CS231N Lecture 3: Regularization and Optimization
| 字段 | 内容 |
|---|---|
| 作者/整理 | 基于 Zane Durante 授课内容整理 |
| 来源 | Stanford CS231N |
| 日期 | 2025年4月8日 |

回顾:图像分类与线性分类器
本节课开始之前,讲者首先回顾了前一节课的核心内容。图像分类是计算机视觉中的基础任务:给定一张图片,将其映射到一组预定义标签中的某一个。
来源:Slides 第2页。
图像分类的核心挑战
图像分类面临多个困难:
- 语义鸿沟(Semantic Gap):人类看到的是“猫”,计算机看到的是一个三维像素数组(\(32 \times 32 \times 3 = 3072\) 个数值)
- 光照变化(Illumination):不同光照条件下像素强度差异巨大
- 形变(Deformation):猫等柔性物体可以扭曲弯折成各种形状
- 遮挡(Occlusion):物体可能被部分遮挡
- 背景混淆(Background Clutter):物体可能与背景融为一体
- 类内差异(Intra-class Variation):同一类别的不同实例外观差异很大
来源:Slides 第3页。
数据驱动方法与线性分类器
由于无法用简单的 if-else 规则处理所有情况,我们转向数据驱动方法。线性分类器的核心思想是:将图像展平为向量 \(\mathbf{x} \in \mathbb{R}^{3072}\),通过权重矩阵 \(W \in \mathbb{R}^{10 \times 3072}\) 进行矩阵乘法得到各类别的分数:
- \(W\):权重矩阵,每一行代表一个类别的“模板”
- \(\mathbf{b}\):偏置向量,每个类别一个偏置值
- 输出:10 个类别的分数向量

来源:Slides 第6页。
线性分类器的三种视角
- 代数视角:矩阵乘法 \(W\mathbf{x} + \mathbf{b}\),每行独立计算一个类别的分数
- 模板视角:将每行权重还原为图像形状,可视化每个类别学到的“模板”
- 几何视角:每行权重定义一条决策边界(\(W_i \cdot \mathbf{x} + b_i = 0\)),将输入空间划分为不同区域
几何视角的优势在于可以直观判断线性模型的能力边界——如果数据无法被一条直线分开,线性模型就无能为力。
损失函数
有了模型和分数,如何衡量模型的好坏?这就需要损失函数。给定数据集 \(\{(x_i, y_i)\}_{i=1}^N\),总损失定义为:

来源:Slides 第14页。
Softmax 损失(交叉熵损失)是最常用的分类损失函数:
- 先对分数做指数变换使其全为正
- 再除以总和得到概率分布(所有值之和为 1)
- 取正确类别概率的负对数作为损失
Softmax 的作用
Softmax 将任意一组浮点数转换为概率分布:所有输出值之和为 1,且每个值表示对应类别的概率。分数越高的类别获得越大的概率值。当正确类别的概率接近 1 时损失接近 0;当正确类别的概率很低时损失很大。
本章小结
图像分类是计算机视觉的核心任务,面临语义鸿沟、光照变化等多重挑战。线性分类器通过 \(f = W\mathbf{x} + \mathbf{b}\) 将图像映射到类别分数,Softmax 损失函数衡量预测质量。接下来的问题是:如何在损失函数中加入正则化以防止过拟合,以及如何找到最优的 \(W\)。
正则化
为什么需要正则化
损失函数由两部分组成:

