CS224N Lecture 16: ConvNets and Tree Recursive Neural Networks
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Chris Manning 授课内容整理 |
| 来源 | Stanford Online |
| 日期 | 2024年 |

引言:从 RNN 到 CNN
本节课由 Chris Manning 主讲,介绍两种用于自然语言处理的神经网络技术:卷积神经网络(Convolutional Neural Networks, CNN)和树递归神经网络(Tree Recursive Neural Networks)。虽然在 Transformer 主导的当下,这两种技术的使用频率有所下降,但它们所蕴含的思想仍然具有重要的启发价值。
课程背景与定位
Manning 指出,在任何科学领域中,不同的思想和技术总是交替出现的。即使某种方法当前不是主流,了解它们仍然有价值,因为人们经常以新的方式重新发明和组合这些思想。CNN 和树递归神经网络正是这样的例子——它们包含的核心思想至今仍然活跃在各种模型设计中。
RNN 的局限性
回顾循环神经网络(RNN),它通过从左到右逐词处理来构建句子表示。这种方式有一个关键问题:
- 无法捕获不带前缀上下文的短语:RNN 在每一步都包含了之前所有词的信息。例如,对于句子“Monae walked into the ceremony”,你得到的不是“the ceremony”的表示,而是“Monae walked into the ceremony”的整体表示。
- 最后几个词的信息往往过度主导:由于梯度消失等问题,最终的隐藏状态往往更多地反映句子末尾的内容。
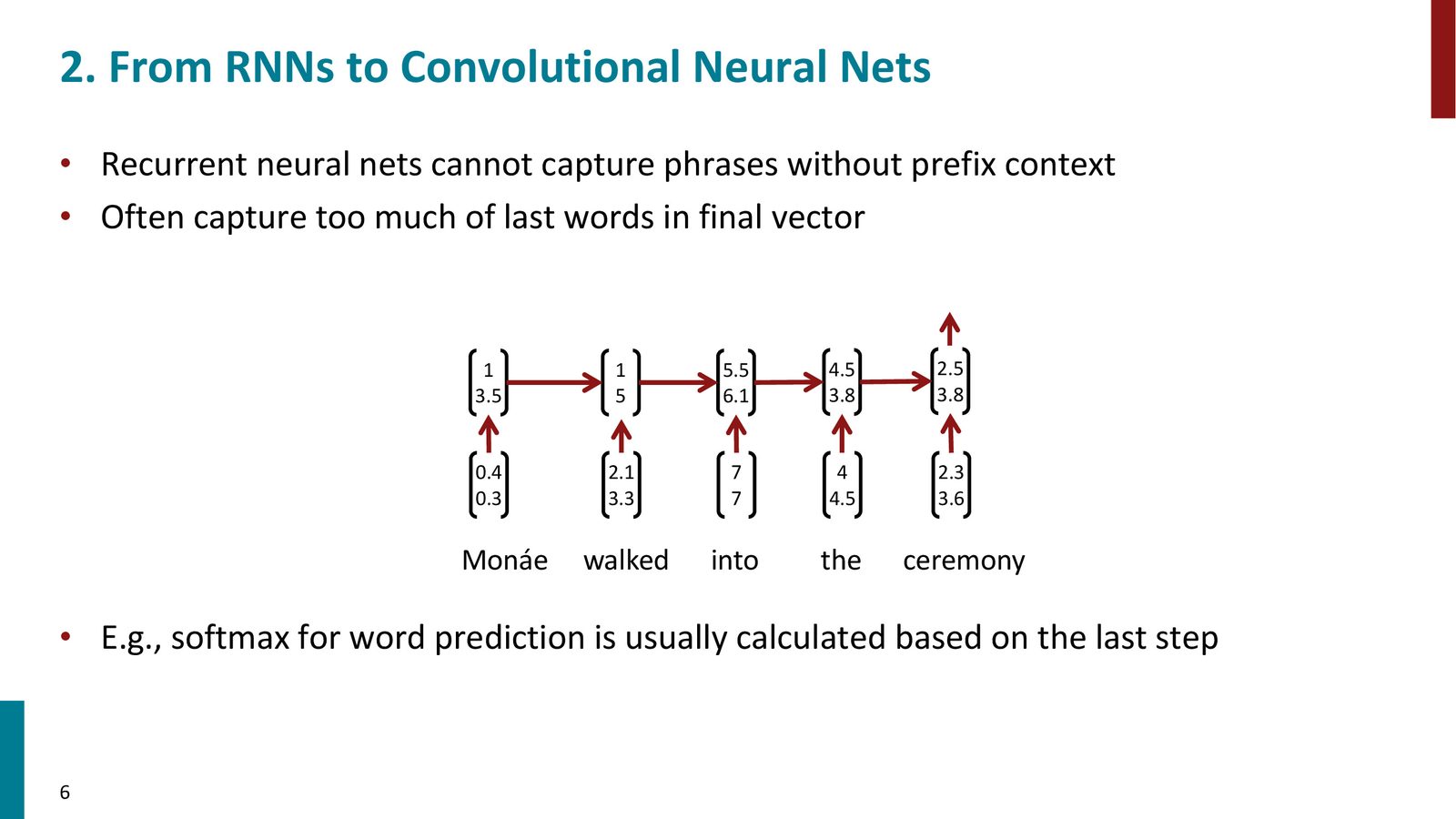
来源:Slides 第6页。
CNN 的核心思想
卷积神经网络提供了一种不同的思路:类似于 n-gram 模型,我们可以对固定长度的词子序列(如 bigram、trigram)计算向量表示,然后通过某种方式聚合这些表示。

来源:Slides 第7页。
CNN 用于 NLP 的核心思想
对于句子“tentative deal reached to keep government open”,CNN 会计算所有 trigram 的向量表示:“tentative deal reached”、“deal reached to”、“reached to keep”等。这种方式不关心子序列是否是合法的语言学成分——它只是机械地对所有固定长度的窗口进行特征提取,然后通过后续操作进行聚合。
本章小结
RNN 从左到右顺序处理文本,无法独立捕获局部短语的表示。CNN 通过滑动窗口的方式,为每个固定长度的子序列计算独立的向量表示,提供了一种互补的文本建模方案。
一维卷积的基本操作
从视觉到语言:2D 卷积到 1D 卷积
CNN 最初为计算机视觉设计,提供了平移不变性——无论目标出现在图像的哪个位置,都能被检测到。在视觉中,卷积核(filter/mask)在 2D 图像上滑动,通过点积计算每个位置的特征值。
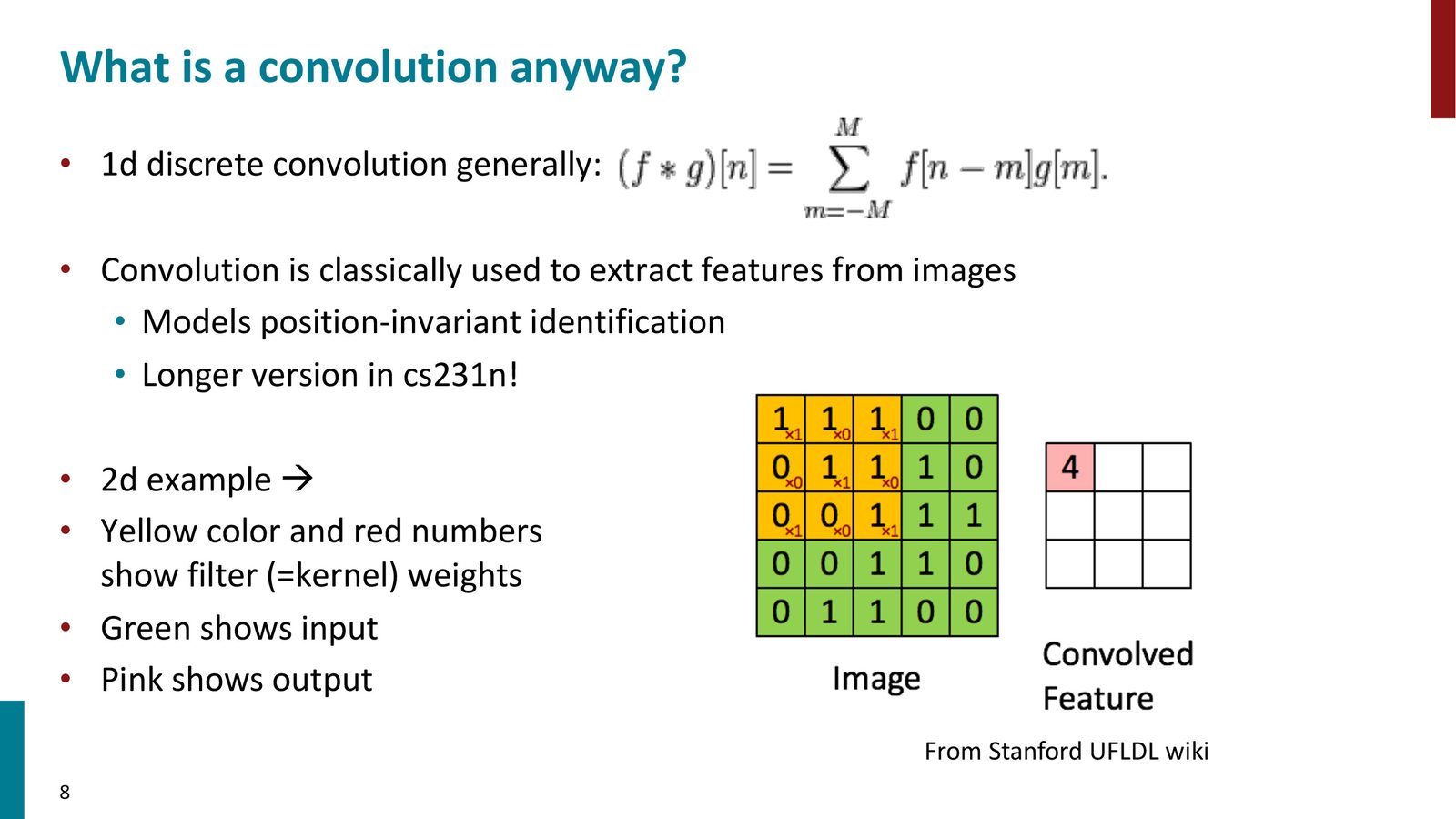
来源:Slides 第8页。
对于语言,我们只需要进行 1D 卷积——因为文本是一维序列。每个词有一个 \(d\) 维的词向量,卷积核覆盖连续的 \(h\) 个词(\(h\) 即 n-gram 的大小),在序列上从头滑动到尾。

来源:Slides 第9页。
单滤波器卷积的计算过程
对于一个 trigram 滤波器,设词向量维度为 \(d=4\),滤波器参数为 \(\mathbf{w} \in \mathbb{R}^{3 \times 4}\)。对于位置 \(i\) 处的 trigram(词 \(i\), \(i+1\), \(i+2\)),计算过程为:
其中:
- \(\mathbf{x}_{i:i+2}\) 是三个词向量的拼接
- \(\mathbf{w}\) 是滤波器权重(与位置无关,参数共享)
- \(b\) 是偏置项
