CS336 Lecture 11: Scaling Laws 2
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Tatsu Hashimoto 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2025年5月15日 |

引言:Scaling Laws 的实践应用
本节课是 Scaling Laws 系列的第二讲,也是最后一讲。与上一讲偏重理论基础不同,本讲更注重案例研究和实践细节。课程分为两个核心部分:
- 案例研究:分析多个实际模型(Cerebras GPT、MiniCPM、DeepSeek LLM 等)如何在训练过程中应用 scaling laws 来做出设计决策
- MuP(Maximal Update Parameterization):深入理解一种让超参数在不同模型规模间保持稳定的参数化方法

来源:Slides 第1页。
本讲的核心问题
- Chinchilla 的 scaling law 方法真的有效吗?在实际大模型训练中表现如何?
- 如何在小规模实验中确定学习率、batch size 等超参数,并可靠地迁移到大规模训练?
- 是否存在某种参数化方式,使得最优超参数不随模型规模变化?

来源:Slides 第2页。
从 Chinchilla 到实践的知识鸿沟
Chinchilla 论文之后,ChatGPT 的出现改变了大语言模型的竞争格局。各大前沿实验室不再公开发表关于 scaling 的详细研究。讲者提到,他与前沿实验室的人交流时,对方明确表示不会透露任何关于 scaling 的细节。因此,我们不得不依赖少数开放的模型训练报告来理解 scaling 在实践中的运作方式。
案例研究概览

来源:Slides 第3页。
讲者指出,在所有公开的 scaling 研究中,DeepSeek 和 MiniCPM 仍然是迄今为止最详细的开放式 scaling 研究——即使到了 2025 年,这一点也没有改变。
本章小结
Scaling laws 不仅是理论上的曲线拟合工具,更是指导实际大模型训练的核心方法论。本讲将通过多个真实案例,展示不同团队如何将 scaling laws 融入从超参数选择到模型规模决策的完整训练流程。
案例研究一:Cerebras GPT
模型概述
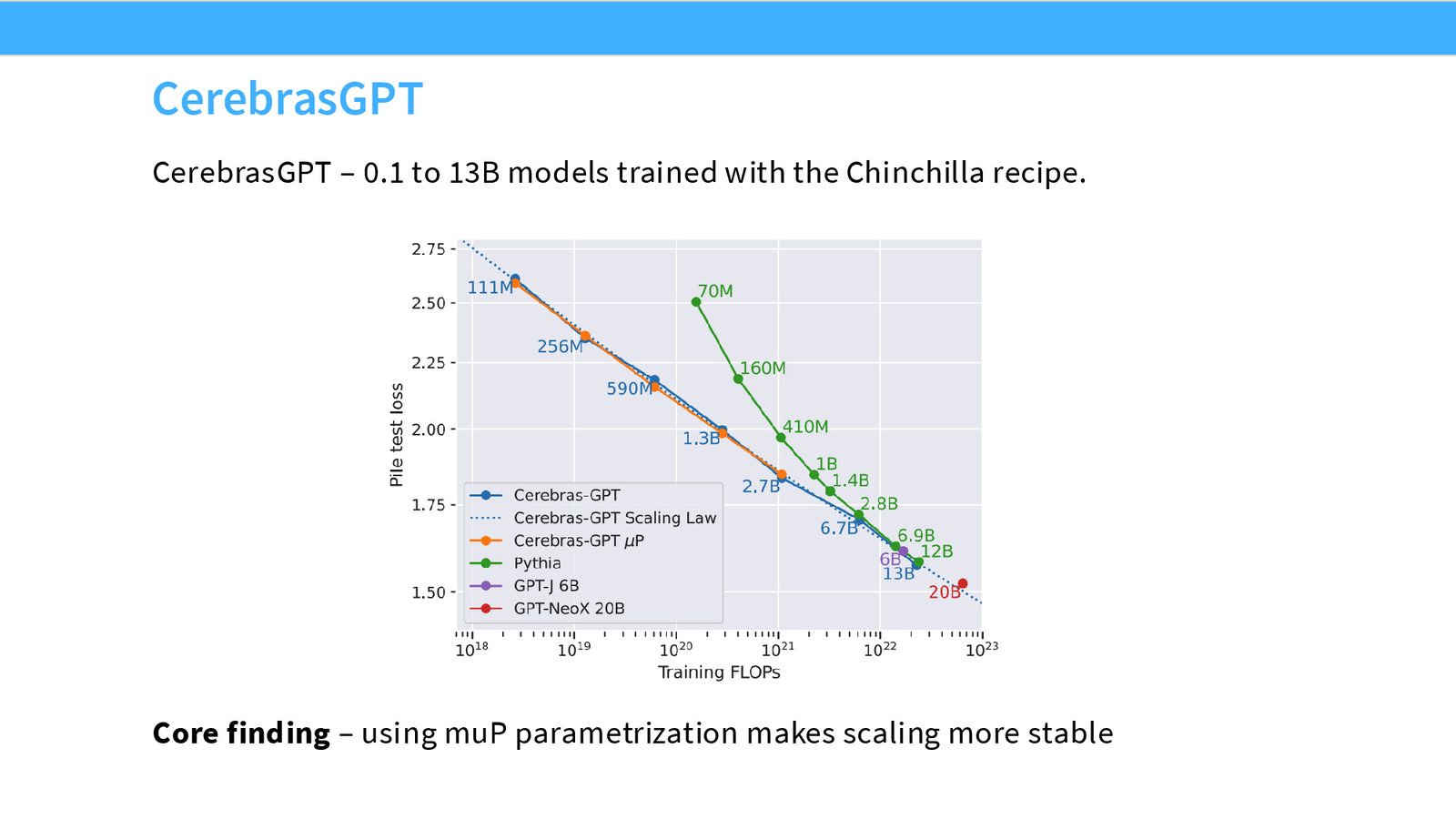
Cerebras GPT 是一个大型模型家族,涵盖 0.1B 到 13B 参数规模,使用 Chinchilla 配方训练(即 token 数与参数数的比值大致为最优比例)。
来源:Slides 第4页。
MuP 的首次大规模公开验证
Cerebras GPT 的核心贡献在于它是最早公开验证 MuP 有效性的大规模模型之一。