来源:Slides 第15页。
Data Loss 衡量模型对训练数据的拟合程度——越低越好。正则化项 \(R(W)\) 的目的则相反:它故意让模型在训练数据上表现稍差,以换取在未见数据上更好的泛化能力。
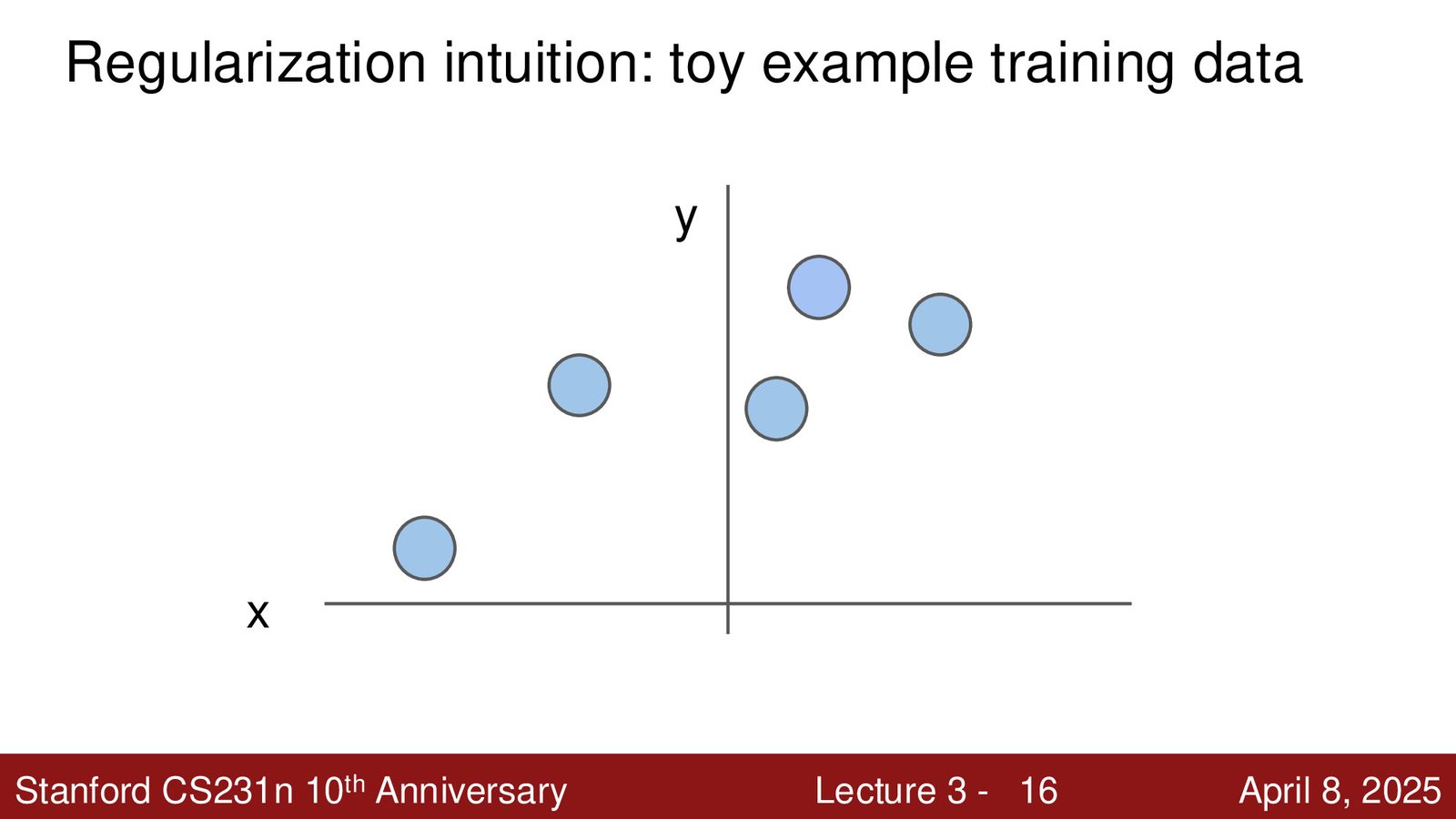
来源:Slides 第16页。
奥卡姆剃刀与正则化
正则化的直觉与奥卡姆剃刀(Occam's Razor)一致:当多个假设都能解释数据时,优先选择最简单的那个。复杂模型(如 \(f_1\))虽然完美拟合训练数据,但在新数据上表现不佳;而简单模型(如 \(f_2\))虽然训练误差略高,但泛化能力更强。
L2 正则化与 L1 正则化
L2 正则化(权重衰减):
对权重矩阵中每个元素取平方后求和。L2 正则化倾向于让权重值分散且均匀较小。
L1 正则化:
对权重矩阵中每个元素取绝对值后求和。L1 正则化倾向于产生稀疏权重(很多值为零)。
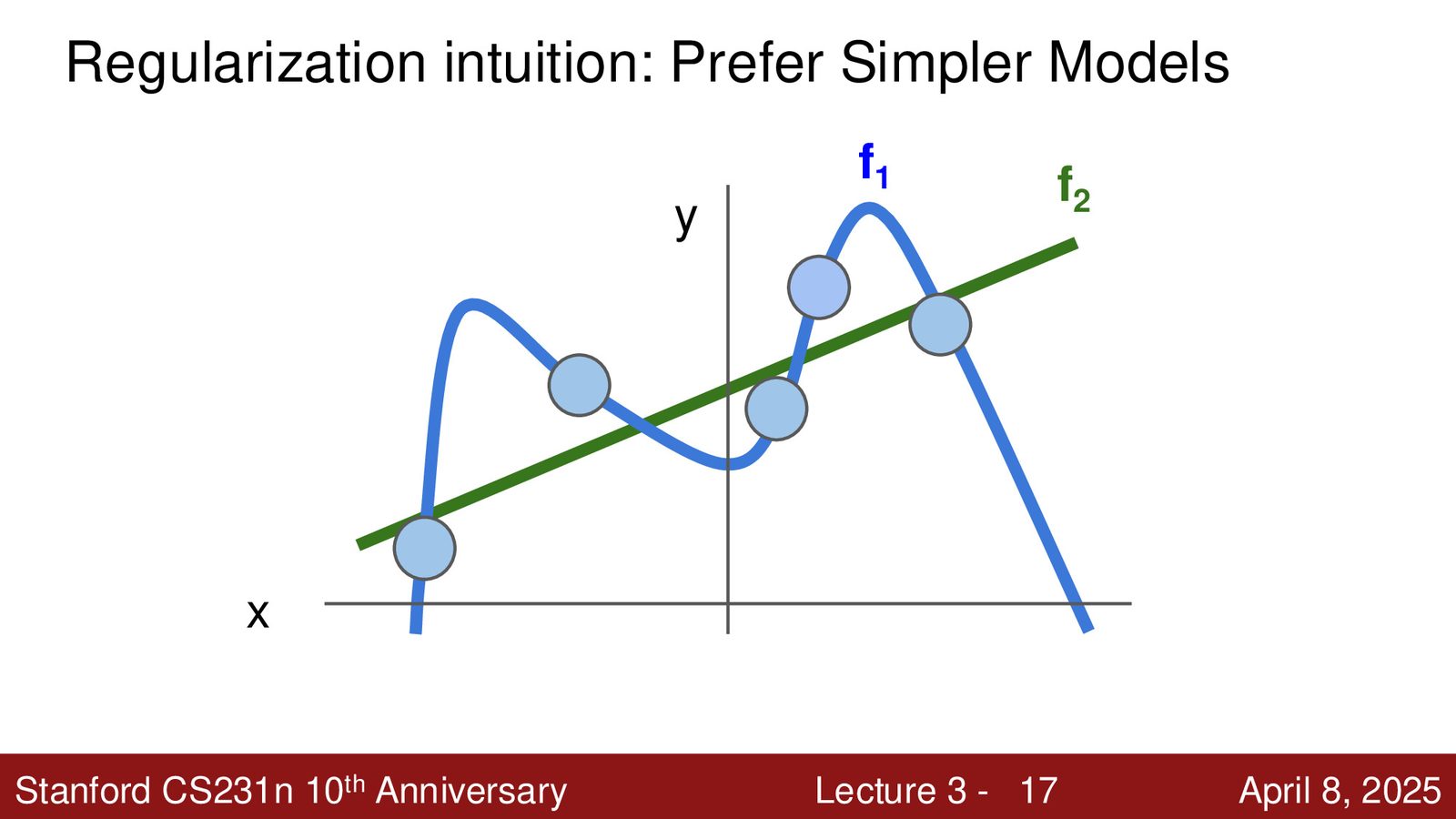
来源:Slides 第17页。
L2 vs L1 正则化的直觉
考虑两组权重 \(\mathbf{w}_1 = [1, 0, 0, 0]\) 和 \(\mathbf{w}_2 = [0.25, 0.25, 0.25, 0.25]\),输入为 \(\mathbf{x} = [1, 1, 1, 1]\),两者的点积相同(都等于 1),数据损失一样。但:
- L2 偏好 \(\mathbf{w}_2\):\(0.25^2 \times 4 = 0.25\) vs \(1^2 = 1\)(\(\mathbf{w}_2\) 的 L2 罚项低 4 倍)
- L1 对两者无差异:\(0.25 \times 4 = 1\) vs \(1 = 1\)(L1 罚项相同)
因此 L2 促进权重分散,L1 促进权重稀疏。
L1 等价性陷阱
当被问“L1 正则化偏好 \(\mathbf{w}_1\) 还是 \(\mathbf{w}_2\)?”时,很多人直觉回答 \(\mathbf{w}_1\)(因为 L1 促进稀疏性)。但实际上在这个例子中,两者的 L1 惩罚值完全相等!L1 在实际优化过程中会产生稀疏解,但这并不意味着任意两组权重的 L1 值不同。
正则化的作用总结
为什么要正则化模型?主要有三个原因:
- 表达权重偏好:根据问题特性选择 L1(稀疏)或 L2(分散)
- 简化模型:防止过拟合,提升测试性能
- 改善优化:L2 正则化可以使损失函数更凸(\(y = x^2\) 是凸函数),有利于优化