- \(f\) 是非线性激活函数(如 sigmoid、ReLU)
卷积的参数共享特性
与全连接层不同,卷积层的核心特性是参数共享:同一个滤波器在所有位置使用相同的权重。这不仅大幅减少了参数量,还赋予了模型平移不变性——无论特定的 n-gram 模式出现在句子的哪个位置,都能被同样的滤波器检测到。
Padding(填充)
在不使用填充的情况下,对长度为 \(n\) 的句子使用大小为 \(h\) 的滤波器,输出长度为 \(n - h + 1\)(缩短了)。为了保持输出长度与输入一致,可以使用 zero padding:
- Same padding:在两端各填充 \(\lfloor h/2 \rfloor\) 个零向量,输出长度 = 输入长度
- Wide convolution:填充更多零向量,输出长度 \(>\) 输入长度
- No padding(narrow convolution):不填充,输出长度 \(<\) 输入长度
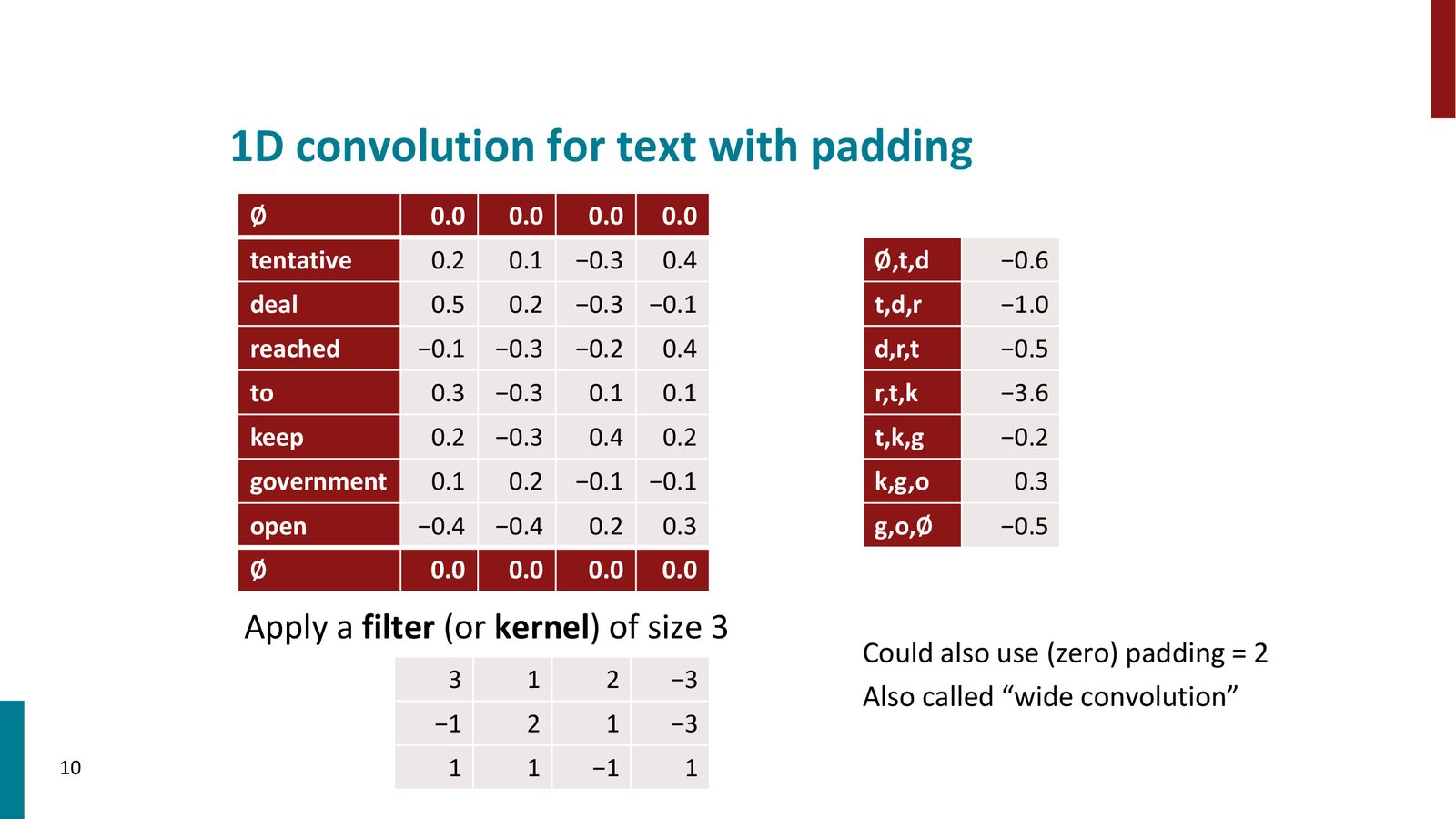
来源:Slides 第10页。
多滤波器卷积
一个滤波器只能检测一种模式。实际应用中,我们会使用 多个滤波器(channels),每个滤波器学习检测不同的特征:
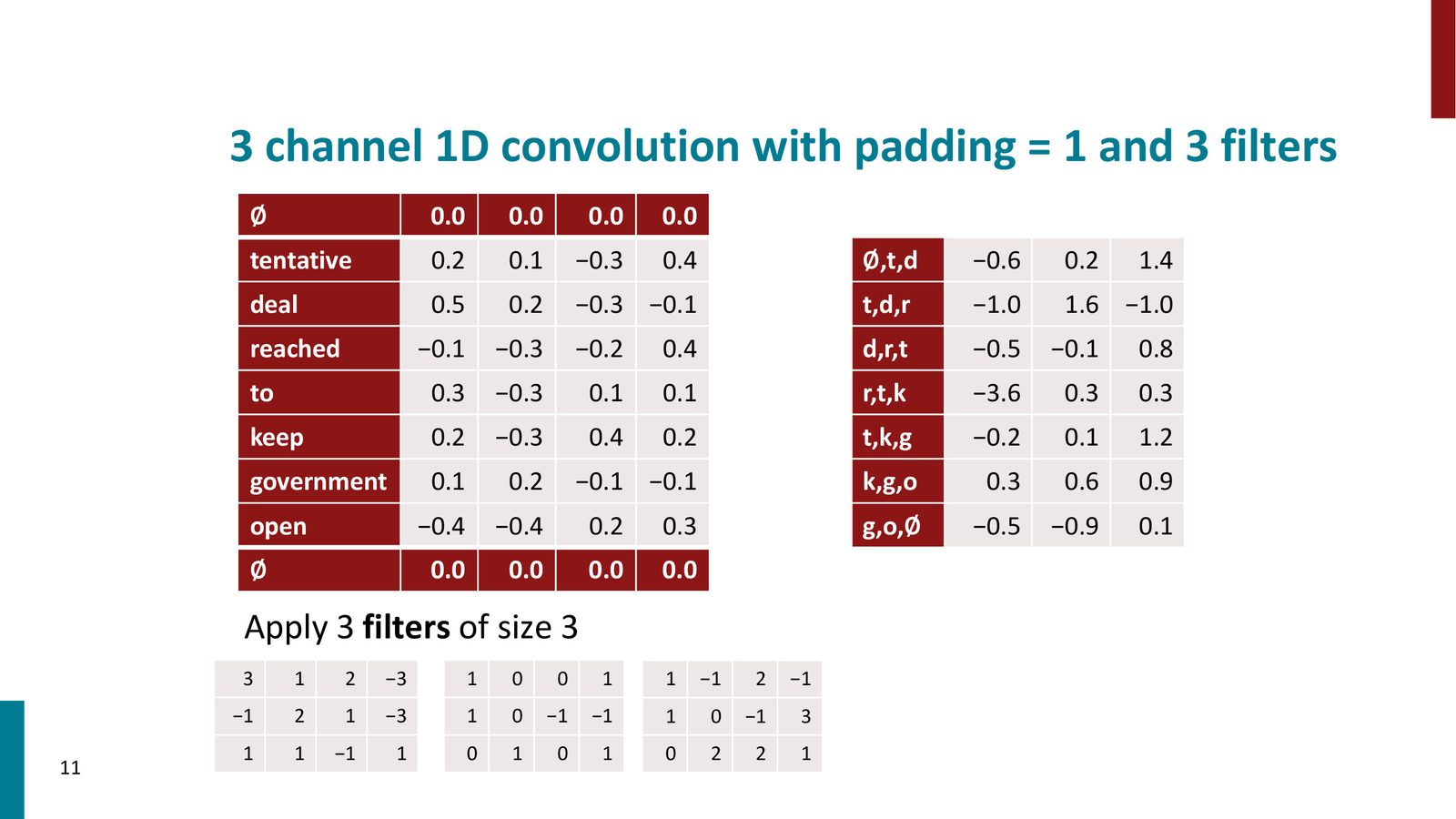
来源:Slides 第11页。
设有 \(m\) 个大小为 \(h\) 的滤波器,输入序列长度为 \(n\)(带 padding),则:
- 每个滤波器产生长度为 \(n\) 的特征图(feature map)
- \(m\) 个滤波器共同产生 \(m \times n\) 的特征矩阵
- 每个位置有一个 \(m\) 维的新表示向量
本章小结
1D 卷积通过在词向量序列上滑动固定大小的滤波器来提取局部特征。通过 padding 控制输出长度,通过多滤波器捕获不同类型的模式。卷积操作的参数共享特性使其高效且具有平移不变性。
池化操作与文本分类
Max Pooling(最大池化)
卷积操作为每个位置产生了特征向量,但对于文本分类任务,我们需要一个固定长度的句子表示。最常用的方法是 Max Pooling(最大池化)。

来源:Slides 第21页。
Max Pooling 的直觉
可以将每个滤波器理解为一个特征检测器。例如,某个滤波器可能学会检测“使用第一人称代词”(匹配 I、my、we、our 等词)。Max Pooling 的作用是:只要这个特征在文本的任何位置被强烈激活,就认为该特征存在。这类似于一个“是否存在某模式”的二值检测器。
具体地,设滤波器 \(j\) 在所有位置产生的特征图为 \(\mathbf{c}_j = [c_{j,1}, c_{j,2}, \ldots, c_{j,n-h+1}]\),则:
对 \(m\) 个滤波器分别做 max pooling,得到最终的句子表示向量:
Average Pooling(平均池化)
另一种池化方式是 Average Pooling。如果将滤波器理解为度量文本某种属性的程度(如“正式程度”),那么平均值可能比最大值更合理——它反映了整体水平而非峰值。
Max Pooling 通常优于 Average Pooling
在实践中,如果只选择一种池化方式,Max Pooling 通常表现更好。这是因为神经网络学到的特征更接近“模式检测器”而非“程度度量器”。当然,也可以同时使用两种池化方式并拼接结果,这有时能带来额外的性能提升。
其他池化变体
Local Max Pooling
不对整个序列做全局 max pooling,而是在局部窗口内做 max pooling。这样可以保留特征出现的大致位置信息,并捕获同一特征在多个位置的出现。
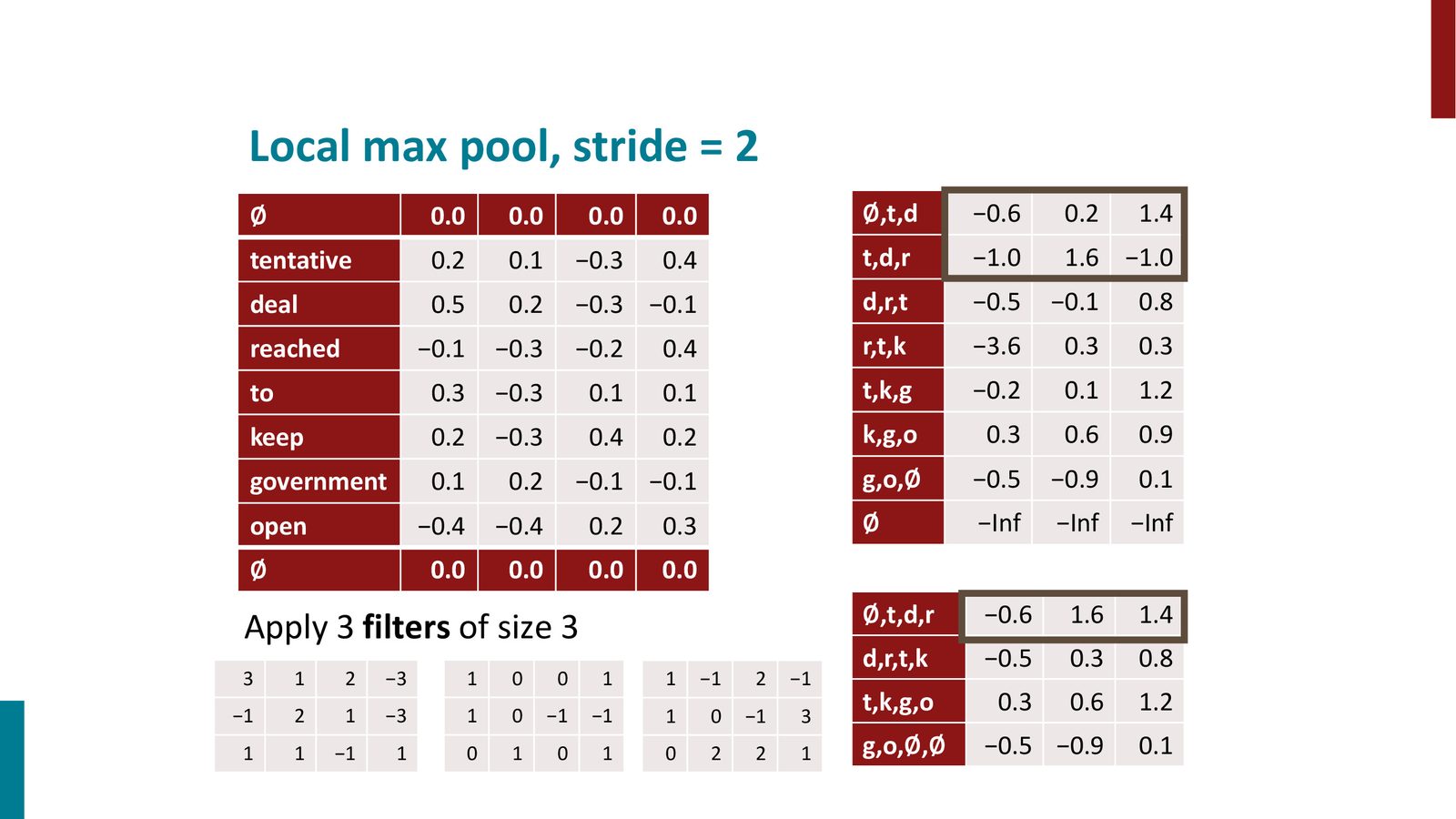
来源:Slides 第16页。
\(k\)-Max Pooling
保留每个通道中最大的 \(k\) 个值(而不是只保留最大的 1 个)。这样可以检测同一特征在文本中出现的次数——如果某个特征在多个位置被激活,\(k\)-max pooling 能够保留这些信息。
Stride(步幅)
