CS336 2026 Lecture 4:Attention Alternatives 与 Mixture of Experts
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS336 Spring 2026 官方讲义整理 |
| 来源 | Stanford CS336 |
| 日期 | 2026 年春季 |

本讲的问题:为什么 Transformer 不总是 full dense compute?
Lecture 4 把两个看似不同的方向放在一起:attention alternatives 和 mixture of experts。前者问:长上下文下,是否每个 token 都必须 attend 所有历史?后者问:每个 token 是否必须激活模型的所有参数?两者的共同目标是 selective computation:把昂贵计算只花在必要位置。
本讲主线
Attention alternatives 选择“看哪些历史状态”;MoE 选择“用哪些专家参数”。二者都是在模型质量、训练效率、推理成本和系统复杂度之间做条件计算 tradeoff。
本讲主线:用选择性计算控制成本
本节建立两条主线:attention alternatives 用更便宜的状态/稀疏机制控制长上下文成本;MoE 用条件计算扩大参数量但控制每 token FLOPs。

展开说明:A T T E N T I O N A LT E R N AT I V E S A N D M I X T U R E S O F E X P E R T S
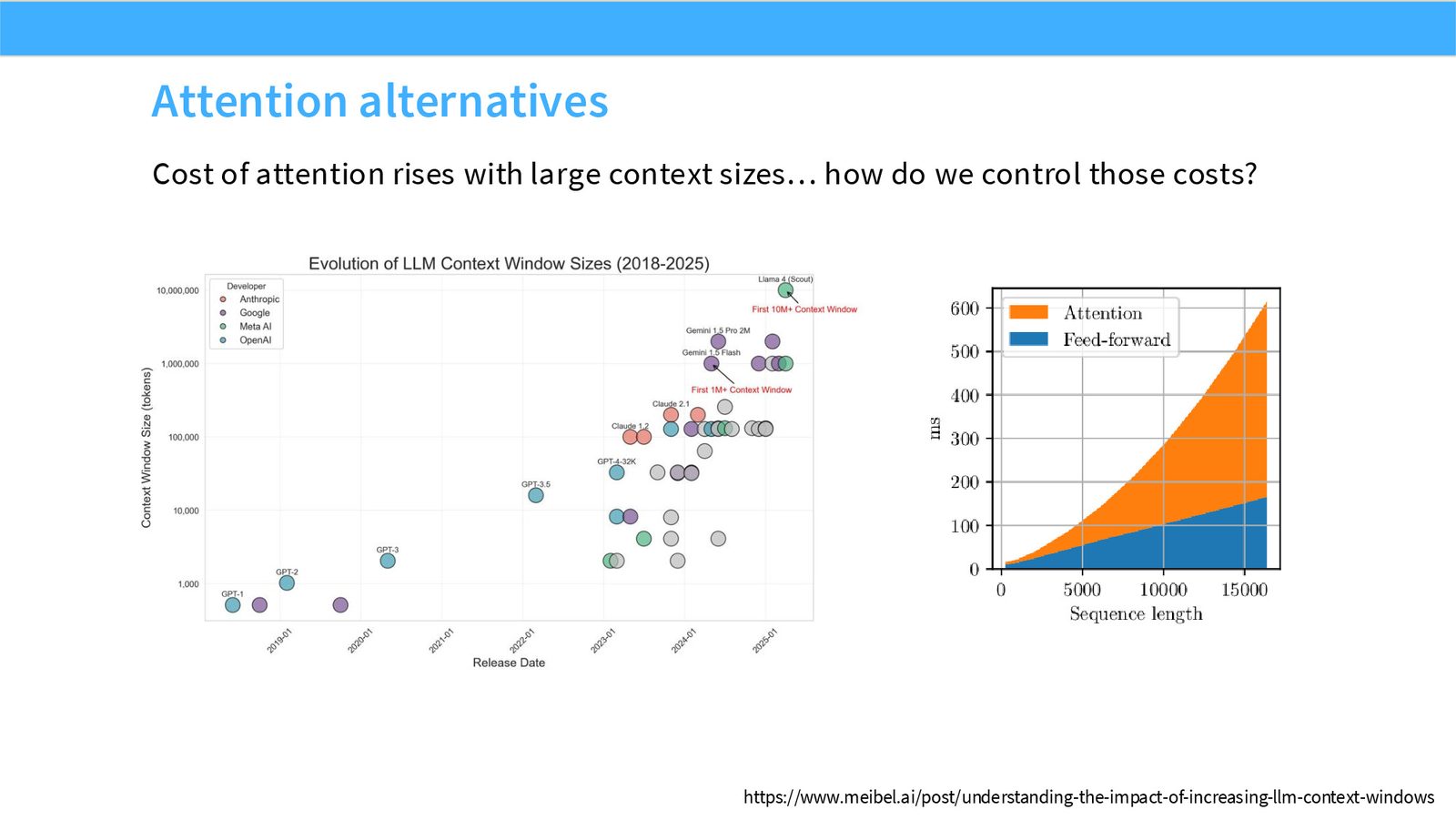
展开说明:Cost of attention rises with large context sizes… how do we control those costs?
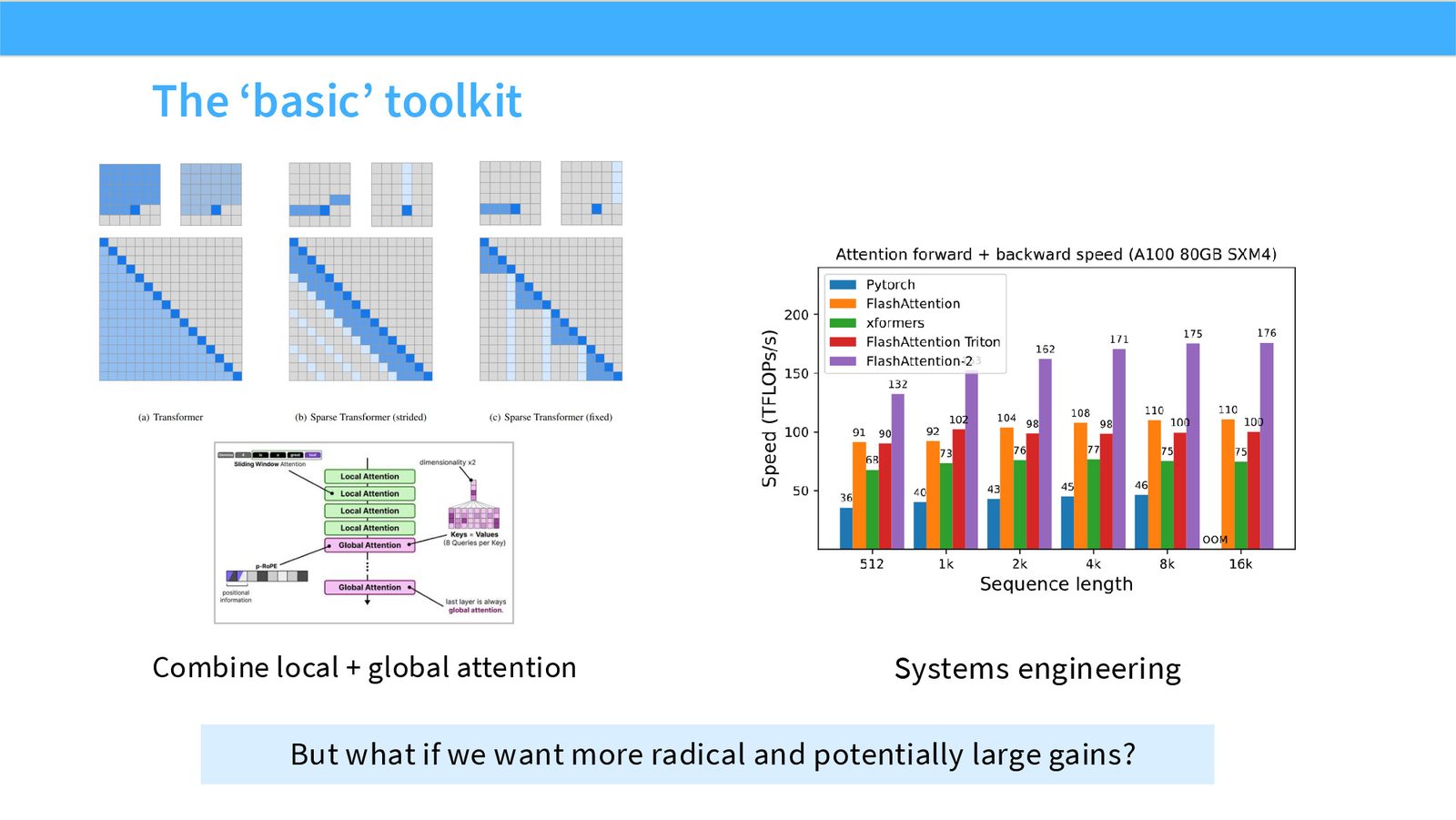
展开说明:Combine local + global attention Systems engineering
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
Attention alternatives:从 full attention 到 hybrid state
本节解释 linear attention、recurrent form、Mamba-2、Gated Delta Net、hybrid attention 和 DeepSeek Sparse Attention。
术语消化:linear attention、state、hybrid、DSA
- Linear attention:把 softmax attention 改写成可重排的核形式,使计算可用前缀状态累积。
- Recurrent/state form:维护一个随位置更新的 state,生成或长上下文时不必显式保存所有 pairwise attention。
- Hybrid attention:把 linear/state layers 和 full attention layers 交替使用,兼顾成本和质量。
- DSA:DeepSeek Sparse Attention,先筛选重要历史位置,再做稀疏 attention。
线性/稀疏变体都在改写这个式子的成本结构:要么避免完整 \(n\times n\) attention matrix,要么只选少量历史位置。

展开说明:Consider the usual attention operation: \(Q\in\mathbb{R}^{n\times d_k}\), \(K\in\mathbb{R}^{n\times d_k}\), \(V\in\mathbb{R}^{n\times d_v}\).
读图:Slide 4 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。

展开说明:Recall that in purely linear attention, we consider the reordering
读图:Slide 5 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
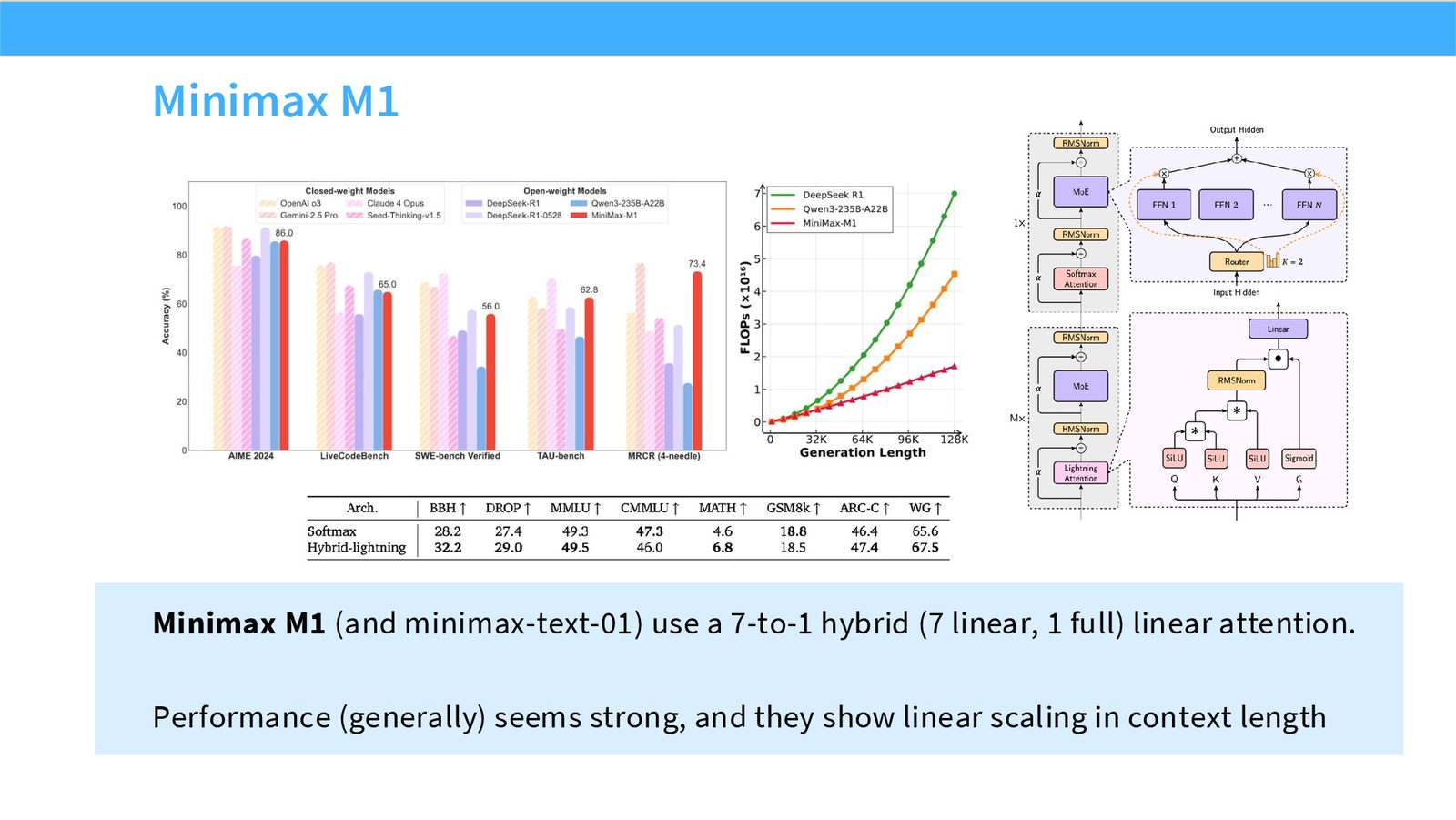
展开说明:Minimax M1 (and minimax-text-01) use a 7-to-1 hybrid (7 linear, 1 full) linear attention.

展开说明:Let’s generalize linear attention a little bit and add per-position weights..
读图:Slide 7 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
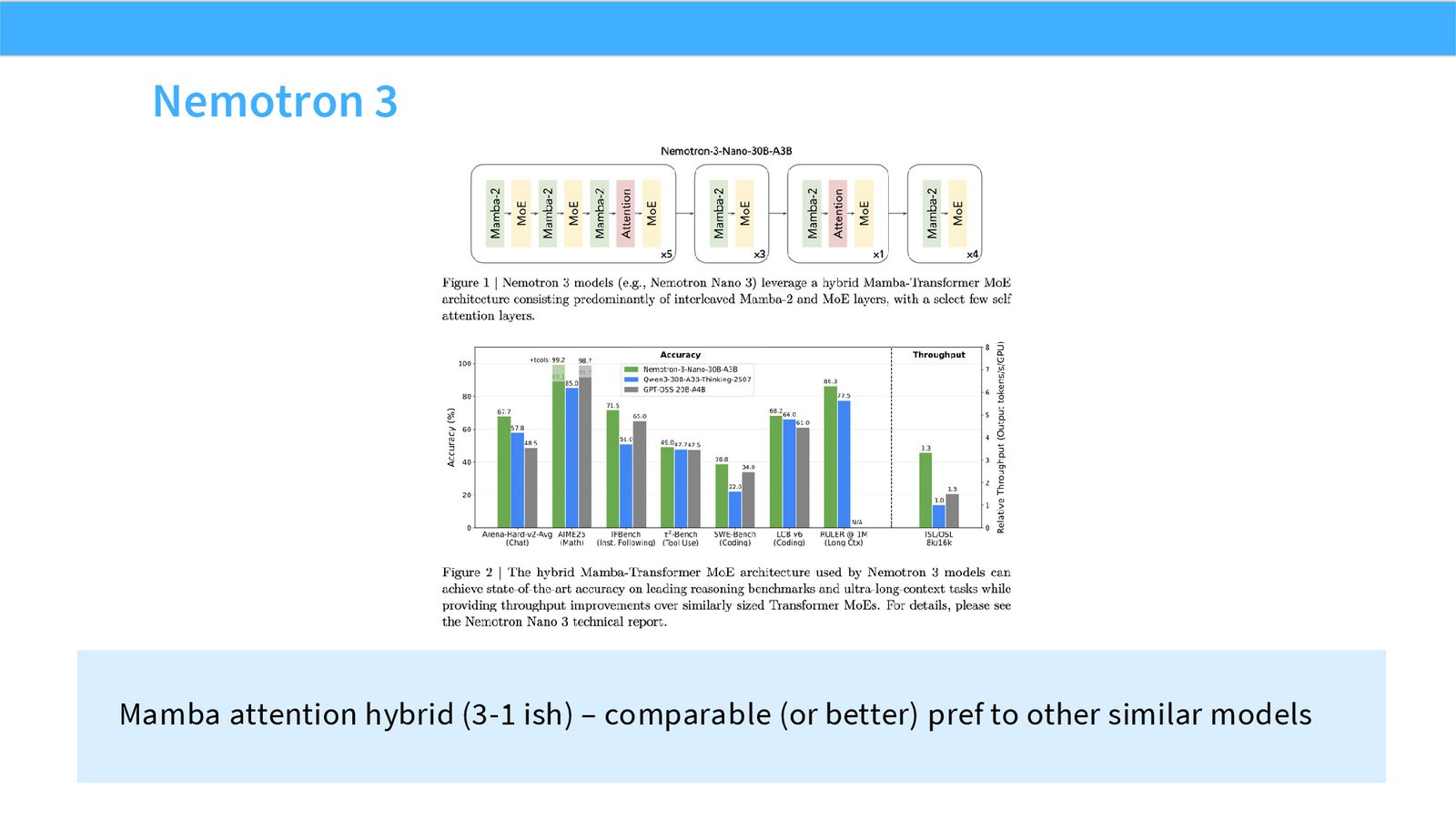
展开说明:Mamba attention hybrid (3-1 ish) – comparable (or better) pref to other similar models

