CS224R Lecture 13: 元强化学习
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于公开课程资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年春季 |

从多任务 RL 到元学习
回顾多任务 RL
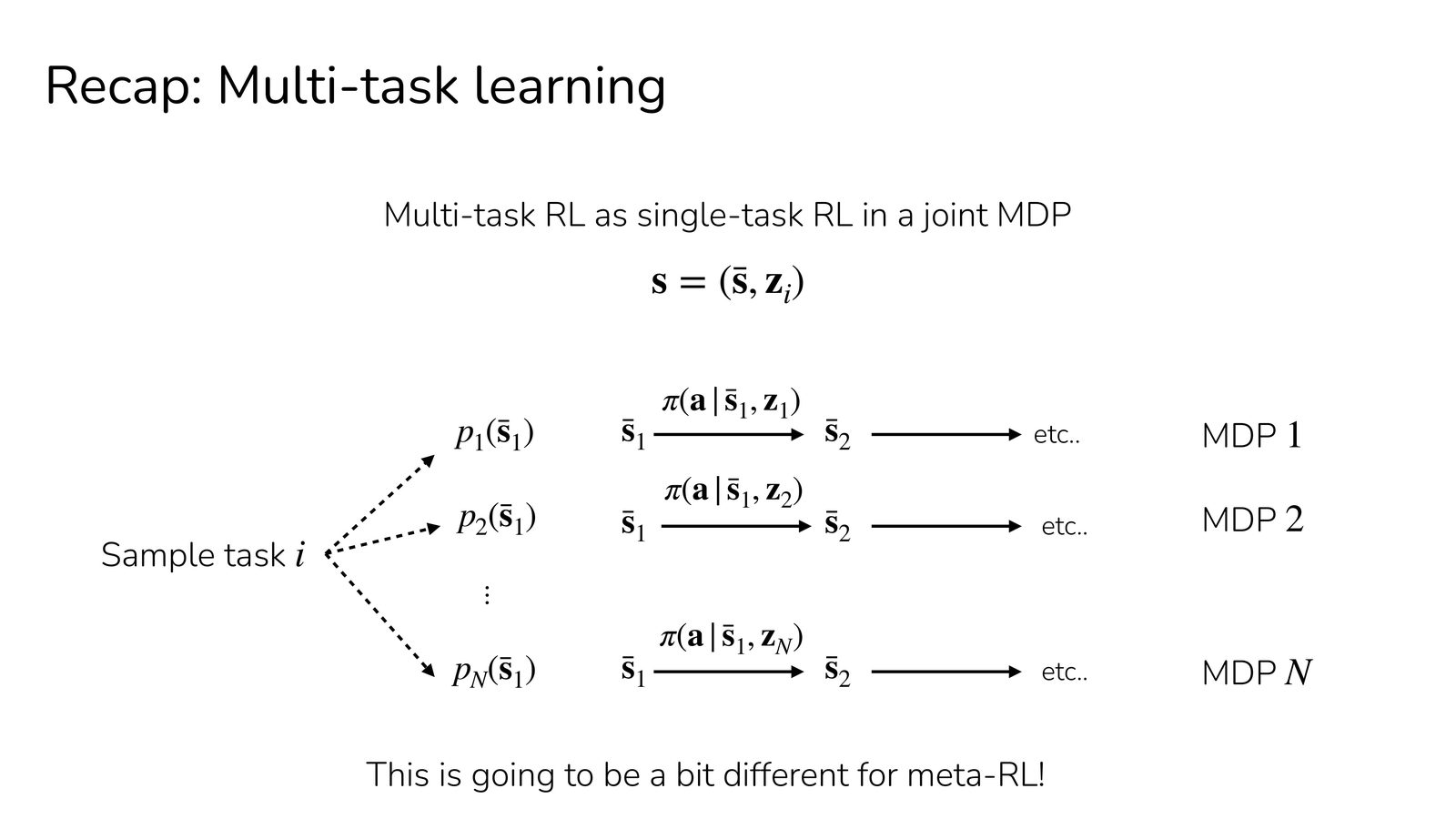
上一讲讨论了多任务 RL:通过将状态增广为 \((s, z)\)(其中 \(z\) 是任务描述),训练条件策略 \(\pi(a|s,z)\) 来处理多个任务。但多任务 RL 有一个关键局限:它假设在训练时就知道所有任务。
多任务 RL 的局限
多任务 RL 通过一个共享策略覆盖所有任务。如果测试时遇到的新任务与训练任务差异较大,性能可能急剧下降。此外,随着任务数量增多,学习一个对所有任务都表现良好的策略变得越来越困难(任务干扰问题)。

元学习的核心思想
Meta-RL 的定义
元强化学习(Meta-RL)的目标不是学习"如何解决一个具体任务",而是学习"如何快速学习新任务"。
形式化地说:给定一个任务分布 \(p(\mathcal{T})\),Meta-RL 在训练阶段利用从 \(p(\mathcal{T})\) 采样的大量任务学习一个"学习算法"或"快速适应机制"。测试时面对一个新任务 \(\mathcal{T}_{\text{new}} \sim p(\mathcal{T})\),仅需少量数据即可适应。
为什么需要 Meta-RL
讲者用一个非常生活化的例子来说明问题:学会操作一台新的 espresso machine。若把这个任务交给从零开始训练的 RL agent,可能要数百万次尝试;而人类只要有一点相关经验和一些指令,就能在几分钟内上手。差异不在于人类更会 “优化奖励”,而在于人类从不从零开始。

Meta-RL 试图弥补的能力缺口
普通 RL 假定每个新任务都要重新收集大量交互数据;Meta-RL 则试图把 “过去做过相似任务” 这一事实编码进学习系统,使其能在新任务上更快进入有效行为区间。
从 transfer learning 到 meta-learning
这节课还把几种常见迁移范式摆在一起比较:
- Forward transfer:先做 source task,再 fine-tune 到 target task。
- Multi-task transfer:同时在多个任务上训练,用 task descriptor 支持零样本泛化。
- Meta-learning:在训练阶段就显式优化 “如何快速适应新任务”。

Meta-RL 的泛化边界
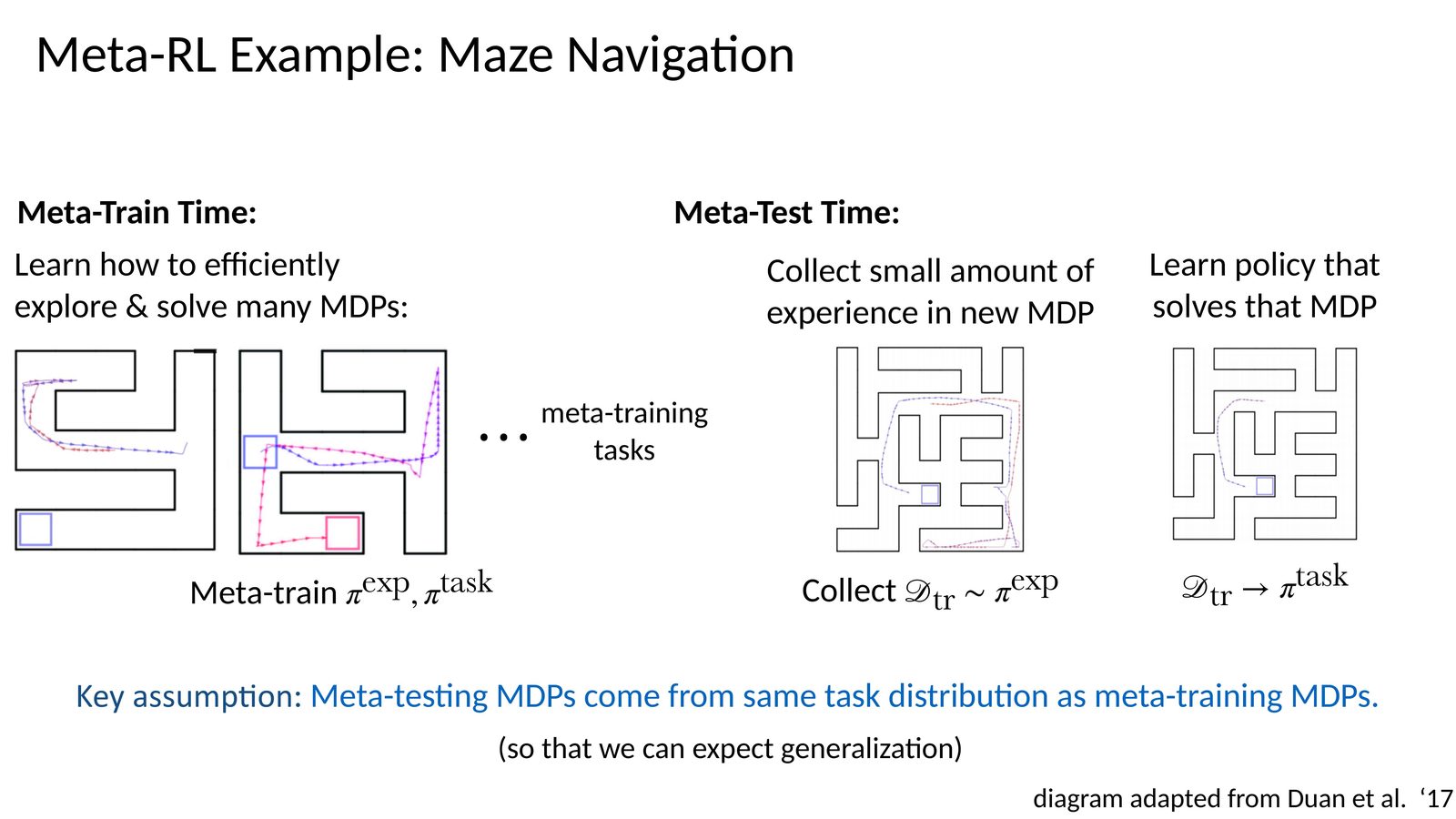
Meta-RL 并不承诺能适应任意新任务。它依赖一个关键假设:meta-test 时遇到的新任务,仍然来自与 meta-train 相近的任务分布。如果测试任务完全跳出训练分布,适应速度与最终表现都可能显著下降。
Few-shot 学习视角
课程还借助 few-shot image classification 与 LLM 的 in-context learning 做了类比。核心共同点是:模型接收的不只是输入 \(x\),还接收一小组示例 \(D_{\text{train}}\),并据此推断当前问题属于哪种任务、应该如何输出。

本章小结
Meta-RL 将学习的层次从"学习策略"提升到"学习如何学习策略",适用于需要快速适应新任务的场景。
Meta-RL 方法分类
Meta-RL 的典型任务设定
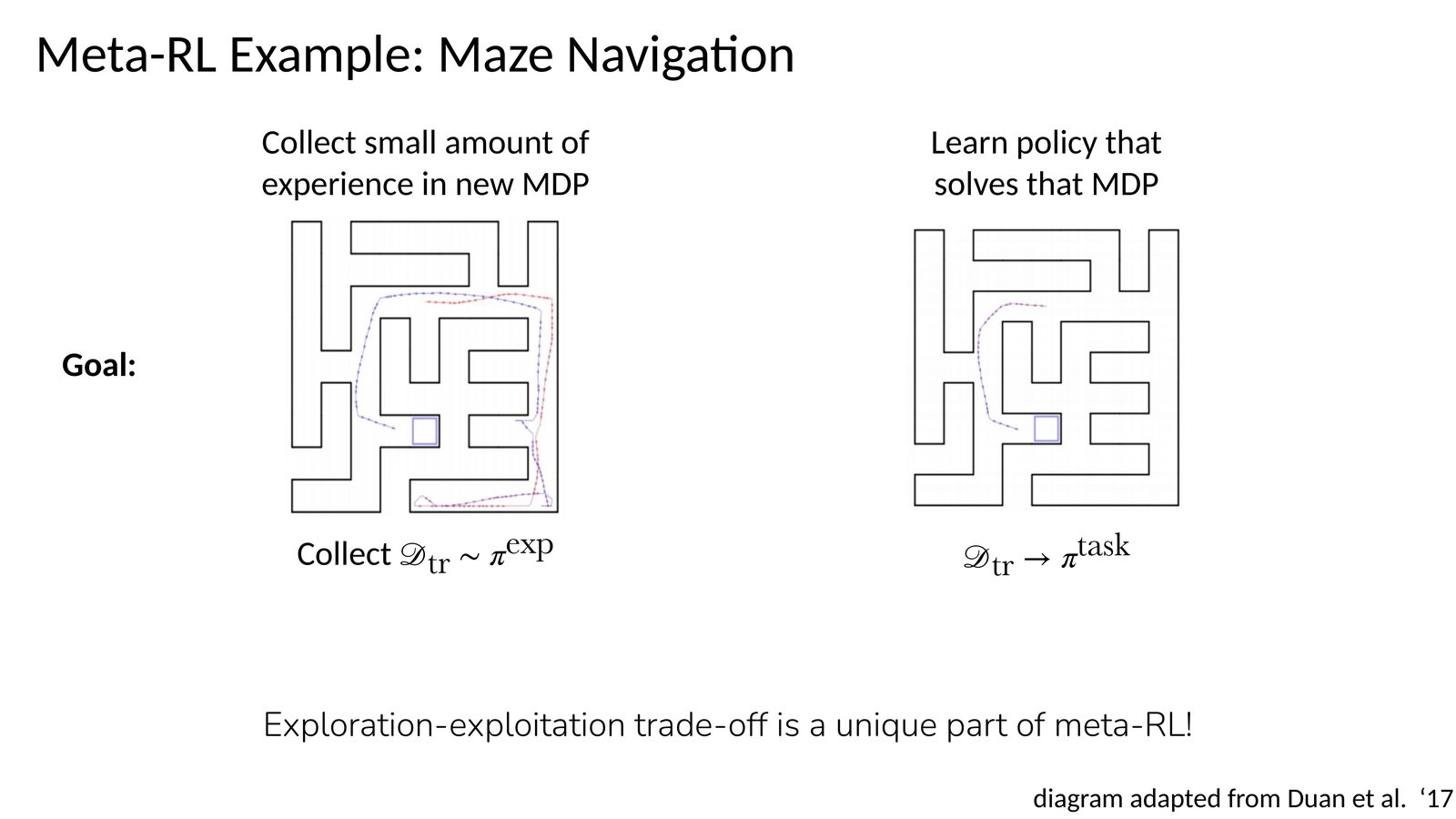
Meta-RL 的经典例子是 maze navigation:先在一个新迷宫里收集少量试探性经验,再用这些经验解出这个迷宫。这里独有的难点是 exploration-exploitation trade-off 发生了变化: 早期交互不仅要赚取当前 reward,还要识别当前到底是哪一个任务。
更正式的问题表述
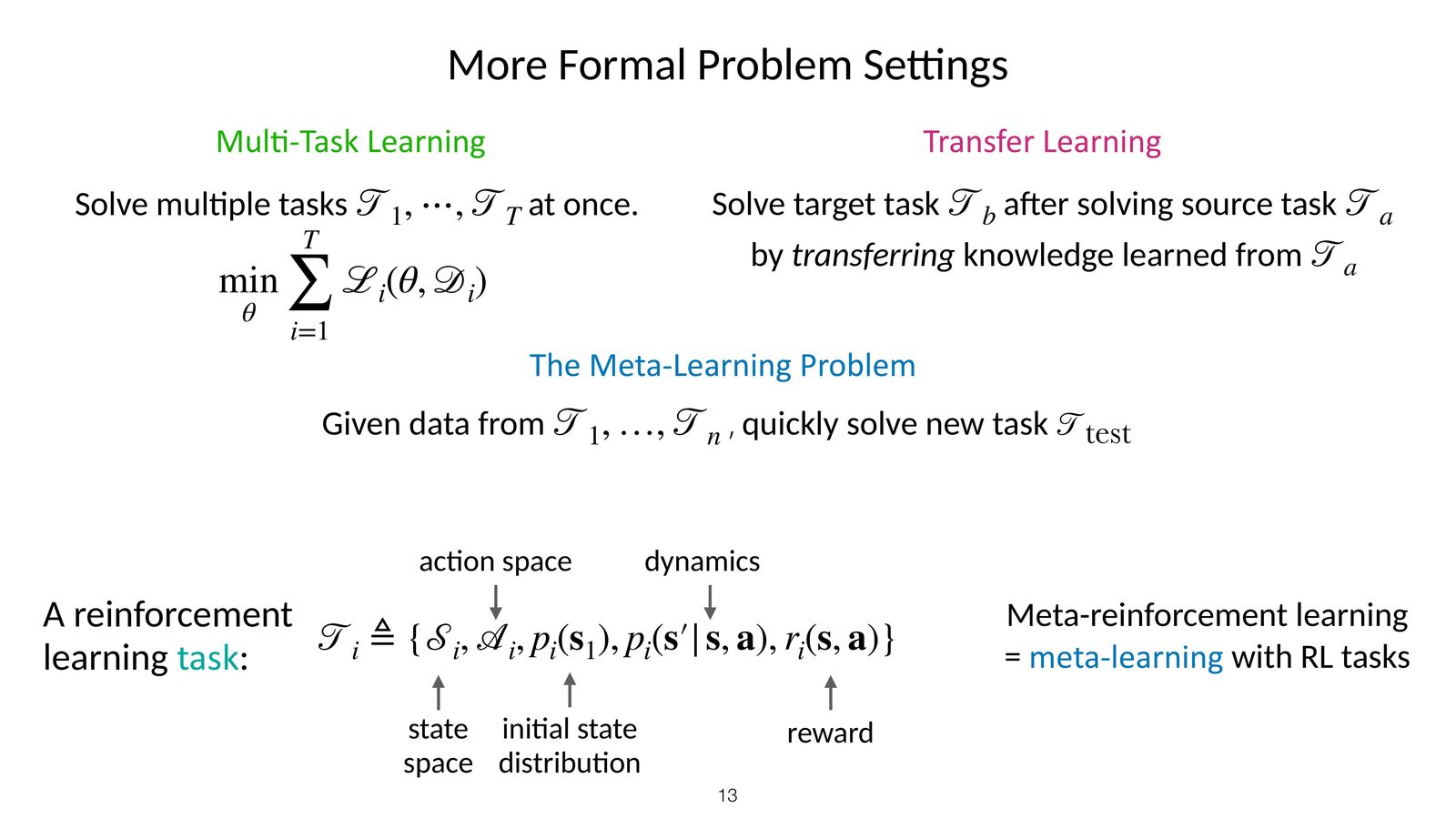
这节课给了一个非常重要的 formal setup:Meta-RL 不是单个 MDP,而是一个任务分布 \(p(\mathcal{T})\)。训练阶段从中抽取许多任务,学习一种适应机制;测试阶段在来自同一分布的新任务上,只给少量经验。
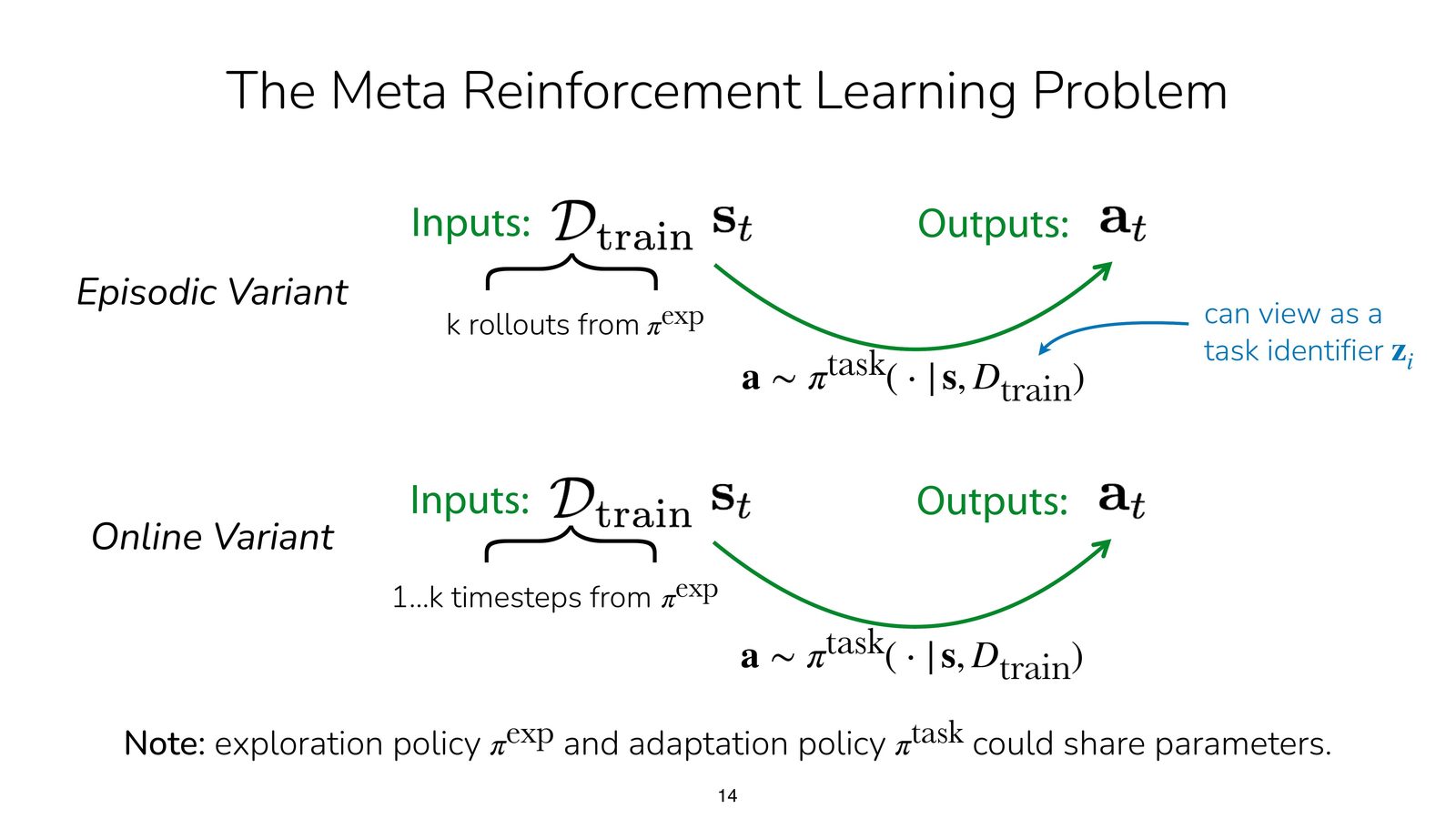
