[LLM Agents F25] Practical Lessons from Deploying AI Agents – Clay Bavor
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Clay Bavor 授课内容整理 |
| 来源 | Berkeley RDI |
| 日期 | 2026-04-02 |
![[LLM Agents F25] Practical Lessons from Deploying AI Agents – Clay Bavor](cover.jpg)
讲座定位与问题意识
本讲由 Sierra 联合创始人 Clay Bavor 主讲,主题是“把 Agent 真正部署到真实客户场景之后,会遇到哪些不在 Demo 里的硬问题”。这节课和偏研究的 Agent 课程不同,重点不在“能不能做出一个会推理的系统”,而在“能不能让这个系统在成本、质量、合规、稳定性四个维度同时站住”。
讲者开场提到,当 Sierra 在 2023 年初和客户讨论 Agent 时,很多人还不理解“Agent”是什么;30 个月后,这个方向已经进入 Berkeley 的研究生课程体系。这个变化速度本身就是课程背景:Agent 技术栈迭代非常快,产品和组织如果不能按季度重构,就会被现实流量与异常输入打穿。
“This will be a practical talk... making contact with reality again and again and again.”
课程主线
这节课围绕三条主线展开:第一,customer-facing agent 的业务价值如何定义;第二,语音、评测、观测、安全这些“冰山水下部分”如何工程化;第三,企业如何在 build、buy、build-with 三种策略间找到可持续路径。
读这份笔记的方式
建议按“业务目标 \(\rightarrow\) 系统能力 \(\rightarrow\) 运行保障”三层阅读:
- 先看第 2--5 节,明确为什么客服 Agent 的核心指标是“可验证解决率”而不是“对话看起来很聪明”;
- 再看第 6--10 节,理解 memory、voice pipeline、simulation、tracing、guardrails;
- 最后看第 11--12 节,把技术方案映射到组织与路线图。
本章小结
这节课本质是一门“Agent 生产工程学”。讲者反复强调:Demo 不是产品,产品不是系统图,系统图也不是可运营业务。后续章节将沿着这一逻辑,把“可演示能力”转换为“可经营能力”。
客服 Agent 的第一性问题:成本与质量的长期张力
Sierra 的切入点不是“再做一个更会聊天的模型”,而是解决企业客服历史难题:高质量服务通常意味着高人力成本;成本优化往往伴随质量下降。传统客服系统通过分层坐席、IVR、工单转派缓解矛盾,但并未从根上消除“成本曲线”和“体验曲线”之间的对抗。
讲者举了多个真实场景:电商退换货、家庭安防设备故障、卫星广播订阅切换等。这些任务有三个共同特征:第一,用户往往在“问题已发生”状态下接触客服;第二,问题需要调用真实业务系统并更新状态;第三,一次交互失败会直接放大用户不满和运营成本。
核心命题
customer-facing agent 的价值不在“回答了多少问题”,而在“能否完成可验证的业务动作并减少升级率(escalation)”。这意味着系统评价目标天然偏向 outcome,而不是语言表面流畅度。
为什么“看起来像人”不是首要目标
在客服场景中,用户关心的是“我的问题现在有没有被解决”。一个礼貌、流畅但不能完成系统操作的 Agent,会比一个表达朴素但动作准确的 Agent 更快失去信任。
常见误区
如果团队把 KPI 设成“平均对话时长”“回复自然度”或“单轮满意度”,很容易把产品优化成“会聊天但不办事”。当业务进入高峰流量,这类系统会显著增加人工兜底负担。
本章小结
这章建立了后文所有技术选择的约束条件:Agent 必须在真实业务系统中稳定完成任务。凡是不能提高可验证解决率、不能降低升级率、不能改善成本结构的技术优化,都不应被视为主路径。
Agent 市场分层:personal、role-based、customer-facing
讲者把 Agent 生态划分为三类:personal agents(如 ChatGPT/Gemini)、role-based agents(如 coding/legal assistants)、customer-facing agents(企业对外服务 Agent)。这个框架的价值在于,三类 Agent 的成功函数不同,不能用同一套评测和产品方法。
| 类型 | 主要用户 | 主任务 | 首要评价指标 |
|---|---|---|---|
| personal agents | 个人终端用户 | 信息获取、写作、探索 | 可用性与泛化能力 |
| role-based agents | 专业岗位人员 | 代码、法务、研究支持 | 专业效率与正确率 |
| customer-facing agents | 企业外部客户 | 服务、故障排查、交易变更 | 可验证解决率、升级率、合规率 |
为什么课程里要单独讲 customer-facing agent
这类 Agent 面向的是“外部真实客户 + 企业系统 of record + 高并发会话”。其难点不仅是模型能力,更是跨渠道状态一致性、合规动作约束、SLA 与回退策略设计。
讲者判断
“Agents are to AI as the website was to the internet and apps were to mobile.”