展开说明:Let’s generalize things further – gate the input and selectively erase the state.
读图:Slide 9 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
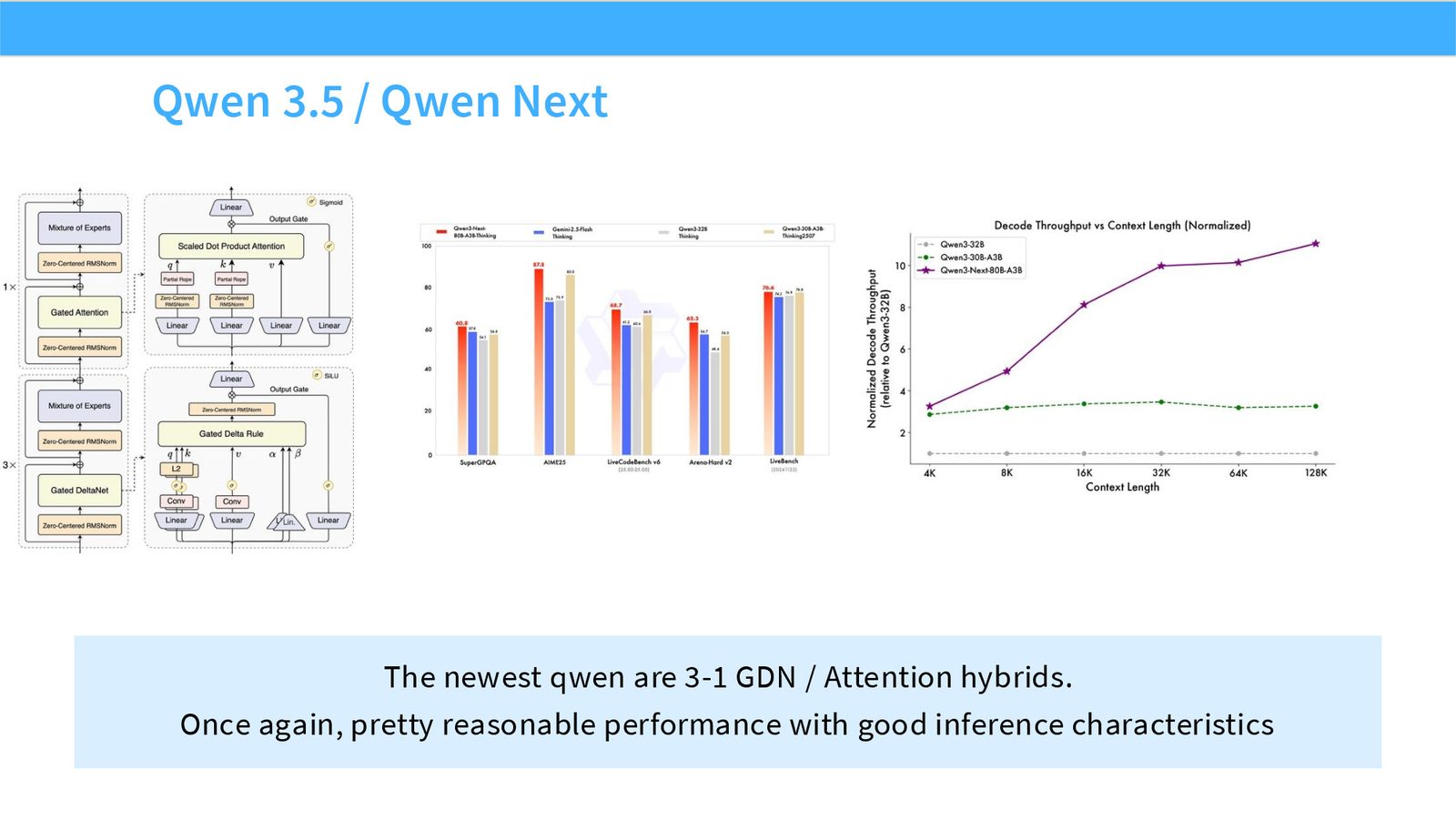
展开说明:The newest qwen are 3-1 GDN / Attention hybrids.
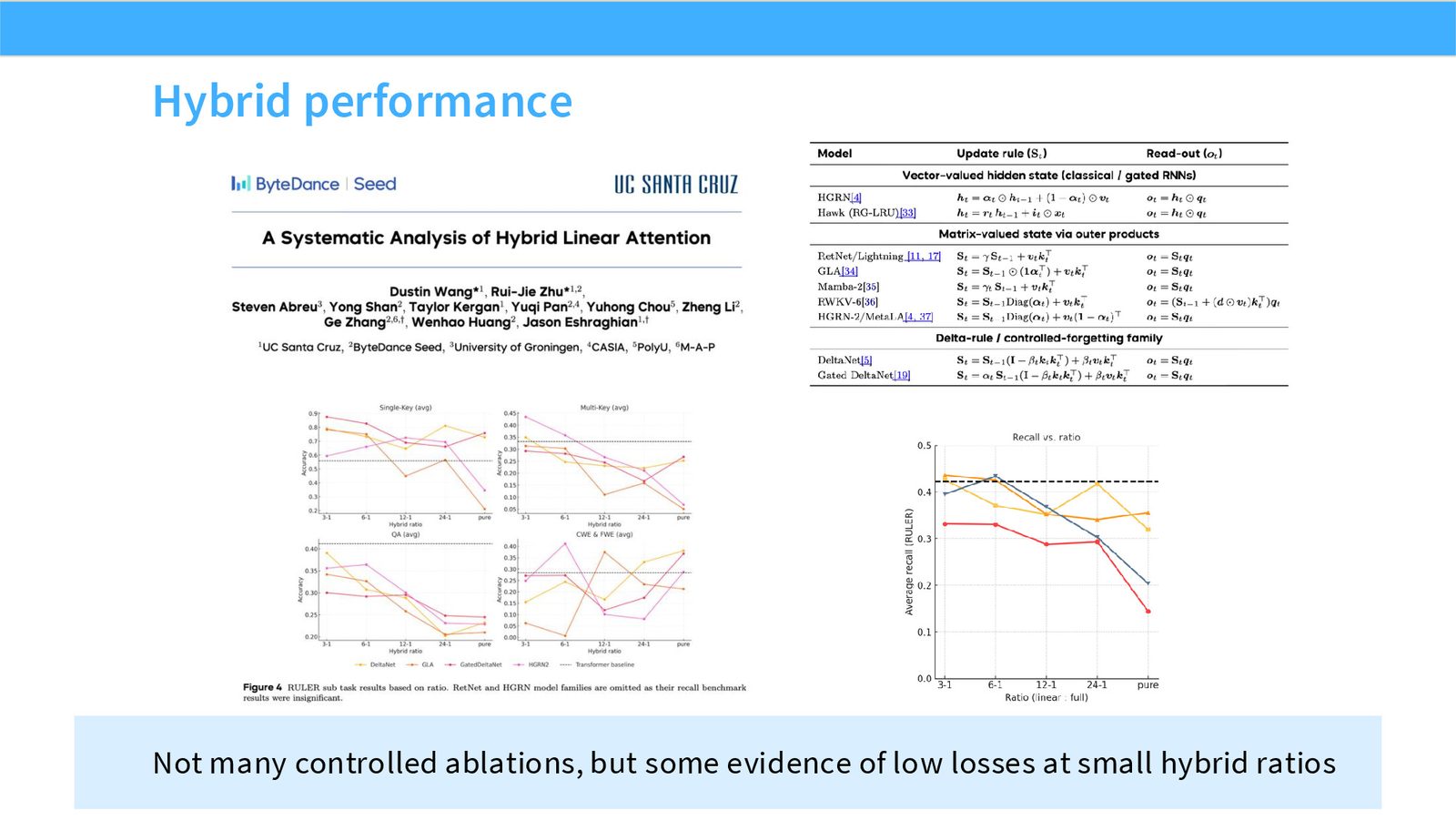
展开说明:Not many controlled ablations, but some evidence of low losses at small hybrid ratios
读图:Slide 11 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。

