CS224R Lecture 9: RLHF 与偏好优化
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Stanford CS224R 公开课程整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年 5 月 12 日 |

从语言模型到助手
预训练语言模型的局限
预训练语言模型学会了补全文本,但这不等于帮助用户。语言建模目标与"满足人类偏好"之间存在根本性的不对齐。
预训练学到了什么
预训练通过大量文本学到了丰富的知识:事实、语法、共指消解、情感分析、基本推理、数学、编程等。但它学到的是"下一个最可能的 token",而不是"用户最想要的回答"。
人类偏好的多样性
真实用户偏好并不是单一的奖赏函数,而是由多个维度组成:任务完成度、创造性、礼貌、可解释性、甚至审美。Archit 在讲座中称“偏好是一个多模态的向量空间,而非单一标量”,并强调在构建信号时一定要分层采集。
我们可以按来源将偏好分为:
- 人类比较:用户或标注者给出回答队列,挑选最优者。
- 可验证指标:数学题目、编程任务、事实一致性等可以自动打分。
- 行为数据:点击率、重写率、跳出率等隐含用户满意度。
- 治理约束:安全、合规要求需要额外的 guardrail 信号。
偏好矩阵建模的洞察
把多个偏好信号组合成 hierarchical preference matrix,能够明确每种信号的作用范围,并在优化时以加权方式对齐不同目标。
多信号偏好可解释化
把 signal 分成primary preference(核心满意度)和secondary constraint(安全、bias)两类,分别用 reward model 和 guardrail filter 处理,能减少 reward hacking 并提升治理透明度。
本章小结
预训练 LM 具有丰富的知识,但要变成助手必须从指令微调、偏好信号拆分、治理信号嵌入等多个维度对齐,才能避免单一 reward 走偏。
Instruction Finetuning
基本方法
收集 (instruction, output) 对,在预训练模型上继续做监督微调。
Instruction Finetuning 的效果
FLAN-T5 在 1800+ 任务上进行 instruction finetuning 后,在未见过的任务上表现显著提升。更大的模型从 finetuning 中获益更多。
数据策略与对齐
- 在数据层面,先做 prompt rewriting 和 canonicalization,减少语义重复,再标注最佳回答与备选回答。
- 用多轮对话模拟,增加上下文依赖;对负样本加入多样化错误类型,提升 robustness。
- 采集指令时,同时保留 user intent metadata(任务类型、复杂度、偏好)以便后续 reward model 进行分层建模。
Instruction 数据的可解释化
把每条 instruction 附上 metadata,使得训练时可以根据意图(如creative vs. factual)动态选用 reward signal,减少因单一 loss 导致的泛化误差。
数据质量胜过模型大小
虽然更大的模型具备更强的底层能力,但 instruction 微调的数据质量决定了最终助手的可靠性。对抗性字段、多样化指令和人工审查是基本保障。
Instruction Finetuning 的局限
- 开放式生成没有标准答案:创意写作等任务无法用唯一正确输出来监督。
- Token 级别的惩罚不区分错误严重程度:语言建模损失对所有 token 错误一视同仁。
- 人类生成的答案本身不完美:标注数据有噪声。
本章小结
Instruction finetuning 是从 LM 到助手的第一步,必须配合数据策略与偏好拆分,才能为 RLHF 或 DPO 提供稳定的初始策略。
RLHF:从人类偏好中强化学习
核心框架
- Instruction Finetuning:作为初始化。
- 训练奖励模型:从人类偏好比较中学习 \(R_\phi(x, y)\)。
- RL 优化:用 PPO 等算法最大化奖励模型的输出。
奖励模型训练
人类比较两个回答并选择更好的那个。使用 Bradley-Terry 模型:
损失函数:
为什么用比较而不是评分
人类给绝对评分时噪声大且校准不一致。成对比较更简单、更可靠:只需判断"A 比 B 好"而不需要"A 是 7.3 分"。
Policy Gradient 用于 LLM
将 LLM 生成视为 RL 问题:
使用 REINFORCE / policy gradient:
直觉:高奖励的生成增加概率,低奖励的生成降低概率。
KL 正则化的必要性
不加约束地优化奖励模型,策略会 exploit 奖励模型的弱点(reward hacking)。标准做法是加入 KL 惩罚:
其中 \(p_{\mathrm{ref}}\) 是 SFT 模型。\(\beta\) 控制策略偏离初始模型的程度。
