[LLM Agents F25 Lecture 05] AI Agents to Automate Science — James Zou
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 James Zou 授课内容整理 |
| 来源 | Berkeley RDI |
| 日期 | 2026-04-02 |
![[LLM Agents F25 Lecture 05] AI Agents to Automate Science — James Zou](cover.jpg)
课程导读:从 AI 工具到 AI 共研者
这节课的核心不只是“AI 可以做科研”,而是科研流程的组织方式正在变化。James Zou 给出的叙事是三段式:第一段是 Virtual Lab(多 Agent 科学团队),第二段是 Paper2Agent(把论文转为可交互 Agent),第三段是 Agents for Science(用真实会议数据观察人机协作与 AI 评审的行为)。
如果把过去十年的科学 AI 记为“模型能力持续增强”,那么这一讲强调的是另一个维度:科学工作流的可编排性。在这个维度里,问题不再是“某个单模型能不能刷高 benchmark”,而是“能不能把一个研究课题从问题定义、知识检索、方案生成、计算验证到结果解释,组织成一个可迭代的 agentic pipeline”。
本讲主线
- 从“单任务 AI 工具”转向“端到端研究协作系统”。
- 核心对象从模型参数变成角色分工 + 交互协议 + 外部工具接入。
- 评估指标从单点准确率扩展到可复现性、错误恢复能力、人与 Agent 的分工质量。
Zou 在开场里反复强调一个概念转移:过去我们通常先有定义明确的问题,再为该问题选一个专用模型;而现在越来越多团队尝试让 Agent 参与更上游、更开放的研究环节。这个变化对应一句非常关键的话:“people are starting to explore AI as a co-scientist”。这句话直接把 Agent 的角色从“执行器”抬到了“协作者”。
为何 2025 年后这个转移突然加速
- LLM 的工具调用、长上下文、代码执行能力形成了基础设施闭环。
- MCP 等协议让“资源如何被模型稳定调用”有了工程标准化路径。
- 科学研究本身是高复杂度、多阶段任务,天然适合多 Agent 协作分治。
常见误解:把 Agent 当成更大参数模型
这节课展示的系统优势大多不来自“更大模型”,而来自编排层设计:角色定义、会议机制、记忆机制、sandbox、critic 角色、human-in-the-loop 纠偏。忽略这些机制,只比较底座模型,往往会得出错误结论。
本章小结
本章建立了整节课的理解框架:这不是单点模型能力展示,而是科研系统工程范式。后续章节可按“组织机制 -> 案例验证 -> 平台化扩展 -> 会议级证据 -> 局限与治理”来阅读。
Virtual Lab:多 Agent 科研组织的最小闭环
Virtual Lab 是本讲第一部分,也是最像“真实研究组数字孪生”的系统。它并不假设一个全能 Agent,而是把科研活动拆成角色协作网络:PI/Professor Agent 负责任务分解与团队配置,多个 Student Agent 按学科专长并行推进,Critic Agent 作为系统内审查者持续挑错。
图\ref{fig:vl-design} 展示了 Virtual Lab 的三层结构:Agent 创建、团队会议、一对一会议。\footnote{来源:Berkeley RDI 课程视频 https://www.youtube.com/watch?v=yqPIsTTdUkc,关键帧时间戳 00:05:32。}
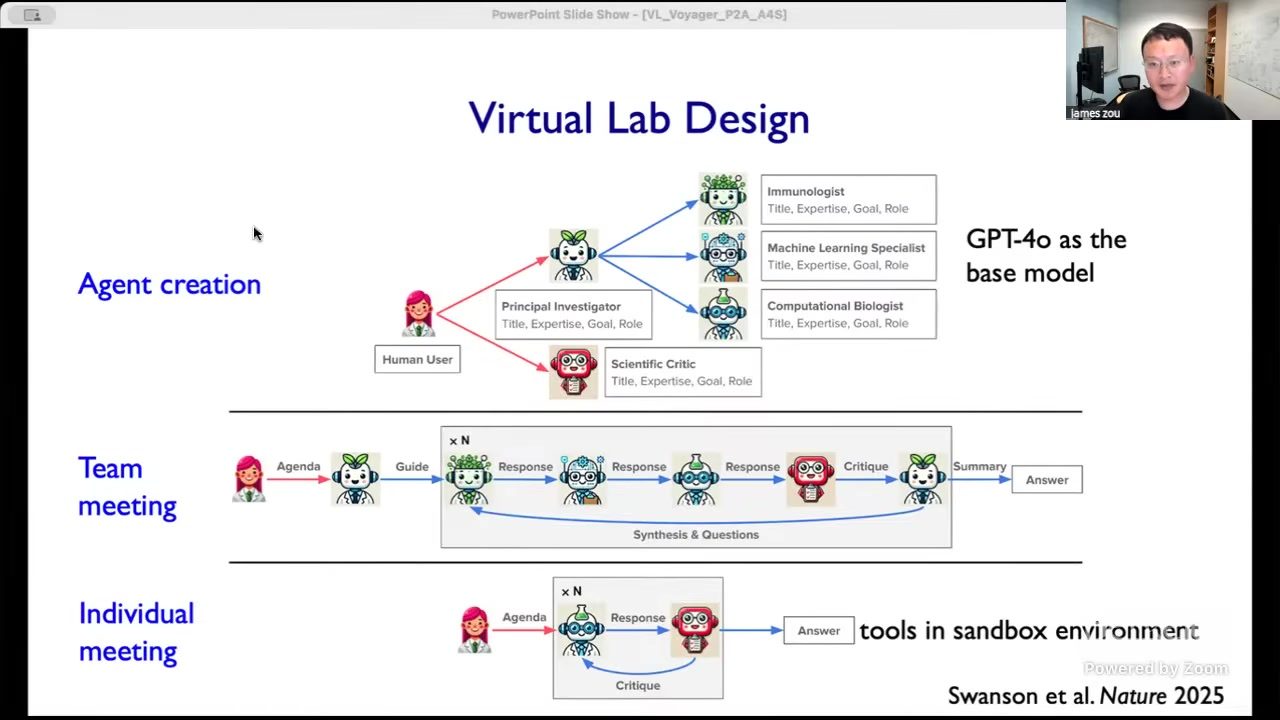
角色定义与任务路由
在 Zou 的描述里,人类研究者通常先与 PI Agent 对话,PI 再决定需要哪些子专家。这意味着系统有一个任务路由层:同样是“生物医药”,不同课题可能需要不同组合,例如 immunology + structure modeling + optimization,或者 genomics + statistics + causal inference。
