CS224R Lecture 12: 多任务 RL 与目标条件 RL
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于公开课程资料整理 |
| 来源 | Stanford Online |
| 日期 | 2025 年春季 |

Model-Based RL 补充:合成数据生成
本讲的前半部分先把上一讲尚未讲完的 model-based RL 收尾。Chelsea Finn 的切入点很明确:如果我们已经学到了一个能够预测未来状态的模型,那么它除了拿来做 planning,还能不能用来制造更多训练数据,从而反过来训练一个更强、更便宜的策略?

从 planning 走向 policy optimization
上一讲讲的是 “给定当前状态,用 learned model 在测试时搜索未来动作序列”。这一讲更进一步:如果测试时反复搜索太贵,能否把 model 提供的预测能力转成策略学习阶段的数据增广工具?
这一节真正要解决的问题
planning 与 policy optimization 的分工不同:
- planning 的优点是灵活,目标换了仍能重算。
- planning 的缺点是 test-time compute 高,而且长 horizon 时模型误差累积明显。
- 直接学策略的优点是部署便宜。
- 直接学策略的缺点是如果训练数据不够,策略很难学稳。
因此,最自然的问题就是:如何用 learned model 为策略制造更多有效数据,同时避免把模型误差放大到无法控制。
Dyna 风格的数据增强
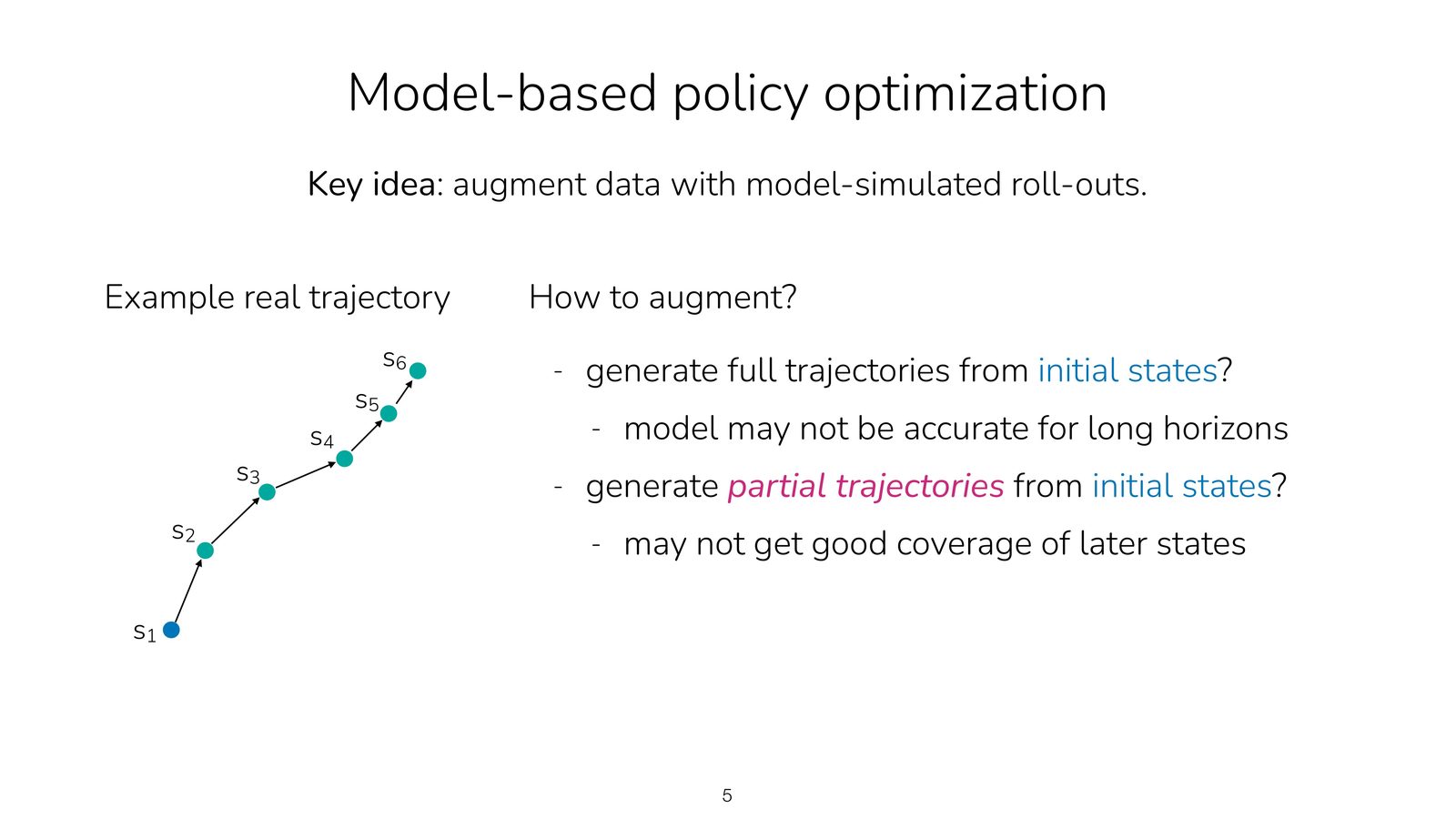
课程把这个问题讲得非常具体。假设我们已经在真实环境中收集到若干轨迹,那么模型生成数据时至少有三种策略:
- 从初始状态开始 rollout 很长的轨迹。
- 只从初始状态开始做短 rollout。