奖励数据质量控制
偏好数据的质量直接决定 reward model 的泛化能力。常见的质量维度有:比较一致性、标注员经验、context diversity 以及 hard negative 比例。
| 维度 | 实施做法 |
|---|---|
| 一致性 | 多轮盲审,计算 Cohen's kappa;不一致条目发送给高级审查 |
| 多样性 | 故意补充 creative、factual、multi-turn prompt,避免 reward 只对某类指令上调 |
| 硬负样本 | 采集 near-miss 回答,让 reward model 区分 subtle flaws |
| 元数据 | 记录 intent、topic、difficulty,以便在训练时按人类意图分层采样 |
质量胜于模型大小
Reward model 归因链上最薄弱的一环通常是 label quality,而不是参数尺寸。构建 audit trail 并把 inconsistency 反馈给 labeler,是提升对齐稳定性的捷径。
策略正则化与采样策略
KL 不只是 regularizer,也是在 sampling 过程中维持多样性的手段:
- 在 PPO 中用 KL constraint 监控策略 drift,如果某次 rollout 的 KL 超阈值立即恢复到 reference。
- 加入 entropy bonus 让策略不会 collapse 到 deterministic 解。
- 通过 temperature sweep 和 rejection sampling 评估 reward model 的 risk surface,并记录在 rollout ledger。
KL 作为审核机制
Archit 强调:“KL 让模型在走得太远之前先听到参考政策的自我批评”,这让 reward model 与 reference policy 之间保持健康对话。
本章小结
RLHF 的完整 pipeline:instruction finetuning \(\to\) 奖励模型训练 \(\to\) PPO 优化。数据质量控制、KL 正则化与采样策略共同保障 reward model 不走偏,才能把 LM 变成可靠的助手。
DPO:Direct Preference Optimization
绕过奖励模型
DPO 的核心洞察
RLHF 中带 KL 约束的 RL 问题有闭式解:
反过来可以将奖励表示为策略的函数:
将此代入 Bradley-Terry 模型,\(Z(x)\) 项相消,得到 DPO 损失:
DPO 的优势:
- 不需要训练单独的奖励模型。
- 不需要 RL 训练(无需 PPO)。
- 只需要标准的监督训练循环。
- 训练更稳定、更简单。
DPO 的直觉
DPO 损失隐式地做了两件事:
- 增加被偏好回答 \(y_w\) 的概率。
- 降低不被偏好回答 \(y_l\) 的概率。
权重由 \(\sigma\) 函数内部的"隐式奖励差"自动调节。
DPO vs. RLHF
- RLHF:训练奖励模型 \(\to\) RL 优化。两阶段,需要 RL 基础设施。
- DPO:直接在偏好数据上优化策略。单阶段,只需 SFT 代码。
- 理论上 DPO 与 RLHF 优化的是同一个目标。
- 实践中 DPO 更简单但可能在某些场景下不如 RLHF 灵活。
实践与参数选择
DPO 训练过程中几个关键要素:
- 选取稳定的 reference policy,通常用 instruction finetuned checkpoint。
- 调整 \(\beta\) 以控制偏好程度:\(\beta\) 越小,策略越接近 reference;越大,则更容易强化偏好。
- 采样权重需要兼顾头部和尾部,避免 reward model 只偏好高概率回答。
| 超参 | 推荐设置 |
|---|---|
| \(β\) | 0.1-1.0,按照偏好强度进行 sweep,观察 KL 与 accuracy trade-off |
| Reference policy | SFT checkpoint + small RL finetuning for stability |
| Batch composition | 保留 balanced ratio 的 winning/losing pair,避免 collapse |
DPO Training Insight
DPO 把 reward scoring 转换成 logits 差值,因此观察 \(\log \pi_\theta / \pi_{\mathrm{ref}}\) shift 就可以直观判断偏好强化程度。
本章小结
DPO 通过将 RL 目标的闭式解代入 Bradley-Terry 模型,将偏好优化简化为纯监督学习问题。结合 \(\beta\) sweep 与参考策略选择可以在精度与稳定性之间取得平衡。
RL for LLM Reasoning
超越偏好:可验证奖励
