CS231N Lecture 16: Multi-Modal Foundation Models
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Ranjay Krishna 授课内容整理 |
| 来源 | Stanford CS231N |
| 日期 | 2025-05-27 |

从单任务模型到 Foundation Models
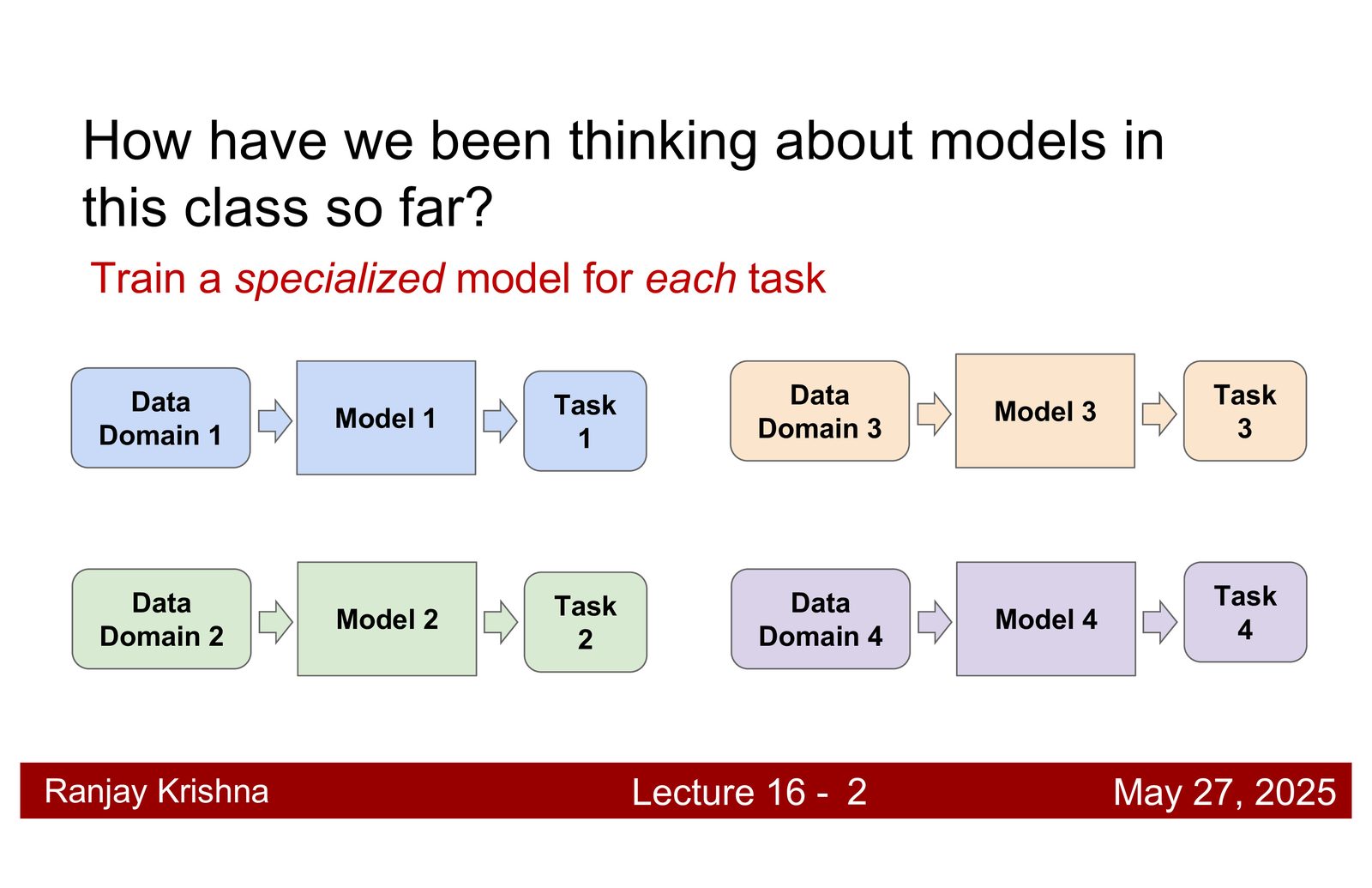
这一讲是 guest lecture,主讲人是 Ranjay Krishna。开场先做了一个很重要的对比:课程前半段学到的,多是为单个任务收集数据、训练单个模型、在固定测试集上评估的范式;而今天的重点,是把视觉系统推进到一个更通用的层次,也就是 foundation models。换句话说,问题不再是“每个任务都单独训练一个模型”,而是“能不能先训练一个大而通用的模型,再适配到很多任务”。\footnote{根据字幕 00:00:05--00:03:40,讲者把课程前半段的单任务流程和 foundation model 的预训练-迁移流程做了对比。}
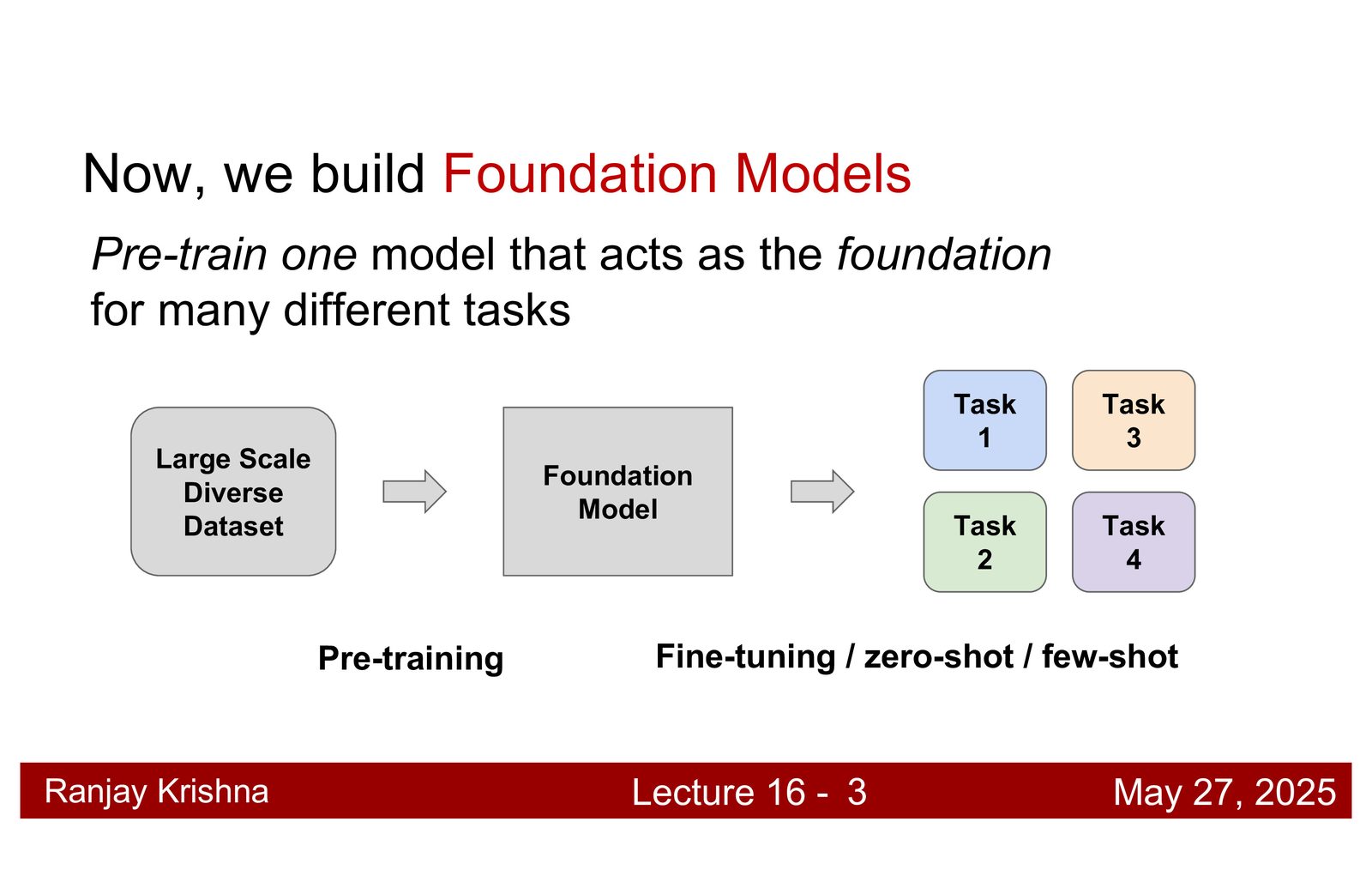
Foundation model 到底是什么
讲者没有给出一个教科书式定义,而是强调了一组更实用的特征。foundation model 不是一个严格的分类术语,而是一种系统设计取向:它应该足够通用、足够鲁棒、拥有较大的参数量、训练数据也足够大,而且通常采用某种自监督或弱监督目标。
Foundation model 的常见特征
- 通用性:同一模型可适配很多不同任务。
- 规模:参数量通常大,训练数据也大。
- 预训练优先:先学表示,再做下游适配。
- 弱监督/自监督:尽量减少对人工标签的依赖。
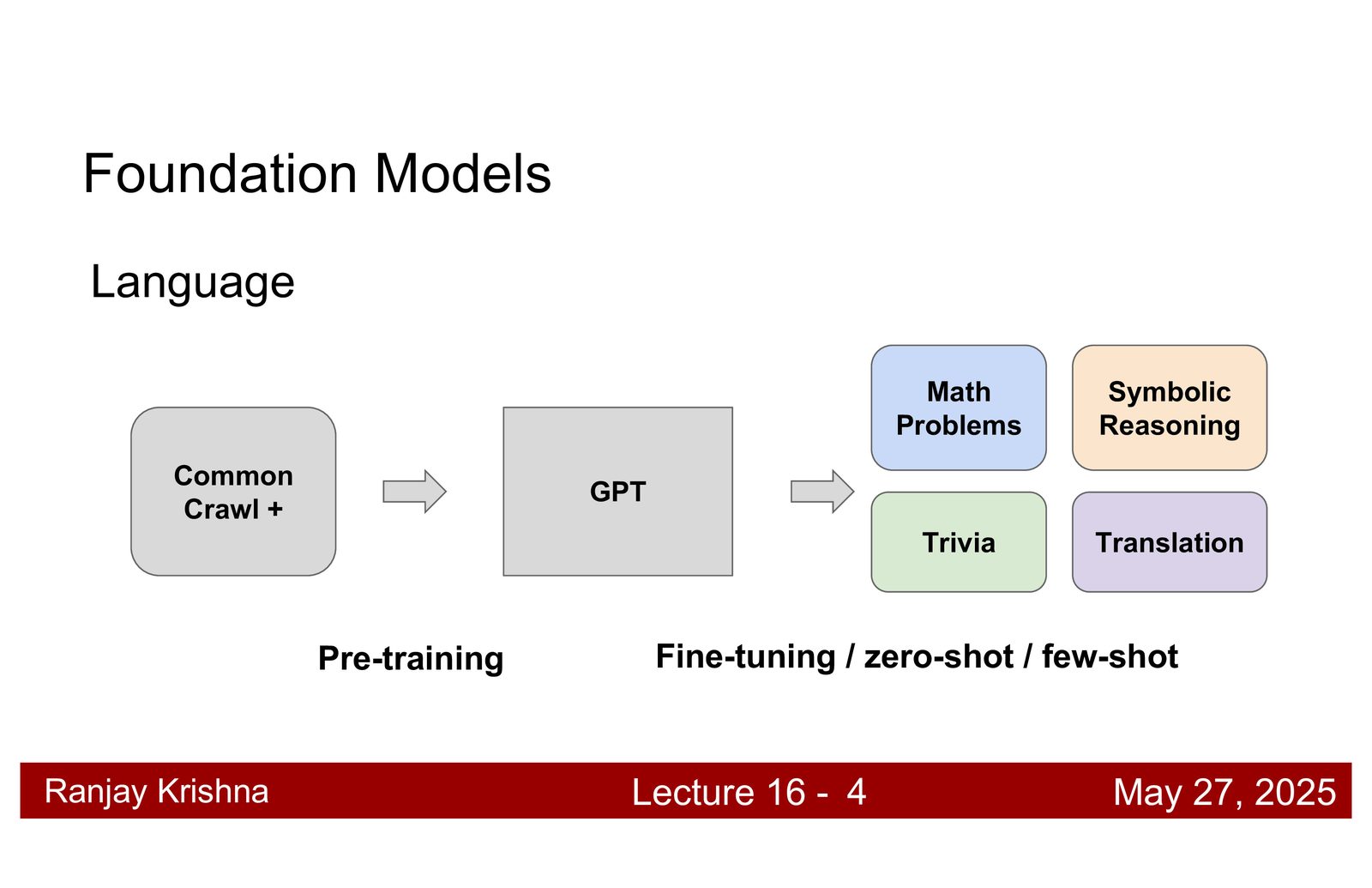
这讲只讨论视觉和多模态系统,不展开语言模型本身,但语言模型的思路会被借用来构建视觉 foundation model,尤其是“如何把输入压成一组 token,再交给一个通用模型去自动完成”这条路线。

为什么视觉也需要 foundation models
视觉任务本身就很碎片化。分类、检测、分割、检索、问答、captioning,各自的数据集、损失函数和评估标准都不一样。如果继续用“一个任务一个模型”的思路,就会不断重复造轮子。foundation model 的价值,在于让同一套表示跨任务复用,而不是只在一个 benchmark 上刷分。\footnote{字幕 00:02:02--00:03:40 中,讲者明确说到它允许在很少数据甚至零数据的情况下适配新任务。}