- 从数据集中所有已出现过的状态出发做短 rollout。
第三种策略是本讲推荐的核心做法,因为它兼顾了覆盖面与误差控制。
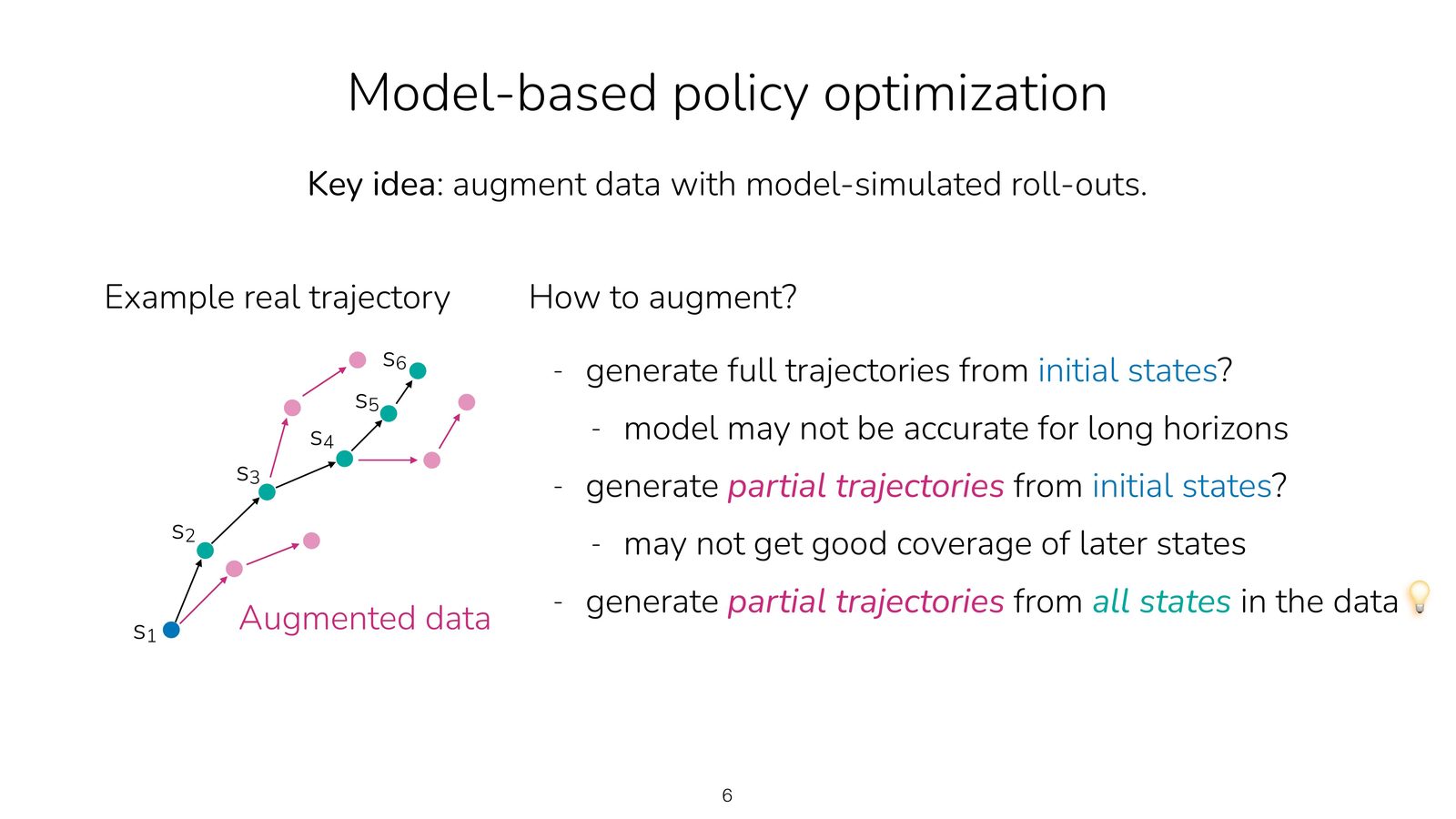
为什么 “短 rollout + 所有状态” 是最稳妥的
- 如果只从初始状态生成长轨迹,模型误差会在长链条上不断放大。
- 如果只从少数起点生成短轨迹,后续状态覆盖又会严重不足。
- 从数据中的所有状态出发做短 rollout,本质上是在真实分布附近做局部外推,最能兼顾稳定性与覆盖度。

什么时候值得学世界模型
model-based RL 的诱惑很强,因为它看起来像 “会想象未来”。但 Chelsea Finn 的判断标准很克制:关键不在于模型是否听起来高级,而在于它是否真的比策略更容易学。

讲者给出的判断原则可以概括成一张简表:
| 场景特征 | 更可能有利于 model-based | 风险点 |
|---|---|---|
| 真实交互昂贵 | 可以靠 synthetic rollout 提高数据效率 | 模型偏差被策略吸收 |
| 动力学相对规则 | 世界模型较容易学出可用近似 | 容易低估长 horizon 误差 |
| 奖励经常变化 | 同一模型可服务多个下游目标 | 不代表模型本身优化了任务表现 |
| 环境高度随机或部分可观测 | 未必适合 | 可能比直接学策略更难 |
不要把 model-based 当成默认更强的路线
世界模型需要单独训练、单独调参,还会引入新的误差来源。若环境动力学本身比策略更难学,或者 rollout 稍长就会失真,那么学模型反而可能让整个系统更脆弱。
世界模型不只有一种形式
课程最后提醒:传统 forward dynamics \(p(s_{t+1}\mid s_t, a_t)\) 只是世界模型的一种。inverse model、多步 inverse model、只预测未来观测的模型、甚至 transition tuple 的联合分布都可能在特定任务里更有用。

