CS336 Lecture 3: Architectures, Hyperparameters
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Tatsu Hashimoto 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年4月15日 |

引言:从他人经验中学习
本节课的主题是“Everything you didn't want to know about LM architecture and training”——深入探讨语言模型架构和训练中那些看似琐碎但实际至关重要的细节。Tatsu Hashimoto 通过系统地调研过去一年发布的 19 个密集模型(dense model),以“趋同进化”的视角揭示了现代 Transformer 架构的设计共识与分歧。
本课核心主题
最好的学习方式是亲手实践;次好的方式是从他人的经验中学习。我们无法训练所有这些 Transformer,但可以通过分析大量已发布模型的架构选择,提炼出可靠的设计原则。

来源:Slides 第3页。
课程分为四个主要部分:
- 架构变体(Architecture Variations):归一化方式、激活函数、位置编码等
- 超参数选择(Hyperparameters):FFN 维度比、注意力头数、宽深比等
- 训练稳定性技巧(Stability Tricks):Z-loss、QK-norm 等
- 注意力变体(Attention Variants):GQA、MQA、滑动窗口注意力等
从原始 Transformer 到现代变体
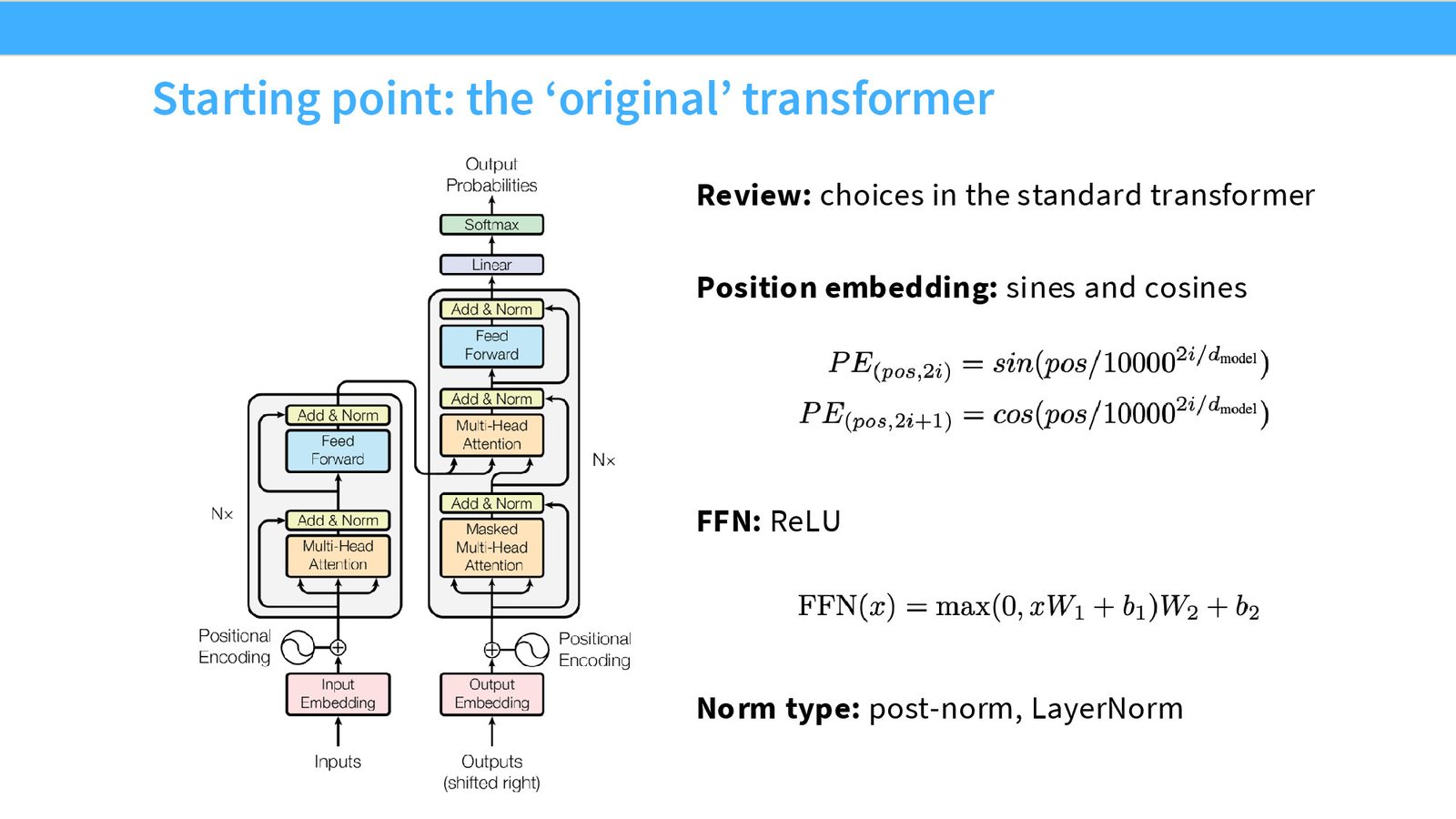
来源:Slides 第4页。
原始 Transformer(2017)的关键设计选择:
- 位置编码:正弦/余弦函数
- 前馈层:ReLU 激活,\(\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2\)
- 归一化:Post-norm(LayerNorm 在残差连接之后)
- 偏置项:所有线性层和归一化层都有偏置
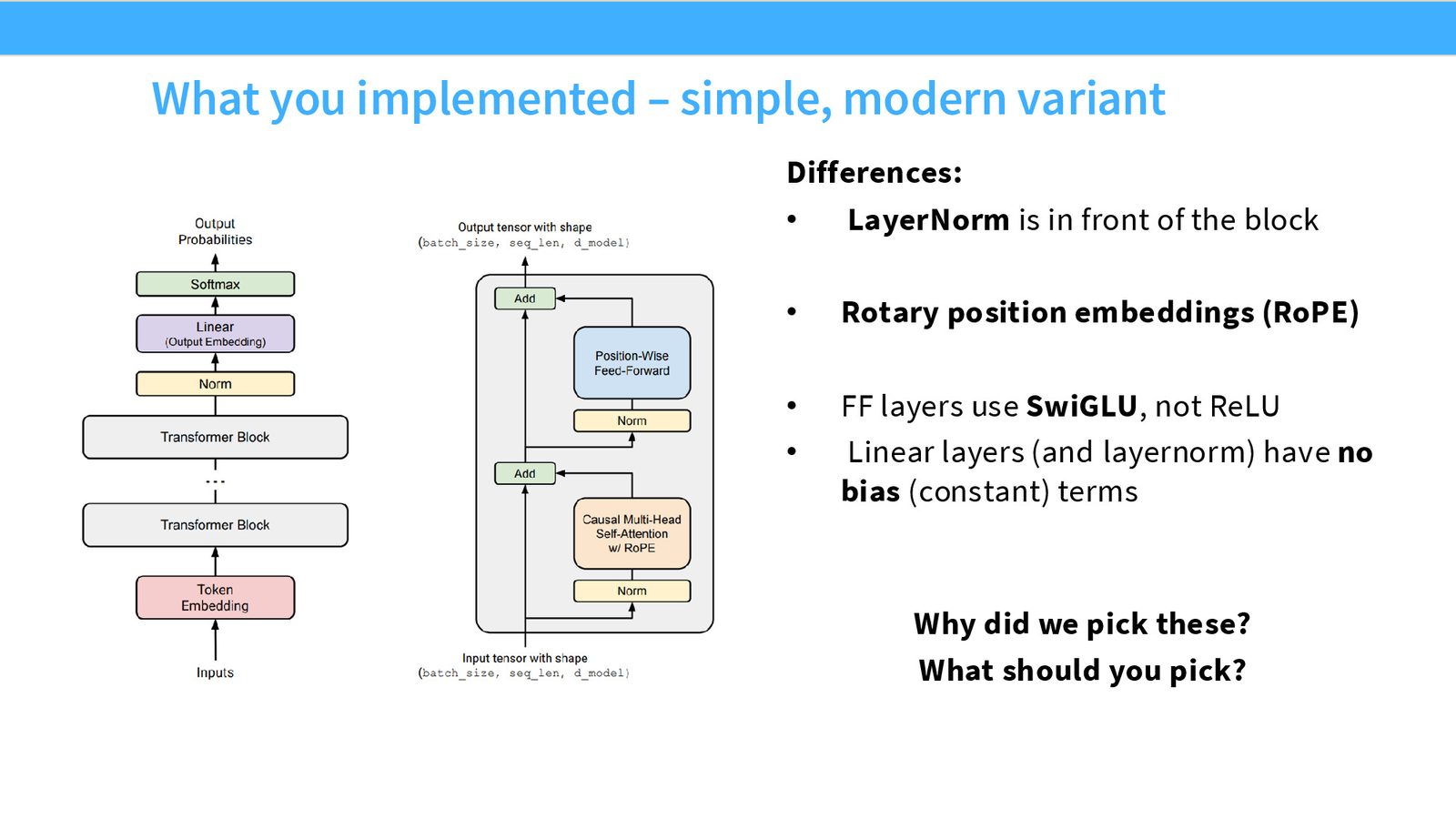
来源:Slides 第5页。
而现代 Transformer(如 LLaMA 系列)的关键变化:
- 位置编码:旋转位置编码(RoPE)
- 前馈层:SwiGLU 激活
- 归一化:Pre-norm(LayerNorm 在残差分支之前)
- 偏置项:全部移除
19 个模型的“趋同进化”
Tatsu 汇编了从 2017 年原始 Transformer 到 2025 年最新模型(Command A、Gemma 3、Qwen 2.5 等)的架构对比表。通过观察这些模型的选择趋势,我们可以清晰地看到架构设计的“趋同进化”——在某些维度上,所有人都收敛到了相同的选择。