展开说明:Instead of attending to every token, do sparse attention (DSA)
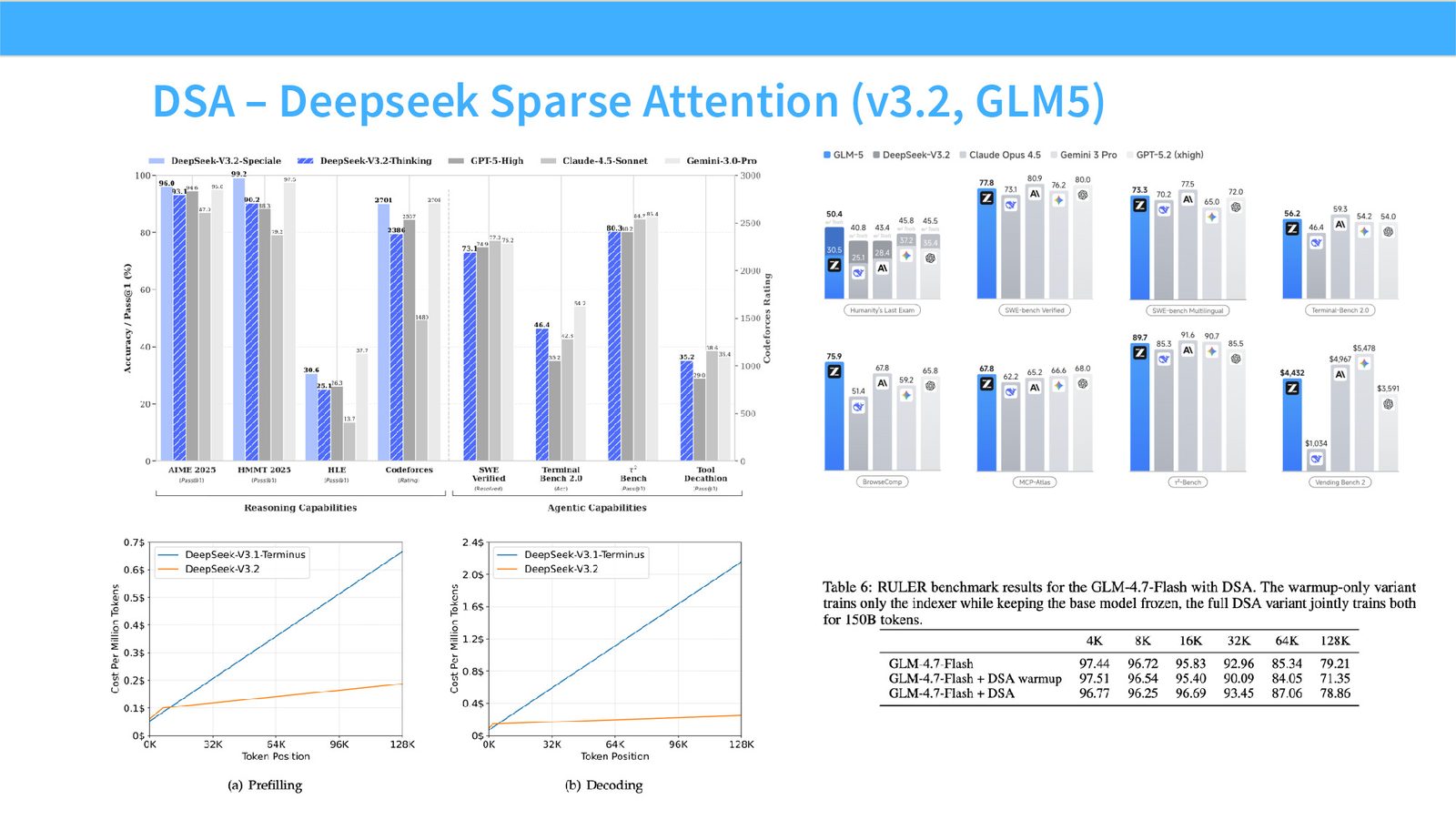
展开说明:DSA – Deepseek Sparse Attention (v3.2, GLM5)
读图:Slide 13 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
MoE 为什么流行:更多参数,不一定更多 FLOPs
本节解释 MoE 的核心动机:同样每 token FLOPs 下增加参数容量,并通过 expert parallelism 扩展到多设备。
什么是 MoE
Mixture of Experts 把 dense MLP 替换成多个 experts,并由 router 为每个 token 选择少量 experts。总参数量可以很大,但每个 token 只激活少量参数,因此每 token FLOPs 可控。
展开说明:GPT4 (?)
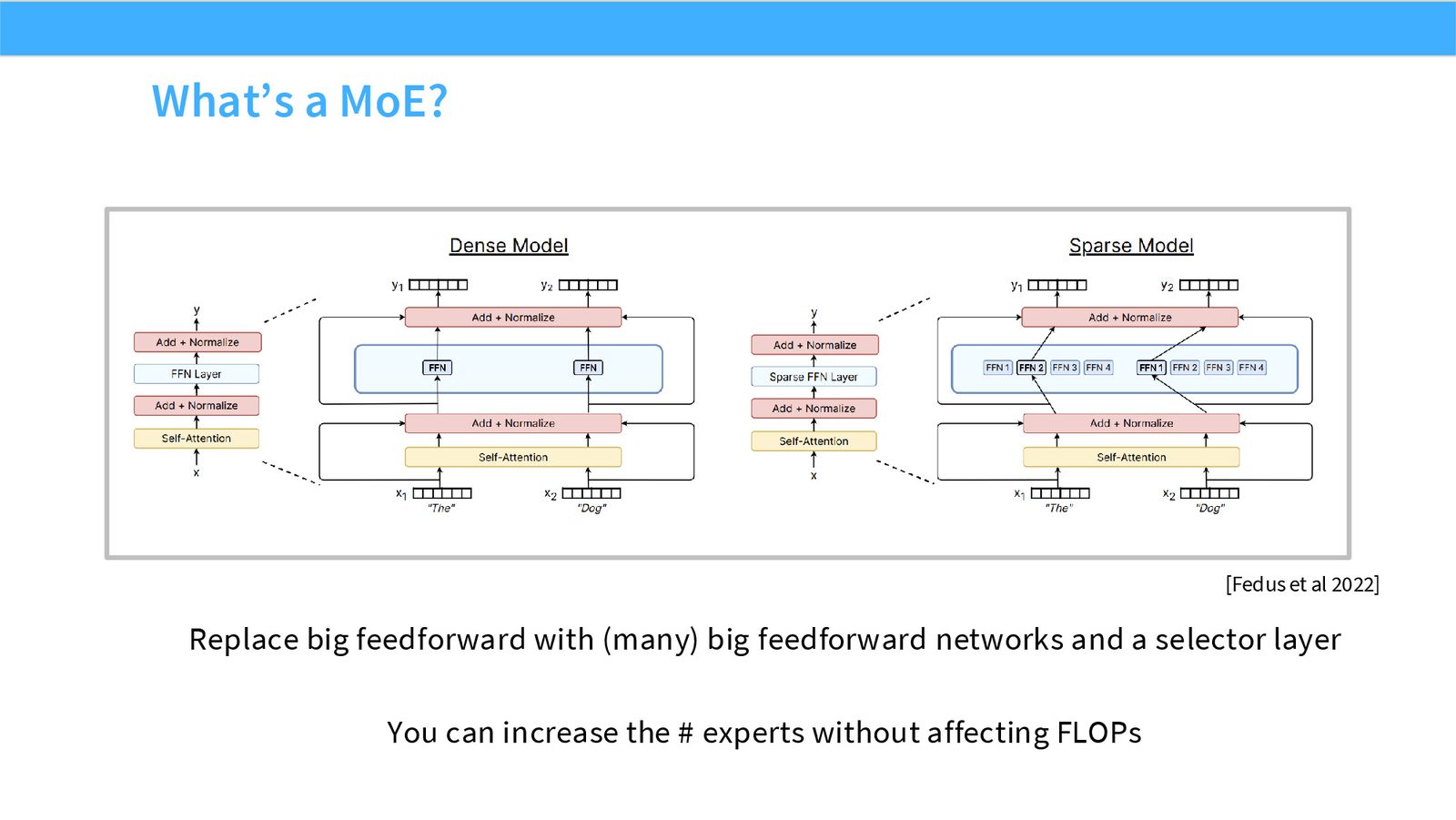
展开说明:[Fedus et al 2022]
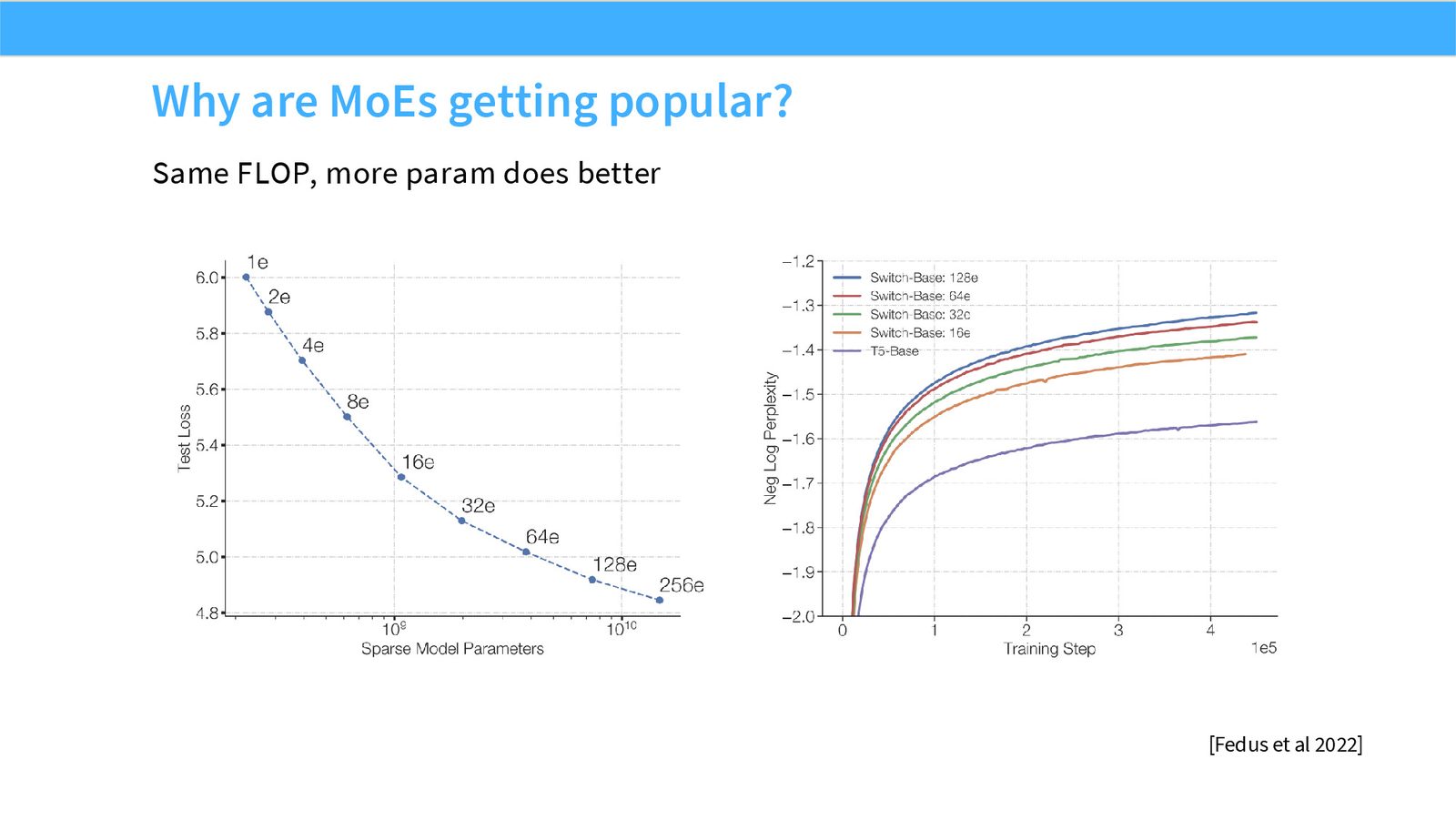
展开说明:Same FLOP, more param does better
读图:Slide 16 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
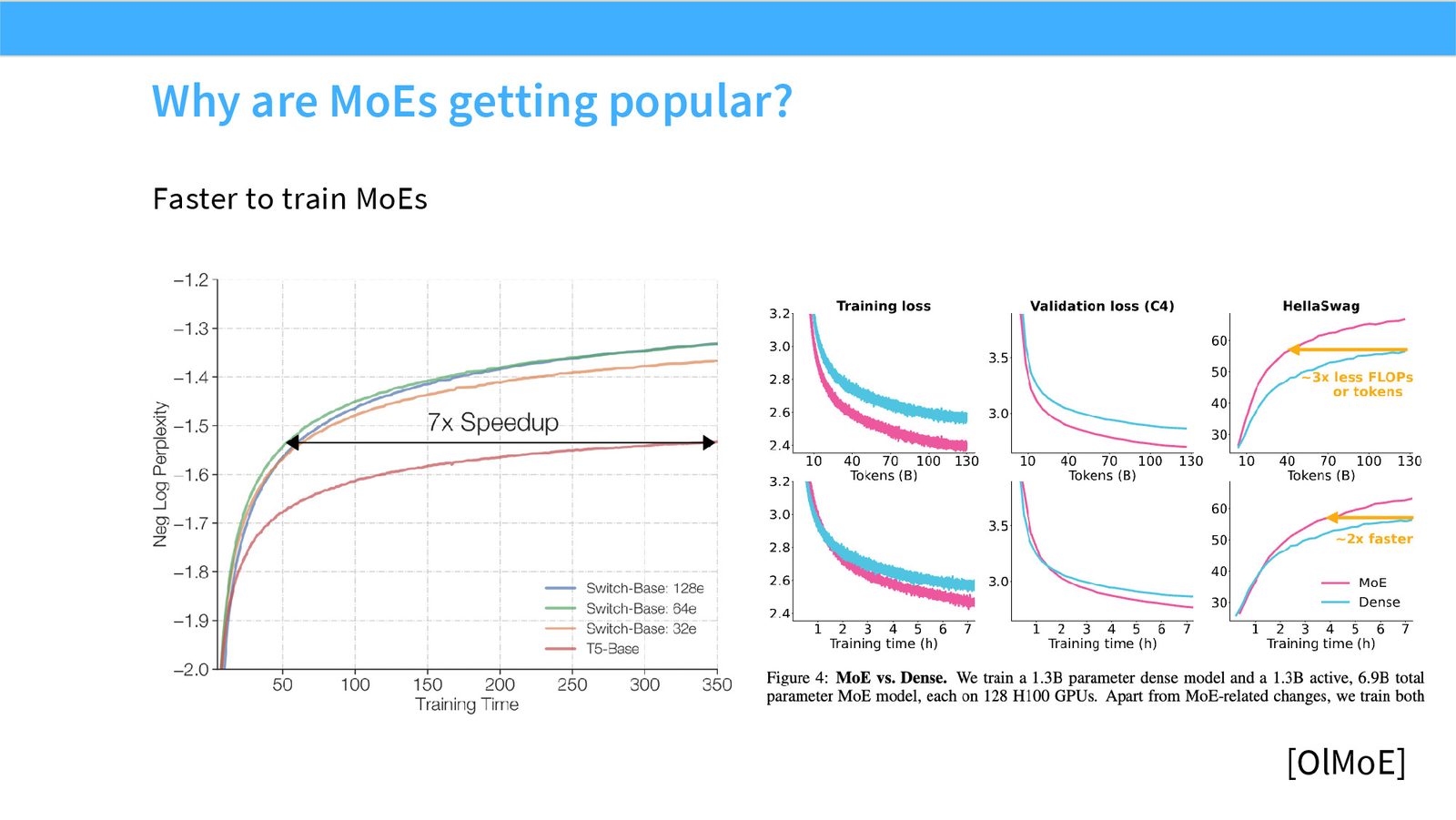
展开说明:Faster to train MoEs
读图:Slide 17 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
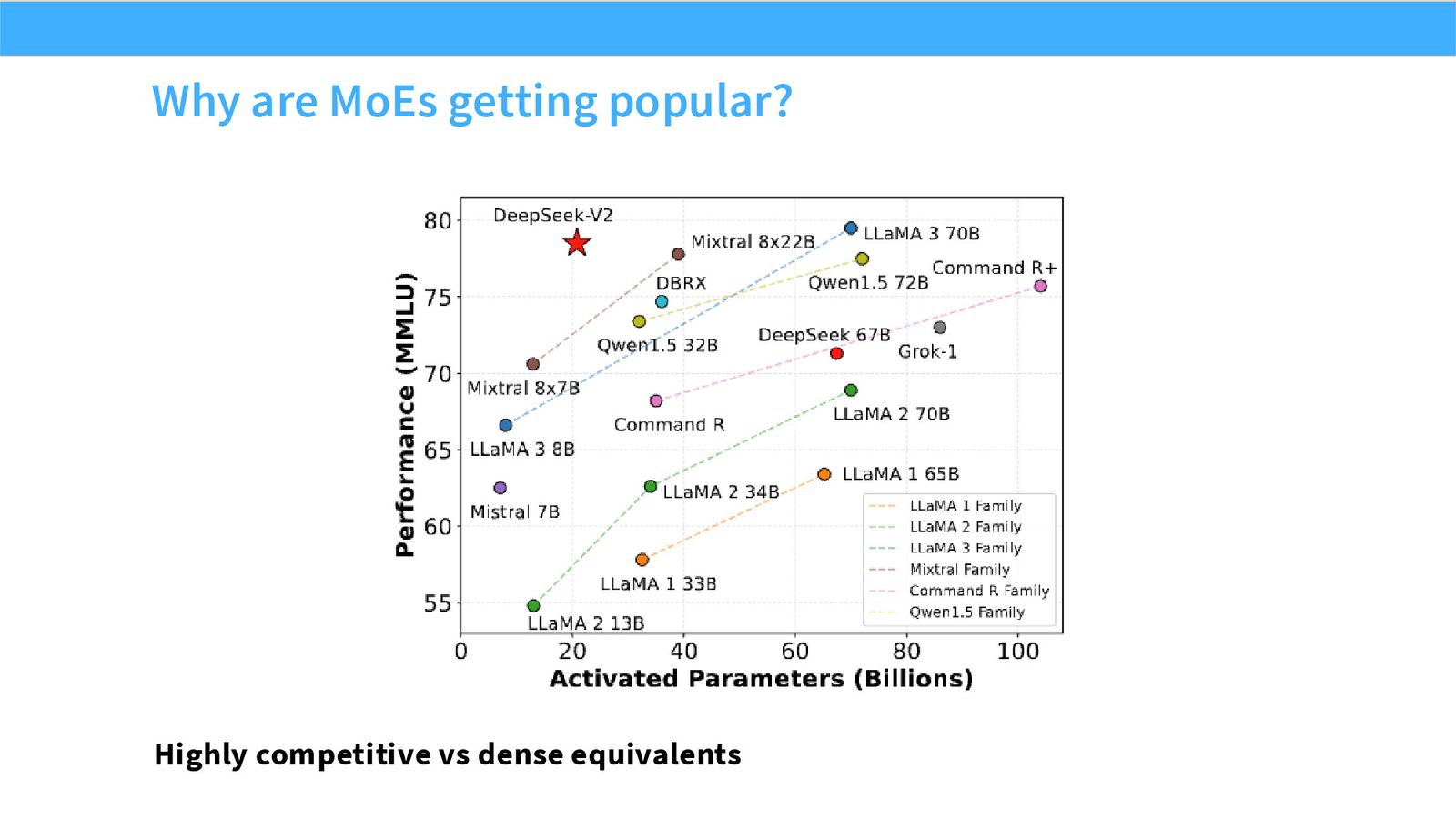
展开说明:Highly competitive vs dense equivalents
读图:Slide 18 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
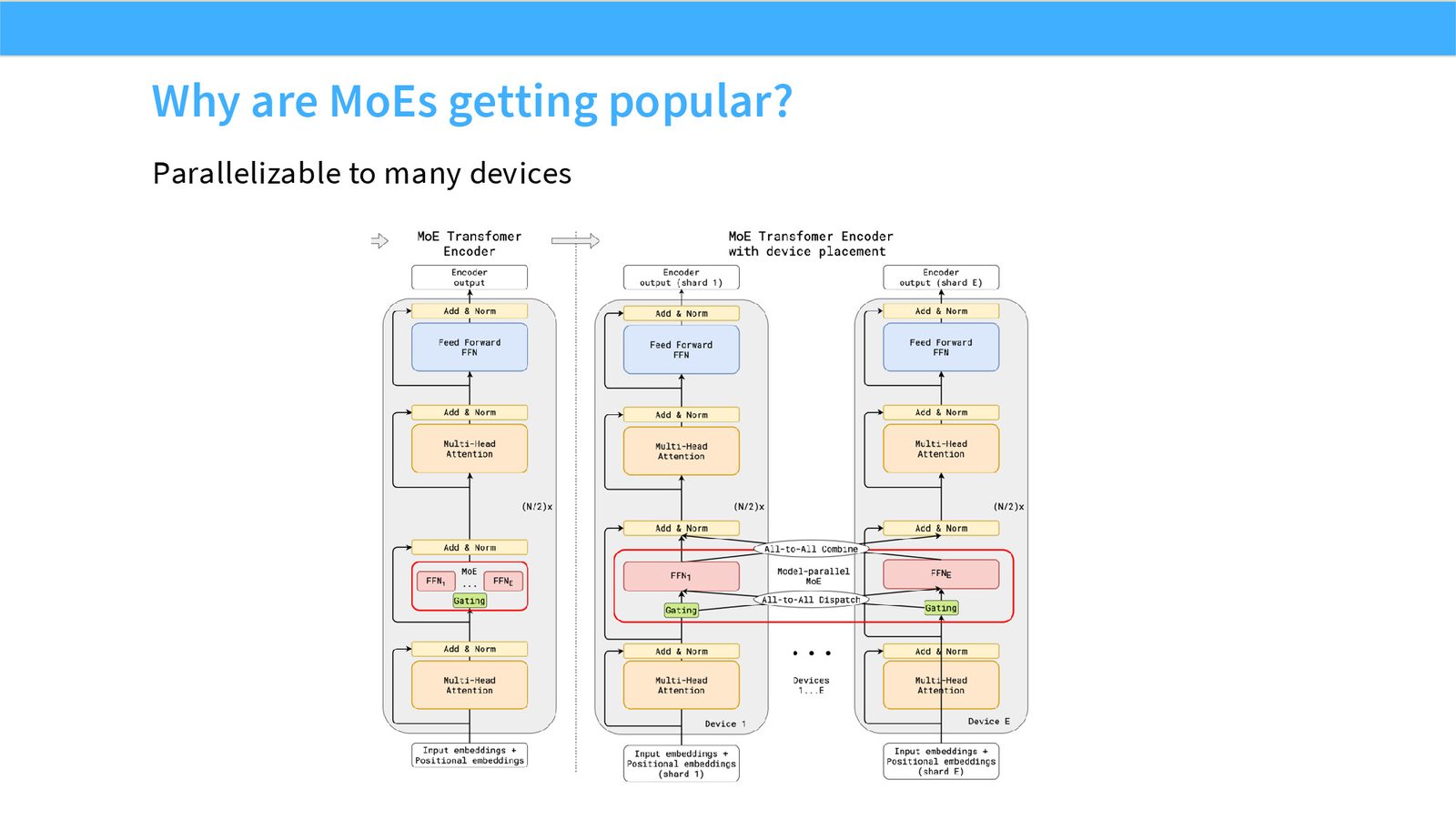
展开说明:Parallelizable to many devices
读图:Slide 19 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
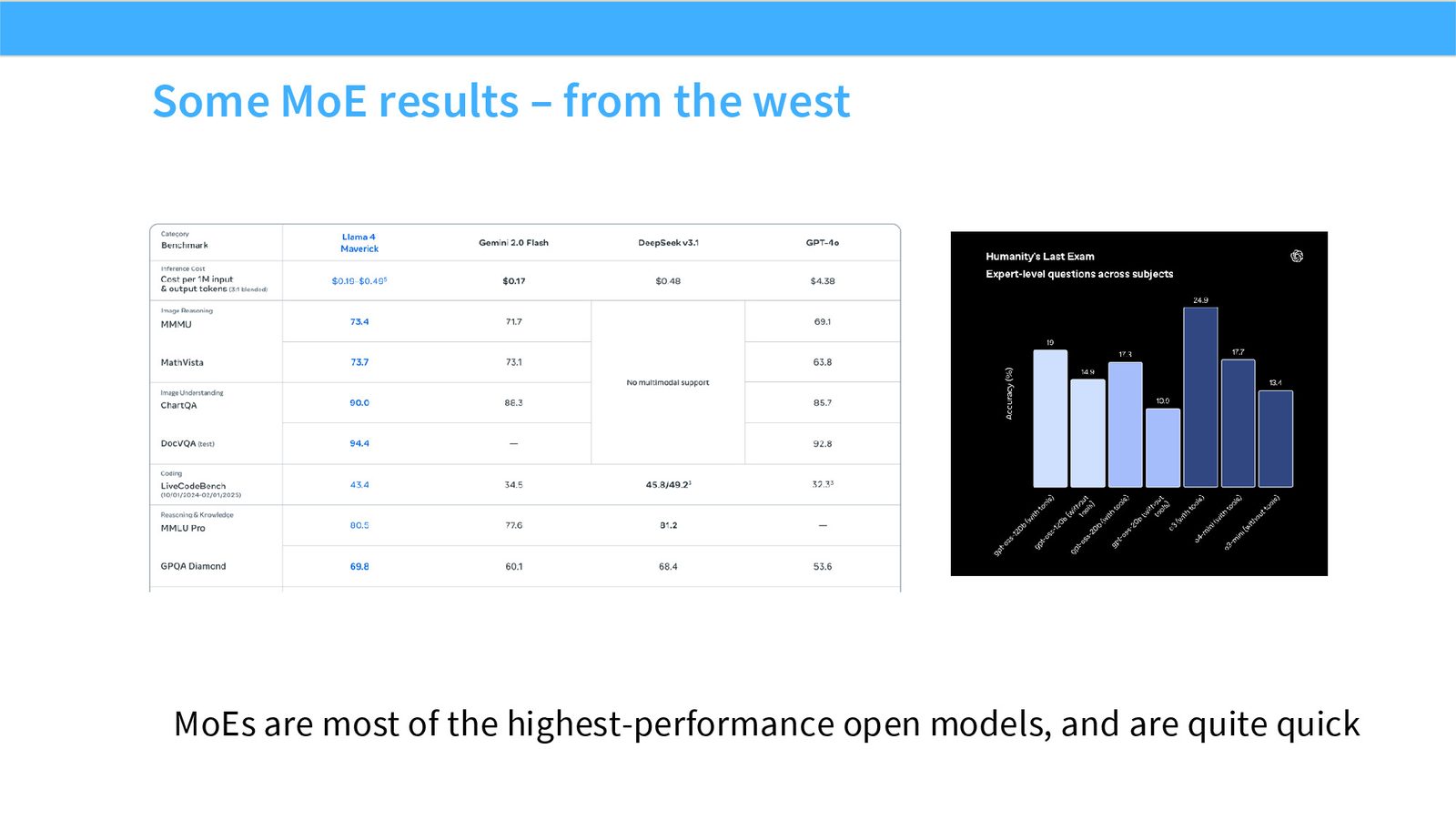
展开说明:MoEs are most of the highest-performance open models, and are quite quick
读图:Slide 20 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
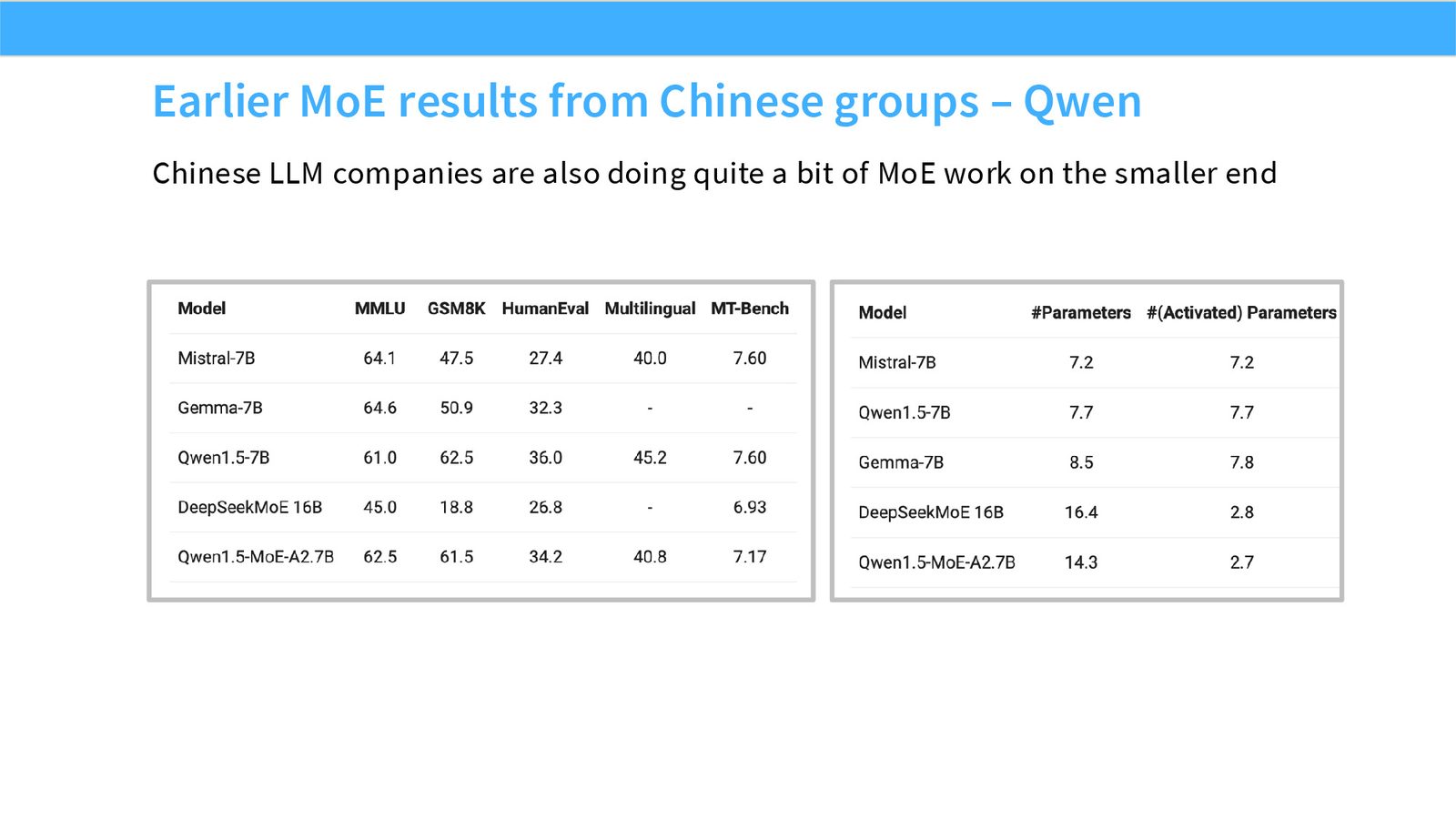
展开说明:Chinese LLM companies are also doing quite a bit of MoE work on the smaller end
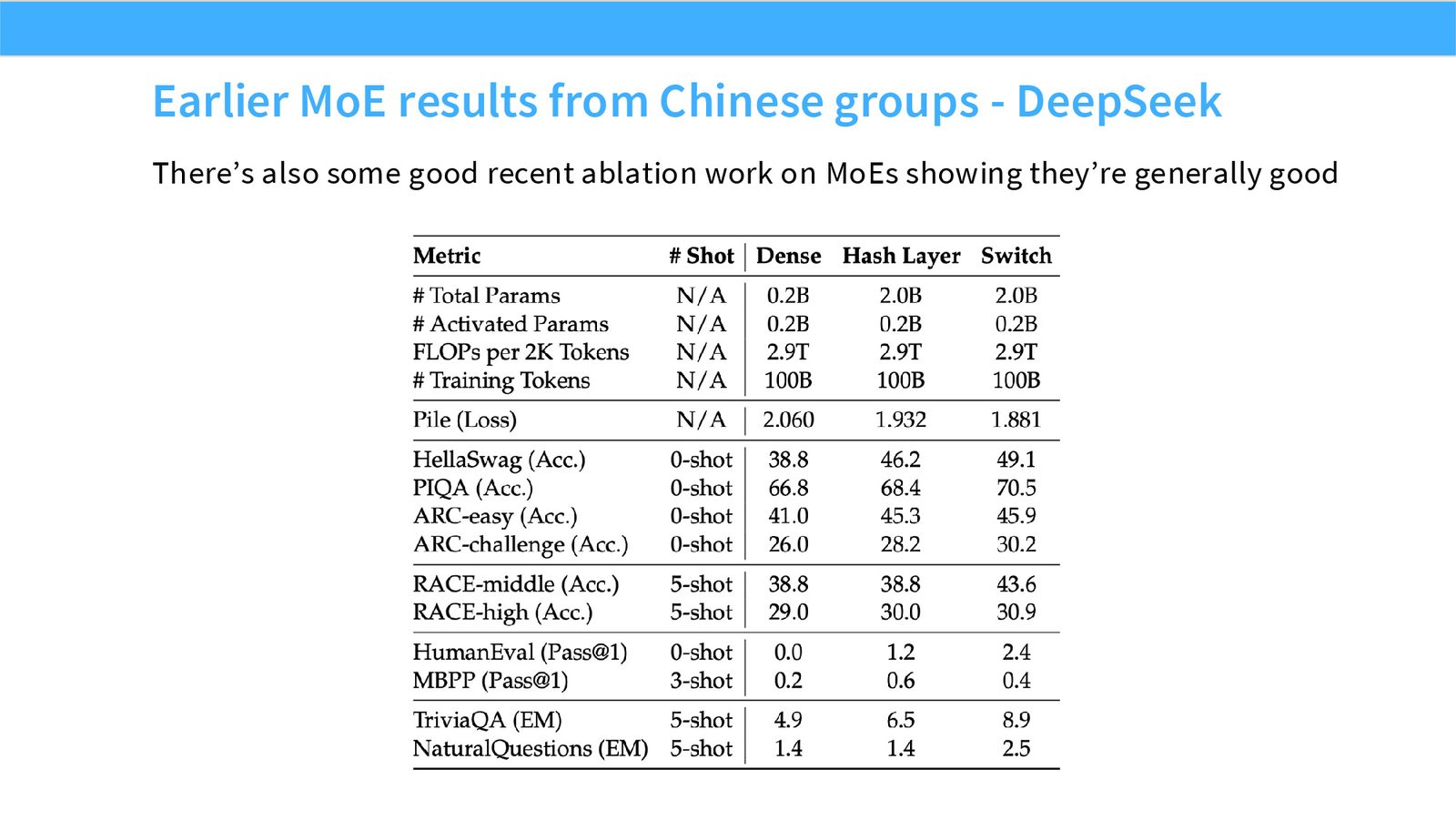
展开说明:There’s also some good recent ablation work on MoEs showing they’re generally good
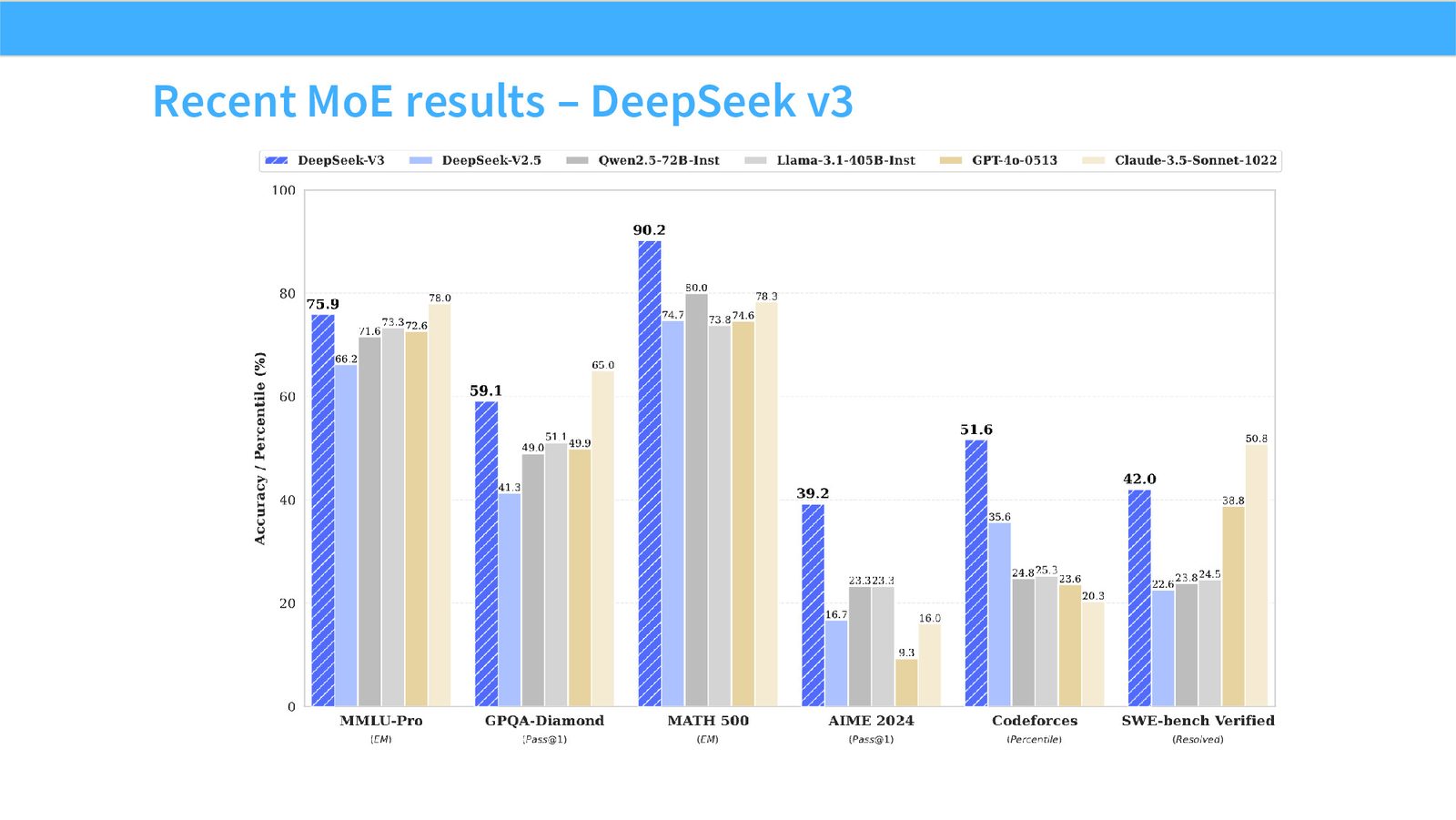
展开说明:Recent MoE results – DeepSeek v3
读图:Slide 23 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
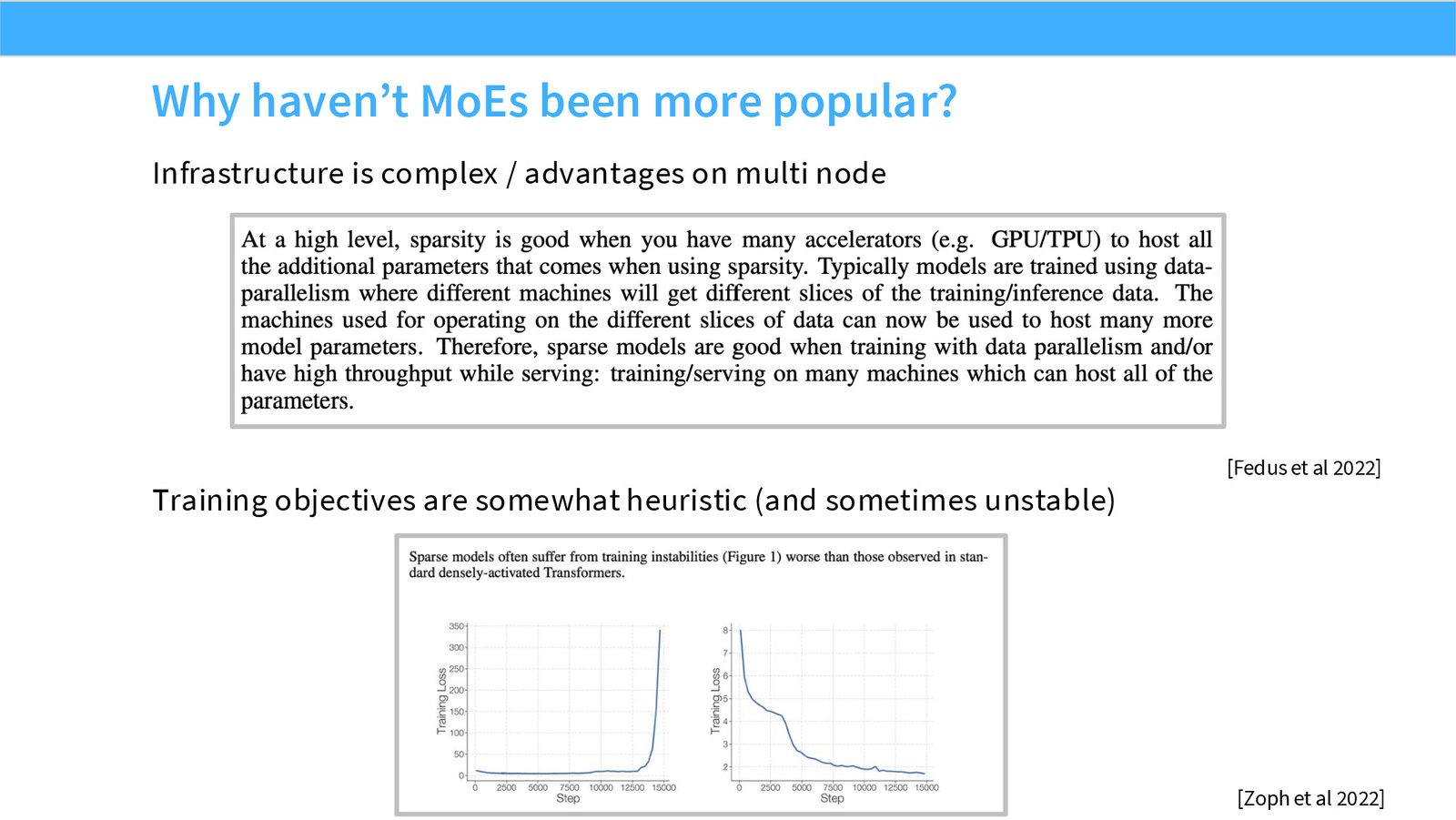
展开说明:Infrastructure is complex / advantages on multi node
读图:Slide 24 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
Routing:token 如何选择 experts
本节解释 routing function、top-k routing、token-choice、shared experts、fine-grained experts 和近期模型配置。
术语消化:router、top-k、shared experts、fine-grained experts
Router 为每个 token 产生 expert scores;top-k routing 选择分数最高的 k 个 experts;shared experts 总是被激活,提供公共容量;fine-grained experts 把专家切得更小更多,提高组合灵活性但增加路由和通信复杂度。
其中 \(r(x)\) 是 router logits,\(g_e(x)\) 是路由权重,\(E_e\) 是第 \(e\) 个 expert。
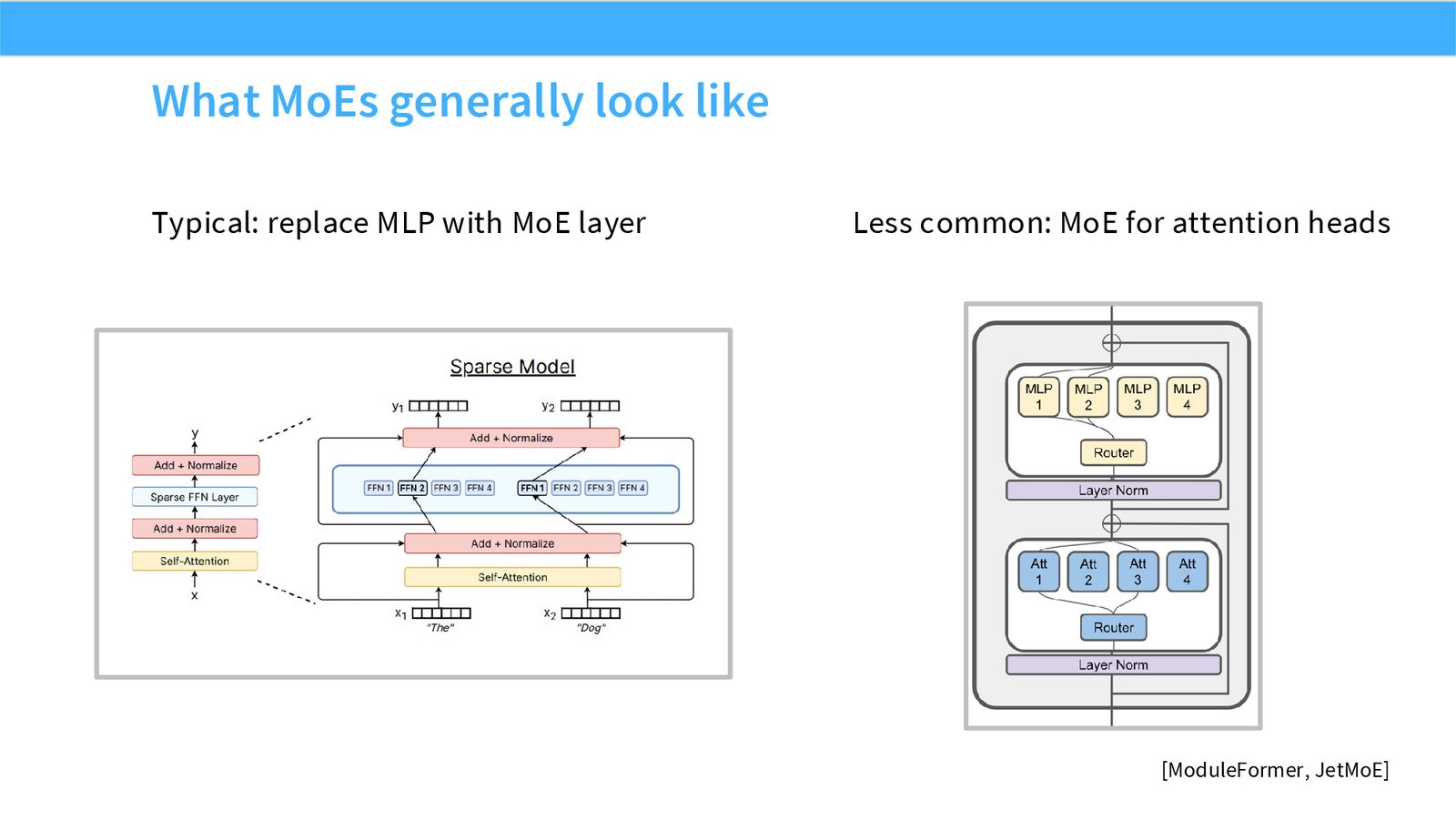
展开说明:Typical: replace MLP with MoE layer Less common: MoE for attention heads