卷积操作中,滤波器不一定要逐位移动。Stride(步幅)控制滤波器每次移动的距离。stride=2 意味着隔一个位置计算一次,输出长度减半。这在滤波器较大时尤其有用,可以减少冗余计算。
Dilation(膨胀卷积)
膨胀卷积不改变滤波器大小,而是在滤波器元素之间插入间隔。例如,dilation=2 的 trigram 滤波器会查看位置 \(\{i, i+2, i+4\}\) 而不是 \(\{i, i+1, i+2\}\)。这使得滤波器能覆盖更大的上下文范围,而不增加参数量。
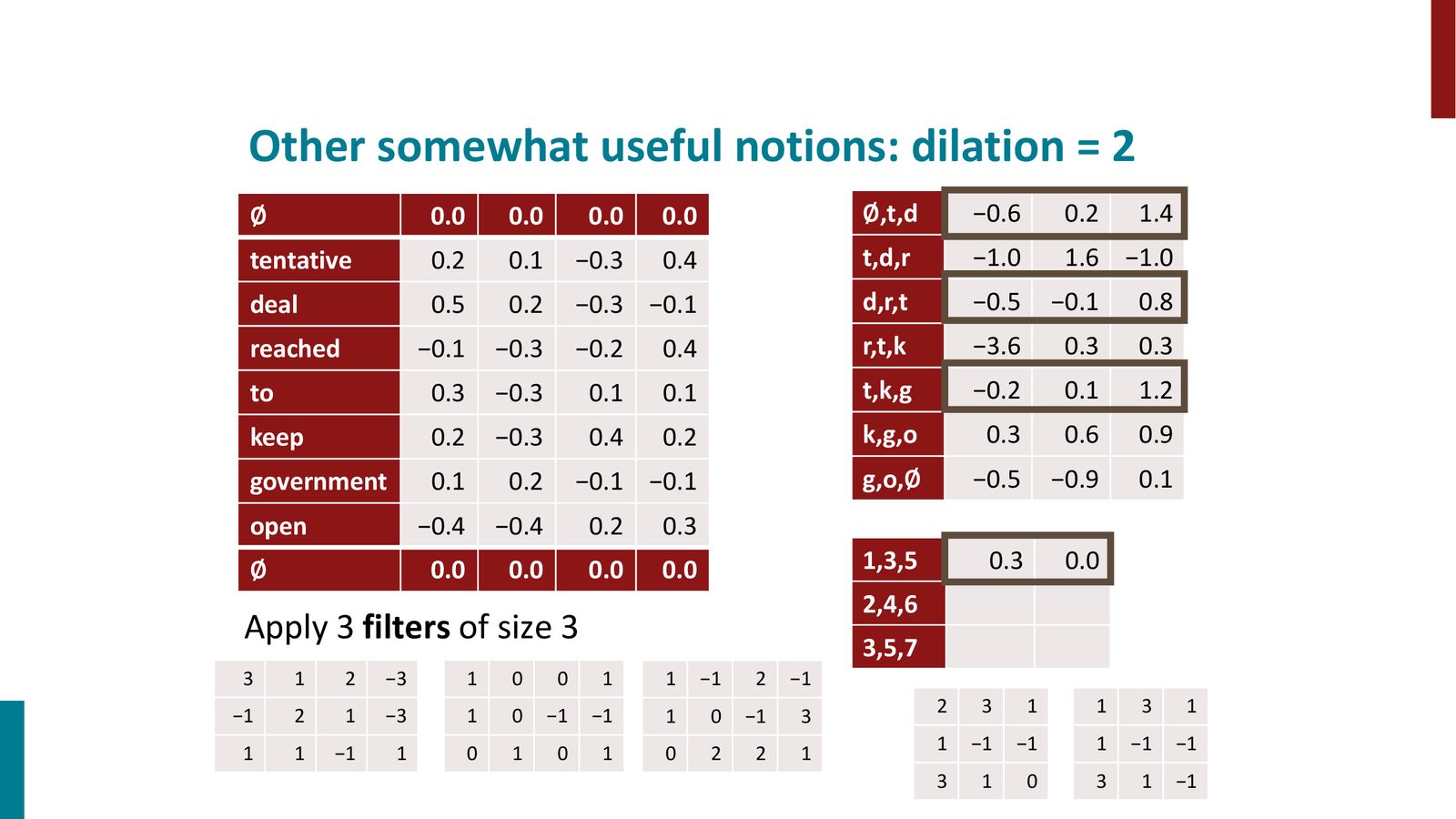
来源:Slides 第18页。
膨胀卷积的应用场景
膨胀卷积在语音处理中比在自然语言处理中更常用。在语音信号中,远距离的时间步之间可能存在有意义的关联,膨胀卷积可以用较少的参数捕获这种远程依赖。在文本中,由于词本身已经是较高层次的单位,膨胀卷积的使用相对较少。
PyTorch 实现
在 PyTorch 中,1D 卷积通过 nn.Conv1d 实现:
import torch.nn as nn
# in_channels: 词向量维度
# out_channels: 滤波器数量
# kernel_size: n-gram 大小
conv = nn.Conv1d(in_channels=300, out_channels=100,
kernel_size=3, padding=1)
# Max pooling over time
pool = nn.AdaptiveMaxPool1d(1)
# 输入: (batch_size, embedding_dim, seq_len)
# 输出: (batch_size, num_filters, 1)
本章小结
池化操作将变长的卷积特征图压缩为固定长度的表示向量。Max Pooling 是最常用的方式,它将每个滤波器视为特征检测器。Local max pooling、\(k\)-max pooling、stride 和 dilation 提供了更丰富的选择,可以根据具体任务灵活使用。
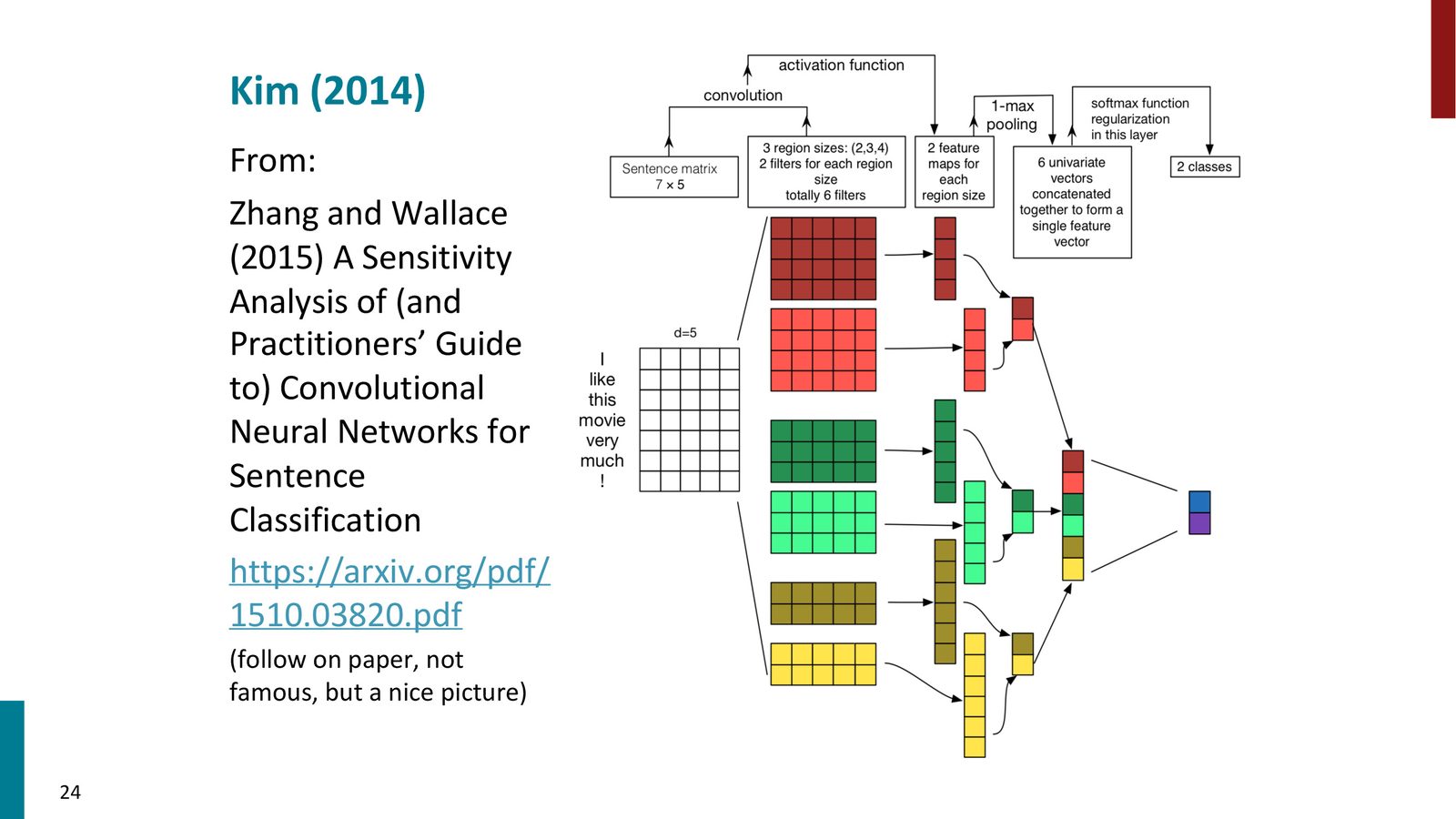
经典模型:Kim (2014) 的 CNN 文本分类器
模型架构
Yoon Kim 在 2014 年提出了一个简洁而有效的 CNN 文本分类模型,这是 CNN 用于 NLP 最著名的工作之一。

来源:Slides 第23页。图来自 Zhang & Wallace (2015) 的可视化。
模型的完整流程如下:
- 输入层:句子中每个词用预训练词向量(如 Word2Vec、GloVe)表示
- 卷积层:使用三种大小的滤波器(bigram、trigram、4-gram),每种 100 个
- Max Pooling:对每个滤波器取全局最大值
- 拼接:将所有滤波器的 max pooling 结果拼接为一个固定长度向量
- Softmax 分类层:\(y = \text{softmax}(W^{(S)}z + b)\)
模型公式
对于使用 \(m\) 个滤波器、滤波器大小分别为 \(h_1, h_2, \ldots\) 的模型:
- 卷积:\(\mathbf{c}_j = f(\mathbf{w}_j \cdot \mathbf{x}_{i:i+h-1} + b_j)\),对每个位置 \(i\)
- Max pooling:\(\hat{c}_j = \max\{\mathbf{c}_j\}\)
- 最终特征向量:\(\mathbf{z} = [\hat{c}_1, \ldots, \hat{c}_m]\)
- 分类:\(y = \text{softmax}(W^{(S)}\mathbf{z} + b)\)
多通道词向量:解决微调困境
Kim 在这篇论文中提出了一个重要的实践技巧:双通道词向量。
来源:Slides 第24页。
词向量微调的陷阱
当在小型监督数据集上微调预训练词向量时,会出现一个问题:
- 训练集中出现的词(如 tedious, dull)的向量被更新,移向“负面情感区域”
- 训练集中未出现的同义词(如 plodding)的向量保持不变
