CS224R Lecture 7: Offline RL
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于公开课程资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年春季 |
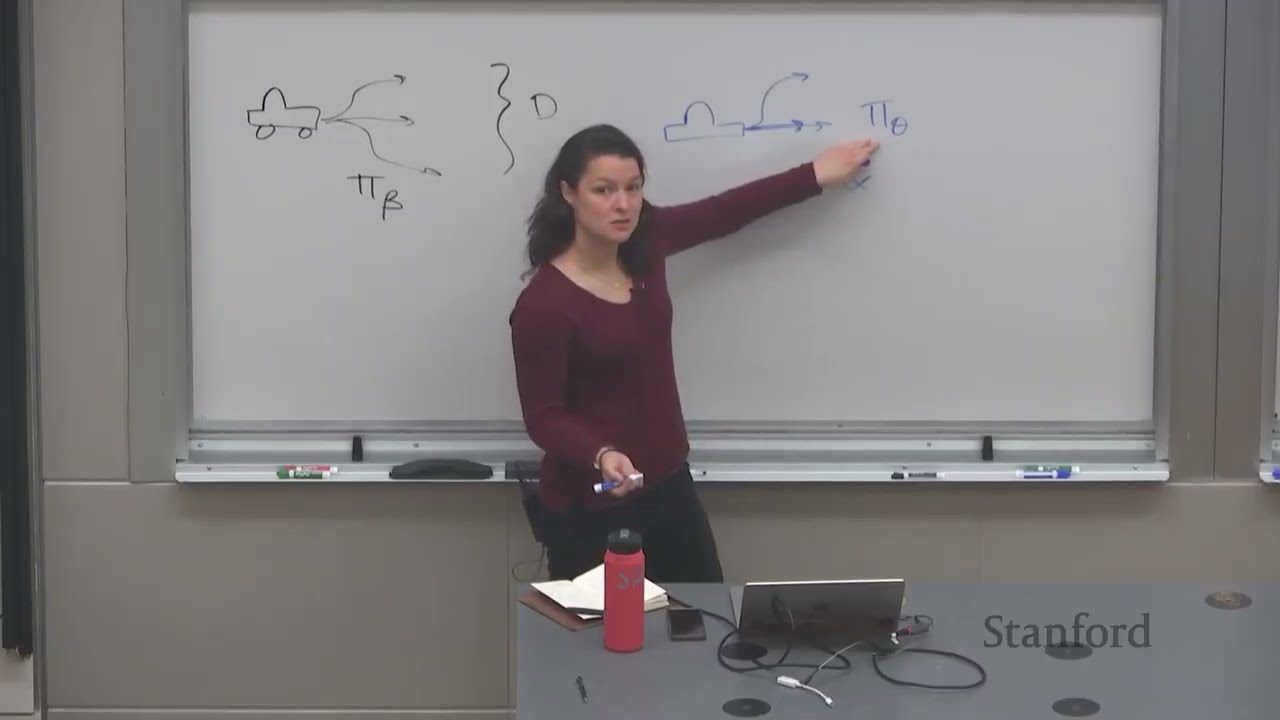
为什么需要 Offline RL
Offline RL 的定义
给定一个由未知行为策略 \(\pi_\beta\) 收集的静态数据集 \(\mathcal{D}\),在不收集新数据的情况下,训练一个能最大化奖励的策略 \(\pi_\theta\)。
Offline RL 的价值:
- 利用人类、现有系统已收集的数据。
- 在线数据收集可能危险或昂贵。
- 复用之前的实验、项目、机器人的数据。
Online vs. Offline RL
Online RL 交替进行"收集数据"和"更新策略"。Offline RL 只有一个静态数据集,训练完成后才部署。也可以先 offline 再 online(混合模式)。
本章小结
Offline RL 解决的是"如何在不与环境交互的情况下,从已有数据中学习好的策略"这一问题。
直接用 Off-Policy 算法?