来源:Slides 第6页。
本章小结
本课的核心方法论是“数据驱动的架构理解”:通过系统调研大量已发布模型的设计选择,识别出哪些是共识(所有人都做的),哪些是有益但非必要的(大多数人做的),哪些仍存在分歧(不同团队做不同选择)。
归一化:Pre-norm、RMS Norm 与偏置项
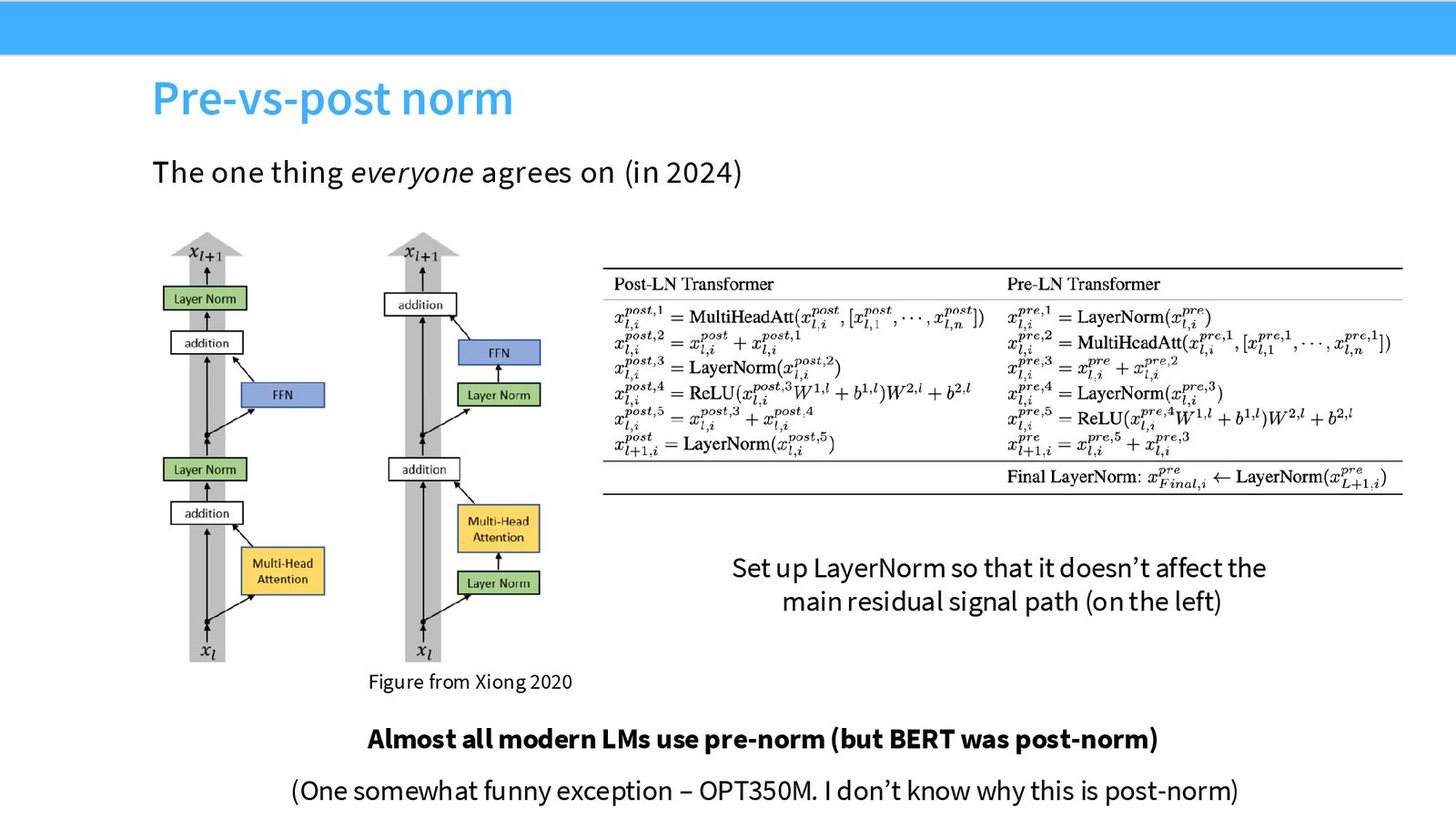
Pre-norm vs Post-norm
这是架构设计中共识最强的一个选择——几乎所有现代语言模型都使用 Pre-norm。

来源:Slides 第8页。
Pre-norm 的核心优势
- 更稳定的训练:残差流保持为恒等连接,梯度可以无障碍地从网络顶部传播到底部
- 无需学习率预热:Post-norm 需要精心设计的 warm-up 策略,Pre-norm 则不需要
- 更少的 loss spike:实验表明 Pre-norm 训练过程中梯度范数更平稳

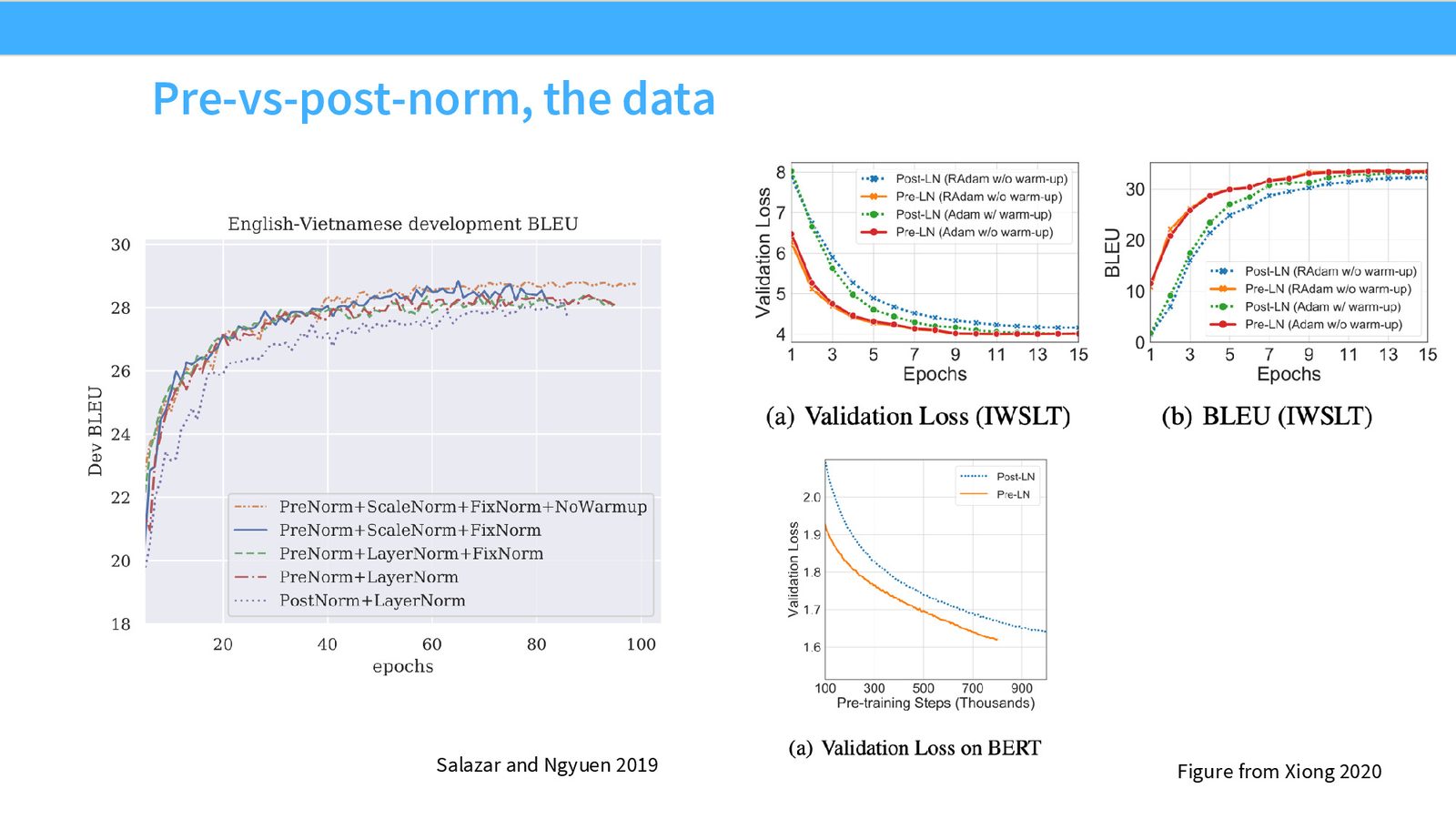
来源:Slides 第9页。来自 Xiong et al. 2020 和 Shleifer & Ott 的工作。
为什么 LayerNorm 不应出现在残差流中?
残差流提供了一条从网络顶部到底部的恒等连接(identity connection),这使得梯度传播非常容易。如果在残差流中插入 LayerNorm,就破坏了这个恒等映射,可能导致梯度衰减或放大,使深层网络难以训练。这也是为什么 ResNet 比普通深度网络更容易训练的核心原因之一。
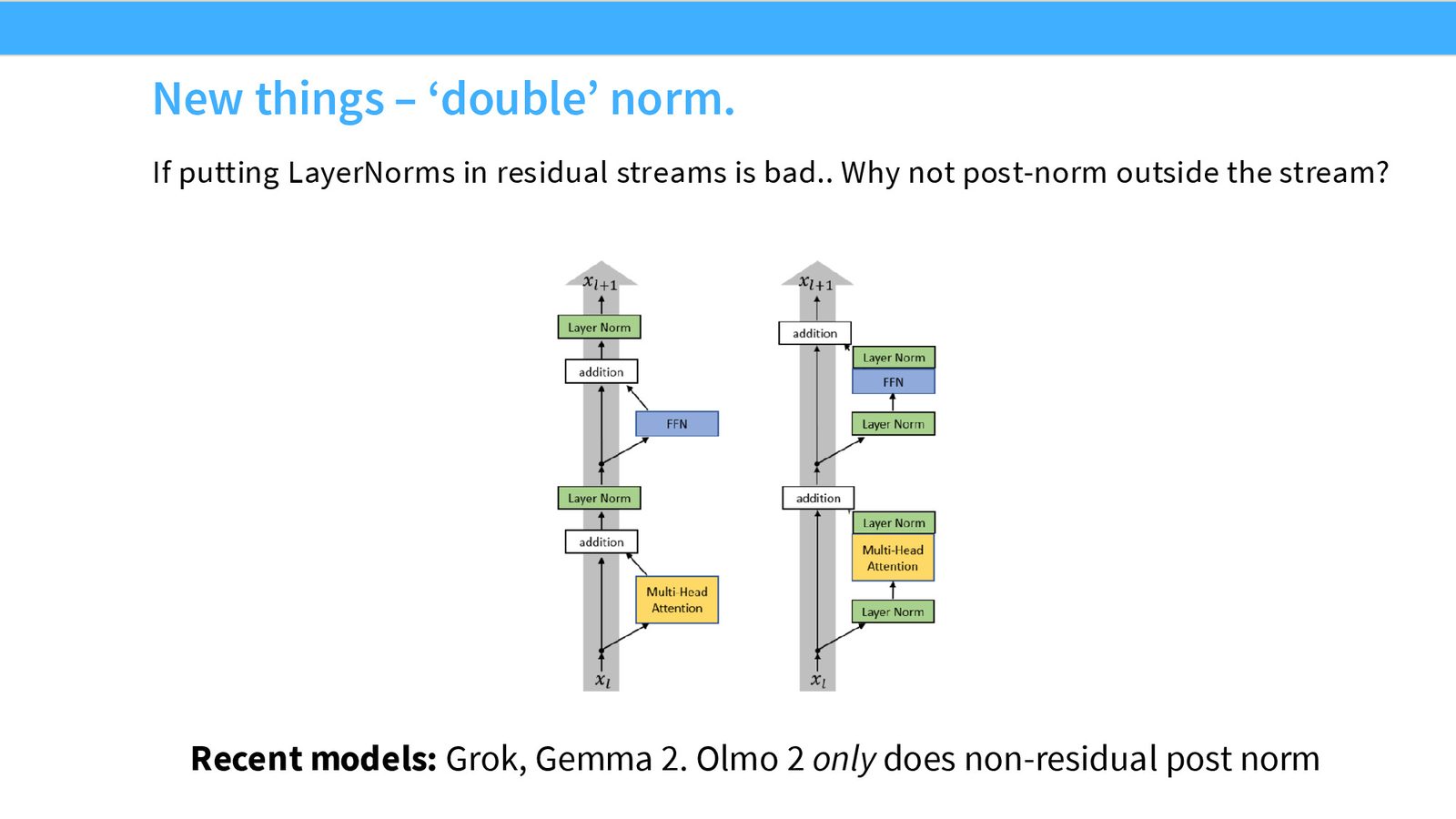
“双重归一化”:最新的创新
最近出现了一种新的归一化放置方式——在残差分支的前后都放置 LayerNorm:
来源:Slides 第10页。
Grok、Gemma 2 采用了这种“双重归一化”方式,OLMo 2 也在注意力和 FFN 之后加入了额外的归一化层。初步评估表明这种方式在大模型上可以进一步提升训练稳定性。
RMS Norm 取代 LayerNorm
来源:Slides 第11页。
标准 LayerNorm 的公式:
- \(\mu\):激活值的均值
- \(\sigma^2\):激活值的方差
- \(\gamma\):可学习的缩放参数
- \(\beta\):可学习的偏移参数
- \(\epsilon\):数值稳定性的小常数
RMS Norm 的简化公式:
RMS Norm 去掉了两个操作:(1)不减去均值 \(\mu\);(2)不加偏移项 \(\beta\)。
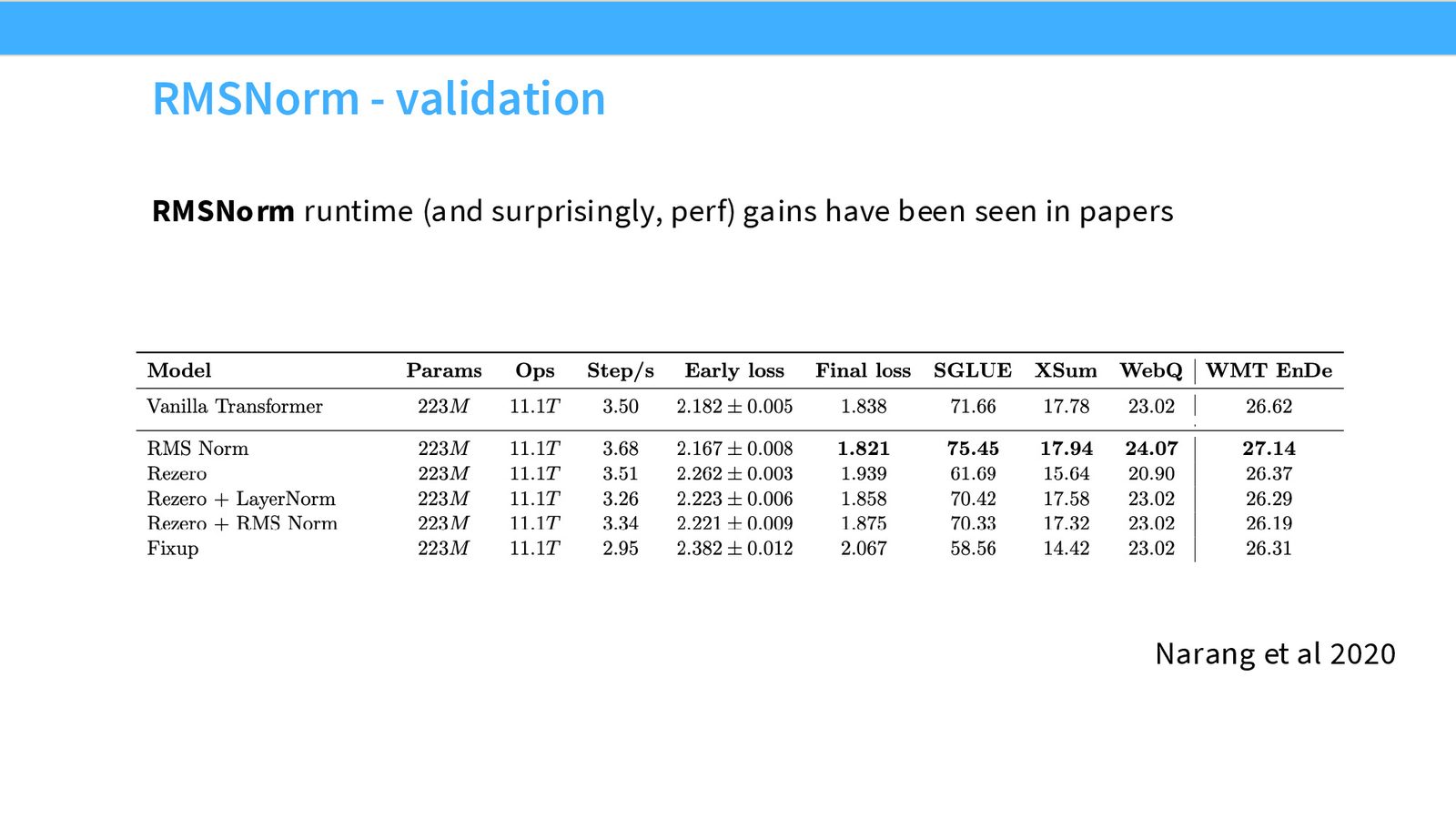
为什么 RMS Norm 更好?
- 性能不降:实验表明 RMS Norm 的模型质量与 LayerNorm 相当
- 速度更快:更少的计算操作(不需要计算均值),更少的参数需要从内存加载
- 关键洞察:归一化操作虽然只占总 FLOP 的 0.17%,但由于内存移动开销,它占了总运行时间的约 25%!因此优化归一化操作对实际速度有重要影响
来源:Slides 第13页。来自 Ivanov et al. 2023,“Data Movement Is All You Need”。
不要只看 FLOP
架构设计不能只关注 FLOP。在现代 GPU 上,内存移动(memory movement)往往是更大的瓶颈。归一化操作只有 0.17% 的 FLOP,但因为涉及大量内存读写,它消耗了 25% 的运行时间。RMS Norm 之所以更快,正是因为减少了内存移动,而非减少了计算量。

