CS224R Lecture 5: Off-Policy Actor-Critic
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于公开课程资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年春季 |
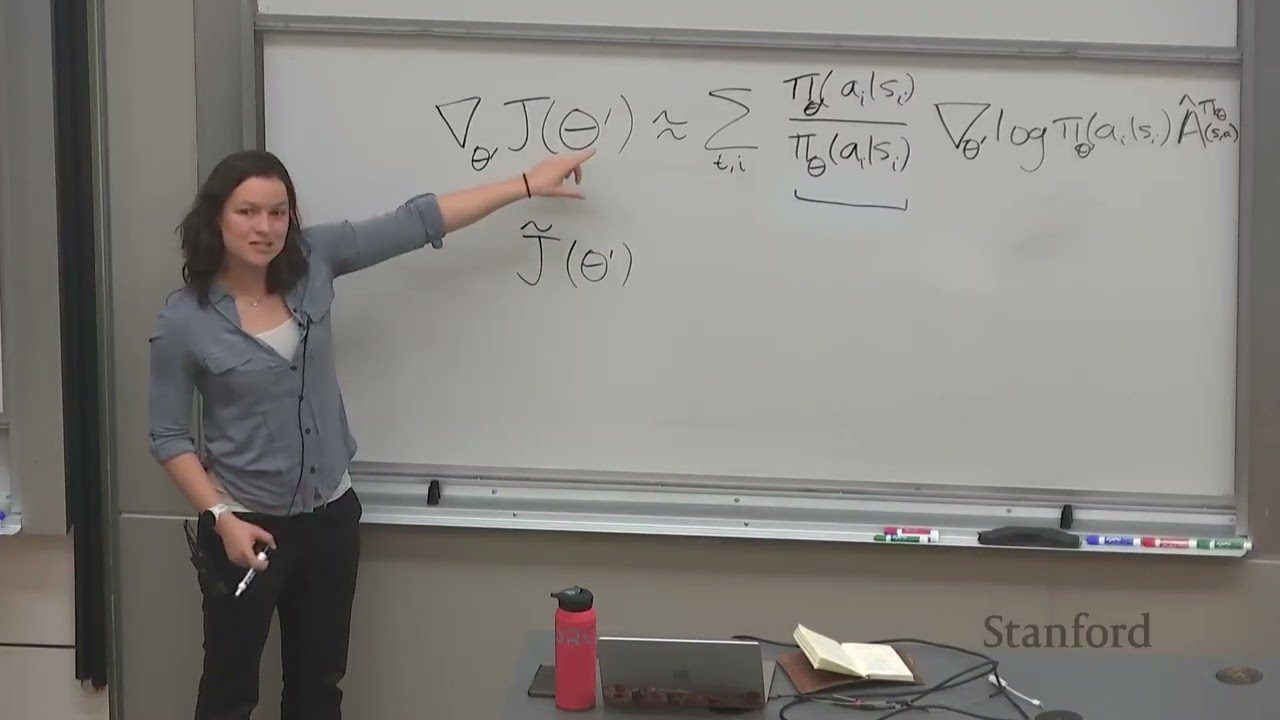
多步梯度更新的问题
On-policy actor-critic 每收集一批数据只能做一步梯度更新,效率很低。我们希望在同一批数据上做多步更新。
Importance Weights 回顾
用旧策略 \(\pi_\theta\) 的数据来更新新策略 \(\pi_{\theta'}\) 时,需要 importance weights:
多步更新的风险
如果对代理目标函数(surrogate objective)做很多步梯度上升,策略会被激励大幅偏离旧策略。此时 importance weights 不再可靠,优势估计也失效,导致过拟合和性能崩塌。
本章小结
多步梯度更新能提高数据效率,但需要约束策略更新的幅度来保持稳定性。
训练监控与日志体系
日志的结构化写法
复制整个训练过程的关键是详细的 logging schema。以下字段是最低要求:
step,episode,wall_time:定位发生问题的 sliceavg_return,std_return,kl_divergence,entropy:衡量 policy 未来趋势buffer_size,td_error_mean,td_error_std:Replay buffer 内部状态learning_rate,grad_norm,value_loss:诊断优化器与 value head
日志粒度与报警
高频 logging(每 1k step)结合 threshold-based alarms(KL > 0.06, return variance > 0.2)能在 divergence 发生前打断训练,特别是在 Sim2Real 环境中避免一次物理损坏。
指标面板
实时可视化 dashboard 通常至少包含:
- PPO ratio distribution histogram
- SAC entropy & Q-value curves
- Batch-wise advantage histogram to detect saturation
本章小结
结构化 logging 与实时 dashboard 能让研究者及时发现 divergence、explosion、overfitting 等 failure modes,从而更快复现核心表现。
Actor-Critic 数据流水线
采集、存储与分发
Actor-Critic 框架的数据流可以拆成四个阶段:采集(rollout)、存储(buffer)、处理(advantage estimation)、分发(learning step)。每个阶段都有陷阱。例如,采集阶段如果数据全部来自一条 deterministic policy,会产生 low diversity,导致 replay buffer 中出现大量 near-duplicate transitions,降低实际更新的有效样本数。
Rollout 与 buffer 的协同
为了保持采集多样性,通常采用 epsilon/entropy noise、随机策略混合等技巧;同时尽量避免把同一个轨迹重复写入 buffer,至少在 enqueue 时做 tenure check(记录 transition 被访问次数)。
优势估计与归因分配
优势估计(advantage estimation)是 Actor-Critic 的中心。常用的算法为 GAE(\(\lambda\)),它在 bias-variance 之间做 trade-off:
选择 \(\lambda=0.95\) 是常见的默认值,同时需要保持值函数 \(\hat{V}\) 的训练稳定,否则 advantage 的方差会暴涨。
本章小结
Actor-Critic 的数据流水线覆盖 rollout、buffer、advantage estimation、update step。每个环节都需要监控,以防剧烈偏移带来的 instability。
PPO:Proximal Policy Optimization
核心思想:限制策略偏移
两种策略:
方法 1:KL 约束
在 LLM 的偏好优化中非常常见。
方法 2:Clipping
不直接约束策略,而是裁剪 importance weights,移除策略大幅偏离的激励:
PPO 的核心目标
这就是 PPO 的最终 surrogate objective。通过 clipping 和 min 操作,策略不再有激励大幅偏离旧策略,即使做多步更新也能保持稳定。
PPO 完整算法
- 从当前策略 \(\pi_\theta\) 采集一批数据
- 拟合价值函数 \(\hat{V}^\pi_\phi\)
- 计算优势 \(\hat{A}^{\pi_\theta}\)
- 在这批数据上对 PPO objective 做多步梯度更新(约 3--10 步)
- 重复
本章小结
PPO 通过 clipping importance weights 来限制策略偏移,允许在同一批数据上做多步更新,是目前最广泛使用的 on-policy RL 算法之一。
