[LLM Agents F25] Multi-Agent AI by Noam Brown
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Noam Brown 授课内容整理 |
| 来源 | Berkeley RDI |
| 日期 | 2026-04-02 |
![[LLM Agents F25] Multi-Agent AI by Noam Brown](cover.jpg)
课程导入:多 Agent 不是新概念,但进入了新阶段
Noam Brown 在开场先把范围说清楚:这讲不是只讲一个特定算法,而是把 自博弈、博弈均衡、人类协作、LLM 推理扩展放到同一个框架里讨论。他强调当前很多团队把多 Agent 当成 “工程编排技巧”,但从历史上看,它首先是一个 决策理论问题,其次才是系统工程问题。
本讲主问题
如果目标是构建现实环境中可部署的 Agent,那么我们到底应该优化什么:Minimax Equilibrium,还是 Population Best Response?
他给出的叙事很有针对性:过去十年游戏 AI 的突破,证明了 “递归式自改进” 在特定假设下非常强;但一旦从二人零和、完美信息跳到多人、非零和、带语言协商的环境,原先的漂亮性质会快速失效。

来源:画面来源:Berkeley RDI 课程视频,时间点约 00:02:10。
为什么这讲对 LLM Agent 特别关键
- 它把 “推理时扩展(test-time scaling)” 和 “多体交互(multi-agent interaction)” 放在统一坐标系。
- 它解释了为什么一些在 benchmark 上有效的 agent scaffold,放到真实协作场景会失灵。
- 它给出一个强烈但可检验的命题:在非二人零和任务中,没有目标群体数据,就学不到稳定协作策略。
本章小结
这讲不是 “多 Agent 技巧汇总”,而是一次目标函数审计。先问 “什么是好策略”,再谈如何训练、如何部署。
自博弈三阶段框架:从 AlphaGo 轨迹到 LLM 推理扩展
Brown 把 AlphaGo 和 LLM 的发展轨迹并排比较,形成了一个三阶段模板:
- 在高质量人类数据上预训练(pre-training on human data);
- 放大推理时计算(large-scale inference compute);
- 递归式自改进(recursive self-improvement)。
他用一句非常直接的话概括当前差距:“In LLMs we don't really have that piece”,这里 “that piece” 指的就是像 AlphaGo 一样的可扩展自博弈自提升。
三阶段框架的洞察
真正稀缺的不是 “模型规模”,而是第三阶段里 可证明、可持续、可工程化 的自改进机制。
这套框架在课堂中的价值,是给研究问题重新排序。传统问法是 “多 Agent 还能再加什么模块?”;Brown 的问法是 “为什么在部分环境里 self-play 可以闭环,在另一些环境里会坍缩到脆弱均衡?”。后者更接近根因。
常见误判
把 “LLM 上还没复现 AlphaGo 式提升” 归因于算力不足,是不充分解释。更常见的根因是任务结构不满足二人零和完美信息假设。
从课程上下文看,这个框架也解释了为什么推理模型(reasoning models)近期进展快,但多 Agent 协作仍显脆弱:前者主要在单体推理链路上吃到了 test-time compute 红利,后者则要额外解决策略相容性与群体分布错配问题。
本章小结
AlphaGo 与 LLM 的类比是有用的,但只能用于定位问题,不能直接迁移结论。决定能否自博弈扩展的,是任务博弈结构而非口号。
二人零和世界:Minimax、Exploitability 与 “稳健但不一定最赚”
从扑克问题切入:两种 “最好” 的冲突
Brown 先抛出课堂投票问题:谁是更好的扑克玩家?
