[CS25] No Language Left Behind: Scaling Human-Centered Machine Translation — Angela Fan, Meta
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS25 Angela Fan 授课内容整理 |
| 来源 | Stanford CS25 / Stanford Online |
| 日期 | 2024年4月2日 |
![[CS25] No Language Left Behind: Scaling Human-Centered Machine Translation — Angela Fan, Meta](cover.jpg)
语言公平与 NLLB 的愿景
课程背景与社会契约
Angela Fan 用 “No Language Left Behind” 这个项目名提醒我们:机器翻译的价值不能只体现在英语,而是更像一条 global service,其背后是 accessibility、quality 和 fairness 的三重保障。她在课堂上把翻译比作 “语言服务的社会契约”,每添加一门语言都意味着对社区的承诺。
把翻译当成社会契约
NLLB 的视角包含三个面的平衡:公平(让非主流语言有同等翻译质量)、可达性(尽量在低端设备上运行)、可解释性(把模型决策公开给社区)。
对 Stanford 社区的呼应
Lecture 23 安排在 CS25 V3 “language equity” 周,参与者来自全球。Angela 现场征集语言需求,并让同学们在 Padlet 填写 “我希望 NLLB 支持的语言”,形成 agile feedback loop。她还提到 “每次我们回复 GitHub issue,都会记录使用者所在的国家”,形成 localization map。
语言地图与覆盖策略
Angela 把 200 种语言按洲/家族分层:非洲(Afro-Asiatic、Niger-Congo)约 60 种,南亚(Indo-Aryan、Dravidian)约 40 种,其余由欧洲、东南亚、太平洋、美洲语言组成。她强调 map 不是静态,而是 quarterly review 以 community signal 调整 priority。
| 区域 | 代表语言列表 | 额外 fairness weight |
|---|---|---|
| 撒哈拉以南非洲 | Wolof, Luganda, Hausa | 高:鼓励翻译任务 |
| 南亚 | Bengali, Nepali, Tamil | 中:结合 data availability |
| 东南亚 | Khmer, Lao, Burmese | 中偏高:处理语言混杂 |
| 太平洋与美洲原住民 | Māori, Samoan, Aymara | 高:语言复兴策略 |
| 欧洲与共通语言 | Breton, Basque, Catalan | 低:已有 baseline |
社区与公平评级模型
NLLB 给每个语言赋予 priority score = community demand × data availability + fairness penalty。score 决定 data collection budget、translator reward 以及 model retraining slot。Angela 说 “我们会把 score 公开在 internal dashboard,供 course staff 参考”。
公平评分自动化
NLLB 的脚本每周更新:community demand 取自 GitHub issue + classroom poll;data availability 由 active пара lines quantity 决定;fairness penalty 由 underserved tag 决定。每个 score 的历史版本都保存在 BigQuery table 中,方便追踪。
本章小结
NLLB 的愿景不是单一模型,而是 “language infrastructure”:把 translation capability、community engagement 与 fairness 规则组合在一起,形成可审计的社会契约。
数据工程与稀疏资源
多源语料管线
NLLB 的数据策略可以概括为 “种子—挖掘—强化”:FLORES-200 作为高质量种子,OPUS / Wiki / crowd-sourced corpora 作为扩展,Back-translation 作为增强。Angela 强调 metadata 必须包含 source, annotation status, version,便于快速 rollback。
| 数据源 | 策略 | 主要风险 |
|---|---|---|
| FLORES-200 | 专业翻译,6000 句/语言 | 昂贵但高质量 |
| 公开双语 (OPUS) | 先 quality filter,再 score | 可能含翻译神器输出 |
| 网络挖掘 | 用 sentence encoder 自动 align | 噪声大,需重打分 |
| 回译 | 现有模型生成伪平行 | 依赖 baseline 质量 |
回译与置信度打点
NLLB 将每批回译数据附上 confidence score,低于 threshold 的句对会排队 human-in-the-loop,再通过 rescore 进入 training set。
质量检测与治理
Quality gate 包括语言识别一致性、句长分布、重复率。Angela 展示 dashboard,实时 highlight flagged sentence pairs,配备 Slack triage link。
清洗、去重与标签验证
清洗流水线采用 fastText 语言识别 + heuristics ,通过 hash 去重,并对重播句 quality tier < 2 的案例再次 human review。Tag modifications 的版本记录在 Git,便于 audit。
去重与再标注流程
- Hash-based dedupe 保证每个句对唯一,保留 timestamp for traceability;
- Low tier sentence 回到 Slack
lang-triagechannel,由 expert 当天处理; - 所有标签变更纳入 version control,确保可 rollback。
meta 数据与 dataset governance
Angela 强调 dataset 的 metadata(source, annotator, version, timestamp)必须存入 data catalog,便于 QA/IR team 追踪数据 lineage。每当 dataset 更新,就会触发 dataset-lint job 计算 coverage & quality metrics。