这一层的意义在于,复杂科研任务并不是一次 prompt 能完成的线性过程,而是带有“先验不完整”和“目标随中间结果更新”特征的动态流程。PI Agent 不是只做拆分,还做团队重构:随着新证据出现,替换或追加 specialist。
PI Agent 的工程职责可以抽象为三件事
- Capacity Planning:为当前课题配置足够、但不过度的专家角色。
- Interface Contract:定义每个 Agent 输入输出格式,减少讨论漂移。
- Iteration Control:决定何时继续探索、何时收敛、何时升级给人类。
会议机制:并行探索与集中汇总
Virtual Lab 的会议不是社交形式,而是计算编排策略。组会让多个 Agent 并行提出假设,单聊用于把某条分支做深,再回到组会做 cross-check。这个机制本质上是在宽搜(breadth-first)与深搜(depth-first)之间切换。
Zou 讲到“AI 团队会议可以在几秒到几分钟内完成”,这使得许多传统团队难以承担的对照实验(不同参数设定、不同先验假设、不同人格配置)可以低成本并行执行。换言之,Virtual Lab 不是“自动写结论”,而是“自动做研究过程中的大量中间尝试”。
会议编排带来的三个直接收益
- 探索覆盖率提高:并行分支数量显著增加。
- 沟通损耗降低:机器间协议化交互替代口语化反复解释。
- 可审计性增强:每轮讨论、每次工具调用都可追踪。
系统行为中的“社会动力学”
课程中特别提到“Agents have their own social dynamics”。这不是噱头,指的是当多个 Agent 拥有不同偏好、不同不确定性处理方式时,系统会出现类似真实团队的行为:有人保守、有人冒进、有人倾向先做可行解、有人倾向追求高潜力路线。
如果没有治理机制,这些“社会动力学”会导致议题漂移、局部共识锁死或重复讨论。Virtual Lab 通过 Critic、会议摘要、PI 汇总三层机制,把动力学从噪声转化为可用信号。
仅靠多数投票不等于高质量科研决策
科研里的“正确”常常是稀疏信号,早期阶段可能只被少数分支捕捉。若系统只做多数投票,会系统性压制少数高价值路径。Virtual Lab 的关键是保留异议并结构化记录,而不是快速投票定稿。
本章小结
Virtual Lab 的核心价值在组织层:PI 路由、并行会议、单聊深挖、Critic 纠偏、最终汇总。它把科研活动从“个人脑内流程”转成“可编排、可追踪、可复盘”的系统流程。
Virtual Lab 实战:COVID 变体 nanobody 设计案例
课程中最具说服力的部分是具体案例:让 Virtual Lab 针对 SARS-CoV-2 新变体设计 binder。这个任务有真实约束:时间紧、数据分布变动快、可用公开数据不完备,且最终需要实验验证而非停留在文本推理。
从“做抗体”到“做 nanobody”的路径转移
在早期讨论中,immunology 角色提出了较反直觉建议:优先设计 nanobody 而不是常规 antibody。Zou 强调这是一个“如果问多数人类研究者,未必先走这条路”的决策点。其后 machine learning 角色给出可计算性理由:nanobody 更小,结构建模与打分稳定性更高,更匹配现有计算工具链。
这段讨论体现了 agentic team 的价值:建议不是凭“灵感”,而是由跨角色互证形成。immunology 给生物学可行性,ML 给计算约束与可执行性,再由 PI 进行任务收敛。
案例中的关键决策逻辑
- 目标不是追求理论上最优 binder,而是追求在当前工具条件下更可验证的方案。
- 路线选择同时受生物机理与计算可操作性约束。
- 系统先选择“可持续迭代”路径,而不是一次性豪赌。
Critic Agent 的作用:防止高置信错误累积
在该案例中,Critic 明确指出:nanobody 公共数据规模较小,若直接按常规深度学习流程推进,容易出现过拟合并导致虚假高分。这个提醒并没有否定主路线,而是迫使团队增加校验与保守性假设。