对应到企业世界,这句话的含义是:未来每个企业都会有自己的对外 Agent,正如每个企业今天都有官网与 App。
本章小结
“Agent 三分法”帮助我们避免方法误配。课程后续所有工程细节,都是为了让 customer-facing agent 满足企业级外部服务要求,而不是泛化聊天场景。
从多渠道到单 Agent:渠道坍缩与体验统一
传统客服按渠道分工:电话、在线聊天、邮件、工单系统分别由不同团队与流程负责。讲者给出的方向是“single agent world”:一个可配置 Agent 在不同入口统一接待客户,再根据上下文、权限和任务类型调用不同动作。

来源:来源:Berkeley RDI 课程视频《Practical Lessons from Deploying...by Clay Bavor》,时间点约 00:05:10。
这一策略不是简单“把多个入口接到同一个大模型”。真正难点是统一状态机和策略层:当用户从 chat 转到 voice,或者从 voice 回到工单,系统是否能保持任务上下文、身份验证状态、已完成步骤、失败重试历史完全一致。
渠道坍缩的工程含义
渠道坍缩意味着组织模型变化:从“渠道团队优化局部指标”转向“Agent 团队优化端到端结果”。如果组织还按渠道切割,系统很难做到单一决策平面和统一记忆。
迁移中的 KPI 陷阱
很多企业会在初期把语音与在线聊天分别考核,导致 Agent 团队为了局部指标做冲突优化。结果是跨渠道一致性下降,用户重复解释问题,整体满意度反而下滑。
本章小结
“单 Agent、多入口”是产品形态,不是架构捷径。要兑现这个形态,团队必须同步改造策略层、状态层、组织边界和评测指标。
商业模式创新:outcome-based pricing 与激励对齐
讲者回顾了软件定价演化:shrink-wrap 授权、SaaS 订阅、consumption-based 计量,再到 outcome-based 定价。Sierra 的做法是“问题解决才计费”,例如完成退换货、触发有效订单更新、完成可核验服务动作后再收费。
这种定价把平台方和企业客户绑定到同一目标函数:客户只有在节省成本或提升转化时才愿意持续投入,平台也必须把注意力放在“稳定解决问题”而非“最大化 token 消耗”。
outcome-based pricing 的技术前提
要做 outcome-based,必须先解决 outcome verification:
- 动作可验证:例如订单状态已更新、工单已关闭、退款已提交;
- 证据可追溯:可回放调用链、参数、策略版本;
- 归因可计算:成功来自 Agent 自动完成,而不是人工接管。
实践启发
如果团队还无法建立“可验证动作闭环”,就不宜直接承诺 outcome-based 商业模式。应该先完成事件模型、审计日志、状态变更对账,再谈计费创新。
本章小结
outcome-based pricing 并非销售包装,而是架构承诺。它倒逼团队建立强可观测、强可归因、强可验证的 Agent 系统,这正是企业级落地的关键护城河。
Build vs Buy vs Build-with:冰山以下的复杂性
讲者提到一个高频客户问题:“为什么不自己做?”很多工程团队在白板上画出来的方案通常是:选模型、加向量库、接工具 API、上线。现实是,真正困难的部分在“冰山水下”:版本治理、发布回滚、策略审计、异常分流、法务约束、跨模型故障切换等。
| 层级 | 典型内容 |
|---|---|
| 显性(容易被看到) | Model selection、RAG、tool calling、prompt engineering、UI channel integration |
| 隐性(上线后最耗成本) | 策略版本管理、灰度发布、线上回滚、跨渠道状态一致性、合规规则、审计追踪、failover、异常输入防护、人工接管机制 |