本章小结
model-based RL 在这一讲里被重新定位为一种数据增强工具:关键不是做最完美的世界模拟,而是用足够准确的局部模型在真实数据附近扩充训练样本,并始终把模型偏差控制在可接受范围内。
多任务强化学习
动机:为什么 RL 迟早要走向 generalist policy
讲者把多任务 RL 的动机说得非常直白:真实世界中的智能系统几乎从不只面对单一任务。通用助手要处理旅行预订、购物、问答;机器人要走路、下蹲、搬运、清理;推荐系统要面对不同用户偏好。真正的问题不是 “某个策略能否学会一个任务”,而是 “我们能否训练出一套能够在许多任务上共享知识的策略”。


任务其实就是一组不同的 MDP
多任务 MDP 的形式化
将多任务问题写成一组 MDP \(\{\mathcal{M}_i\}\),每个任务都可能在状态空间、动作空间、初始状态分布、动力学和奖励函数上发生变化。实际训练时,常把任务标识 \(z_i\) 并入状态,写成:
于是策略就变成条件策略 \(\pi(a\mid s, z)\)。
这个定义比很多直觉化的 “任务标签” 更宽泛。一个任务不一定只是 “做不同事情”,也可能是不同用户、不同初始配置、不同动力学设置,甚至不同身体结构。

任务标识如何提供给策略
任务描述 \(z\) 可以采用多种形式:
- One-hot task ID:实现简单,但几乎不支持零样本泛化。
- 自然语言指令:更适合开放词汇任务,也更容易与 VLA/LLM 结合。
- 目标状态:把任务写成 “去到哪里”。
- 奖励参数或视频示范:适合任务有更复杂语义时使用。

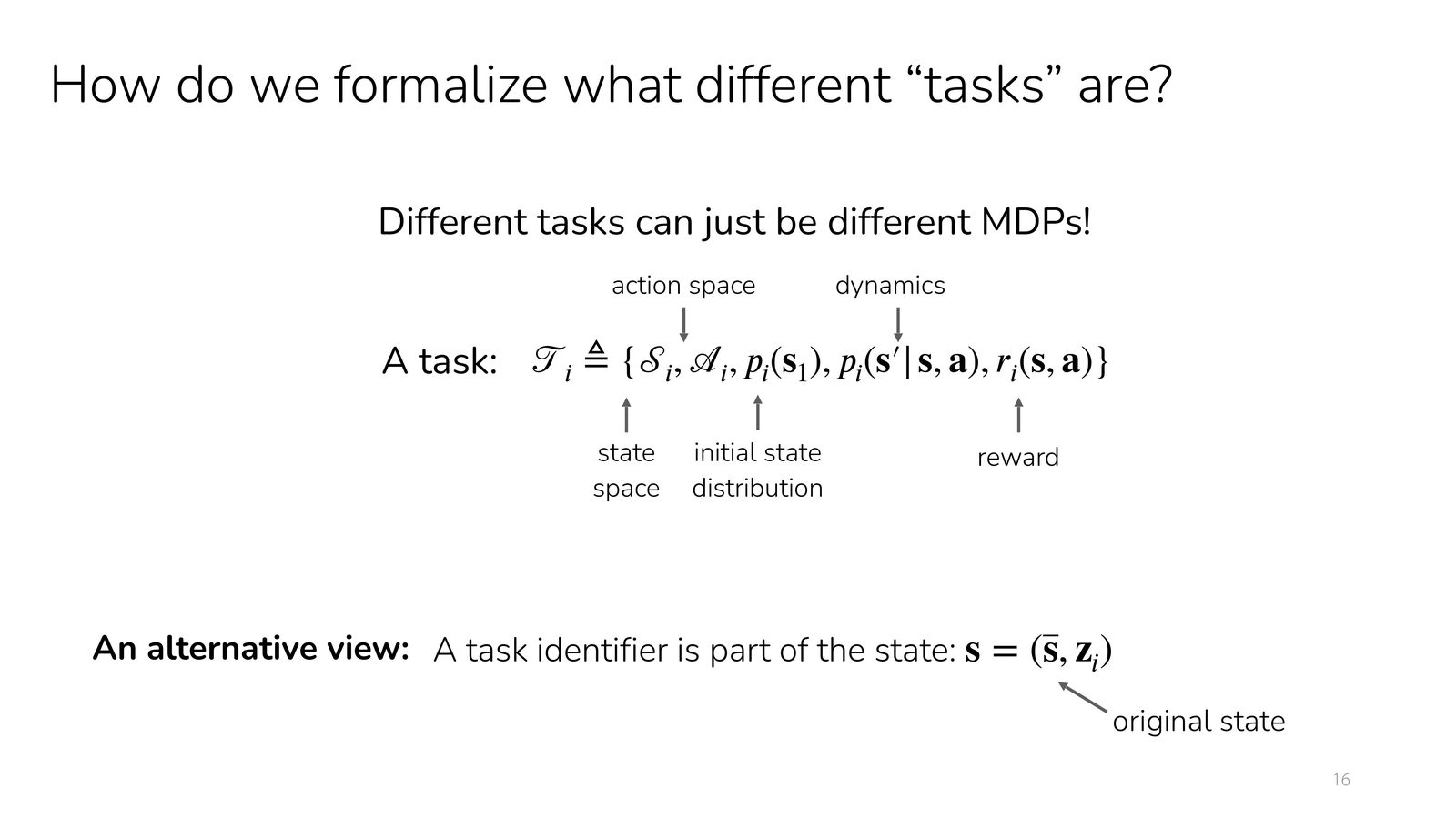
这个重写的重要性
一旦接受 \(s=(\bar{s}, z)\) 的写法,多任务 RL 就不再需要一整套新的 RL 数学。单任务里的 policy、Q-function、critic 基本都可以直接条件化改写:
- \(\pi_\theta(a\mid s)\rightarrow \pi_\theta(a\mid \bar{s}, z)\)
- \(Q_\phi(s,a)\rightarrow Q_\phi(\bar{s}, a, z)\)
这也是多任务 RL 在工程实现上远没有表面那么陌生的原因。
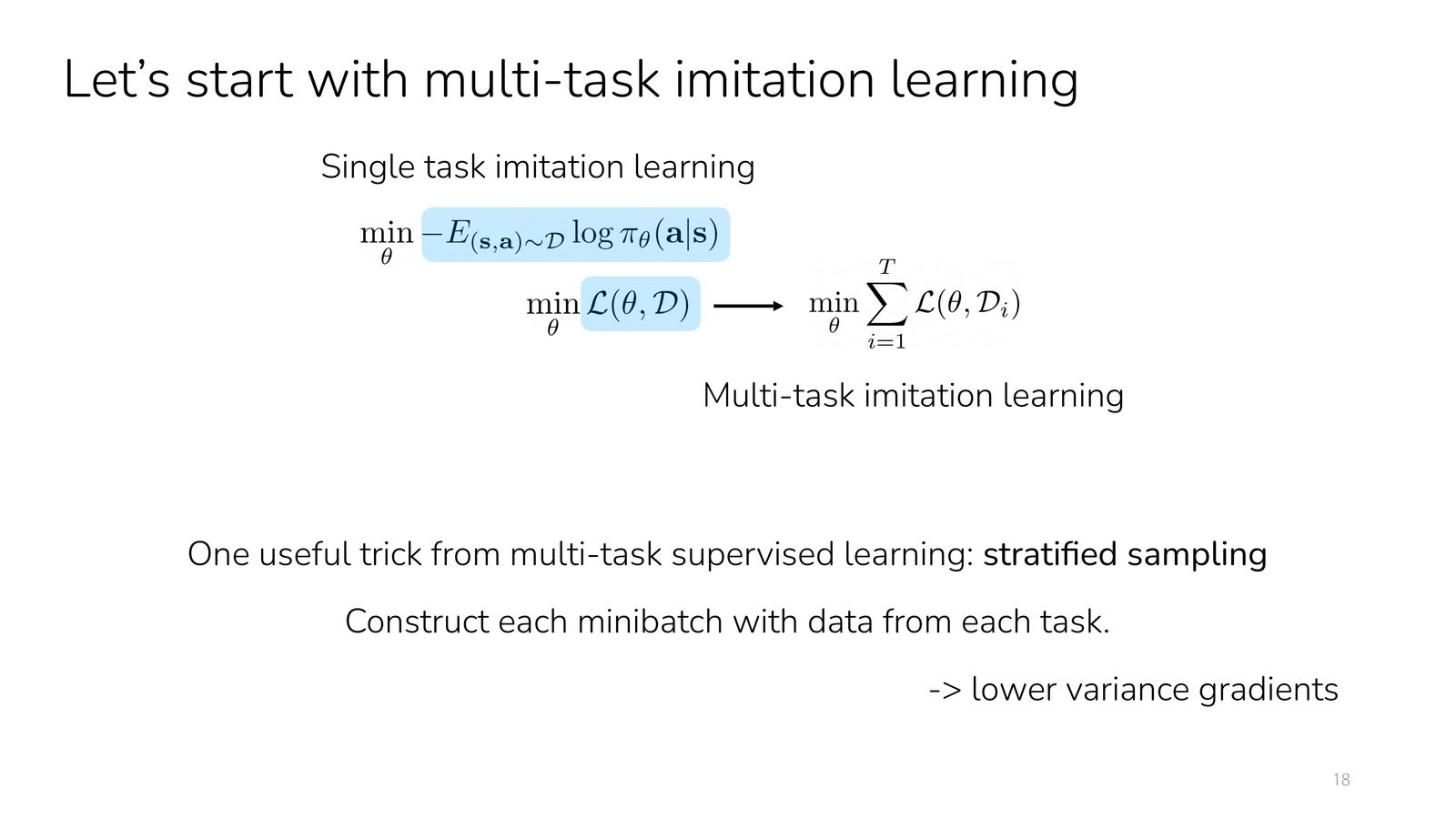
多任务 imitation learning 的具体做法
最直接的多任务学习方式仍然是行为克隆:收集多个任务的演示数据,训练条件策略 \(\pi_\theta(a\mid s,z)\)。但课程特别提醒了一个经常被忽视的实践技巧:stratified sampling。也就是让每个 mini-batch 尽量包含多个任务的数据,避免训练被高频任务主导。
多任务学习为什么能共享数据
不同任务之间经常共享技能子结构。例如 “拿起红方块” 和 “拿起蓝方块” 共享抓取动作;“擦桌子” 和 “收拾厨房” 共享移动与定位能力。多任务学习的本质价值,就是让这些局部技能在共享参数里被复用,而不是为每个任务单独从零学一遍。
从 BC-Z 到 OpenVLA:任务条件的现代输入方式
slides 还特意给了两类例子,说明 task conditioning 近年来如何与 foundation model 融合:
- BC-Z 一类方法用明确的 task embedding 或多模态条件,追求 zero-shot 任务泛化。
- OpenVLA 这类系统则更直接,把任务描述作为 prompt 输入到视觉-语言-动作模型中。
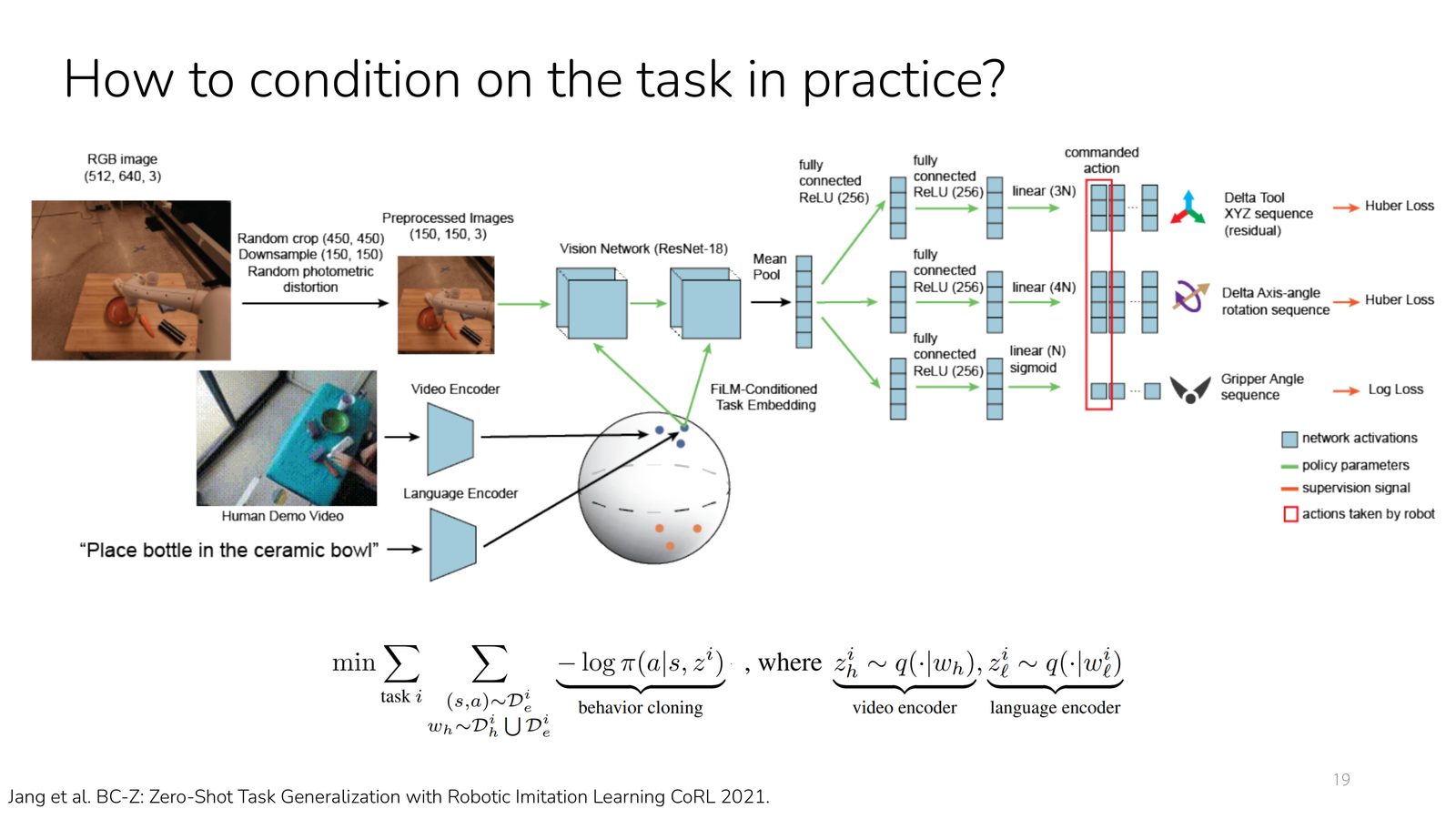
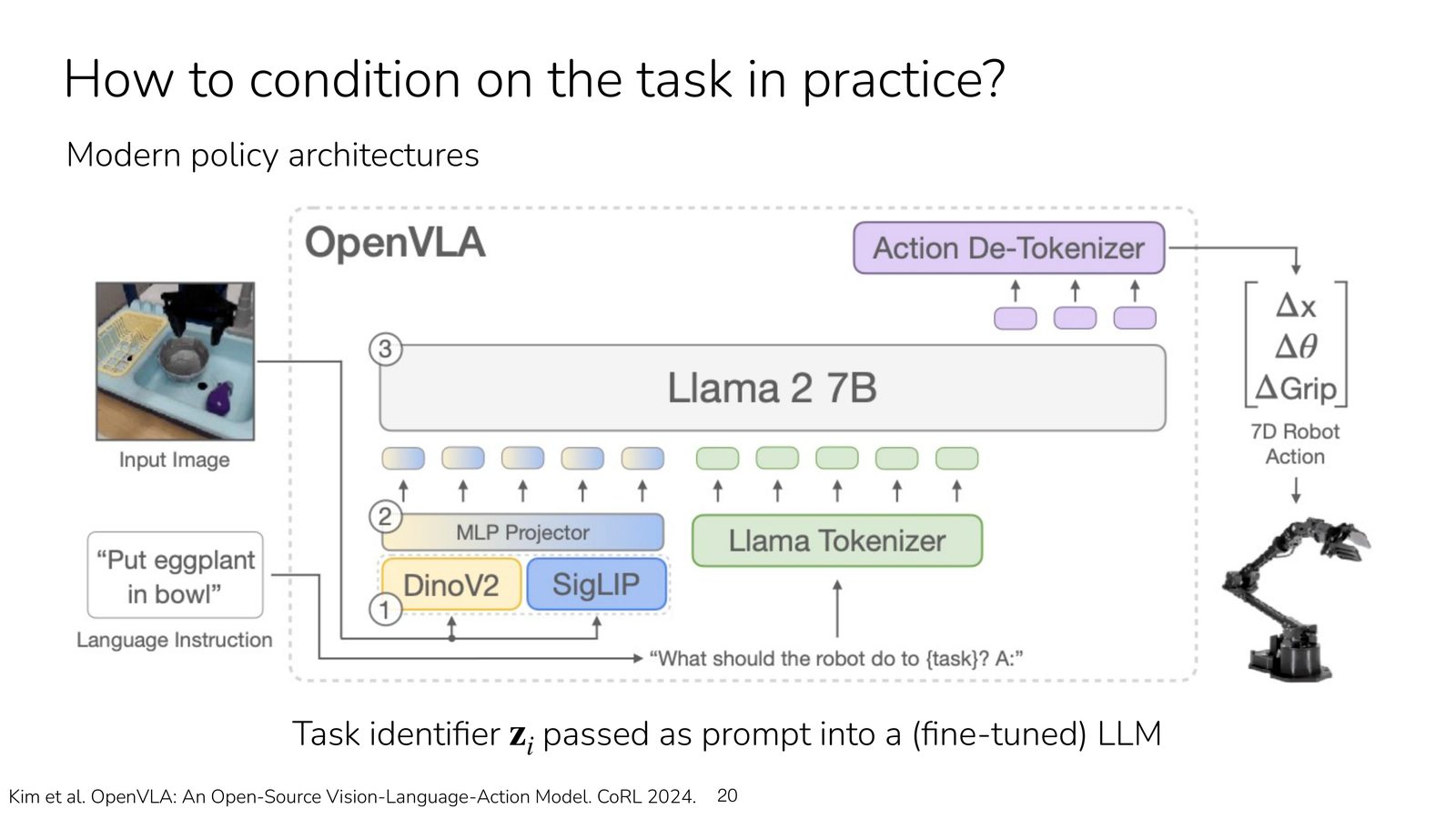


本章小结
多任务 RL 的核心不是 “在一个网络里塞进更多任务”,而是通过条件化把不同任务写成同一策略要解决的一组相关问题。只要任务之间存在共享结构,数据复杂度就有机会被多任务训练摊薄。
