CS231N Lecture 7: Recurrent Neural Networks
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Zane Durante 授课内容整理 |
| 来源 | Stanford University |
| 日期 | 2025 |

引言:从固定输入到序列建模
在之前的课程中,我们一直讨论的是标准的非循环(non-recurrent)神经网络:固定大小的输入映射到固定大小的输出。这种范式适合图像分类等任务,但真实世界中存在大量变长序列数据——语言、视频、音乐、时间序列等。本讲将引入循环神经网络(Recurrent Neural Networks, RNNs),这是一种专门为序列建模设计的神经网络架构。

来源:Slides 第5页。
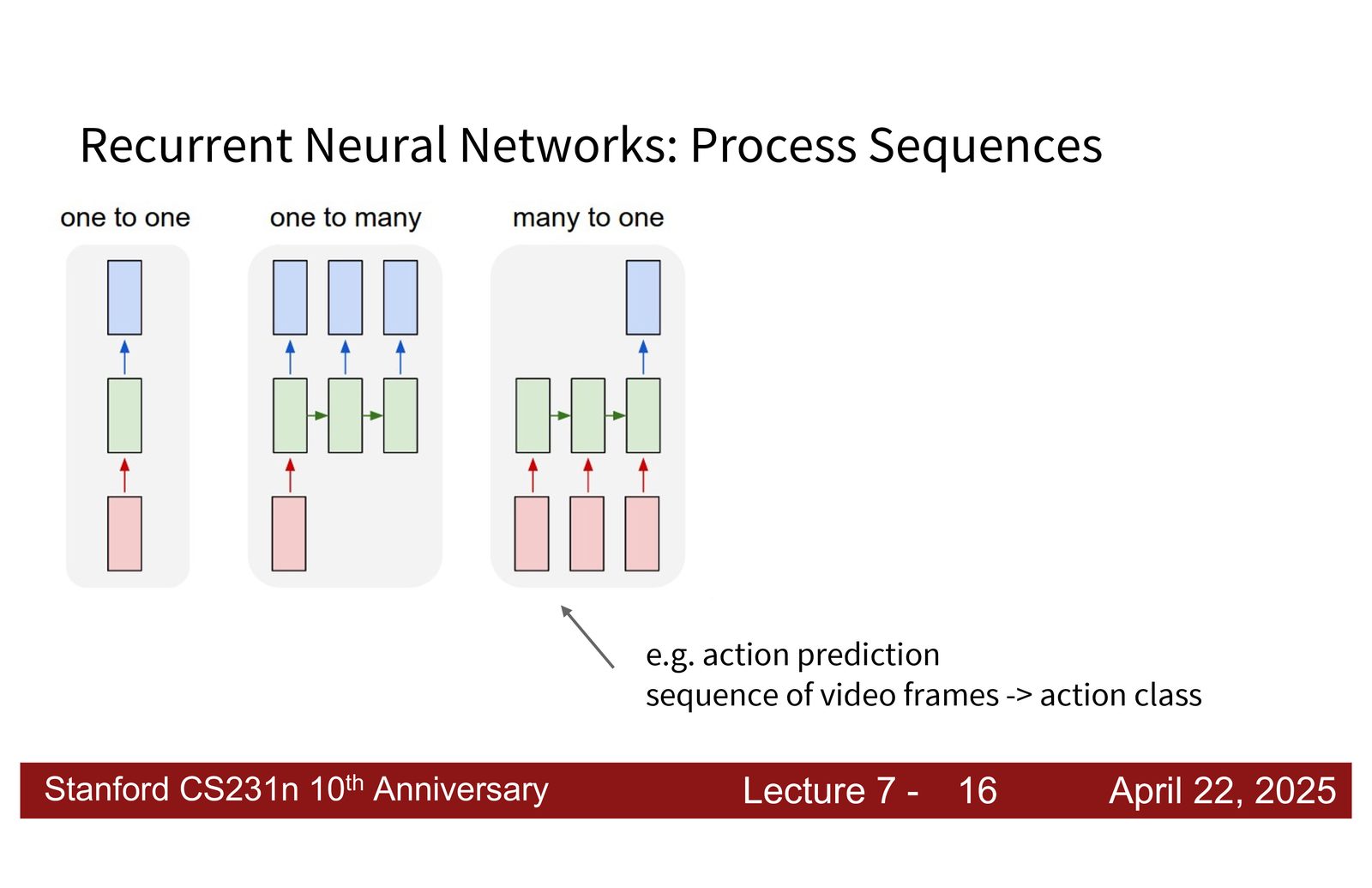
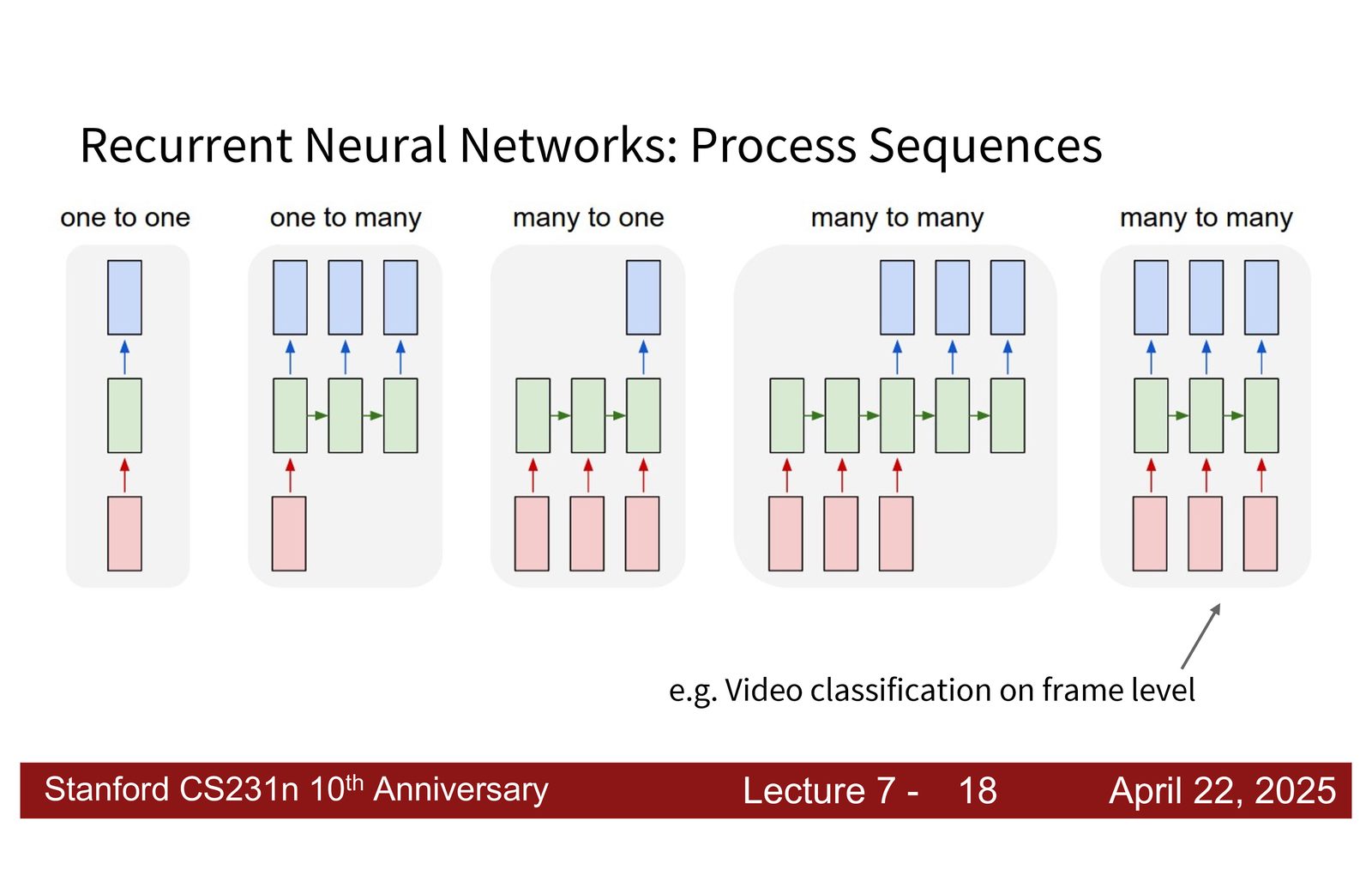
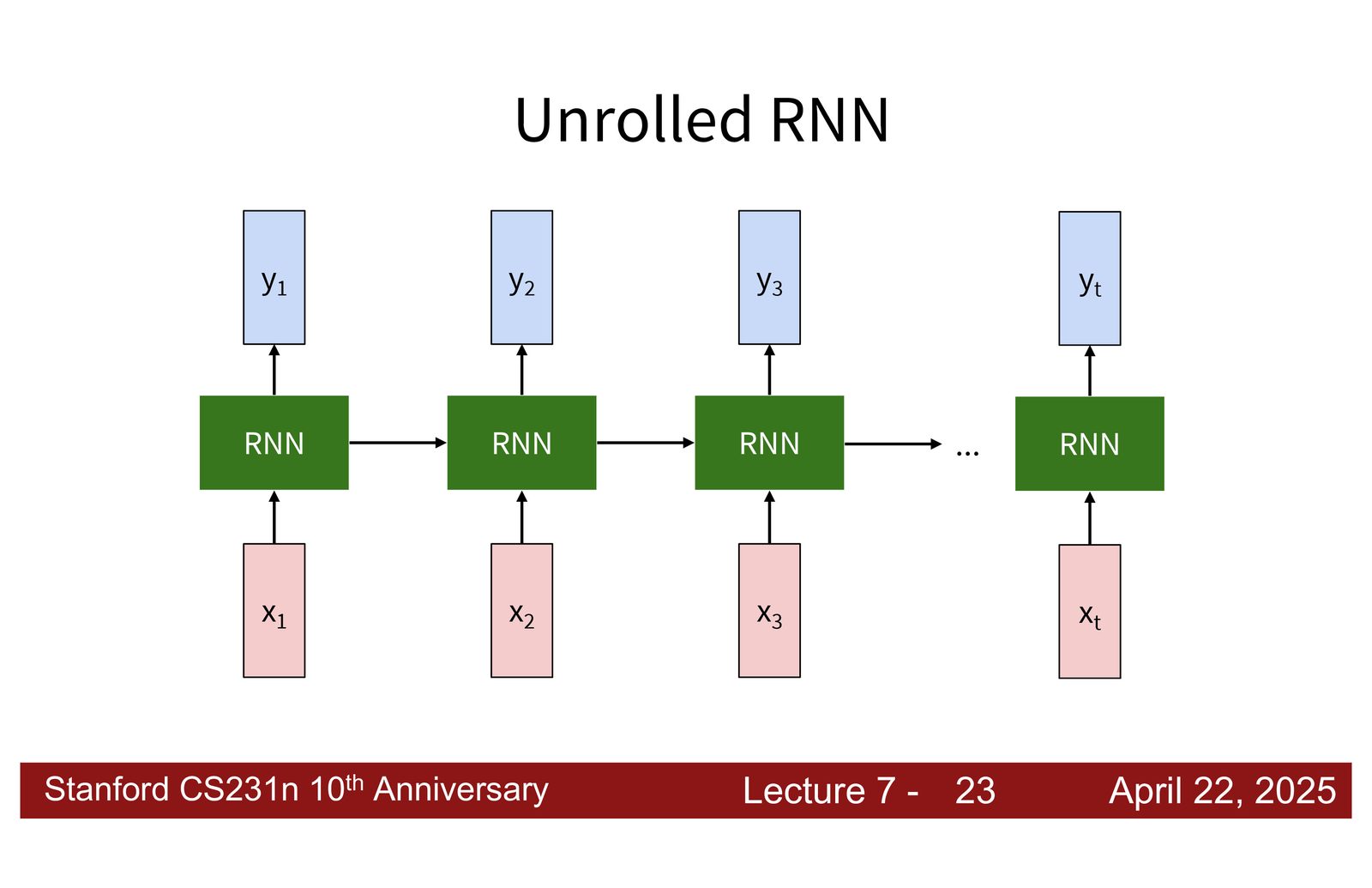
序列建模的五种范式
- One-to-one:固定输入 \(\rightarrow\) 固定输出(如图像分类)
- One-to-many:固定输入 \(\rightarrow\) 变长输出(如图像描述生成)
- Many-to-one:变长输入 \(\rightarrow\) 固定输出(如视频分类、情感分析)
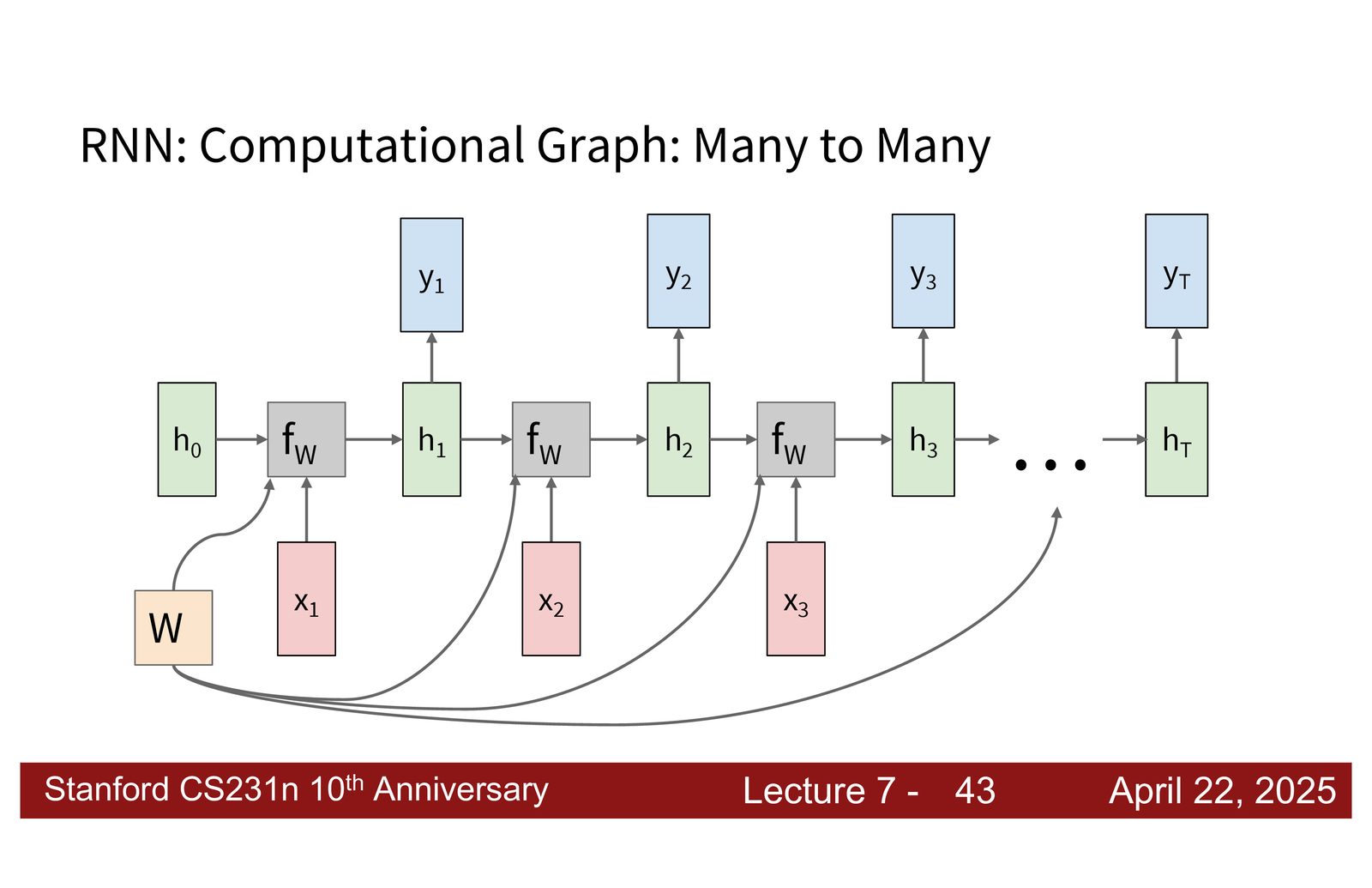
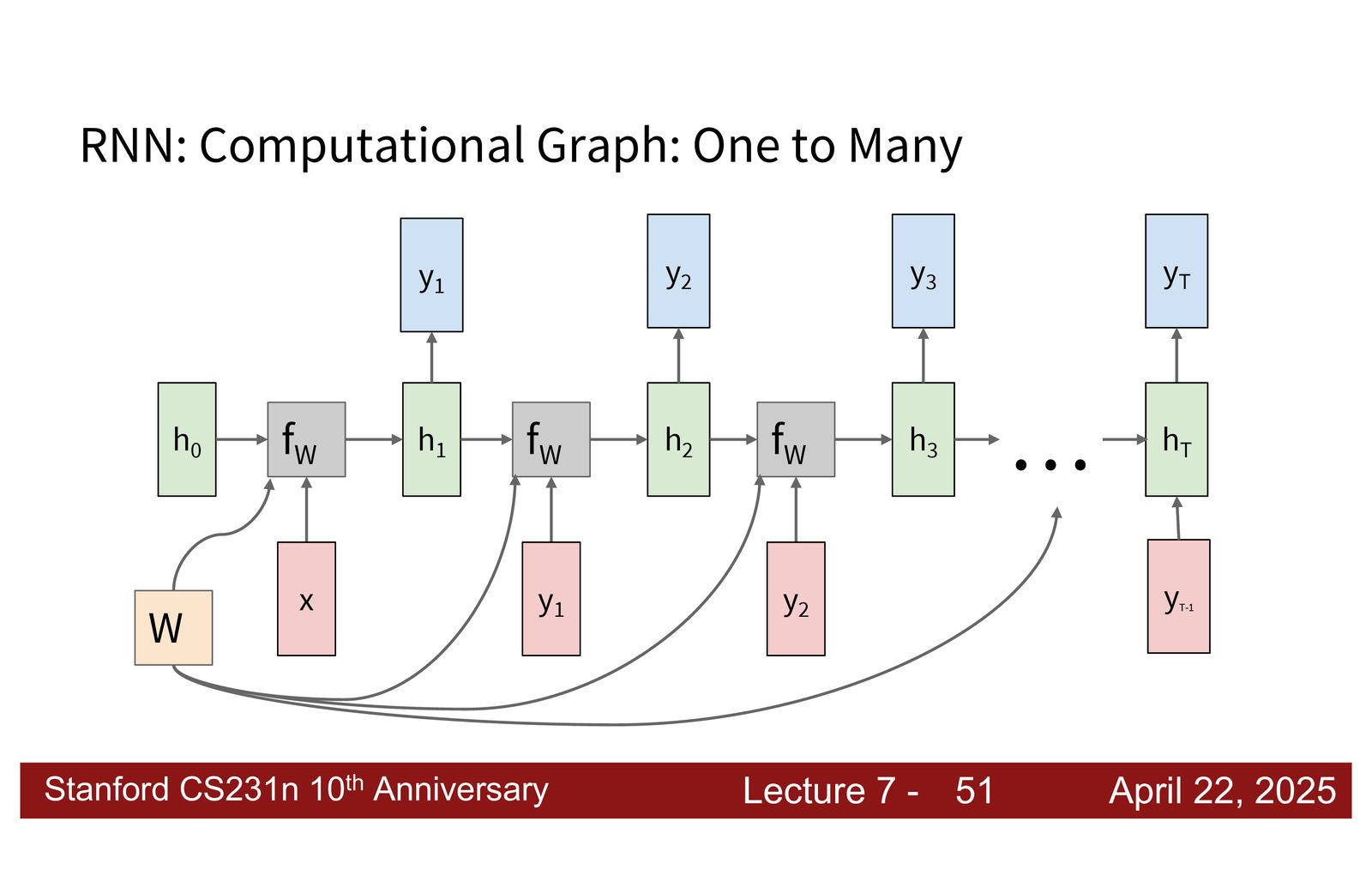
- Many-to-many(异步):变长输入 \(\rightarrow\) 变长输出(如机器翻译)
- Many-to-many(同步):每个输入对应一个输出(如逐帧视频标注)
课程前期回顾
讲者首先对上节课的内容进行了几点澄清:
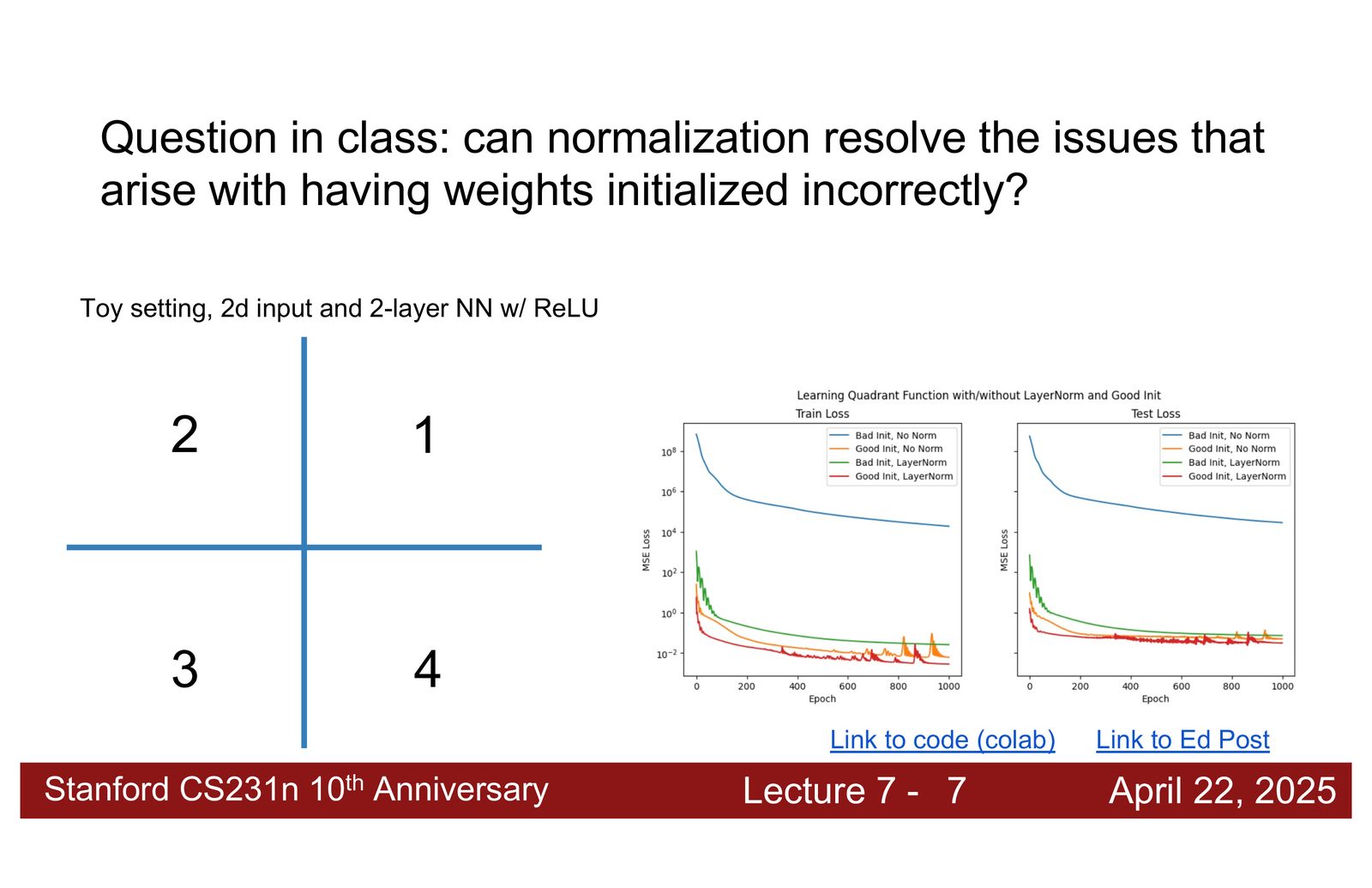
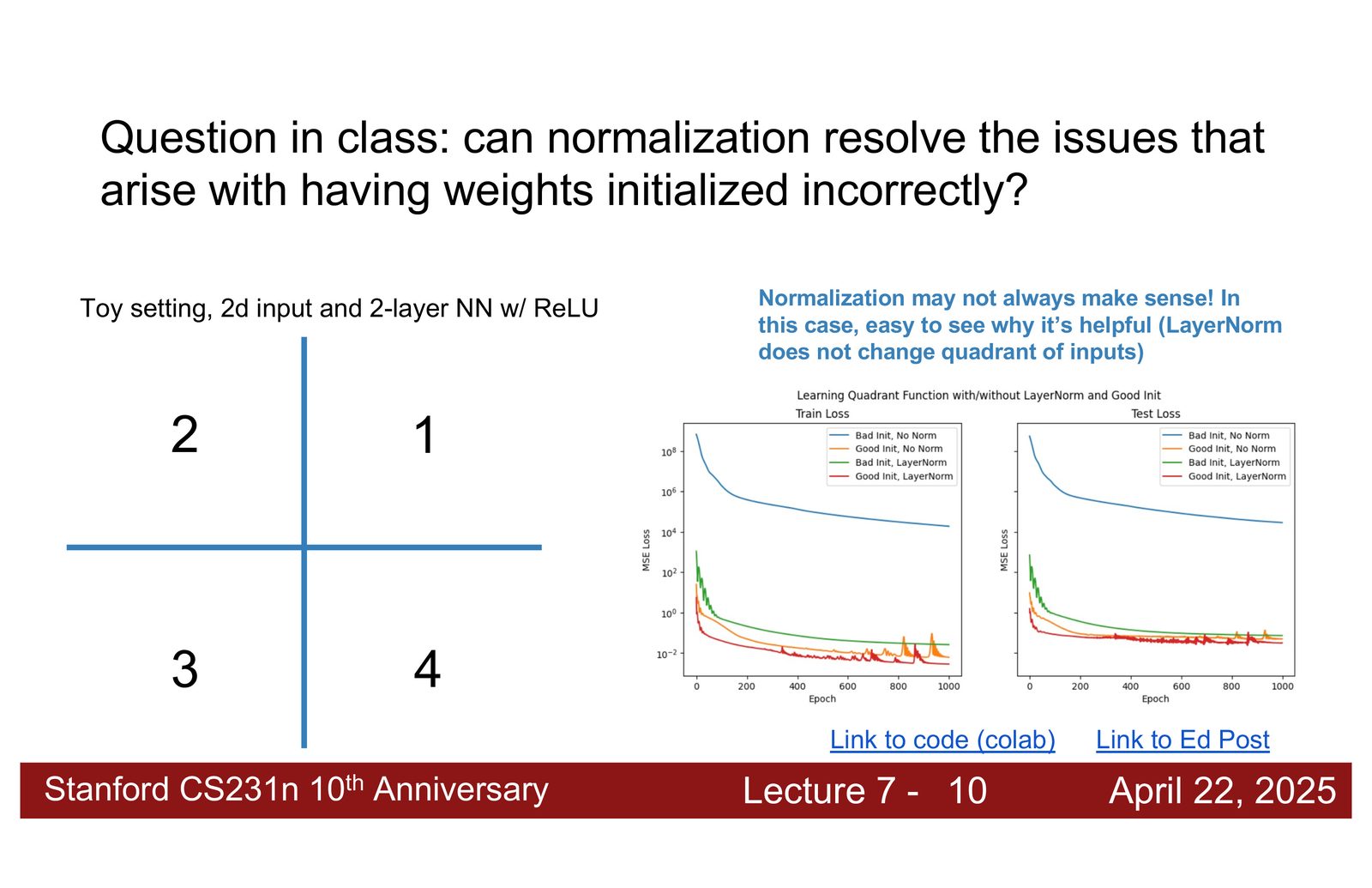
- Dropout 的缩放:超参数 \(p\) 在不同实现中可能表示丢弃概率或保留概率。核心原则是测试时的期望输出应与训练时一致——若训练时丢弃 25% 的激活值,测试时需乘以 0.75 进行缩放。
- Layer Normalization 与权重初始化:Layer Norm 可以缓解不良初始化带来的问题,但无法完全替代良好的权重初始化。在某些需要精确空间信息的任务中,Layer Norm 可能反而损害性能。
本章小结
神经网络不再局限于固定大小的输入输出。通过引入序列建模,我们能够处理语言、视频、对话等变长数据。RNN 正是为这类任务设计的核心架构。
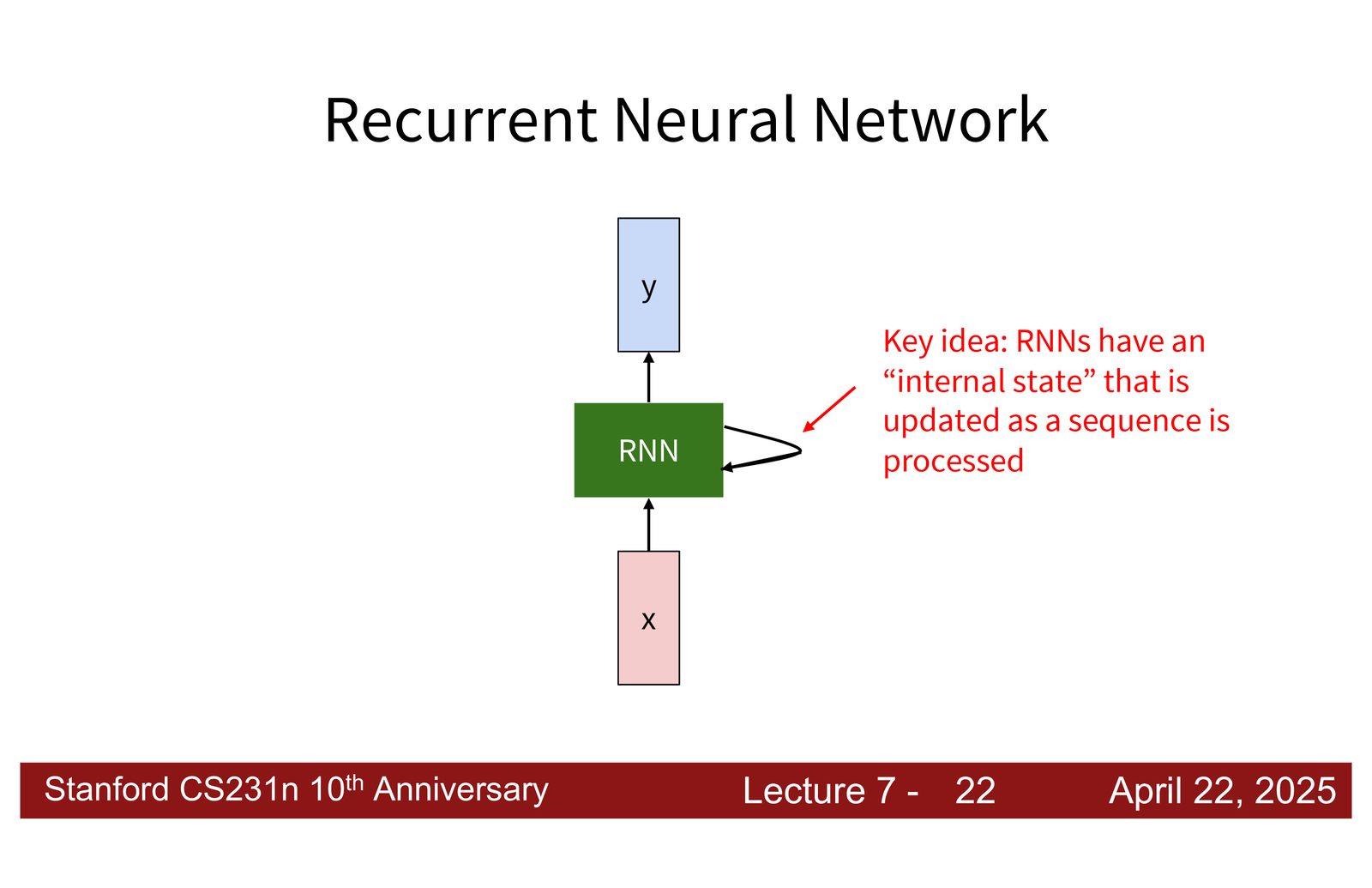
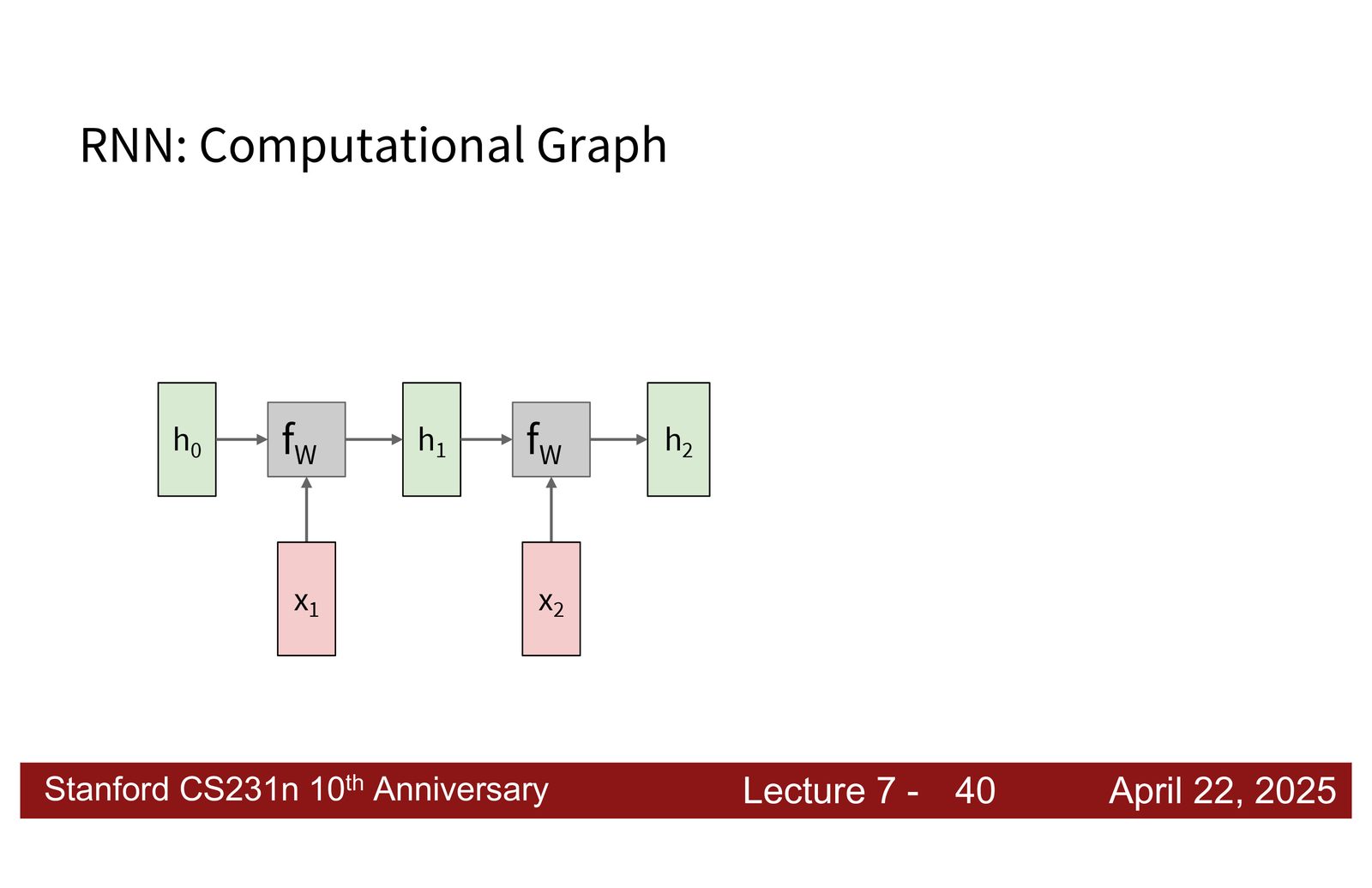