来源:Slides 第19页。
\(\lambda\) 是一个超参数,控制正则化的强度:\(\lambda = 0\) 表示无正则化,\(\lambda\) 越大正则化越强。通常通过验证集来选择最优的 \(\lambda\)。
本章小结
正则化通过在损失函数中添加权重惩罚项来防止过拟合。L2 正则化偏好分散的小权重,L1 正则化偏好稀疏权重。超参数 \(\lambda\) 控制正则化与数据拟合之间的权衡。在后续课程中还会学到更高级的正则化技术(如 Dropout)。
优化基础
既然我们知道了如何衡量一组权重 \(W\) 的好坏(通过损失函数),下一个问题是:如何找到最优的 \(W\)?
损失景观与优化直觉

来源:Slides 第24页。
可以将优化想象为一个人在损失景观中行走,试图找到最低的山谷。关键的类比是:这个人是蒙着眼的——他看不到远处的地形,只能感受脚下地面的坡度,然后决定向哪个方向走。
策略一:随机搜索
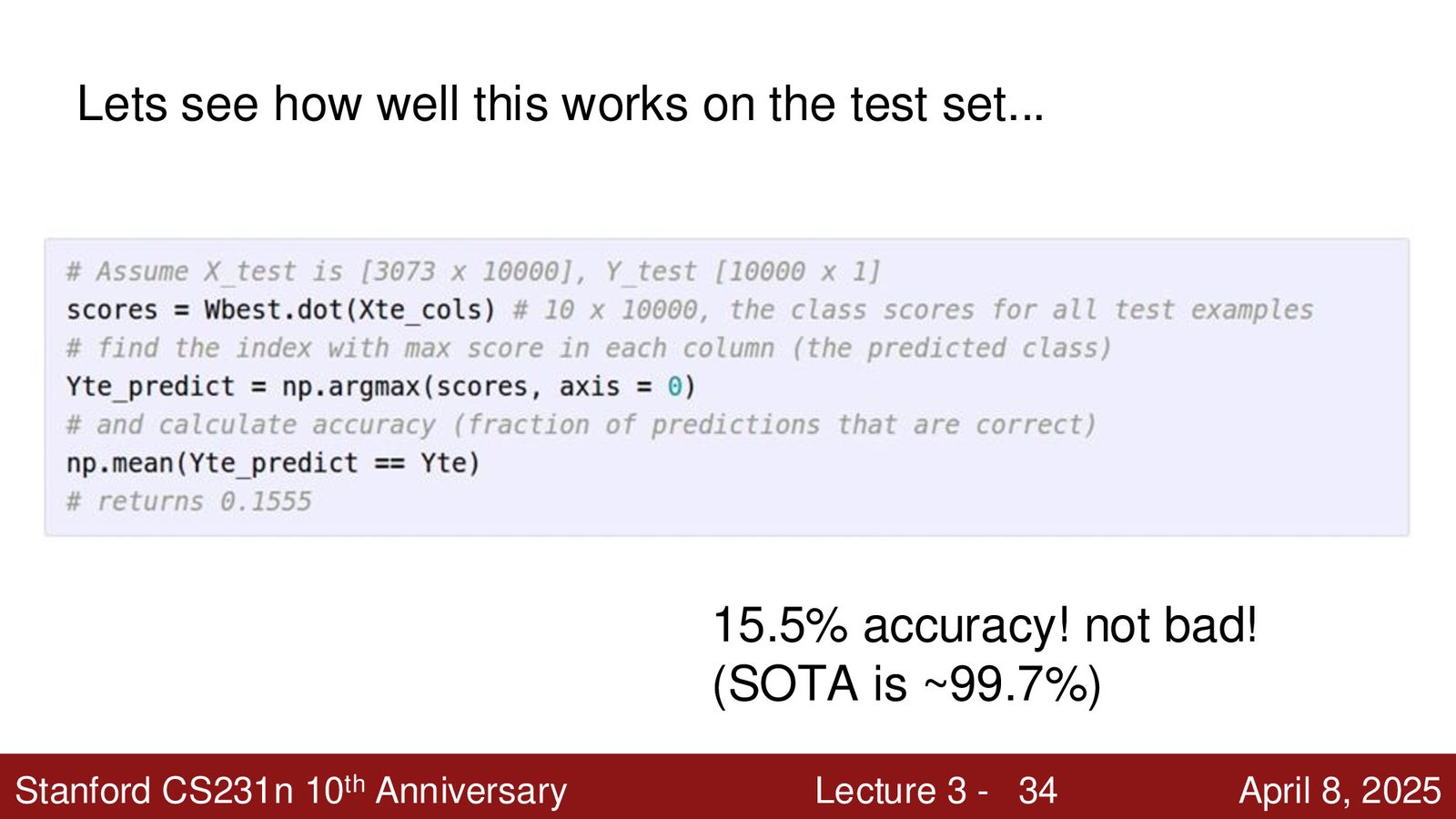
最简单的方法是随机尝试大量不同的 \(W\),选择损失最小的那个:
best_loss = float('inf')
for i in range(1000):
W = np.random.randn(10, 3072) * 0.0001
loss = L(X_train, Y_train, W)
if loss < best_loss:
best_loss = loss
best_W = W
这种方法在 CIFAR-10 上只能达到约 15.5% 的准确率(随机猜测为 10%),而现代深度学习方法可以达到 99.7%。显然不够好,但胜于随机猜测。
策略二:跟随坡度——梯度
更好的策略是“感受地面的坡度,朝下坡方向走”。数学上,这就是计算梯度。
一维导数的定义(极限形式):