为什么这个方向重要
- 标签昂贵,而网络数据丰富。
- 下游任务不断变化,固定任务模型很难复用。
- 统一表示有利于检索、生成、分类和问答等任务的共享。
从 self-supervised 到 multimodal
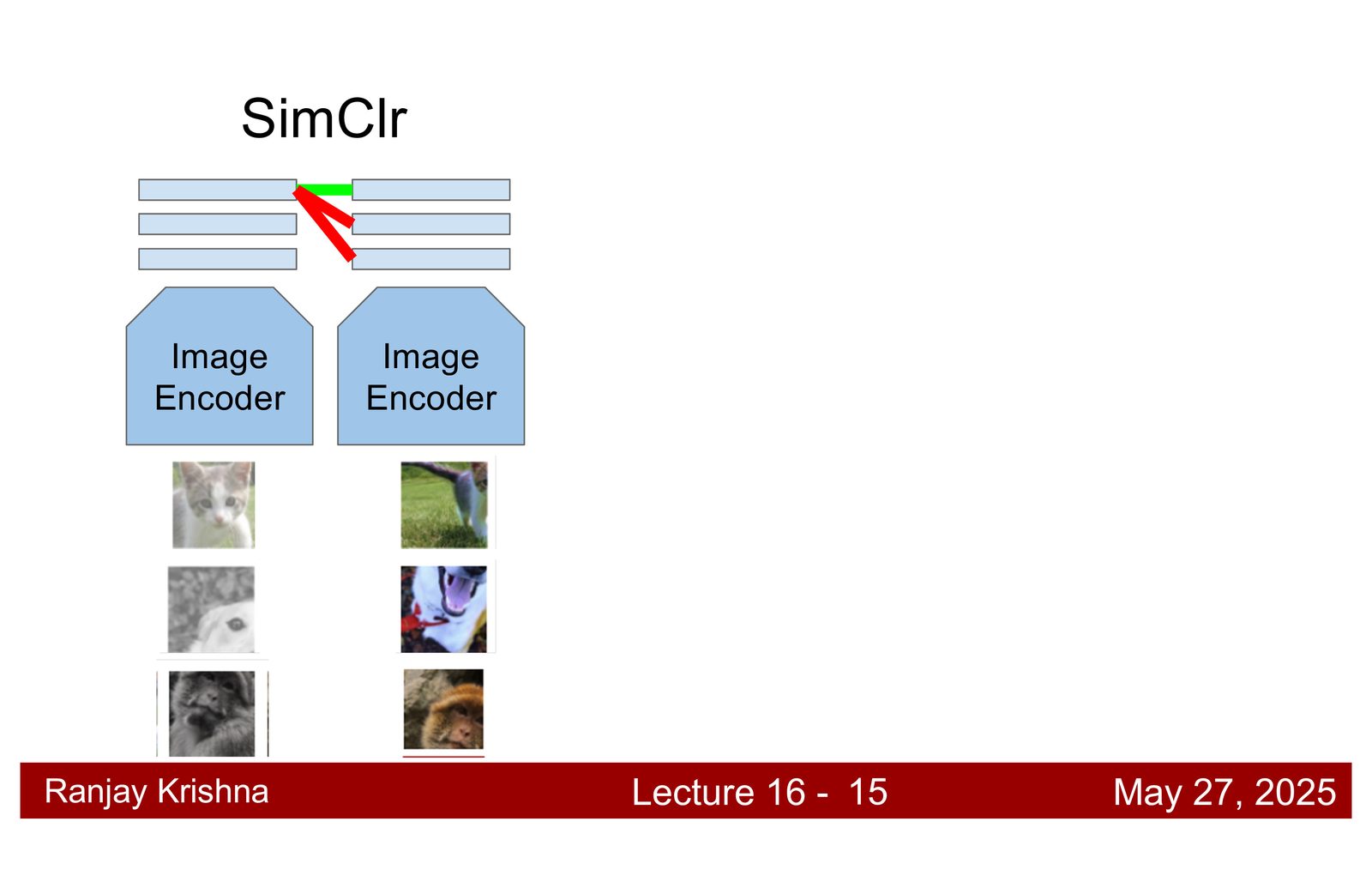
讲者把本讲和前面的 self-supervised learning 联系起来:如果对比学习能把同一张图的不同增强拉近,那么把“图像”和“文本”也放进同一个对比目标里,就能把图文空间统一起来。这就是 CLIP 的出发点。\footnote{字幕 00:03:40--00:06:40 中,讲者先从 self-supervised 的 contrastive objective 过渡到图文对比学习。}

CLIP:把图像和文本放进同一个空间
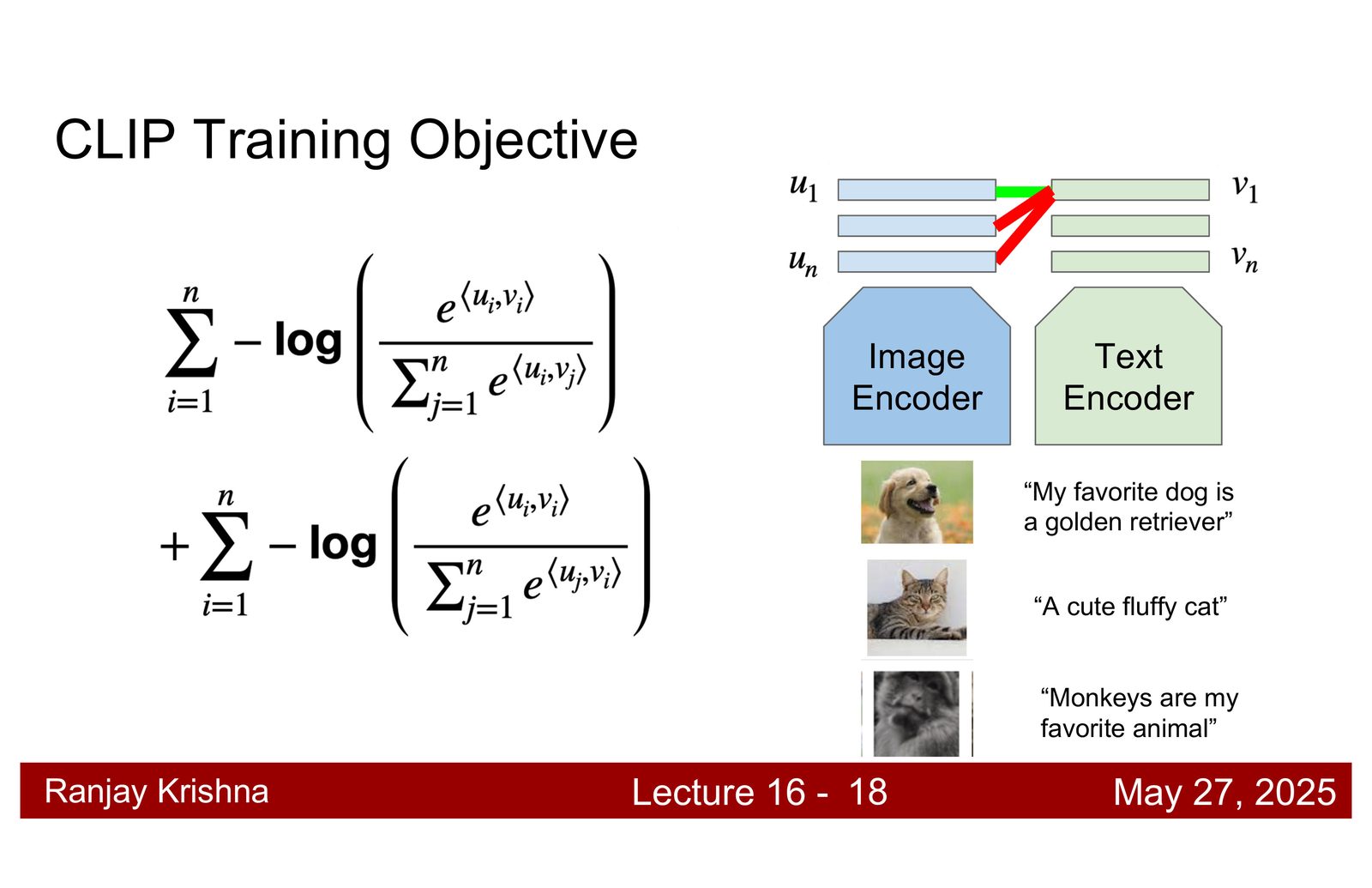
CLIP 是这讲的第一个主角。它的核心是把图像和文本都编码到同一个向量空间里,然后用对比学习把匹配对拉近,把不匹配的样本推远。它不直接学类别标签,而是学跨模态对齐。
对比学习的直觉
CLIP 的训练逻辑,本质上是把“哪个图和哪个文本更像”变成 batch 内的匹配问题。图像编码器和文本编码器各自把输入压成向量,训练时让真实配对的图文相似度更高,其他配对相似度更低。这个目标和 SimCLR 的直觉非常接近,只是从“同一张图的不同增强”扩展成了“图像与语言描述”。\footnote{字幕 00:06:40--00:08:20 中,讲者明确把 CLIP 的图文对比目标放回到 self-supervised contrastive learning 的框架里。}
CLIP 的训练目标
训练数据是一大批图文对。模型同时优化两个方向:
- 图像向量应最接近自己的文本描述。
- 文本向量也应最接近自己的图像。
这是一种对称的 batch 内对比损失。

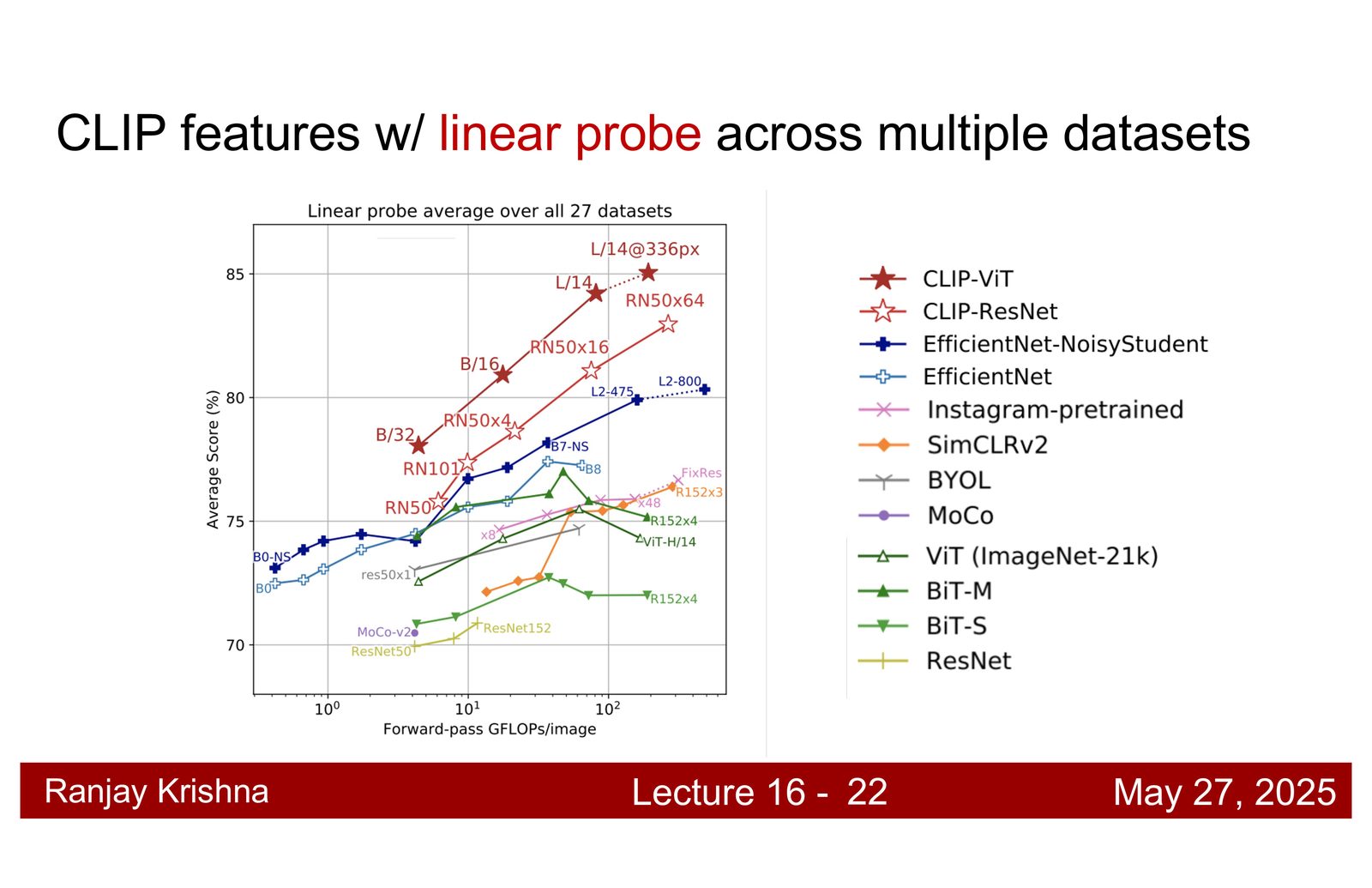
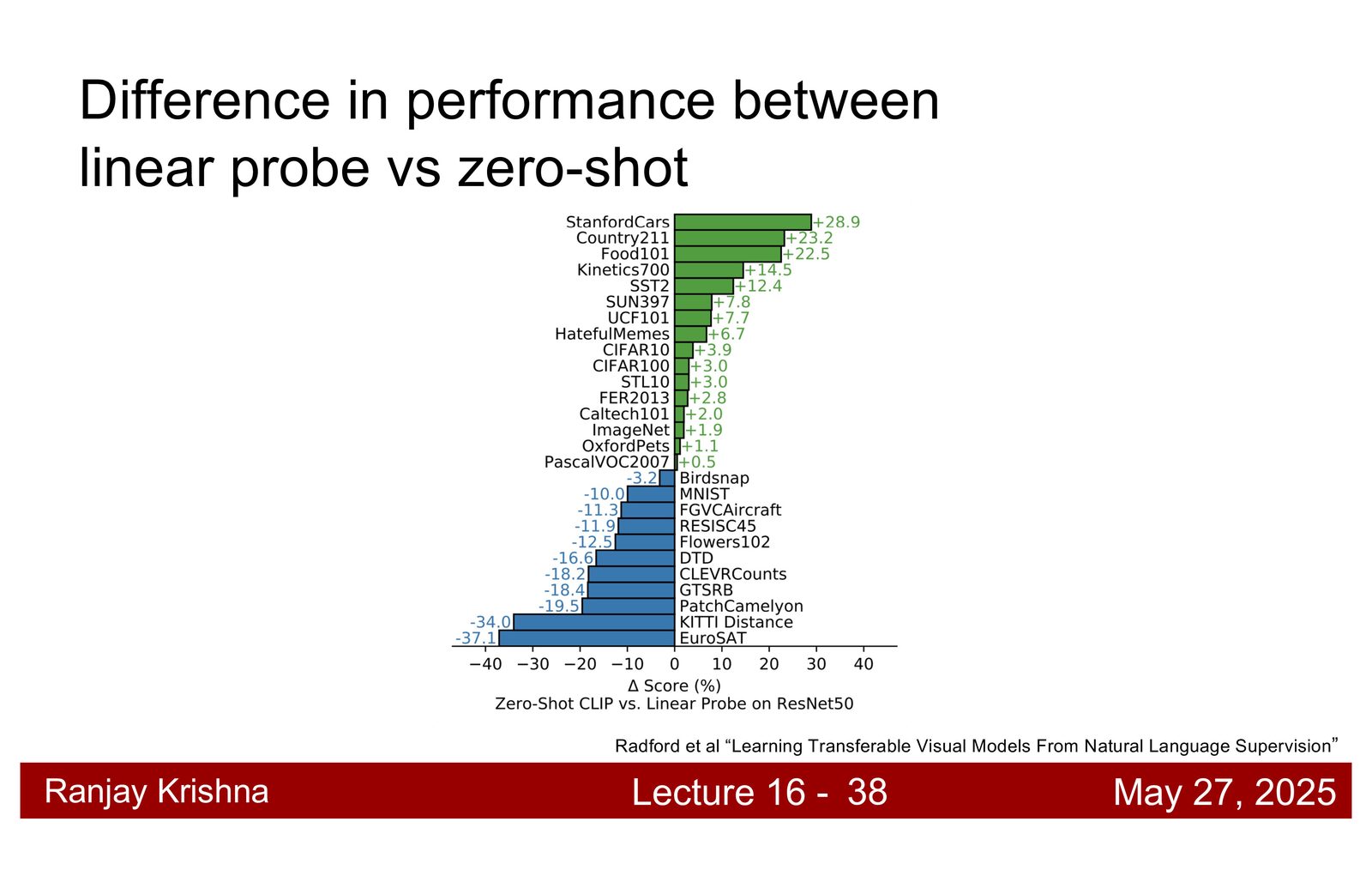
为什么 scale 会决定 CLIP 的成败
CLIP 并不是“一个新的小技巧”突然赢了,而是模型规模和数据规模同时上来了。讲者给出两个关键数字:模型规模大约是 307M 参数,训练图文对来自互联网,规模大约到 4 亿对量级。相比 ImageNet 的 1.3M 图像,这已经是完全不同的数据世界。\footnote{字幕 00:14:10--00:16:10 和 00:17:50--00:18:20 对规模因素有直接说明。}
