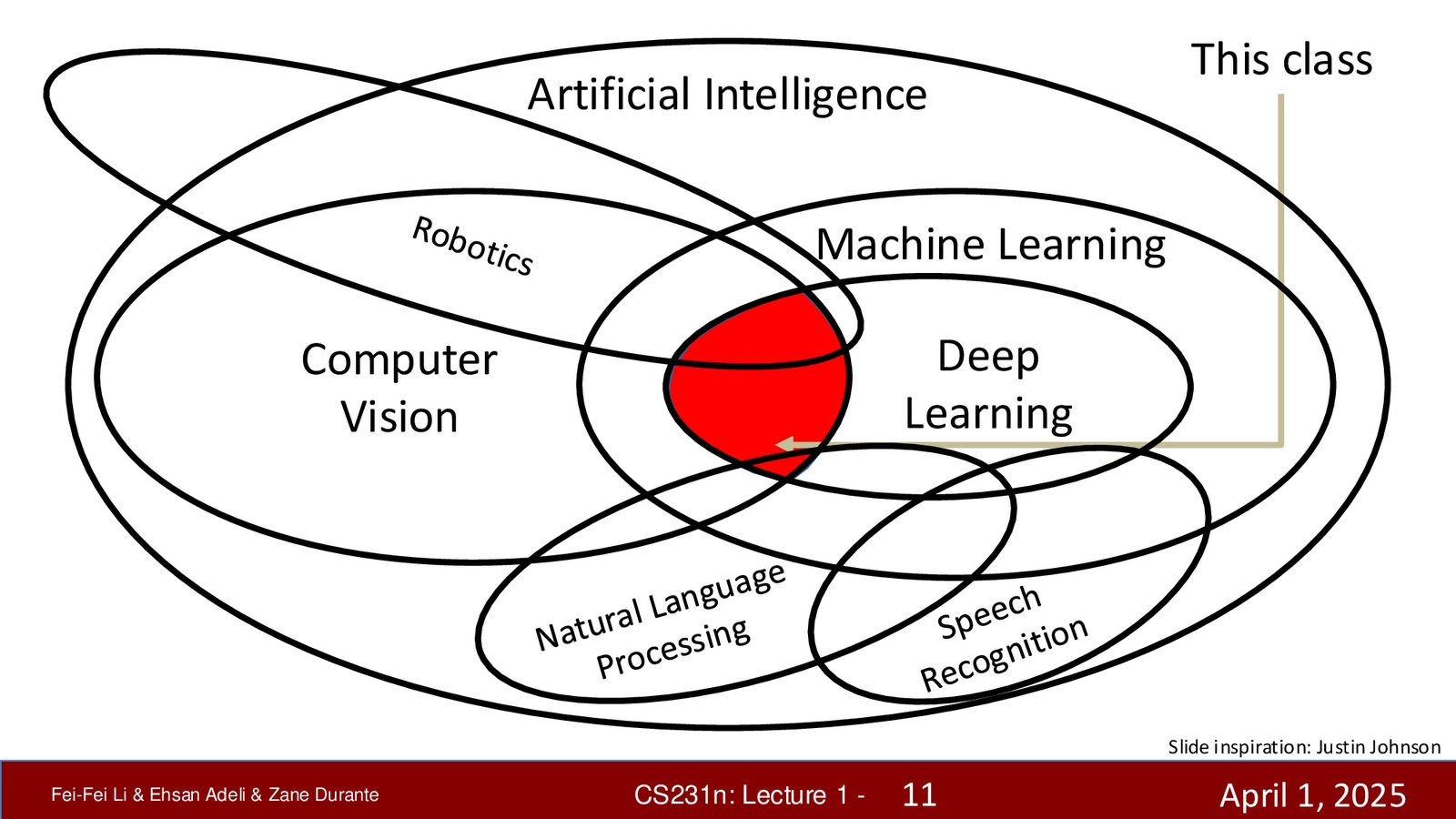
来源:Slides 第11页(Part 1)。
CS231N 的核心范围
本课程不会覆盖计算机视觉或深度学习的全部内容,而是专注于二者的核心交叉:如何使用深度神经网络来解决视觉理解问题。同时,课程内容也与自然语言处理、机器人学等领域有密切联系。
AI 本身是一个高度跨学科的领域,涉及数学、神经科学、计算机科学、心理学、物理学、生物学等基础学科,并在医学、法律、教育、商业等诸多应用领域产生了深远影响。Fei-Fei Li 鼓励学生将课堂所学带入各自热爱的学科方向中。
本章小结
CS231N 是一门聚焦深度学习与计算机视觉交叉领域的课程。AI 是一个跨学科的大领域,而计算机视觉作为智能的基石之一,与深度学习的结合催生了过去十年中最激动人心的技术革命。
视觉的起源:从寒武纪到人类文明
5.4 亿年前的寒武纪大爆发
视觉的历史并非始于人类文明,而是可以追溯到 5.4 亿年前的寒武纪大爆发(Cambrian Explosion)。化石研究显示,在大约 1000 万年的进化时间窗口内(对进化而言极为短暂),地球上的动物物种突然大量涌现。

来源:Slides 第13页(Part 1)。
视觉与智能的关系
寒武纪大爆发最有说服力的理论之一是视觉的出现。最早的动物——三叶虫(trilobite)获得了感光细胞(photosensitive cells),这并非精密的视网膜和透镜系统,而仅仅是一个能收集光线的小孔(pinhole)。然而,这个简单的能力彻底改变了生命的形态:
- 没有感觉的生命只是被动的新陈代谢
- 有了视觉,动物成为环境的积极参与者——觅食、躲避天敌、竞争资源
- 进化压力驱动了神经系统和智能的发展
Fei-Fei Li 总结道:“5.4 亿年的视觉进化史,就是智能的进化史。”
人类是高度视觉化的动物:超过一半的皮层神经元参与视觉处理。我们拥有非常复杂的视觉系统,这也是研究视觉智能如此令人兴奋的原因。
从暗箱到数字相机
人类文明很早就开始尝试制造“看”的机器。从古希腊和古代中国关于针孔成像的思考,到达芬奇对暗箱(Camera Obscura)的研究,再到现代数字相机的爆发——硬件层面的“眼睛”已经无处不在。
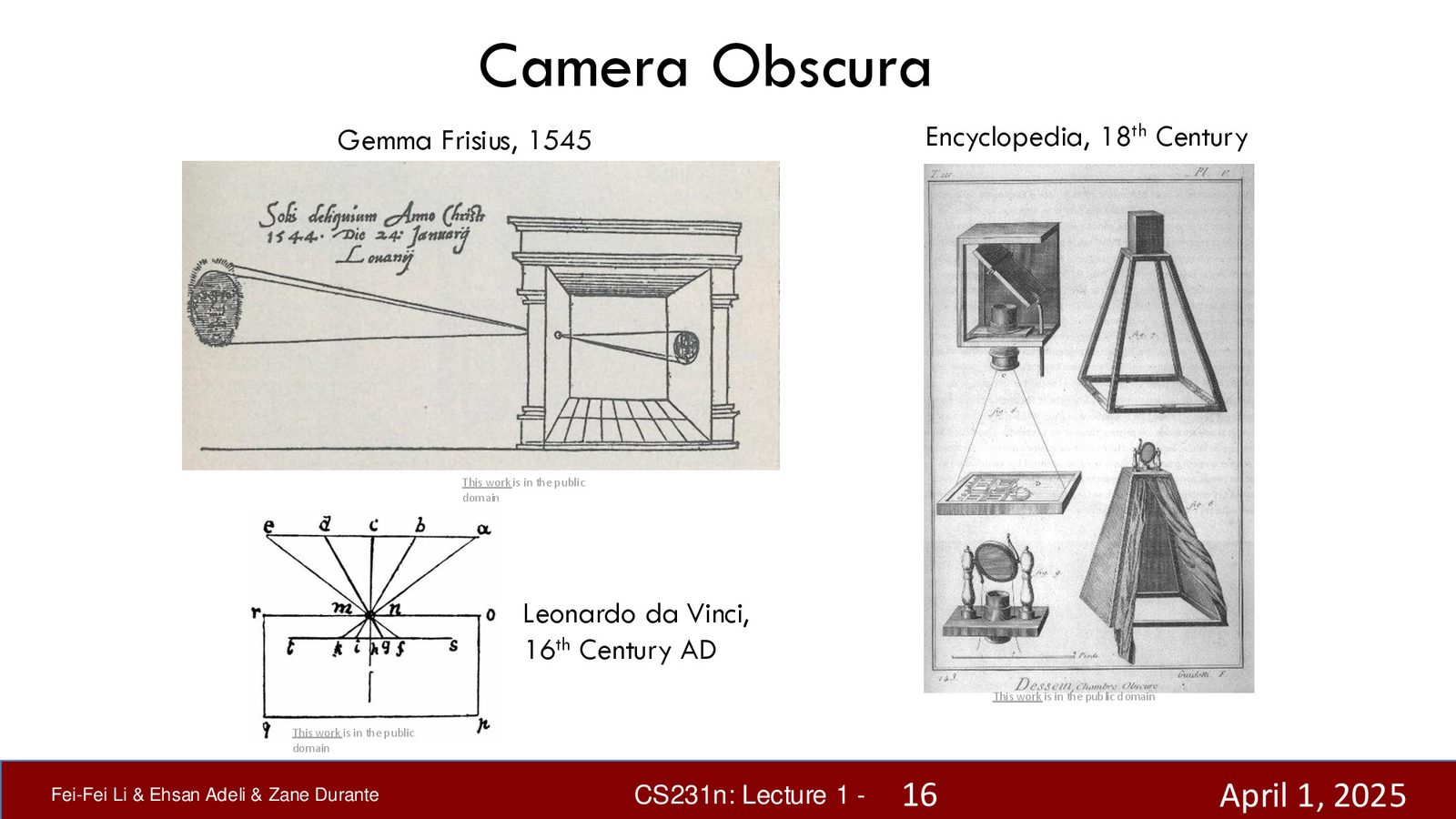
来源:Slides 第16页(Part 1)。
相机不等于视觉
相机只是采集光信号的装置,就像眼睛只是光学器官一样。真正的挑战在于理解视觉信息——这才是计算机视觉要解决的核心问题。正如 Fei-Fei Li 所说:“Cameras are not enough for seeing, just like eyes are not enough for seeing.”
