CS336 2026 Lecture 8:Parallelism Basics 与大模型并行训练
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方幻灯片重新整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |

本讲主线:并行训练是一张状态和通信的账本
读图:Slide 1 为什么重要
标题页看似只给题目,但它标记了课程从 Lecture 7 的通信 primitives 进入系统化并行训练。Lecture 7 让我们认识 rank、world size、collectives(集合通信,所有 rank 共同执行的多 GPU 通信原语,如 all-reduce、all-gather、reduce-scatter)、NCCL;Lecture 8 要回答的是,真实 LLM 训练中如何同时切分参数、梯度、优化器状态、激活、序列、专家和 batch。

读图:Slide 2 的三个学习目标
第一,理解为什么大模型训练不是单卡训练的放大版,而是系统问题。第二,区分多种 parallelization paradigms:data、ZeRO/FSDP、pipeline、tensor、sequence、expert、context。第三,看懂大规模训练 run 的常见布局,也就是 DP/TP/PP/EP/CP 等数字如何组合成一张集群切分图。

本讲的核心判断
并行训练不是选择一个“最强技巧”。它是把训练状态放到不同设备上,并用 collective communication 在正确时刻恢复数学语义。读任何并行方案时,都要问四个问题:切了什么,复制了什么,通信什么,通信走哪条硬件路径。
术语消化:本讲会反复出现的缩写
| 术语 | 定义 | 本讲关系 |
|---|---|---|
| collectives | 集合通信,所有 rank 共同执行的多 GPU 通信原语,如 all-reduce、all-gather、reduce-scatter、broadcast。 | ZeRO、FSDP、TP、EP、CP 都能拆成这些 collective operations。 |
| sharding | 分片,把参数、梯度、optimizer state、activation 或 token 序列切到多张 GPU 上。 | 分片减少单卡显存,但通常增加 all-gather、reduce-scatter 或 all-to-all。 |
| ZeRO | Zero Redundancy Optimizer,按 stage 分片 optimizer state、gradients 和 parameters。 | 解决 data parallel 复制状态的显存浪费。 |
| FSDP | Fully Sharded Data Parallel,PyTorch 风格的 ZeRO-3 实现。 | 按模块临时 all-gather 参数,反向后 reduce-scatter 梯度。 |
| HBM | High Bandwidth Memory,高带宽显存,是 GPU 上的 DRAM。 | 训练状态最终要落在每张 GPU 的 HBM 里,显存容量决定是否需要分片。 |
Part 1:LLM 训练的网络基础
单 GPU scaling 的两堵墙
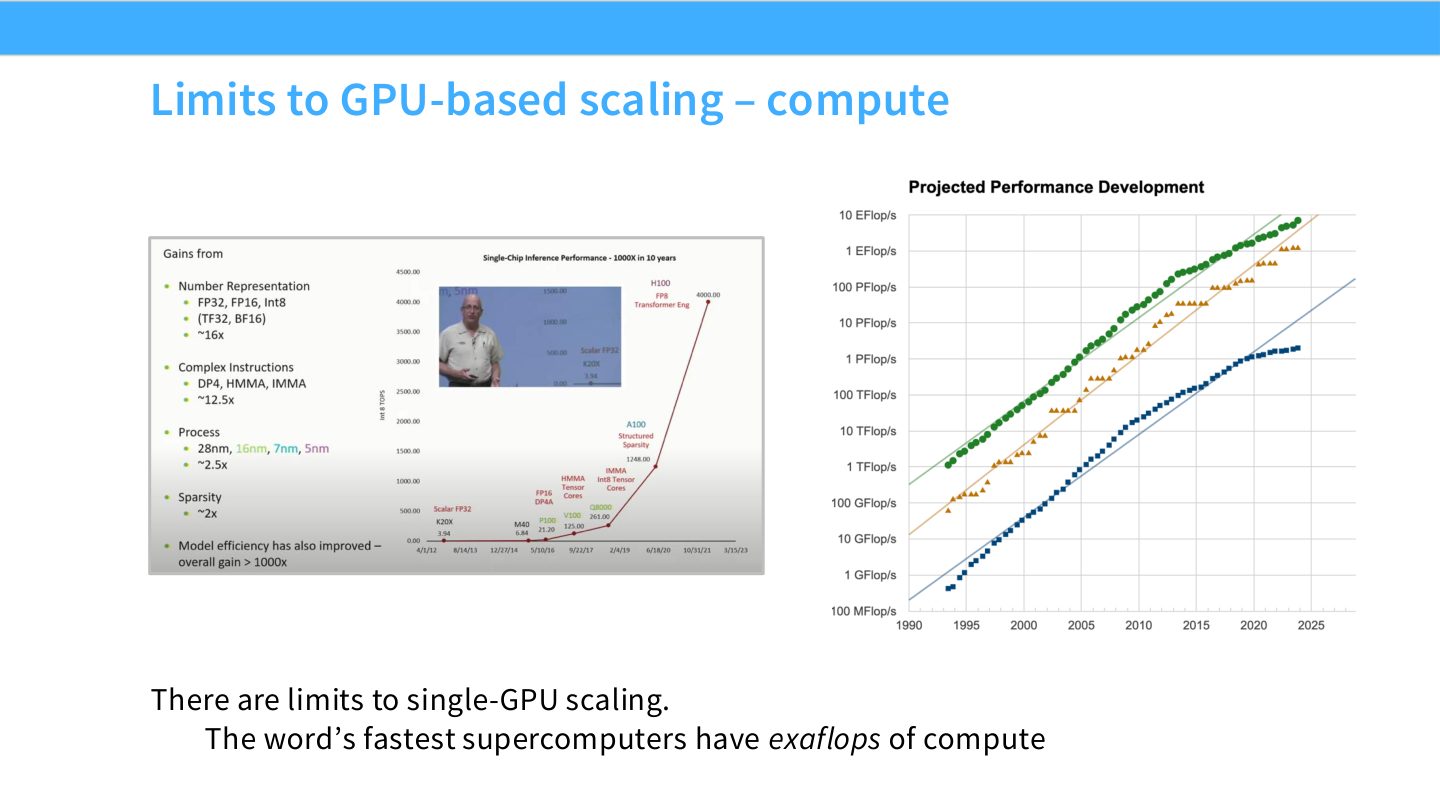
读图:Slide 4 在提醒什么
这页不是说单 GPU 不重要,而是说“算力需求”已经天然越过单卡边界。LLM 训练需要的 FLOPs 可以大到只能用数据中心级计算池完成。因此训练单位从一张 GPU 变成整台服务器、整组 pod,甚至整个 datacenter。
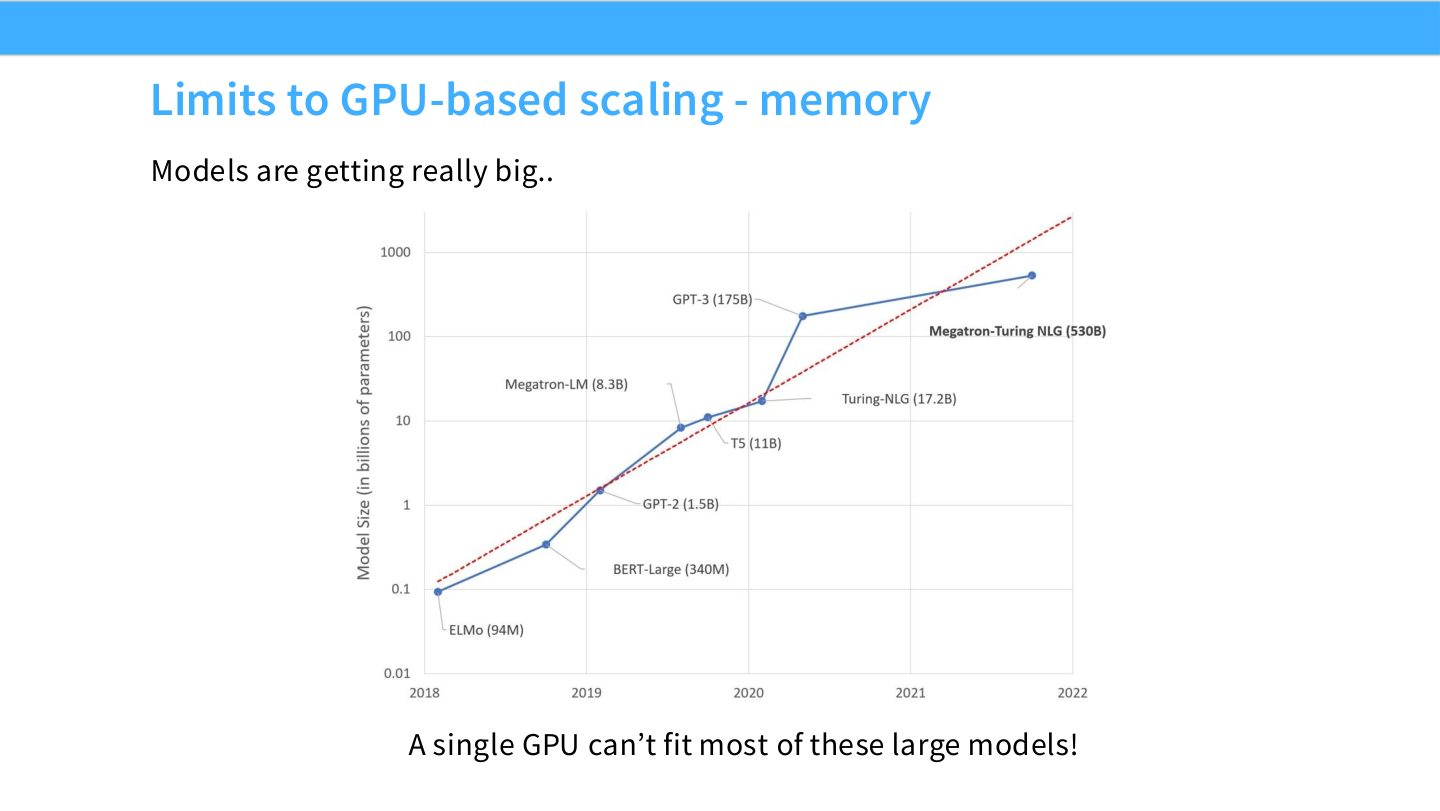
读图:Slide 5 说的是训练状态,不只是参数
图里强调 large models 放不进单 GPU。这里的“放不下”不能只看参数量,还要加上梯度、optimizer state、激活和临时 buffer。推理时能放下的模型,训练时可能因为 Adam 状态和激活而远远超出 HBM。
其中 \(M_{\text{params}}\) 是权重,\(M_{\text{grads}}\) 是梯度,\(M_{\text{optimizer}}\) 是 Adam/AdamW 的一阶动量 \(m\)、二阶动量 \(v\) 和可能的 master weights,\(M_{\text{activations}}\) 是反向传播需要的中间激活,\(M_{\text{buffers}}\) 是通信和算子临时空间。
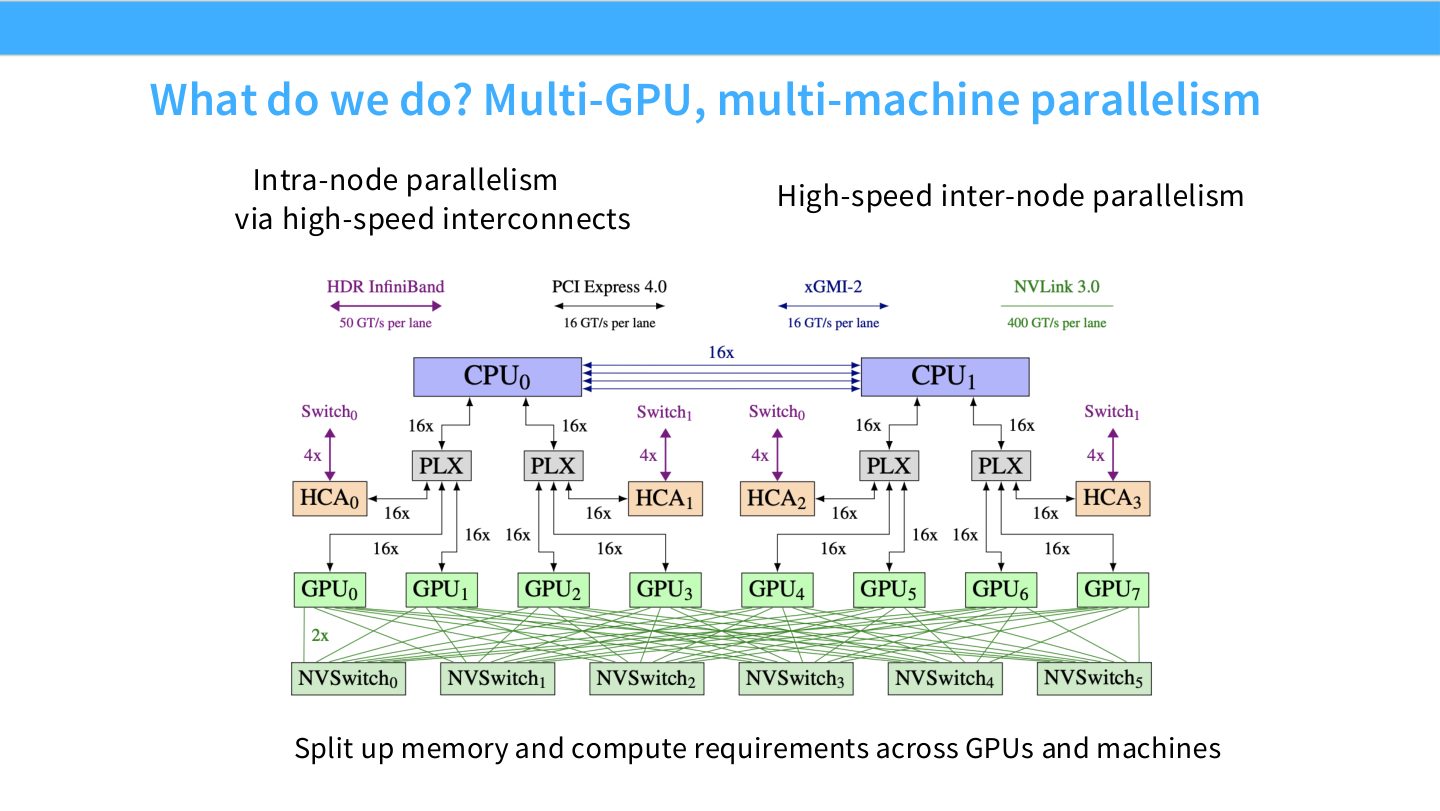
读图:Slide 6 的关键短语
这页同时出现 intra-node parallelism 和 high-speed inter-node parallelism。前者通常依赖 NVLink/NVSwitch,适合高频通信;后者依赖 InfiniBand/RoCE 等高速互连,适合更粗粒度的跨节点同步。并行训练的第一条工程规则就是:高频通信尽量留在快域,低频通信才跨慢域。
collective communication 的最小回顾
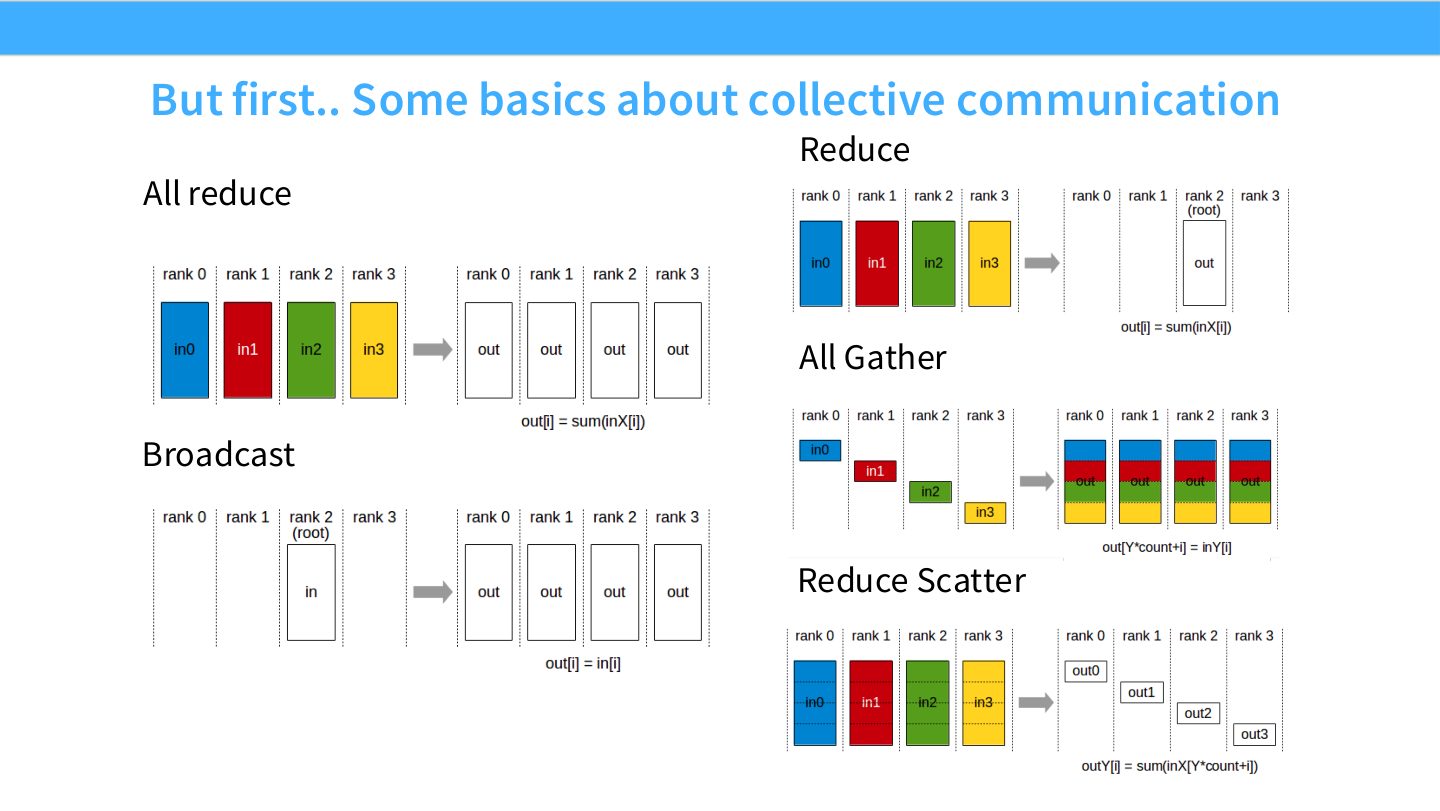
读图:Slide 7 是后续所有并行策略的字母表
如果把分布式训练看成语言,collectives 就是字母。DDP 用 all-reduce 同步梯度;FSDP/ZeRO 用 reduce-scatter 分片梯度,用 all-gather 临时拼参数;MoE/expert parallelism 常用 all-to-all 路由 token。读后面的并行图时,不要先记名字,而要先识别它调用了哪个 collective。
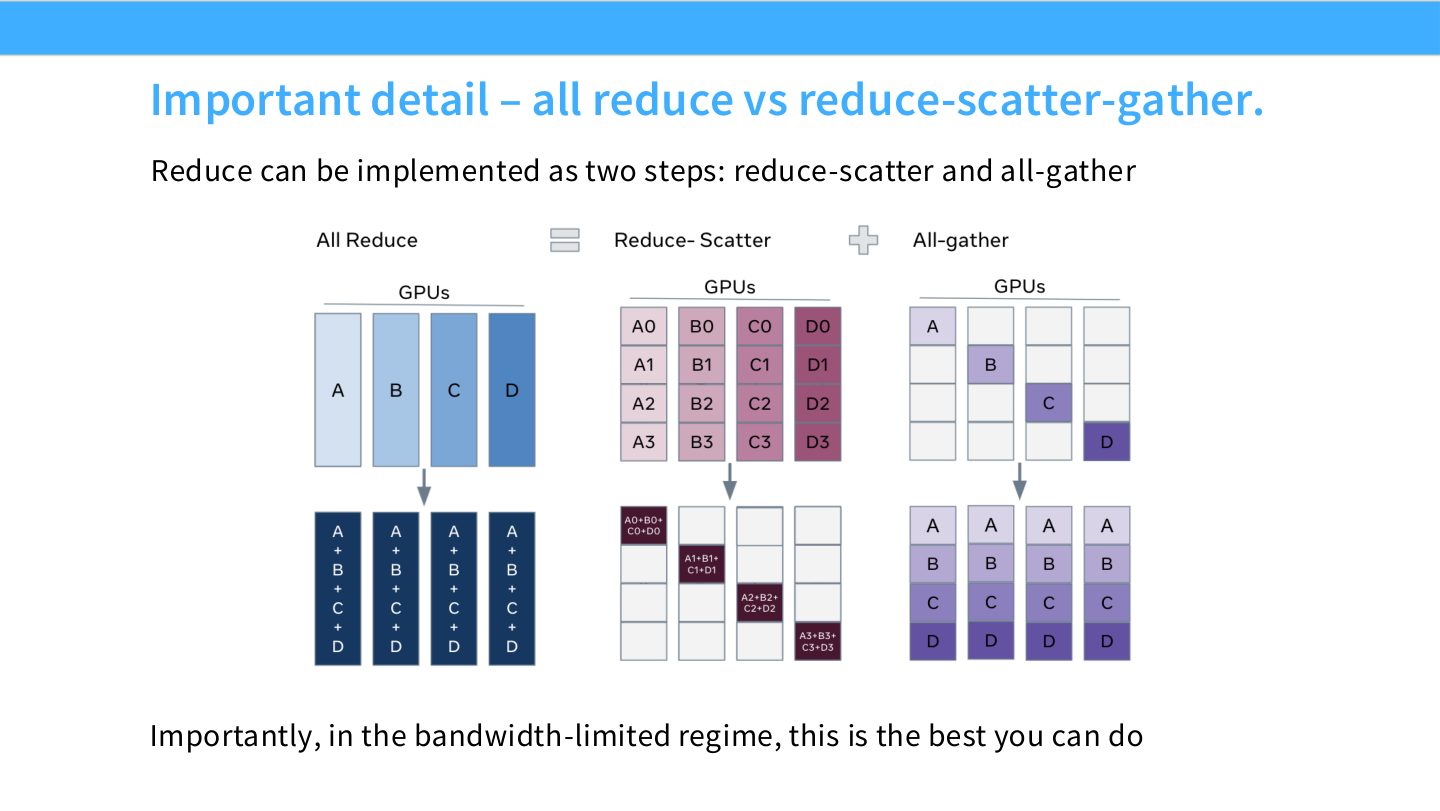
读公式:Slide 8 的等价关系
all-reduce 的语义是“归约后每个 rank 拿到完整结果”。reduce-scatter 先让每个 rank 拿到归约结果的一片;all-gather 再把所有片拼回完整结果。ZeRO/FSDP 的关键就在于:如果每个 rank 不需要长期持有完整结果,就可以停在分片状态,从而省显存。
TPU 和 GPU 网络拓扑的差异
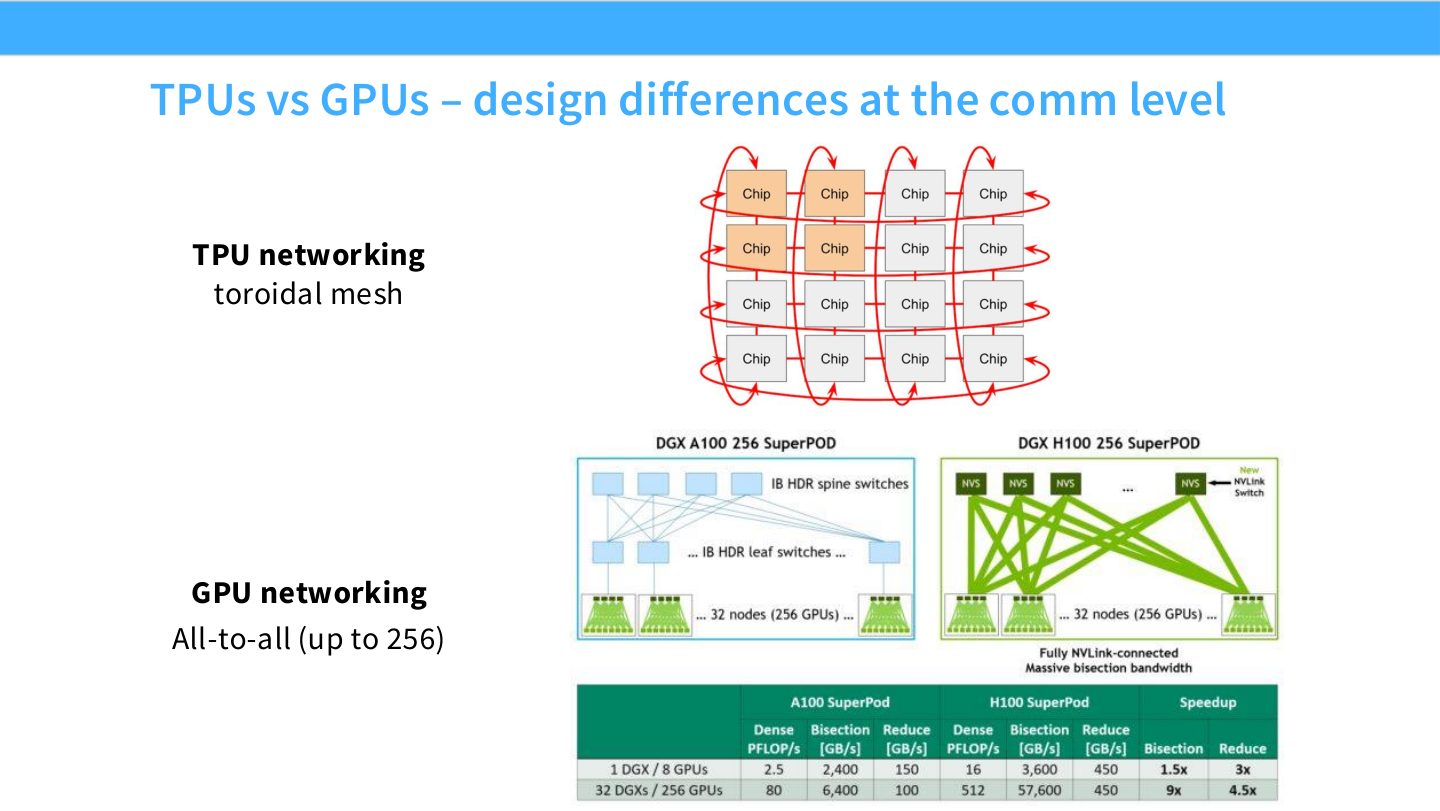
读图:Slide 9 应该比较什么
左侧 TPU mesh 强调结构化近邻连接,适合规则张量切分和编译器规划;右侧 GPU 网络强调较强的全局互连能力,尤其在 NVSwitch 或高速交换网络下有利于 less structured communication。这里不是说哪种一定更好,而是说并行策略要和网络结构一起设计。

