CS231N Lecture 15: 3D Vision
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Jiajun Wu 授课内容整理 |
| 来源 | Stanford CS231N |
| 日期 | 2024 |

引言:从 2D 到 3D
本节课由斯坦福大学助理教授 Jiajun Wu(吴佳俊)主讲,聚焦3D 视觉(3D Vision)。与前面几周讲的卷积神经网络、Transformer、视觉语言模型和生成模型不同,3D 视觉涉及一套全新的表示方式和方法论。
本课三大主题
- 3D 表示:如何在计算机中表示三维物体的几何形状?有哪些显式/隐式表示方式?
- 3D 深度学习:如何将深度学习应用于不同的 3D 数据表示?
- 3D 生成与重建:如何利用 NeRF、3D Gaussian Splatting 等方法从 2D 图像重建或生成 3D 场景?

来源:Slides 第1页。
在 2D 图像中,表示方式非常统一——像素矩阵。但 3D 世界中,物体种类繁多、尺度各异,从大型建筑到细微纹理,需要多种不同的表示方式来捕捉几何、纹理、材质等信息。

来源:Slides 第2页。
为什么 3D 表示很重要
选择一种 3D 表示方式时,需要考虑多个因素:
- 存储:像素易于存储为矩阵,但 3D 点云是不规则的,隐式函数如何存储?
- 创建:如何从图片或语言描述生成新的 3D 形状?
- 编辑操作:简化、细分、平滑、修复等操作是否方便?
- 渲染:如何将 3D 物体渲染成 2D 图像?
- 动画:是否支持人体、动物等的运动模拟?
- 与深度学习的集成:能否方便地输入神经网络进行训练和推理?
3D 视觉的核心问题
3D 视觉在某种意义上是渲染的逆过程:渲染是从 3D 模型生成 2D 图像,而 3D 视觉是从 2D 图像重建 3D 世界。
本章小结
3D 视觉与 2D 图像处理有着本质区别——不存在统一的“像素”式表示。不同的 3D 表示方式各有优劣,选择取决于具体应用场景和与深度学习方法的兼容性。
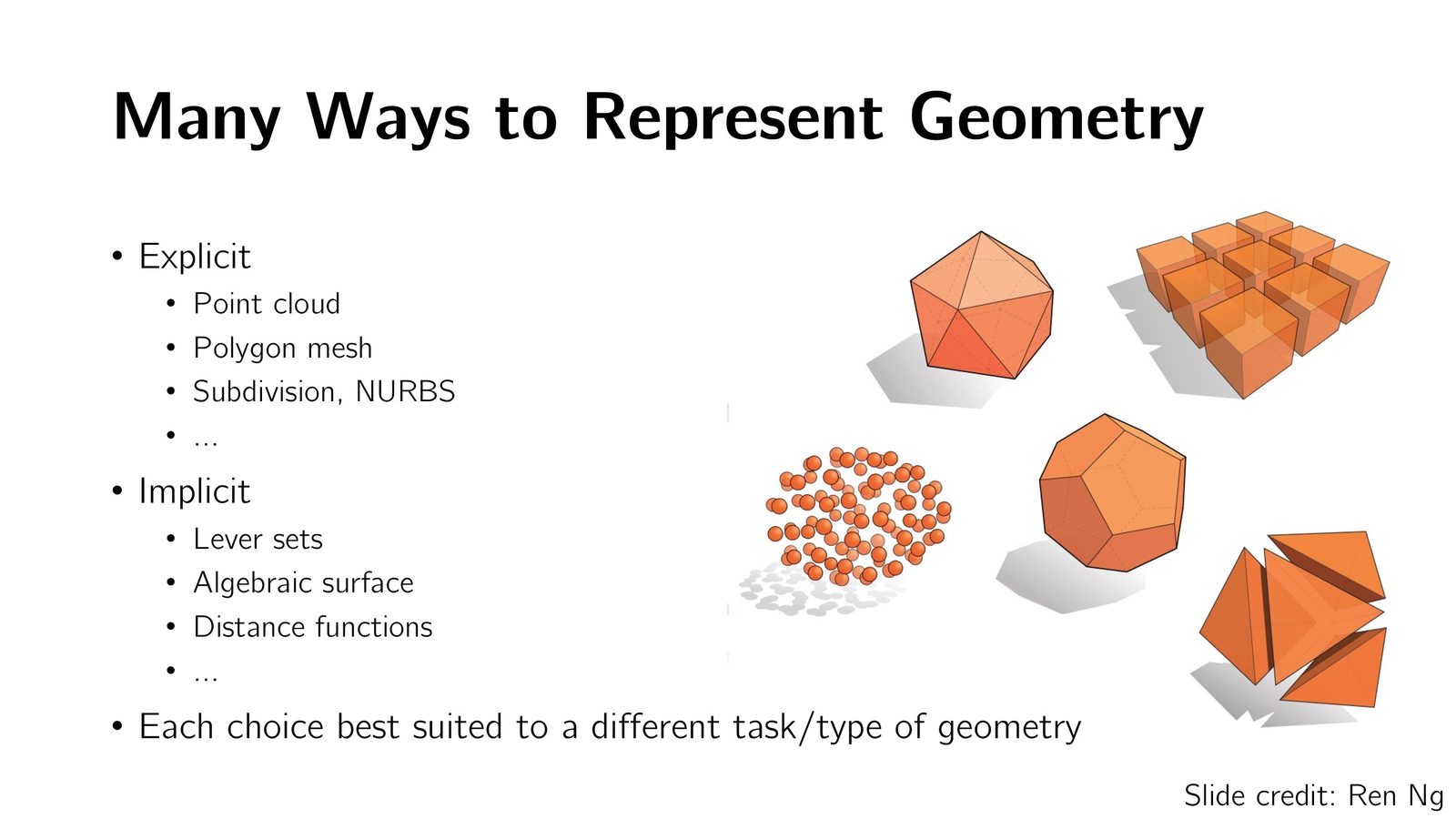
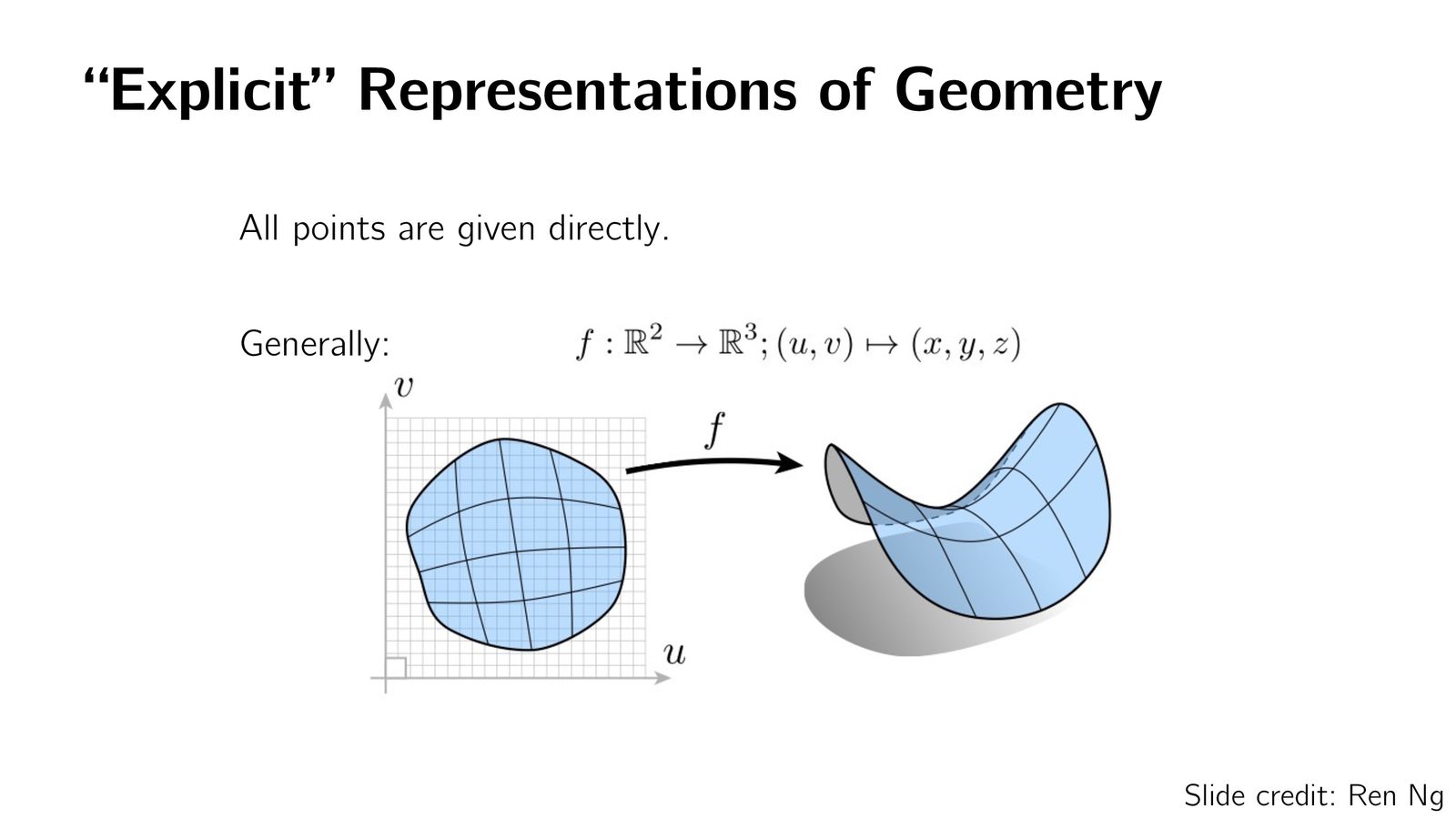
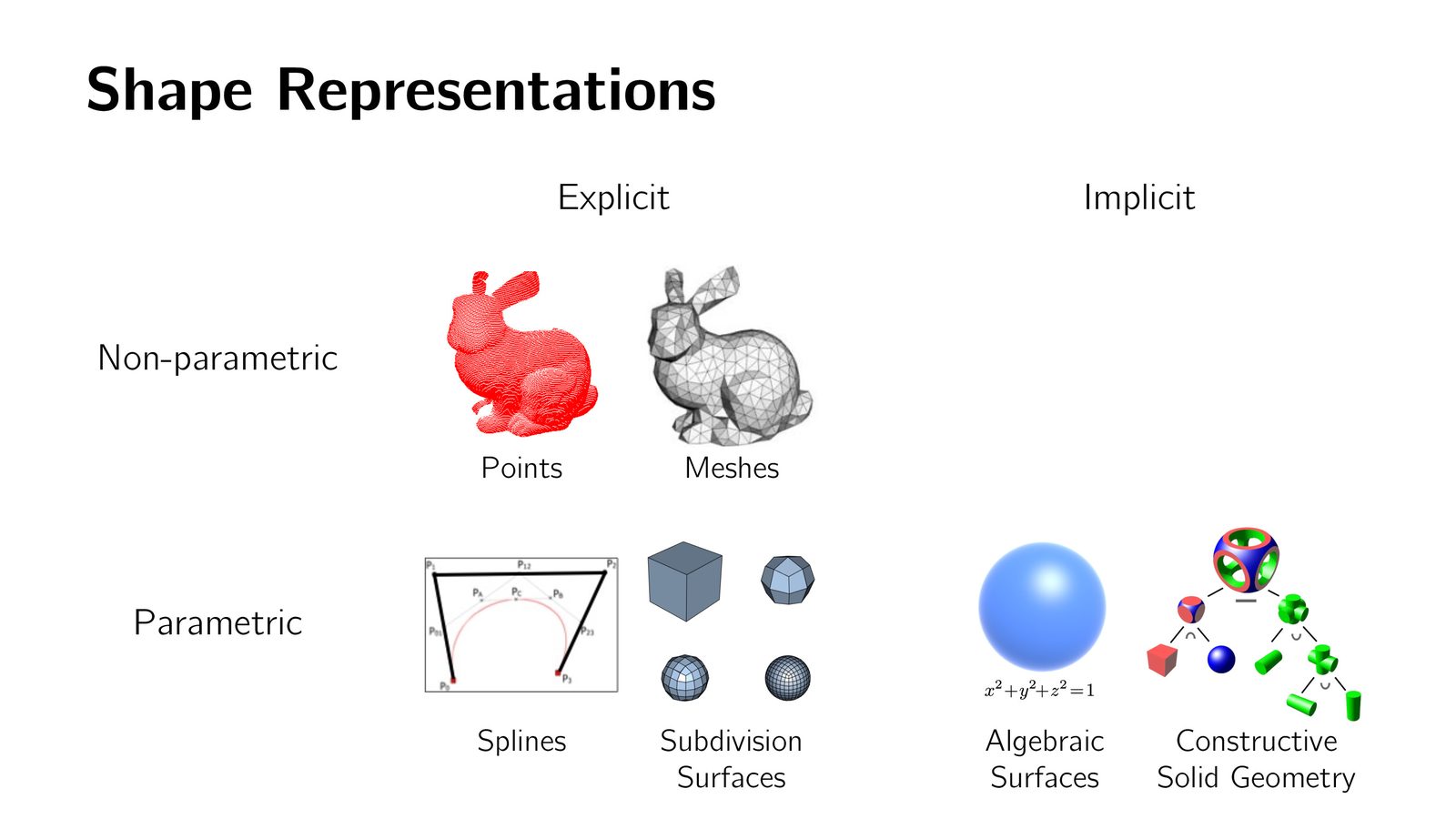
显式 3D 表示
3D 物体的几何表示可以分为两大类:显式表示(Explicit)和隐式表示(Implicit)。显式表示直接给出物体表面或内部的具体坐标信息。