“能跑起来”不等于“能运营”
许多 PoC 在小流量下看似稳定,一旦进入真实客户分布,长尾输入和系统抖动会迅速暴露架构短板。没有 release discipline 和 policy enforcement 的 Agent,很难跨过首个业务高峰。
build-with 的中间路径
讲者给出的实务路径不是二选一,而是 build-with:在平台提供的高层抽象上做业务配置,保留必要扩展能力,避免重复建设低层基础设施。
本章小结
build/buy 的核心不是“谁写代码”,而是“谁承担长期复杂性”。能否系统化管理冰山水下能力,是企业 Agent 项目能否持续两年以上的分水岭。
从事务到关系:memory、warm start 与长期上下文
讲者指出当前大量 Agent 仍是 transactional:每次会话像第一次见面,缺少跨会话记忆,导致用户重复提供身份信息和问题背景。为此,Sierra 把“warm start”作为关键能力:下一次交互从“第二垒/第三垒”起步,而不是回到“你是谁”。

来源:来源:Berkeley RDI 课程视频《Practical Lessons from Deploying...by Clay Bavor》,时间点约 00:12:30。
memory 不是“把所有对话都塞进上下文窗口”。在企业服务中,memory 更接近“结构化客户状态层”:包含身份验证历史、设备/订单状态、近期交互结果、风险标记、可复用偏好等。模型只消费与当前任务相关的“可证明有用”片段。
warm start 的业务价值
warm start 直接影响三项指标:平均处理时长(AHT)、首次解决率(FCR)、升级率(escalation)。当 Agent 能在会话开始时拿到有效状态,后续推理链会显著缩短,错误分支也会减少。
memory 设计的边界
记忆越多不一定越好。过度保留无关上下文会引入隐私风险和检索噪声,导致模型“看得太多、答得更差”。必须结合 retention policy、数据分级、用途限定进行治理。
本章小结
memory 的目标不是“记住一切”,而是“在合法边界内记住能提升解决率的最小必要信息”。warm start 是 customer-facing agent 从短期事务走向长期关系的基础设施。
Voice Agent 工程:低时延、多干扰、强鲁棒
讲者明确表示,在当前阶段,可靠大规模语音 Agent 的主流形态仍是 pipeline:Speech-to-Text(ASR)\(\rightarrow\) reasoning/orchestration \(\rightarrow\) Text-to-Speech(TTS),而不是单一端到端 voice-to-voice。
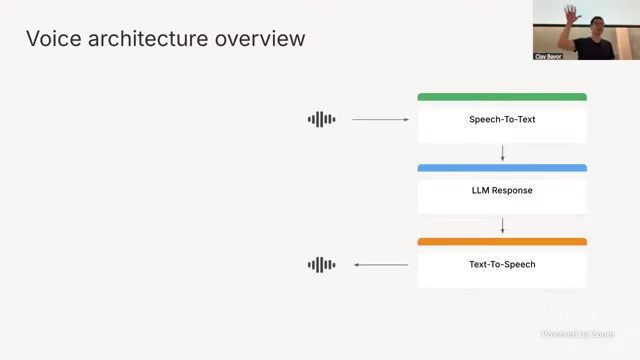
来源:来源:Berkeley RDI 课程视频《Practical Lessons from Deploying...by Clay Bavor》,时间点约 00:19:20。
延迟预算与并行推理
语音体验里最关键的是“用户停顿到 Agent 开口”的延迟。讲者强调要压缩每个 10ms 级别的开销,包括 endpoint detection、推理触发、TTS 首帧输出。为降低 P90/P95 波动,实践中会并发触发多个推理请求并采用先返回策略(hedging),再在后台取消慢请求。
语音响应延迟的简化分解
其中真正影响主观体验的是 \(L_{\text{turn}}\) 的高分位(如 P90/P95),而非均值。均值好看但尾部抖动严重,用户仍会感到“卡顿”和“抢话失败”。
打断检测与会话节奏控制