读图:Slide 10 的两个阵营
mesh 的优势是规则、成本较低、可以把大张量切成局部通信;tree 或 switched all-to-all 的优势是支持更不规则的通信,例如 expert parallel 的 token routing。换句话说,网络不是背景设施,而是决定你能否高效训练 MoE、长上下文模型和大 tensor-parallel block 的核心变量。
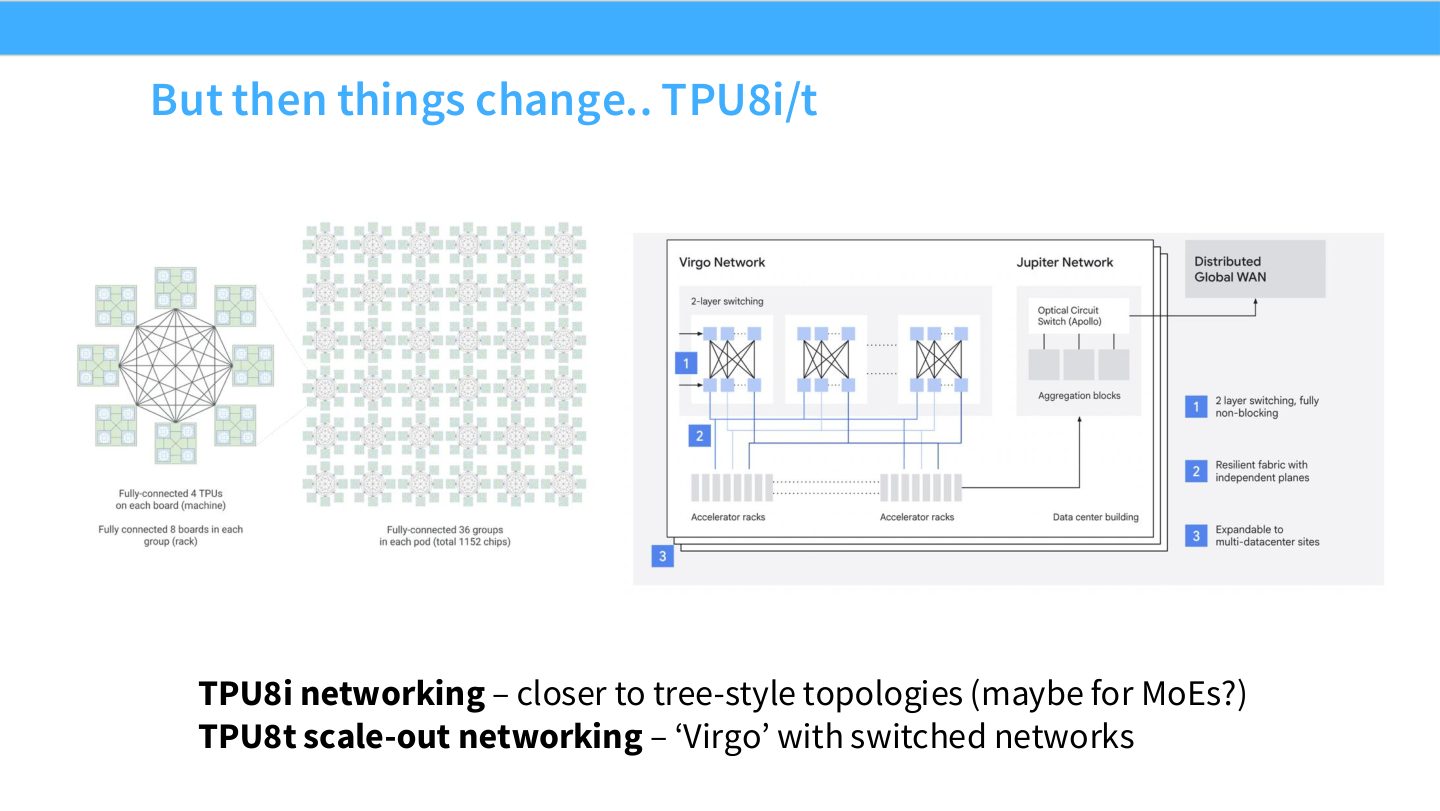
读图:Slide 11 说明硬件也在追随模型结构
这页提示一个趋势:当 MoE、长上下文和不规则并行需求变强,硬件网络也从单纯规则 mesh 向更灵活的 switched network 演化。并行算法和硬件互相塑形,不是先有固定硬件再被动适配模型。

读图:Slide 12 不能推出“越大互连域越好”
完全互连的带宽和灵活性很诱人,但交换芯片、线缆、功耗、故障域、调度复杂度都会随 domain size 上升。训练系统通常选择分层互连:节点内很快,rack/pod 内较快,跨 pod 更慢。并行计划也要分层:高频 TP/EP 放在快域,DP/PP 放到更大域。

读图:Slide 13 的 recap 如何落到工程目标
线性 memory scaling 指最大模型状态随 GPU 数接近线性增长;线性 compute scaling 指可用 FLOPs 随 GPU 数接近线性增长。二者往往冲突:更强的 sharding 提升 memory scaling,但可能增加通信,损害 compute scaling。并行训练设计就是在这两个线性目标之间找可接受的折中。
Part 1 小结
本部分建立了三件事:第一,训练单位已经从单 GPU 变成 datacenter;第二,collectives 是所有并行策略的底层语言;第三,网络拓扑决定哪些通信模式可行。
Part 2:标准 LLM 并行 primitives

读图:Slide 14 是并行策略地图
这页把大模型并行分成三层:data parallel 解决吞吐和数据切分;ZeRO/FSDP 解决 data parallel 下状态重复;model parallel 再把模型内部的 layers、width、sequence、experts、context 切开。真实训练通常不是三选一,而是把这些策略组合成 3D/4D parallelism。
naive data parallelism 与它的显存问题

读公式:Slide 15 中 SGD 的分布式语义
公式 \(\theta_{t+1}=\theta_t-\eta\sum_{i=1}^{B}\nabla f(x_i)\) 中,\(\theta_t\) 是第 \(t\) 步参数,\(\eta\) 是学习率,\(B\) 是 global batch size。data parallel 把 \(B\) 切成 \(M\) 份,每个 rank 算本地梯度,再通过 all-reduce 得到等价于大 batch 的平均梯度。
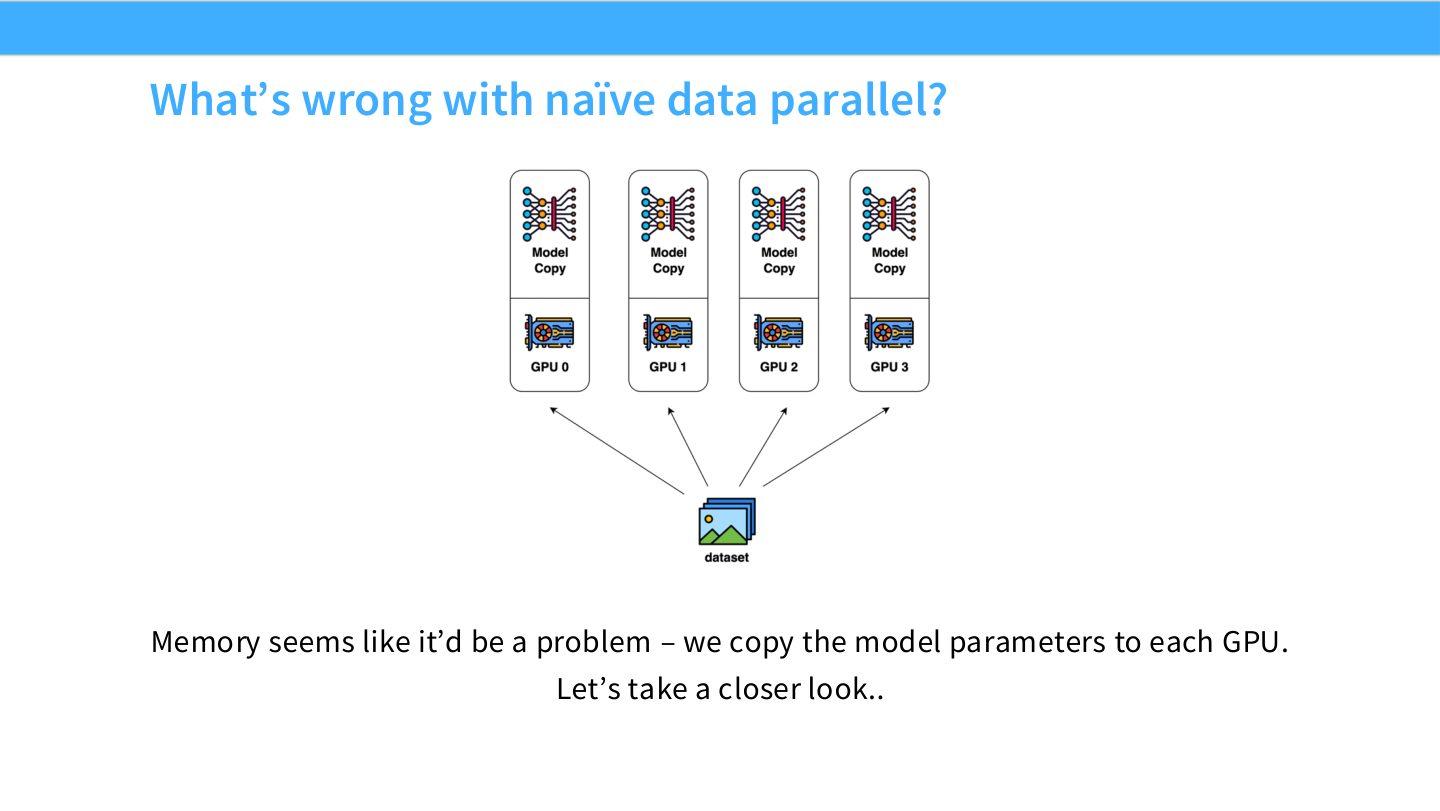
读图:Slide 16 的“memory problem”不是小修小补
DDP 的模型复制让每张卡都有完整参数、完整梯度和完整 optimizer state。即使 batch 被分开,模型状态没有被分开。对超大模型来说,增加 GPU 数并不会降低单卡模型状态,普通 DDP 只能扩吞吐,不能扩容量。

读表:Slide 17 的 16 bytes per param 从哪里来
这页把训练状态拆开:BF16/FP16 模型参数、梯度、FP32 master weights、Adam 一阶动量 \(m\)、二阶动量 \(v\) 等。具体 byte 数会随训练配方变化,但结论稳定:optimizer state 往往比参数本身更重。若每张 GPU 都复制这些状态,显存浪费非常大。
ZeRO:把 data parallel 的重复状态分片

术语消化:ZeRO stage 1/2/3
| 阶段 | 分片对象 | 仍复制什么 | 代价 |
|---|---|---|---|
| ZeRO-1 | optimizer state,如 Adam 的 \(m,v\)。 | 参数和梯度。 | 通信几乎不比 DDP 更贵。 |
| ZeRO-2 | optimizer state 加 gradients。 | 参数。 | 梯度生命周期更复杂。 |
| ZeRO-3/FSDP | optimizer state、gradients、parameters 全部分片。 | 只在需要时临时 gather。 | 前向/反向中频繁 all-gather。 |
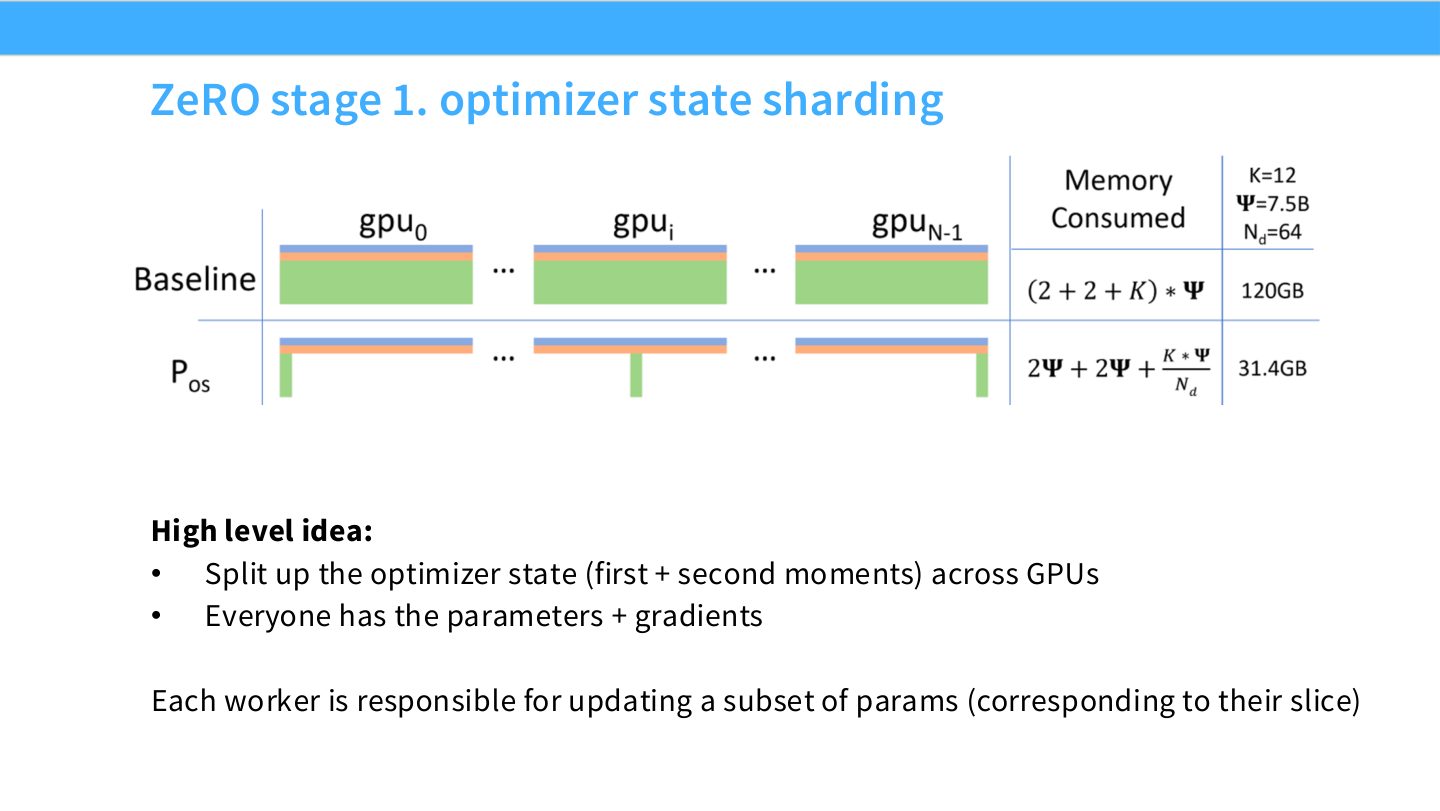
读图:Slide 19 为什么说 ZeRO-1 先切 optimizer state
每个 worker 仍有完整参数和完整梯度,但只负责一部分参数的 optimizer update,因此只需要保存这部分参数对应的 Adam 状态。因为 optimizer state 很大,ZeRO-1 的显存收益明显;又因为参数和梯度仍完整,训练流程相对容易保持。

读图:Slide 20 的四步生命周期
第一,每个 rank 对自己的 batch slice 计算完整梯度。第二,用 reduce-scatter 把梯度归约并发送到负责对应参数 shard 的 rank。第三,每个 rank 用本地 optimizer state 更新自己负责的参数 shard。第四,用 all-gather 收集更新后的参数,让所有 rank 继续拥有完整参数副本。
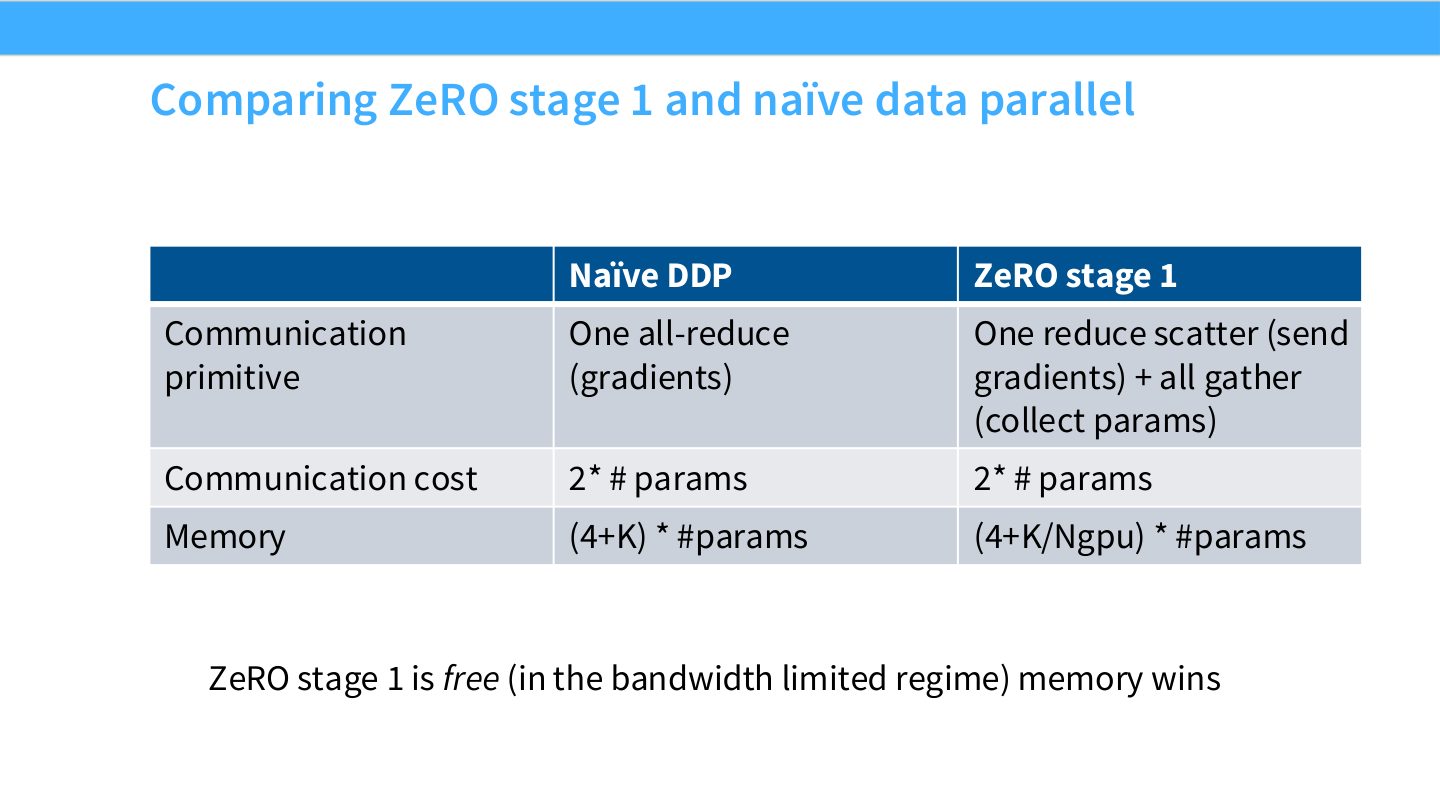
读表:Slide 21 为什么说 ZeRO-1 近似免费
DDP 的梯度 all-reduce 可以看成 reduce-scatter 加 all-gather;ZeRO-1 正是用这两个阶段分别完成梯度归约和参数收集。因此总通信量仍约为 \(2\times\#\text{params}\),但 optimizer state 不再每卡复制。所谓“free”指通信账本相近,不是实现没有复杂度。