图\ref{fig:vl-discussion} 对应课程中的讨论总结页。\footnote{来源:Berkeley RDI 课程视频,关键帧时间戳 00:22:10。}

没有 Critic 的多 Agent 系统会怎样
- 早期错误假设可能在多轮会议中被反复引用,形成“共识幻觉”。
- 当所有角色共享同类训练偏差时,系统更易出现一致但错误的推理链。
- 如果没有显式反方角色,PI 的汇总常把“流畅度”误判为“正确性”。
实验结果与外部验证
Virtual Lab 案例不是止于文字报告。课程展示了实验验证曲线和候选结构信息,说明至少在该任务上系统给出的候选在目标变体上表现出积极信号。图\ref{fig:vl-exp} 是相应关键帧。\footnote{来源:Berkeley RDI 课程视频,关键帧时间戳 00:18:54。}
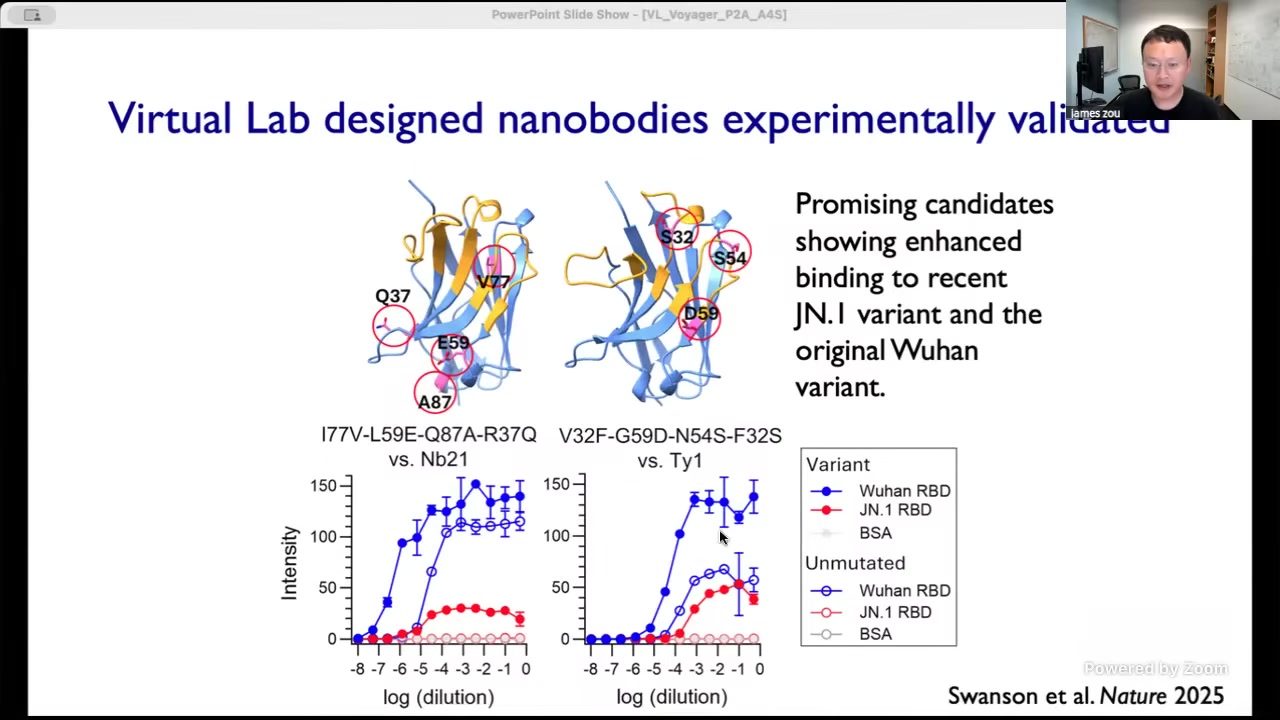
要注意的是,Zou 的论证方式并非“AI 已经取代实验科学家”,而是“AI 团队可以更快生成值得实验资源投入的候选”。这点很关键,因为科研瓶颈常在实验预算和周期,任何能提高候选质量与优先级排序效率的系统,都能在真实研发中放大价值。
该案例可迁移的方法论
- 先建立可计算、可验证的候选生成循环,再追求更高复杂度目标。
- 在数据稀疏场景里引入保守角色(Critic)和外部验证关口。
- 把“模型输出”转成“实验可执行清单”作为交付物。
本章小结
nanobody 案例给出的不是某个神奇 prompt,而是一套可以重复执行的科研闭环:多角色提出方案、Critic 抑制风险、实验侧验证候选、再反馈回下一轮迭代。
Agent School 与可靠性工程:让系统持续变强
Virtual Lab 的长期价值依赖于“能否自我更新”。课程中提到的 Agent School 可以理解为研究团队的持续培训机制:指定主题、检索文献、学习工具、回到任务中应用。其重点不是一次训练,而是能力增量可累积。
Agent School 的训练单元
从字幕内容看,训练主题包括 AlphaFold 等新工具使用、跨领域知识补齐、任务相关文献快速吸收。人类提供关键主题和边界,Agent 执行学习与整合。这是典型的人机分工:人定义方向,机器承担高吞吐知识摄取与初步结构化。
Agent School 的输入/输出接口
- 输入:学习主题、约束条件、目标任务上下文。
- 中间产物:文献摘要、工具使用脚本、失败案例归档。
- 输出:可被 PI 调度的新角色能力或升级版工作流。
外部记忆与 sandbox:从会话体到工程体
Zou 在问答中多次强调外部 memory 与 sandbox。memory 让 Agent 不必反复丢失上下文,sandbox 让工具调用可控可复现实验。二者结合后,系统从“聊天模型”升级为“研究执行体”。
memory + sandbox 的组合价值
- memory 负责长期一致性:保存假设、证据、反例与版本。
- sandbox 负责执行可靠性:固定依赖、记录命令、可重放运行。
- 二者共同降低“看起来懂”但“做不出来”的风险。
图\ref{fig:vl-school} 展示了 Agent School 的关键页。\footnote{来源:Berkeley RDI 课程视频,关键帧时间戳 00:14:40。}

Human-in-the-loop 的真实作用
课程给出非常务实的表述:人类不必逐句监督 Agent,但要在关键节点干预,防止 topic drift 和误设前提。尤其在开放性科学任务中,“问题定义本身”就是高价值决策,不能完全外包。
把人类放在末端验收会导致系统性风险
如果人类只在最终结果阶段介入,前期错误假设可能已经驱动大量无效计算与错误实验优先级。更稳妥做法是在选题、假设变更、关键工具切换、外部验证前后设置人工闸门。
人格多样性与并行会议
Zou 还提到给不同 Agent 配置不同人格和偏好,在并行会议里比较结果。其本质是制造有控制的“认知异质性”,避免单一推理路径导致的脆弱性。对于科研而言,这等价于把“不同导师风格/学科传统”程序化复用。
可操作实践:并行人格实验