- 结果是,原本相似的词(tedious 和 plodding)在向量空间中被拉开距离
- plodding 可能被错误地分类为正面词
这就是为什么微调词向量有时会帮助、有时会损害模型性能。
Kim 的解决方案很简单:使用两个通道的词向量,一个允许微调,一个保持固定(frozen)。每个滤波器同时在两个通道上操作,这样模型可以同时利用:
- 微调通道:针对具体任务优化的词表示
- 固定通道:保持原始语义关系的词表示
实验结果
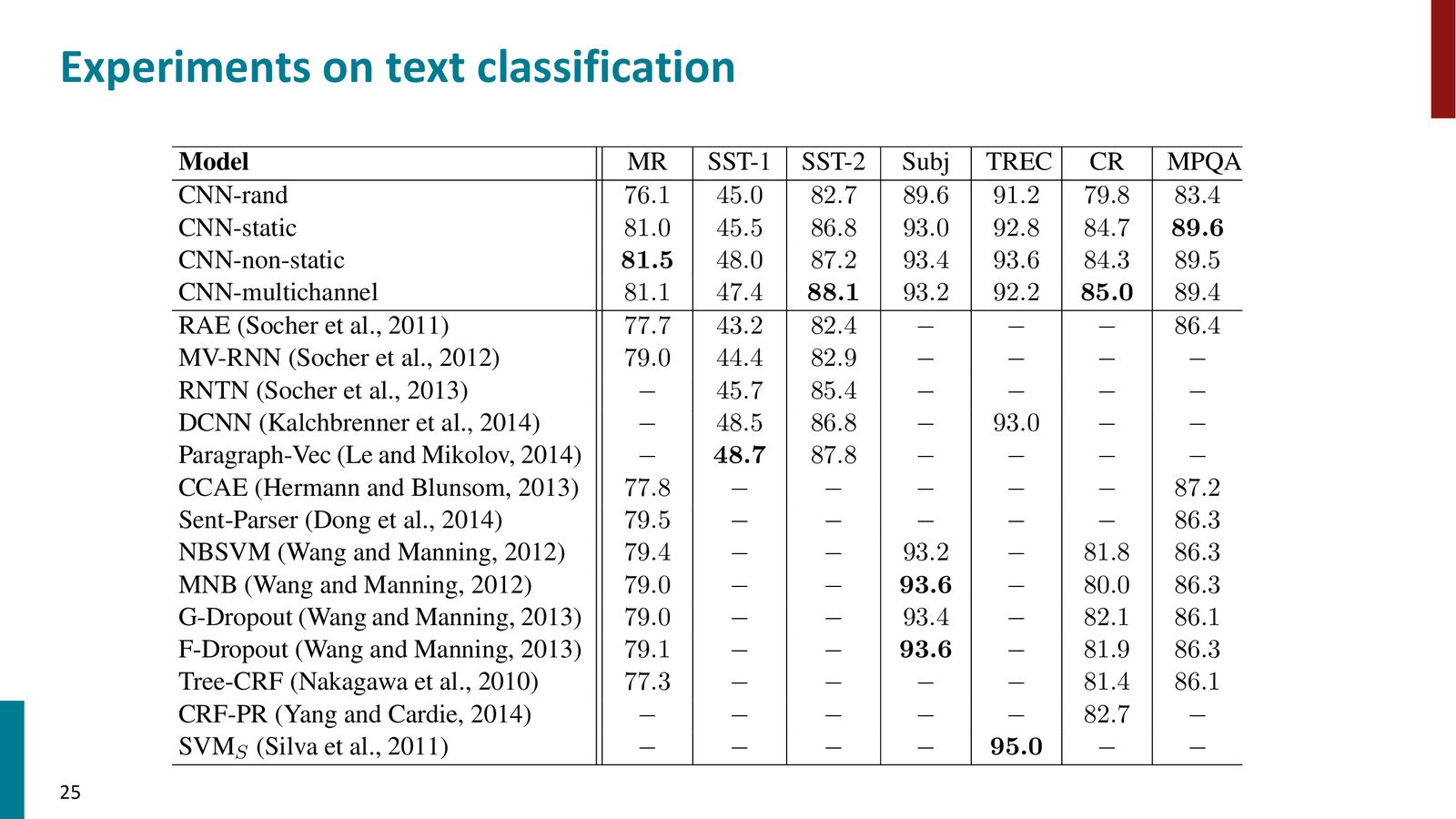
来源:Slides 第25页。
Kim 的 CNN 在多个数据集上取得了竞争力强的结果,包括 Stanford Sentiment Treebank(SST)、Movie Reviews(MR)、Subjectivity(Subj)和问题分类(TREC)等。

来源:Slides 第26页。
实验比较中的公平性问题
Manning 指出了这篇论文实验对比中的一个细微问题:Kim 使用了 Dropout(2012 年提出),而许多对比方法是在 Dropout 出现之前发表的。Dropout 本身可以带来 2--4% 的准确率提升。更严谨的做法应该是为所有对比方法都加上 Dropout 再进行比较。尽管如此,这项工作仍然证明了简单的 CNN 架构在文本分类任务上的有效性。
本章小结
Kim (2014) 展示了一个极其简洁的 CNN 文本分类架构:多种大小的滤波器 + Max Pooling + Softmax。双通道词向量技巧有效缓解了小数据集上微调词向量的问题。这个模型虽然简单,却在当时取得了接近最优的结果。
NLP 模型工具箱的演进
Manning 在此处回顾了 NLP 中可用的建模工具,形成了一个从简单到复杂的技术谱系:

来源:Slides 第27页。
- 词向量 + 词袋模型:最简单的分类方式,忽略词序
- 窗口模型:类似 CNN 但更 ad hoc,早期课程中介绍
- CNN:擅长分类任务,容易并行化
- RNN:认知上更合理(从左到右阅读),但难以并行化
- Transformer:目前 NLP 的主流,Vision 领域也在越来越多地使用
Batch Normalization vs Layer Normalization
Manning 补充了一个关于归一化的知识点。在 CNN 中通常使用 Batch Normalization(先于 Layer Normalization 被发明),而 Transformer 中使用 Layer Normalization:
- Layer Norm:在特征维度上计算统计量(对单个样本的所有特征做归一化)
- Batch Norm:在 batch 维度上计算统计量(对 batch 中所有样本的同一特征做归一化)
两者都实现了“零均值、单位方差”的标准化效果,但在不同架构中各有优势。
1x1 卷积的意义
一个看似无意义的概念:1x1 卷积(size-1 convolution)。它实际上等价于对每个位置独立地施加一个全连接层,即:
这与 Transformer 中的 Feed-Forward Layer(FFN)完全相同——在每个 token 位置独立地进行非线性变换。1x1 卷积的参数量远少于跨越整个序列的全连接层。
1x1 卷积 = Position-wise FFN
Transformer 中每个位置独立的前馈网络(Feed-Forward Network),从卷积的视角来看,就是一个 1x1 卷积。这种“在单个位置进行非线性变换”的操作是一个跨架构的通用设计模式。
本章小结
NLP 模型工具箱经历了从词袋模型到 Transformer 的演进。不同架构各有优势:CNN 擅长分类和并行化,RNN 更符合人类阅读直觉,Transformer 兼具两者优点。Batch Norm 和 Layer Norm 是不同架构中常用的归一化技术,1x1 卷积与 Transformer 的 FFN 在数学上等价。
深度 CNN:VD-CNN 字符级文本分类
动机:向视觉学习