来源:Slides 第3页。
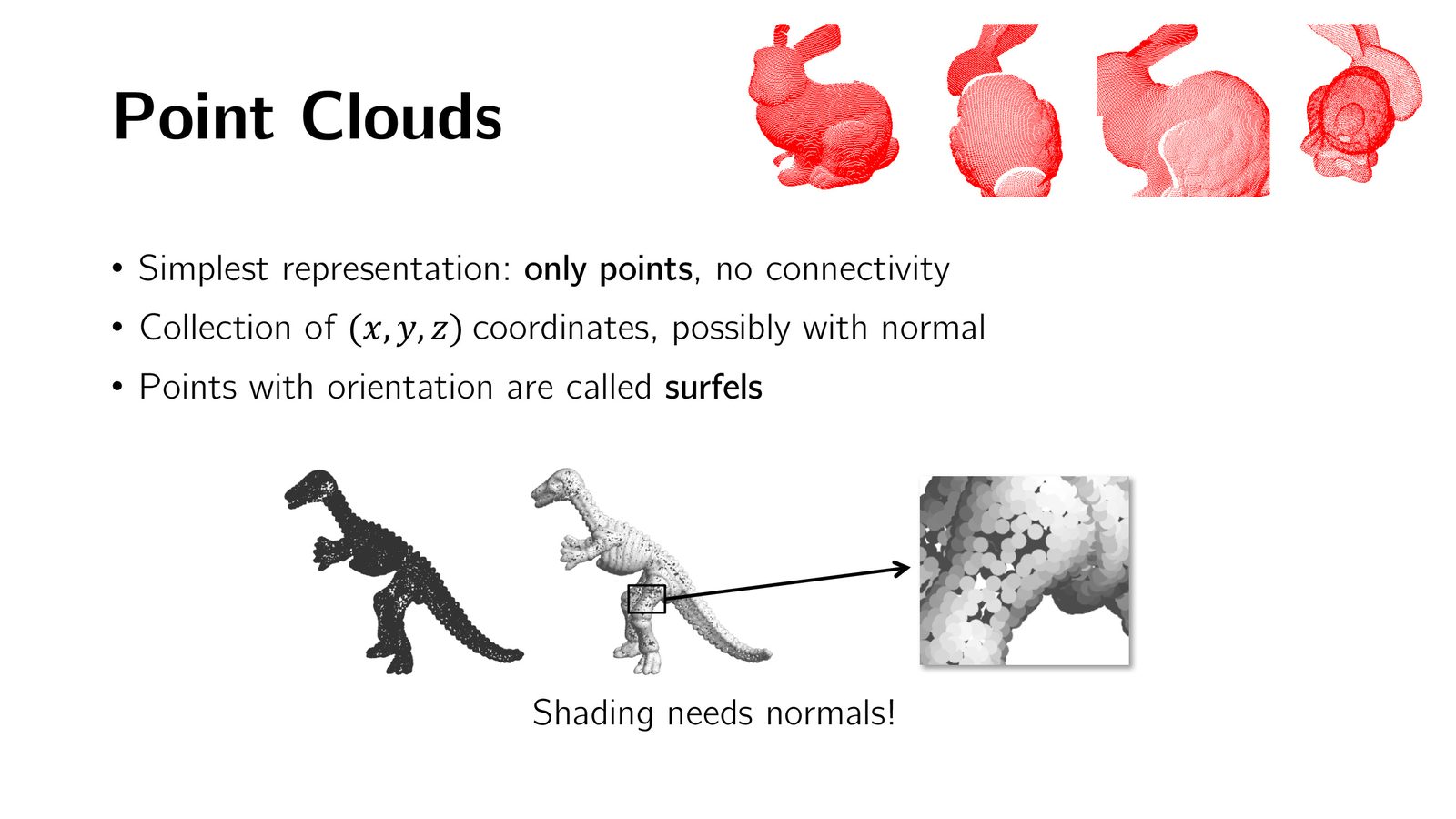
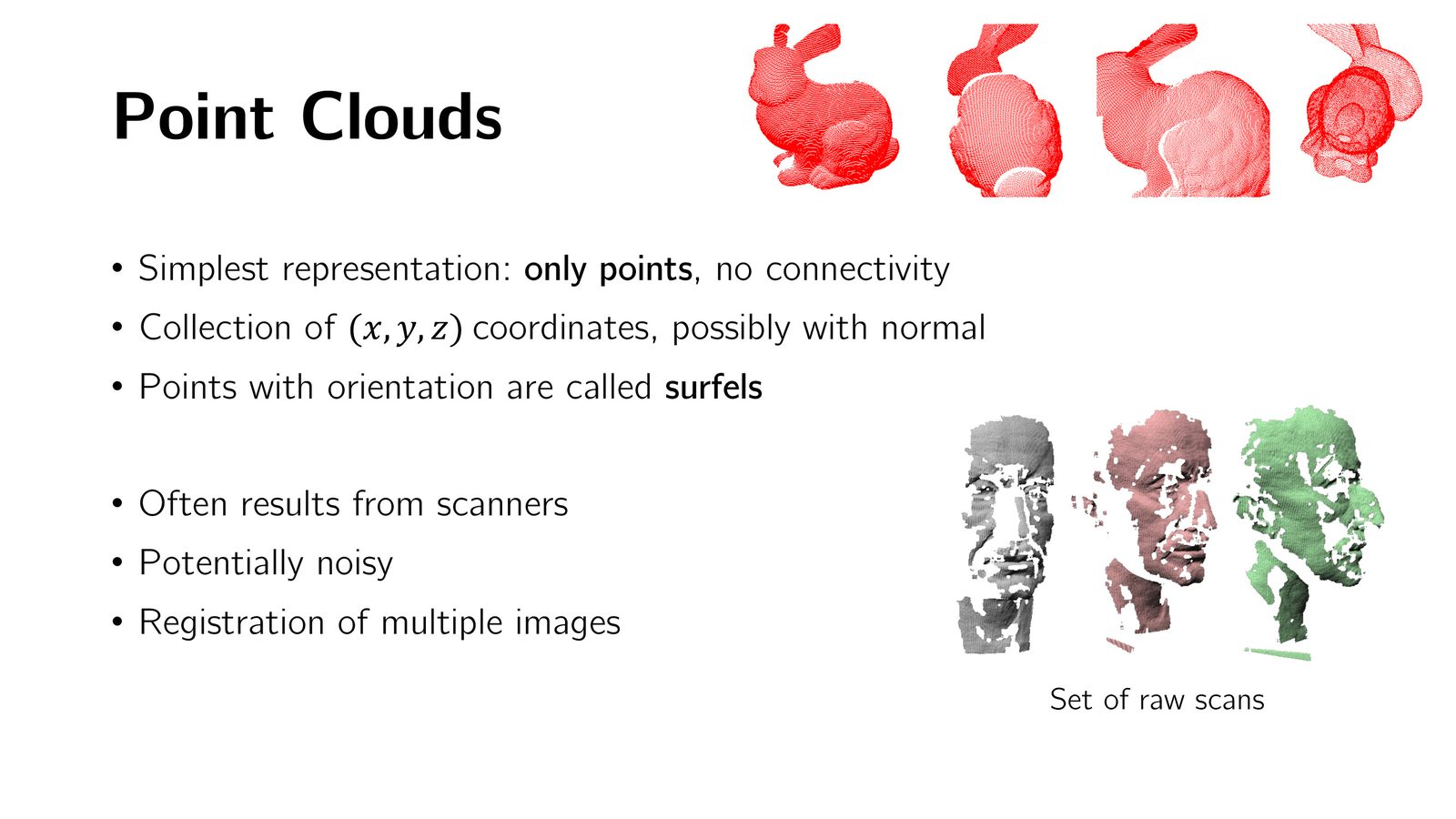
点云(Point Cloud)
点云是最简单的 3D 表示,由一组 3D 点的坐标构成,存储为 \(3 \times N\) 矩阵(\(xyz\) 坐标 \(\times\) 点数)。
来源:Slides 第4页。
点云的优势:
- 是 3D 传感器(深度相机、3D 扫描仪、iPhone AR Kit 等)的原始输出格式
- 非常灵活,不受拓扑约束,可以表示任意形状
- 适合处理大规模多样化数据集
点云的局限:
- 采样可能不均匀(兔子头部点多,尾部点少)
- 没有连接信息,无法直接进行细分或简化操作
- 缺乏拓扑信息——仅凭点无法区分圆环(torus)和球体
- 不支持平滑渲染