视觉的根本难题:从 2D 到 3D 的逆问题
视觉的一个根本难题在于:真实世界是三维的,但视觉感知到的(无论是视网膜还是相机传感器)是二维的投影。从二维图像恢复三维世界的完整信息,在数学上是一个不适定问题(ill-posed problem)。
自然界的解决方案之一是发展出多只眼睛(大多数动物是两只),通过三角测量来估计深度。但仅靠两只眼睛远远不够,还需要理解对应关系(correspondences)等复杂计算。
语言与视觉的哲学差异
Fei-Fei Li 提出了一个深刻的观察:语言不存在于自然界中——它是人类大脑生成的、一维的、序列化的产物。这也是为什么大语言模型(LLM)如此成功——语言的结构天然适合序列建模。而视觉则植根于物理世界,受物理定律、材料属性等约束,这使得视觉问题具有本质上不同的挑战。
本章小结
视觉是生命进化的核心驱动力,从5.4亿年前的寒武纪大爆发到现代数字相机的普及,人类对“看”的追求从未停止。但真正的挑战不在于采集图像,而在于理解图像——从二维投影中恢复三维世界的语义信息。这是一个数学上不适定的、计算上极具挑战性的问题。
计算机视觉简史
本节按时间线梳理计算机视觉领域的关键里程碑,从神经科学的早期发现到深度学习革命。
1950s–1960s:视觉研究的萌芽
Hubel & Wiesel 的视觉通路研究(1959)
1950年代,Hubel 和 Wiesel 对哺乳动物视觉通路进行了开创性的电生理实验。他们将电极插入麻醉猫的初级视觉皮层(primary visual cortex,位于后脑勺附近),发现了两个重要事实:

来源:Slides 第18页(Part 1)。
Hubel & Wiesel 的两大发现
- 感受野(Receptive Field):初级视觉皮层中的每个神经元只响应视野中一个局部区域的特定简单模式(如特定方向的边缘)。
- 层级结构(Hierarchical Processing):视觉通路是分层的——浅层神经元检测简单特征(方向边缘),深层神经元检测更复杂的特征(角点、物体部件),最终构成一个庞大的计算网络。
这两个发现后来深刻影响了卷积神经网络的设计。Hubel 和 Wiesel 因此于 1981 年获得诺贝尔医学奖。
计算机视觉的诞生(1963–1966)
- 1963年:Larry Roberts 完成了被公认为计算机视觉领域的第一篇博士论文,研究如何从图像中理解简单几何形状的表面、角点和特征。
- 1966年:MIT 的 Seymour Papert 发起了著名的 Summer Vision Project,目标是“在一个暑假内解决计算机视觉问题”。

来源:Slides 第21页(Part 1)。
AI 的过度乐观传统
就像 AI 历史上的许多故事一样,早期研究者严重低估了视觉问题的难度。事实上,直到今天——将近60年后——计算机视觉仍未被完全“解决”。这提醒我们对技术的能力保持谦逊。
1970s–1980s:理论框架与特征提取
David Marr 的视觉计算理论
1970年代,David Marr 撰写了计算机视觉领域的奠基之作。他提出了一个系统化的视觉处理框架,受到神经科学和认知科学的深刻启发:
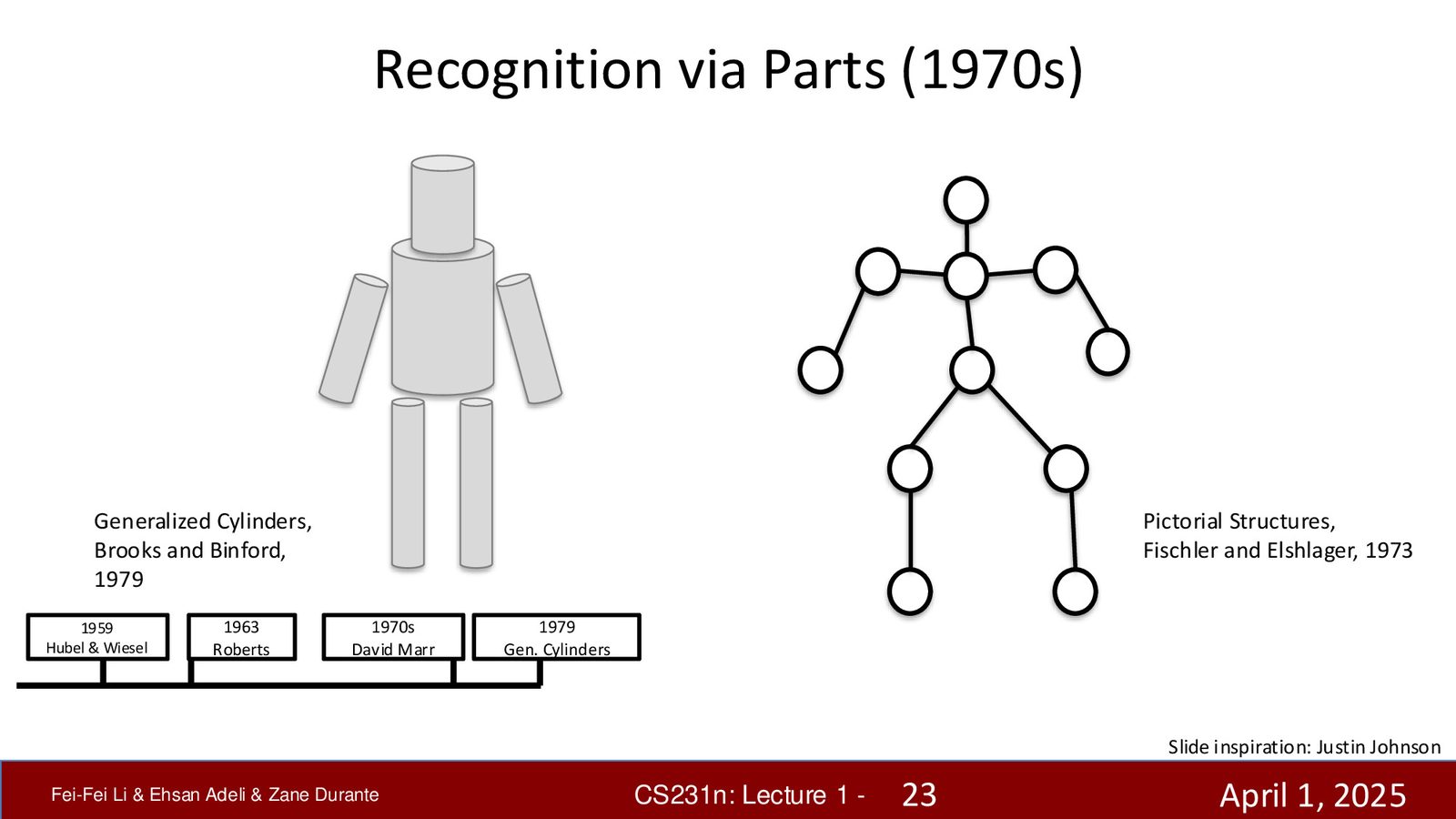
来源:Slides 第23页(Part 1)。
David Marr 的三级视觉表示