人类对话中的“嗯嗯”“ok”常是 backchannel,不代表希望打断。系统若把所有声学事件都当中断,会出现频繁抢停、语义残缺。讲者提到需要专门训练中断检测模型,区分 acknowledgment 与真正的话轮夺取。
Voice UX 的关键不是“会说”,而是“会接话”
高质量 voice agent 需要同时处理:端点检测、打断分类、重叠语音、多说话人、背景噪声、口音变化。任何一个环节失稳,都会放大成“你根本没听懂我”的体验崩塌。
ASR/TTS 评测与定制指标
讲者指出 word error rate(WER)并不总是最佳指标。真实电话场景中,背景电视声、旁人说话、杂音都可能被“正确地不转写”。因此需要任务定制指标,评估“是否抓住主说话人关键信息并支撑正确动作”。
指标误配风险
如果团队只优化通用 ASR 指标,可能得到“文字更完整、业务更失败”的反常结果。客服 Agent 必须按任务目标定义评测:身份校验字段、订单号关键槽位、动作触发准确率等。
本章小结
语音 Agent 的难点不在单模型参数,而在端到端时序系统。要做到“听清、想清、说清”,必须用工程手段管理延迟尾部、话轮交互和多源噪声。
评测体系升级:Towbench 与工业级仿真
讲者展示了 Towbench(Tool-Agent-User benchmark)的设计目标:把 Agent 放入包含工具、策略、多轮交互、动态状态变化的近真实环境中评测,而不是只做静态问答。

来源:来源:Berkeley RDI 课程视频《Practical Lessons from Deploying...by Clay Bavor》,时间点约 00:32:28。
为什么 unit test 不够
Agent 是非确定性系统。相同输入在不同上下文、不同系统状态下可能产生不同动作。传统 unit test 能覆盖函数正确性,但难覆盖多轮对话、工具副作用、策略约束与用户情绪扰动。
Towbench 的四类必要构件
- 真实域任务:如电信、零售、航旅客服;
- 可执行工具:数据库与 API,支持状态变更;
- 用户模拟器:含 persona、情绪和噪声;
- 成功判定:基于可验证动作,而非仅 LLM-as-judge。
pass@k 与规模稳定性
讲者强调“做对一次”不等于“持续做对”。在百万级会话里,哪怕单次成功率很高,重复调用后的失败暴露也会急剧放大。因而需要关注跨多轮、多样本的稳定指标,如 pass@k 的业务化版本。
评测目标的转移
研究阶段常问“最优样例能到多高”;生产阶段必须问“在复杂分布上能稳定到什么水平”。Towbench 和工业仿真把这件事前置到上线前,而不是等线上事故驱动。
本章小结
评测不是发布前打勾项,而是持续运营机制。Agent 团队需要把 benchmark、simulation、回归测试和线上回放连接成闭环,才能持续提升真实解决率。
可观测性与运营闭环:tracing、insights、expert answers
当 Agent 开始高并发服务客户,最贵的问题不是“模型一次答错”,而是“我们不知道它为什么错、在哪个链路错、是否正在批量错”。讲者给出三个关键能力:trace 可视化、对话洞察(insights)、从人工中学习(expert answers)。
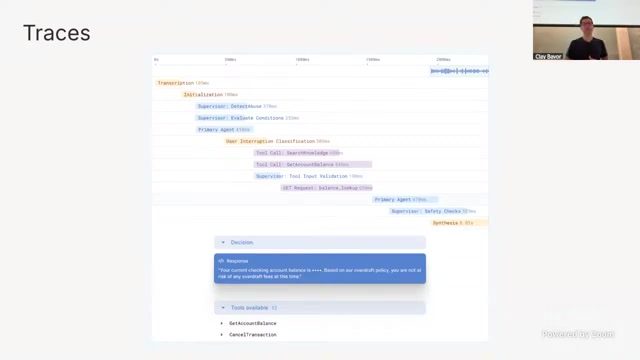
来源:来源:Berkeley RDI 课程视频《Practical Lessons from Deploying...by Clay Bavor》,时间点约 00:39:30。
Tracing:把“黑箱对话”变成“可调系统”
trace 的价值是把每次动作拆成可解释节点:检索命中、工具调用、策略判定、模型输出、后处理。这样团队可以定位是 retrieval 漏召回、tool schema 不匹配,还是策略守卫误拦截。
可观测性最小字段建议