- 选项 A:对任何对手长期 head-to-head 都不亏(稳健);
- 选项 B:一年内总盈利最高(收益最大化)。
这两个选项在国际象棋/围棋里往往重合,但在扑克里可能不重合。A 对应 Minimax/Nash 语义,B 更接近对群体分布的 exploit 策略。
术语对齐
- Minimax Equilibrium:在最坏对手下保证不亏损的策略集合。
- Exploitability:相对最优反制(best response)的可被剥削程度。
- Population Best Response:针对某个对手分布最大化收益的策略。
Exploitability 的工程意义
课程中用 Rock-Paper-Scissors 举例。若策略总是出 Rock,则对手最佳反制是总出 Paper,exploitability 极高。若等概率随机化三种动作,则 exploitability 为 0。
这个例子对应到线上 Agent 部署非常现实:当模型面向海量用户暴露接口,策略弱点会被群体发现并复用,因此 “最坏情况稳健性” 不能忽略。
可部署系统的底线
当策略会长期暴露在开放环境中,先压低 exploitability,再追求额外收益,通常比反过来更稳妥。
Minimax 为什么在扑克里仍然 “能赢”
Brown 给出关键解释:在复杂不完美信息游戏中,Minimax 不等于 “只能打平”。因为对手会犯负期望错误(negative EV actions),你即便只守住均衡,也会在长期统计上获利。
这与课堂原句一致:“As your opponents make mistakes, you profit.” 该命题在德扑职业策略里几乎是共识。
误区:把 Minimax 误解成保守策略
Minimax 是风险边界,不是被动保守。它提供的是 “不被系统性击穿” 的地板,而非 “永不利用对手” 的天花板。
Sound Self-Play 的条件
Brown 反复强调:在二人零和前提下,sound self-play 才有收敛保证。这里 sound 不是口号,至少包含:
- 足够探索(sufficient exploration);
- 对策略混合分布的正确逼近;
- 训练过程不会系统性塌陷到可被反制的局部策略。
在理论极限(无限容量和算力)下,这一性质很强:无需人类示范数据,也能收敛到不亏策略。

来源:画面来源:Berkeley RDI 课程视频,时间点约 00:09:40。
本章小结
二人零和提供了一个少见的 “理论与工程同向” 场景:Minimax 定义清晰、可用 exploitability 量化、可由 sound self-play 逼近。但这组性质不应被外推到所有 Agent 任务。
不完美信息下的算法细节:为什么 PPO 不够,Regret 家族更关键
价值依赖混合概率,不只依赖动作本身
Brown 通过 “Rock-Paper-Scissors Plus” 展示难点:某动作价值取决于其被选择概率。也就是说,算法不仅要学 “做什么”,还要学 “按什么频率做”。
形式化可写为:
在不完美信息博弈中,\(\pi_i\) 的混合比例本身就是优化对象。
为什么 PPO 在这里会失效
PPO 对单智能体 MDP 很强,但在需要精确概率混合与对手建模的场景,没有天然收敛到 Minimax 的保证,容易振荡或落入次优循环。
Fictitious Play 到 Regret Matching
课程回顾了三类经典方法:
- Fictitious Play:对历史平均策略做 best response,理论收敛但速度慢。
- Regret Matching:按正 regret 分配动作概率,显著加速。
- Hedge/Regularized BR:用正则化 best response 平衡收敛速度与稳定性。
算法演化主线
从 “精确 best response” 走向 “正则化 best response”,本质是用可控偏差换收敛速度和数值稳定性,这也是现代大规模博弈训练的核心工程策略。
扑克实战与方法选择
Brown 提到其博士阶段扑克系统击败顶级职业选手,关键不是大模型,而是:
- 在不完美信息条件下做有效搜索;
- 在巨大策略空间内逼近低 exploitability 均衡。
Regret 系方法是其中的关键部件。

来源:画面来源:Berkeley RDI 课程视频,时间点约 00:18:30。
工程告警:理论收敛不等于系统安全
即使理论上可收敛,有限模型容量和有限训练步数也会留下 exploitable 缺口。实际部署前应做对抗探测与 exploitability 评估,而不是只看平均胜率。