目标条件强化学习
把目标状态当成任务描述
Goal-conditioned RL 是多任务 RL 最重要、也最自然的特例:任务标识不再是抽象 task ID,而是一个目标状态 \(g\)。此时策略写成 \(\pi(a\mid s,g)\),奖励写成目标达成奖励或目标距离:
目标条件 RL 的形式化
- 策略:\(\pi(a \mid s, g)\)
- 稀疏奖励:\(r(s,a,g)=1\) 当且仅当 \(d(s,g)<\epsilon\)
- 稠密奖励:\(r(s,a,g)=-d(s,g)\)
- 目标:学到一条从任意起点去往任意目标的通用策略
一旦把目标也视为 task descriptor,那么多任务 RL 的很多技巧都能直接搬到 goal-reaching 任务上。
经验能否跨目标复用
这一节真正有意思的地方在于:Chelsea Finn 并没有把 HER 讲成一个孤立技巧,而是先问了一个更普遍的问题。假设我们在任务 1 上收集到了一条经验,这条经验是否也能对任务 2 有帮助?如果可以,我们就该尝试用新的任务标签和新的奖励重新解释这条轨迹。

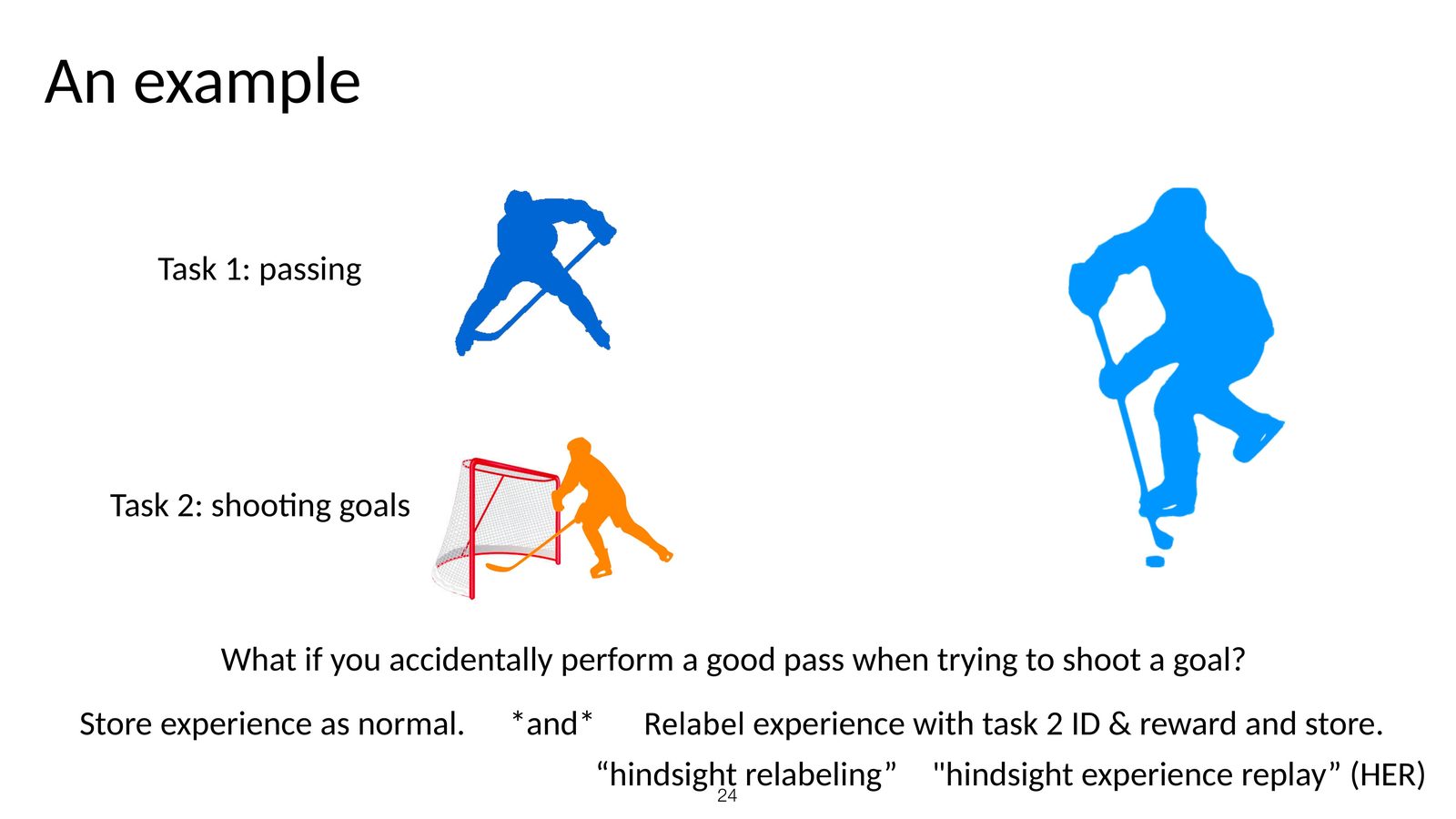
Hindsight Relabeling 的通用流程
HER(Hindsight Experience Replay)
HER 的核心思想是:即使轨迹没有完成原目标,也可以用它实际完成的其他目标来重新标记这条轨迹。
课程把这个过程拆成四步:
- 用当前策略收集轨迹 \(\tau=(s_{1:T}, a_{1:T}, z, r_{1:T})\)。
- 先按原任务标签把数据存进 replay buffer。
- 再挑选新的任务/目标,重算奖励,形成 relabeled trajectory。
- 把原始轨迹与 relabeled 轨迹一起用于 off-policy 更新。