在数学、编程等领域,答案是否正确可以自动验证。此时不需要人类偏好,可以直接用正确性作为奖励进行 RL 训练。
RL for Reasoning 的兴起
DeepSeek-R1 等模型展示了 RL 训练能让 LLM 学会推理中的自我纠错和思维链等能力。这是 RL 在 LLM 中除对齐之外的另一个重要应用方向。
可验证奖励的设计
可验证任务常见信号包括:
- 逻辑一致性:自动判别数学解答是否满足步骤逻辑。
- 合成推理:用 symbolic executor 检查推理链条,reward 直接反馈到 token。
- 生成式验证:用 verifier LM 对 candidate 回答打分,作为 auxiliary reward。
| 任务类别 | 可验证信号 | 典型指标 |
|---|---|---|
| 数学推理 | steps correctness | chain-of-thought accuracy、full solution correctness |
| 编程 | unit test pass rate | pass@k、runtime exceptions |
| 知识问答 | factuality consistency | TruthfulQA、F1 against evidence |
自监督 verifier 的作用
当人工比较不可行时,引入自监督 verifier(如 program executor 或 verifier LM)可以生成 reward signal,保障 reasoning RL 的闭环。
实验与评估
DeepSeek-R1 等工作常用 baseline:Instruction tuned LM + RLHF contrast、DPO、RL for reasoning pipeline。验证方法包括 LM 生成、多轮提示和 external verifier 检查。
Reasoning RL 的洞察
“RL 为模型提供了自我纠错的机制,而不是仅仅加强模仿”——这种反馈让 model 在面对长链推理或 multi-hop question 时更愿意 traverse deeper reasoning tree。
评估时也要考虑 inference latency,因为 reasoning RL 常常需要 rollouts 和 verifier,部署时需要权衡 real-time 体验。
本章小结
RL 在 LLM 中不仅用于对齐(RLHF/DPO),也服务于 reasoning:通过可验证奖励与 verifier pipeline,模型得到自我纠错的监督;实验中需要同时考量 correctness 与 latency trade-off。
评估与证据
Benchmark Stack
偏好优化的目标是让模型在多种 benchmark 上展现一致进步。常见的评估层次:
| 层次 | 示例指标 | 说明 |
|---|---|---|
| 自动化 benchmark | HumanEval、MMLU、TruthfulQA | 量化能力与 reasoning |
| 偏好一致性 | Pairwise Preference Accuracy | 奖励模型能否预测人类偏好 |
| 对齐检查 | Red Team、Safety Gym | 模型在安全边界内的表现 |
| 部署指标 | Rejection Rate、Hallucination Rate | 实际使用中体验质量 |
Evidence Matrix
部署前需要整理 evidence matrix,搭建对齐与验证的证据链:
| Evidence | Source | Metric | Decision Use |
|---|---|---|---|
| Pairwise human ranking | crowdsourced label studio | Accuracy | Reward model calibration |
| Automated guardrails | prompt test suite | Reject rate | Safety filter tuning |
| Long-context consistency | multi-turn benchmark | Drift score | Deployment guardrail |
| Deployment logs | tooling + telemetry | Incident count | Postmortem loop |
Calibration 与 Robustness
不仅需要对齐 evaluation,还要在不同语义注入、上下文长度、token budget 变动时保持稳定。常见措施有:
- 对 reward model 输出做 temperature calibration 到 0-1 区间
- 建立 multi-context benchmark,检测 evidence drift
- 用 counterfactual prompt (e.g.