展开说明:Routing function.
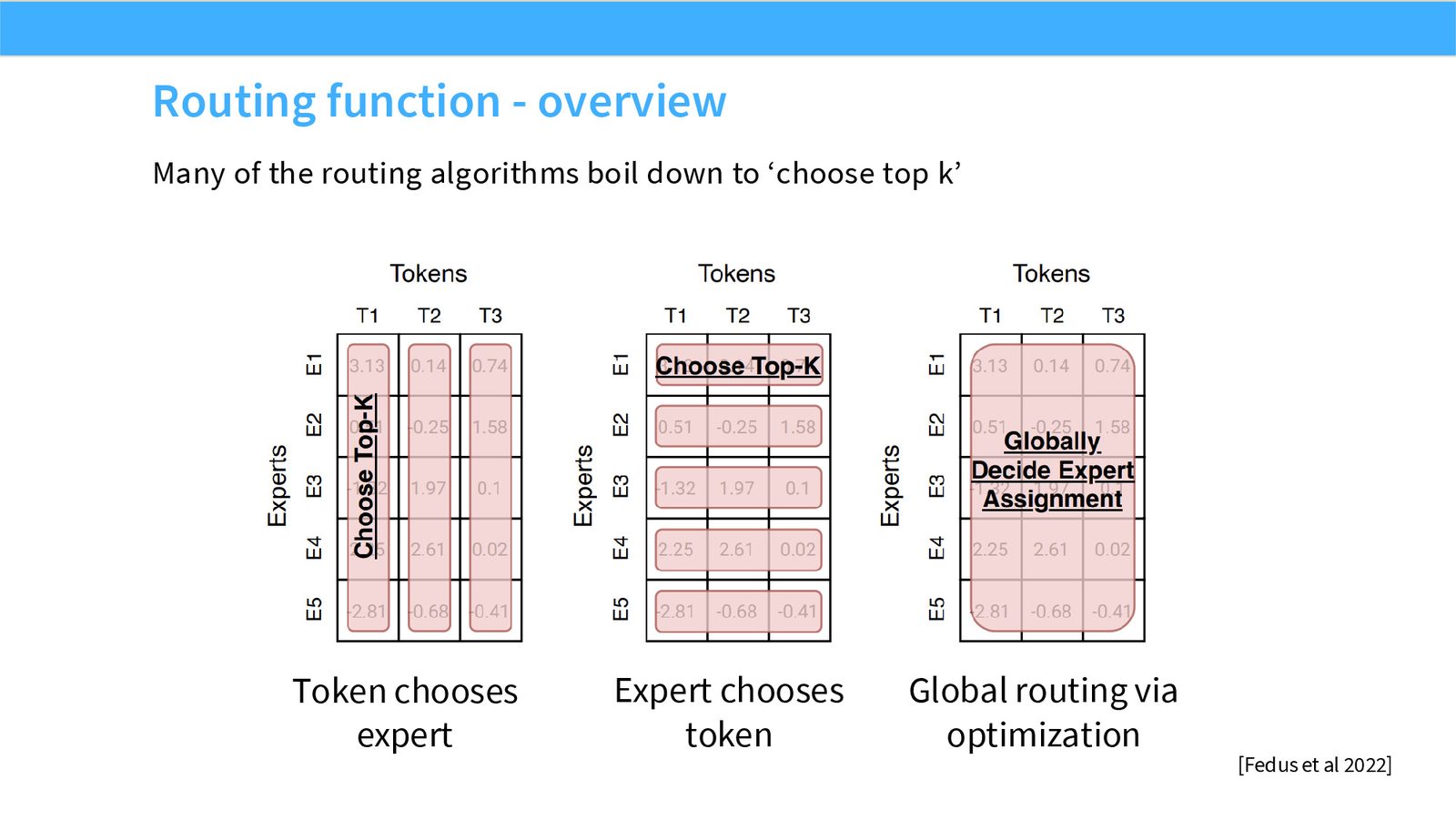
展开说明:Many of the routing algorithms boil down to ‘choose top k’
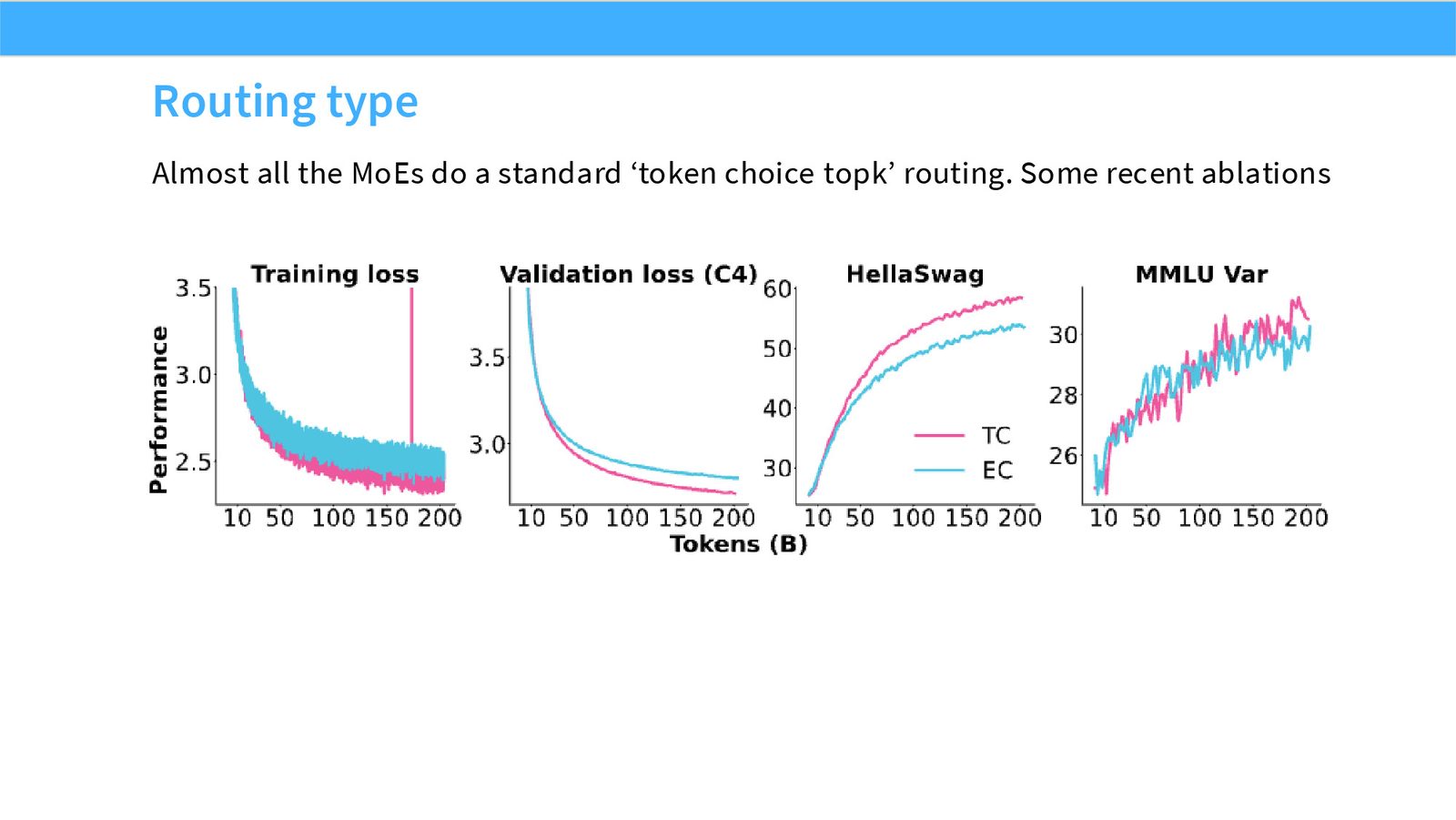
展开说明:Almost all the MoEs do a standard ‘token choice topk’ routing. Some recent ablations
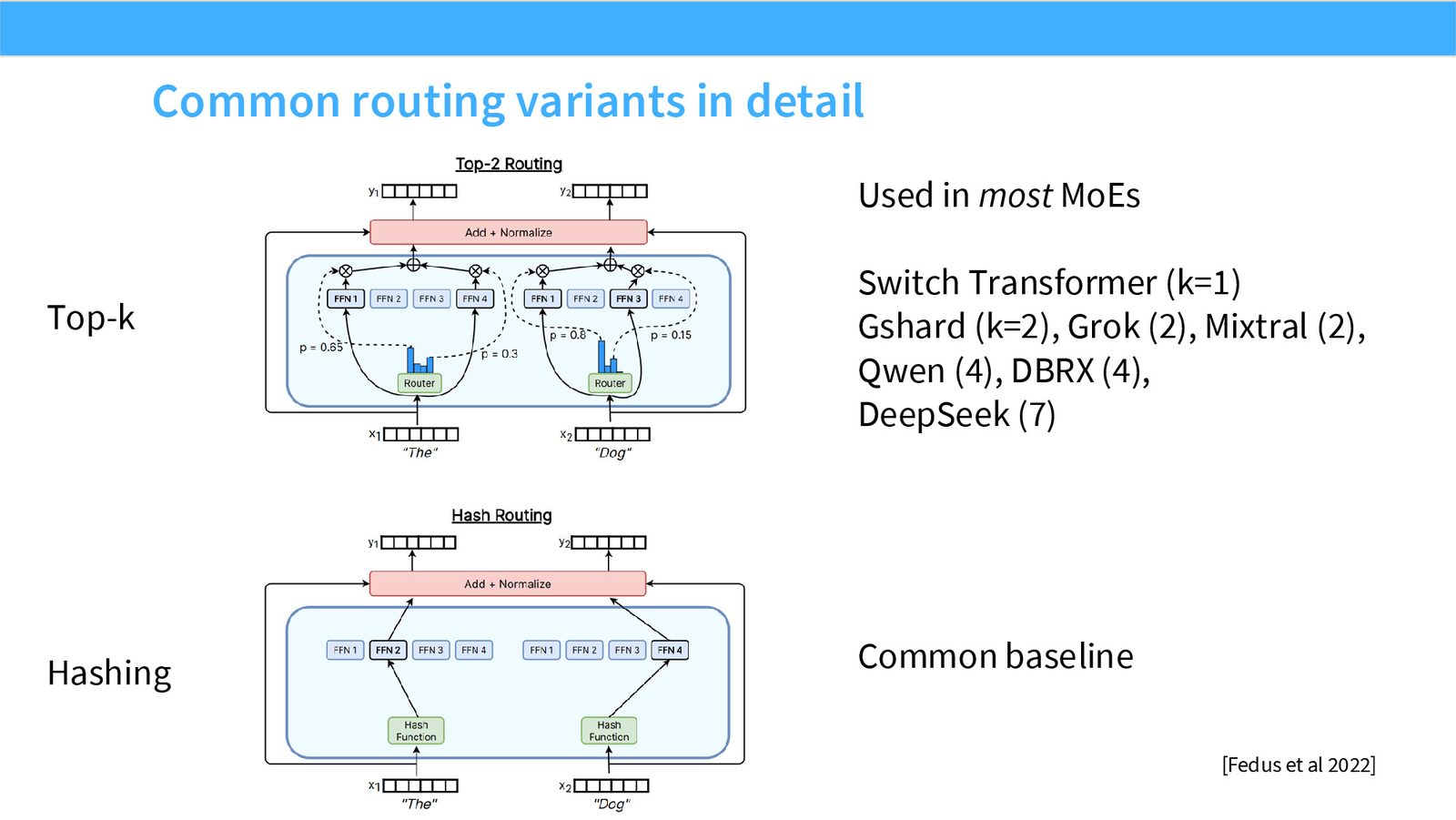
展开说明:Used in most MoEs
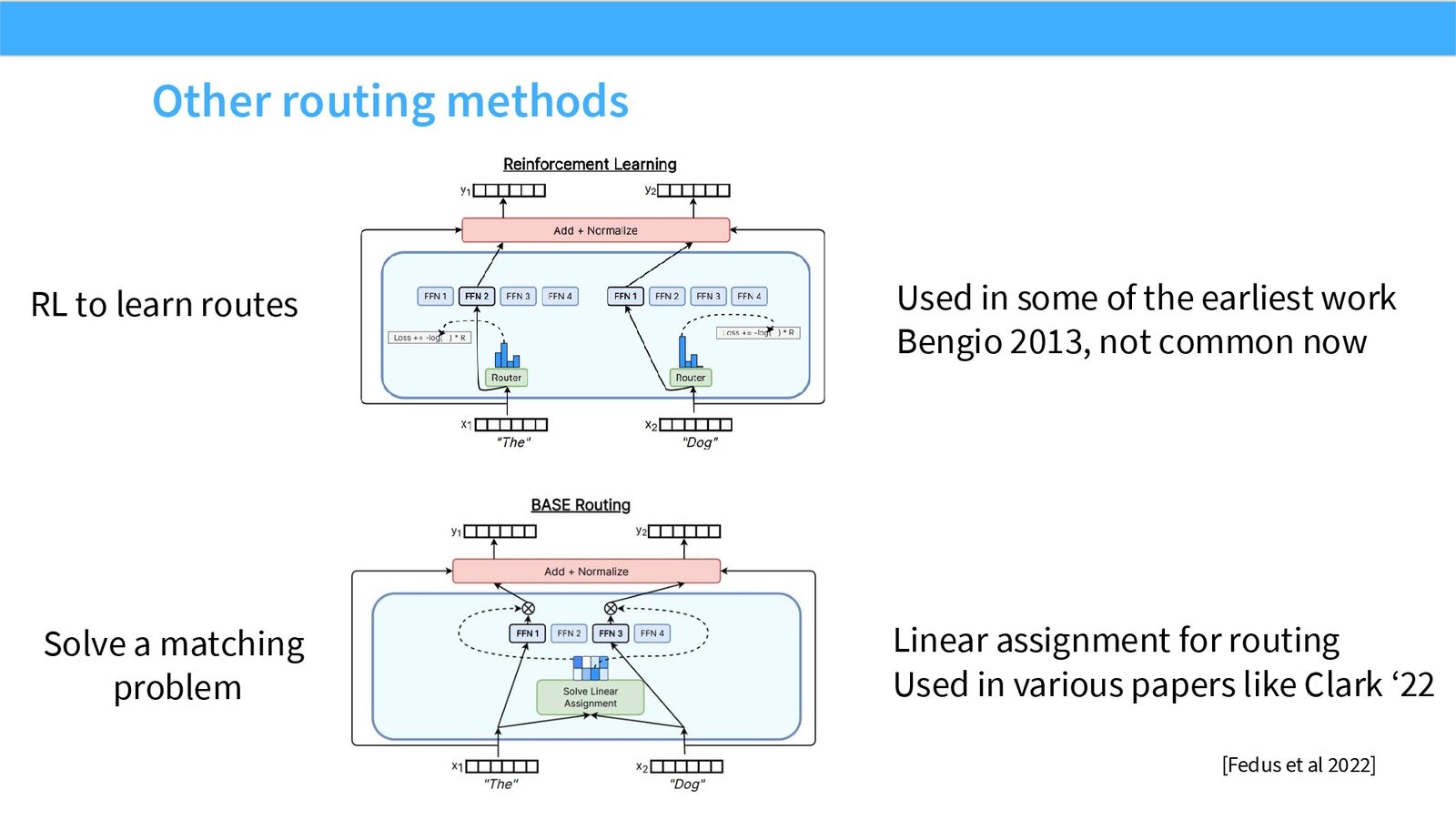
展开说明:RL to learn routes Used in some of the earliest work