读图:Slide 22 的简单扩展为何有效
ZeRO-2 的想法是:既然 reduce-scatter 后每个 rank 已经拿到归约梯度的一片,就不必再让每张卡长期保存完整梯度。这样进一步节省显存,尤其在大模型和小 batch 的设置下,梯度存储也可能成为压力源。
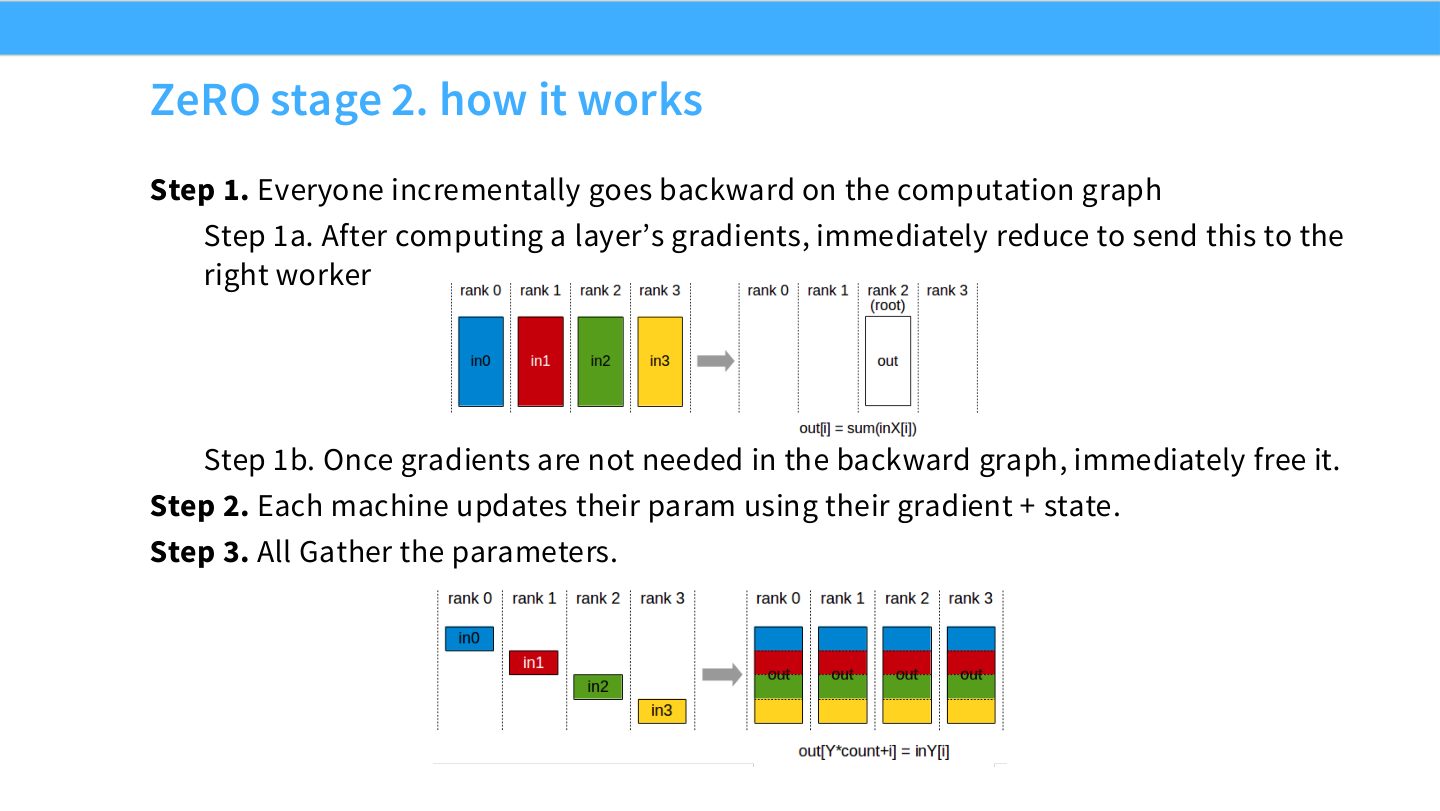
读图:Slide 23 的难点是“生命周期”
ZeRO-2 不是等 backward 完成后一次性处理所有梯度,而是某层梯度一产生就可以 reduce-scatter 到负责 rank,并释放不再需要的完整梯度。这样能降低峰值显存,但需要精确管理梯度产生、通信、释放和 optimizer update 的顺序。

读图:Slide 24 为什么叫 shard everything
ZeRO-3/FSDP 不再让每张卡常驻完整参数。参数也被分片存储,某一层 forward 前再 all-gather 该层需要的完整参数;用完后释放。反向传播时同理,在需要参数和梯度时临时恢复局部完整视图,再 reduce-scatter 回分片。
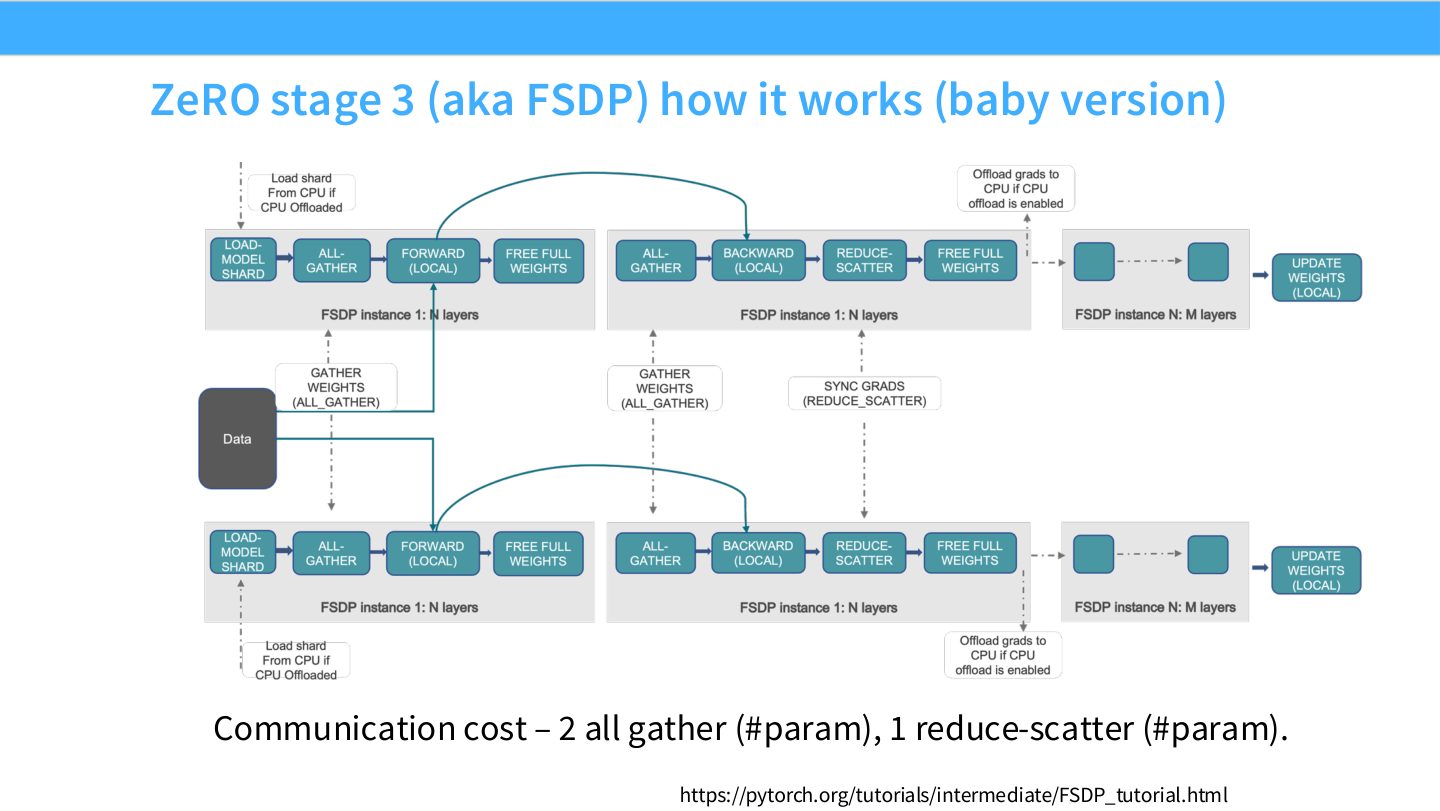
读图:Slide 25 的成本不能只看总 byte
ZeRO-3 的通信量级可接受,但通信被插入到每层 forward/backward 的关键路径中。是否快,取决于 prefetch、overlap、模块粒度、bucket 大小和网络拓扑。它解决显存,不保证自动提高吞吐。
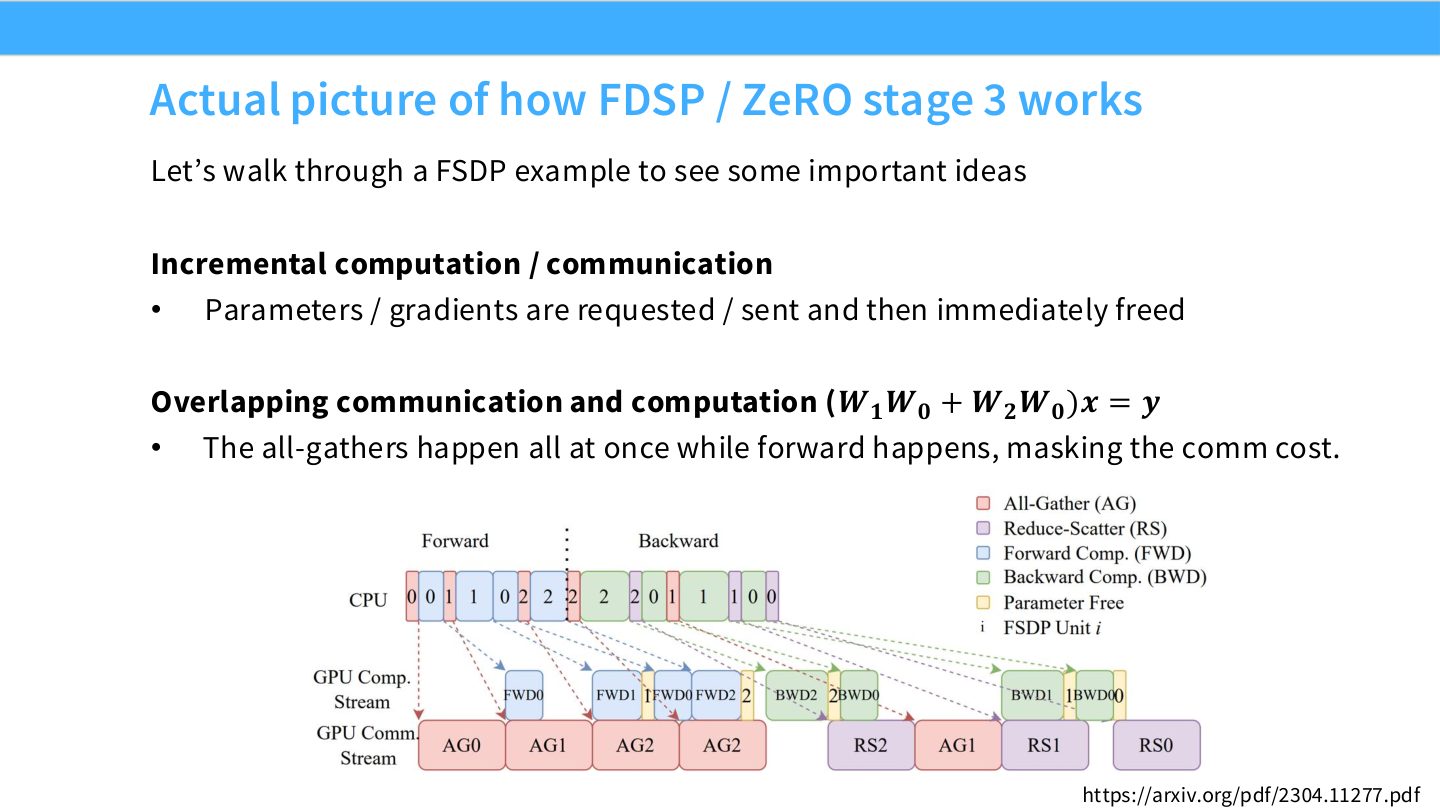
读图:Slide 26 应该跟踪三条时间线
第一条是 forward/backward 计算时间线;第二条是参数 all-gather 和梯度 reduce-scatter 的通信时间线;第三条是 HBM 中参数 shard、临时完整参数、梯度 buffer 的生命周期。高质量 FSDP 实现要让通信尽量提前或重叠,同时及时释放临时完整参数以降低峰值显存。

读图:Slide 27 的结论如何使用
若模型能放下但 optimizer state 太重,ZeRO-1 往往是低风险选择。若梯度显存也成问题,ZeRO-2 有收益。若参数本身放不下,必须上 ZeRO-3/FSDP 或其他模型并行。这里的“free”都以通信量级为口径,实际速度仍要看 overlap 和实现。

读表:Slide 28 不是死记数字,而是学会算账
每参数 bytes 会随精度、optimizer、master weight、gradient accumulation、activation checkpointing 改变。读这页要关注方法:先估计每卡 HBM,再扣除 activation 和 buffer,再按 data-parallel world size 估计分片状态能容纳多少参数。显存预算永远要留余量,因为通信 buffer 和碎片化会吃掉空间。
data parallel 剩下的问题
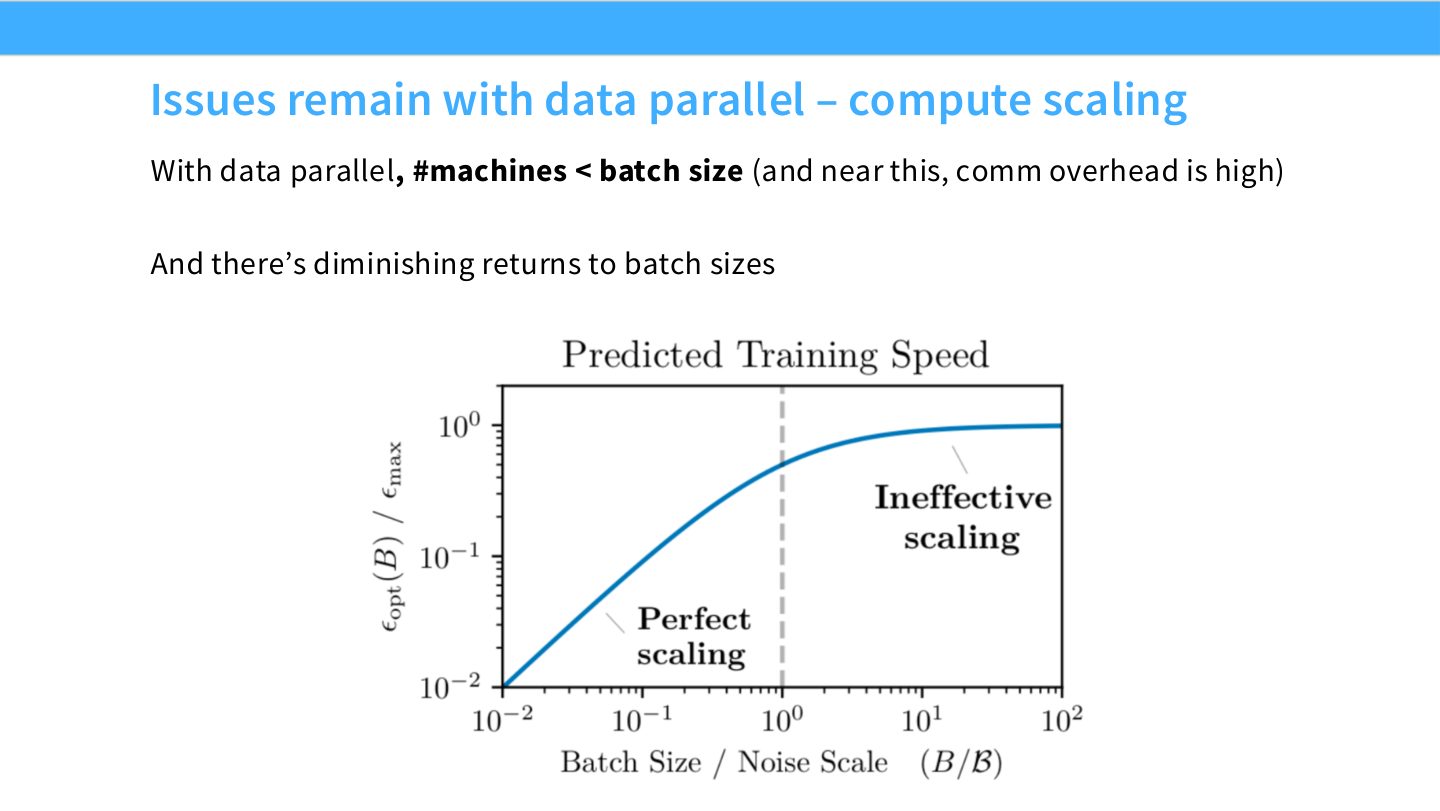
读图:Slide 29 说的是“吞吐扩展到哪里停”
data parallel 增加 rank 会增加 global batch 或减小 per-rank batch。若 global batch 过大,优化收益递减;若 per-rank batch 过小,GPU 利用率下降且通信占比上升。因此 DP 不是无限扩展 compute 的答案。
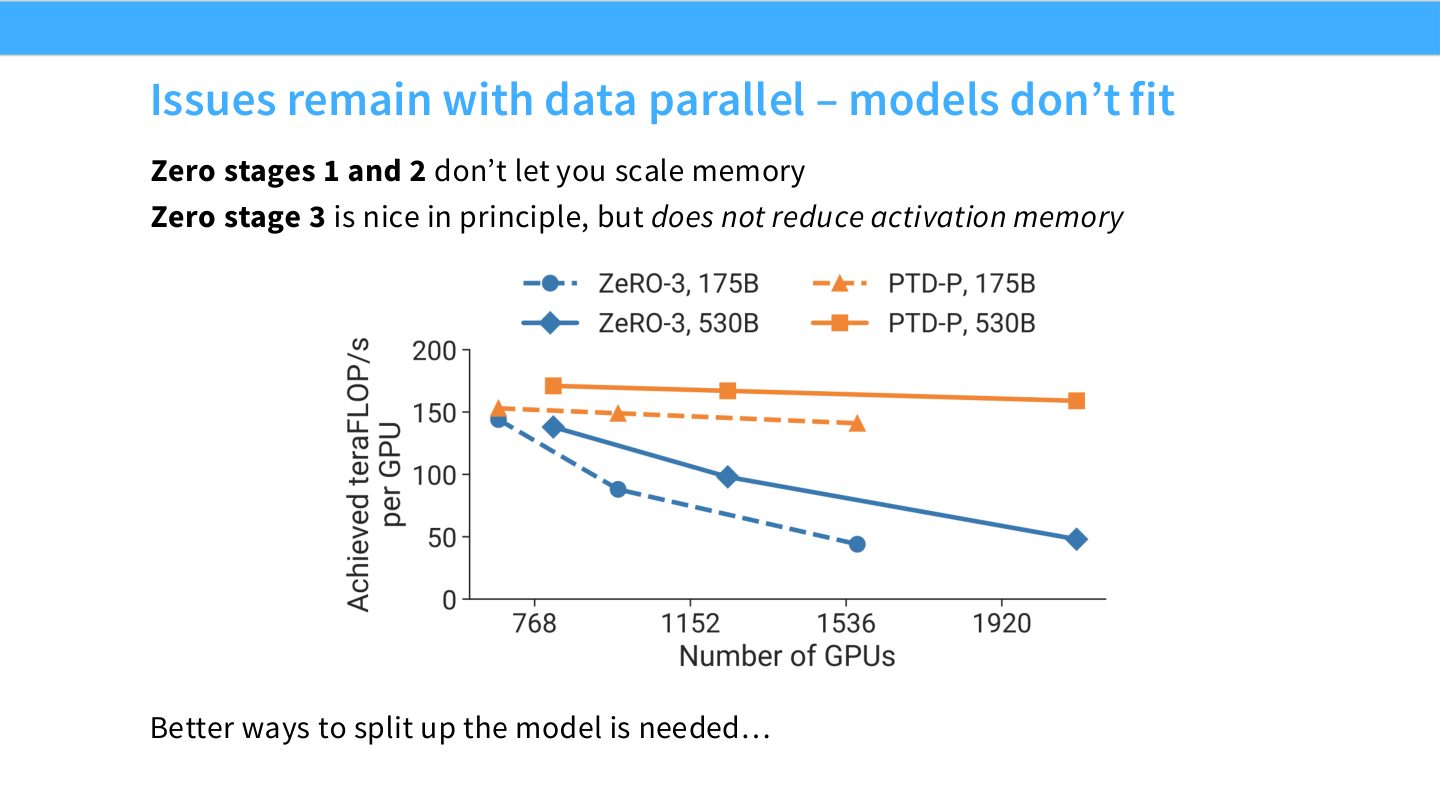
读图:Slide 30 把 ZeRO 的边界讲清楚
ZeRO-1/2 主要分片 optimizer state 和 gradients,参数仍复制。ZeRO-3 能分片参数,但 activation memory 仍然随 sequence length、batch、层数增长。若模型层或激活本身太大,就要切模型内部结构,而不是只靠 data parallel 的状态分片。