- 为同一课题设置保守、激进、成本敏感三种 PI 策略。
- 对比三组输出在新颖性、可执行性、验证成本上的差异。
- 让 Critic 对每组给出失败模式预测,再做合并决策。
本章小结
Agent School、memory、sandbox、HITL、人格多样性一起构成了系统长期可靠性的骨架。它们解释了为什么某些多 Agent 系统“越跑越稳”,另一些系统“越跑越飘”。
Paper2Agent:把论文从 PDF 变成可调用能力
第二部分讨论的 Paper2Agent 指向一个更大的问题:科研知识如何传播。Zou 指出,传统论文是“passive artifact”,即便附代码,使用门槛仍高。Paper2Agent 的目标是把方法、代码、数据与使用流程打包成可直接对话调用的 Agent。
图\ref{fig:paper2agent-main} 是该部分主流程图。\footnote{来源:Berkeley RDI 课程视频,关键帧时间戳 00:29:27。}
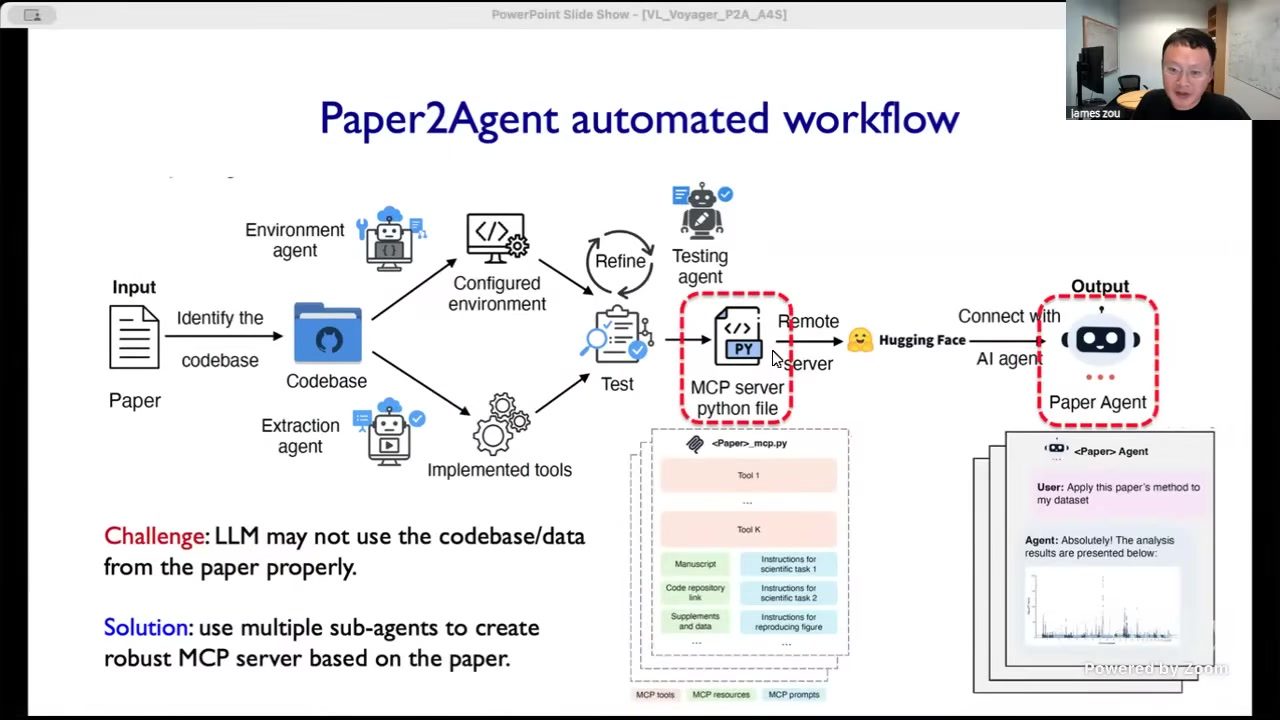
从文献阅读到工具可用的中间断层
多数科研复现痛点不在“看不懂论文摘要”,而在“环境配不起来、脚本跑不动、参数含义不明确、数据前处理缺失”。Paper2Agent 的价值是把这段最耗时、最易出错的中间层结构化为机器流程。
Paper2Agent 典型流水线
- Environment Agent:重建论文代码环境,固定依赖。
- Extraction Agent:抽取核心工具接口与关键脚本。
- Testing Agent:验证能否重现实验结论。
- MCP Packaging:把可调用资源封装为标准协议接口。
为什么是 MCP,而不是临时脚本拼接
课程给出非常工程化的答案:MCP 提供了统一的资源暴露方式,使下游聊天 Agent 可以稳定调用论文能力,而不是每次重新写胶水代码。这样“论文复用”从一次性劳动变成可持续基础设施。
Paper MCP 的三个组成
- 工具层:可执行函数与参数约束。
- 资源层:数据、文档、复现脚本、补充材料。
- 工作流层:任务顺序、失败恢复、结果摘要模板。
对研究者工作方式的直接影响
传统模式下,研究者要先读长 PDF,再下载 repo、搭环境、改配置。Paper2Agent 模式下,研究者可先表达任务目标,由 Paper Agent 反向调度工具并返回结构化结果。这里不是取消阅读,而是把“机械复现步骤”优先自动化,让人把精力转向问题选择与结果解释。
图\ref{fig:paper2agent-discussion} 给出了课程讨论页。\footnote{来源:Berkeley RDI 课程视频,关键帧时间戳 00:36:20。}

Paper2Agent 并非“任何论文都能一键变 Agent”
Zou 明确提到并非所有论文都能可靠转换:文档缺失、代码不可运行、数据访问受限、实验步骤未公开都会导致 MCP 质量下降。Paper2Agent 在某种意义上也充当了“可复现性压力测试器”。
本章小结
Paper2Agent 的突破点是知识载体升级:从可读文本升级为可调用能力。它不是替代论文,而是让论文在实践层面真正“可用”,并用 MCP 把可用性标准化。
Paper2Agent 评测与 Agent-to-Agent 协作
有了流程设计,还要看证据。本节聚焦两类结果:一是 Paper2Agent 相对直接“把论文+repo 喂给通用 coding agent”的性能差异;二是多个 Paper Agent 协作时是否能生成新见解。
性能与稳健性:先建稳固 MCP,再做下游推理
课程中给出的结论是:先构建 robust paper MCP,再执行任务,整体准确性与稳定性优于直接让通用 coding agent 现场摸索 repo。并且在展示案例中,Paper2Agent runtime 约为对照方式的三分之一以内,说明预处理阶段的结构化投资能够在推理阶段回收。
为什么“预处理重”反而可能“总时长更短”
- 直接执行时错误多、回滚多、重试多,累计成本高。
- MCP 先把环境和接口固定,减少推理时不必要分支。
- 复用同一 MCP 时,后续任务边际成本快速下降。