Conneau et al. (2017) 提出了 VD-CNN(Very Deep CNN),灵感来自视觉领域的深度网络。当时存在一个有趣的对比:
- 视觉:已经使用 30--100 层的深度 CNN(如 ResNet)
- NLP:LSTM 模型通常只有 2--4 层,最多 8 层
此外,视觉模型从原始像素开始,而 NLP 模型从词开始。VD-CNN 的思路是:像视觉一样,从原始字符开始,使用深度 CNN 进行文本分类。
VD-CNN 架构
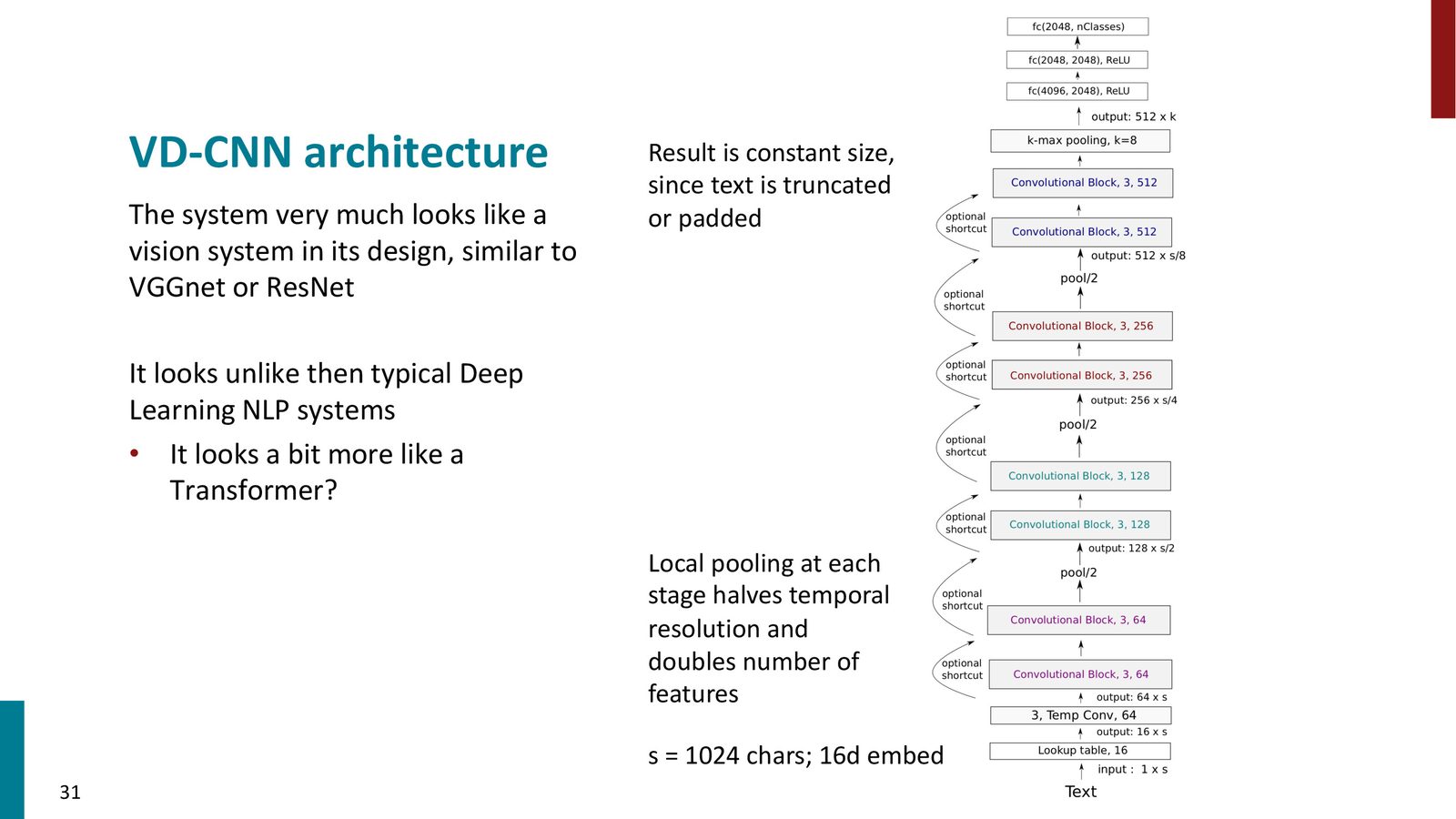
来源:Slides 第31页。
VD-CNN 的架构设计与视觉网络(如 VGGNet、ResNet)非常相似:
- 输入:1024 个字符,每个字符用 16 维嵌入表示
- 第一组卷积块:64 个 size-3 滤波器 \(\times\) 2 层(带残差连接)
- Local Pooling(pool/2):序列长度减半 \(\rightarrow\) 512
- 第二组卷积块:128 个 size-3 滤波器 \(\times\) 2 层
- Local Pooling:\(\rightarrow\) 256
- 第三组卷积块:256 个 size-3 滤波器 \(\times\) 2 层
- Local Pooling:\(\rightarrow\) 128
- 第四组卷积块:512 个 size-3 滤波器 \(\times\) 2 层
- \(k\)-Max Pooling(\(k=8\)):保留 8 个最大激活值
- 全连接层:fc(4096, 2048) \(\rightarrow\) fc(2048, 2048) \(\rightarrow\) fc(2048, nClasses)
VD-CNN 的视觉网络设计模式
VD-CNN 借鉴了视觉深度网络的三个关键设计:
- 逐步下采样:局部池化在每一阶段将序列长度减半,同时特征维度翻倍
- 残差连接:允许梯度直接通过跳跃连接传播,缓解深度网络的训练困难
- 顶部全连接层:在所有卷积层之后使用多个全连接层做最终分类
这种“逐层缩小空间分辨率、增加特征维度”的金字塔结构是深度 CNN 的标志性设计。
感受野分析
在第四组卷积块处,每个 trigram 滤波器的感受野已经覆盖了约 24 个字符(约 6 个词的长度)。这意味着最高层的每个特征已经能感知到较长范围的上下文。
实验结果

来源:Slides 第33页。
VD-CNN 在以下数据集上进行了评估:
- 新闻分类(AG News、Sogou News)
- 知识图谱分类(DBpedia)
- 情感分析(Yelp、Amazon Reviews)
关键发现:
- 29 层模型一致优于 9 层和 17 层模型——更深确实更好
- 在 Yelp 和部分 Amazon 数据集上超越了当时的最优方法
- 仅使用字符级输入,无需预训练词向量
字符级 CNN 的意义
VD-CNN 证明了可以完全从字符级别出发,通过深度卷积网络达到甚至超越词级别模型的性能。这消除了对预训练词向量的依赖,也天然地处理了未登录词(OOV)问题。这种从“原始信号”出发的设计哲学后来也影响了 Transformer 中子词分割(subword tokenization)的思路。
本章小结
VD-CNN 将视觉领域深度 CNN 的设计模式成功迁移到文本分类。通过字符级输入、深层卷积(最多 29 层)、残差连接和逐层池化,在多个大规模数据集上取得了竞争力强的结果,证明了深度和原始信号输入的价值。
树递归神经网络
语言的递归结构
本课的后半部分转向一种完全不同的建模思路——树递归神经网络(Tree Recursive Neural Networks)。这是 Manning 和学生在 Stanford 从 2010 年开始发展的一系列工作。
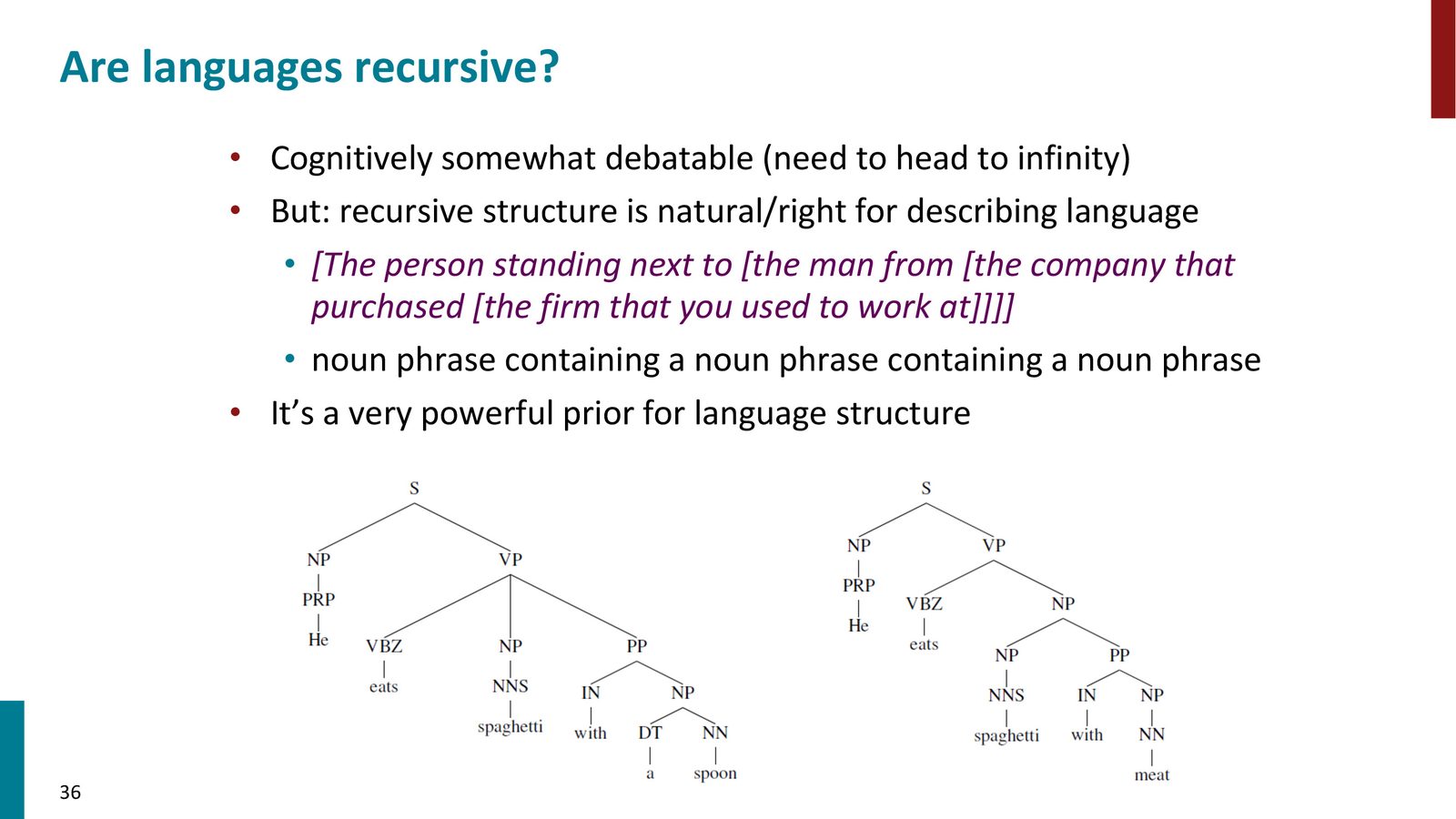
来源:Slides 第36页。
其动机来自语言学中对人类语言结构的基本观察:
语言的递归性
人类语言的一个核心特性是递归结构——同样的句法结构可以嵌套在自身内部。例如:
“[The person standing next to [the man from [the company that purchased [the firm that you used to work at]]]].”
这个句子包含了四层嵌套的名词短语,每一层都有相同的句法结构。这种无限嵌套的能力是人类语言区别于其他动物交流系统的关键特征。
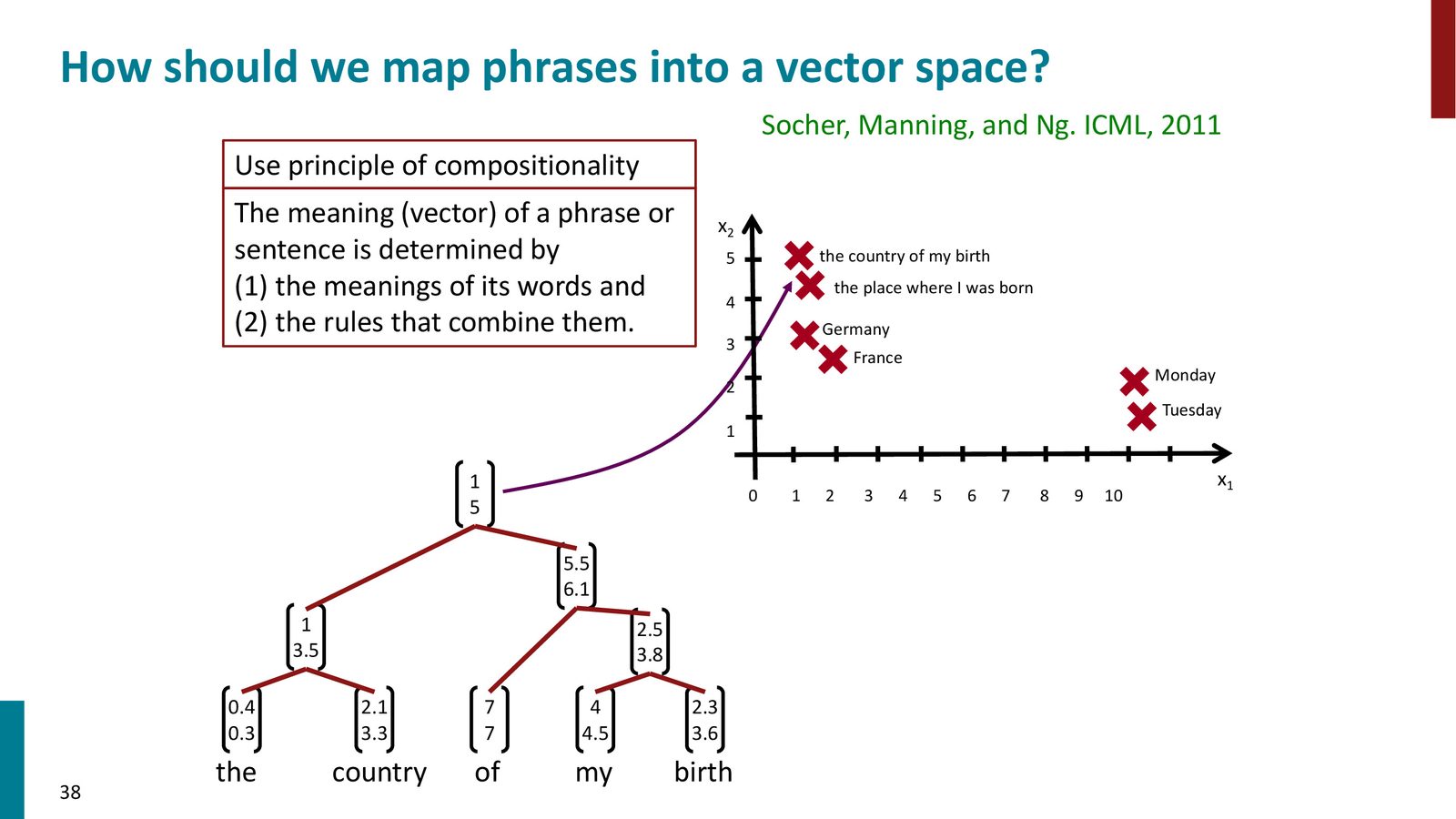
来源:Slides 第38页。
组合性原则
树递归神经网络的理论基础是语言学和语言哲学中的组合性原则(Principle of Compositionality):
Frege 的组合性原则
一个短语或句子的意义由其组成词的意义和组合它们的规则共同决定。
如果我们有词向量来表示词的意义,那么我们应该能够根据句法结构,通过某种组合函数,递归地构建短语和句子的意义表示。例如,“the country of my birth” 应该在向量空间中出现在与地名词(如 France、Japan)相近的位置。
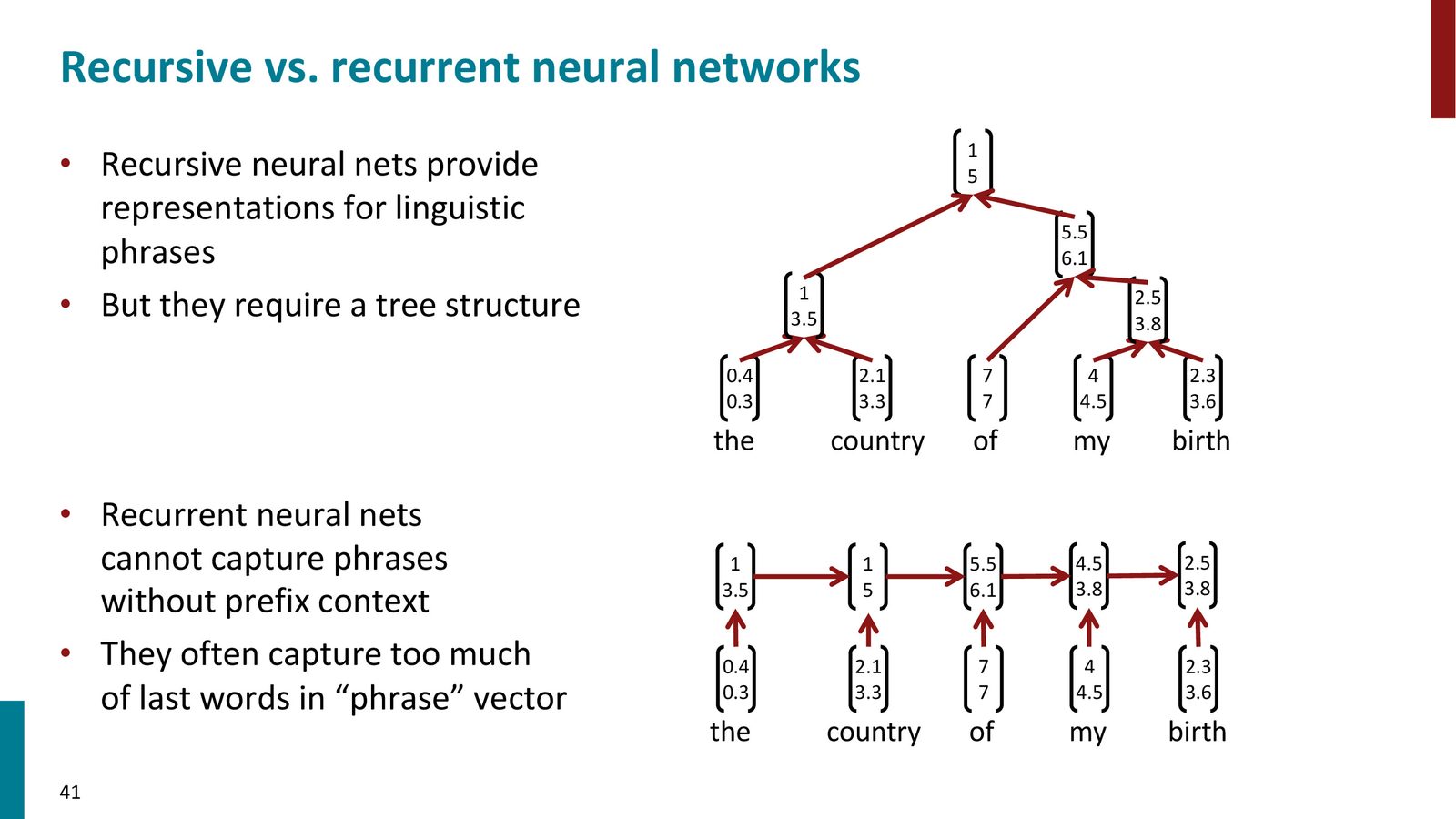
来源:Slides 第41页。
简单递归神经网络
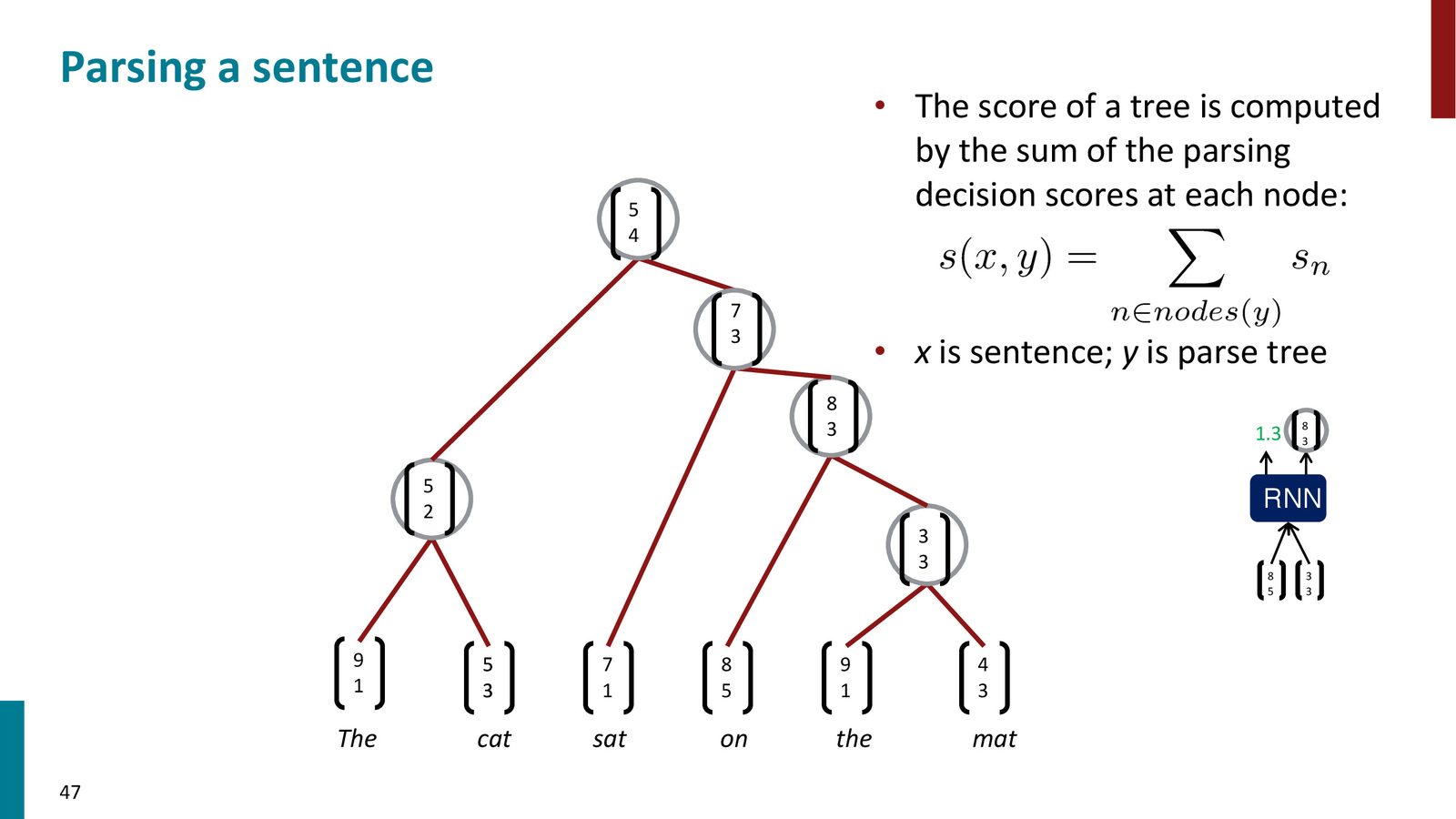
最基本的树递归神经网络使用一个共享的权重矩阵 \(W\) 在树的所有节点处进行组合:
其中:
- \(\mathbf{c}_1, \mathbf{c}_2 \in \mathbb{R}^d\) 是两个子节点的向量表示
- \(W \in \mathbb{R}^{d \times 2d}\) 是共享的组合矩阵
- \(\mathbf{b}\) 是偏置向量
- \(f\) 是非线性激活函数
- \(\mathbf{p} \in \mathbb{R}^d\) 是父节点的表示
同时,可以学习一个评分函数来判断两个节点是否应该合并为一个成分:
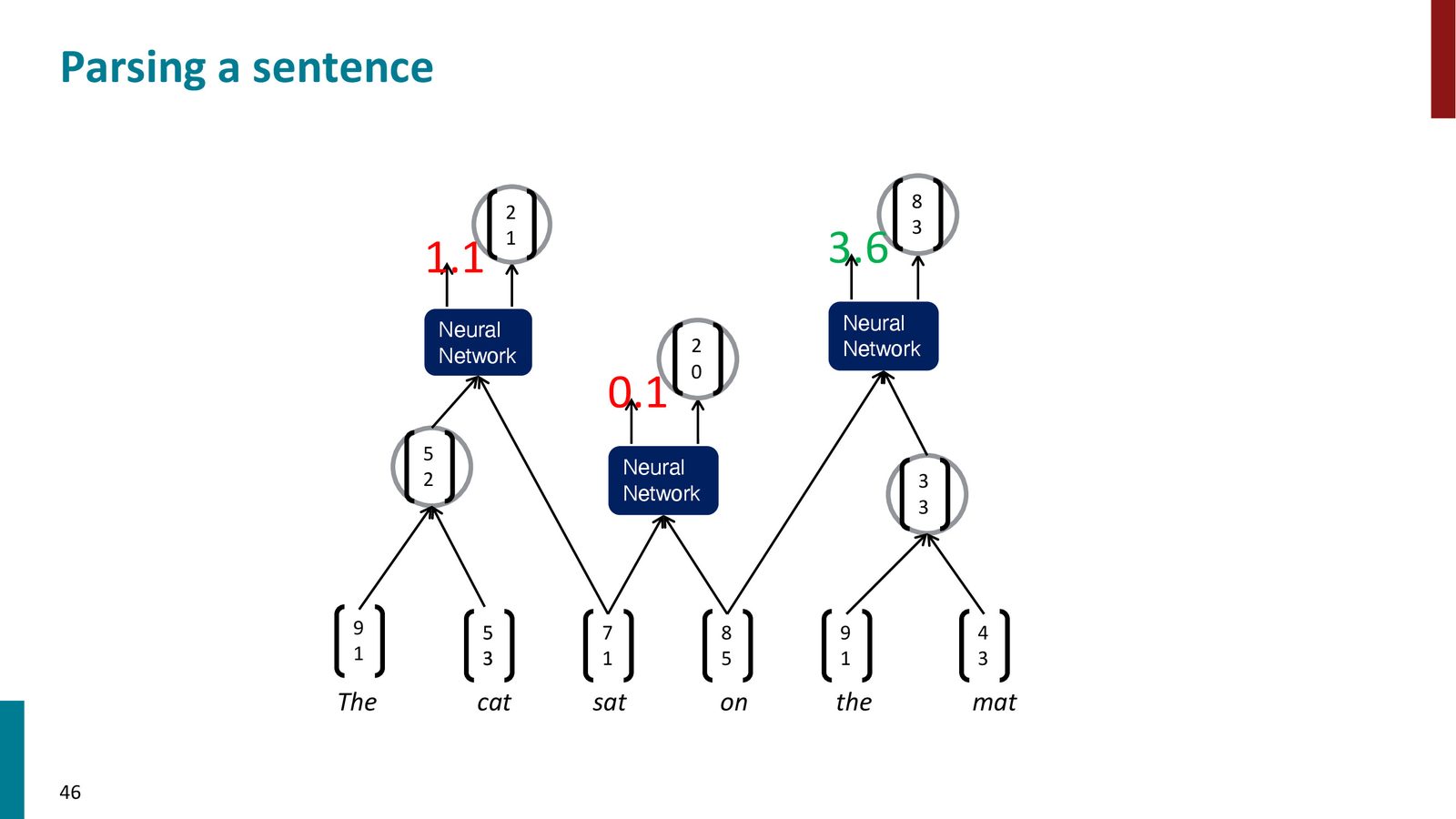
来源:Slides 第46页。
贪心分析算法
利用上述评分函数,可以构建一个贪心的句法分析器:
- 初始化:所有词的词向量
- 计算所有相邻词对的合并得分
- 选择得分最高的对,合并为一个新节点
- 更新相邻关系,重新计算涉及新节点的得分
- 重复直到只剩一个根节点
来源:Slides 第47页。
简单 TreeRNN 的局限性
使用单一权重矩阵 \(W\) 在所有节点处组合存在明显局限:
- 无法区分不同类型的语法组合(形容词+名词 vs 动词+宾语)
- 对所有词对采用完全相同的交互方式
- 表达能力受限,性能仅与 bigram Naive Bayes 分类器相当
本章小结
树递归神经网络基于语言的递归结构和组合性原则,沿句法树自底向上构建短语和句子的向量表示。简单的 TreeRNN 使用共享权重矩阵进行节点组合,并可用于贪心句法分析。但单一权重矩阵的表达能力不足,需要更强大的组合函数。
递归神经张量网络与情感分析
情感分析的挑战
情感分析看似简单——检测正面词(great, wonderful)和负面词(poor, bad)即可。但真实语言中的情感表达远比这复杂:
来源:Slides 第52页。
关键词匹配的失败案例
考虑影评“With this cast and subject matter, the movie should have been funnier and more entertaining.” 关键词匹配会检测到 “funnier”(正面)和 “entertaining”(正面),将其判为正面评价。但由于 “should have been” 的组合语义,这实际上是一条负面评价——影评人认为这部电影不够有趣和娱乐性。这种组合语义是简单方法无法捕获的。
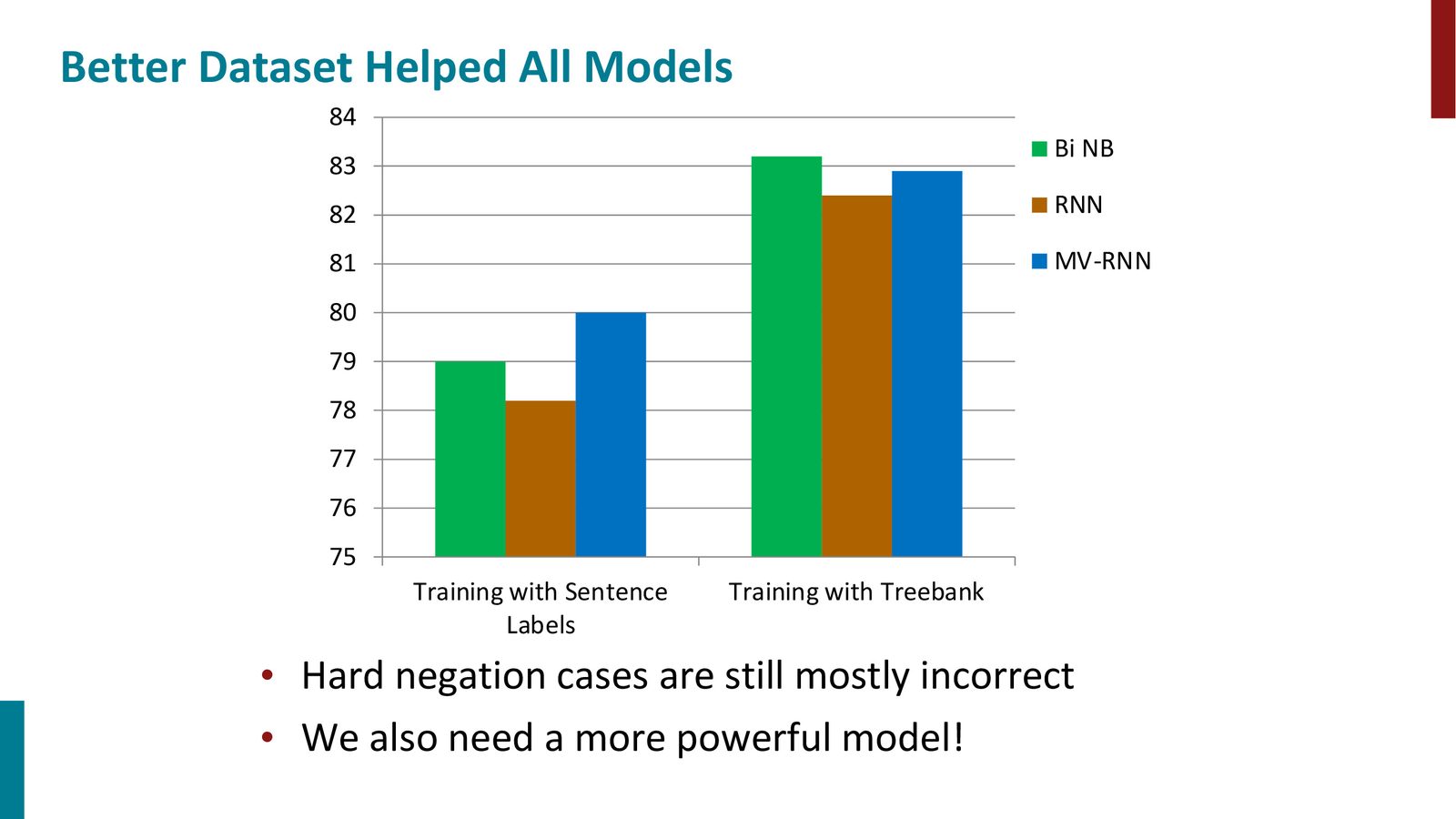
Stanford Sentiment Treebank
为了研究组合语义在情感分析中的作用,Manning 团队构建了 Stanford Sentiment Treebank(SST):

来源:Slides 第51页。
SST 数据集的创新
- 包含 11,855 个句子,共 215,154 个带情感标注的短语