- Primal Sketch:提取边缘、纹理等底层特征(类似 Hubel & Wiesel 发现的初级视觉皮层功能)
- 2.5D Sketch:分离前景和背景,估计局部表面朝向和深度
- 3D Model:恢复完整的三维几何表示——Marr 认为这是视觉理解的终极目标
David Marr 英年早逝,但他的理论框架深刻影响了后续几十年的研究方向。
物体识别与边缘检测的早期尝试
1970年代至1980年代,研究者开始尝试用计算方法识别物体:
- 广义圆柱体(Generalized Cylinders,Brooks & Binford,斯坦福):用简单几何体组合来表示物体
- 组合模型:用部件(parts)的组合来描述人体和其他物体
- 边缘检测(Edge Detection):从数字图像中提取边缘信息

来源:Slides 第25页(Part 1)。
然而,这些方法的能力非常有限,仅能处理高度简化的场景,距离真正的“视觉理解”还有很大距离。这一时期也正是 AI 寒冬的开始:AI 各个子领域(视觉、专家系统、机器人)都未能兑现早期的宏大承诺,研究经费大幅缩减。
1990s–2000s:认知科学的启示与数据驱动的开端
认知神经科学的北极星
尽管处于 AI 寒冬之中,认知和神经科学的研究仍在蓬勃发展,并为计算机视觉指明了方向:

来源:Slides 第31页(Part 1)。
认知科学的三条启示
- 场景上下文影响物体识别:将图像打乱后,即使目标物体的位置和像素完全一致,人类识别该物体的能力也会显著下降(Biederman 实验)
- 视觉处理极其快速:人类在仅 150 毫秒内就能产生分类信号(Thorpe 实验),这在生物神经网络中仅相当于几个“跳”的处理时间
- 专化的脑区:人脑发展出了专门识别面孔(FFA)、场所(PPA)和身体部位的特化区域(MIT 1990年代发现)
这些发现告诉我们:物体识别是视觉智能的核心能力,也应该成为计算机视觉的首要研究目标。
从特征工程到数据集
1990年代至2000年代初期,计算机视觉领域出现了一系列重要进展:
- 1997年:Normalized Cuts(图像分割)
- 1999年:SIFT 特征(尺度不变特征变换)——手工设计的特征提取方法
- 2001年:Viola-Jones 人脸检测算法——5年后被应用于消费级数码相机的自动对焦功能
- 2004--2007年:Caltech-101、PASCAL VOC 等小型数据集出现
互联网的兴起和数字相机的普及为计算机视觉提供了前所未有的数据资源。这标志着从“靠算法”到“靠数据+算法”的范式转变的开始。
本章小结
计算机视觉的发展经历了从神经科学启发(1950s)到理论框架建立(1970s)、AI 寒冬中的坚持(1980s--1990s),再到数据驱动范式萌芽(2000s)的漫长历程。每一个阶段都为后来的深度学习革命奠定了不可或缺的基础。
深度学习的崛起
在计算机视觉循序渐进发展的同时,一条平行的研究路线也在默默推进——这就是神经网络和后来的深度学习。
神经网络的早期探索
感知机与 Minsky 的批评
神经网络的历史可以追溯到 1958 年 Frank Rosenblatt 提出的感知机(Perceptron)。然而,1969 年 Marvin Minsky 和 Seymour Papert 证明感知机无法学习 XOR 逻辑函数,导致神经网络研究遭受重大挫折。
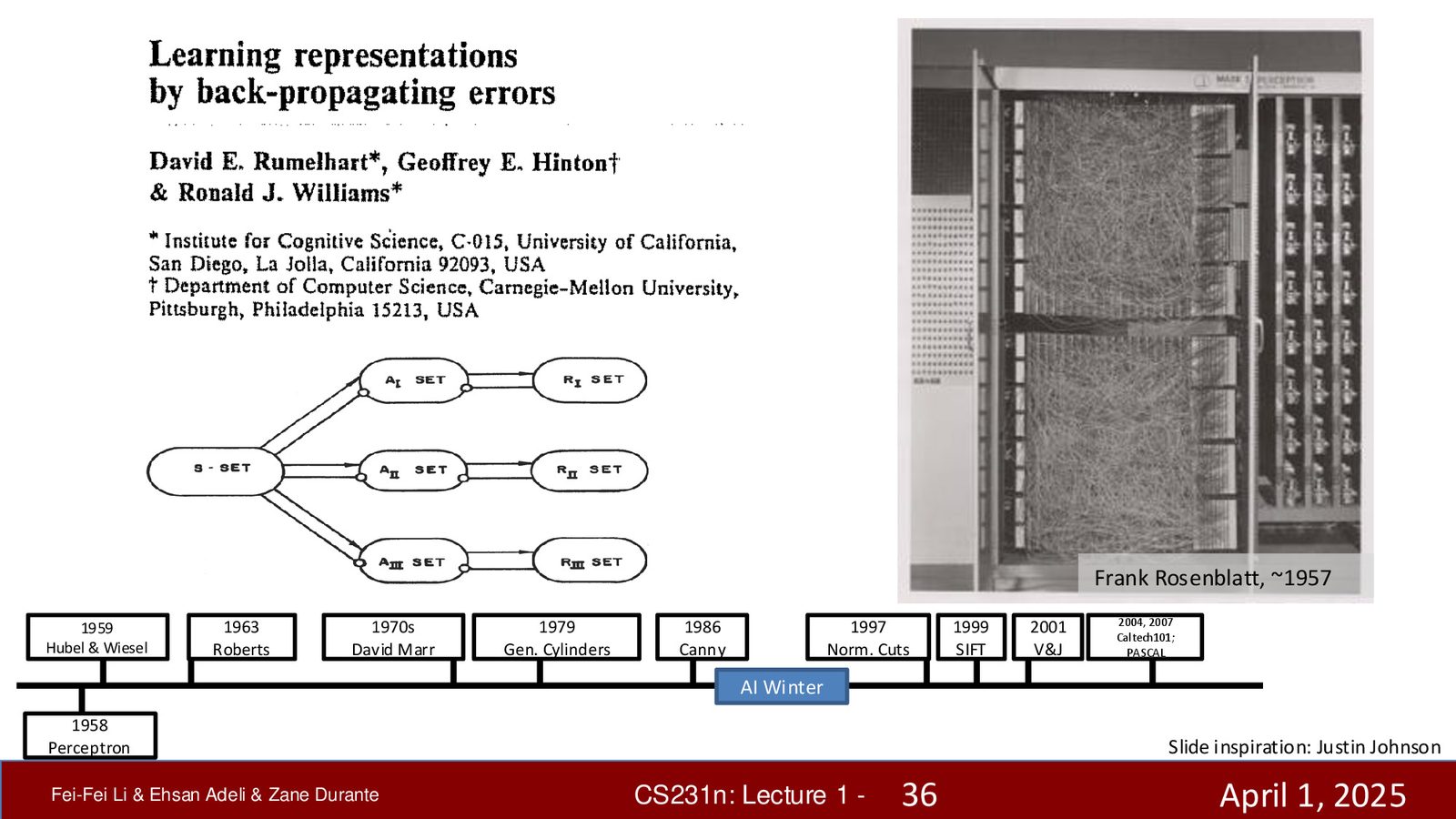