Meta-RL 的输入输出
以 episodic 版本为例:
- 输入:来自某个任务的少量 rollout / experience \(D_{\text{train}}\)
- 输出:一个根据 \(D_{\text{train}}\) 调整后的策略 \(\pi(a\mid s, D_{\text{train}})\)
也就是说,传统多任务 RL 中显式给出的 task ID,在 Meta-RL 里被一小段交互经验替代了。
方法 1:基于上下文的方法(Context-Based)
核心思想是将新任务的经验作为上下文输入给策略网络,让网络根据上下文推断任务并做出决策。
上下文策略
其中 \(c = \{(s_1, a_1, r_1, s_1'), \ldots, (s_k, a_k, r_k, s_k')\}\) 是在新任务上收集的少量经验。策略网络需要从这些经验中推断出任务的特性。
常用架构:
- 将上下文通过 RNN/LSTM 编码为隐状态
- 将上下文通过 Transformer 的注意力机制编码
- 将上下文通过集合编码器(permutation-invariant)编码
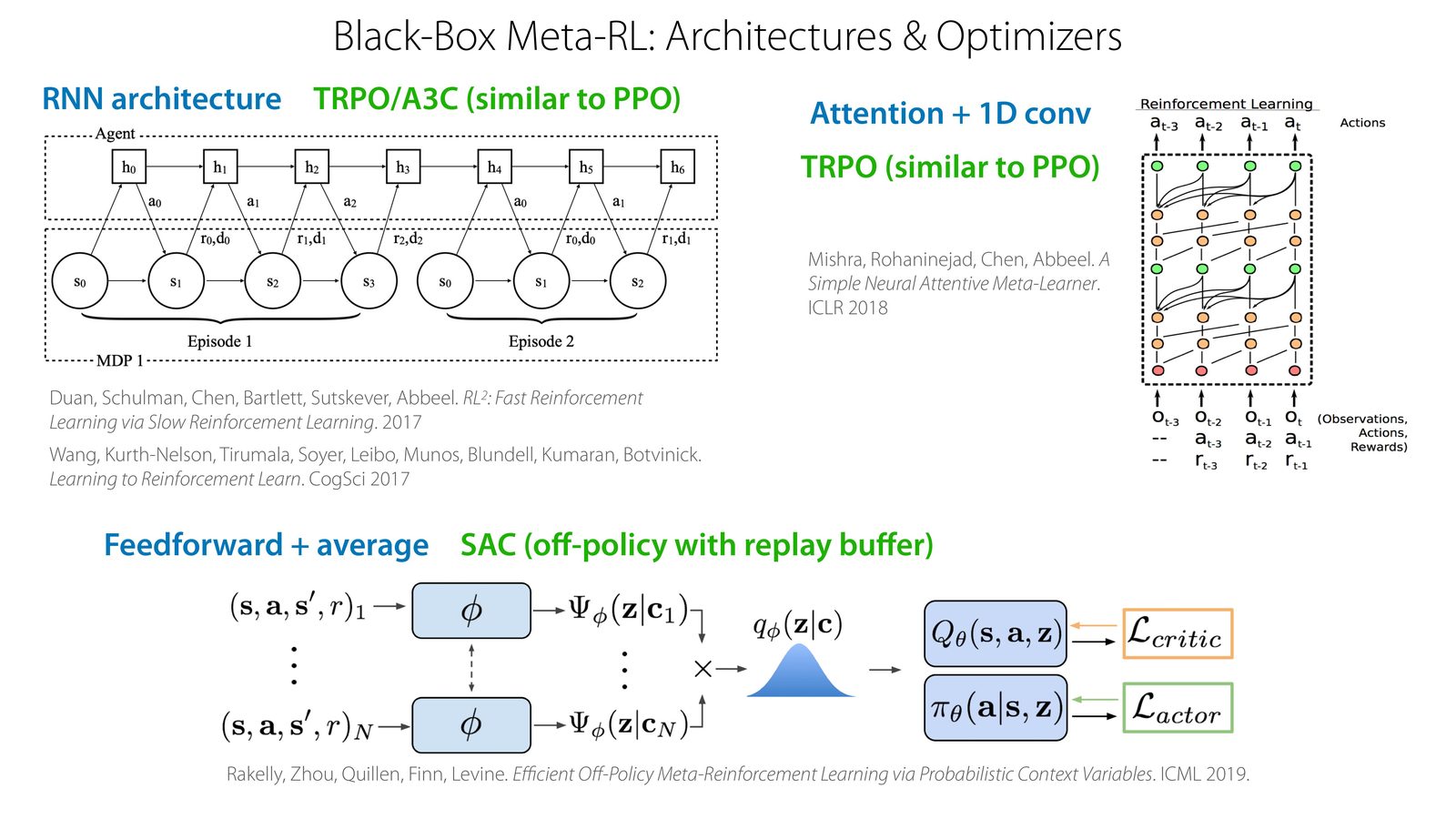
RL2 (Learning to Reinforcement Learn)
RL\(^2\) 是最早的 context-based meta-RL 方法之一。它将整个 RL 过程视为一个更大的 POMDP,其中 RNN 的隐状态编码了关于当前任务的"信念"。外层 RL 算法训练 RNN 使其能在内层快速适应新任务。
Black-box Meta-RL 的训练循环
这门课重点讲的是 black-box meta-RL:不显式写出某个贝叶斯更新公式,而是直接用一个带记忆的神经网络,把 “如何根据经验适应” 这件事学进参数里。
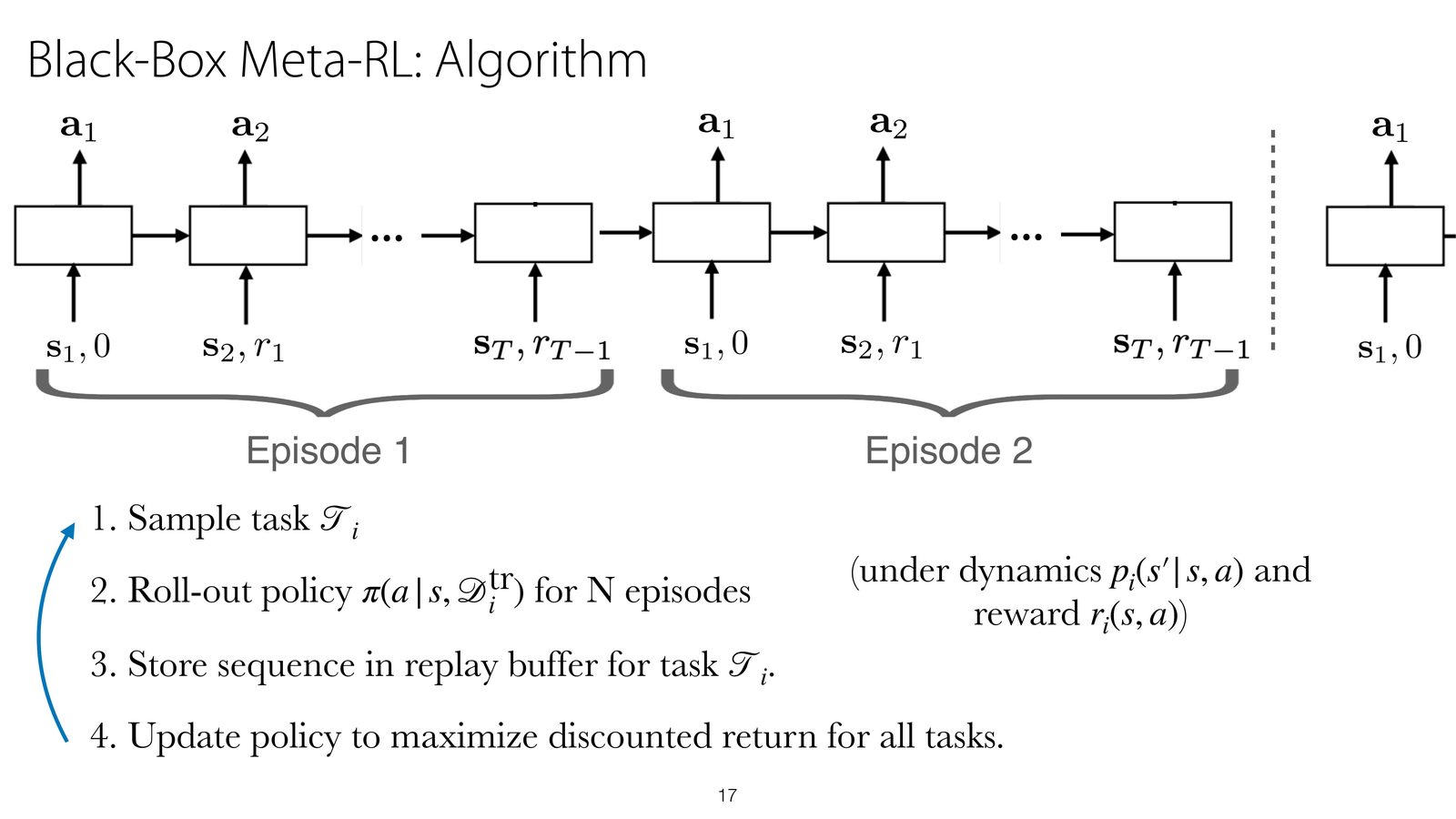
它和普通 recurrent policy 有什么不同
表面上看,black-box meta-RL 很像 “带 RNN 的 RL”,但课程特别强调了两个额外条件:
- reward 通常作为输入的一部分进入网络;
- 隐状态需要在同一任务的多个 episode 之间持续保留。