来源:Slides 第5页。
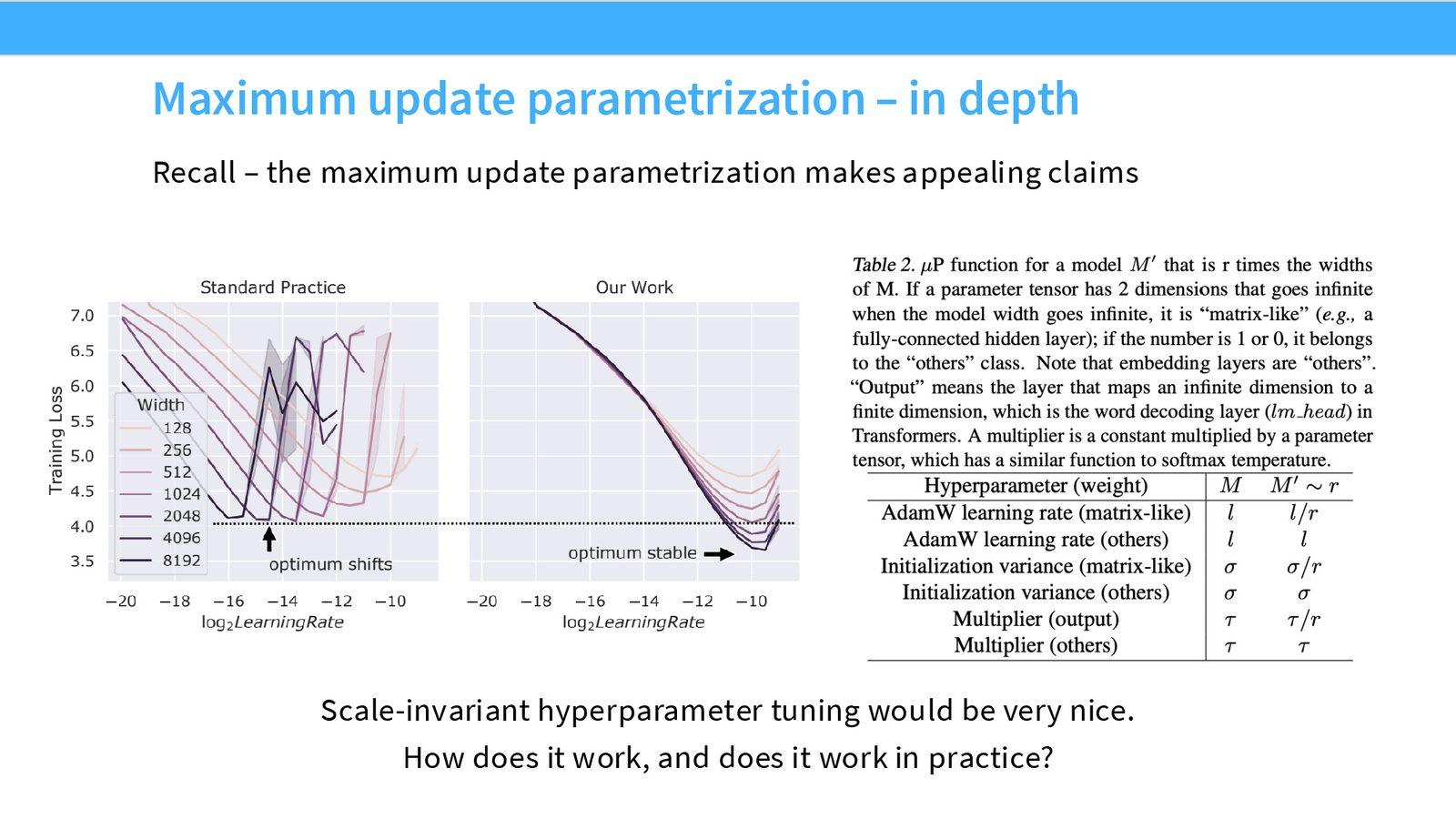
MuP 带来更可预测的 Scaling
使用标准参数化(SP)时,实际性能围绕 scaling law 预测值有较大振荡——这是因为不同规模的模型需要不同的学习率,而手动调优不可能完美。使用 MuP 后,振荡显著减小,实际性能更接近 scaling law 的预测曲线。
MuP 实现细节
Cerebras 团队在论文附录中提供了一张非常实用的对照表,清楚列出了标准参数化(SP)和 MuP 之间的具体差异。
来源:Slides 第6页。
MuP 的实践要点可以简单概括为:
- 初始化:非 embedding 参数按 \(1/\text{width}\) 缩放
- 学习率:每层学习率按 \(1/\text{width}\) 缩放(对 Adam 优化器)
- Embedding:保持常数缩放
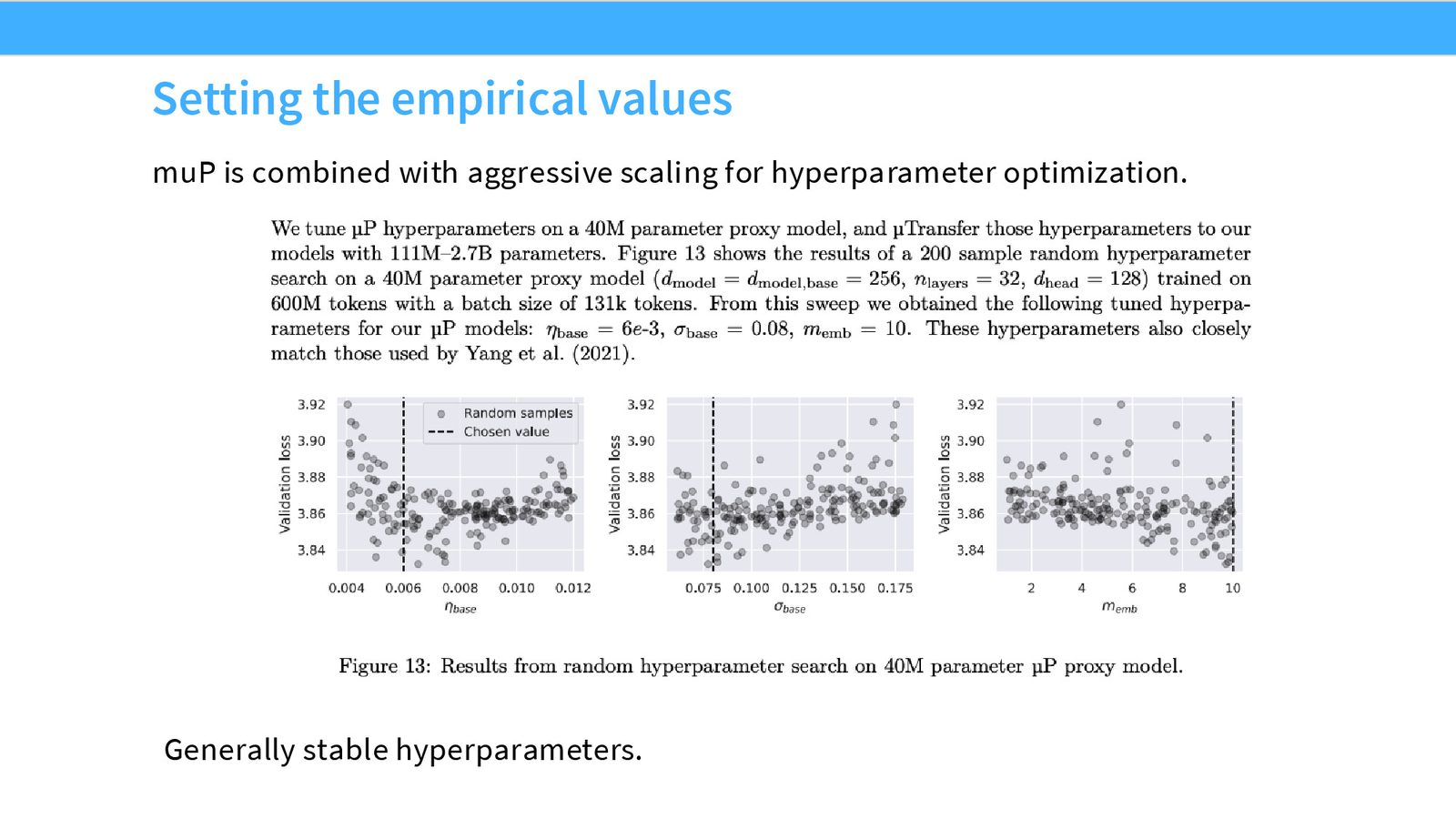
小模型代理搜索策略
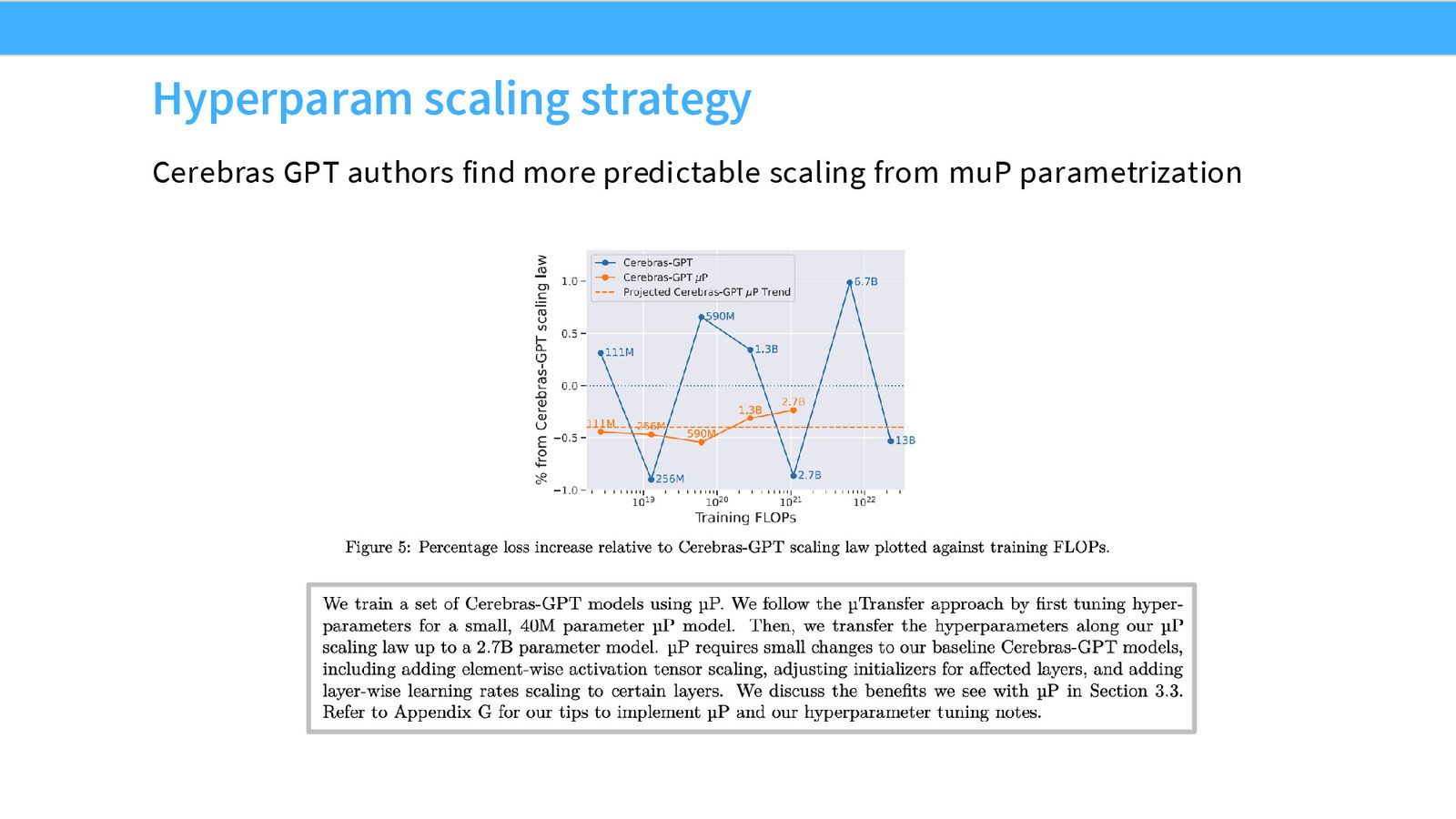
来源:Slides 第7页。
Cerebras 团队将模型缩小到仅 40M 参数,在此规模上进行广泛的超参数搜索,然后利用 MuP 的超参数迁移特性将最优配置放大到 13B 规模。这一策略实现了约 5x 的计算节省。
小模型代理搜索的局限性
将实验缩小到 40M 参数是非常激进的做法。对于训练真正巨大的模型(如数百亿参数),这种程度的缩小是否仍然可靠尚不确定。但这一策略在 Cerebras GPT、MiniCPM 和 DeepSeek 中都有不同形式的体现——训练较小的代理模型,然后尝试稳定地放大。
本章小结
Cerebras GPT 提供了 MuP 的首次大规模公开验证,证明了通过合理的参数化可以使 scaling 更加可预测。其核心策略是:小规模搜索超参数 + MuP 迁移到大规模,从而大幅减少了超参数调优的计算开销。
案例研究二:MiniCPM
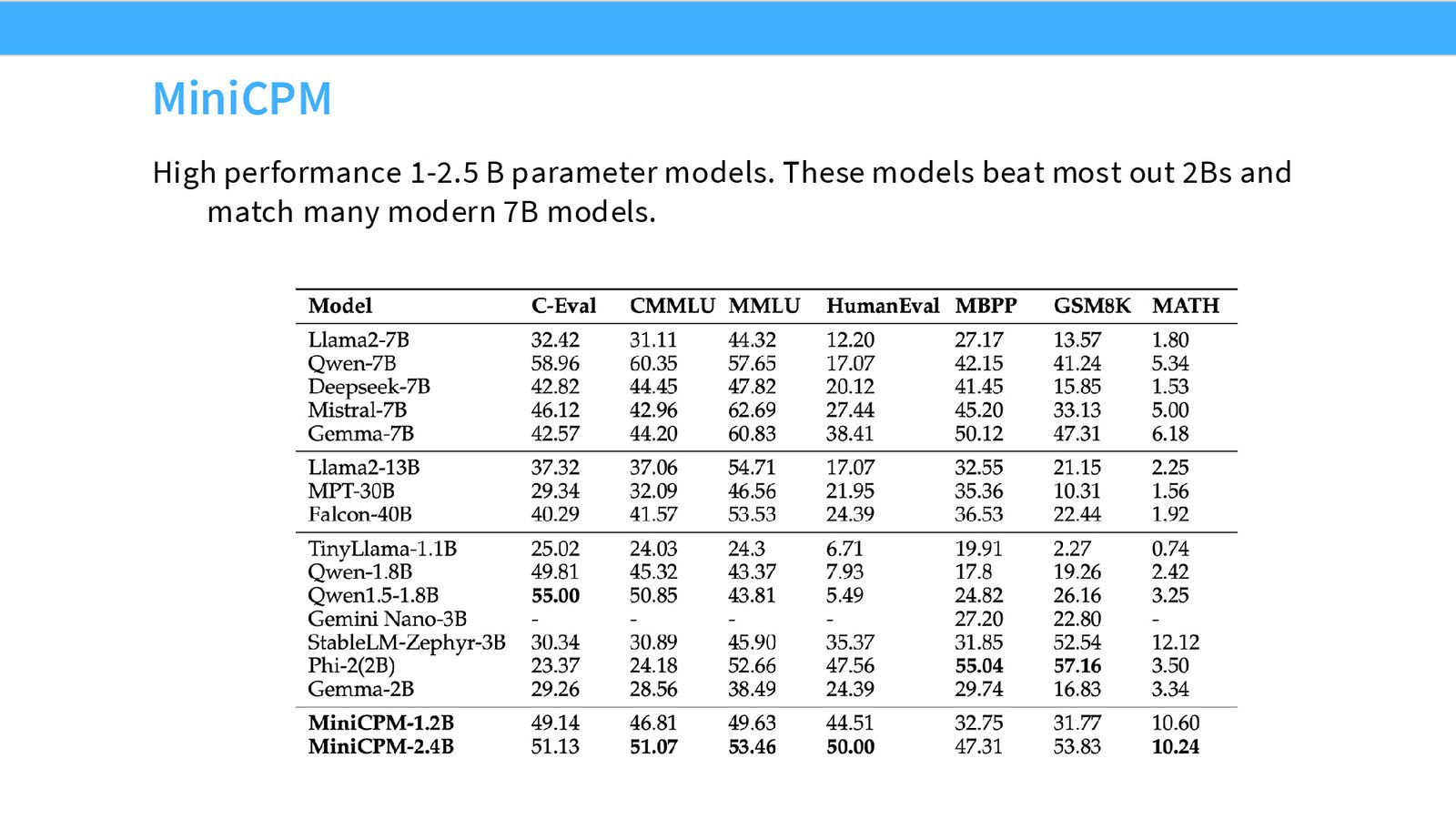
模型概述与动机
MiniCPM 来自中国的研究团队,目标是训练高质量的小语言模型(1.2B--2.4B 参数),通过大量计算实现远超同规模模型的性能。

来源:Slides 第8页。
MiniCPM 的研究价值
讲者指出,MiniCPM 虽然在西方学术圈没有获得足够关注,但它是最早展示中国研究组在 scaling 和模型优化方面达到前沿水平的论文之一。其 scaling 研究的深度和质量与 DeepSeek 不相上下。
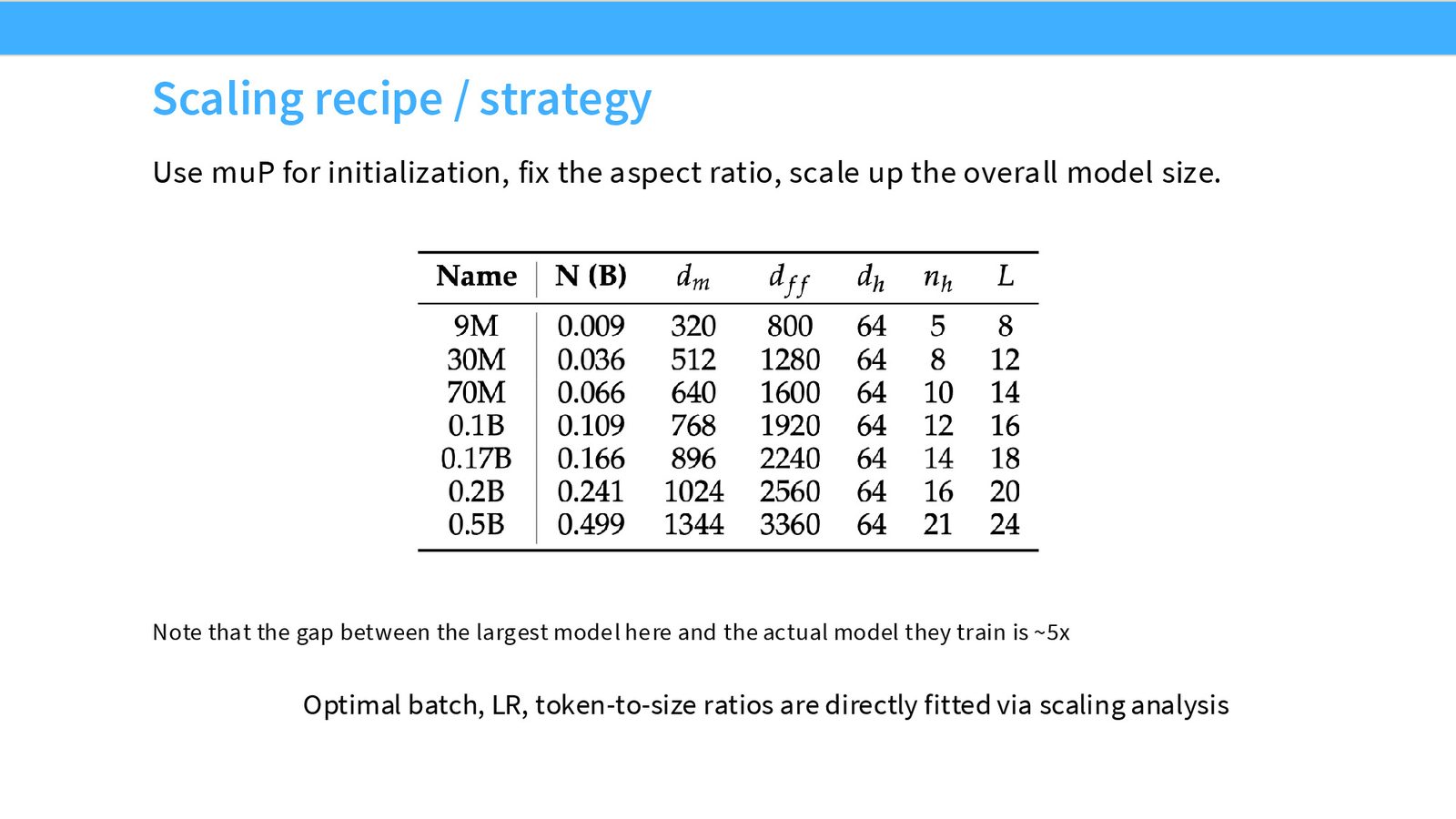
MuP + 超参数搜索
MiniCPM 同样使用了 MuP 来稳定和简化 scaling 过程。
来源:Slides 第9页。
MiniCPM 在超参数搜索和稳定扩展方面与 Cerebras GPT 采用了非常类似的策略:在小规模模型(约 9M--30M 参数)上进行大量超参数搜索,然后利用 MuP 确保学习率等关键超参数在更大规模下保持稳定。