来源:Slides 第5页。
点云缺乏拓扑信息
给定一组点,无法判断物体是实心的还是有孔的。例如,圆环和球体的点云在某些采样下可能看起来相似。这是点云表示的根本局限。
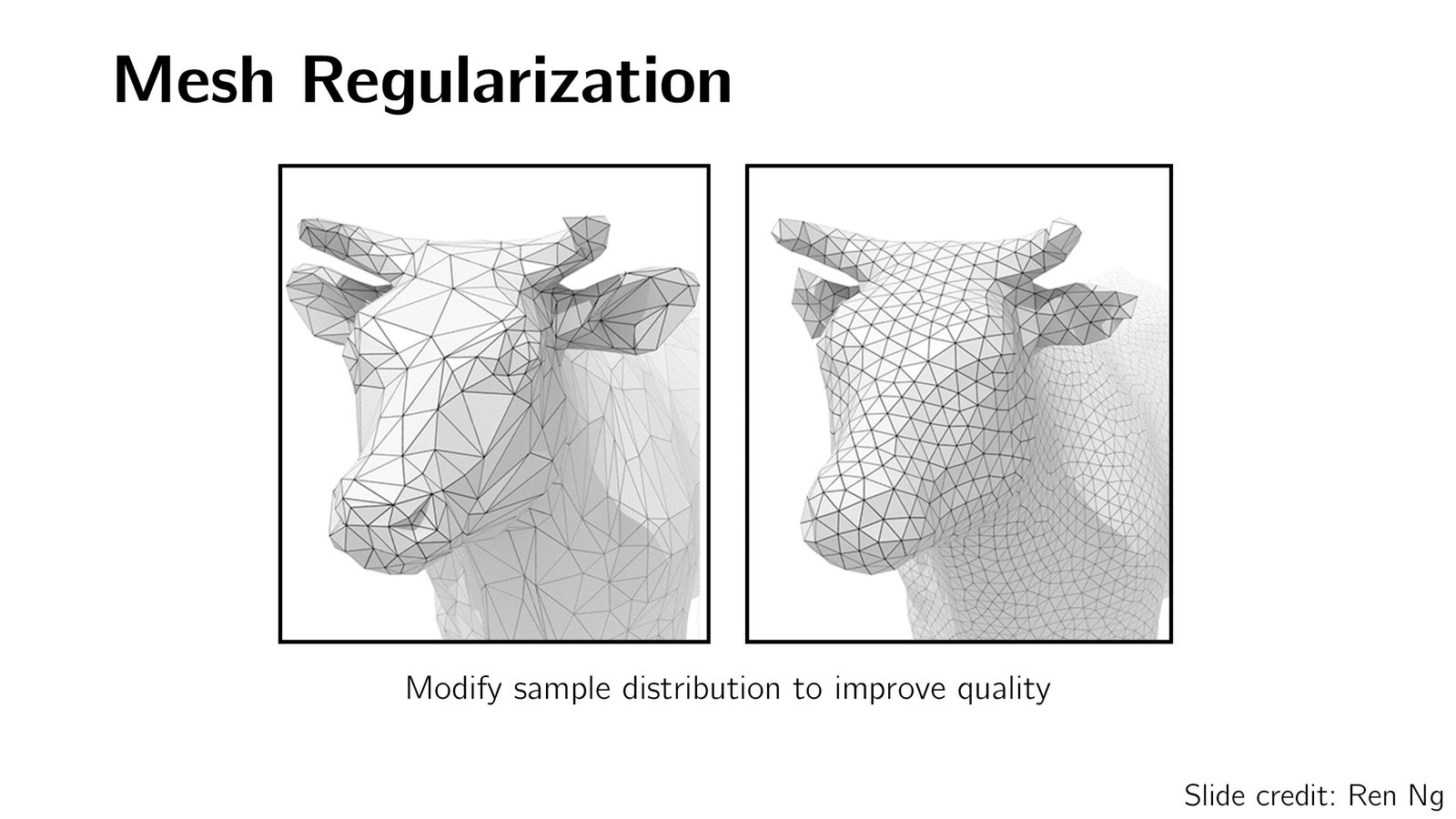
多边形网格(Polygon Mesh)
为了补充点云缺乏的连接信息,自然引入了多边形网格——不仅存储顶点,还存储面(面通常是三角形或四边形)。
来源:Slides 第6页。
网格是图形引擎和游戏中最广泛使用的 3D 表示。复杂的网格可以达到数千万三角形(如 5600 万三角形的 David 雕塑),甚至 Google Earth 使用万亿级三角形来表示地球表面。