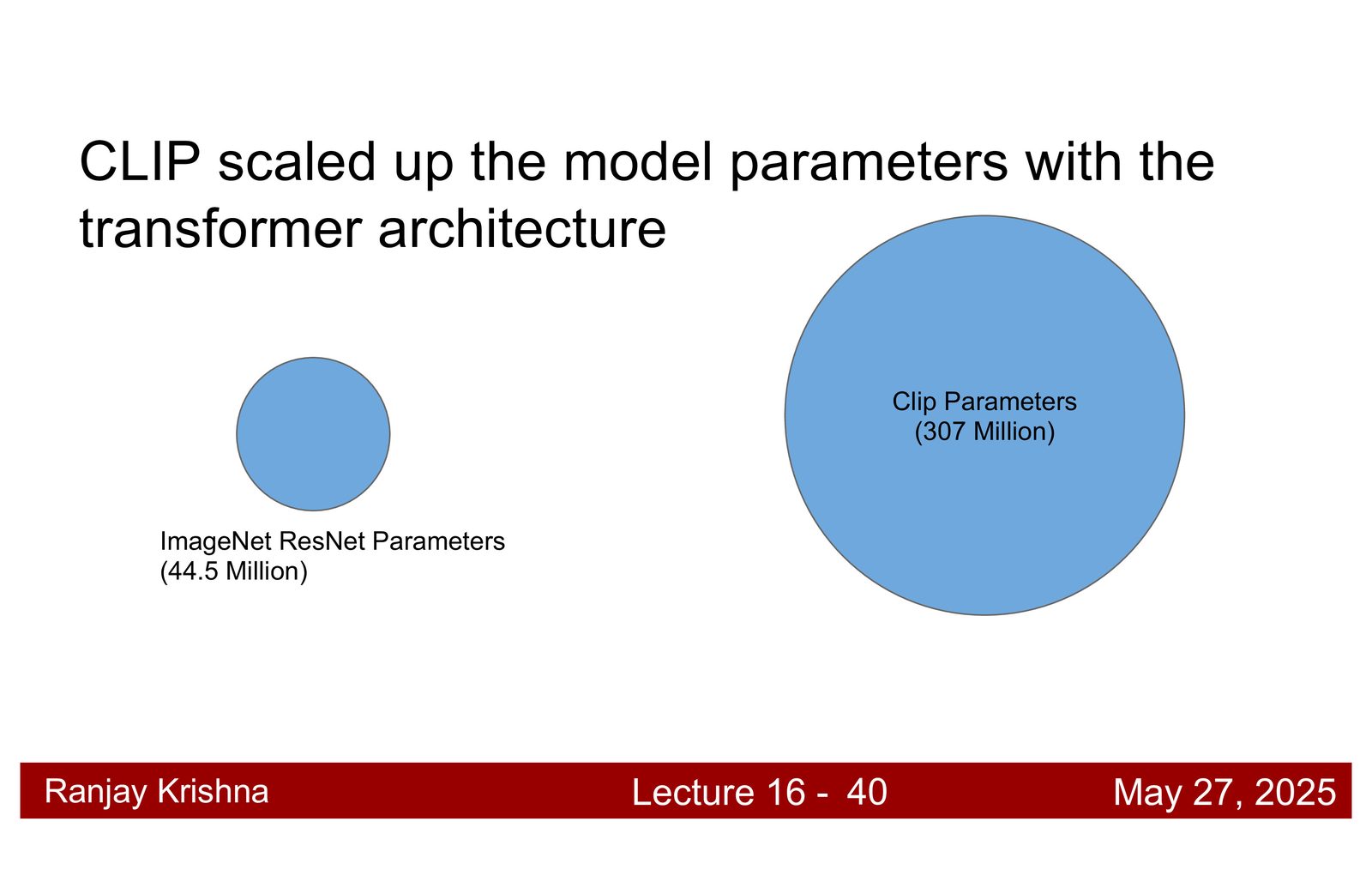
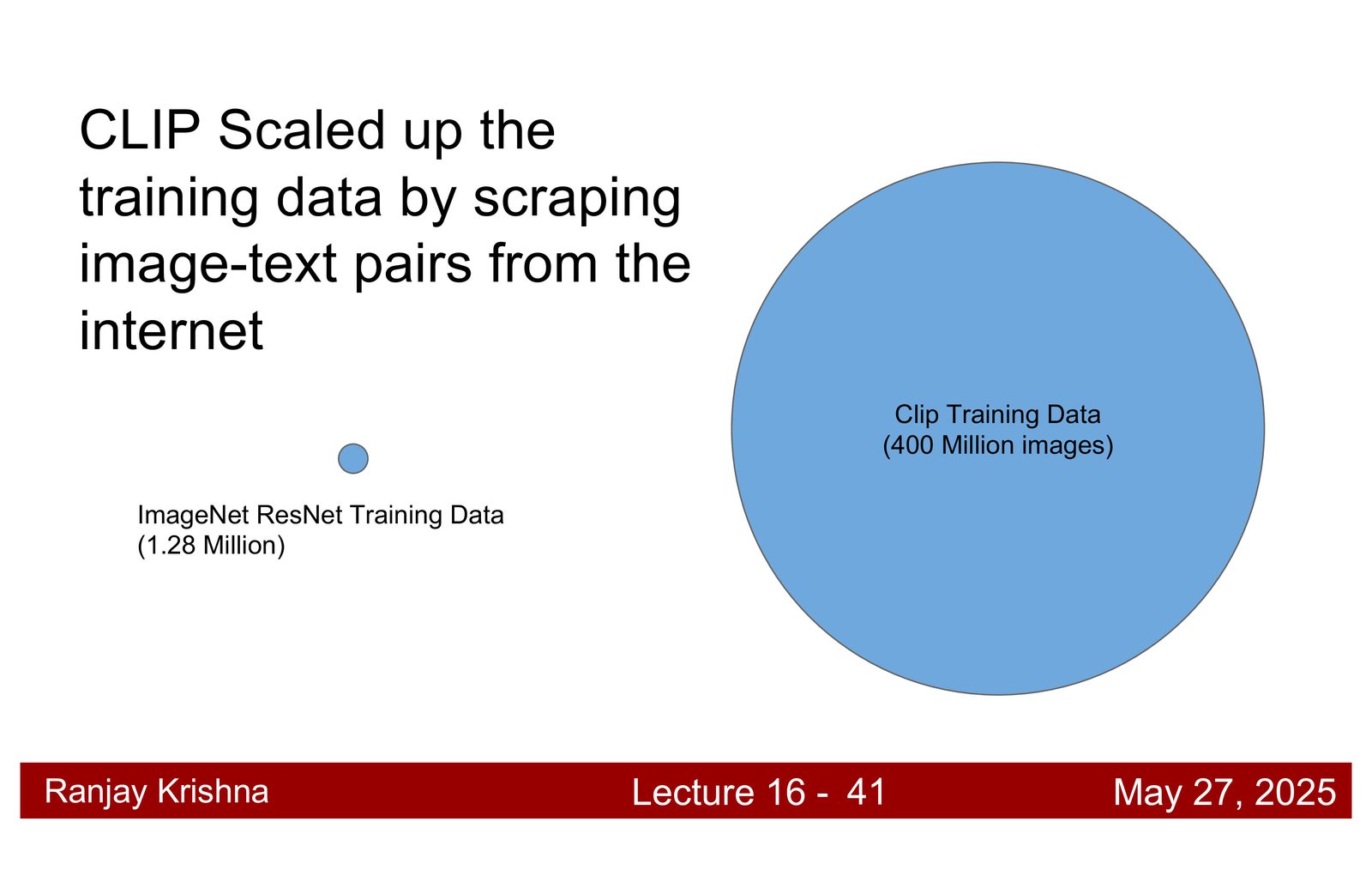
为什么 scale 不是“可有可无”
CLIP 的很多能力并不是来自某个神奇结构,而是来自足够大的 batch、足够大的模型和足够多样的图文监督。没有 scale,很多看起来优雅的对比学习结论其实都学不出来。
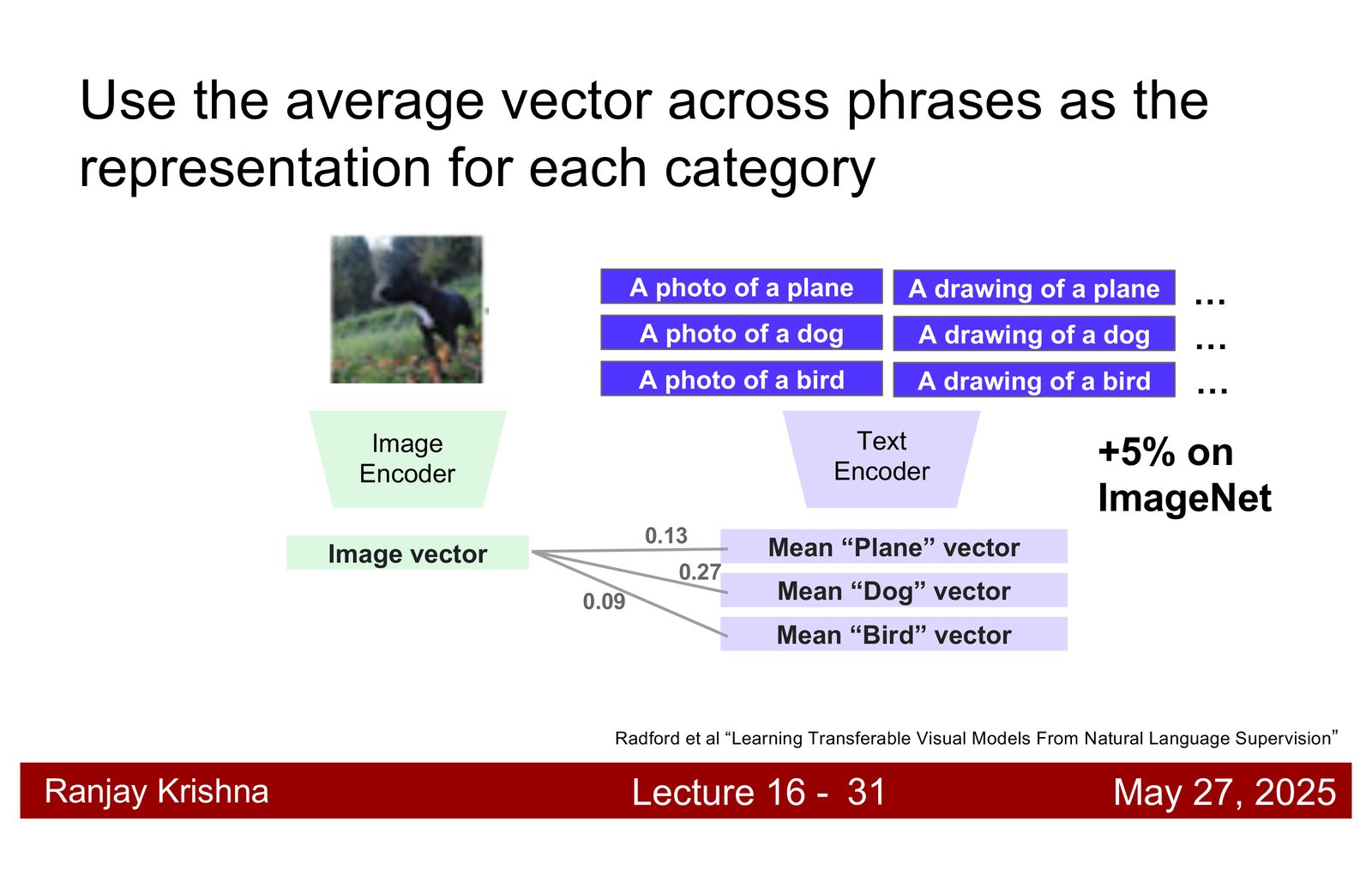
零样本分类怎么做
CLIP 最有影响力的能力,是 zero-shot 分类。做法很简单:为每个类别写一个文本 prompt,编码成文本向量,再把输入图像编码成图像向量,用最近邻或点积选出最匹配的类别。\footnote{字幕 00:11:00--00:14:10 中,讲者用 plane/dog/bird 的例子解释了 zero-shot 分类。}


对新数据集,流程就是:
- 为类别写 prompt,例如
a photo of a dog。 - 把 prompt 编码成类别原型。
- 把图像编码成向量。
- 按相似度做分类。
为什么 prompt 很重要
CLIP 训练时见到的是句子片段,不是孤立词,所以单个类别词往往不如带语境的短语好用。prompt ensemble 进一步把多个描述取平均,通常还能再提升一点性能。
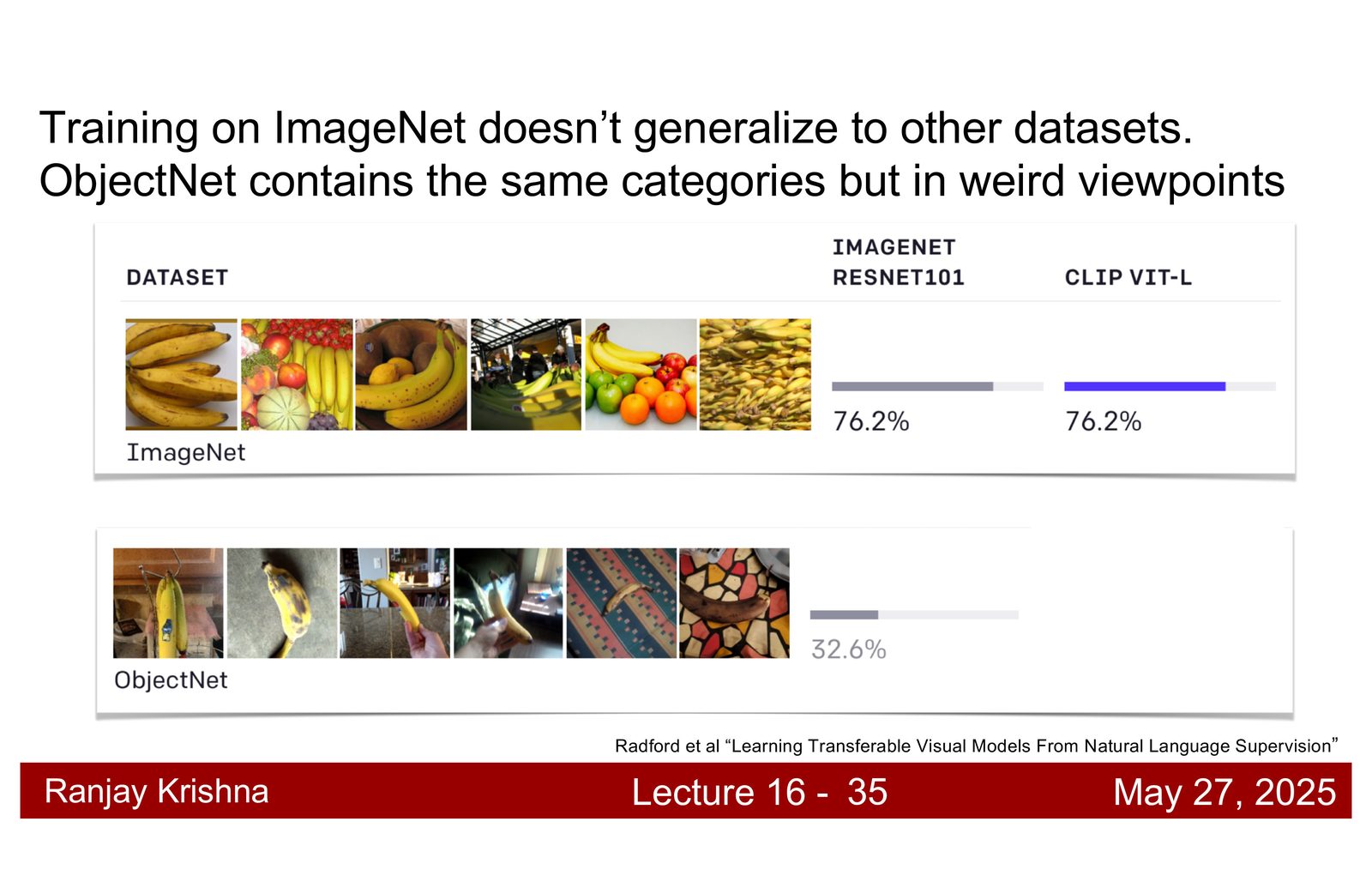
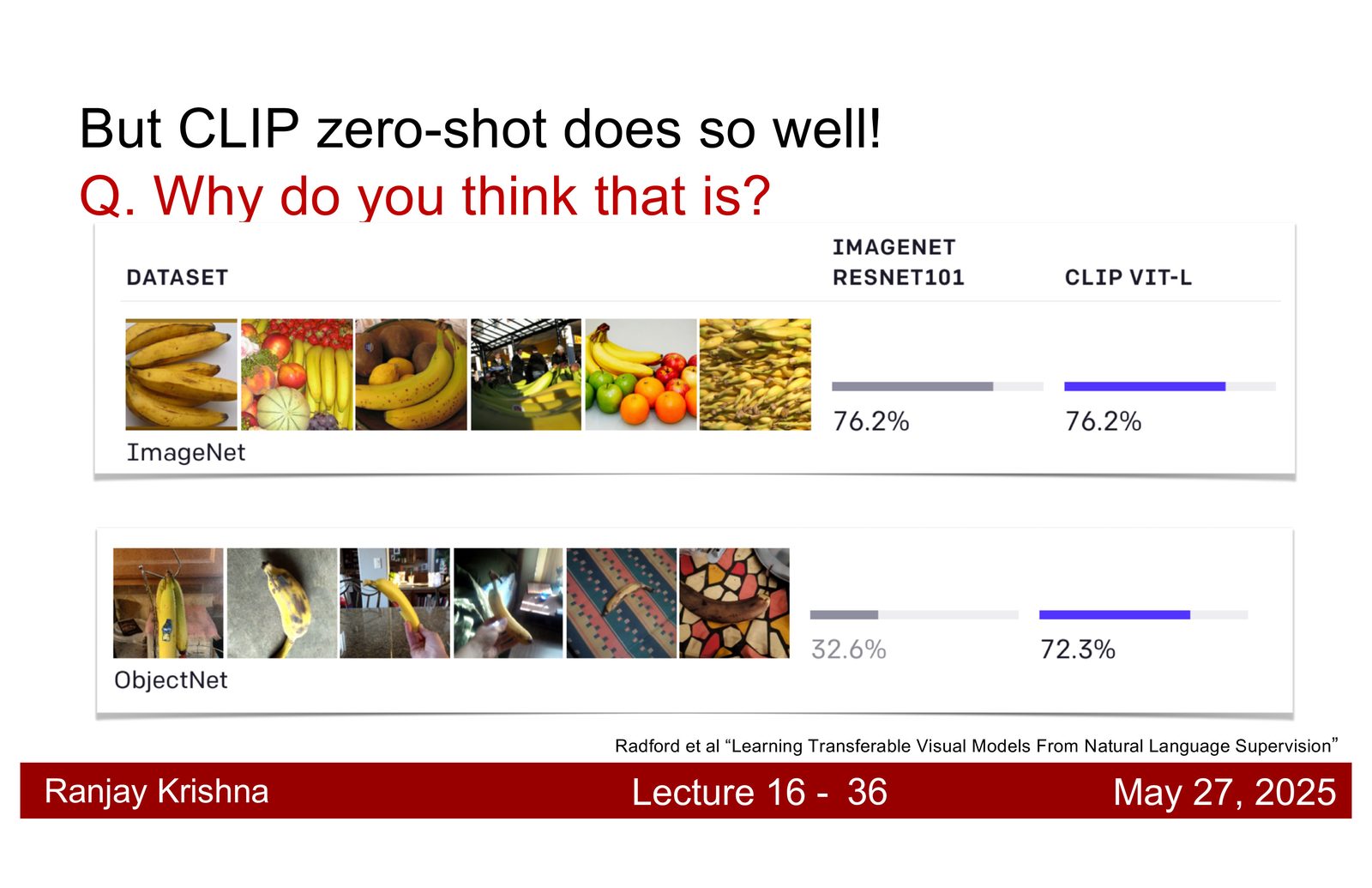
为什么 CLIP 会泛化得更好
讲者对这个问题给了两个解释。第一,互联网文本比 ImageNet label 丰富得多,它不是只有“dog”这样的单词,而是包含形状、颜色、关系、场景和上下文信息。第二,图文对的总量远超过手工分类数据,所以模型见过的组合更广、更杂,也更容易对 out-of-distribution 样本保持鲁棒。\footnote{字幕 00:14:50--00:16:20 和 00:16:20--00:17:40 对 CLIP 的泛化原因做了直接总结。}

CLIP-style 模型的优点
- 训练目标简单,容易扩展。
- 推理很快,检索和分类都方便。
- open-vocabulary 能力强,适合跨域迁移。
- 很容易和其他模型做 chaining。
CLIP 的局限:batch、组合关系和分布外样本