来源:Slides 第10页。
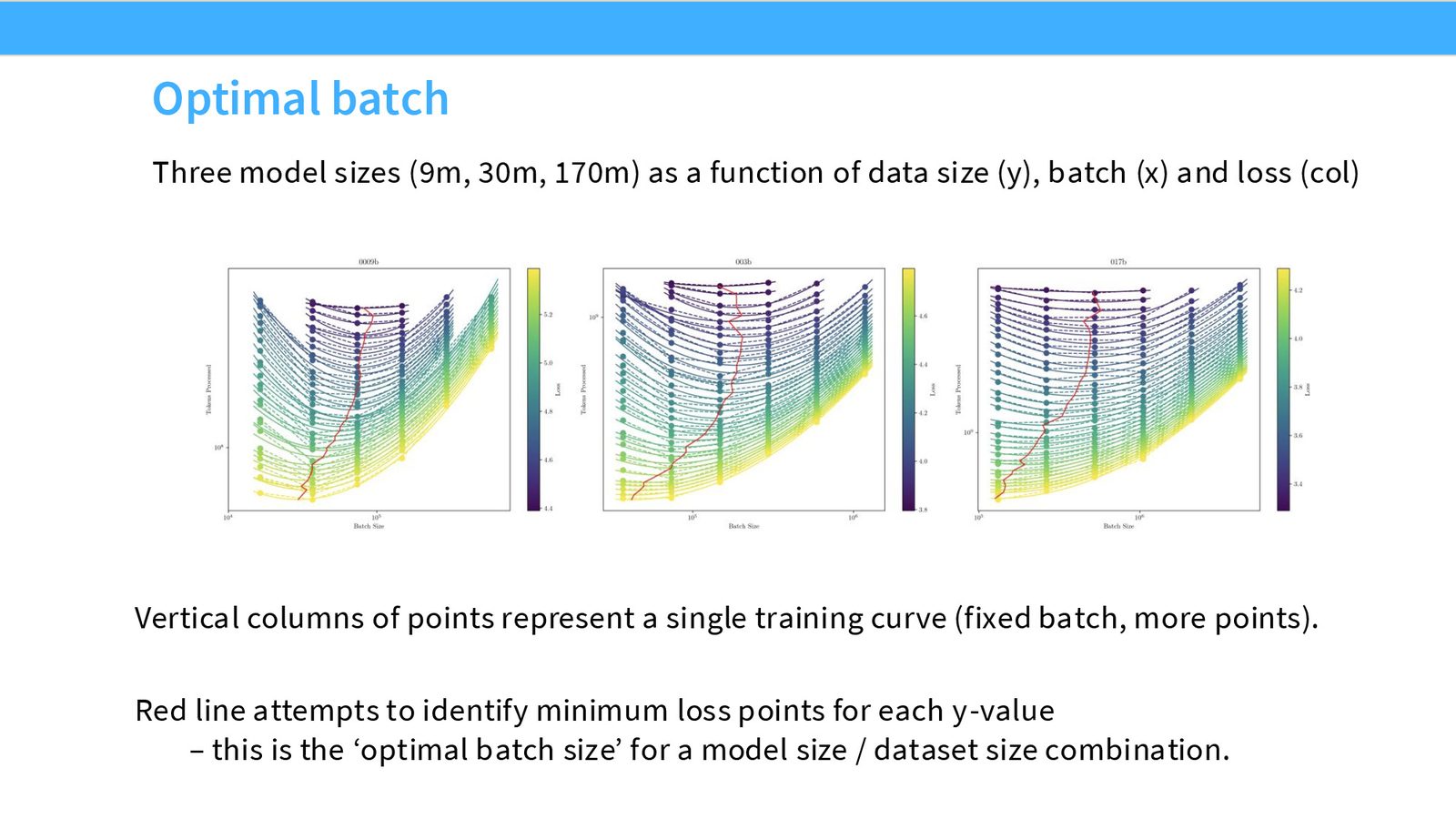
学习率稳定性验证
来源:Slides 第11页。
学习率迁移的经验验证
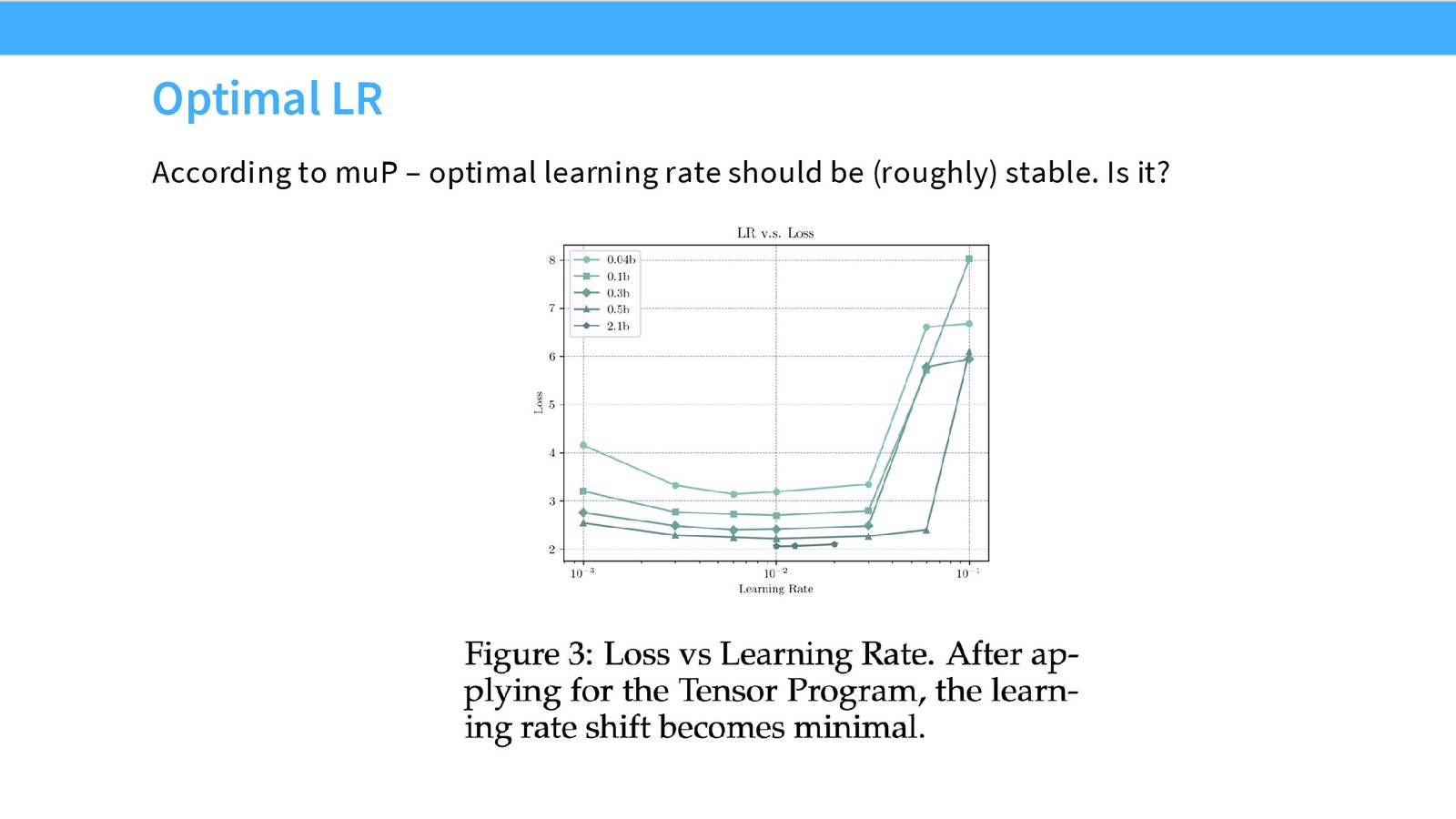
如果 MuP 有效,那么从小模型到大模型,最优学习率应保持不变。MiniCPM 的实验清楚地展示了这一点:不同规模的模型在 \(\sim 10^{-2}\) 处都达到最低 loss,且 loss 曲线呈现宽阔的 basin(不敏感区域)和陡峭的不稳定边界——这与 Kaplan 论文中的早期观察一致。
WSD 学习率调度:Chinchilla 的高效替代
MiniCPM 最重要的贡献之一是推广了WSD(Warmup-Stable-Decay)学习率调度。
来源:Slides 第13页。
Cosine 学习率的致命缺陷
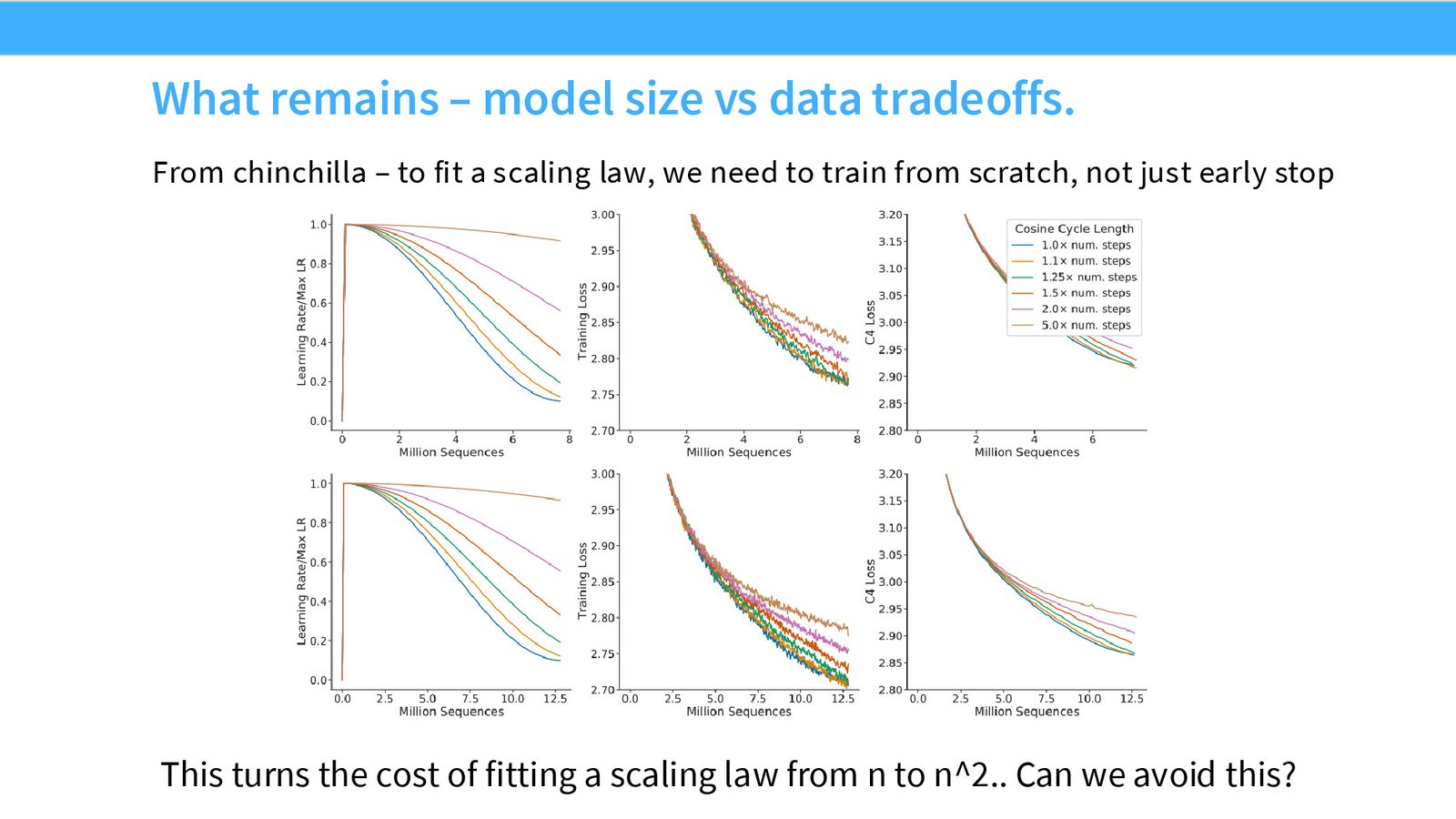
使用 Cosine 学习率调度时,不能从一次训练中取早期 checkpoint 来推断不同数据量下的 scaling 行为。因为不同数据目标对应不同的 Cosine 曲线——短数据训练的 Cosine 下降很快,长数据训练的 Cosine 下降很慢。这意味着要拟合 Chinchilla scaling law,需要对每个数据量-模型规模组合从头训练,计算量接近 \(n^2\) 级别。很多人在这个问题上踩过坑。
WSD 学习率调度分为三个阶段:
- Warmup:与 Cosine 相同的升温阶段
- Stable:学习率保持恒定的平坦阶段
- Decay:快速冷却到最小学习率
WSD 的核心优势:一次训练,多次复用
WSD 的 Stable 阶段是平坦的,这意味着可以共享同一个 Stable 阶段的训练。要获取不同数据量的结果,只需从 Stable 阶段的不同 checkpoint 分别执行 Decay,而不需要从头重新训练。这使得 Chinchilla 式的 data scaling 分析几乎可以在一次训练的成本内完成。
WSD 训练曲线特征
来源:Slides 第14页。
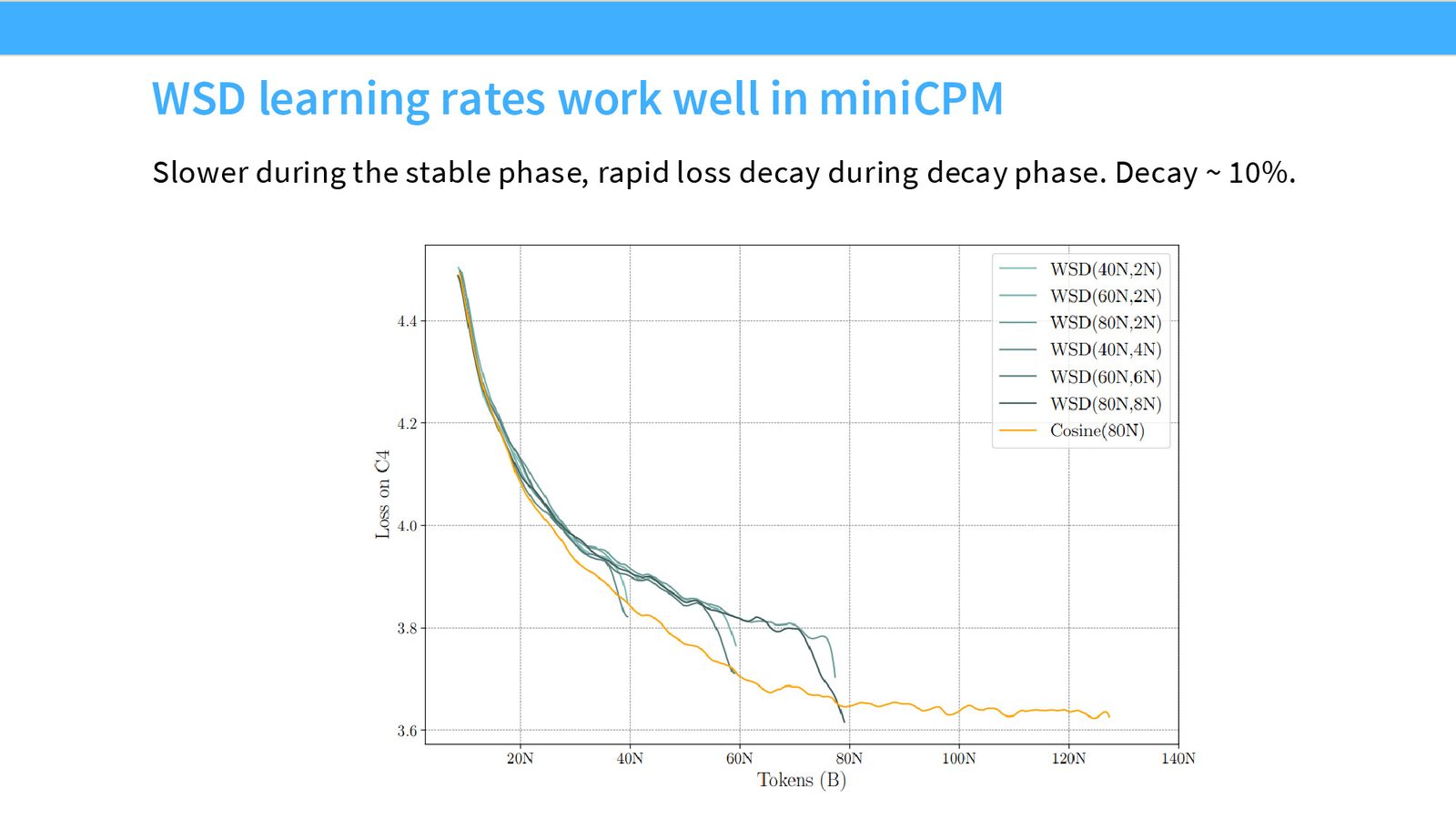
WSD 的训练曲线看起来有些“不正常”——在 Stable 阶段,loss 缓慢下降;一旦进入 Decay 阶段,loss 会急剧下降,直到达到终点。这种急剧下降是正常现象,不必担忧。
Cool-down 阶段的重要性
实验表明,大部分 loss 的降低发生在 Decay(Cool-down)阶段。如果不执行 Cool-down,会导致巨大的 loss 损失。这揭示了优化器学习率设计的核心权衡:高学习率帮助模型远离初始化点进行探索,而 Cool-down 则让模型在好的区域精细收敛(退火)。
Chinchilla 复现与 Token-Parameter 比例