什么时候可以安全做 relabeling
课程在 slide 上给出了三个前提:
- 奖励函数在新任务下是可计算的。
- 不同目标之间的动力学保持一致或足够一致。
- 训练算法是 off-policy,因为同一条经验会被重复利用。
为什么 goal-conditioned RL 特别适合 HER
goal-conditioned 场景里,relabeling 简化到了最优雅的形式:如果轨迹最后到达了 \(s_T\),那就把目标改成 \(g'=s_T\),并据此重算整条轨迹的奖励。于是,一条原本因为没达到指定目标而 “全零奖励” 的失败轨迹,立即变成一条在新目标下的成功样本。

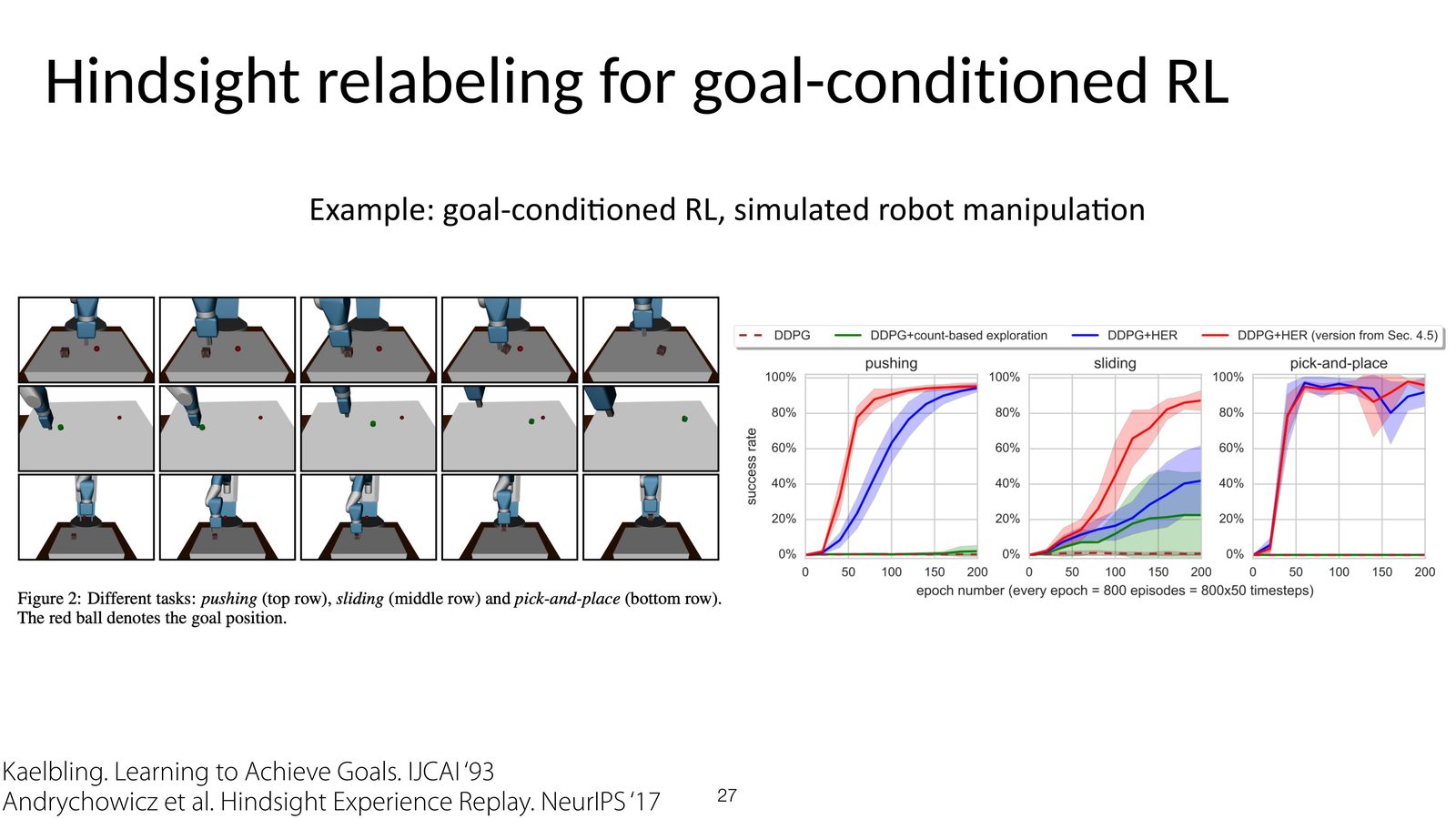
HER 的隐含假设
HER 不是在任何任务上都能无脑使用。它要求奖励能够对新目标重算,要求目标之间共享动力学,还要求 replay buffer 中的重标记样本不会破坏训练稳定性。若奖励本身非常语义化或不可重评,HER 就未必适用。
HER 为什么这么有效
HER 最深刻的地方在于它改变了我们对失败数据的看法。很多 RL 轨迹之所以 “没用”,不是因为它们没有信息,而是因为我们给它们贴了过于狭窄的目标标签。HER 通过 hindsight 的重写,把 “没有达到我想去的地方” 变成 “但我确实到达了某个地方”,于是每条轨迹都为可达性结构提供了监督。
本章小结
Goal-conditioned RL 把多任务 RL 的思想推到了最自然的形态,而 HER 则进一步说明:在稀疏奖励任务里,真正稀缺的不是经验,而是如何解释经验的方式。
总结与延伸
本讲完整串起了三条路线:用 learned model 扩充数据、用任务条件化构建 generalist policy、用 hindsight relabeling 把失败轨迹转化为有效监督。三者虽然表面不同,本质都在回答同一个问题:如何让有限经验服务更多决策。