Agent-to-Agent 协作:方法 Agent 与数据 Agent 自动对接
Zou 描述了一个有代表性的场景:某团队发布方法论文,另一团队发布数据论文。过去需要作者间大量沟通才能完成对接;现在可让两个 Paper Agent 基于各自 MCP 先自动探索“方法是否适配该数据”,再把高价值候选提交给人类复核。
课程举例里,AlphaGenome 相关方法 Agent 与 ADHD GWAS 数据 Agent 协作后,识别到新的潜在线索(splicing error 与风险关联)。这个例子最值得注意的并非结论本身,而是机制:跨论文协作从社会网络驱动,变为协议驱动。
Agent-to-Agent 科研协作的四步模板
- 能力声明:每个 Agent 公开可做什么、不能做什么。
- 任务对齐:定义共同目标与评价指标。
- 协作执行:交换中间结果并触发互相调用。
- 人类复核:对高影响结论做统计与实验双重验证。
概念漂移与边界控制
问答环节有人追问:底层模型有预训练知识,如何避免超出论文证据边界的“概念漂移”?课程回答非常清楚:关键不在于禁止外部知识,而在于用文档完备、可测试、可追责的 paper MCP 作为主执行边界,并在不满足条件时触发降级或拒答。
如果没有边界控制,Paper Agent 会变成“会说但不保真”
- 对外看起来流畅,实际引用与实现脱节。
- 对代码细节的错误想当然会污染后续分析链。
- 在多 Agent 协作中错误会跨 Agent 传播并放大。
本章小结
Paper2Agent 的实用价值建立在两点:稳健 MCP 带来的工程收益,以及多 Agent 协作带来的知识组合收益。前者提升效率与可靠性,后者提升科研搜索空间。
Agents for Science:把“AI 做科研”变成可测量现象
第三部分最重要的贡献是方法学:不是再展示单个 demo,而是组织一个真实会议,把投稿、评审、人机分工数据公开,进而把大量讨论变成可分析数据。
Zou 把会议规则设为“AI 必须是一作并完成主要工作,人类可协作”。这在当下主流会议制度下很激进,但正因激进,才有机会系统观察 AI-first 研究范式的优劣。
会议设计与样本规模
课程报告中,会议收到 300+ 投稿,录用 48 篇,覆盖工程、物理、医学健康、社会科学等方向。每篇都要提交 AI involvement checklist,按 hypothesis、experimental design、data analysis、writing 四阶段标注人机贡献比。
为何这套会议设计有研究价值
- 规则显式化:避免“用了 AI 但不披露”导致的数据偏差。
- 过程结构化:将贡献按科研阶段拆解,而不是笼统自报。
- 结果可对照:AI 评审结果可与人类 spot-check 交叉比较。
图\ref{fig:conference-questions} 和图\ref{fig:conference-reviews} 对应该部分关键帧。\footnote{来源:Berkeley RDI 课程视频,关键帧时间戳 00:44:40。}\footnote{来源:Berkeley RDI 课程视频,关键帧时间戳 00:52:30。}

人机协作模式观察
课程结论之一是:录用论文整体上保留了更多人类介入,尤其在假设提出和实验设计前段;而在后段(数据分析、写作)更容易出现 AI 主导。这与实际科研风险分布一致,前段决策错误会造成后续系统性偏航,因此人类更倾向把控上游环节。
四阶段协作启示
- Hypothesis:人类主导方向选择,AI 提供候选与反例。
- Experiment Design:人机共设约束,避免不可执行方案。
- Data Analysis:AI 负责高吞吐执行,人类做统计审查。
- Writing:AI 可承担初稿整合,人类负责论证强度与责任边界。
AI 评审的异质性:保守、激进与居中
课程中使用 GPT-5、Gemini 2.5 Pro、Claude Sonnet 4 作为评审 Agent。观察到明显评分风格差异:GPT-5 相对保守,Gemini 相对更积极,Claude 在展示数据里更接近人类评分分布。这说明“AI 评审”不是单一实体,而是带模型风格偏置的评估系统。