来源:Slides 第16页。
MiniCPM 使用 WSD 学习率调度后,利用方法一和方法三复现了 Chinchilla 分析。他们得到了极高的 token/parameter 比例——192:1。
192:1 比例的可信度存疑
讲者对 MiniCPM 的 192:1 token/parameter 比例持保留态度——这远高于其他任何复现结果。Chinchilla 原始论文得到 20:1,Llama 3 得到约 39:1,Hunyuan 得到 96:1。MiniCPM 团队认为 LLaMA 风格架构和更好的数据质量可以支撑更高的比例,但这一数字仍是一个显著的异常值。
来源:Slides 第17页。
核心 Takeaway:20:1 只是起点
Chinchilla 的 20 token/parameter 比例只是一个起点,实际可以远远超越。Llama 3 等现代模型的训练比例远超 20:1,且并没有出现严重的收益递减。不同架构、不同数据质量、不同优化策略都会影响这一最优比例。
本章小结
MiniCPM 的核心贡献包括:(1)推广了 WSD 学习率调度,使 Chinchilla 式分析的计算成本大幅降低;(2)通过 MuP 实现了学习率的跨规模迁移;(3)展示了超越 Chinchilla 比例的可能性。WSD 现已被广泛采用。
案例研究三:DeepSeek LLM
模型概述
DeepSeek LLM 是原始 DeepSeek 论文(2024年初),包含 7B 和 67B 参数模型。
来源:Slides 第19页。
DeepSeek 的科学态度
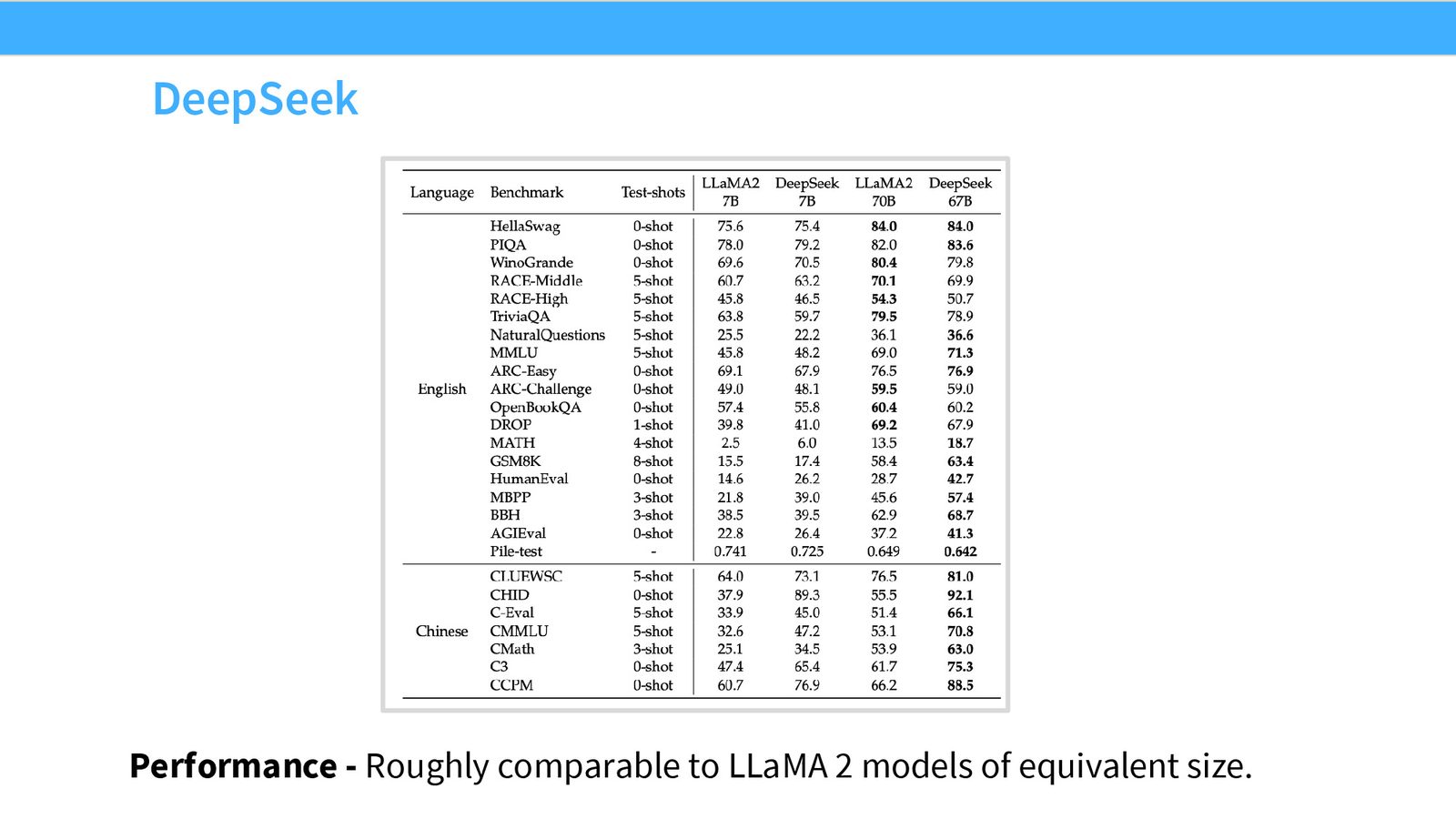
讲者特别强调,阅读 DeepSeek LLM 的原始论文就能看出这是“非常认真的科学家”在做研究——他们进行了大量仔细的 scaling ablation,真正试图在放大模型之前把一切都做对。这种态度是那些在 scaling 上取得成功的团队所共有的。
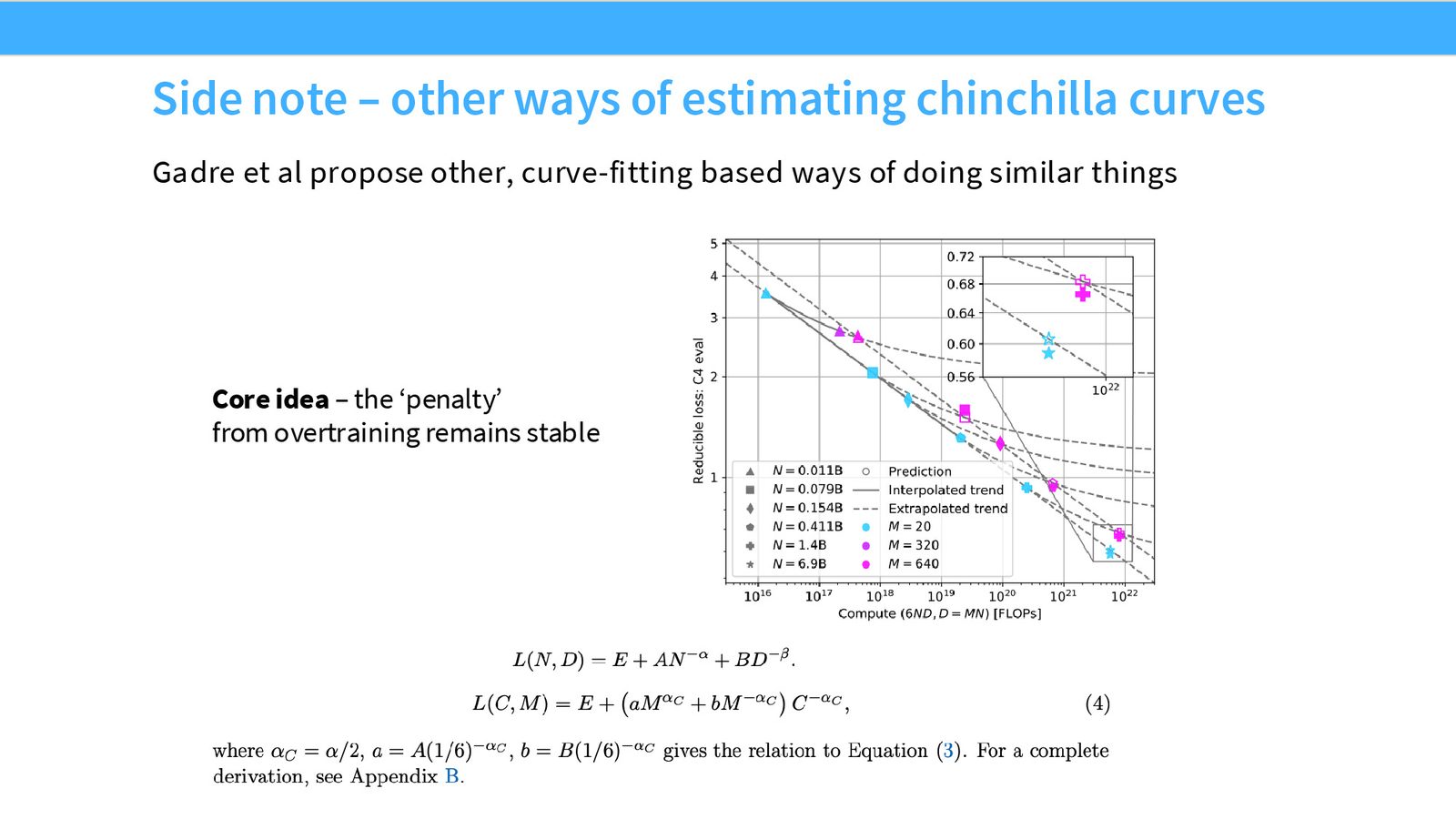
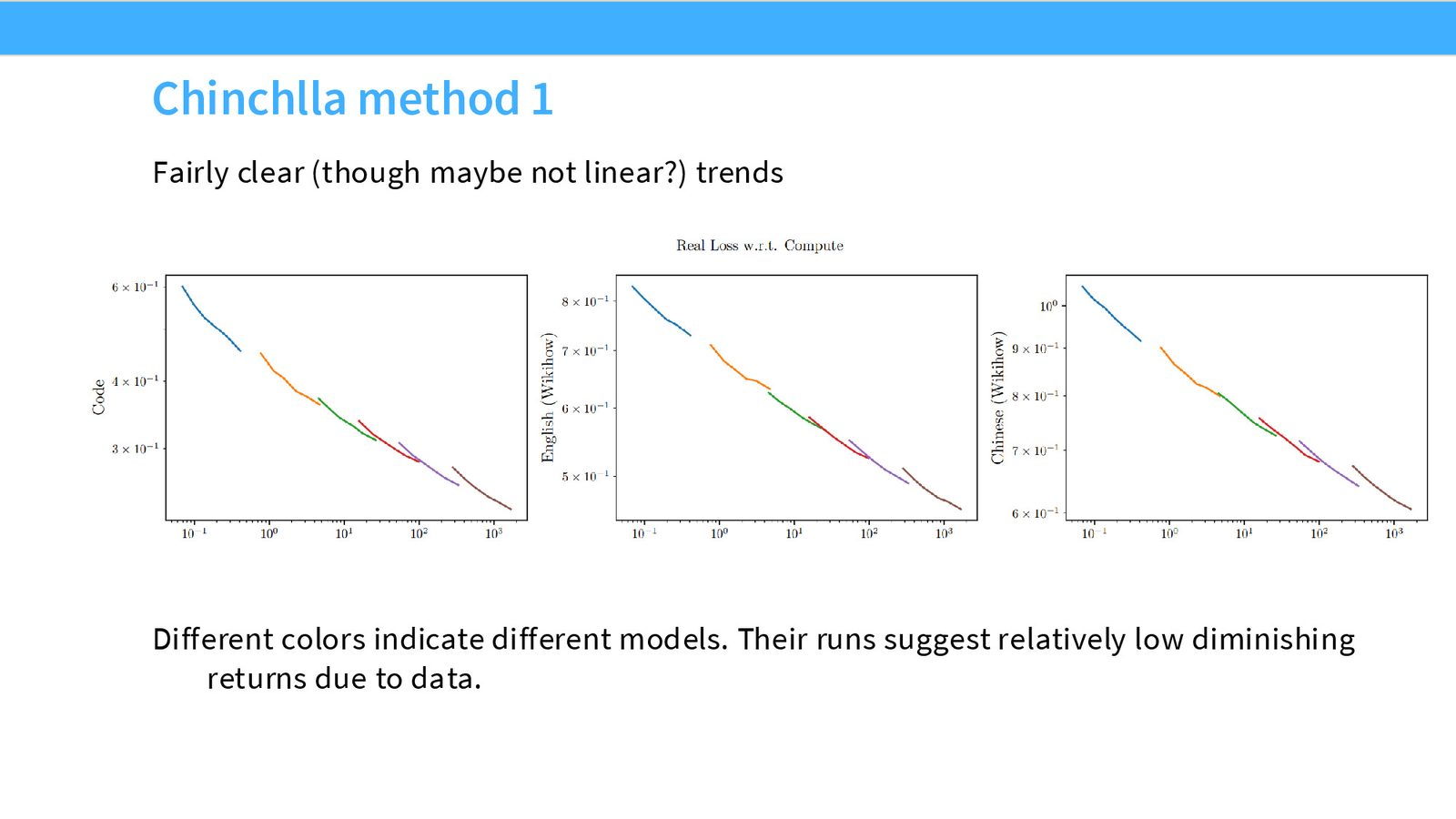
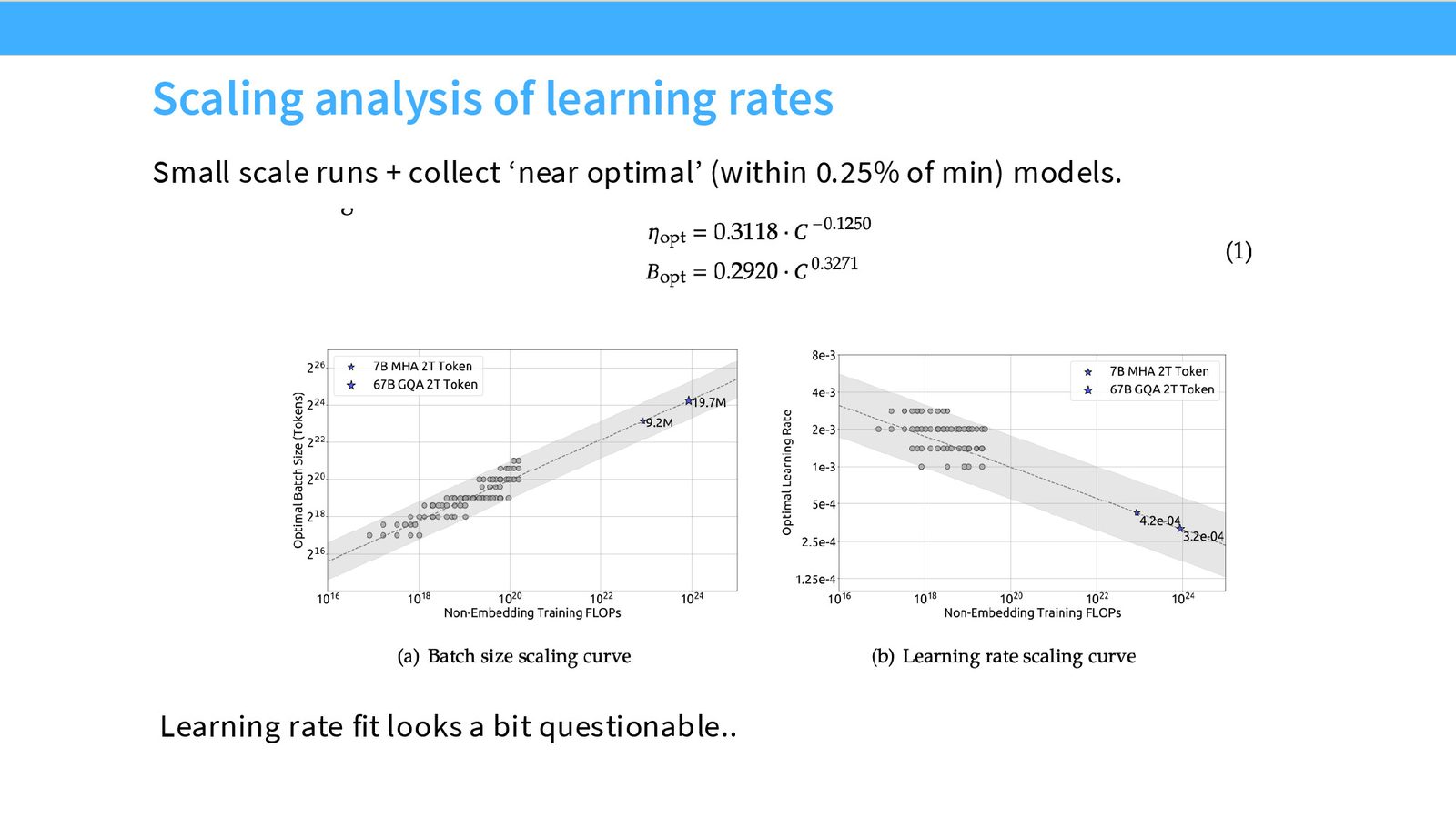
直接拟合 Scaling Law 的策略
与 Cerebras GPT 和 MiniCPM 不同,DeepSeek 没有使用 MuP。他们采取了一种更直接的方法:直接拟合学习率和 batch size 随计算量变化的 scaling law。
来源:Slides 第20页。
DeepSeek 的具体策略是:
- 在多个不同 FLOP 规模的小模型上运行学习率和 batch size 的网格搜索
- 找到每个规模下的最优学习率和 batch size
- 将最优值拟合为计算量的函数(即 scaling law)
- 外推到目标规模来预测最优超参数