能否直接把 SAC 这样的 off-policy 算法用在静态数据集上?
Q 函数过估计问题
当 Q 函数在数据集中未见过的动作上被查询时,随机初始化的 Q 值可能任意高或低。策略会寻找 Q 函数过度乐观的动作——这些动作恰恰是 Q 函数最不可靠的地方。 \[6pt] 策略更新后,Q 值会被大幅过估计,导致性能崩塌。根本原因是学习策略 \(\pi_\theta\) 与行为策略 \(\pi_\beta\) 之间的分布偏移。
本章小结
直接使用 off-policy 算法在 offline 设置下会失败,因为 Q 函数在 out-of-distribution 动作上过估计。Offline RL 的核心挑战就是缓解这种过估计。
Offline RL 优于模仿学习
轨迹拼接(Trajectory Stitching)
Offline 数据可能不包含完整的好轨迹,但可能包含片段性的好行为。例如轨迹 A 的前半段很好,轨迹 B 的后半段很好。好的 offline RL 方法能将这些片段拼接起来,学到比任何单条轨迹都好的策略。模仿学习做不到这一点。
本章小结
Offline RL 通过利用奖励信息和轨迹拼接,能够超越行为策略的表现,这是纯模仿学习无法做到的。
隐式策略约束方法
Filtered/Weighted Imitation Learning
最简单的 baseline:只模仿数据中高奖励的轨迹或转移,或按奖励加权。
IQL:Implicit Q-Learning
IQL 的核心思想:避免在数据集之外的动作上查询 Q 函数。
拟合 V 函数:使用 expectile 损失,使 \(V\) 倾向于学习数据中 Q 值较高的那部分行为:
其中 expectile 损失对正误差给更大权重(\(\lambda > 0.5\)),使 \(V\) 偏向数据中更好的动作。
拟合 Q 函数:使用 \(V\) 而非 \(\max\) 来避免 OOD 查询:
本章小结
IQL 通过完全避免在数据外动作上查询 Q 函数来解决过估计问题,是一种简洁优雅的 offline RL 方法。
Conservative 方法
CQL:Conservative Q-Learning
CQL 的思路更直接:在 Q 函数更新中加入惩罚项,主动压低 Q 值。
- 第一项:标准 TD 更新。
- 第二项:压低所有动作的 Q 值(\(\mu\) 覆盖整个动作空间)。
- 第三项:恢复数据中动作的 Q 值(不要过度压低)。
可以证明:对足够大的 \(\alpha\),学到的 Q 值在策略分布下是保守的(低估而非高估)。
CQL 的实现
当使用最大熵正则化时,最优的 \(\mu(a|s) \propto \exp(Q(s,a))\),此时惩罚项变为 \(\log \sum_a \exp(Q(s,a))\),无需显式构造 \(\mu\)。
本章小结
CQL 通过主动压低 Q 值来防止过估计,是另一种有效的 offline RL 方法。与 IQL 的隐式约束不同,CQL 显式地构造保守估计。
数据集与分布问题
数据质量的三维观察
Offline RL 的数据集并非黑盒,讲者强调:理解数据的来源、覆盖范围和奖励分布,才能有效指导算法选择。
- 覆盖度:状态-动作组合是否均匀,是否存在稀疏区域
- 奖励结构:奖励是否稠密、有噪声、有异常值
- 行为多样性:是否仅包含一条行为策略,或多种策略的混合
用数据质量驱动算法选择
当数据覆盖面广、奖励干净时,更激进的 bootstrapping 方法(如 IQL)可以发挥;当数据存在低质量样本或奖励漂移时,优先使用 Conservative 方法或基于 reward 的 sample filtering。
| 数据特征 | 示意说明 | 风险 | 推荐策略 |
|---|---|---|---|
| 高奖励、低覆盖 | 同一轨迹重复出现 | 过拟合、缺乏泛化 | 加强 regularization、引入数据增强 |
| 低奖励但多样 | 多个 suboptimal 策略 | Q overestimation on rare good actions | 过滤低奖励样本、使用 expectile distortion |
| 混合行为 | 多策略混合而未标注 | 难以定义行为策略 | 赋予 behavior cloning 更高权重的分段训练 |
本章小结
Offline RL 的成功依赖于对数据覆盖度、奖励质量和行为多样性的精准理解。按数据特征调整策略(filter/IQL/CQL)比固定算法更稳妥。
案例:构建混合数据管线
项目组经常将 simulator logs、human logs 与 expert trajectories 混合,按照 reward 和 importance sampling 重新加权样本:
- 先计算每条轨迹的 effective sample size。
- 按 reward percentile 将数据分成 bin 并赋予不同 sampling weight。
- 用 IQL expectile 评估每个 bin 中 Q 的分布,两端重采样以保持稳定。