本章小结
不完美信息环境下,策略概率建模是第一公民。仅靠单智能体 RL 基线通常不足,Regret 家族方法更贴近问题结构。
超越二人零和:Population Best Response、Ultimatum 与人类数据必要性
核心转折:多方博弈下 Minimax 失去解释力
进入非二人零和后,课程结论很明确:“求一个 Minimax” 不再是有意义目标。关键问题转为 “你要对哪个群体最优”。这个群体可能是同类 Agent,也可能是人类玩家,二者分布差异巨大。
Brown 的强主张
若目标是与人类合作并稳定获益,避免使用 human data 基本是死路(dead end)。
Ultimatum Game:同一规则,不同文化分布
在 Ultimatum Game 中,理论 Nash 均衡与人类真实行为常显著偏离。课堂中给出的经验范围是:很多人会在 20%--30% 以上才愿意接受报价,过低报价即使理性上 “应接受” 也会被拒绝。
这对 Agent 训练的含义
没有目标人群行为数据,模型只能学到 “在自博弈里自洽”,却学不到 “在真实人群里可协作”。前者可达成,后者不可自动涌现。
Diplomacy 案例:DORA 与 SearchBot 的交叉失配
课程中最有说服力的证据来自 Diplomacy:
- DORA:纯 self-play 训练,在某些设定里可达超人;
- SearchBot:人类数据驱动策略,在自身群体里表现更稳。
当两类策略群体交叉对战时,出现明显分布错配:各自都可能在 “非本群体” 环境中退化。这证明了多均衡共存与群体依赖性。

来源:画面来源:Berkeley RDI 课程视频,时间点约 00:38:20。
策略评估的常见错误
只在 “同类自博弈池” 里评估就宣布 SOTA,往往会高估跨群体泛化。对外部署前必须做跨群体、跨文化、跨协议评测。
可操作训练配方
Brown 给出的配方可总结为三步:
- 收集目标群体数据并训练 imitation model;
- 放大 inference-time compute,以更准确建模群体行为;
- 让 RL 在 “人类仿真群体环境” 中继续优化。
这是 Cicero 及相关系统成功路径的抽象版本。其本质不是放弃 RL,而是让 RL 在正确分布上优化。
本章小结
非二人零和任务里,“先定义群体,再定义最优” 是必要顺序。没有群体数据,Population Best Response 无法落地。
从竞争到协作:LLM Agent-Agent Cooperation 的机会与硬约束
为什么需要多 Agent 协作
Brown 先从 reasoning model 的成功讲起:test-time compute 增加,性能持续上升。但串行 Chain-of-Thought 存在硬延迟边界,长时任务不可能无限线性等待。
协作侧动机
- Latency:并行采样/并行推理可换取墙钟时间。
- Diversity:不同模型/不同策略在子问题上有互补优势。
- Routing:任务可分发到更擅长的专家模型,类似工具调用。
Consensus 与 Best-of-N
课程中比较了两类简单但高频的并行策略:
- Consensus:多次采样后取多数答案,适合短答案任务;
- Best-of-N:多样本后由验证器选最优,适合可验证任务。
性能与效率权衡
这类方法能降低延迟并提升上界,但通常 计算效率更差,且依赖答案可比较性或可验证性,不是通用解。

来源:画面来源:Berkeley RDI 课程视频,时间点约 00:28:15。
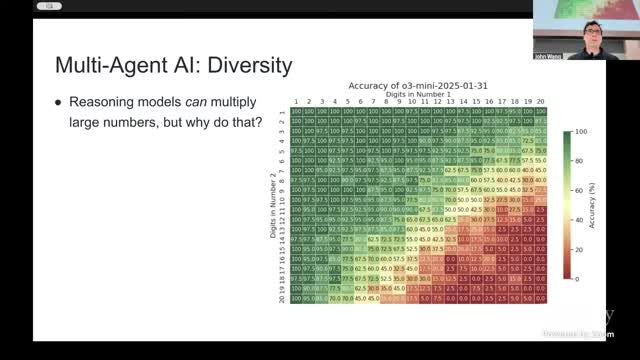
Diversity 与模型路由
Brown 用 “大数乘法应交给计算器” 的比喻说明:最强模型不应吞掉所有任务。多 Agent 的一个高性价比形式,是把路由(routing)当作策略层,让查询进入最匹配专家。
把多 Agent 当银弹的风险
过度堆叠 scaffold 往往得到 “更复杂但更脆” 的系统。若没有稳定通信协议、冲突仲裁与状态一致性,多 Agent 只会放大错误传播。
本章小结
协作式多 Agent 的收益真实存在,但当前更多体现在可验证子任务和路由层。开放式长链协商仍是短板。
当前边界与研究路线:从 “能跑” 到 “可靠协商”
为什么自然语言通信是机会窗口
Brown 指出,多智能体研究历史上长期卡在 “如何让体之间形成通信协议”。LLM 时代这一步骤被显著简化,Agent 可直接用自然语言协商,这是前所未有的红利。