讲者并没有把 CLIP 神化。相反,后半部分花了很多时间讲它的局限。第一个问题是 batch size 依赖:batch 越大,负样本越丰富,模型越有机会学到细粒度差异;但如果 batch 太小,就容易只学到“猫和车不一样”这种粗粒度区分,学不到真正细的类别边界。\footnote{字幕 00:21:50--00:23:40 对 batch size 和 hard negatives 的重要性有明确讨论。}

第二个问题是 compositionality。mug in grass 和 grass in mug 词元相同,但语义完全不同;CLIP 很容易混掉这种关系,因为它更擅长整体对齐,而不是精细的关系解析。

组合关系为什么难
组合关系要求模型不只识别对象,还要识别对象之间的角色和方向。只靠更大的 batch 能改善一些细粒度区别,但并不能自动学会真正的结构化语义。
hard negatives 不是银弹
一个自然的修补方向是 hard negative fine-tuning:专门把容易混淆的反例放进 batch,逼模型学会更细粒度区别。这个方法短期内确实能改善部分混淆,但讲者也提醒,它可能带来新的问题:过度强调反例会让模型把本来应该接近的样本也强行推开,最后反而损害 generalization。\footnote{字幕 00:23:40--00:24:55 中,讲者明确说 hard negative 训练最终可能伤害泛化。}


一个更成熟的判断
CLIP 的问题不是“还不够大”,而是它需要更好的数据构造策略、更明确的组合监督和更稳定的训练信号。简单堆 batch 并不能自动解决语义结构问题。
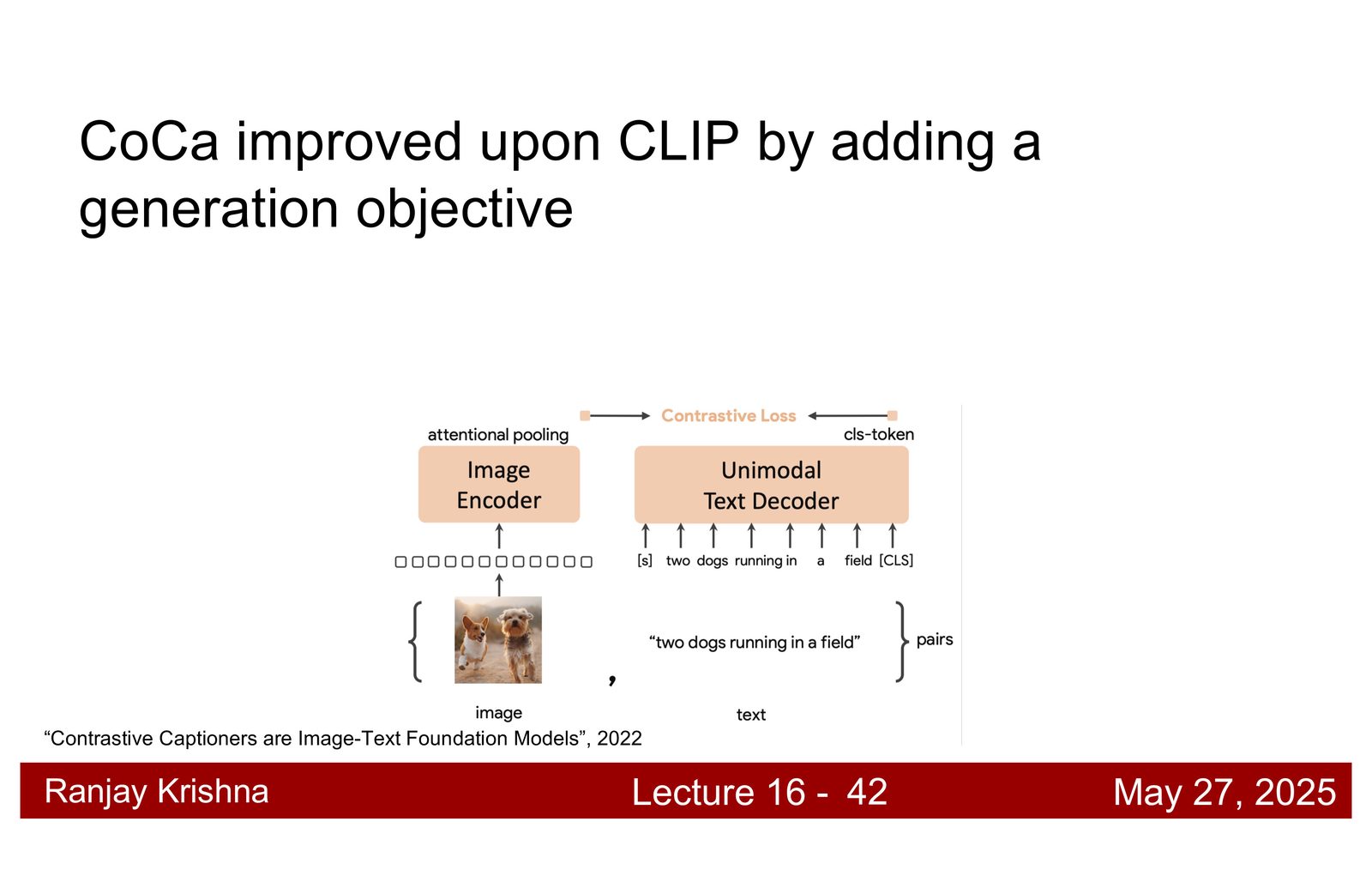
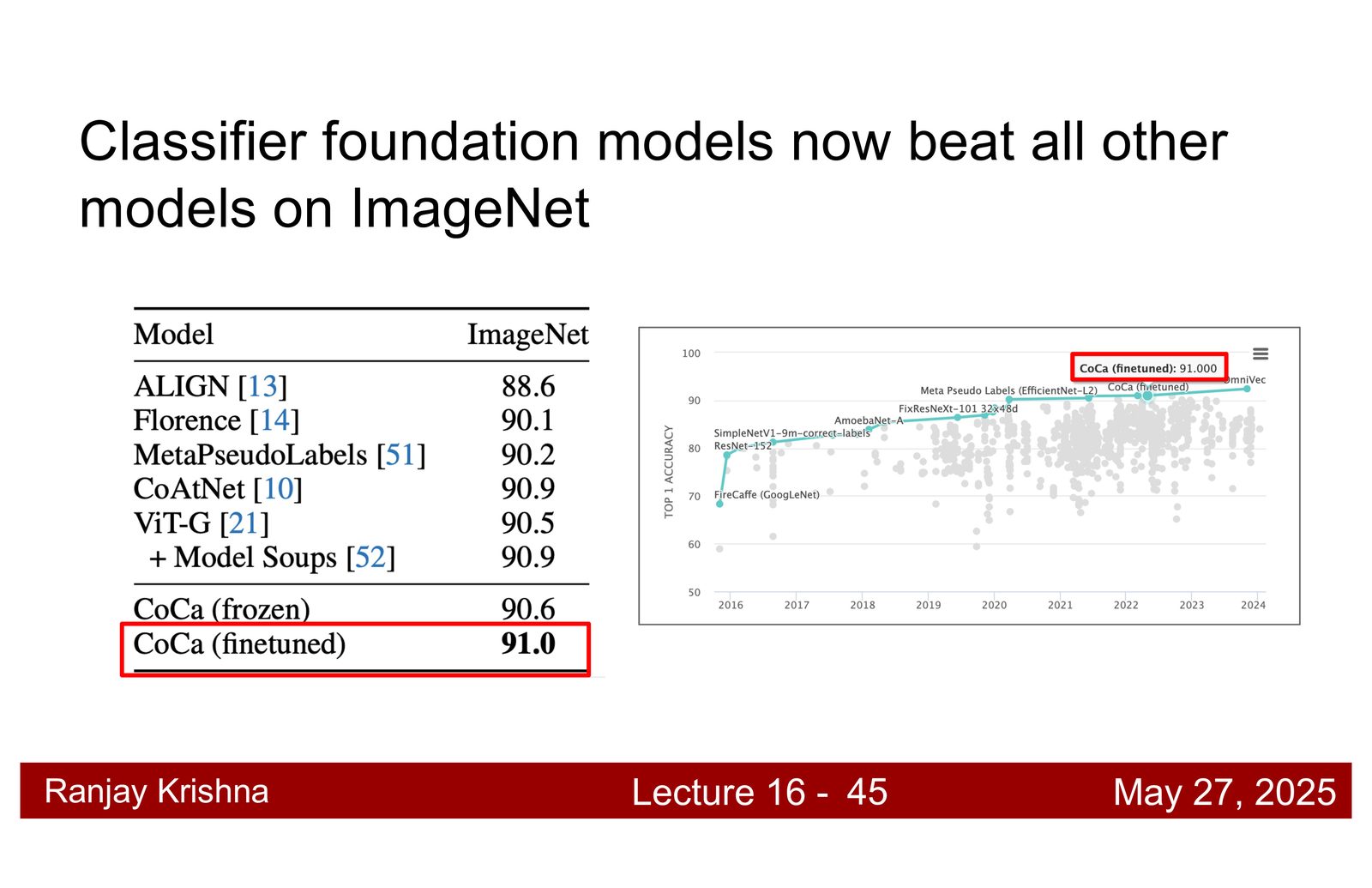
CoCa:对比学习之外再加一个生成头
CLIP 已经很强,但它还是一个纯对比编码器。讲者接着引入 CoCa,思路很直接:如果只做对齐,模型会偏向“会认”;如果再加 captioning 生成目标,模型就必须“会说”,而会说通常意味着必须保留更多细粒度语义。\footnote{字幕 00:19:27--00:19:50 对 CoCa 的动机做了直接说明。}
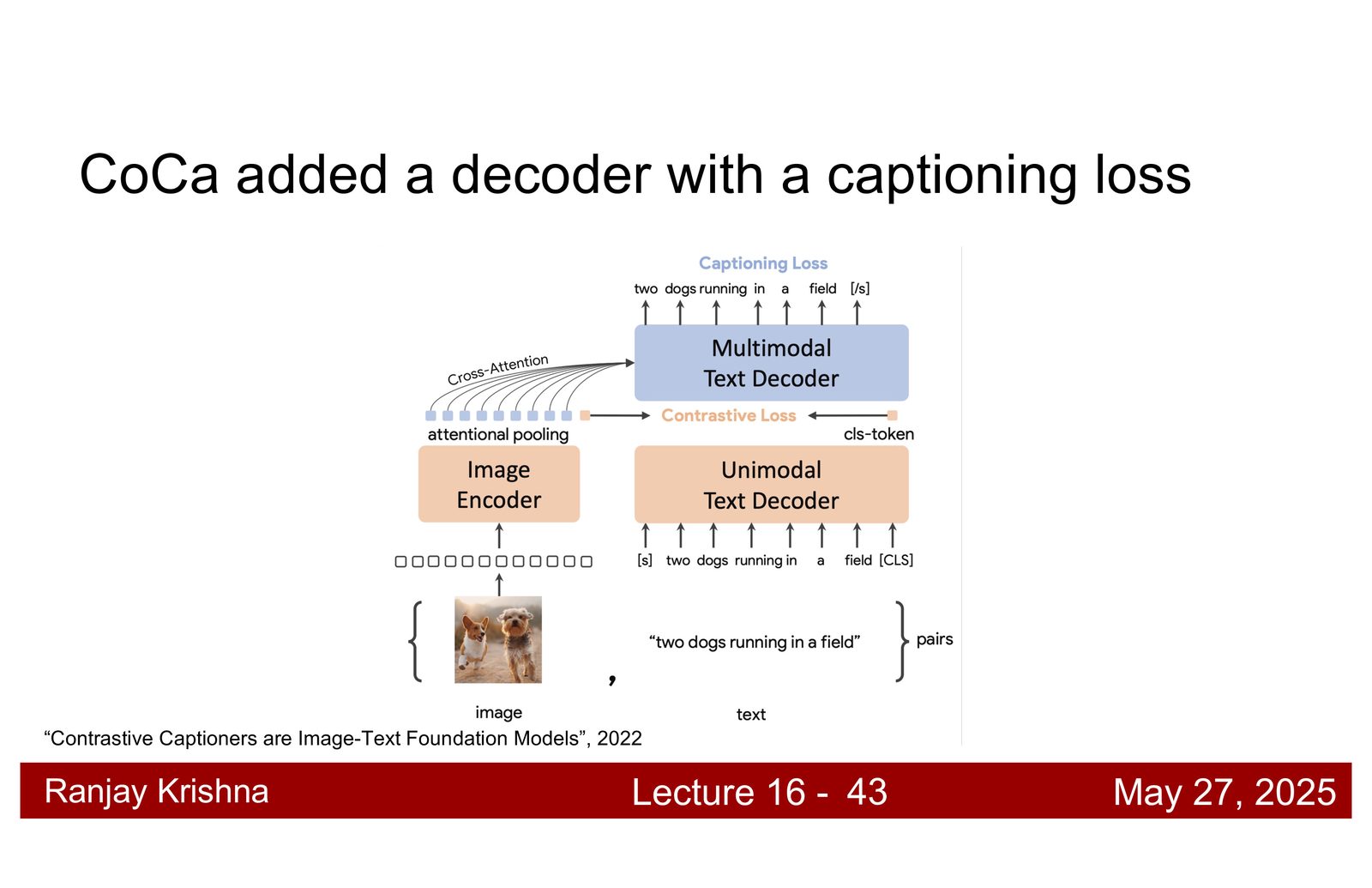
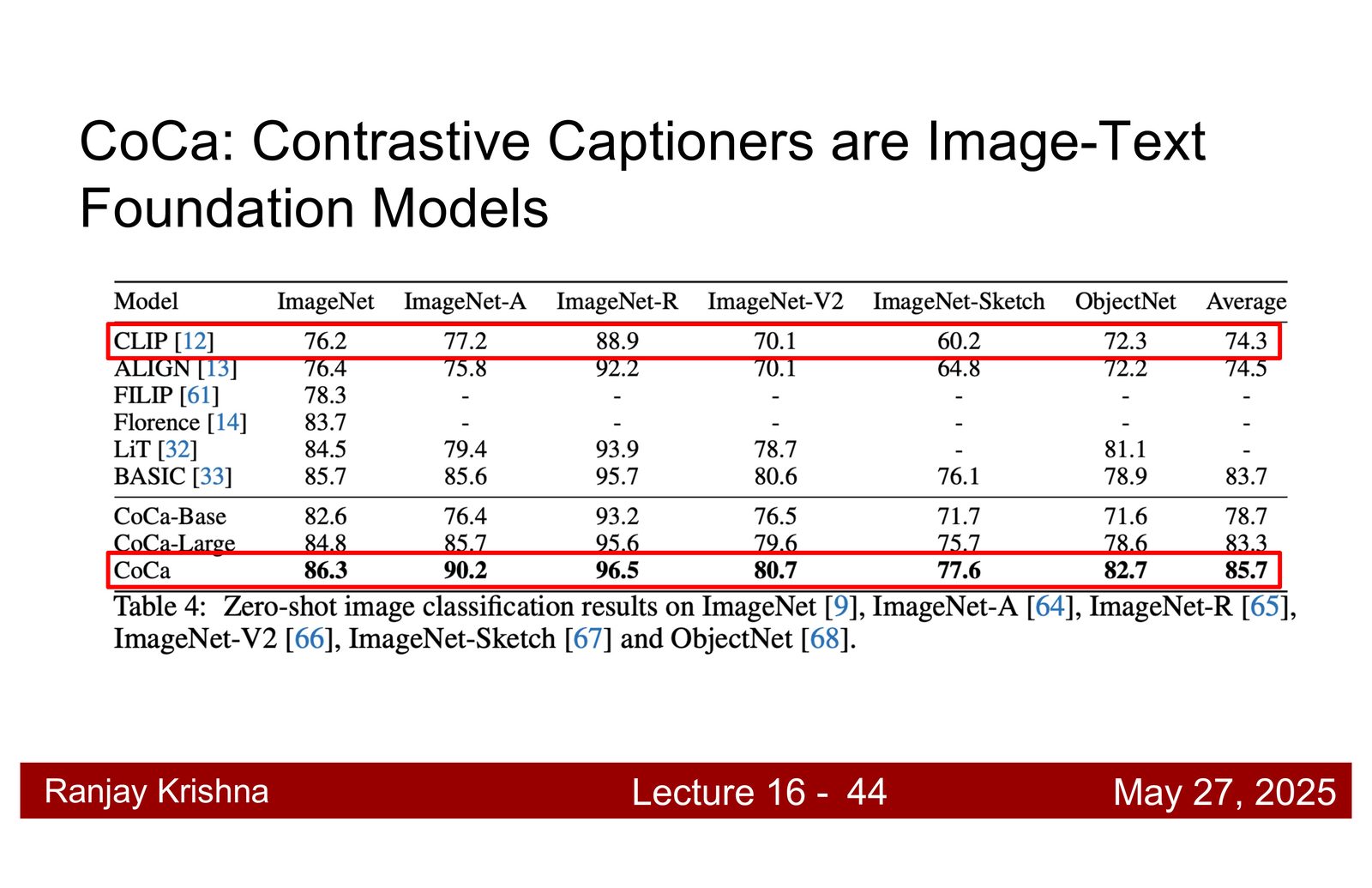
为什么要加 captioning
对比学习擅长对齐图文,但生成目标会迫使模型保留更多区域级、属性级和关系级语义。CoCa 的思路是:既要对齐,也要会说。
CoCa 的直觉