来源:Slides 第21页。
学习率 Scaling Law 的可信度
讲者对 DeepSeek 的学习率 scaling law 表示怀疑——“我大概也能拟合一条水平线,看起来也差不多对”。Batch size 的 scaling 趋势更为清晰。总体而言,超参数的 scaling 总是看起来比较嘈杂,但 isoFLOP 分析的 scaling 则非常干净——这是一个在所有研究中反复出现的规律。
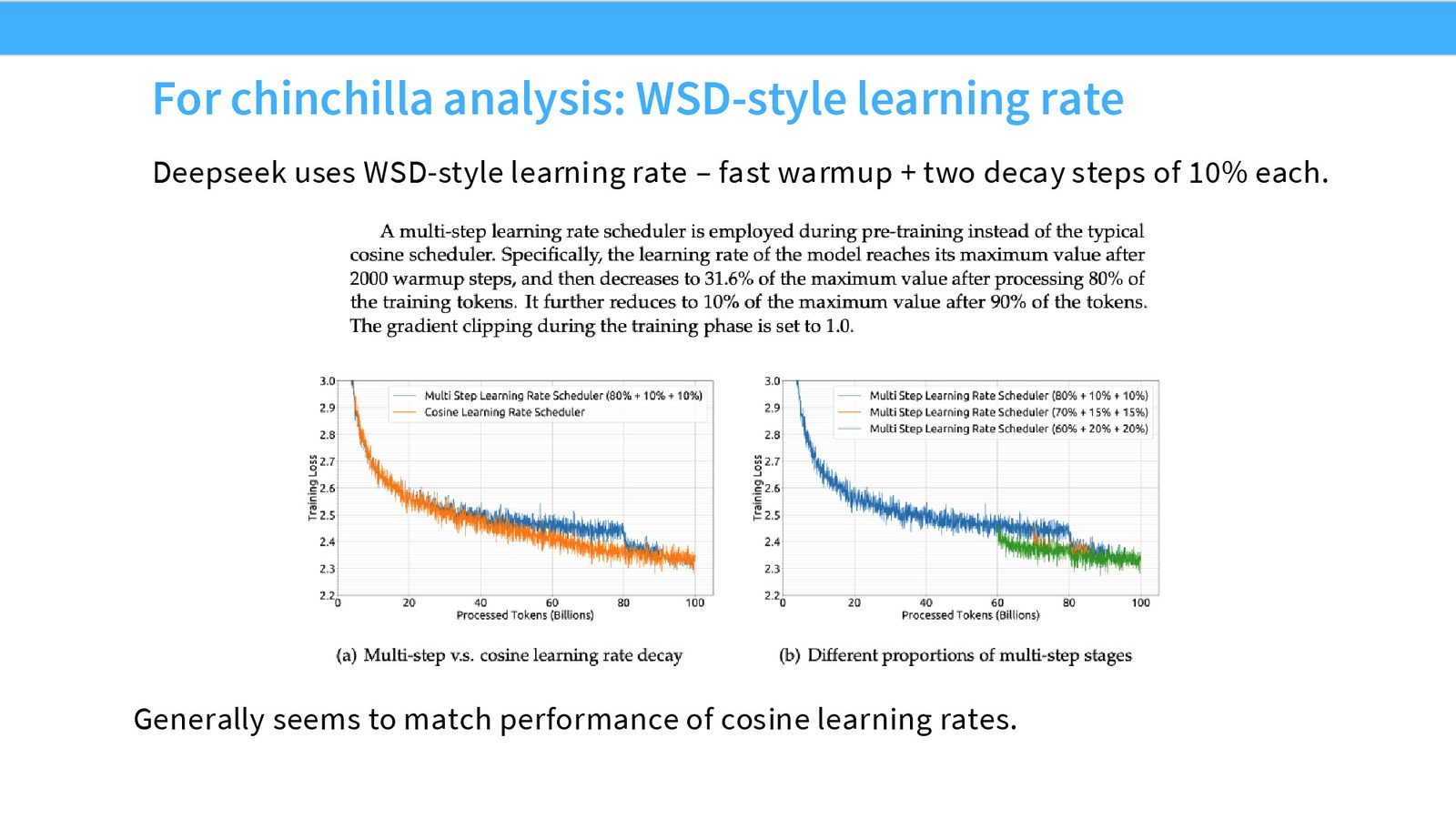
WSD 学习率与 Chinchilla 复现
DeepSeek 同样使用了 WSD 风格的学习率调度,不过他们的方案稍有不同——使用了两段 Decay(各占总训练的约 10%),总计约 20% 的计算预算用于 Cool-down。
来源:Slides 第22页。
IsoFLOP 分析
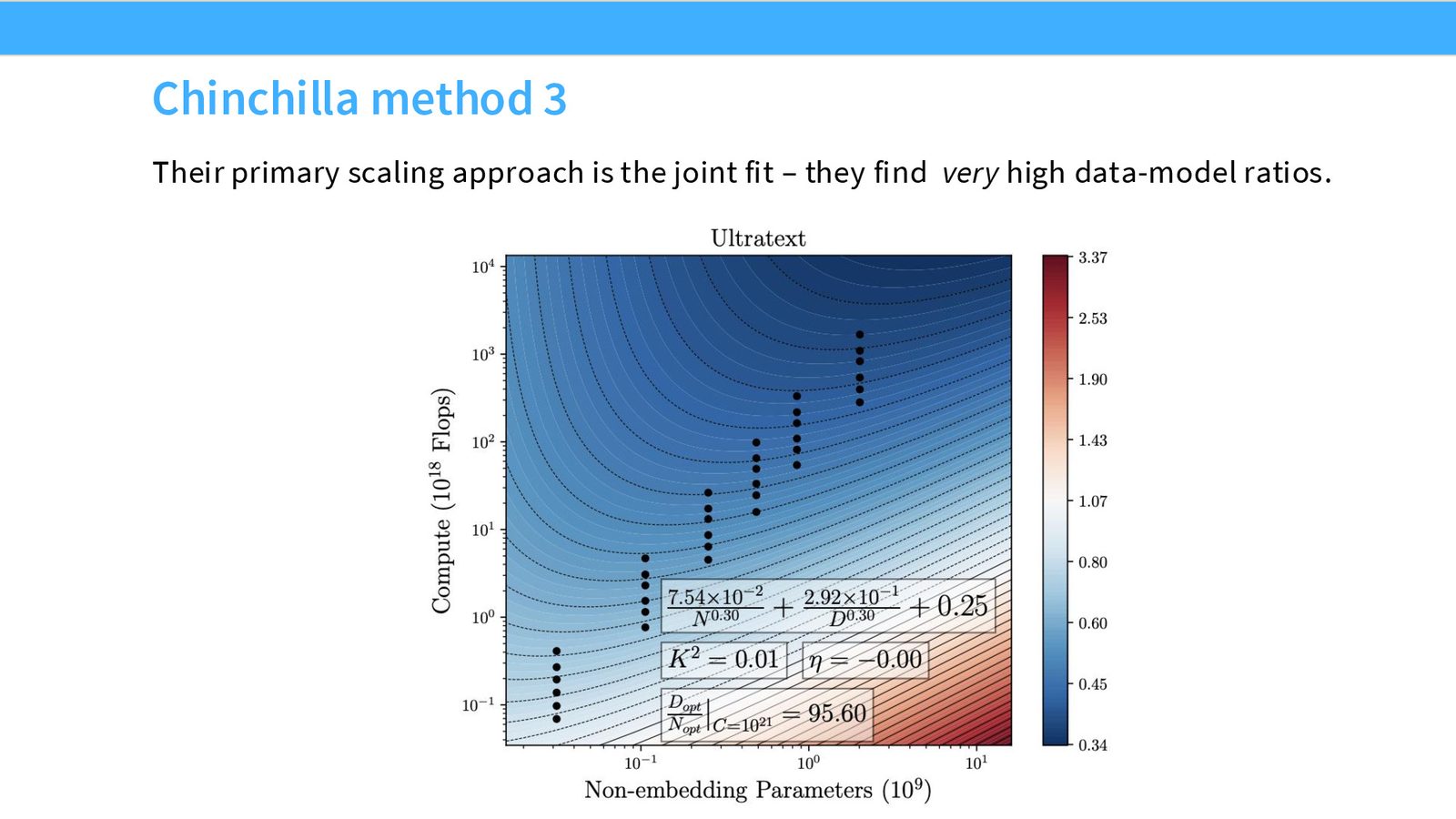
来源:Slides 第23页。
DeepSeek 的 Chinchilla 复现非常干净。讲者称赞他们没有简单地照搬 Chinchilla 的 20:1 比例,而是从头进行了完整的 isoFLOP 分析,确保自己的 token/parameter 配比是合理的。
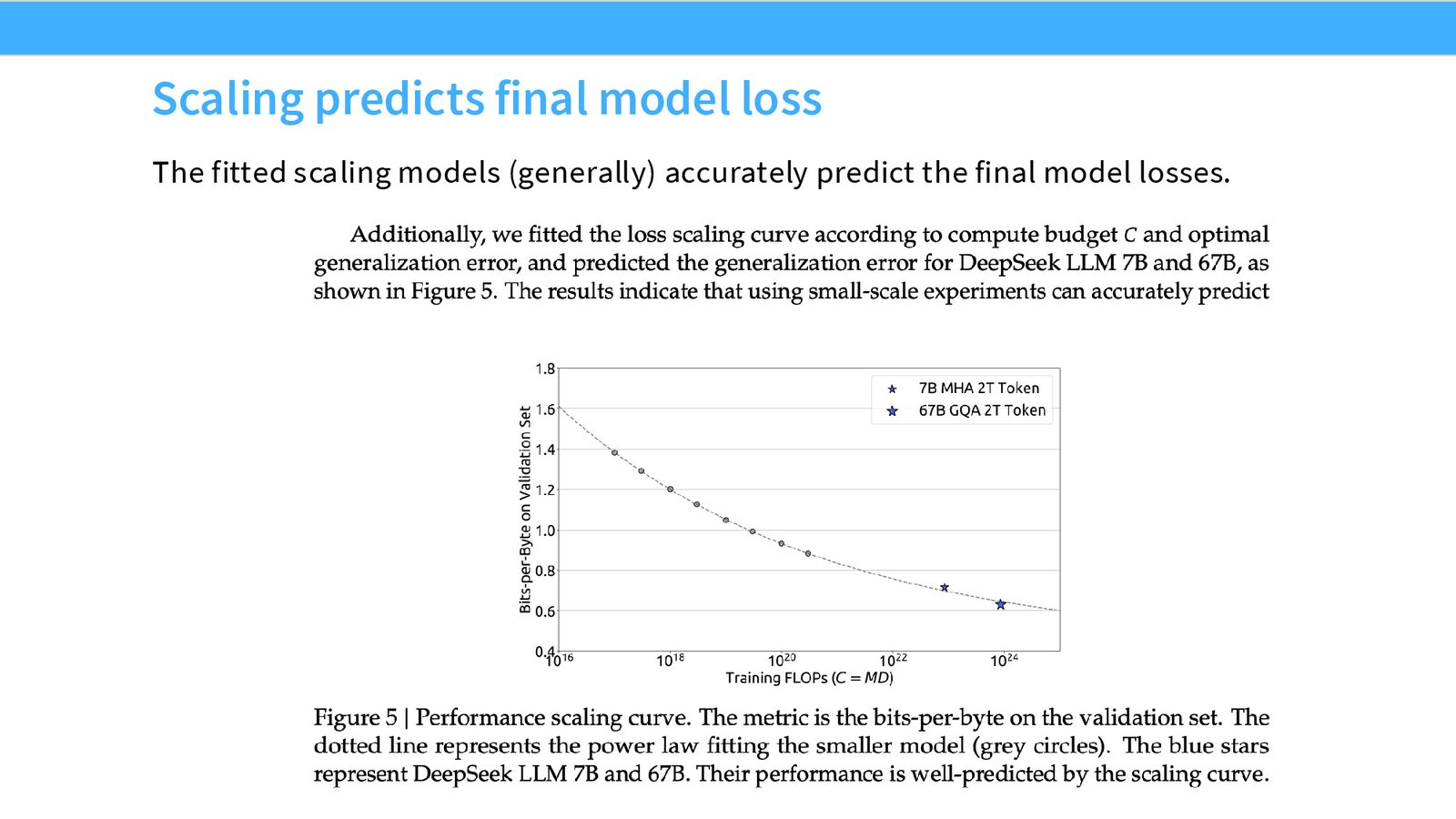
Scaling 预测验证