时代性变化
过去需要专门学习 emergent communication,现在默认就有高带宽语言通道。研究瓶颈从 “会不会说” 转向 “说了能否可靠达成一致”。
行业复盘:为什么很多团队说 “先别急着多 Agent”
课程引用了 Cognition 与 Anthropic 的工程复盘:多 Agent 在部分场景有效,但系统常见特征是 “有效但脆”。典型问题包括:
- 长上下文协商中目标漂移;
- 多轮互审导致延迟和成本失控;
- 冲突协调失败时,整体可靠性不如单 Agent。
可落地的可靠性指标
- 协议一致率:多 Agent 对任务目标和约束解释是否一致;
- 冲突收敛率:分歧是否在有限轮内收敛;
- 代价回报比:相对单 Agent 的质量提升是否覆盖额外 token 与时延;
- 失败可恢复性:单个子 Agent 异常是否会拖垮全局。
从课程结论到工程决策
把本讲压缩成一句决策规则是:先判定任务结构,再选优化目标,再选算法家族。
如果任务更接近二人零和,优先 exploitability 与稳健收敛;
如果任务是多人协作,优先群体分布建模与跨群体验证。
来源:画面来源:Berkeley RDI 课程视频,时间点约 00:49:10。
部署前的最低防线
不要把 “demo 上可运行” 误判为 “生产可依赖”。多 Agent 系统必须在对抗输入、跨分布人群、长任务链条下做稳定性回归。
本章小结
LLM 让多 Agent 研究从 “通信可行性” 跨到 “协商可靠性” 阶段。接下来几年的主战场是评测协议、鲁棒协同机制与成本可控的系统化落地。
工程化蓝图:把课程观点映射为可执行研发流程
第一步:先写清楚 “你要对谁最优”
很多团队在项目立项时直接写 “提升 Agent 成功率”,但没有定义成功率针对的群体。按照本讲观点,这会在多人任务中造成根本性偏差。一个可执行写法应至少包含以下字段:
- 目标群体:同类 Agent、人类用户、还是混合群体;
- 目标行为:稳健不亏、平均收益最大,还是合作满意度最大;
- 约束条件:时延、成本、可解释性、安全策略上限。
立项阶段的硬要求
若任务是 “与人协作”,训练分布里必须显式包含目标人群行为样本;否则上线后的群体错配几乎必然发生。
对应到课程原话,所谓 “population” 不是抽象概念,而是必须落在数据治理文档中的实体对象。谁是 population,谁就决定了策略最优性的定义边界。
第二步:训练链路按三层解耦
结合 Brown 在 Diplomacy/Hanabi 的经验,推荐把训练流程拆成三层,每层单独验收:
- Behavior Layer:imitation model,先拟合目标群体可观测行为;
- Inference Layer:放大 test-time compute,提高行为预测与策略评估精度;
- Policy Layer:在前两层构建的环境分布上做 RL 优化。
为什么要分层验收
若把 imitation、search、RL 全揉进一个端到端指标,模型退化时很难定位是 “群体建模失败” 还是 “策略优化失败”。分层验收能把排障成本降一个量级。
一个可复现实验模板如下:
# Layer 1: fit target population
imitation_model = train_imitation(human_or_target_data)
# Layer 2: improve test-time modeling
planner = build_inference_scaler(imitation_model, search_budget=B)
# Layer 3: optimize policy in modeled population
policy = train_rl(env_with(planner), objective="population_utility")
evaluate(policy, cross_population_benchmarks)
端到端捷径的代价
直接在稀疏奖励上做 RL,短期可能拿到局部高分,但会把 “错误人群假设” 固化进策略,后期修复成本极高。
第三步:评测矩阵必须覆盖跨群体迁移
课程里 DORA 与 SearchBot 的交叉失败,本质上就是评测矩阵不完整的反例教材。最低建议是三轴评测:
- 同群体(in-population)表现;
- 异群体(out-of-population)表现;
- 长回合稳定性(multi-turn stability)表现。