来源:Slides 第36页(Part 1)。
Neocognitron(1980):第一个“深度”网络
日本研究者 Fukushima 在 1980 年提出了 Neocognitron——一个约5--7层的神经网络,直接受到 Hubel & Wiesel 视觉通路研究的启发:
- 浅层使用卷积(convolution)函数处理简单特征
- 深层汇聚(pooling)浅层信息,处理更复杂的特征
- 可以识别手写数字和字母
Neocognitron 的局限
Neocognitron 的所有参数都是手工设计的——Fukushima 需要一丝不苟地调整数百个参数才能让网络工作。它是一项杰出的工程成就,但缺乏系统化的学习机制,无法扩展到更复杂的任务。
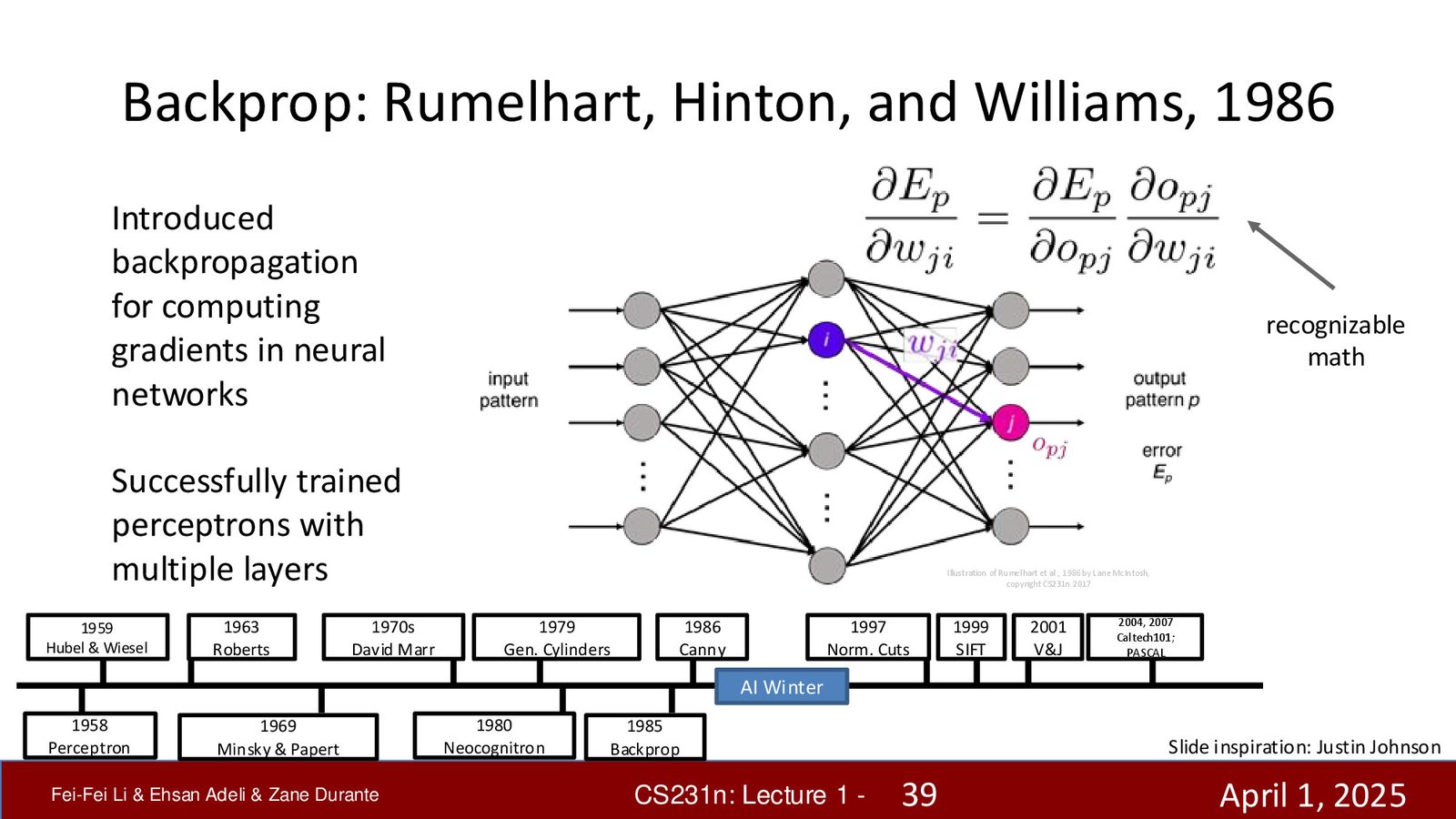
反向传播:分水岭时刻(1986)
1986年,David Rumelhart、Geoffrey Hinton 和 Ronald Williams 发表了具有里程碑意义的论文“Learning Representations by Back-propagating Errors”。反向传播(Backpropagation)基于微积分的链式法则,提供了一种数学上严格的学习规则:
- 将输入通过网络前向传播,得到输出
- 计算输出与正确答案之间的误差
- 将误差信息反向传播到网络的每一层
- 根据梯度信息更新所有参数
反向传播的革命性意义
反向传播的出现意味着:
- 不再需要手工调参——网络可以通过数据自动学习参数
- 理论上可以训练任意深度的网络
- 为后续所有深度学习方法奠定了计算基础
反向传播至今仍是几乎所有深度学习模型训练的核心算法。
LeNet 与早期应用(1998)
Yann LeCun 在 1990 年代于贝尔实验室创建了 LeNet——大约7层的卷积神经网络,结合反向传播进行端到端训练,成功应用于手写数字和字母识别。LeNet 被部署到美国部分邮局和银行,用于自动读取支票上的数字。
来源:Slides 第39页(Part 1)。
然而,LeNet 之后神经网络的发展遭遇了瓶颈:虽然在简单任务(手写数字)上表现优秀,但在复杂的自然图像识别任务(识别猫、狗、椅子、花朵等)上却完全不行。
数据的觉醒:ImageNet(2009)

来源:Slides 第43页(Part 1)。
Fei-Fei Li 和她的团队认识到,整个领域都低估了数据的重要性。神经网络是高容量(high-capacity)模型,需要大量数据才能学会泛化;缺乏数据不仅是不方便,更是一个根本性的数学问题——涉及到泛化和过拟合的深层原理。
ImageNet 的诞生
- 从近10亿张互联网图像中筛选清洗,最终得到 1500万张标注图像
- 覆盖 22,000 个物体类别(参考了认知心理学文献,这大约是人类在早期生活中学会识别的类别数量级)
- 其子集(100万+图像、1000个类别)被用于举办国际大赛——ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
数据是深度学习的一等公民
在深度学习的早期,大多数研究者只关注网络架构,忽视了数据的重要性。Fei-Fei Li 的洞察是:数据和算法一样重要。高容量模型如果没有足够的数据支撑,必然会过拟合。这一认识对于后来 LLM 时代“数据为王”的理念具有深远的先见性。