因此网络记住的不只是单条轨迹,而是 “我已经在这个任务上观察到了什么”。
常见架构与优化器
black-box meta-RL 的实现空间很大:可以用 RNN、attention、Transformer,也可以配 TRPO/A3C 或 SAC 等不同 outer-loop RL 优化器。
方法 2:基于梯度的方法(Gradient-Based)
MAML(Model-Agnostic Meta-Learning)
MAML 的核心思想是学习一组好的初始化参数 \(\theta\),使得对任何新任务,只需少量梯度步即可适应。
内层更新(任务适应):
外层更新(元学习):
关键:外层优化的目标是让适应后的参数 \(\theta_i'\) 在任务 \(\mathcal{T}_i\) 上表现好,而非原始参数 \(\theta\)。
MAML 的计算开销
MAML 需要对"梯度"求梯度(二阶导数),计算开销较大。虽然可以用一阶近似(如 FOMAML、Reptile)来降低开销,但这会牺牲一定的精度。在 RL 中,由于策略梯度本身方差就很高,MAML 的训练稳定性是一个挑战。
两类方法的比较
| Context-Based | Gradient-Based | |
|---|---|---|
| 适应方式 | 前向传播(推断) | 梯度下降 |
| 适应速度 | 极快(一次前向) | 需要若干梯度步 |
| 表达能力 | 受限于网络容量 | 理论上可精确适应 |
| 训练难度 | 相对容易 | 需要二阶优化 |
| 典型方法 | RL\(^2\), PEARL | MAML, ProMP |
Black-box Meta-RL 的案例
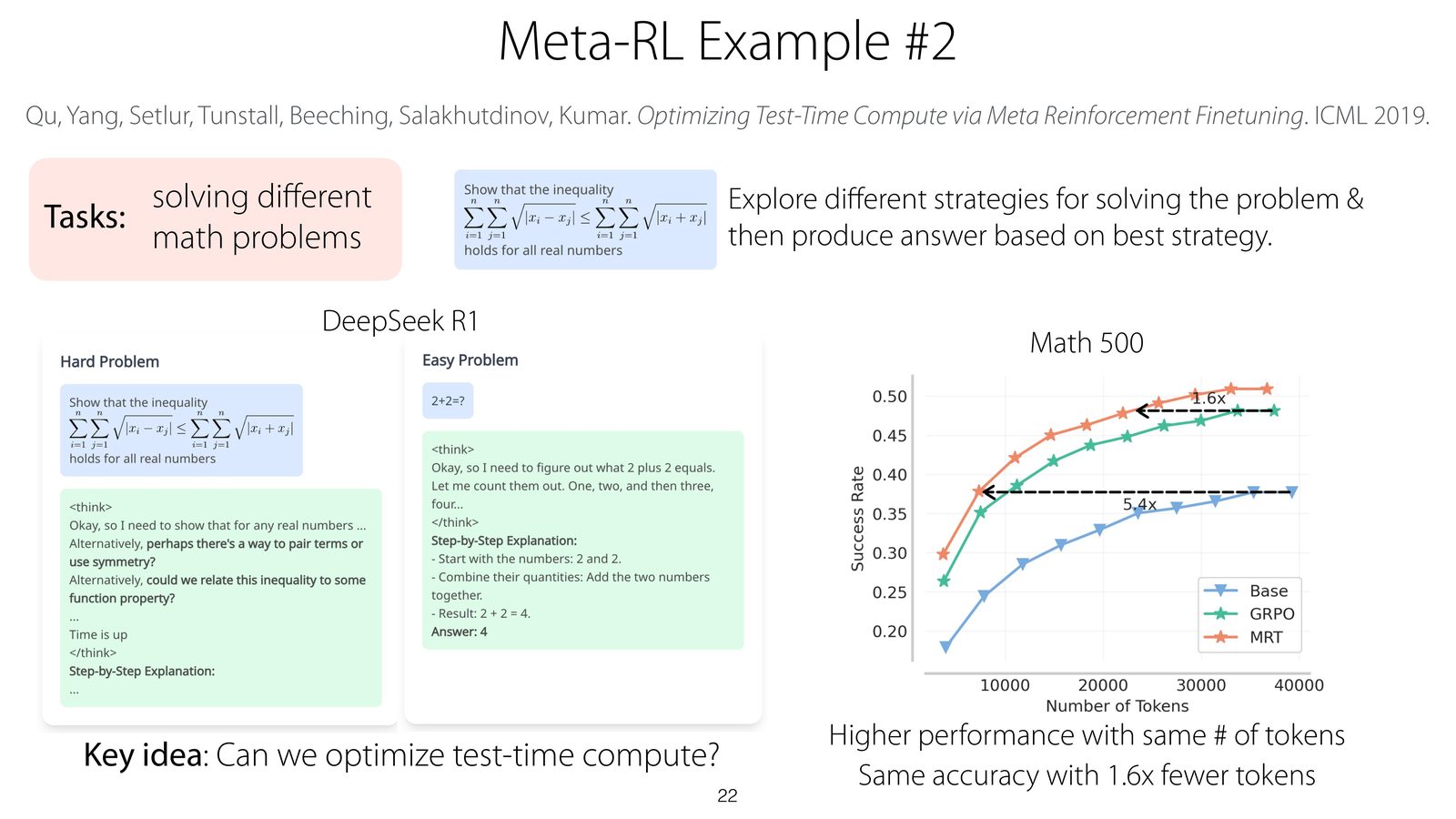
课程给了两个很有代表性的案例。第一个是视觉迷宫导航:模型在大量小迷宫上 meta-train,测试时要在看不见过的迷宫里快速探索并找到出口。第二个案例更贴近当前大模型语境:把不同数学题看作不同任务,优化 test-time compute,让模型在固定 token 预算下更高效地尝试、验证并选择策略。

Meta-RL 与多任务策略的关系