| 评测轴 | 核心指标 | 报警阈值示例 | 诊断意义 |
|---|---|---|---|
| 同群体效能 | 平均收益/胜率 | 相比基线提升 \(<2%\) | 训练是否学到任务主干能力 |
| 异群体鲁棒性 | 跨群体收益掉点 | 掉点 \(>15%\) | 是否过拟合单一均衡盆地 |
| 长程一致性 | 多轮目标一致率 | 低于 85% | 协商机制是否可持续 |
| 资源效率 | token/时延成本 | 成本翻倍收益 \(<5%\) | 并行扩展是否具有性价比 |
第四步:上线策略从 “强模型” 转向 “稳协议”
课程后半段关于 scaffold 脆弱性的讨论,实操上意味着架构重点要从 “再加一个 agent” 转为 “协议正确性”。建议至少具备:
- 统一任务语义层(shared task schema);
- 冲突仲裁层(conflict resolver);
- 回退执行层(fallback to single-agent safe mode)。
这三层并不华丽,但通常比再加一个复杂协作循环更能提升生产可靠性。
本章小结
课程观点可以落成一条研发流水线:群体定义 \(\rightarrow\) 分层训练 \(\rightarrow\) 跨群体评测 \(\rightarrow\) 协议化上线。这个顺序不应颠倒。
案例演练:三类典型任务如何选目标与算法
案例 A:对抗型任务(接近二人零和)
如果任务形态类似对抗博弈(例如红蓝攻防模拟),优先目标应是低 exploitability 而非短期平均收益。可采用:
- 自博弈主线训练;
- 周期性 best-response probing;
- 以 exploitability 和 worst-case utility 作为主验收指标。
选择依据
当环境允许对手针对性学习你的策略时,最坏情况风险比平均分更能预测线上生存能力。
案例 B:人类协作型任务(典型非二人零和)
例如谈判助手、多方排期助手、协同决策助手。此类任务应把 Population Best Response 绑定到真实用户群体,并强制包含文化/习惯差异数据切片。
推荐流程:
- 先训练行为模仿模型,覆盖不同用户子群体;
- 再做策略优化,目标是群体总体效用加权;
- 最后做跨群体回归,防止某个子群体被系统性伤害。
分群建模建议
至少按地区、行业、任务偏好、风险容忍度做分桶,否则 “平均最优” 往往意味着 “局部严重失配”。
案例 C:工具调用型任务(代码/数据分析 Agent)
这类任务中多 Agent 收益主要来自路由与并行验证,不必一上来做复杂协商。实践上可以采用:
- Planner-Agent 负责拆分子任务;
- Specialist-Agents 分别处理检索、代码、验证;
- Verifier-Agent 做结果一致性检查并回传置信度。
其收益机理更接近 “专家系统”,而不是 “多方博弈”,因此评测重点也应转为正确率-时延-成本三角。
错误迁移
把谈判博弈中的策略算法原样搬到工具调用任务,常常只会增加 token 消耗,不会增加有效正确率。
统一决策表:先分类,再选目标
| 任务类型 | 优先目标 | 首选方法族 | 主评测指标 |
|---|---|---|---|
| 对抗型 | 低 exploitability | self-play + regret 系 | worst-case utility |
| 人类协作型 | population utility | imitation + inference scaling + RL | 跨群体收益与满意度 |
| 工具调用型 | 正确率/时延比 | routing + verifier 架构 | pass@k、时延、成本 |
本章小结
同样叫 “多 Agent”,三类任务的优化目标几乎不同。先分类再建模,能避免大量无效实验。
失败模式与修复手册:从课程结论到排障 SOP
失败模式 1:只在自博弈池里高分
症状是离线对战胜率很高,但一接入真实用户或异构 Agent 池就显著退化。根因通常是策略只学到单均衡盆地。
修复动作
引入 cross-population league:每轮训练后都与历史版本、人类行为模型、异构外部策略对战,并把退化样本回流训练。
失败模式 2:协作链路过长导致收益反转
多 Agent 层数增加后,质量提升停滞而时延与成本持续上升,典型于 “反复互审” 架构。
简化策略
- 先测单次路由 + 单次验证是否已覆盖 80% 增益;
- 超过两轮协商必须给出边际收益证据;