- 不仅标注整句情感,还标注了每一个中间短语的情感
- 使用 5 级情感标注:非常负面、略微负面、中性、略微正面、非常正面
- 仅仅使用 phrase-level 标注就能提升 Naive Bayes 分类器 4% 的准确率(79% \(\rightarrow\) 83%)
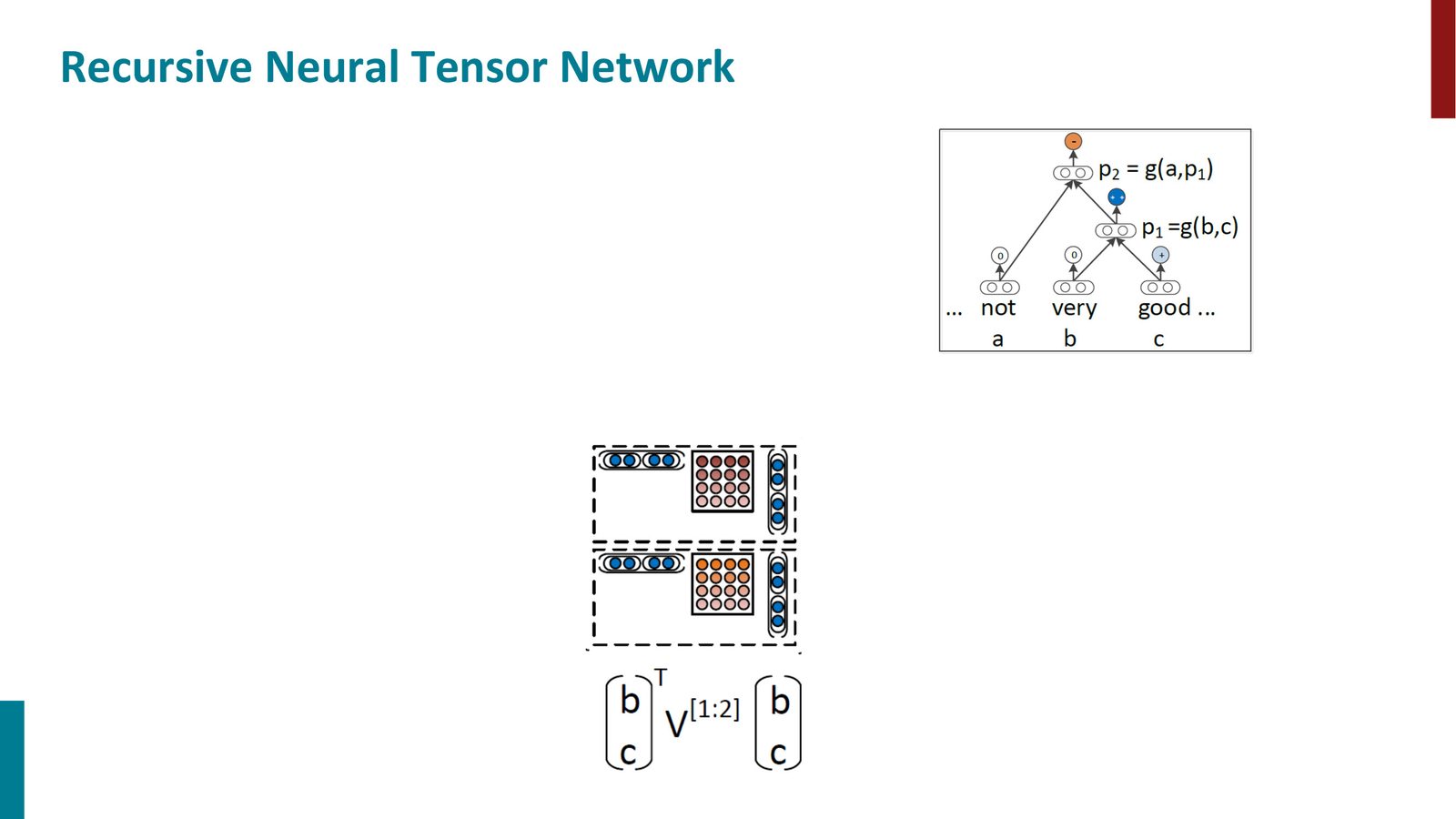
递归神经张量网络(RNTN)
为了克服简单 TreeRNN 的表达能力限制,Manning 团队提出了递归神经张量网络(Recursive Neural Tensor Network, RNTN)。
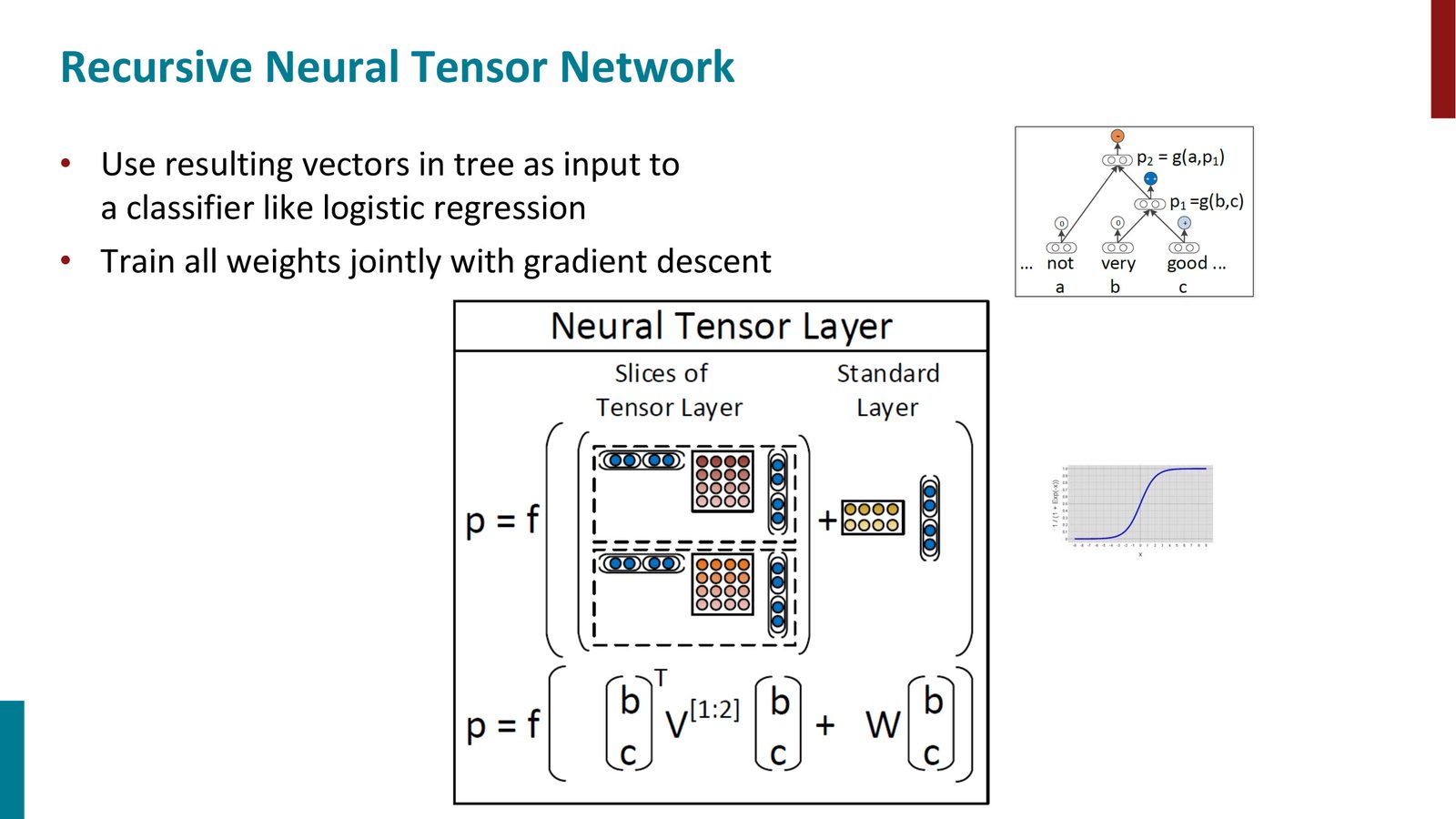
来源:Slides 第56页。
RNTN 的核心创新是 Neural Tensor Layer:
其中:
- \(V^{[1:d]} \in \mathbb{R}^{2d \times 2d \times d}\) 是三维张量
- \(\mathbf{c}_1^T V^{[k]} \mathbf{c}_2\) 计算了两个子节点之间的乘法交互
- \(W\) 项保留了标准的线性组合
- 张量项使得模型能根据两个子节点的具体内容,产生不同的组合方式
为什么需要乘法交互
在语言中,不同类型的词组合方式差异很大:
- “red ball”(形容词+名词):red 为 ball 添加属性
- “kick the ball”(动词+宾语):ball 是动作的对象,角色完全不同
- “not good”(否定+正面词):not 翻转了 good 的极性
简单的线性组合 \(W[\mathbf{c}_1; \mathbf{c}_2]\) 无法区分这些不同的交互模式。张量层通过 \(\mathbf{c}_1^T V \mathbf{c}_2\) 实现了依赖于输入内容的组合方式——当 \(\mathbf{c}_1\) 和 \(\mathbf{c}_2\) 不同时,张量项会产生不同的交互效果。
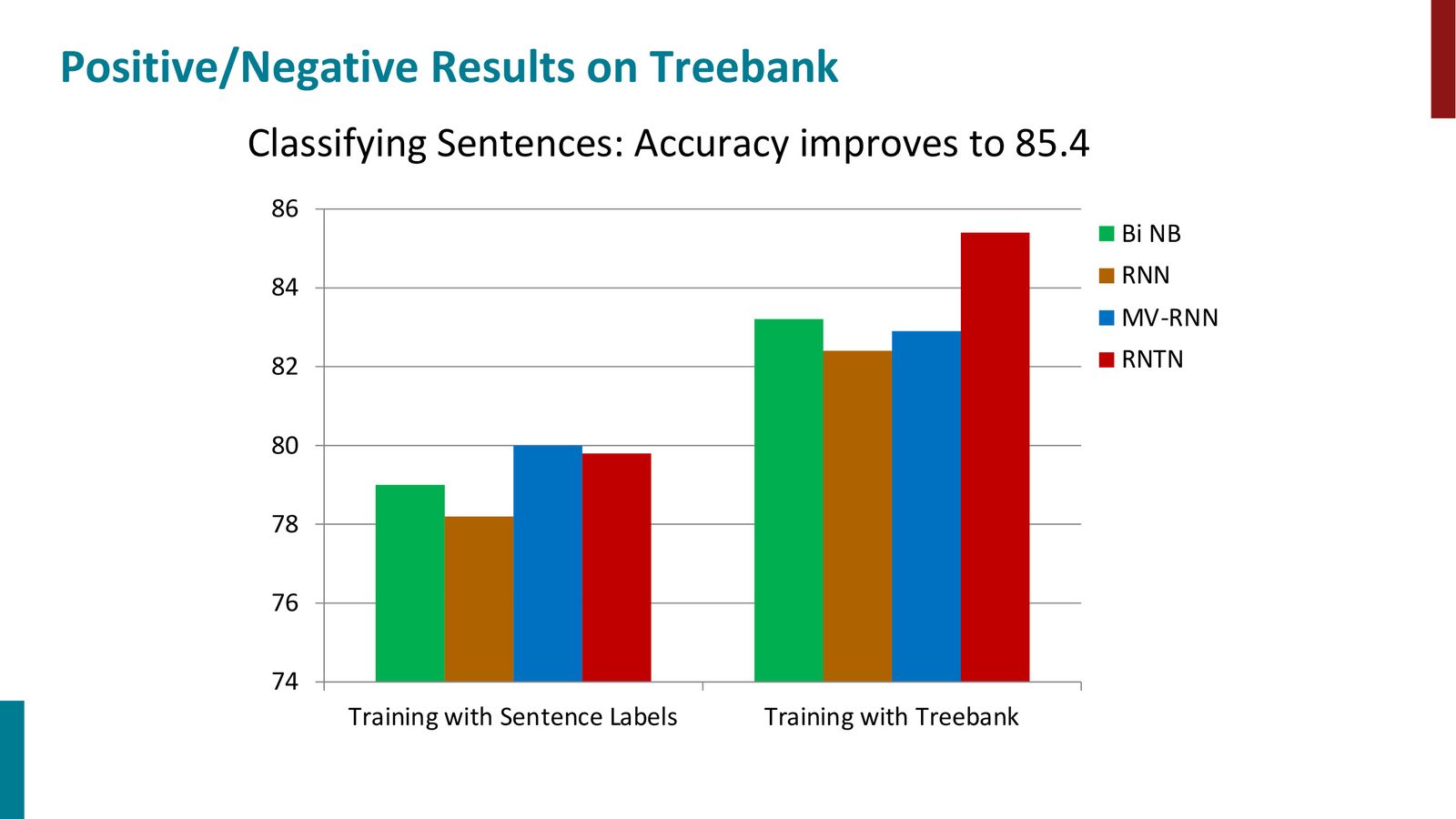
RNTN 在情感分析上的表现
来源:Slides 第54页。
RNTN 相比 bigram Naive Bayes 模型提升了约 2 个百分点。虽然绝对提升不大,但更有价值的是其对组合语义的建模能力。
否定建模:RNTN 的亮点
RNTN 最令人印象深刻的能力是对否定(negation)的处理:

来源:Slides 第58页。
否定建模的关键测试
考虑两种情况:
- 否定正面句(如“not good”):相对容易,因为 “not” 本身在统计上与负面语境相关,它的出现会自然降低正面程度
- 否定负面句(如“not dull”):这是真正的挑战。“not” 是负面词,“dull” 也是负面词,简单的加法/平均模型会得出“更加负面”的错误结论。正确答案应该是情感被翻转为正面
RNTN 是当时唯一能正确处理“否定负面词使情感变正面”这一现象的模型。这种能力来自张量层的乘法交互——它能学会“not + 负面词 = 正面”这样的非线性组合规则。
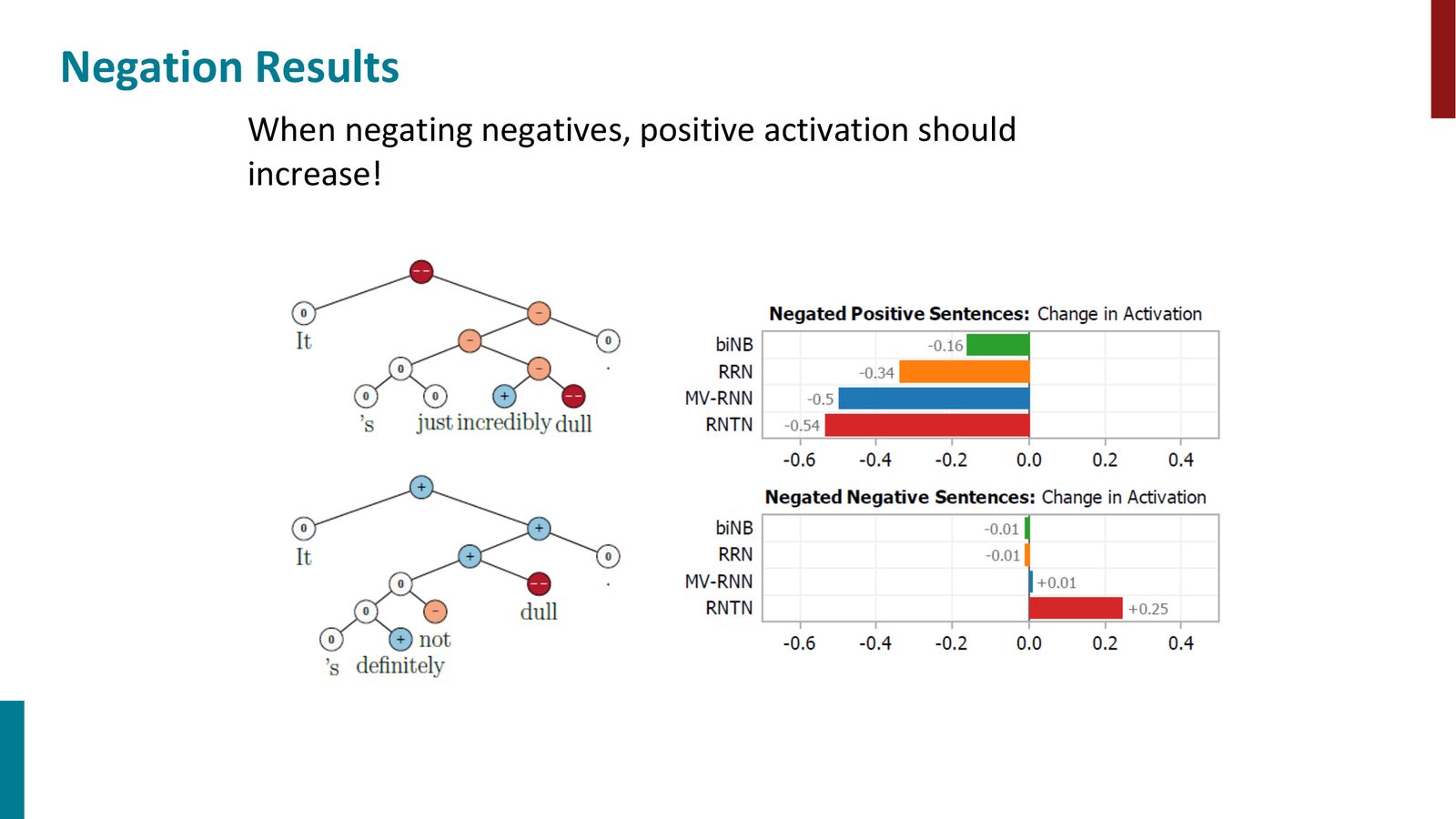
来源:Slides 第59页。
可解释的组合语义
RNTN 的另一个优点是其可解释性。由于模型在句法树的每个节点都产生情感预测,我们可以观察情感如何在组合过程中变化:
来源:Slides 第57页。
这种逐节点的情感可视化在语言学上非常有意义——它展示了模型如何理解语言的组合语义。
本章小结
RNTN 通过张量层实现了词对之间的乘法交互,使得不同类型的语法组合可以产生不同的效果。在 Stanford Sentiment Treebank 上,RNTN 展现了优秀的组合语义建模能力,特别是在处理否定等复杂语言现象时。其逐节点的情感预测提供了很好的可解释性。
树递归神经网络的反思与展望
为什么树递归网络没有成为主流
Manning 坦诚地分析了树递归神经网络最终未能竞争过 Transformer 的原因:
- 严格的上下文无关骨架:信息只能沿树结构流动,没有像 Transformer 中 attention 那样的全局信息交互
- 依赖句法分析:需要预先获得(或同时学习)句法树结构,增加了系统复杂度
- 难以并行化:树结构的计算具有天然的序列依赖性
- Transformer 的通用性:Transformer 的 self-attention 在每一层都允许任意位置之间的信息交互,这种更灵活的信息流在实践中表现更好
灵活性 vs 语言学正确性
树递归网络在语言学正确性方面更有优势——它能更准确地建模否定、量词等语言现象,因为它尊重了语言的层次结构。但 Transformer 在灵活性和规模化方面具有压倒性优势。这揭示了一个深层矛盾:对于当前的深度学习范式,更灵活(但可能“不那么正确”)的模型往往比更有结构约束(但“更正确”)的模型表现更好。即使到今天,Transformer 模型在处理否定等现象时仍然不如树递归网络。
未来方向
Manning 表示他仍然对一个问题感兴趣:能否将树结构的优势与 Transformer 的灵活性结合起来?这个方向的研究可能包括:
- 在 Transformer 中引入结构化的归纳偏置
- 使用树结构作为 attention 的指导或正则化
- 结合组合语义的思想来增强大语言模型对否定、量词等现象的处理能力
本章小结
树递归神经网络因其严格的树结构约束和不够灵活的信息流而未能成为主流。然而,它在语言学正确性方面的优势(特别是否定建模)至今仍具有启发价值。将结构化的语言学知识与灵活的神经网络架构相结合,仍然是一个开放的研究方向。
总结与延伸
讲者的核心总结
本节课覆盖了两种不同于 RNN 和 Transformer 的文本建模方法:
- 卷积神经网络:通过滑动窗口提取局部 n-gram 特征,配合池化操作产生固定长度的句子表示。从简单的 Kim (2014) 单层 CNN 到 VD-CNN 29 层深度字符级网络,展示了 CNN 在文本分类中的潜力。
- 树递归神经网络:基于语言学的组合性原则,沿句法树自底向上构建短语和句子的语义表示。RNTN 通过张量层实现了对否定等复杂组合语义的建模。
全课知识图谱

关键 Takeaways
五条核心洞见
- CNN 是文本分类的有力工具:多种大小的滤波器 + Max Pooling 形成了一个简洁高效的文本分类流水线
- 深度和原始信号输入有价值:VD-CNN 证明了字符级深度 CNN 可以匹敌词级别模型
- 语言的组合语义需要被建模:关键词匹配无法处理否定、反讽等复杂语言现象
- 结构化模型有其独特优势:树递归网络在否定建模等方面优于 Transformer,这提示我们结构化的语言学知识仍有价值
- 灵活性与结构之间的权衡:当前 NLP 的发展趋势是更灵活、更少约束的模型,但这不意味着结构化方法已经过时
拓展阅读
- Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. EMNLP. https://arxiv.org/abs/1408.5882
- Conneau, A. et al. (2017). Very Deep Convolutional Networks for Text Classification. EACL. https://arxiv.org/abs/1606.01781
- Socher, R. et al. (2013). Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. EMNLP. https://nlp.stanford.edu/ socherr/EMNLP2013_RNTN.pdf
- Zhang, Y. & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification. https://arxiv.org/abs/1510.03820
- Tai, K.S. et al. (2015). Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks. ACL. https://arxiv.org/abs/1503.00075