把 captioning 当作一种更难的自监督约束,比只做 image-text matching 更能逼出 richer features。也就是说,它不是替代对比学习,而是在它上面多加一层语言压力。
多模态语言模型:从图文对齐到图文对话
有了 CLIP / CoCa 这条线,下一步自然就是把视觉 token 接进语言模型。讲者先提到了 LLaVA,再提 Flamingo,说明多模态模型的真正目的,不是只做“看图分类”,而是让视觉成为 LLM 推理的上下文。\footnote{字幕 00:26:00--00:29:00 先把视觉语言模型和 autoregressive 语言模型联系起来,再引出 LLaVA / Flamingo。}
LLaVA:最直接的连接方式
LLaVA 的思路很朴素:先用 CLIP image encoder 把图像变成一组 token,再用一个小的投影层把这些视觉 token 映射到 LLM 能理解的空间,最后把它们和文本 token 拼在一起做 next-token prediction。它的关键不是“又发明了一套视觉编码”,而是把已有的视觉特征和已有的语言模型接到了一起。

LLaVA 的关键组件
- 图像编码器负责把图像压成 token。
- 一个线性投影把视觉特征对齐到 LLM embedding 空间。
- LLM 负责生成回答、描述和推理。
讲者还指出,CLIP encoder 并不只有 CLS token 真正有用,penultimate layer 的特征更有空间信息,因此在做多模态接入时,通常会偏向使用更底层、更细粒度的视觉表示,而不是只用最终聚合向量。\footnote{字幕 00:30:19--00:30:59 对 penultimate features 的用途有直接说明。}
Flamingo:把视觉上下文喂进每一层
Flamingo 是这讲里更重要的多模态架构案例。它延续了“视觉 encoder + LLM”的总体方向,但做法比简单拼接更精细。它把视觉特征先经过 perceiver sampler 压缩,再用 gated cross-attention 把视觉上下文注入 LLM 的每一层。也就是说,语言模型不是只在输入端看一眼图像,而是在每层都能选择性回看视觉信息。\footnote{字幕 00:31:20--00:35:10 对 Flamingo 的 cross-attention 和 perceiver sampler 有详细解释。}
Flamingo 的设计重点
- 视觉 encoder 和语言模型大多冻结,训练成本更可控。
- cross-attention 让 LLM 在生成时能动态读取视觉上下文。
- perceiver sampler 把视觉 token 压到固定长度,避免输入过长。