读图:Slide 31 的 model parallel 和 ZeRO-3 有何不同
两者都可能把参数放在多张卡上,但通信语义不同。ZeRO-3 保持 data-parallel 视角,需要时 gather 参数;model parallel 则让不同 rank 持有模型不同结构部分,并在前向/反向中传递激活或 partial results。它改变了模型计算图的并行执行方式。
pipeline parallelism:沿 depth 维切模型
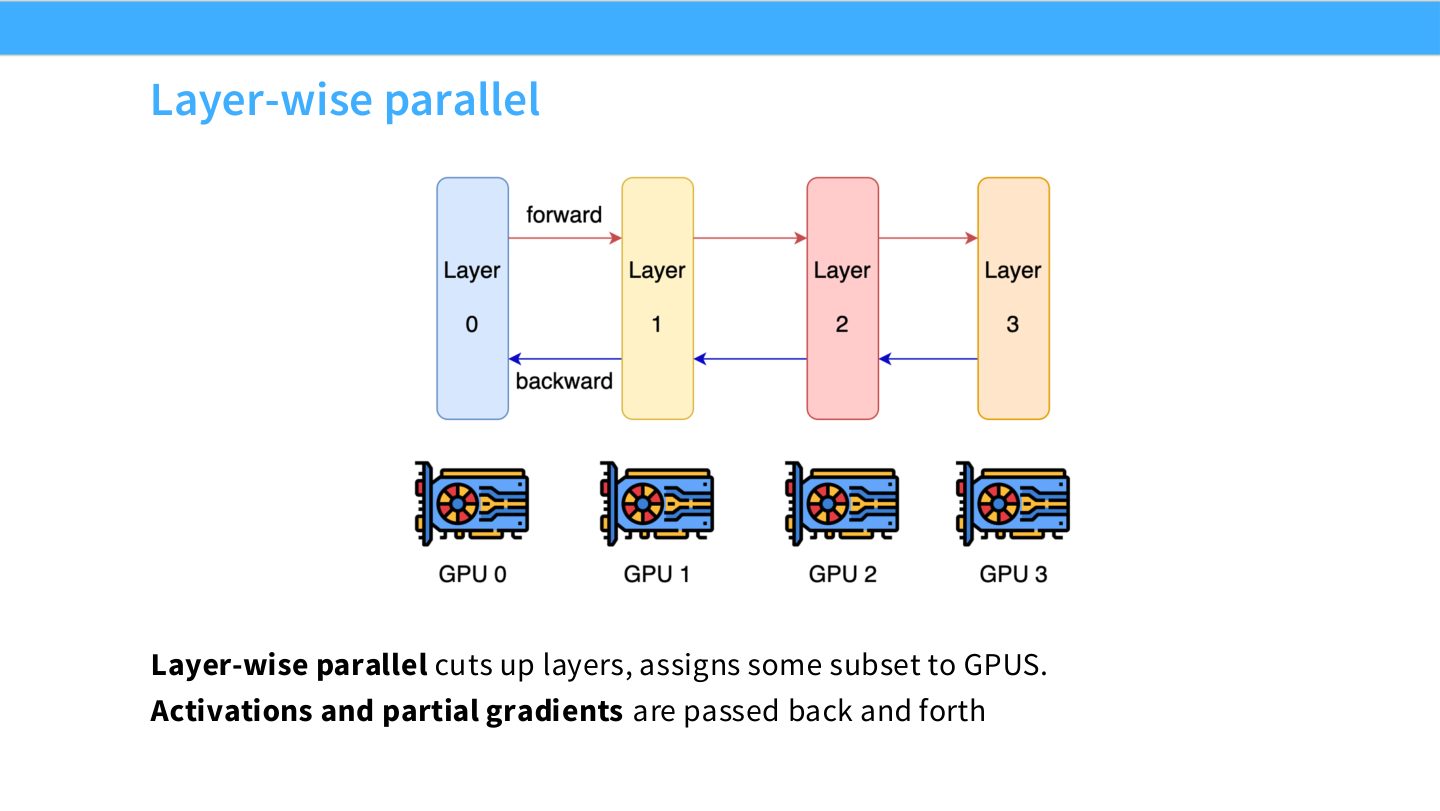
读图:Slide 32 是 pipeline 的 naive 起点
图中模型深度被切成多个 stage。每个 GPU 保存一段连续层,前向时激活向后传,反向时梯度向前传。这个策略能让单卡只存部分层,但如果一次只处理一个 batch,绝大多数 GPU 会等待。
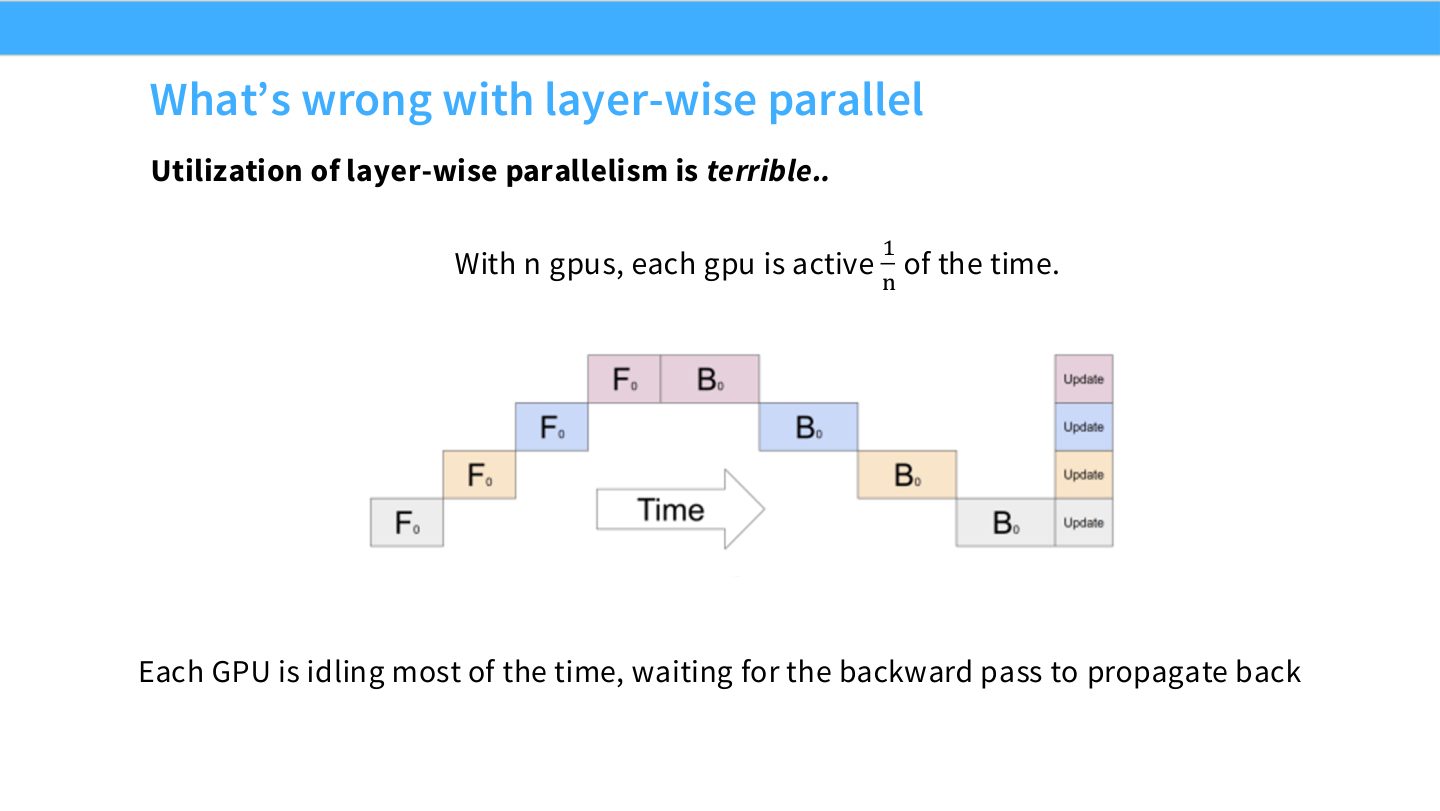
读图:Slide 33 的空闲来自依赖链
前向必须从第一段层算到最后一段,反向又必须从最后一段传回第一段。如果没有 microbatch,不同 stage 很难同时工作。利用率低不是硬件慢,而是调度图本身串行。

读公式:Slide 34 的 bubble 比例
若有 \(P\) 个 pipeline stages 和 \(M\) 个 microbatches,简单调度下 bubble 比例常近似写作
其中 \(P-1\) 是填满或排空流水线时的空闲 stage 数,\(M\) 是 microbatch 数。增加 \(M\) 能降低 bubble,但 microbatch 过小会损害 kernel efficiency 并增加调度开销。

读图:Slide 35 的 pipeline 优势
pipeline parallel 的通信主要是 stage 边界 activation,大小约随 batch、sequence、hidden dimension 增长,而不是每层都同步整个参数矩阵。因此它比 tensor parallel 更能跨较慢链路使用,也能明显降低每卡参数显存。
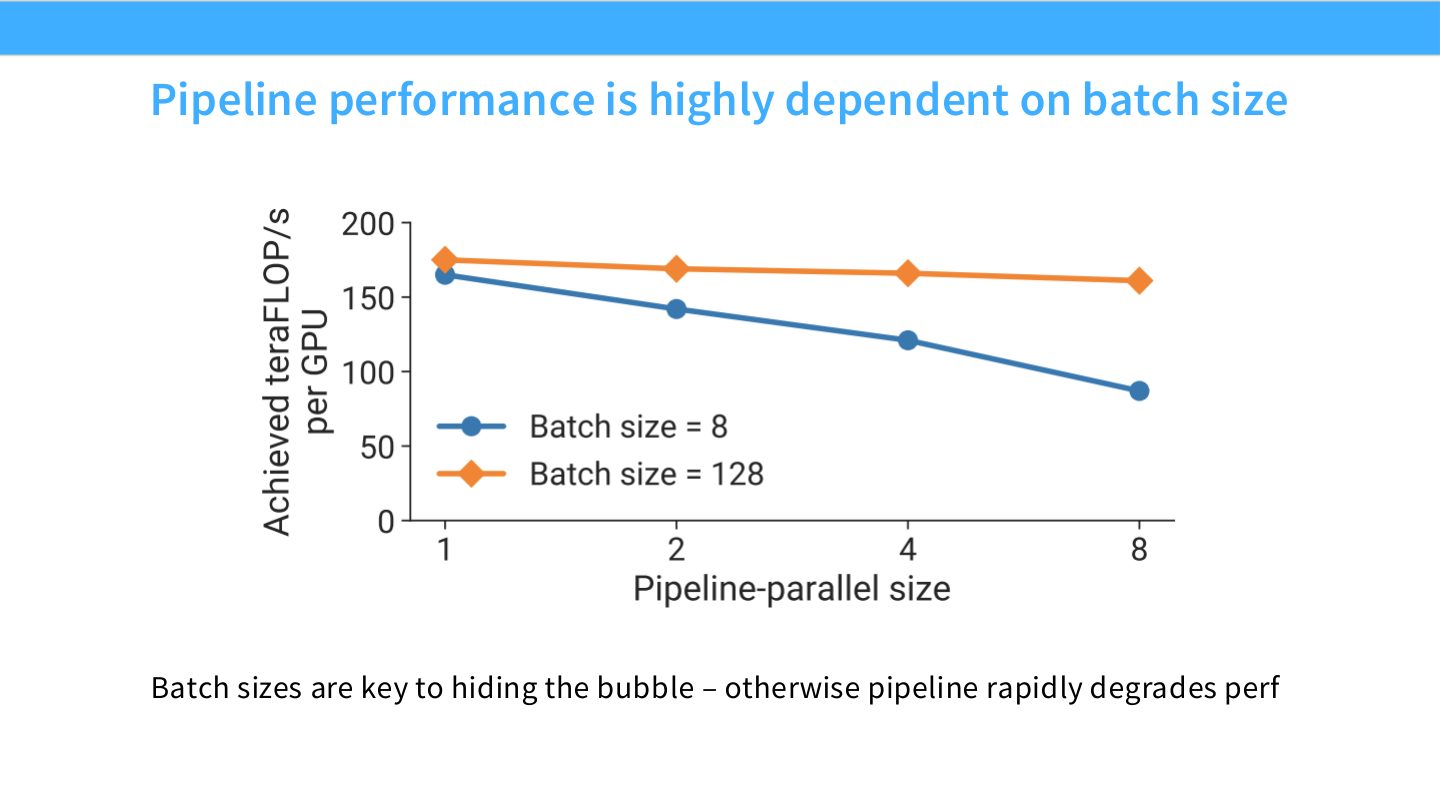
读图:Slide 36 的曲线意味着调度和优化耦合
为了提升 pipeline 利用率,常希望更多 microbatches;但 microbatch 数和 global batch、gradient accumulation、optimizer stability 相关。系统吞吐不能脱离训练优化讨论,单纯把 pipeline 填满可能改变有效 batch 和收敛行为。
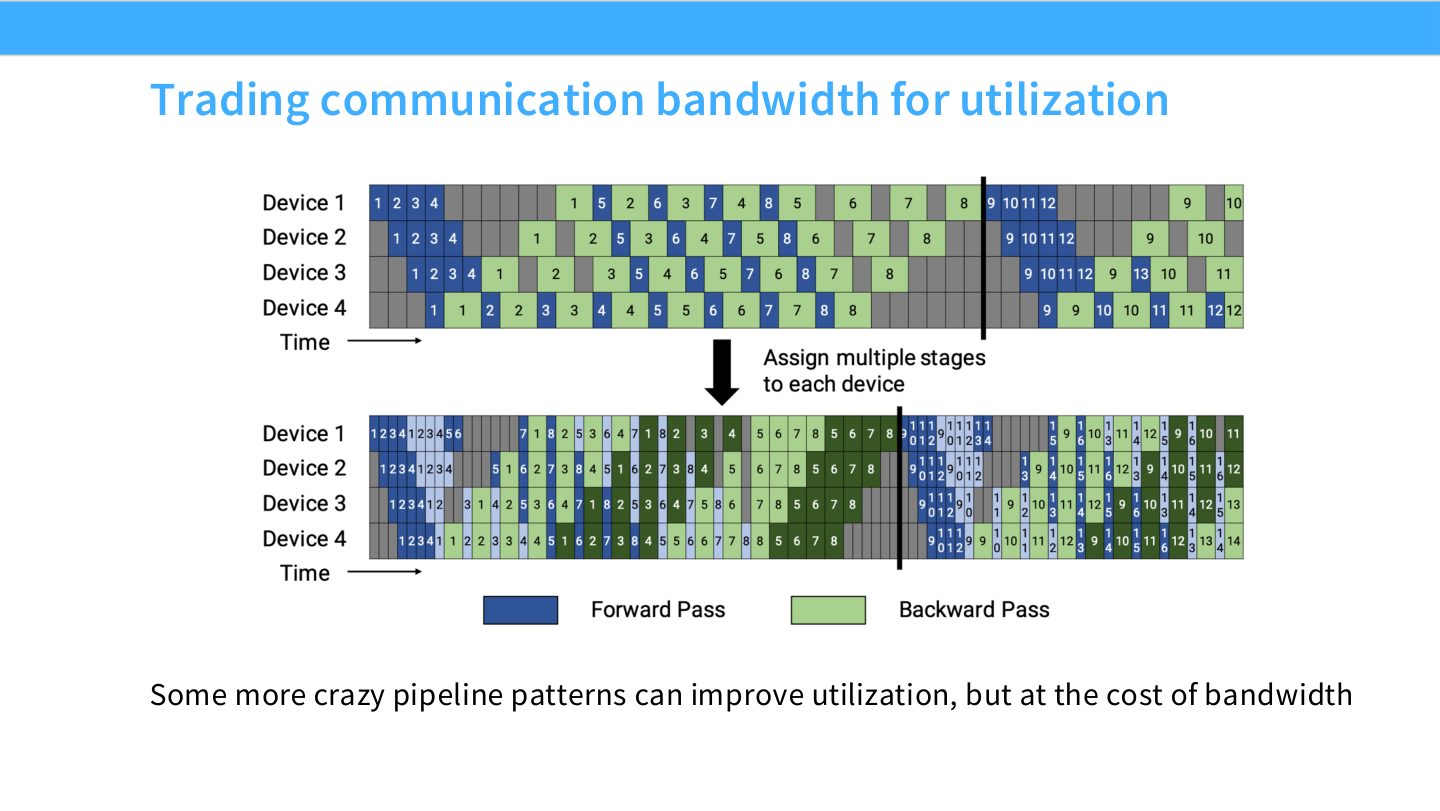
读图:Slide 37 的 trade-off
复杂 pipeline 调度能减少空闲时间,但代价通常是更多 activation 交换、更复杂 buffer 管理,以及更难和 tensor/data parallel 组合。高利用率并不总是端到端最优,还要看通信链路是否承受得住。
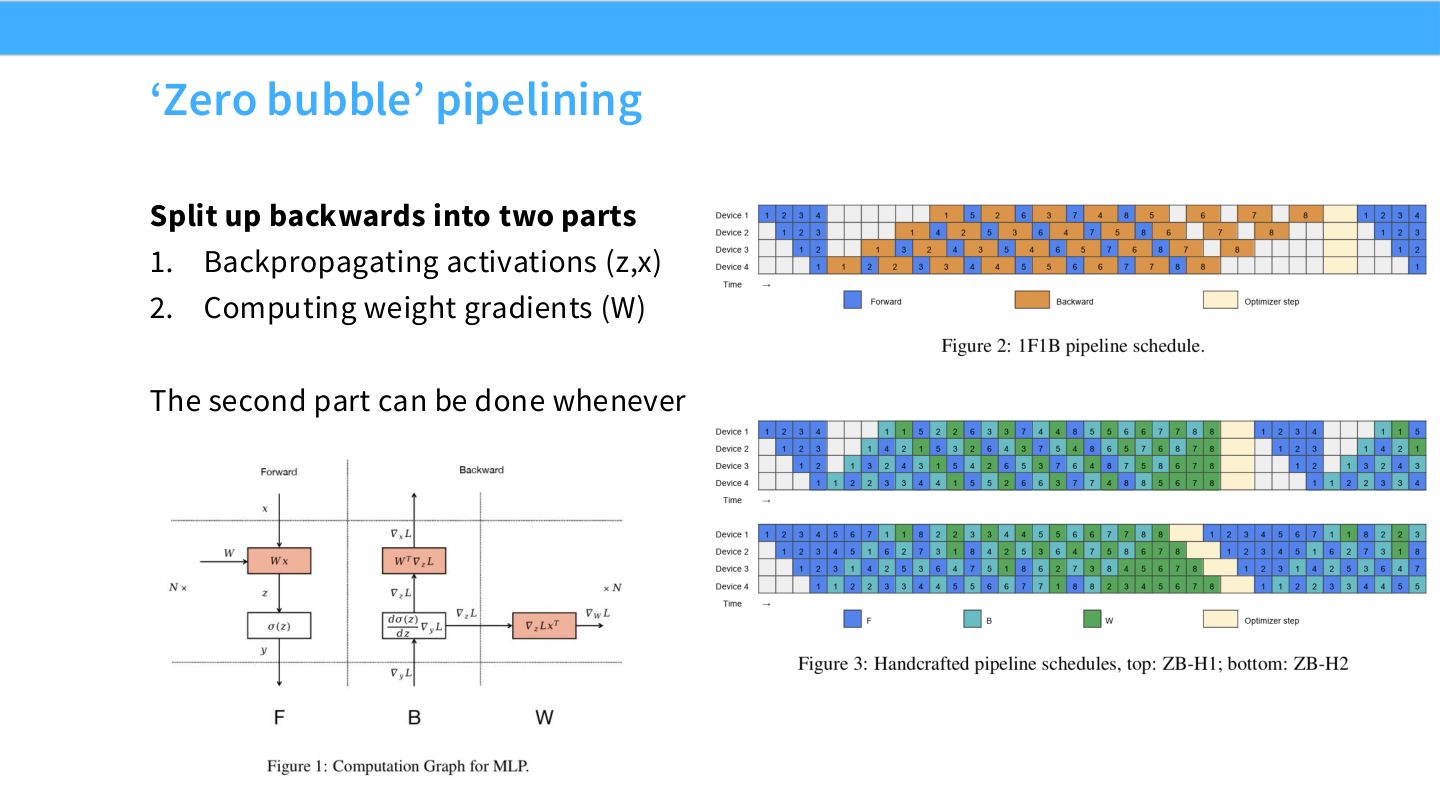
读图:Slide 38 为什么能减少 bubble
反向传播可以拆成对输入激活的梯度传播,以及对权重梯度的计算。前者影响前一 stage 的反向进度,后者有更多调度自由度。zero-bubble 思路利用这种依赖差异,把可延后的 weight-gradient 计算放到原本空闲的时间段。
tensor parallelism:沿 width 维切模型
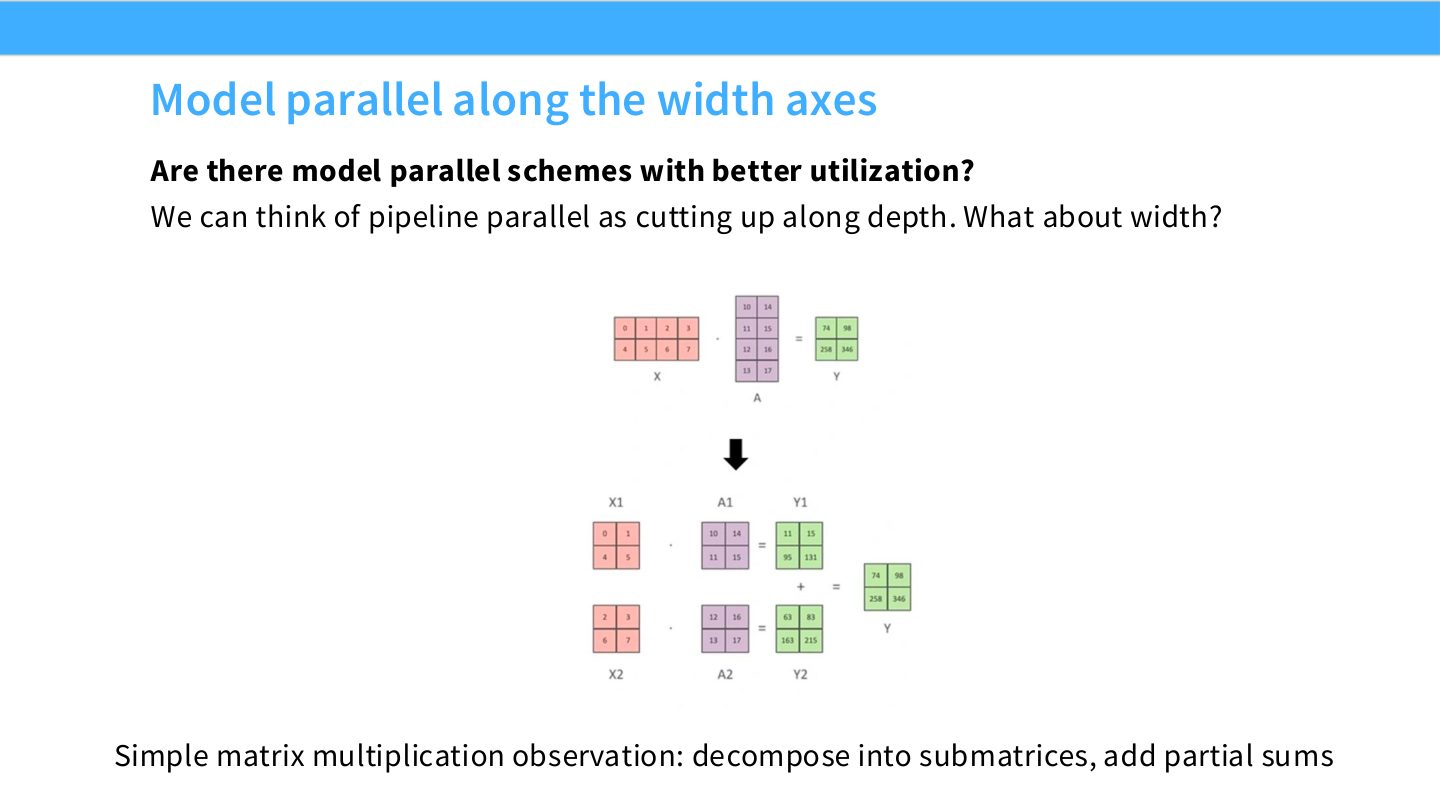
读图:Slide 39 的矩阵乘法观察
如果 \(Y=XW\),可以按 \(W\) 的列切分输出,也可以按行切分输入贡献。tensor parallel 的基本思想就是利用矩阵乘法可分解性,让不同 GPU 计算同一层的不同部分,而不是把不同层放在不同 GPU 上。
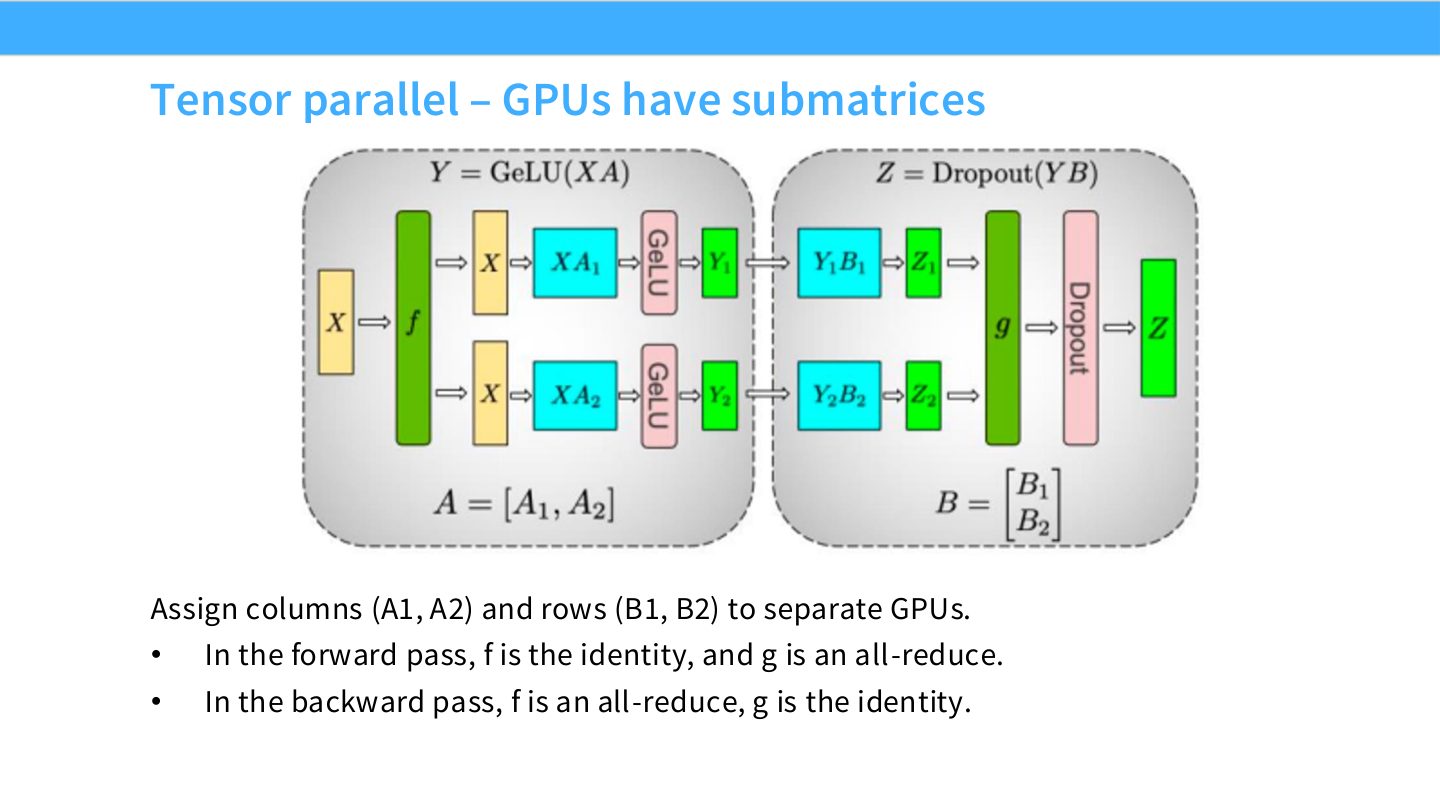
读图:Slide 40 的 \(f\) 和 \(g\) 是通信位置
图中的 \(f\) 和 \(g\) 可以是 identity,也可以是 all-reduce。某些线性层 forward 不需要立即通信,但 backward 需要;另一些线性层相反。Megatron 风格 tensor parallel 的效率来自把 column-parallel 和 row-parallel linear 成对安排,让通信尽量少且位置可控。
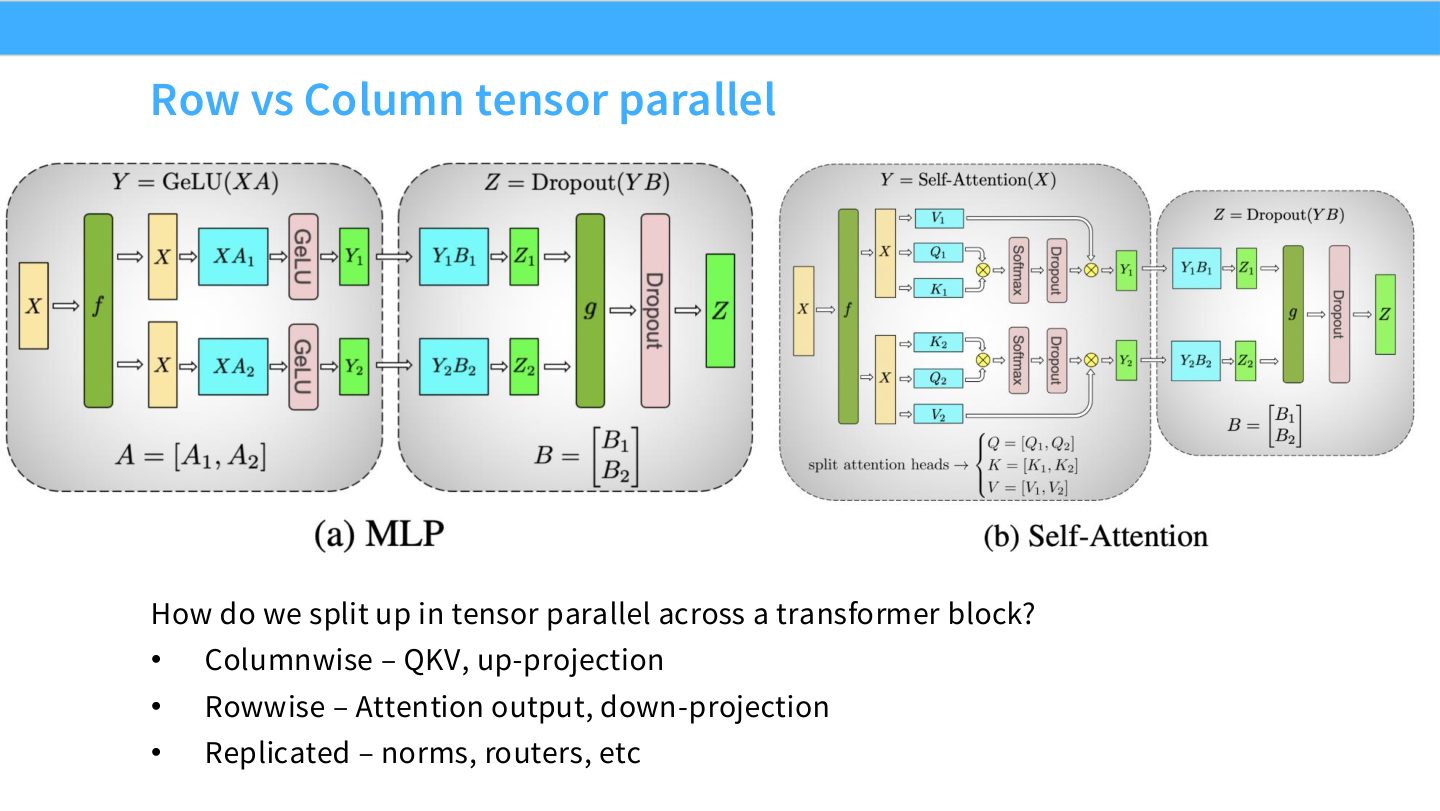
读图:Slide 41 如何对应 Transformer 结构
QKV 和 up-projection 常用 columnwise 切分,因为它们把 hidden dimension 扩到多个输出通道;attention output 和 down-projection 常用 rowwise 切分,因为它们把分片结果聚回 hidden dimension。LayerNorm、router 等小模块通常复制,因为切分收益小且会增加额外通信。
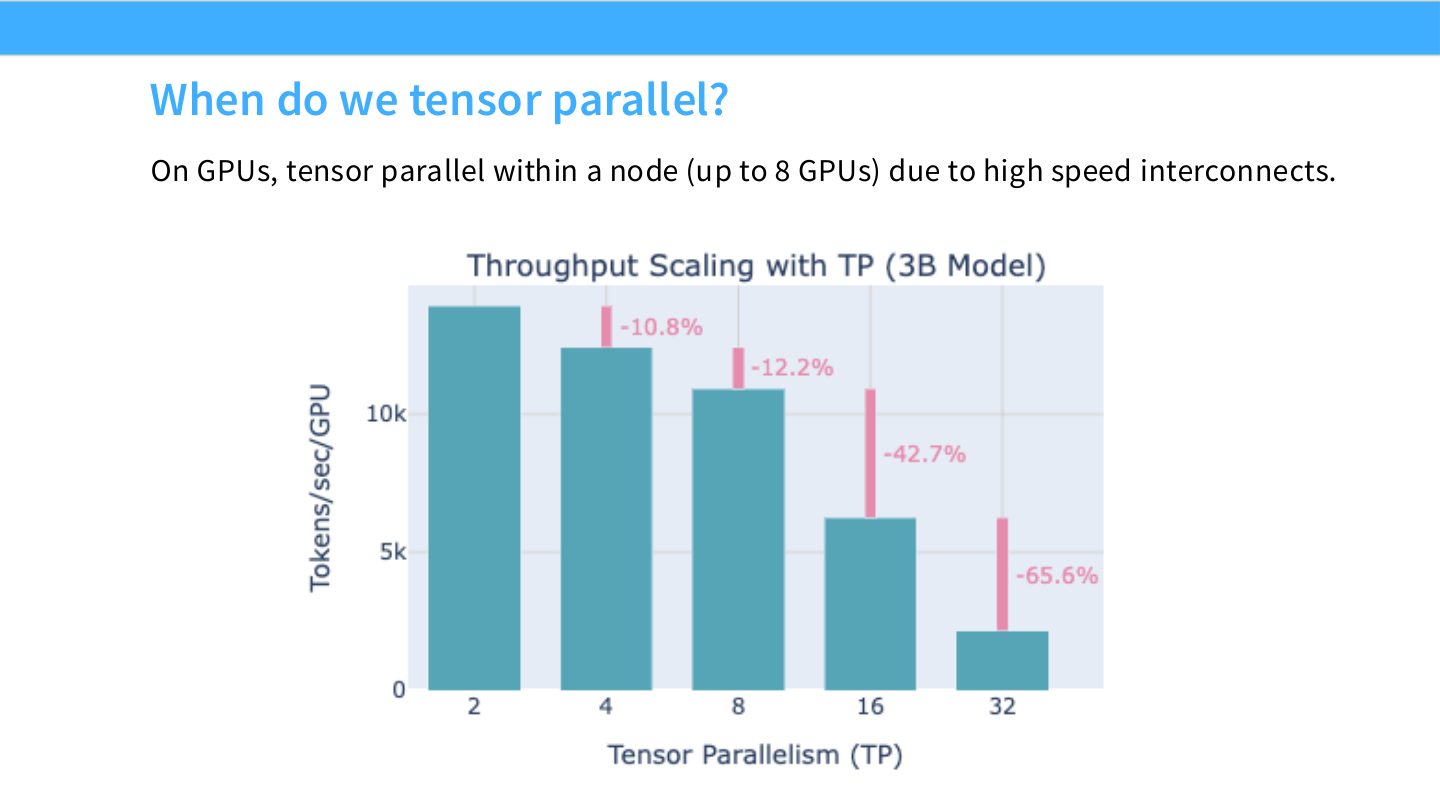
读图:Slide 42 是硬件约束,不是习惯
TP 的通信发生在每个 block 的多个位置,频率远高于 data parallel 梯度同步或 pipeline stage 边界通信。若把 TP 放到跨节点慢链路,通信 latency 和 bandwidth 很容易压过本地 matmul 收益。因此常见建议是 TP size 不超过单节点 GPU 数。