讲者专门用一页 slides 解释了一个容易混淆的点:多任务策略依赖显式 task ID \(z_i\),而 Meta-RL 把经验本身当成 task identifier。换句话说,多任务策略是 “我告诉你现在是哪一类任务”,而 Meta-RL 是 “你自己从交互里推断出来”。
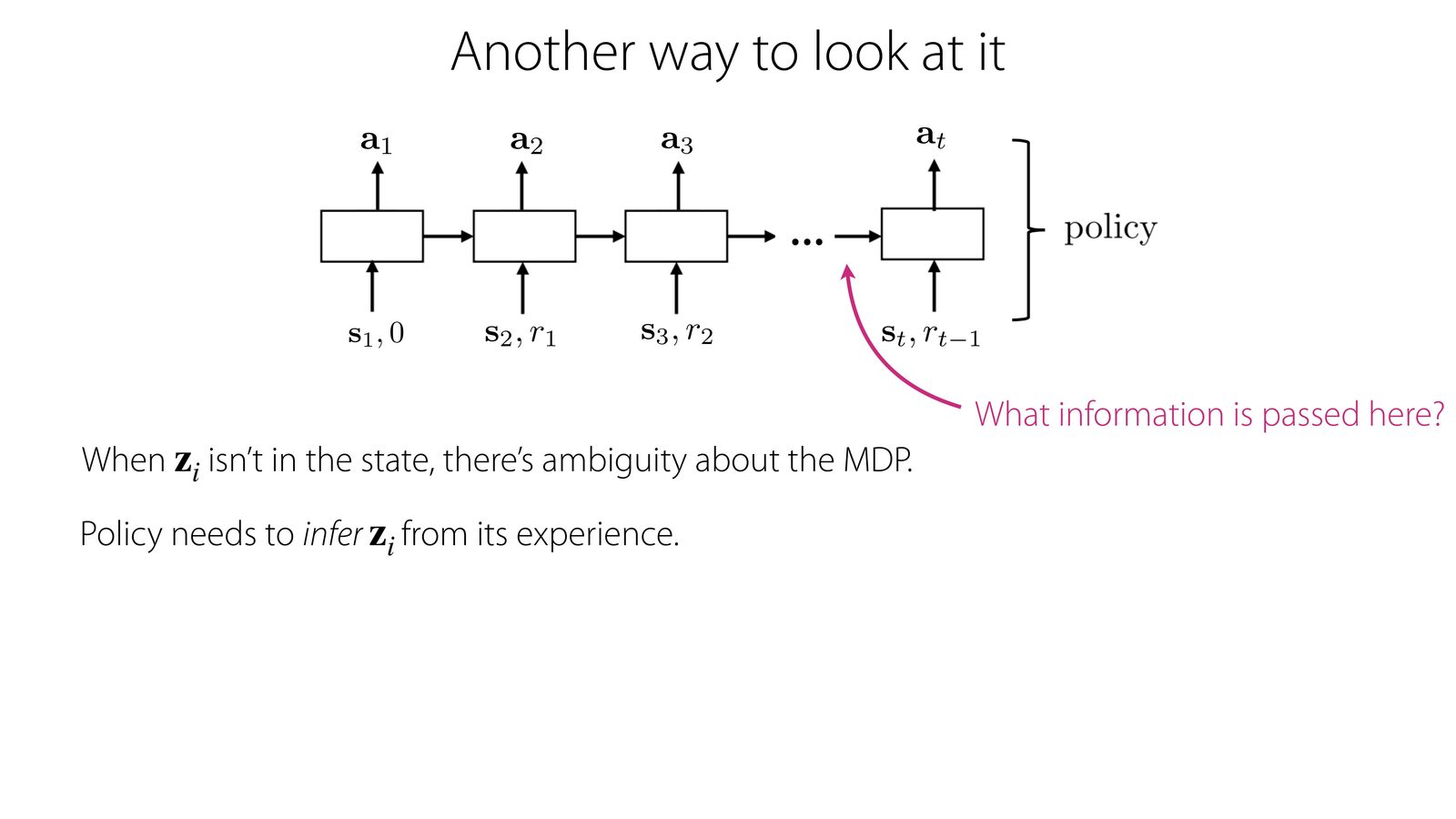
本章小结
Meta-RL 有两大技术路线:context-based 方法通过编码经验实现隐式适应,gradient-based 方法通过学习好的初始化实现快速微调。
探索为何在 Meta-RL 中更难
Meta-RL 的探索问题并不等于普通探索
在普通 RL 中,探索的目标是找到高回报动作;而在 Meta-RL 中,探索还承担了另一层责任:辨认当前任务到底是什么。因此同一个行为即便短期不产生 reward,也可能因为大幅降低任务不确定性而有长期价值。

走廊例子:有信息但没奖励的探索
课程用 hallway 例子解释了这一点。如果目标在哪一端需要先看墙上的提示,那么 “先去看提示” 是正确的 meta-exploration 行为,但它本身并不会直接产生任务奖励。于是端到端只按最终 reward 优化时,优化器很难意识到这种前期无奖探索的长期价值。

耦合问题(coupling problem)
如果探索没做好,执行阶段拿不到好 reward;而如果执行阶段长期拿不到好 reward,探索阶段也收不到足够清晰的训练信号。这种相互依赖会让优化陷入很差的局部最优。
厨房例子:探索与执行相互卡死
讲者引用的 cooking 例子把这个问题讲得更清楚:如果 agent 先找不到食材,就无法学会做菜;但如果它从不会做菜,最终 reward 又不足以告诉它哪种找食材方式才有价值。结果就是 exploration 和 execution 两边互相拖累。
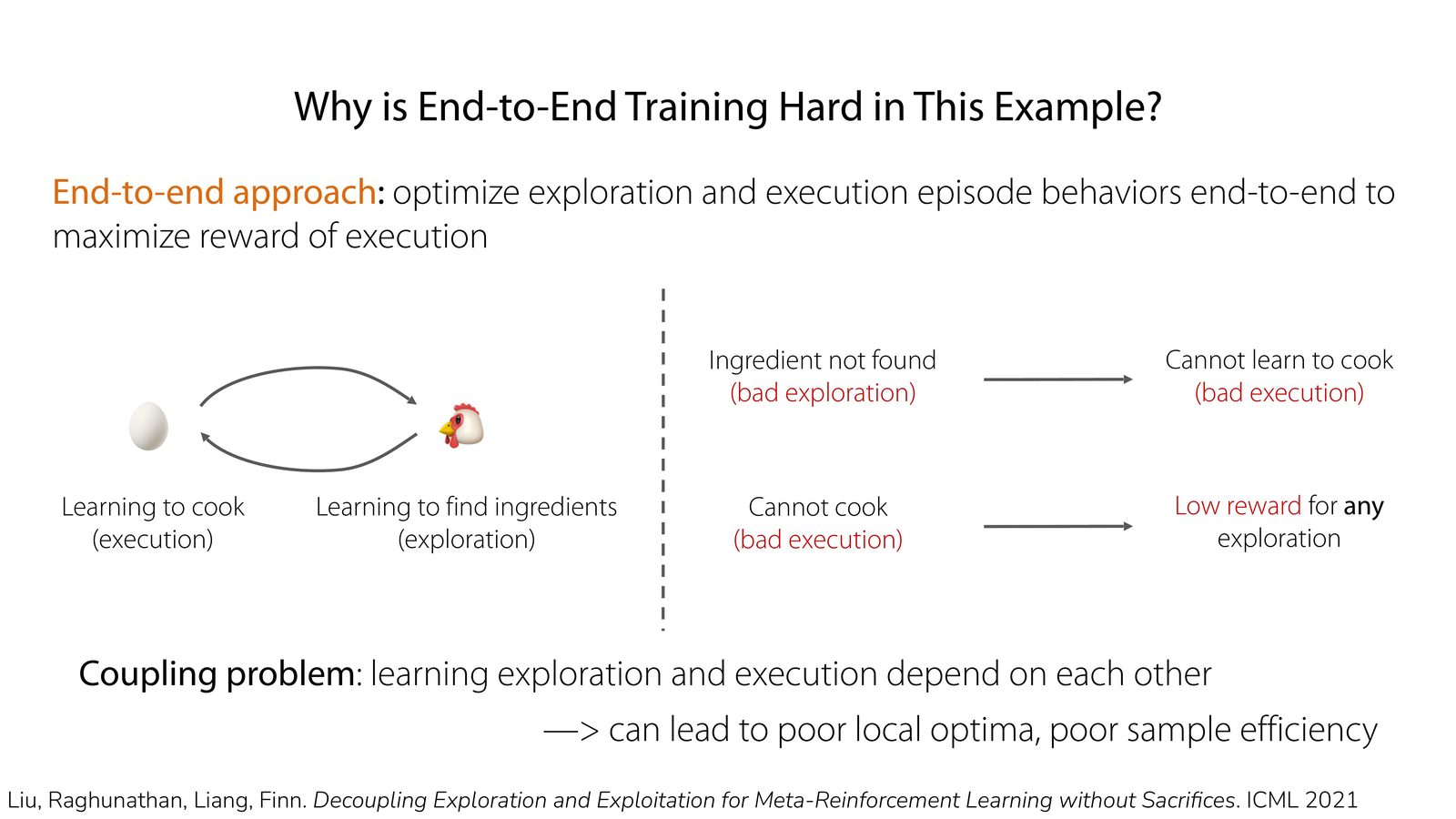
替代思路:把探索结构显式建进去
因此,课程并没有停留在 “端到端学就好”,而是进一步介绍了几类替代策略:
- Posterior sampling / Thompson sampling:显式维护任务后验,从后验中采样潜在任务并据此行动。
- Intrinsic rewards:为信息收集本身提供额外奖励。