来源:Slides 第7页。
网格支持丰富的操作:
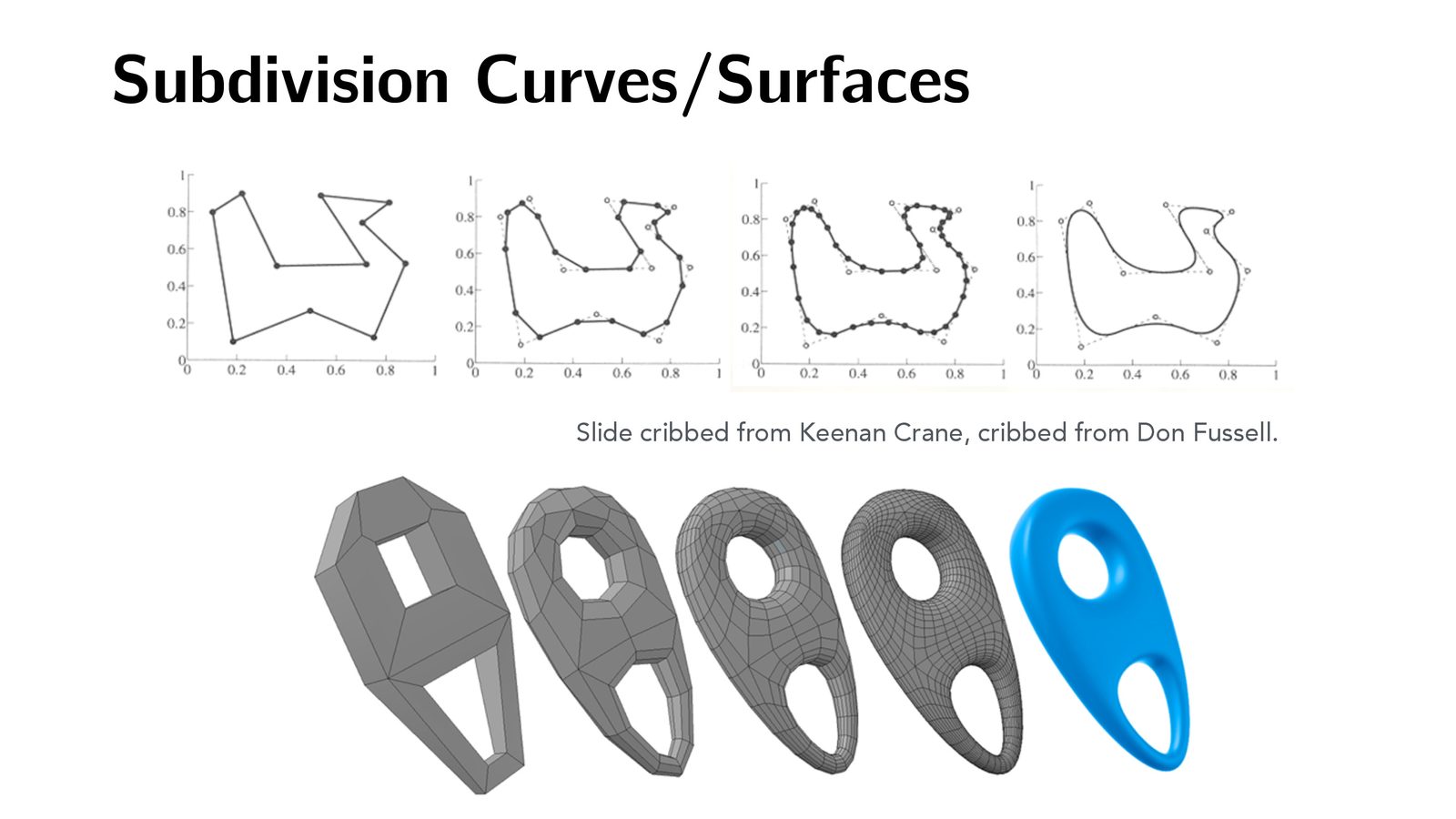
- 细分(Subdivision):增加三角形数量以捕捉更多细节
- 简化(Simplification):减少三角形数量以提高处理速度
- 正则化(Regularization):使三角形大小均匀、形状规则
网格与深度学习的兼容性挑战
网格的不规则性(每个面可能有不同数量的顶点,分辨率可变)使其难以直接输入标准 CNN。这是 3D 深度学习起步较晚的重要原因之一——人们需要找到将不规则 3D 数据适配到神经网络的方法。
参数化表示(Parametric Representations)
对于具有规则结构的物体(如圆、球、工业零件),可以用参数函数来表示其形状。
来源:Slides 第8页。
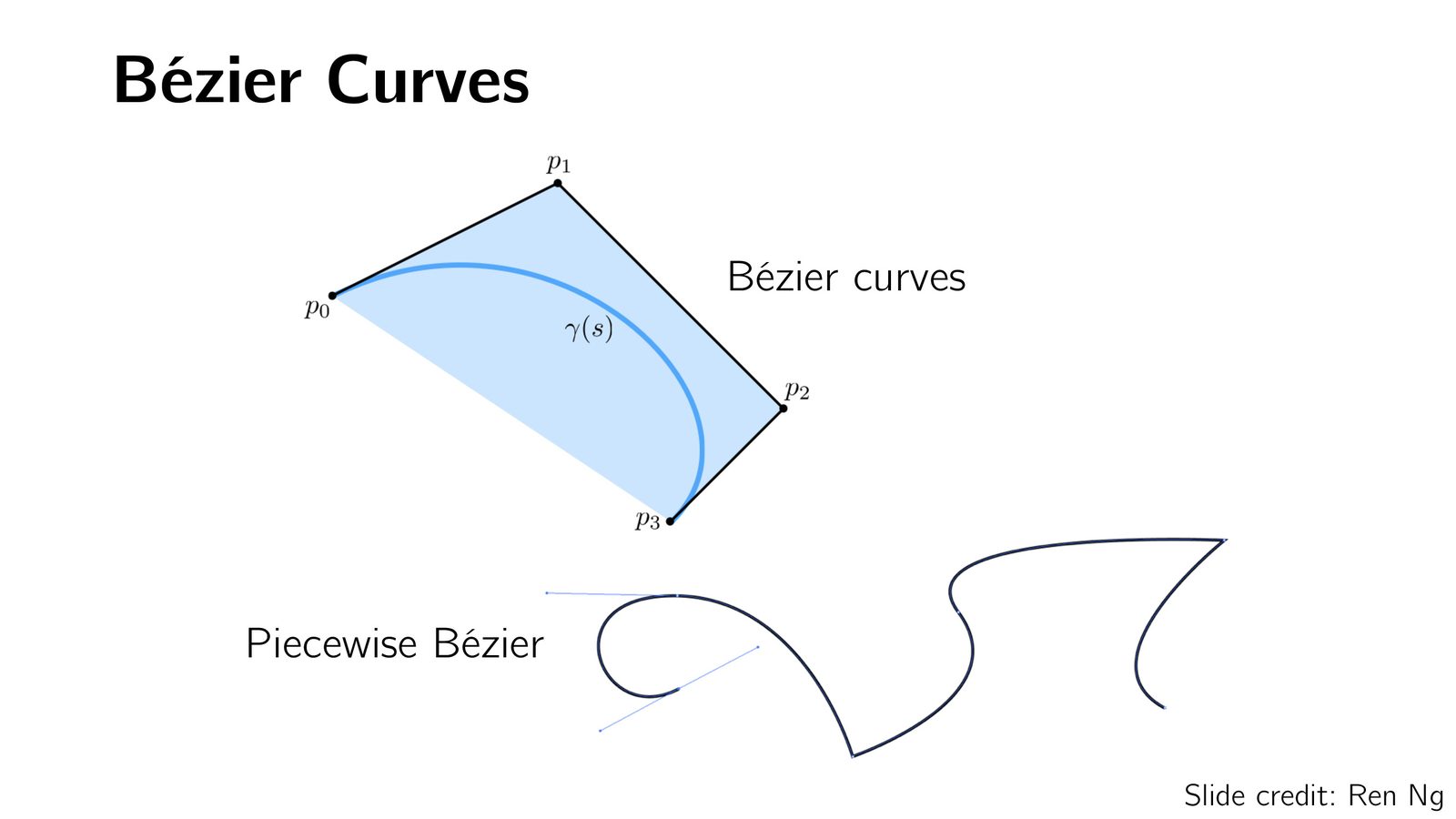
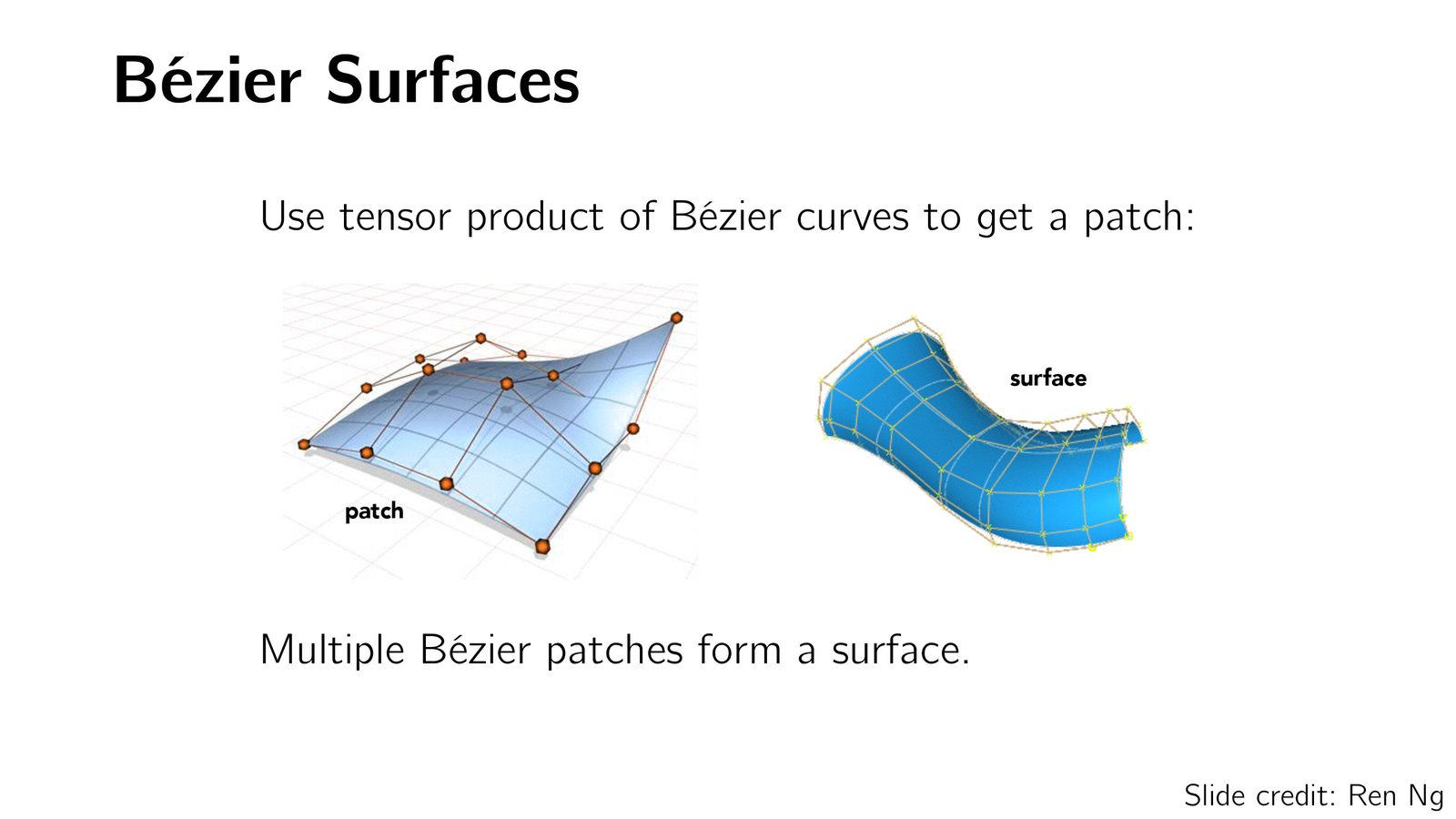
更复杂的参数化表示包括 B\'{e}zier 曲线/曲面和 B-Spline,通过少量控制点就能表示光滑的自由曲面。
显式表示的核心特点
显式表示易于采样——给定参数值,直接计算得到物体表面上的点。但难以判断某个任意点是在物体内部还是外部。
本章小结
- 点云:最简单,是传感器的原始格式,但缺乏拓扑信息
- 网格:最广泛使用,支持丰富操作,但不规则性使其难以直接与深度学习集成
- 参数化曲面:用函数紧凑地表示规则形状,支持细分操作
- 显式表示共同的优势是采样容易,共同的劣势是内外判断困难
隐式 3D 表示
隐式函数的基本思想
隐式表示通过一个函数 \(f(x, y, z) = 0\) 来定义物体表面:满足等式的点在表面上,\(f < 0\) 的点在内部,\(f > 0\) 的点在外部。