读图:Slide 43 的比较维度
TP 没有 pipeline bubble,包装模型相对直接,但依赖高速互连;PP 可跨慢链路且省参数显存,但有 bubble 和调度复杂度。选择 TP 还是 PP,不是看名字先进,而是看模型层宽、深度、节点内互连、跨节点链路和 batch size。
activation memory 与 sequence parallelism
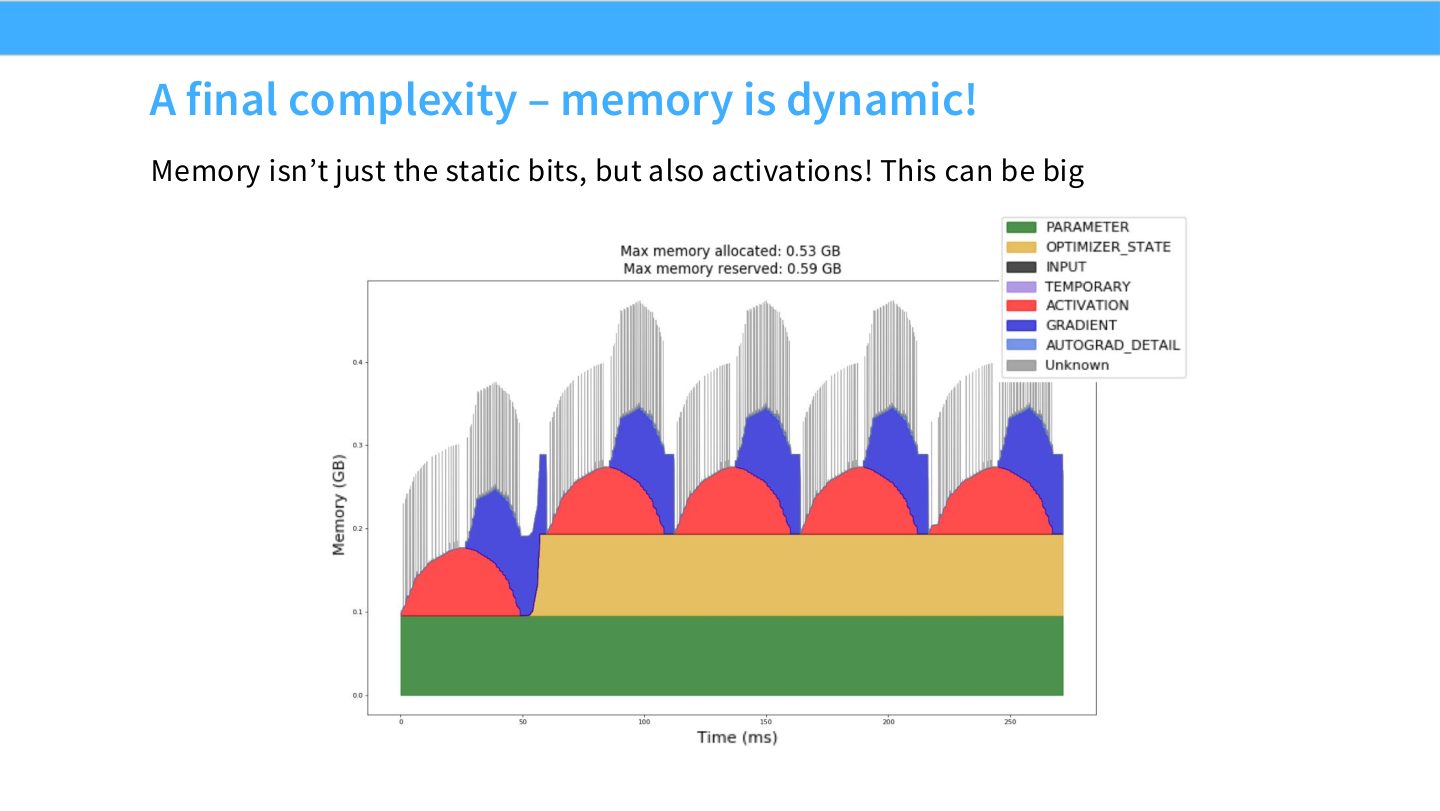
读图:Slide 44 为什么转向 activation
前面 ZeRO 和 model parallel 主要围绕参数、梯度、optimizer state,但训练峰值显存常被 activations 推高。长序列、高 batch、深层网络都会让 activation memory 成为新的瓶颈,尤其在需要保存中间结果给 backward 时。
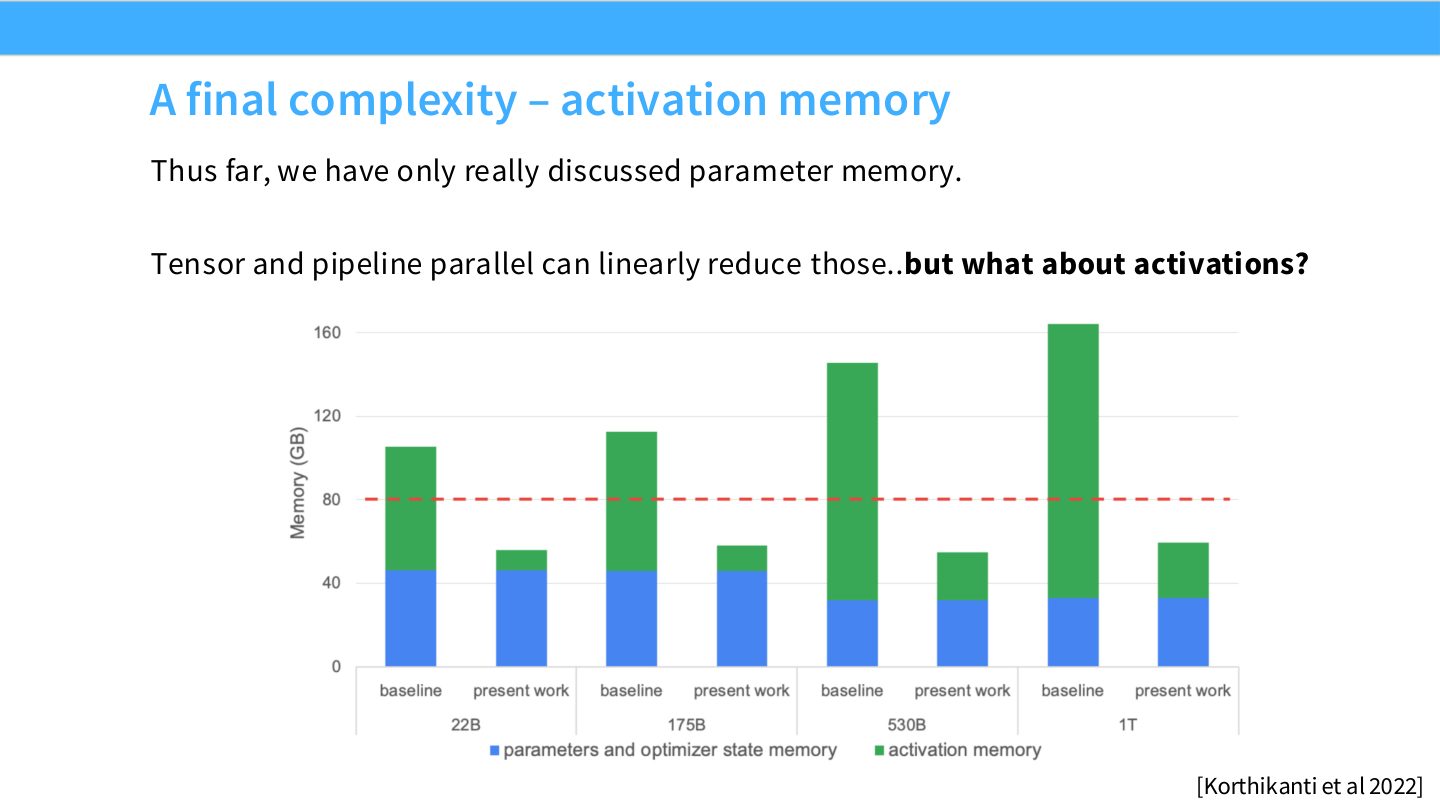
读图:Slide 45 的隐藏提醒
模型参数被切开,不代表所有 activation 自动被切开。某些 LayerNorm、dropout、attention input/output 仍按完整 sequence 或 hidden 保存在每个 rank 上。要让 memory 真正随设备数线性扩展,必须显式处理 activation 的切分和重算。

读公式:Slide 46 的符号和含义
这里 \(s\) 表示 sequence length,\(b\) 表示 microbatch size,\(h\) 表示 hidden dimension,\(a\) 可理解为 attention heads 或相关维度。二次 attention 项随 \(s^2\) 增长,FlashAttention 类方法可减少显式存储;剩余 \(sbh\) 项来自 LayerNorm、dropout、attention/MLP 输入等点操作或中间张量。