展开说明:Most papers do the old and classic top-k routing. How does this work?
读图:Slide 31 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
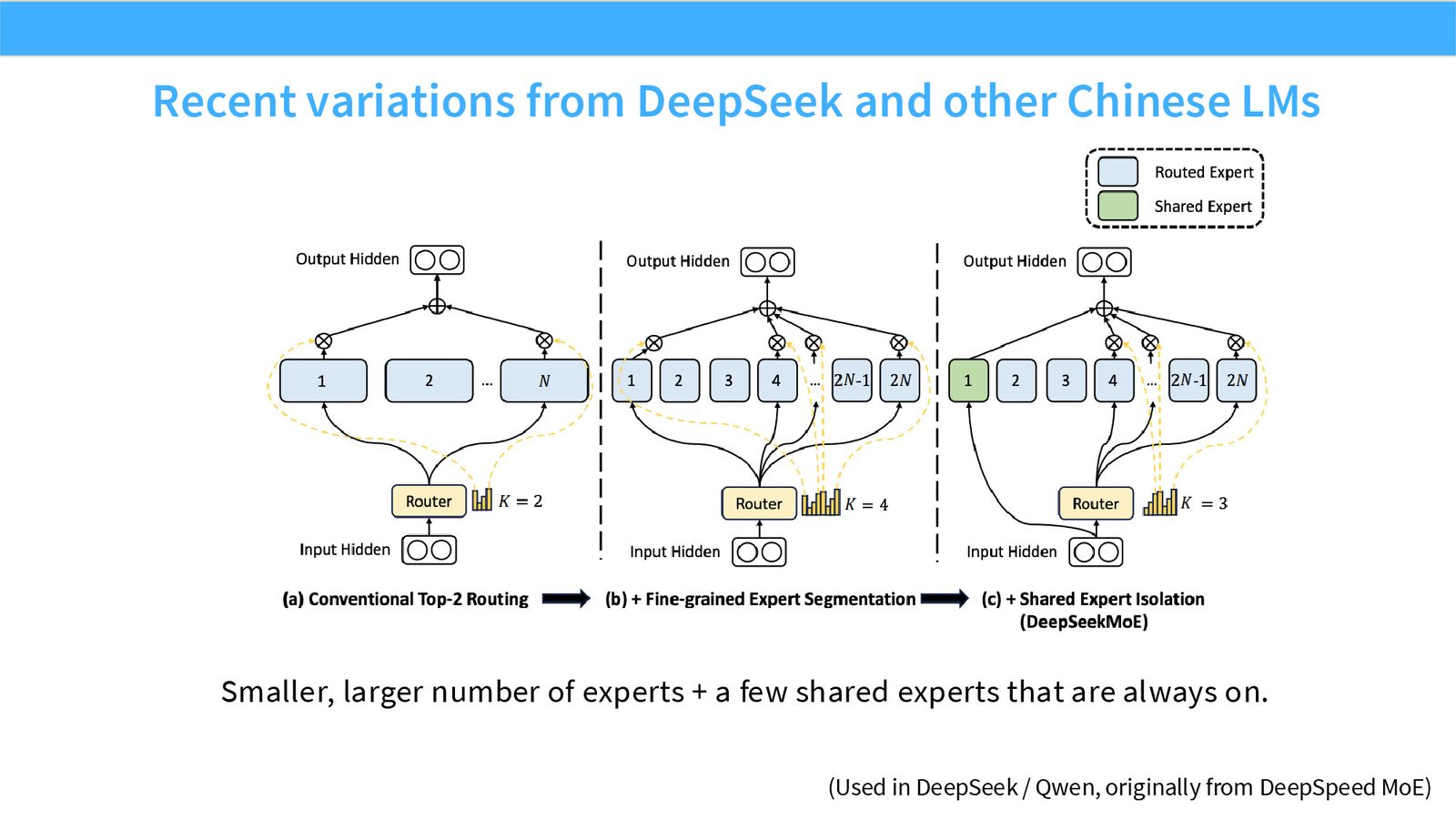
展开说明:Smaller, larger number of experts + a few shared experts that are always on.
读图:Slide 32 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
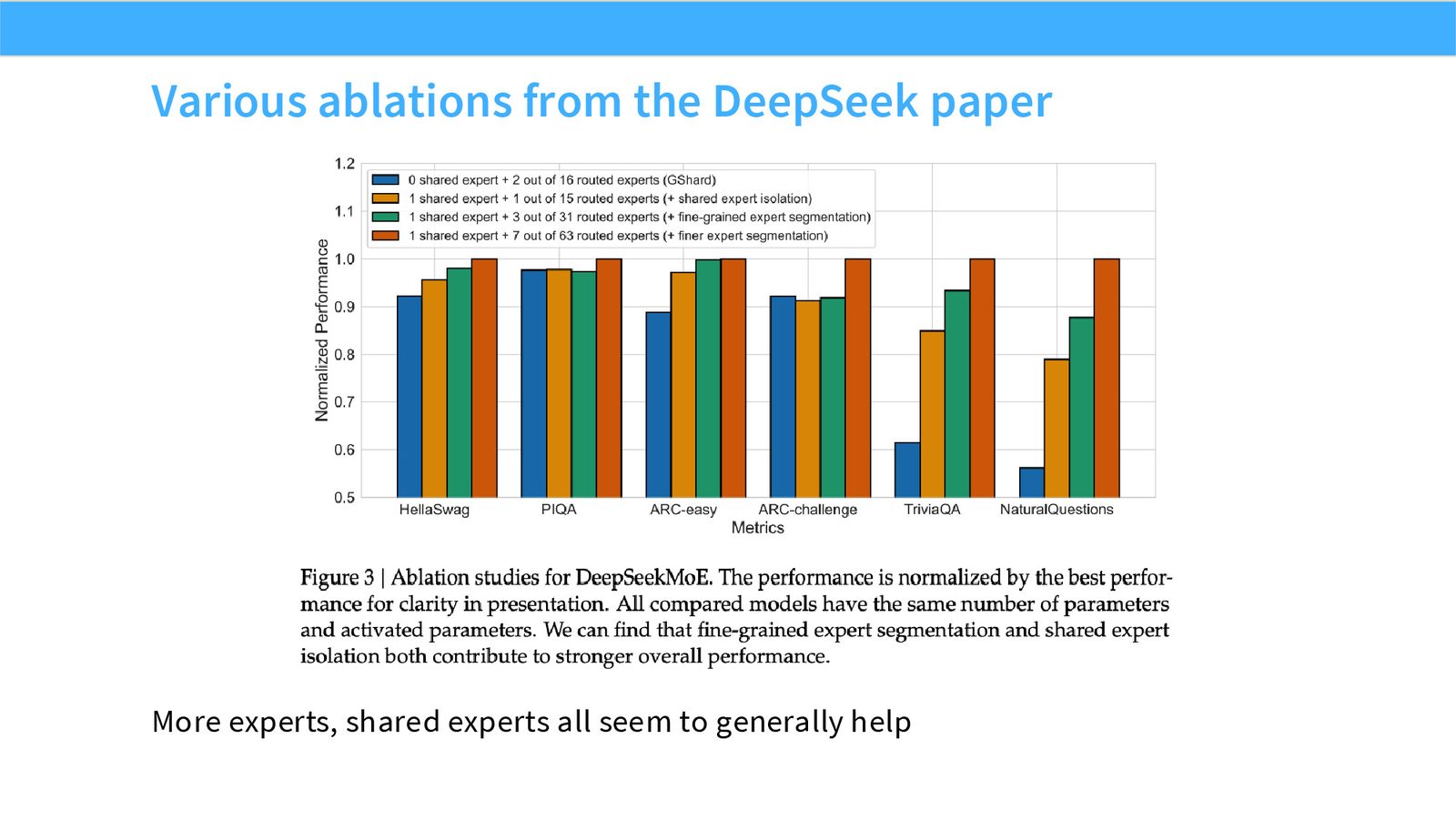
展开说明:More experts, shared experts all seem to generally help
读图:Slide 33 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
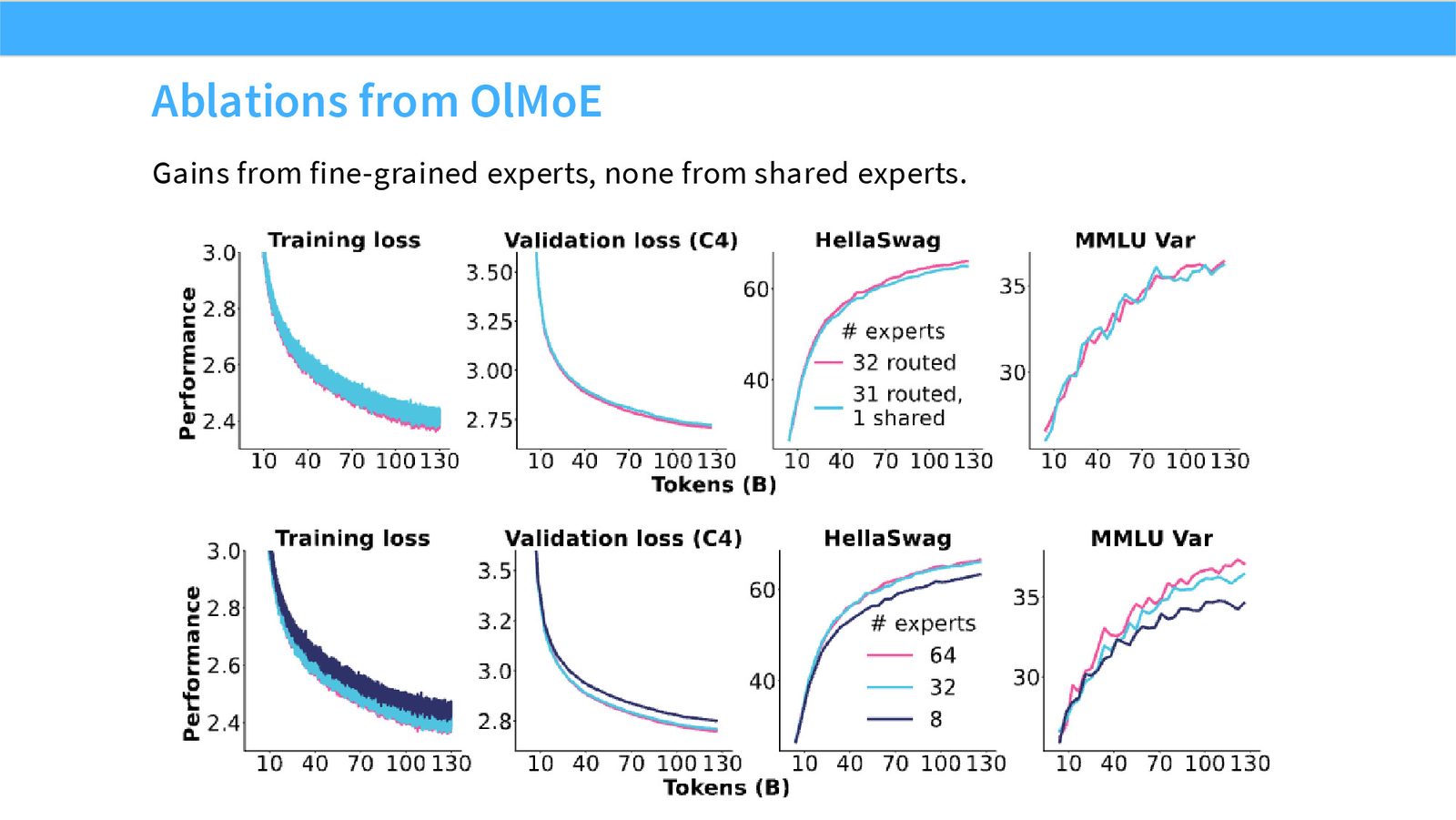
展开说明:Gains from fine-grained experts, none from shared experts.
读图:Slide 34 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
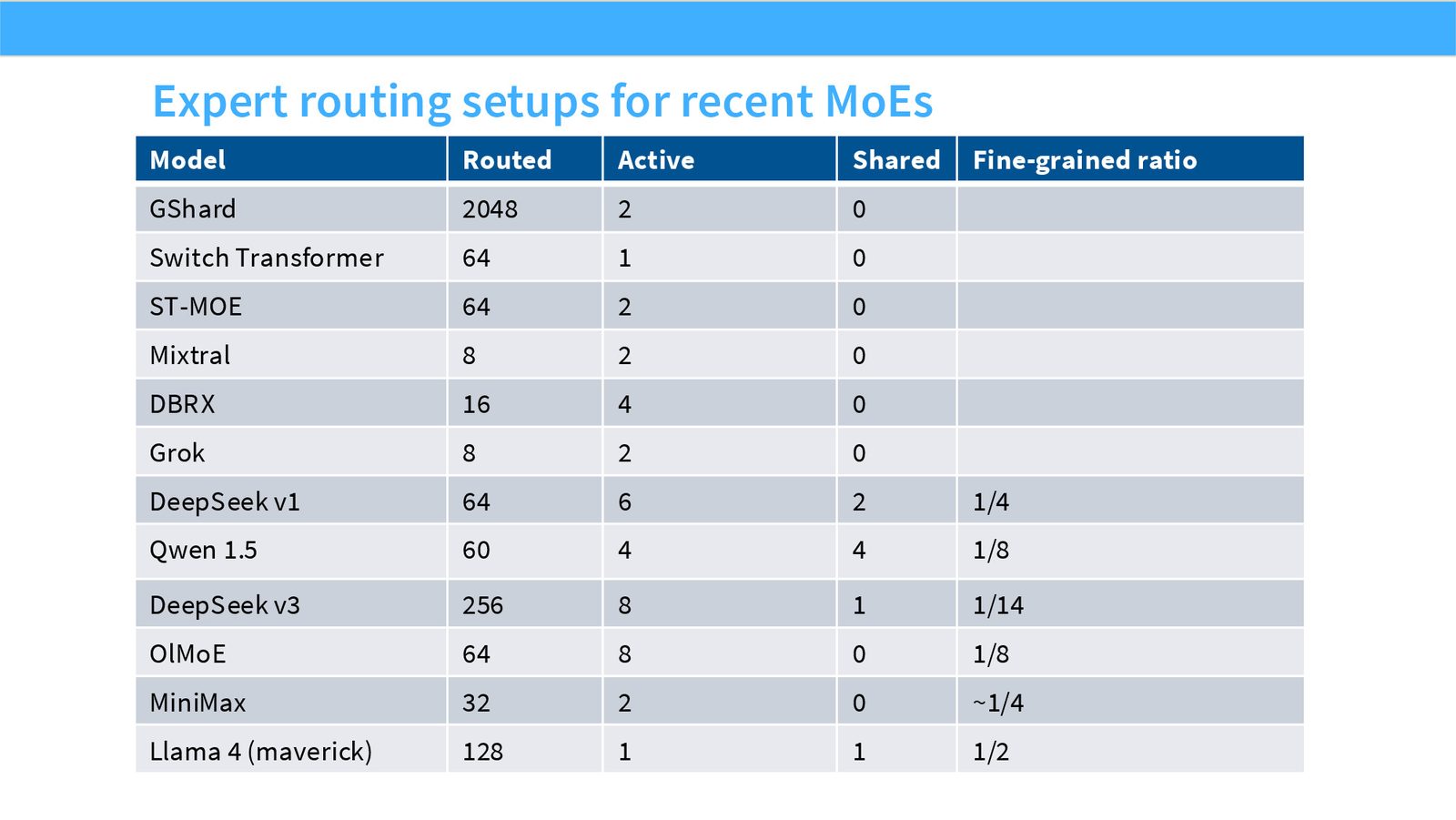
展开说明:Model Routed Active Shared Fine-grained ratio
读图:Slide 35 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
Training MoEs:负载均衡、随机路由与系统效率
本节处理 MoE 训练的核心难题:既要稀疏计算,又要专家负载均衡,还要保持可训练稳定。
MoE 训练的核心矛盾
MoE 想要稀疏激活来省 FLOPs,但系统效率要求 experts 被均匀使用。如果 router 总把 token 发给少数 experts,就会出现负载不均、通信拥塞、部分 experts 欠训练。

展开说明:Major challenge: we need sparsity for training-time efficiency…
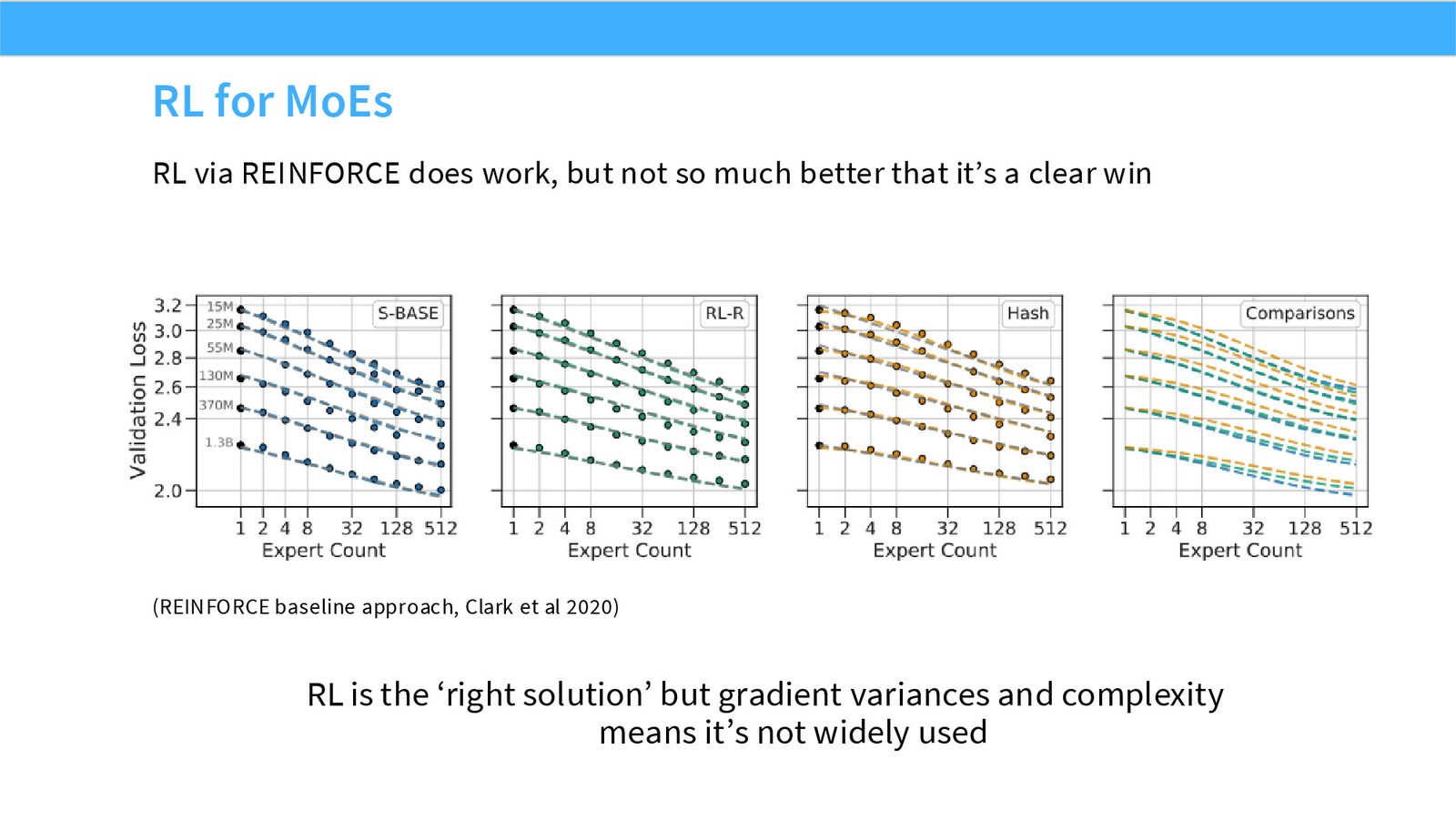
展开说明:RL via REINFORCE does work, but not so much better that it’s a clear win

展开说明:From Shazeer et al 2017 – routing decisions are stochastic with gaussian perturbations.