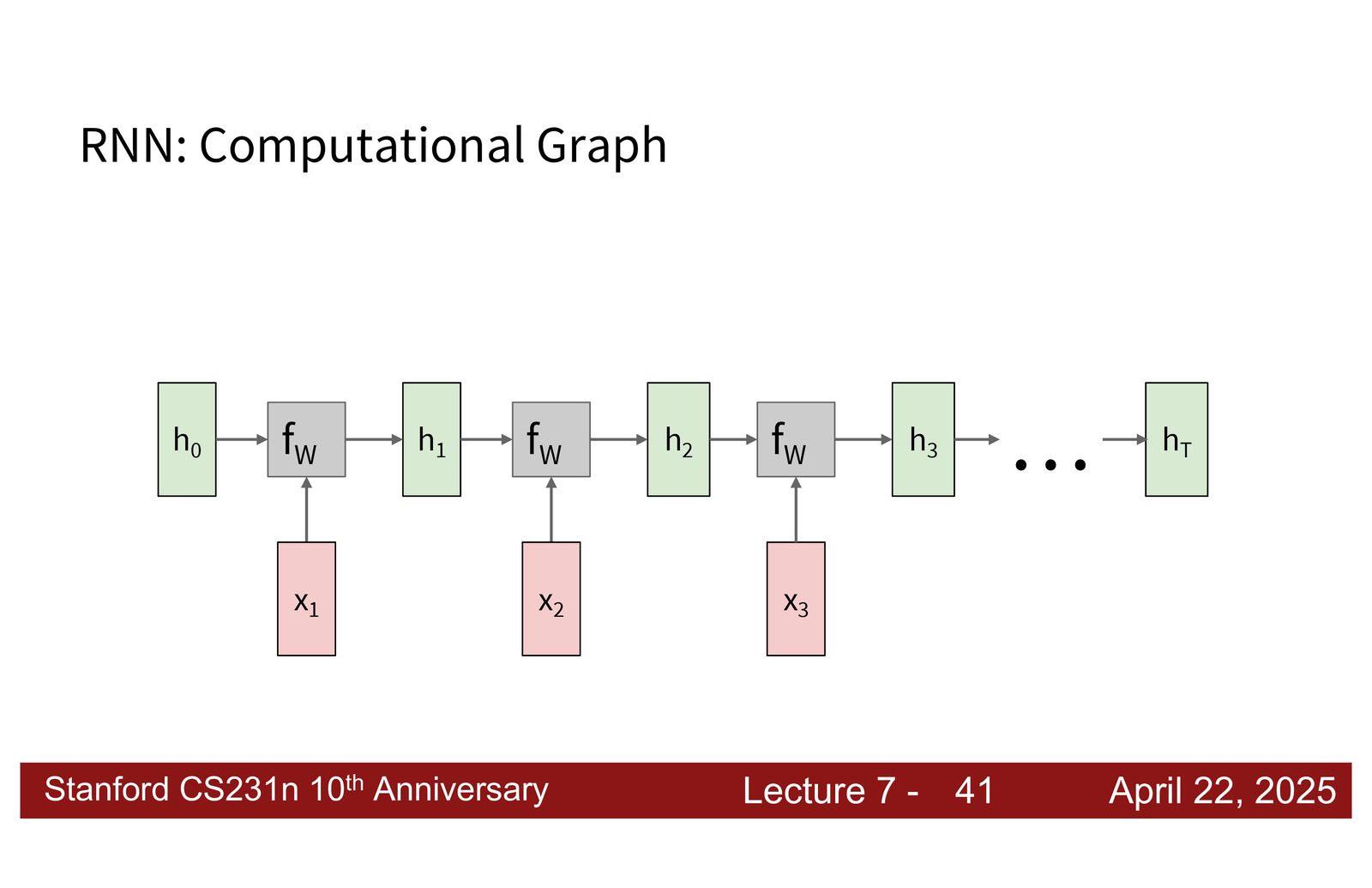
循环神经网络基础
RNN 的核心思想
RNN 的核心特征是引入了一个隐藏状态(hidden state),该状态在处理序列时不断更新。每接收一个新输入,RNN 都会基于当前输入和上一步的隐藏状态,计算新的隐藏状态。
来源:Slides 第7页。
RNN 的数学公式
RNN 在每个时间步 \(t\) 执行以下计算:
隐藏状态更新:
输出计算:
其中:
- \(h_t\):时间步 \(t\) 的隐藏状态向量
- \(x_t\):时间步 \(t\) 的输入向量
- \(f_W\):带参数 \(W\) 的状态转移函数(每个时间步共享相同的参数)
- \(f_Y\):将隐藏状态映射到输出的函数
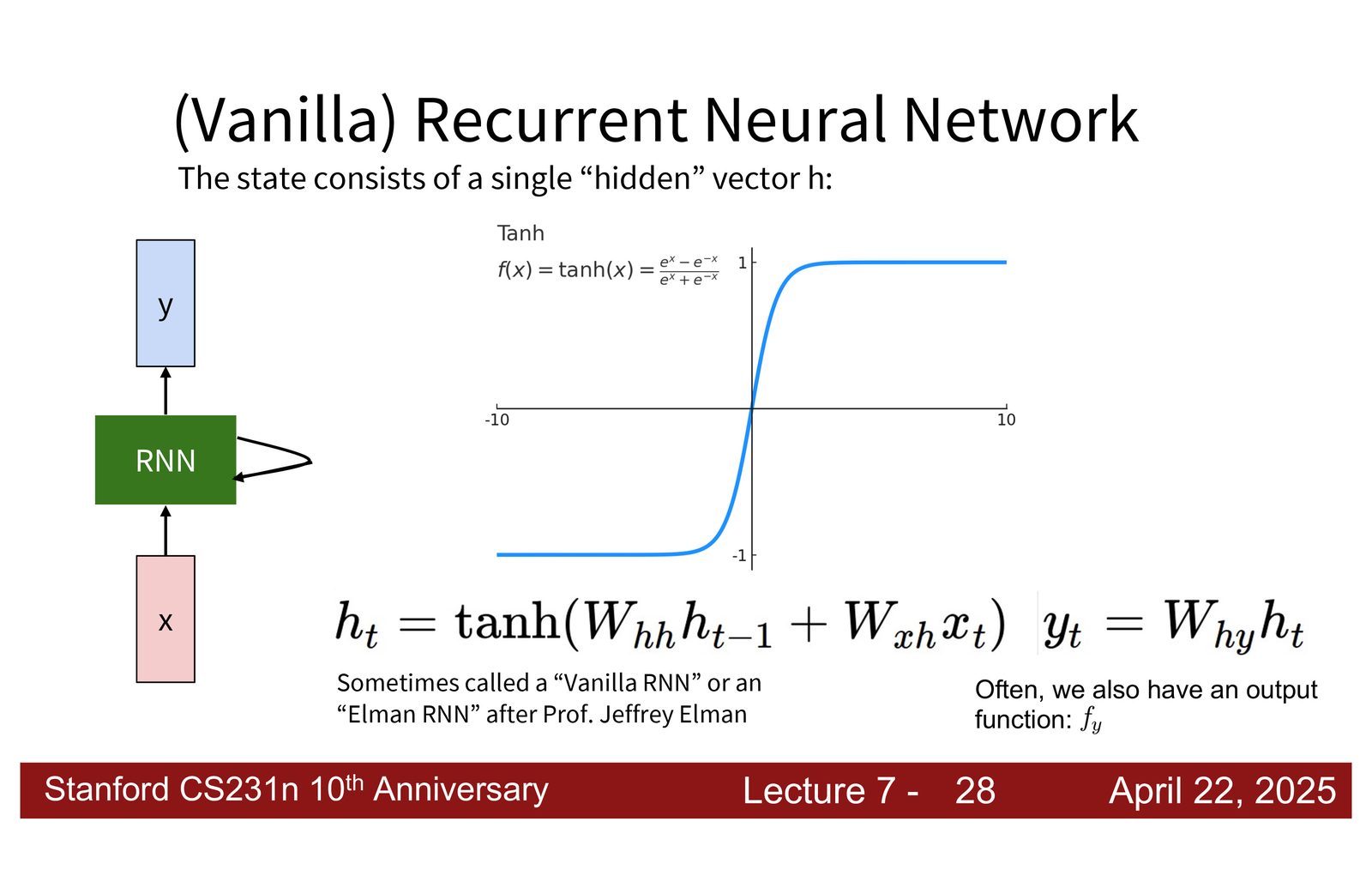
Vanilla RNN 的具体形式
最常见的 RNN 形式(称为 Vanilla RNN)使用 \(\tanh\) 作为激活函数:
来源:Slides 第10页。
为什么使用 激活函数
\(\tanh\) 的输出范围为 \([-1, 1]\),具有以下优势:
- 有界性:反复应用不会导致隐藏状态爆炸
- 零中心:能表示正负值,比 sigmoid 更适合作为隐藏状态的激活函数
- 非线性:提供必要的表达能力
但 \(\tanh\) 的导数最大值为 1(在 \(x=0\) 处),这意味着梯度在反向传播时几乎总是在衰减——这是导致梯度消失的重要原因之一。
三组权重矩阵
RNN 中有三组关键的权重矩阵:
| 权重矩阵 | 作用 | 维度 |
|---|---|---|
| \(W_xh\) | 将输入 \(x_t\) 变换到隐藏状态维度 | \(d_h × d_x\) |
| \(W_hh\) | 将上一步隐藏状态变换为当前步的贡献 | \(d_h × d_h\) |
| \(W_hy\) | 将隐藏状态映射到输出 | \(d_y × d_h\) |
所有时间步共享同一组权重
RNN 在每个时间步使用完全相同的权重矩阵 \(W_{hh}\)、\(W_{xh}\)、\(W_{hy}\)。这意味着:
- 模型大小不随序列长度增长
- 梯度计算时需要将各时间步的梯度累加
- 模型对序列中不同位置施加相同的变换规则
本章小结
RNN 通过引入隐藏状态和参数共享的循环结构,实现了对变长序列的建模。其核心计算包含两个矩阵乘法(输入到隐藏、隐藏到隐藏)加一个非线性激活函数,以及一个从隐藏状态到输出的线性映射。
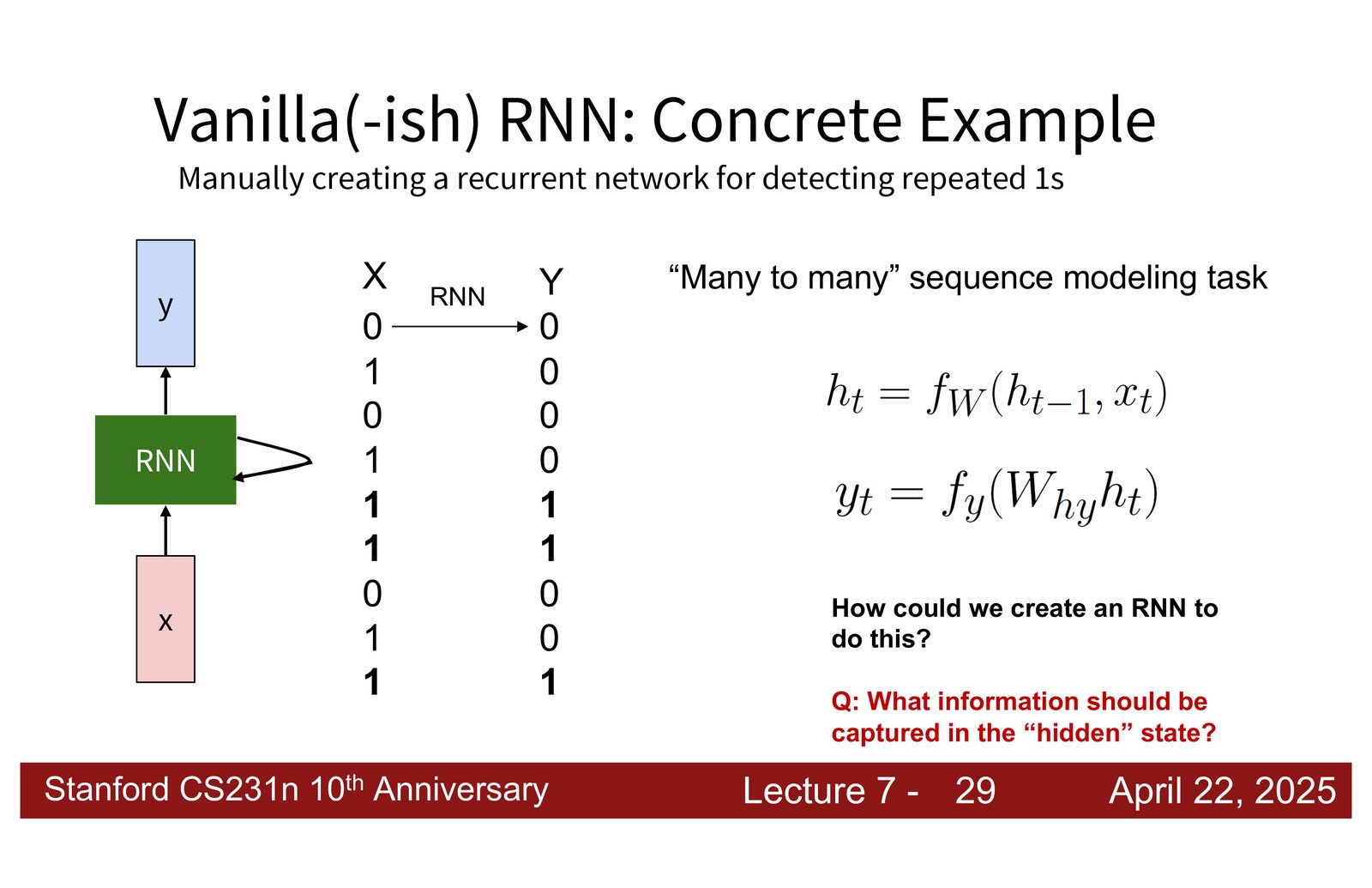
手工构造 RNN:一个玩具示例
为了深入理解 RNN 的前向传播过程,讲者通过一个手工设计的玩具示例,展示了如何构造权重矩阵来实现特定功能。
任务定义
目标:给定一个 0 和 1 的序列,当连续出现两个 1 时输出 1,否则输出 0。
![玩具示例任务:检测连续的两个 1。输入序列 \([0,1,0,1,1,1,0,1]\),对应输出 \([0,0,0,0,1,1,0,0]\)](slides-images/slide-011.jpg)