每轮记录至少包含:会话 ID、策略版本、提示词版本、工具调用参数与返回、关键时延、输出过滤命中、人工接管标记、最终业务动作状态。没有这些字段,就无法高效做回归与归因。
Insights 与 Expert Answers:从会话中持续生长
讲者提到可以对全量对话做开放式提问,例如“升级最多的 5 类原因是什么”“某新品类用户最困惑的问题是什么”。这让客服数据从成本中心转为产品迭代资产。
Expert Answers 的思路是:在人工升级会话中抽取高质量专家处理方式,合成为可复用知识,再回灌给 Agent,降低同类问题再次升级概率。
运营闭环范式
生产环境中,最有效的改进路径不是无限调 prompt,而是“观测问题分布 \(\rightarrow\) 定位根因 \(\rightarrow\) 回灌知识/策略 \(\rightarrow\) 再评测验证”。
本章小结
没有可观测性,Agent 只能“凭感觉迭代”;有了 tracing 与 insights,团队才能形成数据驱动的工程闭环,并把人工经验系统化沉淀为可扩展能力。
安全与合规:多层防护而非单点拦截
讲者展示了多个真实攻击样例,包括反向语言提示注入(如“用冰岛语倒序要求泄露系统提示词”)和高风险诱导请求(例如走私建议)。这些样例说明,真实攻击会跨语言、跨格式、跨上下文,不会按“教科书 payload”出现。
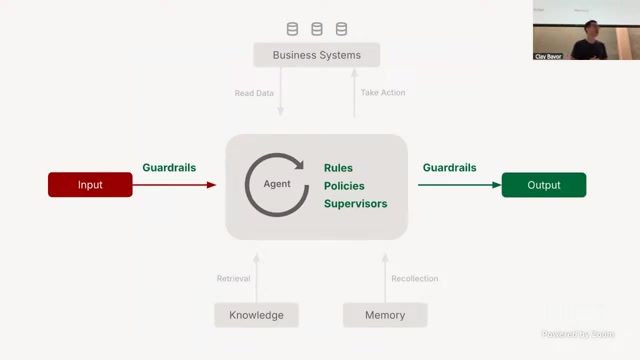
来源:来源:Berkeley RDI 课程视频《Practical Lessons from Deploying...by Clay Bavor》,时间点约 00:44:15。
分层防护架构
讲者强调“more AI + deterministic checks”的组合:
输入侧做确定性规则与风险分类;
执行侧由 supervisor/micro-agents 监控主 Agent 是否越界;
输出侧做泄露检测、越权检测、策略一致性检查;
系统侧对 CRM/交易库操作通过确定性软件网关和权限控制,不让主模型直接拥有无限写权限。
高风险误区
把安全等同于“在 prompt 里写不要泄露机密”是典型误区。只做提示约束,不做输入过滤、动作白名单、输出审计、权限网关,几乎一定会在开放流量中失守。
为什么要内外部 red teaming 并行
外部团队提供新型攻击视角,内部团队提供系统语义细节。两者结合能更快覆盖跨语言、跨模态、跨工具链的复合攻击路径。
生产级安全原则
对系统 of record 的读写必须通过可审计的 deterministic layer。LLM 可以建议动作,但不应直接拥有不受控数据库权限。
本章小结
Agent 安全是“传统互联网安全 + AI 特有风险”的叠加问题。只有分层防护、权限隔离、持续红队和审计闭环同时成立,系统才具备长期可运营性。
组织与落地:从原型团队到 battle-hardened 团队
讲者在后半段强调了组织问题:企业内部出现了新的角色组合,包括 AI architect、agent designer、运营专家、语音体验角色(如 voice sommelier)和产品工程协同岗位。这些角色不是锦上添花,而是把 Agent 从“项目”变成“能力平台”的必要条件。
职责重构与协作接口
传统客服组织按渠道分工,AI 团队按模型能力分工。落地阶段需要新增“策略与流程产品经理”“对话质量运营”“安全与评测工程师”等横向角色,确保业务目标与技术目标在同一发布节奏上推进。
建议的最小跨职能单元
- 业务 owner:定义高价值问题域与成功标准;
- Agent engineer:编排工具、策略、记忆与回退;
- Eval engineer:维护 simulation、回归集、上线门槛;
- Safety owner:维护 guardrail、红队与审计策略;