change numeric context) 验证 reward 变化趋势一致 - 记录 rejection case IDs 以便 drill-down
偏好模型 drift 误判的风险
即便 reward model 在训练集表现良好,也可能在实际 prompt 中 drift。如果没有 calibration 和 drift detection,就无法保证 alignment 在部署后仍然成立。
部署指标与 evidence ranking
当模型进入灰度或全量部署后,evaluation stack 需要稳健对接监控层:
- Rejection/deferral rate:判断 guardrail 是否过于宽松或严格。
- Hallucination trend:按 topic 分组,查看 hallucination rate 是否在特定方向聚集。
- Latency drift:策略更新后 latency 是否突破 SLO。
- Evidence score:把 benchmark、human eval、deployment logs 建立分层排序,为 decision board 提供实时依据。
Evidence ranking 的价值
把不同阶段的 evidence 赋予不同权重(例如:部署 logs > benchmark),可以在不牺牲安全的前提下快速推进版本迭代。
评价仪表盘需要实时可视化
Archit 提醒:“Evidence matrix 不是写在文档里的表格,而是在 dashboard 上不断更新的热力图”,只有实时可视化才能发现 drift 盲点。
本章小结
评估与证据体系需要从 benchmark 到部署层层覆盖,Evidence Matrix 是把不同信号拼接成可执行结论的枢纽,deploy metrics 则把 evaluation stack 延伸到 production。
工程与监控
RLHF Pipeline Timeline
把 RLHF pipeline 拆成阶段,便于团队协作:
- 数据构建周:instruction + comparison data 采集
- 奖励建模周:重复训练 + calibration + validation
- 策略优化周:PPO 或 DPO 迭代 + KL/entropy tuning
- 质量检查周:benchmark + red team + human eval
- 监控与 rollout:gradual deployment + drift monitoring
Action Timeline
每个阶段都定义清晰的 deliverable:数据构建结果、奖励模型 blueprints、PPO checkpoint、审查报告、部署决策。这样团队才知道什么时候可以推进下一步。
Operational Monitoring
部署后必须持续监控 hallucination、rejection、latency。

观察盘的指标设计
推荐同时展示:Reward score drift、human rejection rate、token latency、deploy coverage。不同指标组合可以帮助团队快速判断是 model drift 还是 data drift。
| 指标 | 说明 |
|---|---|
| Reward score drift | 用 rolling window 比较 current vs baseline reward distribution |
| Reject ratio | 审查反馈的拒绝率,用于评估 guardrail 灵敏度 |
| Latency P99 | 保障 transformer + verifier pipeline 不超出 SLO |
| Human override count | 人工干预次数,用来 calibrate automation trust |
Governance Checklist
| 控制点 | 核心问答 | 输出 |
|---|---|---|
| Reward model approval | 是否经过 blind eval validation? | Approval checklist |
| Policy guardrails | 是否有 automatic rejection for forbidden topics? | Guardrail rules |
| Deployment gating | 是否逐步扩容、扣留异常? | Rollout policy |
Drift Detection 架构
一旦模型上线,需要检测两类 drift:prompt drift(用户输入变化)与 distribution drift(输出行为变化)。
- 在 logging pipeline 中捕获 prompt signature(hash + metadata)