- 若 expectile 跳出预设区间,退回 conservative 模式或过滤掉异常 bin。
混合数据管线的好处
不同数据源 bias 各异:simulator 更精确但缺乏多样性,human data 有噪声但更自然。混合管线通过 re-weighting 让算法既稳健又具泛化。
分布偏移与诊断
Shift Detection Checklist
Offline 环境往往面临两个维度的偏移:环境动力学(transition shift)和 reward 描述(reward shift)。需要定期监控。
- 统计当前 policy 与行为策略的 state-action marginals 变化(KL or JS divergence)。
- 监测 reward distribution drift;如果 reward 因外部因素变动,需重新标注或归一化。
- 用 behavior cloning 误差评估偏移敏感度;高误差暗示模型在“陌生”区域。
Distribution shift 的早期信号
若仅对日志数据运行目标 policy 时 reward 波动剧烈,且 action entropy 迅速走高,说明 policy 正在探索离训练集较远的区域,需要及时插入 conservative regularization。
| 诊断方法 | 输出指标 | 典型阈值 |
|---|---|---|
| KL divergence(s|s_β) | 低于 0.2 | 状态分布未大幅漂移 |
| Reward overlap | 中位数差异 < 5% | reward shift 受控 |
| BC loss ratio | 训练 vs 当前 > 1.5 | 可能进入 OOD 区域 |
本章小结
检测 distribution shift 需要多维指标组合:动作 space divergence、reward drift、BC loss ratio。提前触发 conservative 策略或调整 reward scaling,可以预防 catastrophic failure。
评估与基准
多层评估框架
讲者把评估分成三层:离线基准(benchmarks)、模拟部署(sandbox)、实际回放(replay evaluation)。
- 离线 benchmark:D4RL 类型的任务,关注 normalized score。
- 模拟部署:用 simulator 跑 policy with hold-out reward to detect inflated Q-values。
- 回放评估:把 policy 产生的 trajectory 反写入日志,检查 reward/constraint 是否满足。
评估越多越好,但须留出 human-in-the-loop
自动 benchmark 只能检验 capacity;要理解 failure modes,还需要串联 human audit:观察 policy 在关键情景(edge case)下的行为,补充 qualitative assessment。
来源:Slides 第3页,高亮 offline RL 的评估阶梯。
评估中的对比表
| 评估阶层 | 主要目的 | 常用工具 |
|---|---|---|
| 离线 benchmark | 快速对齐整体能力 | D4RL, OpenAI 的 offline suites |
| Replay evaluation | 观察 policy 在 replay buffer 中的 reward | replay simulator, human audit |
| Sandbox deployment | 用 simulator 到达准生产环境 | per-domain simulator + twin models |
本章小结
评估应该包括 benchmark、sandbox 尝试和回放验证三层,每层都可捕捉不同 failure 模式。人类审查仍不可或缺。
部署与监控
Log + Replay 基础设施
部署 offline policy 前需要准备 logging pipeline:
- 同步 policy 输出与环境 reward,确保 reward trace 链接输出行为。
- 记录 policy 的 action entropy、Q variance,以便复现失败。
- 针对 high-risk state 定义 alert threshold(如 Q variance > 0.5)。
Deployment 最常见失误
用“Offline policy + online fine-tuning” 代替 robust evaluation:上线后才发现 reward drift。正确做法是先用 replay simulator 复验,再逐步放开 online interaction 门槛。
监控仪表板
| Dashboard 组件 | 指标 | 触发条件 |
|---|---|---|
| Policy behavior | Action distribution shift | KL > 0.3 |