来源:Slides 第28页。
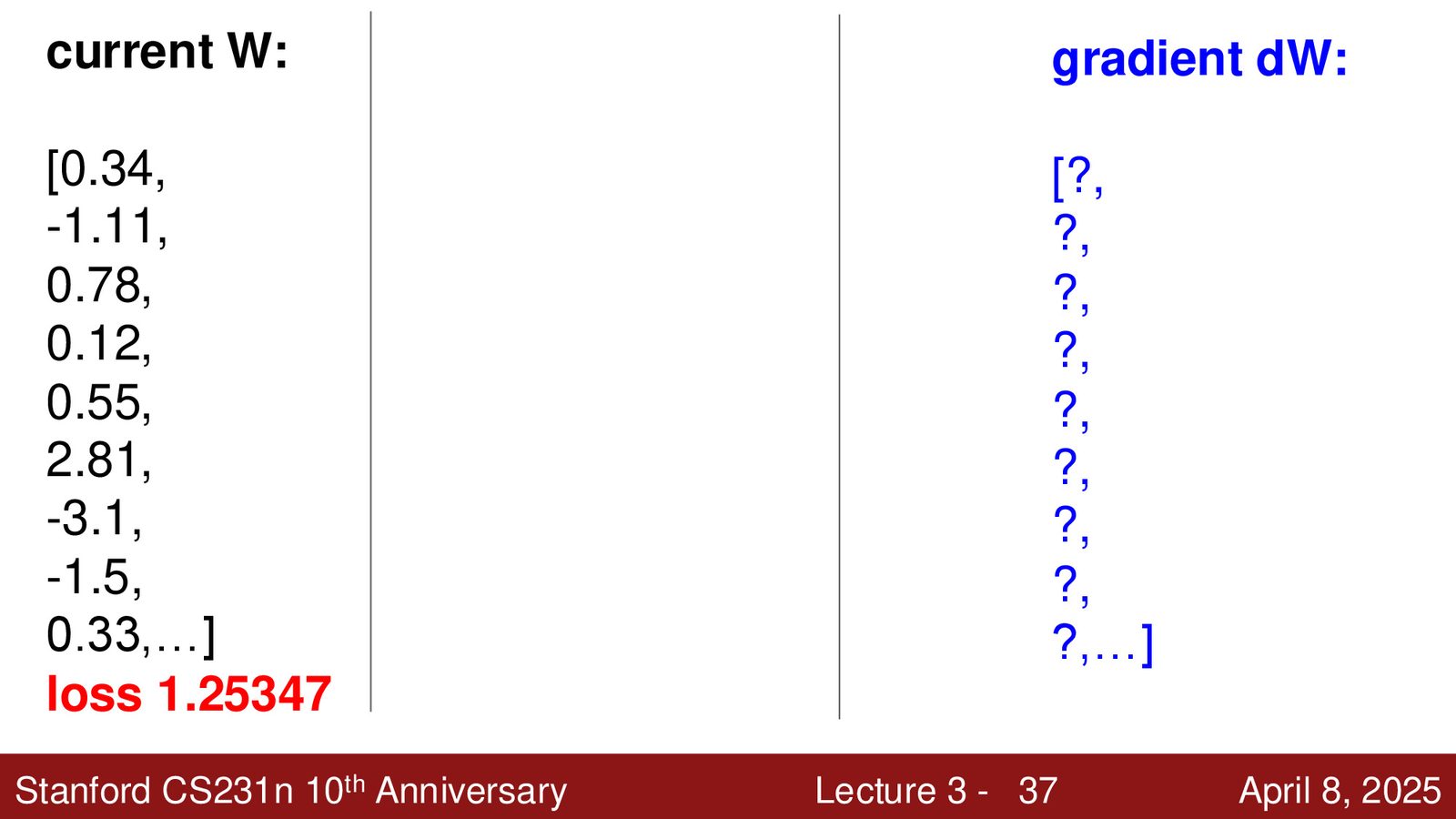
在多维情况下,使用梯度——对每个维度分别计算偏导数,得到一个向量:
梯度指向函数增长最快的方向,因此负梯度方向是下降最快的方向。