来源:Slides 第12页。
隐藏状态设计
为了完成这个任务,隐藏状态需要记录两条信息:当前输入值和上一步的输入值。讲者将隐藏状态设计为三维向量 \(h_t = [\text{current}, \text{previous}, 1]^T\),其中第三个维度固定为 1(用于输出阶段的偏置计算)。

来源:Slides 第13页。
权重矩阵构造
输入权重 \(W_{xh}\):
当 \(x_t = 1\) 时,\(W_{xh} x_t = [1, 0, 0]^T\)(记录当前值为 1);当 \(x_t = 0\) 时,结果为零向量。
隐藏状态权重 \(W_{hh}\):
- 第一行全零:当前值完全由 \(W_{xh} x_t\) 决定
- 第二行 \([1,0,0]\):将上一步的“当前值”复制为这一步的“前一步值”
- 第三行 \([0,0,1]\):保持常数 1 不变
输出权重 \(W_{hy}\):
输出 \(y_t = \text{ReLU}(W_{hy} h_t) = \text{ReLU}(\text{current} + \text{previous} - 1)\)。只有当 current \(= 1\) 且 previous \(= 1\) 时,\(y_t = 1\)。
来源:Slides 第16页。
从手工构造到梯度学习
这个玩具示例的目的是帮助理解 RNN 的计算过程。在实际应用中:
- 我们不需要手工设计权重矩阵——通过梯度下降自动学习
- 隐藏状态的维度通常远大于 3(可以是数百到数千维)
- 隐藏状态中学到的“特征”往往是高度抽象且不易解释的
本章小结
通过手工构造 RNN 的权重矩阵,我们直观地看到了 RNN 如何通过隐藏状态在时间步之间传递信息。两组权重矩阵分别负责“处理当前输入”和“继承历史信息”,它们的加和经过激活函数后形成新的隐藏状态。
RNN 的训练:时间反向传播
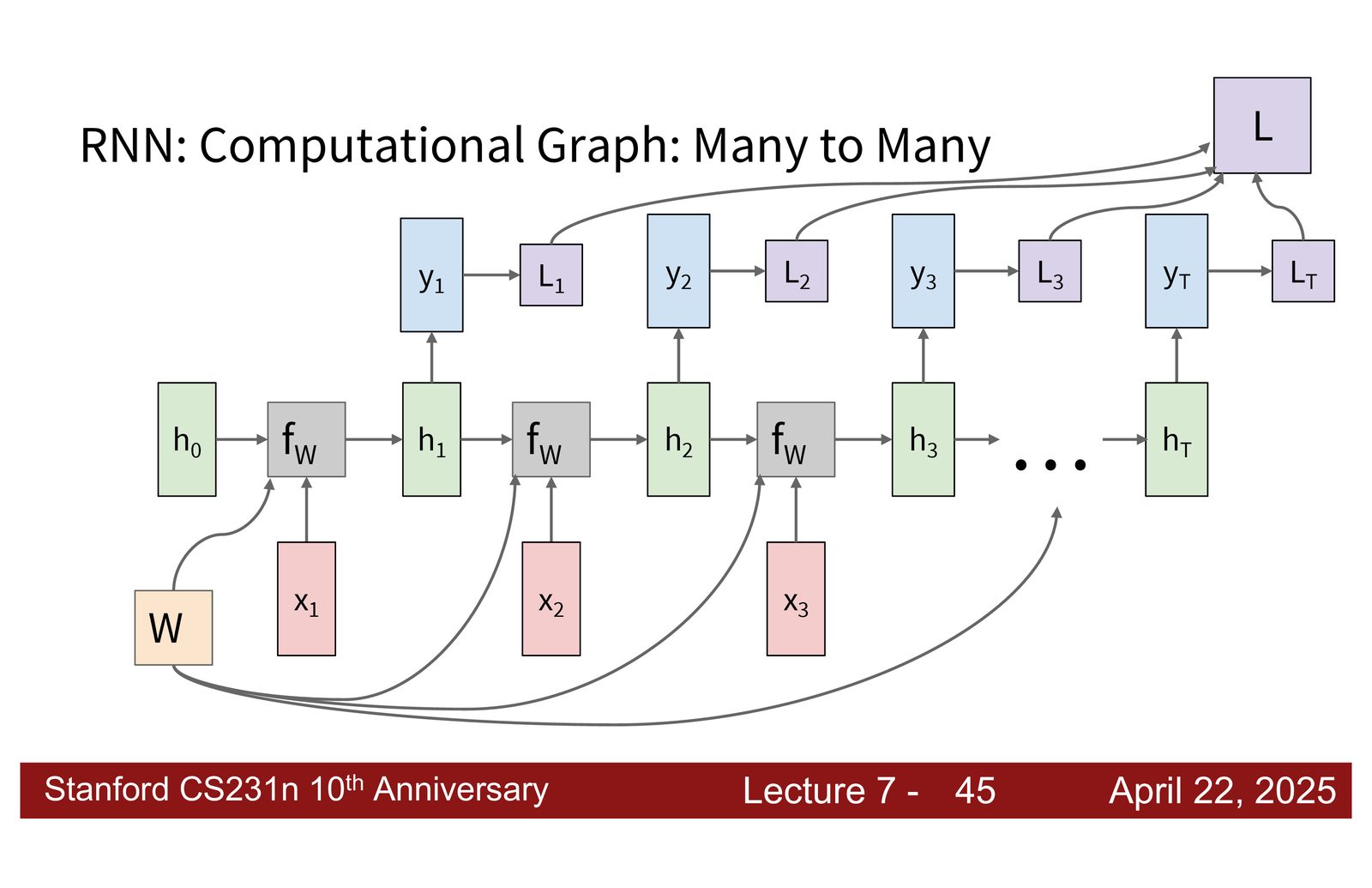
计算图与损失函数
在 many-to-many 设置中,RNN 在每个时间步都产生输出并计算损失。总损失为各时间步损失之和:
来源:Slides 第18页。
时间反向传播(BPTT)
由于所有时间步共享相同的权重矩阵 \(W\),计算 \(\frac{\partial L}{\partial W}\) 时需要:
- 分别计算每个时间步对 \(W\) 的梯度贡献
- 将所有时间步的梯度累加
这个过程称为Backpropagation Through Time (BPTT)。可以将其理解为:在概念上将 \(W\) 视为每个时间步使用了不同的“副本”,分别计算各副本的梯度,最后因为它们实际上是同一个 \(W\) 而将梯度求和。
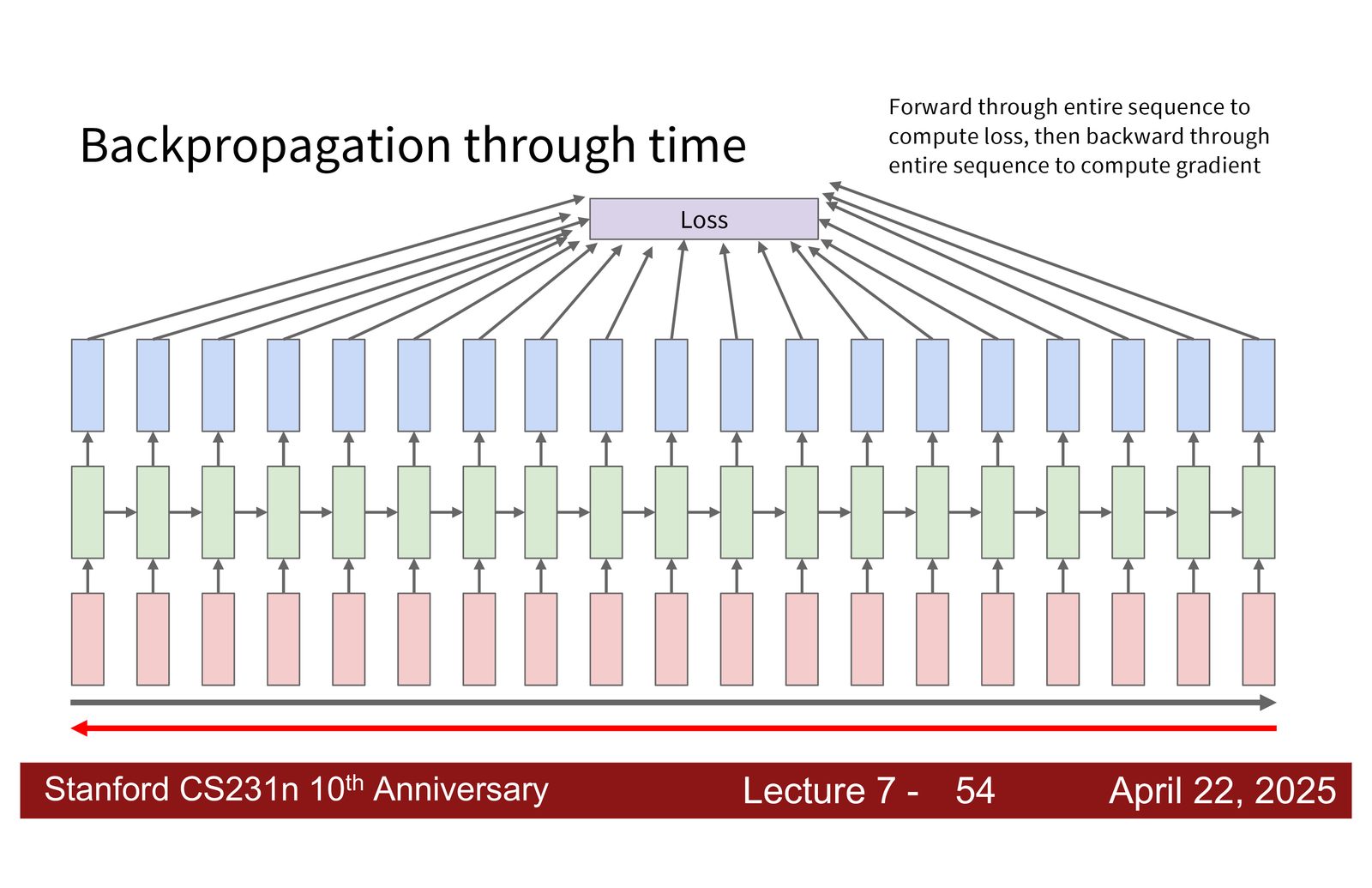
BPTT 的内存问题
对于长序列,BPTT 需要在内存中保存所有时间步的激活值和梯度。这会导致 GPU 内存迅速耗尽。