来源:Slides 第24页。
成功的 Scaling 外推
DeepSeek 展示了令人印象深刻的 scaling 外推能力:基于 \(\sim 10^{20}\) FLOP 规模的小实验拟合的 scaling law,成功预测了高达 \(10^{24}\) FLOP 规模的 7B 和 67B 模型的最终性能。这证明了 scaling laws 在实际模型训练中的预测价值。
本章小结
DeepSeek 采取了与 Cerebras GPT 和 MiniCPM 不同的策略:不使用 MuP,而是直接拟合超参数的 scaling law。他们的成功表明,只要足够仔细地进行 scaling 分析(尤其是 isoFLOP 分析),就能获得可靠的 scaling 预测,即使超参数 scaling 本身有些嘈杂。
近期模型的 Scaling 实践
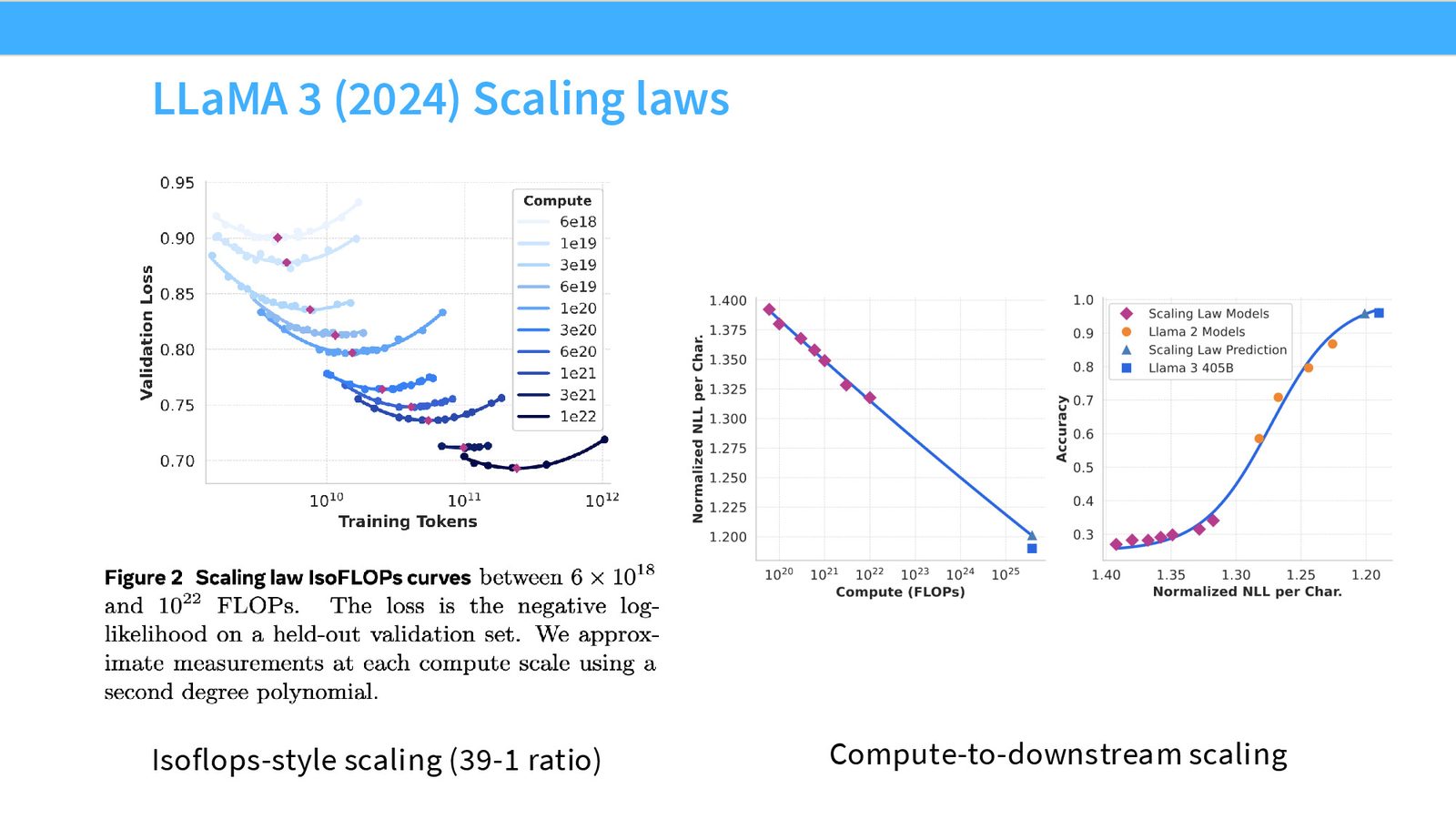
Llama 3
来源:Slides 第26页。
Llama 3 复现了 isoFLOP 分析,得到约 39:1 的最优 token/parameter 比例——高于 Chinchilla 的 20:1,但远低于 MiniCPM 的 192:1。
来源:Slides 第27页。
Llama 3 的另一个有趣贡献是尝试将 scaling 从 log-likelihood 扩展到下游任务准确率。他们拟合了 sigmoid 函数,将 NLL(负对数似然)映射到 MMLU 等 benchmark 的分数,并成功预测了 Llama 3 405B 的下游性能。
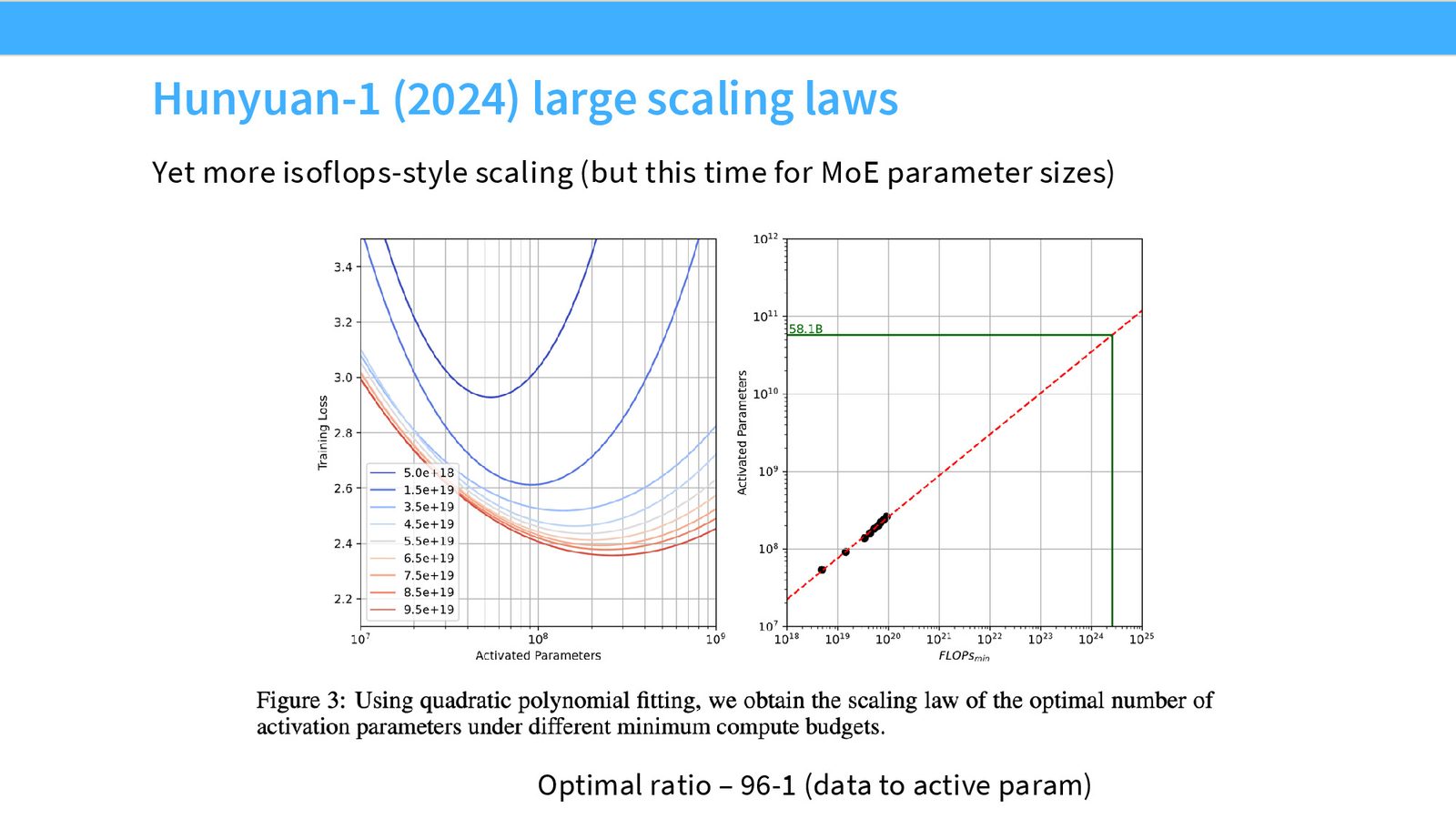
Hunyuan Large
来源:Slides 第28页。
Hunyuan Large(混元大模型)同样复现了 Chinchilla 式分析,得到 96:1 的比例。由于架构差异(可能使用了 MoE 等),不同论文的比例自然会有所不同。
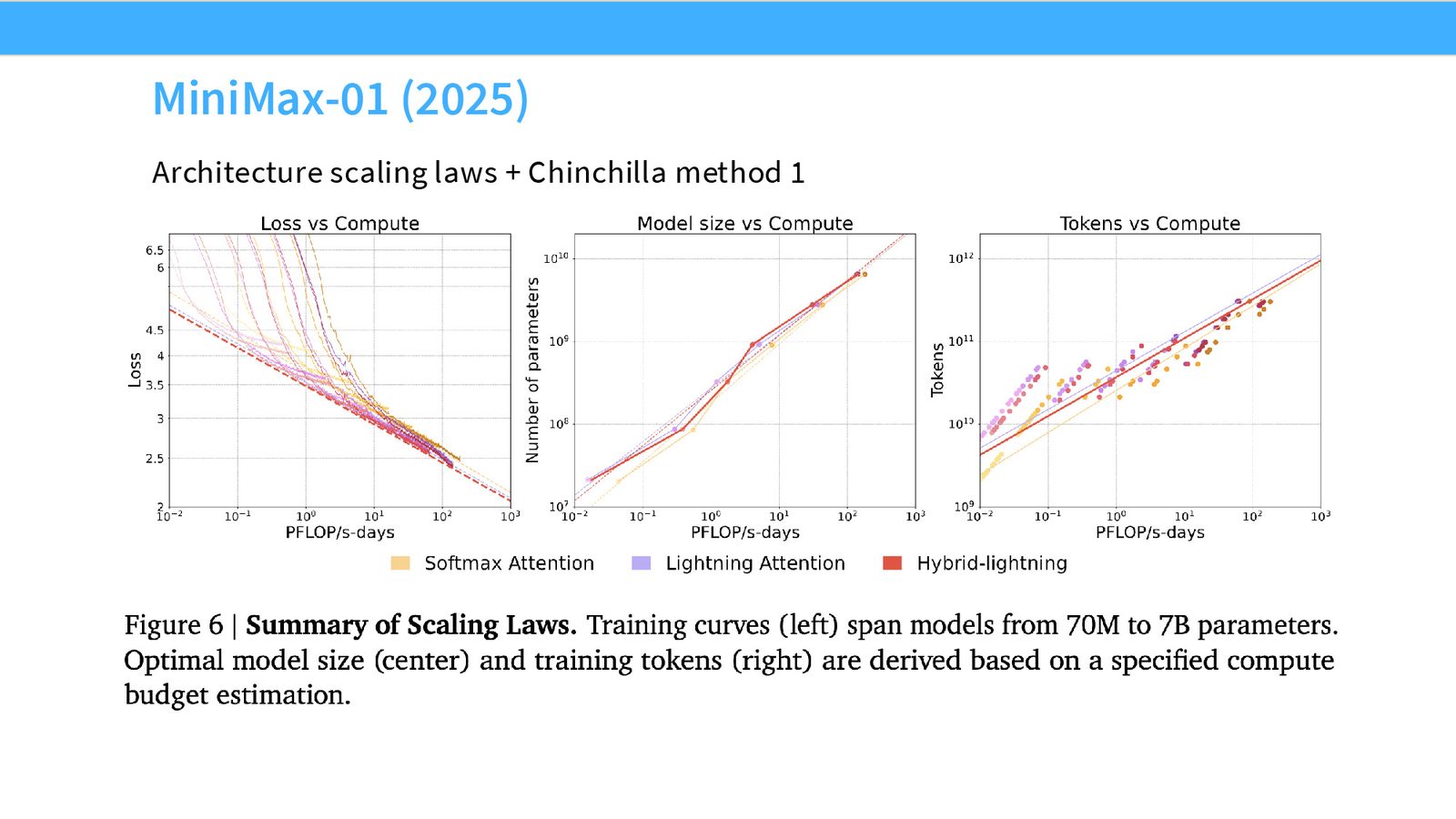
MiniMax-01:Architecture Scaling
来源:Slides 第29页。
MiniMax-01 展示了 scaling laws 的另一种应用:架构选择验证。他们比较了标准 Softmax attention、线性 Lightning attention 和混合模型的 scaling 曲线,发现三者在 compute-matched 下性能基本一致,从而为使用线性注意力实现长上下文提供了 scaling 层面的理论支撑。
用 Scaling Law 比较架构
在 Mamba、DeltaNet 等线性注意力的研究论文中,经常看到类似的 compute-matched scaling 比较。MiniMax-01 的独特之处在于它不仅仅是学术论文中的小规模比较,而是在接近实际生产规模的模型上进行了验证。
案例研究总结
来源:Slides 第30页。
Scaling 实践中的共同模式
- Chinchilla 复现是最一致、最可靠的 scaling 分析——所有团队都做了,且结果非常干净
- 超参数 scaling(学习率、batch size)总是更嘈杂,不同团队使用不同策略:MuP(Cerebras、MiniCPM)或直接拟合 scaling law(DeepSeek)
- 固定宽高比后仅调整总模型规模,是处理架构 scaling 的通用做法
- WSD 学习率调度已被广泛采用,因其大幅降低了 data scaling 分析的成本
本章小结
从 Chinchilla 原始论文的 20:1 到 Llama 3 的 39:1、Hunyuan 的 96:1,不同团队在不同条件下得到不同的最优比例。20:1 不是一个稳定的常数,但 isoFLOP 分析的方法论本身非常可靠且可复现。所有认真做 scaling 的团队都在某种程度上重复了 Chinchilla 的分析。
MuP 理论推导
核心思想:两个稳定性条件
MuP(Maximal Update Parameterization)基于两个简单而自然的想法:
来源:Slides 第32页。
MuP 的两个 Axiom
当我们增大模型宽度 \(n\) 时:
- 条件 A1(初始化稳定性):每个坐标的激活值 \(h_i^{(l)}\) 应保持 \(\Theta(1)\)——不随宽度爆炸或消失。等价地,激活向量的 \(\ell_2\) 范数应为 \(\Theta(\sqrt{n_l})\)。
- 条件 A2(更新稳定性):一步梯度下降后,每个坐标的激活值变化量 \(\Delta h_i^{(l)}\) 也应保持 \(\Theta(1)\)。
如果违反了这些条件,那么随着模型变宽,要么初始激活值爆炸/消失,要么梯度更新爆炸/消失——两者都会导致训练不稳定。
条件 A1:推导初始化规则
考虑一个深度线性网络(无非线性激活函数):
其中 \(W^{(l)} \sim \mathcal{N}(0, (\sigma^{(l)})^2)\),即每个元素独立采样自零均值高斯分布,标准差为 \(\sigma^{(l)}\)。
来源:Slides 第33页。
根据随机矩阵理论,当 \(n_l, n_{l-1} \to \infty\) 时,高斯矩阵 \(W^{(l)}\) 的算子范数集中于:
为了保证 \(\|h^{(l)}\| \approx \sqrt{n_l}\)(即每个坐标为 \(\Theta(1)\)),我们需要选择:
简单来说,这就是 \(\sigma \sim 1/\sqrt{\text{fan\_in}}\),再加上一个当 fan_in 远大于 fan_out 时的修正因子。
来源:Slides 第34页。
与 Kaiming 初始化的关系
条件 A1 推导出的初始化规则本质上就是 Kaiming 初始化(\(\sigma \sim 1/\sqrt{\text{fan\_in}}\))。如果你已经在使用 Kaiming 初始化,那么你已经满足了 MuP 的第一个条件。MuP 的真正新贡献在于条件 A2 所推导出的学习率规则。
条件 A2:推导学习率规则
来源:Slides 第35页。
SGD 的权重更新为:
当 batch size 为 1 时,这是一个秩一矩阵。要使 \(\|\Delta h^{(l)}\| = \Theta(\sqrt{n_l})\)(即每个坐标的变化为 \(\Theta(1)\)),需要:
推导中还引入了一个额外假设:Loss 的变化也应为 \(\Theta(1)\)——即模型每步的改善量不应随宽度而爆炸或消失。