来源:Slides 第14页。来自 Narang et al. 2020。
移除偏置项

来源:Slides 第15页。
现代 Transformer 普遍去掉了所有线性层中的偏置项 \(b\)。原因与 RMS Norm 类似:
- 偏置项对模型质量的贡献可以忽略不计
- 去掉偏置减少了内存移动开销
- 去掉偏置有助于训练稳定性——这一点虽然理论解释不完善,但经验证据非常清晰
本章小结
归一化层设计的三条铁则
- Pre-norm 是基本共识:LayerNorm 必须放在残差分支的外部(不在残差流中)
- RMS Norm 是默认选择:更快、更简洁、性能不降
- 去掉偏置项:在线性层和归一化层中都去掉偏置,提升速度和稳定性
激活函数与门控线性单元
从 ReLU 到 GELU
来源:Slides 第17页。
激活函数的演变:
- ReLU:\(\text{ReLU}(x) = \max(0, x)\),原始 Transformer 使用
- GELU:\(\text{GELU}(x) = x \cdot \Phi(x)\),其中 \(\Phi\) 是标准正态分布的 CDF。GPT 系列使用
- Swish/SiLU:\(\text{Swish}(x) = x \cdot \sigma(x)\),其中 \(\sigma\) 是 sigmoid 函数
GELU 和 Swish 的形状类似 ReLU,但在零点附近更平滑(可微),且在负值区域有一个小的“凹陷”。
门控线性单元(GLU)

来源:Slides 第18页。
门控线性单元是现代 Transformer 中最重要的架构创新之一。标准 FFN:
GLU 变体:
- \(W_1\):第一个线性变换(投影到隐藏空间)
- \(V\):门控矩阵(额外参数)
- \(\odot\):逐元素乘法(门控操作)
- \(W_2\):第二个线性变换(投影回原始空间)
三种 GLU 变体
- ReGLU:\((\text{ReLU}(xW_1) \odot xV) W_2\)
- GEGLU:\((\text{GELU}(xW_1) \odot xV) W_2\),Google T5V1.1、Gemma 系列使用
- SwiGLU:\((\text{Swish}(xW_1) \odot xV) W_2\),LLaMA、PaLM、OLMo 等使用,是当前最流行的选择

来源:Slides 第20页。来自 Shazeer 2020 的原始 GLU 论文。

来源:Slides 第21页。
门控机制的普遍有效性
门控(Gating)是深度学习中反复出现的有效模式。从 LSTM 的门控机制到 Highway Networks,再到 Transformer 中的 GLU,门控操作让网络能够动态选择性地传递信息。GLU 本质上是让网络学习“哪些隐藏特征应该被保留,哪些应该被抑制”。
GLU 不是必须的
虽然 GLU 变体普遍更好,但不使用 GLU 也能训练出优秀的模型。例如:
- GPT-3 使用标准 GELU(非门控),仍是经典模型
- Nemotron 340B 使用 Squared ReLU
- Falcon 2 11B 使用标准 ReLU
GLU 提供了一致的小幅增益,但绝非成功的必要条件。
本章小结
- SwiGLU 是当前最流行的 FFN 激活方式,在保持参数量不变的前提下一致优于非门控变体
- 门控线性单元引入了额外的参数矩阵 \(V\),为保持总参数量不变,通常将隐藏维度缩小为原来的 \(2/3\)
- 激活函数的具体选择(ReLU vs GELU vs Swish)对性能的影响远小于是否使用门控机制
Transformer 块结构与位置编码
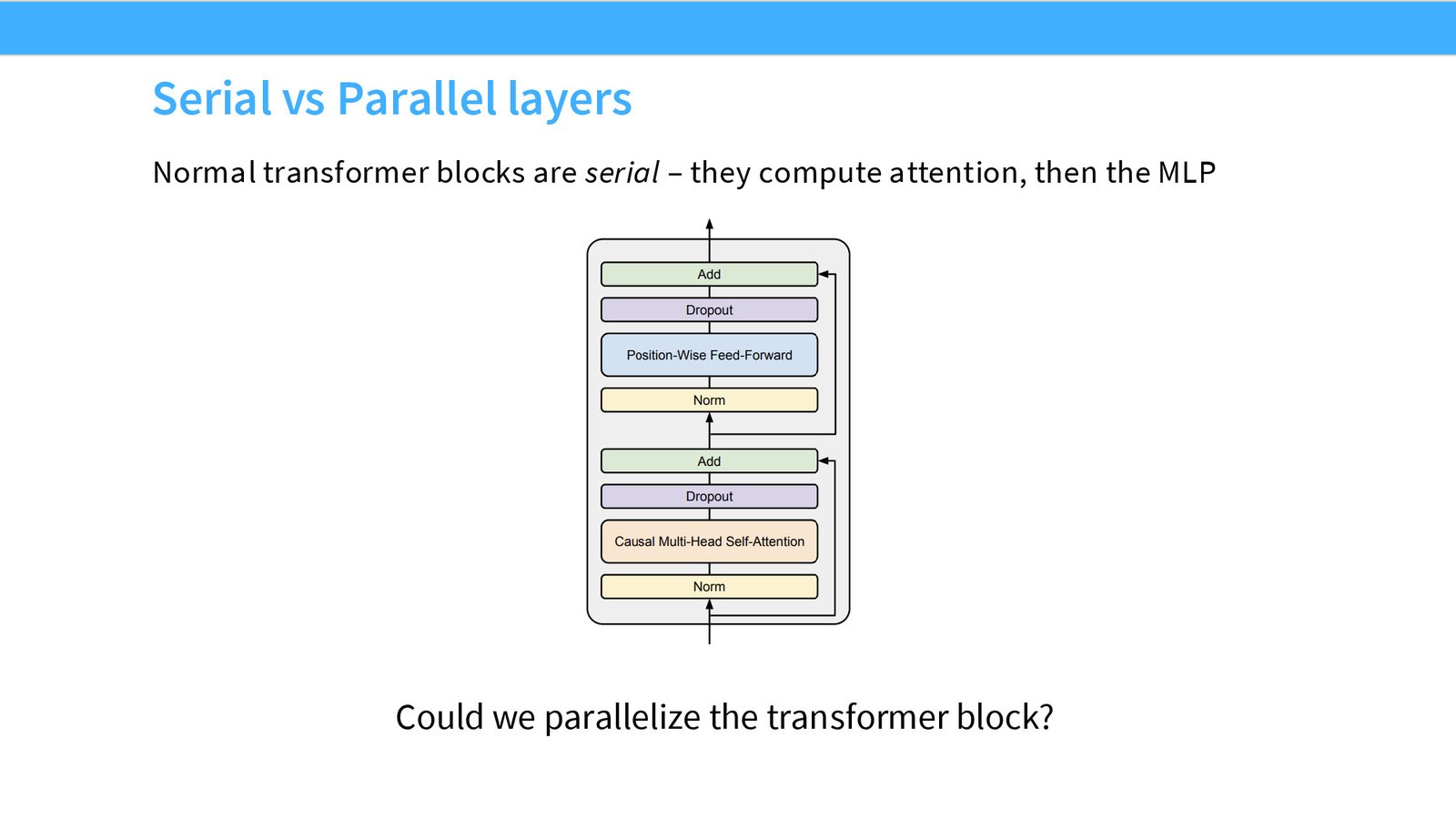
串行层 vs 并行层