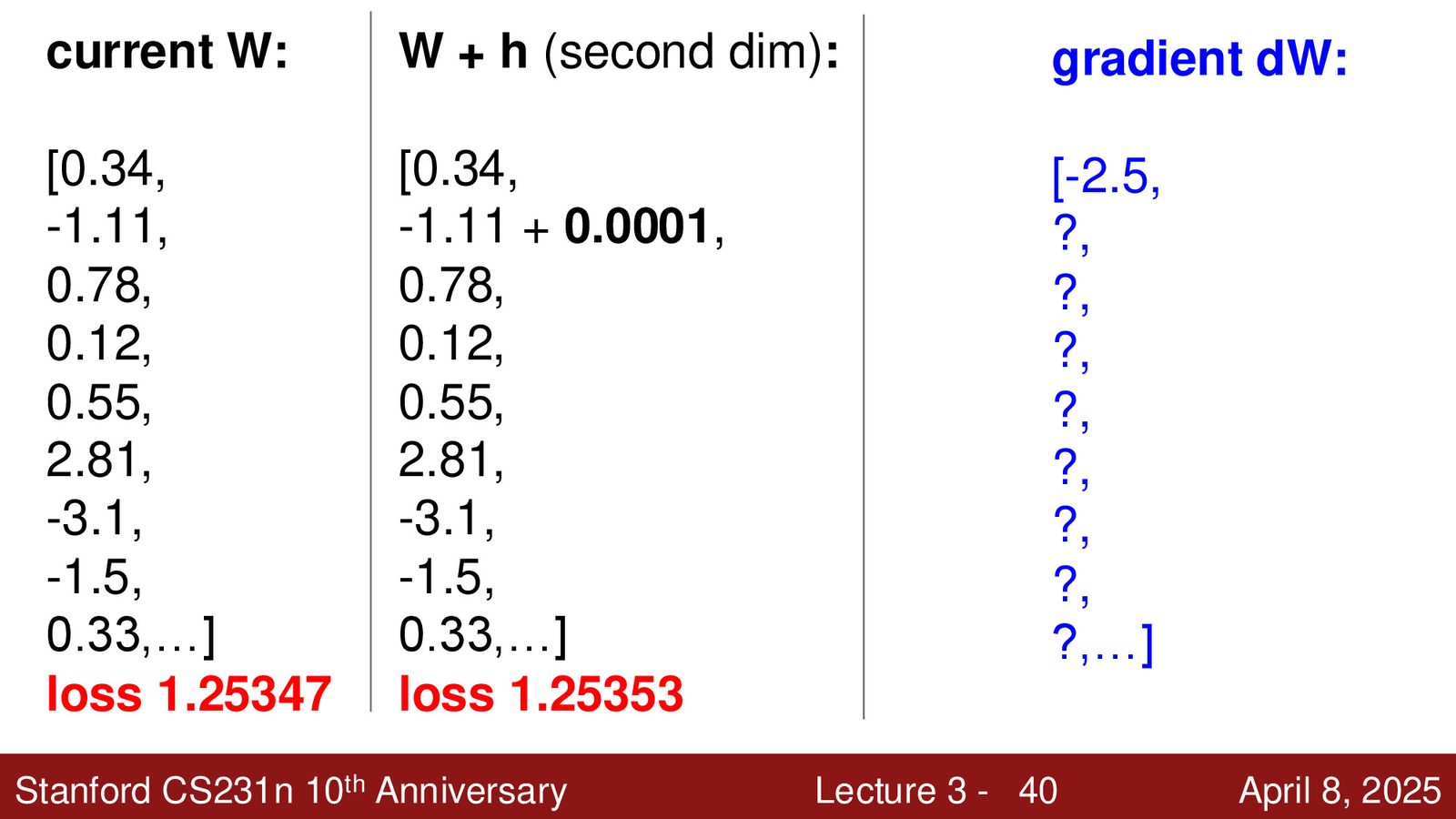
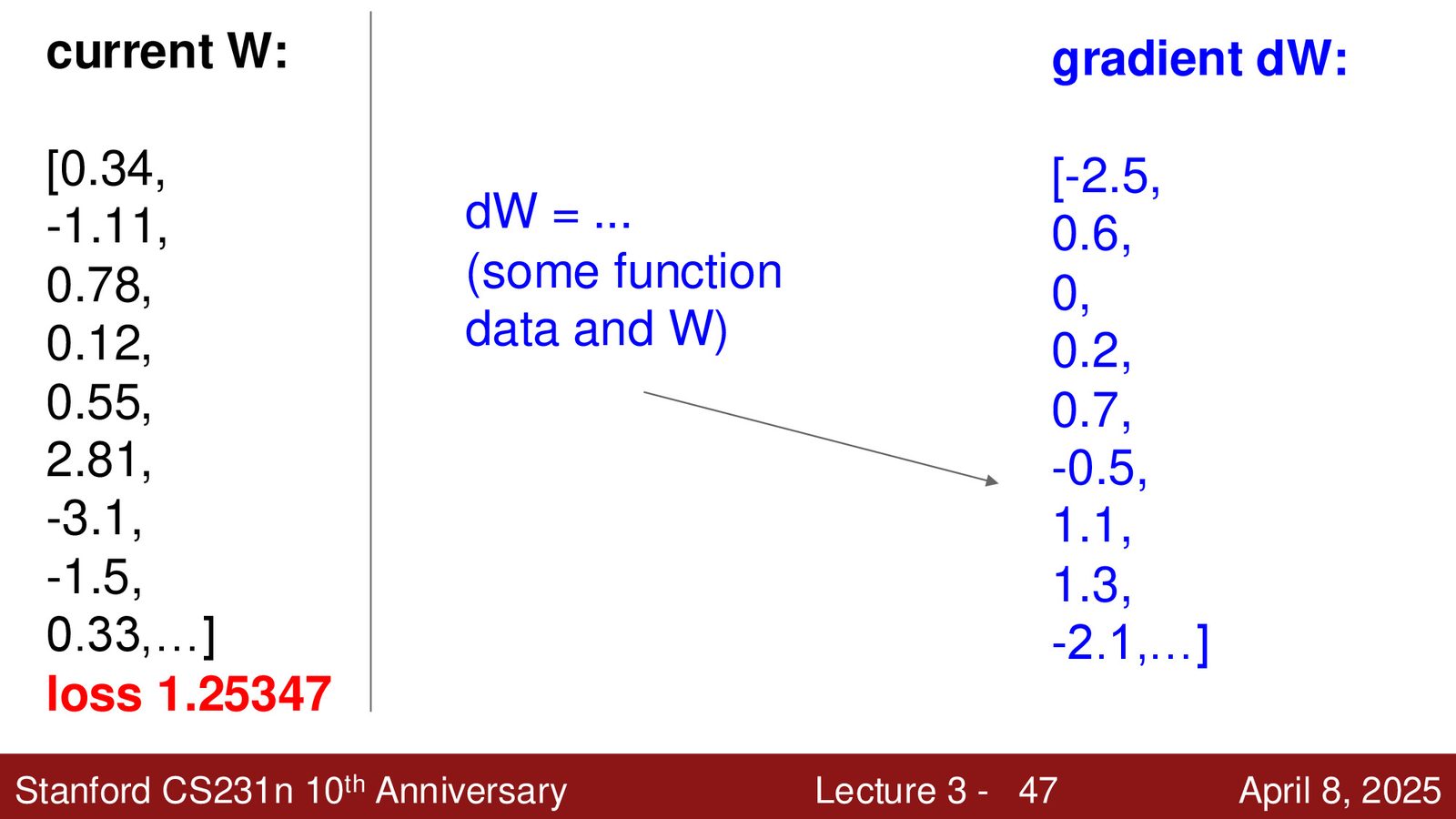
数值梯度 vs 解析梯度