SAC:Soft Actor-Critic
更彻底的 Off-Policy
PPO 仍然需要定期重新收集数据。SAC 走得更远:使用 replay buffer 存储所有历史数据,从中随机采样来更新 Q 函数和策略。
拟合 Q 函数
SAC 直接拟合 \(Q^\pi\) 而不是 \(V^\pi\),使用 TD 更新:
为什么 Q 函数可以用 off-policy 数据
Q 函数的 TD target \(r(s,a) + \gamma \mathbb{E}_{a' \sim \pi}\left[Q(s', a')\right]\) 中,\(a'\) 是从当前策略采样的(而不是从数据中读取的)。因此 \((s, a, s')\) 转移数据可以来自任何策略,只要 \(a'\) 是新采样的即可。
策略更新
策略优化目标加入了熵正则化:
熵项 \(-\alpha \log \pi_\theta\) 鼓励策略保持一定的随机性,有助于探索。
SAC 完整算法
- 用当前策略与环境交互,将转移 \((s, a, r, s')\) 存入 replay buffer \(\mathcal{B}\)
- 从 \(\mathcal{B}\) 采样 mini-batch
- 更新 Q 函数(用 TD target)
- 更新策略(最大化 Q + 熵)
- 重复步骤 1-4
PPO vs. SAC
- PPO:On-policy(加少量 off-policy),用 clipped surrogate objective。每次收集新数据后做几步更新。更稳定、更易调参。
- SAC:完全 off-policy,用 replay buffer + Q 函数。数据效率更高。适合连续动作空间。
两者都是目前最常用的深度 RL 算法。
本章小结
SAC 通过拟合 Q 函数并使用 replay buffer 实现了完全 off-policy 的 actor-critic 算法,数据效率远高于 on-policy 方法。熵正则化鼓励探索并提高稳定性。
Replay Buffer 管理与数据挑选
为何大小与采样策略关键
Replay buffer 提供多轮训练的数据,但它的设计直接影响性能。两个核心维度是容量和采样策略:
- 容量:太小会频繁覆盖旧样本而丢失多样性,太大则降低训练时效。实务中通常选择能存下数百万条 transition。
- 采样策略:均匀采样最简单,Prioritized Experience Replay 允许高 TD error 的 transition 更常被访问。
采样策略对效果的直接影响
High TD 文本的 transition 通常包含更难的决策或崩盘场景,优先返回它们可以让 Q 函数更快收敛;但如果优先级过度,可能造成估计偏差。通常的折衷是使用 \(\beta\) 衰减为 1 的 importance-sampling 权重来校正偏置。
清洗回放数据:过滤 vs. 补充
每当 agent 执行新策略,就应评估新采集数据的质量:
- 过滤:移除 reward 异常、超出边界的 transition(例如撞墙后得 reward 为 1),避免训练噪音;
- 补充:人为合成带有特定标签的 transition(例如 reward shaping、domain randomization)帮助 agent 学习罕见但关键的情境。
回放 buffer 的污染效应
如果 buffer 长期积累低质量数据(例如 policy 崩溃后的 exit transitions),模型可能会在错误的示例上继续优化。定期清空 buffer 7% 左右最低 reward 的样本并重新收集,可以避免“data poisoning”。
本章小结
Replay buffer 的容量、采样策略和数据清洗策略共同决定 off-policy 学习的稳定性。适度的优先级采样、IS 校正以及对异常 transition 的剔除/采样,可以避免模型在旧数据上过拟合或被噪音拖累。
超参调优与实验复现
常见超参数组合
在 CS224R 的实验中,Chelsea 和团队使用以下组合取得了稳定表现:
- PPO:clip \(\epsilon=0.1\)、batch size=64、learning rate=2e-4、value coeff=0.5、entropy coeff=0.01。
- SAC:Q learning rate=3e-4、policy learning rate=3e-4、replay buffer size=10e5、batch size=256、target smoothing coeff=0.005。
- Replay buffer:prioritized sampling weight \(\alpha=0.6\),importance sampling exponent \(\beta\) 从 0.4 线性增长到 1.0。
复现要点
对抗性地复现实验需要固定随机种子和 deterministic rollout。建议每次 run 记录
- seed、env name、max episode length
- optimizer state(Adam momenta)与 learning rate schedule
- buffer size、prioritization hyperparameters