评审自动化的风险不在于“会不会打分”,而在于“评分偏置可否校正”
如果会议把单模型评审结果直接当最终判断,可能把某一类风格偏好固化成制度偏见。更稳妥的是多模型委员会 + 人类抽检 + 评分校准曲线共同作用。
引用幻觉检测:可量化的真实痛点
会议还上线了自动引用核验流程:抽取每篇参考文献标题并检索匹配。报告显示约 44% 投稿参考文献可完全核验,约 56% 至少出现一条不可核验引用(多数是少量错误,也有极端样本)。
这组数字的重要性在于:它把“AI 写作可能胡编引用”从坊间印象变成结构化证据,也为后续治理提供可操作指标。
引用核验应成为 AI-first 论文的默认基础设施
- 投稿阶段自动核验并返回 warning 列表。
- 评审阶段强制作者对不可核验引用逐条回应。
- 录用后公开核验报告,形成可追责记录。
本章小结
Agents for Science 的价值在于把争论变成数据:我们不仅看到 AI 可以做什么,也看到它在哪些环节必须受约束、哪些环节需要人类补位。
局限性、治理策略与下一步研究议程
Zou 在结尾强调了局限性,这部分非常关键,因为它决定系统能否进入真实科研生产。我们可以把局限分成能力边界、上下文边界、验证边界三类。
能力边界:擅长工具使用,不擅长原创方法发明
课程观点是当前 Agent 更擅长调用与组合既有工具,而非从零发明下一代基础方法。人类研究者在原创方法层仍有明显优势。两者互补路径是:人类造新方法,Agent 负责大规模扩散和落地应用。
上下文边界:缺元数据时会做出无效假设
Zou 给出一个典型问题:给 Agent 数据却不说明预处理流程,Agent 会自行补全前提并造成错误结论。因此,科学 Agent 要求更高的数据与流程元数据质量,不能仅靠“自然语言说明”。
科学场景下最危险的不是语法错误,而是前提错误
前提错了,后续每一步都可能形式正确但语义失真。科研系统必须优先记录数据来源、预处理、实验条件、统计假设,并把这些信息纳入 Agent 的硬约束上下文。
验证边界:计算结论必须闭环到真实实验
课程反复强调,很多科学问题最终要靠实验和现实世界数据验证。纯计算闭环最多给出候选,不应直接替代实验决策。稳健流程应是“Agent 生成候选 -> 人类筛选 -> 实验验证 -> 结果回流”。
面向实验科学的闭环模板
- 计算阶段:Agent 生成候选与置信区间。
- 评审阶段:人类确认可行性、伦理与资源约束。
- 实验阶段:按预注册协议执行验证。
- 回流阶段:把失败样本和异常元数据写回记忆库。
治理建议:从能力竞赛转向责任架构
如果未来 AI-first 科研成为常态,治理重点应放在责任可追踪,而非只看结果新颖度。具体可从三层建设:过程可审计(日志、版本、调用链)、结果可核验(代码/数据/引用自动检查)、角色可问责(哪一步由谁主导、谁批准)。
可执行治理清单
- 对所有 Agent 调用保留结构化 trace 与配置快照。
- 将 reproducibility 检查与引用核验作为投稿前门槛。
- 对高风险结论设置强制 human sign-off。
- 在评审体系中纳入“协作质量”而非只看结论文本。
本章小结
当前科学 Agent 的问题不是“能不能生成答案”,而是“答案如何被约束、验证并承担责任”。这决定了它能否从 demo 走向科学共同体的可信基础设施。
问答精读:从课堂观点到团队 SOP
除了主讲内容,问答环节给了很多工程化细节,尤其是如何把 “Virtual Lab + Paper2Agent + MCP” 真正落地成可持续流程。本章把这些问答信息整理成可执行 SOP,避免只停留在概念层面。
如何触发 Agent 之间的自主协作
针对“Agent-to-Agent 对话如何触发”的问题,课程回答是通过 paper MCP 的标准接口,把多个论文能力挂到同一协调器(通常是 chatbot 或 orchestration agent)上,再由协调器识别任务中可组合的资源并发起调用。
这与很多团队的常见做法不同。常见做法是让单个 Agent 靠长上下文“知道所有东西”,最终导致上下文拥挤、路由不清晰、可解释性差。课程给出的做法是能力模块化与调用协议化,使协作触发条件可以显式配置。