来源:Slides 第29页。
数值梯度:用有限差分近似导数(\(h\) 取一个很小的值如 \(10^{-5}\))
- 优点:实现简单
- 缺点:速度慢(需要遍历每个参数)、近似值(不精确)
解析梯度:通过微积分推导损失函数对 \(W\) 的导数公式
- 优点:精确、快速
- 缺点:推导可能出错
梯度检查(Gradient Check)
实践中的标准做法是:用解析梯度进行训练(快速且精确),但用数值梯度进行验证——确保两者结果一致。如果解析梯度的实现有 bug,梯度检查可以立即发现。这是作业中常见的调试手段。
本章小结
优化的目标是在损失景观中找到最低点。梯度给出了损失函数在当前点的下降方向。实践中使用解析梯度计算,并通过数值梯度进行验证。接下来将介绍具体的优化算法。
梯度下降与高级优化器
梯度下降算法
梯度下降是训练所有深度学习模型的基础算法:
- \(\alpha\):学习率(步长),控制每一步走多远
- \(\nabla_W L\):损失函数对权重的梯度
- 负号:沿梯度反方向走(下坡)

来源:Slides 第31页。
何时停止训练?
梯度下降的迭代过程何时结束?通常有两种策略:(1)设定固定的迭代次数;(2)设定停止准则,当损失的减少量低于某个阈值(如 \(10^{-5}\))时停止。实践中更常用固定迭代次数。
随机梯度下降(SGD)
标准梯度下降需要在整个训练集上计算损失和梯度,当数据量很大时计算代价极高。随机梯度下降(Stochastic Gradient Descent, SGD)通过在每步只使用一个小批量(mini-batch)来近似完整梯度:
for t in range(num_iterations):
mini_batch = sample_data(X_train, batch_size=256)
dW = compute_gradient(mini_batch, W)
W = W - learning_rate * dW
来源:Slides 第33页。
Epoch 的概念
实践中不是完全随机采样,而是将数据集打乱顺序后依次遍历。遍历完整个数据集一次称为一个 epoch。多个 epoch 的训练可以让模型反复学习所有数据。
SGD 的问题