- Task dynamics / reward prediction:显式学习任务相关的动力学或奖励模型,帮助分辨任务。
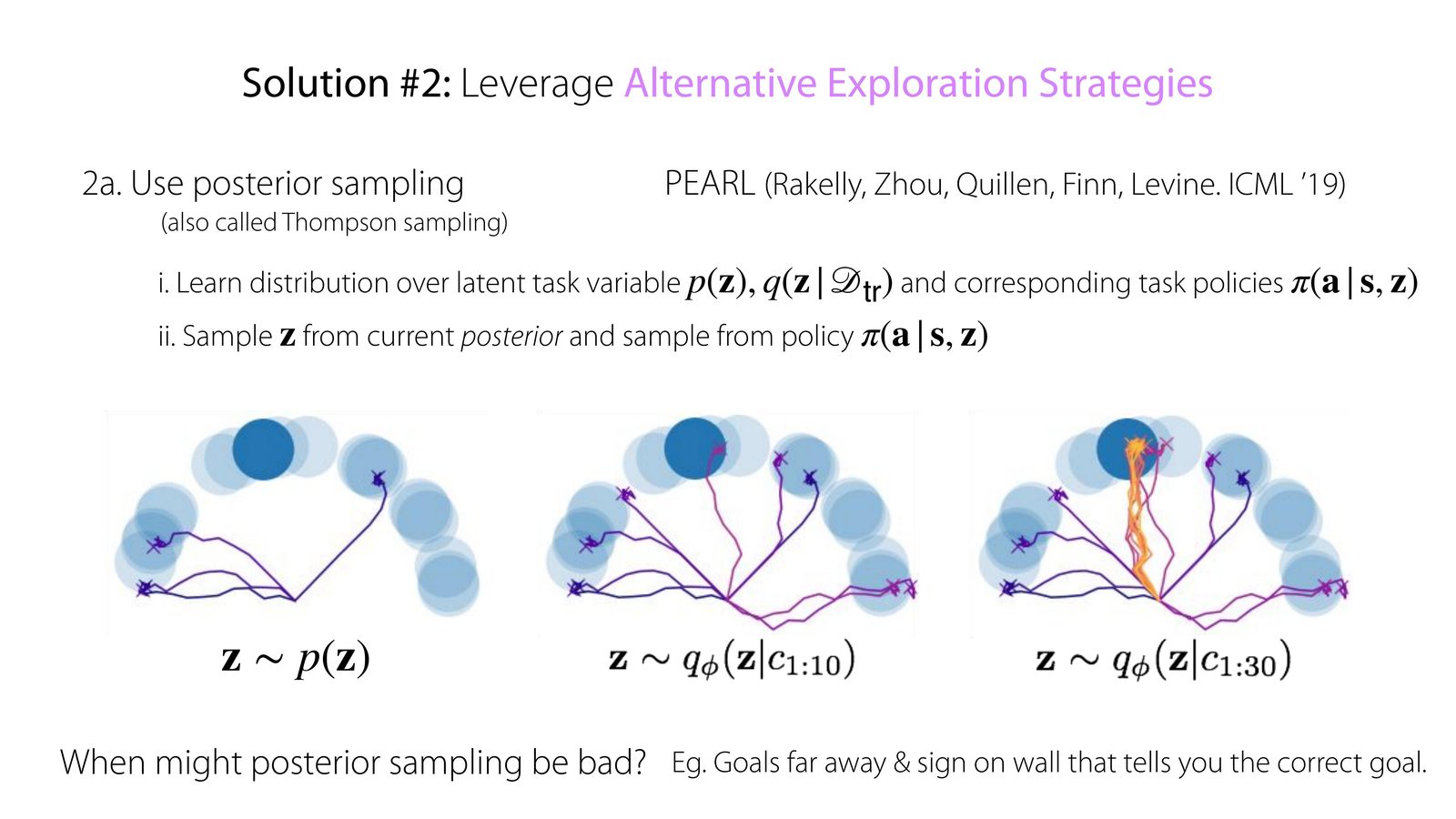

PEARL 的核心直觉
PEARL 学一个 latent task variable \(z\) 的先验与后验,再让策略条件化于 \(z\)。一旦后验收缩,策略就不再需要靠隐状态 “猜” 当前任务,而是显式依据当前 belief 采取动作。这比纯黑盒记忆网络更有结构,但也引入了更强的建模假设。
Meta-RL 的理论视角
Meta-RL 作为 POMDP
Meta-RL 的 POMDP 视角
可以将 meta-RL 视为在一个更大的 POMDP 中做 RL:
- 隐状态包含任务身份
- 观测是当前状态和历史经验
- 最优策略需要在交互过程中推断任务身份(贝叶斯推断)
从这个视角看,context-based 方法本质上是在近似这个 POMDP 的最优策略。
后验采样与 Thompson Sampling
在理想情况下,meta-RL 的最优行为应该类似于 Thompson Sampling:
- 维护对任务身份的后验信念 \(p(\mathcal{T} | \text{history})\)
- 从后验中采样一个任务假设
- 按照该假设下的最优策略行动
- 收集新数据后更新后验
本章小结
从理论角度看,Meta-RL 可以统一理解为在任务不确定的 POMDP 中做最优决策,这为理解和改进 meta-RL 方法提供了原则性的框架。
Meta-RL 的应用
机器人操作
Meta-RL 在机器人领域有天然的应用场景:机器人需要快速适应不同的物体、不同的抓取目标、不同的动力学参数等。
大语言模型中的 In-Context Learning
In-Context Learning 作为 Meta-Learning
大语言模型的 in-context learning(通过 prompt 中的示例来完成新任务)可以看作是一种 context-based meta-learning。LLM 在预训练阶段见过大量"任务",学会了从上下文中推断任务并生成对应的输出。这与 RL\(^2\) 的思想一脉相承。