- 用 rolling window 统计 reward score distribution
- 提供 alert,当 KL divergence vs zscore 超阈值时触发 human review
- 建立
drift ticket,包含 snapshot prompt, reward score, output diff
Drift detection 不只是 anomaly detection
它需要 context-aware thresholds:不同任务(summaries vs math)对 reward score 的 variance 本身就不同。缺乏 context-specific threshold,会造成大量假告警。
本章小结
工程层面要把 timeline、监控和治理结合起来,监控 dashboard 和 checklist 是部署后信任的重要基础。
Ops Playbook
- Observe:聚合 reward scores、rejection logs、prompt hash。
- Assess:用 evidence matrix 与 counterfactual prompt 检查 drift。
- Act:让 AI 推荐 low-risk 缓解动作并生成 rollback plan,人工批准后执行。
- Document:把决策写回 checklist / runbook,供下一轮 evaluation 使用。
| 阶段 | 输出 | 核心参与者 |
|---|---|---|
| Observe | Reward + guardrail logs | SRE + Data Eng |
| Assess | Evidence scorecard + drift report | Alignment + QA |
| Act | Rollback plan/mitigation action | Product + Legal |
| Document | Runbook entry + retrospective | Ops + PM |
Ops runbook 的价值
把每次 Act 往返写成 runbook 条目,不仅可以 guarantee 复现,也在 board review 时提供透明的 audit trail。
AI 主要做 triage,决策仍需人类把关
即使 AI 建议某条规则,仍要在高风险线路上让人类审核,防止自动化误判导致不可逆后果。
本章小结
工程层面要把 timeline、监控、治理、drift detection 与 ops playbook 串成闭环,才能在灰度/全量阶段维持 alignment 信任。
部署与信任
部署复盘与回滚
每次 release 后都需要做 pre-mortem、post-mortem 与 rollback 验证:
- Pre-mortem:在 rollout 之前模拟 worst-case prompt drift,确认 guardrail 覆盖。
- Post-mortem:收集 rejection log、reward score drift,在 incident log 中备注。
- Rollback 验证:设计 rollback playbook,先在 staging 里演练 restore checkpoint、recover guardrail。
预拟事故的价值
在产品经理批准 rollout 之前先做一次预估风险演练,可以把 high-risk prompt 列入 watchlist,避免事故发生时手忙脚乱。
| 复盘阶段 | 内容 |
|---|---|
| Pre-mortem | drift risk list、evidence matrix 检查、guardrail traceability |
| Post-mortem | reward score drift graph、human override log、root cause analysis |
| Rollback | reference checkpoint + runbook、alert escalation path |
多角色治理与信任
Alignment pipeline 不只是 research,治理团队、法律、SRE 都需要参与:
- 研发团队负责 reward model + policy update。
- 运营/监控团队负责 drift alert、dashboard。
- 法务/合规负责 guardrail audit、privacy review。
- PM + decision board 根据 evidence ranking 最终决定 rollout 或 rollback。
多角色治理的设想