最小可用协作触发器(建议实现)
- 定义每个 paper MCP 的能力描述:输入类型、输出类型、前置条件。
- 在协调器中实现“任务需求 \(\rightarrow\) 能力匹配”规则。
- 允许协作链路有拒绝分支:能力不满足时直接回退给人类。
- 对每次跨 MCP 调用记录 trace,用于后续失效分析。
关于上下文成本与 token 开销
问答还提到 MCP 的 token overhead 相对较低,核心原因是很多上下文被移到了工具与资源层,而不是全部塞进 prompt。对工程团队来说,这意味着优化重点应放在接口设计与资源检索准确率,而不是单纯压缩提示词。
控制上下文成本的三条策略
- 把可执行能力放进 MCP 工具,不把流程细节重复写进会话上下文。
- 先检索再拼接:只把当前任务需要的 paper 片段拉入上下文。
- 将中间状态结构化存储,避免每轮对话重复传输历史长文本。
如果团队只盯着“本轮 token 少了多少”,而忽略了失败重试次数与人工兜底成本,通常会做出局部最优决策。课程案例里 Paper2Agent 的优势之一正是减少失败回滚,降低总体执行时间。
证据时间轴:关键结论对应到视频片段
为方便后续复核与组内复盘,表\ref{tab:evidence-index} 把本讲关键论点映射到时间戳、证据类型和可执行动作。这样团队在二次讨论时可以直接回看对应片段,而不是凭记忆复述。
| 时间戳 | 课堂信息点 | 证据类型 | 可执行动作 |
|---|---|---|---|
| 00:01–00:03 | AI 从工具转向 co-scientist | 主讲开场定义 | 统一团队术语,区分工具层与协作层目标 |
| 00:03–00:06 | Virtual Lab 角色与会议机制 | 系统结构说明 | 为本地项目定义 PI/Student/Critic 最小角色集 |
| 00:05:32 | Agent 创建 + 组会 + 单聊流程图 | 幻灯片关键帧 | 按图实现路由器、并行会话、汇总器三模块 |
| 00:06–00:09 | nanobody 路线与 Critic 介入 | 案例讨论文本 | 在高风险任务默认开启反方 Agent |
| 00:14:40 | Agent School 学习流程 | 幻灯片关键帧 | 建立周度主题学习队列与能力回归测试 |
| 00:18:54 | 候选结果实验验证示意 | 幻灯片关键帧 | 为每轮候选绑定实验优先级与验证预算 |
| 00:21–00:25 | memory/sandbox/HITL 设计 | 问答与方法总结 | 对所有任务持久化记忆与可重放执行日志 |
| 00:26–00:30 | Paper2Agent 目标与流程 | 主讲流程讲解 | 选择高价值论文先做 MCP 化 |
| 00:29:27 | 环境/抽取/测试 Agent 管线 | 幻灯片关键帧 | 先搭建三 Agent 流水线再做下游 UI |
| 00:32–00:33 | 评测中相对 baseline 更稳更快 | benchmark 口述结果 | 用同任务 A/B 测试验证本地收益 |
| 00:34–00:37 | Agent-to-Agent 协作发现新线索 | 协作案例讲解 | 为方法 MCP 与数据 MCP 建自动匹配器 |
| 00:47–00:48 | 300+ 投稿、48 篇录用 | 会议统计口述 | 参考其 checklist 设计内部项目评审模板 |
| 00:50–00:52 | 多模型评审风格差异 | 评审分布观察 | 使用多评审 Agent + 校准,不用单模型定生死 |
| 00:52:30 | 评审可抓错但会 sycophancy | 幻灯片关键帧 | 给评审 Agent 加反谄媚提示与硬约束模板 |
| 00:53–00:54 | 参考文献幻觉核验结果 | 自动检查统计 | 在稿件提交流程中前置引用核验 |
| 00:58–01:00 | 局限:原创能力与上下文边界 | 主讲反思 | 把人类聚焦在方法创新和前提设定 |
| 01:00–01:01 | 强调闭环人机协作 | 课程收束观点 | 固化“计算-实验-回流”闭环到团队 SOP |