来源:Slides 第35页。
SGD 存在四个主要问题:
- 高条件数/窄谷:梯度在陡峭方向很大、平坦方向很小,导致来回震荡而非直接走向最优点
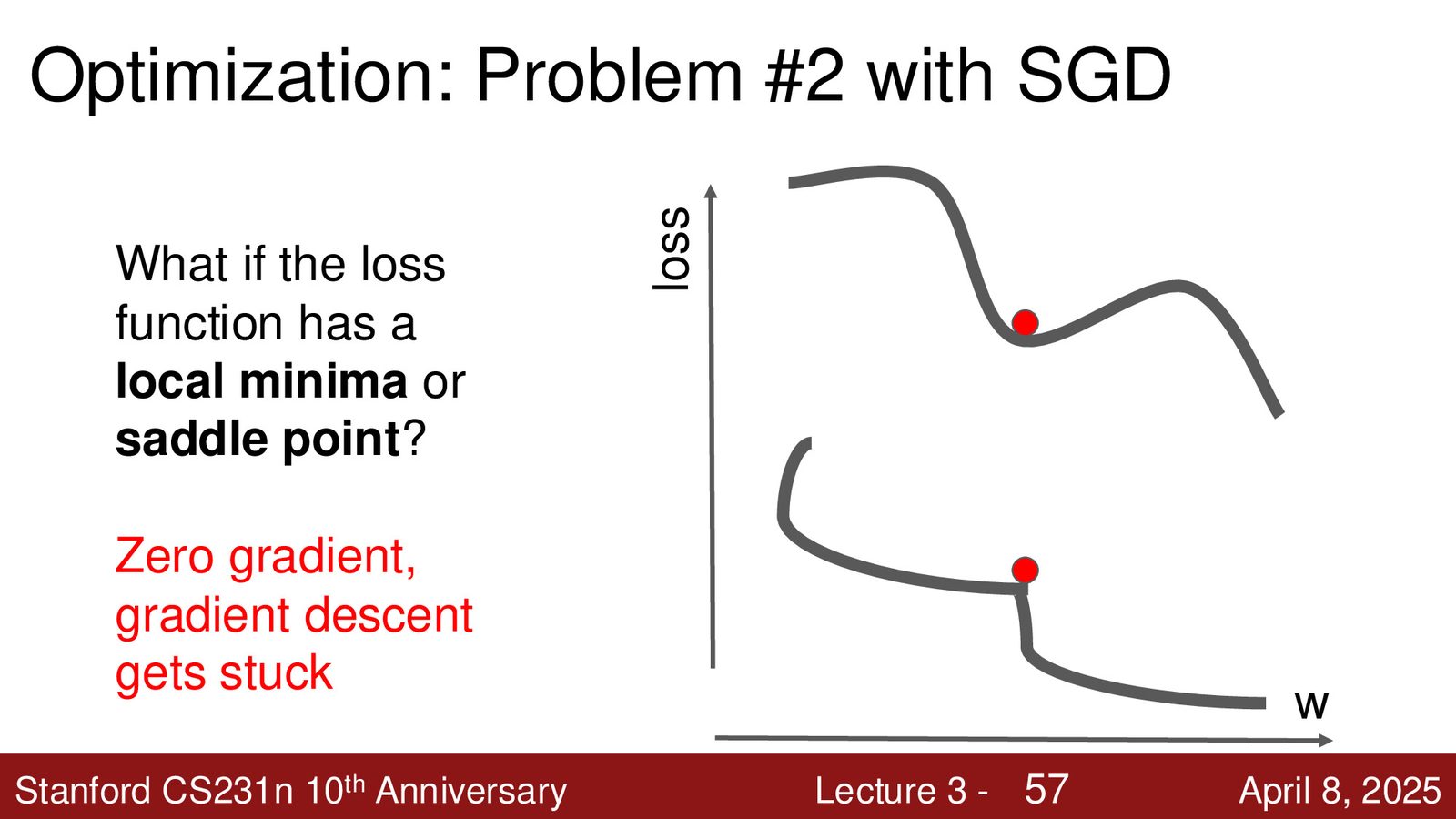
- 局部极小值:可能陷入局部最优,无法继续下降
- 鞍点:在高维空间中更常见——梯度为零但不是极值点
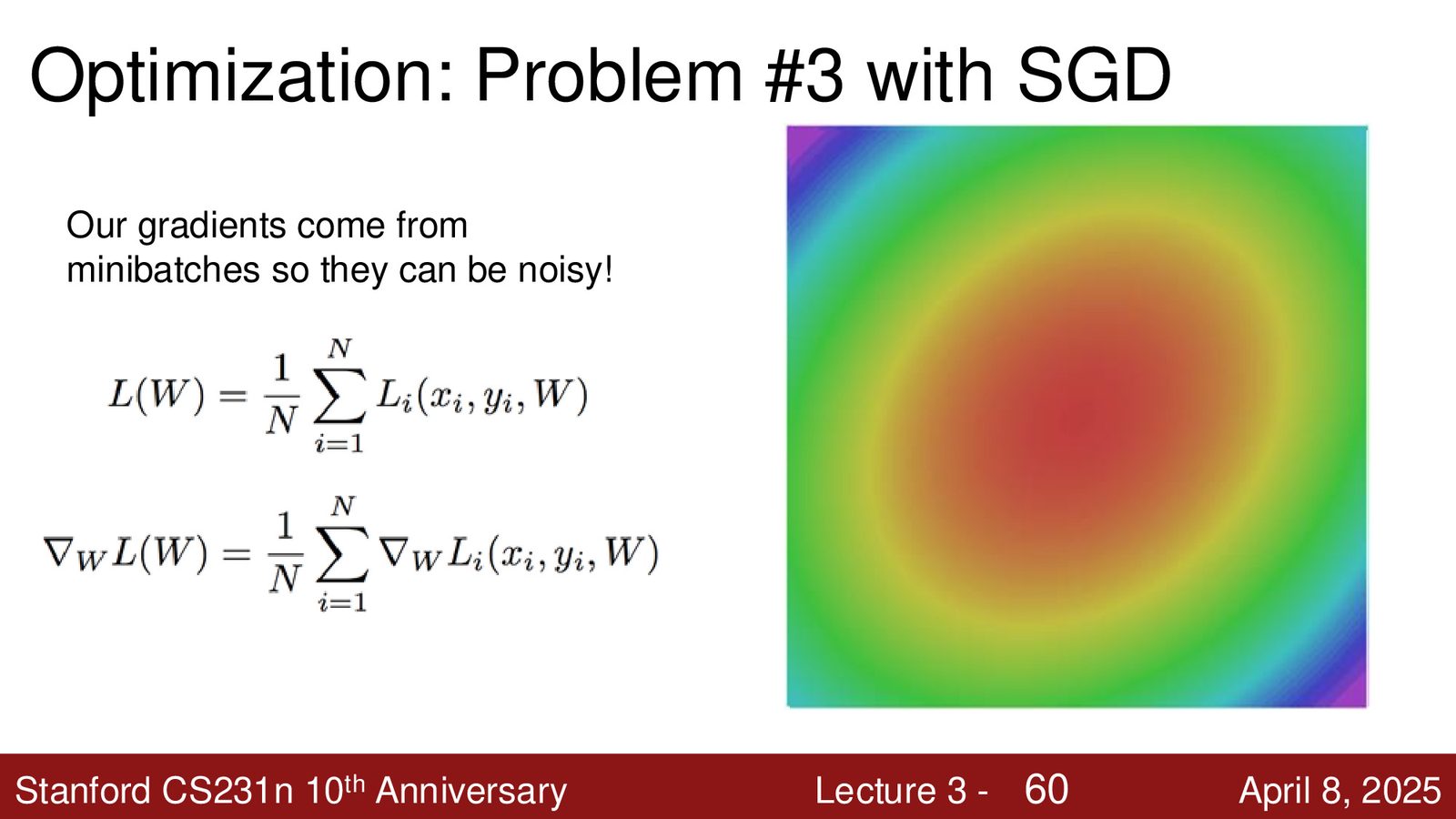
- 梯度噪声:因为只用了数据子集,每步梯度是有噪声的
来源:Slides 第36页。
鞍点在高维空间中比局部极小值更常见
研究表明,随着模型参数维度增加,鞍点出现的频率远高于局部极小值。在鞍点处,某些方向是“谷底”而另一些方向是“山顶”,梯度在所有方向上为零,导致优化停滞。这是大型神经网络训练中的一个严重实际问题。
SGD + Momentum
动量方法借鉴了物理学中滚球的概念:球在下坡时会积累速度,即使遇到平坦区域也能凭借惯性继续前进。
来源:Slides 第39页。
数学形式如下:
- \(\mathbf{v}_t\):速度向量(过去梯度的加权平均)
- \(\rho\):动量系数(通常取 0.9),控制历史梯度的权重
- 更新方向不再是当前梯度,而是速度向量
动量解决 SGD 三大问题
- 局部极小值:积累的速度使球能“滚出”浅的局部极小值
- 鞍点:历史动量推动模型继续穿越平坦区域
- 窄谷震荡:垂直方向的来回震荡在速度累加中相互抵消,而水平方向的一致运动不断累积
- 噪声:多步梯度的平均效果减少了单步噪声的影响
RMSProp
RMSProp 由 Hinton 在 2012 年提出,核心思想是逐元素缩放梯度——在梯度大的方向走小步,在梯度小的方向走大步。
来源:Slides 第46页。
- \(\mathbf{s}_t\):梯度平方的指数移动平均
- 陡峭方向:\(\mathbf{s}_t\) 大,除以大数 \(\rightarrow\) 步长变小
- 平坦方向:\(\mathbf{s}_t\) 小,除以小数 \(\rightarrow\) 步长变大