种子敏感性
为防止偶发崩溃,必须在 logging 中包括每条 rollout 的 return、length、advantages 的 std。若 return variance 超出预期,应立即停止训练,排查是否 replay buffer 中充斥着 high-loss transitions。
本章小结
超参数配比与记录日志是实验重现的关键。固定 seed、记录 optimizer state、监控 variance 并设置自动中断阈值,能显著降低 long-tail failure 的出现概率。
策略安全与正则化
防止策略崩溃的 Regularization
无论是 PPO 还是 SAC,当策略更新过猛都会导致性能崩盘。实务中常用的 regularization 包括:
- KL penalty:在 objective 中加入 \(\lambda D_{\mathrm{KL}}(\pi_{\theta'}\|\pi_\theta)\),直接惩罚过大偏移。
- Entropy decay:在 SAC 中调节 \(\alpha\),让策略在训练后期逐步减少探索以收敛。
- Gradient clipping:限制梯度范数避免步长过大。
监控策略行为
推荐的监控指标:
- Average KL divergence between successive policies
- Episode variance of returns—high variance signals instability
- Q-value rollout test—simulate fixed rollout to check escalation
自动告警设计
设定门限(例如 KL > 0.05 时报错,episode std dev 增加 30% 时停止训练)可以让 pipeline 自动回退到 prior checkpoint。这种机制在 Walls-Free RL(Sim2Real)项目中广泛采用。
本章小结
安全调度需要 regularization 与监控指标结合。KL penalty、entropy decay、gradient clipping 是常见防过度偏移手段,而 KL、variance 和 Q-value rollout 监控提供实时风险预警。
Reward Shaping 与价值稳定
价值函数稳定的微调技巧
在 off-policy 更新中,Q 函数预测 drift 会严重影响 actor。实践中常见的 stabilizer 包括:
- Target smoothing:在 TD target 中使用 twin Q average + Polyak average smoothing coefficient \(\tau\)。
- Reward clipping:将 reward 限制在 \([-1,1]\),避免爆炸性 gradient。
- Value normalization:在 batch_level 对 Q 值做人口归一化,减少 scale drift。
Shaping 的设计原则
Reward shaping 需要遵从 potential-based shaping theorem,确保 shaping term 不改变最优策略:
其中 \(\Phi\) 是 potential function。一个实用的 \(\Phi(s)\) 例子是 distance-to-goal,提升 agent 在 early stages 的 guiding signal。
错误 shaping 的后果
若 shaping 直接奖励“接近目标”而非“完成任务”,agent 可能提前停留在潜在 reward 高的状态,造成 reward hacking。这就是为什么 potential-based shaping 需严格依据 MDP structure。
本章小结
Reward shaping 和 value stabilization 是保持 long-term training 稳定的核心。target smoothing、reward clipping 与 potential-based shaping 搭配使用可以有效避免 value explosion 与 reward hacking。
评估与部署建议
多维评估池
训练完成后不要仅仅依赖单个 benchmark,建议的 multi-evaluation pool 包括:
- Policy rollouts in multiple seeds and environments
- Stress tests with adversarial perturbations (e.g., shifted dynamics)
- Human-in-the-loop scoring for safety-critical behaviors
部署图谱
Deployment checklist:
- Validate ability to recover from buffer corruption / reset seeds
- Ensure logging of policy drift and extreme rewards
- Provide rollback snapshot and auto-stop when variance spikes
Sim2Real 的守则