本章小结
Meta-RL 的思想已经渗透到了机器人学和自然语言处理等多个领域,in-context learning 可以看作是 meta-learning 在大规模预训练中的自然涌现。
总结与延伸
Meta-RL 的核心价值在于实现快速适应:
- 多任务 RL 学习一个覆盖所有任务的策略,meta-RL 学习快速适应新任务的能力
- Context-based 方法通过编码历史经验实现隐式推断
- Gradient-based 方法(MAML)通过学习好的初始化实现快速微调
- 理论上 meta-RL 等价于在任务不确定的 POMDP 中做最优决策
- LLM 的 in-context learning 是 meta-learning 的大规模实现
本讲方法地图
| 路线 | 适应机制 | 优势 | 难点 |
|---|---|---|---|
| Multi-task RL | 显式 task descriptor \(z\) | 结构简单,支持参数共享 | 遇到新任务时缺乏快速适应机制 |
| Black-box Meta-RL | 经验上下文 + 记忆网络 | 表达能力强,端到端统一 | 训练难、探索难、样本效率受 outer RL 约束 |
| Gradient-based Meta-RL | 学可快速微调的初始化 | 适应机制清晰 | 二阶优化开销大,RL 场景稳定性差 |
| Structured exploration (PEARL 等) | 后验采样/内在奖励/任务建模 | 更容易把探索结构显式化 | 可能引入较强假设,在部分环境中次优 |
实现 Black-Box Meta-RL 的检查清单
真正动手实现这类算法时,最容易出错的不是公式,而是 “任务边界” 和 “记忆边界”。如果训练代码把 episode、task、hidden state 和 replay buffer 混在一起,最后学到的往往只是一个普通 recurrent policy,而不是能跨任务适应的 meta-policy。
| 模块 | 常见错误 | 更稳妥的做法 |
|---|---|---|
| Task sampling | 同一批次里的任务边界不清晰 | 显式记录 task id / task episode 边界 |