来源:Slides 第23页。
标准 Transformer 块是串行的:先做 Attention,再做 MLP。并行变体则同时计算两者:
串行:\(x_{out} = x + \text{MLP}(x + \text{Attn}(x))\)
并行:\(x_{out} = x + \text{Attn}(x) + \text{MLP}(x)\)
并行层的优势在于系统效率——可以融合共享的 LayerNorm,矩阵乘法可以并行执行。GPT-J 首创了这种方式,PaLM 将其扩展到大规模。但从表达能力角度看,串行层更好(因为组合两次计算比相加更具表达力),因此大多数最近的模型仍选择串行层。
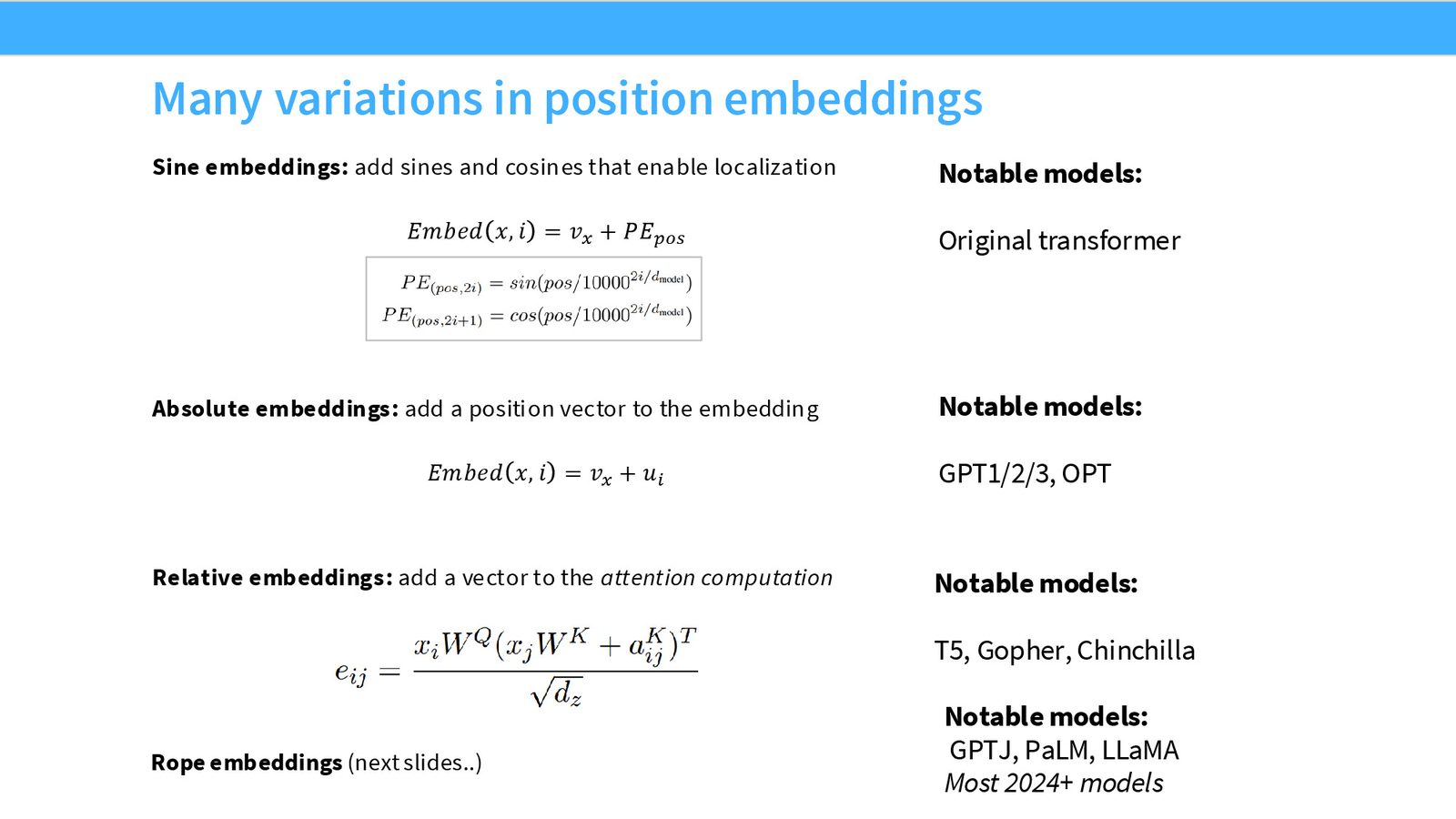
位置编码的演变

来源:Slides 第26页。
位置编码经历了丰富的探索:
- 正弦编码(Sinusoidal):原始 Transformer
- 绝对位置编码(Absolute):GPT 系列、OPT,学习位置向量直接加到 embedding 上
- 相对位置编码(Relative):T5、Gopher,在 attention 计算中加入相对位置信息
- ALiBi:一度流行但已被超越
- RoPE(Rotary Position Embedding):当前的绝对共识
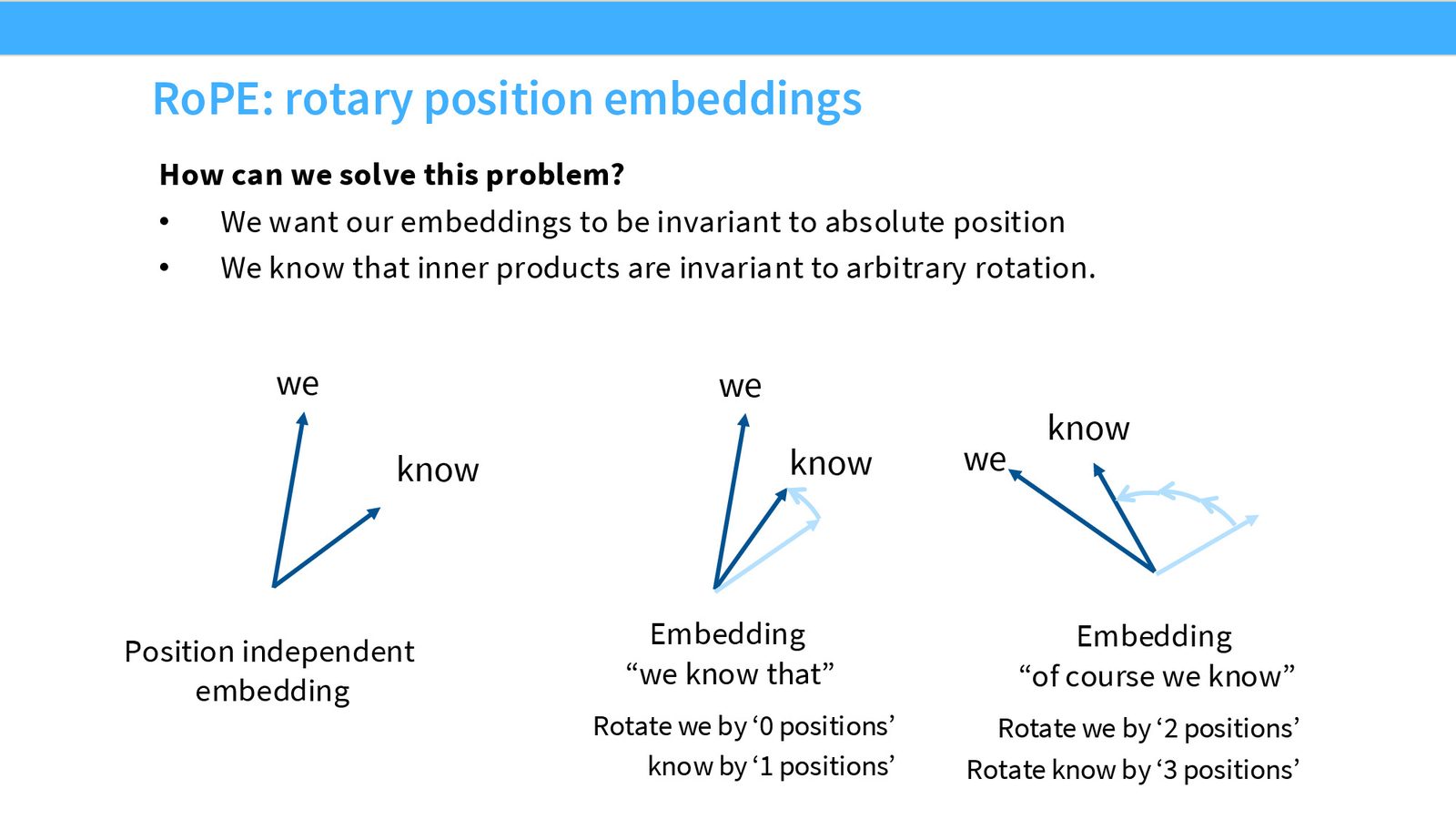
RoPE:旋转位置编码
来源:Slides 第27页。
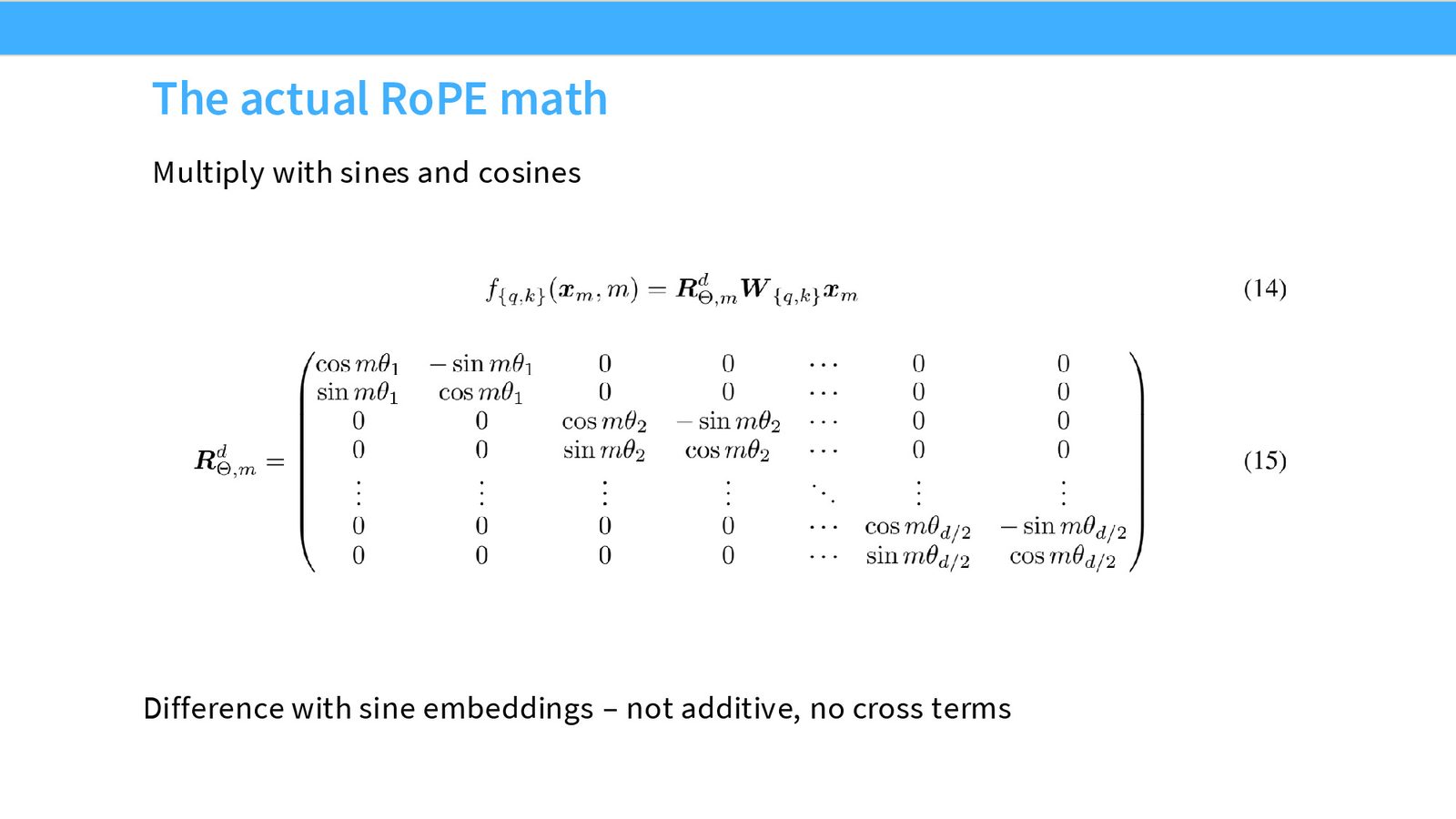
RoPE 的设计目标:找到一种位置编码函数 \(f\),使得两个位置 \(i\) 和 \(j\) 的嵌入向量的内积只依赖于它们的相对距离 \(i - j\):
RoPE 的核心思想
旋转不改变向量间的夹角,因此不改变内积。RoPE 将位置信息编码为对向量的旋转操作——位置 \(m\) 的向量被旋转 \(m \cdot \theta\) 角度。由于旋转的相对性质,两个向量的内积只取决于它们旋转角度的差,也就是位置的差。