- 对长链任务设置强制 early-stop 与单 Agent 回退。
失败模式 3:通信一致但决策不一致
看上去 Agent 间交流顺畅,但最终动作互相冲突。说明共享语义层不足,存在 “同词异义”。
协议层警报
只要出现 “文本看似一致但执行冲突”,优先修协议 schema,不要先盲调模型参数。
失败模式 4:文化子群体系统性受损
在谈判或协作任务里,某些用户群体长期收益更低,说明群体建模与加权目标存在偏差。这是训练目标层面的缺陷,不是单次 prompt 能修复的问题。
| 症状 | 优先排查项 | 推荐修复 |
|---|---|---|
| 跨群体掉点明显 | 训练分布是否覆盖目标人群 | 扩充人群样本并做分群目标重加权 |
| 成本暴涨收益小 | 协作轮数与验证器质量 | 减少协商轮次,提升 verifier 准确率 |
| 策略易被利用 | exploitability 探测是否缺失 | 增加 best-response 对抗评测 |
| 长任务漂移 | 共享状态与记忆压缩策略 | 强化 state schema 与阶段性重规划 |
从排障到治理:最小化运营闭环
可把线上治理流程固化为 “监测 \(\rightarrow\) 归因 \(\rightarrow\) 回流 \(\rightarrow\) 回归”:
- 监测:实时记录跨群体性能、冲突率、回退率;
- 归因:区分模型能力不足、协议缺陷、分布漂移;
- 回流:将失败轨迹标注并进入增量训练池;
- 回归:以固定回归集检查修复是否引入新退化。
这个闭环与 Brown 在课程中强调的思想一致:多 Agent 不是一次性设计,而是持续博弈中的动态系统。
本章小结
多数失败不是 “模型太弱”,而是 “目标定义、群体建模、协议治理” 三者有断层。先修系统边界,再追求模型上限。
概念深挖:把 lecture07 变成可验证研究命题
Minimax 与 Population Best Response 的形式化差异
为了避免概念漂移,可以把两者写成不同优化问题。
Minimax(以二人零和为例)通常写作:
Population Best Response 则是:
两式的差异不在符号,而在 “谁定义了对手分布”。Minimax 的对手是最坏情形,PBR 的对手是群体分布。多人协作任务里,后者往往才是部署目标。
课程中的隐含逻辑
Brown 并非否定 Minimax,而是强调其适用域。离开二人零和后,继续把 Minimax 当总目标,等价于把错误 inductive bias 注入训练过程。
为什么 “二人零和中 cheap talk 无效” 值得重视
课程给出的是一个非常工程化的证明直觉:若通信动作对发送方有利,接收方会忽略;若通信动作对发送方有害,发送方不会说;唯一稳定情况是通信无效。
这个结论可转化为系统设计原则:在严格对抗任务中,花大量预算做自然语言协商机制,边际收益通常很低。
设计原则
当任务接近二人零和时,优先投入 “策略鲁棒性与对抗评测”,而非 “多轮语言协商复杂度”。
反过来,在非零和或协调博弈中,通信可显著改变可达均衡集合。此时 “是否能通信” 不是关键,“通信后是否能稳定收敛” 才是关键。
从课堂陈述到可检验实验:命题矩阵
为了让讲义可直接用于研究立项,下面把课程核心观点转成实验命题:
| 命题 | 最小实验设计 | 可接受结论标准 |
|---|---|---|
| P1:自博弈外推受限 | 在同任务中比较 self-play-only 与 human-augmented 两条线,并做跨群体评测 | self-play-only 在跨群体指标显著退化 |
| P2:PPO 在不完美信息混合策略上不稳 | 用同一环境对比 PPO 与 regret 系,统计 exploitability 下降曲线 | regret 系在稳定性和收敛速率上占优 |
| P3:Consensus 只在短答案优势明显 | 分别在短答案与长文生成任务中测 consensus 增益 | 短答案提升显著,长文本提升有限或回撤 |
| P4:Best-of-N 依赖验证器质量 | 固定采样预算,替换不同 verifier 并测最终正确率 | 验证器精度与系统增益呈强正相关 |
| P5:人群分布决定协作最优策略 | 在不同文化/偏好分组上训练并交叉测试 | 组内最优策略在组外交叉明显失配 |
实验汇报中的常见失真
只报 “平均分提升” 而不报跨群体方差,会掩盖部署风险。对多 Agent 系统,方差往往比均值更有决策价值。
研究者常问问题(FAQ)
Q1:是否还值得做纯 self-play?