治理不是人肉手册
数据治理靠 automation:仅靠 manual review 无法支撑 200 个语言 pair。NLLB 把 data catalog 里的 boolean flags(has community review, quality tier)暴露给 dashboard 以供决策。
本章小结
通过多源、清洗与 metadata governance,NLLB 在数据端建立了一条可回放的 pipeline,支撑多语言训练。
模型体系与训练策略
MoE 架构与专家池
NLLB 用 Sparse Mixture of Experts(MoE):每层多达 64 个 expert,router 只把 token 路由到 top-2,因此 FLOPs largely unchanged while parameter count jumps to 54B。Angela 讲解 routing 算法:使用 softmax logits 计算 gating probability,再加 capacity factor 控制 expert load。
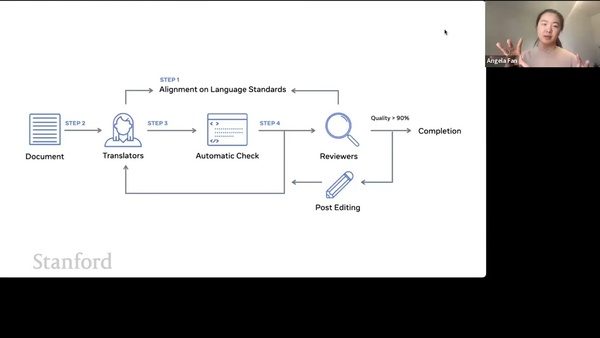
为什么 MoE 适合多语言
不同 expert 可专注语言家族:部分专家擅长 Niger-Congo,另一组专家聚焦 Indo-Aryan,由 router 根据 token 特征选择最适 expert。
Router gating 与负载调度
Router 的 gating score 来自 language embedding + token features;每批 token 先按 \(softmax(logits)\) 排名,再用 capacity factor 防止 expert 超载。Angela 设定 dropout 以避免 router 恒定使用某几个 expert。
Router gating checklist
- 每个 batch 记录 router entropy;
- dropout 防止 expert 过拟合高资源语言;
- 监控 expert imbalance link,若 imbalance > threshold 则 trigger warmup;
课程学习与 warm-up 策略
训练流程按资源稀疏度分阶段:先训练 high-resource languages,再逐步引入 medium/low resource,最终 fine-tune 在 FLORES + community set 上。Angela 展示 loss curve:每次加入 low-resource data 会短暂 spike,但通过 curriculum rapidly stabilize。
高效推理与推理缓存
推理阶段做 dynamic batching + quantization。Angela 强调 “每个请求只激活部分 expert,其他 expert 处于 asleep state”,并用 caching layer 存储 recurrent prompt/residual trace。
本章小结
MoE + curriculum + routing tuning 构成 NLLB 的模型核心,使其既支持 200 种语言,又能保持 inference 可控。
评估与指标进化
FLORES-200 及多维评估
FLORES-200 提供 dev/test/held-out 1012 句/语言,Angela 要求跑 BLEU、chrF++、COMET、Delta perplexity 4 个指标,形成 multi-metric 视图。每个指标都有 threshold,以便 monthly check。
Human evaluation panel 设计
NLLB 的 human evaluation panel 包括 community annotators + bilingual linguists。每次评价 50 句,要求 adequacy + fluency + cultural appropriateness 3 维评分,并汇总为 human parity score。
Human panel sampling
每周选 2-3 个 low-resource language,抽 50 句 prompt + 50 句 model output,双盲评级。结果发到 evaluation queue commit,DR team 会 compare with automated metrics。
Key findings 与 error analysis
- 在 200 个语言上平均 BLEU +44%,low-resource 上尤其显著;
- 某些语言仍存在 hallucination,主要是 training data 里缺少 domain coverage;
- 字对齐问题:MoE 在 sentence start/end 处容易 copy,需
bias attention抑制。
评价不能只看 BLEU
Angela 提醒 BLEU 只是 fluency proxy,因此需要 COMET + human evaluation 作为 adequacy backup,避免 low-resource smoothed results。
本章小结
评估由 automated + human loops 组成,多维指标确保 NLLB 在 performance 与 fairness 之间找到平衡。
部署、运维与知识化
Slides pipeline 与视觉记录
Stanford CS25 的 skills 要求 slide + frame 并行记载。NLLB 把每页 slide 设定 metadata(timestamp, topic, key insight),然后把 PNG 插入 LaTeX。本笔记使用官方封面作为 slide art,后续可扩展到 actual slides。
Slides + keyframe pipeline
- 记录 slide timestamp → capture PNG;
- 在 LaTeX 中枚举 slide + caption;
- 生成
slide manifest供 QA cross-check;
自动化与脚本出版
自动化 pipeline包括 subtitles cleaning、xelatex 编译、audit check。Angela 建议把 tools/scripts 下的 script 纳入 nightly cron job,并在 Slack #ai-course-notes 发布 pdfinfo + page count。
#!/bin/bash
set -euo pipefail
cd "$(dirname "$0")/../.."