来源:Slides 第28页。
在高维空间中,RoPE 将 \(d\) 维向量切分为 \(d/2\) 对二维子空间,每对子空间以不同的频率 \(\theta_i\) 旋转:

来源:Slides 第29页。
- \(m\):位置索引
- \(\theta_i = 10000^{-2i/d}\):第 \(i\) 对维度的旋转频率
- 频率从高到低排列,高频维度捕获近距离关系,低频维度捕获远距离关系
RoPE 的关键实现细节
与绝对/正弦位置编码不同,RoPE 不在输入层添加位置向量,而是在每一层 attention 计算时,对 query 和 key 进行旋转。这意味着位置信息在每一层都被重新注入。此外,\(\theta\) 是预设的(非学习参数),所以旋转操作本质上只是一个固定的矩阵乘法,不影响训练稳定性。
来源:Slides 第30页。来自 LLaMA 的实现。
架构变体的总结表
来源:Slides 第32页。
本章小结
架构变体的共识与分歧
强共识(几乎所有模型都做的):
- Pre-norm(LayerNorm 在残差流外部)
- RoPE 位置编码
- 无偏置项
中等共识(大多数模型做的):
- RMS Norm 替代 LayerNorm
- SwiGLU/GEGLU 替代 ReLU/GELU
- 串行层(而非并行层)
超参数选择
FFN 维度比:\(d_ff / d_model\)
来源:Slides 第34页。
对于前馈层的隐藏维度 \(d_\text{ff}\)(相对于模型维度 \(d_\text{model}\)),存在一个非常稳固的约定:
- 非门控 FFN(ReLU/GELU):\(d_\text{ff} = 4 \times d_\text{model}\)
- GLU 变体:\(d_\text{ff} = \frac{8}{3} d_\text{model} \approx 2.67 \times d_\text{model}\)
GLU 变体的缩小因子 \(2/3\) 是为了保持参数量不变——GLU 引入了额外的门控矩阵 \(V\),所以需要相应缩小 \(W_1\) 和 \(V\) 的维度。

来源:Slides 第35页。
T5 的大胆尝试:64 倍的 FFN 比例
Google 的 T5 11B 模型有一个非常不寻常的设置:\(d_\text{model} = 1024\),\(d_\text{ff} = 65536\),比例高达 64倍!这远超标准的 4 倍约定。T5 团队的理由是:更宽的矩阵可以获得更好的系统并行效率。但有趣的是,后续的 T5 V1.1 回到了更标准的 2.5 倍比例,说明极端偏离约定可能并不是最优选择。

来源:Slides 第37页。来自 Kaplan et al. 的 scaling laws 论文。
注意力头维度

来源:Slides 第39页。
标准约定是保持:
即增加头数时,每个头的维度相应减小,而不是增加总的注意力参数量。GPT-3、T5、PaLM、LLaMA 2 等模型的 \(d_\text{model} / (n_\text{heads} \times d_\text{head})\) 比值都非常接近 1。
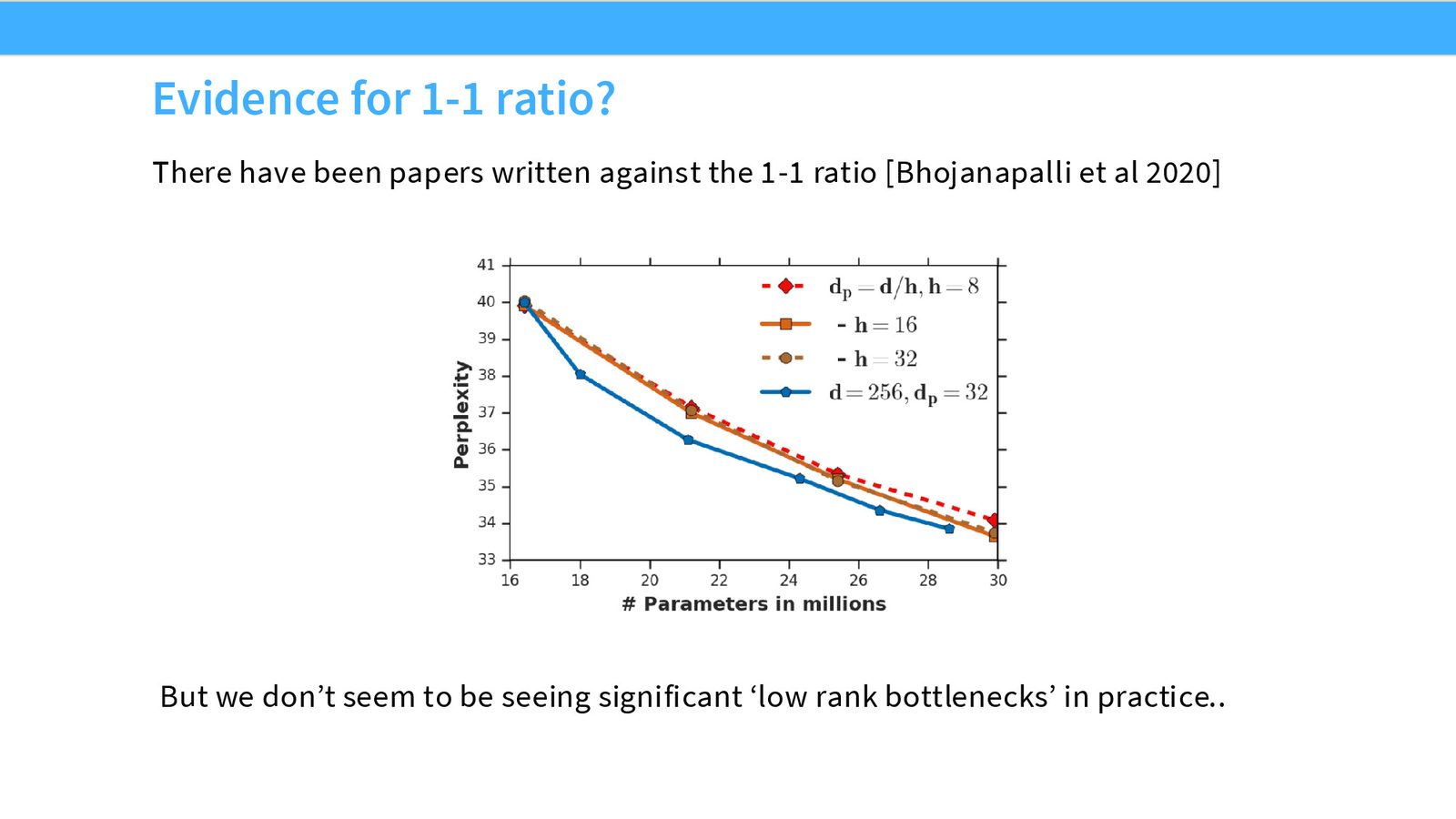
低秩瓶颈的理论担忧
Bhojanapalli et al. (2020) 指出,当头数很多而每头维度很小时,attention 矩阵的秩会变低,可能限制模型的表达能力。但实际上,大多数采用 1:1 比例的模型表现良好,低秩瓶颈似乎在实践中不是严重问题。
宽深比(Aspect Ratio)
模型的“形状”由两个关键数字决定:\(d_\text{model}\)(宽度)和 \(n_\text{layers}\)(深度)。它们的比值称为宽深比:

来源:Slides 第41页。来自 Kaplan et al. 的 scaling laws 论文。
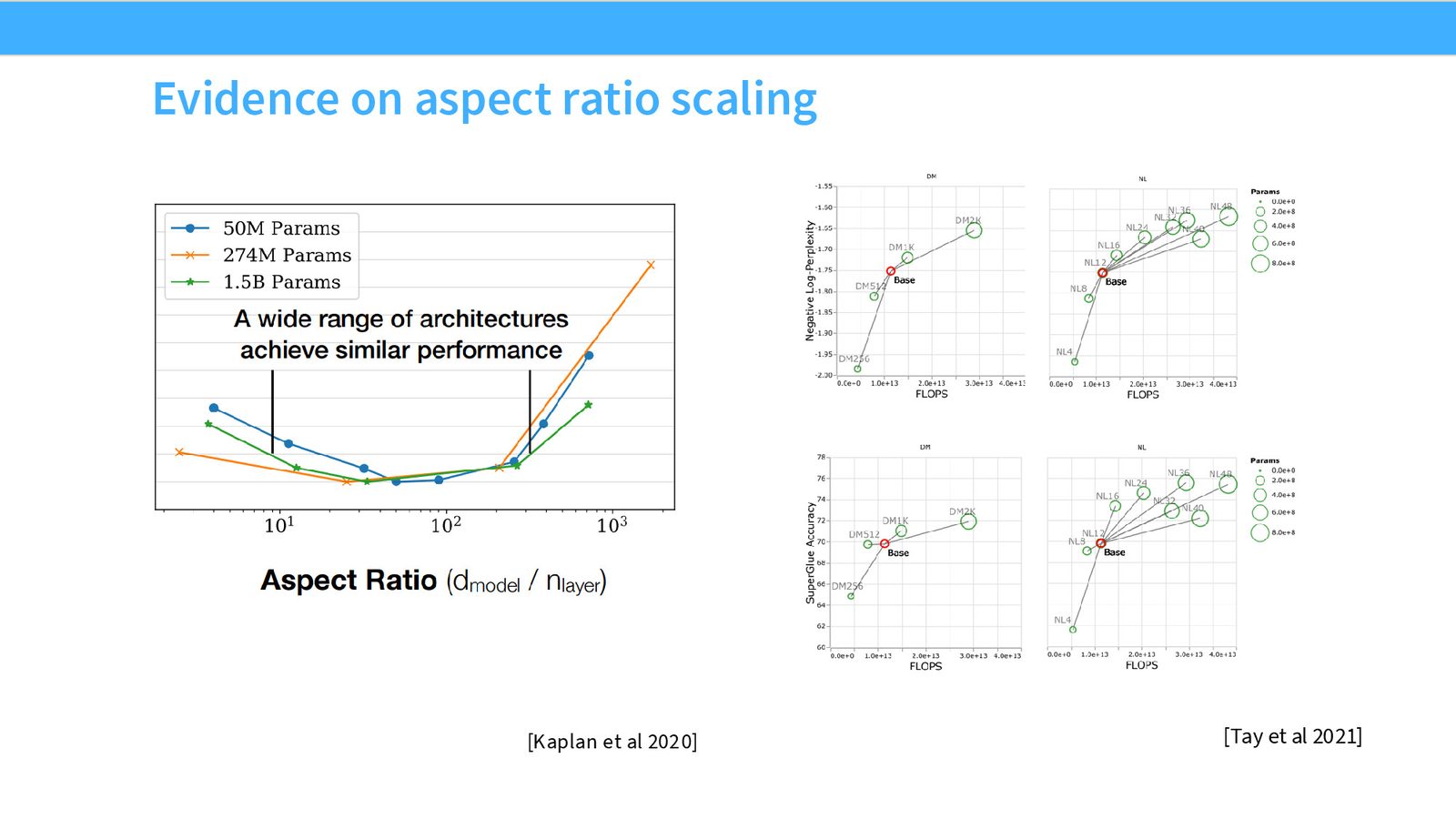
宽深比的经验法则
大量模型(GPT-3、LLaMA 系列)都遵循 \(d_\text{model} / n_\text{layers} \approx 128\) 的比例。Kaplan et al. 的实验表明,这个最优比例在 50M 到 1.5B 参数的不同尺度上保持一致——这是一个非常好的消息,意味着你可以在小模型上确定比例,然后直接缩放到大模型。
宽深比与并行化策略
宽深比不仅影响模型表达能力,还直接决定了可以使用的并行化策略:
- 更深的模型:适合流水线并行(Pipeline Parallelism),将不同层放在不同设备上
- 更宽的模型:适合张量并行(Tensor Parallelism),将矩阵切分到不同设备上
张量并行需要快速网络(高带宽、低延迟),流水线并行对网络要求较低。因此,你的硬件拓扑可能反过来影响最优的宽深比选择。

来源:Slides 第42页。
词表大小
来源:Slides 第44页。
词表大小有明显的增长趋势:
- 早期单语模型(GPT-2、早期 LLaMA):30K--50K tokens
- 现代多语言/生产模型(GPT-4、Qwen、Gemma):100K--250K tokens
更大的词表能更高效地编码非英语语言和特殊字符(如 emoji),从而降低推理成本——Cohere 强调其大词表可以显著减少非英语文本的 token 数量。
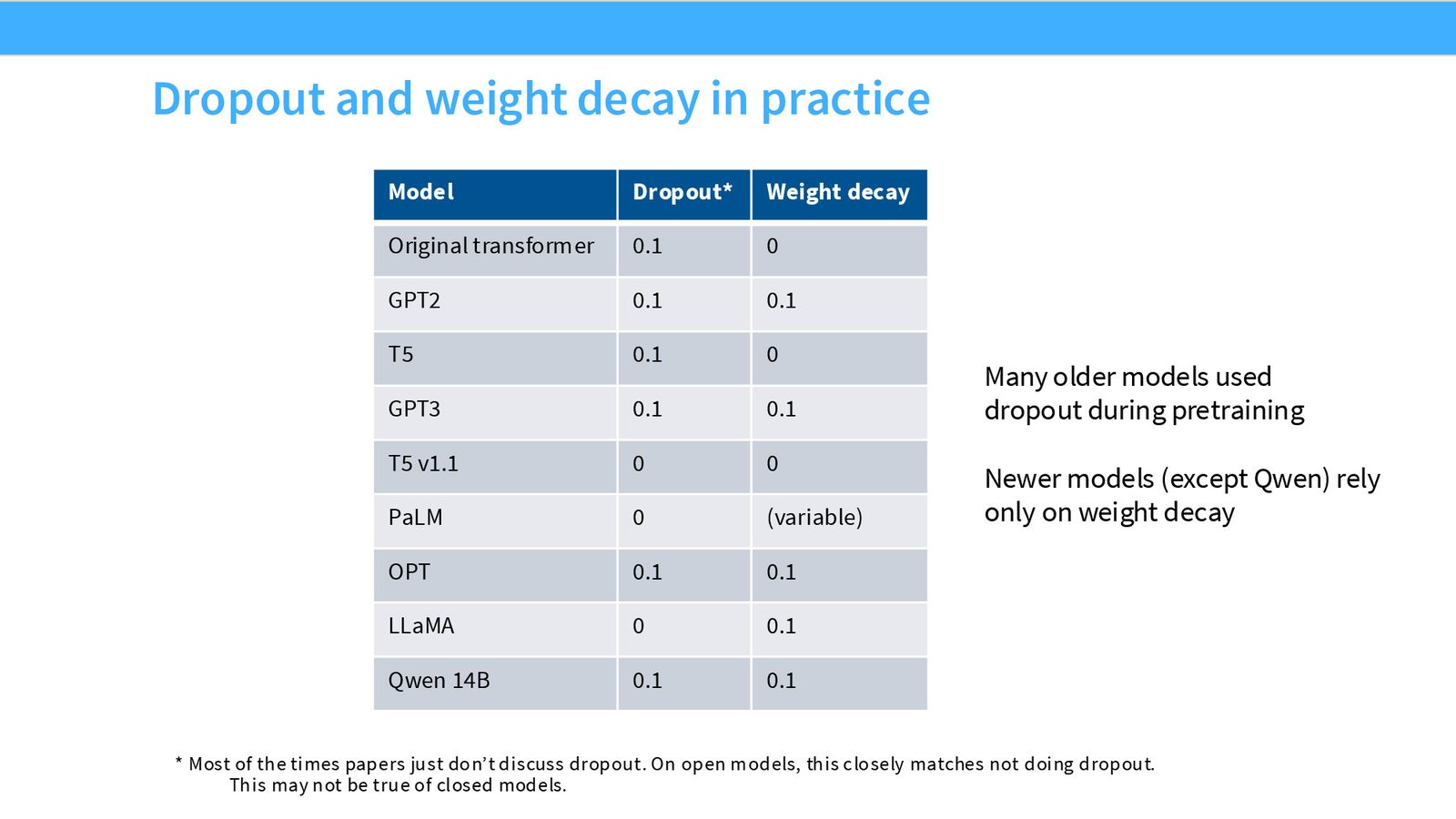
正则化:Dropout 与 Weight Decay
来源:Slides 第47页。
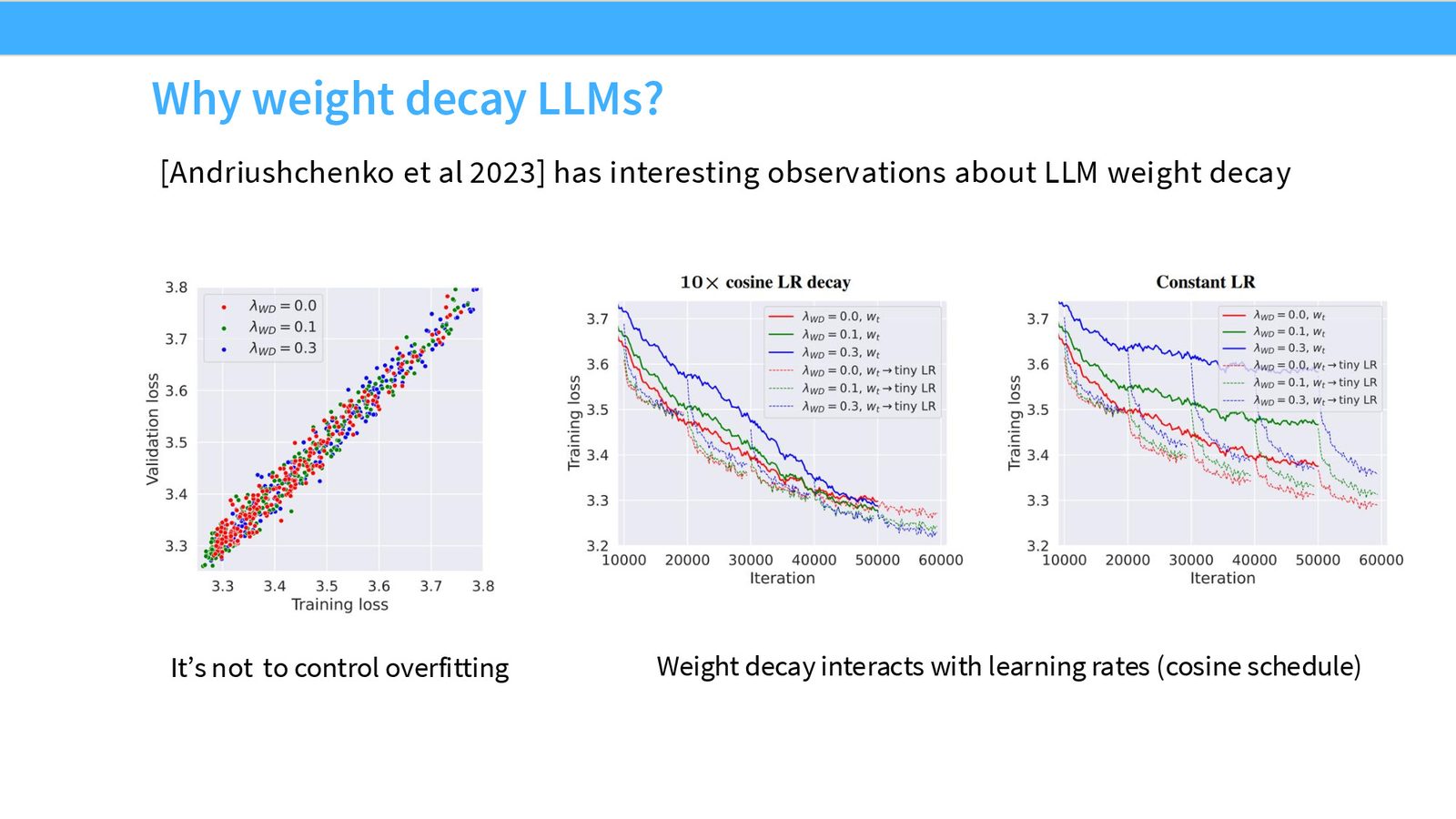
Weight Decay 的反直觉作用
在大语言模型预训练中使用 weight decay 不是为了防止过拟合——模型通常只训练一个 epoch,根本不可能过拟合。Weight decay 的真正作用是改善训练动力学:在 cosine learning rate schedule 下降阶段,weight decay 产生一种“隐式加速”效果,使模型获得更好的训练损失。