\label{tab:evidence-index}
团队落地模板:四周试点方案
为了把本讲快速转成组织收益,可以采用一个四周试点:
- 第 1 周:选题与基线。选择 1--2 个复现负担高的论文任务,记录人工 baseline 时间与错误类型。
- 第 2 周:Paper2Agent 化。完成 environment/extraction/testing 三 Agent 管线,产出首版 MCP。
- 第 3 周:接入 Virtual Lab。给 MCP 配置 PI、两个 specialist 和 Critic,跑两轮并行会议。
- 第 4 周:复盘与治理。对比成功率、耗时、人工介入点;补充引用核验和 human sign-off 规则。
试点常见失败模式
- 一上来就追求全自动,导致边界条件未定义清楚。
- 只记录最终答案,不记录中间调用与失败重试轨迹。
- 缺少统一评价指标,最后无法判断是否优于人工 baseline。
建议在试点前把成功标准写死:例如任务完成率、平均耗时、人工审阅时长、引用错误数、可复现实验比例。这样在汇报阶段才能客观回答“这套系统值不值得继续投入”。
本章小结
问答环节的最大价值是把理念转成工程动作:协作触发要协议化、上下文成本要系统性看总账、评审与引用核验要前置到流程。按证据时间轴执行,团队可以在一个月内完成第一轮可衡量试点。
总结与延伸
本讲最重要的启发是:科研 Agent 的竞争力来自系统编排,而非单一模型分数。Virtual Lab 说明多角色协作可以提升开放性科研任务的探索效率;Paper2Agent 说明知识传播可以从静态文档升级为可调用能力;Agents for Science 说明我们可以用会议级数据衡量人机协作与 AI 评审的真实表现。
全讲总结表
| 主题 | 关键结论 | 对实践者的直接动作 |
|---|---|---|
| Virtual Lab 组织范式 | PI 路由 + 多专家协作 + Critic 审查可显著提升开放任务稳定性 | 先定义角色与会议协议,再优化 prompt;把 Critic 设为默认角色 |
| Agent School 与可靠性 | memory/sandbox/HITL 是长期可用性的基础,不是可选项 | 建立外部记忆库、可重放执行环境、关键节点人工闸门 |
| Paper2Agent 与 MCP | 先构建 robust MCP 再执行任务,准确性和效率更优 | 对高价值论文先做环境重建与接口封装,沉淀为复用资产 |
| Agent-to-Agent 协作 | 协议驱动协作可发现跨论文新组合机会 | 建立方法 Agent 与数据 Agent 的匹配与对接流程 |
| Agents for Science 证据 | AI 评审可发现细节错误,但存在模型偏置与谄媚风险 | 使用多模型评审委员会 + 人类抽检 + 校准策略 |
| 治理与边界 | 科研 Agent 需要可审计、可核验、可问责的责任结构 | 将引用核验、复现检查、human sign-off 纳入默认流程 |
进一步阅读
- Swanson et al., Virtual Lab(课程中介绍为 Nature 2025 相关工作,建议结合公开视频与论文正文阅读)。
- Miao et al., Paper2Agent(课程中介绍为 arXiv 2025 相关工作,关注 MCP 封装与评测设置)。
- Agents for Science 会议资料与公开评审(关注 AI involvement checklist 与引用核验机制)。
- Model Context Protocol (MCP) 官方文档(理解资源暴露、工具调用和协议边界)。
- 关于 AI 评审偏置与 sycophancy 的近期研究(用于设计多模型评审和评分校准)。
从课程落地角度看,最值得先做的小型试点是:选择一个复现成本高但影响大的论文子领域,先落地 Paper2Agent;再把经过验证的能力接入团队版 Virtual Lab,最后用 checklist 记录人机分工与错误类型,形成自己的“小型 Agents for Science”数据闭环。