在现实部署中,必须有 fallback policy(例如 script policy)以及 safety net monitors;同时 log policy decisions to enable post-hoc analysis—这一点对于医疗/航行应用尤为重要。
本章小结
评估应结合多样化 rollouts、adversarial stress tests 与人类打分。部署前建 checklist、snapshot 与 rollback 机制可避免生产环境的失控。
幻灯片精华
核心概念图
PPO vs SAC 结构对比
Q 函数稳定性案例
Replay Buffer 与 Sim2Real
策略蒸馏流程图
性能雷达
PDF 图示资源
Slide 展示 PPO/SAC 在不同维度(data efficiency, stability, deployment cost)上的 radar chart。
模拟-真实迁移示意
训练与部署工作流
调试与日志示例
Overfit 与 Regularization 诊断
使用 entropy 进行监控
部署后的长期监控
本章小结
幻灯片中的可视化帮助总结 actor-critic 数据流、PPO/SAC 的权衡、Q function 的平滑处理与回放架构在 Sim2Real 中的应用,为后续工程提供直观参考。
案例对比与设计模式
PPO / SAC 在不同任务上的表现
在多项 benchmark 中的规律如下:
- 低维离散 env(CartPole、Acrobot):PPO 足以胜任,SAC 的 entropy 可能导致高 exploration variance。
- 高维连续 env(Humanoid、Walker2D):SAC 更稳定,SAC + twin Q networks for target smoothing 避免 Q divergence。
- 分布转移场景(Sim2Real):Replay buffer + prioritized sampling + policy bootstrap layer 是关键,SAC 的 off-policy 特性更具优势。
混合方案
在 Sim2Real or offline RL 场景下,常见做法是先用 SAC 收敛 policy,再用 PPO 重新 fine-tune 以满足 safety constraints(PPO 提供切实的 clipping guardrails)。
工程设计模式
两个常见模式:
- Dual Agent Pattern:PPO policy + SAC policy 并行训练,training job 根据 metrics 自动选择更稳定的版本部署。
- Safety Gate Pattern:在 deployment path 前置一个 rule-based gate(supervisory policy),在 gate 判定 KL divergence > threshold 时暂停 agent 并 fallback。
不要只看 reward
某些 env reward 设计过于简单(如仅完成任务即高 reward),容易让 agent exploit reward shape。务必结合 episode length、entropy、KL divergence 一起评估。
本章小结
案例对比展示了 PPO 在低维 env 中的稳定性、SAC 在高维 env 与 Sim2Real 的优势,并推荐使用 dual agent 与 safety gate 模式来组合能力与可控性。
Sim2Real 与策略蒸馏
Sim2Real 的分布转移策略
将实验室训练迁移到物理世界时,Dynamics gap 会显著降低性能。常见对策包括:domain randomization(随机化环境参数)、system identification(模型化真实动力学)、解析 backup policy 作为 fallback。lecture 中强调的 Sim-to-Real index 通过对比 sim rollout 和 real rollout 的 total variation distance 得出 policy drift 指标。
策略蒸馏与小模型部署
Distillation pipeline 一般分为:teacher run -> dataset harvest -> student training -> student evaluation。优质的 dataset 需要覆盖 teacher 出错的 edge cases。student training 中通常使用 mse + kl loss 复合 objective 维持行为一致性。
为何 distillation 还是必要
即使 teacher 能取得最尖端表现,因其体量大、推理成本高,仍需 distill 到 latency-friendly policy。蒸馏过程将 teacher 的 knowledge 以 soft target 形式写入 student,使 student 可以在 resource-constrained device 上运行。
本章小结
Sim2Real 需要 domain randomization、system ID 与 fallback policies。策略蒸馏将 teacher 的能力转移到更轻量 student,是部署到移动/嵌入式平台的关键途径。