本讲核心总结表
| 主题 | 核心问题 | 关键技巧 | 主要限制 |
|---|---|---|---|
| Model-based RL | 如何降低真实交互成本 | learned model + short synthetic rollout | 模型偏差、长 horizon 误差累积 |
| 多任务 RL | 如何在任务间共享经验与技能 | task conditioning + shared policy | 负迁移、任务分布不均衡 |
| Goal-conditioned RL | 如何学习通用到达策略 | 目标作为条件输入策略 | 目标表示和奖励设计困难 |
| HER | 如何让失败轨迹也有训练价值 | hindsight relabeling + off-policy reuse | 需要可重算奖励和共享动力学 |
进一步思考
- 当 task descriptor 从 one-hot 变成自然语言后,多任务 RL 与 foundation model 的界线正在模糊。
- HER 的成功提醒我们:很多看似 “失败” 的数据,其实只是缺少恰当的标签和解释方式。
- 课程最后预告的下一个问题非常自然:既然可以在多个任务间共享知识,那么能否进一步做到对全新任务的快速适应?
从多任务共享走向快速适应
这节课结尾其实埋下了一个很重要的研究转折:如果多任务 RL 解决的是 “在一批已知任务之间共享结构”,那么下一步自然就会问,面对一个此前从未见过的新任务,能不能像 in-context learning 那样快速适配,而不是重新训练整个策略?

从这个角度看,本讲中的三条主线恰好构成了后续研究的基础:
- Model-based RL 让 agent 更善于复用已有经验和环境结构。
- 多任务 RL 让策略学会在多个任务间共享参数与行为模式。
- HER 说明同一条轨迹可以在不同目标解释下反复提供监督。