把 evidence matrix 声明为 multi-stakeholder checkpoint,例如:每次 policy update 都要让 compliance team 复核 long-form prompts。
风险放大链条
如果缺乏 governance checkpoint,就会出现 reward model fine-tune 后拉高某类 prompt,但 compliance 没有 catch,导致 high-risk reply 直接进入 production。
本章小结
部署与信任需要 pre-mortem/post-mortem+rollback 以及多角色的 evidence governance,只有这样才能在不断迭代的 RLHF pipeline 中维持 alignment 信任。
案例与研究方向
Visual Agent Evidence
关键幻灯片展示了 evidence matrix 与 agent swarm 之间的耦合:
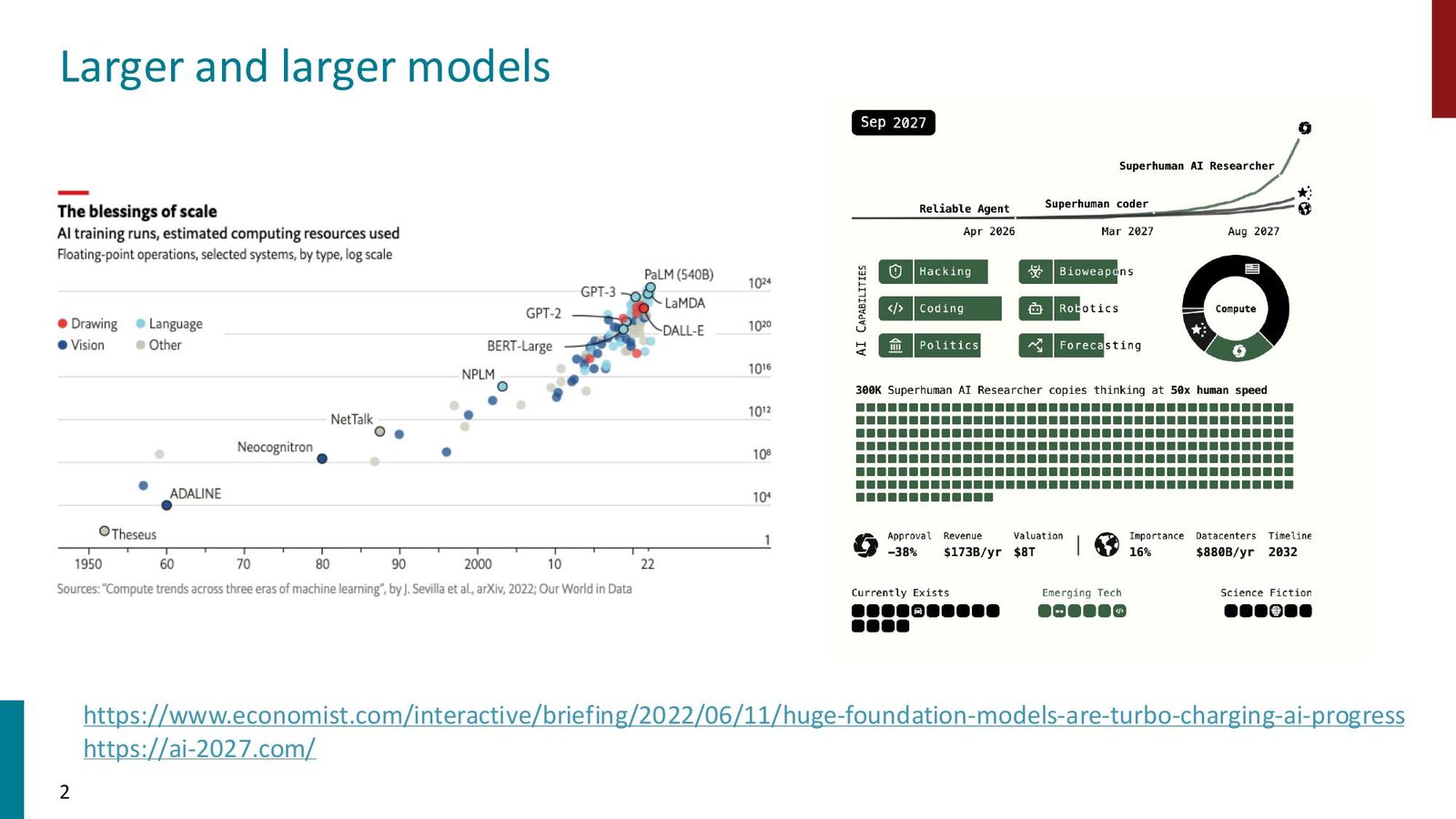
Slides 与实践映射
Slide 3 把 timeline、monitoring、governance 串成矩阵,提醒团队在每个阶段都要有明确的可交付 artifact。
幻灯片到产出的映射
在部署前,把 slide 中的 timeline、artifact 与 checkpoints 映射为 sprint backlog,可以确保每个 deliverable 都有人负责。
Research Directions
未来研究可以关注:
- 把 reward model calibration 与 policy evaluation auto-connected
- Multi-agent 身份下的 preference alignment
- Explainability layer 使 KL 约束可解释
- Sim-to-real research 让 reward model 适应更宽泛场景
Archit 还特别强调,需要把理论研究与实际 deployment 反馈循环起来:新的研究方向必须能生成可执行 playbook,而不仅仅是 paper-level insight。
研究方向的工程可解释性
让研究成果可落地的关键是工程可解释性:解释 KL margin、reward model drift、agent dash board 指标,才能让产品经理和法律团队信任 alignment pipeline。
本章小结
案例部分把 slide 上的视觉证据、agent swarm 结构与未来研究方向串起来,提醒我们 RLHF 还在快速演化。
行动清单与下一步
部署前准备
在 rollout 之前,需要收敛以下交付物:
- Data readiness:确认 preference dataset 覆盖新的 prompt cluster,避免 distribution shift。
- Model readiness:检查 RLHF 有 limit order,DPO/dRL 版本保持 KL margin。
- Governance readiness:所有 guardrail policies 都写入 policy doc,compliance team 签署。
准备阶段的自动化清单
把 readiness checklist 反向链接到 issue tracker,每个 item 通过 automation bot ping 相关 owner,确保没有漏项。
上线后反馈
部署后要保持持续反馈循环:
- 依赖 evidence dashboard 触发 auto-alert,当 reward drift+latency spikes 同时发生时自动 escalate。
- 每周汇报 ops scorecard:reward score drift、human override、rejection trend。
- 用 post-deployment study 检查 new prompts、adversarial tests、user complaints 是否同步反馈到 labeling pipeline。
持续反馈的重要性
Auto-alert 帮助快速发现 drift,但真正的 alignment 还是要靠 weekly review meeting,把 quantitative signals 转换成 qualitative insights。
本章小结
完整的行动清单包括部署前的 readiness checklist 与 deployment 后的 feedback loop,只有严密闭环才能把 RLHF pipeline 的 research 变成 resilient product。
幻灯片与可视化证据
策略与证据分层:Slide 0-04