读图:Slide 47 的剩余 10sbh 项是什么
TP 切分了 attention 和 MLP 中的大矩阵乘法,但 LayerNorm、dropout 和某些输入张量仍是按完整 hidden 或 sequence 存放的点操作张量。这些项不会随 TP size 自动降低,因此需要 sequence parallel 把 sequence dimension 也切开。
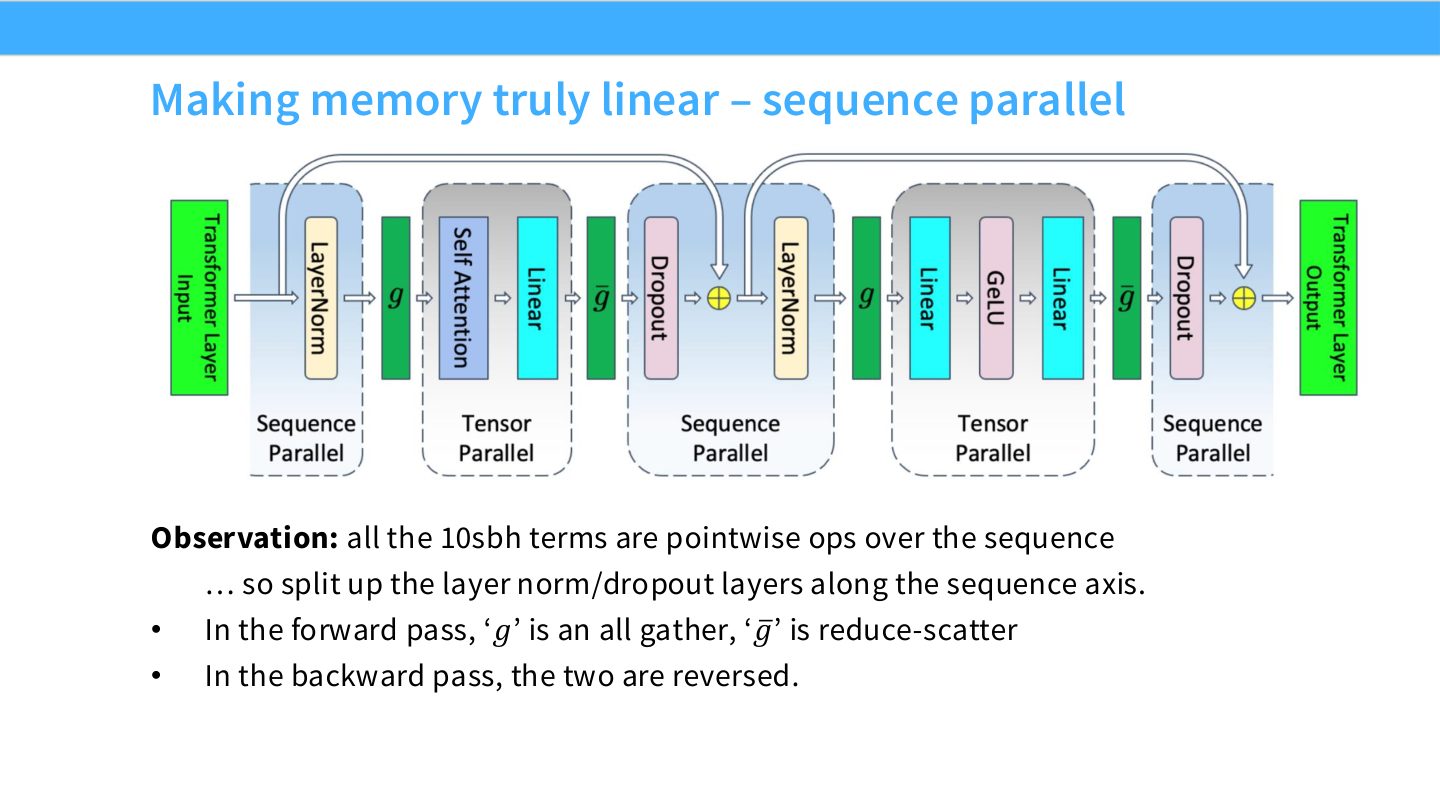
术语消化:sequence parallel 的机制
Sequence parallelism 沿 sequence dimension 分片 activation。对 LayerNorm、dropout 这类逐 token 或逐元素操作,按 sequence 切分不改变数学语义;但某些需要完整序列交互的操作仍要通信。它的角色通常是补足 TP 后 activation memory 没有线性下降的部分。
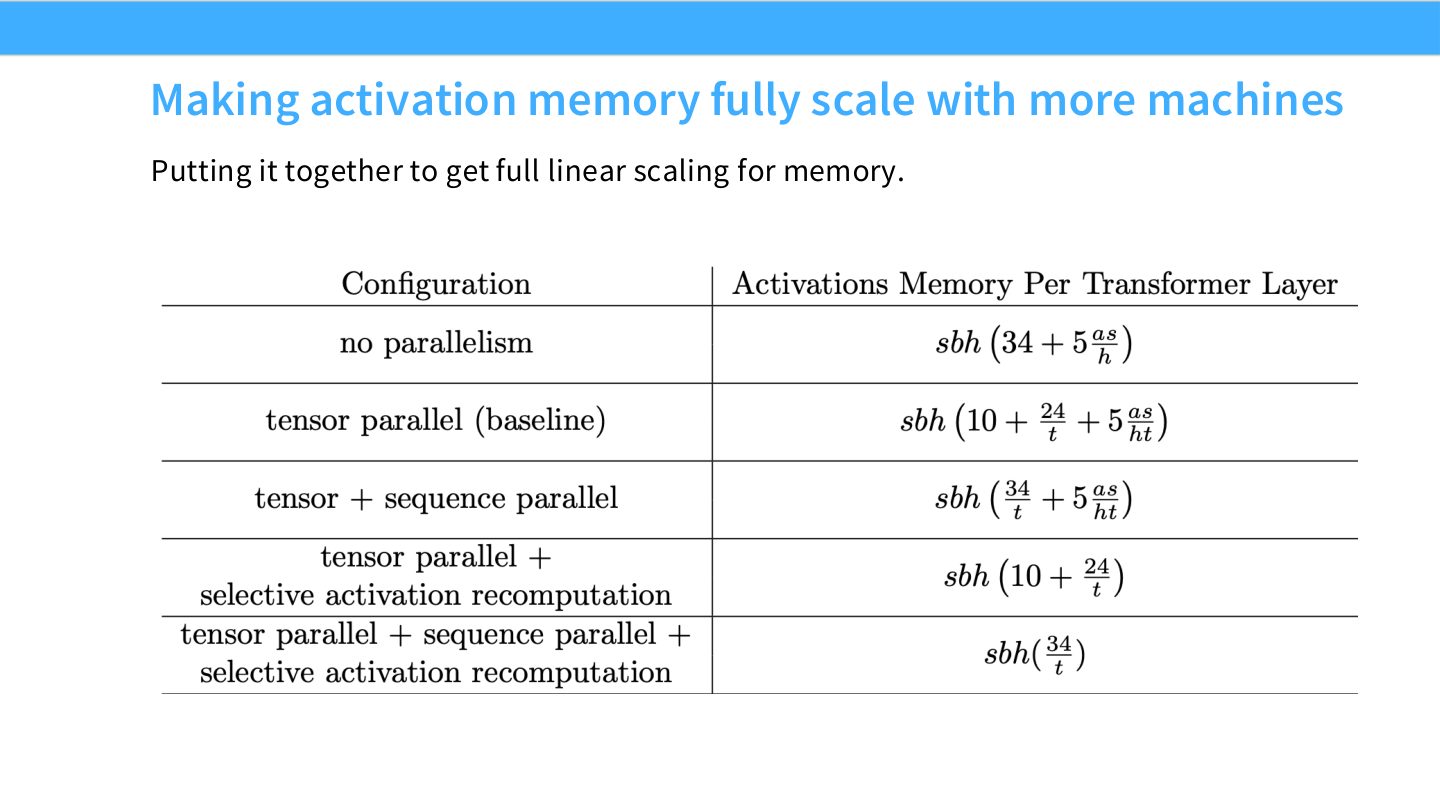
读图:Slide 49 的“fully scale”是什么意思
这页不是说 activation memory 完全免费,而是说通过 TP 切矩阵乘法相关张量,通过 SP 切点操作相关张量,剩余 activation 才更接近随 parallel size 线性下降。它体现了本讲方法论:看到未被分片的状态,就引入对应维度的 sharding。
expert parallelism 与 context parallelism
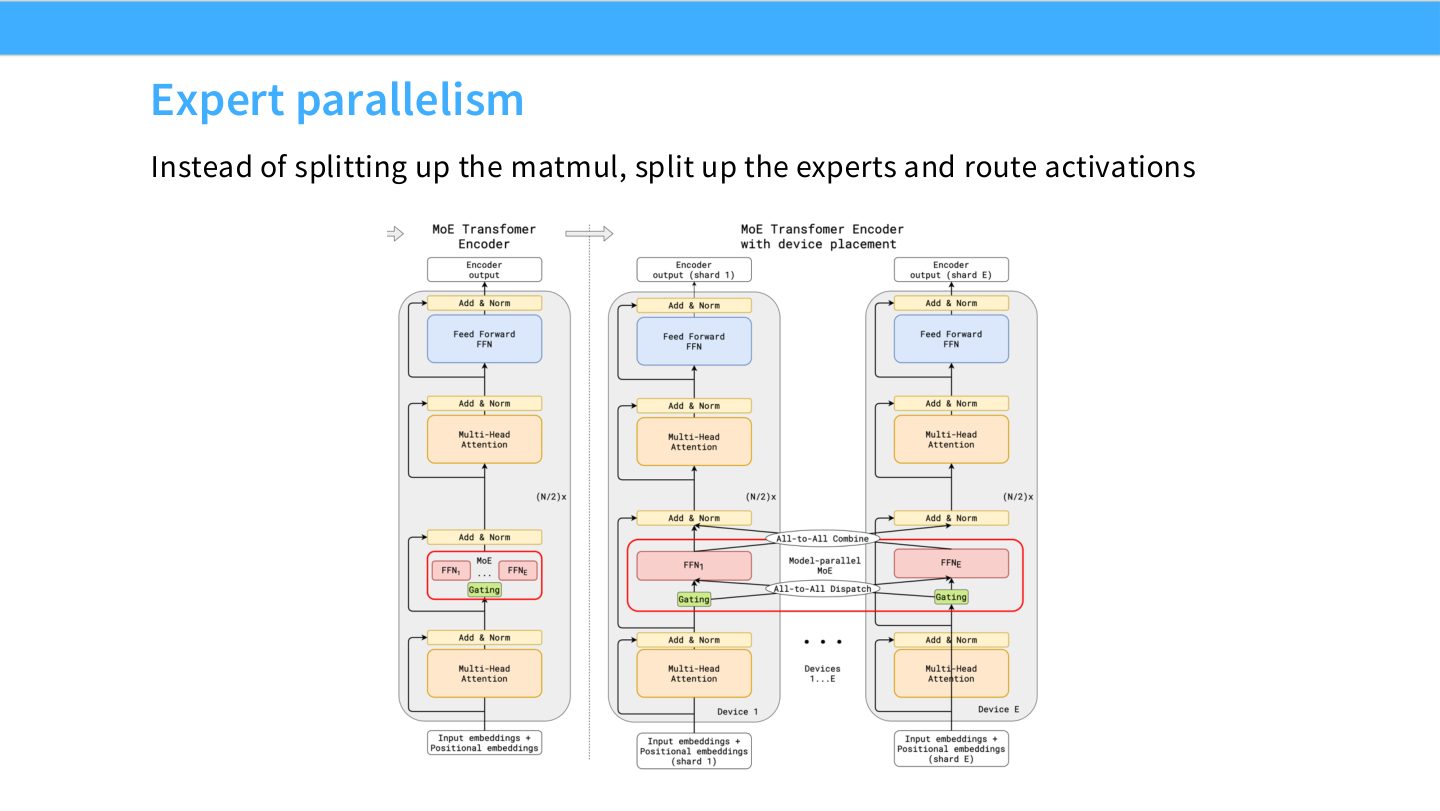
读图:Slide 50 的 EP 与 TP 差异
TP 把一个 dense matmul 切成子矩阵;EP 把不同 experts 放到不同 rank,token 根据 router 选择 expert。EP 的参数容量扩展更自然,但通信变成 token dispatch 和 all-to-all,负载均衡成为核心问题。
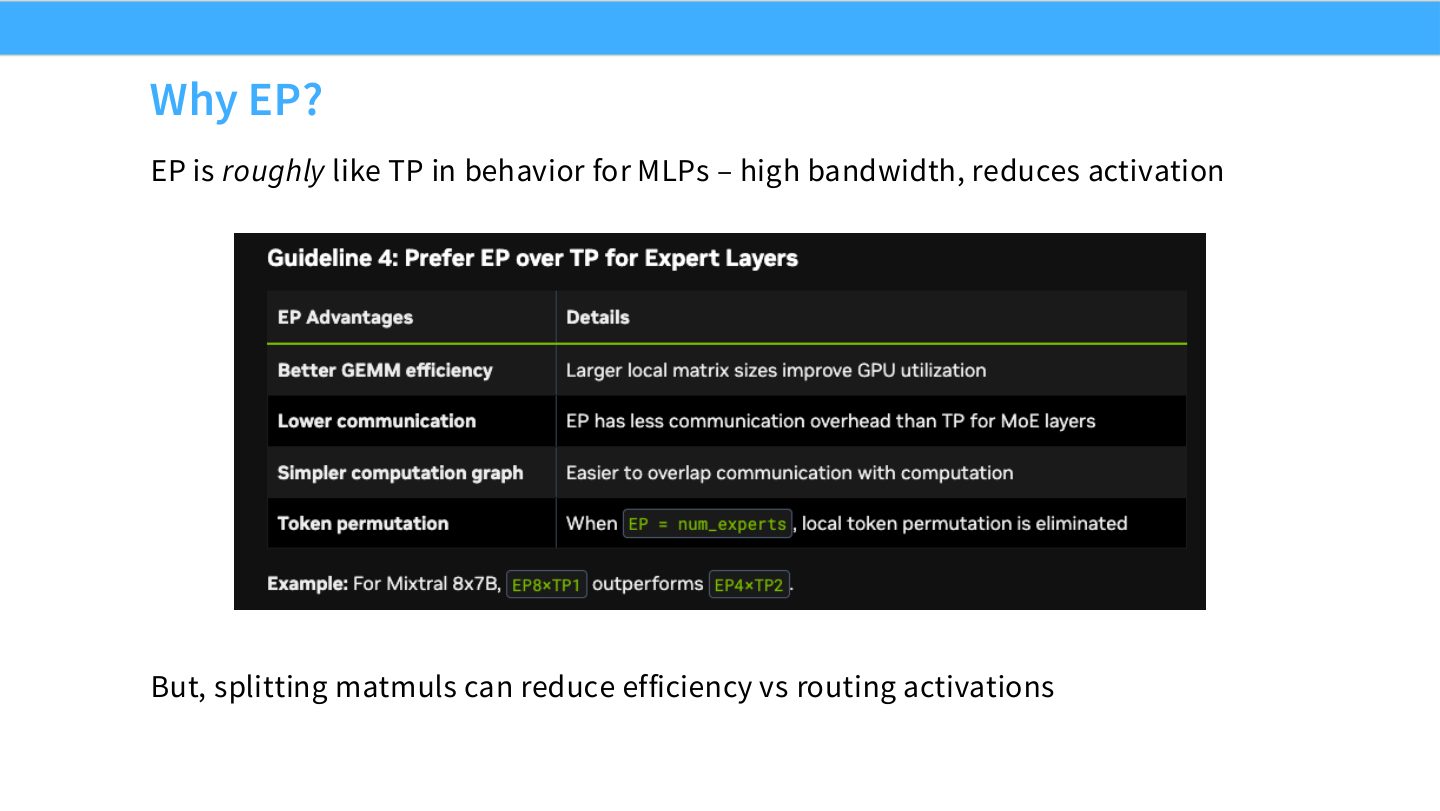
读图:Slide 51 的系统取舍
TP 保持 dense computation,但子矩阵切分可能让 GEMM shape 不理想;EP 保持每个 expert 的 matmul 更完整,但要把 token 路由到对应 rank。哪种更快取决于 expert 数、token 分布、all-to-all 带宽、负载均衡和 kernel efficiency。
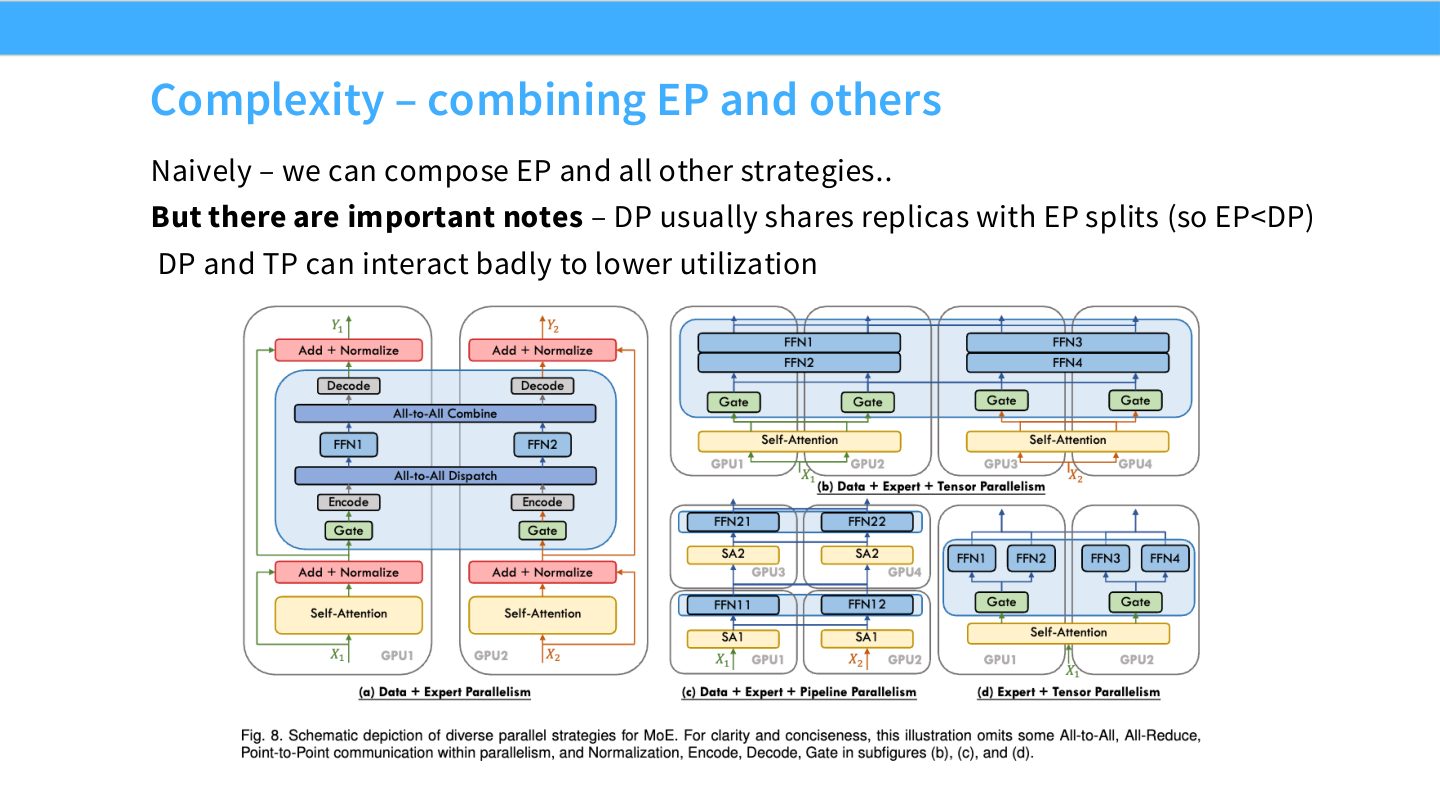
读图:Slide 52 的组合不是乘法那么简单
理论上 DP、TP、PP、EP 都能组合;实践中 process group 会互相嵌套,某些切分维度会让 GEMM 变小或让 all-to-all 跨慢链路。EP 通常需要让 expert group 和 data group 的关系谨慎设计,否则负载均衡和通信域都会出问题。

读图:Slide 53 的不平衡来自结构异质性
MoE 层通常替换 FFN/MLP,而 attention 仍是 dense 或其他结构。因此 MLP 部分可能需要 EP,attention 部分可能仍需要 TP/SP/CP。若把同一并行配置强加给两者,可能导致一部分算子利用率高,另一部分通信或计算失衡。
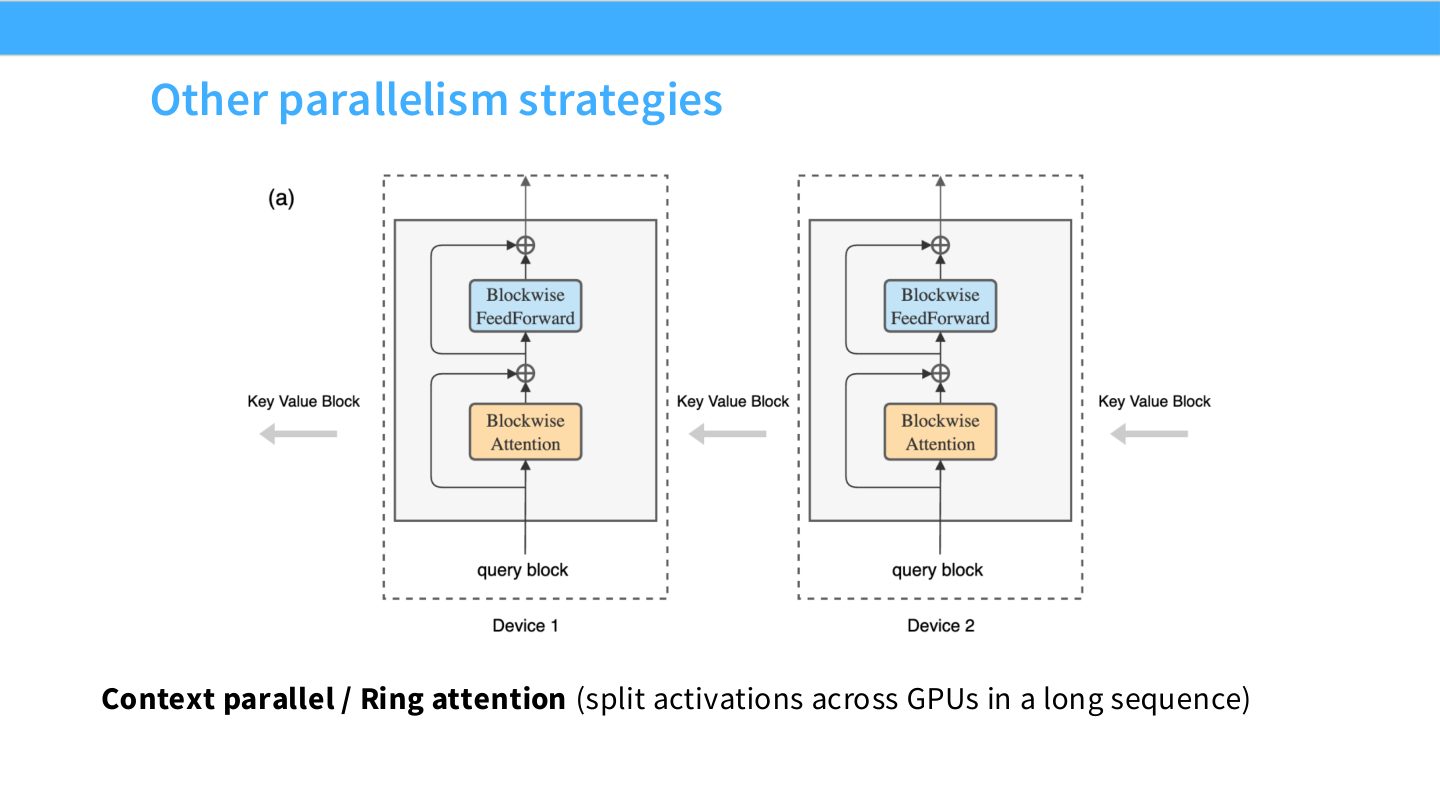
术语消化:SP 与 CP 的区别
Sequence parallel 通常服务于点操作 activation memory 的线性缩放;context parallel 或 ring attention 处理的是长上下文 attention 中序列维度的跨设备计算。CP 需要在 attention 计算中交换 K/V 或中间统计量,目标是让超长 sequence 不被单卡 HBM 和 attention 计算图限制。
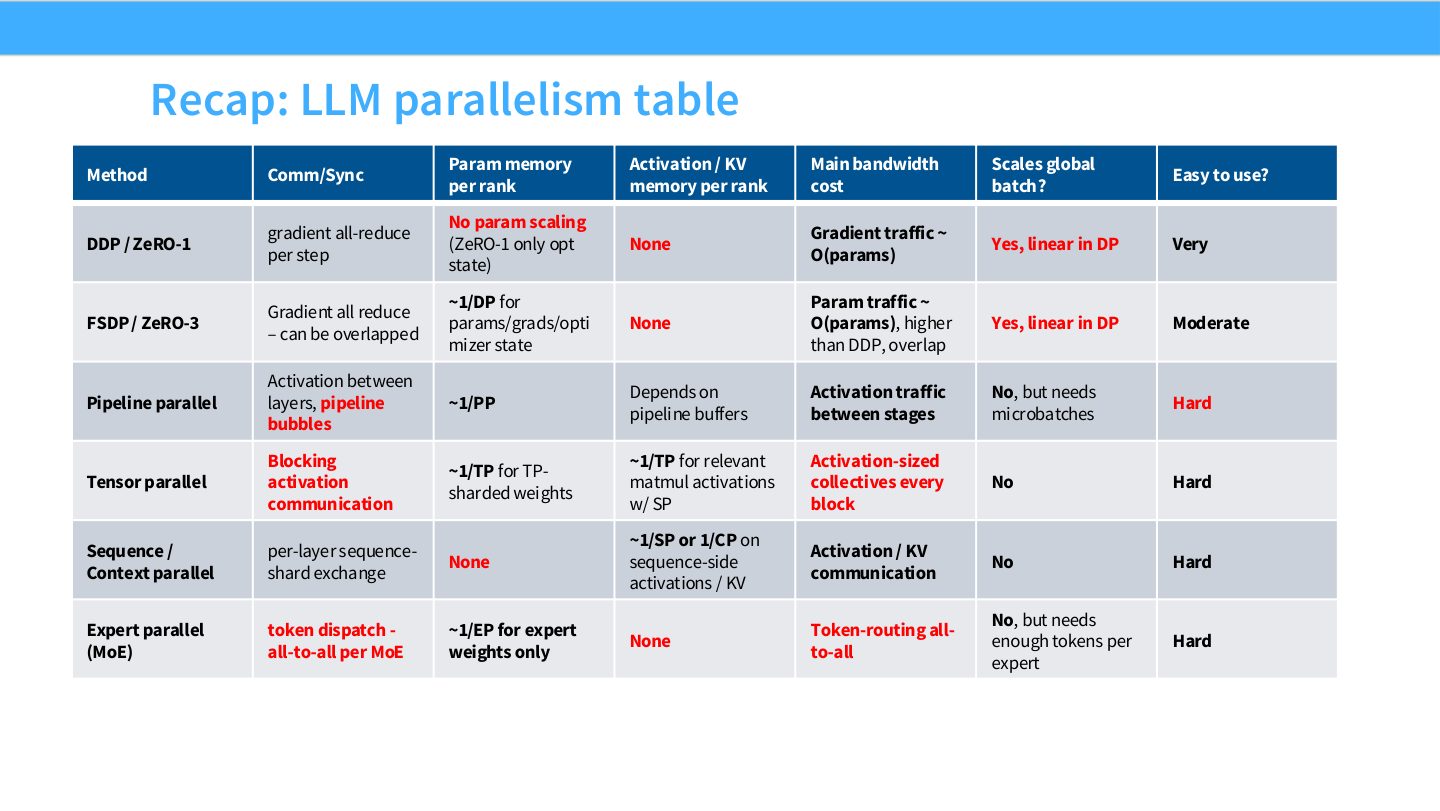
读表:Slide 55 应该横向比较
先看每 rank 参数显存:DDP/ZeRO-1 不降参数,ZeRO-3、TP、PP、EP 可降不同部分。再看 activation/KV:TP/SP/CP 对 activation 或长上下文更关键。然后看 main bandwidth cost:all-reduce、all-gather、reduce-scatter、all-to-all 的频率不同。最后看 global batch scaling:DP 扩 batch,模型并行不一定扩 batch。
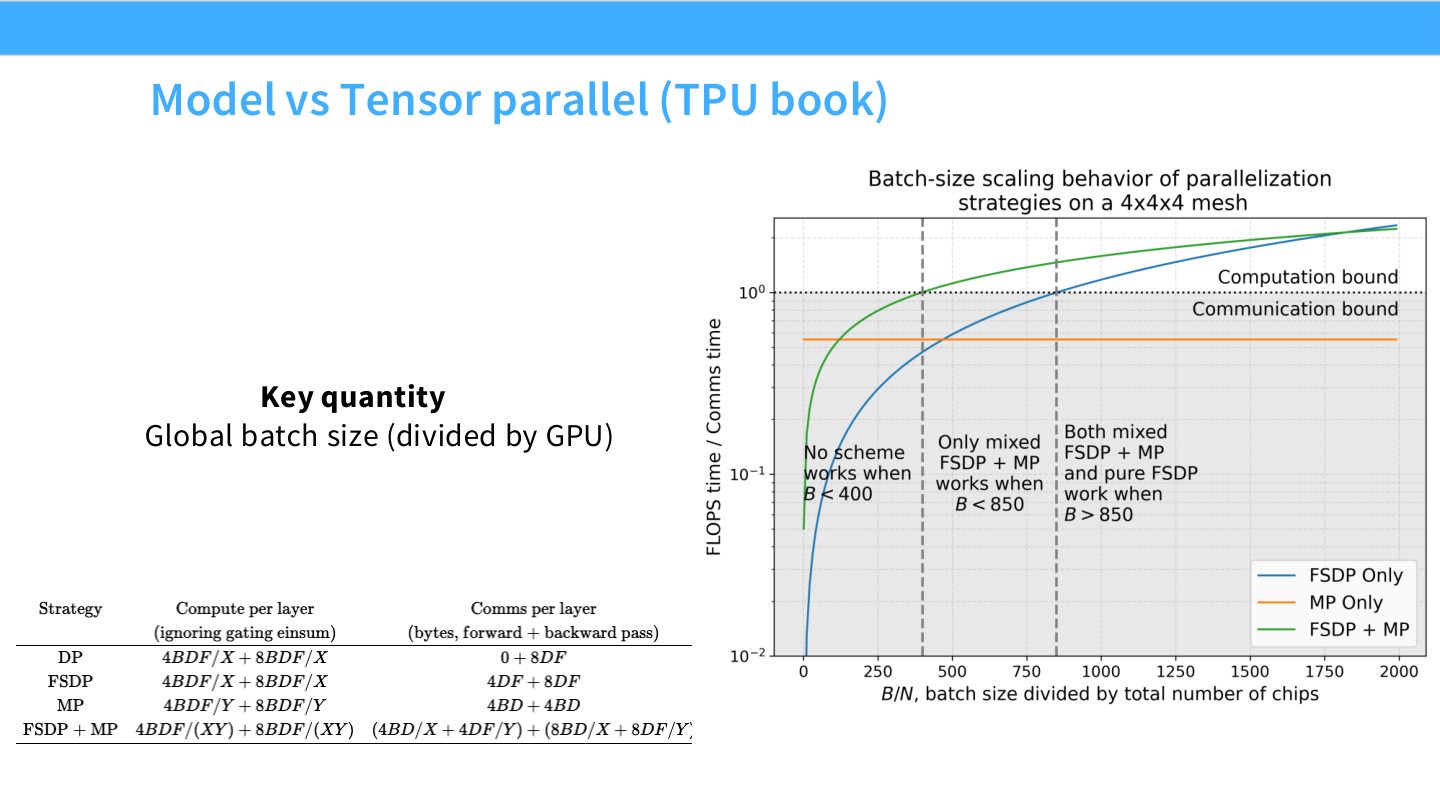
读图:Slide 56 提醒 batch 与并行配置耦合
global batch 被 GPU 数切分后,per-device batch 会影响算子效率和优化。若 GPU 太多而 batch 不够大,data parallel 会把每卡工作量切得太薄;此时更需要 model/tensor/pipeline parallel 来增加每卡有效计算,而不是继续扩大 DP。
Part 2 小结
Part 2 形成一张并行策略地图:DP 切 batch,ZeRO/FSDP 切训练状态,PP 切 depth,TP 切 width,SP/CP 切 sequence/context,EP 切 experts。每种策略都不是免费午餐,它们只是在 memory、communication、utilization、implementation complexity 之间换瓶颈。
Part 3:组合并行与真实模型配置
3D/4D parallelism 的经验规则
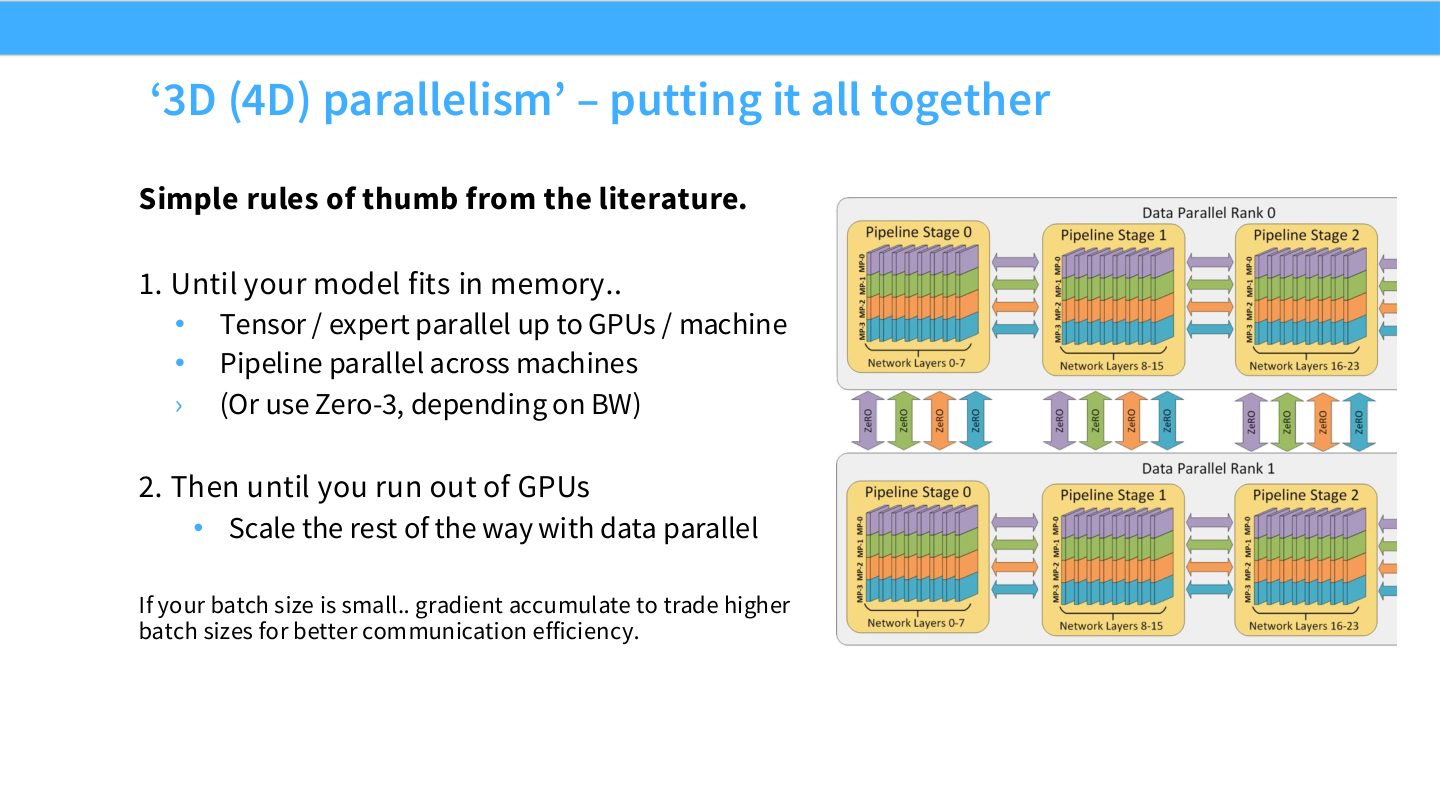
读图:Slide 57 的规则顺序
第一,模型放不下时,优先用 TP/EP 到单机 GPU 上限,再用 PP 跨机器,或者使用 ZeRO-3/FSDP。第二,模型能放下后,用 DP/FSDP 增加吞吐。第三,TP/EP 通常限制在高速节点内,PP 可跨节点,DP 可扩到更大范围。这个顺序体现了“先解决容量,再解决吞吐”的工程逻辑。