总结与延伸
- Off-policy actor-critic 方法通过复用旧数据来提高效率。
- PPO 用 clipping 限制策略偏移,允许多步更新,兼顾稳定与性能。
- SAC 结合 replay buffer 与熵正则,实现完全 off-policy 更新。
- Replay buffer 管理、策略安全监控与部署 checklist 让算法适用于真实系统。
拓展阅读
- Schulman et al., Proximal Policy Optimization Algorithms (PPO 原文, 2017)。
- Haarnoja et al., Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor (SAC 原文, 2018)。
- Open Perfect Blend (Hugging Face)——通用 SFT 数据集混合方案。
- mergekit——开源模型合并工具。
- TRL (Hugging Face)——最全面的 Post-Training 工具库。
- Rafailov et al., Direct Preference Optimization (NeurIPS 2023)——DPO 原始论文。
- Hu et al., LoRA: Low-Rank Adaptation of Large Language Models (ICLR 2022)——LoRA 原始论文。
- Snell et al., Scaling LLM Test-Time Compute (2024)——Test-Time Compute 的理论基础。
- Chatbot Arena (https://arena.lmsys.org)——基于人类偏好的模型排名。
总结表与工程路线
| 重点内容 | 作用 | 关键风险与对策 |
|---|---|---|
| PPO + clipping | 支持多步更新,稳定 on-policy 训练 | clip 过松导致策略飙升;保持 1%–5% clip 并监控 KL |
| SAC + replay buffer | 数据效率高,可复用历史 transition | buffer 污染;定期清洗 + priority sampling + IS 校正 |
| Replay buffer 管理 | 保持样本多样性与时效性 | drift;定期刷新最旧/最差样本并补充 high-reward case |
| 策略安全 + 监控 | KL/variance/rollout 监控风险趋势 | variance spike 触发 rollback;自动报警 |
| 部署 checklist | snapshot、logging、auto stop | production drift;fallback policy + rollback |
附录:常见实践问题
在训练深度 RL 时无可避免地会遇到一些反复出现的问题,这里记录几个讲座中提到或合理推断的 case:
- 为何策略出现 sudden collapse: 这通常发生在 importance sampling weight 太高或 clipping 超出 1.2 之后。建议每训练 epoch 后计算
std(ratio)和max(ratio),若均值超过 0.12 则退回上个 checkpoint。 - 为何 replay buffer 中存在重复轨迹: 原因通常是高频重置(reset 从相近状态开始)。解决方法是在 buffer 中插入
prioritized eviction,优先清除similarity > 0.9的 transition 对。 - 如何控制 entropy decay: 在 SAC 中 entropy 系数 \(\alpha\) 不应固定,而是让 value head 估计 entropy target(例如 0.2),并用
log_alpha自动调节。 - 如何对抗 reward hacking: 设立
constraint auxiliary rewards,例如-0.2罚金 for hitting unnatural states,并在 reward shaping 中使用 potential-based theorem 保证 optimal policy 不变。 - 如何保持 training trace: 使用 structured logging 记录
config, seed, buffer stats, loss curves,并将这些记录上传至 centralized experiment dashboard,便于 future debugging。 - 何时应切换算法: 如果 training variance 超出 checkpoint window(例如 10 连续 episodes variance > 50% of mean),可以将 job 转成 PPO + SAC dual training,让 PPO 作为 anchor policy。
别把附录当作 checklist
这些问题只是常见 heuristics,不能替代具体环境的 ablation。即便在相似的 env 中,也应该验证 variance、kl 与 reward 的纵向变化,并据此微调 thresholds。