多轮对话和 few-shot reasoning
Flamingo 的强项不是单轮 caption,而是多轮对话与 in-context learning。你可以先给几个图文示例,再让它描述新的图;也可以先给几个问答示例,再问新图。它会把这些上下文当成“例子”,而不是重新训练一个新任务模型。\footnote{字幕 00:37:00--00:39:30 展示了多轮对话、few-shot captioning 和 question answering。}

为什么 in-context learning 重要
它让多模态模型更像“通用接口”,而不是“专用分类器”。研究者不必为每个任务重新微调,只要通过示例就能让模型进入新的任务模式。
Grounding 到像素,才能减少幻觉
讲者后来介绍了一个很有意思的点:如果模型回答“有几条船”,它很容易直接猜一个数字。但如果模型必须先“指向”图中被计数的对象,再给出最终答案,决策就更 grounded,幻觉也会少一些。Momo 就是这样一种做法:先把 decision-making grounded in the pixels,再做最终输出。\footnote{字幕 00:47:29--00:48:30 对 grounding 到 pixels 的设计做了直接说明。}
grounding 的意义
如果模型必须先指出证据,再给出答案,它就更难完全靠语言先验胡编。grounding 不是万能解药,但它会迫使模型把输出和视觉证据绑定起来。
Momo:开放、可复现、可评估的多模态模型
讲者还介绍了他们自己的 Momo。它的亮点不是“更大”,而是更开放:open weights、open data、open code,外加公开评测和用户研究。训练数据规模只有约 70 万图文对,但因为做了精心筛选和 grounding,效果能和更大模型接近。讲者甚至提到,他们做了 870 名用户、325,000 对 pairwise comparison 的用户研究,Momo 在 ELO 上逼近 GPT-4o。\footnote{字幕 00:47:32--00:49:00 和 00:50:00--00:50:40 讨论了 Momo 的数据规模、用户研究和 ELO 结果。}

为什么 open matters
如果模型只靠私有数据和私有训练细节,社区就无法知道为什么它会强,也无法独立复现。开放 weights、data 和 code,才可能把模型能力真正扩散到研究社区。
Chaining:把多个模型串起来做单个模型做不到的事