| Hidden state | 在不同任务之间错误复用隐状态 | 只在同一任务的多轮 episode 中保留记忆 |
| Reward input | 没把 reward/history 作为适应线索输入网络 | 明确把 \((s,a,r,s')\) 序列作为上下文 |
| Meta-test protocol | 测试时直接用训练任务或泄漏任务标签 | 仅给少量新任务交互数据,严格按分布外 held-out task 评估 |

为什么 exploration 被单独拿出来讲
这节课其实已经给出答案:在普通 RL 里,探索是为了找到高奖励行为;在 Meta-RL 里,探索还要承担识别任务的职责。于是 “看起来暂时没收益” 的动作,可能恰恰是最关键的适应步骤。也正因为这种双重角色,很多 black-box meta-RL 方法虽然概念统一,但在复杂探索环境中会显著退化。
把 exploration 单独拉出来讨论的价值在于,它提醒我们不要把 Meta-RL 简化成 “带记忆的策略网络”。真正困难的部分是:如何让 agent 先花少量代价搞清楚自己面对的是什么任务,再把剩余预算花在正确的执行策略上。 这也是后续从 posterior sampling、intrinsic reward 到 task dynamics prediction 一整条研究线存在的原因。
拓展阅读
- Finn et al., “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks (MAML),” ICML 2017
- Duan et al., “RL\(^2\): Fast Reinforcement Learning via Slow Reinforcement Learning,” ICLR 2017
- Rakelly et al., “Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables (PEARL),” ICML 2019
- Zintgraf et al., “VariBAD: A Very Good Method for Bayes-Adaptive Deep RL,” ICLR 2020