值得,但要把目标限定在对抗稳健或可控博弈子空间,不要默认它会自动学到人类协作规范。
Q2:多 Agent 与工具调用有什么关系?
工具调用可视为 “异构专家协作” 的最简形式,通常比开放式自由协商更易控、也更容易评测。
Q3:如何判断是否该加更多 agent?
看边际收益曲线。如果新增 agent 只带来很小质量提升但显著增加时延与成本,应回退为更简单架构。
Q4:课程中提到的 “现在是好时机” 如何理解?
因为通信门槛已由 LLM 大幅降低,真正瓶颈转移到协议可靠性和群体泛化,这是可做出新贡献的空白地带。
本章小结
lecture07 的最大价值是把讨论从 “多 Agent 要不要做” 推进到 “在什么目标和分布下做才对”。当命题可检验、指标可复现时,这门课就从观点变成了研究工具。
总结与延伸
全讲核心观点总表
| 主题 | 课程观点 | 工程含义 |
|---|---|---|
| 优化目标 | 二人零和可用 Minimax;多人协作需 Population Best Response | 先定义目标群体,再定义最优策略,避免目标错配 |
| 自博弈边界 | Self-play 在特定博弈假设下极强,超出后性质丢失 | 不要把游戏 AI 成功经验直接平移到开放式 Agent 任务 |
| 算法选择 | PPO 类方法在不完美信息博弈无收敛保证;Regret 家族更贴结构 | 训练与评估中显式监控 exploitability 与混合策略质量 |
| 人类协作 | 无 human data 难以学到稳定的人类协作策略 | 建立高质量人类轨迹库与文化分布覆盖,作为训练底座 |
| 协作扩展 | Consensus/Best-of-N 有效但受任务可验证性约束 | 多 Agent 先落地在可验证子任务与路由层,再扩展到开放协商 |
| 系统现实 | 当前多 Agent scaffold 常见 “有效但脆” | 以一致率、收敛率、成本回报比做上线门槛 |
给学习者的复盘清单
- 你当前任务属于哪类博弈结构?是否真的适合 Minimax 叙事?
- 你的评测人群是谁?训练分布与目标分布是否一致?
- 你的多 Agent 增益来自并行采样、专家路由,还是可靠协商?
- 你是否有明确的失败恢复与冲突仲裁机制?
进一步阅读
- Noam Brown 等,Libratus/Pluribus 相关论文(不完美信息博弈与低 exploitability 求解)。
- Bakhtin, Wu, Brown 等,DORA(No-Press Diplomacy from Scratch)。
- CICERO 相关论文(自然语言谈判 Agent,与人类同场对抗)。
- Regret Matching、CFR(Counterfactual Regret Minimization)及其加速变体文献。
- Cognition 与 Anthropic 关于 multi-agent scaffold 的工程复盘文章。
结语
这讲最值得带走的不是某个技巧,而是一条方法论:目标函数必须与部署群体一致。当这一点成立时,多 Agent 才会从 “复杂编排” 走向 “稳定增益”。