来源:Slides 第10页。
隐式表示与显式表示的互补关系
- 显式表示:采样容易(直接得到表面点),内外判断困难
- 隐式表示:内外判断容易(代入函数看符号),采样困难(需要求解方程)
这一对偶关系贯穿整个 3D 视觉研究。
隐式表示的组合性
隐式表示的一大优势是组合性(Composability)——可以通过布尔运算组合简单形状来构建复杂形状。

来源:Slides 第11页。
给定两个隐式函数 \(f_1\) 和 \(f_2\):
- 并集:\(\min(f_1, f_2)\)
- 交集:\(\max(f_1, f_2)\)
- 差集:\(\max(f_1, -f_2)\)
这种组合能力广泛应用于CAD(计算机辅助设计)和工业制造中。
有符号距离函数(SDF)
如果隐式函数的值表示到表面的有符号距离(内部为负,外部为正),则称为有符号距离函数(Signed Distance Function, SDF)。SDF 不仅能判断内外,还能通过加法实现形状的平滑混合(Smooth Blending),产生自然的过渡效果。

来源:Slides 第13页。
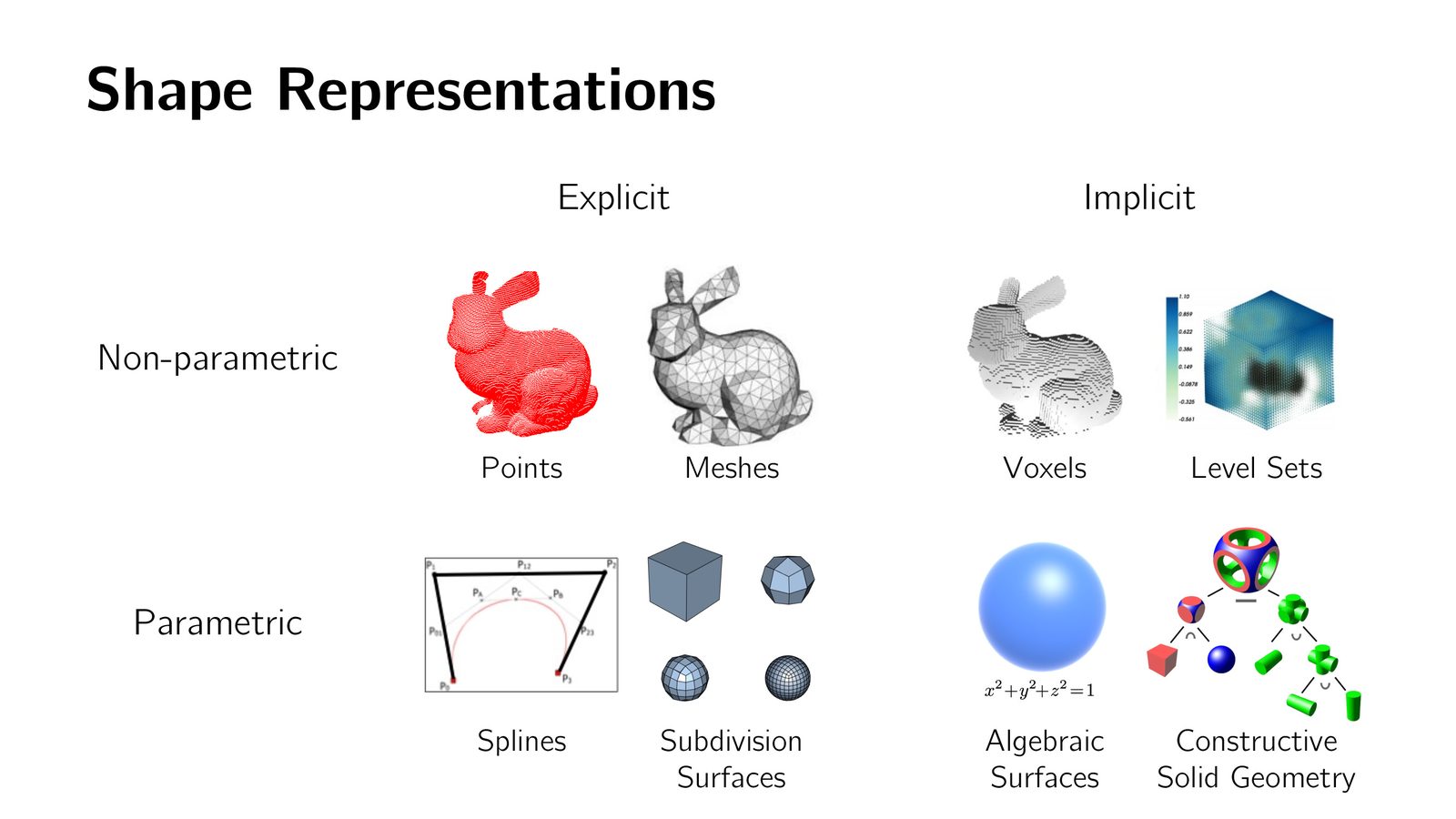
水平集方法与体素
对于复杂形状,闭合形式的隐式函数可能不存在。一个实用的方法是:在 3D 网格上预计算隐式函数值,存储为 3D 矩阵——这就是水平集方法(Level Set Method)。

来源:Slides 第14页。
进一步简化——如果只关心每个网格点是在物体内部还是外部(二值化),就得到了体素(Voxel)表示。
来源:Slides 第15页。
体素 = 3D 像素
体素(Voxel)是 2D 像素在 3D 空间的直接推广。像素是 \(n \times n\) 矩阵,体素是 \(n \times n \times n\) 3D 矩阵。这种类比使得体素成为最早被深度学习采用的 3D 表示——只需将 2D 卷积替换为 3D 卷积即可。
本章小结
- 隐式表示通过函数 \(f(x,y,z)=0\) 定义物体表面
- 优势:内外判断容易,支持布尔组合,SDF 允许平滑混合
- 劣势:采样困难,复杂形状难以写出闭合函数
- 水平集和体素将隐式函数离散化为 3D 矩阵,便于存储和计算
- 体素是最早与深度学习集成的 3D 表示
3D 数据集
数据集的演进
在深度学习时代之前,3D 数据集很小。Princeton Shape Benchmark 仅有 1800 个模型、180 个类别(平均每类 10 个模型)。