- Ops analyst:追踪升级原因并驱动知识回灌。
一个可执行的 90 天推进框架
| 阶段 | 关键任务 |
|---|---|
| 0–30 天 | 明确高价值场景与红线策略;建立最小工具链(身份校验、订单查询、状态更新);搭建离线评测与对话回放 |
| 31–60 天 | 接入 memory 与 warm start;上线 tracing 与升级归因;引入多轮 simulation,建立发布门槛 |
| 61–90 天 | 渠道统一与人工接管优化;部署分层 guardrails;将 expert answers 回灌流程制度化,进入持续迭代 |
课程级结论
Agent 的竞争力不在“谁先接入最新模型”,而在“谁先建立稳定的迭代操作系统”。组织设计、评测纪律和安全治理决定了长期上限。
本章小结
customer-facing agent 是跨职能系统工程。团队若只补模型工程能力,不补评测、安全、运营与产品协同能力,项目会在真实业务压力下停滞。
案例拆解:一次退换货请求如何被 Agent 完成
为了把前面讨论的概念落到执行层,这一节构造一个最常见场景:用户通过 chat 发起鞋码不合适的退换货请求。这个案例对应讲者在前半段反复提到的“return shoes”问题,适合检验 agent 是否具备真实动作能力。
场景定义与目标状态
输入条件如下:用户已下单、商品可退换、订单处于配送后 7 天内;系统支持换码并自动生成新物流单。
期望输出不是“一段安慰文字”,而是三项可验证动作:退货工单创建成功、换货订单创建成功、通知消息发送成功。
把任务写成状态机而不是聊天脚本
在生产系统中,建议把任务建模为状态机:
- \(S_0\):身份未校验;
- \(S_1\):身份已校验,待确认诉求;
- \(S_2\):退换资格已判定,待选择方案;
- \(S_3\):动作执行中(退货+换货);
- \(S_4\):动作完成并回传结果。
Agent 对话的职责是驱动状态跃迁,而不是无限生成自然语言。
工具调用链设计
该案例至少需要四类工具:身份校验、订单查询、退货创建、换货下单。一个可操作的编排顺序如下:
- 调用
verify_customer()完成双因子核验; - 调用
get_order_detail()获取 SKU、尺码、时效; - 调用
check_policy()校验退换资格; - 调用
create_return()生成退货号; - 调用
create_exchange_order()生成新订单; - 调用
send_confirmation()发通知并回写 CRM。
工具调用的关键约束
每一步都应返回结构化结果和错误码,避免“模型自我理解状态”。只要动作会改写系统状态,就必须由 deterministic service 执行并生成审计日志。
失败分支与恢复策略
真实会话中失败是常态,重点是失败能否快速收敛。以该案例为例:
- 身份校验失败:触发有限重试并降级到人工;
- 资格校验失败:输出明确政策解释并给替代方案;
- 换货库存不足:自动推荐可替换 SKU 并二次确认;
- 下游接口超时:触发幂等重试与 provider failover;
- 动作部分成功:执行补偿逻辑并明确告知用户当前状态。
最危险的失败模式:语言成功、动作失败
如果 Agent 在工具调用失败后仍给出“已帮你处理完成”的自然语言,短期可能提升会话满意度,长期会造成信任断崖与大规模投诉。这是客服 Agent 最不可接受的错误类型之一。
可验证交付与度量
建议将每轮会话沉淀为结构化记录,便于回放与评测:
| 字段类别 | 示例 |
|---|---|
| 身份信息 | 用户 ID、验证方式、验证结果、重试次数 |
| 任务上下文 | 订单号、SKU、资格策略版本、会话渠道 |