来源:Slides 第20页。
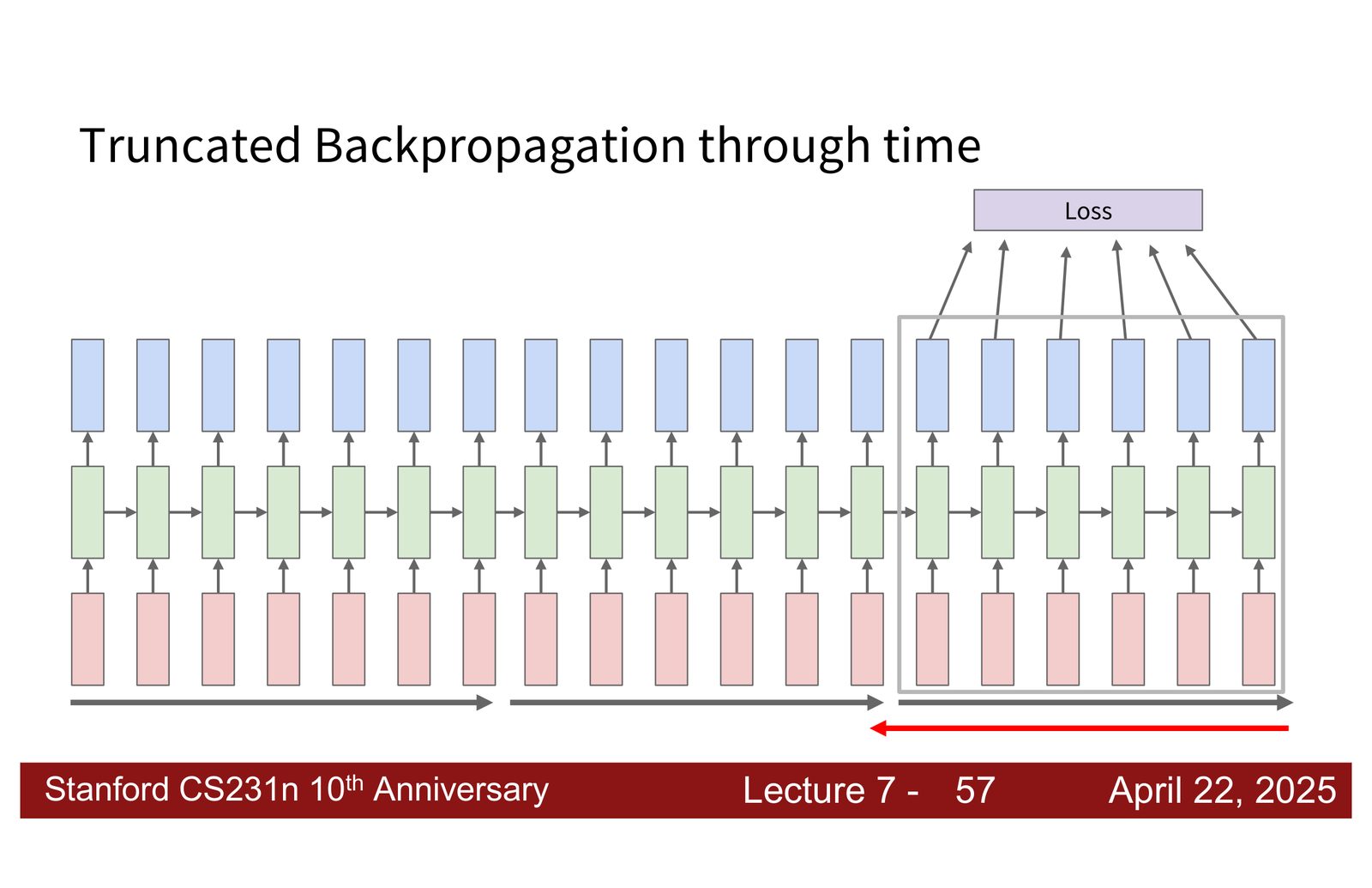
截断 BPTT
解决方案:将长序列分割为固定长度的“块”(chunk),在每个块内独立执行前向传播和反向传播。
来源:Slides 第21页。
具体流程:
- 处理第一个块:从 \(h_0\) 开始,计算隐藏状态和损失,执行反向传播,更新权重
- 处理第二个块:用第一个块的最终隐藏状态作为起始 \(h_0\),但不传播梯度
- 重复直到序列结束
截断 BPTT 的信息损失
截断 BPTT 是一种近似方法:
- 前向传播:隐藏状态在块之间传递,信息得以保留
- 反向传播:梯度在块边界被截断,长距离依赖的梯度信号会丢失
在 many-to-many 设置中,信息损失更为明显,因为每个块只看到局部的损失。理想情况下当然是将整个序列放入内存一次性计算,但这对长序列不可行。
本章小结
RNN 的训练通过 BPTT 实现,本质上是在展开的计算图上执行标准反向传播。截断 BPTT 通过将序列分块来控制内存消耗,但代价是丢失了跨块的梯度信息。
字符级语言模型
自回归生成
RNN 可以训练为字符级语言模型:给定前面的字符,预测下一个字符。这本质上是一个逐时间步的分类问题。

来源:Slides 第23页。
语言模型的训练与推理
训练时:
- 输入真实序列,目标是下一个字符
- 每个时间步计算交叉熵损失
- 无需人工标注——文本本身就是监督信号(自监督学习)
推理时(生成):
- 给定一个起始字符(或起始 token)
- 从输出概率分布中采样一个字符
- 将采样结果作为下一步的输入
- 重复直到生成结束 token 或达到最大长度
Embedding 层
在实际实现中,通常不直接使用 one-hot 编码作为输入,而是使用Embedding 层:一个可学习的查找表,将每个离散 token 映射为一个稠密向量。
One-hot vs Embedding
- One-hot:稀疏、高维(维度 = 词表大小),不包含语义信息
- Embedding:稠密、低维(通常 64--512 维),通过训练自动学习语义关系
- 数学上,用 one-hot 向量做矩阵乘法等价于从 Embedding 矩阵中取出对应行
- Embedding 在优化上更高效,且能学到有意义的表示
采样策略
贪心解码的问题
如果每次都选择概率最大的字符(贪心解码),模型会反复生成相同的序列。实际做法是:
- 随机采样:按概率分布采样
- 温度调节:\(p_i = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}}\),温度 \(T\) 控制分布的“尖锐度”
- Beam Search:同时维护多个候选序列,选择整体概率最高的
- Top-k / Top-p 采样:只从概率最高的 \(k\) 个(或累积概率达到 \(p\) 的)token 中采样
生成效果展示