展开说明:Stochastic jitter in Fedus et al 2022. This does a uniform multiplicative perturbation for the

展开说明:Another key issue – systems efficiency requires that we use experts evenly..
读图:Slide 40 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
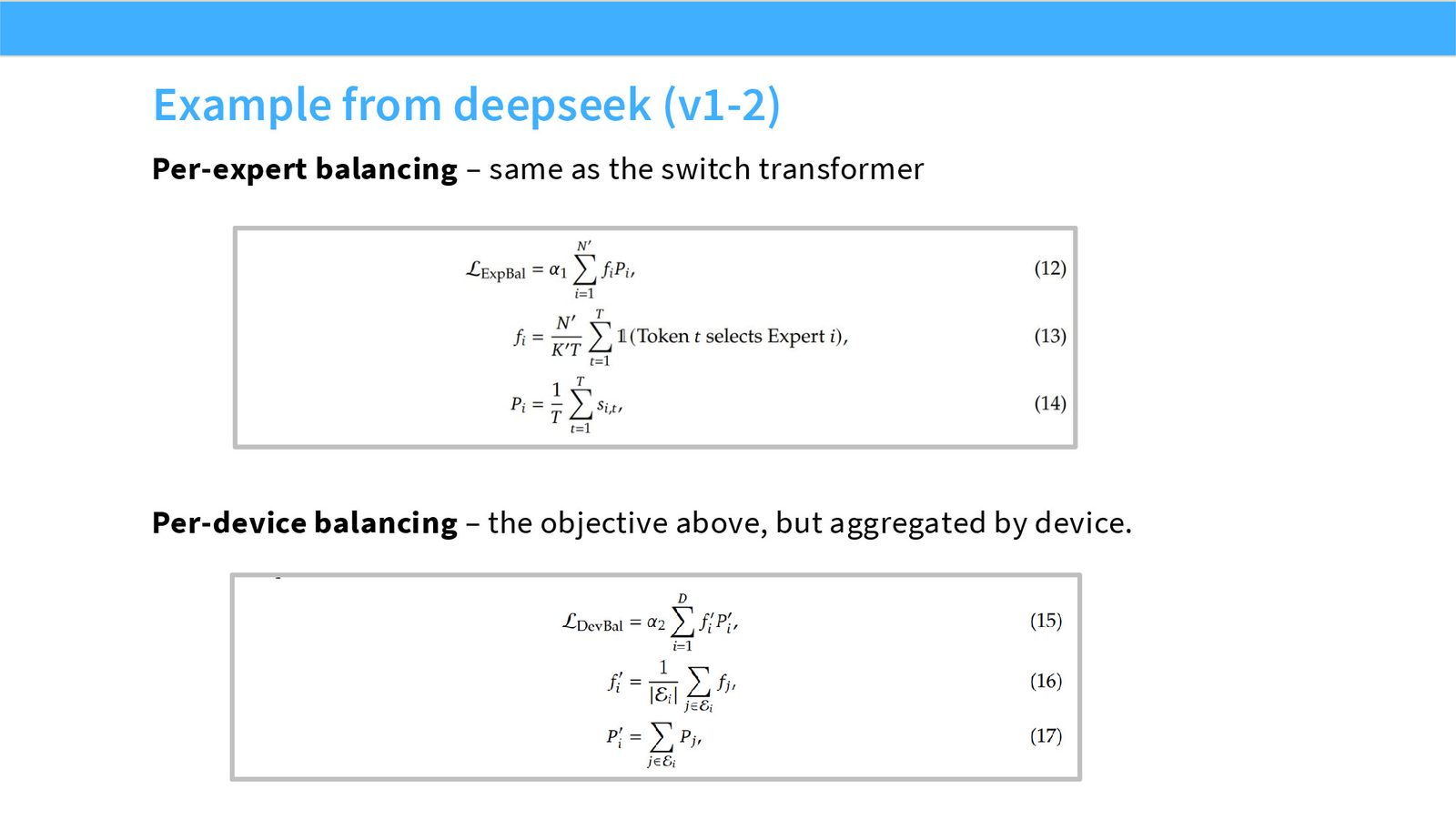
展开说明:Per-expert balancing – same as the switch transformer
读图:Slide 41 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。

展开说明:Set up a per-expert bias (making it more likely to get tokens) and use online learning
读图:Slide 42 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
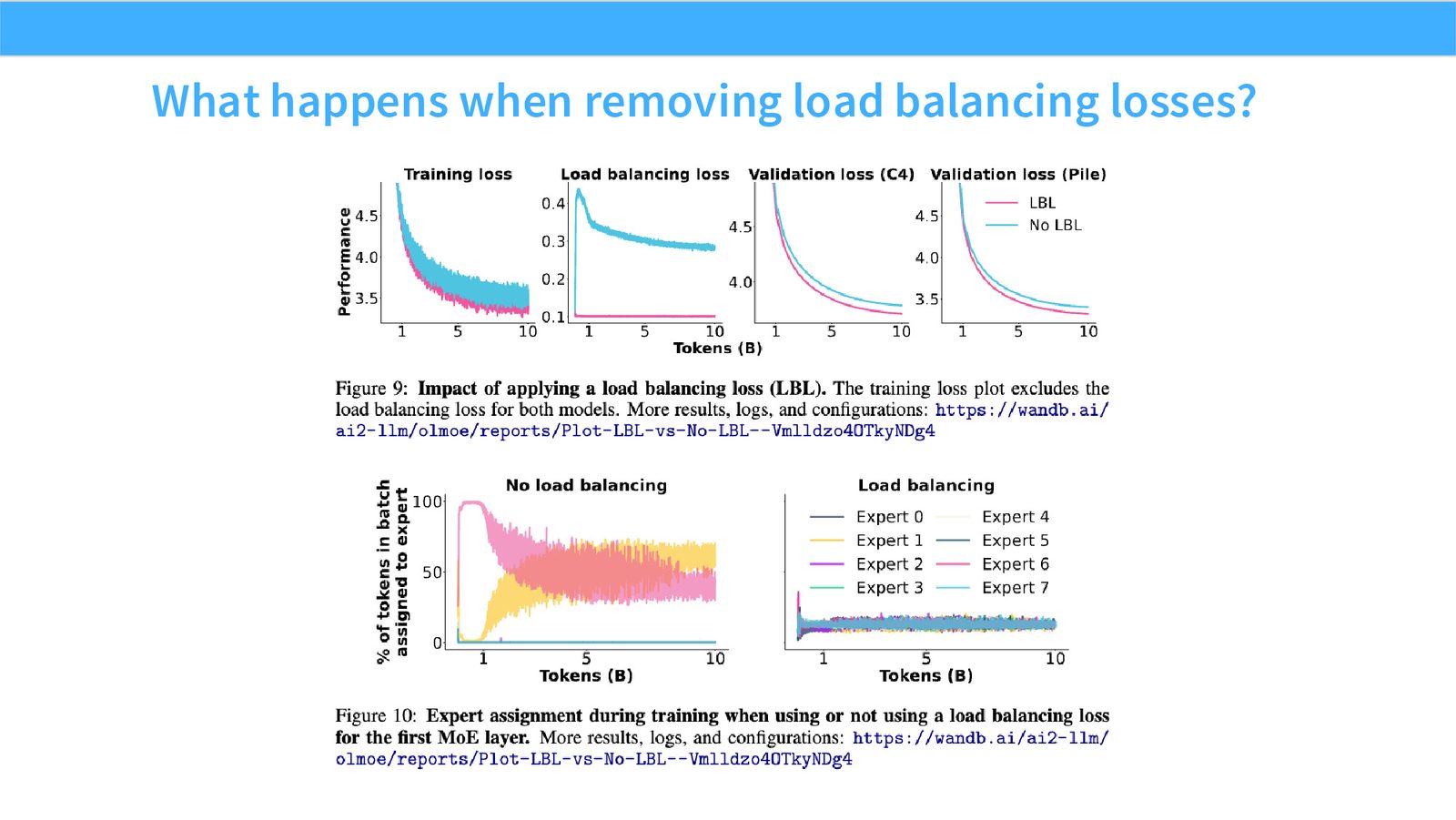
展开说明:What happens when removing load balancing losses?
读图:Slide 43 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
MoE systems side:expert parallelism 与通信
本节解释 MoE 作为系统问题:all-to-all dispatch、expert parallelism、通信压缩和随机性。
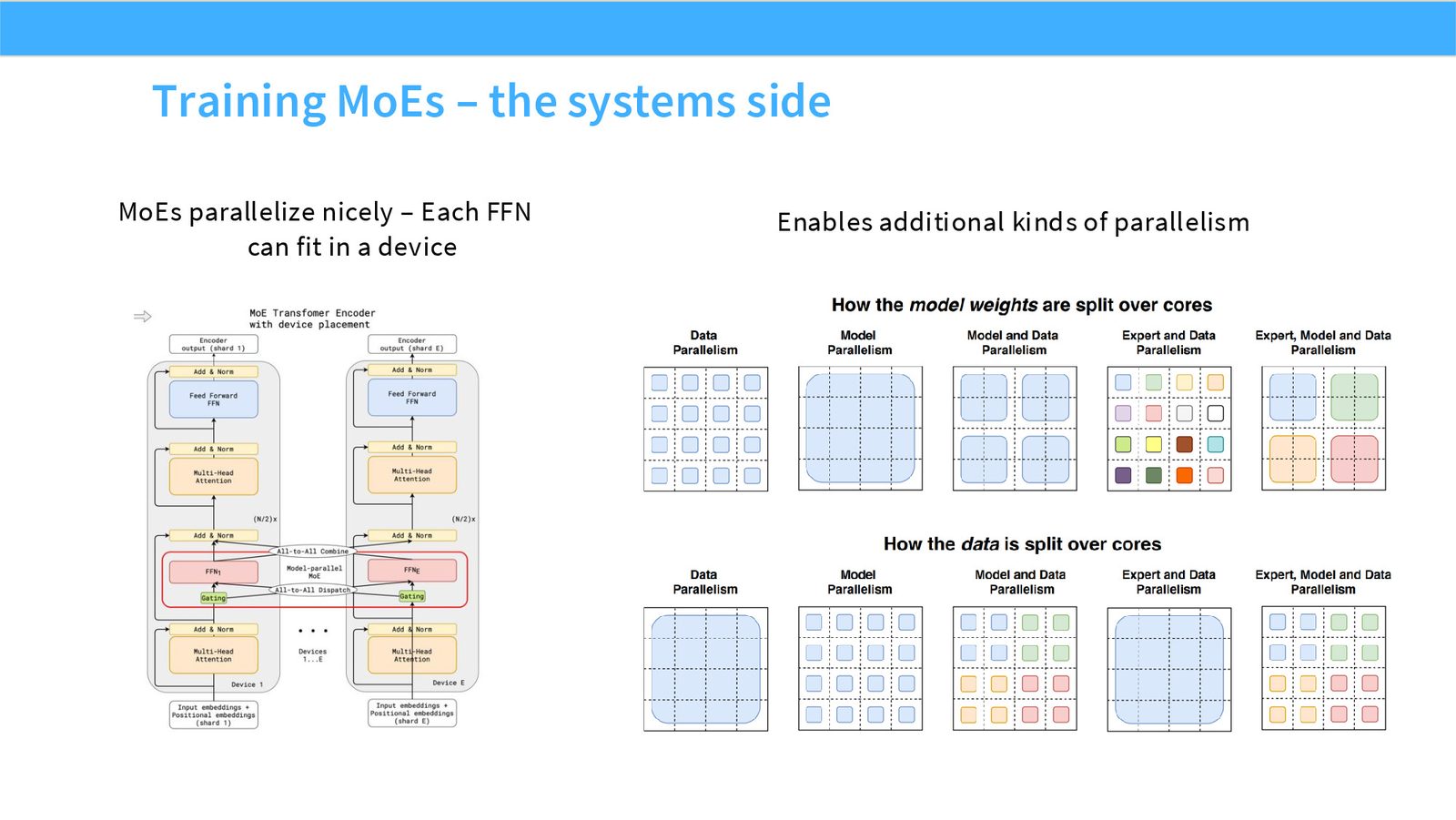
展开说明:MoEs parallelize nicely – Each FFN Enables additional kinds of parallelism
读图:Slide 44 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
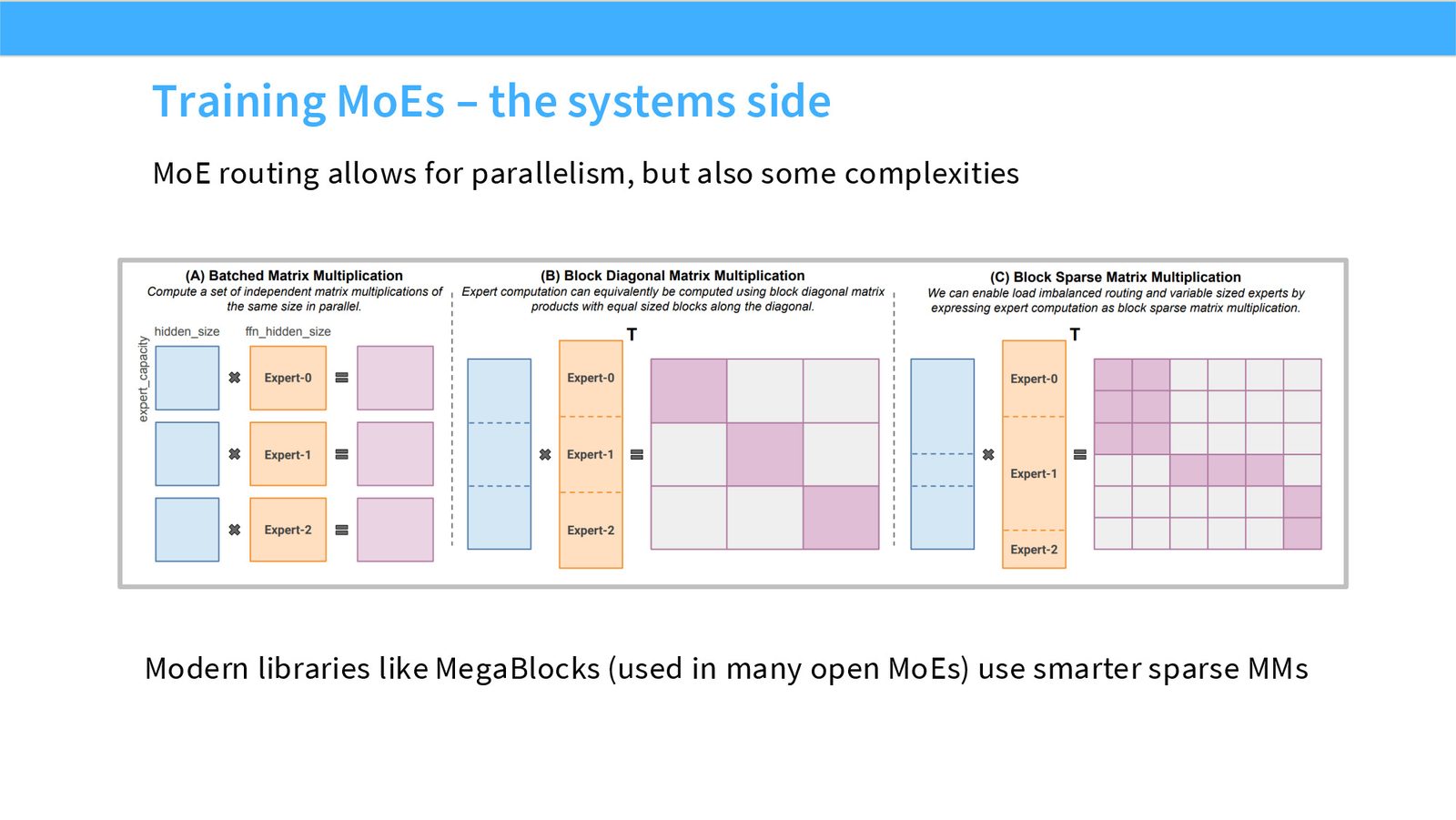
展开说明:MoE routing allows for parallelism, but also some complexities
读图:Slide 45 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
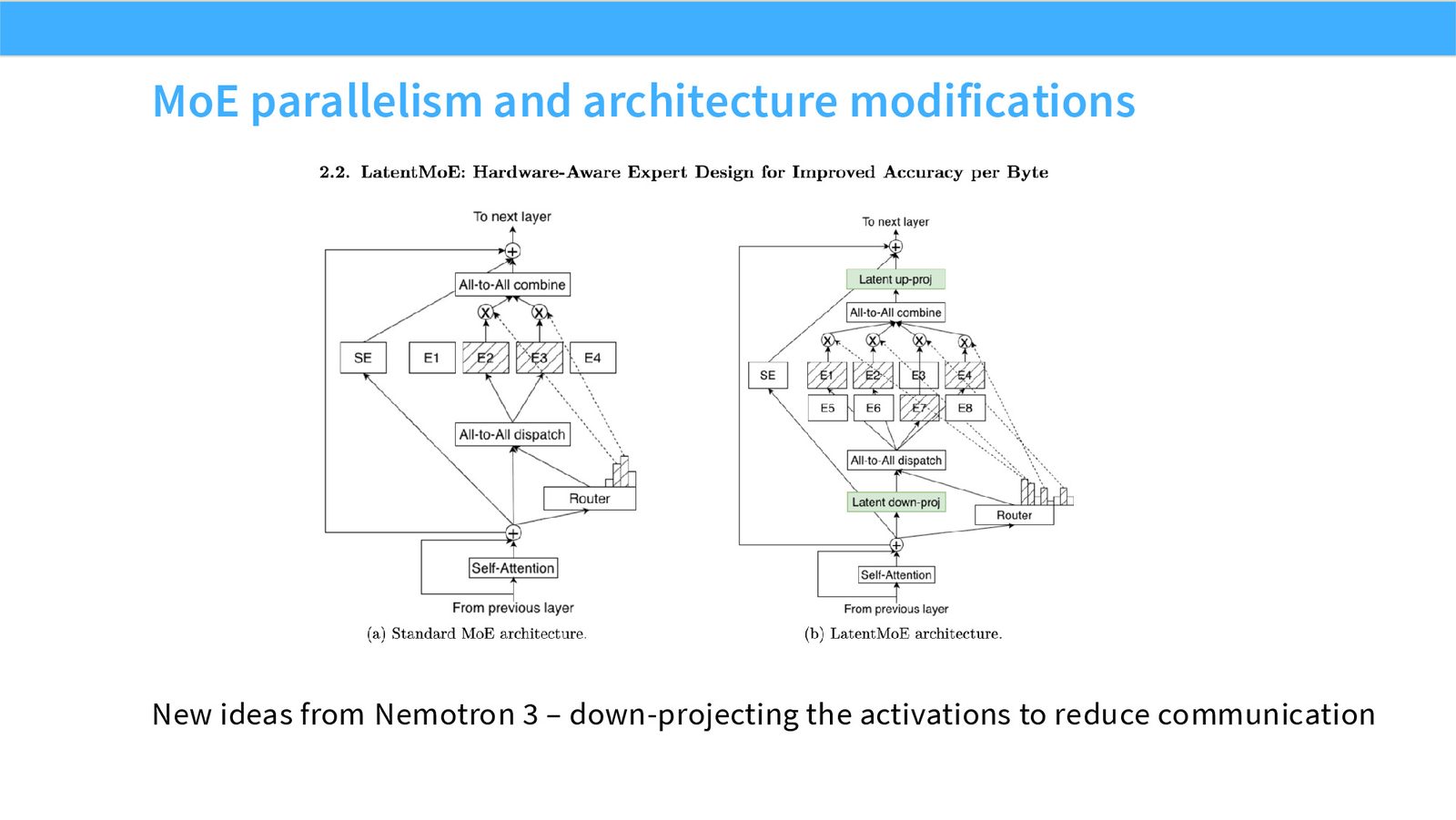
展开说明:New ideas from Nemotron 3 – down-projecting the activations to reduce communication
读图:Slide 46 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
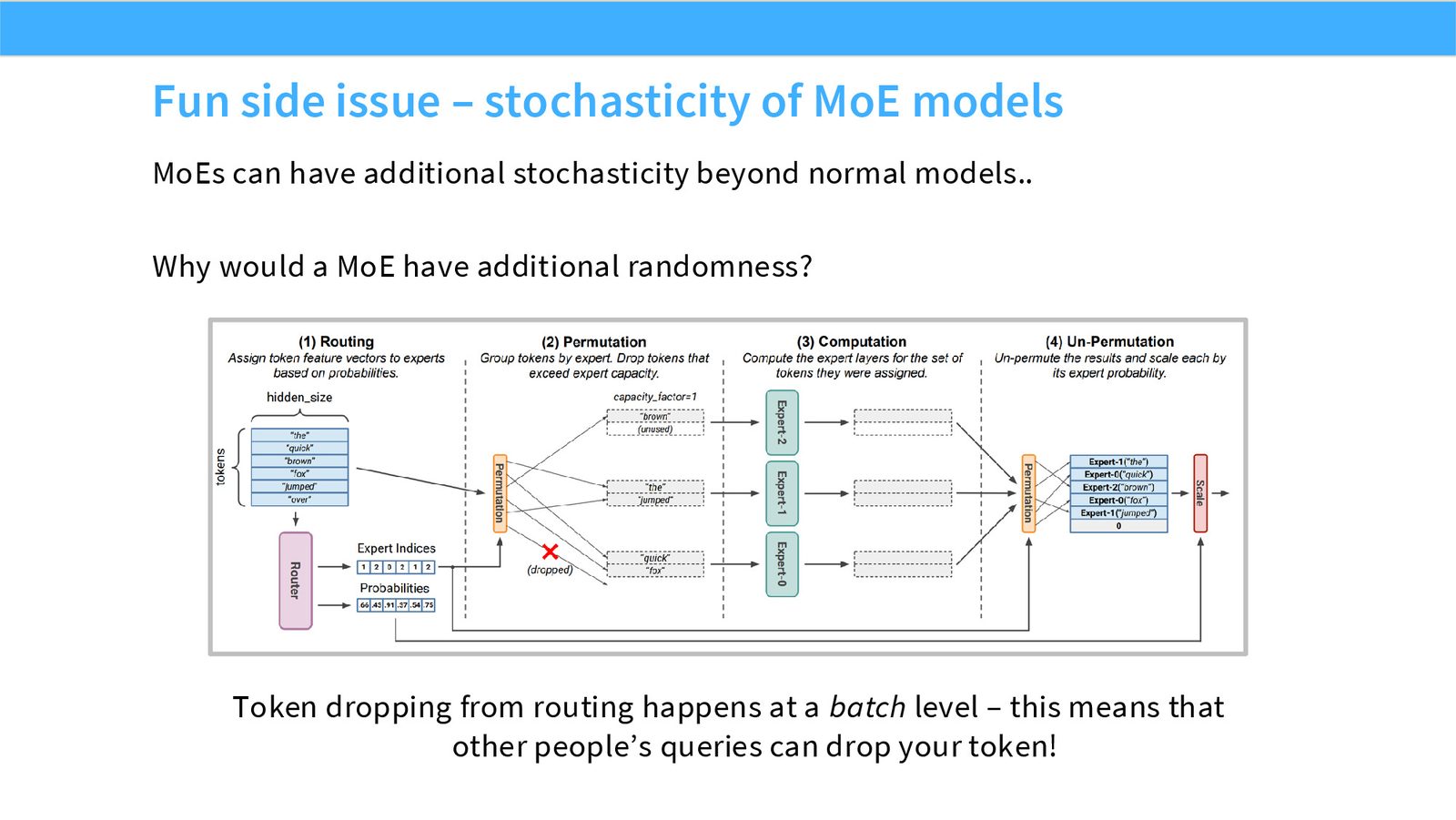
展开说明:MoEs can have additional stochasticity beyond normal models..
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
MoE 稳定性、fine-tuning 与 upcycling
本节解释 router z-loss、fine-tuning overfit、dense-to-MoE upcycling。