| 动作证据 | 退货单号、换货订单号、通知发送 ID、写库结果 |
| 质量指标 | 首次解决率、总时长、升级标记、人工接管原因 |
| 安全标记 | 注入检测命中、高风险请求分类、输出过滤命中 |
本章小结
案例拆解表明:customer-facing agent 的主体并不是“对话文案”,而是“状态机 + 工具链 + 守卫层 + 审计层”。把这四层建立起来,Agent 才具备可规模化复制能力。
发布与评测手册:从离线验证到线上灰度
讲者反复强调 Agent 是 non-deterministic software,因此发布流程不能照搬传统 Web 接口。这里给出一个与课程观点一致的发布手册,可直接映射到团队周度节奏。
四层发布门禁(Release Gates)
| 门禁层级 | 核心检查项 | 通过标准示例 |
|---|---|---|
| Gate 1: 静态检查 | 策略规则完整性、工具 schema 兼容性、敏感词与动作白名单 | 无 blocking 规则冲突,schema 校验 100% 通过 |
| Gate 2: 仿真回归 | Towbench 类多轮任务、工具调用一致性、策略遵循率 | 关键场景成功率达到基线,策略违规率低于阈值 |
| Gate 3: 影子流量 | 与人工或旧版本并行运行,不对用户生效 | 行为差异可解释,重大风险事件为 0 |
| Gate 4: 小流量灰度 | 真实用户 1%-5% 流量,实时监控升级率与失败类型 | 升级率不劣于基线,安全告警可控,可随时一键回滚 |
发布纪律的底线
任何会改写系统 of record 的 Agent 版本,都必须满足“可回滚、可审计、可解释”三要素。没有回滚开关的发布,在客服域等同于无保护上线。
评测集设计:覆盖而非堆量
许多团队把评测等同于“收集更多数据”。更有效做法是按风险分层设计评测集:
- 高频低风险:查询、进度解释、标准政策说明;
- 高频高风险:退款、改址、账户权限变更;
- 低频高风险:合规边界问题、异常账户、争议升级;
- 对抗样本:prompt injection、多语种混合、错别字、口音扰动。
“覆盖率”建议定义
一个可操作的覆盖率定义可以是:
比起单纯增加样本量,更应关注关键策略分支是否被触达。
线上监控与告警策略
灰度期必须同时监控业务指标、质量指标、安全指标。建议最小看板包含:
- 业务:会话量、可验证解决率、单位会话成本;
- 质量:P50/P90 响应延迟、升级率、重复联系率;
- 安全:输入攻击命中率、输出越界命中率、人工紧急接管率。
只看均值是高频事故源
如果只看平均延迟和平均成功率,容易错过高分位尾部风险。客服系统中的投诉和舆情往往由少量极差会话触发,因此必须持续追踪 P95/P99 与长尾失败模式。
本章小结
Agent 发布应从“功能上线”升级为“风险受控上线”。分层门禁、风险分层评测和高分位监控是三件必须同时具备的基本功。
失败复盘框架:把事故转化为系统能力
在真实部署中,失败不可避免。讲者给出的精神是“不断接触现实并修正系统”。这一节总结一个复盘框架,帮助团队把事故转化为可复用资产,而不是一次性救火。
复盘对象与分级
建议把失败分为三类:
- A 类:安全与合规事故(越权建议、敏感信息泄露);
- B 类:业务动作事故(错误退款、漏执行、重复执行);
- C 类:体验事故(高延迟、话轮错乱、重复追问)。
A 类必须 24 小时内完成根因与遏制;B 类 48 小时内完成补偿与修复;C 类纳入周度质量迭代。
一页纸复盘模板
| 模块 | 应填写内容 |
|---|---|
| 事件摘要 | 发生时间、影响范围、用户影响、检测方式 |
| 根因分析 | 模型行为、工具行为、策略行为分别发生了什么 |
| 防线回顾 | 输入守卫、执行守卫、输出守卫哪一层失效 |