来源:Slides 第18页。
关键里程碑:
- ShapeNet(斯坦福主导):300 万模型总量,常用子集 ShapeNet Core 有 5 万模型、55 个类别
- Objaverse / Objaverse-XL(AI2):100 万至 1000 万模型,涵盖更多类别和更高质量纹理
- CO3D(Meta + Oxford):真实物体的 360 度视频,约 19000 个物体
- ScanNet:真实室内场景扫描,约 1500--3000 个房间
3D 数据远少于 2D 数据
即使最大的 3D 数据集(\(\sim\)1000万模型)也远小于 2D 图像数据集(LAION-5B 有 50 亿图像)。这个巨大的数据量差距是 3D 视觉面临的核心挑战之一,也是为什么越来越多的方法试图利用 2D 基础模型的先验知识来辅助 3D 理解。
3D 视觉的核心任务
来源:Slides 第20页。
本章小结
3D 数据集从千级规模发展到千万级,但仍远小于 2D 数据。利用大规模 2D 基础模型的先验知识来弥补 3D 数据不足,正成为主流研究方向。
深度学习在 3D 数据上的方法
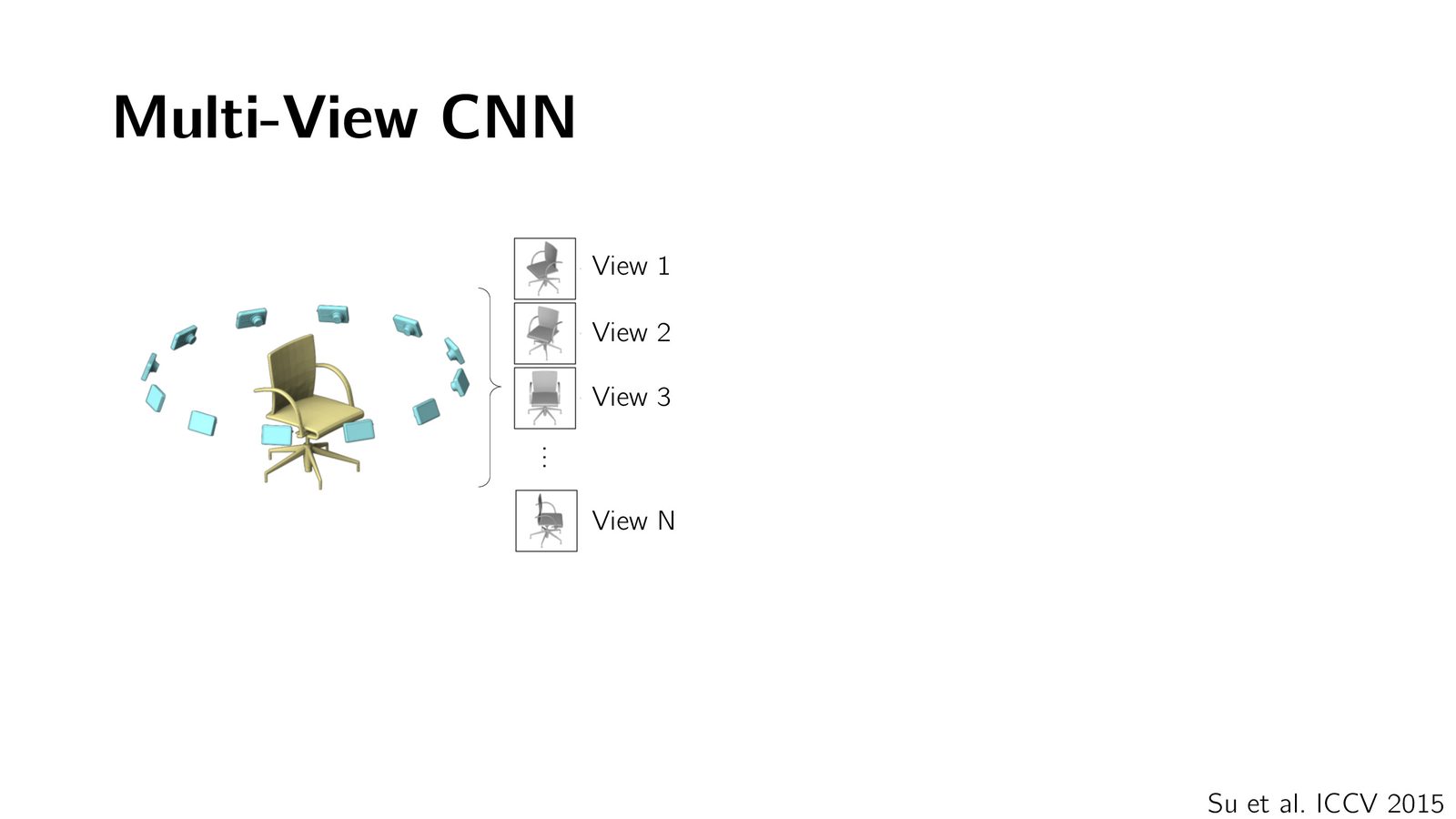
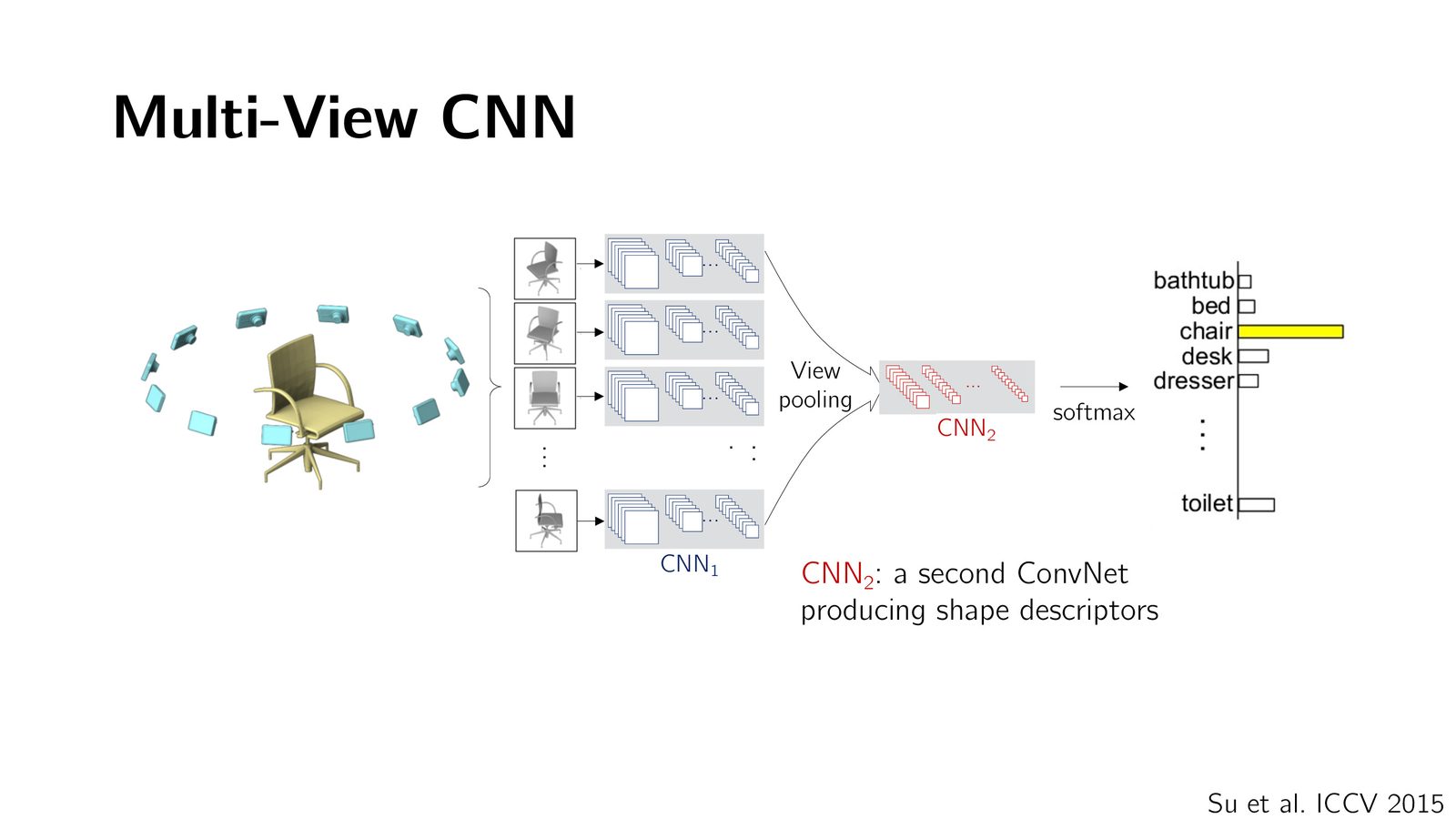
方法一:多视图 CNN(Multi-view CNN)
最早将深度学习应用到 3D 数据的方法非常直接:将 3D 物体从多个角度渲染成 2D 图像,然后用已有的 2D CNN(如在 ImageNet 上预训练的模型)进行分类。
来源:Slides 第21页。
多视图方法的回归
多视图方法最初因为“不够 3D native”而被研究者抛弃,但随着 2D 图像/视频基础模型(如 V3 等)变得越来越强大,这一趋势正在回归——因为 2D 模型训练所用数据量可能比 3D 数据多百万倍。
方法二:体素 CNN(Volumetric CNN)
最直接的 3D 原生方法:将 2D 卷积扩展为 3D 卷积,在体素数据上运行。
来源:Slides 第22页。
体素方法的计算瓶颈
体素分辨率为 \(N^3\),将 2D 的 \(N^2\) 复杂度提升了一个维度。当 \(N=256\) 时,体素需要 \(256^3 \approx 1700\) 万个元素,内存和计算量巨大。而且大量体素对应空白区域,造成严重浪费。为缓解这一问题,人们开发了稀疏卷积(Sparse Convolution)和八叉树(Octree)等技术。
来源:Slides 第24页。
方法三:PointNet — 直接处理点云
PointNet(Stanford, Qi et al. 2017)是 3D 深度学习领域的里程碑工作,提出了直接在点云上运行的神经网络。