来源:Slides 第36页。
最终推导结果非常简洁:
- \(n_l\):第 \(l\) 层的输出维度(fan_out)
- \(n_{l-1}\):第 \(l\) 层的输入维度(fan_in)
SGD vs Adam 的 MuP 差异
对于 SGD,\(\eta_{\text{SGD}} = \text{fan\_out}/\text{fan\_in}\)——在 Transformer 中,MLP 层的 fan_out/fan_in 通常是固定常数(如 4),所以 MuP 对 SGD 的影响很小,与标准参数化几乎没有区别。
对于 Adam,\(\eta_{\text{Adam}} = 1/\text{fan\_in}\)——这意味着每一层的学习率随宽度反比缩放。这与标准做法(全局恒定学习率)有根本区别。这就是 MuP 在 Adam 下的核心贡献。
MuP 总结:从推导到实践

来源:Slides 第37页。
MuP 的实用总结
初始化:\(\sigma^{(l)} = \frac{1}{\sqrt{\text{fan\_in}}} \cdot \min\left(1, \sqrt{\frac{\text{fan\_in}}{\text{fan\_out}}}\right)\)
(与 Kaiming 初始化基本一致)
学习率(Adam):\(\eta^{(l)} \propto \frac{1}{\text{fan\_in}^{(l)}}\)
(这是关键差异——标准做法使用全局恒定学习率)
实践效果:如果使用 Adam + MuP,你可以在小模型上找到最优学习率,然后直接迁移到大模型,无需重新搜索。

来源:Slides 第38页。
物理学的启发:重正化
MuP 的核心思想——当某个参数趋于无穷时,我们要求关键量保持稳定(不爆炸、不消失)——实际上与物理学中的重正化(renormalization)思想高度一致。这是一个在物理中被反复验证的强大方法论,如今在深度学习中找到了自然的应用。
Attention 层的特殊处理

来源:Slides 第39页。
标准 Transformer 使用 \(1/\sqrt{d}\) 缩放 attention score(Scaled Dot-Product Attention)。但在 MuP 框架下,基于激活值和更新稳定性的分析,应该使用 \(1/d\) 缩放。这是一个微妙但重要的区别。
本章小结
MuP 基于两个自然条件——初始化时激活值稳定、梯度更新后激活值变化稳定——推导出了精确的初始化规则和每层学习率规则。对于 Adam 优化器,关键变化是每层学习率按 \(1/\text{fan\_in}\) 缩放。深度线性网络是推导的简化模型;将结论推广到非线性激活、attention 层、GLU 等需要额外分析。
MuP 的实证验证
大规模 Ablation 研究

来源:Slides 第41页。
讲者介绍了一篇发表于 CoLM 的论文《A Large-Scale Exploration of \(\mu\)-Transfer》,该论文通过大量 ablation 实验系统检验了 MuP 的适用范围和局限性。
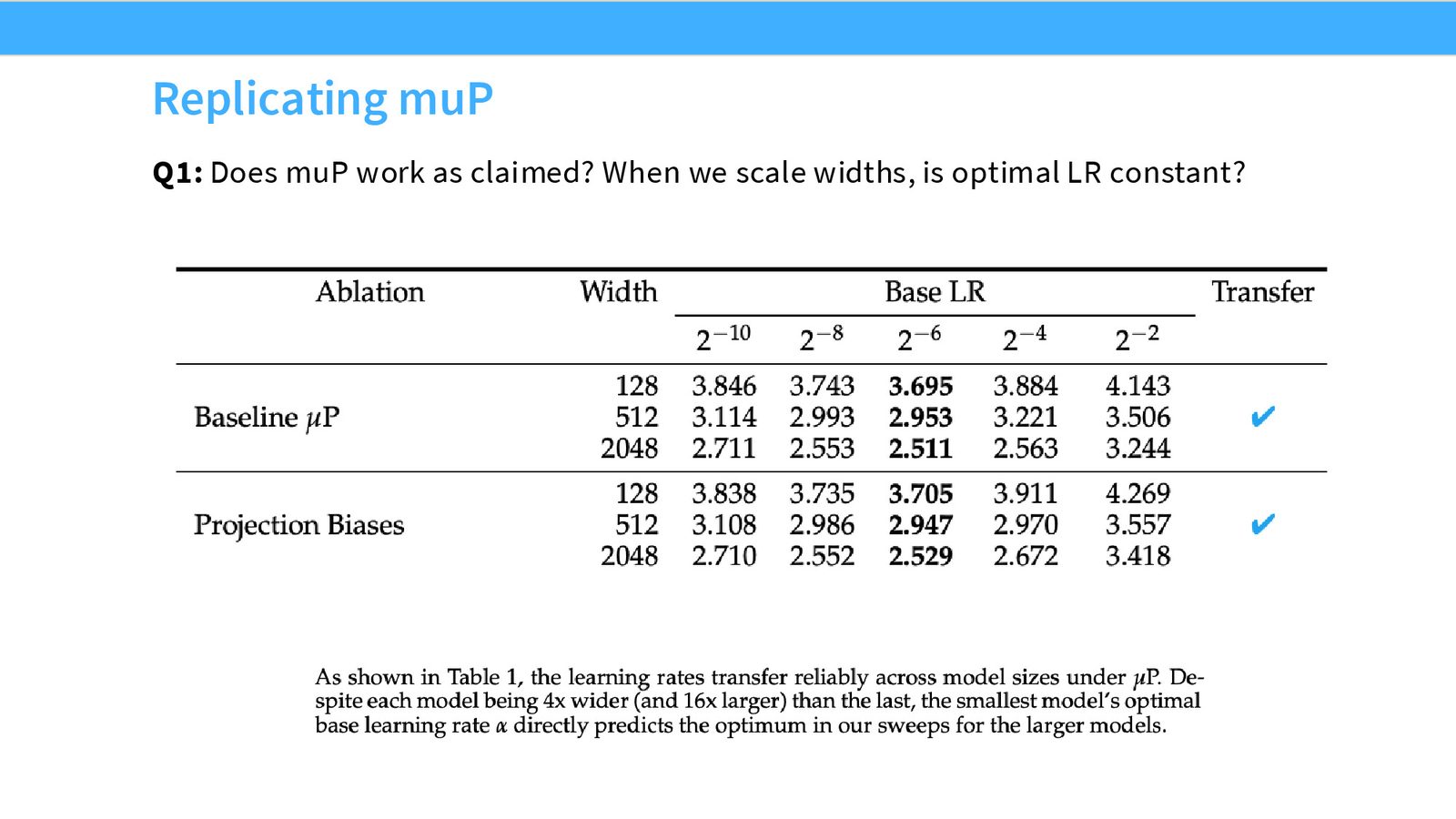
基础验证:MuP 有效吗?