展开说明:[Zoph 2022]
读图:Slide 48 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
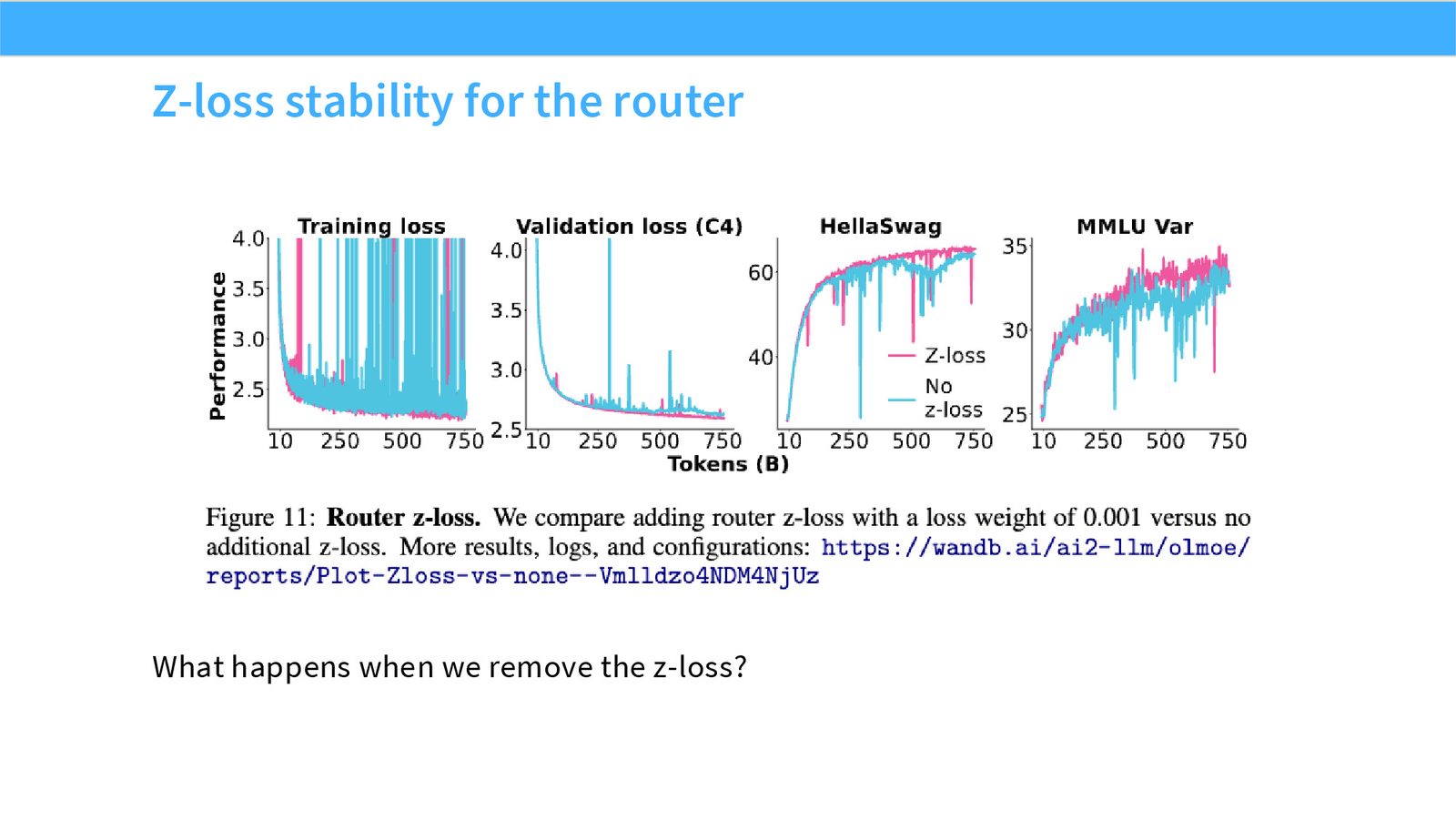
展开说明:What happens when we remove the z-loss?
读图:Slide 49 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
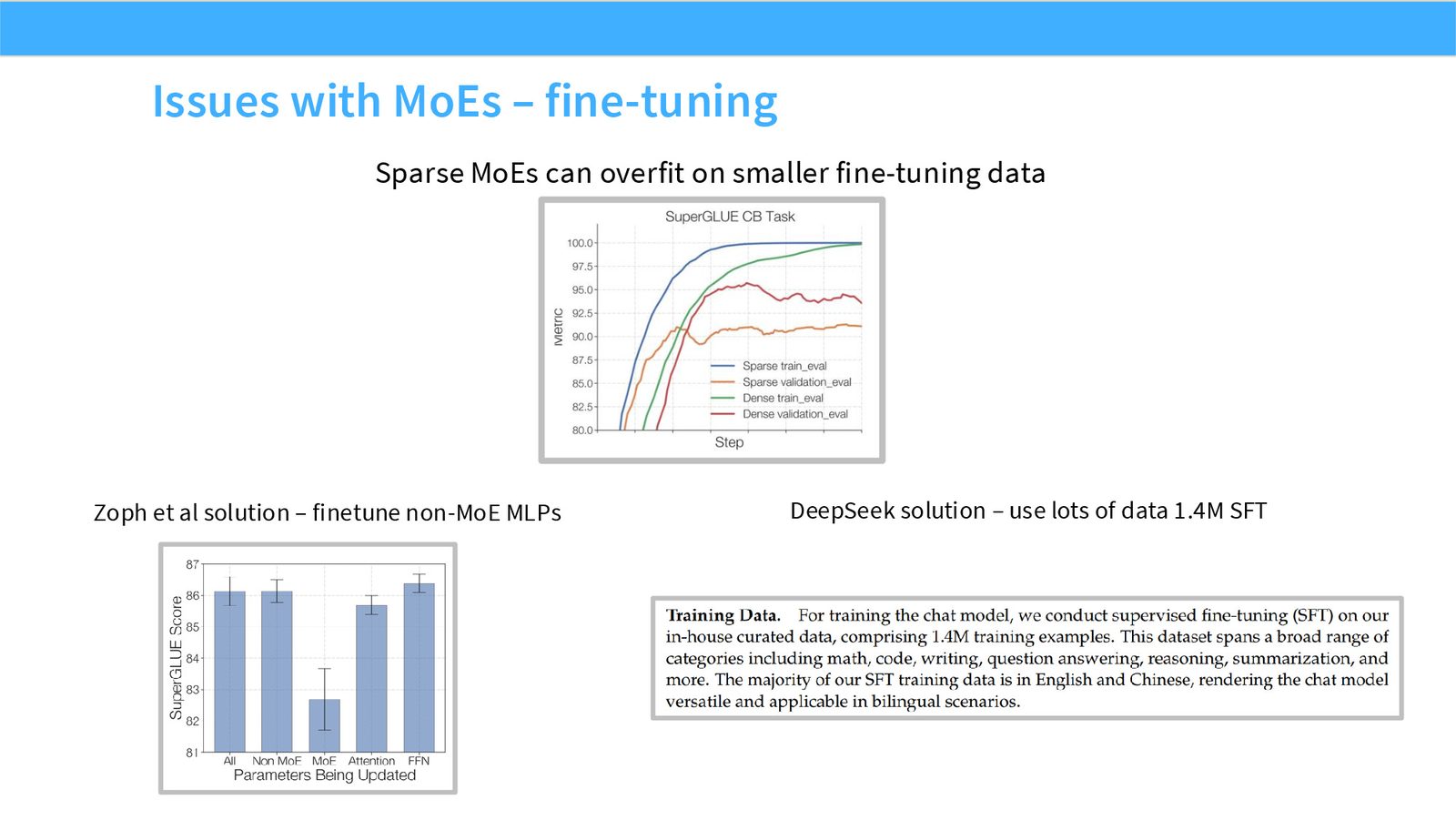
展开说明:Sparse MoEs can overfit on smaller fine-tuning data
读图:Slide 50 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
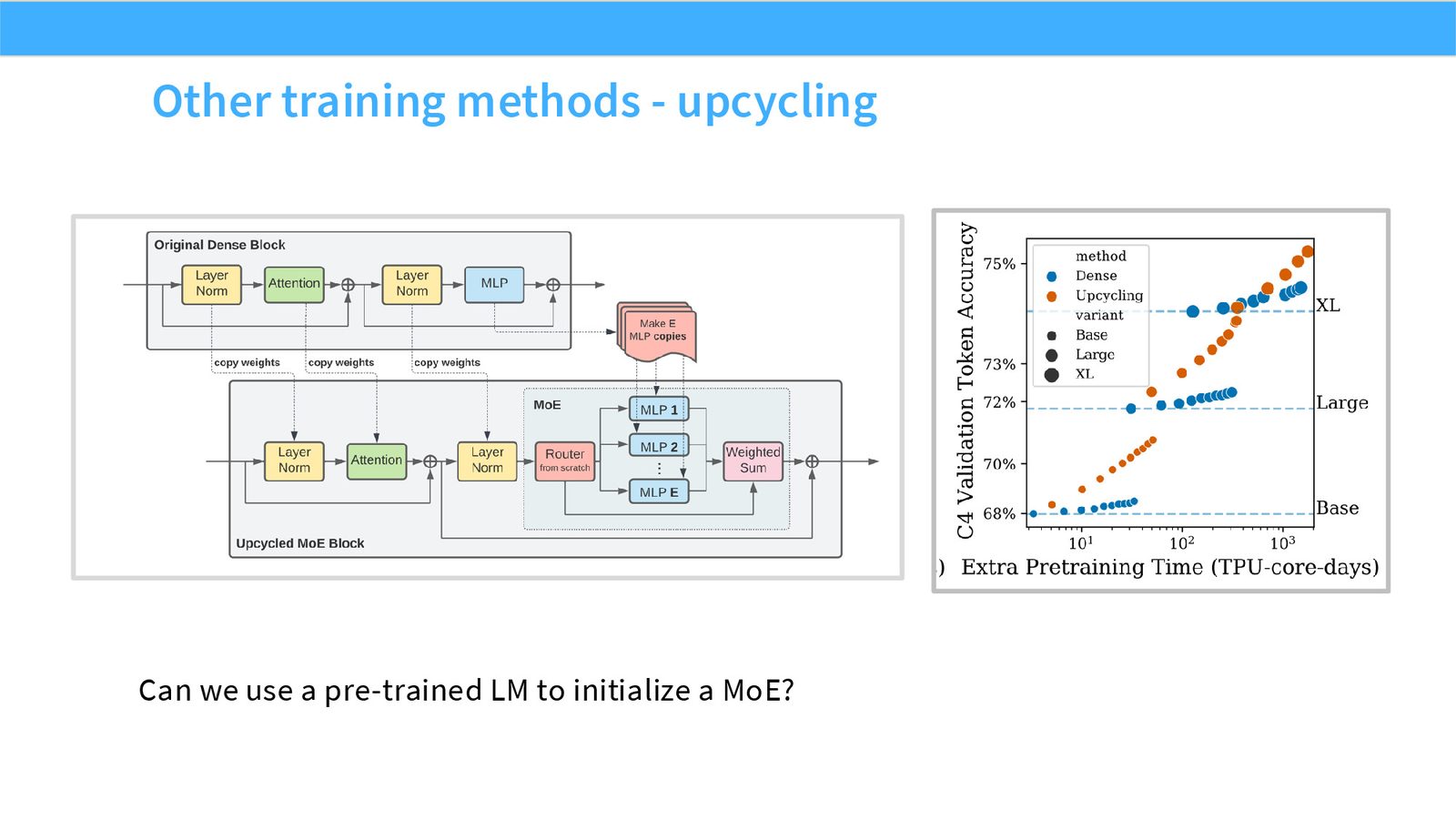
展开说明:Can we use a pre-trained LM to initialize a MoE?
读图:Slide 51 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。