用仅 112 行 Python 代码实现的字符级 RNN,训练在莎士比亚十四行诗上,可以生成风格相似的文本。随着训练的进行,生成质量逐步提升:
来源:Slides 第26页。
来源:Slides 第27页。
这正是当今大语言模型的雏形——从字符级预测发展到 token 级预测,从 RNN 发展到 Transformer,但自回归预测下一个 token 的核心思想始终未变。
本章小结
字符级语言模型展示了 RNN 在文本生成方面的潜力。其核心思想——自回归地预测下一个 token——直接启发了现代大语言模型的设计。从 Karpathy 2015 年的“The Unreasonable Effectiveness of Recurrent Neural Networks”到 GPT 系列,这一范式延续至今。
RNN 隐藏状态的可解释性
RNN 的一个有趣特性是,我们可以直接观察隐藏状态中各个神经元的激活值,并发现其中一些具有高度可解释的语义。
![RNN 隐藏状态可视化:使用 激活函数,值域为 \([-1, 1]\),红色表示接近 \(-1\),蓝色表示接近 \(+1\)](slides-images/slide-028.jpg)
来源:Slides 第29页。
讲者展示了在代码和文本数据上训练的 RNN 中发现的几种可解释的隐藏单元:

来源:Slides 第30页。

来源:Slides 第31页。

来源:Slides 第32页。

来源:Slides 第34页。
RNN 的自发特征学习
这些可解释的隐藏单元从未被明确设计或监督——它们完全是模型在训练过程中自发学会的。这与我们手工构造的玩具 RNN 形成了有趣的对比:
- 玩具示例中,我们手动指定隐藏状态追踪“当前值”和“前一步值”
- 训练好的 RNN 自动学会追踪引号状态、代码深度等更复杂的概念
- 但并非所有隐藏单元都可解释——大部分单元的激活模式看起来是随机的
本章小结
RNN 隐藏状态中的某些神经元能够自发地学习到有意义的特征,如引号追踪、行长度计数、代码嵌套深度等。这种可解释性是 RNN 架构的一个独特优势。
RNN 的优势与局限
优势

来源:Slides 第35页。
- 可处理任意长度的输入:没有上下文长度限制(与 Transformer 形成对比)
- 理论上可利用任意远的历史信息:如果隐藏状态有效地编码了历史,计算可以依赖很久以前的输入
- 模型大小不随输入长度增长:参数数量固定,只由隐藏状态维度决定
- 每个时间步应用相同的变换:对称性和概念简洁性
局限
- 训练时难以并行化:计算 \(h_t\) 必须先计算 \(h_{t-1}\),这是一个严格的顺序依赖
- 实际上难以访问远距离信息:固定大小的隐藏状态无法无损地编码任意长的历史
- 梯度消失/爆炸:长序列的反向传播中,梯度会指数级衰减或增长
训练的不可并行性是 RNN 的致命弱点
现代深度学习的成功很大程度上依赖于 GPU 的大规模并行计算能力。RNN 的顺序依赖结构使得它无法充分利用 GPU 的并行性——这正是 Transformer 最终取代 RNN 的核心原因之一。在训练时,Transformer 可以同时处理序列中的所有位置,而 RNN 必须逐步计算。