读图:Slide 58 的 Megatron 建议怎么读
Megatron 的建议不是固定答案,而是一组经过实践验证的起点。基础配置通常先选 TP、PP、DP;更复杂模型再引入 EP、CP、sequence parallel、activation recomputation 和 communication overlap。实际配置要根据模型结构、硬件域和 profiling 调整。
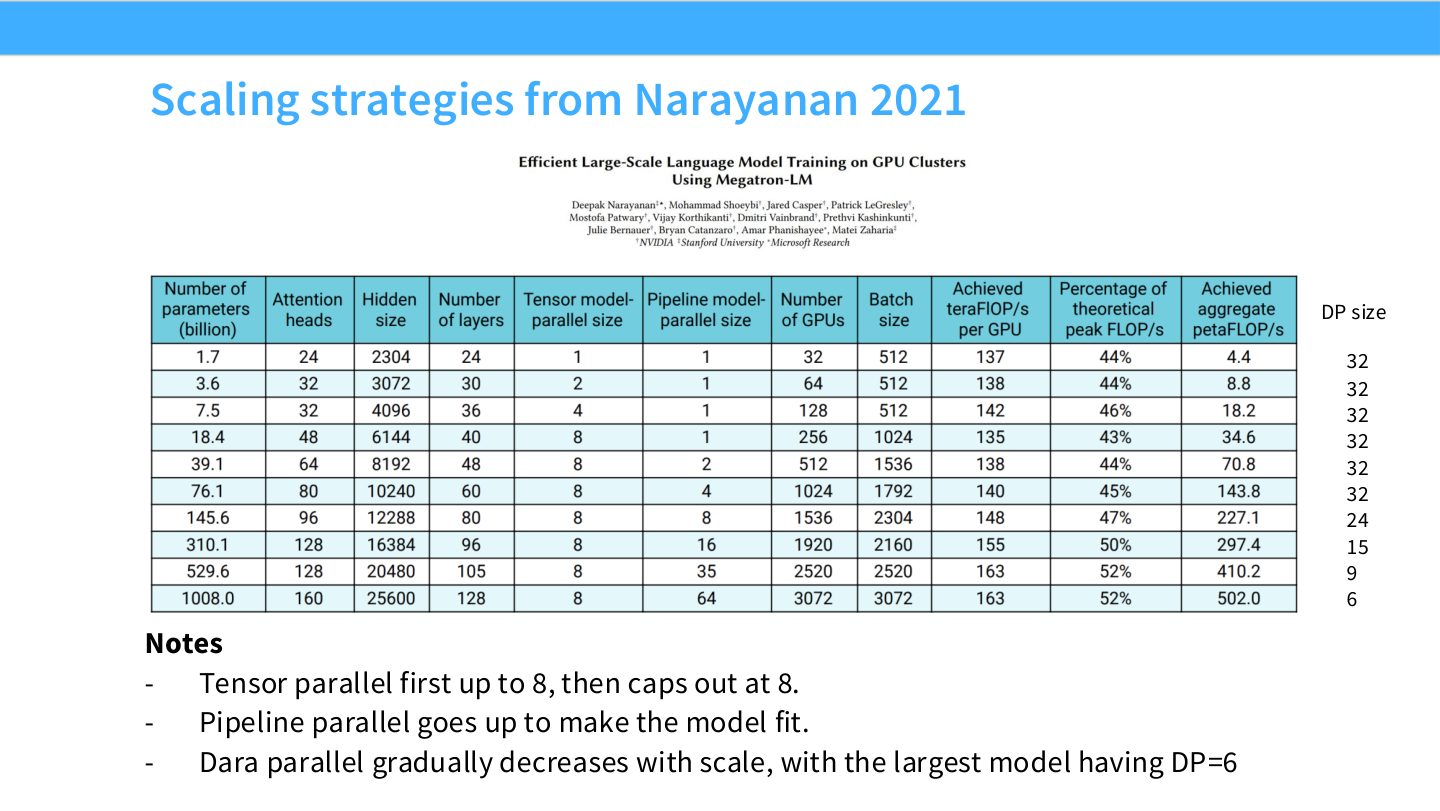
读表:Slide 59 的趋势
表中 TP 很快达到 8 并封顶,通常对应单节点 8 GPU 的高速互连域。模型继续变大时,PP 增加以容纳更多层和参数;总 GPU 数固定或增长时,DP size 反而下降,因为更多 GPU 被用来放模型而不是复制模型处理更多 batch。
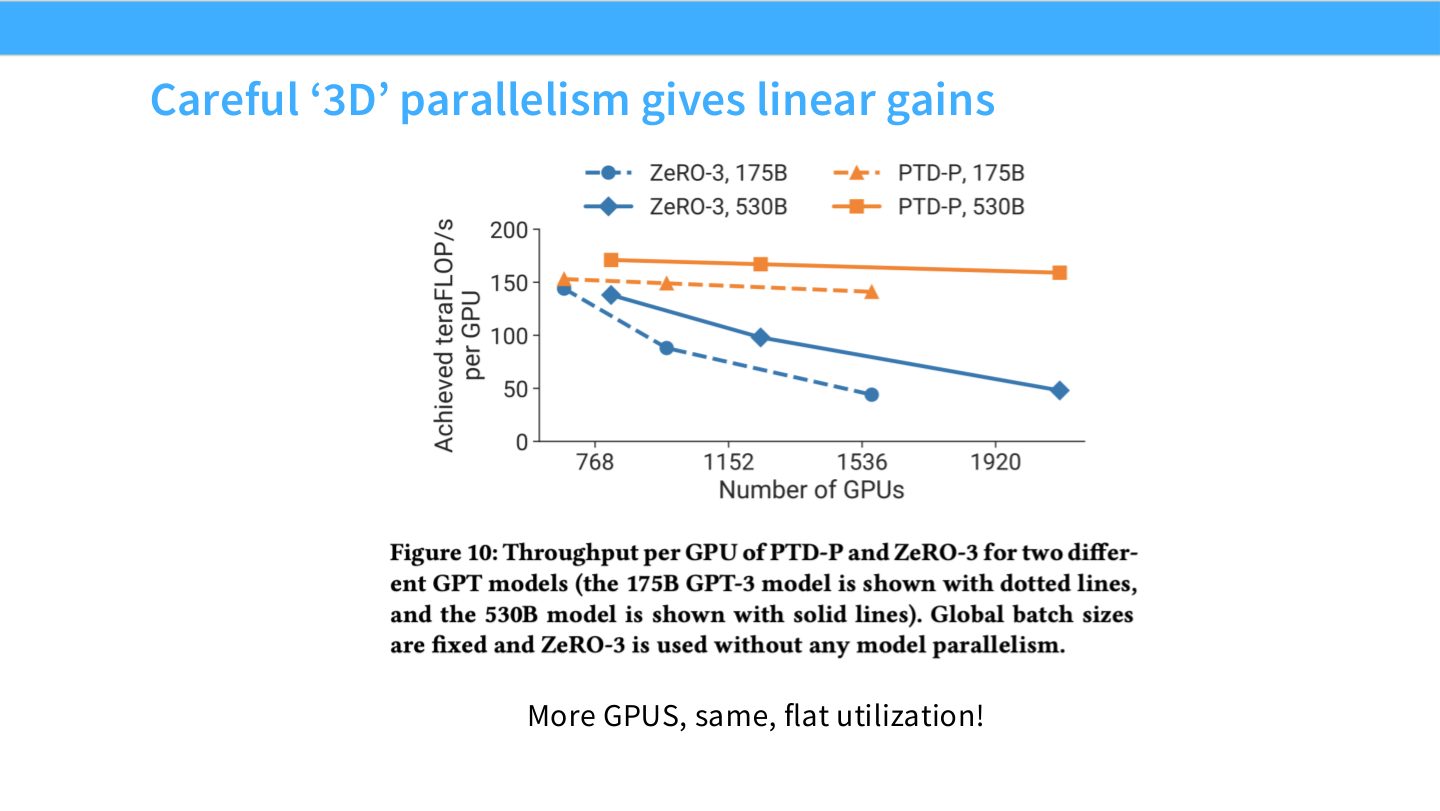
读图:Slide 60 的“linear gains”有前提
接近线性扩展来自把高频通信放在快链路、把模型切分均衡、把 bubble 控制住、让 DP 规模不超过有效 batch。它不是并行维度越多越好,而是每个维度都服务于明确瓶颈。
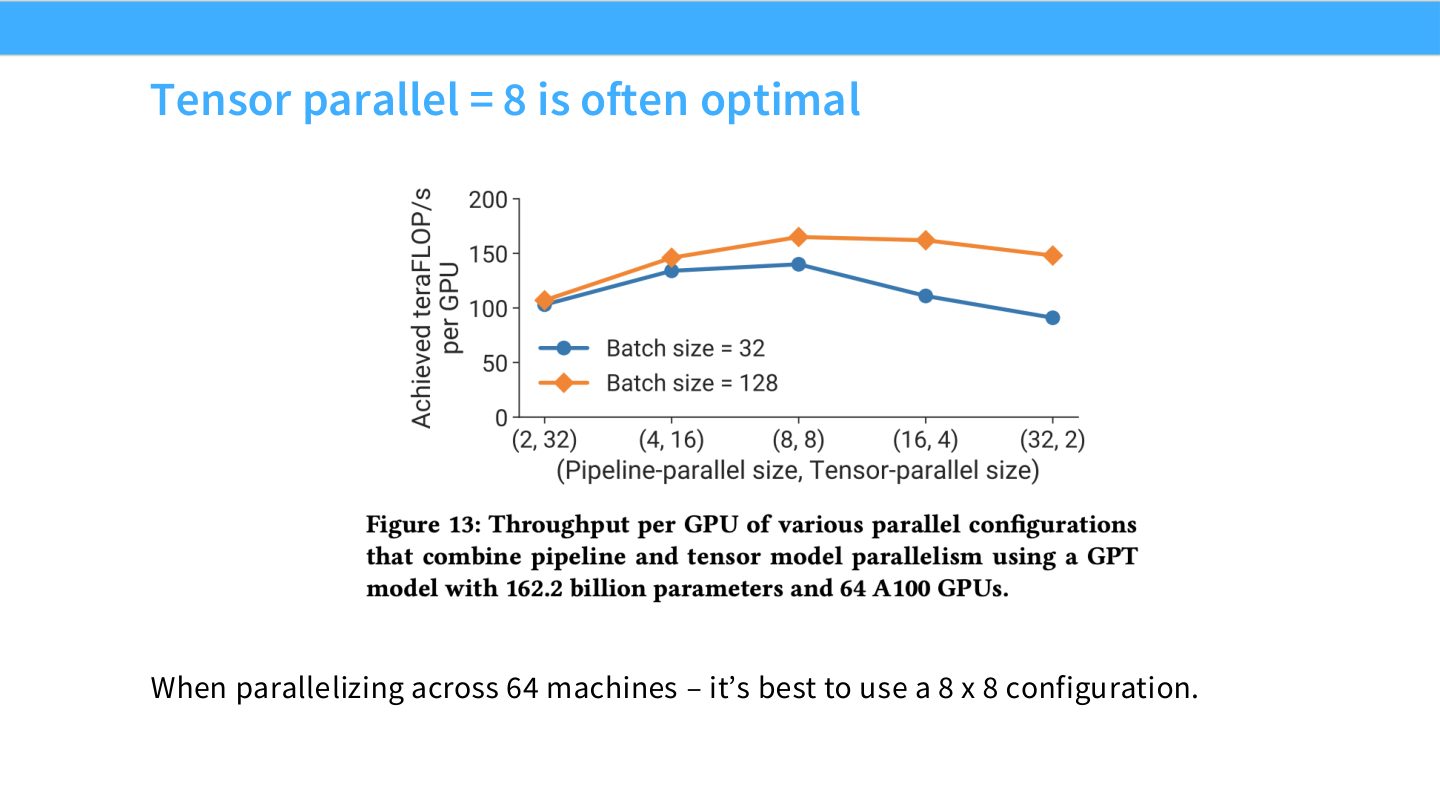
读图:Slide 61 为什么 TP=8 常出现
8 常对应单节点 GPU 数或一个高速互连域大小。TP 再扩大可能跨节点,引入高频跨节点通信;TP 太小又可能单层放不下或每卡计算太重。因此 TP=8 是许多 GPU 集群上的硬件甜点,而不是数学常数。
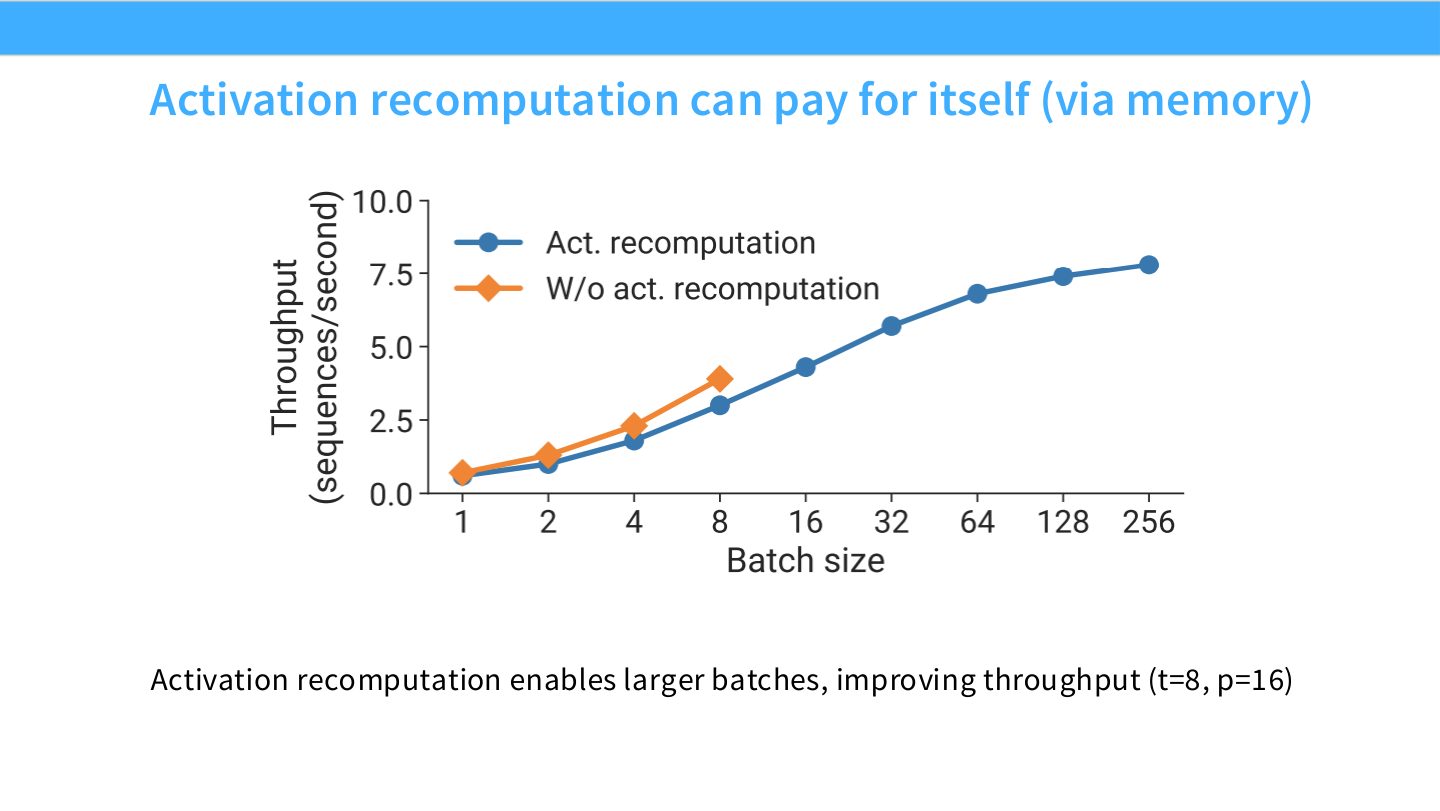
读图:Slide 62 为什么 recomputation 可能“pay for itself”
Activation recomputation 或 checkpointing 用额外 forward 计算换显存。如果省下的显存允许更大 microbatch/global batch,GPU 利用率可能提高,pipeline bubble 可能下降,整体吞吐反而变好。因此它不是简单“慢一点换省显存”,而是可能改变可行 batch regime。
近期模型配置案例