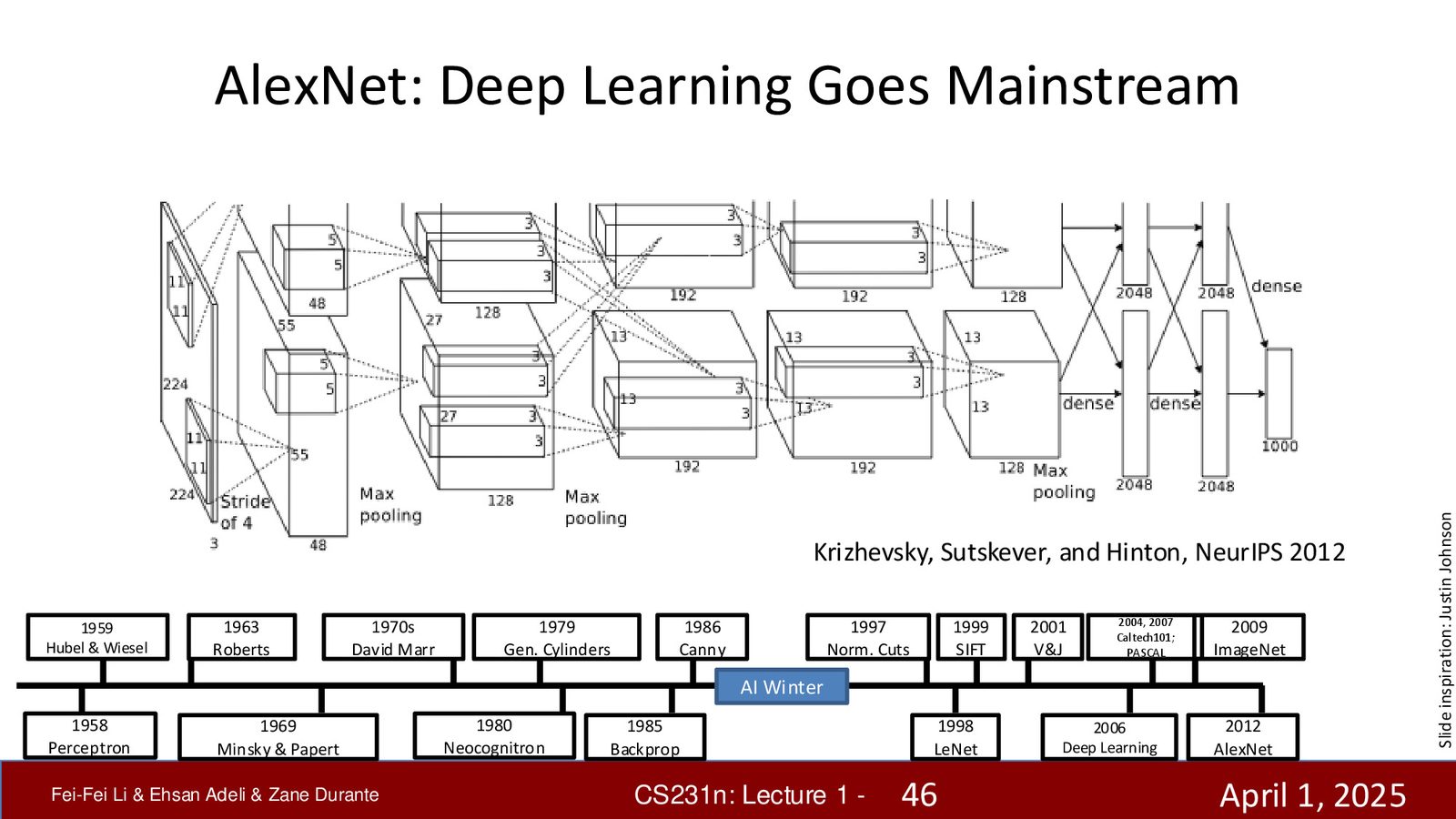
AlexNet:深度学习革命的引爆点(2012)
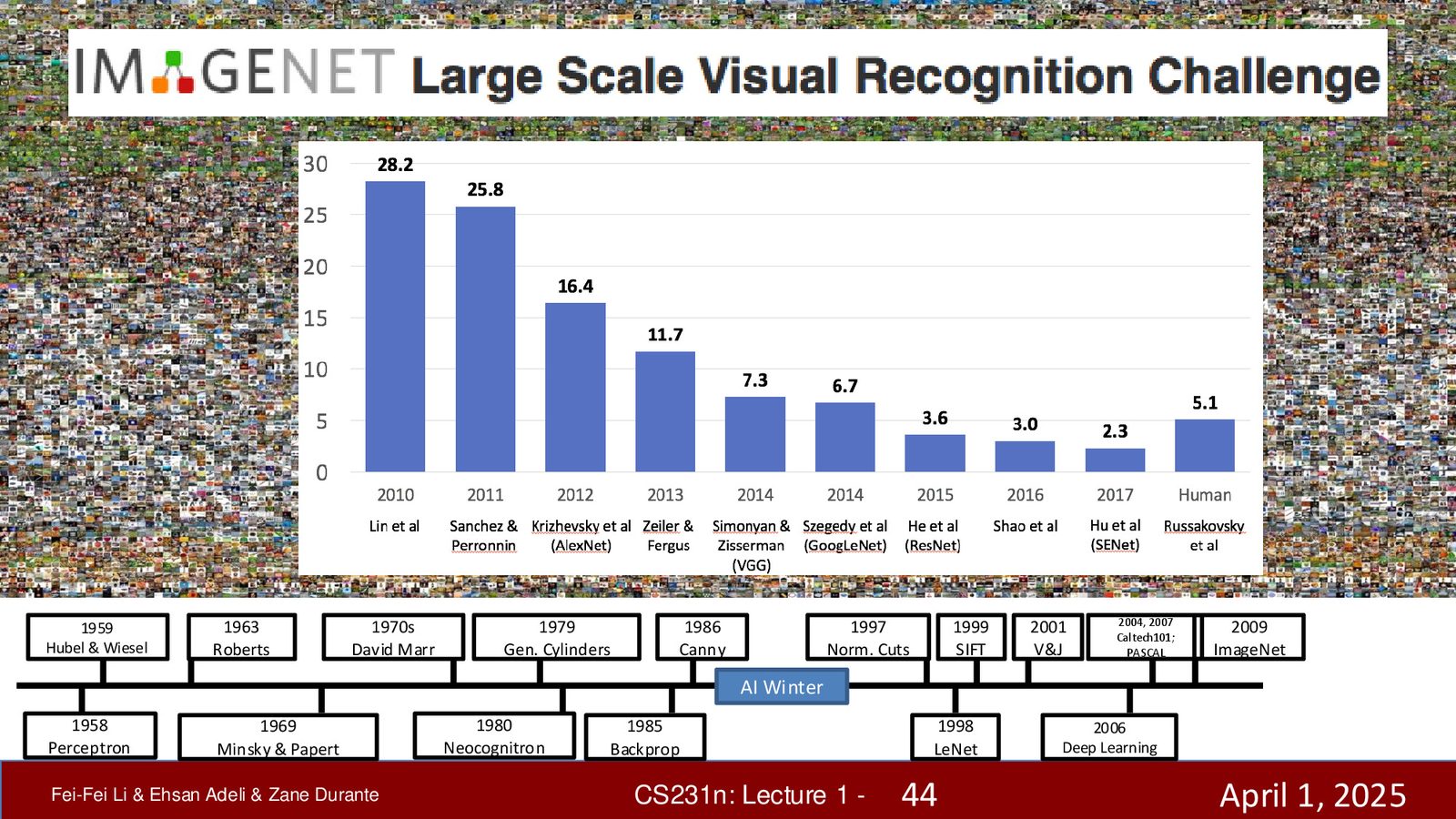
来源:Slides 第44页(Part 1)。
2012 年,Jeff Hinton 和他的学生 Alex Krizhevsky、Ilya Sutskever 参加 ImageNet 挑战赛,使用卷积神经网络(后称 AlexNet),将错误率从上一年的 25.8% 降低到 16.4%——几乎减半。
来源:Slides 第46页(Part 1)。
从 Neocognitron 到 AlexNet:两个关键突破
AlexNet 的架构与32年前的 Neocognitron 惊人地相似。它们之间的关键差异在于:
- 反向传播(1986):数学上严格的学习规则,取代了手工调参
- 大规模数据(ImageNet,2009):百万级标注图像,让高容量模型能够学会泛化
许多人将 2012 年视为现代 AI 的诞生年或深度学习革命的起点。
2012 年后的深度学习爆发
AlexNet 之后,各种更强大的架构相继诞生,在 ImageNet 挑战赛中持续刷新纪录:
| 年份 | 模型 | Top-5 错误率 | 关键创新 |
|---|---|---|---|
| 2012 | AlexNet | 16.4% | CNN + GPU 训练 |
| 2013 | ZFNet | 11.7% | 更好的可视化和调优 |
| 2014 | VGGNet / GoogLeNet | 7.3% / 6.7% | 更深的网络 / Inception 模块 |
| 2015 | ResNet | 3.6% | 残差连接,152层 |
| 2017 | SENet | 2.3% | 超越人类水平(5.1%) |
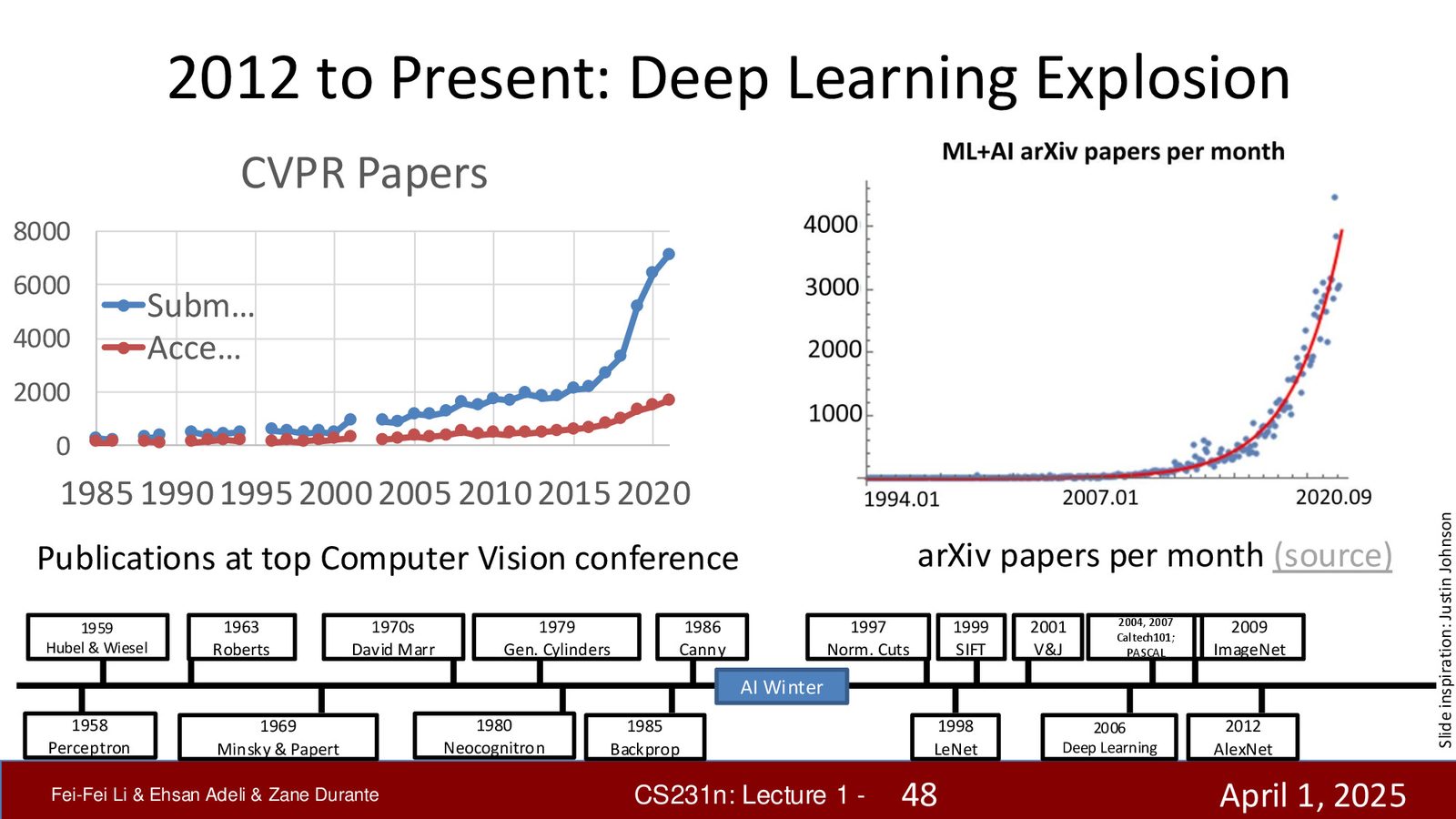
来源:Slides 第48页(Part 1)。
本章小结
深度学习的崛起是一个长达数十年的过程:从感知机(1958)到反向传播(1986)到 LeNet(1998),再到 ImageNet(2009)和 AlexNet(2012)。2012 年的 ImageNet 挑战赛是一个历史性的转折点,两大要素的汇聚——反向传播算法和大规模标注数据——彻底释放了神经网络的潜力,开启了深度学习革命。
深度学习时代:计算机视觉的爆发
视觉识别任务的全面突破
2012 年之后,深度学习迅速在计算机视觉的各个任务上取得了突破性进展:

来源:Slides 第51页(Part 1)。
- 物体检测(Object Detection):不仅识别“图中有什么”,还定位“在哪里”
- 图像分割(Image Segmentation):对每个像素进行分类
- 视频分类(Video Classification):理解视频中的动作和活动
- 图像描述(Image Captioning):自动为图像生成文字描述(Andrej Karpathy 在 Fei-Fei Li 实验室的博士论文工作)
- 关系理解(Relationship Understanding):理解物体之间的空间和语义关系
- 风格迁移(Style Transfer):将一种视觉风格应用到另一张图像上