本章小结
RNN 在理论上具有处理无限长序列的能力,但在实践中受到训练效率(不可并行)和梯度流动(消失/爆炸)的严重限制。这些局限性推动了 LSTM、GRU 以及最终 Transformer 的诞生。
RNN 在计算机视觉中的应用
图像描述生成(Image Captioning)
最经典的 CNN + RNN 应用是图像描述生成:用 CNN 提取图像特征,用 RNN 生成自然语言描述。
来源:Slides 第38页。
来源:Slides 第39页。
来源:Slides 第41页。
共现偏置与幻觉
早期的图像描述模型存在严重的共现偏置问题:
- 看到海滩就假设有冲浪板
- 看到手持物体就猜测是常见搭配
- 看到棒球运动就默认是“投球”而非“接球”
这种幻觉(hallucination)问题在今天的视觉语言模型中依然普遍存在。其根源在于模型学习了训练数据中的统计关联,而非真正理解场景内容。
视觉问答(Visual Question Answering)
来源:Slides 第43页。
其他应用
RNN 在计算机视觉中的其他应用包括:
- 视觉对话(Visual Dialogue):围绕图像进行多轮对话
- 视觉导航(Visual Navigation):根据视觉输入生成移动指令序列
本章小结
RNN 与 CNN 的结合开创了视觉-语言多模态模型的先河。尽管这些方法已被 Transformer 基础的模型所取代,但 CNN+RNN 的架构思想——将视觉编码器与序列生成器组合——在今天的视觉语言模型(如 LLaVA、GPT-4V)中以不同形式延续。
多层 RNN
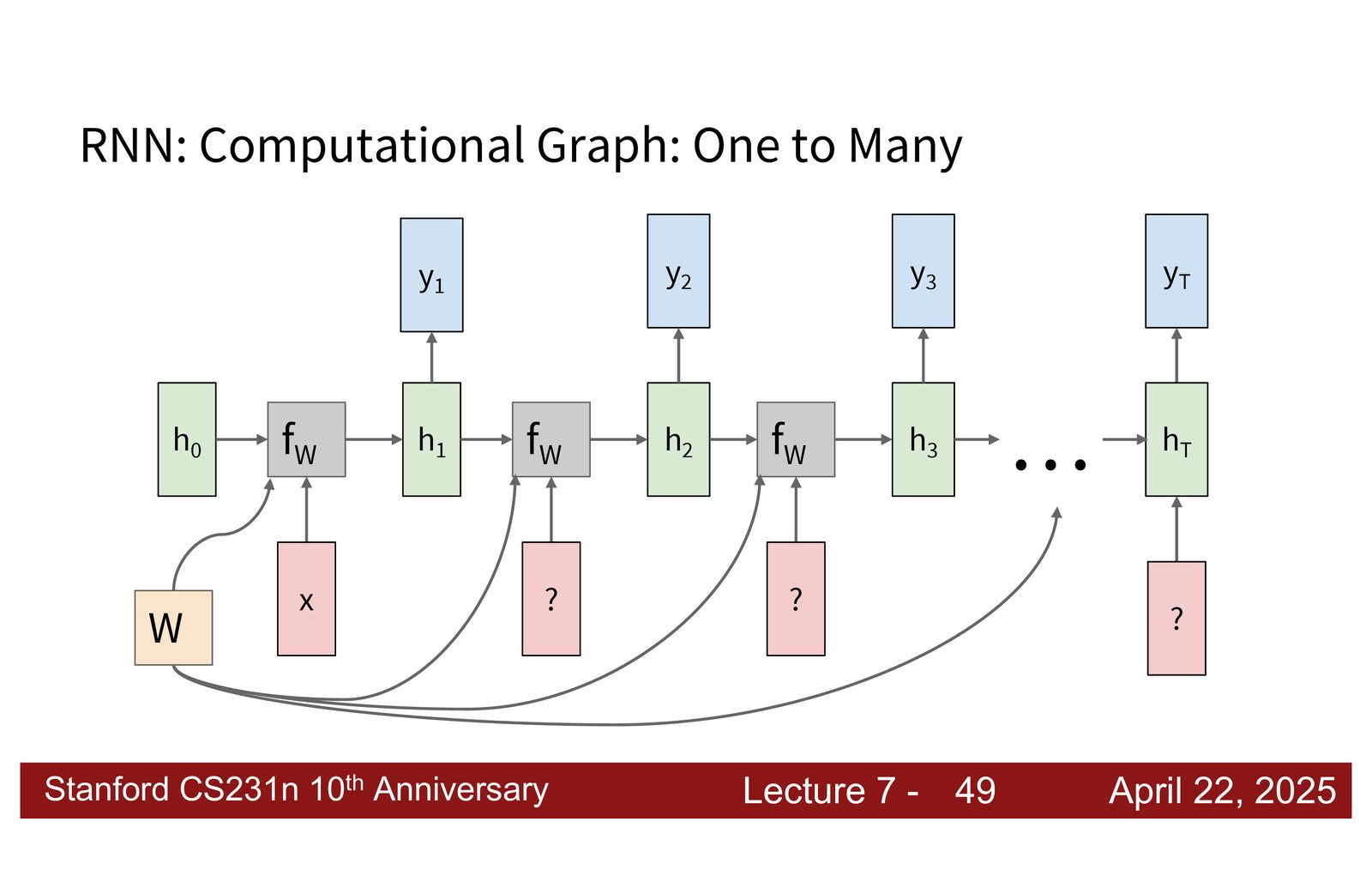
来源:Slides 第47页。
多层 RNN 的组织方式如下:
- 层内:同一层的所有时间步共享权重,隐藏状态沿时间维度传递
- 层间:第 \(l\) 层的输出作为第 \(l+1\) 层的输入
- 每一层有独立的权重矩阵
这形成了一个二维的计算网格(时间 \(\times\) 深度),进一步加剧了训练时的计算瓶颈。
本章小结
多层 RNN 通过堆叠 RNN 层来增加模型的表达能力,但也使得计算图更加复杂,训练更加困难。
梯度消失/爆炸与 LSTM
梯度消失问题的根源
反向传播中,隐藏状态之间的梯度为:
这个乘积在时间步之间反复累乘,导致:
来源:Slides 第49页。
梯度消失/爆炸的数学分析
- \(\tanh\) 导数:\(\tanh'(x) \in [0, 1]\),只有在 \(x = 0\) 时取最大值 1。多次乘以小于 1 的值 \(\rightarrow\) 指数衰减(梯度消失)。
-
\(W_{hh}\) 的奇异值:
-
最大奇异值 \(\sigma_{\max} > 1\):梯度爆炸
- 最大奇异值 \(\sigma_{\max} < 1\):梯度消失