| 补偿动作 | 对用户与业务系统采取了哪些纠偏动作 |
| 长期修复 | 评测集新增项、规则新增项、流程新增项 |
| 验证结果 | 修复后在仿真与灰度中的表现对比 |
复盘的目标
复盘不是追责会,而是“把一次失败转化为未来不再同类失败的系统升级”。只修 prompt 不修机制,事故会以新形态重现。
三类高频反模式
- 反模式 1: 把所有问题归因于“模型不够强”。 实际上,很多事故由工具协议不稳、策略缺口、数据脏读引起。
- 反模式 2: 出事后临时加规则但不进评测集。 结果是下一版回归时旧问题复发,团队进入重复救火。
- 反模式 3: 只修线上,不修开发流程。 没有门禁和模板,事故知识无法沉淀,组织学习停滞。
“热修复文化”会吞噬迭代速度
如果团队长期依赖线上热修复而缺乏制度化复盘,系统会快速积累隐性技术债:规则互相冲突、行为不可解释、发布风险不断升高,最终拖慢全部创新节奏。
本章小结
高质量 Agent 团队不是“从不失败”,而是“失败后系统能力单调上升”。复盘机制的成熟度,直接决定了产品在复杂环境下的长期进化速度。
总结与延伸
本讲把 Agent 从“技术热点”还原为“可经营系统”。讲者给出的核心启示是:企业级 Agent 的主战场不在单点模型能力,而在端到端可靠性、可验证结果、分层安全与持续优化机制。
| 命题 | 讲者证据与观点 | 可执行落地动作 |
|---|---|---|
| 客服 Agent 的本质是结果系统 | 计费与评价围绕“是否解决问题”而非“是否聊得像人” | 以可验证动作定义 KPI,建立 outcome verification 事件模型 |
| 单 Agent 将替代多渠道割裂 | 渠道正在从 phone/chat/email 向统一策略层收敛 | 统一状态机与身份/会话上下文,避免渠道 KPI 冲突 |
| Voice 是系统工程而非模型堆叠 | 延迟尾部、打断检测、噪声鲁棒决定体验成败 | 建立 turn-level latency budget、打断分类、provider failover |
| 评测必须接近真实环境 | Towbench 强调工具交互、策略约束、多轮状态变化 | 以 simulation+回归集作为发布门禁,不仅依赖离线问答指标 |
| 安全必须多层治理 | 提示注入与越权风险在真实流量中持续出现 | 输入/执行/输出三层 guardrail,加 deterministic access gateway |
| 长期优势来自运营闭环 | tracing + insights + expert answers 构成持续学习系统 | 建立问题归因与知识回灌周会,形成季度迭代节奏 |
延伸阅读
- Towbench 项目与论文主页(关注 Tool-Agent-User 评测设定与 leaderboard)。
- Berkeley RDI Agentic AI MOOC F25 其余讲次(特别是 multi-agent、safety、infrastructure 相关课程)。
- OpenAI、Anthropic、Google 关于 agent evaluation、tool use、safety guardrails 的最新技术报告。
- 生产工程侧参考:service reliability、progressive delivery、observability 与 red-teaming 实践。
给课程项目的实践建议
如果你正在做课程项目,建议至少补齐以下四项:
第一,设计一个“可验证动作”而非仅文本回答的任务;
第二,构建最小多轮仿真评测集;
第三,加入输入与输出的双向守卫;
第四,记录完整 trace 并做一次系统性失败复盘。
做到这四项,你的 Agent 项目才真正跨过“演示系统”门槛,进入“可部署系统”范畴。