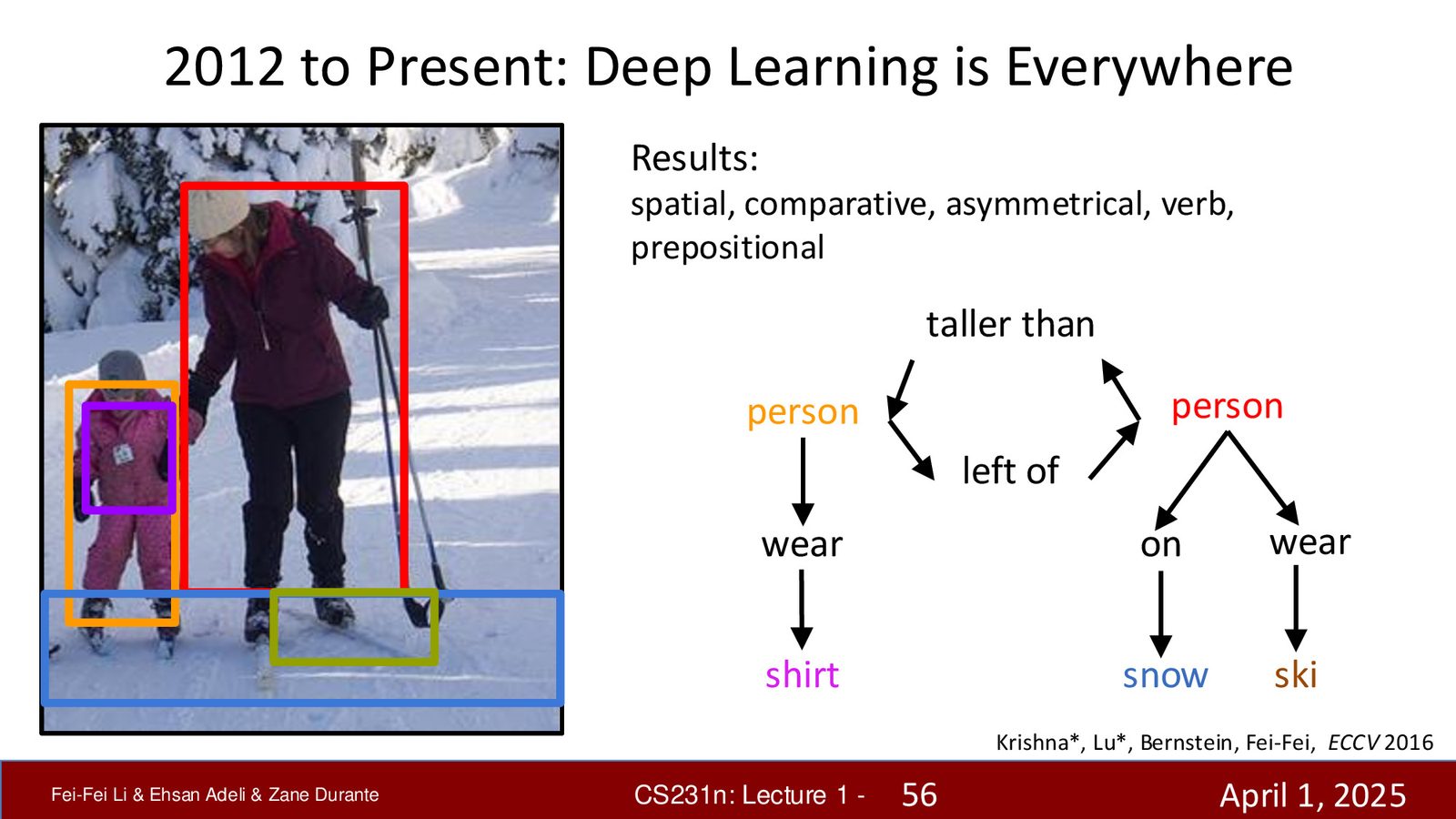
来源:Slides 第56页(Part 1)。来源:Krishna, Lu, Bernstein, Fei-Fei, ECCV 2016。
三大驱动力的汇聚
Fei-Fei Li 总结了推动当前 AI 爆发的三大汇聚力量:
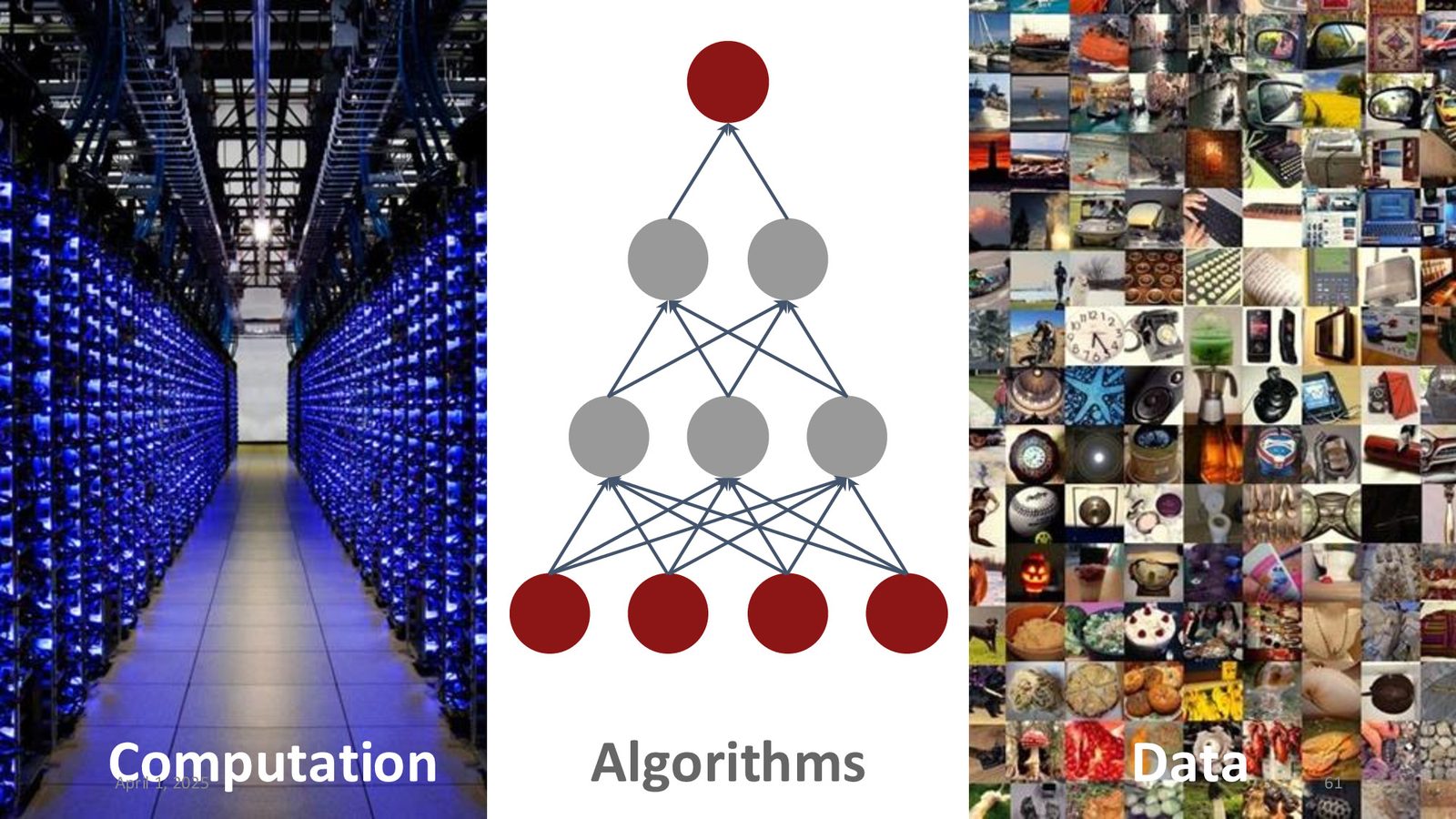
来源:Slides 第61页(Part 1)。
AI 爆发的三大驱动力
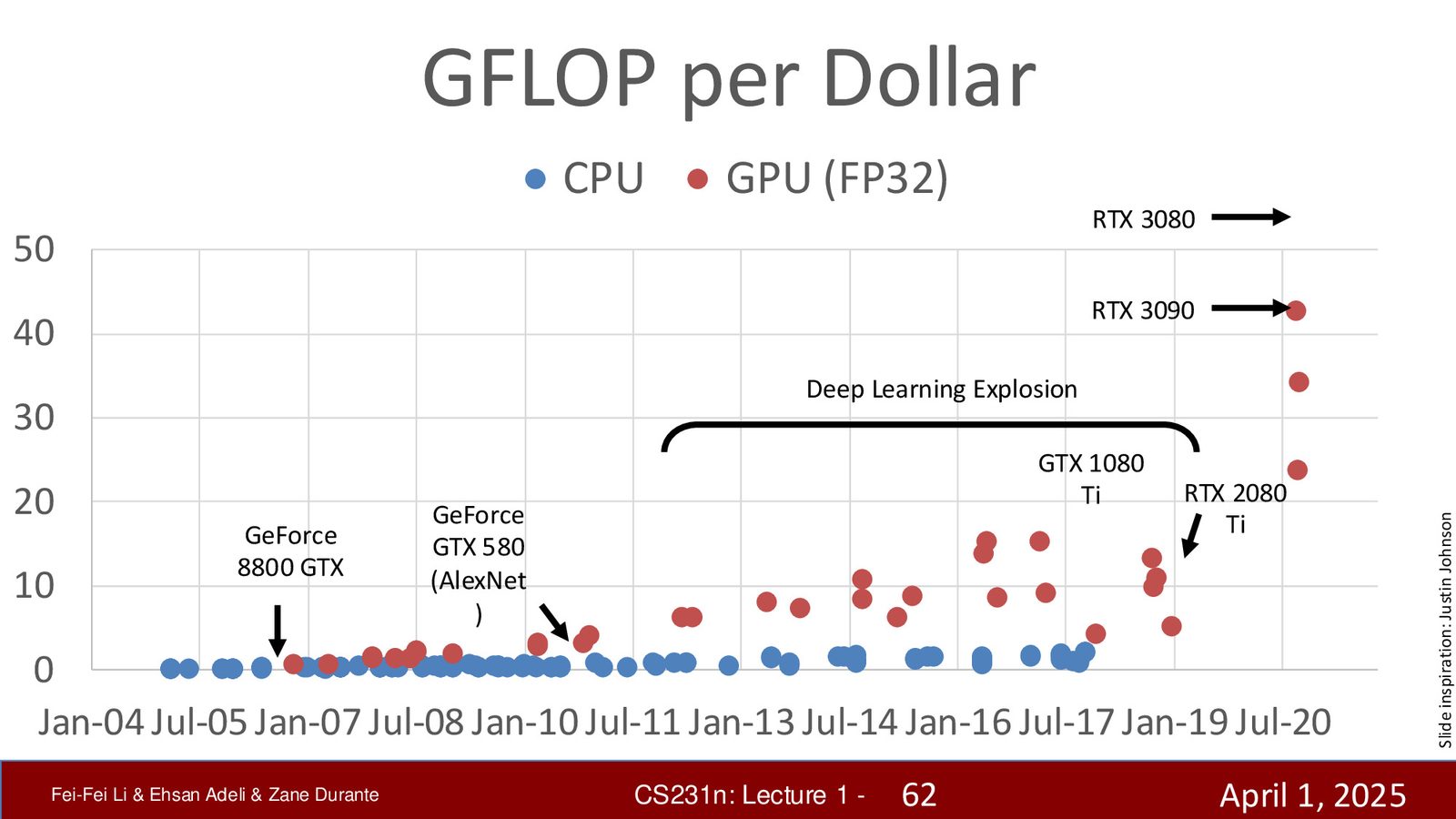
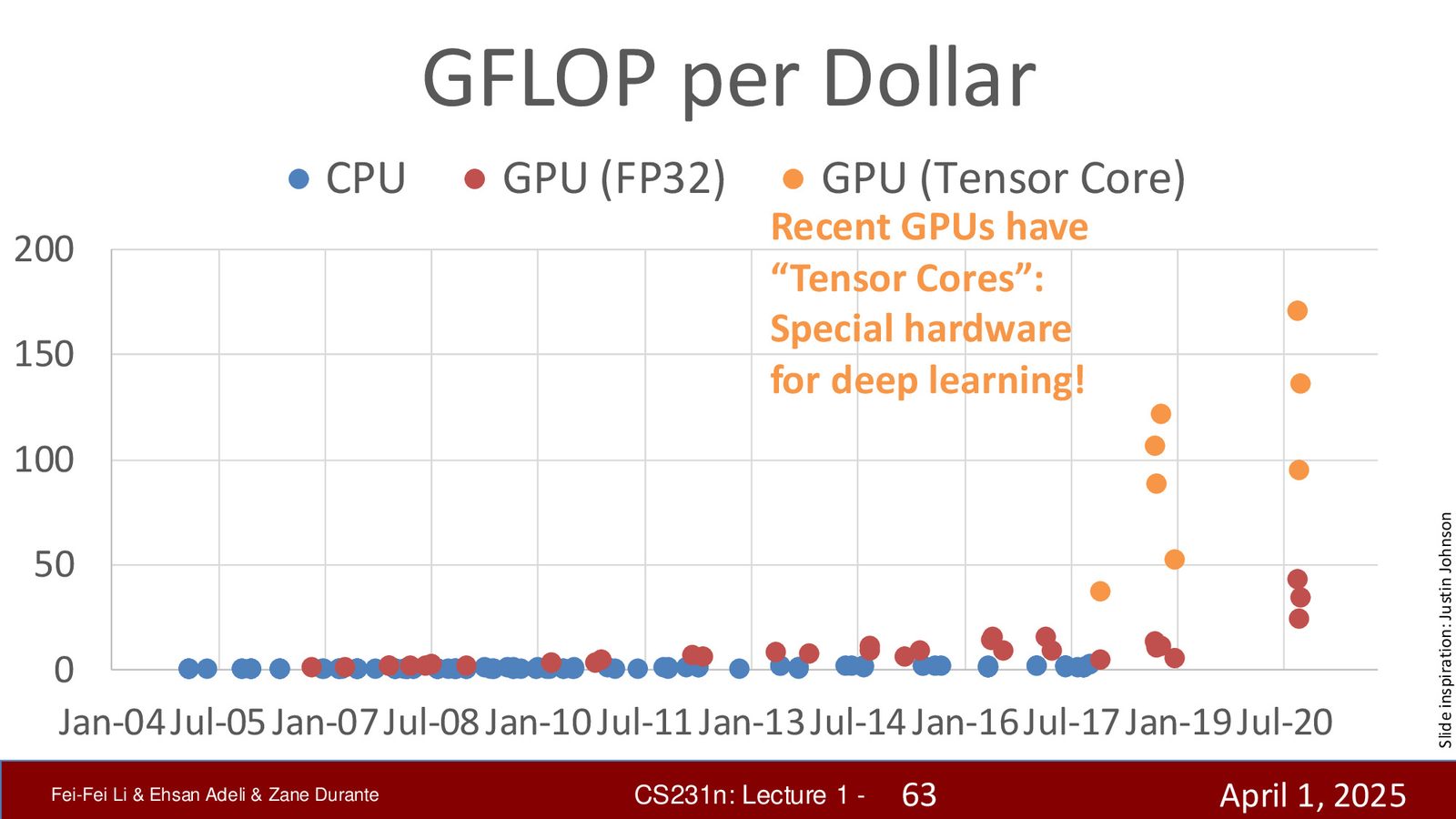
- 计算力(Computation):GPU 性能的指数级增长(2020年后加速尤为明显),NVIDIA GPU 的 GFLOPS/dollar 大幅提升
- 算法(Algorithms):从 CNN 到 Transformer,不断涌现的网络架构创新
- 数据(Data):互联网和数字相机提供了海量训练数据
这三者的同时就绪,将 AI 从“寒冬”推向了 Fei-Fei Li 所说的“AI Global Warming”——一个目前看不到减速迹象的爆发时代。
生成式 AI 时代
课程也展示了生成式 AI 的最新进展:
- 人脸生成:使用 GAN 等技术生成逼真的人脸
- 文生图(Text-to-Image):DALL-E、Midjourney 等模型可以根据文字描述生成图像
- 视频理解与生成:多模态模型结合视觉、语音等多种信息源
应用领域
深度学习驱动的计算机视觉已经在众多领域产生了深远影响:
- 医学影像:放射学、病理学等视觉密集型医学领域
- 科学发现:如首张黑洞照片的计算成像
- 环境与可持续发展:遥感监测、生态保护
- 自动驾驶:道路场景理解、行人检测
- 机器人学:具身智能、操作和导航
本章小结
深度学习在 2012 年后彻底改变了计算机视觉的面貌。从目标检测到图像分割,从图像描述到生成式 AI,深度神经网络在几乎所有视觉任务上都取得了突破。计算力、算法和数据三大力量的汇聚,将 AI 推入了一个前所未有的爆发期。
伦理与社会影响
AI 的双刃剑效应
Fei-Fei Li 在演讲结尾强调:强大的工具伴随着巨大的责任。计算机视觉可以造福社会,也可能造成伤害。
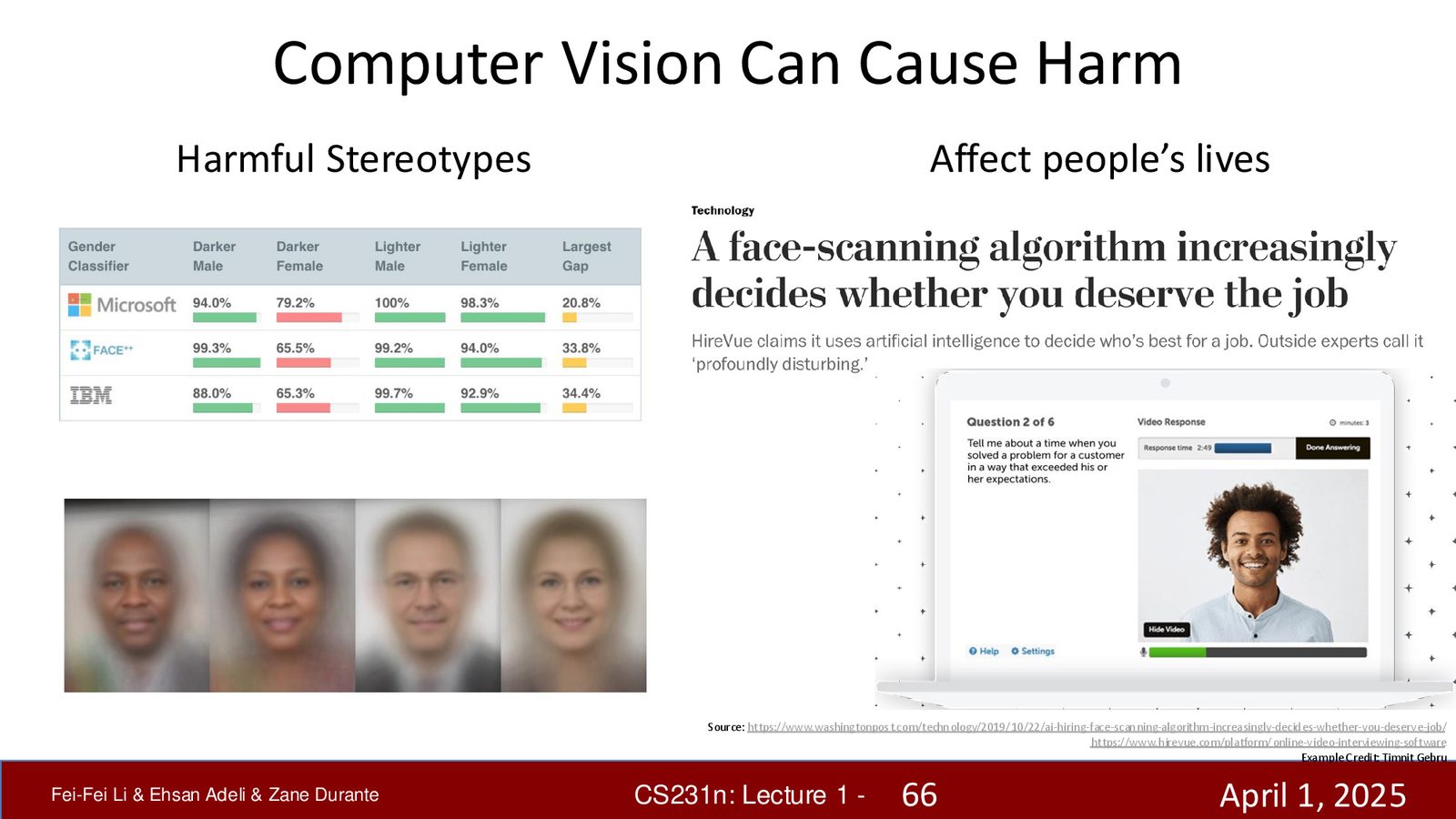
来源:Slides 第66页(Part 1)。
数据偏见与 AI 公平性
当前所有大型 AI 算法都由数据驱动,而数据是人类活动和历史的产物,天然携带了各种偏见。面部识别算法已被多次发现存在种族和性别偏见——对深色皮肤女性的识别错误率远高于浅色皮肤男性。当 AI 被用于影响人们的生活(招聘、贷款审批等)时,这些偏见可能被系统性地放大。
AI 应用的积极一面
Fei-Fei Li 特别提到了 AI 在医疗健康领域的应用。她和 Ehsan Adeli、Zane Durante 共同研究使用计算机视觉为老龄人口和患者提供照护支持。AI 在医学影像分析等领域可以极大地提升效率和准确性,惠及更多患者。
人类视觉的启示
Fei-Fei Li 最后指出,尽管计算机视觉已经取得了巨大进步,但人类视觉的丰富性、微妙性和情感深度仍然远超当前 AI 的能力。理解并欣赏人类视觉的卓越之处,应该是持续激励研究者前进的动力。
本章小结