梯度爆炸可以通过梯度裁剪(gradient clipping)解决:当梯度范数超过阈值时进行缩放。但梯度消失更加棘手——这正是 LSTM 要解决的问题。
LSTM 的核心思想
LSTM(Long Short-Term Memory)通过引入门控机制和细胞状态(cell state)来缓解梯度消失问题。
来源:Slides 第50页。
LSTM 的四个门:
- Gate Gate(候选值):计算要写入的候选信息 \(\tilde{c}_t = \tanh(W_g [h_{t-1}, x_t])\)
- Input Gate:决定是否写入 \(i_t = \sigma(W_i [h_{t-1}, x_t])\)
- Forget Gate:决定遗忘多少历史信息 \(f_t = \sigma(W_f [h_{t-1}, x_t])\)
- Output Gate:决定输出多少 \(o_t = \sigma(W_o [h_{t-1}, x_t])\)
细胞状态更新:\(c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t\)
隐藏状态输出:\(h_t = o_t \odot \tanh(c_t)\)
LSTM 解决梯度消失的关键:Cell State Highway
细胞状态 \(c_t\) 的更新路径(图中顶部通道)不经过 \(\tanh\) 激活函数,只涉及逐元素乘法(forget gate)和加法(input gate)。这意味着:
- 只要 forget gate 不为零,梯度就能相对无损地沿时间反向传播
- 类似于 ResNet 中的跳跃连接——提供了梯度的“高速公路”
- LSTM 并不保证解决梯度消失,但使得模型更容易学习长距离依赖
LSTM 与 ResNet 的联系
来源:Slides 第52页。
跳跃连接的普适原理
ResNet 和 LSTM 解决的问题在本质上是相同的:
- ResNet:随着网络深度增加,梯度消失使得深层难以训练 \(\rightarrow\) 引入跳跃连接
- LSTM:随着序列长度增加,梯度消失使得远距离信息难以利用 \(\rightarrow\) 引入 cell state highway
核心思想是一致的:提供一条不经过非线性变换的“直达路径”,让信息和梯度能够更自由地流动。
GRU 简介
GRU(Gated Recurrent Unit)是 LSTM 的一个简化变体,将 forget gate 和 input gate 合并为一个 update gate,减少了参数量,同时保持了类似的性能。
本章小结
梯度消失是 Vanilla RNN 难以处理长序列的根本原因。LSTM 通过引入门控机制和无激活函数的 cell state 通道来缓解这一问题。这与 ResNet 中的跳跃连接异曲同工——都通过提供梯度“高速公路”来改善深层/长距离的训练。
现代回归:状态空间模型
RNN 思想的复兴
尽管 Transformer 在过去几年统治了深度学习,但 RNN 的核心思想正在以状态空间模型(State Space Models, SSMs)的形式回归。