| Reward | Mean reward vs reference | 差异 > 5% |
| Q stability | Q variance | > 0.4 |
本章小结
可靠部署依赖日志、replay 复制与监控仪表板。提前设置 alert 和 entropy 控制,可以让 offline policy 在上线后更稳。
监控仪表可视化示例
来源:Slides 第4页,展示典型 dashboard,中列展示 reward drift 控制。
治理与安全
Policy Governance Checklist
- 安全审查:是否涵盖 CBRN 相关 scenario
- 成本审查:是否记录 compute/trajectory 预算
- 行为审核:是否有人观察 policy 注释并签字
Governance 不是拉闸,是预告
治理是把 deployment pipeline 变成一个可解释的流程,不是“突然停掉”。每次 policy change 都要留 trace,从 dataset 到 training 到 evaluation 都要可追责。
本章小结
治理的关键是 traceability、对齐审查和形成明确的 sign-off 流程。只有这样,Offline RL 才能在高风险场景落地。
Tooling 与自动化
自动化流水线
Offline RL 需要把 data -> training -> eval -> deploy 串成流水线。典型组件:
- Data versioning:每次训练都指向数据、reward log、behavior policy ID。
- Training orchestration:Pipeline.com、Kubeflow pipeline 触发 training job。
- Evaluation orchestration:自动化地从 replay buffer 取 key states 运行 benchmark。
- Deployment gate:若 metrics 异常,自动回滚并通知 owner。
流水线中断会导致 drift
一旦 pipeline 的任一环节(data/eval/deploy)缺失,后续变化就无法追踪。必须强制所有 code change 通过 pipeline 生成的 artifact,避免“手动跑”。
支持工具与集成
讲者列举了几款与 offline RL 结合良好的工具:
- Data-versioned storage(Feathr, Deep Lake)存储 dataset metadata。
- Experiment tracking(Weights & Biases)记录 Q variance、KL drift。
- Policy registry:记录 policy hash, deploy timestamp, sign-off, governance doc link。
- Replay simulator:用 deterministic seeds replay 训练轨迹并记录 divergences。
本章小结
Automation pipeline 不只是流水线,而是把 offline RL 的各个 artifact 变成 traceable product。实时 logging + tooling 集成让 governance 更容易。
案例研究:现实世界的 Offline RL
复杂 reward 工程
在人机交互系统中,reward often包含多个目标(accuracy, fairness, latency)。讲者描述 LinkedIn 项目:在 notification 系统中同时优化 CTR 和 retention,因此要在 dataset 中标记 reward components 以便 later decomposed training。
多目标 reward 的 practical trick
在 dataset 中预先计算 reward vector(CTR, retention, quality),并在 offline training 时用 linear combination + CVaR regularization 控制 worst-case outcomes。
可视化演示
来源:Slides 第6页,强调 reward vector 与 deployment metrics 的一一映射。
本章小结
现实案例中 reward 是多维的,务必在数据层面明确每个维度的意义,否则 offline policy 会 misalign。
Open Research Directions
Maximizing offline + online handoff
几位讲者都提到 hybrid strategies:先 offline,再有限 online fine-tuning。关键问题是如何安全地 handoff:
- 制定 clear boundary:什么情况下允许 query environment?