来源:Slides 第48页。
Weight decay 不影响过拟合差距
实验表明,不同程度的 weight decay 并不改变训练 loss 和验证 loss 之间的差距。这证实了 weight decay 在预训练中的作用不是正则化,而是优化器动力学层面的——它通过与学习率调度的复杂交互,帮助模型在训练后期更快地收敛。
本章小结
超参数选择的“安全默认值”
- FFN 维度比:非门控 \(4\times\),GLU \(\sim\)2.67\(\times\)
- 注意力头维度:\(d_\text{model} = n_\text{heads} \times d_\text{head}\)(比值为 1)
- 宽深比:\(d_\text{model} / n_\text{layers} \approx 128\)
- 词表大小:100K--200K(多语言场景)
- 正则化:不用 dropout,使用 weight decay
这些默认值经过大量模型验证,可以直接采用。但也要记住:没有哪个超参数是“写在石头上”的,合理偏离也能训练出好模型。
训练稳定性技巧
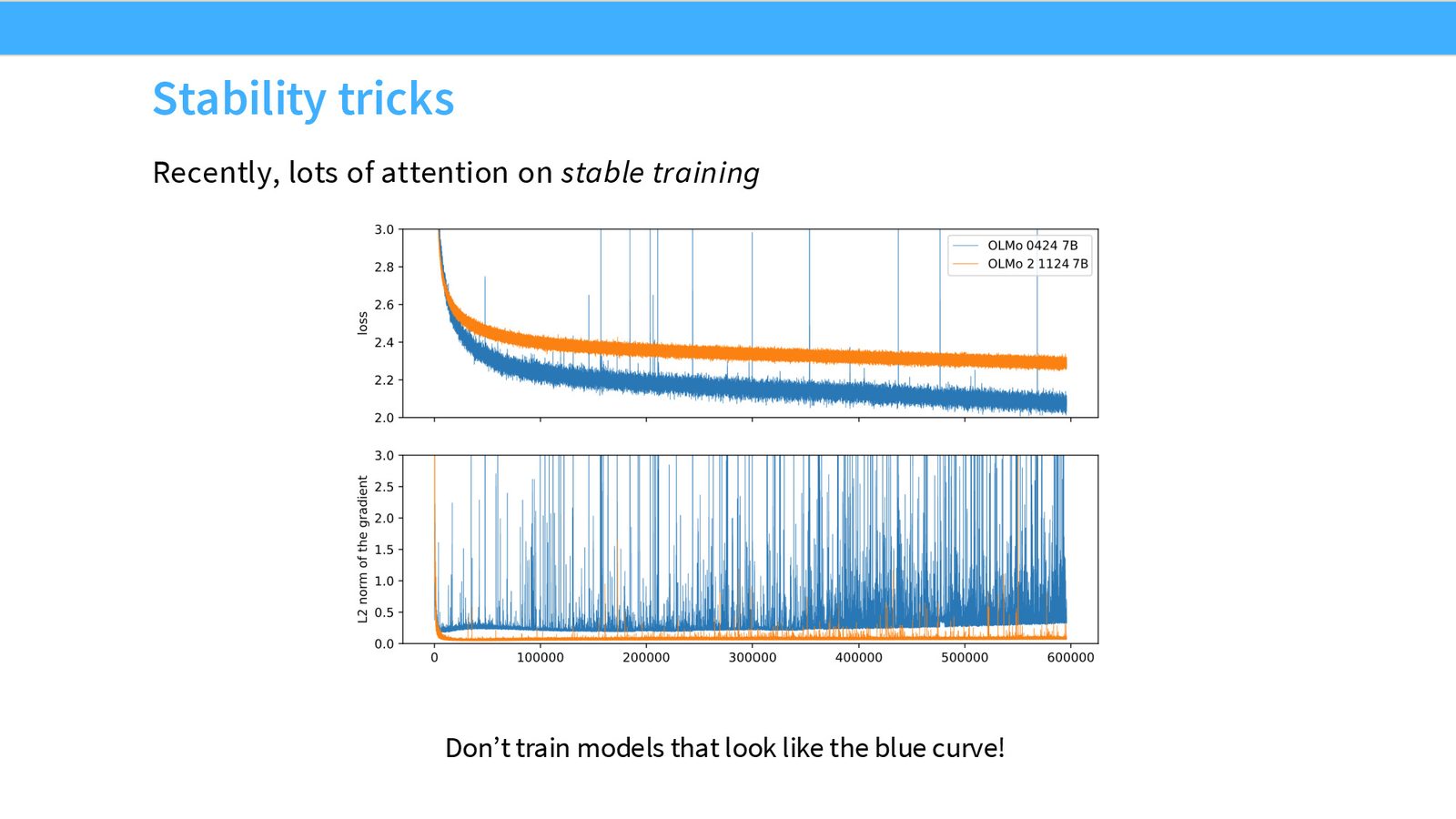
稳定性问题的来源
来源:Slides 第51页。来自 OLMo 2 论文。
随着模型规模增大和训练时间延长,训练不稳定问题日益突出。梯度范数的剧烈尖刺可能导致训练崩溃,这在大规模训练中是一个严重的工程问题。
Softmax 是稳定性的“问题儿童”
Transformer 中有两个 softmax 操作,它们是稳定性问题的主要来源:
- 输出层 softmax:将 logits 转换为概率分布
- 注意力 softmax:将 attention scores 转换为权重
Softmax 涉及指数运算和除法,都是数值敏感的操作。logits 过大会导致指数溢出,归一化因子 \(Z\) 过大会导致数值不稳定。
Z-loss:稳定输出 softmax
来源:Slides 第53页。
Z-loss 的核心思想是:如果 softmax 的归一化因子 \(Z(x) = \sum_i e^{u_i(x)}\) 接近 1(即 \(\log Z \approx 0\)),那么 softmax 就处于数值稳定的状态。
损失函数变为:
- \(\mathcal{L}_\text{CE}\):标准交叉熵损失
- \(\alpha\):Z-loss 的权重(PaLM 使用 \(10^{-4}\))
- \(\log^2 Z(x)\):惩罚归一化因子偏离 1 的程度
Z-loss 的直觉
当 Z-loss 成功将 \(\log Z(x)\) 压到接近 0 时,softmax 中的指数和对数运算互相抵消,输出退化为简单的线性操作 \(u_i(x) / 1 = u_i(x)\),这是一个数值非常稳定的状态。PaLM 最早在大规模语言模型中采用此技巧,随后被 OLMo、DCLM、Baichuan 2 等模型采纳。
QK-norm:稳定注意力 softmax

来源:Slides 第55页。来自 NVIDIA 的工作。
QK-norm 的做法是在计算 attention scores 之前,对 query 和 key 向量分别进行 LayerNorm:
QK-norm 的来源与效果
QK-norm 最初来自视觉和多模态模型社区(Dehghani 2023,训练大型 Vision Transformer 时提出)。后被 Chameleon、Gemma 2、DCLM、OLMo 2 等文本模型采用。NVIDIA 的实验表明,QK-norm 不仅提升稳定性,还能提升模型质量——因为训练更稳定后可以使用更激进的学习率,将优化器“推得更远”。
Logit Soft Capping
另一种稳定 attention softmax 的方法是软截断(soft capping):
当 logits 远超过 cap 值时,\(\tanh\) 将其截断到 \(\pm 1\),从而限制 softmax 的最大输入。Gemma 2 使用了这种技术。但 NVIDIA 的评估表明,soft capping 在某些情况下反而降低性能,因此其采用不如 QK-norm 广泛。

来源:Slides 第57页。
LayerNorm 的惊人有效性
纵观整个课程的架构讨论,LayerNorm 在稳定训练方面的有效性令人印象深刻:
- Pre-norm:LayerNorm 放在残差分支前端
- Double-norm:LayerNorm 放在残差分支前后
- QK-norm:LayerNorm 放在 query 和 key 上
LayerNorm 几乎是“遇到不稳定就加 norm”的万能工具,而且通常不会损害模型质量。
本章小结
- 训练不稳定的主要来源是 softmax 操作中的指数运算和除法
- Z-loss:通过辅助损失项稳定输出 softmax 的归一化因子
- QK-norm:通过 LayerNorm 控制注意力 softmax 的输入大小
- Soft capping:通过 tanh 截断限制 logits 大小(效果不如 QK-norm)
- 这些技巧在过去一年成为大规模训练的标配,尤其是 Z-loss + QK-norm 的组合
注意力头变体
推理时的 KV Cache 与内存瓶颈
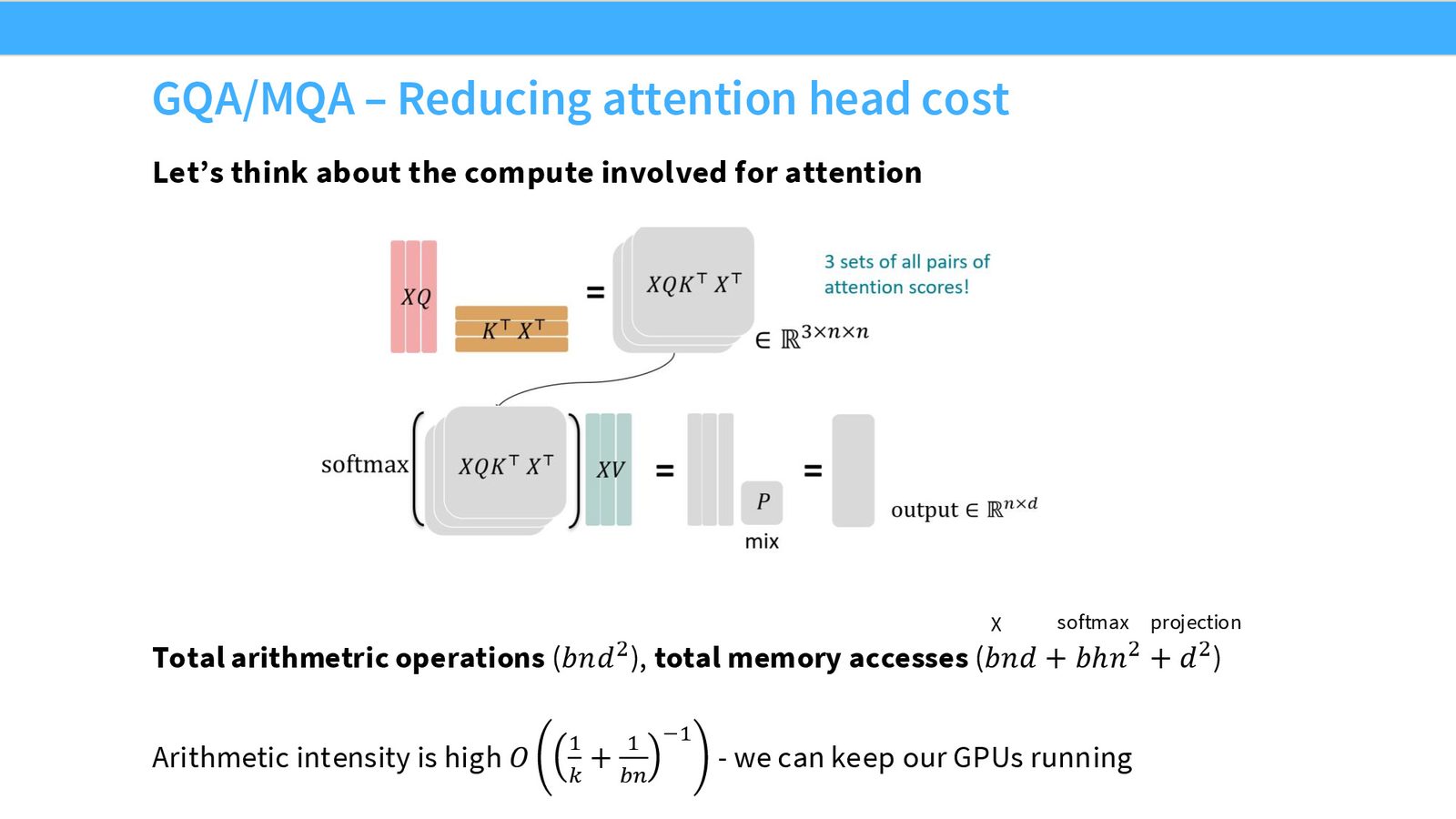
来源:Slides 第59页。
在训练时,attention 的算术强度很高——大量的矩阵乘法让 GPU 保持高利用率。但在推理时,模型必须逐 token 生成,每次只计算 attention 矩阵的一行:

来源:Slides 第61页。
推理时的算术强度急剧下降
训练时的算术强度(计算/内存访问比)\(\propto D\),推理时变为 \(\propto \frac{1}{N/D + 1/B}\)。
这意味着:推理时需要很短的序列长度 \(N\) 或很大的隐藏维度 \(D\) 才能保持高利用率。KV cache 的大小为 \(2 \times n_\text{layers} \times n_\text{heads} \times d_\text{head} \times N\),对于长序列这是一个巨大的内存开销。
Multi-Query Attention(MQA)
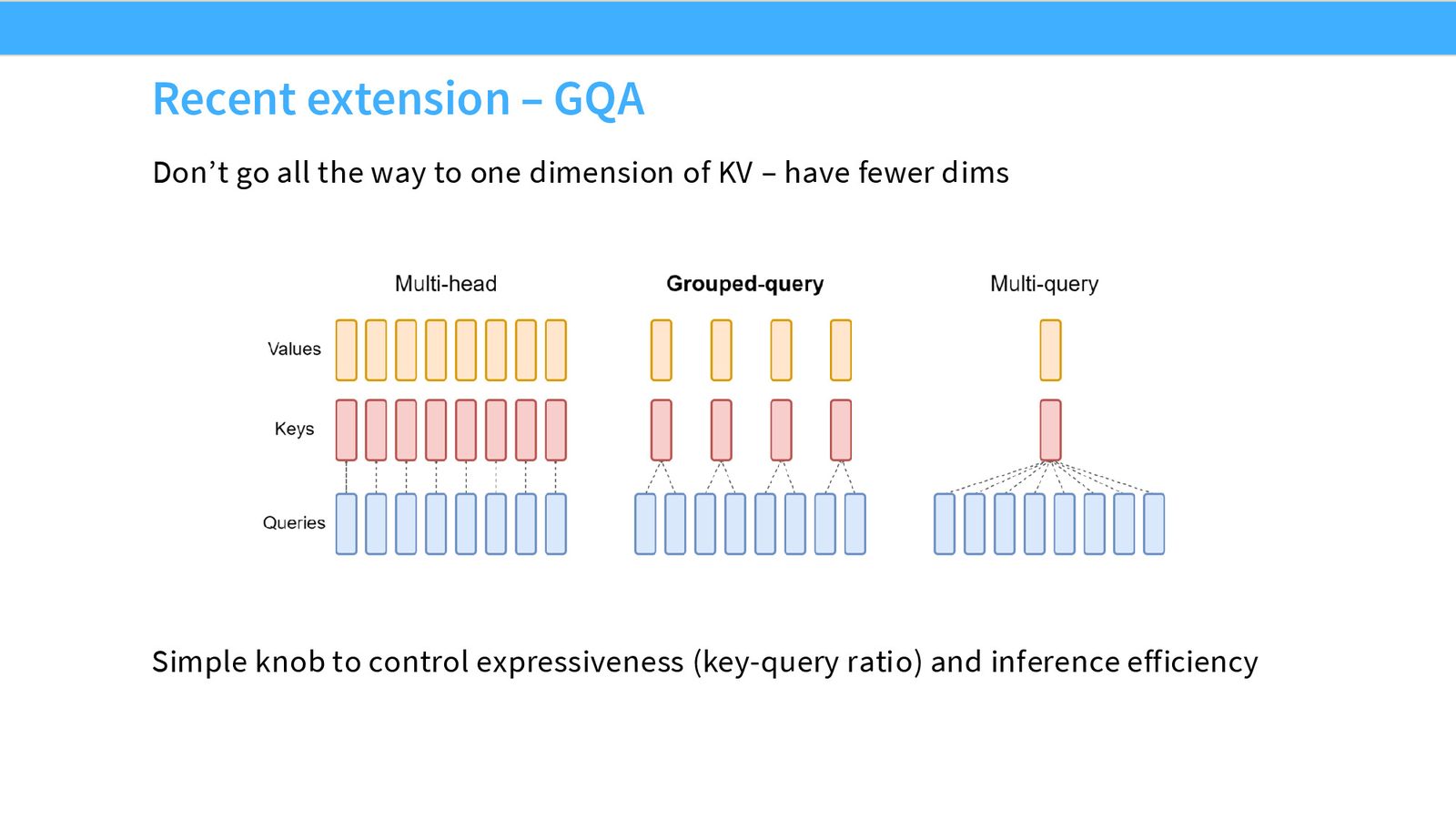
来源:Slides 第63页。
MQA(Multi-Query Attention)的核心思想:所有 query 头共享同一组 key 和 value。
- Multi-Head Attention(MHA):\(H\) 个 query 头,\(H\) 个 KV 头
- Multi-Query Attention(MQA):\(H\) 个 query 头,1 个 KV 头
- Grouped-Query Attention(GQA):\(H\) 个 query 头,\(G\) 个 KV 头(\(1 < G < H\))
GQA 是 MHA 和 MQA 之间的折中,让若干个 query 头共享一组 KV,既减少了 KV cache 的大小,又保留了一定的表达能力。
GQA/MQA 的收益
- KV cache 大小:MQA 减少 \(H\) 倍,GQA 减少 \(H/G\) 倍
- 推理吞吐量:大幅提升,因为减少了内存访问
- 训练时质量:GQA 几乎不损失模型质量,MQA 可能略有下降
LLaMA 2/3、Gemma、Mistral 等现代模型普遍使用 GQA。
稀疏注意力与滑动窗口

来源:Slides 第65页。来自 Child et al. 2019。
为了支持更长的上下文,几种技术被组合使用:
- 滑动窗口注意力(Sliding Window Attention):每层只关注位置周围的局部窗口。有效感受野 = 窗口大小 \(\times\) 层数
- 稀疏注意力(Sparse Attention):用结构化的稀疏模式(如对角线)在减少计算量的同时保持长程依赖
混合注意力模式:支撑超长上下文

来源:Slides 第68页。
最近的模型(LLaMA 4、Gemma、Command A)采用了一种巧妙的混合策略:
混合注意力架构
在每 4 个 Transformer 块中:
- 3 个块使用滑动窗口注意力 + RoPE:高效处理局部上下文
- 1 个块使用全注意力,无位置编码:处理任意长度的全局信息
这种设计的精妙之处在于:
- 全注意力只在少数层中出现,控制了计算开销
- 全注意力层不使用位置编码,因此不受上下文长度限制
- RoPE 只在局部窗口中使用,不需要长程外推
这就是 LLaMA 4 声称支持 1000 万 token 上下文的技术基础。
本章小结
- GQA 已成为大型模型的标配,在几乎不损失质量的前提下大幅减少推理时的 KV cache 开销
- 滑动窗口注意力配合少量全注意力层,实现了系统效率与超长上下文的平衡
- 注意力模式的设计日益受到推理成本的驱动——训练时的表达能力不再是唯一考量
总结与延伸
讲者的核心总结
来源:Slides 第50页。
Tatsu Hashimoto 在课程结尾强调:
- 多数架构选择有明确的“安全默认值”——可以直接从现有模型复制,不需要重新探索
- 不要只关注 FLOP——内存移动在现代 GPU 上是同等重要甚至更重要的考量
- 稳定性正在成为核心关注点——随着模型规模增大,训练稳定性技巧从“锦上添花”变为“必要条件”
- 推理效率正在反向影响架构设计——GQA、滑动窗口等技术不是为了更好的训练,而是为了更高效的推理
全课知识图谱

关键 Takeaways
五条核心原则
- 趋同进化是真实的:在 Pre-norm、RoPE、SwiGLU 等方面,几乎所有模型都收敛到了相同的选择
- 内存移动和 FLOP 同等重要:RMS Norm 替代 LayerNorm、去掉偏置项的收益主要来自减少内存移动
- 超参数空间比想象中更平坦:在“安全默认值”周围有一个宽阔的最优区域,不必过度调参
- LayerNorm 是稳定性的瑞士军刀:几乎所有稳定性改进都涉及在某处添加 LayerNorm
- 推理成本正在重塑架构设计:GQA、滑动窗口等创新的驱动力是推理效率,而非训练质量
拓展阅读
- Vaswani et al., “Attention Is All You Need” (2017): https://arxiv.org/abs/1706.03762
- Shazeer, “GLU Variants Improve Transformer” (2020): https://arxiv.org/abs/2002.05202
- Su et al., “RoFormer: Enhanced Transformer with Rotary Position Embedding” (2021): https://arxiv.org/abs/2104.09864
- Ainslie et al., “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints” (2023): https://arxiv.org/abs/2305.13245
- Kaplan et al., “Scaling Laws for Neural Language Models” (2020): https://arxiv.org/abs/2001.08361
- Narang et al., “Do Transformer Modifications Transfer Across Implementations and Applications?” (2021): https://arxiv.org/abs/2102.11972
- Groeneveld et al., “OLMo 2” (2024): https://arxiv.org/abs/2501.00656
- Ivanov et al., “Data Movement Is All You Need” (2021): https://arxiv.org/abs/2007.00072