技术进步必须伴随伦理反思。数据中的人类偏见会被 AI 系统继承和放大,这要求研究者和从业者高度关注公平性、透明度和社会影响。同时,AI 也在医疗等领域展现了巨大的正面潜力。
CS231N 课程概览
第二部分由 Ehsan Adeli 讲授,介绍了 CS231N 2025 年春季学期的课程架构和核心内容。
什么是计算机视觉
计算机视觉的核心目标是让机器“看见”并理解图像和视频。最基础的任务是图像分类(Image Classification):给模型一张图像,模型输出一个类别标签。
来源:Slides 第2页(Part 2)。
从线性分类到深度学习
线性分类器是最简单的方法:在特征空间中用一个超平面分隔不同类别。但当数据不是线性可分时,线性分类器就力不从心了。神经网络通过堆叠多层非线性变换来建模复杂的决策边界,这就是“深度”学习的含义——深度来自于多层级的表示学习。
课程四大主题
课程内容组织为四大主题模块:
主题一:深度学习基础
前几周的内容涵盖:
- 图像分类与线性分类器
- 损失函数与优化
- 正则化(Regularization)——控制模型复杂度,防止过拟合
- 神经网络的前向传播与反向传播
- 训练技巧与调试方法
主题二:感知与理解视觉世界
来源:Slides 第3页(Part 2)。
涵盖的核心视觉任务:
- 语义分割(Semantic Segmentation):为每个像素分配类别标签(如草地、猫、天空),但不区分同类别的不同个体
- 目标检测(Object Detection):定位并分类图像中的物体,输出边界框(bounding box)
- 实例分割(Instance Segmentation):最精细的任务,结合检测和分割,每个物体实例拥有独立的掩码
- 视频理解:视频分类、动作识别
- 多模态理解:结合视觉、听觉等多种模态
- 可视化与可解释性:理解模型关注图像的哪些区域
涵盖的核心模型架构:
- 卷积神经网络(CNN):从图像到卷积、池化、全连接的处理流水线
- 循环神经网络(RNN):处理序列数据
- Transformer 与注意力机制:当前最先进的架构
主题三:生成式与交互式视觉智能
- 自监督学习(Self-supervised Learning):从无标注数据中学习表示,是训练大规模模型的关键技术
- 生成模型:包括风格迁移、文生图(Text-to-Image)
- 扩散模型(Diffusion Models):通过逆转逐步加噪过程来生成图像(课程作业三将实现一个从文字生成表情符号的扩散模型)
- 视觉语言模型(Vision-Language Models):在共享表示空间中连接文本和图像
- 3D 视觉:从图像重建三维表示,对机器人和 AR/VR 至关重要
- 具身智能(Embodied AI):视觉驱动的智能体在物理世界中感知、规划和执行
主题四:以人为中心的 AI
- 大规模分布式训练:数据并行(Data Parallelism)、模型并行(Model Parallelism)等策略
- AI 伦理与社会影响:偏见、公平性、对人类生活的影响
学习目标
Ehsan Adeli 总结了本课程的核心学习目标:
- 将计算机视觉应用形式化为具体的任务
- 开发和训练视觉模型——处理图像和视频数据的深度学习模型
- 理解该领域的现状与发展方向
学术认可

来源:Slides 第7页(Part 2)。
深度学习领域已获得最高等级的学术认可:
- 2018年图灵奖:授予 Geoffrey Hinton、Yoshua Bengio 和 Yann LeCun,表彰他们在深度学习领域的概念性和工程性突破
- 2024年诺贝尔物理学奖:授予 Geoffrey Hinton 和 John Hopfield,表彰他们对神经网络的基础性贡献
本章小结
CS231N 2025年春季课程覆盖四大主题:深度学习基础、视觉感知与理解、生成式与交互式视觉智能、以人为中心的 AI。课程从最基础的线性分类器出发,逐步深入到 CNN、Transformer、扩散模型、视觉语言模型等前沿架构,最终涵盖 3D 视觉、具身智能等最新研究方向。
拓展阅读
- CS231N 课程官网:http://cs231n.stanford.edu/
- Hubel & Wiesel 原始论文:“Receptive fields of single neurones in the cat's striate cortex” (1959)
- David Marr, Vision: A Computational Investigation (1982)
- MIT Summer Vision Project 原文:https://dspace.mit.edu/handle/1721.1/6125
- Rumelhart, Hinton & Williams, “Learning representations by back-propagating errors” (Nature, 1986)
- Krizhevsky, Sutskever & Hinton, “ImageNet Classification with Deep Convolutional Neural Networks” (NeurIPS, 2012)
- Deng et al., “ImageNet: A Large-Scale Hierarchical Image Database” (CVPR, 2009)
- Fei-Fei Li, “How we teach computers to understand pictures” (TED Talk)
总结与延伸
核心知识脉络
本节课建立了一条从生物视觉到人工视觉的完整认知链:

关键 Takeaways
五条核心原则
- 视觉是智能的基石:5.4亿年的进化告诉我们,视觉感知是驱动智能发展的核心力量。理解视觉就是理解智能。
- 数据与算法同等重要:深度学习的突破不仅仅依赖于更好的算法(反向传播),还依赖于大规模的标注数据(ImageNet)。数据是深度学习的一等公民。
- 生物学启发贯穿始终:从 Hubel & Wiesel 的感受野到卷积神经网络的设计,神经科学的发现一直是算法创新的重要灵感来源。
- 三大力量缺一不可:计算力、算法和数据的同时就绪,才引爆了深度学习革命。单独依靠任何一个维度都不够。
- 技术进步必须伴随伦理反思:AI 的强大能力带来了偏见、公平性和社会影响等严肃议题,技术开发者有责任正视这些挑战。
展望
CS231N 接下来的课程将从图像分类和线性分类器开始,系统地构建深度学习在计算机视觉中的完整知识体系。2025年的课程还新增了大规模分布式训练、扩散模型、视觉语言模型等反映当前研究前沿的内容。正如 Fei-Fei Li 所说,我们正处于“AI 全球变暖”时期——一个激动人心且看不到放缓迹象的技术加速时代。