讲者在最后一段把视角收回到系统设计:foundation model 真正强的地方,不只是“单模型很聪明”,而是可以把多个模型串起来做一件单个模型做不到的事。这就是 chaining。它的基本思想,是把不同模型的长处组合起来,形成一个更可靠、更通用的系统。\footnote{字幕 01:00:25--01:06:30 对 chaining、program generation、retrieval 和 tool use 有非常完整的说明。}
为什么要 chaining
讲者用一个很直观的例子说明:如果 CLIP 认不出一个新类别,但 GPT 能把这个类别描述清楚,那就可以把 GPT 的描述喂给 CLIP 重新做分类。也就是说,text generation 和 visual recognition 可以互相补位。\footnote{字幕 01:01:10--01:02:40 用 Mima、viaduct 等例子说明描述信息可以帮助分类。}

chaining 的本质
把一个模型当作另一个模型的“工具”或者“中间表示生成器”。它的价值不是替代单模型,而是把多个模块的互补能力组合起来。
VisProg:把问题写成程序
讲者进一步介绍了 visual programming 的思路:让 GPT 先生成一个程序,再由程序去调用对象检测、分割、计数等视觉工具。这样,复杂问题就可以拆成多个步骤,每一步由最擅长的模型完成。例如“图里总共有几个船上的人”,可以先检测每张图中的人,再把检测结果加总。\footnote{字幕 01:02:40--01:05:50 对 VisProg 的程序生成思路做了详细说明。}

为什么程序化很自然
很多视觉问题本来就适合分解成子问题:先找对象,再数数量,再做逻辑判断。把这些步骤显式写成程序,往往比让一个模型直接“一步到位”更稳定。
retrieval 和例子选择
chaining 不只是调用工具,还包括 retrieval。给模型什么 examples,会显著影响它的行为;如果能够检索最相关的 in-context examples,系统就会比盲目塞一堆例子更好。讲者把这看作“retrieval for prompting”,本质上和传统检索系统是一类问题。\footnote{字幕 01:05:40--01:06:30 对检索式 few-shot prompting 有直接说明。}
系统成本会迅速上升
chaining 能力越强,系统也越重:要调用多个模型、多个检索器、多个 verifier,成本和延迟都会上升。所以它是能力增强,也是工程复杂度的增加。
hallucination 与 verifier