来源:Slides 第42页。
实验设置:固定深度,将宽度从 128 扩展到 2048。在最小宽度上扫描学习率,找到最优值。如果 MuP 有效,这个最优学习率应该直接迁移到更大宽度。
结果:学习率确实可靠迁移。不同宽度的最优学习率都是 \(2^{-6}\)。
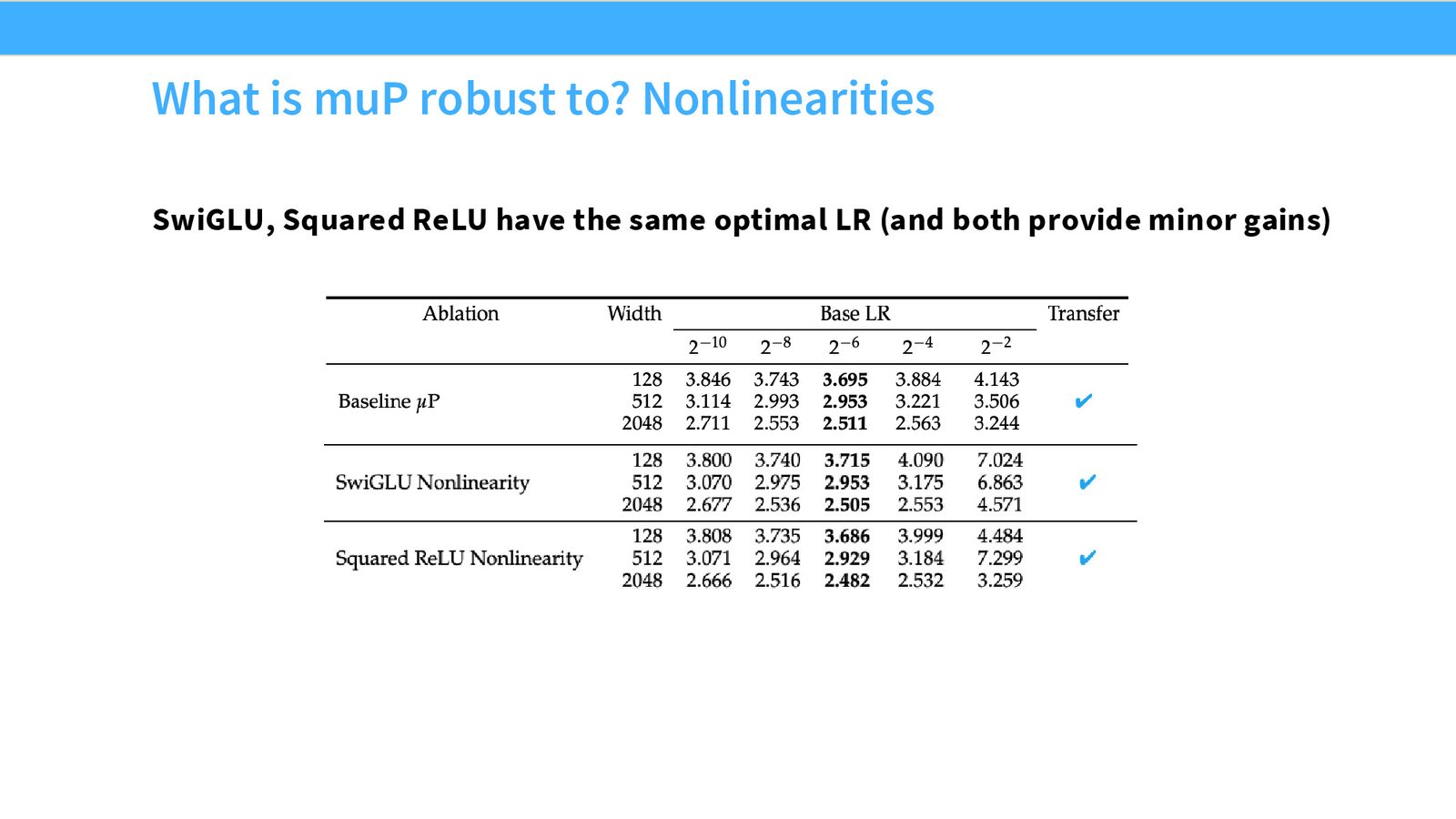
MuP 对什么鲁棒?

来源:Slides 第43页。
论文测试了多种架构变体:
| 变体 | 学习率迁移 | 备注 |
|---|---|---|
| 非线性激活(SwiGLU、Squared ReLU) | 有效 | 最优 LR 不变 |
| Batch size 变化(\(× 4\) 上下) | 有效 | 最优 LR 不变 |
| 初始化变体(Query 初始化为零等) | 有效 | 最优 LR 不变 |
| Unembedding 层 SP vs MuP | 有效 | 最优 LR 不变 |

来源:Slides 第44页。
MuP 在何时失效?
来源:Slides 第46页。
MuP 失效的三种情况
- 可学习的 bias/gain:如果在 RMSNorm 中添加可学习的 gain 参数,MuP 会失效。需要移除这些参数。
- 非标准优化器:如 Lion(取梯度的 sign 作为更新方向)。MuP 是为特定优化器(SGD/Adam/AdamW)设计的,使用完全不同的优化器自然无法保证学习率迁移。
- 强 Weight Decay:较强的 weight decay 会破坏 MuP 的学习率迁移。这是一个显著的实践限制,因为 weight decay 是标准训练中常用的正则化手段。
标准参数化 vs MuP 的对比
来源:Slides 第48页。
使用标准参数化时,在小模型上找到的最优学习率不能直接用于大模型——大模型会因为更新过大而训练失败。学习率必须随规模可预测地下降。
大规模验证
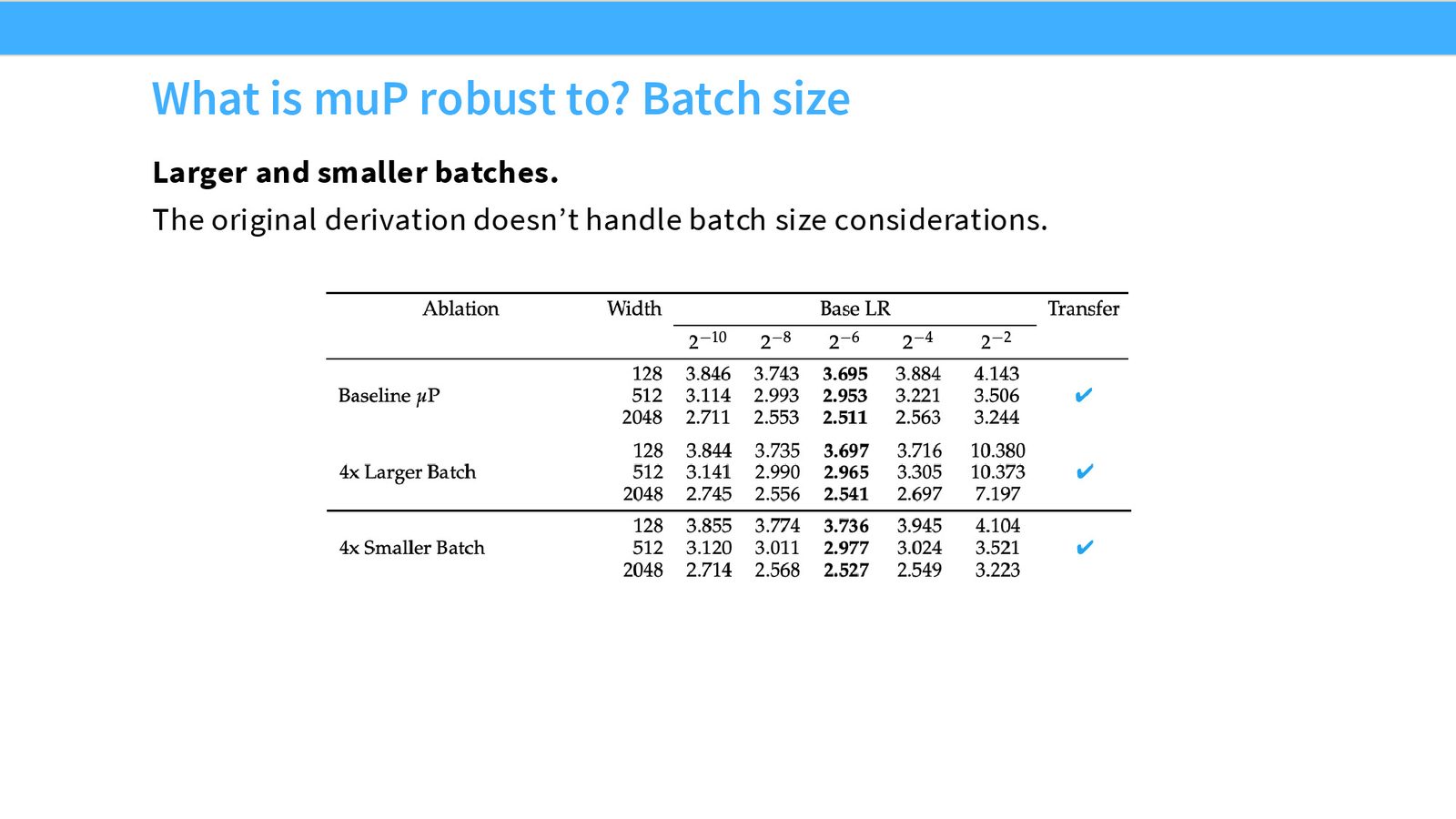
来源:Slides 第49页。
论文还进行了一次大规模“hero run”验证:将在中小规模上找到的最优学习率直接用于 10B 参数模型,结果证实该学习率仍然是最优的。这为 MuP 的实用性提供了重要的经验支持。
Meta 的 Llama 4 与 MuP
讲者提到,Meta 在 Llama 4 中使用了一种名为 “MetaP” 的技术,这是 MuP 的一个变体。虽然 Llama 4 的论文尚未发表,但这表明 MuP 类方法正在被前沿实验室采用。不过,MuP 目前还不是行业共识——并非所有团队都使用它。
本章小结
经验验证表明,MuP 在大多数标准设置下(Adam/AdamW 优化器、常见非线性激活、合理的 batch size 范围)可以可靠地实现学习率的跨规模迁移。主要失效场景包括可学习的 norm gain、非标准优化器和强 weight decay。
总结与延伸
讲者的核心总结

来源:Slides 第51页。
Tatsu Hashimoto 在课程结尾总结了 Scaling Laws 实践的三个层面:
- 超参数设置:通过 scaling laws 或 MuP 来确定学习率和 batch size,避免在大规模训练上进行代价高昂的网格搜索
- 稳定性策略:使用 MuP 或 assume stability(假设超参数不随规模变化)来简化 scaling 流程
- 高效数据分析:使用 WSD 学习率调度来降低 Chinchilla 式 data scaling 分析的计算成本
全课知识图谱
本课建立了从理论到实践的完整认知链:

关键 Takeaways
七条核心原则
- Chinchilla 分析是最可靠的 Scaling 工具:isoFLOP 分析在所有团队、所有复现中都表现出色,是 scaling 的“黄金标准”
- 20:1 只是起点:实际最优 token/parameter 比例因架构、数据质量、优化策略而异,可以显著高于 20:1
- 超参数 Scaling 总是嘈杂的:学习率、batch size 的 scaling law 不如 loss scaling law 干净,但获取正确的数量级即可
- WSD 是实用的学习率调度:它使 Chinchilla 式分析几乎可以在一次训练中完成
- MuP 解决了学习率迁移问题:通过合理的初始化和每层学习率缩放,可以在小模型上搜索最优学习率并直接迁移
- MuP 不是万能的:它对 weight decay、非标准优化器、可学习 gain 敏感
- 认真的 Scaling 分析是区分成功与失败的关键:DeepSeek 等模型的成功与其仔细的 scaling 研究密不可分
拓展阅读
- Cerebras GPT 论文:https://arxiv.org/abs/2304.03208
- MiniCPM 技术报告:https://arxiv.org/abs/2404.06395
- DeepSeek LLM 论文:https://arxiv.org/abs/2401.02954
- Llama 3 论文:https://arxiv.org/abs/2407.21783
- Yang et al., Tensor Programs V (MuP):https://arxiv.org/abs/2203.03466
- 《A Large-Scale Exploration of \(\mu\)-Transfer》:系统验证 MuP 鲁棒性的 ablation 研究
- 《A Practitioner's Guide to MuP》:MuP 的实践入门指南
- Hoffmann et al., Training Compute-Optimal Language Models (Chinchilla):https://arxiv.org/abs/2203.15556
- 过度训练惩罚分析(UW + Apple):估算超越 Chinchilla 比例时的 loss 退化