- 在 offline phase 就评估 online potential(e.g., Q variance in shifted states)。
- 用 meta-RL 训练 supervisor policy decide when to go online。
Counterfactual auditing
目前 governance 仍依赖 replay logs,未来可能采用 counterfactual referents:生成 hypothetical trajectories to test safety constraints before deployment。
Counterfactual auditing
用 learnt world model 生成“如果 policy 做了不同动作会怎样”的对比,使 safety team 了解潜在 failure trajectory,可以更快识别 policy drift。
本章小结
Research 方向包括 offline→online handoff、counterfactual auditing、以及更强的 interpretability(如 gradient-level tracebacks)。
Slides Gallery
Slide: Monitoring Architecture
来源:Slides 第5页,强调 offline RL 的监控控制室。
Slide: Real-world Deployment Flow
来源:Slides 第7页,展示 rollout → monitor → replay 的闭环。
本章小结
用 slides Gallery 把治理/监控方案可视化,有助于向 stakeholders 演示整个 pipeline。
案例研究:机器人控制
Offline policy in robotics
在 robotics 任务中,数据采集成本高,offline RL 可大幅减少 real-world trials。典型做法:
- 在 simulator 训练 policy 并在 physical robot 上 replay 关键 traj。
- 用 offline dataset 中的 reward multiplier 强调安全相关动作(如 low velocity)。
- 记录 each deployment run 中 sensor readings 以便对错误进行 counterfactual audit。
| Task | Data source | Safety guardrail | Offline method |
|---|---|---|---|
| Arm manipulation | Robot logs + human demos | Collision penalties | CQL |
| Drone navigation | Simulation + recorded flights | Wind model alert | IQL + replay |
本章小结
机器人案例强调:data source 多元、reward carefully shaped、monitoring & replay 必不可少。
Counterfactual Tracebacks
Replay-based counterfactuals
Counterfactual auditing 在部署前生成 hypothetical alternatives:
- 选择 high-risk state from replay buffer。
- Use world model to generate alternative actions。
- Score each trajectory via reward + safety classifier。
- 若任何 alternative 违反 constraints,则触发人工审查。
| 步骤 | 说明 |
|---|---|
| State selection | 从 KL drift 高或人工标记的 state 中挑选 |
| Action generation | 用 policy + noise 或 prioritized replay 生成备选 action |
| Audit | 用 reward + constraint classifier scoring |
| Action | 若 flagged,则回退训练或提高 conservative regularization |
可视化演示
来源:Slides 第8页,强调 alternative trajectory scoring。
本章小结
Counterfactual audit 让 governance 团队在 policy off-behavior 发生前就可识别异常路径。
Operations Checklist
部署前核查清单
Operations readiness checklist
- 归档数据版本 ID 与 reward log。
- Training job config 附带 human sign-off。
- Monitoring dashboard 设定 alert threshold。
- Governance doc 记录 expected failure modes。
| 检查项 | 频率 | 执行人 |
|---|---|---|
| Dataset audit | 每次数据版本发布 | Data engineer |
| Policy rehearse | 每次 major update | RL engineer + ops |
| Monitor smoke test | 每次 deployment | Devops |
| Governance sign-off | 每次 governance change | Compliance owner |
本章小结
Operations checklist 让 offline RL pipeline 的每个阶段都留痕,方便后续审计。
Training-Deployment Playbook
Step-by-step plan
这份 playbook 把 training 和 deployment 串起来:
- Run offline baseline (IQL/CQL) & log metrics.
- Conduct replay evaluation on hold-out states.
- If metrics pass, run sandbox rollouts with limited online interaction.
- Monitor dashboards; if alerts fire, rerun training with higher conservatism.