讲者最后强调,模型输出并不总可信。尤其在多模态场景里,hallucination 还是常见问题。一个现实的系统往往不会把单模型的输出直接交给用户,而是先经过 verifier 或其他检查模块。换句话说,chain 的价值不只是“接上更多模型”,也在于“把风险分层”。\footnote{字幕 01:05:30--01:06:30 讨论了 hallucination 和 verifier,强调大模型输出通常会再过一层验证。}
verifier 的角色
- 检查输出和视觉证据是否一致。
- 降低 hallucination 被直接暴露给用户的风险。
- 让系统从“单点信任”变成“多点审查”。
总结与延伸
本章小结
这门课最后一讲想留下的,不只是几个模型名字,而是一套判断框架。
Lecture 16 的核心 takeaway
- foundation model 的本质是大规模、通用、可迁移的预训练表示。
- CLIP 用图文对比学习把图像和文本放进统一空间。
- zero-shot 分类可以直接把文本当成类别原型。
- scale 对 CLIP 的成功至关重要,尤其是数据和参数。
- CoCa 说明在对比学习之外,加上生成目标也很有价值。
- LLaVA 和 Flamingo 把视觉 token 接进 LLM,打开了多模态对话和 few-shot reasoning。
- grounding、retrieval 和 verifier 是降低幻觉、提升系统可靠性的关键手段。
- 真正强的系统往往是 chaining,而不是单模型裸奔。
这一讲最值得记住的系统观
模型越强,系统设计越不能简化。视觉 foundation model 的价值,不只是“让模型会更多”,而是“让模型更容易被组合、验证和复用”。
最现实的限制
开放模型、开放数据、开放代码虽然重要,但真正“可复现”的能力仍然很难。很多最强的视觉语言模型,外界只能看到结果,看不到完整训练配方。这个缺口本身就是未来研究的主战场。
延伸阅读
- Radford et al., Learning Transferable Visual Models From Natural Language Supervision
- Yu et al., CoCa: Contrastive Captioners are Image-Text Foundation Models
- Liu et al., LLaVA
- Alayrac et al., Flamingo
- Winoground / ARO / CREPE 等 compositionality benchmarks
- CuPL: prompting CLIP-style models with richer class descriptions