展开说明:Uses the MiniCPM model (topk=2, 8 experts, 4B active params).
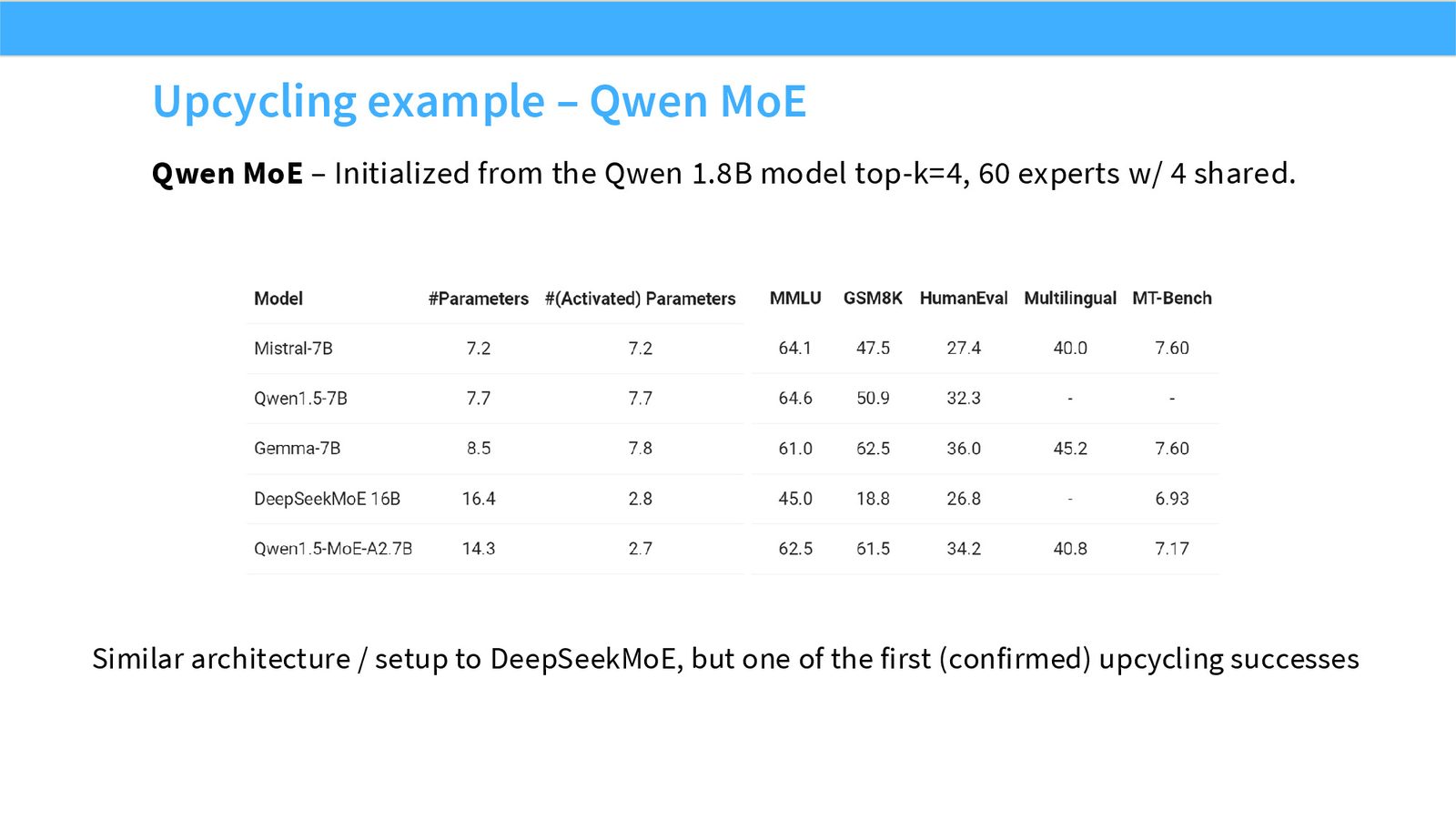
展开说明:Qwen MoE – Initialized from the Qwen 1.8B model top-k=4, 60 experts w/ 4 shared.
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
DeepSeek MoE case study:MoE、MLA、MTP 的组合
本节把 DeepSeek v1/v2/v3 作为案例,观察 shared experts、fine-grained experts、MLA 和 MTP 如何组合。
first-use glossary:MLA 与 MTP
MLA 是 Multi-head Latent Attention,把 K/V cache 压缩为低维 latent 后再投影恢复,降低长上下文推理内存。MTP 是 Multi-Token Prediction,让轻量模块预测多个未来 token,可用于改善训练信号或推理草稿。DeepSeek v3 把 MoE、MLA、MTP 等选择组合成一套系统 recipe。
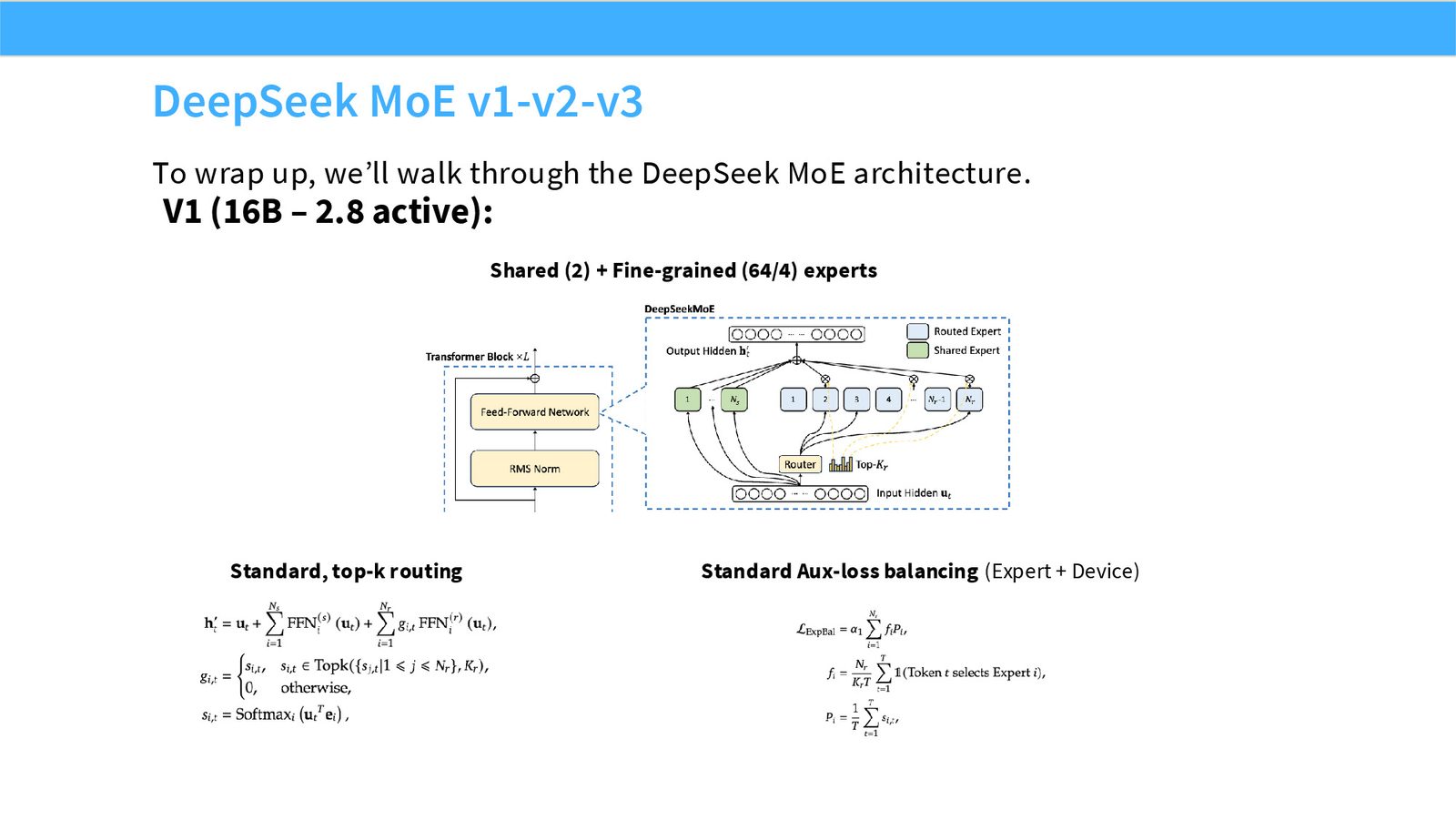
展开说明:To wrap up, we’ll walk through the DeepSeek MoE architecture.
读图:Slide 54 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
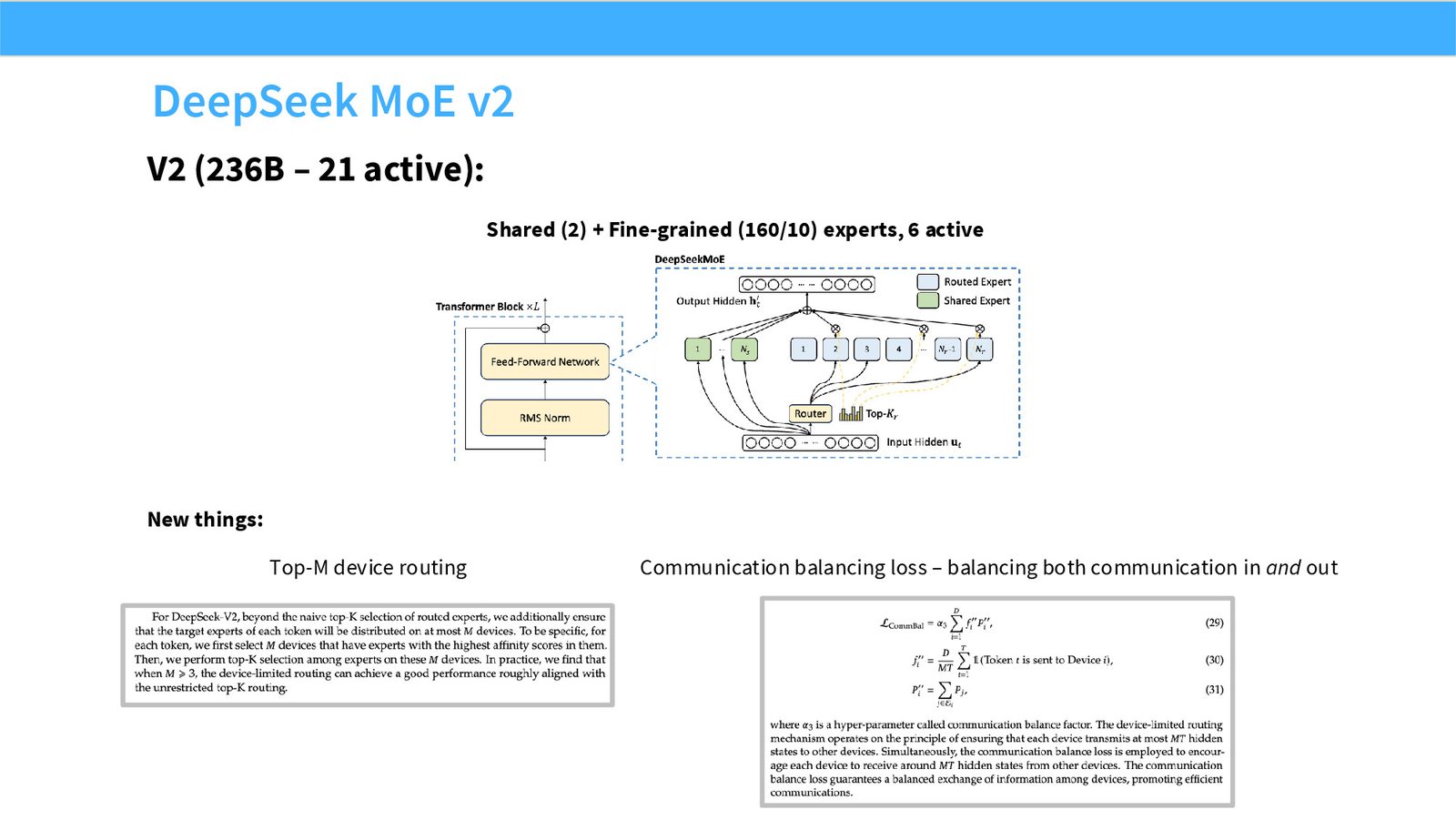
展开说明:V2 (236B – 21 active):
读图:Slide 55 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
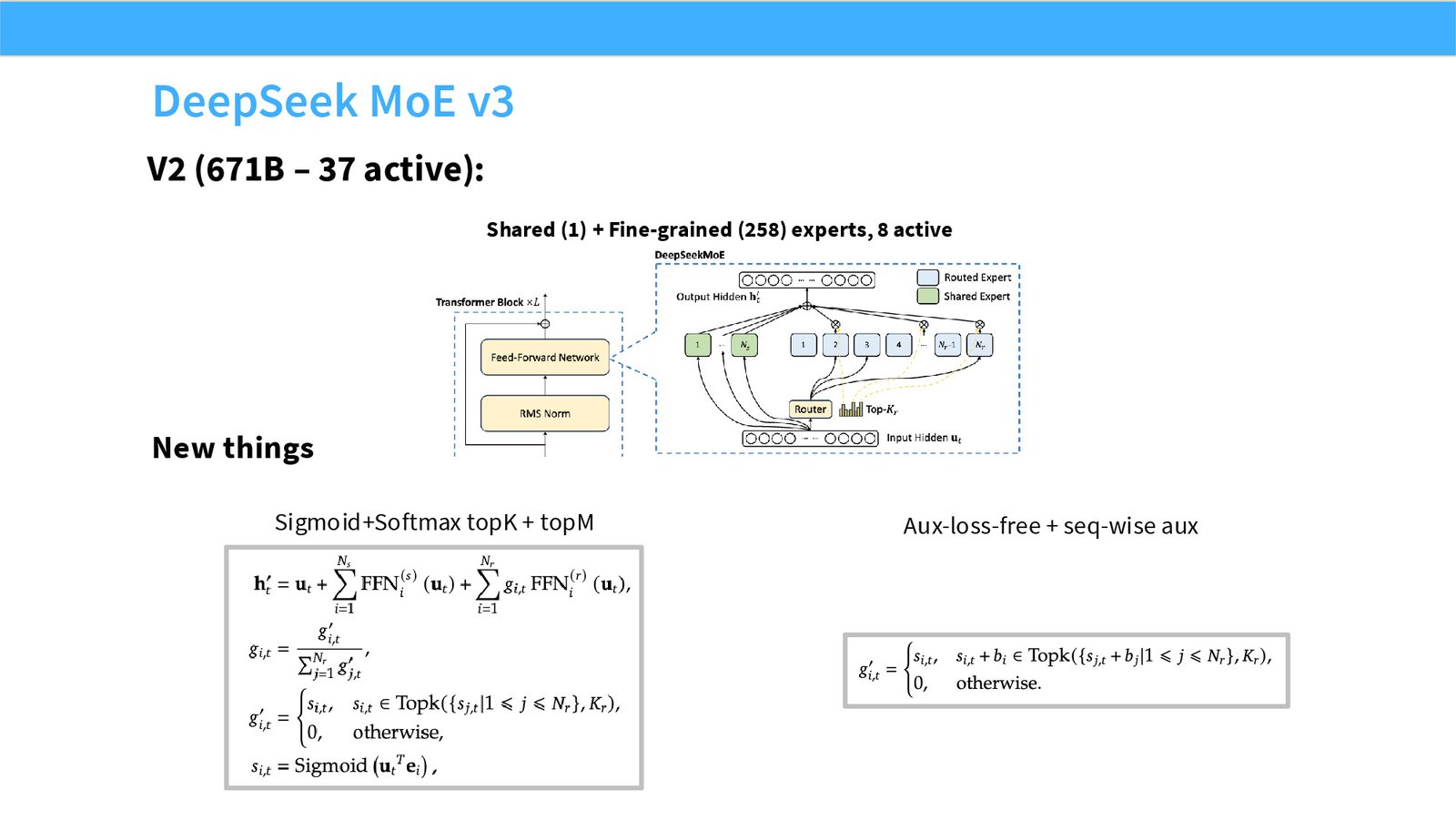
展开说明:V2 (671B – 37 active):
读图:Slide 56 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
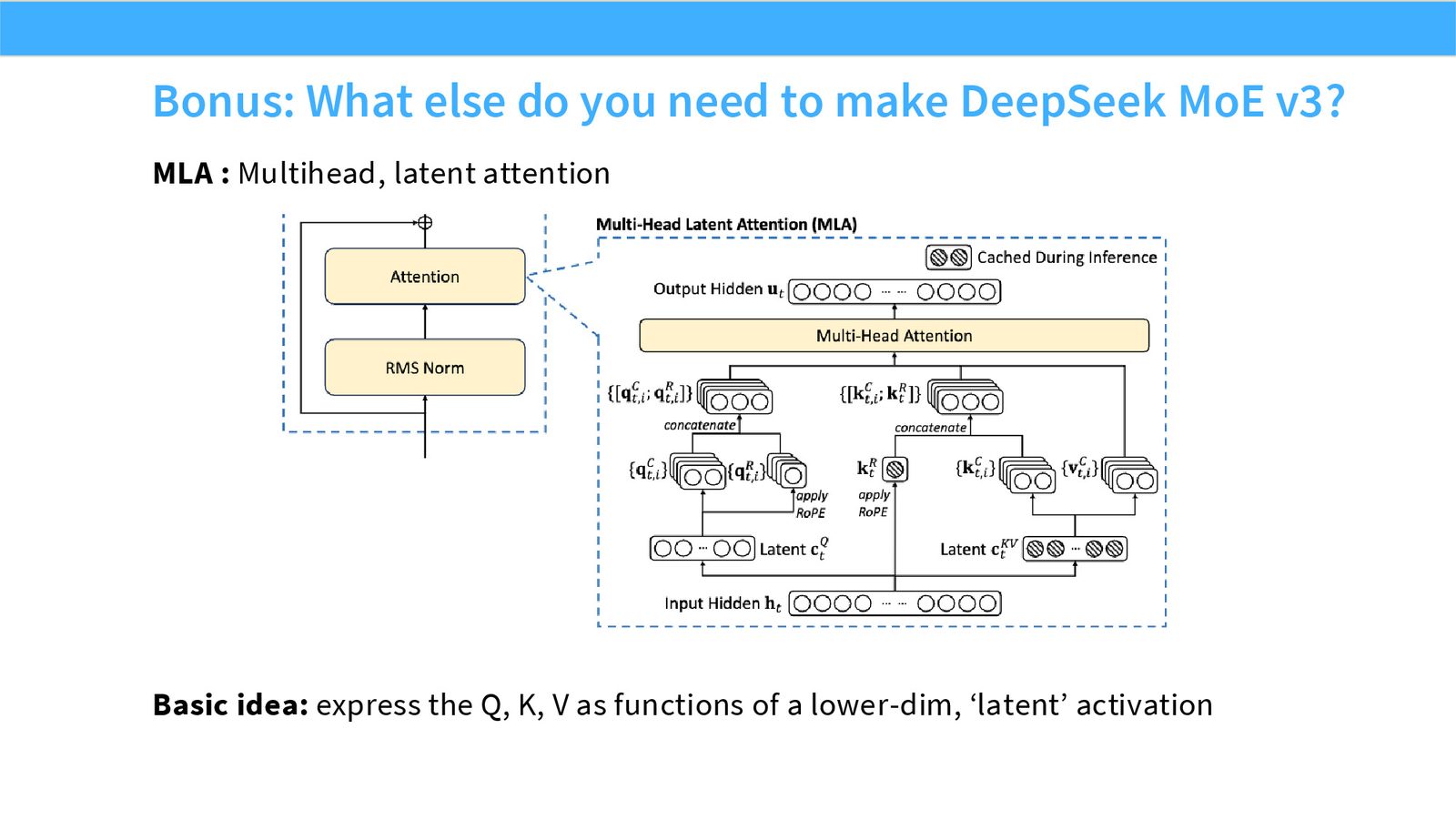
展开说明:MLA : Multihead, latent attention
读图:Slide 57 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。

展开说明:Basic idea: express the Q, K, V as functions of a lower-dim, ‘latent’ activation
读图:Slide 58 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
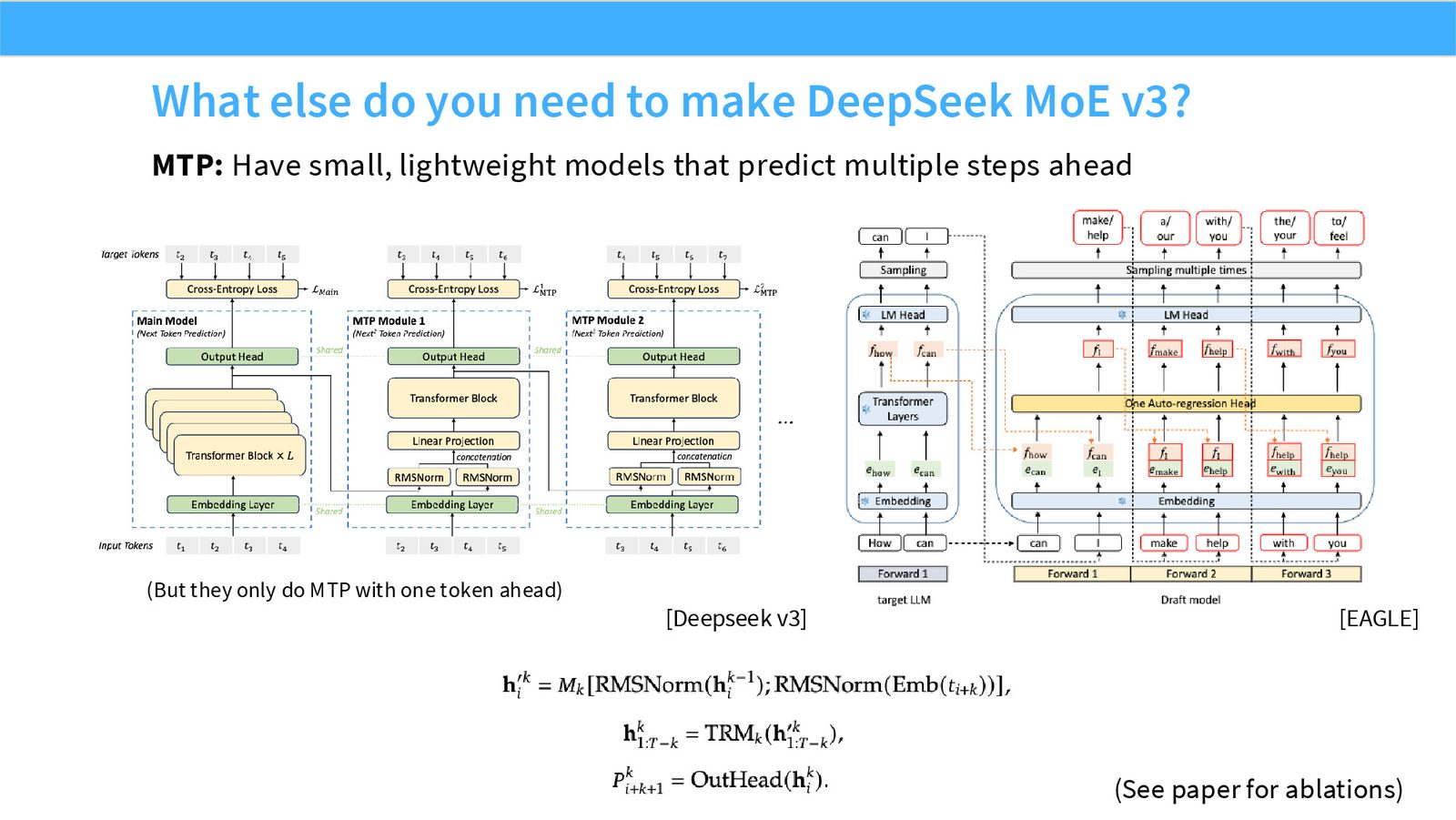
展开说明:MTP: Have small, lightweight models that predict multiple steps ahead
读图:Slide 59 应该怎么看
这页是机制或证据页。先看它比较的是 compute、参数量、routing、负载均衡还是通信;再看结论支持的是质量提升、训练速度、推理成本还是系统复杂度。MoE 和 attention alternatives 的图常把模型结构和系统代价混在一起,读图时要分清“算法机制”和“硬件执行成本”。
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
总结:Selective computation 的两条路
最后把 attention alternatives 和 MoE 统一为 selective computation:不是所有 token 都需要看所有历史,也不是所有 token 都需要激活所有参数。

展开说明:MoEs take advantage of sparsity: not all inputs need the full model.
本章小结
本节的共同线索是 selective computation:通过结构选择让 token 不必总是访问所有历史或所有参数。但选择性越强,越需要额外机制保证信息流、负载均衡和训练稳定。
综合对照:Attention alternatives 与 MoE 的共同结构
| 方向 | 省什么 | 新增什么问题 |
|---|---|---|
| Linear/state attention | 省完整 \(n^2\) attention matrix 和长上下文读写 | 状态表达力、长程依赖、与 full attention 的混合比例。 |
| Sparse/local attention | 省远距离 token 的 attention 成本 | 全局信息如何周期性传播,哪些 token 应该被选中。 |
| MoE | 省每 token 激活全部参数的 FLOPs | routing、load balancing、all-to-all、expert undertraining、fine-tuning 稳定性。 |
| MLA/MTP 等扩展 | 省 KV cache 或改善多 token 预测 | 与 RoPE/attention 几何、推理系统、训练目标的兼容性。 |
最终 takeaway
Lecture 4 的核心不是“linear attention vs MoE 谁更好”,而是学会看 selective computation 的三件事:选择规则是什么、节省了哪种资源、为了这个节省引入了什么新的系统或训练问题。
总结与延伸
Attention alternatives 和 MoE 是现代 LLM 架构里最重要的两类非 dense 思路。前者改变 token 如何访问上下文,后者改变 token 如何访问参数。二者都能带来 scale 或 inference efficiency 的收益,但都把问题转移到 routing、state design、load balancing、communication 和 stability 上。
拓展阅读
- Linear attention, Mamba-2, Gated DeltaNet, DeepSeek Sparse Attention.
- Switch Transformer, GShard, DeepSeek MoE, OlMoE, Mixtral, Qwen MoE.
- JAX Scaling Book sections on attention and inference systems.