来源:Slides 第27页。
PointNet 需要解决两个关键问题:
PointNet 的两大设计要求
- 排列不变性(Permutation Invariance):点的编号顺序不影响输出
- 采样不变性(Sampling Invariance):不同采样密度下输出应一致
解决方案极其简洁:对每个点独立计算嵌入,然后用对称函数(如 max pooling 或 sum)聚合所有点的特征。
PointNet 的工作流程:
- 输入 \(N\) 个点,每个点有 \((x, y, z)\) 坐标
- 对每个点独立地通过 MLP 计算高维嵌入
- 用 max pooling 聚合所有点的特征为一个全局向量
- 通过全连接层输出分类结果
后续改进包括 PointNet++(引入局部特征)、图神经网络(将点作为图节点、邻近关系作为边)等。
点云的距离度量
对于点云生成任务,需要定义两个点云之间的“距离”。两种常用度量:

来源:Slides 第29页。
Chamfer Distance:
Earth Mover's Distance (EMD):
两种距离的区别
Chamfer Distance 计算简单但对异常值敏感;EMD 需要求解最优传输问题,计算复杂但更鲁棒。实际应用中,Chamfer Distance 因计算效率更常被使用。
本章小结
- 多视图 CNN:利用强大的 2D 预训练模型,但丢失了 3D 原生信息
- 体素 CNN:最直接的 3D 扩展,但面临 \(O(N^3)\) 的计算瓶颈
- PointNet:通过排列不变的对称函数,开创了直接处理点云的范式
- 不同方法各有优劣,选择取决于数据格式和任务需求
神经隐式表示(Neural Implicit Representations)
从传统到神经网络
2019 年前后,研究者意识到一个关键洞察:深度网络本质上就是在学习一个复杂的隐式函数——输入空间大(像素),输出空间小(类别)。那么,为何不直接用神经网络来表示一个 3D 物体的隐式函数?
来源:Slides 第35页。
2019年的四篇里程碑论文
2019年几乎同时出现了四篇提出相同思想的论文:
- DeepSDF(Park et al.):学习有符号距离函数
- Occupancy Networks(Mescheder et al.):学习占用概率
- IM-NET(Chen & Zhang):隐式场解码器
- DISN(Xu et al.):深度隐式表面网络
核心思想一致:用 MLP 接收 \((x,y,z)\) 坐标作为输入,输出该点是否在物体内部的概率或到表面的距离。
网络结构非常简单:
从几何到外观:NeRF
如果隐式函数不仅输出几何(密度),还输出颜色,就可以实现从任意视角的渲染。这就是 2020 年 NeRF(Neural Radiance Fields)的核心思想。
来源:Slides 第39页。
- \((x, y, z)\):3D 位置
- \((\theta, \phi)\):观察方向
- \(\sigma\):体密度(density)
- \(\mathbf{c} = (r, g, b)\):颜色
体渲染公式:对于一条射线 \(\mathbf{r}(t) = \mathbf{o} + t\mathbf{d}\):
- \(T_i\):透射率(transmittance),表示光线到达第 \(i\) 个采样点前未被遮挡的概率
- \(\alpha_i\):不透明度(opacity)
- \(\delta_i\):相邻采样点间距

来源:Slides 第40页。
NeRF 的训练与推理
训练:仅需多张已知相机位姿的照片。对每张照片的每个像素发射射线,通过体渲染合成颜色,与真实像素颜色计算 MSE 损失,反向传播更新 MLP 权重。\ 推理:给定新的相机位姿,即可渲染出该视角的图像——实现新视角合成(Novel View Synthesis)。

来源:Slides 第41页。
3D Gaussian Splatting
NeRF 虽然效果出色,但渲染速度慢——需要沿每条射线密集采样大量 3D 点并查询 MLP。很多采样点对应的是空白区域,造成计算浪费。
3D Gaussian Splatting(3DGS,2023)提出了一种加速方案:用一组3D 高斯椭球(Gaussian Blobs)来显式表示场景。

来源:Slides 第43页。
NeRF vs 3D Gaussian Splatting
- NeRF:纯隐式(MLP),密集采样,渲染慢但表示紧凑
- 3DGS:半显式(高斯点云),稀疏采样,渲染快(可实时)但存储量大
3DGS 仍保留隐式查询的优势(每个高斯有密度和颜色属性),但因为知道“哪里有东西”,避免了对空白区域的无效采样。

来源:Slides 第44页。
本章小结
- 神经隐式表示用 MLP 作为 3D 物体的隐式函数,输入坐标、输出占用/距离/颜色
- NeRF 将隐式表示扩展到辐射场,实现了从 2D 图像学习 3D 场景并渲染新视角
- 3D Gaussian Splatting 结合显式点云和隐式属性,实现了接近实时的渲染速度
- 这一系列方法打通了 2D 图像数据与 3D 场景理解之间的桥梁
3D 生成模型
3D 形状生成的早期方法
早期的 3D 生成模型直接在 3D 数据上训练 GAN 或 VAE:

来源:Slides 第46页。
3D 生成的局限
早期方法受限于 3D 数据量少,生成效果有限且局限于特定类别(如椅子、汽车)。突破的关键在于利用 2D 图像/视频基础模型的先验知识来辅助 3D 生成。
利用 2D 先验的 3D 生成
通过可微渲染,可以将 3D 生成与 2D 判别器/损失函数连接起来,利用大规模 2D 数据训练的模型来指导 3D 生成。

来源:Slides 第49页。
基于扩散模型的 3D 生成
近年来,Score Distillation Sampling(SDS)等技术使得利用预训练的 2D 扩散模型(如 Stable Diffusion)来指导 3D 生成成为可能。代表性工作包括 DreamFusion、Magic3D 等。
来源:Slides 第53页。
来源:Slides 第56页。
前沿方向:大规模 3D 生成
最新的研究方向包括:
- 单图像到 3D:从一张图片重建完整 3D 模型
- 文本到 3D:从文字描述直接生成 3D 物体
- 视频到 4D:从视频重建动态 3D 场景
- 3D 基础模型:训练能泛化到多类别的统一 3D 生成模型

来源:Slides 第58页。
本章小结
- 早期 3D 生成直接在 3D 数据上训练,受限于数据规模
- 可微渲染打通了 3D 生成与 2D 监督之间的桥梁
- 利用 2D 扩散模型先验(如 SDS)实现了高质量的文本到 3D 生成
- 3D 生成正朝着大规模、多类别、基础模型的方向发展
总结与延伸
讲者的核心总结
Jiajun Wu 在课程最后回顾了 3D 视觉研究的发展轨迹:
- 表示方式决定了方法论:从体素到点云到隐式函数,每种表示催生了不同的深度学习方法
- 显式与隐式的互补:采样容易 vs 查询容易,二者各有所长
- 2D-3D 联合学习是趋势:3D 数据稀缺,但 2D 数据丰富。通过可微渲染和隐式表示,可以有效利用 2D 先验
- NeRF 和 3DGS 改变了游戏规则:从 2D 图像直接学习 3D 场景,不再需要显式的 3D 监督
全课知识图谱

关键 Takeaways
五条核心原则
- 没有统一的 3D “像素”:不同表示各有优劣,选择取决于任务
- 显式 vs 隐式是核心对偶:采样容易与查询容易的权衡贯穿始终
- PointNet 的简洁之道:排列不变 + 对称聚合,简单而强大
- NeRF 用 2D 图像学 3D:通过可微体渲染,无需 3D 监督
- 数据差距驱动方法创新:3D 数据远少于 2D,利用 2D 先验是关键策略
拓展阅读
- PointNet: https://arxiv.org/abs/1612.00593
- DeepSDF: https://arxiv.org/abs/1901.05103
- Occupancy Networks: https://arxiv.org/abs/1812.03828
- NeRF: https://arxiv.org/abs/2003.08934
- 3D Gaussian Splatting: https://arxiv.org/abs/2308.14737
- DreamFusion: https://arxiv.org/abs/2209.14988
- ShapeNet: https://shapenet.org/
- Objaverse: https://objaverse.allenai.org/