- Only after compliance sign-off release to production; keep governance log updated.
| 阶段 | 负责人 | 输出 artifact |
|---|---|---|
| Training | RL engineer | model weights, training logs, Q variance plot |
| Evaluation | ML ops | replay traces, benchmark report |
| Deployment | Devops | rollout plan, dashboard alerts, governance sign-off |
本章小结
Playbook 让 devops clear about which artifact drives each stage;没有 playbook,pipeline 会断裂。
Frontier Workshop Notes
Workshop focus areas
Lecturer 还建议定期 workshop,集中解决 offline RL 中的 open problems:
- Lab session:Replay buffer introspection,手动审核 high-risk trajectories。
- Governance: simulate counterfactual audits + compliance docs in same meeting。
- Tooling:swap data versioning backends, evaluate time-to-recover metrics。
来源:Slides 第9页列出 workshop 的 checkpoint 及责任人。
本章小结
Workshop 模式可以把 research insights 快速翻译成 operational improvements,避免 knowledge silo。
未来挑战
可解释与审计的灵活组合
随着模型越来越强,单纯的 replay evaluation 不再能保证安全,必须引入 mechanistic interpretability 和 audit trails。
- 记录每个 action 触发的 Q gradient 信息,便于 reverse engineer。
- 将 audit log 与 governance checklist 搭配,形成 "explain -> sign off" 循环。
- 在 policy update 时触发 automated sanity checks 并留存 diff。
忽略解释性会导致合规缺失
若没有办法解释为什么 policy 选择某个动作,治理团队会将其标记为“不透明”,从而延迟部署。解释性与 compliance 是两个互为支撑的维度。
适应法规与政策变更
讲者强调政策变化对 offline RL 项目影响巨大:数据共享限制、logging 要求、甚至禁止某些 reward shaping 方式。需要实时跟踪法规并将文档化变更归档。
本章小结
未来的 offline RL 项目必须把 interpretability 和 governance 绑在一起,并保持政策文档与技术文档同步,才能在监管压力下稳健前行。
总结与延伸
- Offline RL 在静态数据下优化策略,需要平衡模仿和探索。
- 数据集的覆盖度与 reward 质量直接决定方法的鲁棒性。
- IQL 通过 expectile V 来隐式约束搜索,CQL 通过 explicit penalty 施加 conservatism。
- 多层评估、日志化监控与治理框架是成功部署的关键。
- 监测分布 shift、Q variance、action entropy 让部署后风险可控。
总结表
| 维度 | 核心问题 | 应对措施 | 典型工具 | |
|---|---|---|---|---|
| 数据集 | 覆盖度、奖励质量 | 过滤低奖励、加权 imitation | D4RL, dataset diagnostics | |
| 算法 | 大幅偏移导致 Q 过估计 | IQL expectile, CQL penalty | IQL codebase, CQL repo | |
| 评估 | benchmark score vs deployment performance | 多层评估、human audit | D4RL + replay evaluation + human review | |
| 部署 | 监控 drift、reward shift | logging/alert + replay | dashboards, entropy targets | |
| 治理 | traceability + sign-off | records, policy reviews | notebooks, compliance logs | |
| Tooling | pipeline automation | data-versioning, policy registry | W\ | B, Feathr, Kubeflow |
| Research | offline→online handoff safety | counterfactual auditing | world models, meta RL supervisors |
进一步行动
- 先用 dataset diagnostics 表识别好/坏轨迹,再决定是 filter、IQL 还是 CQL。
- 在部署前构建 replay simulator,通过 replay 复现高风险场景。
- 建立 monitor dashboard(action KL、reward gap、Q variance),并给 devops team 明确 alert threshold。
- 将每次 policy 更新的 audit info(data version、reward log、human sign-off)写入治理日志。
拓展阅读
- Levine et al., Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems (2020)。
- Kostrikov et al., Offline Reinforcement Learning with Implicit Q-Learning (IQL, 2022)。
- Kumar et al., Conservative Q-Learning for Offline Reinforcement Learning (CQL, 2020)。
- Laskin et al., Offline Reinforcement Learning with Dense Rewards for Realistic Tasks (2023)。
- cs224r course notes repository for practical code samples: https://cs224r.stanford.edu/spring_2025/lecture/07.html