Slide 0-04 展示了多个 evidence signal 如何在同一个 timeline 中被收集与审查,提醒 teams 不能只关注一个 benchmark,而要将 evidence matrix 变成操作性的 dashboard。
分层 evidence dashboard
在 dashboard 中将 benchmark、human eval、deployment logs 做 stacked view,可以更容易定位哪一层 signal 首先 drift。
运营节奏:Slide 0-05

每个阶段都配有 artifacts:data stage 有 prompt catalog;training stage 有 KL margin report;deployment stage 有 drift alarm;monitoring stage 有 ops playbook。这样的节奏图可以作为 quarterly planning 的 reference。
操作节奏的关键
用 timeline+artifact view 让跨职能团队可以在 planning 会议中快速达成共识,从而避免 alignment 逻辑在交付与监控之间断层。
质量矩阵:Slide 0-06

该幻灯片把 quality gate、trust signal 和 governance checkpoints 组合成一个矩阵,便于把 evidence 逐层传递给 product、ops、legal。
不要孤立强化某条 signal
只加强 automation metric(如 latency)而不结合 governance checklist,会导致高效但不安全的版本上线。Slide 0-06 提醒我们要在矩阵中保持 balance。
本章小结
这些幻灯片提供了 visual anchor,把 abstract 的 RLHF pipeline 编织成 layer-by-layer 的 evidence-dashboard、ops rhythm、governance matrix,有助于 cross-team alignment。
总结与延伸
- 从预训练 LM 到助手需要三步:instruction finetuning、奖励建模、策略优化。
- RLHF:训练奖励模型 + PPO 优化,是 ChatGPT 等模型的核心技术。
- DPO:将偏好优化简化为监督学习,无需 RL 基础设施。
- KL 正则化防止 reward hacking,是偏好优化的关键组件。
- RL 在 LLM 推理(数学、编程)中展现出巨大潜力。
- 偏好比较比绝对评分更可靠,Bradley-Terry 模型是标准框架。
- 部署阶段需要 evidence dashboard、drift alarm 与 ops playbook,形成实时监控闭环。
- 将每次 drift intervention 写入 runbook,与 governance checklist 联动,确保审计跟踪和快速恢复。
总结表
| 主题 | 核心收获 | 工程行动 |
|---|---|---|
| Instruction Finetuning | 提供基本能力 | 用大规模 instruction data 初始化模型 |
| RLHF + KL | 通过奖励模型 + KL 限制实现 alignment | 维持 reference policy,避免 reward hacking |
| DPO | 偏好优化可以不依赖 RL | 直接训练策略,降低基础设施复杂度 |
| Pipeline Monitoring | 需要 timeline + checklist | 建立 dashboard、guardrail checklist |
| Evidence Matrix | 多信号联合验证对齐 | 把 benchmark, drift, red team 和 logs 结构化 |
| Deployment Trust | Pre-mortem/post-mortem + multi-role governance | 建立 rollback runbook、明确责任与 evidence matrix 对齐 |
拓展阅读
- Ouyang et al., Training Language Models to Follow Instructions with Human Feedback (InstructGPT, 2022)。
- Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO, 2023)。
- DeepSeek-AI, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2025)。
- Chung et al., Scaling Instruction-Finetuned Language Models (FLAN-T5, 2022)。