来源:Slides 第47页。
Adam 优化器
Adam(Adaptive Moment Estimation)是现代深度学习中最常用的优化器,它结合了 Momentum 和 RMSProp 的优点:

来源:Slides 第48页。
Adam 的初始步长问题
Adam 的 \(\beta_1, \beta_2\) 通常初始化为接近 1 的值(如 0.9, 0.999),而 \(\mathbf{m}_0 = \mathbf{v}_0 = 0\)。这意味着在第一步中,\(\mathbf{v}_1\) 会非常接近零,导致除以极小数,产生一个不合理的大步长。为此 Adam 引入了偏差修正(bias correction),通过 \(\hat{\mathbf{m}}_t = \mathbf{m}_t / (1 - \beta_1^t)\) 和 \(\hat{\mathbf{v}}_t = \mathbf{v}_t / (1 - \beta_2^t)\) 来补偿初始时刻的估计偏差。
常用默认参数:\(\beta_1 = 0.9\),\(\beta_2 = 0.999\),\(\epsilon = 10^{-8}\),\(\alpha = 10^{-3}\)。

来源:Slides 第51页。
AdamW:解耦权重衰减

来源:Slides 第52页。
标准 Adam 在计算梯度时包含 L2 正则化项,这意味着正则化会影响动量和自适应学习率的计算。AdamW 则将权重衰减从梯度计算中分离出来——动量和二阶矩只基于数据损失的梯度计算,L2 正则化在最终更新时才加入。
为什么 AdamW 更受欢迎?
在 Adam 中,L2 正则化的梯度会影响动量和自适应学习率的估计,这可能并非我们期望的行为。AdamW 让优化器专注于损失景观的导航,而正则化仅作为一个独立的权重缩减步骤。Meta 的 LLaMA 系列模型都使用 AdamW 优化器。
本章小结
- SGD:最基础的优化器,存在窄谷震荡、局部极小值和鞍点问题
- SGD + Momentum:通过速度累积解决上述问题
- RMSProp:通过逐元素缩放梯度,在平坦方向走大步、陡峭方向走小步
- Adam:结合 Momentum 和 RMSProp,加偏差修正,是最常用的优化器
- AdamW:解耦权重衰减,在许多实际任务中表现更好
学习率调度
学习率的重要性
学习率是训练中最重要的超参数之一。选择不当会导致灾难性后果:

来源:Slides 第54页。
- 过高:损失不降反升,模型“跳出”损失景观
- 偏高:损失无法继续下降,在最优点附近震荡
- 过低:收敛极其缓慢,浪费计算资源
- 适中:快速下降后持续改进
学习率衰减策略
训练过程中动态调整学习率是现代深度学习的标准做法。几种常见策略:
1. 阶梯式衰减(Step Decay):每经过固定迭代次数,将学习率乘以一个因子(如 0.1)。训练 ResNet 时常用此策略。
来源:Slides 第56页。
2. 余弦退火(Cosine Annealing):学习率按半个余弦周期从最大值平滑降到零:

来源:Slides 第57页。
3. 线性衰减和逆平方根衰减等其他方案。
4. 线性预热(Linear Warmup):训练初期先从很小的学习率线性增长到目标值,然后再按照某种策略衰减。这可以避免初始时不稳定的大步长。
来源:Slides 第59页。
线性缩放规则
经验法则:如果将 batch size 增大 \(n\) 倍,学习率也应相应增大 \(n\) 倍。直觉是:更大的 batch 提供更准确的梯度估计,因此可以“迈更大的步”。这一规则在许多实际场景中被证明有效。
本章小结
学习率是最关键的超参数。实践中几乎所有现代模型都使用学习率调度:先预热后衰减。余弦退火 + 线性预热是最流行的组合之一。batch size 增大时应按比例增大学习率。
补充:二阶优化方法

来源:Slides 第62页。
前面介绍的所有方法都是一阶优化——只用到梯度(一阶导数)信息。二阶优化方法(如 Newton 方法)利用 Hessian 矩阵(二阶导数矩阵)直接估计极值点位置:
二阶方法在深度学习中不实用
对于有 \(N\) 个参数的模型,Hessian 矩阵大小为 \(N \times N\)。现代大模型有数十亿参数,存储和求逆 Hessian 是完全不可行的。因此深度学习几乎全部使用一阶方法(SGD、Adam 等)。二阶方法在小规模凸优化问题中仍然有用。
总结与延伸
全课知识图谱
本课建立了从损失函数到实用训练方法的完整链条:

关键 Takeaways
五条核心原则
- 正则化是必需的:仅最小化数据损失必然导致过拟合,正则化通过牺牲训练精度换取泛化能力
- 梯度是优化的基石:无论使用什么优化器,本质都是在用梯度信息指导参数更新
- Adam 是默认选择:除非有特殊原因,否则从 Adam/AdamW 开始
- 学习率需要调度:固定学习率几乎不是最优选择,预热 + 衰减是标准做法
- 实践胜于理论:优化器的选择最终是经验性的——尝试几种方案,选效果最好的
拓展阅读
- Kingma & Ba, Adam: A Method for Stochastic Optimization (2015): https://arxiv.org/abs/1412.6980
- Loshchilov & Hutter, Decoupled Weight Decay Regularization (AdamW, 2019): https://arxiv.org/abs/1711.05101
- Goyal et al., Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour (2017): https://arxiv.org/abs/1706.02677
- CS231N 课程主页: http://cs231n.stanford.edu/