来源:Slides 第53页。
状态空间模型相比 Transformer 的关键优势:
- 无限上下文长度:像 RNN 一样,没有固定的上下文窗口限制
- 线性时间推理:计算量与序列长度成线性关系,而非 Transformer 的二次方
- 固定内存占用:推理时只需维护固定大小的状态,不需要 KV cache 的线性增长
RNN vs Transformer 的核心权衡
- Transformer:训练可并行(快),推理时 KV cache 随序列增长(慢),\(O(n^2)\) 注意力开销
- RNN/SSM:训练难以并行(慢),推理时固定状态(快),\(O(n)\) 线性开销
- 当前研究热点:如何兼得两者优势——训练时的并行性 + 推理时的效率
本章小结
以 Mamba 和 RWKV 为代表的状态空间模型正在挑战 Transformer 的统治地位,特别是在长上下文场景中。RNN 的核心概念——循环状态更新、线性时间推理——正以更现代的形式焕发新生。
拓展阅读
- Andrej Karpathy: The Unreasonable Effectiveness of Recurrent Neural Networks, 2015 http://karpathy.github.io/2015/05/21/rnn-effectiveness/
- Hochreiter & Schmidhuber: Long Short-Term Memory, Neural Computation, 1997
- Gu & Dao: Mamba: Linear-Time Sequence Modeling with Selective State Spaces, 2023 https://arxiv.org/abs/2312.00752
- Peng et al.: RWKV: Reinventing RNNs for the Transformer Era, 2023 https://arxiv.org/abs/2305.13048
总结与延伸
讲者的核心总结
Zane Durante 在课程结尾总结了三个要点:
- Vanilla RNN 概念简洁但性能有限
- LSTM 等变体通过门控机制选择性传递信息,缓解了梯度消失问题
- RNN 的核心思想(循环状态、线性复杂度)正在通过状态空间模型回归研究前沿
全课知识图谱

关键 Takeaways
五条核心原则
- 隐藏状态是 RNN 的灵魂:它在时间步之间传递信息,编码序列的“记忆”
- 参数共享使模型泛化:所有时间步共享权重,使 RNN 能处理任意长度的输入
- 梯度消失是长序列的天敌:\(\tanh\) 和权重矩阵的反复累乘导致远距离梯度信号衰减
- LSTM 的 cell state 是解药:无激活函数的直通路径,类似 ResNet 的跳跃连接
- RNN 并未过时:状态空间模型正在以线性复杂度挑战 Transformer 的二次方开销