它们共同指向一个更大的问题:如果经验、任务条件和目标解释都能重用,那么策略是否也应当具备更强的 test-time adaptation 能力?
实现这讲方法时最容易踩的坑
这节课虽然概念上分成三部分,但真正写代码时常常会把坑踩在数据管线上。尤其是 HER 和多任务条件化策略,往往不是算法公式错了,而是 replay buffer、task descriptor 和 reward recomputation 之间没有接好。

| 实现模块 | 最常见错误 | 更稳妥的做法 |
|---|---|---|
| Synthetic rollout | rollout 太长导致模型偏差主导训练 | 从真实数据中的中间状态出发,只做短 rollout |
| Task conditioning | task ID 和状态没有同步送入 policy / critic | 统一把 \((, z)\) 当作条件输入接口 |
| HER relabeling | 只改目标,不重算整条轨迹奖励 | 明确实现 reward recomputation 与 buffer 写回逻辑 |
| Replay buffer | 原始样本和 relabeled 样本分布失衡 | 记录采样比例,必要时做分层采样 |
拓展阅读
- Andrychowicz et al., “Hindsight Experience Replay,” NeurIPS 2017
- Schaul et al., “Universal Value Function Approximators,” ICML 2015
- Yu et al., “Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning,” CoRL 2020
- Ghosh et al., “Learning to Reach Goals via Iterated Supervised Learning,” ICLR 2021