读图:Slide 63 的意义
小到 7B 量级的模型在现代多卡节点上可能主要靠 FSDP/ZeRO-3 解决显存和吞吐,不一定需要复杂 TP/PP/EP。并行复杂度应与模型规模匹配,过早引入所有并行维度会增加工程风险。

读图:Slide 64 的 DeepSeek 配置
DeepSeek V3 中 PP、EP、ZeRO-1、all-to-all overlap 等同时出现。MoE 模型的核心压力来自 experts 和 token routing,因此 EP 规模很大;attention/activation 相关部分仍需要 TP/SP/PP。这里体现了异构模型结构需要异构并行策略。

读图:Slide 65 说明并行策略会随架构变化
Dense 模型常依赖 TP/PP/DP;当模型走向 MoE,expert parallelism 会替代一部分 dense tensor parallel。策略变化不是追潮流,而是模型计算形态从“一个大 dense MLP”变成“多个 experts 加 routing”。
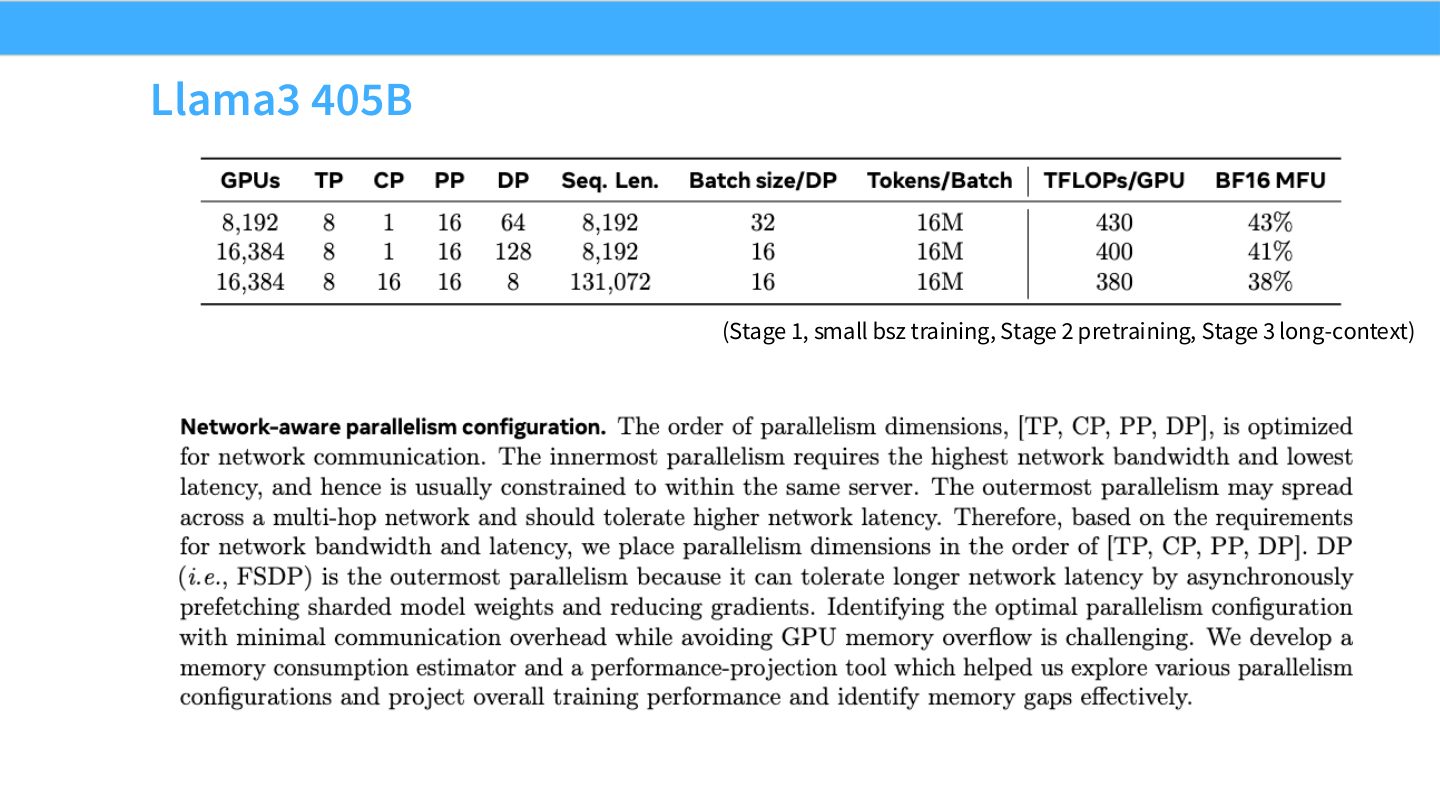
读图:Slide 66 的阶段化训练
同一个模型在不同阶段可能使用不同并行和 batch 配置。早期小 batch、主预训练、长上下文扩展的瓶颈不同:有时是参数显存,有时是吞吐,有时是 KV/activation 和 sequence length。因此并行配置是训练计划的一部分,不是一次性固定。
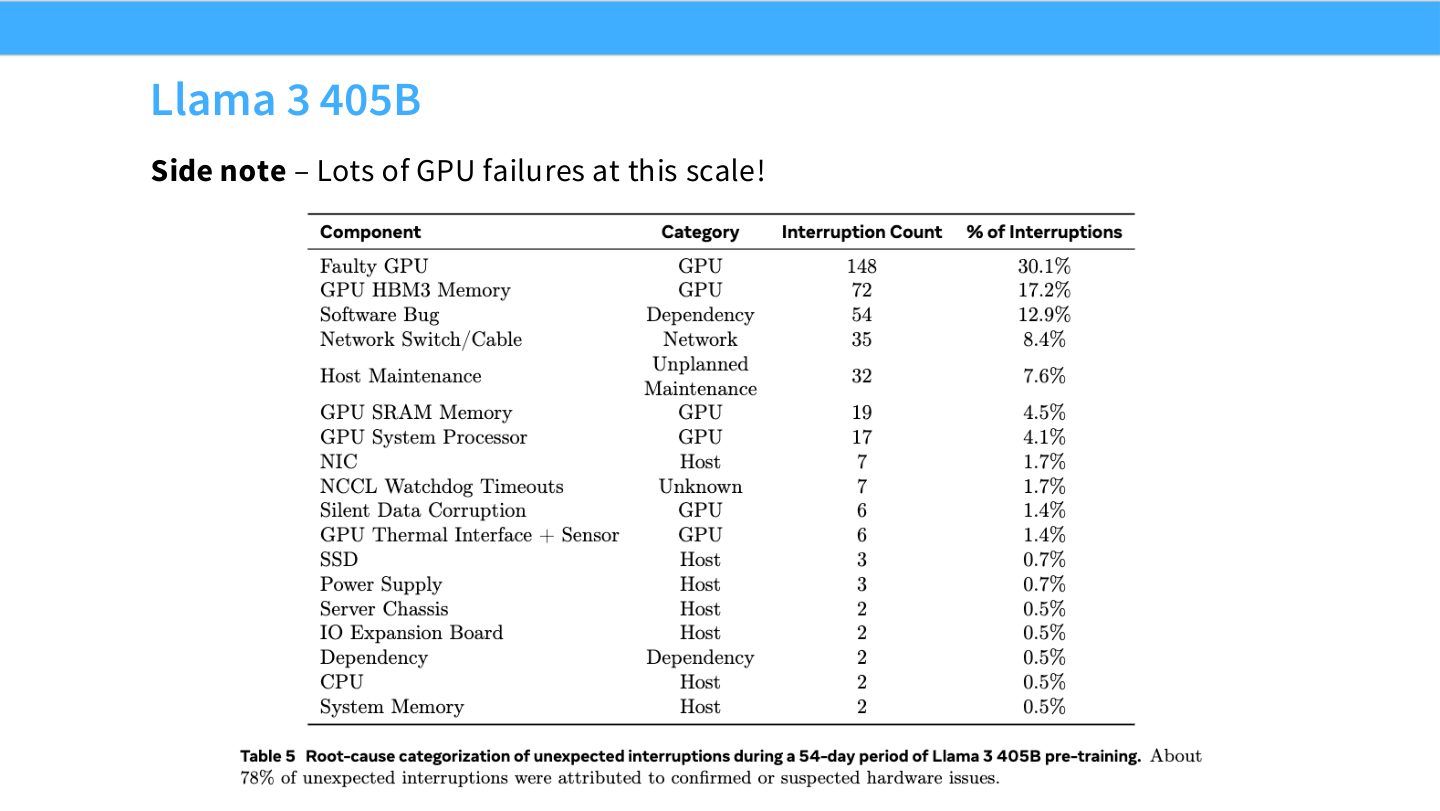
读图:Slide 67 的系统含义
GPU 数越多,单个硬件故障的期望频率越高。并行训练不只要跑得快,还要 checkpoint、恢复、容错、监控和动态剔除故障节点。大型训练的系统工程包括可靠性,而不仅是并行算法。

读图:Slide 68 的 Gemma 2 配置
Gemma 2 的例子说明,即使没有 MoE,也常组合 FSDP/ZeRO-3、TP、SP、DP。参数、activation 和吞吐各自需要不同维度来解决,尤其当模型有多个尺寸版本时,并行策略也会随模型大小调整。
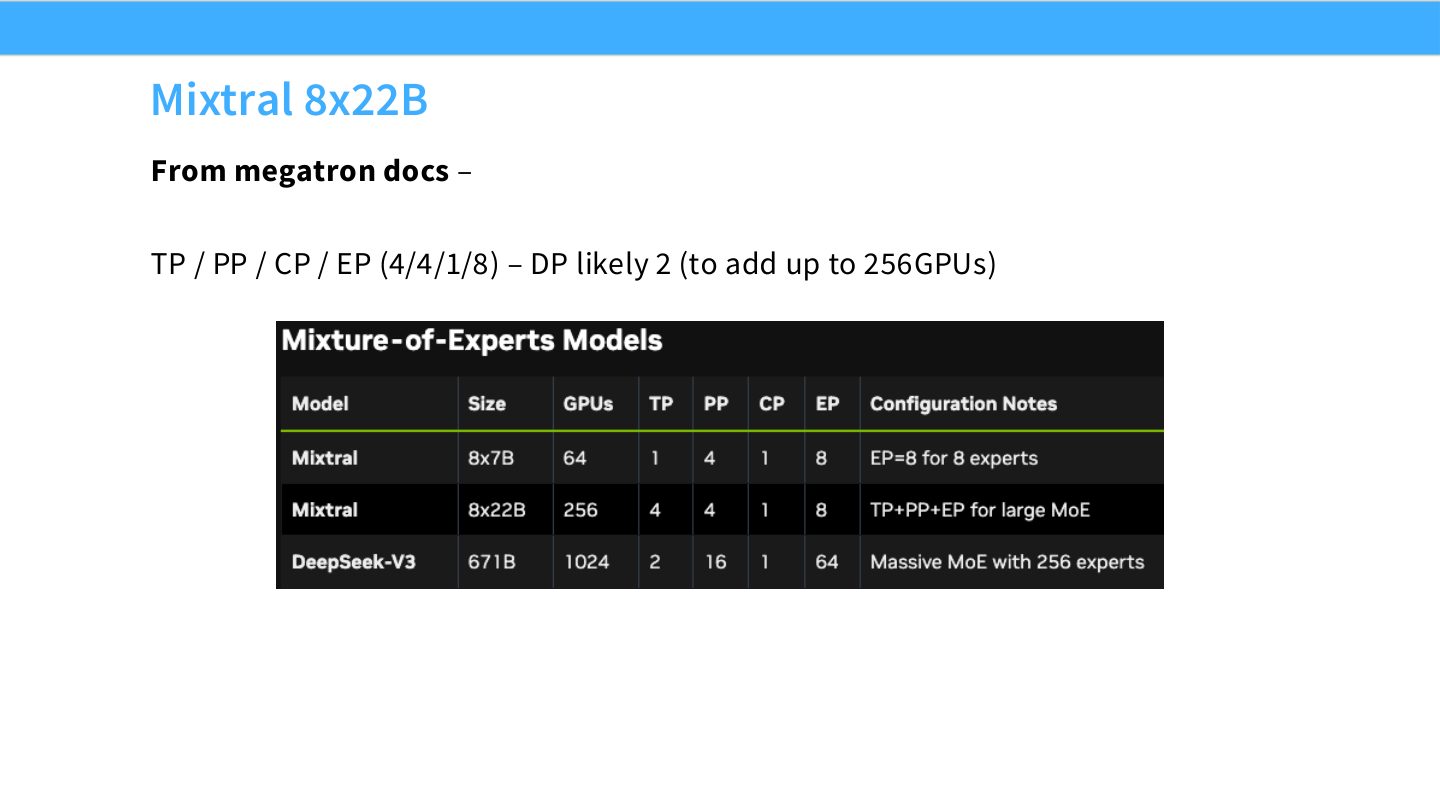
读图:Slide 69 的 Mixtral MoE 配置
Mixtral 是 MoE 模型,因此 EP 很自然出现;TP/PP/CP 处理 dense attention、深度切分和长上下文;DP 补充吞吐。MoE 模型的并行配置通常更高维,因为 MLP experts、attention、context 和 batch 的瓶颈不同。

读图:Slide 70 的 CP=64 为什么醒目
长上下文扩展会让 attention 和 KV/activation 压力显著上升,因此 context parallel 可能成为主维度之一。CP 数字很大说明序列维度本身已经成为核心扩展对象,而不只是把参数切开。
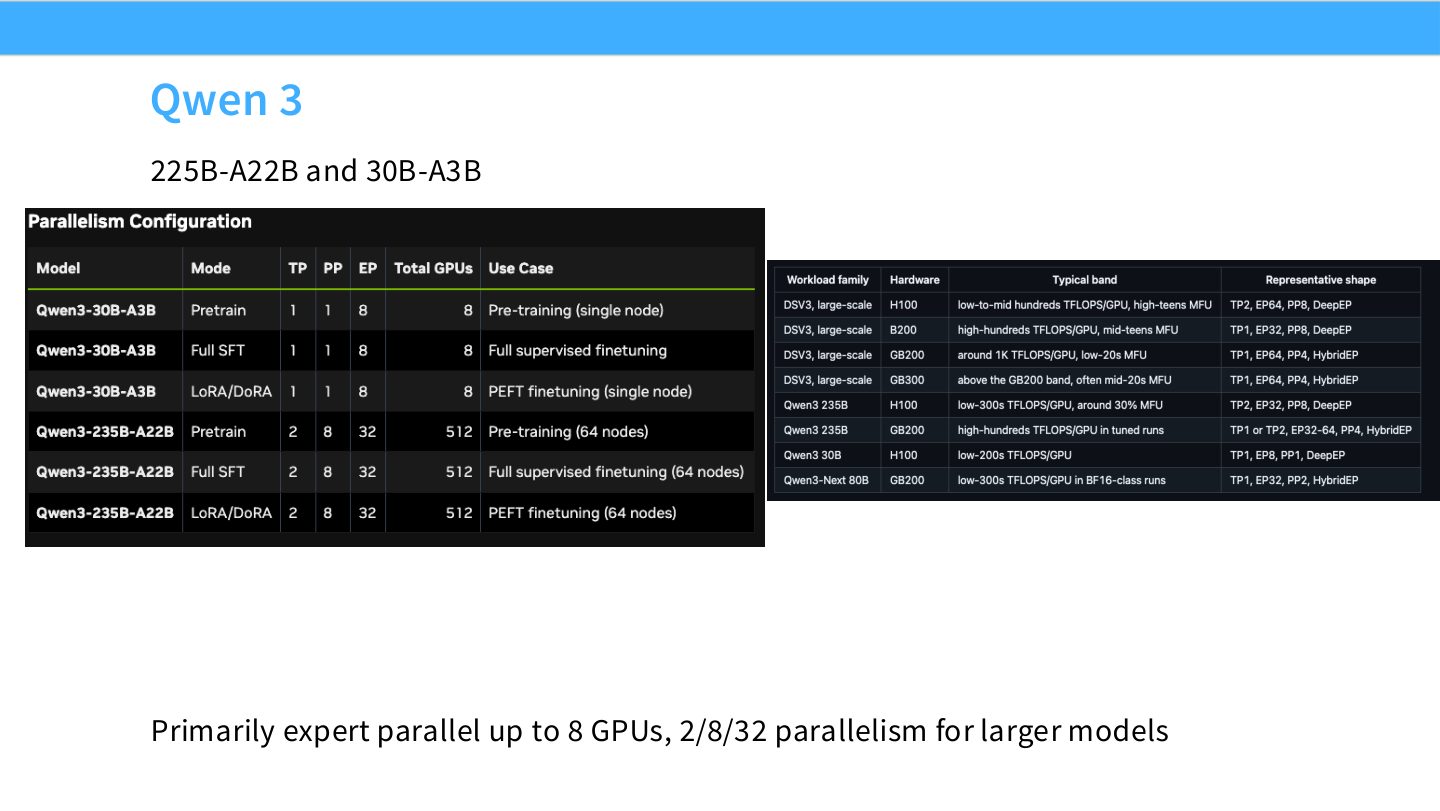
读图:Slide 71 的 Qwen 配置
Qwen 3 的 MoE 配置说明 expert parallel 可以成为主要扩展方式。A22B/A3B 代表 activated parameters 少于总参数,系统瓶颈不只是“总参数存储”,还包括每 token 激活专家数量、路由通信和 expert load balance。
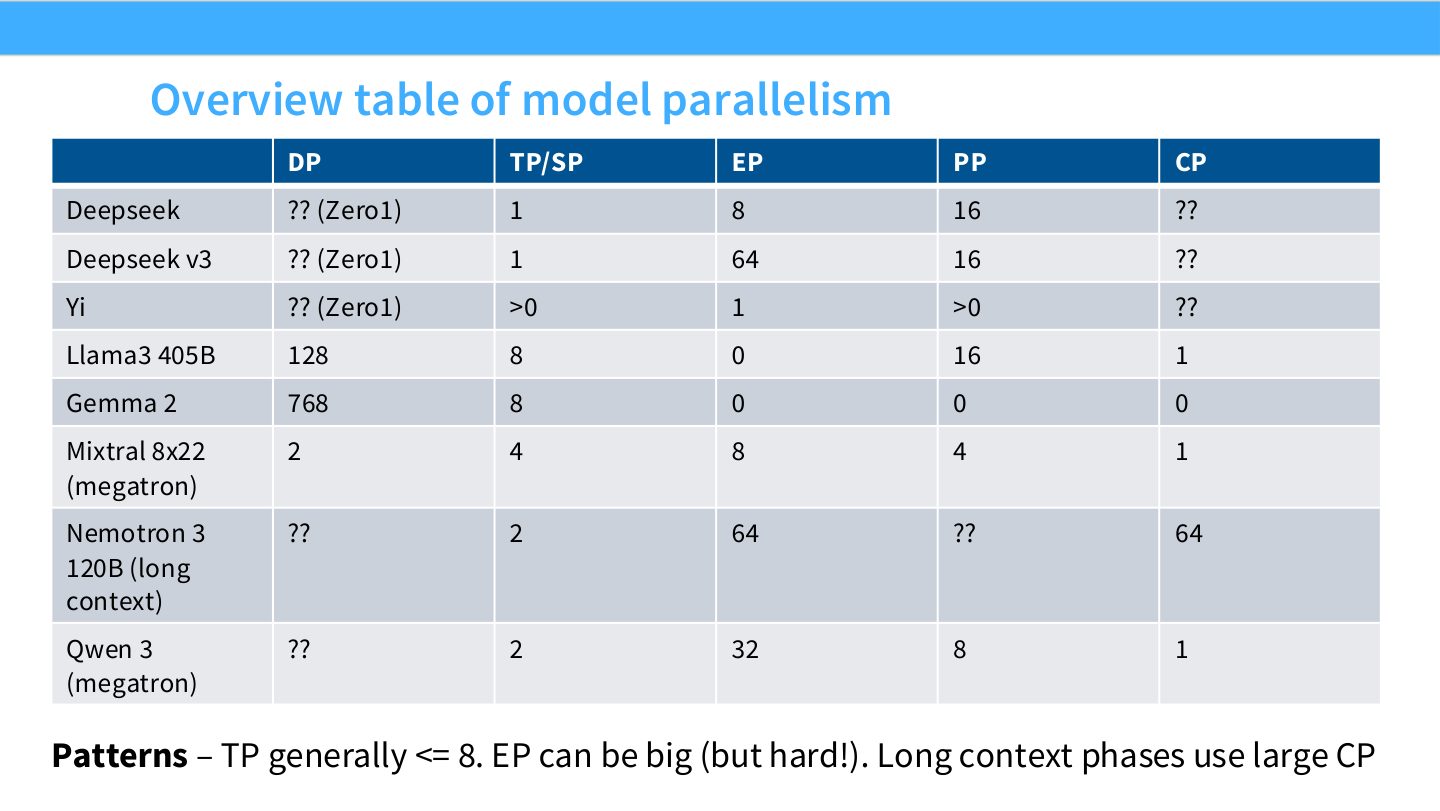
读表:Slide 72 不要把公开配置当唯一真相
这张表最有价值的是比较维度:DP、TP/SP、EP、PP、CP 如何随模型类型变化。Dense 模型更依赖 TP/SP/PP/DP;MoE 模型显著引入 EP;长上下文模型提高 CP。公开配置可能不完整或随训练阶段变化,因此它们应作为推理线索,而不是可直接复制的 recipe。

读图:Slide 73 的最终结论
超过某个规模后,multi-GPU、multi-node parallelism 是必要条件;没有单一方案能解决所有问题;可解释的经验规则通常先问模型是否 fit,再问吞吐如何扩展,最后按硬件域安排 TP/EP/PP/DP/CP。真正可靠的配置来自账本、benchmark 和 profiling,而不是名词堆叠。
Part 3 小结
大模型训练的组合并行遵循一个朴素原则:把高频通信放在快链路,把大状态按最自然的维度分片,把调度空泡和负载不均控制在可接受范围内。近期模型配置之所以复杂,是因为现代 LLM 同时有 dense attention、MoE experts、长上下文、深层网络和庞大训练 batch。
本章小结
Lecture 8 把网络拓扑、collectives、状态分片、模型切分和真实模型配置连成一张系统账本。前两部分回答“为什么要并行、有哪些切法”,最后一部分回答“怎样把这些切法按硬件层次组合起来”。
总结与延伸
Lecture 8 是 CS336 中把分布式训练从“API 原语”推到“系统设计”的关键一讲。它把 Lecture 7 的 collectives 放进真实 LLM 训练:DDP 用 all-reduce;ZeRO/FSDP 用 reduce-scatter 和 all-gather;pipeline 用 send/recv 或 stage 边界通信;tensor parallel 在每层通信;sequence/context parallel 处理 activation 和长上下文;expert parallel 则围绕 all-to-all 和负载均衡展开。
最终 takeaways
- 单 GPU scaling 同时受 compute 和 memory 限制,训练单位会自然扩大到 datacenter。
- collectives 是并行训练的底层语言;all-reduce = reduce-scatter + all-gather 是理解 ZeRO/FSDP 的核心。
- ZeRO-1/2 主要降低 data parallel 的状态重复,ZeRO-3/FSDP 进一步分片参数,但通信更进入关键路径。
- pipeline parallel 沿 depth 切,省参数显存且可跨慢链路,但要处理 bubble。
- tensor parallel 沿 width 切,利用率高但通信高频,通常限制在高速节点内。
- sequence/context/expert parallelism 分别处理 activation、长上下文和 MoE experts。
- 真实训练常用 3D/4D 组合;配置的正确性来自状态和通信账本,而不是并行名词数量。
拓展阅读
- Stanford CS336 Spring 2026 Lecture 8 official slides.
- ZeRO: Rajbhandari et al., Zero Redundancy Optimizer.
- Megatron-LM and Megatron-Core documentation on tensor, pipeline, sequence, context, and expert parallelism.
- PyTorch FSDP documentation and tutorial.
- Narayanan et al. 2021 on efficient large-scale language model training.