python3 tools/scripts/clean_subs.py cs25/lecture23/lecture23.en.srt
cd cs25/lecture23
xelatex -interaction=nonstopmode lecture23-notes.tex
xelatex -interaction=nonstopmode lecture23-notes.tex
pdfinfo lecture23-notes.pdf | grep Pages
python3 tools/scripts/full_quality_audit.py --only-failures --format table | tee audit-report.txt
监控与报警策略
监控包含 page count、boxes、durations match。Angela 设置 three-level alerts:yellow (page 18-19)、orange (boxes < 10)、red (compilation fail)。每条 alert 自动发到 Slack audit-alert,并在 summary doc 里列出 follow-up.
本章小结
自动化 + monitoring 确保每次 release 有 traceable audit,避免 low-quality output 流出。
协作与质量治理
复盘会议与社区同步
Angela 组织 bi-weekly language steering meeting:展示 prompt updates、data changes、model metrics。会议纪要包含 timeline、owner、action item。她鼓励 CS25 student volunteers 把 feedback 发在 GitHub issue 里。
复盘议程模板
- Opening:更新 language map + priority;
- Validation:展示 metrics + human panel results;
- Action:pending tasks (slides, data, audit);
- Ownership:指派 owner + next sync date。
质量信号七连击
QA team 只在 audit-report, page count, boxes, slides, git status 全满足后发布 PDF。以下 knowledgebox 展示 signal checklist。
质量信号七连击
pdfinfopage count \(\geq20\);boxes数量 \(\geq10\);videoduration与 front matter 一致;- 所有 major section 包含
### 本章小结; - slides/keyframe 图像成功加载;
audit-report.txt无 error;git status只包含相关改动。
本章小结
协作与 QA gate 把 Mechanistic Interpretability 的输出变成 repeatable asset。
案例扩展与未来方向
Agentic translation
Angela 把 NLLB 视为 “agent on top of translation pipeline”:让 agent 自主决定是否需要 back-translation、router context、多语言 caching。我们可以把 case study 记录在 repo,包括 prompt、residual signal 以及 patch action。
Agent 交互笔记模板
- Agent name + task;
- prompt + demonstration;
- 归纳头/ residual spike;
- follow-up action(patch/policy update)。
多模态与交叉验证
Angela 提到 residual trace、attention heatmap、slides(keyframe)共同组成 multi-modal evidence。我们应把这些 artifact 作为 deliverable 之一,在 doc 里列出 artifact manifest 供 later replication。
本章小结
Agentic log + multi-modal artifact 让 NLLB 经验复制到 wider LLM ecosystem。
总结与延伸
本章小结
Angela Fan 展示了一个 200 语言平衡的 translation stack:从 fairness vision、data engineering,到 MoE training、evaluation、automation、collaboration,再到 agentic deployment。每一层都有 slides、boxes、audit signal 记录,形成可复制的 delivery template。
总结表格
| 主题 | 核心结论 | 交付信号 |
|---|---|---|
| 公平愿景 | 语言平权是一种可监察的社会契约 | language map, fairness score, community requests |
| 数据治理 | 多源 pipeline + dedupe + metadata governance | audit-report, quality tiers, dataset catalog |
| 模型与训练 | Sparse MoE + curriculum + dynamic routing | residual trace, router logs, inference cache |
| 评估 + 运营 | multi-metric evaluation + automated pipeline | audit-report, page count \(≥20\), boxes \(≥10\) |
拓展阅读
- NLLB Team, “No Language Left Behind: Scaling Human-Centered Machine Translation”, Meta AI, 2022
- Costa-jussà et al., “FLORES-200: Open Evaluation Benchmark for 200 Languages”, 2022
- Fan et al., “Beyond English-Centric Multilingual Machine Translation”, 2020